
GAN Lecture 2 (2018)_Conditional Generation
课程主页:提供作业相关
PS: 这里只是课程相关笔记
1. Basic Idea of Conditional GAN
上一课大致我们了解下 GAN 是个什么鬼,输入一个随机向量,它可以输出一张图片,但实际上我们没法控制我们想要输出的图片。本节课所讲的 Conditional Generation 可以给一段文字输入,然后输出一张语义相关的图片。
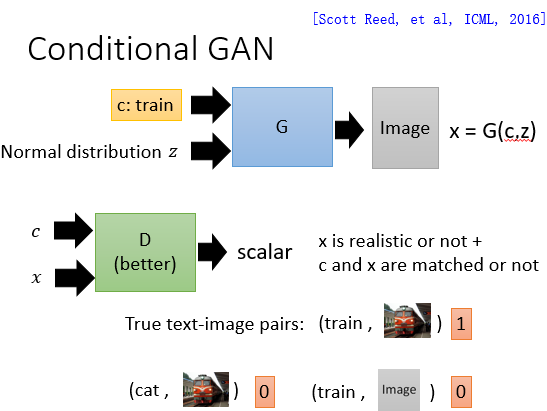
如图所示:Generator 的输入除了随机向量 z,还有约束信息 c。同样的,Discriminator 的输入除了 x 还有约束标签 c,特别的 Discriminator 除了要判断 x 是真是假,还要判断 c 和 x 是否匹配。
2. Alogrithm

同一般的 GAN 类似,我们先固定 Generator 训练 Discriminator,再固定 Discriminator 训练 Generator:
- 首先从数据集中采样 m 对“正样本” $c^i, x^i$,然后采样 m 个随机向量和 m 个 condition 输入 Generator 得到 m 个生成的“负样本” $G(\tilde{c}^i, z^i)$,再从数据集中采样 m 个与 condition 无关的样本,也作为“负样本” $\hat{x}$,然后这三类样本送入 Discriminator 中训练。
- 然后我们采用 m 个随机向量再加上 m 个 condition 输入 Generator 得到 m 个生成的“正样本”,以期能骗过 Discriminator。

