实时光线追踪(3)Software Ray Tracing
- Screen Space Ray Tracing
- Height Field Ray Tracing
- Voxel Tracing
- Ray-aligned Occupancy Map Array(ROMA) [2023]
- SDF Tracing / Sphere Tracing
- Global SDF + Mesh SDF
- AABB Tree + Local Distance Field [2023]
- Enhanced Sphere Tracing [2014]
- Accelerating Sphere Tracing [2018]
- Segment Tracing [2020]
- Automatic Step Size Relaxation [2023]
- SDF Cone Tracing [2018]
- Ray Tracing Harmonic Functions [2024]
- Backface Distance Fields: Relaxing Signed Distance Fields [2025]
- 一些实践
- 参考
Screen Space Ray Tracing
SSRT 可能是大家都比较熟悉的软件光追方式,它主要就是将屏幕所看到的表面几何信息当成一个场景,利用屏幕的 depth texture 来做 ray marching:每次 marching 一步后就可以检测当前点的 z 值与在 depth texture 中对应的 depth 哪个更小,如果 depth 更小则说明 marching 碰到了屏幕中的 pixel,就可以访问对应的屏幕信息作为 hit point 的属性。
而在实践中,还可以借助 hi-z(depth texture 的 mipmap)来优化 marching 性能,因为 mip 层级高的 depth texture 相当于为更高层级的 bounding volume 表示,这样就可以实现大步的 marching。
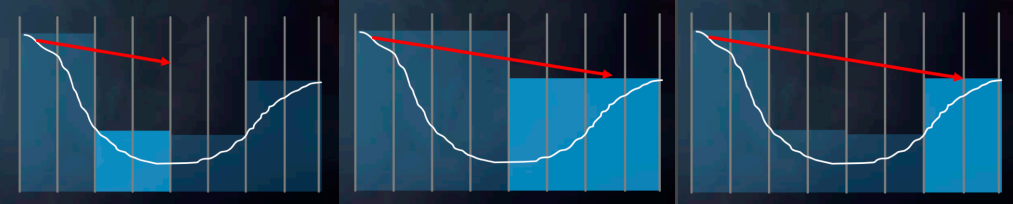
显而易见的问题是:如果 marching 最终走出了屏幕外,那么 SSRT 将无能为力去处理(因为只记录了屏幕上的信息)。并且 SSRT 的命中判断是保守的:即 SSRT 产生 hit 了则 ground truth ray tracing 必定会产生 hit,但 SSRT miss 了但 ground truth ray tracing 不一定会 miss。
以上内容均在我以前的博文(基于屏幕空间的实时全局光照(Real-time Global Illumination Based On Screen Space) - KillerAery - 博客园 (cnblogs.com) )也有大概介绍。
Linear Ray Marching + 二分法
虽然 hi-z ray marching 方法看上去比原始 ray marching 方法要好,但实际上原始 ray marching 稍微 hack 改造一下有时候反而比基于 hi-z 的方法要更快(其实是取决于场景)。
hack 的核心要点:
- 步长为屏幕空间上的单位为基准(步长为 n pixels),而非世界空间。
- 每次 marching 后,可以计算测试点对应的深度与对应的屏幕深度的差,用于 scale 下一步的步长。这是因为深度差较大时,大概率是极大距离远离表面的,因此可以尝试更大步长。
- 最后一步使用二分法求出交点,会相当程度地增加精确度。
- 一个比较连续的深度图会更适合这种 linear ray marching + 二分法的方法,否则精确度会下降较多。因此该方法不太适用于几何复杂的场景,亦或者该方法只用于补充计算一些效果(如 contact shadow,并不需要获取颜色,只需要知道 SSRT 是否 miss,并且还有 shadowmap 方法兜底)。
