实时阴影技术(2)Shadow Ray & Shadow Volume
Shadow Ray 概述
shadow mapping 系列技术(PCF、PCSS、VSSM 等)的原理在于从光源发出 ray(通过光栅化方式实现)来记录最近的物体深度,并将与 shading point 的深度比大小来判定 shading point 是否被遮蔽;而 shadow ray 思路恰好相反,但更直观:从 shading point 出发向光源发射 ray 来检测 shading point 是否被遮蔽。
两种方式各有利弊,前者的主要缺陷在于记录的 shadow map 分辨率是有限的,容易精度不够;后者的主要缺陷在于 ray tracing 的开销可能会很大。当然,在一些工业界方法也存在结合两种方式的混合方法。本文将主要讲解 shadow ray 相关技术,并适当扩展一些。
当然 ray tracing 的方式有很多种,这里仅讲解一部分 ray tracing 方式应用于 shadow ray 的内容。
Distance Field Soft Shadows(DFSS)
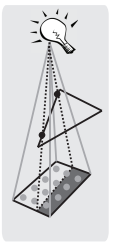
DFSS 是一种依赖 SDF 的 shadow ray 技术,它将点 \(o\)(Shading Point)与光源面中心点 \(p_{light}\) 相连形成一条方向为 \(l\) 的中心线段,而这条中心线上各个点 \(p_i\) 都可以通过 SDF 查得与其最近几何物体的距离并且推算出安全角度(点\(o\) 能打到光源面的直线与中心线的最大夹角)为 \(\theta_i = arcsin \frac{\operatorname{SDF}(p_i)}{p_i-o}\)
那么所有这些点中对应的安全角度之中取最小的安全角度 \(\theta = min\{\theta_i\}\) ,这个安全角度与最大角度的比例决定了光源面的光照覆盖率,也就决定了点 \(o\) 的Visibility。

计算某个点 \(p_i\) 的安全角度时,直观的几何关系便是:
而在实践中,往往会使用:
这样的近似公式实际效果相当接近原几何关系,而且也能减少复杂的 arcsin 运算开销,最后它还能通过 \(k\) 这个参数来调整阴影的硬软程度。
如下图分别为 \(k=32\) 、\(k=8\)、\(k=2\) 的效果:

具体算法过程:
-
将 \(o\) 点(shading point)设为第一个步进点,即 \(p_0 = o\)
-
每次算出下一个步进点 \(p_{i+1} = p_{i} + l \cdot SDF(p_{i})\) 并记录安全角度 \(\theta_i = \min \left\{\frac{k \cdot \operatorname{SDF}(p_i)}{p_i-o}, 1.0\right\}\)
-
重复 "步骤2",直到满足 \(l \cdot (p_{i+1}-p_{light}) < 0\) (即意味着已经步进到光源点背面了)
-
