剖析虚幻渲染体系(18)- 操作系统
- 18.1 操作系统综述
- 18.2 计算机硬件概览
- 18.3 内核
- 18.4 进程
- 18.5 线程
- 18.6 同步机制
- 18.7 线程高级主题
- 18.8 作业
- 18.9 内存
- 18.10 动态链接库
- 18.11 文件和I/O
- 18.12 多处理器系统
- 18.13 Android
- 18.14 UE Platform
- 18.15 本篇总结
- 特别说明
- 参考文献
18.1 操作系统综述
迄今为止,博主在博客中阐述的内容包含渲染技术、性能优化、图形API、Shader、GPU、游戏引擎架构、图形驱动等等技术范畴的内容,这些内容都仅仅局限于单个应用程序之中,常常让人有”只缘身在此山中“的感叹。现在是时候更进一步了——进入操作系统(Operating System,OS)的范畴,以更高的层次去看待渲染体系,以便我们能够高屋建瓴,练就深厚的技术内功。
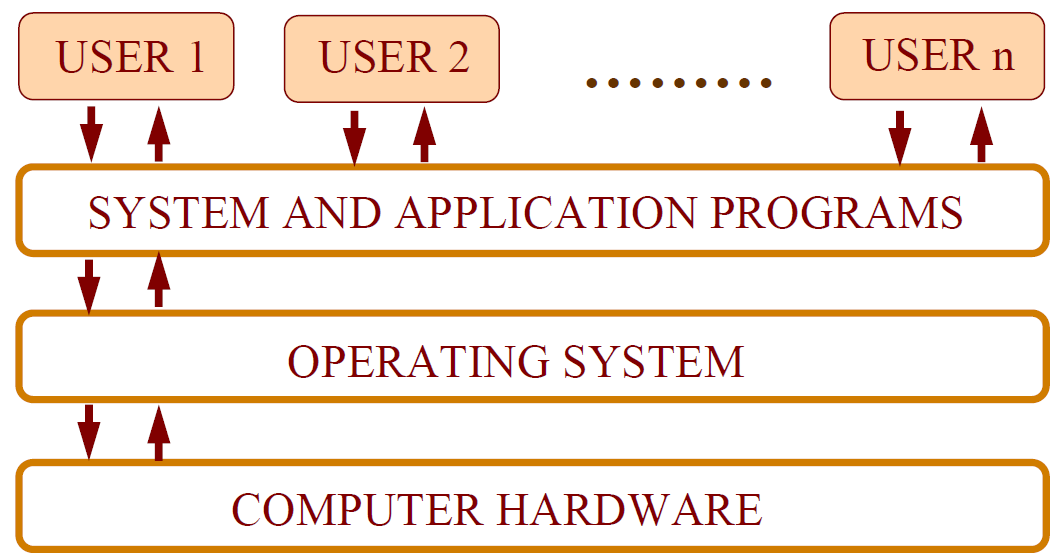
本篇将站在应用层开发者的视角,去阐述Windows、Linux等操作系统的相关技术内幕(如果是操作系统开发者,则博主不认为是很贴切的目标读者),主要包含但不限于以下内容:
- 操作系统的架构。
- 操作系统的概念。
- 操作系统的技术。
- 操作系统的机制和原理。
- 操作系统的UE封装和实现。
操作系统经历了数十年的发展历程,从最初的形态,到当前的琳琅满目,无论是技术、体验、应用等方面都有了质的飞跃。
UNIX操作系统最早于20世纪70年代开发,是一个支持多个用户同时使用的多任务操作系统。它的特点是基于命令行,支持同时运行数千个小程序,易于从单个程序创建管道,内置多用户支持和分区。面临的挑战是基于命令行,寻找帮助和文档可能很繁琐,许多不同的变体(下图)。
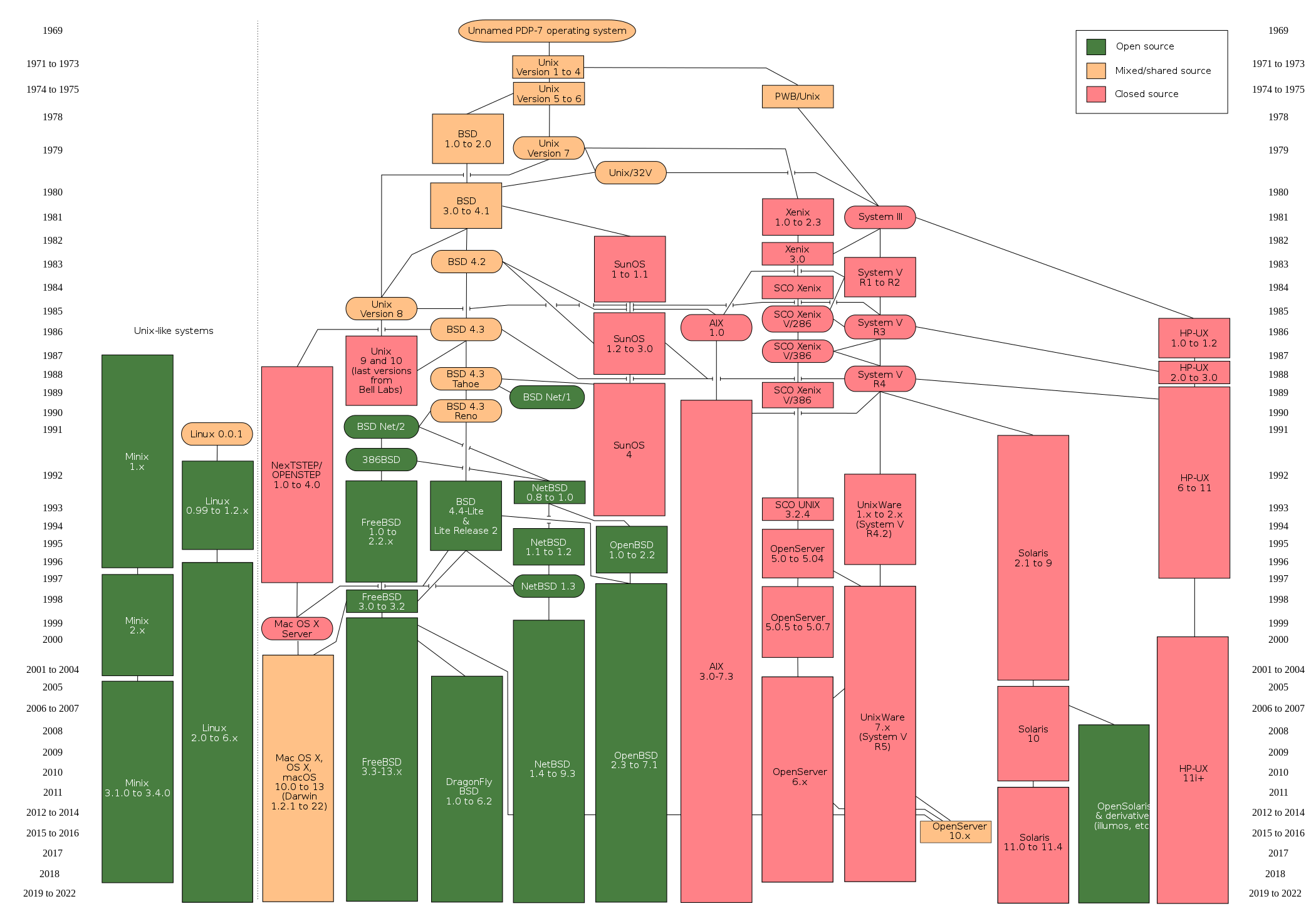
Unix系统和它的衍生体。
同样流行且知名的还有Windows、MacOS、Android、Linux等操作系统。
18.1.1 操作系统功能
操作系统位于应用程序和硬件之间,调解访问并抽象出接口,程序通过陷阱或例外请求服务,设备通过中断请求关注等。操作系统执行许多功能,具体而言,有:
- 实现用户界面。
- 在用户之间共享硬件。
- 允许用户之间共享数据。
- 防止用户相互干扰。
- 在用户之间调度资源。
- 促进I/O操作。
- 从错误中恢复。
- 资源存储核算。
- 促进并行操作。
- 组织数据以实现安全快速访问。
- 处理网络通信。
操作系统是一组程序,用于控制应用程序的执行,并充当计算机用户和计算机硬件之间的中介。操作系统是一种管理计算机硬件并为应用程序运行提供环境的软件,示例有Windows、Windows/NT、Linux、OS/2和MacOS。OS涉及的主题常常是以下几方面:
操作系统提供以下几大类功能:
- 作业管理:识别作业,确定优先级,确定主内存的可用性,并准备运行作业或程序的时间表。
- 进程管理:减少计算机系统处理器和输入/输出设备的空闲时间。
- 输入/输出管理:在各种设备及其驱动程序的帮助下,管理计算机的输入和输出流。
- 数据管理:跟踪磁盘和其他存储设备上的数据。
- 文件管理:负责文件相关活动,如:创建、删除、操作文件和目录。
- 内存管理:根据不同程序的需要分配和释放可用内存。
- 虚拟存储:在不增加物理大小的情况下增加主内存的容量,使用虚拟内存存储指令和数据。
- 安全管理:为敏感数据提供密码安全,以阻止未经授权的访问。
- 在线处理:等待用户的操作指令,并立即执行。
常见的模块或子系统有内存管理、IO系统、文件系统、进程、线程、中断、安全、信息服务等等,它们之间有着错综复杂的关联:
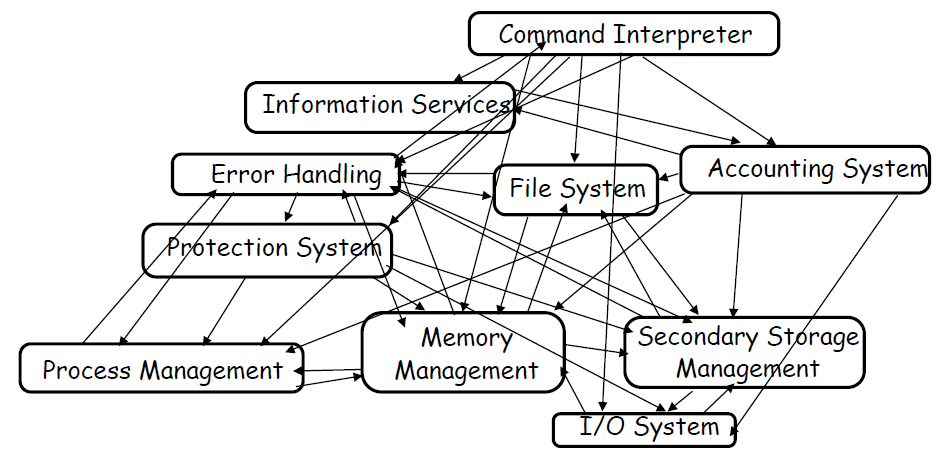
操作系统的目标是:1、使计算机系统方便用户使用;2、有效地使用计算机硬件;3、执行用户程序并使解决用户问题更容易。
可以分别从用户、系统视角来看待操作系统。
计算机的用户视图取决于使用的界面。一些用户可能使用PC,在这种情况下,系统设计为只有一个用户可以利用资源,并且主要是为了便于使用,其中主要关注的是性能而不是资源利用率。一些用户可能使用连接到大型机或小型计算机的终端,其他用户可以通过其他终端访问同一台计算机,这些用户可以共享资源和交换信息。在这种情况下,操作系统被设计为最大限度地利用资源,以便有效地利用所有可用的CPU时间、内存和I/O。其他用户可以坐在工作站上,连接到其他工作站和服务器的网络,在这种情况下,操作系统被设计为在个人可见性和资源利用率之间进行折衷。
而从系统角度来看,可以将系统视为资源分配器,也就是说,一个计算机系统有许多可用于解决问题的资源。操作系统充当这些资源的管理器,必须决定如何将这些资源分配给程序和用户,以便能够高效、公平地操作计算机系统。操作系统的不同视角是,它需要控制各种I/O设备和用户程序,即操作系统是用于管理用户程序执行的控制程序,以防止错误和不当使用计算机。资源可以是CPU时间、内存空间、文件存储空间、I/O设备等。
操作系统服务是操作系统为程序的执行提供了环境,也为程序提供一些服务,每个操作系统提供的服务可能与其他操作系统不同,使得编程任务更容易。
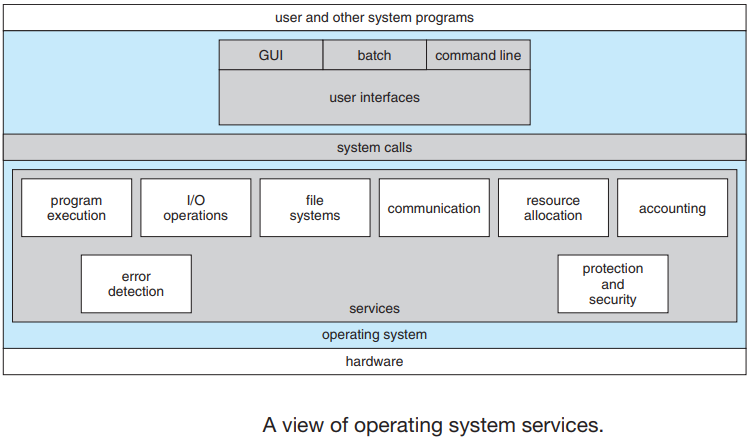
操作系统服务概览。
操作系统提供的各种服务如下:
-
程序执行:系统必须能够将程序加载到主内存分区并运行该程序,程序必须能够正常终止此执行以成功执行,或异常终止以显示错误。
-
I/O操作:完成设备分配和I/O设备控制任务,提供通知设备错误、设备状态等。
-
文件系统操作:完成打开文件、关闭文件的任务,程序需要按名称创建和删除文件,允许文件操作,如读取文件、写入文件、附加文件。
-
通信:在同一计算机系统上或在计算机网络上的不同计算机系统之间完成进程间通信的任务,在安全模式下提供消息传递和共享内存访问。
-
错误检测:操作系统应针对任何类型的溢出(如算术溢出)采取适当的操作;除以零错误、访问非法内存位置和用户CPU时间过大。完成错误检测和恢复任务(如果有),例如打印机卡纸或缺纸。跟踪CPU、内存、I/O设备、存储设备、文件系统、网络等的状态。如果出现致命错误,如RAM奇偶校验错误、功率波动,则中止执行。
-
资源分配:完成资源分配到多个作业的任务,在资源使用后或作业终止时回收分配的资源,当多个用户登录到系统时,必须将资源分配给每个用户。对于资源在各个进程之间的当前分配,操作系统使用CPU调度运行时间,以确定将为哪个进程分配资源。
![]()
-
账户:操作系统跟踪哪些用户使用了多少和哪种计算机资源,维护系统活动日志以进行性能分析和错误恢复。
-
保护:完成保护系统资源免受恶意使用的任务,采用安全方案防止未经授权的访问/用户进行安全计算,使用登录密码和注册对合法用户进行身份验证。操作系统负责硬件和软件保护,操作系统保护存储在多用户计算机系统中的信息。
-
系统调用:系统调用提供进程和操作系统之间的接口,它们通常以汇编语言指令的形式提供。有些系统允许直接从高级语言程序(如C、BCPL和PERL等)进行系统调用,根据使用的计算机,系统调用以不同的方式进行。系统调用可以大致分为5大类:
-
进程管理和控制:
- 结束,中止:运行中的程序需要能够正常(结束)或异常(中止)执行。
- 加载、执行:执行一个程序的进程或作业可能要加载并执行另一个程序。
- 创建、终止进程:有一个系统调用指定用于创建新进程或作业(创建流程或提交作业),或者终止创建的作业或进程。
- 获取或设置进程属性:如果创建新作业或进程,我们应该能够控制其执行,以便确定和重置作业或进程的属性。
- 等待时间:创建新作业或进程后,我们可能需要等待它们完成执行(等待时间)。
- 等待事件、信号事件:我们可以等待特定事件发生(等待事件),然后,作业或进程在该事件发生时发出信号(信号事件)。
- 分配、释放内存。
-
文件管理/文件操作/文件处理:
- 创建文件,删除文件:我们首先需要能够创建和删除文件。两个系统调用都需要文件名及其某些属性。
- 打开文件,关闭文件:创建文件后,我们需要打开并使用它。当不再使用该文件时,我们将其关闭。
- 读取、写入、重新定位文件:打开后,我们还可以读取、写入或重新定位文件(回放或跳到文件末尾)。
- 获取文件属性,设置文件属性:对于文件或目录,我们需要能够确定各种属性的值,并在必要时重置它们。需要两个系统调用获取文件属性和设置文件属性
-
设备管理:
- 请求设备,释放设备:如果系统有多个用户,首先请求设备,在完成设备后,必须释放它。
- 读取、写入、重新定位:一旦设备被请求并分配,就可以读取、写入和重新定位设备。
-
信息维护/管理:
- 获取时间或日期、设置时间或日期:大多数系统都有一个系统调用来返回当前的日期和时间或设置当前的日期与时间。
- 获取系统数据,设置系统数据:其他系统调用可能会返回有关系统的信息,如当前用户数、操作系统版本号、可用内存量等。
- 获取进程属性,设置进程属性:操作系统保留有关其所有进程的信息,并且有系统调用来访问这些信息。
-
通讯管理:
- 创建、删除连接。
- 发送、接收消息。
- 连接、分离远程设备(安装/远程登录)。
- 传输状态信息(字节)。
通讯管理有两种模式:
- 消息传递模式:信息通过操作系统提供的进程间通信设施进行交换,网络中的每台计算机都有一个已知的名称。类似地,每个进程都有一个进程名,该进程名被转换为操作系统可以引用的等效标识符。get-host-id和get-processed系统调用来执行此转换,然后将这些标识符传递给文件系统提供的通用打开和关闭调用,或传递给特定的打开连接系统调用。收件人进程必须授予其权限,才能与接受连接呼叫进行通信。通信源称为客户端和接收方,称为服务器,通过读消息和写消息系统调用交换消息。关闭连接调用终止连接。
- 共享内存模式:进程使用映射内存系统调用访问其他进程拥有的内存区域,他们通过读写共享区域中的数据来交换信息,这些进程确保它们不会同时写入同一位置。
![]()
-

18.1.2 操作系统种类
操作系统可分为以下几类。
18.1.2.1 批处理操作系统
在批处理系统(Batch System)类型的操作系统中,用户定期(如每天、每周、每月)将作业提交到一个中心位置,该位置的系统用户不直接与计算机系统交互。为了加快处理速度,具有类似需求的作业被分批处理,并作为一个组在计算机中运行。因此,程序员将把程序留给操作员,每个作业的输出将发送给适当的程序员。这种类型的主要任务是自动将控制权从一个作业转移到下一个作业。
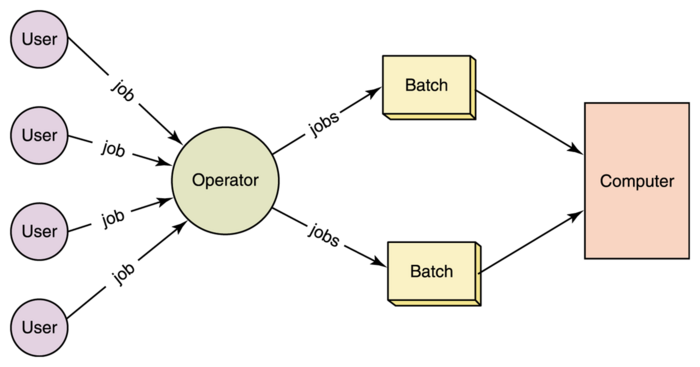
此种操作系统的优势是简单、连续的作业调度,尽量减少人为干预,由于作业成批处理,提高了性能和系统吞吐量。缺点是从用户的角度来看,由于批处理,周转时间可能会很长,程序调试困难,作业可以进入无限循环,可能会损坏显示器,由于缺乏保护方案,一项作业可能会影响待定作业。
应用案例是工资系统、银行对账单等。注意,周转时间是指用户提交流程或作业与完成该流程或作业之间所用的时间。
联机的全称是在线同步外围设备操作(Simultaneous Peripheral Operation On-Line,SPOOL),是暂时保存数据以供设备、程序或系统使用和执行的过程,数据被发送到其他易失性(临时存储器)存储器并存储在其中,直到程序或计算机请求执行。
18.1.2.2 分时操作系统
时间共享系统(Time-Sharing)也被称为分时系统、多用户系统,提供用户与系统之间的在线通信,用户直接发出指令并接收中间响应,因此称为交互式系统。它允许多个用户同时共享计算机系统,CPU在几个程序之间快速多路复用,这些程序保存在内存和磁盘上,一个程序在磁盘上交换内存和内存。
CPU通过在多个作业之间切换来执行多个作业,但切换频繁,用户可以在每个程序运行时与之交互。交互式计算机系统提供用户和系统之间的直接通信,用户直接使用键盘或鼠标向操作系统或程序发出指令,并等待即时结果。因此,响应时间将很短。分时系统允许许多用户同时共享计算机,由于此系统中的每个操作都很短,因此每个用户只需要很少的CPU时间。系统可以快速地从一个用户切换到另一个用户,因此每个用户都会感觉整个计算机系统都是专门用于自己的使用的,即使它是由许多用户共享的。
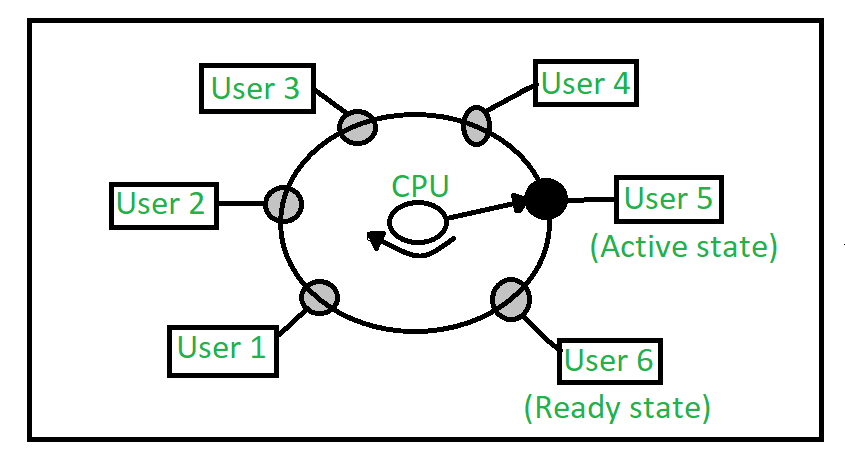
在上图中,用户5处于活动状态,但用户1、用户2、用户3和用户4处于等待状态,而用户6处于就绪状态。一旦用户5的时间片完成,时间片就移到下一个就绪用户,即用户6。在此状态下,用户2、用户3、用户4和用户5处于等待状态,用户1处于就绪状态。这个过程以同样的方式继续,以此类推。
分时系统的优点是有效共享和利用计算机资源,对许多用户的快速响应时间,CPU空闲时间完全消除,适合在线数据处理和用户对话。
分时系统的缺点是比多道程序操作系统更复杂,系统必须具有内存管理和保护,因为多个作业同时保存在内存中,分时系统还必须提供文件系统,因此需要磁盘管理,它为需要复杂CPU调度方案的并发执行提供了机制。示例:Multics、UNIX等。
18.1.2.3 实时操作系统
实时系统(Real-Time System)的特点是提供即时响应,保证关键任务按时完成。对于要在计算机上执行的每个功能,此类型必须具有已知的最大时间限制。当处理器的操作或数据流有严格的时间要求时,使用实时系统,实时系统可用作专用应用中的控制设备。
当处理器的操作或数据流有严格的时间要求时,使用实时系统,控制科学实验、医学成像系统和一些显示系统的系统是实时系统。传感器将数据传送到计算机,计算机分析数据并调整控件以修改传感器输入。
实时系统的缺点是:只有当实时系统在时间限制内返回正确的结果时,才认为它能够正确运行,辅助存储有限或丢失,而数据通常存储在短期内存或ROM中,缺少高级操作系统功能。
实时系统有两种类型:
- 硬实时系统:保证关键任务按时完成,例如突如其来的任务发生在一个突然的时刻。
- 软实时系统:是一种限制较少的实时系统,其中关键任务的优先级高于其他任务,并在计算之前保持该优先级。与硬实时系统相比,这些系统的实用性更为有限。偶尔错过最后期限是可以接受的。
示例:QNX、VX工作,数字音频或多媒体包含在这一类别中,是一种特殊用途的操作系统,其中对处理器的操作有严格的时间要求。实时操作系统有明确定义的固定时间限制,处理必须在时间限制内完成,否则系统将失败。只有在时间限制内返回正确的结果,实时系统才能正常运行。这些系统的特点是将时间作为关键参数。
实时操作系统的优点:
- 最大化消费:设备和系统的最大利用率,从而从所有资源中获得更多输出。
- 任务转移:在这些系统中分配给转移任务的时间非常少。例如,在较旧的系统中,将一个任务转移到另一个任务大约需要10微秒,而在最新的系统中则需要3微秒。
- 专注于应用程序:专注于运行应用程序,而对队列中的应用程序不那么重要。
- 嵌入式系统中的实时操作系统:由于程序的大小很小,RTOS也可以用于嵌入式系统,如传输和其他系统。
- 无错误:这些类型的系统是无错误的。
- 内存分配:内存分配在这些类型的系统中管理得最好。
实时操作系统的缺点:
- 有限的任务:同一时间运行的任务很少,并且它们很少集中在少数应用程序上,以避免错误。
- 使用繁重的系统资源:有时系统资源不是很好,而且也很昂贵。
- 复杂算法:算法非常复杂,设计者很难写下去。
- 设备驱动和中断信号:需要特定的设备驱动程序和中断信号来尽早响应中断。
- 线程优先级:设置线程优先级并不好,因为这些系统不太容易切换任务。
实时操作系统的例子有:科学实验、医学成像系统、工业控制系统、武器系统、机器人、空中交通控制系统等。

18.1.2.4 多道程序操作系统
多程序设计(Multiprogramming)概念通过组织作业增加CPU利用率,CPU总有一个作业要执行。操作系统同时在内存中保留多个作业,如下图所示。

这组作业是作业池中保留的作业的子集,操作系统拾取并开始执行内存中的一个作业,当一个作业需要等待时,CPU只需切换到另一个作业,依此类推。
多道程序操作系统很复杂,因为操作系统为用户做出决定,称为作业调度。如果多个作业准备同时运行,系统将从中选择一个,称为CPU调度。其他功能包括内存管理、设备和文件管理。
多道程序系统的优点是有效的资源利用率(CPU、内存、外围设备),消除或最小化浪费的CPU空闲时间,增加的吞吐量(在给定的时间间隔内,相对于提交执行的作业数量,执行的作业数)。
多道程序系统的缺点是在程序执行期间,不提供用户与计算机系统的交互,磁盘技术的引入解决了这些问题,而不是将卡片从读卡器读入磁盘,这种处理形式称为联机,复杂且相当昂贵。
18.1.2.5 多处理器/并行/紧耦合系统
这些系统有多个处理器进行紧密通信,共享计算机总线、时钟、内存和外围设备,例如UNIX、LINUX。多处理器系统有三个主要优点:
- 增加的吞吐量:每单位时间计算的进程数。通过增加处理器的数量,可以在更短的时间内完成工作。N个处理器的加速比不是N,但小于N。因为在保持所有部件正常工作时会产生一定的开销。
- 提高可靠性:如果功能可以在多个处理器之间正确分配,那么一个处理器的故障不会停止系统,而是会降低系统速度。这种即使发生故障仍能继续运行的能力使系统具有容错能力。
- 经济伸缩:多处理器系统可以节省资金,因为它们可以共享外围设备、存储和电源。
多处理系统的类型包括:
- 对称多处理(Symmetric Multiprocessing,SMP):每个处理器运行操作系统的相同副本,这些副本根据需要彼此通信。例如:Encore版本的UNIX for multi-max计算机。实际上,包括Windows NT、Solaris、Digital UNIX、OS/2和LINUX在内的所有现代操作系统现在都支持SMP。
- 非对称多处理(主-从处理器,Master – Slave Processors):每个处理器都是为特定任务设计的。主处理器控制系统,并将工作安排和分配给从处理器。Ex-Sun的操作系统SUNOS版本4提供非对称多处理。
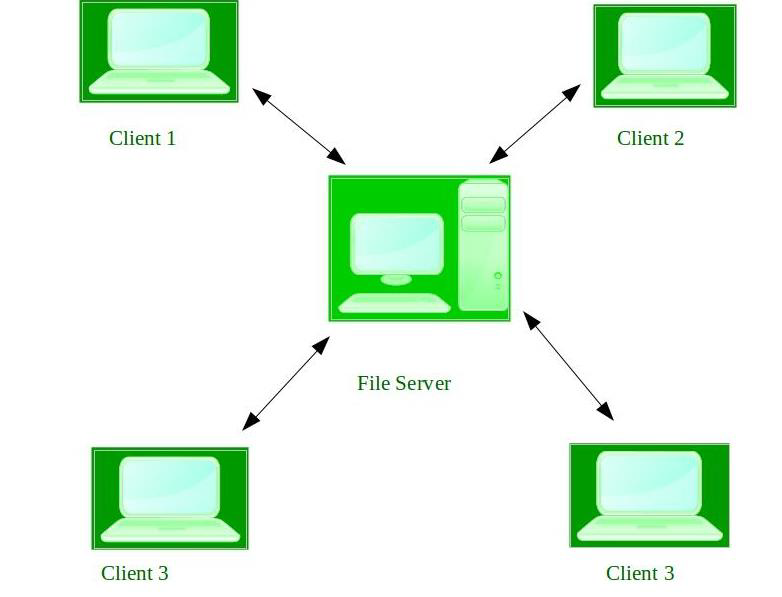
18.1.2.6 分布式/松耦合系统
与紧耦合系统相比,处理器不共享内存或时钟,相反,每个处理器都有自己的本地内存。处理器通过各种通信线路(如高速总线或电话线)相互通信,分布式系统的功能依赖于网络。通过能够通信,分布式系统能够共享计算任务并为用户提供丰富的功能集,网络因所使用的协议、节点和传输介质之间的距离而异。
TCP/IP是最常见的网络协议,分布式系统中的处理器大小和功能各不相同,可以是微处理器、工作站、小型计算机和大型通用计算机,网络类型基于节点之间的距离,例如LAN(在房间、楼层或建筑物内)和WAN(在建筑物、城市或国家之间)。
分布式操作系统的优点:资源共享,计算速度加快,负载共享/负载平衡,可靠性,通讯。
分布式操作系统的缺点:主网络故障将停止整个通信,为了建立分布式系统,所使用的语言还没有很好的定义,这些类型的系统并不容易获得,因为它们非常昂贵。不仅底层软件非常复杂,而且还没有被很好地理解。示例是LOCUS等。
18.1.2.7 网络操作系统
这些系统在服务器上运行,并提供管理数据、用户、组、安全、应用程序和其他网络功能的能力。此类操作系统允许通过小型专用网络共享访问文件、打印机、安全、应用程序和其他网络功能。网络操作系统的另一个重要方面是,所有用户都清楚底层配置、网络中所有其他用户的配置、他们的个人连接等,这就是为什么这些计算机通常被称为紧耦合系统的原因。
网络操作系统的优点:高度稳定的集中式服务器,安全问题通过服务器处理,新技术和硬件升级很容易集成到系统中,可以从不同位置和类型的系统远程访问服务器。网络操作系统的缺点:服务器成本高昂,用户必须依赖中央位置进行大多数操作,需要定期维护和更新。
网络操作系统的示例有Microsoft Windows Server 2003、Microsoft Windows Server 2008、UNIX、Linux、Mac OS X、Novell NetWare和BSD等。
18.1.3 操作系统结构
操作系统体系结构的设计传统上遵循关注点分离原则,这一原则建议将操作系统结构化为相对独立的部分,这些部分提供简单的单个功能,从而使设计的复杂性保持可控。
18.1.3.1 简单结构
有几个商业系统没有定义良好的结构,例如操作系统开始时是小的、简单的和有限的系统,然后扩展到超出其原始范围。MS-DOS就是这种系统的一个例子,没有仔细地划分成模块。另一个有限结构的例子是UNIX操作系统,没有CPU执行模式(用户和内核),因此应用程序中的错误可能会导致整个系统崩溃。
 g)
g)
18.1.3.2 单片结构
在这个模型中,对于每个系统调用,都有一个服务过程来处理和执行它。实用程序执行多个服务程序所需的操作,例如从用户程序中获取数据。程序分为三层,如下图所示。
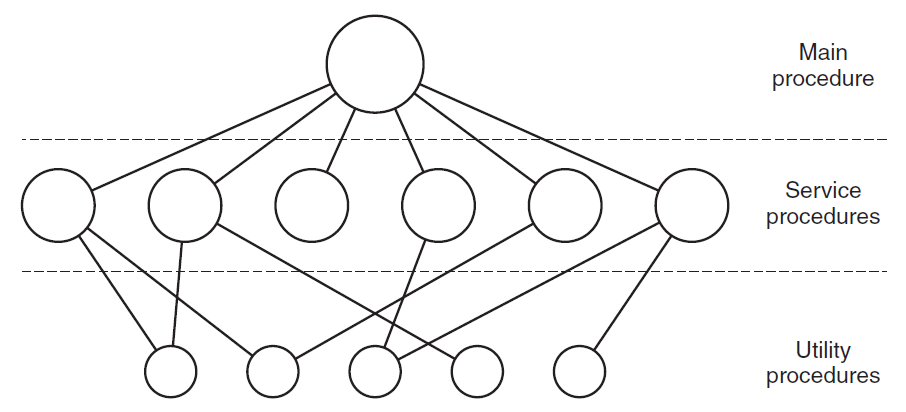
操作系统体系结构的单片设计不适合操作系统的特殊性质。尽管设计遵循关注点分离,但没有尝试限制授予操作系统各个部分的权限,整个操作系统以最大权限执行。
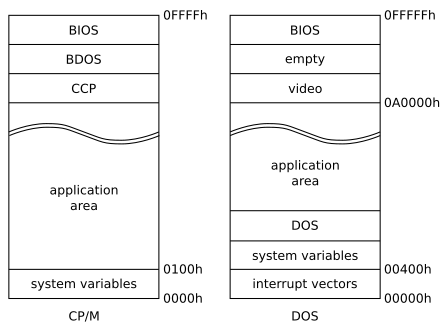
单片操作系统内的通信开销与任何其他软件内的通信开支相同,被认为相对较低。CP/M和DOS是单片操作系统的简单示例,CP/M和DOS都是与应用程序共享单个地址空间的操作系统。在CP/M中,16位地址空间以系统变量和应用程序区域开始,以操作系统的三个部分结束,即CCP(控制台命令处理器)、BDOS(基本磁盘操作系统)和BIOS(基本输入/输出系统)。在DOS中,20位地址空间从中断向量数组和系统变量开始,然后是DOS的常驻部分和应用程序区域,最后是视频卡和BIOS使用的内存块。
18.1.3.3 分层结构
在分层方法中,操作系统被划分为多个层(级别),每个层都构建在较低层之上。底层(第0层)是硬件,最顶层(第N层)是用户界面。

操作系统的分层通用架构。
分层方法的主要优点是模块化,层的选择使得每个用户只具有较低层的功能(或操作)和服务。这种方法简化了调试和系统验证,即可以调试第一层,而不必考虑系统的其余部分。一旦调试了第一层,就假定它在调试第二层时正常工作,依此类推。如果在调试特定层的过程中发现错误,则该错误必须位于该层上,因为它下面的层已被调试。
这样,当系统被分解为多个层次时,系统的设计和实现就简化了。每个层仅使用较低层提供的操作来实现,层不需要知道这些操作是如何实现的;它只需要知道这些操作是做什么的。分层方法首先在操作系统中使用。它被定义为六层。
| 层 | 功能 |
|---|---|
| 5 | 用户程序 |
| 4 | I/O管理 |
| 3 | 操作进程通讯 |
| 2 | 内存管理 |
| 1 | CPU调度 |
| 0 | 硬件 |
分层方法的主要缺点:
1、主要困难在于对层的仔细定义,因为一个层只能使用它下面的那些层。例如,虚拟内存算法使用的磁盘空间的设备驱动程序必须低于内存管理例程的级别,因为内存管理需要使用磁盘空间的能力。
2、效率低于非分层系统(每一层都会增加系统调用的开销,最终的结果是系统调用比非分层系统花费的时间更长)。
其中,Unix系统的架构如下图所示:

Unix可分为内核和系统程序。Unix内核包括系统资源管理、接口和设备驱动程序,如CPU调度、文件系统、内存管理和I/O管理。
Linux是针对Intel 386/486/Pentium机器的完整Unix克隆,充当计算机系统的硬件和软件之间的通信服务,其内核包含了任何操作系统中所期望的所有特性,部分功能包括:
- 多任务处理(一种在多个独立作业之间共享单个处理器的技术)。
- 虚拟内存(允许重复、扩展使用计算机的RAM以提高性能)。
- 快速TCP/IP驱动程序(用于快速通信)。
- 共享库(使应用程序能够共享公共代码)。
- 多用户能力(意味着数百人可以通过网络、互联网、笔记本电脑/计算机或连接到这些计算机串行端口的终端同时使用计算机)。
- 保护模式(允许程序访问物理内存,并保护系统的稳定性)。
Windows XP是一个基于增强技术的多任务操作系统,集成了Windows 2000的优点,如基于标准的安全性、可管理性和可靠性,以及Windows 98和Windows Me的最佳功能,如即插即用和易于使用的用户界面。Windows XP的体系结构如下图所示,采用分层结构,由硬件抽象层、内核层、执行层、用户模式层和应用程序组成。
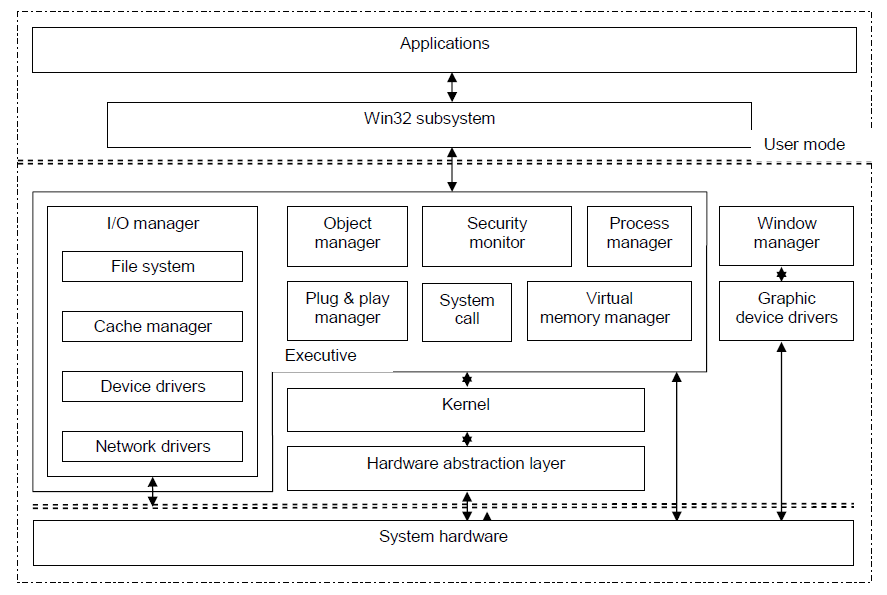
Windows XP的每个内核实体都被视为一个对象,由执行程序中的对象管理器管理。用户模式应用程序可以通过进程中的对象句柄调用内核对象。使用内核对象来提供基本服务,以及对客户端-服务器计算的支持,使Windows XP能够支持多种应用程序。Windows XP还提供虚拟内存、集成缓存、抢占式调度、更强的安全模式和国际化功能。
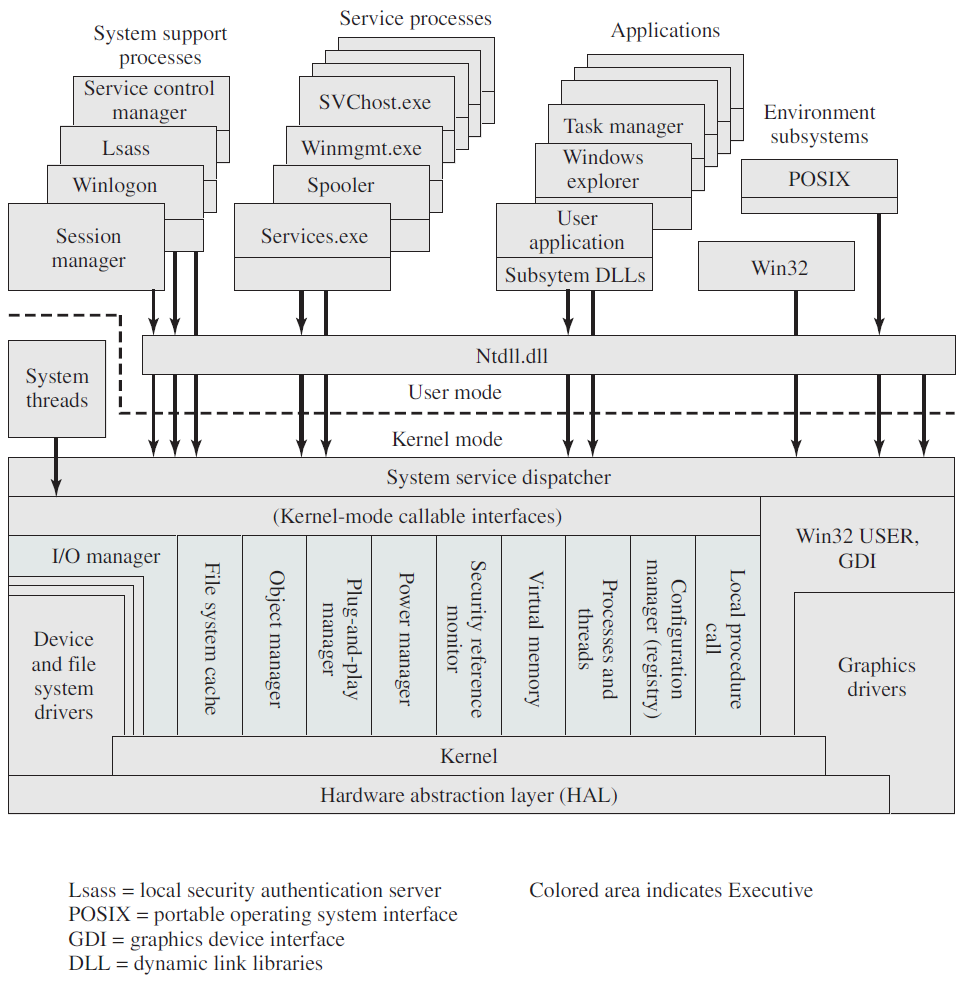
Windows和Windows Vista架构图。
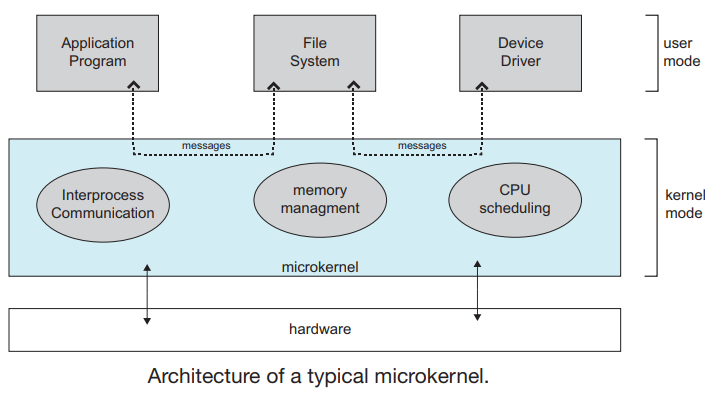
18.1.3.4 微内核结构
通过删除内核的所有不重要部分并将其作为系统级和用户级程序实现来构建操作系统,通常提供最少的进程和内存管理以及通信设施, 操作系统组件之间的通信通过消息传递提供。
微内核的优点是扩展操作系统变得容易得多,对内核的任何更改都会减少,因为内核更小,微内核还提供了更高的安全性和可靠性。主要缺点是由于消息传递增加了系统开销,性能较差。
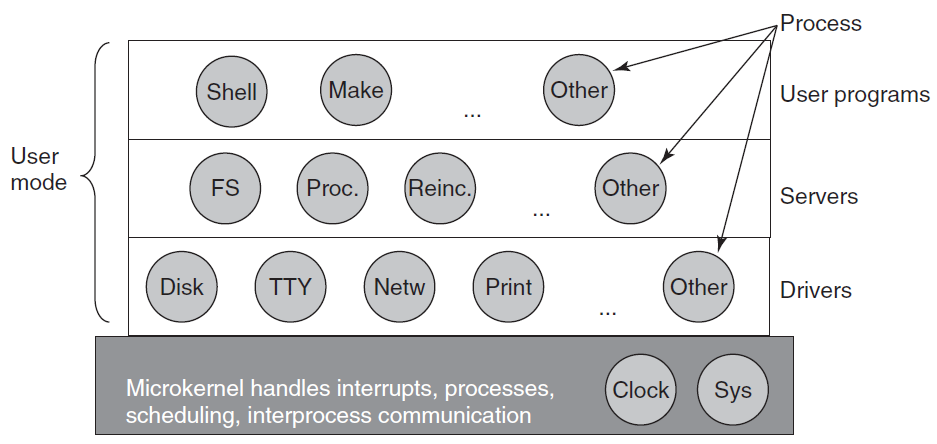
MINIX 3微内核只有大约12000行C语言和1400行汇编语言,用于捕捉中断和切换进程等非常低级的功能。C代码管理和调度进程,处理进程间通信(通过在进程之间传递消息),并提供一组大约40个内核调用,以允许操作系统的其余部分完成其工作。这些调用执行诸如将处理程序挂接到中断、在地址空间之间移动数据以及为新进程安装内存映射等功能。MINIX 3的进程结构如下图所示,内核调用处理程序标记为Sys。时钟的设备驱动程序也在内核中,因为调度程序与它紧密交互。其他设备驱动程序作为单独的用户进程运行。
