
3.Spark设计与运行原理,基本操作
1、图文阐述Spark生态系统的组成及各组件的功能。
Spark生态圈即BDAS.Spark具有很强的适应性,能够读取HDFS、Cassandra、HBase、S3和Techyon为持久层读写原生数据,能够以Mesos、YARN和自身携带的Standalone作为资源管理器调度job,来完成Spark应用程序的计算。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件,这些组件可以非常容易地把各种处理流程整合在一起,而这样的整合,在实际数据分析过程中是很有意义的。不仅如此,Spark的这种特性还大大减轻了原先需要对各种平台分别管理的依赖负担。下面,通过一张图描述Spark的生态系统,具体如下图1所示。

通过上面图片可以看出,Spark生态系统主要包含Spark Core、Spark SQL、Spark Streaming、MLib、GraphX以及独立调度器,下面对上述组件进行一一介绍。推荐了解黑马程序员大数据培训课程。
(1)Spark Core:Spark核心组件,它实现了Spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core中还包含了对弹性分布式数据集(Resilient Distributed Datasets,RDD)的API定义,RDD是只读的分区记录的集合,只能基于在稳定物理存储中的数据集和其他已有的RDD上执行确定性操作来创建。
(2)Spark SQL:用来操作结构化数据的核心组件,通过Spark SQL可以直接查询Hive、 HBase等多种外部数据源中的数据。Spark SQL的重要特点是能够统一处理关系表和RDD在处理结构化数据时,开发人员无须编写 MapReduce程序,直接使用SQL命令就能完成更加复杂的数据查询操作。
(3)Spark Streaming:Spark提供的流式计算框架,支持高吞吐量、可容错处理的实时流式数据处理,其核心原理是将流数据分解成一系列短小的批处理作业,每个短小的批处理作业都可以使用 Spark Core进行快速处理。Spark Streaming支持多种数据源,如 Kafka以及TCP套接字等。
(4)MLlib:Spark提供的关于机器学习功能的算法程序库,包括分类、回归、聚类、协同过滤算法等,还提供了模型评估、数据导入等额外的功能,开发人员只需了解一定的机器学习算法知识就能进行机器学习方面的开发,降低了学习成本。
(5) GraphX: Spark提供的分布式图处理框架,拥有图计算和图挖掘算法的API接口以及丰富的功能和运算符,极大地方便了对分布式图的处理需求,能在海量数据上运行复杂的图算法。
(6)独立调度器、Yarn、 Mesos: Spark框架可以高效地在一个到数千个节点之间伸缩计算,集群管理器则主要负责各个节点的资源管理工作,为了实现这样的要求,同时获得最大的灵活性, Spark支持在各种集群管理器( Cluster Manager)上运行, Hadoop Yarn、Apache Mesos以及 Spark自带的独立调度器都被称为集群管理器。
Spark生态系统各个组件关系密切,并且可以相互调用,这样设计具有以下显著优势。
(1) Spark生态系统包含的所有程序库和高级组件都可以从 Spark核心引擎的改进中获益。
(2)不需要运行多套独立的软件系统,能够大大减少运行整个系统的资源代价。
(3)能够无缝整合各个系统,构建不同处理模型的应用。
综上所述,Spak框架对大数据的支持从内存计算、实时处理到交互式查询,进而发展到图计算和机器学习模块。Spark生态系统广泛的技术面,一方面挑战占据大数据市场份额最大的Hadoop,另一方面又随时准备迎接后起之秀Flink、Kafka等计算框架的挑战,从而使Spark在大数据领域更好地发展。
2、阐述Spark的几个主要概念及相互关系:
Master, Worker; RDD,DAG;
Application, job,stage,task; driver,executor,Claster Manager
DAGScheduler, TaskScheduler.
