
6. RDD综合练习:更丰富的操作
一、集合运算练习
union(), intersection(),subtract(), cartesian()
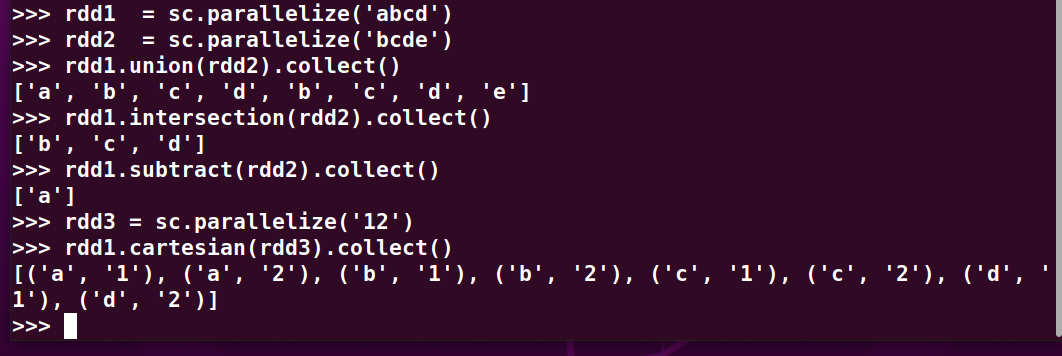
>>> rdd1 = sc.parallelize('abcd')
>>> rdd2 = sc.parallelize('bcde')
>>> rdd1.union(rdd2).collect()
>>> rdd1.intersection(rdd2).collect()
>>> rdd1.subtract(rdd2).collect()
>>> rdd3 = sc.parallelize('12')
>>> rdd1.cartesian(rdd3).collect()
二、内连接与外连接
join(), leftOuterJoin(), rightOuterJoin(), fullOuterJoin()
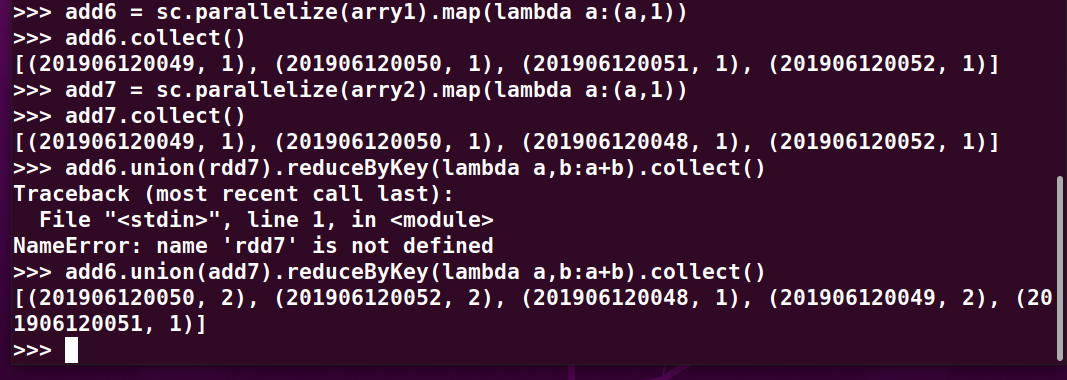
>>> arry1 = [201906120049,201906120050,201906120051,201906120052]
>>> arry2 = [201906120049,201906120050,201906120048,201906120052]
>>> rdd4 = sc.parallelize(arry1).map(lambda line :(line,'06'))
>>> rdd4.collect()
>>> rdd5 = sc.parallelize(arry2).map(lambda line :(line,'07'))
>>> rdd5.collect()
>>> rdd4.join(rdd5).collect()
>>> rdd4.leftOuterJoin(rdd5).collect()
>>> rdd4.rightOuterJoin(rdd5).collect()
>>> rdd4.fullOuterJoin(rdd5).collect()

