8. SparkSQL综合作业
综合练习:学生课程分数
网盘下载sc.txt文件,创建RDD,并转换得到DataFrame。

>>> lines = spark.sparkContext.textFile('file:///home/hadoop/wc/sc.txt')
>>> parts = lines.map(lambda x:x.split(','))
>>> people = parts.map(lambda p : Row(p[0],p[1],int(p[2].strip()) ))
>>> from pyspark.sql.types import IntegerType,StringType
>>> from pyspark.sql.types import StructField,StructType
>>> from pyspark.sql import Row
>>> fields = [StructField('name',StringType(),True),StructField('course',StringType(),True), StructField('age',IntegerType(),True)]
>>> schema = StructType(fields)
>>> lines = spark.sparkContext.textFile('file:///home/hadoop/wc/sc.txt')
>>> parts = lines.map(lambda x:x.split(','))
>>> people = parts.map(lambda p : Row(p[0],p[1],int(p[2].strip()) ))
>>> schemaPeople = spark.createDataFrame(people,schema)
>>> schemaPeople.printSchema()
>>> schemaPeople.show(10)
分别用DataFrame操作和spark.sql执行SQL语句实现以下数据分析:
1.总共有多少学生?
>>> schemaPeople.select(schemaPeople['name']).distinct().count()
2.开设了多少门课程?
>>> schemaPeople.select(schemaPeople['course']).distinct().count()

3.每个学生选修了多少门课?
>>> schemaPeople.groupBy('name').count().show()
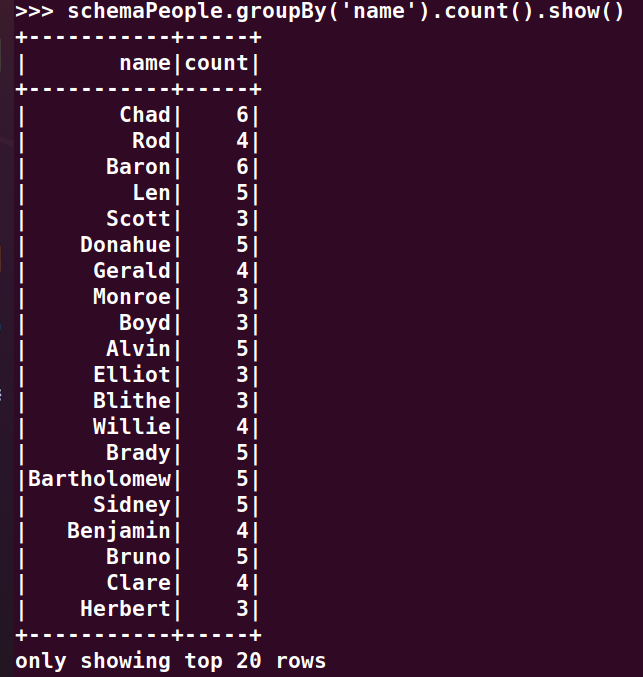
4.每门课程有多少个学生选?
>>> schemaPeople.groupBy('course').count().show()
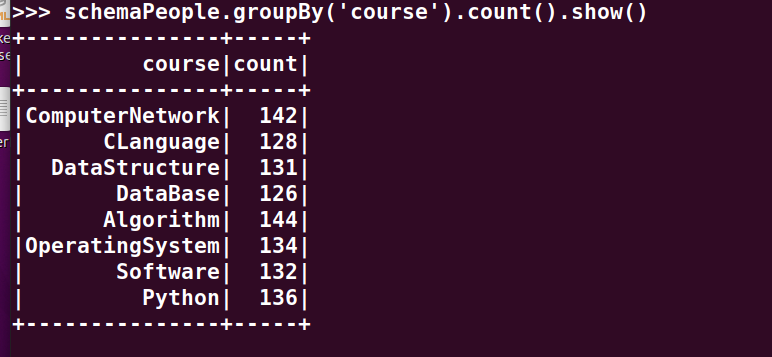
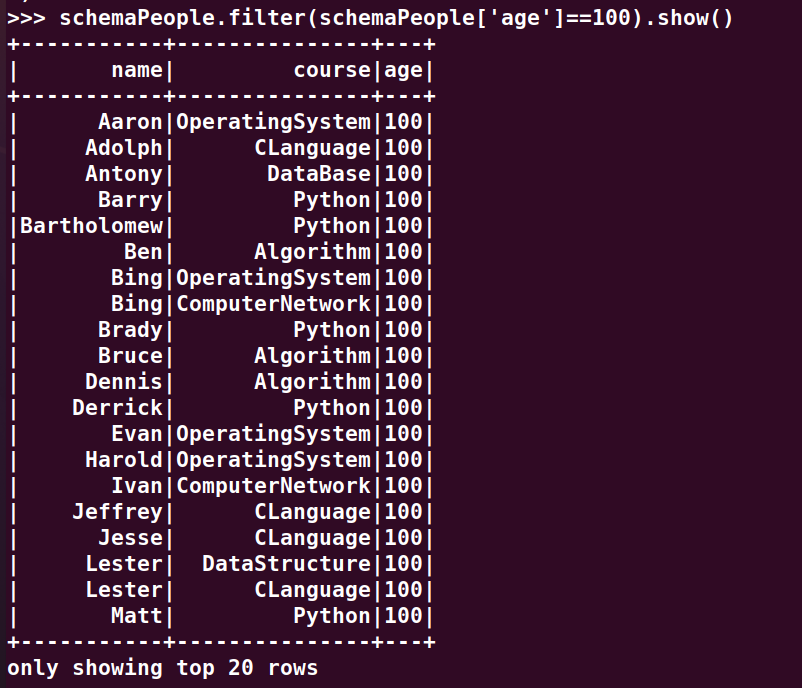
5.有多少个100分?
ilter(schemaPeople['age']==100).show()
6.Tom选修了几门课?每门课多少分?
>>> schemaPeople.filter(schemaPeople['name']=='Tom').show()