取所有次步进的最小安全角度 \(\theta = min\{\theta_i\}\) ,则可见度则为 \(Visibility = \frac{\theta}{c}\) (其中 \(c\) 为点 \(o\) 与光源面连接的最大角度)

使用 Distance Field Soft Shadows 的好处很多:
- 计算阴影很快(假设已经生成了SDF的情况下,比传统Shadow Mapping类技术是要快的多)
- 阴影质量很高,而且完美解决 Shadow Ance / Peter Panning / 采样噪声等传统Shadow Mapping会出现的问题
然而代价是:
- SDF 需要预计算,这就意味着场景物体需要是静态的,当然也可以使用一些算法使能和动态物体相结合,尽量减少重新生成SDF的成本。
- SDF 需要较大的存储空间(一般采用三维数组表示空间各个网格的SDF值,但是可以使用八叉树等空间数据结构或者其它方法做进一步优化)。
- 仍可能会导致错误的阴影效果:不能把安全角度与最大角度的比例简单地当成是光照覆盖率,例如一条细长的线碰到了 marching 路径从而导致安全角度为 0,但此时不能认为 shading point 没有光照(因为一条细线只是占了一点点光照面积)。
Hybrid Frustum-Traced Shadows(HFTS)[2016]
该方法被应用于育碧的《全境封锁》游戏中。
Irregular Z-Buffer(IZB)Pass
传统 shadow map 方法中,pixels 和 ligth space(其实就是 shadow map 空间)texels 的对应关系往往不是平衡的:可能会多个 pixels 映射到同一个 light space 的 texel 中,从而造成采样率不够的现象。
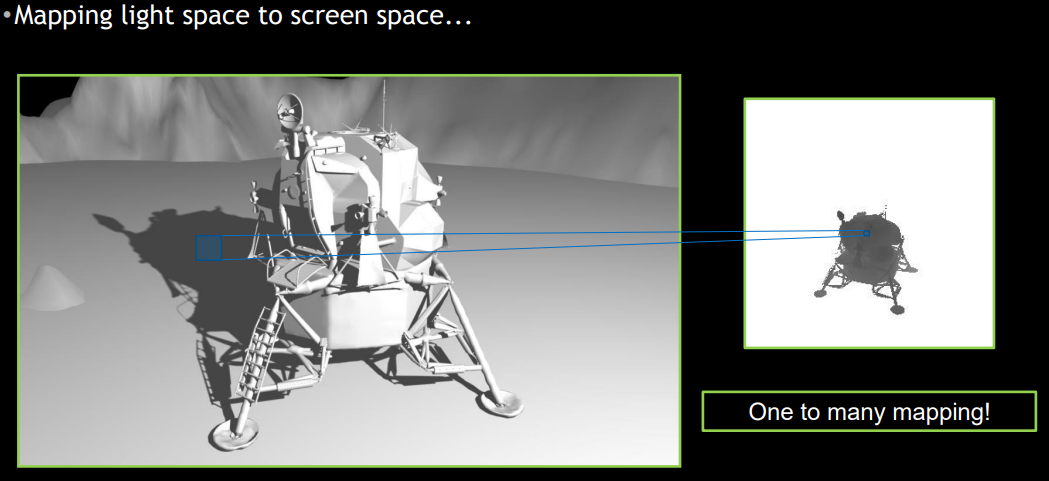
最直观的做法就是增大 shadow map 分辨率以让每个 light space texel 被尽可能少的 pixel 所映射,当然这种通过增加分辨率来无脑增加采样数的做法肯定是不可取的。而在 frustum-traced shadows 方案中,将会利用 IZB 来让每个 light space texel 都拥有自己的 pixels list,并通过后续的 frustum tracing 遍历列表来增加采样数,实现高质量阴影。
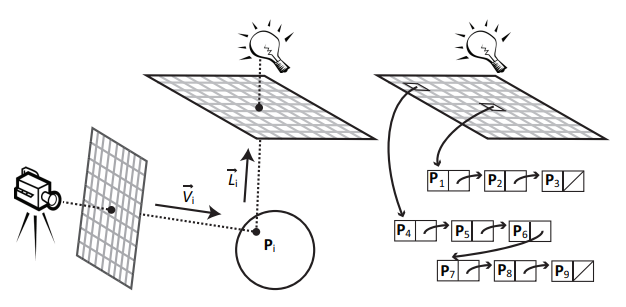
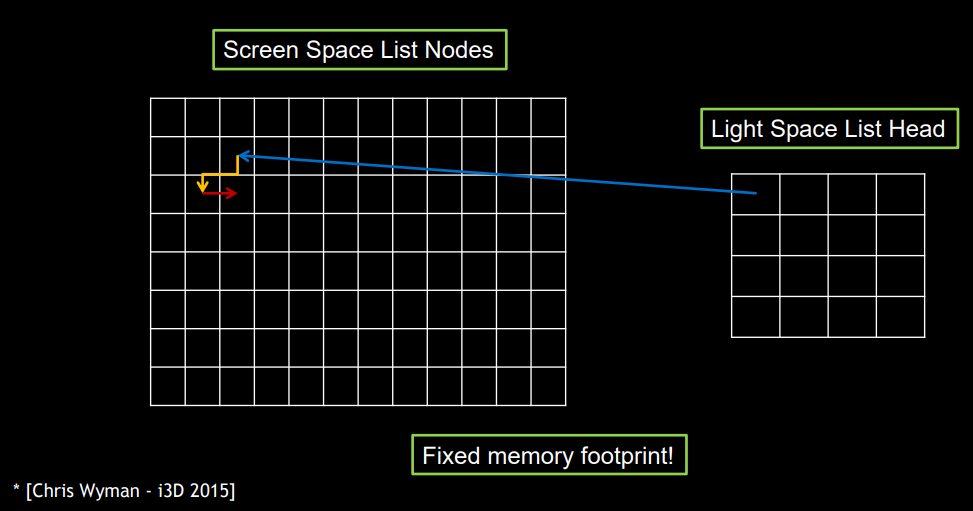
首先,我们有一张屏幕空间的 list node map + light space 的 list head map。
- list head map 需初始化每个 texel 值为 null 标记。
IZB Pass 所做的便是进行一次 full-screen pass,该 pass 需要依赖 depth buffer 的输入:
- 将 pixel 变换到 light space 后会对应某个 light space texel,然后当前 pixel 位置与该 light space texel 中的内容进行原子交换操作,交换后得到的值实际相当于 next node(可能是 null 标记,也可能是别的 pixel 位置)。
- 将本 pixel 得到的 next node 值写入到 list node map。
当生成了 IZB 后,相当于知道了 light space 每个 texel 对应有哪几个 pixels。
Frustum Tracing Pass
不过这里需要强调,pixel 在世界空间中的实际形式是 quad。我们去计算 pixel 的 shadow factor 实际上就相当于在进行 frustum tracing:pixel quad 有多少面积比例被 casters 遮挡(更具体地,一般是在 quad 上放置有限的样本点,测试有多少样本点被遮挡)。
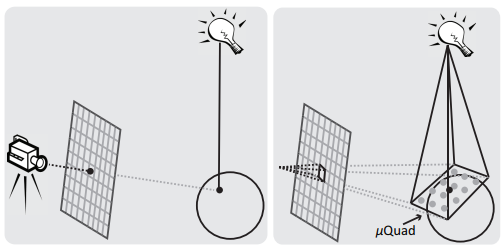
首先,我们有一张屏幕空间的 visibility mask texture 来表示每个 pixel 的 visibility。
Frustum Tracing Pass 所做的便是在 light space 下对所有 casters 进行保守光栅化(conservative rasterization),然后在 fragment shader 中遍历对应的 pixels list,依次对每个 pixel quad:
- 进行 frustum-triangle test,这个操作比较费计算量,因此 paper 采用了如下实现:
- 每个三角形的边投影到 quad 上,并将投影后的边(已经变成了2D向量)扔去 LUT 查表直接得到 quad 上各个样本点的可见性。
- 将通过测试的样本结果利用原子OR操作写入到 visibility mask texture 对应的 pixel 位置。
通过 frustum tracing pass,我们就有了一张屏幕空间的 visibility mask texture(来决定每个 pixel 的 visibility)。
甚至可以在后续计算直接光照时启用 early stencil test 来剔除掉不必要计算直接光照的 pixels。
Shadow Map Z-Prepass
但是可以想到, frustum tracing pass 的计算复杂度是 casters 所产生的 light space fragments 数量乘上单个 list 里 pixel quads 的数量。
- 为了避免过多的 fragments,作者建议应当在 Frustum Tracing Pass 之前 先进行一个 Shadow Map Z-Prepass(这个实际上和正常的 shadow map depth pass 没啥区别,也不需要保守光栅化)
- 通过 shadow map z-prepass 先绘制一遍深度后,后续的 frustum tracing pass 就可以开启 early-z 剔除掉大量 fragments。这样计算复杂度就变成了 light space pixels 数量乘单个 list 里 pixel quads 的数量。