基本概念
在开始之前需要先了解Spark中Application,Job,Stage等基本概念,官方给出的解释如下表:
| Term | Meaning |
|---|---|
| Application | 用户编写的Spark应用程序,包括一个Driver和多个executors |
| Application jar | 包含用户程序的Jar包 |
| Driver Program | 运行main()函数并创建SparkContext进程 |
| Cluster manager | 在集群上获取资源的外部服务,如standalone manager,yarn,Mesos |
| deploy mode | 部署模式,区别在于driver process运行的位置 |
| worker node | 集群中可以运行程序代码的节点(机器) |
| Executor | 运行在worker node上执行具体的计算任务,存储数据的进程 |
| Task | 被分配到一个Executor上的计算单元 |
| Job | 由多个任务组成的并行计算阶段,因RDD的Action产生 |
| Stage | 每个Job被分为小的计算任务组,每组称为一个stage |
| DAGScheduler | 根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler |
| TaskScheduler | 将TaskSet提交给worker运行,每个executor运行什么task在此分配 |
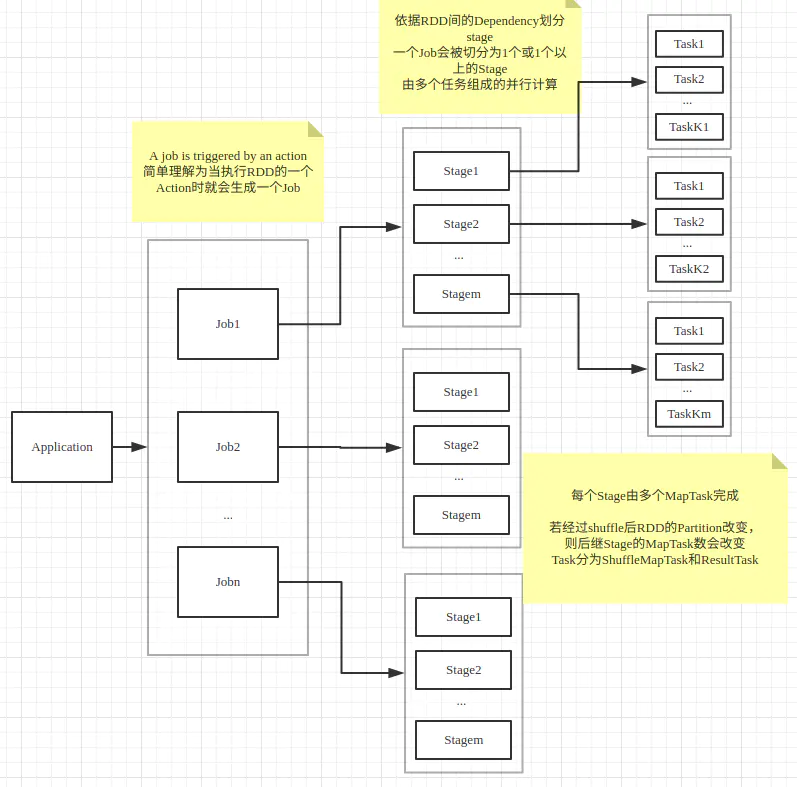
Job-Stage-Task之间的关系
如下图所示,一个Spark程序可以被划分为一个或多个Job,划分的依据是RDD的Action算子,每遇到一个RDD的Action操作就生成一个新的Job。
每个spark Job在具体执行过程中因为shuffle的存在,需要将其划分为一个或多个可以并行计算的stage,划分的依据是RDD间的Dependency关系,当遇到Wide Dependency时因需要进行shuffle操作,这涉及到了不同Partition之间进行数据合并,故以此为界划分不同的Stage。
