
LSeg
Paper: 《LANGUAGE-DRIVEN SEMANTIC SEGMENTATION》
Code: https://github.com/isl-org/lang-seg
一、大体内容
前面CLIP中提到后续很多工作对其进行了扩展,本文提出了的LSeg 模型,就是借鉴CLIP利用文本编码器和图像编码器,将文本标签和图像像素嵌入到共同空间进行语义图像分割。该模型在零样本和少样本语义分割任务中表现出色,具有高度灵活性,能处理未见类别且在固定标签集任务上与传统方法相当。
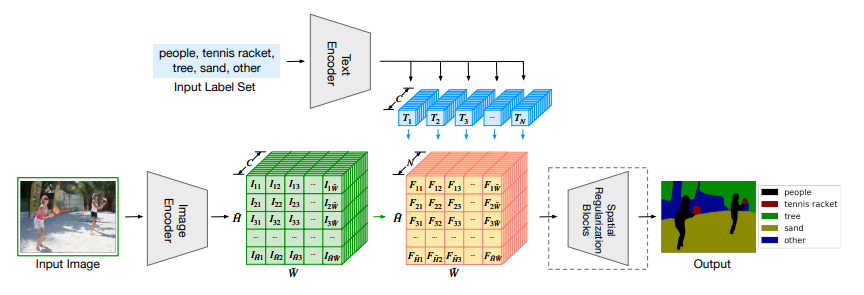
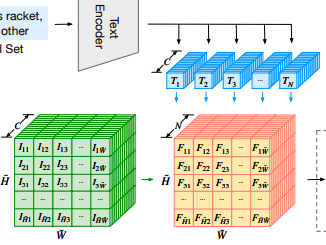
大体流程如上图所示,上方沿用了CLIP的文本编码器,输入类别后经过编码器得到对应的类别特征T,下方输入图片经过图像编码器(ViT + Decoder)得到降采样后的图像特征I,再与类别特征T进行点乘得到特征F,由于F的大小相比于原图像进行了下采样,所以最后再经过一个Spatial Regulanization Block模块恢复至原图像大小,并输出每个像素的类别信息,进而实现图像分割。
二、贡献点
- 提出新模型:提出了 LSeg 模型,将文本标签和图像像素嵌入到共同空间,通过文本编码器和图像编码器的协同工作,实现了基于语言驱动的语义图像分割。
- 实现零样本学习:LSeg 模型能够在零样本学习的情况下,可以对未见类别进行语义分割。
- 灵活的标签处理:该模型可以动态处理不同长度、内容和顺序的标签集。用户可以在测试时根据需求任意扩展、收缩或重新排序标签集,模型能够实时调整并生成相应的分割结果,增强了模型的实用性和适应性。