Hybrid
- Frustum-traced IZB 虽然效果准确,但是只能提供硬阴影效果。
- 而 HFTS 实际上就是根据与的 occluder 距离,来混合 Frustum-traced IZB 和 PCSS 的结果。
- Frustum-traced IZB 开销较为昂贵,因此在 frustum tracing pass 中最好只处理部分重要的 casters 而非所有 casters。
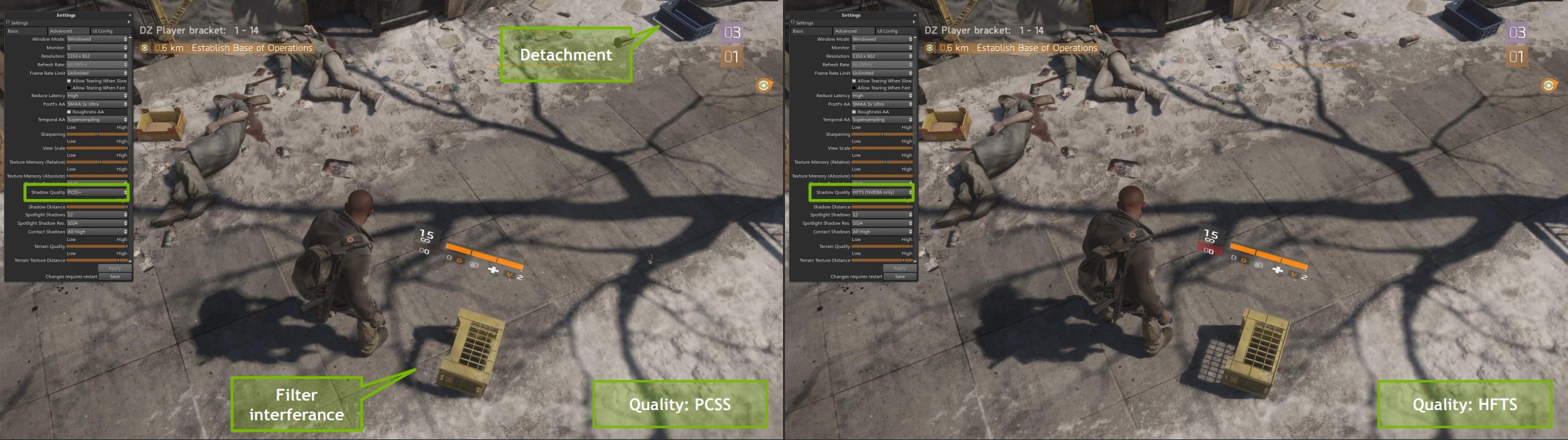
Contact Shadows
接触阴影(Contact Shadows)是用一条从 shading point 朝光源方向的 ray 去做遮挡测试,用于补足传统 shadow map 在近处/细节处的阴影缺失。但该 ray 只能在 screen space 上进行 marching,因此本质上是一种 SSRT(screen space ray tracing)版的 shadow ray。
而接触的含义在于 Contact Shadows 很适合用于补足物体与地面/墙面接触处那种非常细、非常近的阴影(例如植被与地面等)。这类阴影对分辨率非常敏感,而传统 shadow map 方法往往会因为 texel 尺寸、深度精度、bias 等因素变糊或者断掉。

但注意的是,Contact Shadows 往往只是一种补充高精度阴影的手段:因为屏幕信息是有限的(例如无法感知屏幕外的 occluder),它不能承担完全的阴影效果职责。
为此,我们往往需要将其和另一些阴影方法搭配使用,例如最主流的搭配方式是 shadow map + contact shadows:shadow map 因为其阴影深度分辨率有限,在离摄像机近的物体上呈现的阴影效果往往是大颗锯齿状,此时利用 contact shadow 可以补充 pixel 粒度(高精度)的阴影效果。
Hi-Z Marching/Linear Marching
shadow ray 不需要知道精确的 hit point,而只需要知道是否相交(是否被遮挡了)了,因此和 SSRT 相比可以有一些更激进的 marching 策略。
Contact Shadows 基本上有两种 ray marching 方式:
-
基于 hi-z 的 marching:(和 SSRT 基本一致)效果精确,开销还行。
-
linear marching:固定大步走性能往往更好,大部分时候都够用,但少数 case 下可能会穿过薄物体造成效果失真。而小步走性能又会不如 hi-z marching。
为什么性能更好?因为 hi-z 每次 marching 的步长都需要依赖上一次 marching 的结果,而 linear marching 每次 marching 步长都是独立的,可以并行执行多次 marching 所产生的采样指令,更好的隐藏采样所带来的 latency。
-
结合两种方式。
SMRT(Shadow Map Ray Tracing)
