




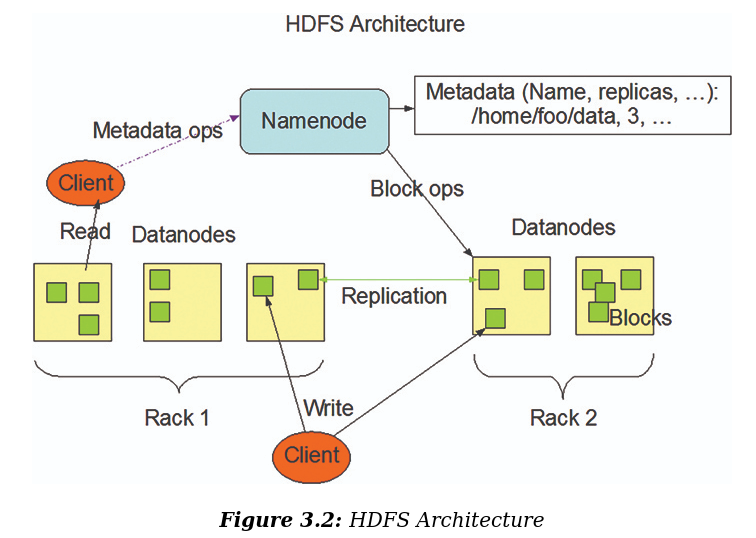




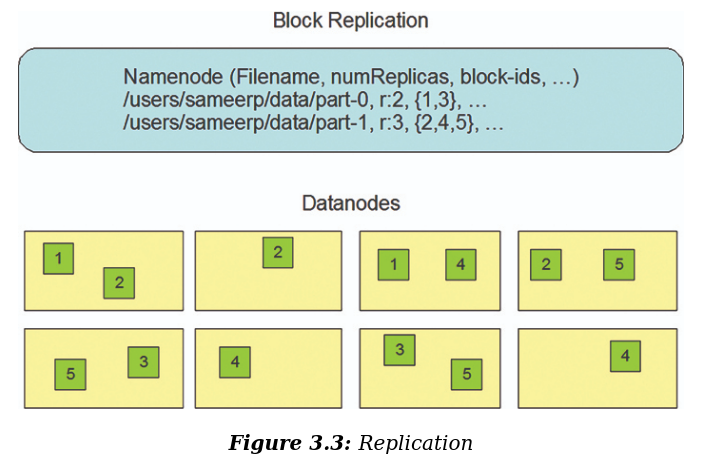





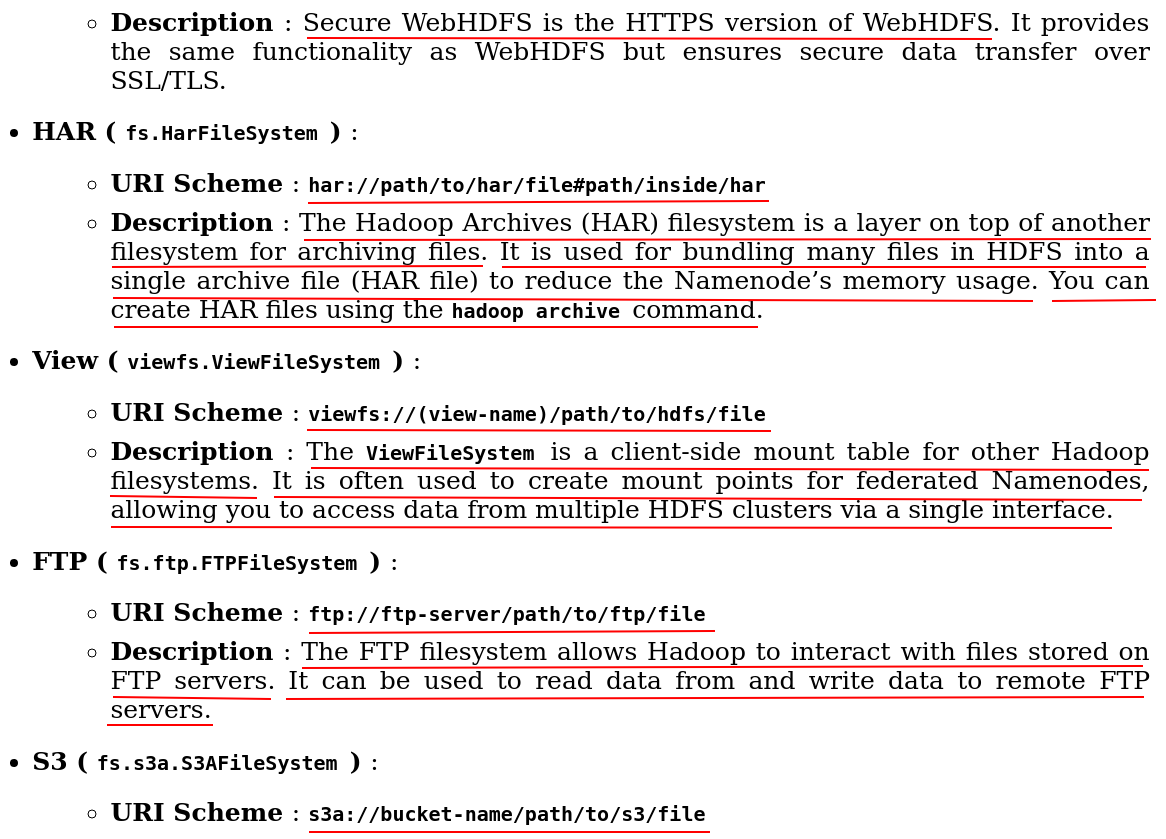