多个考勤文件,签到日期汇总,出勤次数统计
>>> add6 = sc.parallelize(arry1).map(lambda a:(a,1))
>>> add6.collect()
>>> add7 = sc.parallelize(arry2).map(lambda a:(a,1))
>>> add7.collect()
>>> add6.union(add7).reduceByKey(lambda a,b:a+b).collect()
三、综合练习:学生课程分数
网盘下载sc.txt文件,通过RDD操作实现以下数据分析:
- 持久化 scm.cache()
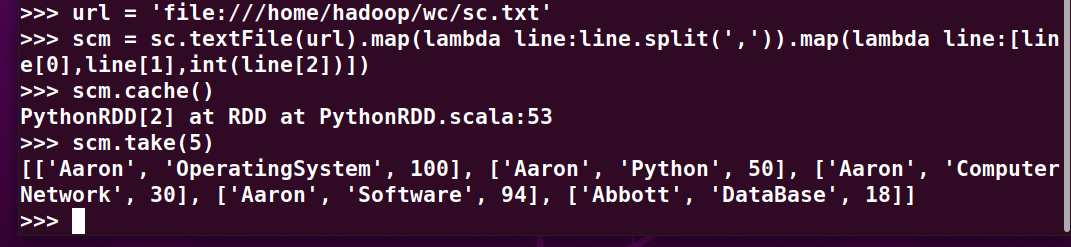
>>> url = 'file:///home/hadoop/wc/sc.txt'
>>> scm = sc.textFile(url).map(lambda line:line.split(',')).map(lambda line:[line[0],line[1],int(line[2])])
>>> scm.cache()
>>> scm.take(5)
- 总共有多少学生?map(), distinct(), count()
>>> scm.count()
>>> scm.map(lambda line : line[0]).distinct().count()

- 开设了多少门课程?
>>> scm.map(lambda line : line[1]).distinct().count()

- 生成(姓名,课程分数)键值对RDD,观察keys(),values()
>>> name = scm.map(lambda line:(line[0],(line[1],line[2])))
>>> name.take(5)

- 每个学生选修了多少门课?map(), countByKey()
>>> name.countByKey()

- 每门课程有多少个学生选?map(), countByValue()
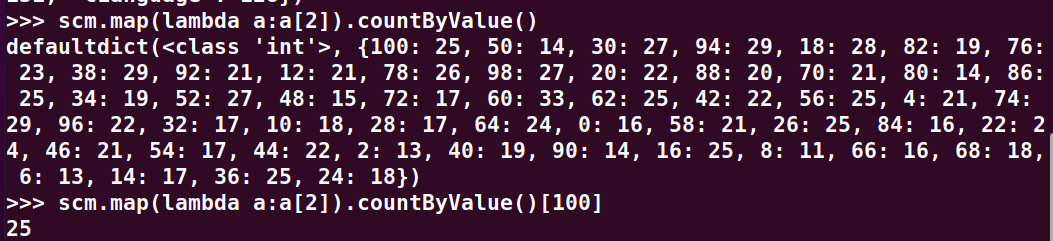
>>> name.values().countByKey()
>>> scm.map(lambda a:a[1]).countByValue()


- 有多少个100分?
>>> scm.map(lambda a:a[2]).countByValue()
>>> scm.map(lambda a:a[2]).countByValue()[100]
- Tom选修了几门课?每门课多少分?filter(), map() RDD
>>> scm.filter(lambda a:a[0]=='Tom').collect()

- Tom选修了几门课?每门课多少分?map(),lookup() list
>>> name = scm.map(lambda line:(line[0],(line[1],line[2])))
>>> name.lookup('Tom')

- Tom的成绩按分数大小排序。filter(), map(), sortBy()
>>> scm.filter(lambda a:a[0]=='Tom').sortBy(lambda line:line[2]).collect()

- Tom的平均分。map(),lookup(),mean()
>>>import numpy as np
>>> np.mean(scm.filter(lambda a:a[0]=='Tom').map(lambda a:a[2]).collect())

- 生成(姓名课程,分数)RDD,观察keys(),values()
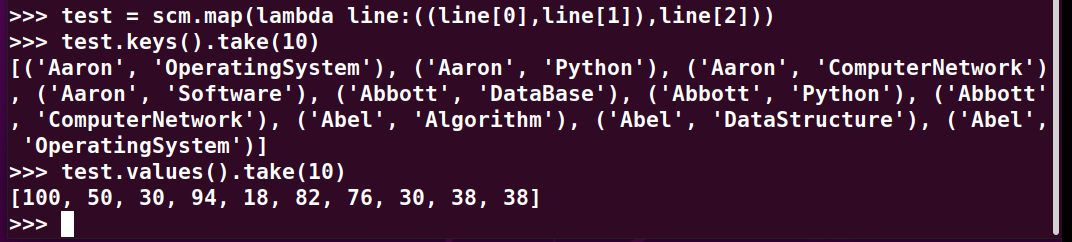
>>> test = scm.map(lambda line:((line[0],line[1]),line[2]))
>>> test.keys().take(10)
>>> test.values().take(10)
- 每个分数+5分。mapValues(func)
>>> test = scm.map(lambda line:((line[0],line[1]),line[2]))
>>> test.mapValues(lambda a:a+5).take(3)