SMRT 和 Contact Shadows 思路非常相似,也是从 shading point 朝光源方向进行 ray marching,只不过这次不是在 screen space 上,而是在 shadow map space 上进行。
因此 SMRT 往往需要和 shadow map 方法进行结合,例如 UE5 就是提供了可以在 CSM/VSM 上进行 SMRT 的方式。
Shadow Map Space Contact Hardening Shadows [2023]
来自GDC2023《战神:诸神黄昏》Santa Monica Studio 的分享。
传统 PCF/PCSS 是一种实现软阴影的 trick,真正 ground truth 的软阴影效果应当是对整个光源面积进行采样,而非用固定单个样本点来计算(shadow map 就是从光源中心点来生成的,只考虑了单个点的 visibility 关系)。因此要实现接近 ground truth 的软阴影最好使用方便在光源面积上采样的 shadow ray 技术。
在古早的 paper 中,也有人尝试过生成多个 shadow map(相当于光源面积上的几个样本点),但是很容易想象到其性能开销有多爆炸。
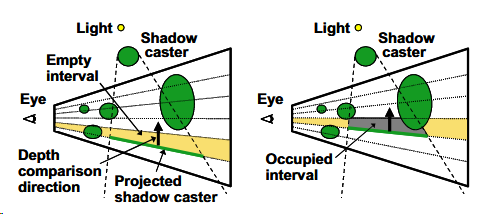
Santa Monica Studio 采用了 shadow map space 的 ray marching 技术来实现 shadow ray,但稍微不同的是每次 marching 后,并不是简单的直接根据和 shadow depth 比大小的结果来判断是否被遮蔽,而是:
- shading point 的 z 值和 marching 后对应的 shadow depth 比大小的结果记为 \(b_{s}\)
- marching 后的 z 值和 marching 后对应的 shadow depth 比大小的结果记为 \(b_{m}\)
- 只有 \(b_s \neq b_m\) 时才视为该次 marching 被遮蔽。
如下图,左边和中心两条 shadow ray 都在 marching 过程中出现遮蔽情况,而右边 shadow ray 怎没有被遮蔽。
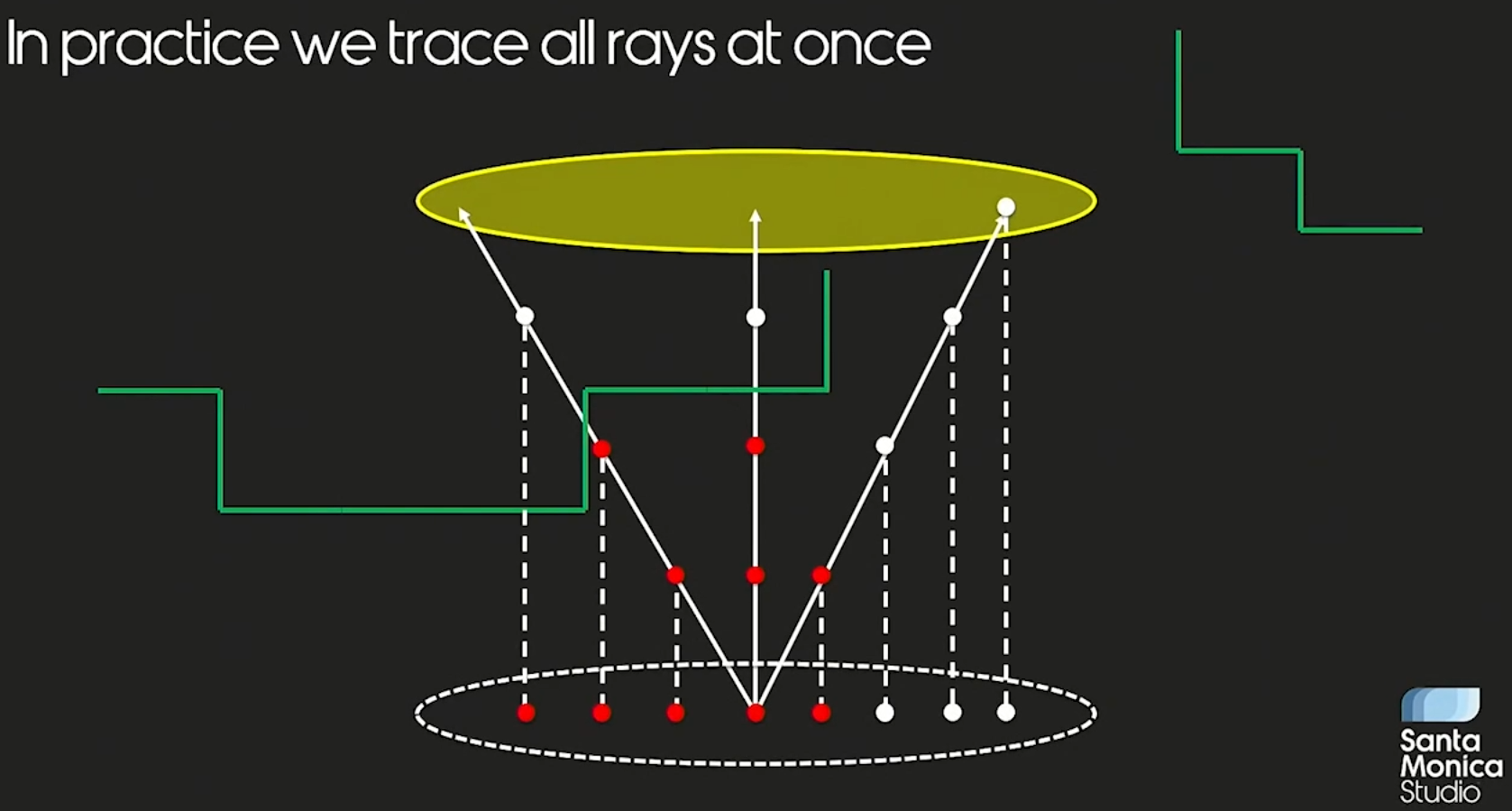
这种遮蔽判断方法,在比较多细物体(如绳子、树叶)的情况下可以更加 ground truth 的表示软阴影,效果比 PCF/PCSS 类算法高一个档次。

Shadow Volumes 概述
实际上,除了 shadow map 和 shadow ray 两大类方法,还有第三类更古老的方法:shadow volumes。其算法核心在于为计算出每个 caster 所遮挡的体积(阴影体积),在判定 shading point 是否被遮挡时,实际上就是在计算 shading point 是否在 shadow volumes 内部(在内则意味着被遮蔽,在外意味着没有被遮蔽)。
Point in Polygon Strategies