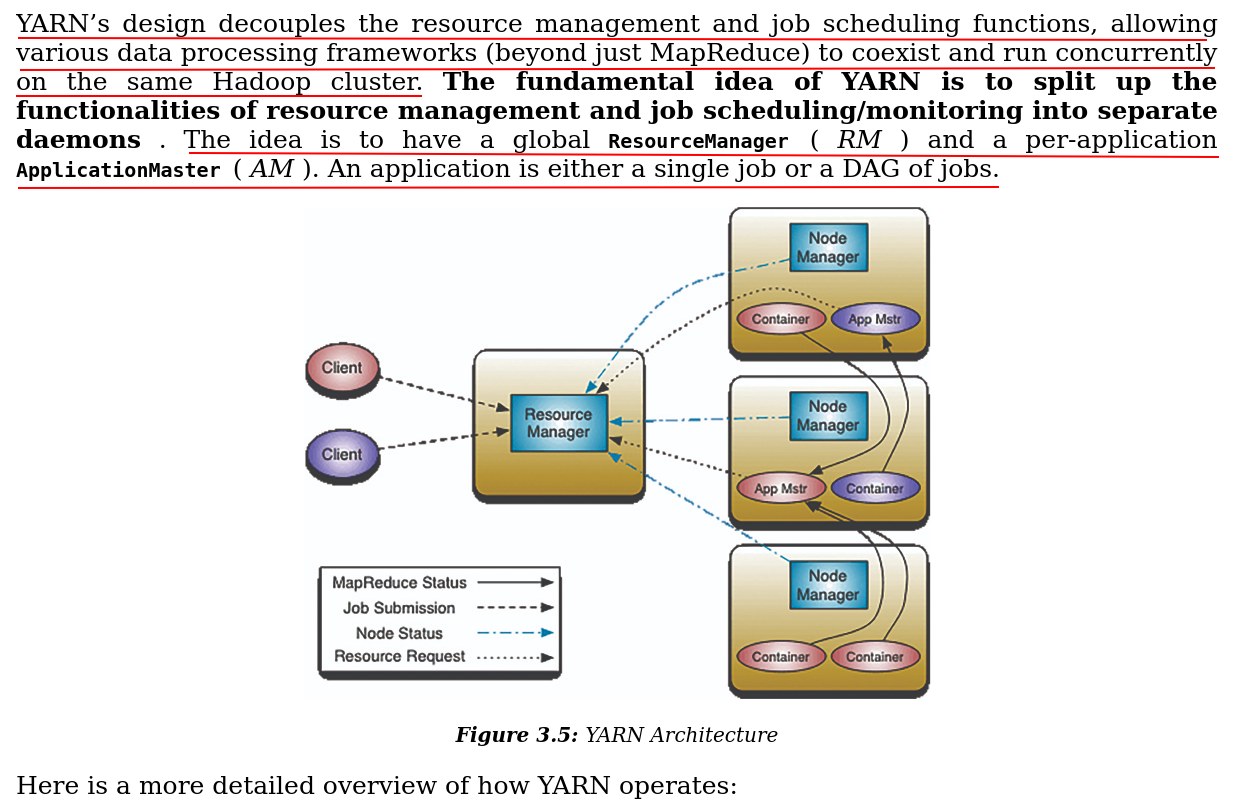
























See https://www.cnblogs.com/zhangzhihui/p/18733011 .