Stage是由Task组组成的并行计算,因此每个stage中可能存在多个Task,这些Task执行相同的程序逻辑,只是它们操作的数据不同。一般RDD的一个Partition对应一个Task,Task可以分为ResultTask和ShuffleMapTask。
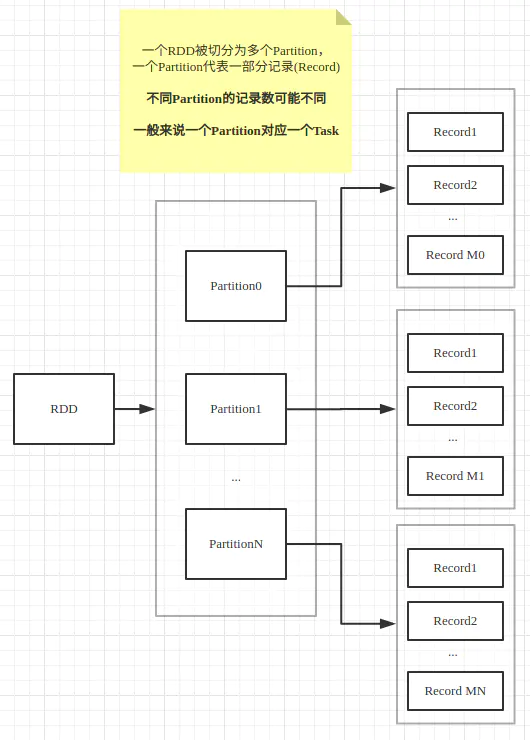
RDD-Partition-Records-Task之间的关系
通常一个RDD被划分为一个或多个Partition,Partition是Spark进行数据处理的基本单位,一般来说一个Partition对应一个Task,而一个Partition中通常包含数据集中的多条记录(Record)。
注意不同Partition中包含的记录数可能不同。Partition的数目可以在创建RDD时指定,也可以通过reparation和coalesce等算子重新进行划分。
通常在进行shuffle的时候也会重新进行分区,这是对于key-valueRDD,Spark通常根据RDD中的Partitioner来进行分区,目前Spark中实现的Partitioner有两种:HashPartitioner和RangePartitioner,当然也可以实现自定义的Partitioner,只需要继承抽象类Partitioner并实现numPartitions and getPartition(key: Any)即可。
