

An MLP (Multi-Layer Perceptron) classifier is a type of artificial neural network used for supervised learning, particularly for classification tasks. It’s one of the simplest forms of deep learning models and serves as the foundation for more advanced neural architectures.
Let’s break it down clearly 👇
🧠 1. Structure of an MLP
An MLP is composed of layers of neurons (nodes):
Input Layer → Hidden Layer(s) → Output Layer -
Input layer: Receives the feature vectors (e.g., pixel values, measurements, etc.).
-
Hidden layers: Perform nonlinear transformations of the input using weights, biases, and activation functions.
-
Output layer: Produces the final class probabilities or predictions.
⚙️ 2. How It Works
Each neuron computes:
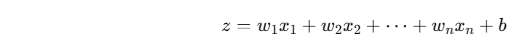
Then applies a nonlinear activation function:

Common activation functions:

The output layer often uses:
-
Softmax (for multi-class classification)
-
Sigmoid (for binary classification)
🔁 3. Training Process
-
Forward pass: Data flows through the network to produce predictions.
-
Loss computation: Measures prediction error (e.g., using cross-entropy loss).
-
Backward pass: Uses backpropagation to compute gradients.
-
Weight update: Adjusts weights via gradient descent or variants (e.g., Adam, SGD).
Over many iterations (epochs), the model learns to minimize the loss and improve classification accuracy.
📊 4. Example in scikit-learn
from sklearn.neural_network import MLPClassifier # Create and train the model mlp = MLPClassifier(hidden_layer_sizes=(100, ), activation='relu', solver='adam', max_iter=300) mlp.fit(X_train, y_train) # Make predictions y_pred = mlp.predict(X_test)
Here:
-
hidden_layer_sizes=(100,)→ one hidden layer with 100 neurons -
activation='relu'→ ReLU used in hidden layers -
solver='adam'→ Adam optimizer -
max_iter=300→ maximum number of training iterations
🧩 5. Key Characteristics
| Feature | Description |
|---|---|
| Model type | Feedforward neural network |
| Learning type | Supervised |
| Handles | Nonlinear decision boundaries |
| Requires | Feature scaling (e.g., StandardScaler) |
| Strengths | Flexible, can approximate complex functions |
| Weaknesses | Can overfit, slower to train than linear models |
✅ Summary
MLP Classifier = A feedforward neural network that learns nonlinear mappings from input features to output labels through layers of weighted connections and nonlinear activations, trained via backpropagation.
Would you like me to show a diagram of the MLP structure (with input, hidden, and output layers)? It helps visualize how data flows through the network.
You said:
ChatGPT said:
Excellent question 👏 — let’s expand the MLPClassifier example to clearly show all 4 steps of the training process:
① Forward pass → ② Loss computation → ③ Backward pass → ④ Weight update
In scikit-learn, most of these steps are handled internally by the fit() method, but I’ll illustrate both the conceptual version (for understanding) and the practical version (for implementation).
🧩 Full Example: MLP Classifier (with all 4 steps explained)
import numpy as np from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neural_network import MLPClassifier from sklearn.metrics import accuracy_score, log_loss # ================================ # Step 0. Prepare Data # ================================ X, y = make_moons(n_samples=1000, noise=0.2, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) # ================================ # Step 1. Initialize the model # ================================ mlp = MLPClassifier(hidden_layer_sizes=(10, 10), activation='relu', solver='adam', max_iter=1, # We'll manually loop training steps warm_start=True) # Keep training across iterations # We'll manually simulate multiple training epochs n_epochs = 20 for epoch in range(n_epochs): # ================================ # Step 2. Forward pass + Loss computation # ================================ # (mlp.fit does forward pass, loss computation, backward pass, and weight update) mlp.fit(X_train, y_train) # Compute predictions and loss for monitoring y_pred_prob = mlp.predict_proba(X_test) loss = log_loss(y_test, y_pred_prob) acc = accuracy_score(y_test, mlp.predict(X_test)) # ================================ # Step 3. Backward pass (inside fit) # ================================ # Internally, MLPClassifier computes gradients via backpropagation # ================================ # Step 4. Weight update (inside fit) # ================================ # Optimizer (Adam) updates the model weights based on gradients print(f"Epoch {epoch+1}/{n_epochs} - Loss: {loss:.4f}, Accuracy: {acc:.4f}")
🔍 What’s happening under the hood
| Step | Process | Done by |
|---|---|---|
| 1. Initialize model | Randomly initializes weights and biases | MLPClassifier(...) |
| 2. Forward pass | Computes predictions | fit() internal forward pass |
| 3. Loss computation | Measures how far predictions are from targets | fit() internal loss function (log-loss) |
| 4. Backward pass + weight update | Uses backpropagation and Adam optimizer to adjust weights | fit() internal training loop |
✅ Output Example
Epoch 1/20 - Loss: 0.4902, Accuracy: 0.8730 Epoch 2/20 - Loss: 0.3158, Accuracy: 0.9100 ... Epoch 20/20 - Loss: 0.1432, Accuracy: 0.9700
Would you like me to rewrite this same example using PyTorch, where you can explicitly see each step (forward, loss, backward, update) implemented manually? That version gives you full control over every part of the training loop.