- 性能优异:在多个少样本语义分割基准测试中,LSeg 模型取得了极具竞争力的结果。在 PASCAL-5i、COCO-20i 和 FSS-1000 等数据集上,LSeg 模型的零样本性能优于现有零样本基线方法,甚至与部分少样本方法相当。在固定标签集的任务上,LSeg 模型与传统语义分割算法的准确性相当,证明了其有效性。
三、细节
3.1 训练
Lseg使用了CLIP的大致框架和预训练参数,只是训练方式上采用的不是对比学习而是采用的有监督学习。
- 文本编码器:将潜在标签集嵌入连续向量空间,输出向量对输入标签顺序不变且数量可变,文中使用预训练的 CLIP 模型,训练的时候固定权重不动。
- 图像编码器:基于密集预测 transformers(DPT)架构,为每个输入像素生成嵌入向量。
在训练过程中,采用ViT或ResNet的ImageNet预训练权重来初始化图像编码器的骨干网络,同时对DPT解码器进行随机初始化。在此期间,文本编码器保持冻结状态。将在7个不同的分割数据集上进行训练,使用交叉熵损失函数,只更新图像编码器的权重。
3.2 词像素相关张量
通过内积关联图像和标签特征,图像特征是H x W x C,文本特征是C x N,两者点乘后得到H x W x N的特征。
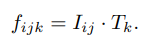
训练时最大化图像与对应真实类别文本特征的点积,使用逐像素 softmax 目标函数。
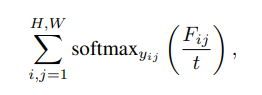
3.3 空间正则化
因图像编码器预测分辨率低于输入图像,使用深度卷积或带有最大池化操作的模块进行空间正则化和上采样,最后用双线性插值恢复到原始分辨率。
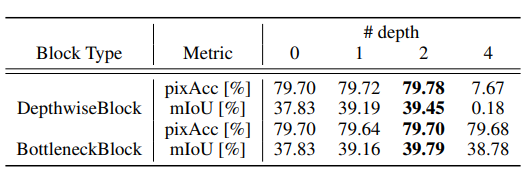