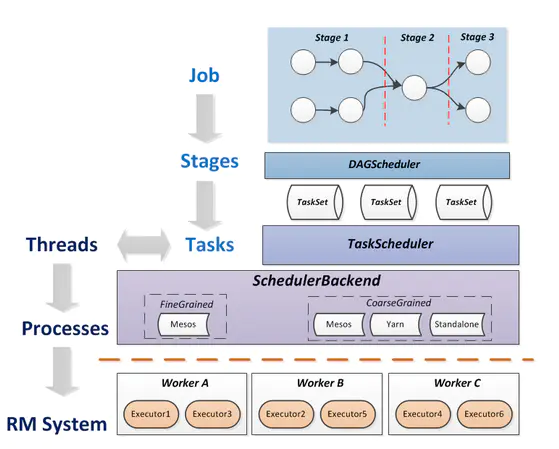
将上面的概念串联起来,可以得到下面的运行层次图:
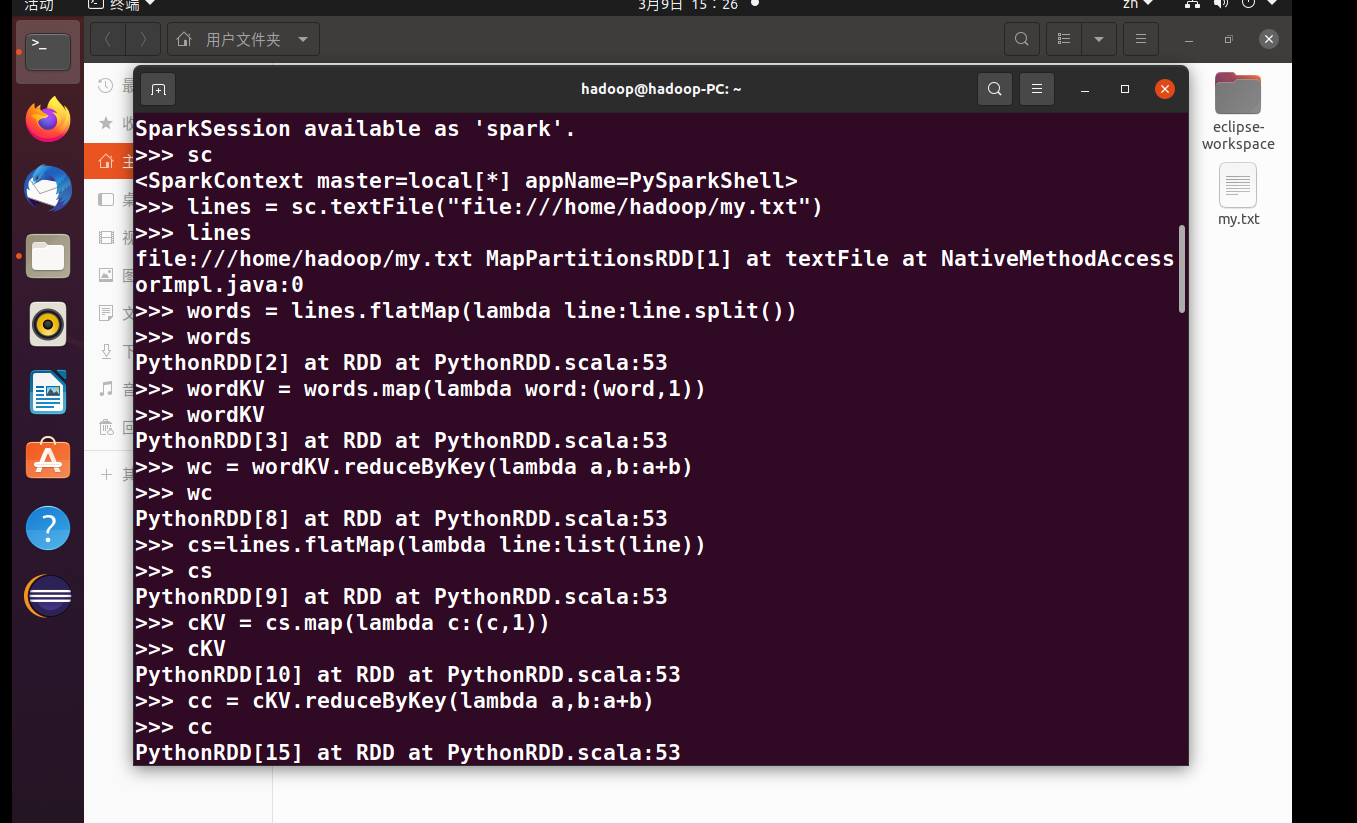
3、在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
>>> sc
>>> lines = sc.textFile("file:///home/hadoop/my.txt")
>>> lines
>>> words=lines.flatMap(lambda line:line.split())
>>> words
>>> wordKV=words.map(lambda word:(word,1))
>>> wordKV
>>> wc=wordKV.reduceByKey(lambda a,b:a+b)
>>> wc
>>> cs=lines.flatMap(lambda line:list(line))
>>> cs
>>> cKV=cs.map(lambda c:(c,1))
