
从零实现 CIFAR10 模型
需要用到的库
- torch
安装有问题可参考网上教程
pip install torch
- tensorflow
pip install tensorflow
- protobuf
pip install protobuf
CIFAR10 模型

参数计算
- 默认 stride=1,dilation=1,根据公式计算 padding

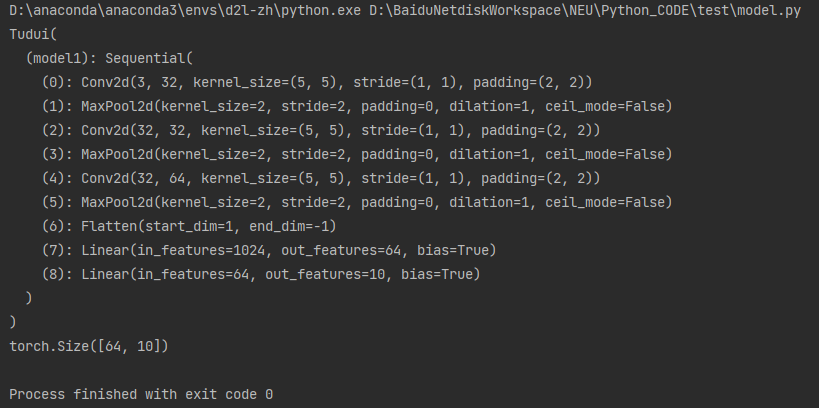
model.py
import torch
from torch import nn
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
tudui = Tudui()
print(tudui)
input = torch.ones((64, 3, 32, 32))
output = tudui(input)
print(output.shape)
train.py
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
from model import *
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_data = torchvision.datasets.CIFAR10("./dataset", train=True, download=True,
transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
train_data_size = len(train_data)
test_data_size = len(test_data)
print(f"训练数据集的长度为:{train_data_size}")
print(f"测试数据集的长度为:{test_data_size}")
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
tudui = Tudui()
tudui.to(device)
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
total_train_step = 0
total_test_step = 0
epoch = 20
writer = SummaryWriter("./logs_train")
for i in range(epoch):
start_time = time.time()
tudui.train()
print(f"--------第 {i + 1} 轮训练开始--------")
for data in train_dataloader:
optimizer.zero_grad()
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
loss.backward()
optimizer.step()
total_train_step += 1
if total_train_step % 100 == 0:
end_time = time.time()
print(f"训练次数:{total_train_step}, Loss:{loss.item()}, 训练所花时间:{end_time - start_time}")
writer.add_scalar("train_loss", loss.item(), total_train_step)
tudui.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
total_test_step += 1
print(f"整体测试集上的 Loss:{total_test_loss}")
print(f"整体测试集上的正确率:{total_accuracy / test_data_size}")
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
if epoch % 10 == 0:
# torch.save(tudui, f"tudui_{i}.pth")
torch.save(tudui.state_dict(), f"tudui_{i}.pth")
print("模型已保存")
writer.close()
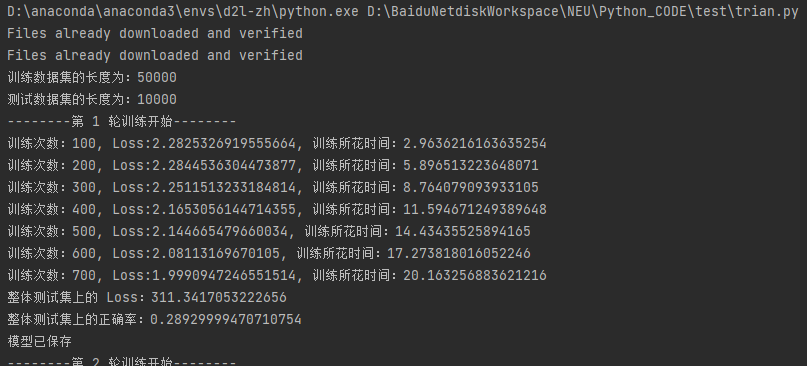
CPU 效果
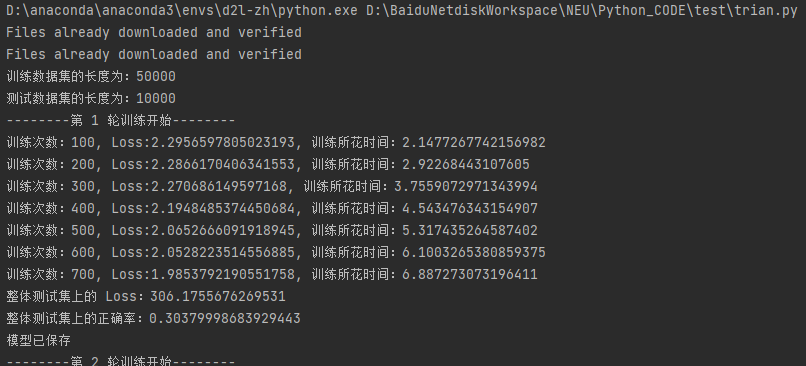
GPU 效果
使用 tensorboard 的 SummaryWriter 进行可视化

tensorboard --logdir="./logs_train"
test.py

import torch
import torchvision
from model import *
from PIL import Image
test_data = torchvision.datasets.CIFAR10("./dataset", train=False, download=True,
transform=torchvision.transforms.ToTensor())
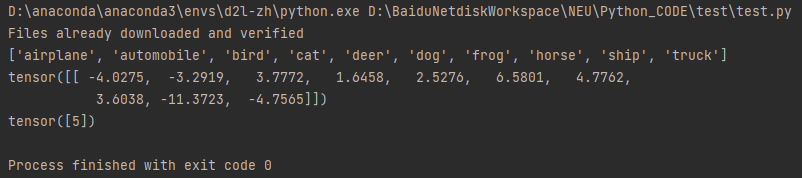
print(test_data.classes)
image_path = "./imgs/dog.png"
image = Image.open(image_path)
image = image.convert("RGB")
# print(image)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)), torchvision.transforms.ToTensor()])
image = transform(image)
image = torch.reshape(image, (1, 3, 32, 32))
model = Tudui()
model.load_state_dict(torch.load("./tudui_19.pth"))
# print(model)
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
补充
如果电脑没有 GPU,可以借助第三方平台使用 GPU

 浙公网安备 33010602011771号
浙公网安备 33010602011771号