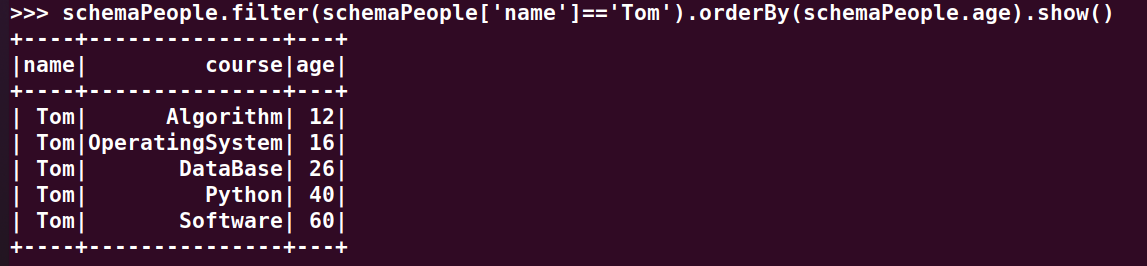
7.Tom的成绩按分数大小排序。
>>> schemaPeople.filter(schemaPeople['name']=='Tom').orderBy(schemaPeople.age).show()
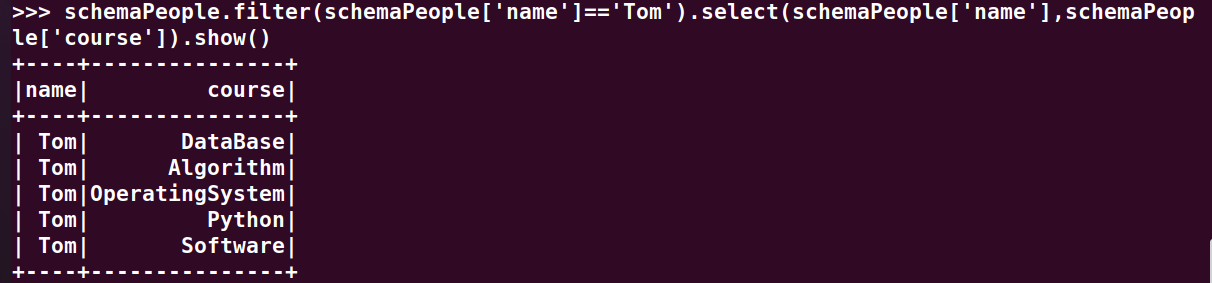
8.Tom选修了哪几门课?
>>> schemaPeople.filter(schemaPeople['name']=='Tom').select(schemaPeople['name'],schemaPeople['course']).show()
9.Tom的平均分。
>>> schemaPeople.registerTempTable('people')
>>> spark.sql('select avg(age) from people where name = "Tom" ').show()

10.'OperatingSystem'不及格人数
>>> spark.sql('select count(name) from people where course = "OperatingSystem" and age < 60').show()

11.'OperatingSystem'平均分
>>> spark.sql('select avg(age) from people where course = "OperatingSystem" ').show()