Solaris结构图如下:

18.1.3.5 客户端-服务器结构
微内核思想的一个微小变化是区分两类进程,即服务器(每个进程都提供一些服务)和客户端(使用这些服务)。此模型称为客户机-服务器模型,通常最底层是微内核(但非必需),其本质是客户端进程和服务器进程的存在。
客户端和服务器之间的通信通常是通过消息传递进行的。为了获得服务,客户端进程构造一条消息,说明它想要什么,并将其发送到适当的服务。然后,该服务完成工作并返回答案。如果客户机和服务器碰巧在同一台机器上运行,则可以进行某些优化,如消息传递。
这种想法的一个明显的概括是让客户端和服务器运行在不同的计算机上,通过局域网或广域网连接,如下图所示。由于客户端通过发送消息与服务器通信,客户端不需要知道消息是在自己的机器上本地处理的,还是通过网络发送到远程机器上的服务器。就客户而言,在这两种情况下都会发生同样的事情:发送请求,然后回复。因此,客户机-服务器模型是一种抽象,可以用于单个机器或机器网络。

18.1.3.6 虚拟机
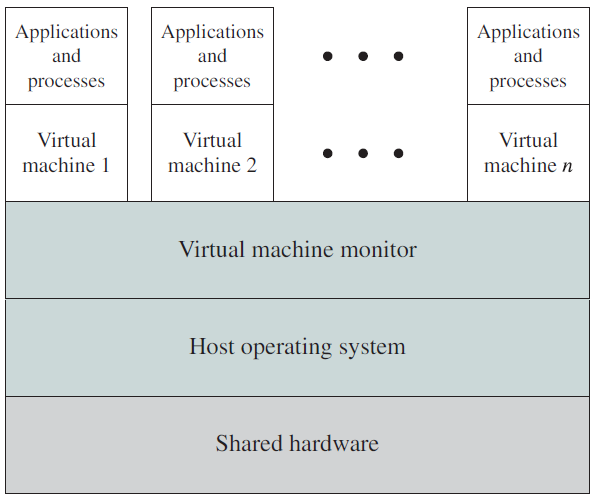
虚拟机涉及的概念。
虚拟机采用分层方法得出其逻辑结论,将硬件和操作系统内核视为硬件,提供与底层裸硬件相同的接口。操作系统产生了多个进程的错觉,每个进程都使用自己的(虚拟)内存在自己的处理器上执行,共享物理计算机的资源以创建虚拟机。CPU调度可以创建用户拥有自己处理器的外观。联机和文件系统可以提供虚拟读卡器和虚拟行打印机。普通用户分时终端充当虚拟机操作员的控制台。
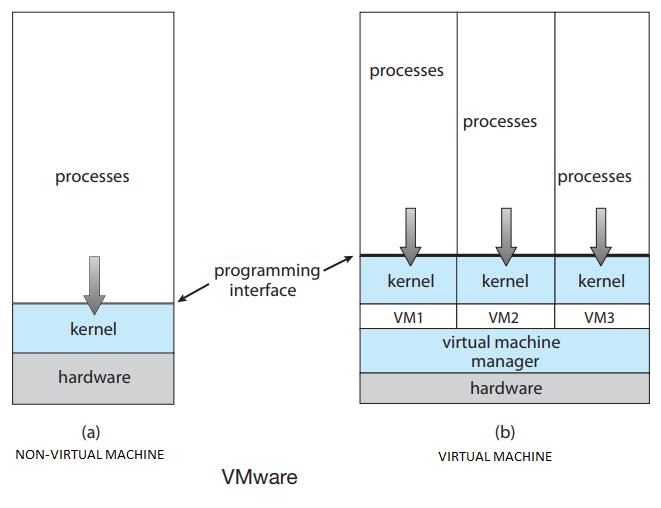
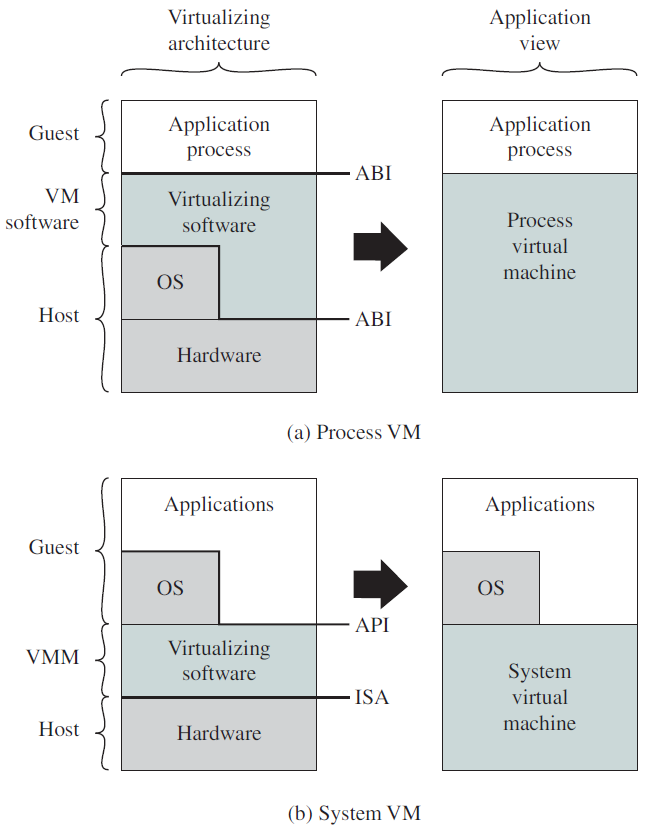
虚拟机概念提供了对系统资源的完全保护,因为每个虚拟机都与所有其他虚拟机隔离。然而,这种隔离不允许直接共享资源。虚拟机系统是操作系统研究和开发的完美工具。系统开发是在虚拟机上进行的,而不是在物理机上进行,因此不会中断正常的系统操作。虚拟机概念很难实现,因为需要为底层机器提供精确的副本。它的缺点是虚拟机包括由于大量模拟虚拟机操作而增加的系统开销,VM OS的效率取决于VM监视器必须模拟的操作数。虚拟机可分为进程和系统两个级别:
VM/370是于1979由Seawright和MacKinnon推出的虚拟机,它基于一个敏锐的观察:分时系统提供(1)多道程序设计和(2)扩展机器,与裸硬件相比,具有更方便的接口。VM/370的本质是将这两个功能完全分离。
系统的核心,即虚拟机监视器,在裸硬件上运行并执行多道程序设计,向上一层提供的不是一个,而是几个虚拟机,如图1-28所示。然而,与所有其他操作系统不同,这些虚拟机不是扩展机,具有文件和其他漂亮的功能。相反,它们是裸硬件的精确副本,包括内核/用户模式、I/O、中断以及真实机器所拥有的所有其他内容。

虚拟化在Web托管领域也很流行。如果没有虚拟化,Web托管客户就不得不在共享托管和专用托管之间进行选择。当一家网络托管公司提供虚拟机出租时,一台物理机可以运行许多虚拟机,每个虚拟机看起来都是一台完整的机器。租用虚拟机的客户可以运行他们想要的任何操作系统和软件,但成本仅为专用服务器的一小部分(因为同一物理机同时支持多个虚拟机)。
虚拟化的另一个用途是为那些希望能够同时运行两个或更多操作系统(例如Windows和Linux)的最终用户提供的,因为他们喜欢的一些应用程序包在一个上运行,而另一些在另一个上运行。这种情况如图下图(a)所示,其中术语“虚拟机监控器”已重命名为类型1虚拟机监控程序,现在常用的是,因为“虚拟机监控”需要的击键次数比人们现在准备好的要多。
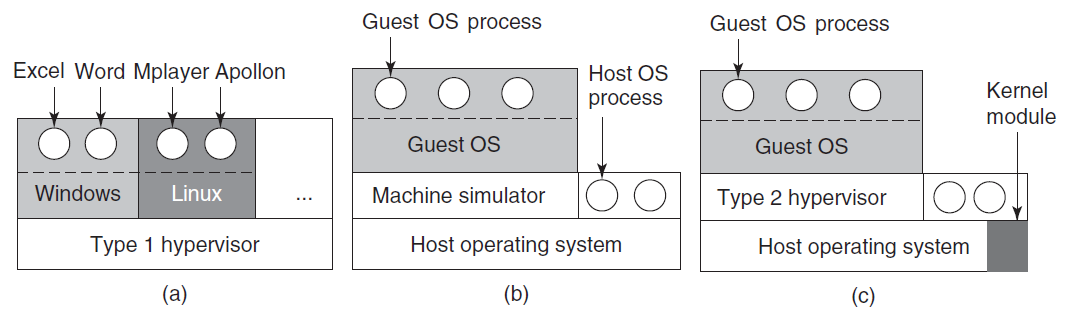
(a) 1类虚拟机监控程序。(b) 纯类型2管理程序。(c) 一个实用的2型管理程序。
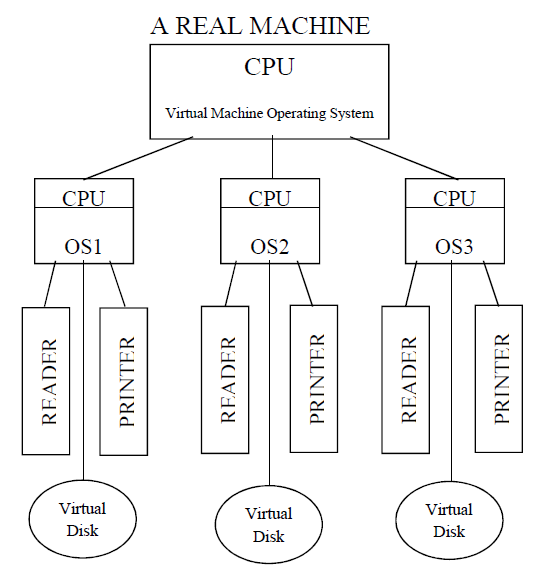
虚拟计算机的一种架构示例。
使用虚拟机的另一个领域是运行Java程序,但方式有所不同。当Sun Microsystems发明Java编程语言时,它还发明了一种称为JVM(Java Virtual Machine)的虚拟机(即计算机体系结构)。Java编译器为JVM生成代码,然后通常由软件JVM解释器执行。这种方法的优点是,JVM代码可以通过Internet发送到任何具有JVM解释器并在其中运行的计算机,例如,如果编译器生成了SPARC或x86二进制程序,那么它们就不可能如此容易地发布和运行。使用JVM的另一个优点是,如果解释器实现正确(并不是小事),可以检查传入的JVM程序的安全性,然后在受保护的环境中执行,这样它们就不会窃取数据或造成任何损坏。
18.1.4 操作系统组件
游戏开发是一个非常复杂的过程和项目,如果没有模块化架构和高效开发环境的帮助,几乎是不可行的。当前市面上的各种产品共享由以下抽象层次组成的结构,从上到下分别是:游戏应用、游戏引擎、图形API、操作系统、设备驱动、硬件设备。
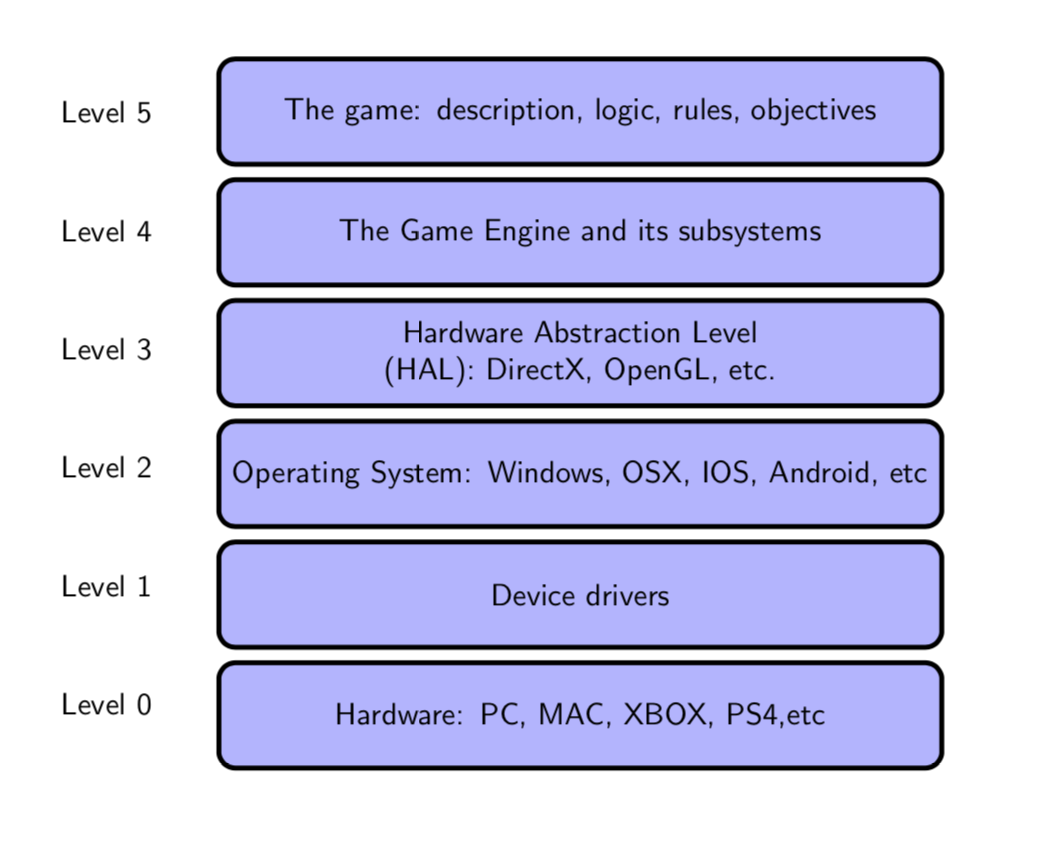
下图是更加详细的层级模块,其中操作系统(OS)处于图形API等第三方SDK和驱动之间,充当着承上启下的重要作用和通讯桥梁,是整个计算机层级架构极其重要的组成部分。
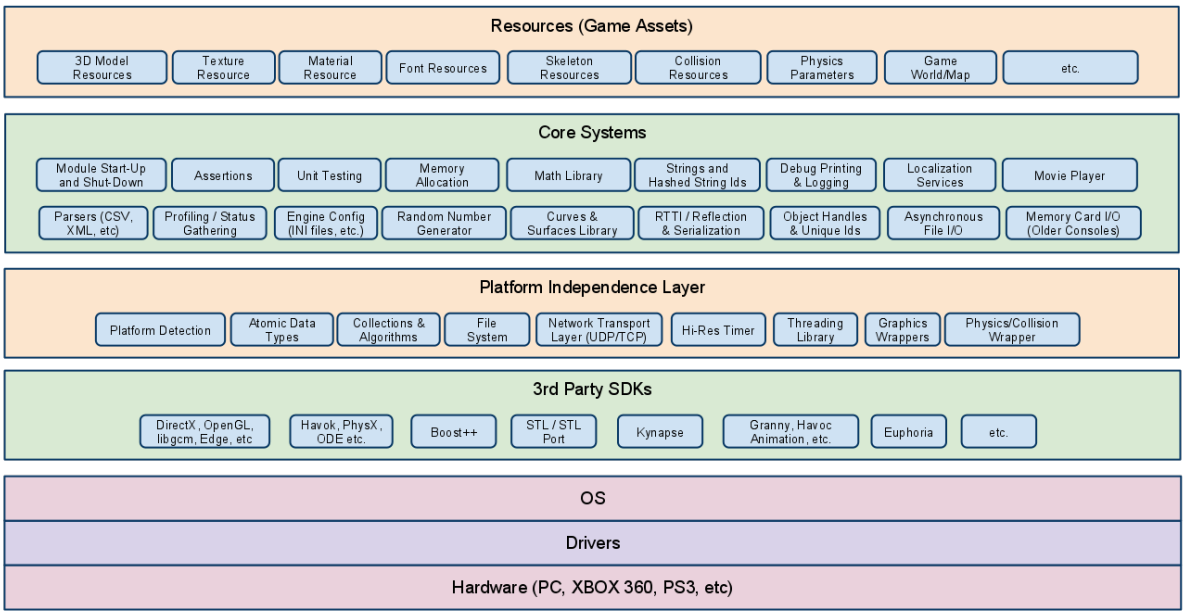
计算机系统可以分为四个部分:硬件、操作系统、应用程序和用户。系统组件的抽象视图如图1所示。
1、硬件:如CPU、内存和I/O设备。
2、操作系统:在计算机系统的操作中提供正确使用硬件的方法,类似于政府。
3、应用程序:解决用户的计算问题,如:编译器、数据库系统和web浏览器。
4、用户:人、机器或其他计算机。
在顶层,计算机由处理器、内存和I/O组件组成,每种类型有一个或多个模块。这些组件以某种方式互连,以实现计算机的主要功能,即执行程序。有四个主要结构要素:
- 处理器:控制计算机的操作并执行其数据处理功能。当只有一个处理器时,它通常被称为中央处理单元(CPU)。
- 主存储器:存储数据和程序。易丢失,当计算机关闭时,内存中的内容会丢失。相反,即使计算机系统关闭,磁盘内存的内容也会保留。主存储器也称为实存储器或主存储器。
- I/O模块:在计算机及其外部环境之间移动数据外部环境由各种设备组成,包括辅助存储器设备(如磁盘)、通信设备和终端。
- 系统总线:提供处理器、主存储器和I/O模块之间的通信。

操作系统所处的层级如下图所示:
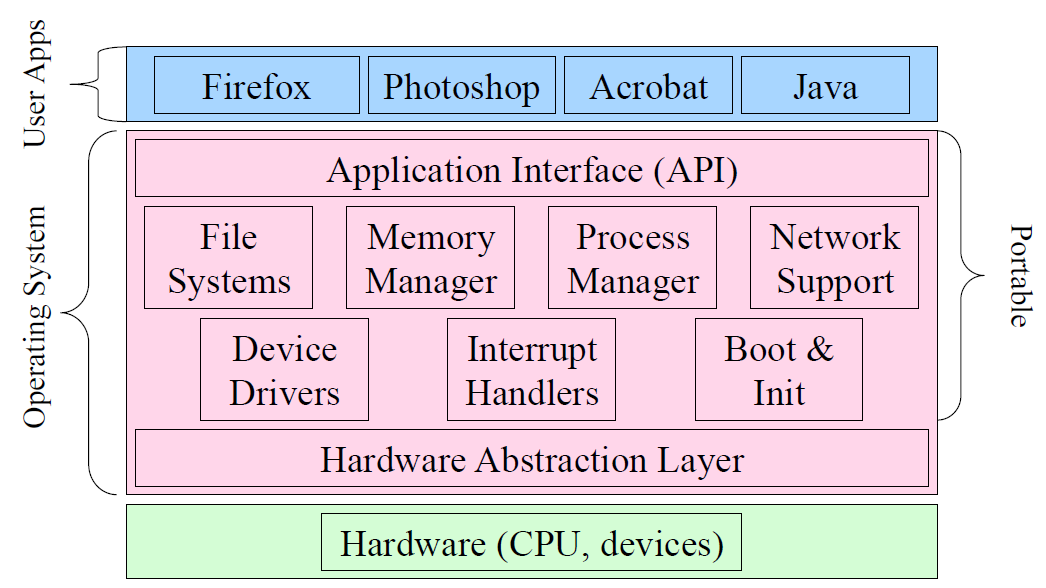
通用系统架构如下图,展示了Windows的总体架构,包含了用户模式和内核模式组件。

上图中出现的概念的简要说明如下:
-
用户模式:
-
用户进程。是基于镜像文件(image file)的普通进程,在系统上执行,例如Notepad.exe、cmd.exe、explorer.exe等。
-
子系统DLL。子系统DLL是实现子系统API的动态链接库(DLL),子系统是内核公开的功能的特定视图。从技术上讲,从Windows 8.1开始,只有一个子系统——Windows子系统。子系统dll包括众所周知的文件,如kernel32.dll、user32.dll、gdi32.dll,advapi32.dll和combase.dll和许多其他dll。它们主要实现了Windows的官方API。
-
NTDLL.DLL。实现Windows本机API的系统范围DLL,是代码的最底层,仍处于用户模式,最重要的作用是将系统调用转换到内核模式,还实现了堆管理器、映像加载器和用户模式线程池的某些部分。
-
服务进程。服务进程是正常的Windows进程,与服务控制管理器(SCM,在services.exe中实现)通信,并允许对其生命周期进行一些控制。SCM可以启动、停止、暂停、恢复并向服务发送其他消息。
-
系统进程。系统进程是一个概括术语,用于描述通常“就在那里”的进程,在通常情况下,这些进程不会直接通信。尽管如此,它们仍然很重要,其中一些对系统的功能至关重要,终止其中一些会导致致命的系统崩溃。一些系统进程是原生进程,意味着它们只使用原生API(由NTDLL实现的API)。系统进程的示例包括Smss.exe、Lsass.exe、Winlogon.exe、Services.exe等。
-
子系统进程。Windows子系统进程,运行镜像Csrss.exe,可视为内核助手,用于管理在Windows系统下运行的进程。它是一个关键的进程,如果被杀死,系统将崩溃。通常有一个CSRS.exe实例,因此在标准系统中存在两个实例——一个用于会话(通常为0),一个用于登录用户会话(通常为1)。尽管CSRS.exe是Windows子系统的“管理器”(目前仅剩的一个),其重要性不仅仅是此角色。