hdfs dfs -ls <path> : List files and directories in HDFS.
zzh@ZZHPC:~$ hdfs dfs -ls / Found 2 items drwxr-xr-x - zzh supergroup 0 2025-02-24 22:07 /tmp drwxr-xr-x - zzh supergroup 0 2025-02-24 22:05 /user
hdfs dfs -mkdir <path> : Create a directory in HDFS.
zzh@ZZHPC:~$ hdfs dfs -mkdir /chapter-3 zzh@ZZHPC:~$ hdfs dfs -ls / Found 3 items drwxr-xr-x - zzh supergroup 0 2025-02-25 09:08 /chapter-3 drwxr-xr-x - zzh supergroup 0 2025-02-24 22:07 /tmp drwxr-xr-x - zzh supergroup 0 2025-02-24 22:05 /user zzh@ZZHPC:~$ hdfs dfs -chmod 777 /chapter-3 zzh@ZZHPC:~$ hdfs dfs -ls / Found 3 items drwxrwxrwx - zzh supergroup 0 2025-02-25 09:08 /chapter-3 drwxr-xr-x - zzh supergroup 0 2025-02-24 22:07 /tmp drwxr-xr-x - zzh supergroup 0 2025-02-24 22:05 /user
hdfs dfs -put <localSrc> <dest> : Copy files or directories from the local file system to HDFS.
zzh@ZZHPC:~$ echo 'aaa' > a.txt zzh@ZZHPC:~$ hdfs dfs -put a.txt /chapter-3 zzh@ZZHPC:~$ hdfs dfs -ls /chapter-3 Found 1 items -rw-r--r-- 1 zzh supergroup 4 2025-02-25 09:13 /chapter-3/a.txt
hdfs dfs -get <src> <localDest> : Copy files or directories from HDFS to the local file system.
hdfs dfs -cat <file> : Display the contents of a file in HDFS.
zzh@ZZHPC:~$ hdfs dfs -cat /chapter-3/a.txt aaa
hdfs dfs -rm <path> : Remove files or directories from HDFS.
zzh@ZZHPC:~$ hdfs dfs -rm /chapter-3/a.txt Deleted /chapter-3/a.txt
hdfs dfs -du <path> : Display the summary of space used by a file or directory in HDFS.
hdfs dfs -chmod <permission> <directory/file> : Change permissions for a file or directory.
hdfs dfs -mv <path> : Move files/directories.

hadoop jar <jarFile> <mainClass> [args]: Submit a MapReduce job to the cluster using a specified JAR file and main class.hadoop job -list: List all running and completed MapReduce jobs.hadoop job -kill <jobId>: Terminate a running MapReduce job.

hadoop version : Display Hadoop version information.
zzh@ZZHPC:~$ hadoop version Hadoop 3.4.1 Source code repository https://github.com/apache/hadoop.git -r 4d7825309348956336b8f06a08322b78422849b1 Compiled by mthakur on 2024-10-09T14:57Z Compiled on platform linux-x86_64 Compiled with protoc 3.23.4 From source with checksum 7292fe9dba5e2e44e3a9f763fce3e680 This command was run using /home/zzh/Downloads/sfw/hadoop-3.4.1/share/hadoop/common/hadoop-common-3.4.1.jar
hadoop classpath : Print the classpath needed to run Hadoop utilities.
