
基于pandas的数据清洗 -- 重复值的清洗
开发环境
- anaconda
- 集成环境:集成好了数据分析和机器学习中所需要的全部环境
- 安装目录不可以有中文和特殊符号
- jupyter
- anaconda提供的一个基于浏览器的可视化开发工具
df = DataFrame(data=np.random.randint(0,100,size=(8,6)))
df.iloc[1] = [1,1,1,1,1,1]
df.iloc[3] = [1,1,1,1,1,1]
df.iloc[5] = [1,1,1,1,1,1]
df
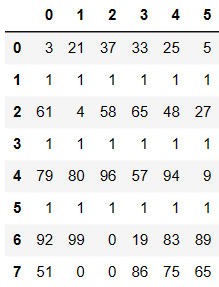
# 检测哪些行存有重复的数据
df.duplicated(keep='first')
0 False
1 False
2 False
3 True
4 False
5 True
6 False
7 False
dtype: bool
df.loc[~df.duplicated(keep='first')]
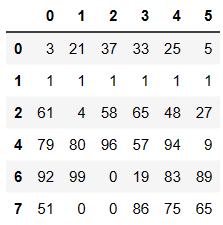
# 异步到位删除
df.drop_duplicates(keep='first')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号