
groupVIT
Paper: 《GroupViT: Semantic Segmentation Emerges from Text Supervision》
Code: https://github.com/NVlabs/GroupViT
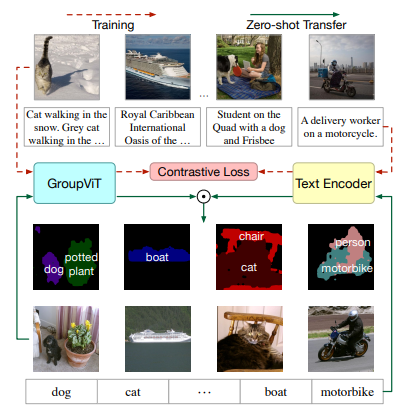
一、大体内容
前面提到的LSeg只是借鉴CLIP利用文本编码器和图像编码器,将文本标签和图像像素嵌入到共同空间进行语义图像分割,实际还是在7个数据集上采用监督学习的方式进行训练的,但如何用文本作为监督信号,以达到无监督训练的方式更加可取。这一篇GroupViT则是利用文本作为监督信号,无需手工标注的分割mask,而是像CLIP一样利用图像文本对进行训练,从而完成了无监督的分割任务,并实现零样本学习。

大体流程如上图所示,Transformer Layers文中共12层,划分成两个部分,每一部分都是6层,输入图片(224 x 224)先划分成无重叠的patch(16 x 16),经过一个线性映射层得到图片每个块的特征(196 x 384),group tokens维度是64 x 384,表示64个组,384是为了和块的特征维度对齐,块特征和group特征都输入到transformer层中,再经过一个Grouping Block将图像patch embedding分配给group tokens,所以第二层的输入维度变为64x384,再一次进行group,其维度变为8 x 384,经过Transformer层和Grouping Block之后得到特征维度是8 x 384,再经过一个transformer层后得到相同维度特征,为了和文本特征进行配对学习,这里直接对特征进行平均池化操作得到1x384的特征,采用对比损失进行训练。
二、贡献点
- 提出了Grouping Vision Transformer (GroupViT),通过分层自注意力机制动态将图像区域分组为任意形状的语义段。每个阶段通过分组块合并较小的段,形成层次化的语义结构。
- 仅使用图像文本对比损失(结合多标签文本提示)进行训练,无需像素级标注,完成了无监督学习的分割任务,零样本推理准确度进一步提升
三、细节
3.1 多阶段分组
结构上,该方案可视为在经典的VIT框架中创新性地融入了groupBlock与可学习的Group Tokens。具体而言,VIT被划分为若干阶段,每阶段后均接入一个Grouping Block,其核心功能是将图像特征精准分配至各group tokens。
这些group tokens如一个个聚类中心,高效地聚合周围特征相似的点,进而形成一个个独立的group。每个阶段的输入由两部分组成:图像特征与可学习的group tokens。二者通过Transformer强大的自注意力机制进行深度学习与融合。
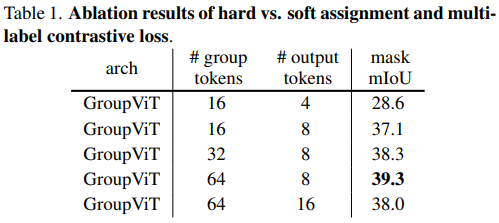
与单一的Cls_token不同,group tokens在数量上更为丰富,这一设计更符合分割任务的需求。每个小块都拥有其独特的特征表示,初始阶段group数量较多,如64个,对应分割效果较为细致;随着阶段的推进,group数量逐渐减少至8个,分割区域相应扩大,同时维度也逐渐降低,实现了高效的特征提取与降维。
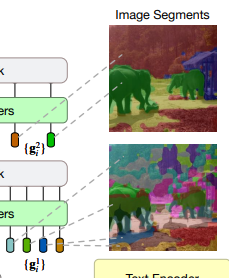
还进行了不同数量阶段的效果对比实验。