zzh@ZZHPC:~$ hadoop classpath /home/zzh/Downloads/sfw/hadoop-3.4.1/etc/hadoop:/home/zzh/Downloads/sfw/hadoop-3.4.1/share/hadoop/common/lib/*:/home/zzh/Downloads/sfw/hadoop-3.4.1/share/hadoop/common/*:/home/zzh/Downloads/sfw/hadoop-3.4.1/share/hadoop/hdfs:/home/zzh/Downloads/sfw/hadoop-3.4.1/share/hadoop/hdfs/lib/*:/home/zzh/Downloads/sfw/hadoop-3.4.1/share/hadoop/hdfs/*:/home/zzh/Downloads/sfw/hadoop-3.4.1/share/hadoop/mapreduce/*:/home/zzh/Downloads/sfw/hadoop-3.4.1/share/hadoop/yarn:/home/zzh/Downloads/sfw/hadoop-3.4.1/share/hadoop/yarn/lib/*:/home/zzh/Downloads/sfw/hadoop-3.4.1/share/hadoop/yarn/*
hadoop envvars : Display computed Hadoop environment variables.
zzh@ZZHPC:~$ hadoop envvars JAVA_HOME='/usr/lib/jvm/java-21-openjdk-amd64' HADOOP_COMMON_HOME='/home/zzh/Downloads/sfw/hadoop-3.4.1' HADOOP_COMMON_DIR='share/hadoop/common' HADOOP_COMMON_LIB_JARS_DIR='share/hadoop/common/lib' HADOOP_COMMON_LIB_NATIVE_DIR='lib/native' HADOOP_CONF_DIR='/home/zzh/Downloads/sfw/hadoop-3.4.1/etc/hadoop' HADOOP_TOOLS_HOME='/home/zzh/Downloads/sfw/hadoop-3.4.1' HADOOP_TOOLS_DIR='share/hadoop/tools' HADOOP_TOOLS_LIB_JARS_DIR='share/hadoop/tools/lib'
hadoop dfsadmin -report : Get a report on the overall HDFS cluster status.
zzh@ZZHPC:~$ hadoop dfsadmin -report
WARNING: Use of this script to execute dfsadmin is deprecated.
WARNING: Attempting to execute replacement "hdfs dfsadmin" instead.
Configured Capacity: 62163619840 (57.89 GB)
Present Capacity: 6227054592 (5.80 GB)
DFS Remaining: 6226284544 (5.80 GB)
DFS Used: 770048 (752 KB)
DFS Used%: 0.01%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (1):
Name: 127.0.0.1:9866 (ip6-localhost)
Hostname: ZZHPC
Decommission Status : Normal
Configured Capacity: 62163619840 (57.89 GB)
DFS Used: 770048 (752 KB)
Non DFS Used: 52745646080 (49.12 GB)
DFS Remaining: 6226284544 (5.80 GB)
DFS Used%: 0.00%
DFS Remaining%: 10.02%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Tue Feb 25 09:43:23 CST 2025
Last Block Report: Tue Feb 25 08:51:17 CST 2025
Num of Blocks: 6
zzh@ZZHPC:~$ hdfs dfsadmin -report
Configured Capacity: 62163619840 (57.89 GB)
Present Capacity: 6225506304 (5.80 GB)
DFS Remaining: 6224736256 (5.80 GB)
DFS Used: 770048 (752 KB)
DFS Used%: 0.01%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (1):
Name: 127.0.0.1:9866 (ip6-localhost)
Hostname: ZZHPC
Decommission Status : Normal
Configured Capacity: 62163619840 (57.89 GB)
DFS Used: 770048 (752 KB)
Non DFS Used: 52747194368 (49.12 GB)
DFS Remaining: 6224736256 (5.80 GB)
DFS Used%: 0.00%
DFS Remaining%: 10.01%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 0
Last contact: Tue Feb 25 09:46:32 CST 2025
Last Block Report: Tue Feb 25 08:51:17 CST 2025
Num of Blocks: 6
hadoop dfsadmin -safemode [enter|leave|get] : Enter, leave, or get the HDFS safe mode status.
zzh@ZZHPC:~$ hadoop dfsadmin -safemode get WARNING: Use of this script to execute dfsadmin is deprecated. WARNING: Attempting to execute replacement "hdfs dfsadmin" instead. Safe mode is OFF zzh@ZZHPC:~$ hdfs dfsadmin -safemode get Safe mode is OFF
hadoop dfsadmin -refreshNodes : Refresh the list of DataNodes.
zzh@ZZHPC:~$ hadoop dfsadmin -refreshNodes
WARNING: Use of this script to execute dfsadmin is deprecated.
