
5.RDD操作和综合实例
一、词频统计
A. 分步骤实现
1、准备文件
- 下载小说或长篇新闻稿
- 上传到hdfs上
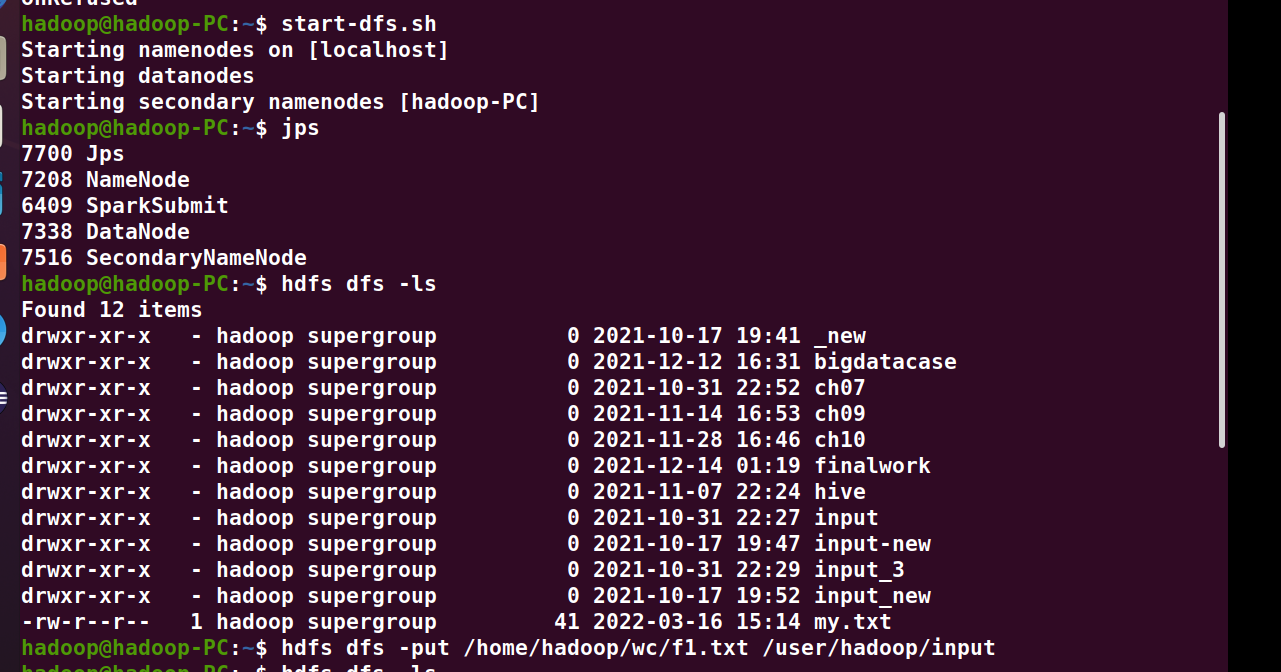
2、读文件创建RDD
>>> text = sc.textFile("file:///home/hadoop/wc/f1.txt")
3、分词
>>> import re >>> pattern = " |\,|\.|\'|\!|\?|\:|\ " >>> words = text.flatMap(lambda line:re.split(pattern, line))

4、排除大小写lower(),map()
>>> words1 = words.map(lambda word:word.lower())

-
标点符号re.split(pattern,str),flatMap(),
-
停用词,可网盘下载stopwords.txt,filter(),
-
长度小于2的词filter()
>>> with open('/home/hadoop/wc/stopwords.txt') as f: ... stops=f.read().split() ... >>> stops >>> words2 = words1.filter(lambda word:word not in stops) >>> words3 = words2.filter(lambda word: len(word)>2 )


5、统计词频
6、按词频排序
>>> words4 = words3.map(lambda a:(a,1)).reduceByKey(lambda a,b:(a+b)) >>> rdd = words4.sortBy(lambda kv:kv[1],False,numPartitions = 1) >>> rdd.foreach(print)