Failure Case
此外,SSRT 还有一个效果问题:由于相交检测是简单的深度比较,这就相当于把摄像机所看到的 depth texture 都当成了完全实心的场景,但是这样在一些 case 下是不正确的(特别是一个小物体放进摄像机的近处,然后遮挡了大部分场景)。
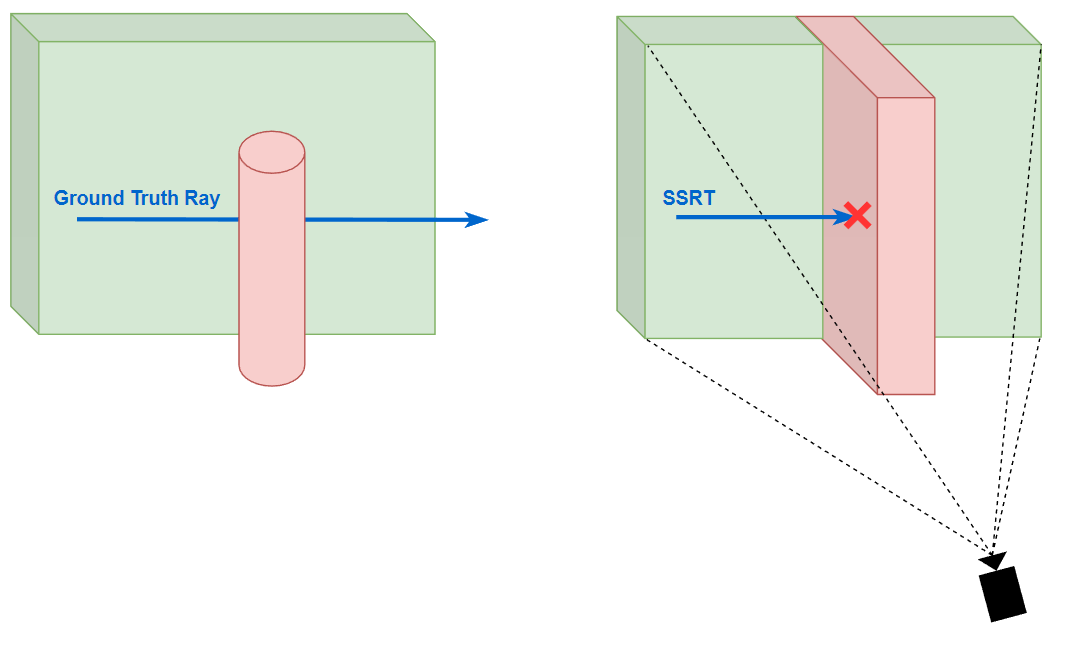
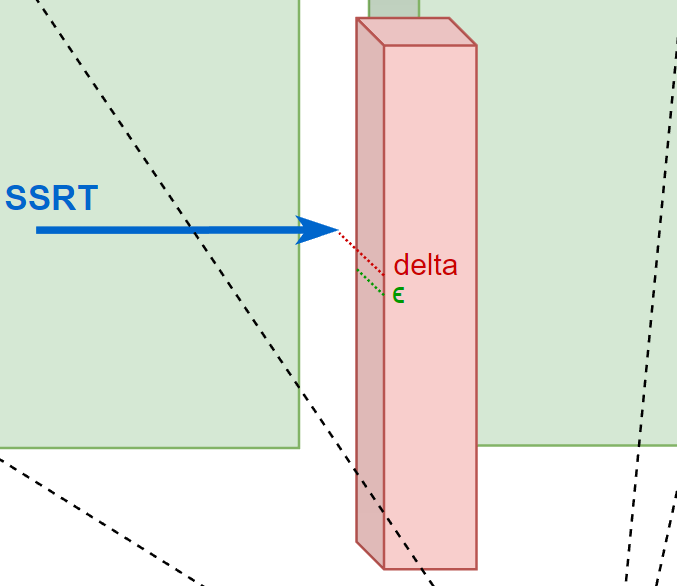
为了改进这一点,在 marching 的时候我们不能简单地认为 depth texture 的 depth 值小于 z 值就是发生碰撞了,而是同时还要额外检测 z 和 depth 的相差值 delta,如果大于一定阈值 $\epsilon \((\)\epsilon $ 可以与 depth 相关),我们是无法断定是否发生碰撞的(因为不知道这个 pixel 的 “深度柱” 是实心的还是空心的),应当选择放弃本次 SSRT(视为 SSRT miss)。
Height Field Ray Tracing
HFRT(height field ray tracing) 中的 height field 基本是用来描述大地地形的,而地形往往是表面平滑的且实心的,不会像 screen space depth texture 那样可能有镂空问题或者表面突变问题。
与 SSRT 相同的是,HFRT 的命中判断也是保守的:即 HFRT 产生 hit 了则 ground truth ray tracing 必定会产生 hit,但 HFRT miss 了但 ground truth ray tracing 不一定会 miss。
与 SSRT 不同的是:
-
HFRT 的 ray tracing 方式类似 relief map(浮雕贴图),即一般采用 ray marching + 二分找零点,效率往往更高:
- 先用 marching 走固定的大步长,直到遇到更低的地形。

- 再用二分法找到交点,一般是小于一定阈值便认为成功命中,结束算法:

depth texture 无法保证其表示的表面是连续的,从而也不能转换成找零点问题。
- height field 基本只有高度信息,而不像 SSRT 那样拥有丰富的几何、材质和颜色信息(屏幕上的 G-Buffer 等),因此往往仅用于判断 ray 是否被命中地形物体以及命中点的位置和法线。
Voxel Tracing
Voxelization
voxelization 涉及的内容太多(投影、孔洞问题等),存储的结构也由很多种(3d texture clipmap,sparse octree 等),由于本文主要涉及 ray tracing 本身,因此不多展开。
其实是懒得写了XD,以后再补。

Voxel Ray Marching
最简单的方法便让 marching 步长固定为一个 voxel 的边长,每 marching 一步就采样当前位置所在的 voxel 并且累加 alpha 值(不透明物体占据 voxel 时alpha 值为 1,半透明物体占据 voxel 时 alpha 值为0到1间的某个值,不存在物体在 voxel 的位置时则 alpha 值为 0),如果累积的 alpha 值仍然小于一定阈值则继续 marching:
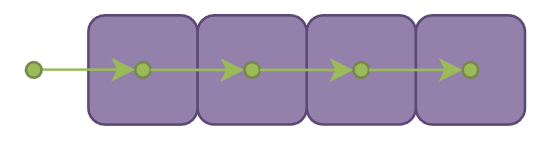
但是由于 voxel 并不像球那样中心点到表面都一样的距离,在斜方向的情况下很容易出现 marching 后仍然停留在同一个 voxel 从而产生重复采样。
当然,可以通过判断当前 voxel 是否和上一个 voxel 一样来决定是否放弃本次采样并继续 marching;但更好的 marching 方式应当是使用直线绘制算法中的 DDA (Digital Differential Analyzer) 算法来决定步长:将 ray 方向分别映射到 x,y,z 三个轴,取最大值的轴作为主步进轴;每次 marching 必须要满足在这个主步进轴走 1 个单位距离(即 1 个 voxel 边长),而另外两个轴对应的步进距离也能通过比例算出:
// 仅伪代码,不做边界检查
vector3 voxelMarchingStep_DDA(vector3 origin, vector3 end)
{
vector3 offset = end - origin;
vector3 dir = normalize(offset);
float maxScalar = max(max(abs(dir.x), abs(dir.y)), abs(dir.z));
vector3 step = dir / maxScalar * voxelSize;
return step;
}
Voxel Cone Tracing [2011]
将一堆从相同 origin 点出发的 rays 近似成一个 cone 的形式。
类似 voxel ray tracing,voxel cone tracing 累积的 alpha 值小于一定阈值则继续 marching;不同的是随着 marching 越来越远离 origin 点,cone 的直径也越来越大。而 voxel cone tracing 聪明地对 voxels 的 3d texture 生成预过滤的 mipmap:在 cone 半径小的时候在 mipmap level 低的 voxel texture 去采样,在 cone 半径大时候在 mipmap level 高的 voxel texture 去采样。
当然,本身 voxels 便是不准确的场景表达,而预过滤的 texture 更进一步会导致高频信息的丢失,尤其是 mipmap level 高时。因此 voxel cone tracing 往往仅适用于搜集不那么准确的光照。
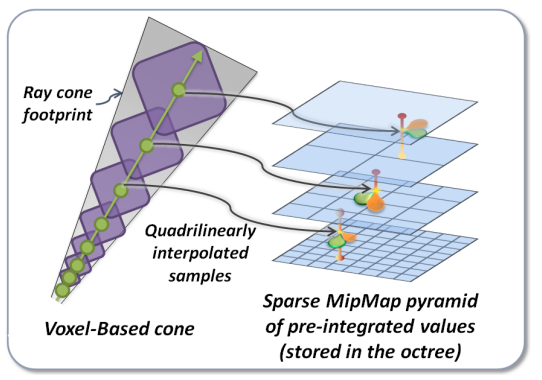
以下是一些 voxel cone tracing 的数学关系。
一次 marching 步长 \(step\) 取决于 cone 的直径 \(d\):
\[step = max(d, voxelSize(level)) \]当前应该去哪个 mipmap level 采样 voxel 也需要取决于直径 \(d\) :
\[level = \log_2(\frac{d}{voxelSize(maxLevel)}) \]而直径 \(d\) 又取决于 marching 总共走过的距离 \(t\) 和 cone 的张角 \(ψ\):
\[d = 2 * t * tan\frac{ψ}{2} \]
Hierarchical Digital Differential Analyzer Tracing(HDDA)[2014]
如果有层次结构的 voxel(如含 mipmap 的 3d texture),还可以采用 HDDA(Hierarchical Digital Differential Analyzer)算法:大概思想就是先在高层级的 voxels 上进行 marching 和采样,如果发现存在非空 voxel,再降级到底层级的 voxel 进行 marching 和 采样。
Ray-aligned Occupancy Map Array(ROMA) [2023]
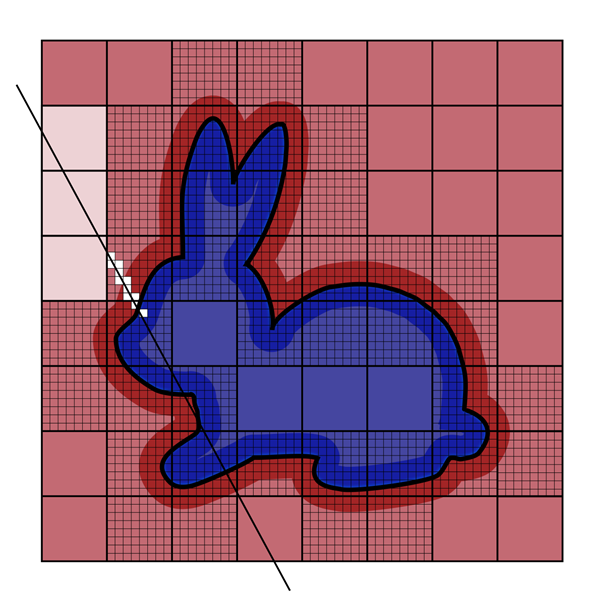
这个新方法类似于 voxel ray marching,先对场景进行 voxelization 输出一个 bit map(bit 为 1 代表存在物体,0 代表没有物体)称之为 occupancy map。
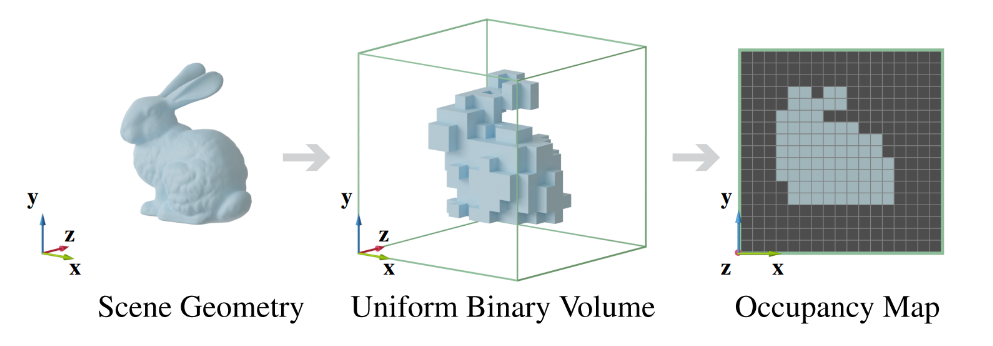