WARNING: Attempting to execute replacement "hdfs dfsadmin" instead.
Refresh nodes successful
zzh@ZZHPC:~$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
hadoop namenode -format : Format the HDFS filesystem (used cautiously).
yarn application -list : List all YARN applications.
zzh@ZZHPC:~$ yarn application -list
2025-02-25 09:54:20,073 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032
Total number of applications (application-types: [], states: [SUBMITTED, ACCEPTED, RUNNING] and tags: []):0
Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
yarn application -kill <appId> : Kill a running YARN application.
yarn logs -applicationId <appId> : View the logs of a specific YARN application.
hadoop distcp : Copy data between HDFS clusters efficiently.
hadoop archive : Create and manage Hadoop archives.
zzh@ZZHPC:~$ hdfs dfsadmin -printTopology Rack: /default-rack 127.0.0.1:9866 (ip6-localhost) In Service
We can also run $HADOOP_HOME/bin/hdfs to see the full list of commands in Hadoop, as follows:
zzh@ZZHPC:~$ hdfs
Usage: hdfs [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
OPTIONS is none or any of:
--buildpaths attempt to add class files from build tree
--config dir Hadoop config directory
--daemon (start|status|stop) operate on a daemon
--debug turn on shell script debug mode
--help usage information
--hostnames list[,of,host,names] hosts to use in worker mode
--hosts filename list of hosts to use in worker mode
--loglevel level set the log4j level for this command
--workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
cacheadmin configure the HDFS cache
crypto configure HDFS encryption zones
debug run a Debug Admin to execute HDFS debug commands
dfsadmin run a DFS admin client
dfsrouteradmin manage Router-based federation
ec run a HDFS ErasureCoding CLI
fsck run a DFS filesystem checking utility
fsImageValidation run FsImageValidation to check an fsimage
haadmin run a DFS HA admin client
jmxget get JMX exported values from NameNode or DataNode.
oev apply the offline edits viewer to an edits file
oiv apply the offline fsimage viewer to an fsimage
oiv_legacy apply the offline fsimage viewer to a legacy fsimage
storagepolicies list/get/set/satisfyStoragePolicy block storage policies
Client Commands:
classpath prints the class path needed to get the hadoop jar and the required libraries
dfs run a filesystem command on the file system
envvars display computed Hadoop environment variables
fetchdt fetch a delegation token from the NameNode
getconf get config values from configuration
groups get the groups which users belong to
lsSnapshot list all snapshots for a snapshottable directory
lsSnapshottableDir list all snapshottable dirs owned by the current user
snapshotDiff diff two snapshots of a directory or diff the current directory contents with a snapshot
version print the version
Daemon Commands:
balancer run a cluster balancing utility
datanode run a DFS datanode
dfsrouter run the DFS router
diskbalancer Distributes data evenly among disks on a given node
httpfs run HttpFS server, the HDFS HTTP Gateway
journalnode run the DFS journalnode
mover run a utility to move block replicas across storage types
namenode run the DFS namenode
nfs3 run an NFS version 3 gateway
portmap run a portmap service
secondarynamenode run the DFS secondary namenode
sps run external storagepolicysatisfier
zkfc run the ZK Failover Controller daemon
SUBCOMMAND may print help when invoked w/o parameters or with -h.






