
【原创】ARM平台内存和cache对xenomai实时性的影响
1. 问题概述
对ti am5728 xenomai系统latency测试时,在测试过程中发现,内存压力对latency影响极大,未添加内存压力下数据如下(注:文中所有测试使用默认gravity,对实时任务cpu已使用isolcpus=1隔离,另外文中的结论可能只对ARM平台有效):
stress -c 16 -i 4 -d 2 --hdd-bytes 256M
| user-task ltaency | kernel-task ltaency | TimerIRQ | |
|---|---|---|---|
| 最小值 | 0.621 | -0.795 | -1.623 |
| 平均值 | 3.072 | 0.970 | -0.017 |
| 最大值 | 16.133 | 12.966 | 7.736 |
添加参数--vm 2 --vm-bytes 128M模拟内存压力。(创建2个进程模拟内存压力,不断重复:申请内存大小128MB,对申请的内存每隔4096字节处写入一个字符’Z‘,然后读取检查是否还是’Z‘,校查后释放,回到申请操作)
stress -c 16 -i 4 -d 2 --hdd-bytes 256M --vm 2 --vm-bytes 128M
添加内存压力后的latency,测试10分钟(因时间原因未测1小时),测试数据如下:
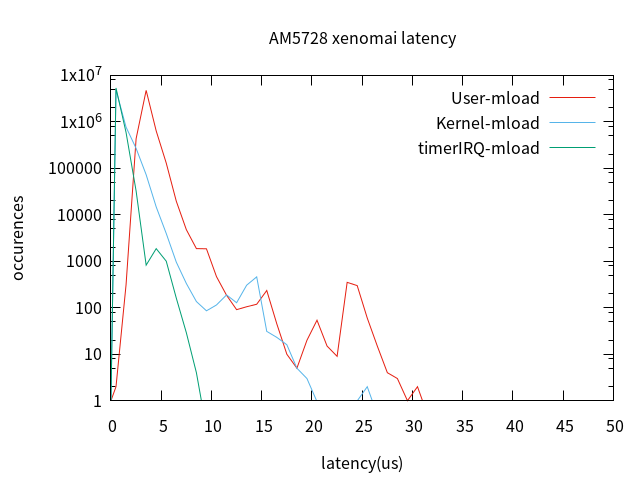
| user-task ltaency | kernel-task ltaency | TimeIRQ | |
|---|---|---|---|
| 最小值 | 0.915 | -1.276 | -1.132 |
| 平均值 | 3.451 | 0.637 | 0.530 |
| 最大值 | 30.918 | 25.303 | 8.240 |
| 标准差 | 0.626 | 0.668 | 0.345 |
可以看到,添加内存压力后,latency最大值是未加内存压力最大值的2倍。
2. stress 内存压力原理
stress工具对内存压力相关参数有:
-m, --vm N fork N个进程对内存malloc()/free()
--vm-bytes B 每个进程操作的内存大小为B bytes (默认 256MB)
--vm-stride B 每隔B字节访问一个字节 (默认4096)
--vm-hang N malloc睡眠N秒后free (默认不睡眠)
--vm-keep 仅分配一次内存,直到进程结束时释放
这参数可用来模拟不同的压力,--vm-bytes表示每次分配的内存大小。--vm-stride每隔B字节访问一个字节,主要模拟cache miss的情况。--vm-hang指定对内存持有的时间,分配频率。
对于上面参数--vm 2 --vm-bytes 128M ,表示创建2个进程模拟内存压力,不断重复:申请内存大小128MB,对申请的内存每隔4096字节处写入一个字符’Z‘,然后读取检查是否还是’Z‘,校查后释放,回到申请操作。回顾我们的问题,其中涉及影响实时性的变量有:
(1).内存分配大小
(2).latency测试过程中stress是否分配/释放内存
(3).内存是否使用访问
(4).每次内存访问的步长大小
进一步总结内存实时性影响因素有:
-
cache 影响
- cache miss率高
- 内存速率(带宽)
-
内存管理
- 内存分配/释放操作
- 内存访问缺页(MMU拥塞)
下面针对这几个影响设计测试参数,进行测试排查。
2. cache 因素
关闭cache 可用于模拟100%缓存未命中,从而测量可能由如内存总线和片外存储器的拥塞引起的缓存未命中的最坏情况的影响。
2.1 未加压
am5728 这里不测试L1 Cache的影响,主要测试L2 cache,配置内核关闭L2 cache,重新编译内核。
System Type --->
[ ] Enable the L2x0 outer cache controller
为确认L2 cahe已经关闭,使用下面的程序验证,申请大小为SIZE个int的内存,对内存里的整数加3,第一个for步长为1,第二个for步长为16(每个整数4字节,16个64字节,cacheline的大小刚好为64)。因为后面的for循环步长为16 ,在没有cache 时,第二个for循环的执行时间应为第一个for的1/16,以此来验证L2 Cache 已经关闭。