-
-
内核模式:
- 执行层(Executive)。执行层是NtOskrnl.exe(“内核”)的上层,承载了内核模式下的大部分代码。主要包括各种管理器:对象管理器、内存管理器、I/O管理器、即插即用管理器、电源管理器、配置管理器等,远远大于底层的内核层。
-
内核。内核层实现内核模式操作系统代码的最基本和时间敏感部分,包括线程调度、中断和异常调度以及各种内核原语(如互斥和信号量)的实现。一些内核代码是用CPU特定的机器语言编写的,以提高效率并直接访问CPU特定的细节。
- 设备驱动程序。设备驱动程序是可加载的内核模块,其代码以内核模式执行,因此拥有内核的全部功能。经典设备驱动程序提供了硬件设备和操作系统其余部分之间的粘合剂,其他类型的驱动程序提供过滤功能。
-
Win32k.sys。Windows子系统的内核模式组件,本质上是一个内核模块(驱动程序),用于处理Windows的用户界面部分和经典的图形设备接口(GDI)API。意味着所有窗口操作都由该组件处理,系统的其余部分对UI几乎一无所知。
- 硬件抽象层(HAL)。HAL是最接近CPU的硬件上的抽象层,允许设备驱动程序使用不需要中断控制器或DMA控制器等详细和特定知识的API。当然,这一层对于为处理硬件设备而编写的设备驱动程序非常有用。目标是将特定于硬件的例程从“核心”操作系统中分离出来,提供便携性,提高可读性。
-
Hyper-V管理程序。如果支持基于虚拟化的安全性(VBS),则Hyper-V管理程序存在于Windows 10和server 2016(及更高版本)系统上。VBS提供了额外的安全层,其中实际的机器实际上是由Hyper-V控制的虚拟机。
下图是微内核结构示意图:
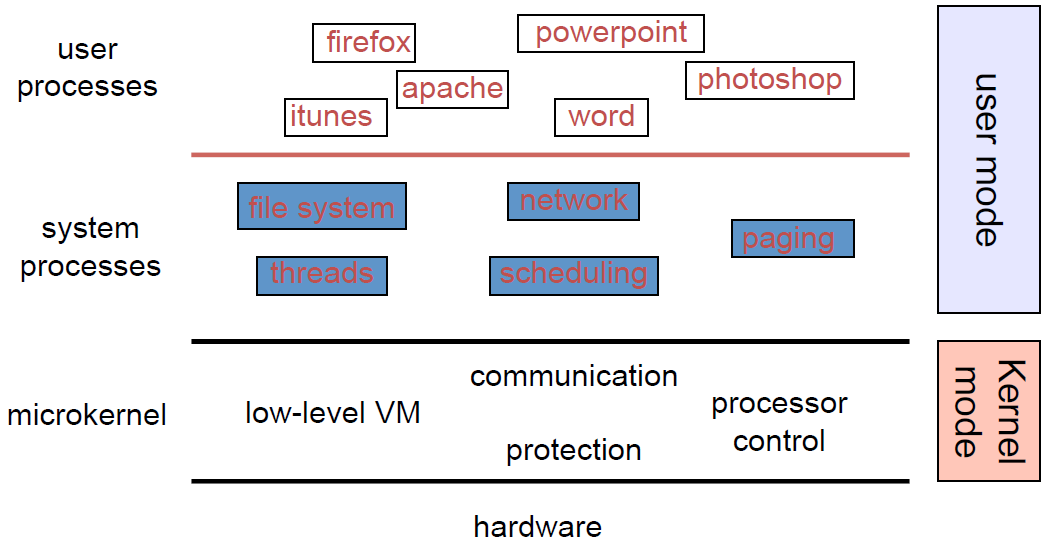
OS的组件通常包含控制程序、系统服务程序、工具类程序等。其中,控制程序创建环境以运行其它程序,通过图形接口,控制和维护计算机操作,例如windows环境的GUI。系统服务程序无需用户干预即可执行特定功能,可以手动启动,也可以配置为在启动操作系统时自动启动,在运行操作系统时在后台运行,可能会影响系统性能、响应能力、能效和安全性,例如任务调度程序、windows更新、信使服务、即插即用、索引服务等。工具类程序执行与管理系统资源相关的非常具体的任务,关注各种计算机组件的操作方式,常用实用程序是磁盘格式化实用程序、防病毒实用程序、备份实用程序、文件管理器、磁盘清理等。
操作系统提供由进程通过涉及环转换的机制访问的服务,以将控制转移到执行所需功能的内核。这有一个显著的缺点,即每个服务调用都涉及上下文切换的开销,其中保存处理器状态并执行保护域传输。然而,正如A High Performance Kernel-Less Operating System Architecture所发现的,在支持分段的处理器体系结构上,通过不执行环转换,可以在访问操作系统提供的服务时获得显著的性能提升。KLOS是基于这种设计构建的无内核操作系统,它的服务调用机制比当前广泛实施的服务或系统调用机制快了一个数量级,比传统陷阱/中断提高了4倍,比Intel SYSENTER/SYSEXIT快速系统调用模型提高了2倍。

KLOS的架构图。
18.1.5 操作系统高性能开发
常见的OS高性能开发技术包含:
-
在线和离线操作。为每个I/O设备编写了一个称为设备控制器的特殊子程序,一些I/O设备已配备用于在线操作(它们连接到处理器)或离线操作(它们由控制单元运行)。
-
缓冲。缓冲区是一个主存储器区域,用于在I/O传输期间保存数据。输入时,数据通过I/O通道放入缓冲区,当传输完成时,处理器可以访问数据。可以是单缓冲或双缓冲。
-
联机(同时进行外围设备在线操作)。联机将磁盘用作非常大的缓冲区,它很有用,因为设备访问不同速率的数据。缓冲区提供了一个等待站,当较慢的设备赶上时,数据可以在这里暂存。联机允许一个作业的计算和另一个作业I/O之间的重叠。
-
多道程序处理。在多道程序设计中,几个程序同时保存在主存中,CPU在它们之间切换,因此CPU总是有一个要执行的程序。操作系统开始从内存执行一个程序,如果该程序需要等待,例如I/O操作,操作系统将切换到另一个程序。多程序设计提高了CPU利用率。多道程序设计系统提供了一种环境,在这种环境中,各种系统资源得到了有效利用,但它们不提供用户与计算机系统的交互。优势是CPU利用率高,似乎许多程序几乎同时分配CPU。缺点是需要CPU调度,要在内存中容纳许多作业,需要内存管理。
-
并行系统。系统中的处理器上有2个及以上,这些处理器共享计算机总线、时钟、内存和I/O设备。优点是提高吞吐量(以时间单位完成的程序数)。
-
分布式系统。在几个物理处理器之间分配计算,涉及通过通信链路连接2个或多个独立的计算机系统。因此,每个处理器都有自己的OS和本地内存,处理器通过各种通信线路(如高速总线或电话线)相互通信。
![]()
分布式系统的优点:
- 资源共享,可以共享文件和打印机。
- 计算速度加快。可以对作业进行分区,以便每个处理器可以并发执行一部分任务(负载共享)。
- 可靠性。如果一个处理器出现故障,其余处理器仍然可以正常工作。
- 通信。如电子邮件、ftp。
-
个人计算机。专用于单个用户的计算机系统,PC操作系统既不是多用户系统,也不是多任务系统。PC操作系统的目标是最大限度地提高用户的便利性和响应能力,而不是最大限度地利用CPU和I/O。比如Microsoft Windows和Apple Macintosh。
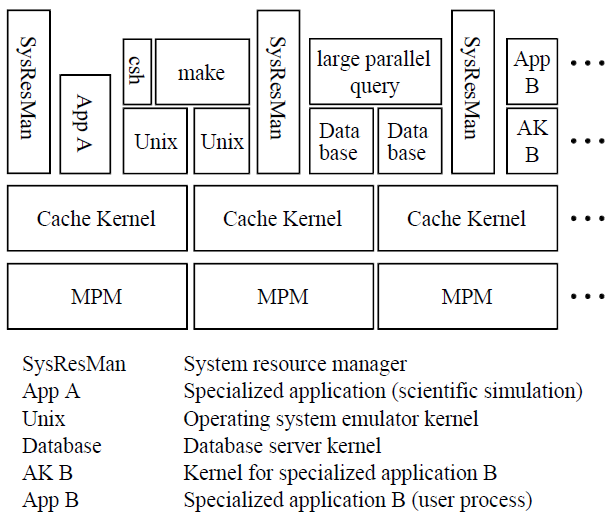
A caching model of operating system kernel functionality描述了操作系统功能的缓存模型,可以缓存内核缓存线程和地址空间等操作系统对象,就像传统硬件缓存内存数据一样。用户模式应用程序内核处理这些对象的加载和写回,实现特定于应用程序的管理策略和机制。在多处理器上实现缓存内核及其性能测量的经验表明,该缓存模型可以提供与传统单片操作系统相比具有竞争力的性能,同时还可以提供系统资源的应用程序级控制、更好的模块化、更好的可伸缩性、更小的大小以及故障控制的基础。
如下图所示,各种应用程序、服务器内核和操作系统仿真器可以在同一硬件上同时执行。一个称为系统资源管理器(SRM)的特殊应用程序内核,每个缓存内核/MPM复制一个,管理其他应用程序内核之间的资源共享,以便它们可以同时共享相同的硬件,而不会产生不合理的干扰。例如,它可以防止运行大型模拟的恶意应用程序内核中断提供在同一ParaDiGM配置上运行的分时服务的UNIX模拟器的执行。
软件架构一览。
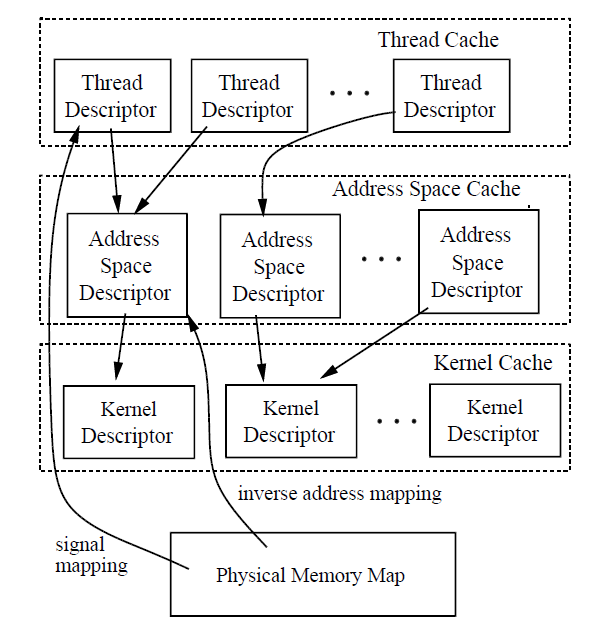
下图显示了Cache Kernel对象之间的依赖关系。图中的箭头表示从箭头尾部的对象到头部的对象的引用,因此是缓存依赖项。例如,物理内存映射中的信号映射引用一个线程,该线程引用一个引用其所属内核对象的地址空间。因此,当线程、地址空间或内核被卸载时,必须卸载信号映射。
缓存数据架构。
18.2 计算机硬件概览
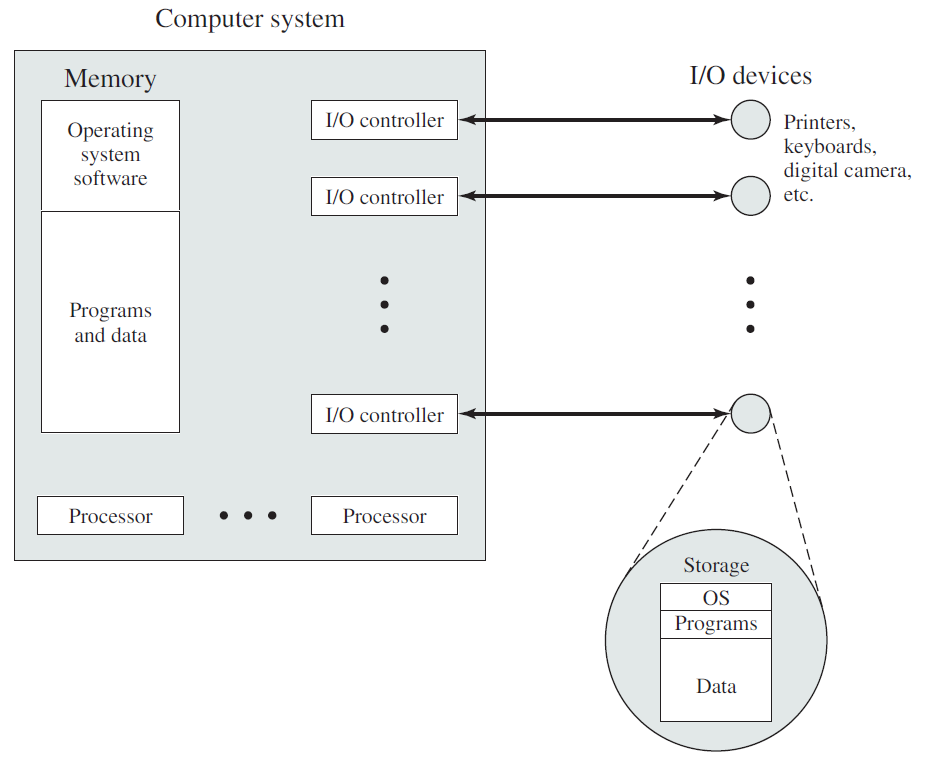
操作系统与运行它的计算机的硬件紧密相连,它扩展了计算机的指令集并管理其资源。一台简单的个人计算机可以抽象为类似于下图的模型,CPU、内存和I/O设备都通过系统总线连接,并通过它彼此通信。现代个人电脑的结构更复杂,涉及多条总线。
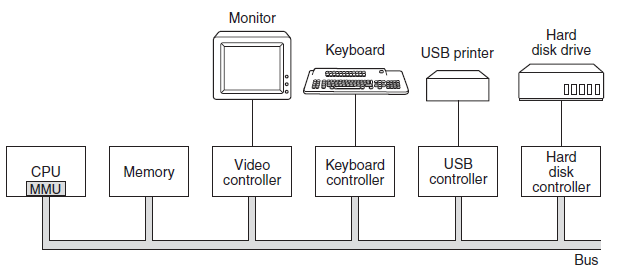
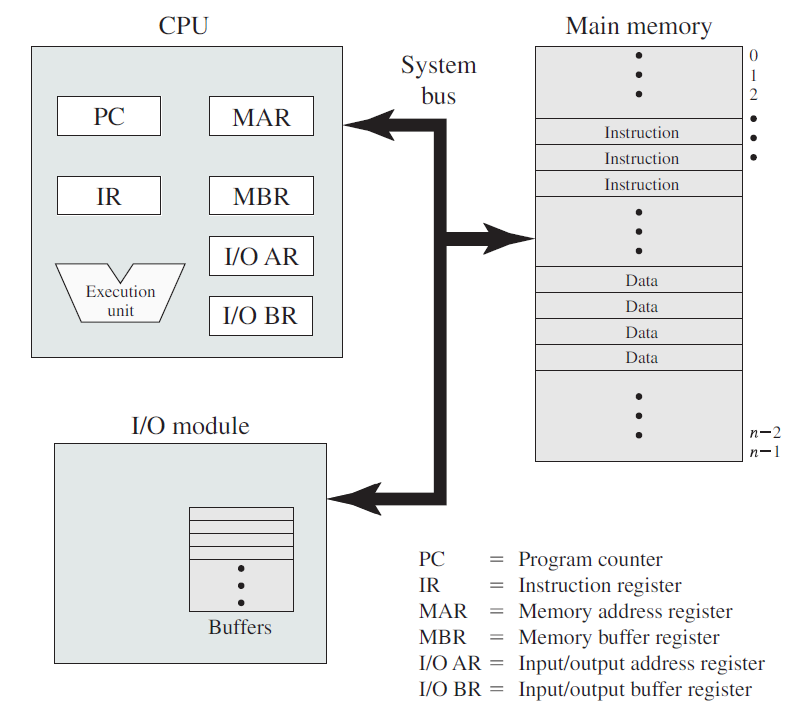
计算机硬件架构抽象图。
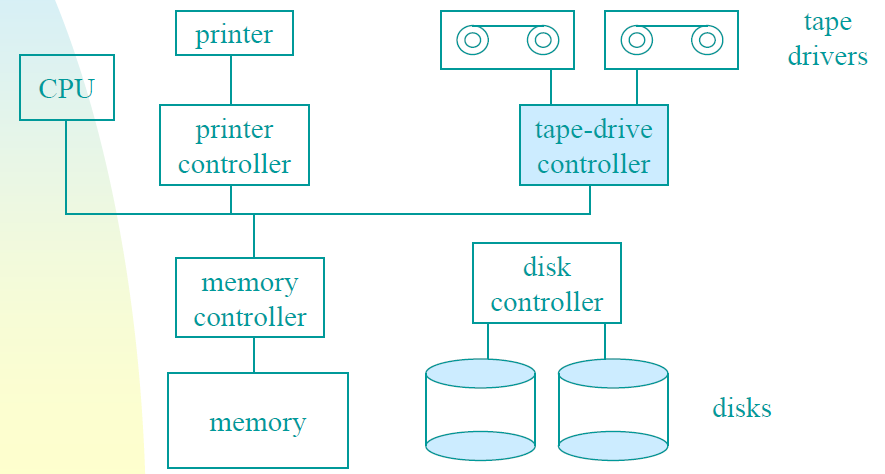

计算机硬件组成图。
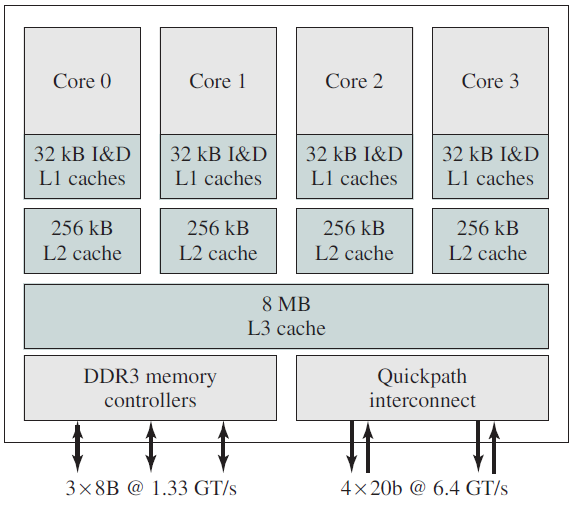
Intel Core i7结构图。
18.2.1 CPU
计算机的“大脑”是CPU,它从内存中获取指令并执行它们。每个CPU的基本周期是从内存中获取第一条指令,对其进行解码以确定其类型和操作数,然后执行,然后获取、解码和执行后续指令。循环重复,直到程序结束。以这种方式执行程序。
每个CPU都有一组特定的指令可以执行。因此,x86处理器无法执行ARM程序,而ARM处理器无法执行x86程序。因为访问内存以获取指令或数据字比执行指令需要更长的时间,所以所有CPU都包含一些寄存器来保存关键变量和临时结果。因此,指令集通常包含将字从内存加载到寄存器,并将字从寄存器存储到内存的指令。其他指令将来自寄存器、内存或两者的两个操作数组合成一个结果,例如添加两个字并将结果存储在寄存器或内存中。