为了判断 shading point 是否在 volumes 内部,实际上就是一个 point in polygon 问题(判断点是否在一个多边形内部)。
而图形学中一个最常用的算法是基于 ray casting,其思路是:作一射线从该点往任意方向投射,如果射线与多边形边的相交次数为奇数,则点在多边形之内;否则,点则在多边形之外。
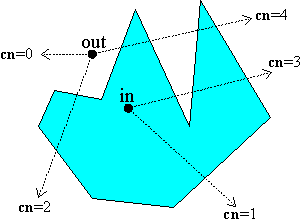
当然针对 point in polygon 问题,还可以有其它算法(例如另一个更常见的算法则是 winding number)或者改进策略(Point in Polygon Strategies (realtimerendering.com))。但是本文将主要介绍基于 ray casting 的 point in polygon 算法,这是因为显卡提供了光栅化硬件,利用光栅化与光线追踪的对偶性,可以让我们高效使用该算法:
将 shadow volumes 视为 mesh 并进行两次 draw(如图所示),
- 第一次 draw 只绘制正面,并设置模板测试状态为深度测试成功时将模板值+1(其实就是将深度测试通过的点视为相交点,利用 stencil 来增加计数)。
- 第二次 draw 只绘制背面,并设置模板测试状态为深度测试成功时将模板值-1(因为硬件中的模板测试不包含判断奇数偶数,因此这里使用了减法来抵消计数)
这两次 draw call 的 pixel shader 内容均为空,因为只是单纯在利用深度测试&模板测试硬件,无需写入别的东西。
最后得到的 stencil buffer 中,若模板值为 0 意味着该 pixel 不被遮蔽,若模板值为其他数值则意味着该 pixel 在阴影体积内部。这样就可以给后续的直接光照着色阶段使用。
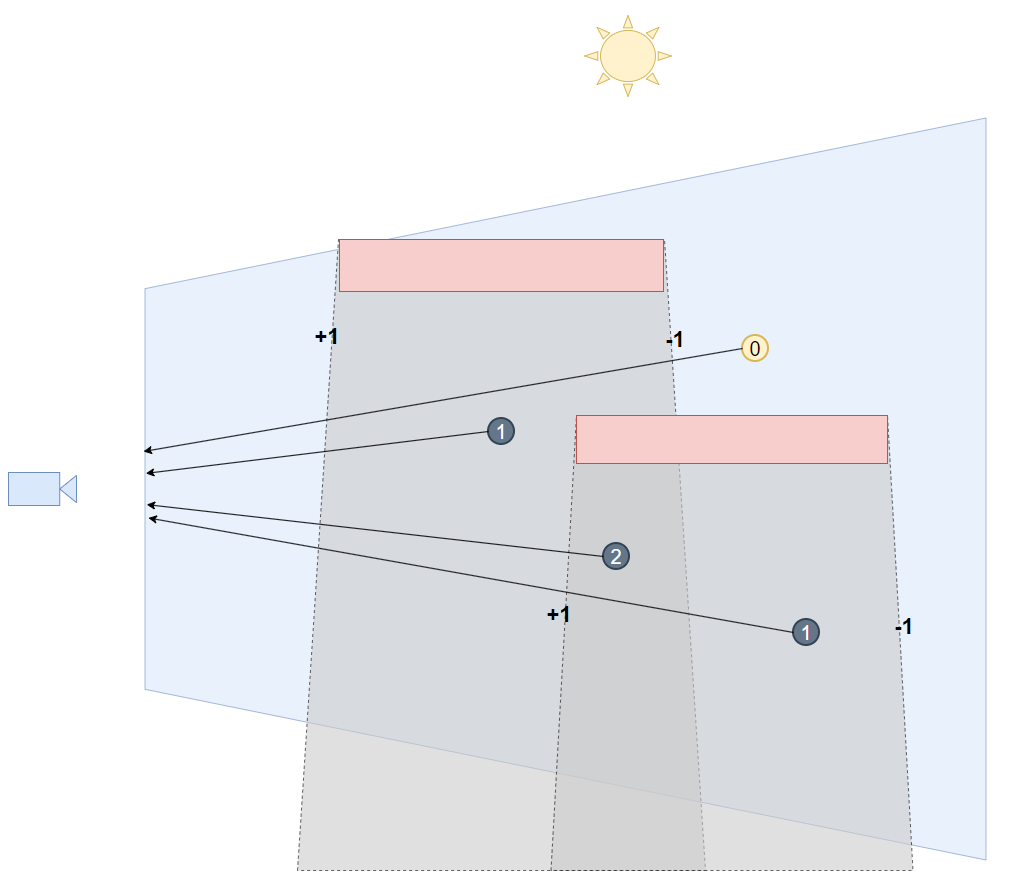
Z-Fail
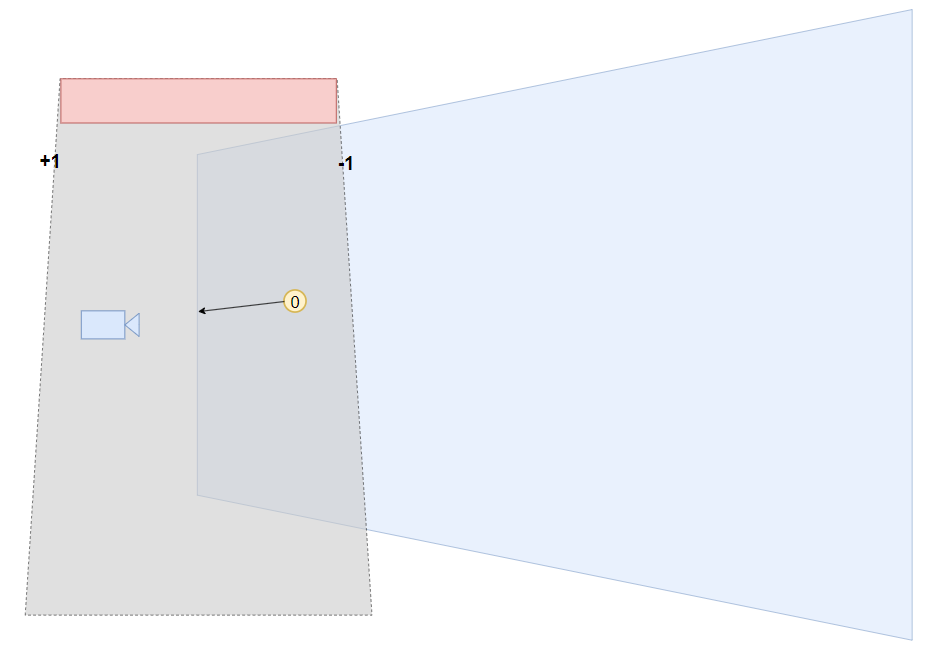
然而上述 naive 光栅化方法是存在 failure case 的,即一旦 shadow volumes 与摄像机的 near plane 相交时, 很可能会错误地被光栅化硬件剔除了正面,从而导致 stencil 计数错误。
如下图所示,该点位于 shadow volumes 内部,本应该是被遮蔽的,却因为剔除掉了 volume 的正面,计数并没有呈现出所期望的“1”。
z-fail 算法:其实只要稍微逆转一下思维,我们将之前 naive 方法中的 “深度测试成功时” 统统换成 “深度测试失败时”,将可以解决该问题:深度测试失败的点意味着射线是往远平面投去,并且因为远平面往往设置在较远的位置,基本上 shadow volumes 是不会接近远平面的(更何谈相交)。
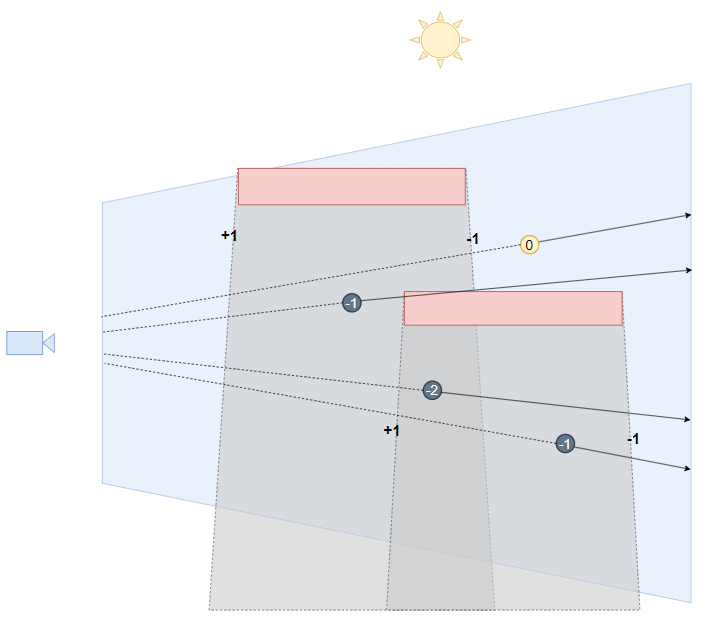
该算法最早于 1998 至 2000 间被多人使用,而后 John Carmack 将其发扬光大并集成于 Doom3 的引擎中,因此也被称为 Carmack's Reverse 算法。卡神,又是你..