传统的 Discriminator 一般是图中上面那种,但大佬认为下面那种更合适,大佬认为上面那种只一个 score 容易让网络 confuse。
3. Some Paper
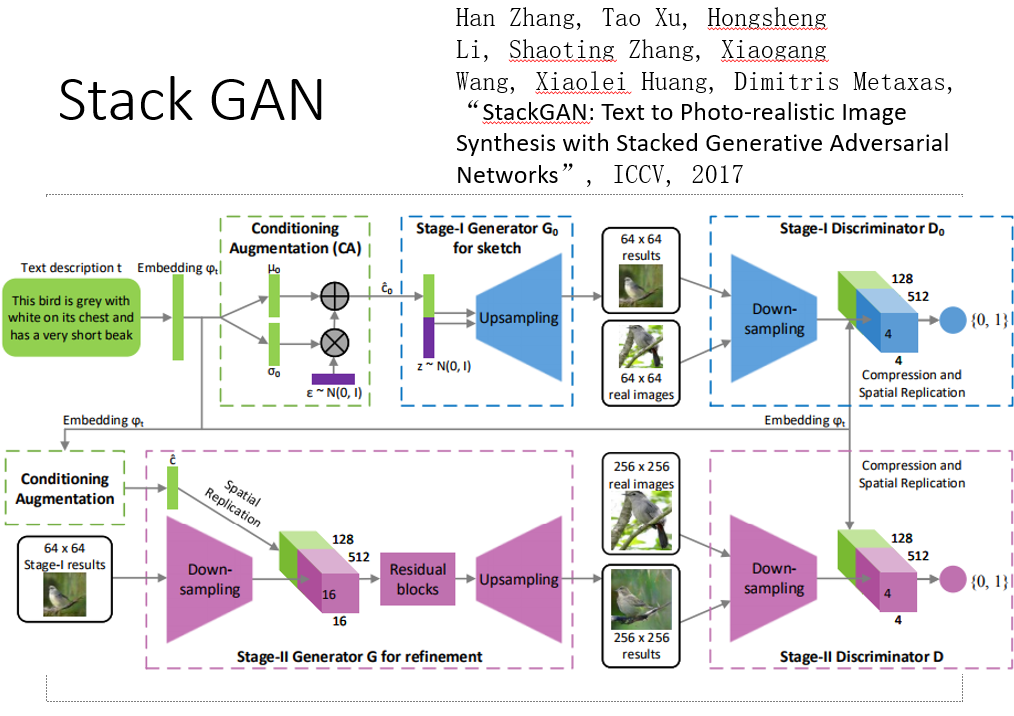
大佬说如果你想要生成分辨率较高的图片,可以参考 Stack GAN 的思想,即先生成小图再通过小图生成大图。
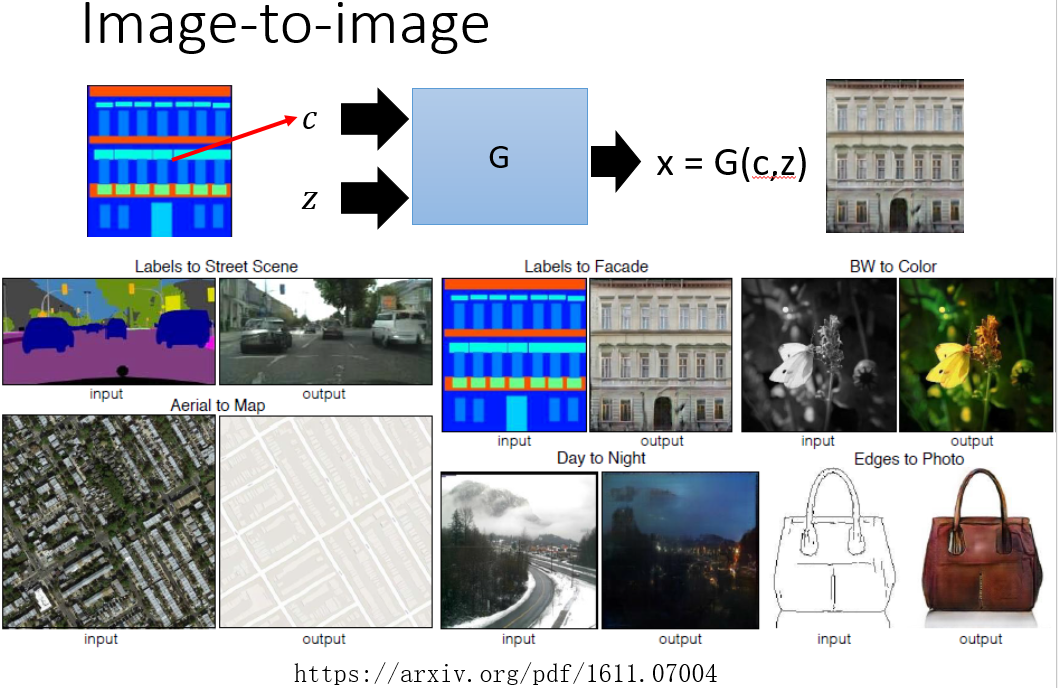
Image to Image 这篇论文则是结合了 Conditional GAN(容易产生一些奇怪的东西) 和传统的方法(输出的图像太模糊),来生成质量更好的图片。而对于 Image to Image 的 GAN 来说,由于输入输出图片可能都很大,网络容易过拟合或者很难收敛,这个时候我们可以让 Discriminator 每次只检查图片上的一个 patch。

当然 GAN 也可以用到语义增强、视频生成等等


 浙公网安备 33010602011771号
浙公网安备 33010602011771号