求每门课的平均分
- lookup(),np.mean()实现
>>> course = scm.map(lambda line:(line[1],line[2])) >>> import numpy as np >>> np.mean(list(map(int,course.lookup('OperatingSystem'))))

- reduceByKey()和collectAsMap()实现
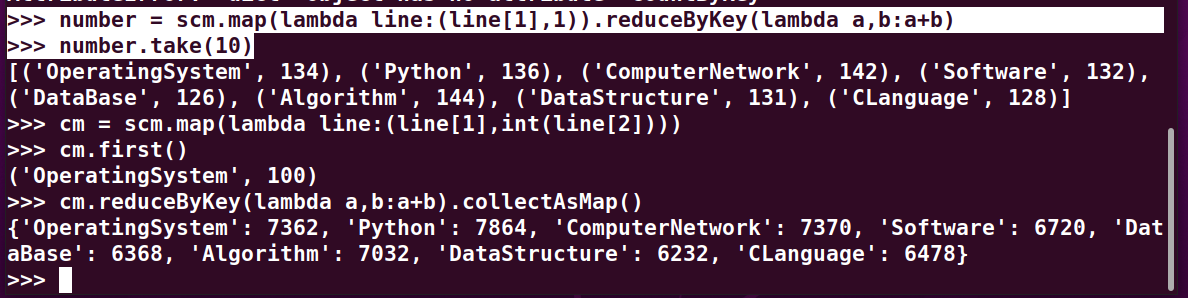
>>> cm = scm.map(lambda line:(line[1],int(line[2]))) >>> cm.first() >>> cm.reduceByKey(lambda a,b:a+b).collectAsMap() >>> number = scm.map(lambda line:(line[1],1)).reduceByKey(lambda a,b:a+b) >>> number.take(10)
- combineByKey(),map(),round()实现,确到2位小数
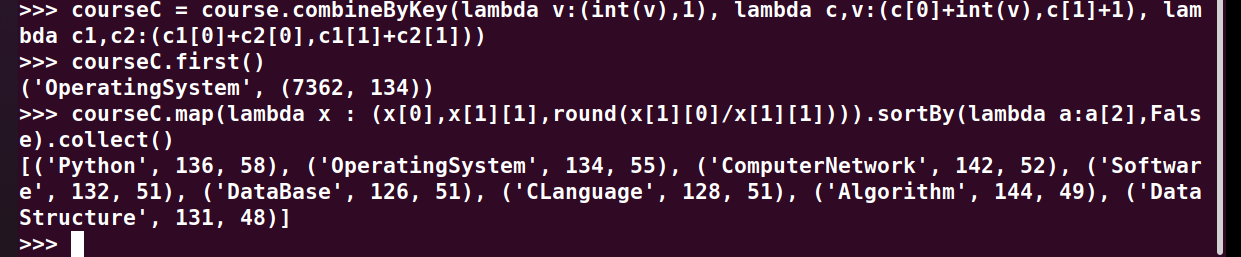
>>> courseC = course.combineByKey(lambda v:(int(v),1), lambda c,v:(c[0]+int(v),c[1]+1), lambda c1,c2:(c1[0]+c2[0],c1[1]+c2[1])) >>> courseC.first() >>> courseC.map(lambda x : (x[0],x[1][1],round(x[1][0]/x[1][1]))).sortBy(lambda a:a[2],False).collect()
- 比较几种方法的异同。
用lookup(),np.mean()实现来实现求课程的平均分,他是通过python语句来导包用mean()方法来实现的,如果想列出全部课程的平均分就得通过循环来实现;
reduceByKey()和collectAsMap()来实现求课程的平均分,就累列出两个rdd出来一个为(课程,总分),一个为(课程,总人数)然后通过写循环语句的实现;
combineByKey(),map(),round()实现课程的平均分则不用那么麻烦,可以把将实现课程的平均分的函数直接写在combineByKey()方法内,不用写循环语句。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号