CC Shadow Volumes [2004]
由于每个物体都会产生 shadow volume,在复杂场景下 shadow volume 的 draw call 次数会变得很多,并且每个 volume 都可能生成大量的 fragments。我们初衷本来是想通过 shadow volumes 的方式减少需要计算直接光照的 pixels 数量(减少 pixel shader 负载),但是却为此大幅度增加了光栅化与深度&模板测试的负载(太多 fragments 生成了),这是非常不划算的。
CC Shadow Volumes 旨在利用各种 culling/clamping 技巧来尽可能减少 volume 的体积,从而减少 fragments 数量的生成。
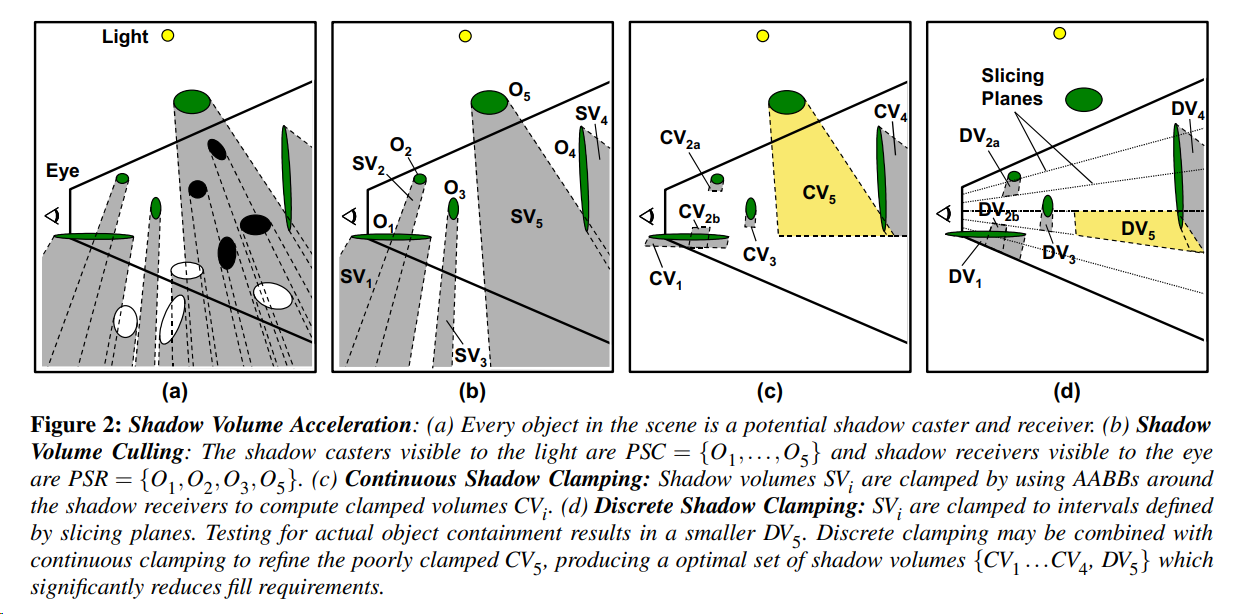
步骤:
-
一开始,场景中的所有物体都是潜在的 caster 和 receiver。
-
Shadow Volume Culling【CPU 方法】
- receivers culling:在 eye space 下对所有 receivers 进行视锥剔除和遮挡剔除。
- casters culling:在 light space 下对所有 casters 进行遮挡剔除(相当于剔除大 volume 里涵盖的小 volumes)。
-
Continuous Shadow Clamping【CPU 方法】:在 light space 下,对 shadow volume 建立 AABB,并找到与之相交的 receiver AABBs,并根据这些 receivers 的 zmin & zmax 来在 z 轴上对该 shadow volume 进行切分。
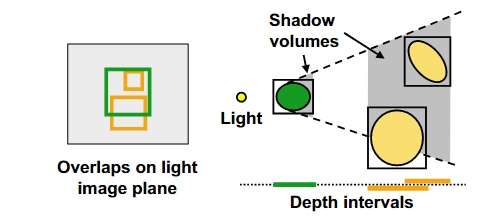
-
Discrete Shadow Clamping【GPU 方法】:在 eye space 下,按 tile 划分来切分成若干层 slice,slice 和一个 shadow volume 的交集称为 interval;在 light space 下按从底层到上层的顺序绘制各层 slice 的 clipping planes;每绘制一层 slice,就利用硬件 occlusion query 来判断是否有物体在 interval 之中,并在 CPU 获取 occlusion query 结果(只要没有 fragment 通过深度测试则意味着可以剔除本 empty interval)。
是否过时?
缺陷:
- CPU 压力大:需要在 CPU 上构造 shadow volume mesh。
- 性能可控性差:shadow map 开销与其分辨率相关,比较固定;shadow volume 开销则与视角相关,容易出现性能波动。
- 光栅化与深度&模板测试的负载加重:见 CC Shadow Volumes 开头分析。
- 只支持硬阴影。
虽然 shadow volume 有很多严重缺陷,但是这些都是基于整个场景都使用 shadow volume 的缺陷分析;在现代管线中,我们完全可以使用 hybrid 方法结合 shadow map,shadow ray 以及 shadow volume 的优点,这里就抛砖引玉部分想法:
- 如果光源和物体都不动,那么 shadow volume 没必要每帧重新构造。
- 只对大型遮挡物生成 shadow volumes,并将 shadow volume 中的 casters 剔除掉,减少 shadow map 的 draw call。
- shadow map 不善于处理半透明阴影,可以尝试为半透明物体生成 shadow volume。
- shadow volume pass 和 shadow depth pass 一样是光栅化负载和带宽负载多(fragment shader 无内容),可以与计算负载多的 compute shader pass 一起并行(async compute)。
- 现在 GPU driven pipeline 越来越流行,可以利用 compute shader 来构造 shadow volume mesh 及 cluster culling,这样会大大提升 shadow volume 的性能。
- shadow volume 在 per-object shadows 技术中得到应用,详见我博客里的实时阴影系列(1)Shadow Map。
- ...