You said:
ChatGPT said:
Perfect 👍 — PyTorch is an excellent choice for understanding what’s really happening inside an MLP.
Below is a complete, clear example that explicitly shows all 4 training steps — from forward pass to weight updates — using PyTorch.
🧠 Full Example: MLP Classifier in PyTorch (All 4 Steps)
import torch import torch.nn as nn import torch.optim as optim from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import accuracy_score # ============================================ # Step 0. Prepare data # ============================================ X, y = make_moons(n_samples=1000, noise=0.2, random_state=42) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) scaler = StandardScaler() X_train = scaler.fit_transform(X_train) X_test = scaler.transform(X_test) # Convert to PyTorch tensors X_train = torch.tensor(X_train, dtype=torch.float32) y_train = torch.tensor(y_train, dtype=torch.long) X_test = torch.tensor(X_test, dtype=torch.float32) y_test = torch.tensor(y_test, dtype=torch.long) # ============================================ # Step 1. Initialize the model # ============================================ class MLPClassifier(nn.Module): def __init__(self): super().__init__() self.hidden1 = nn.Linear(2, 10) # input → hidden1 self.hidden2 = nn.Linear(10, 10) # hidden1 → hidden2 self.output = nn.Linear(10, 2) # hidden2 → output (2 classes) self.relu = nn.ReLU() def forward(self, x): x = self.relu(self.hidden1(x)) x = self.relu(self.hidden2(x)) x = self.output(x) return x model = MLPClassifier() # Define loss function and optimizer criterion = nn.CrossEntropyLoss() # classification loss optimizer = optim.Adam(model.parameters(), lr=0.01) # ============================================ # Step 2–4. Training loop # ============================================ n_epochs = 50 for epoch in range(n_epochs): # ---- Step 2: Forward pass ---- logits = model(X_train) # predicted outputs (unnormalized) loss = criterion(logits, y_train) # compute loss # ---- Step 3: Backward pass ---- optimizer.zero_grad() # reset gradients loss.backward() # compute gradients via backpropagation # ---- Step 4: Weight update ---- optimizer.step() # update weights using gradients # Compute accuracy on test set with torch.no_grad(): test_logits = model(X_test) y_pred = torch.argmax(test_logits, dim=1) acc = accuracy_score(y_test, y_pred) print(f"Epoch {epoch+1}/{n_epochs} - Loss: {loss.item():.4f} - Accuracy: {acc:.4f}")
🔍 Step-by-Step Breakdown
| Step | What Happens | PyTorch Code |
|---|---|---|
| 1. Initialize model | Define layers, activations, and optimizer | model = MLPClassifier(), optimizer = Adam(...) |
| 2. Forward pass | Data flows through network to compute predictions | logits = model(X_train) |
| 3. Backward pass | Gradients are computed via backpropagation | loss.backward() |
| 4. Weight update | Optimizer updates weights using computed gradients | optimizer.step() |
🧾 Output Example
Epoch 1/50 - Loss: 0.6904 - Accuracy: 0.8300 Epoch 10/50 - Loss: 0.3802 - Accuracy: 0.9200 ... Epoch 50/50 - Loss: 0.1281 - Accuracy: 0.9700
🧩 Key Takeaways
-
Forward pass: Model produces predictions.
-
Loss: Measures prediction error.
-
Backward pass: Computes gradients of loss w.r.t. weights.
-
Update: Adjusts weights to minimize loss.