input_data.txt:
apple banana pear tomato apple peach apple grape banana watermelon apple pear orange strawberry
mapper.py:
#!/usr/bin/env python3 import sys # Input: Lines of text # Output: Key-value pairs (word, 1) for each word in the input for line in sys.stdin: line = line.strip() words = line.split() for word in words: print(f'{word}\t1')
reducer.py:
#!/usr/bin/env python3 import sys # Input: Key-value pairs (word, 1) # Output: Key-value pairs (word, total_count) current_word = None current_count = 0 for line in sys.stdin: line = line.strip() word, count = line.split('\t', 1) try: count = int(count) except ValueError: continue if current_word == word: current_count += count else: if current_word: print(f'{current_word}\t{current_count}') current_word = word current_count = count if current_word: print(f'{current_word}\t{current_count}')
zpy313zzh@ZZHPC:/zdata/Github/ztest$ chmod a+x *.py
zpy313zzh@ZZHPC:/zdata/Github/ztest$ cat input_data.txt | /zdata/Github/ztest/mapper.py
apple 1
banana 1
pear 1
tomato 1
apple 1
peach 1
apple 1
grape 1
banana 1
watermelon 1
apple 1
pear 1
orange 1
strawberry 1
zpy313zzh@ZZHPC:/zdata/Github/ztest$ cat input_data.txt | /zdata/Github/ztest/mapper.py | sort -k1,1 | /zdata/Github/ztest/reducer.py
apple 4
banana 2
grape 1
orange 1
peach 1
pear 2
strawberry 1
tomato 1
watermelon 1
zpy313zzh@ZZHPC:/zdata/Github/ztest$ hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.4.1.jar \
> -files mapper.py, reducer.py \
> -mapper mapper.py \
> -reducer reducer.py \
> -input input_data.txt \
> -output wordcount_output
Found 1 unexpected arguments on the command line [reducer.py]
Try -help for more information
Streaming Command Failed!
zpy313zzh@ZZHPC:/zdata/Github/ztest$ hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.4.1.jar \
> -files mapper.py,reducer.py \
> -mapper mapper.py \
> -reducer reducer.py \
> -input input_data.txt \
> -output wordcount_output
packageJobJar: [/tmp/hadoop-unjar13736853640478168979/] [] /tmp/streamjob5972075337645535523.jar tmpDir=null
2025-02-25 11:06:43,987 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032
2025-02-25 11:06:44,078 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032
2025-02-25 11:06:44,389 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/zzh/.staging/job_1740450976508_0001
2025-02-25 11:06:45,098 INFO mapreduce.JobSubmitter: Cleaning up the staging area /tmp/hadoop-yarn/staging/zzh/.staging/job_1740450976508_0001
2025-02-25 11:06:45,108 ERROR streaming.StreamJob: Error Launching job : Input path does not exist: hdfs://localhost:9000/user/zzh/input_data.txt
Streaming Command Failed!
zpy313zzh@ZZHPC:/zdata/Github/ztest$ hdfs dfs -mkdir input output zpy313zzh@ZZHPC:/zdata/Github/ztest$ hdfs dfs -put input_data.txt input zpy313zzh@ZZHPC:/zdata/Github/ztest$ hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.4.1.jar \ > -files mapper.py,reducer.py \ > -mapper mapper.py \ > -reducer reducer.py \ > -input input/input_data.txt \ > -output output packageJobJar: [/tmp/hadoop-unjar8270243772529611636/] [] /tmp/streamjob7121439135091768576.jar tmpDir=null 2025-02-25 11:10:24,260 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032 2025-02-25 11:10:24,345 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032 2025-02-25 11:10:24,419 ERROR streaming.StreamJob: Error Launching job : Output directory hdfs://localhost:9000/user/zzh/output already exists Streaming Command Failed!