除了用于保存变量和临时结果的通用寄存器外,大多数计算机还具有程序员可见的几个专用寄存器。其中之一是程序计数器,它包含要提取的下一条指令的内存地址。获取该指令后,程序计数器将更新为指向其后续指令。另一个寄存器是堆栈指针,它指向内存中当前堆栈的顶部。堆栈包含每个已进入但尚未退出的过程的一个帧。过程的堆栈框架保存那些不保存在寄存器中的输入参数、局部变量和临时变量。另一个寄存器是PSW(程序状态字)。该寄存器包含由比较指令、CPU优先级、模式(用户或内核)和各种其他控制位设置的条件代码位。用户程序通常可以读取整个PSW,但通常只能写入其部分字段。PSW在系统调用和I/O中起着重要作用。
操作系统必须完全了解所有寄存器。当对CPU进行多路复用时,操作系统通常会停止正在运行的程序以(重新)启动另一个程序。每次停止运行的程序时,操作系统必须保存所有寄存器,以便在程序稍后运行时恢复。
为了提高性能,CPU设计者早已放弃了一次获取、解码和执行一条指令的简单模型。许多现代CPU都具有同时执行多条指令的功能。例如,CPU可能有单独的提取、解码和执行单元,因此在执行指令n时,它也可能是解码指令n+1和提取指令n+2。这种组织称为管道,如下图(a)所示,用于三级管道。较长的管道是常见的。在大多数管道设计中,一旦指令被提取到管道中,就必须执行它,即使前面的指令是执行的条件分支。管道给编译器编写者和操作系统编写者带来了极大的麻烦,因为它们向他们暴露了底层机器的复杂性,并且他们必须处理它们。
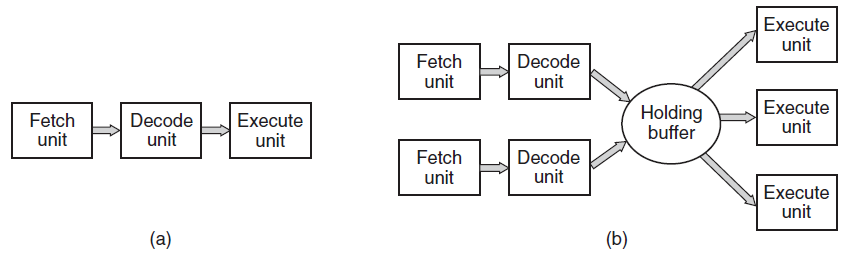
比管道设计更先进的是超标量(superscalar)CPU,如上图(b)所示。在这种设计中,有多个执行单元,例如一个用于整数运算,一个用于浮点运算,另一个用于布尔运算。两个或多个指令被同时获取、解码并转储到一个保持缓冲区,直到它们可以执行为止。一旦执行单元可用,它就会查看保持缓冲区中是否有它可以处理的指令,如果有,就从缓冲区中删除该指令并执行它。这种设计的一个含义是,程序指令经常乱序执行。在大多数情况下,要由硬件来确保产生的结果与顺序实现所产生的结果相同,但正如我们将看到的那样,操作系统上强加了令人讨厌的复杂性。
如前所述,除嵌入式系统中使用的非常简单的CPU外,大多数CPU都有两种模式,内核模式和用户模式。通常,PSW中的一个位控制模式。在内核模式下运行时,CPU可以执行其指令集中的每一条指令,并使用硬件的每一项功能。在台式机和服务器上,操作系统通常以内核模式运行,从而可以访问整个硬件。在大多数嵌入式系统上,一小部分以内核模式运行,其余操作系统以用户模式运行。
用户程序总是在用户模式下运行,该模式只允许执行指令的子集和访问功能的子集。通常,在用户模式下,所有涉及I/O和内存保护的指令都是不允许的。当然,也禁止将PSW模式位设置为进入内核模式。
要从操作系统获取服务,用户程序必须进行系统调用,该调用会进入内核并调用操作系统。TRAP指令从用户模式切换到内核模式,并启动操作系统。工作完成后,根据系统调用后的指令将控制权返回给用户程序。可以将其视为一种特殊的进程调用,它具有从用户模式切换到内核模式的附加属性。
值得注意的是,除了执行系统调用的指令之外,计算机还有陷阱(trap),大多数其它陷阱是由硬件警告异常情况(如试图除以0或浮点下溢)引起的。在所有情况下,操作系统都会得到控制,并且必须决定要做什么。有时程序必须因错误而终止,其他时候可以忽略错误(下溢数字可以设置为0)。最后,当程序事先宣布要处理某些类型的条件时,可以将控制权传递回程序,让它处理问题。
除了多线程之外,现在许多CPU芯片上都有四个、八个或更多完整的处理器或内核。下图中的多核芯片有效地携带了四个微型芯片,每个芯片都有自己的独立CPU,一些处理器(如Intel Xeon Phi和Tilera TilePro)已经在单个芯片上运行了60多核。使用这种多核芯片肯定需要多处理器操作系统。
顺便说一句,就绝对数量而言,没有什么能比得上现代GPU(图形处理单元),GPU是一个拥有数千个微内核的处理器,它们对于许多并行完成的小计算非常有用,比如在图形应用程序中渲染多边形。他们不太擅长连续任务,也很难编程。虽然GPU对操作系统很有用(例如,加密或处理网络流量),但操作系统本身不太可能在GPU上运行。
(a) 具有共享二级缓存的四核芯片。(b) 具有独立二级缓存的四核芯片。
18.2.2 内存
任何计算机的第二个主要部件是内存。理想情况下,内存应该非常快(比执行指令快,这样CPU就不会被内存占用),非常大且非常便宜。目前没有任何技术能够满足所有这些目标,因此采取了不同的方法。内存系统被构造为一个层次结构,如下图所示。与低层相比,顶层具有更高的速度、更小的容量和更高的每比特成本,通常是10亿或更多倍。
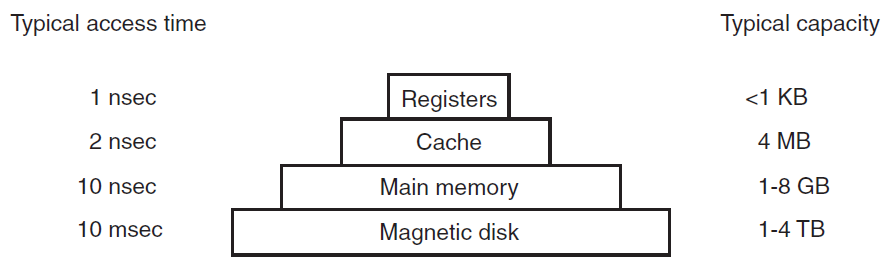
内存层级架构和速度示意图。
顶层由CPU内部的寄存器组成,它们由与CPU相同的材料制成,因此与CPU一样快,因此,访问它们没有任何延误。它们的可用存储容量通常是32位CPU上的32×32位,64位CPU上为64×64位,两种情况下都小于1 KB。程序必须在软件中自行管理寄存器(即决定在其中保存什么)。
高速缓存主要由硬件控制。主内存被划分为缓存行,通常为64字节,缓存线0中的地址为0到63,缓存线1中的地址是64到127,依此类推。最常用的缓存行保存在CPU内部或非常靠近CPU的高速缓存中,当程序需要读取内存字时,缓存硬件会检查所需的行是否在缓存中。如果是,称为缓存命中,则请求从缓存中得到满足,并且没有内存请求通过总线发送到主内存。缓存命中通常需要大约两个时钟周期,缓存未命中必须转移到内存中,会导致大量时间损失。由于高速缓存的成本较高,其大小受到限制,有些机器有两级甚至三级缓存,每级缓存都比前一级缓存更慢、更大。
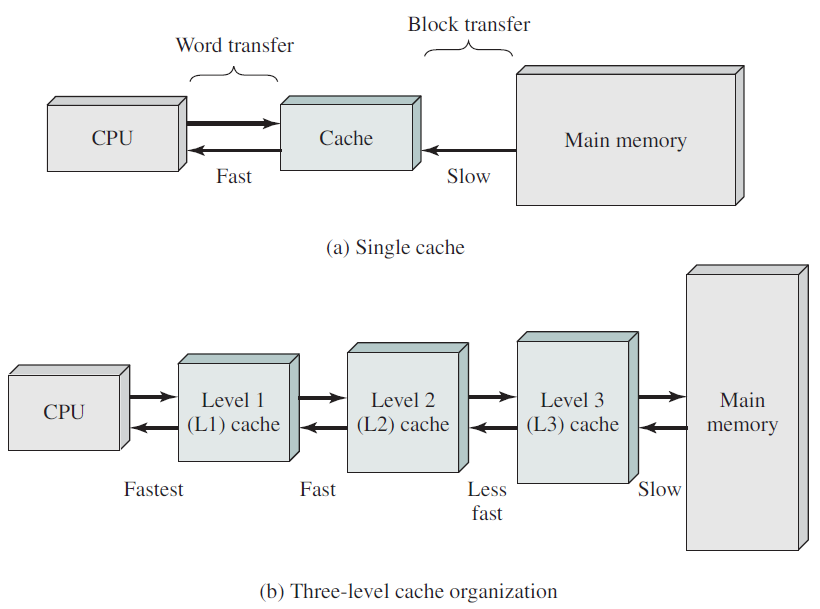
缓存和内存结构。
缓存在计算机科学的许多领域都扮演着重要角色,不仅仅是缓存RAM行。每当一个资源可以划分为多个部分时,其中一些部分的使用量比其他部分大得多,缓存通常用于提高性能。操作系统一直在使用它。例如,大多数操作系统将频繁使用的文件(片段)保存在主内存中,以避免重复从磁盘获取它们。类似地,转换长路径名的结果如下:
/home/ast/projects/minix3/src/kernel/clock.c
可以缓存到文件所在的磁盘地址,以避免重复查找。最后,当网页(URL)的地址转换为网络地址(IP地址)时,可以缓存结果以供将来使用。还有许多其他用途。在任何缓存系统中,很快就会出现几个问题,包括:
1、何时将新项目放入缓存。
2、将新项目放入哪个缓存行。
3、需要插槽时要从缓存中删除的项。
4、将新收回的项目放在较大内存中的何处。
并非每个问题都与每个缓存情况相关。对于CPU缓存中的主内存缓存行,通常在每次缓存未命中时都会输入一个新项。要使用的缓存行通常是通过使用引用的内存地址的一些高位来计算的。例如,对于4096条64字节和32位地址的缓存行,可以使用位6到17来指定缓存行,其中位0到5是缓存行内的字节。在这种情况下,要删除的项与新数据进入的项相同,但在其他系统中可能不是。最后,当缓存行被重写到主内存时(如果缓存行在被缓存后已被修改),内存中要重写它的位置是由所讨论的地址唯一确定的。
缓存是一个好主意,现代CPU有两个缓存。第一级缓存或L1缓存始终位于CPU内部,通常将解码的指令送入CPU的执行引擎。大多数芯片都有第二个L1缓存,用于存储大量使用的数据字,一级缓存通常每个为16 KB。此外,通常还有一个称为L2缓存的第二个缓存,它保存了几兆字节的最近使用的内存字。一级缓存和二级缓存的区别在于定时,对一级缓存的访问不会有任何延迟,而对二级缓存的存取会延迟一个或两个时钟周期。
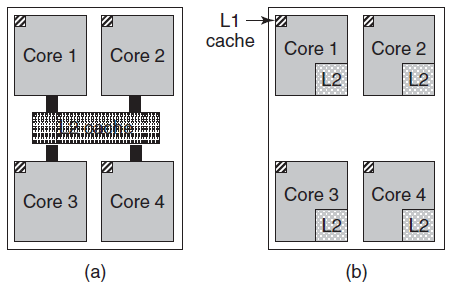
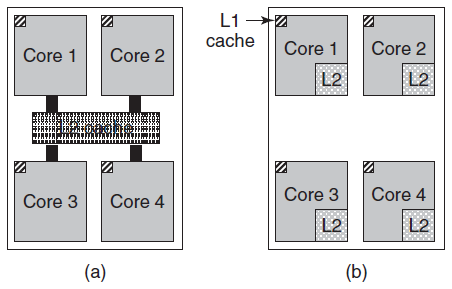
在多核芯片上,设计者必须决定缓存的位置。在下图(a),所有核心共享一个二级缓存。这种方法用于Intel多核芯片。相反,在下图(b)中,每个内核都有自己的二级缓存,AMD采用了这种方法。每种策略都有其优缺点,例如,Intel共享的二级缓存需要更复杂的缓存控制器,但AMD方法使保持二级缓存一致性更加困难。
在上上图的层次结构中,主内存紧随其后,是内存系统的主力,通常称为RAM(随机存取存储器),更早之前称之为磁芯存储器,因为20世纪50年代和60年代的计算机使用微小的可磁化铁氧体磁芯作为主存储器,所有无法从缓存中满足的CPU请求都会转到主内存。