通过实验验证,正则化块的个数为两个效果最佳,文中也没有给出解释(实验验证了)
3.4 Zero-shot数据集
PASCAL-5i 是将原始PASCAL VOC 2012 数据集划分成4等分组,每个组由 5 个类组成,i=1表示这5类类别知道,而其他的类别不知道,这样就可以用于做zero-shot推理。
COCO-20i则是把COCO 80个类别进行分组
3.5 其他问题点
文中没有说明图像编码器为什么采用CLIP的会更差?
文本和图像特征点乘后,加了两个block,个数多了为什么效果变差?
四、效果
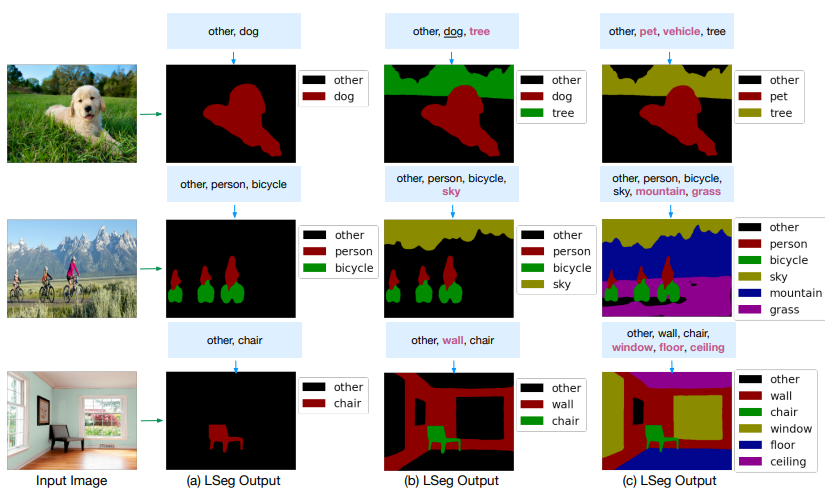
下图可以看到分割效果还是很不错的,而且能识别出一些超类,比如第一行的小狗,可以分类成宠物,而不是车辆。
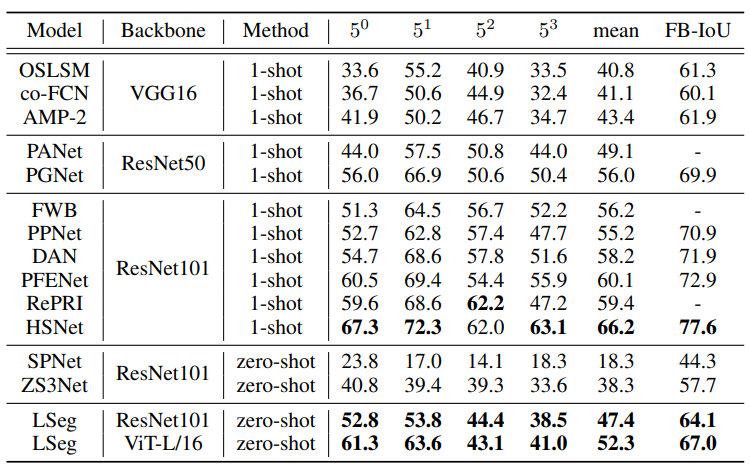
4.1 Zero-shot
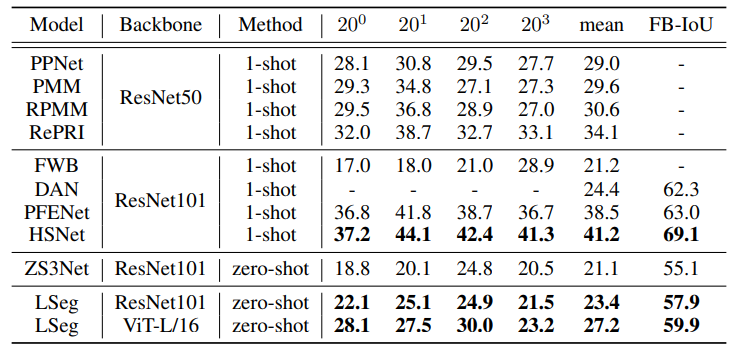
可以看到在zero-shot上性能表现还可以,但是相比于监督学习准确率提升空间还是很大的
-
PASCAL-5i
-
COCO-20i
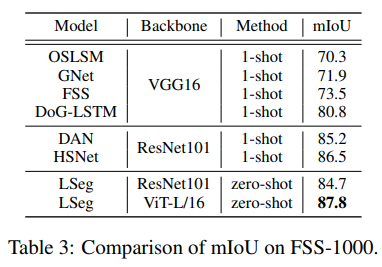
-
FSS-1000
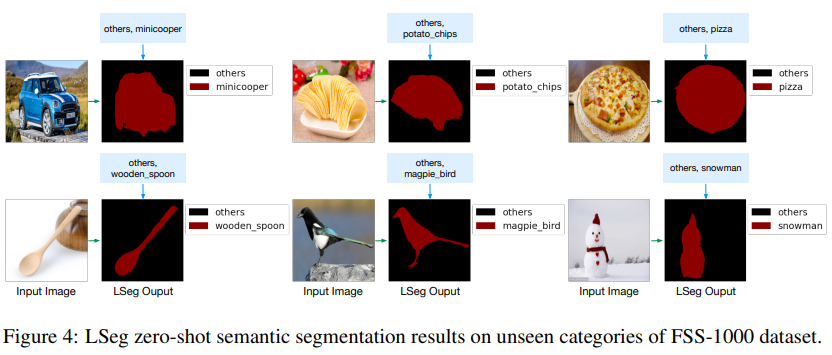
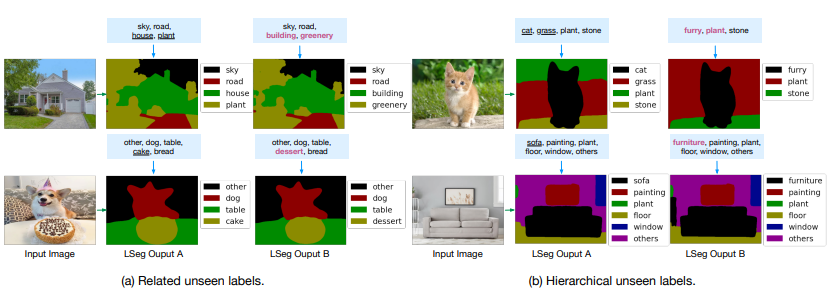
4.2 其他实验
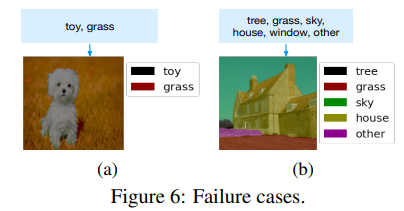
五、自测效果





 浙公网安备 33010602011771号
浙公网安备 33010602011771号