在理想情况下,如果 ray tracing 方向与 occupancy map 的 z 轴方向一致(也就是所谓的 ray-aligned,见下右图),那么从 map 中读取一个字节就相当于能做 8 次 voxel marching;而更普遍的情况下, ray tracing 方向不会和 map 的 z 轴方向一致(下左图),可能需要读取多个字节并只用到其中少部分 bit 来做 voxel maching。
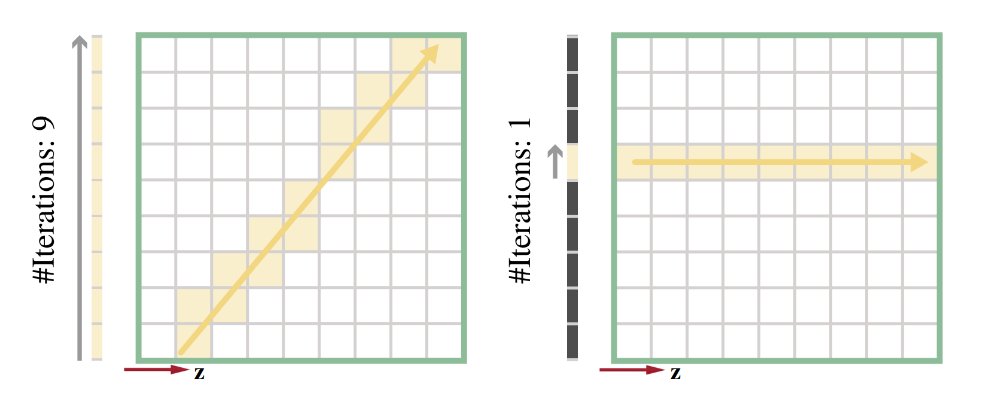
预生成ROMA
为此可以对初始方向生成的 occupancy map 进行若干个角度的旋转(半球方向上呈现近似均匀),每次旋转都走 CS 来生成一张对应角度的 occupancy map。
生成其它方向的 occupancy map 不需要再次走光栅化(或者说 voxelization),而是可以通过 CS 来做,避免 draw call。
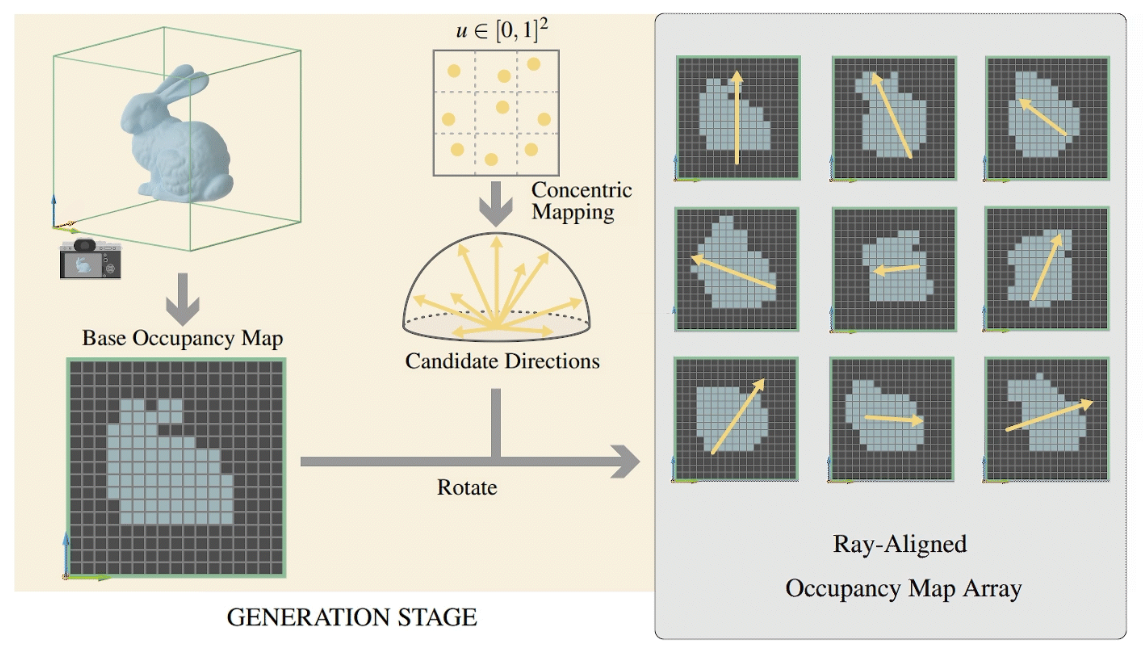
ROMA Tracing
当我们要做 voxel ray marching 时,把 ray 的方向通过 concentric mapping 索引到对应的 ray-aligned occupancy map,并在该 map 里进行 marching。这时候得益于 ray-aligned,采样一个 32 bit 的 texel,就能相当于做了 32 次 voxel ray marching,非常高效。
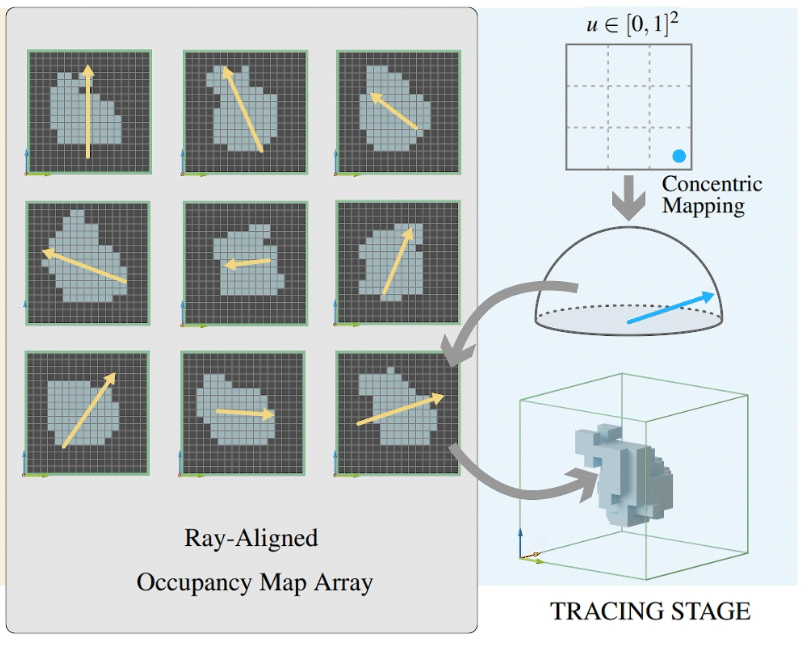
该方法能够有效节省大量带宽,但是生成的 occupancy map 数量毕竟是有限的(一般为8×8个map),很难完全匹配所有方向的 ray,所以精度上会有一定的损失。
SDF Tracing / Sphere Tracing
所谓的 SDF tracing(或者更正式的叫法为 sphere tracing),其实就是基于 SDF 的 ray marching。其基本原理非常简洁,也非常聪明:从点 \(x_{0}\) 开始投射一条 ray,然后进行若干次 marching,每次 marching 的起点为上一次 marching 的终点,而 marching 的步长取为起点 \(x_{n}\) 的 SDF 值 \(f(x_n)\) 。
SDF 代表着离该点最近的几何表面有多远,也就是说在 SDF 值范围内,这个 ray 绝对不会与任何几何表面相交。
当然 \(f(x_n)\) 在有限步数下无法收敛到刚好为 0,实现中往往用一个小的阈值 $\epsilon $ 来做命中判断。
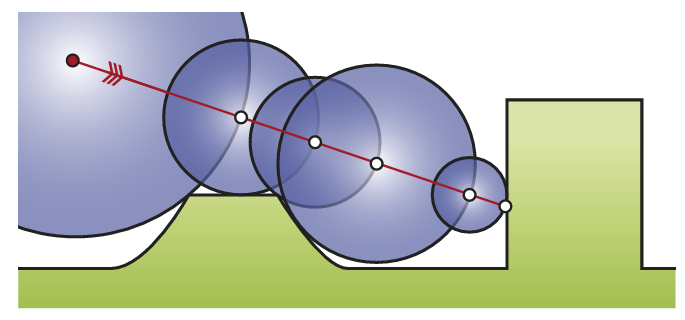
在实践中,最常用 3D texture 来存储 SDF,也就是说 SDF 是以均匀网格的形式存储的,每个 cell 存储一个 SDF 值。容易想到,对整个场景构建高精度的 SDF 将会耗费巨量带宽和存储空间,并且在实时渲染领域往往是不可以承担的。
Global SDF + Mesh SDF
UE5 Lumen 为了解决场景的 SDF 表示问题,为每个 mesh 单独预生成了一个高精度的 sdf(称之为 mesh sdf),然后将场景中每个 mesh sdf 实时合成一个低精度的场景 sdf(称之为 global sdf)。
这样就可以先在 global sdf 进行低精度的 sdf tracing,当 marching 到存在 mesh sdf 的区域时,就可以访问对应的 mesh sdf 进行高精度的 sdf tracing。
global sdf 可视化:

mesh sdf 可视化:

AABB Tree + Local Distance Field [2023]
源于 AMD 的方案(Real-time Sparse Distance Fields for Games | GDC2023)。由于篇幅有限,这里只讲个大概,实际上还有更多细节和优化策略,感兴趣的建议看引用的原文。