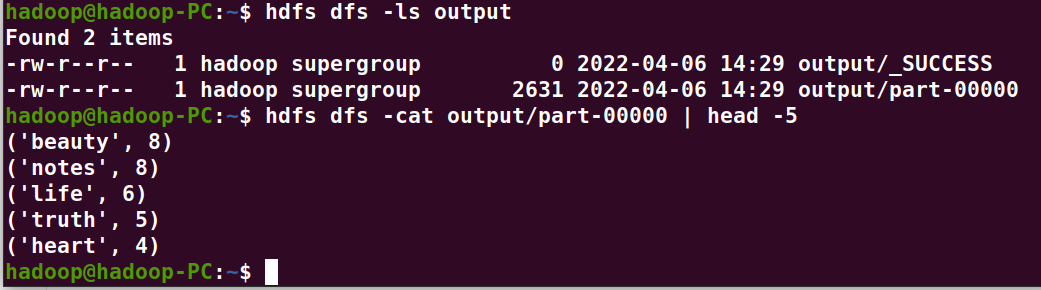
7、输出到文件
8、查看结果
>>> out_url = "output" >>> rdd.saveAsTextFile(out_url)
hadoop@hadoop-PC:~$ start-dfs.sh hadoop@hadoop-PC:~$ hdfs dfs -ls hadoop@hadoop-PC:~$ hdfs dfs -ls output hadoop@hadoop-PC:~$ hdfs dfs -cat output/part-00000 | head -5 hadoop@hadoop-PC:~$ stop-dfs.sh
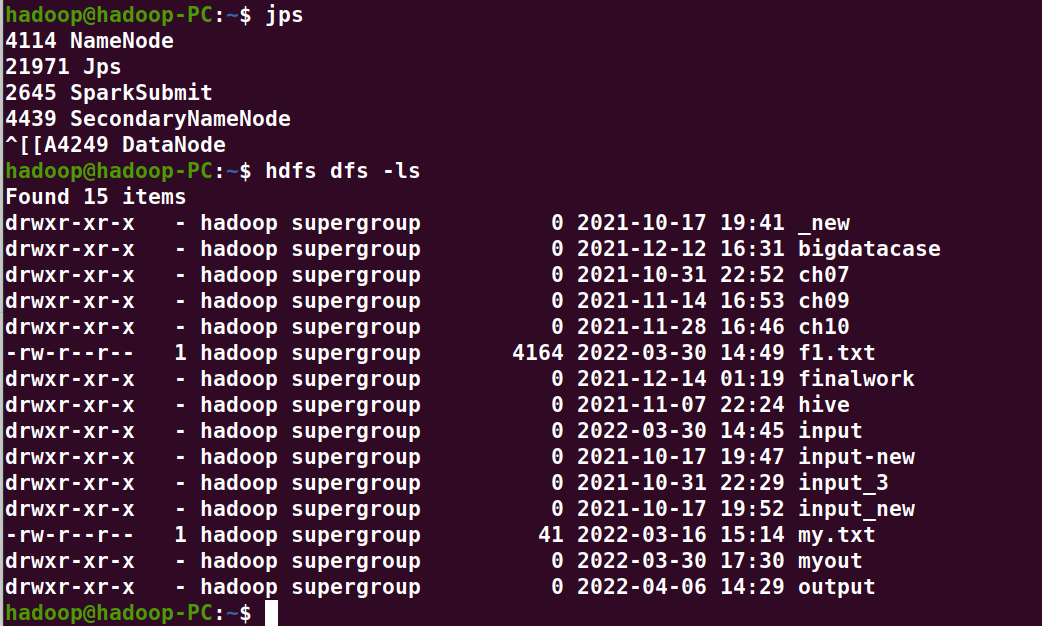
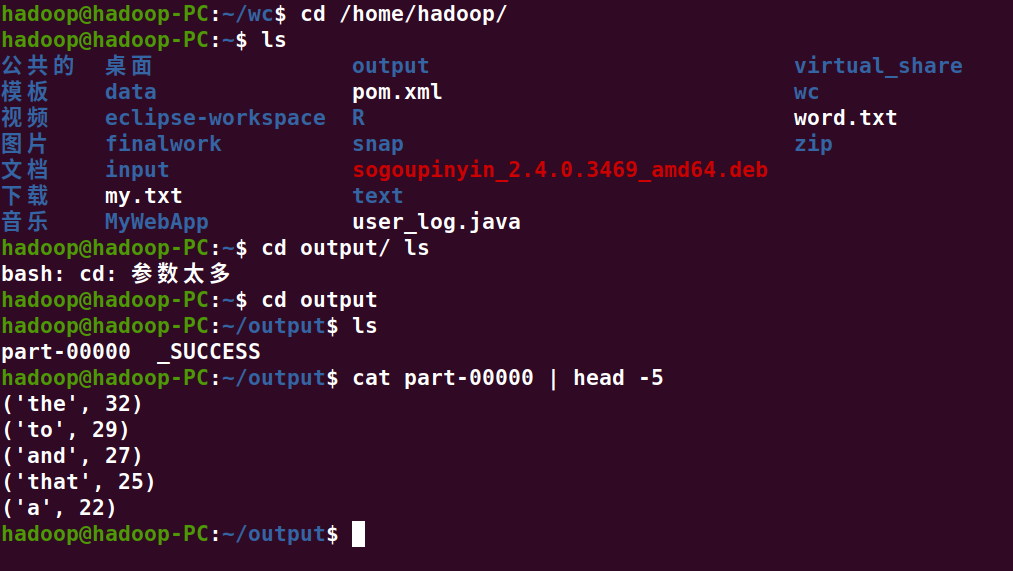
B. 一句话实现:文件入文件出
>>> sc.textFile("file:///home/hadoop/wc/f1.txt").flatMap(lambda line:line.split(" ")).map(lambda word : (word,1)).reduceByKey(lambda x,y : x+y).sortBy(lambda wc:wc[1],False).saveAsTextFile("file:///home/hadoop/output")