>>> cKV
>>> cc=cKV.reduceByKey(lambda a,b:a+b)
>>> cc
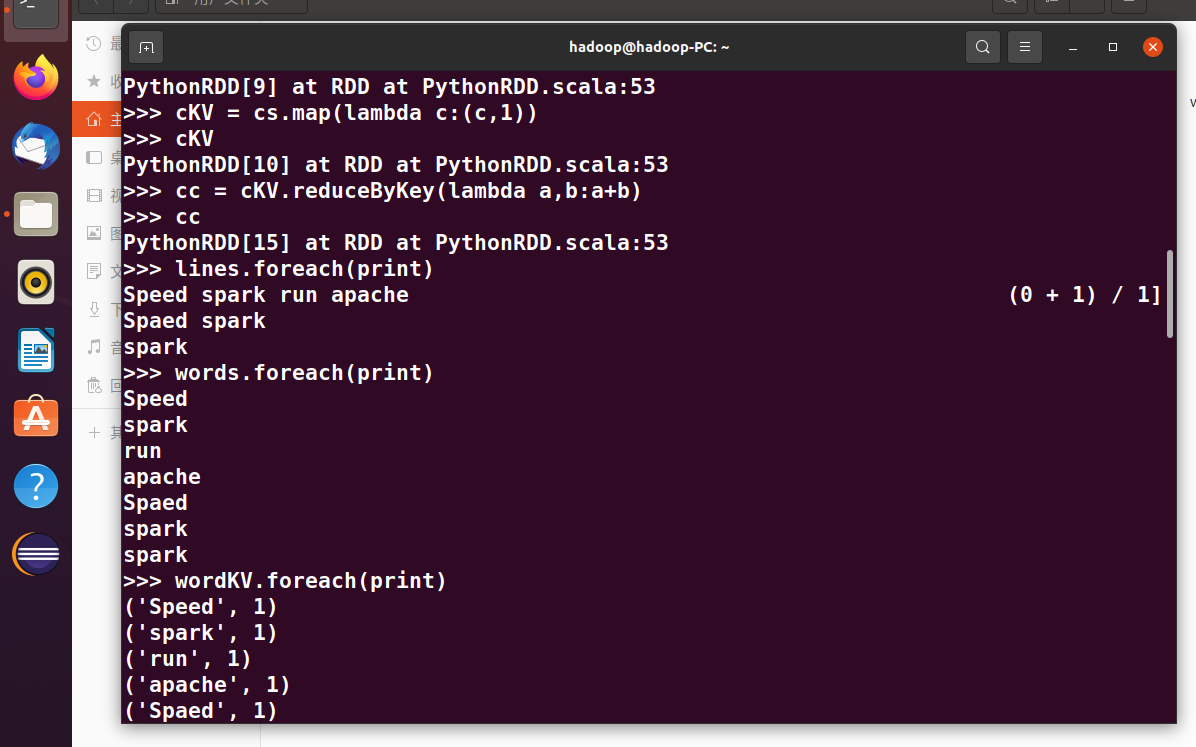
>>> lines.foreach(print)
>>> words.foreach(print)
>>> wordKV.foreach(print)
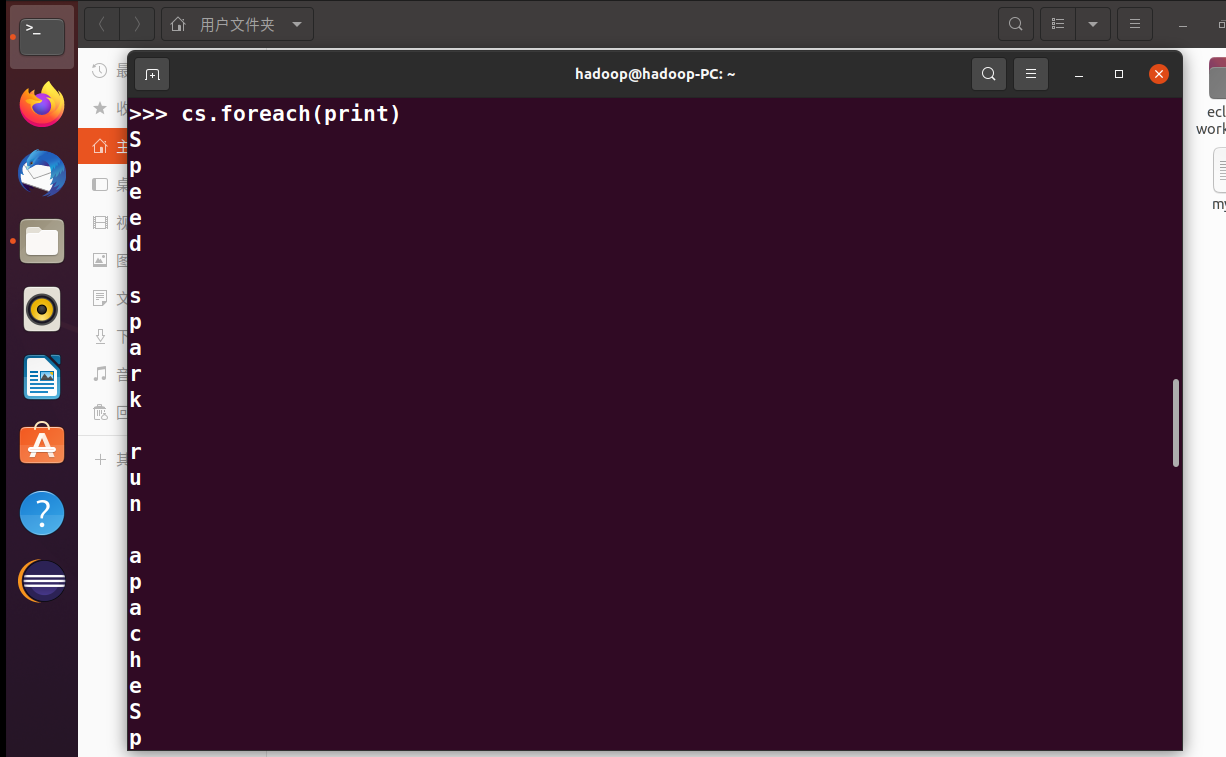
>>> cs.foreach(print)
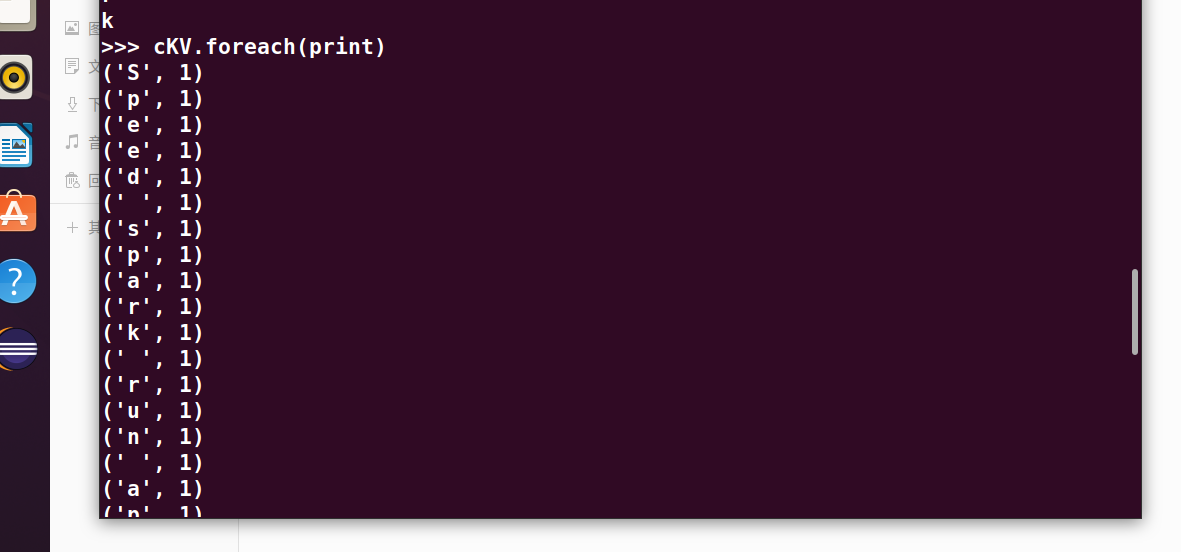
>>> cKV.foreach(print)
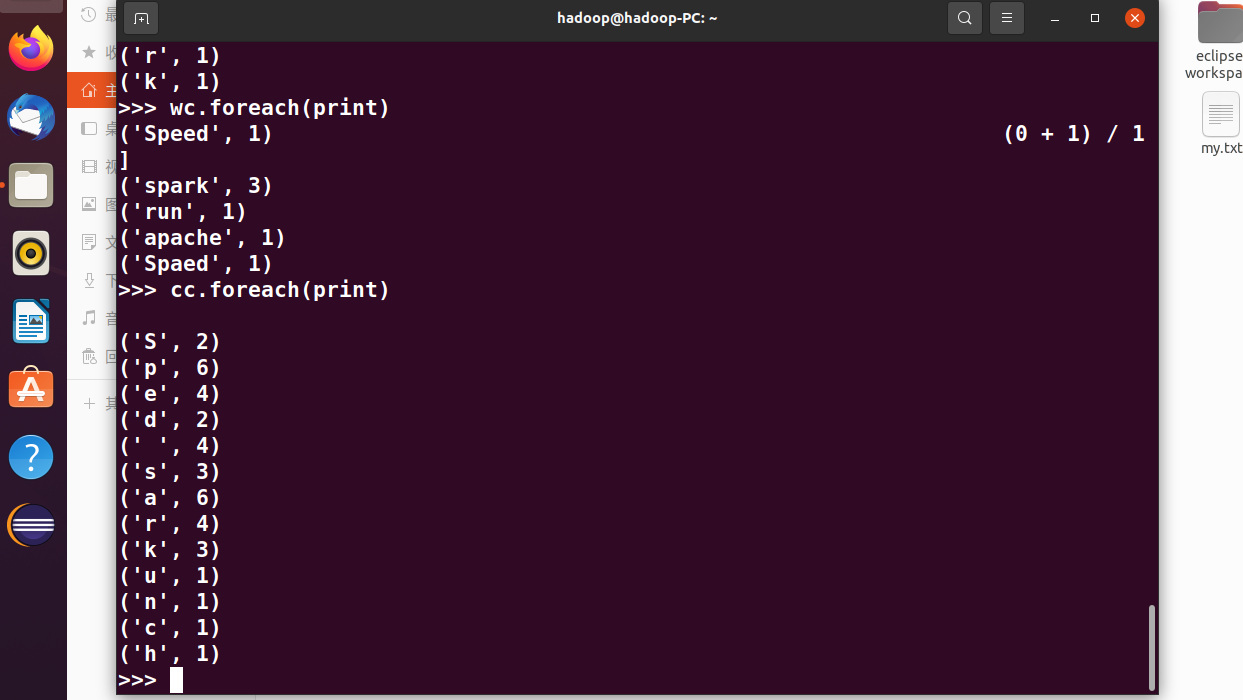
>>> wc.foreach(print)
>>> cc.foreach(print)
自己生成sc
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc=SparkContext(conf=conf)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号