为每个 mesh 预生成 mesh sdf 会限制 mesh 的动态性(不允许动态拉伸或者顶点偏移等),而 AMD 给出的方案则是实时根据局部区域的 triangles 去生成 local DF,并将这些 local DF 以 3-level AABB Tree 的形式组织起来(一个 local DF 就是一个叶结点)。
其具体流程如下:
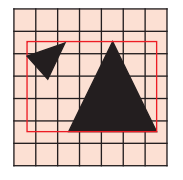
- 对场景中各种 mesh 进行体素化(voxelization),并将 triangle ID 添加到对应 voxel 的 triangle list。
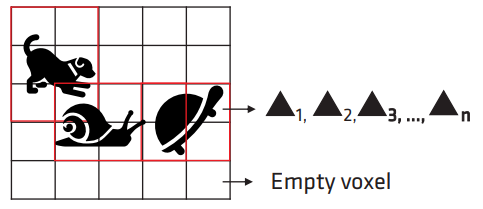
- 对每个非空的 voxel 创建一个对应的 brick,一个 brick 就是一个所谓的 local DF,包含 8x8 个 brixels(brixel 存储了 DF 值)。
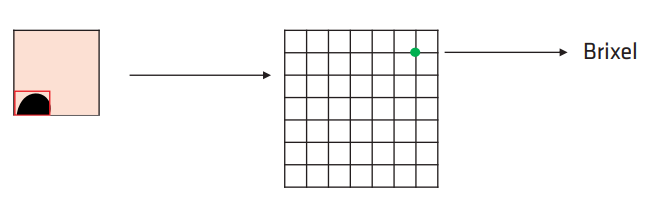
-
对每个 brick,遍历对应 voxel 的 triangle list:
- 计算出 brick 内的 AABB box(红线框)。
- 先对与 triangles 有相交的 brixels 填充 DF 值(其实就是离最近三角形的距离)。
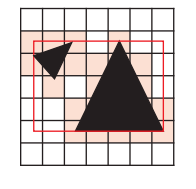
- 而没有相交的 brixels 在随后使用 Eikonal / Jump flooding 算法来填充 DF 值。
-
对于边界的 brixels,则参与所有邻接 bricks 的计算。
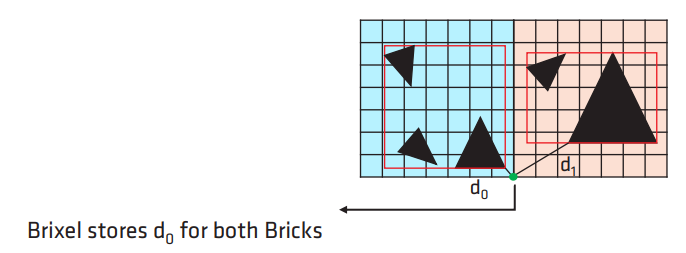
-
对计算出来的 AABB boxes 构建出一棵 3-level AABB tree,以供后续 sdf tracing 查询使用。

Enhanced Sphere Tracing [2014]
传统 sphere tracing 算法中,在点 \(x_n\) 的 ray marching 步长应取为 SDF 值 \(f(x_{n})\),而这种 marching 其实是保守的。
实际上我们可以采用更激进的步长倍数 \(\alpha\) ,只要 \(x_n\) 的SDF 值加激进 marching 后到达 \(x_{n+1}\) 后的 SDF 值 \(f(x_{n+1})\) 大于本次激进 marching 的步长 \(\alpha f(x_n)\)(即 \(f(x_n) + f(x_{n+1}) > \alpha f(x_{n})\),在几何上实际就是表现为两个 sphere 相交),那么就说明 ray 可以安全通过本次激进 marching,否则应当退回到点 \(x_n\) 的位置重新进行保守的 marching。
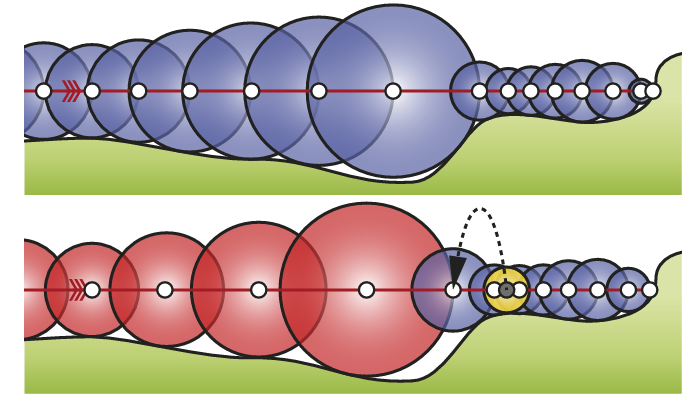
当然,过于激进的步长倍数会导致过多的回退,而过保守的步长倍数则不会带来效率的提升,因此应该针对自己的场景调整 \(\alpha\) 参数(引入一些动态调整 \(\alpha\) 的方法,如下面的 accelerating sphere tracing),而原 paper 的作者推荐大约 \(\alpha = 1.2\) 倍步长为性能最佳。
Accelerating Sphere Tracing [2018]
更进一步的激进策略是:永远假设前两次 marching 所形成的 sphere 都相切于同一平面,那么下一次可以尝试 marching 这样一个 sphere:与该平面相切,也刚好与上一次的 marching sphere 相切;如果尝试失败则回退至保守 marching。
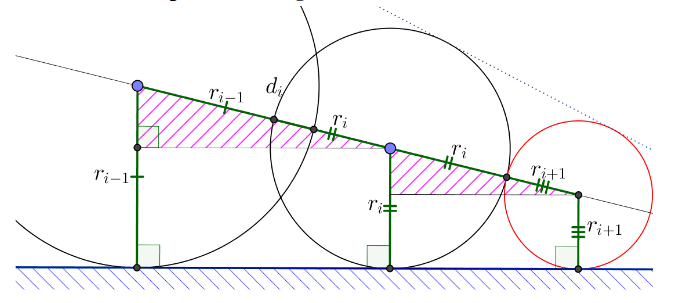
那这个尝试 marching 的具体步长应该是多少呢?