zpy313zzh@ZZHPC:/zdata/Github/ztest$ hdfs dfs -rmdir output
zpy313zzh@ZZHPC:/zdata/Github/ztest$ hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.4.1.jar \
> -files mapper.py,reducer.py \
> -mapper mapper.py \
> -reducer reducer.py \
> -input input/input_data.txt \
> -output output
packageJobJar: [/tmp/hadoop-unjar6350135663166708986/] [] /tmp/streamjob10767542825012848308.jar tmpDir=null
2025-02-25 13:04:58,606 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032
2025-02-25 13:04:58,694 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032
2025-02-25 13:04:58,841 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/zzh/.staging/job_1740450976508_0008
2025-02-25 13:04:59,037 INFO mapred.FileInputFormat: Total input files to process : 1
2025-02-25 13:04:59,078 INFO mapreduce.JobSubmitter: number of splits:2
2025-02-25 13:04:59,182 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1740450976508_0008
2025-02-25 13:04:59,182 INFO mapreduce.JobSubmitter: Executing with tokens: []
2025-02-25 13:04:59,298 INFO conf.Configuration: resource-types.xml not found
2025-02-25 13:04:59,298 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2025-02-25 13:04:59,350 INFO impl.YarnClientImpl: Submitted application application_1740450976508_0008
2025-02-25 13:04:59,370 INFO mapreduce.Job: The url to track the job: http://ZZHPC:8088/proxy/application_1740450976508_0008/
2025-02-25 13:04:59,371 INFO mapreduce.Job: Running job: job_1740450976508_0008
2025-02-25 13:05:03,435 INFO mapreduce.Job: Job job_1740450976508_0008 running in uber mode : false
2025-02-25 13:05:03,436 INFO mapreduce.Job: map 0% reduce 0%
2025-02-25 13:05:06,474 INFO mapreduce.Job: Task Id : attempt_1740450976508_0008_m_000000_0, Status : FAILED
Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 127
at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:326)
at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:539)
at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:129)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)
at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:466)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:350)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)
at java.base/java.security.AccessController.doPrivileged(AccessController.java:714)
at java.base/javax.security.auth.Subject.doAs(Subject.java:525)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1953)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
2025-02-25 13:05:06,482 INFO mapreduce.Job: Task Id : attempt_1740450976508_0008_m_000001_0, Status : FAILED
Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 127
at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:326)
at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:539)
at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:129)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)
at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:466)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:350)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)
at java.base/java.security.AccessController.doPrivileged(AccessController.java:714)
at java.base/javax.security.auth.Subject.doAs(Subject.java:525)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1953)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
2025-02-25 13:05:09,508 INFO mapreduce.Job: Task Id : attempt_1740450976508_0008_m_000000_1, Status : FAILED
Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 127
at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:326)
at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:539)
at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:129)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)
at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:466)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:350)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)
at java.base/java.security.AccessController.doPrivileged(AccessController.java:714)
at java.base/javax.security.auth.Subject.doAs(Subject.java:525)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1953)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
2025-02-25 13:05:09,509 INFO mapreduce.Job: Task Id : attempt_1740450976508_0008_m_000001_1, Status : FAILED
Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 127
at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:326)
at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:539)
at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:129)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)
at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:466)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:350)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)
at java.base/java.security.AccessController.doPrivileged(AccessController.java:714)
at java.base/javax.security.auth.Subject.doAs(Subject.java:525)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1953)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
2025-02-25 13:05:13,527 INFO mapreduce.Job: Task Id : attempt_1740450976508_0008_m_000000_2, Status : FAILED
Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 127
at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:326)
at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:539)
at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:129)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)
at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:466)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:350)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)
at java.base/java.security.AccessController.doPrivileged(AccessController.java:714)
at java.base/javax.security.auth.Subject.doAs(Subject.java:525)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1953)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
2025-02-25 13:05:14,534 INFO mapreduce.Job: Task Id : attempt_1740450976508_0008_m_000001_2, Status : FAILED
Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 127
at org.apache.hadoop.streaming.PipeMapRed.waitOutputThreads(PipeMapRed.java:326)
at org.apache.hadoop.streaming.PipeMapRed.mapRedFinished(PipeMapRed.java:539)
at org.apache.hadoop.streaming.PipeMapper.close(PipeMapper.java:129)
at org.apache.hadoop.mapred.MapRunner.run(MapRunner.java:61)
at org.apache.hadoop.streaming.PipeMapRunner.run(PipeMapRunner.java:34)
at org.apache.hadoop.mapred.MapTask.runOldMapper(MapTask.java:466)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:350)
at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:178)
at java.base/java.security.AccessController.doPrivileged(AccessController.java:714)
at java.base/javax.security.auth.Subject.doAs(Subject.java:525)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1953)
at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:172)
2025-02-25 13:05:16,545 INFO mapreduce.Job: map 100% reduce 100%
2025-02-25 13:05:16,551 INFO mapreduce.Job: Job job_1740450976508_0008 failed with state FAILED due to: Task failed task_1740450976508_0008_m_000000
Job failed as tasks failed. failedMaps:1 failedReduces:0 killedMaps:0 killedReduces: 0
2025-02-25 13:05:16,616 INFO mapreduce.Job: Counters: 14
Job Counters
Failed map tasks=7
Killed map tasks=1
Killed reduce tasks=1
Launched map tasks=8
Other local map tasks=6
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=11447
Total time spent by all reduces in occupied slots (ms)=0
Total time spent by all map tasks (ms)=11447
Total vcore-milliseconds taken by all map tasks=11447
Total megabyte-milliseconds taken by all map tasks=11721728
Map-Reduce Framework
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
2025-02-25 13:05:16,616 ERROR streaming.StreamJob: Job not successful!
