

from __future__ import annotations import logging from datetime import datetime from airflow.sdk import dag, task log = logging.getLogger(__name__) @dag( schedule=None, start_date=datetime(2021, 1, 1), catchup=False, tags=['example'] ) def tutorial_taskflow_api_virtualenv(): @task.virtualenv( serializer='dill', system_site_packages=False, requirements=['funcsigs'] ) def extract(): import json data_string = '{"1001": 301.27, "1002": 433.21, "1003": 502.22}' return json.loads(data_string) @task(multiple_outputs=True) def transform(order_data_dict: dict): total_order_value = 0 for value in order_data_dict.values(): total_order_value += value return {"total_order_value": total_order_value}
What does the "multiple_outputs=True" mean?
In Airflow’s TaskFlow API,
@task(multiple_outputs=True) means the dictionary returned by the task will be split into multiple XCom values, one per key, instead of being stored as a single XCom object.
Without multiple_outputs=True (default behavior)
If your task returns a dictionary like this:
return {"total_order_value": total_order_value} Airflow stores the entire dictionary as one XCom under the key return_value.
Downstream tasks must pull the whole dict:
result = transform(order_data_dict) # result == {"total_order_value": 1234.56}
With multiple_outputs=True
Airflow treats each key/value pair as a separate XCom:
return { "total_order_value": total_order_value }
Internally, Airflow pushes:
-
XCom key:
"total_order_value" -
XCom value:
total_order_value
How this changes downstream usage
You can access individual outputs directly:
output = transform(order_data_dict) # Access by key total = output["total_order_value"]
This works naturally in TaskFlow DAGs and makes the DAG more readable.
Why it’s useful
-
Cleaner dependency wiring
-
No need to unpack dictionaries manually
-
Easier to pass only the needed value to downstream tasks
-
Works especially well when a task produces several logically separate results
Example:
@task(multiple_outputs=True) def stats(): return { "count": 100, "total": 2500, "average": 25 } count = stats()["count"] average = stats()["average"]
Important constraints
-
The return value must be a dictionary
-
Dictionary keys must be strings
-
Each value must be XCom-serializable
In your specific example
Your task returns:
{"total_order_value": total_order_value}
So multiple_outputs=True allows downstream tasks to directly reference:
transform(order_data_dict)["total_order_value"]
instead of handling a nested dictionary.
Summary
-
multiple_outputs=True= split dict return into multiple XComs -
Each key becomes its own output
-
Improves clarity and composability in TaskFlow DAGs
Sure — here’s a side-by-side example that shows exactly how behavior differs.
Example DAG snippet
1️⃣ WITHOUT multiple_outputs=True (default)
from airflow.decorators import task @task def transform(order_data_dict: dict): total_order_value = sum(order_data_dict.values()) order_count = len(order_data_dict) return { "total_order_value": total_order_value, "order_count": order_count, } @task def load(total): print(f"Total order value: {total}")
Usage
result = transform({"1001": 301.27, "1002": 433.21})
# result is a single dict
load(result["total_order_value"])
What happens internally
-
One XCom is pushed
-
Key:
"return_value" -
Value:
{ "total_order_value": 734.48, "order_count": 2 }
You must manually index into the dictionary.
2️⃣ WITH multiple_outputs=True
from airflow.decorators import task @task(multiple_outputs=True) def transform(order_data_dict: dict): total_order_value = sum(order_data_dict.values()) order_count = len(order_data_dict) return { "total_order_value": total_order_value, "order_count": order_count, } @task def load(total): print(f"Total order value: {total}")
Usage
result = transform({"1001": 301.27, "1002": 433.21})
# Each key behaves like its own output
load(result["total_order_value"])
What happens internally
-
Two XComs are pushed
-
Key:
"total_order_value"→734.48 -
Key:
"order_count"→2
-
No dictionary unpacking required.
Side-by-side summary
| Feature | Without multiple_outputs | With multiple_outputs=True |
|---|---|---|
| Return type | Dict | Dict |
| XComs created | 1 | One per key |
| XCom key(s) | return_value |
Dict keys |
| Downstream access | result["key"] |
result["key"] |
| Internal structure | Single object | Split outputs |
| Readability | OK | Cleaner for multiple values |
When you should use multiple_outputs=True
✅ Task returns several logically independent values
✅ You want clean, readable downstream wiring
❌ Task returns a single value or a deeply nested structure
Visual mental model
Without
transform ──► {"a": 1, "b": 2}
With
transform ──► a = 1
└─► b = 2
If you want, I can also show how this looks in the Airflow UI (XCom tab) or how it behaves with classic operators vs TaskFlow.
Great catch — and you’re thinking in exactly the right direction 👍
The key point is TaskFlow API vs. raw XCom semantics. Let’s clear this up precisely.
Short answer (important)
In TaskFlow API code, your original examples were already correct.
You do NOT write:
transform(... )['return_value']
in downstream Python code — even without multiple_outputs=True.
That return_value key exists only at the XCom storage level, not in the Python object you work with in DAG code.