由相似三角形易得 \(\frac{d_i}{r_i+r_{i+1}}=\frac{r_{i-1}-r_i}{r_i-r_{i+1}}\)
那么尝试的步长应为:
这种策略比 enhanced sphere tracing 回退次数减少了许多,有更好的加速效果。
Segment Tracing [2020]
需假设场景是 \(C^2\) 连续(意味着如果场景有棱角就会有一些artifact),并通过 SDF 导数来算出一个更长的安全步长。
原 paper 中用到了一堆数学定义(如 Lipschitz)和方法推导,就懒得细剖了。
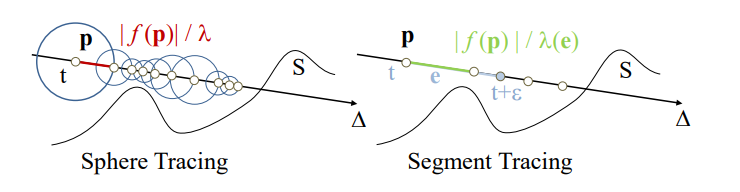
更具体来讲,在 ray 的方向分成一段段线段(segment),然后算 segment 的顶点和末尾点的 SDF 一阶导,并由此推算出这段 segment 附近的大概安全区域(SDF 一阶导相当于往最近表面的反方向,由两个导数信息就可以推算出大概的表面信息),并算出 ray 如果要经过这块区域时最远的安全步长是多少。
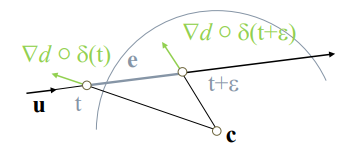
虽然该方法可以显著减少 marching 次数,但是不一定有优化,因为其代价是需额外多次采样 SDF 来求导。
当然也可以预生成 SDF 梯度图,不过代价是:
- 额外的显存占用(SDF 梯度值甚至是 SDF 值的2或3倍占用,不过倒是可以降一下分辨率压缩一下梯度值来降低总体存储占用,感觉不太精确的梯度值来指导 Segment Tracing 效果可能不会差到哪里去)。
- 每次 marching 时需要额外一次采样 SDF 梯度图。
可以根据实际情况来评估是否有收益(例如 SDF 值过小的时候再采样 SDF 梯度可能会比较划算)。
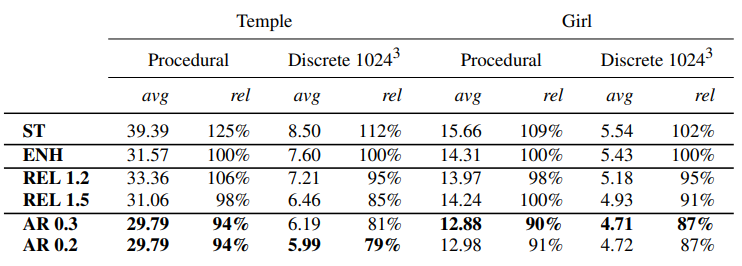
Automatic Step Size Relaxation [2023]
2023 年的新 paper。accelerating sphere tracing 的缺点在于它永远假设最近两次 marching 都相切于同一平面,遇到某些曲面多的场景容易造成过多的 fall back,而 automatic step size relaxation 则可以根据历史 marching 的情况动态调整步长(有点类似于梯度下降法学习),近似可以实现 marching 在平面多的地方调整为走相切平面的激进步长(即 accelerating sphere tracing),而曲面多的地方则调整为走更保守的步长。
伪代码如下:

\(M\) 是最近 marching 时假设相切于同一平面时计算而得的斜率,\(m\) 是历史的近似斜率,然后 \(\beta\) 为当前斜率混合系数(也可以理解成学习率),作者给出的数据是 \(\beta\) 为 0.2 或 0.3 时最好。
通过每次 marching,不断更新近似斜率 \(m\),然后用它来指导下一次 marching,就能近似实现根据历史动态调整未来步长的效果。
原论文给出性能数据如下,但我还没实验过实际性能表现,但是值得一试,理论上应该是最优的。
SDF Cone Tracing [2018]
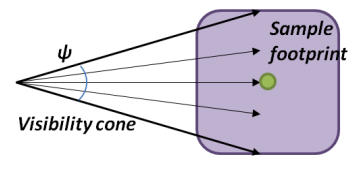
如果有多条从相同起点出发且出射方向相近的 rays,可以将它们合并成一个 cone,先进行 SDF cone tracing,hit 到物体时再分裂成原始的多条 rays 并分别进行 SDF ray tracing。
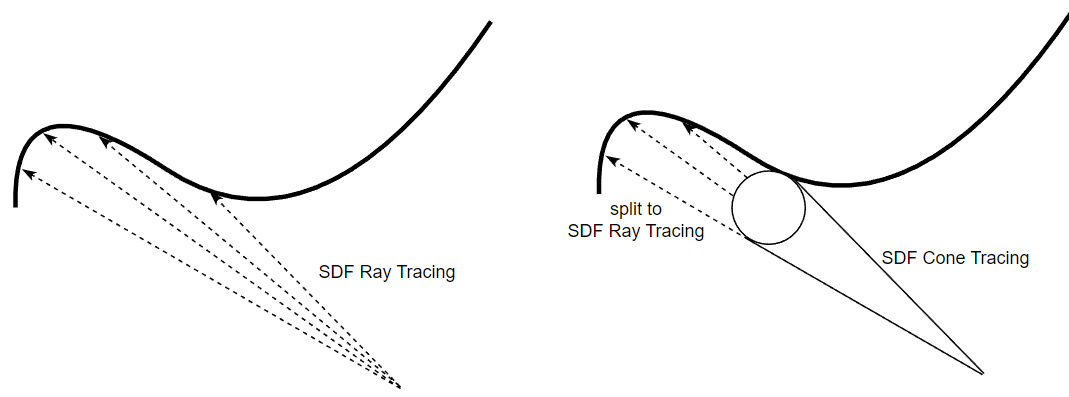
SDF cone tracing 的过程基本和 sphere tracing 差不多,只是步长不一样:第 n 次 marching 不是走到 \(x_{n} + f(x_{n})\) 的位置(对应下图 \(P'\) 的位置),而是走到 \((x_n+f(x_n))* A\) 的位置(对应下图 \(P''\) 的位置)。
这是因为 ray tracing 本质上是一个点在 marching 而 cone tracing 是一个半径逐渐变大的球在 marching,\(P''\) 是能保证这个球绝对安全的最远位置。
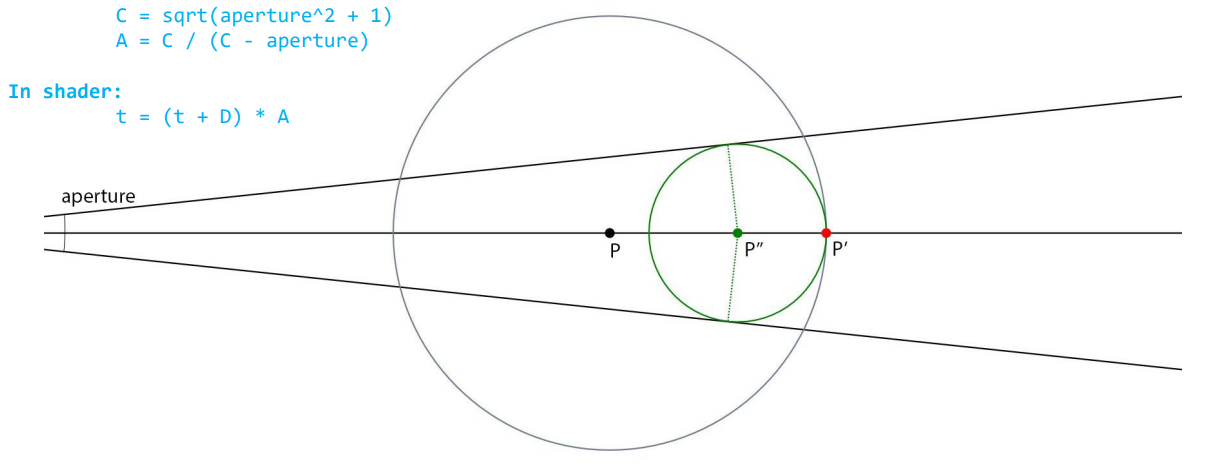
可以看到 SDF cone tracing 的 marching 往往是比 SDF ray tracing(sphere tracing)要短的,会导致更多步长。但如果 rays 共享 cone tracing 从而减少的总步长次数大于 cone tracing 带来的额外步长次数,那么这个策略便能有很大用处(尤其对于一堆集中方向的 glossy/specular rays)。
Ray Tracing Harmonic Functions [2024]
简单来说,SDF 值是指从一个点往所有方向去记录看到最近物体的距离,并在这些距离之中取最短的距离作为 SDF 值(所有方向的最短距离);而 SH 可以提供方向性的 SDF 值,也就是看往某个方向的最短距离。