除了主存储器之外,许多计算机还有少量非易失性随机存取存储器。与RAM不同,非易失性存储器在电源关闭时不会丢失其内容。ROM(只读存储器)是在工厂编程的,以后不能更改。它既快又便宜,在一些计算机上,用于启动计算机的引导加载程序包含在ROM中。此外,一些I/O卡附带ROM,用于处理低级设备控制。
EEPROM(电可擦除PROM)和闪存也是非易失性的,但与ROM相反,它们可以擦除和重写。然而,写它们比写RAM需要更多数量级的时间,因此它们的使用方式与ROM相同,只是有了一个额外的功能,即现在可以通过在现场重写它们来纠正程序中的错误。
闪存也常用作便携式电子设备的存储介质,在数码相机中用作胶片,在便携式音乐播放器中用作磁盘,仅举两个用途。闪存的速度介于RAM和磁盘之间。此外,与磁盘内存不同,如果擦除次数太多,它就会磨损。
另一种存储器是CMOS,它是易失性的。许多计算机使用CMOS存储器来保存当前时间和日期,CMOS存储器和增加时间的时钟电路由一个小电池供电,因此即使拔下电脑插头,时间也能正确更新。CMOS存储器还可以保存配置参数,例如从哪个磁盘启动。之所以使用CMOS,是因为它耗电很少,以至于原厂安装的电池通常可以使用几年。然而,当它开始出现故障时,计算机可能会出现阿尔茨海默病,忘记它多年来知道的事情,比如从哪个硬盘启动。
18.2.3 磁盘
磁盘存储每比特比RAM便宜两个数量级,通常也要大两个数量级别,唯一的问题是随机访问数据的时间慢了近三个数量级,原因是磁盘是一种机械装置,如下图所示。
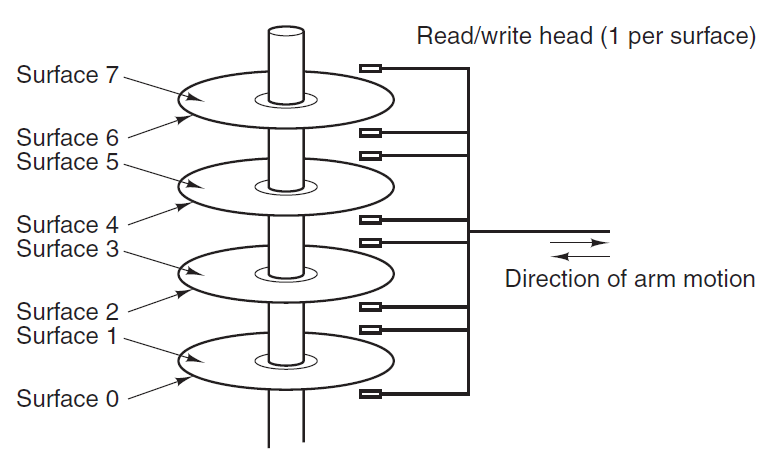
磁盘由一个或多个旋转速度为5400、7200、10800 RPM或以上的金属盘组成。一个机械臂从角落绕着盘片旋转,类似于老式33-RPM留声机上播放乙烯基唱片的拾取臂,信息以一系列同心圆写入磁盘。在任何给定的手臂位置,每个头部都可以读取一个称为轨道的环形区域,给定手臂位置的所有轨道一起构成一个圆柱体。
每个磁道被划分为若干扇区,通常每个扇区512字节。在现代磁盘上,外圆柱体包含的扇区比内圆柱体多。将臂从一个圆柱体移动到另一个圆柱体大约需要1毫秒。根据驱动器的不同,将其移动到随机圆柱体通常需要5到10毫秒。一旦臂位于正确的轨道上,驱动器必须等待所需扇区在磁头下旋转,根据驱动器的RPM,额外延迟5毫秒到10毫秒。一旦扇区位于磁头之下,低端磁盘的读取或写入速度为50 MB/秒,而高速磁盘的读取和写入速度为160 MB/秒。
有时,我们会听到人们谈论实际上根本不是磁盘的磁盘,如SSD(固态磁盘)。SSD没有移动部件,不包含磁盘形状的盘片,并将数据存储在(闪存)内存中。它们与磁盘相似的唯一方式是,存储了大量数据,这些数据在断电时不会丢失。
许多计算机支持一种称为虚拟内存的方案,该方案通过将程序放在磁盘上并将主内存用作执行最频繁的部分的缓存,使运行大于物理内存的程序成为可能。此方案需要动态重新映射内存地址,以将程序生成的地址转换为字所在的RAM中的物理地址。此映射由CPU的一部分MMU(内存管理单元)完成。
缓存和MMU的存在会对性能产生重大影响。在多道程序设计系统中,当从一个程序切换到另一个程序(有时称为上下文切换)时,可能需要从缓存中清除所有修改过的块,并更改MMU中的映射寄存器。这两种操作昂贵很大,应该被开发者注意并规避。
18.2.4 I/O设备
IO存储设备根据速度和介质,有着以下的层级关系:
Linux中的网络分层如下:

CPU和内存不是操作系统必须管理的唯一资源,I/O设备还与操作系统进行大量交互,通常由两部分组成:控制器和设备本身。
控制器是物理控制设备的一个或一组芯片,接受来自操作系统的命令,例如从设备读取数据,并执行这些命令。在许多情况下,设备的实际控制是复杂和详细的,因此控制器的工作是为操作系统提供一个更简单(但仍然非常复杂)的接口。例如,磁盘控制器可能会接受从磁盘2读取扇区11206的命令。然后,控制器必须将此线性扇区编号转换为圆柱体、扇区和磁头。由于外部圆柱体的扇区比内部圆柱体的多,并且一些坏扇区已重新映射到其他扇区,因此这种转换可能会变得复杂。然后,控制器必须确定磁盘臂在哪个圆柱体上,并向其发出命令,以移入或移出所需数量的圆柱体。它必须等到正确的扇区在磁头下旋转,然后开始读取和存储从驱动器上下来的位,删除前导码并计算校验和。最后,它必须将输入的位组合成单词并存储在内存中。为了完成所有这些工作,控制器通常包含小型嵌入式计算机,这些计算机被编程来完成它们的工作。
另一部分是实际设备本身。设备有相当简单的接口,既是因为它们不能做很多事情,也是为了使它们成为标准。例如,需要后者,以便任何SATA磁盘控制器都可以处理任何SATA盘。SATA代表串行ATA,ATA代表AT附件,是围绕当时功能极为强大的6-MHz 80286处理器而构建的。SATA目前是许多计算机上的标准磁盘类型。由于实际的设备接口隐藏在控制器后面,操作系统看到的只是控制器的接口,可能与设备的接口有很大的不同。
因为每种类型的控制器都不同,所以需要不同的软件来控制每种控制器,与控制器对话、发出命令并接受响应的软件称为设备驱动程序,每个控制器制造商必须为其支持的每个操作系统提供一个驱动程序。例如扫描仪可能附带OS X、Windows 7、Windows 8和Linux的驱动程序。
要使用该驱动程序,必须将其放入操作系统中,以便它可以在内核模式下运行。驱动程序实际上可以在内核外运行,现在像Linux和Windows这样的操作系统确实提供了一些支持,绝大多数驱动程序仍在内核边界以下运行。目前只有极少数系统(如MINIX 3)在用户空间中运行所有驱动程序,必须允许用户空间中的驱动程序以受控方式访问设备,但并不简单。
有三种方法可以将驱动程序放入内核。第一种方法是用新的驱动程序重新链接内核,然后重新启动系统,例如许多较旧的UNIX系统。第二种方法是在操作系统文件中输入一个条目,告诉它需要驱动程序,然后重新启动系统。在引导时,操作系统会找到所需的驱动程序并加载它们,如Windows。第三种方法是让操作系统能够在运行时接受新的驱动程序,并动态安装它们,而无需重新启动。这种方式过去很少见,但现在越来越普遍了。热插拔设备,如USB和IEEE 1394设备,始终需要动态加载的驱动程序。
每个控制器都有少量用于与其通信的寄存器。例如,最小磁盘控制器可能具有指定磁盘地址、内存地址、扇区计数和方向(读或写)的寄存器。为了激活控制器,驱动程序从操作系统获取命令,然后将其转换为适当的值,写入设备寄存器。所有设备寄存器的集合构成I/O端口空间。
在某些计算机上,设备寄存器被映射到操作系统的地址空间(它可以使用的地址),因此它们可以像普通内存字一样读取和写入。在这类计算机上,不需要特殊的I/O指令,用户程序可以通过不将这些内存地址放在其可及范围内而远离硬件(例如,通过使用基址和限制寄存器)。在其他计算机上,设备寄存器放在一个特殊的I/O端口空间中,每个寄存器都有一个端口地址。在这些机器上,内核模式下有特殊的IN和OUT指令,允许驱动程序读取和写入寄存器。前一种方案不需要特殊的I/O指令,但会占用一些地址空间。后者不使用地址空间,但需要特殊说明。这两种系统都被广泛使用。
输入和输出可以用三种不同的方式完成。在最简单的方法中,用户程序发出一个系统调用,然后内核将其转换为对相应驱动程序的过程调用。然后,驱动程序启动I/O并在一个紧密的循环中持续轮询设备,以查看是否完成了操作(通常有一些位表示设备仍在忙)。当I/O完成时,驱动程序将数据(如果有)放在需要的位置并返回。然后,操作系统将控制权返回给调用者。这种方法称为繁忙等待,其缺点是占用CPU轮询设备直到完成。
第二种方法是驱动程序启动设备,并在完成时要求其中断。此时,驱动返回。然后,如果需要,操作系统会阻止调用者,并寻找其他工作。当控制器检测到传输结束时,它会生成一个中断以完成信号。
中断在操作系统中非常重要,所以让我们更仔细地研究一下这个想法。在下图(a)中,我们看到I/O的三步过程。在步骤1中,驱动程序通过写入其设备寄存器来告诉控制器要做什么。然后,控制器启动设备。当控制器完成读取或写入它被要求传输的字节数时,它在步骤2中使用某些总线向中断控制器芯片发送信号。如果中断控制器准备接受中断(如果它忙于处理更高优先级的中断,则可能不会接受),它在CPU芯片上断言一个管脚,在步骤3中告诉它。在步骤4中,中断控制器将设备的编号放在总线上,这样CPU就可以读取它,并知道哪个设备刚刚完成(许多设备可能同时运行)。
一旦CPU决定接受中断,程序计数器和PSW通常被推到当前堆栈上,CPU切换到内核模式。设备编号可用作内存部分的索引,以查找该设备的中断处理程序的地址。这部分内存称为中断向量。一旦中断处理程序(中断设备驱动程序的一部分)启动,它将删除堆叠程序计数器和PSW并保存它们,然后查询设备以了解其状态。当处理程序全部完成时,它返回到以前运行的用户程序,返回到尚未执行的第一条指令。这些步骤如下图(b)所示。