Why this feels confusing
You’re mixing two layers:
| Layer | What you see |
|---|---|
| Python DAG code (TaskFlow) | XComArg objects |
| Airflow internals / XCom table / UI | Keys like return_value |
The TaskFlow API abstracts away the "return_value" XCom key.
Correct mental model
What transform() returns in DAG code
result = transform(...)
result is NOT:
-
a dict
-
an actual value
-
an XCom payload
It is an XComArg proxy object.
Airflow resolves it at runtime.
Case 1️⃣ WITHOUT multiple_outputs=True
@task def transform(): return {"a": 1, "b": 2}
DAG code
result = transform() result["a"] # ✅ valid result["b"] # ✅ valid
Internally (XCom storage)
-
Key:
"return_value" -
Value:
{"a": 1, "b": 2}
Airflow automatically translates:
result["a"] → “Pull XCom return_value, then index key 'a'”
Case 2️⃣ WITH multiple_outputs=True
@task(multiple_outputs=True) def transform(): return {"a": 1, "b": 2}
DAG code
result = transform() result["a"] # ✅ valid result["b"] # ✅ valid
Internally (XCom storage)
-
Key:
"a"→1 -
Key:
"b"→2
Airflow translates:
result["a"] → “Pull XCom with key 'a'”
Why you never write ['return_value'] in TaskFlow DAGs
This would only be needed if you were manually pulling XComs, e.g.:
ti.xcom_pull( task_ids="transform", key="return_value" )
But TaskFlow is explicitly designed so you don’t do that.
The real difference (this is the important part)
Even though DAG code looks the same, the difference is:
| Aspect | Without multiple_outputs | With multiple_outputs=True |
|---|---|---|
| XCom payload | One dict | Multiple scalar XComs |
| XCom size limit risk | Higher | Lower |
| Partial reusability | No | Yes |
| UI visibility | One entry | Multiple entries |
| Performance (large dicts) | Worse | Better |
Practical rule of thumb
-
TaskFlow DAG code → never use
'return_value' -
Use
multiple_outputs=Truewhen:-
You return multiple independent values
-
Values are large
-
You want cleaner XComs and better scaling
-
Your intuition was good — the confusion comes from knowing too much about XCom internals 😄
If you want, I can also show:
-
how this looks in the Airflow UI
-
a failing example where
multiple_outputs=Trueactually matters -
how classic operators differ from TaskFlow
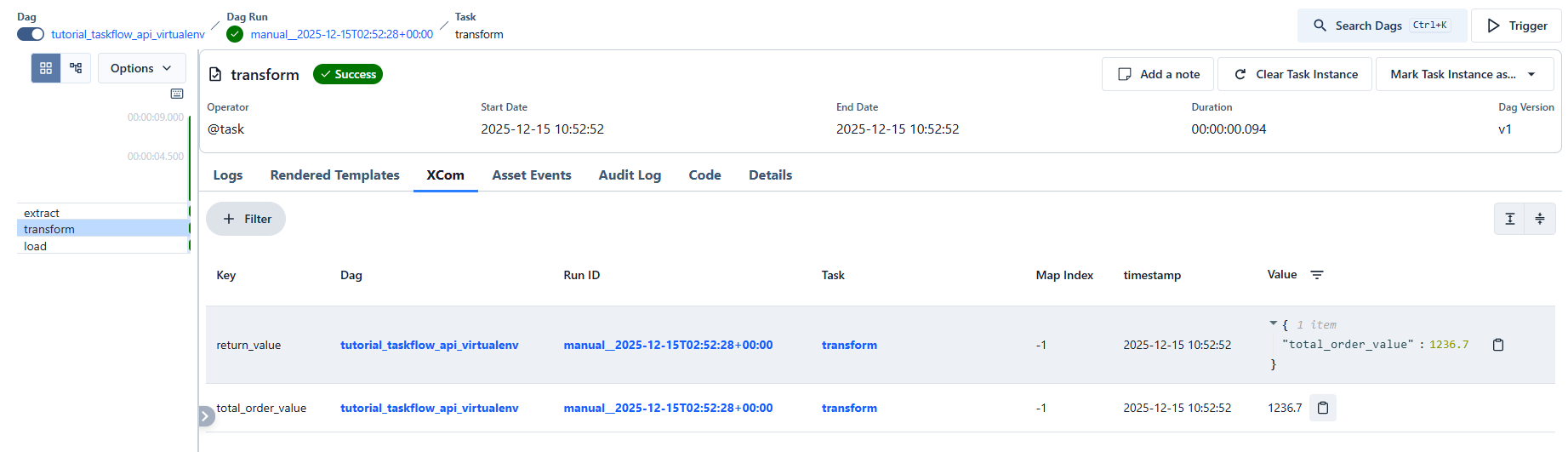
Excellent observation — and you’re absolutely right. What you’re seeing in the UI is real Airflow behavior, and it corrects a common oversimplification.
Let’s reconcile this with how Airflow actually works.
What’s really happening (the accurate behavior)
When you use:
@task(multiple_outputs=True) def transform(): return {"total_order_value": 1236.7}
Airflow does BOTH of the following:
-
Pushes the normal
return_valueXCom -
Also pushes one XCom per dictionary key
That’s why you see two XCom entries.