Streaming Command Failed!
Changed the shebang line from '#!/usr/bin/env python' to '#!/usr/bin/env python3' and the command ran successfully:
zpy313zzh@ZZHPC:/zdata/Github/ztest$ hadoop jar $HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.4.1.jar -files mapper.py,reducer.py -mapper mapper.py -reducer reducer.py -input input/input_data.txt -output output
packageJobJar: [/tmp/hadoop-unjar9462115612604755836/] [] /tmp/streamjob17175212678417692090.jar tmpDir=null
2025-02-25 13:14:13,604 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032
2025-02-25 13:14:13,702 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032
2025-02-25 13:14:13,850 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/zzh/.staging/job_1740450976508_0009
2025-02-25 13:14:14,048 INFO mapred.FileInputFormat: Total input files to process : 1
2025-02-25 13:14:14,085 INFO mapreduce.JobSubmitter: number of splits:2
2025-02-25 13:14:14,595 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1740450976508_0009
2025-02-25 13:14:14,595 INFO mapreduce.JobSubmitter: Executing with tokens: []
2025-02-25 13:14:14,708 INFO conf.Configuration: resource-types.xml not found
2025-02-25 13:14:14,708 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2025-02-25 13:14:14,761 INFO impl.YarnClientImpl: Submitted application application_1740450976508_0009
2025-02-25 13:14:14,787 INFO mapreduce.Job: The url to track the job: http://ZZHPC:8088/proxy/application_1740450976508_0009/
2025-02-25 13:14:14,788 INFO mapreduce.Job: Running job: job_1740450976508_0009
2025-02-25 13:14:19,851 INFO mapreduce.Job: Job job_1740450976508_0009 running in uber mode : false
2025-02-25 13:14:19,851 INFO mapreduce.Job: map 0% reduce 0%
2025-02-25 13:14:23,897 INFO mapreduce.Job: map 100% reduce 0%
2025-02-25 13:14:27,914 INFO mapreduce.Job: map 100% reduce 100%
2025-02-25 13:14:28,923 INFO mapreduce.Job: Job job_1740450976508_0009 completed successfully
2025-02-25 13:14:28,984 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=158
FILE: Number of bytes written=937650
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=349
HDFS: Number of bytes written=84
HDFS: Number of read operations=11
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=3916
Total time spent by all reduces in occupied slots (ms)=1643
Total time spent by all map tasks (ms)=3916
Total time spent by all reduce tasks (ms)=1643
Total vcore-milliseconds taken by all map tasks=3916
Total vcore-milliseconds taken by all reduce tasks=1643
Total megabyte-milliseconds taken by all map tasks=4009984
Total megabyte-milliseconds taken by all reduce tasks=1682432
Map-Reduce Framework
Map input records=5
Map output records=14
Map output bytes=124
Map output materialized bytes=164
Input split bytes=206
Combine input records=0
Combine output records=0
Reduce input groups=9
Reduce shuffle bytes=164
Reduce input records=14
Reduce output records=9
Spilled Records=28
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=72
CPU time spent (ms)=1240
Physical memory (bytes) snapshot=774602752
Virtual memory (bytes) snapshot=8315166720
Total committed heap usage (bytes)=444596224
Peak Map Physical memory (bytes)=299085824
Peak Map Virtual memory (bytes)=2771279872
Peak Reduce Physical memory (bytes)=181252096
Peak Reduce Virtual memory (bytes)=2773655552
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=143
File Output Format Counters
Bytes Written=84
2025-02-25 13:14:28,984 INFO streaming.StreamJob: Output directory: output


 浙公网安备 33010602011771号
浙公网安备 33010602011771号