

强化学习SQL算法(soft q leanring)中的squash_correction是否存疑?
SQL算法的官方实现地址:
https://openi.pcl.ac.cn/devilmaycry812839668/softlearning
提两个问题:
-
SQL算法的原始论文中在计算Q loss function的时候建议使用重要性采样,而实际代码中却使用的是均匀采样,同时也没有采样重要性采样的方法进行修正,而原始论文中在这一步的推导公式中也没有加入重要性采样的分布比重这一参数项;
-
SQL的官方实现中进行了squash_correction,也就是加入了log_det_jacobian,关于squash_correction这部分的理论知识,见:
https://www.cnblogs.com/xyz/p/18621025
重要的数学推导为:

由于在官方实现中https://openi.pcl.ac.cn/devilmaycry812839668/softlearning已经对policy的tanh变换进行了Bijector,那么在进行policy loss function计算的时候是不应该在进行squash_correction的,但是官方实现中却进行了squash_correction,见:
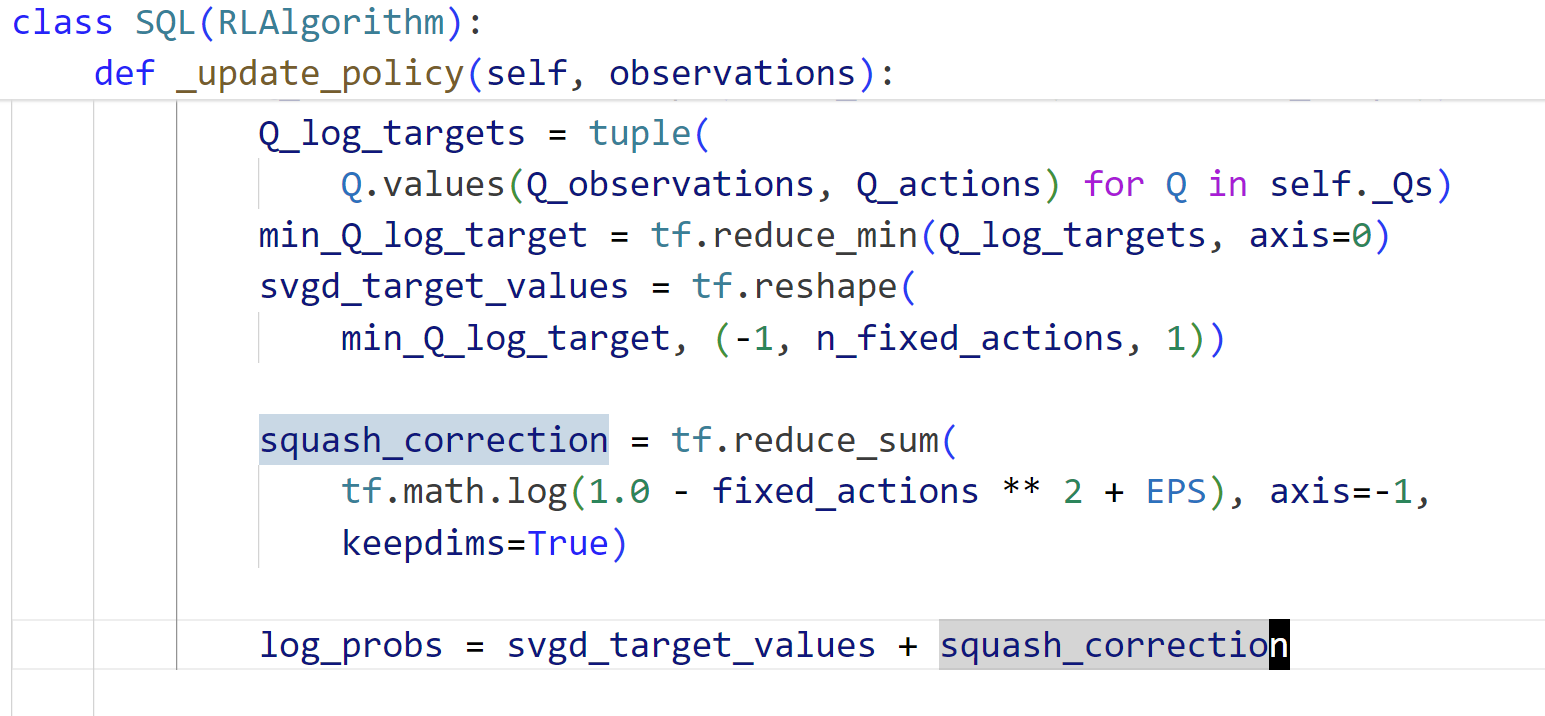
因为在代码的policy实现部分已经对tanh进行了Bijector,那么policy在进行sample的时候获得的action是squash之后的,也就是说我们获得的action就是Y,而不是X,因此不需要再考虑Y=tanh(X)所带来的squash校准问题,代码地址:

根据数学推导:
之所以强化学习中很多代码在采样后tanh变换后进行squash修正,是因为其都是在tanh变换之前采样的,如:
https://colab.research.google.com/github/google/brax/blob/main/notebooks/training_torch.ipynb 中就是进行的X采样,而不是Y采样,因此其需要进行squash_correction,因此引入log_det_jacobian,而在SQL算法的实现中由于采用了tfp.bijectors.Tanh(),因此其采样是对Y进行的采样,因此不应该进行squash_correction。
而SQL代码中进行的squash_correction从形式上看更像是对logP(X=x)的求解,而其进行KL计算时源分布是tanh变换后的分布,因此目标分布部分的logP应该是logP(Y=y)而不应该是logP(X=x)。
PS:
以上只是个人的一些理解,是否正确没有定论,只是阐述下个人的代码理解和数学推导理解和强化学习算法的一些理解。
posted on 2024-12-22 14:22 Angry_Panda 阅读(54) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号