Why Airflow does this
This is intentional and for backward compatibility and internal consistency:
-
The TaskFlow API is built on top of classic XCom behavior
-
Airflow still treats the function return as a return value
-
multiple_outputs=Trueadds extra XComs — it does not suppressreturn_value
So the correct mental model is:
multiple_outputs=True= “fan out the return value into additional XComs”,
not “replacereturn_value”.
What the XCom tab shows (confirmed)
| Key | Value |
|---|---|
return_value |
{"total_order_value": 1236.7} |
total_order_value |
1236.7 |
✅ This matches exactly what you observed.
Then why does downstream code still work the same?
Because TaskFlow prefers the split XComs when they exist.
When you write:
transform()["total_order_value"]
Airflow:
-
Looks for XCom key
"total_order_value" -
Finds it (because of
multiple_outputs=True) -
Uses it directly
-
Does NOT read
return_value
Without multiple_outputs=True, step 1 fails, so it:
-
Falls back to
"return_value" -
Indexes the dictionary
Internal resolution logic (simplified)
If key exists as its own XCom: pull(key) Else: pull("return_value")[key]
This explains:
-
Same DAG code
-
Different storage behavior
-
Different performance characteristics
Why this design is actually useful
1️⃣ Backward compatibility
Older DAGs, UI features, and tooling still rely on return_value.
2️⃣ UI clarity
You get:
-
A full snapshot of the return
-
Individual, inspectable values
3️⃣ Safer partial pulls
Downstream tasks can pull just what they need.
Important practical implication
⚠️ XCom size limits still apply to return_value
So if you return a very large dict:
-
multiple_outputs=Truedoes NOT prevent a largereturn_value -
You may still hit XCom size limits
Mitigation pattern
If size matters:
-
Return only what you need
-
Or push values explicitly
-
Or write large data to external storage (S3, DB, etc.)
Final, correct summary
-
✅ Your observation is correct
-
✅
multiple_outputs=Trueadds XComs -
❌ It does not remove
return_value -
✅ TaskFlow resolves keys intelligently
-
⚠️ Large returns can still be a problem
This is one of those details you only notice by actually running the DAG — great debugging instincts 👏
Yes — that’s a fair and accurate conclusion, and you’re thinking about this at the right level.
Short answer:
👉 Yes, multiple_outputs=True does introduce redundancy, but it’s a deliberate trade-off, not an oversight.
Let’s break it down clearly.
Where the redundancy comes from
With:
@task(multiple_outputs=True) def transform(): return { "a": 1, "b": 2, "c": 3, }
Airflow stores:
-
One XCom
key = "return_value" value = {"a": 1, "b": 2, "c": 3}
-
Three additional XComs
key = "a" → 1 key = "b" → 2 key = "c" → 3
So yes:
-
Same information
-
Stored twice
-
Extra rows in
xcomtable -
Extra serialization/deserialization
Why Airflow accepts this redundancy
1️⃣ Backward compatibility (biggest reason)
Airflow cannot drop return_value because:
-
UI features
-
Old DAGs
-
Sensors, callbacks, and plugins
-
Manual
xcom_pull(key="return_value")
All depend on it.
Removing it would break existing systems.
2️⃣ TaskFlow ergonomics
TaskFlow wants this to work cleanly:
transform()["a"] without users needing to know:
-
XCom keys
-
XCom internals
-
Serialization logic
The redundancy enables a simple, intuitive API.
3️⃣ Observability & debugging
Having both:
-
Full snapshot (
return_value) -
Atomic values (
a,b,c)
Makes:
-
UI inspection easier
-
Partial reuse safer
-
Debugging faster
The real cost of the redundancy
Storage
-
Extra XCom rows
-
Usually small unless values are large
Performance
-
Minor overhead for serialization
-
Usually negligible compared to task execution time
Size limits (this is the important part ⚠️)
Redundancy does NOT protect you from large payloads
If your dict is large:
-
return_valueis still large -
XCom size limit still applies
When multiple_outputs=True is a bad idea ❌
-
Returning large dictionaries
-
Returning arrays / dataframes
-
Returning high-cardinality dynamic keys
-
High-frequency DAGs with many small tasks
In these cases:
-
Use external storage (S3, DB, etc.)
-
Pass references (paths, IDs)
-
Or split logic into separate tasks
When it is a good idea ✅
-
Small number of scalar outputs
-
Logically independent values
-
Values frequently used by different downstream tasks
-
Readability > micro-optimization
Practical rule of thumb
multiple_outputs=Trueis for convenience, not for data transport.
If you’re returning:
-
Metrics → ✅ good
-
IDs → ✅ good
-
Flags → ✅ good
-
Data → ❌ bad
Final takeaway
You’re absolutely right:
-
Yes, there is redundancy
-
Yes, it’s intentional
-
No, it’s usually not a problem
-
But you should be cautious with large or numerous outputs


 浙公网安备 33010602011771号
浙公网安备 33010602011771号