3.2 Grouping Block
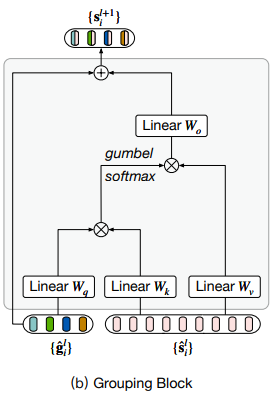
groupBlock 先算一个group tokens和分割tokens的相似性矩阵,
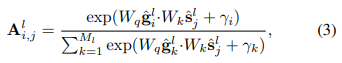
另外由于聚类不可导,所以采用gumbel softmax将其变成一个可导的,可以把图像patch embedding分配给group token,一定程度上也达到了降维的效果。
3.3 训练细节
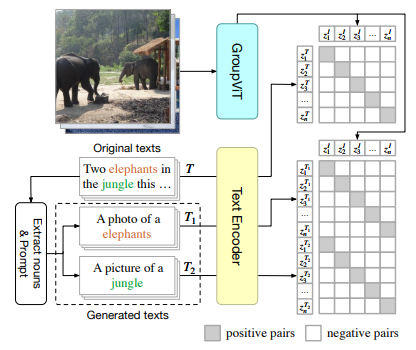
- 输入与生成文本
原始图像 - 文本对:输入一张图像和对应的原始文本(如 "Two elephants in the jungle this morning")。
名词提取与提示生成:从原始文本中随机提取名词(如 "elephants", "jungle"),并通过手工设计的句子模板(如 "A photo of a {noun}")生成多个提示文本(如 "A photo of a elephants" 和 "A photo of a jungle")。 - 正负样本对构建
正样本对:原始图像与原始文本、以及生成的提示文本构成正样本对。
负样本对:其他图像的文本作为负样本对。 - 作用
增强语义分组能力:通过生成与图像中物体相关的提示文本,帮助模型学习更精细的语义概念(如物体类别)。
与零样本分割对齐:训练时使用的提示文本格式与推理时的语义标签一致,确保迁移过程的一致性。
3.4 zero-shot推理
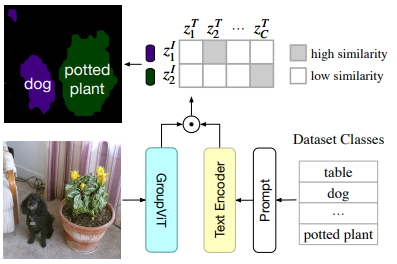
输入图像通过 GroupViT 的分层分组模块生成最终的图像特征,每个段对应一个任意形状的区域。同时,文本编码器将语义标签(如 "dog")转换为词向量。通过计算两者的余弦相似度,给每个区域分配一个相似度最高的类别。
这里也体现了一定的局限性:假如最后只有8个group,那最多检测到8类。文中进行了实验验证,取8个group效果最佳。
3.5 其他思考点
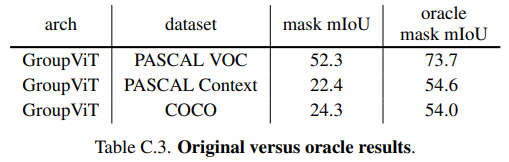
分割很好,分类影响了MIou,采用分割结果和真实标签找最大IOU,然后把类别赋给它,提升很多,说明分割做得很好,只是语义分割不太好。
这和CLIP训练方式也有关系,比较容易学到有明确语义信息的类别,很难学到比较模糊的背景类。后续可以每个类别给一个阈值(阈值越高,类别比较准确,但容易漏识别)或者可学习的阈值,或者直接修改zero-shot推理过程,或者加入约束,把背景类融入到训练中去。
四、效果
4.1 不同阶段group效果
下图还显示了第一阶段分割范围比较小,第二阶段范围会扩大,而且分割确实学习到了一些特征,比如第一行学习的全是眼睛,到第三行学习的是草地这种大范围区域。

4.2 Zero-shot
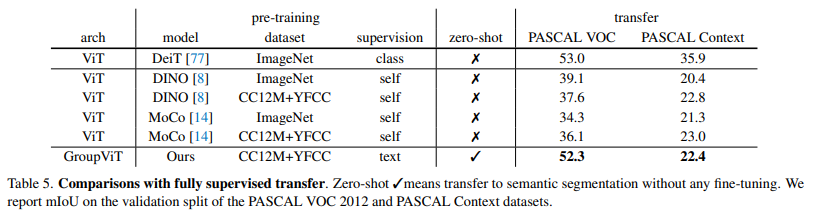
GroupViT 在无像素级标注的情况下,通过文本监督学习到的视觉分组能力可直接迁移到语义分割任务,且性能与需更高监督的方法相当,为零样本语义分割提供了新的基准
4.3 在PASCAL VOC2012数据集部分图上的效果


4.4 在PASCAL Context数据集部分图上的效果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号