很明显,任意方向的 SDF 值和具有方向性的 SDF 值相比,后者往往是更大值(前者的值往往更保守),从而本方法可以加快 ray marching。
代价:
- SDF SH 基本只可能靠烘焙出来
- ray marching 时需要采样更多 texture(例如 SH2 需要采样 4 个系数)
个人初步觉得该方法不如 segment tracing。
Backface Distance Fields: Relaxing Signed Distance Fields [2025]
SDF 仙人又出新成果。来源于 Backface Distance Fields: Relaxing Signed Distance Fields | 2025
先看看 BDF(Backface Distance Fields)的定义:计算到背面表面点(即法线方向与查询点方向相反的表面点)的最近距离。在物体内部,BDF 与 SDF 完全一致;在物体外部,BDF 的步长总是比 SDF 更长。
BDF 理论上可以起到减少 marching 次数的效果,但实际上 BDF marching 可能会穿透物体表面,因此再进入到物体内部时需要反向 marching,直到足够逼近物体表面。因此,BDF 在物体外部 marching 的次数 + 在物体内部的 marching 的次数是否小于纯 SDF marching 的次数是需要考虑的,否则很可能做成负优化。
注:BDF 保证 marching 最多只会穿透一次表面,不会穿透更多。
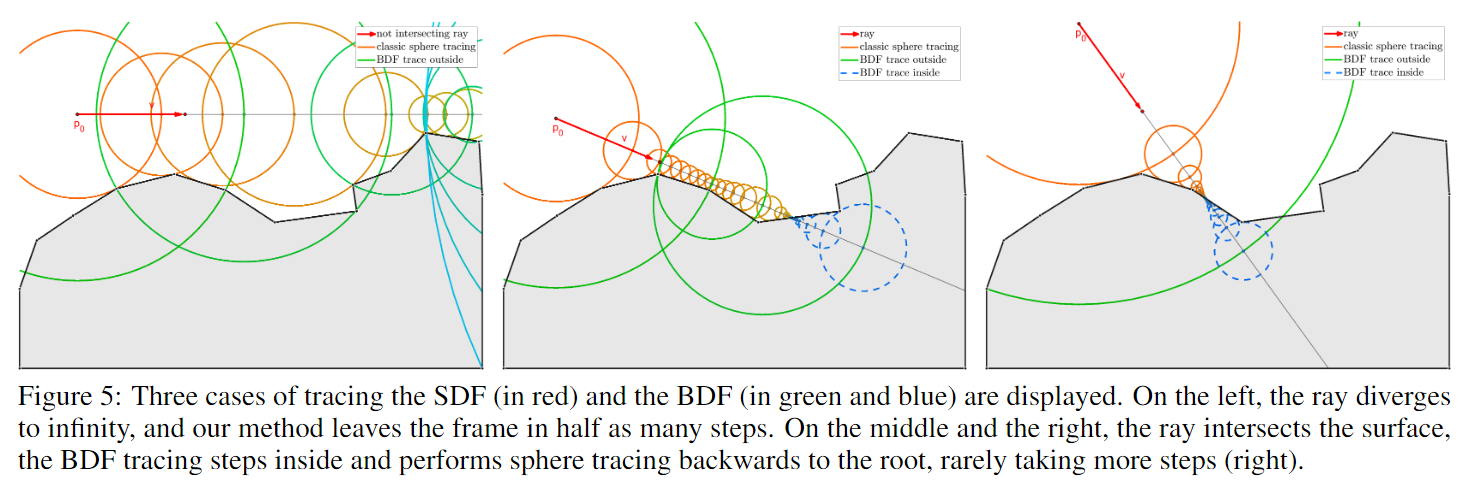
不过,SDF 是平滑变化的(左图),而 BDF 是非平滑有突变的(右图),尤其是在使用三线性采样了低分辨率网格的 BDF 的时候更容易出现 artifact。
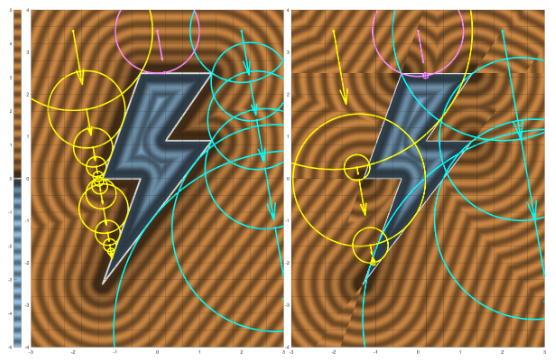
因此要使用 BDF 往往还需要一个 BDF 矫正的过程,怎么做呢?其实就是当前点到达接近表面的区域时,查询一下邻域 3x3x3 的 SDF 值是否有至少一个为负数值(是的话意味着接近表面内部/或者干脆就是在内部),这时候就不要用 BDF 作为步长,而是使用更平滑的 SDF 来作为步长,这样就能避免突变问题。
但是这个查询确实也比较费啊,如果不需要精确的效果,其实也可以考虑查询数量更稀疏的样本,或者甚至就不矫正了。其次是,这个矫正就要求同时存储 SDF 和 BDF,费存储。

原论文给出性能数据如下:
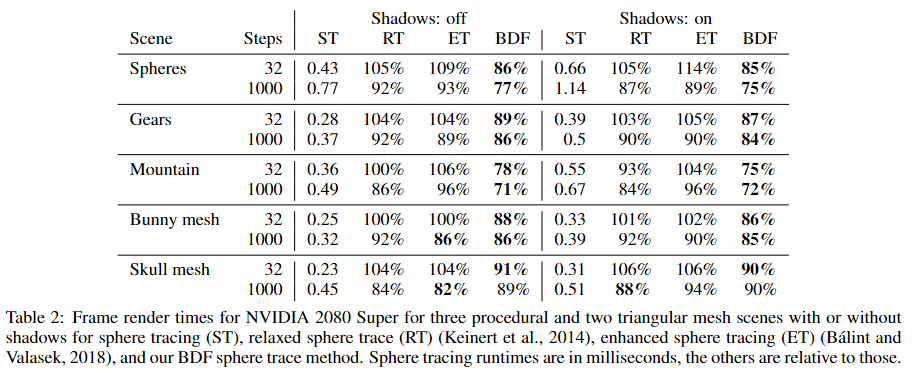
总体来看,这个方法可能在靠近物体时的 marching 会更高效一些,但是远离物体表面的地方其实和 SDF 没太大区别,因此我的一些想法是:
- 考虑结合 SDF 和 BDF:例如 global SDF + mesh BDF。
- 优化 BDF 在物体内部的 marching:既然 BDF 能保证最多穿透一次表面,那么我大可以转化成二分找零点问题,步长就可以等于 max(BDF, 二分距离),从而进一步加速 marching。
- 软光追很多都不需要精确的重建表面的话,就直接去掉矫正步骤吧。
一些实践
Primary Ray
可以通过传统的光栅化流程去做,而不是真的往屏幕投射 primary ray。
Shadow Ray & Visibility Ray
结合 Shadow Map 和 Shadow Ray
可详见 实时阴影技术(2)Shadow Ray & Shadow Volume - KillerAery - 博客园 (cnblogs.com)
光源预处理 - SDF tracing
对于 SDF tracing 来说,不少的 case 下逆向 tracing 会更加效率。例如,对于 point light / spot light ,可以先计算下光源所在位置的 sdf 值(相当于逆向 marching 了一步),当 shading point 往该光源做 shadow ray tracing 时的 max distance 就可以减去这个预计算 sdf 值。
因为很多 shadow ray tracing 都是往相同的光源点投射,因此逆向 marching 实际上就是让这些 rays 共享了一个步长。

更进一步,结合 Ray Tracing Harmonic Functions 的思想,我们可以与计算并存储 SH 系数来表达方向相关的 sdf 值,这能提供更明显的收益。
Material Ray
而除了计算直接光照以外,我们还往往需要计算着色点受到的间接光照,这时候往往需要投射 material ray,获取 hit point 的材质信息以计算 radiance:
对于硬件光追 ray tracing pipeline 来说,material ray 是容易实现的:直接通过 closest hit shader 来计算出 hit point 的材质信息,并之后通过 payload 来获取材质信息即可。