打开 L2 cache情况下前后两个for的执行时间为2000ms:153ms(13倍),关闭 L2 cache后前后两个for的执行时间为2618ms:153ms(17倍,大于16倍的原因是这里使用的是同一块内存,内存申请后没有还没分配物理内存,第一个for循环的时候会执行一些缺页异常处理,所以用时稍长)。
#include<stdlib.h>
#include<stdio.h>
#include<time.h>
#define SIZE 64*1024*1024
int main(void)
{
struct timespec time_start,time_end;
int i;
unsigned long time;
int *buff =malloc(SIZE * sizeof(int));
clock_gettime(CLOCK_MONOTONIC,&time_start);
for (i = 0; i< SIZE; i ++) buff[i] += 3;//
clock_gettime(CLOCK_MONOTONIC,&time_end);
time = (time_end.tv_sec * 1000000000 + time_end.tv_nsec) - (time_start.tv_sec * 1000000000 + time_start.tv_nsec);
printf("1:%ldms ",time/1000000);
clock_gettime(CLOCK_MONOTONIC,&time_start);
for (i = 0; i< SIZE; i += 16 ) buff[i] += 3;//
clock_gettime(CLOCK_MONOTONIC,&time_end);
time = (time_end.tv_sec * 1000000000 + time_end.tv_nsec) - (time_start.tv_sec * 1000000000 + time_start.tv_nsec);
printf("64:%ldms\n",time/1000000);
free(buff);
return 0;
}
没有压力条件下,测试关闭L2 Cache前后latency情况(测试时间为10min),数据如下:
| L2 Cache ON | L2 Cache OFF | |
|---|---|---|
| min | -0.879 | 2.363 |
| avg | 1.261 | 4.174 |
| max | 8.510 | 13.161 |
| 由数据可以看出:关闭 L2Cache后,latency整体升高。在没有压力下,L2 Cahe 命中率高,提高代码执行效率,能够明显提升系统实时性,即同样的一段代码,执行时间变短。 |
2.2 加压(cpu/io)
不对内存加压,仅测试CPU运算密集型任务及IO压力下, L2 Cache关闭与否对latency的影响。加压参数如下:
stress -c 16 -i 4
同样测试10分钟,数据如下:
| L2 ON | L2 OFF | |
|---|---|---|
| min | 0.916 | 1.174 |
| avg | 4.134 | 4.002 |
| max | 10.463 | 11.414 |
结论:CPU、IO压力下,L2 Cache关闭与否似乎不那么重要了
分析:
-
没有加压条件下,L2 cache处于空闲状态,实时任务cache命中率高,latency 平均值所以低。当关闭L2 cache后,100% cache未命中,平均值和最大值均有升高。
-
添加 CPU、IO压力后,18个计算进程抢夺cpu资源,对实时任务来说,当实时任务抢占运行时,L2 Cache已被压力计算任务的数据填满,对实时任务来说几乎100%未命中。所以 CPU、IO压力下,L2 Cache关闭与否 latency差不多。
3. 内存管理因素
经过第2节的测试,压力条件下有无 cache的latency 几乎相同,可以排除Cache。下面进行测试内存分配/释放、内存访问缺页(MMU拥塞)对latency的影响。
3.1 内存分配/释放