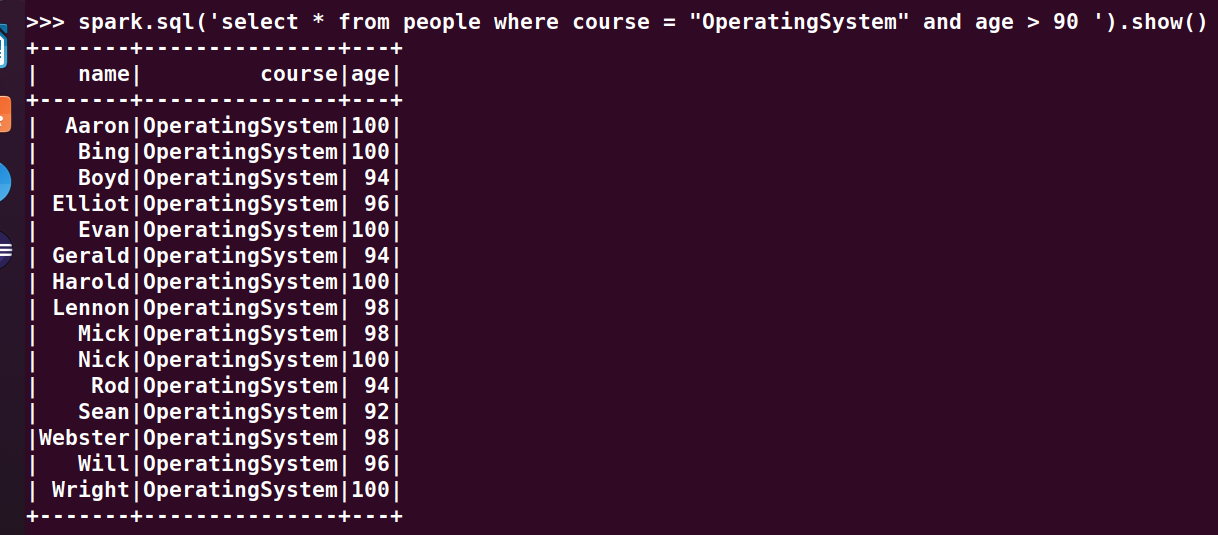
12.'OperatingSystem'90分以上人数
>>> spark.sql('select * from people where course = "OperatingSystem" and age > 90 ').show()
13.每个分数按比例+20平时分。
>>> schemaPeople.select(schemaPeople['name'],schemaPeople['course'],schemaPeople['age']+20).show(5)

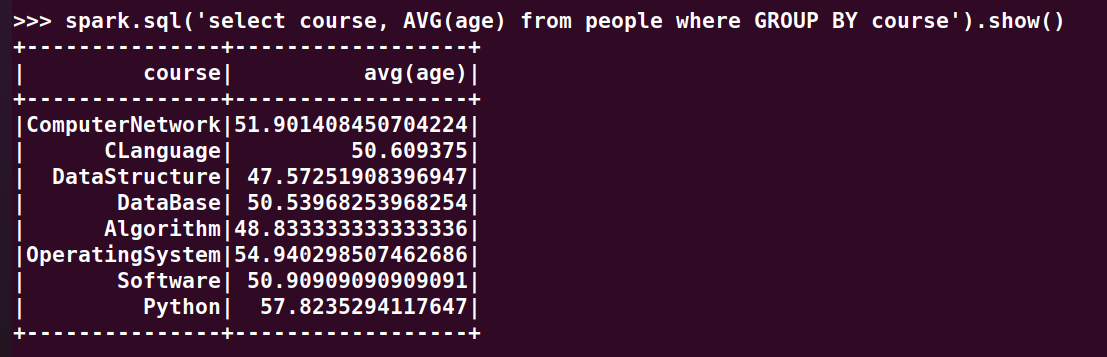
14.求每门课的平均分
>>> spark.sql('select course, AVG(age) from people where GROUP BY course').show()
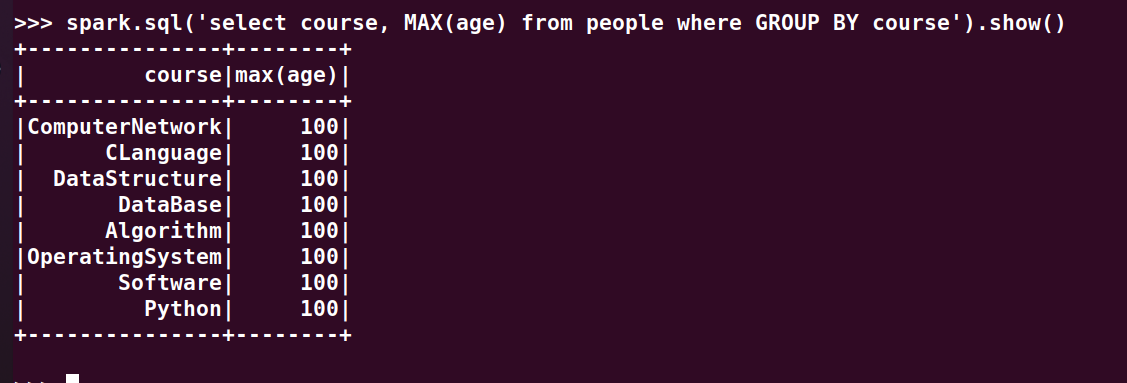
15.求每门课的最高分最低分
>>> spark.sql('select course, MAX(age) from people where GROUP BY course').show()



 浙公网安备 33010602011771号
浙公网安备 33010602011771号
退出 订阅评论 我的博客
[Ctrl+Enter快捷键提交]
【推荐】腾讯云618采购季,年中优惠抢先看,早鸟优惠提前享
· 分享一个 SpringCloud Feign 中所埋藏的坑
· 动画还可以这样控制?
· 理解 RESTful Api 设计
· 从几次事故引起的对项目质量保障的思考
· 聊聊 C# 中的 Visitor 模式
· 横竖都是文远知行,L4自动驾驶不讲武德
· AI公司难逃「豪车定律」?
· 因发表不当言论,开源作者遭OBS项目社区封杀
· 实探上海多家快递转运中心:个人散件寄递业务加速恢复
· “王心凌男孩”救不了芒果超媒
» 更多新闻...