
最远点采样加速---AFPS
PDF: 《An Adjustable Farthest Point Sampling Method for Approximately-sorted Point Cloud Data》
一、背景
前面介绍了FPS采样。
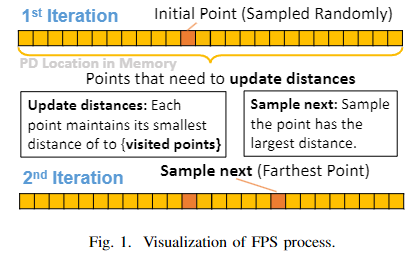
但该算法的固有特性导致了一个问题,即需要持续的重复工作。如果我们想从规模为N的点云中采样K个点,至少需要访问整个点云K-1次,时间复杂度是O(NK),当点云规模变大时计算是比较耗时的。FPS在PointNet++推理中占主导地位,在GPU上,对于一款拥有4352个CUDA核心的RTX-2080ti GPU,FPS大约占总时间成本的53.7%。
二、核心思路
之前有一些工作对其进行了加速处理,但没法进行多核并行处理。
《1997: The Farthest Point Strategy for Progressive Image Sampling》
《2015: The farthest neighbor queries based on R-trees》
AFPS把原始N个点云经过近似排序后划分成M个小块,每一小块执行原有FPS操作,进而可以多核并行处理,另外还引入NPDU限制距离更新的次数,进一步提升速度。
三、 相关细节
3.1 排序
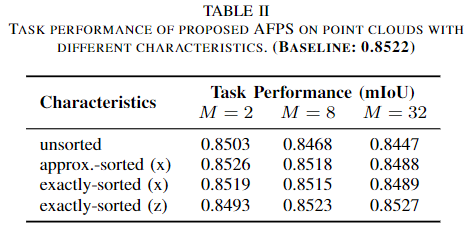
如果直接在未排序的点云数据上实施AFPS会导致采样质量下降。因为AFPS仅从每个分区中分别采样N/M个点。因此,如果一个未排序的点云恰好将所有“代表性点”都集中在同一个分区中,那么点数量的减少(从N减少到N/M)可能会导致遗漏这些“代表性点”。
因此点云数据先按某个轴进行粗排序,使其具有维度局部性,“代表性点”可能会更均匀地分布在不同的分区中,从而减少遗漏的情况。因此,尽管这种方法可能会导致一些微小的性能下降,但它能显著减少计算量。
3.2 分块可调
其中M设置为AFPS中的一个可调节参数。在一种极端情况下,当M等于采样点的数量时,该算法可以在单次迭代中完成,其效果等同于随机采样。而在另一种极端情况下,当M等于1时,AFPS与原始的FPS相同。我们可以选择合适的M值,以实现大幅的延迟降低,同时对任务性能几乎没有影响。
3.3 NPDU
提出了最近点距离更新(NPDU)方法:对于具有维度局部性的点云,我们仅更新新采样点最近邻位置中存储的点的距离。如图3(a)所示,水平条代表存储在内存中的点云,使用NPDU时,每次迭代中只会更新k个邻近点的距离。需要注意的是,如图3(b)所示,NPDU可以很容易地应用于AFPS之上。它限制了每个更小尺度FPS的距离更新次数,进一步降低了计算复杂度。
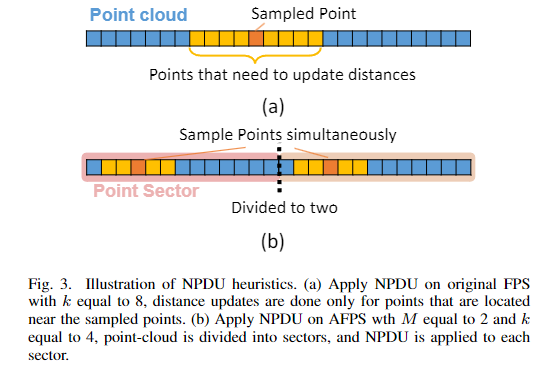
NPDU启发式算法通过以下方式保留了原始FPS的良好特性:由于维度局部性,选择近似邻居的点就足够了,即在一个或多个维度上接近的点。其假设是,在一个维度上接近的点更有可能是三维空间中的邻居。其次,一旦完成了邻近点的距离更新,在未来的迭代中就不太可能对邻近点进行采样。通过应用NPDU,我们可以将每次迭代中的距离更新限制为每个扇区一个常数k。仅更新新采样点附近 k 个邻接点的距离(图3a),避免全局更新。
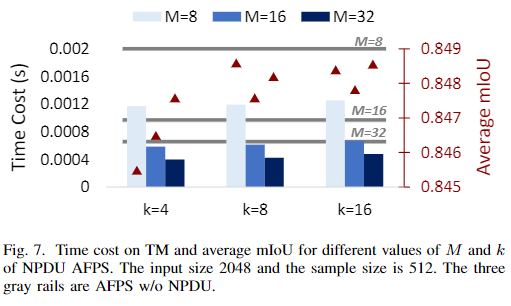
四、效果
-
论文实验结果
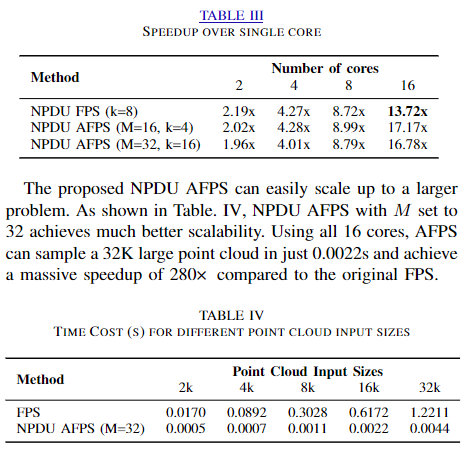
-
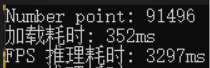
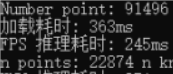
实测效果
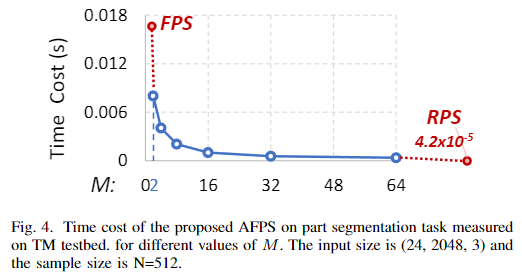
在CPU上分块设置为16后,原始FPS从91496个点云中采样出22874个点需要3.3s,而AFPS差不多0.25s左右。但要留意采样的点和原始FPS有些会有小偏差。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号