
GAN Lecture 3 (2018)_Unsupervised Conditional Generation
课程主页:提供作业相关
PS: 这里只是课程相关笔记
1. Basic Idea of Unsupervised Conditional GAN
上一课讲了 Conditional Generation 类似 style transfer 这样的任务,我们可以使用 Unsupervised Conditional Generation。
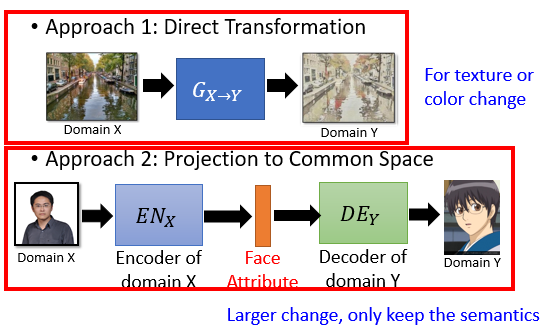
对于简单的风格转换任务来说,我们可以直接训练一个 Generator,但对于图片下面的任务来说可能需要借助 Encoder-Decoder 的思想,先通过 Encoder 获取输入图片的一些高维特征表示,然后再利用 GAN 生成卡通人物。
2. Derect Transformation
对于第一种任务(例如 CycleGAN)来说,可能的方案是这样的,我们希望训练一个 Generator 让它生成的东西能骗过 Discriminator。
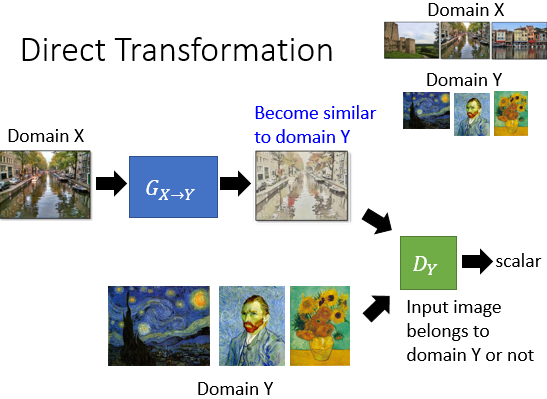
但是,往往事非所愿,Generator 可能会生成一张和输入无关的东西

这就要求我们的 Generator 的输出不仅要能骗过 Discriminator,还要保证与输入相关。
一种方法是无视这个问题,不断的训练就好了。。。
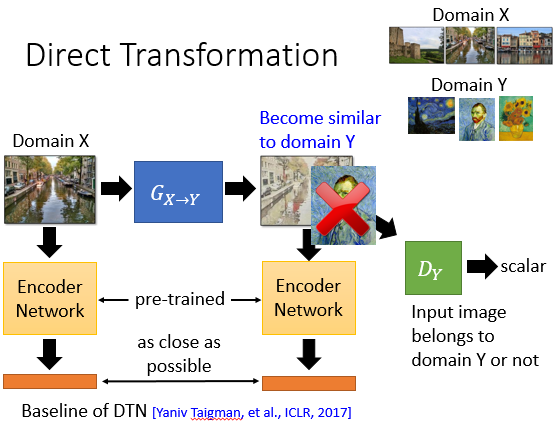
第二种方法是拿一个 Pretrain 好的 Network,然后让输入和输出经过这个 Encoder Network 之后的 Embedding 越接近越好
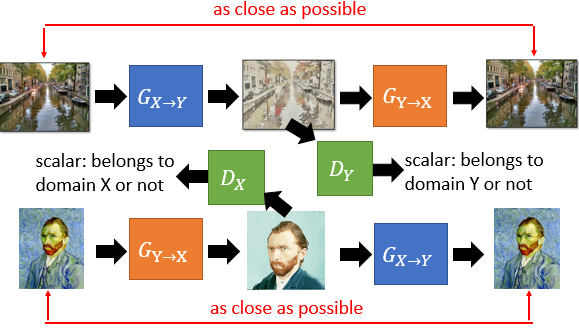
第三种方法是类似 CycleGAN 那种,训练两个 Generator,保证输入和最后的那个输出尽可能相同。
有人就利用 CycleGAN 把动画角色的头发都转成了银色的头发
 |
 |