在2的基础上添加内存分配释放压力,分别测试对大小为1M、2M、4M、8M、16M、32M、64M、128M、256M的内存分配释放操作下latency的数据,每次测试3分钟,为测试MMU拥塞,分别对分配的内存进行步长为'1' '16' '32' '64' '128' '256' '512' '1024' '2048' '4096'的内存访问,测试脚本如下:
#!/bin/bash
test_time=300 #5min
base_stride=1
VM_MAXSIZE=1024
STRIDE_MAXSIZE=('1' '16' '32' '64' '128' '256' '512' '1024' '2048' '4096')
trap 'killall stress' SIGKILL
for((vm_size = 64;vm_size <= VM_MAXSIZE; vm_size = vm_size * 2));do
for stride in ${STRIDE_MAXSIZE[@]};do
stress -c 16 -i 4 -m 2 --vm-bytes ${vm_size}M --vm-stride $stride &
echo "--------${vm_size}-${stride}------------"
latency -p 100 -s -g ${vm_size}-${stride} -T $test_time -q
killall stress >/dev/null
sleep 1
stress -c 16 -i 4 -m 2 --vm-bytes ${vm_size}M --vm-stride $stride --vm-keep &
echo "--------${vm_size}-${stride}-keep----------------"
latency -p 100 -s -g ${vm_size}-${stride}-keep -T $test_time -q
killall stress >/dev/null
sleep 1
stress -c 16 -i 4 -m 2 --vm-bytes ${vm_size}M --vm-stride $stride --vm-hang 2 &
echo "--------${vm_size}-${stride}-hang----------------"
latency -p 100 -s -g ${vm_size}-${stride}-hang -T $test_time -q
killall stress >/dev/null
sleep 1
done
done
L2 Cache打开,对不同大小内存进行分配释放时的latency数据绘图,横轴为内存压力任务每次申请的内存大小,纵轴为该压力下的latency最大值,如下:
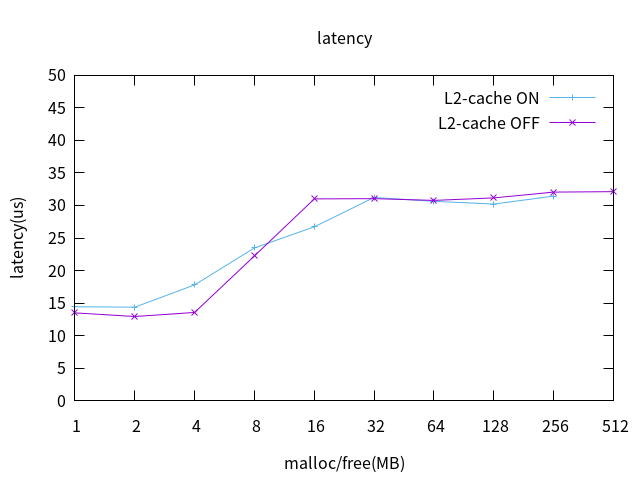
从上图可以看到,两个拐点分别为4MB,16MB ,分配/释放的内存在4MB以内latency不受影响,保持正常水平,分配释放的内存大于16MB时latency达到30us以上,与问题符合。由此可知:普通Linux任务的内存分配释放会影响实时性。
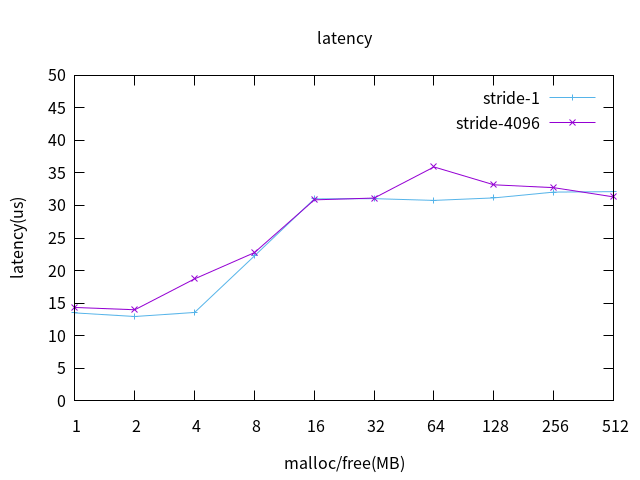
3.2 MMU拥塞
根据内核页大小4K,在3.1的基础 上添加参数–vm-stride 4096,来使stress每次访问内存 都缺页,来模拟MMU拥塞,L2 cache off 测试数据绘图如下:
L2 cache on 测试数据绘图如下:
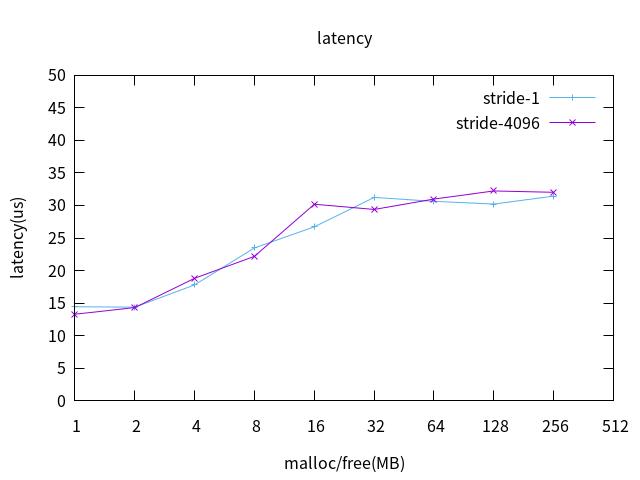
MMU拥塞对实时性几乎没有影响。
4 总结
通过分离各种影响因素后测试得出,施加内存压力后,实时性变差是由于内存的分配释放导致,说明该平台上运行在cpu0上的普通Linux任务对内存的申请释放操作会影响运行在cpu1上的实时任务的实时性。
am5728只有两级cache, L2 Cache 在CPU空闲时能显著提升实时性,但CPU负载过重时导致L2 Cache频繁换入换出,不利于实时任务Cahe命中,几乎对实时性没有任何帮助。
更多信息参考本博客另一篇文章:有利于提高xenomai 实时性的一些配置建议

 浙公网安备 33010602011771号
浙公网安备 33010602011771号