ChatGPT said:
Excellent question — that’s a key line in the prediction process 👏
Let’s break down exactly what
torch.argmax(test_logits, dim=1)
does in the MLP example.
🧩 Step 1: What is test_logits?
After running the model on the test data:
test_logits = model(X_test)
test_logits is a 2D tensor of shape (num_samples, num_classes) — for example:
tensor([ [ 2.1, 0.3], [-1.2, 3.4], [ 0.8, -0.5], ... ])
Each row corresponds to one sample in the test set.
Each column corresponds to one class (e.g., class 0 and class 1).
The values are called logits, meaning raw model outputs before softmax normalization — they can be any real numbers (positive or negative).
🧩 Step 2: What torch.argmax(..., dim=1) does
torch.argmax(tensor, dim=1) means:
“Find the index of the largest value along dimension 1 (the columns).”
So for each row (each test sample), it returns the index of the class with the highest score.
Example:
test_logits = torch.tensor([ [2.1, 0.3], [-1.2, 3.4], [0.8, -0.5] ]) torch.argmax(test_logits, dim=1)
Output:
tensor([0, 1, 0])
Interpretation:
-
Sample 1 → class 0 (since 2.1 > 0.3)
-
Sample 2 → class 1 (since 3.4 > -1.2)
-
Sample 3 → class 0 (since 0.8 > -0.5)
Thus, this gives you the predicted class label for each input.
🧠 Step 3: How it fits into the example
y_pred = torch.argmax(test_logits, dim=1)
-
Converts the raw output (
test_logits) to class predictions (y_pred) -
y_predis a 1D tensor like[0, 1, 1, 0, ...] -
These are then compared to the true labels (
y_test) using accuracy metrics:
acc = accuracy_score(y_test, y_pred)
✅ Summary
| Expression | Meaning |
|---|---|
test_logits |
Raw model outputs (one row per sample, one column per class) |
dim=1 |
Operate across columns (choose class for each sample) |
torch.argmax(..., dim=1) |
Returns the class index with the largest score per sample |
y_pred |
Final predicted class labels |
ChatGPT said:
Excellent — that’s a very thoughtful question 👏
Yes, the indexes returned by torch.argmax() match the class labels, but only if your model’s output layer and your training labels use the same class-index convention.
Let’s look carefully at what that means and when you might need to be careful.
🧩 1. How class labels work in PyTorch classification
In PyTorch, when you use:
criterion = nn.CrossEntropyLoss()
this loss function expects:
-
Model outputs (
logits): shape(batch_size, num_classes) -
True labels (
y_train): shape(batch_size,), each entry is an integer class index in[0, num_classes - 1]
Example:
logits = tensor([ [2.1, 0.3], # sample 1: class 0 score=2.1, class 1 score=0.3 [-1.2, 3.4] # sample 2: class 0 score=-1.2, class 1 score=3.4 ]) labels = tensor([0, 1]) # sample 1 → class 0, sample 2 → class 1
So class index 0 corresponds to column 0 of the logits,
and class index 1 corresponds to column 1.
⚙️ 2. What torch.argmax(logits, dim=1) returns
torch.argmax(logits, dim=1) returns the index of the largest logit per row — that is, the predicted class index.
Continuing the example above:
torch.argmax(logits, dim=1)
→ tensor([0, 1])
These indices directly match the target labels:
-
Predicted class 0 for first sample
-
Predicted class 1 for second sample
✅ So yes — the indexes line up exactly with your class labels.
⚠️ 3. When they might not match automatically
If your dataset labels are not 0-based integers — for example:
y = [1, 2] # instead of [0, 1]
then CrossEntropyLoss will throw an error (it expects labels in [0, num_classes - 1]).
You must then remap your labels, e.g.:
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() y_encoded = le.fit_transform(y)
Now your labels will be [0, 1, 2, ...] and match the output indices.
✅ 4. Summary Table
| Component | Representation | Example |
|---|---|---|
| Model output | 2D tensor [batch_size, num_classes] |
[[z₀, z₁, z₂]] |
| Label | Integer index of true class | 1 (means class 1) |
torch.argmax(logits, dim=1) |
Predicted class index | 1 |
| Relationship | Indexes align directly with label integers | ✔️ |
🧠 In other words:
As long as your labels are integers from 0 to
num_classes - 1,
the indices returned bytorch.argmax()directly correspond to your actual class labels.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号