当然 CycleGAN 也有一些它自己的问题,CycleGAN: a Master of Steganography 这篇论文就提到了 CycleGAN 有隐藏信息的能力,这就和 CycleGAN 的 Cycle Consistency 相矛盾了,anyway 这是大佬们关心的事情。
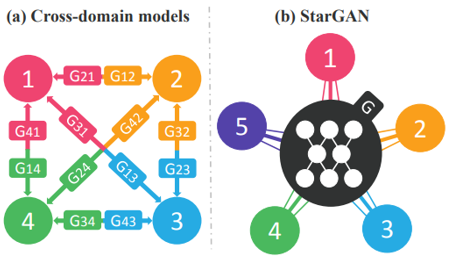
还可以像 StarGAN 一样用同一个 Generator 来完成多个生成任务:
3. Projection to Common Space
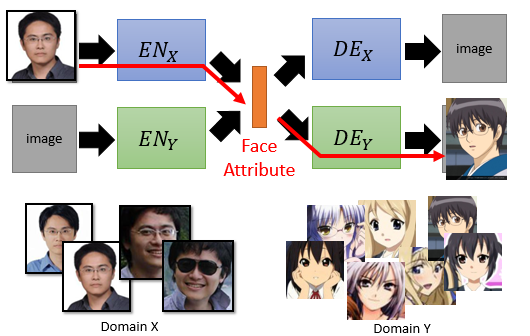
一般来说,我们可能希望训练下图两个 Encoder-Decoder 来完成这类任务
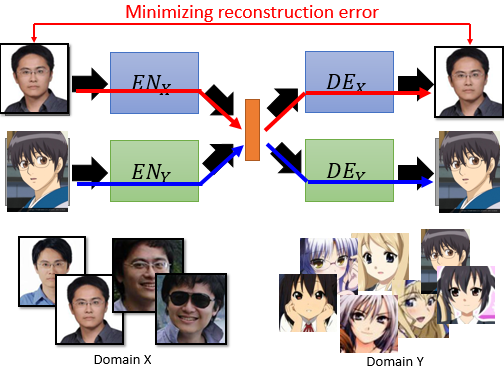
但实际上由于缺少监督信息,我们只能这么做:
当然,你还可以加上 Discriminator 进来(VAE-GAN)以避免生成的图像太模糊
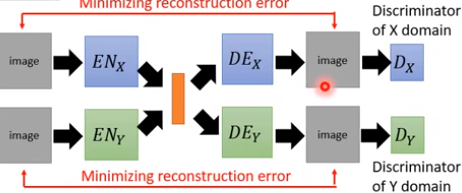
但是这两个 Encoder-Decoder 是分开训练的,完全无关。。。
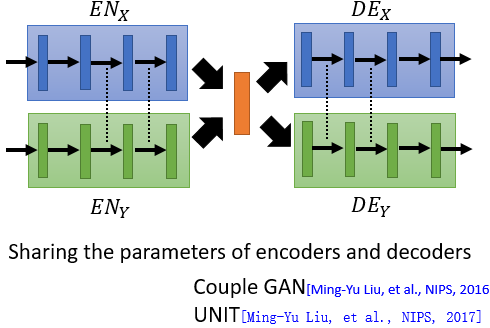
一种解决方案是,然两组 Encoder-Decoder 部分参数共享
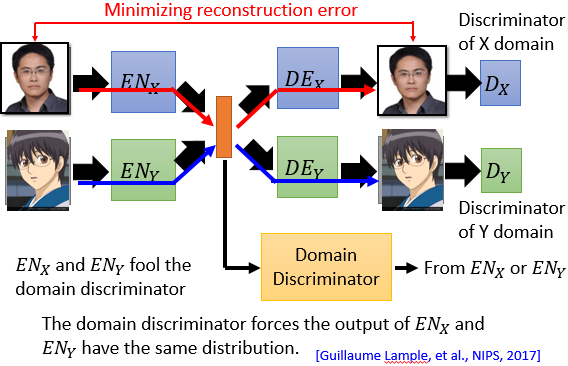
另一种解决方案是,增加一个 Discriminator,然 Encoder 能够骗过 Discriminator,就问你6不6!

当然也可以利用 Cycle Consistency 的思想来解决。
上面这种方法最后比较的是 pixel 级别的图片相似程度,而下面这种方法比较的是高维语义层次的相似度:
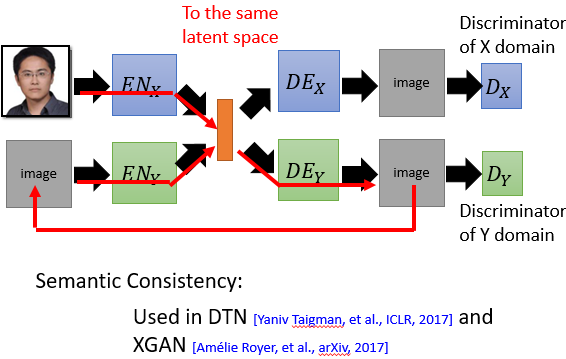
除了图像领域外,Unsupervised Conditional Generation 还可以利用在声音转换等邻域。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号