C. 和作业2的“二、Python编程练习:英文文本的词频统计 ”进行比较,理解并用自己话表达Spark编程的特点。
1.轻量级快速处理
大数据处理中速度往往被置于第一位,Spark允许传统Hadoop集群中的应用程序在内存中以100倍的速度运行,即使在磁盘上运行也能快10倍。Spark通过减少磁盘IO来达到性能的提升,它们将中间处理数据全部放到了内存中。Spark使用了RDD数据抽象,这允许它可以在内存中存储数据,只在需要时才持久化到磁盘。这种做法大大的减少了数据处理过程中磁盘的读写,大幅度的降低了运行时间。
2.易于使用
Spark支持多语言。Spark允许Java、Scala、Python及R(Spark1.4版最新支持),这允许更多的开发者在自己熟悉的语言环境下进行工作,普及了Spark的应用范围,它自带80多个高等级操作符,允许在shell中进行交互式查询,它多种使用模式的特点让应用更灵活。
3.支持复杂查询
除了简单的map及reduce操作之外,Spark还支持filter、foreach、reduceByKey、aggregate以及SQL查询、流式查询等复杂查询。Spark更为强大之处是用户可以在同一个工作流中无缝的搭配这些功能,例如Spark可以通过SparkStreaming(1.2.2小节对SparkStreaming有详细介绍)获取流数据,然后对数据进行实时SQL查询或使用MLlib库进行系统推荐,而且这些复杂业务的集成并不复杂,因为它们都基于RDD这一抽象数据集在不同业务过程中进行转换,转换代价小,体现了统一引擎解决不同类型工作场景的特点。有关Streaming技术以及MLlib库和RDD将会这之后几个章节进行详述。
二、求Top值
网盘下载payment.txt文件,通过RDD操作实现选出最大支付额的用户。
1、丢弃不合规范的行:
- 空行
- 少数据项
- 缺失数据
>>> lines = sc.textFile("file:///home/hadoop/wc/payment.txt") >>> items = lines.map(lambda a : a.split(',')) >>> items1 = items.filter(lambda item:len([i for i in item if len(i)>0 ]) == 4)

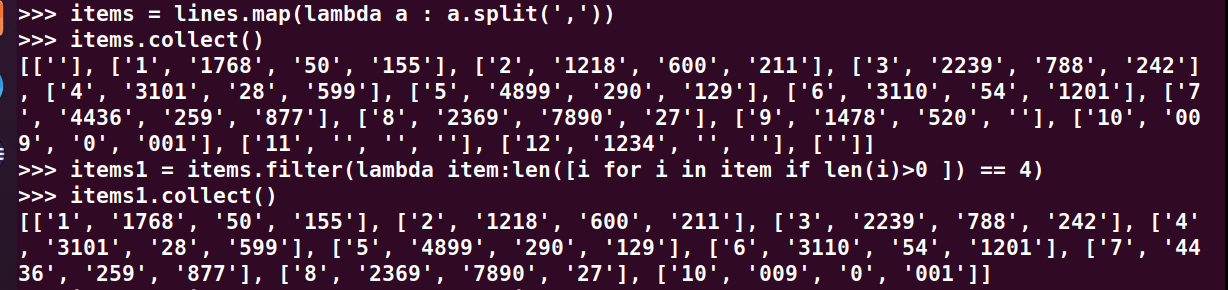
2、按支付金额排序
3、取出Top3
>>> top = items1.sortBy(lambda a : int(a[2]) , False).take(3) >>> top


 浙公网安备 33010602011771号
浙公网安备 33010602011771号