- 若着色点位于屏幕范围内,可以优先尝试 screen space ray tracing,若命中则可以获取屏幕上的 normal, albedo, color 等材质信息。
- 若着色点不在屏幕范围内亦或者 SSRT 没命中,则可以使用 visibility ray + material cache:由于缺少 closest hit shader,我们只能通过投射 visibility ray 得到一个 hit point 的 position,而得不到几何信息或者材质信息。但是我们可以借助 material cache(例如:lumen mesh card/probes/voxels 等)来获取 hit point 的材质信息。
注:几何信息有部分还是可以强行获得的,如通过 SDF 梯度算 normal ,或者 triangle id 获取 3 个 vertex 从而算出 face normal 等。
Distant Ray + Short Ray
我们有多种 ray tracing 方式,每种方式都有它擅长和不擅长的 case,例如:
- SDF tracing 擅长在空旷的区域进行 marching,然而在靠近几何物体的地方其会因 SDF 值过小而导致较小的步长,从而需要更多次数 marching;其次是 SDF tracing 而得的 hit point position 可能不是那么精确。
- voxel tracing 无论在空旷区域还是靠近几何物体的区域都一样的步长,但是其拥有更精细的相交测试精度。
因此我们可以考虑混合两种或者更多种 ray tracing 方式来完成一次完整的 ray tracing 操作,例如远距离 marching 可以交给 SDF tracing,当 SDF 值过小时切换成 voxel tracing 方式,来获取高效且更精确的 hit point。
当然以上只是一点用来抛砖引玉的例子,具体还能怎么混合 ray tracing 方式(可以考虑下混合 hardware ray tracing)就留给读者想象了。
参考
- [Lumen Siggraph 2022 realtimerendering.com](https://advances.realtimerendering.com/s2022/SIGGRAPH2022-Advances-Lumen-Wright et al.pdf)
- Relief texture mapping | 2000
- Interactive indirect illumination using voxel cone tracing | Symposium on Interactive 3D Graphics and Games 2011
- Hierarchical Digital Differential Analyzer for Efficient Ray-Marching in OpenVDB | SIGGRAPH 2014
- Real-time Sparse Distance Fields for Games | GDC-2023
- Enhanced Sphere Tracing | STAG 2014
- Accelerating Sphere Tracing | EUROGRAPHICS 2018
- Segment Tracing Using Local Lipschitz Bounds | 2020
- Rendering (Signed) Distance Function - 知乎 (zhihu.com)
- Automatic Step Size Relaxation in Sphere Tracing | EUROGRAPHICS 2023
- Ray Tracing Harmonic Functions | 2024
- Backface Distance Fields: Relaxing Signed Distance Fields | 2025
- GPU-based clay simulation and ray-tracing tech in Claybook Sebastian Aaltonen Co-founder of Second Order | GDC2018
- [Ray-aligned Occupancy Map Array for Fast Approximate Ray Tracing | Eurographics Symposiuym 2023](https://zheng95z.github.io/publications/roma23#:~:text=ROMA (Ray-aligned Occupancy Map Array) is a ray,and without iterations (as opposed to Distance Fields).)
作者:KillerAery
出处:http://www.cnblogs.com/KillerAery/
本文版权归作者和博客园共有,未经作者同意不可擅自转载,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号