总结 & 思考 & 改进
real-time shadows 的技术有很多,能结合的角度也很多,当自己需要针对项目制定 shadows 管线时可以尽情发挥自己的创造力和想象力,以下我就抛砖引玉一些可能的 idea(当然仅供参考,不一定可行)。
结合 VSM 和 Shadow Volumes
由前面 virtual shadow map 的流程可知,减少 page 的访问就可以减少 page fault 的发生。

那么针对城市场景,我们可以:
- 为每个大型 caster(尤其是建筑)生成一个简化模型 proxy,并根据 proxy 生成对应的 shadow volume。
- 绘制 shadow volumes,对被 volume 覆盖的 pixels 写入 mask。
- 再进行一个 full-screen pixel shader 来对剩下来未遮蔽的 pixels 提交对应的 page 访问请求。
- ..
实际上就是利用 shadow volume 技术来避免相当部分的全阴影区域生成 shadow map。
结合 Shadow Map 和 Shadow Ray
shadow map 分辨率/精度有限,可以利用更高精度的 shadow ray 来补充 shadows 细节。
我们可以通过一套类似流水线的流程去计算 shadows:
- 使用 shadow map 来进行阴影测试:
- 若光源自带 shadow map 且 shading point 在 map 范围内的,可以使用 shadow map 来进行阴影测试:
- 若为阴影:结果视为阴影,终止流程。
- 若不为阴影(性能友好的做法):结果视为非阴影,终止流程。
- 若不为阴影(补充高精度阴影的做法):继续转入下一个流程。
- 若光源没有 shadow map,亦或者 shading point 不在 shadow map 的范围内,则直接转入下一个流程。
- 若光源自带 shadow map 且 shading point 在 map 范围内的,可以使用 shadow map 来进行阴影测试:
- 使用性能开销低的 software ray tracing 技术:
- 针对屏幕范围内的着色点,可以尝试进行 screen space ray tracing/contact shadows,若命中则结果视为阴影,终止流程。
- 如果场景含有 height field,可以尝试进行 height field ray tracing,若命中则结果视为阴影,终止流程。
- 若未命中,则转入下一个流程。
- 使用离屏的 ray tracing 技术来做最后的阴影测试(命中则结果视为阴影,否则为非阴影):
- 其它软件光追。
- 硬件光追:ray query。
工业界常见的组合为:shadow map + contact shadows。当然 shadow ray 技术还有很多种,完全可以根据自己需要进行组合,甚至是 shadow map + 多种 shadow ray 技术的组合。
CSM + 高度场阴影 + SMRT + contact shadows
结合 Precomputed Shadow Map 和 Occlusion Culling
移动端设备上可能对 occlusion query 支持不是很好,往往都采用软件光栅化的方式进行 occlusion culling;而基于软件光栅化的 occlusion culling 往往是先对重要的或大型的 casters 进行光栅化,再对所有小型 casters 进行光栅化,也就是两轮光栅化。
然而既然都有了 precomputed shadow map,何不如加载场景是时读取 precomputed shadow map 并生成一张对应的 mipmap(只需加载时生成一次),将 mipmap 用于替代掉第一轮光栅化的结果?
多光源阴影重用 Probe Visibility
在 probe 类 GI 方案中,有些方案的 probe 是需要记录四面八方的深度的(可能也有深度的平方),这是为了避免漏光现象增强 GI shadows 的一种做法。而实际上,这些 probe 所记录的深度信息也是可以用于 DI shadows 的检测,只是精度没有那么高罢了。
因此,可以在对 DI shadows 精度要求不高的情形下复用,例如多光源阴影的情形下:场景中拥有海量光源,但是每个 pixel 为多个光源发出 shadow rays 是比较耗的,可以直接复用 probe visibility 来做粗糙的阴影(阴影看起来应该也会比较柔和)。
参考
- [1] [GAMES202-高质量实时渲染-闫令琪
- [2] Inigo Quilez :: Distance Field Soft Shadows (iquilezles.org)
- [3] Contact Shadows in Unreal Engine | Unreal Engine 5.3 Documentation
- [4] GDC 2023 | Rendering 'God of War Ragnarok'
- [5] 实时光线追踪(3)Ray Casting - KillerAery - 博客园 (cnblogs.com)
- [6] GDC 2016 | NVIDIA | Advanced Geometrically Correct Shadows for Modern Game Engines
- [7] Symposium on I3D Graphics and Games 2015 | Frustum-Traced Raster Shadows: Revisiting Irregular Z-Buffers
- [8] Wm. Randolph Franklin, "PNPOLY - Point Inclusion in Polygon Test" (2000)
- [9] Joseph O'Rourke, "Point in Polygon" in Computational Geometry in C (2nd Edition) (1998)
- [10] Graphics Gems IV | Point in Polygon Strategies (realtimerendering.com)
- [11] Real-Time Rendering 4th Edition
- [12] EGSR2004 | CC Shadow Volumes
作者:KillerAery
出处:http://www.cnblogs.com/KillerAery/
本文版权归作者和博客园共有,未经作者同意不可擅自转载,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号