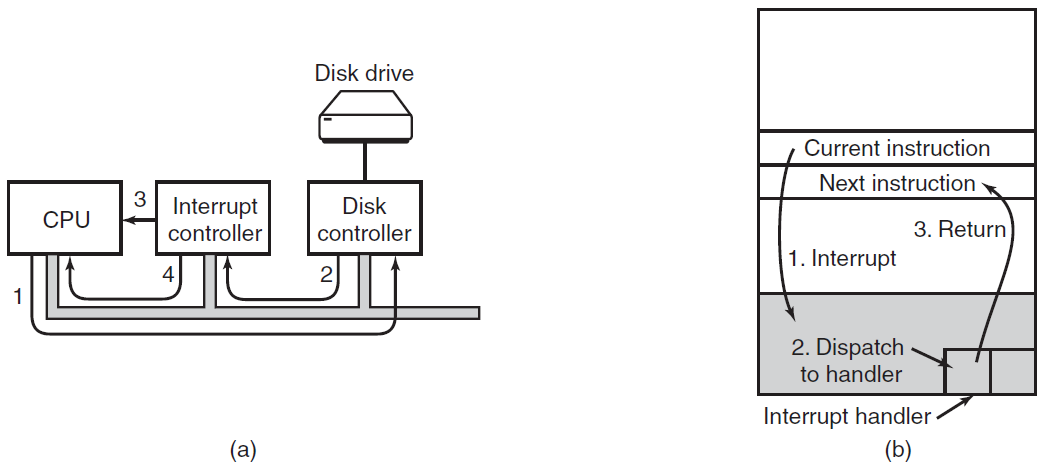
(a)启动I/O设备并获得中断的步骤。(b) 中断处理包括接受中断、运行中断处理程序和返回用户程序。
执行I/O的第三种方法使用特殊的硬件:DMA(直接内存访问)芯片,可以控制内存和某些控制器之间的比特流,而无需持续的CPU干预。CPU设置DMA芯片,告诉它要传输多少字节、涉及的设备和内存地址以及方向,然后让它执行。当DMA芯片完成时,它会触发中断,如上文所述进行处理。
例如,当另一个中断处理程序正在运行时,中断可能(而且经常)发生在非常不方便的时刻。因此,CPU有一种方法可以禁用中断,然后稍后重新启用它们。当中断被禁用时,任何完成的设备都会继续断言其中断信号,但CPU不会中断,直到再次启用中断。如果多个设备在中断被禁用时完成,中断控制器通常根据分配给每个设备的静态优先级决定首先让哪个设备通过。优先级最高的设备获胜并首先得到服务。其他必须等待。
18.2.5 总线
随着处理器和内存的速度越来越快,单个总线(当然还有IBM PC总线)处理所有流量的能力已经到了极限。为了更快的I/O设备和CPU到内存的通信量,添加了额外的总线。由于这一演变,一个大型x86系统目前看起来类似于下图。
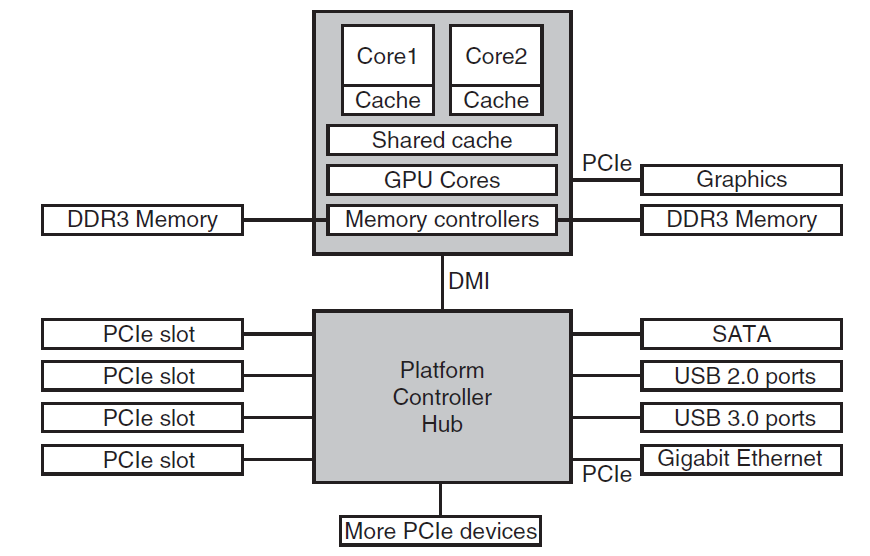
大型x86系统的结构。
该系统有许多总线(例如,缓存、内存、PCIe、PCI、USB、SATA和DMI),每个总线具有不同的传输速率和功能。操作系统必须了解所有这些信息,以便进行配置和管理。
主总线是PCIe(外围组件互连高速)总线,PCIe总线是Intel作为旧PCI总线的继承者而发明的,而旧PCI总线又是原始ISA(行业标准体系结构)总线的替代品。PCIe能够每秒传输数十Gb的数据,比其前代产品快得多,它的性质也非常不同。直到2004年创建,大多数总线都是并行共享的,共享总线架构意味着多个设备使用相同的线路传输数据。因此,当多个设备有数据要发送时,需要一个仲裁器(arbiter)来确定谁可以使用总线。相反,PCIe使用专用的点到点连接,传统PCI中使用的并行总线架构意味着可以通过多条导线发送每个字的数据。例如,在常规PCI总线中,单个32位数字通过32条并行线发送。与此相反,PCIe使用串行总线体系结构,并通过单个连接(称为通道)发送消息中的所有位,就像网络数据包一样。这种方式简单得多,因为不必确保所有32位都在同一时间到达目的地。仍然使用平行性,因为可以有多条平行通道(lane),例如可以使用32条通道并行传输32条消息。随着网卡和图形适配器等外围设备速度的快速增长,PCIe标准每3-5年升级一次。例如,16通道PCIe 2.0提供每秒64 Gb的速率,升级到PCIe 3.0将使速度提高一倍,而PCIe 4.0将使速度再次提高一倍。
与此同时,仍有许多适用于旧PCI标准的传统设备,如上图所示,这些设备连接到单独的集线器处理器。未来,当我们认为PCI不再仅仅是老式的,而是老式的时,所有PCI设备都有可能连接到另一个集线器,而该集线器又将它们连接到主集线器上,从而形成总线树。
在此配置中,CPU通过快速DDR3总线与内存通信,通过PCIe与外部图形设备通信,并通过DMI(直接媒体接口)总线上的集线器与所有其他设备通信。集线器依次连接所有其他设备,使用通用串行总线与USB设备通信,使用SATA总线与硬盘和DVD驱动器交互,使用PCIe传输以太网帧。
此外,每个核心都有一个专用缓存和一个更大的缓存,在它们之间共享,每个缓存都引入另一条总线。
发明USB(通用串行总线)是为了将所有低速I/O设备(如键盘和鼠标)连接到计算机上。然而,对于以8-Mbps ISA作为第一台IBM PC的主总线而成长起来的一代人来说,将以5 Gbps“低速”运行的现代USB 3.0设备称为“低速”可能不是自然而然的。USB使用一个带有四到十一根线(取决于版本)的小连接器,其中一些线为USB设备供电或接地。USB是一种集中式总线,其中根设备每1毫秒轮询一次所有I/O设备,以查看它们是否有流量。USB 1.0可以处理12 Mbps的总负载,USB 2.0将速度提高到480 Mbps,USB 3.0最高不低于5 Gbps。任何USB设备都可以连接到计算机上,将立即运行,而无需重新启动计算机,这是USB设备之前所需的,让一代受挫的用户非常震惊。
SCSI(小型计算机系统接口)总线是一种高性能总线,用于快速磁盘、扫描仪和其他需要大量带宽的设备。如今,它们大多在服务器和工作站上,可以以高达640 MB/秒的速度运行。
要在上图所示的环境中工作,操作系统必须知道哪些外围设备连接到计算机并对其进行配置。这一要求促使英特尔和微软基于苹果Macintosh首次实现的类似概念,设计了一种称为即插即用的PC系统。在即插即用之前,每个I/O卡都有一个固定的中断请求级别和其I/O寄存器的固定地址。例如,键盘为中断1并使用I/O地址0x60至0x64,软盘控制器为中断6并使用I/O位置0x3F0至0x3F7,打印机为中断7并使用I/O位址0x378至0x37A,依此类推。
到目前为止,一切都很好。当用户购买了一张声卡和一张调制解调器卡,而这两张卡都碰巧使用了同一中断(如中断4)时,问题就出现了——会发生冲突,不能一起工作。解决方案是在每个I/O卡上包括DIP开关或跳线,并指示用户请将其设置为选择一个中断级别和I/O设备地址,该中断级别和输入/输出设备地址不会与用户系统中的任何其他地址冲突。不幸的是,极少人能做到,导致混乱。
即插即用所做的是让系统自动收集有关I/O设备的信息,集中分配中断级别和I/O地址,然后告诉每个卡的编号。这项工作与启动计算机密切相关,且不是简单的小事。
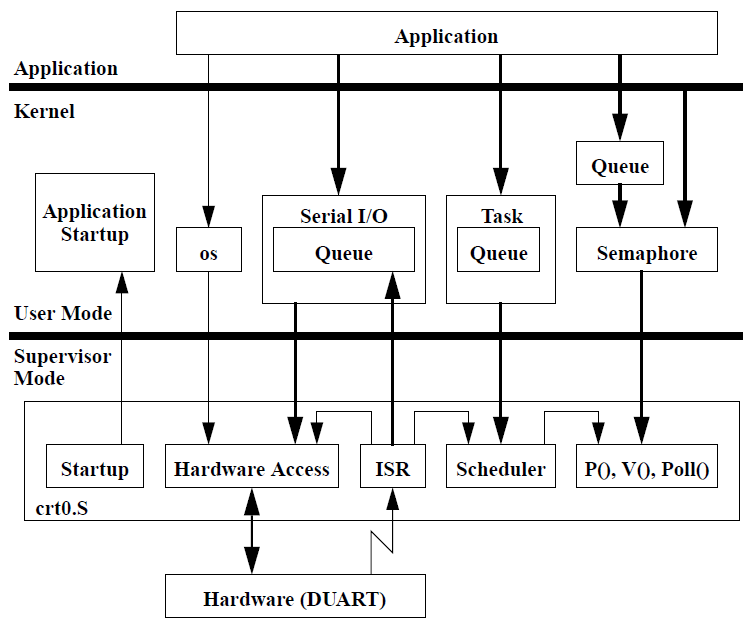
18.3 内核
下面两图显示了主流的内核总体架构。
内核架构1。
内核架构2。
图的底部显示了内核的一部分,该部分(以及从那里调用的函数)在监督者模式下执行。在监督器模式下执行的所有代码都是用汇编程序编写的,并包含在文件crt0.S中。crt0.S中的代码分为启动代码、访问硬件的函数、中断服务例程、任务开关(调度程序)和出于性能原因而用汇编程序写的信号量函数。
图的中间部分显示了在用户模式下执行的内核的其余部分。对crt0.S中代码的任何调用都需要更改为监控模式,即从中间到下部的每个箭头都与一个或多个TRAP指令相关,这些指令会导致监控模式的更改。类os包含一组带有TRAP指令的包装函数,使应用程序能够访问某些硬件部件。SerialIn和SerialOut类称为串行I/O,需要硬件访问,也可以从中断服务例程访问。Class Task包含与任务管理相关的任何内容,并使用内核的supervisor部分进行(显式)任务切换。任务切换也由中断服务例程引起。Semaphore类提供包装函数,使其成员函数的实现在用户模式下可用。内核内部使用了几个Queue类,并且应用程序也可以使用这些类;他们中的大多数使用Semaphore类。
通常,应用程序与内部内核接口无关,与内核相关的接口是在类os、SerialIn、SerialOut、Task、Queue和Semaphore中定义的接口。
18.3.1 内核概述
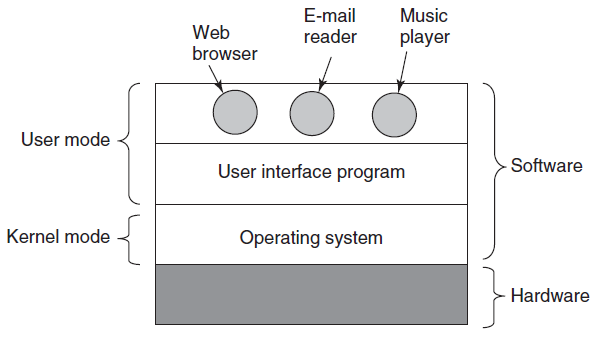
下图给出了内核的主要组件的简单概述。可以看到底部的硬件,硬件由芯片、电路板、磁盘、键盘、显示器和类似的物理对象组成。硬件之上是软件,大多数计算机有两种操作模式:内核模式和用户模式。操作系统是软件中最基本的部分,它以内核模式(也称为管理器模式)运行。在这种模式下,它可以完全访问所有硬件,并可以执行机器能够执行的任何指令。软件的其余部分以用户模式运行,在该模式下,只有机器指令的一个子集可用。特别是,那些影响机器控制或进行I/O输入/输出的指令“被禁止用于用户模式程序。本文反复讨论内核模式和用户模式之间的区别,它在操作系统的工作方式中起着至关重要的作用。
更详细的结构图如下:
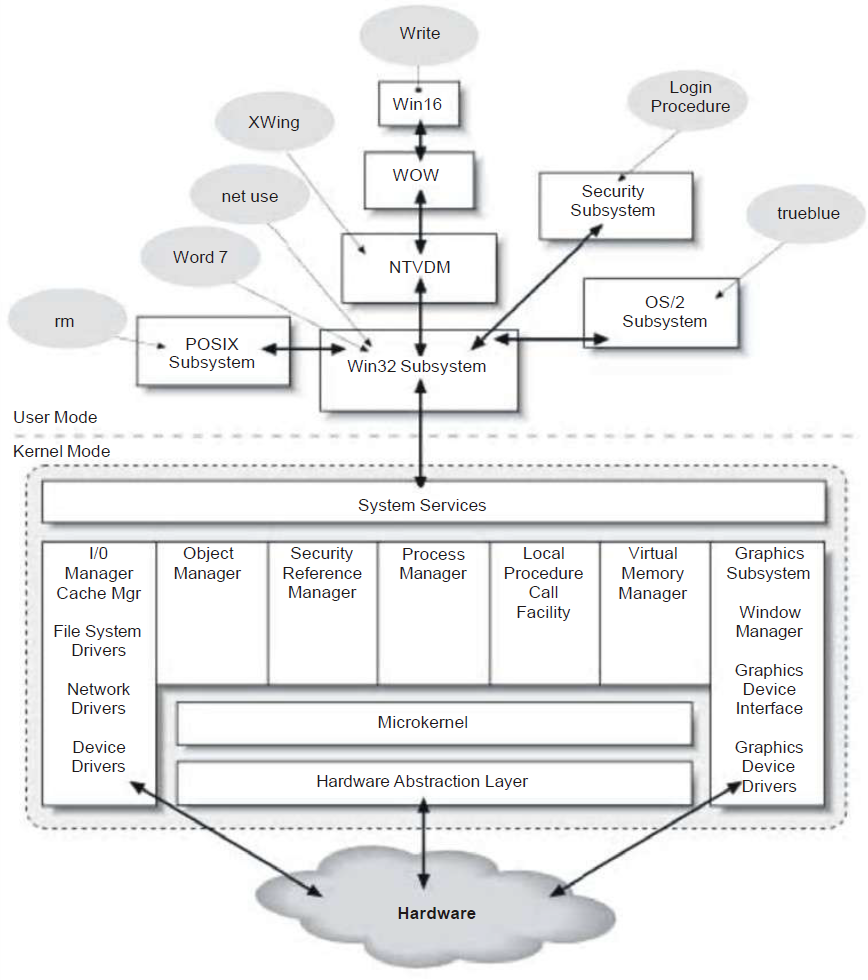
传统的Unix内核架构图如下:

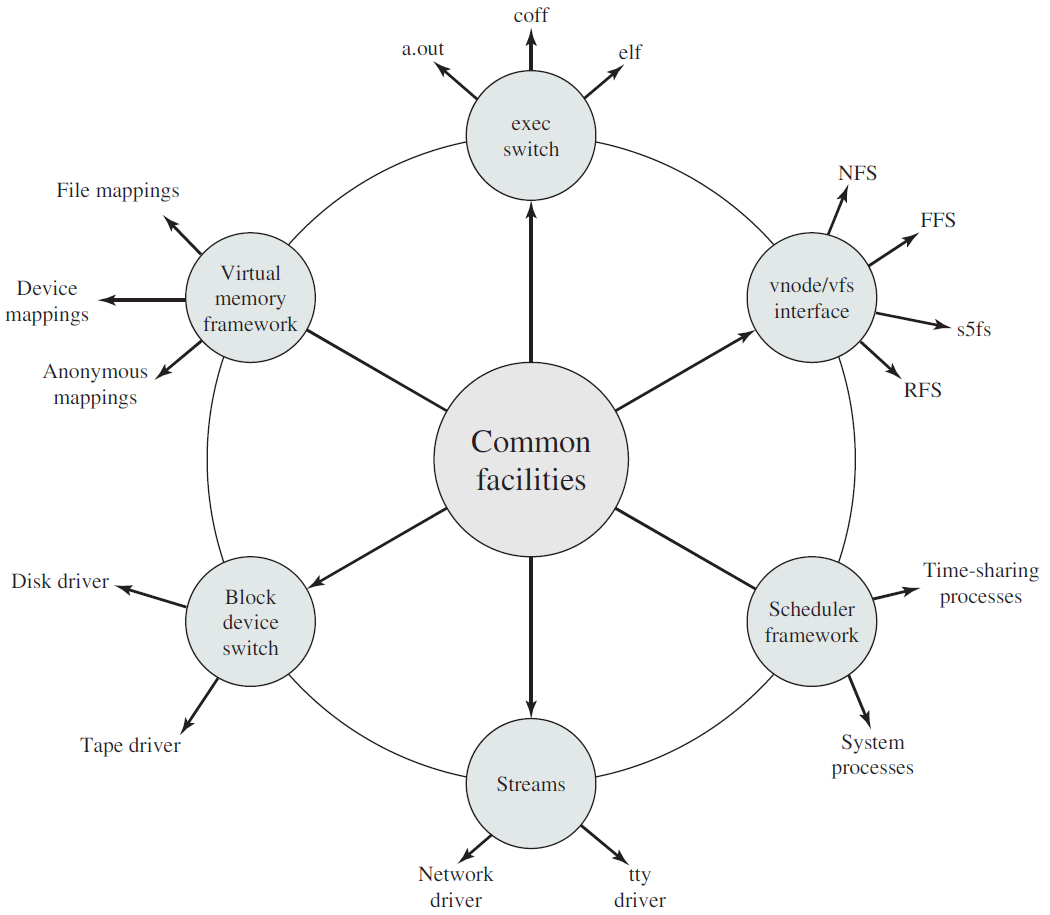
现代Unix内核已经进化成如下架构:
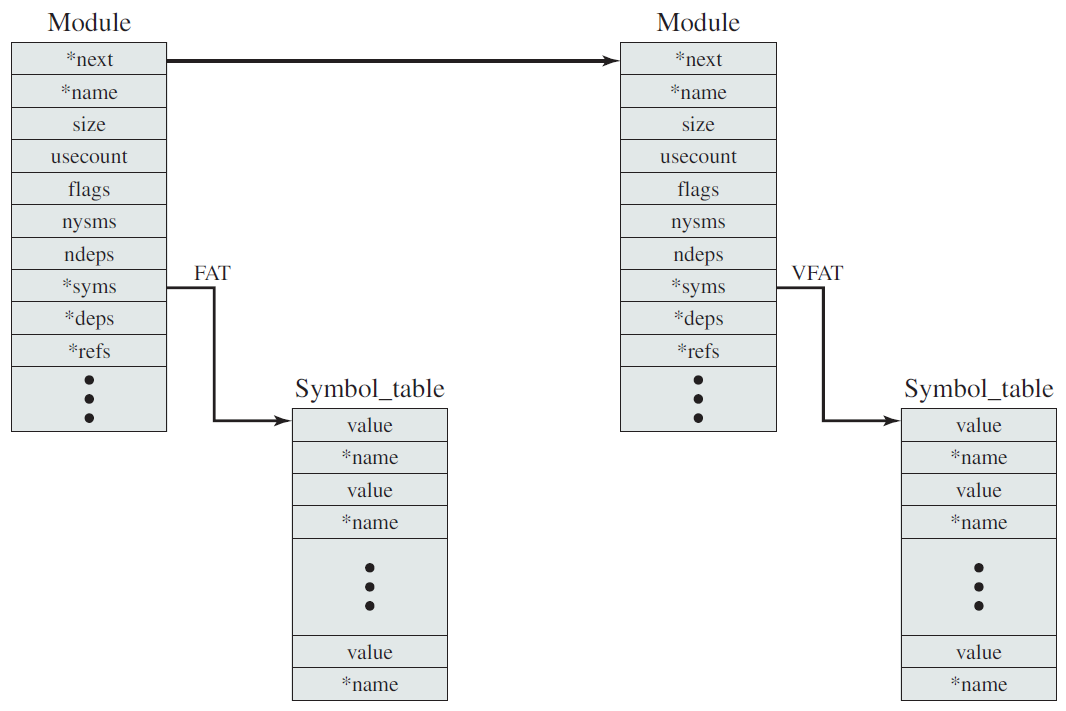
Linux内核模块列表样例如下:
Linux内核组件如下所示:
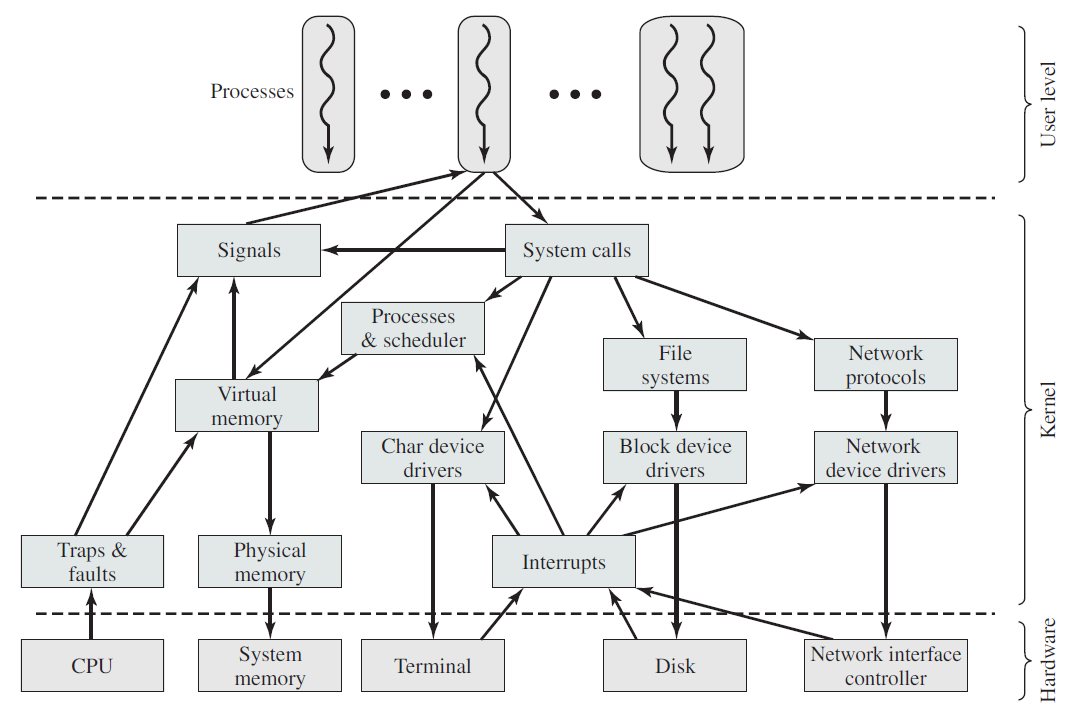
18.3.2 内核对象
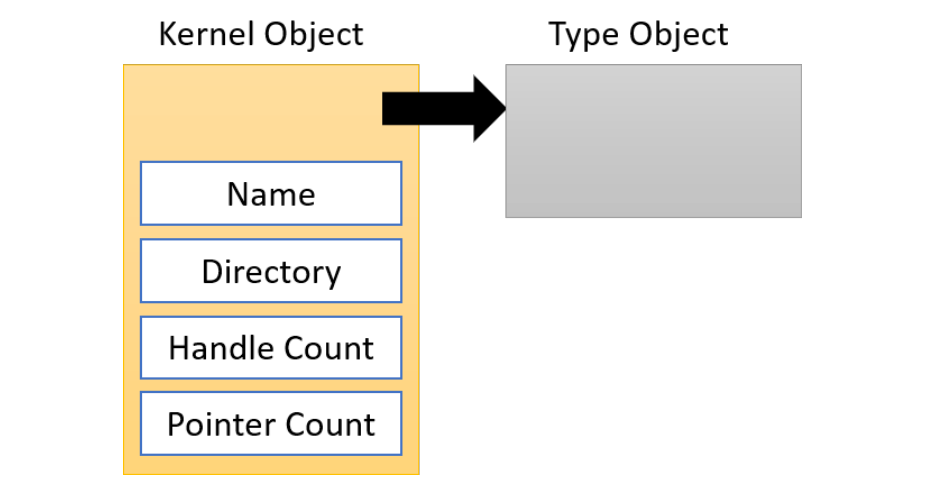
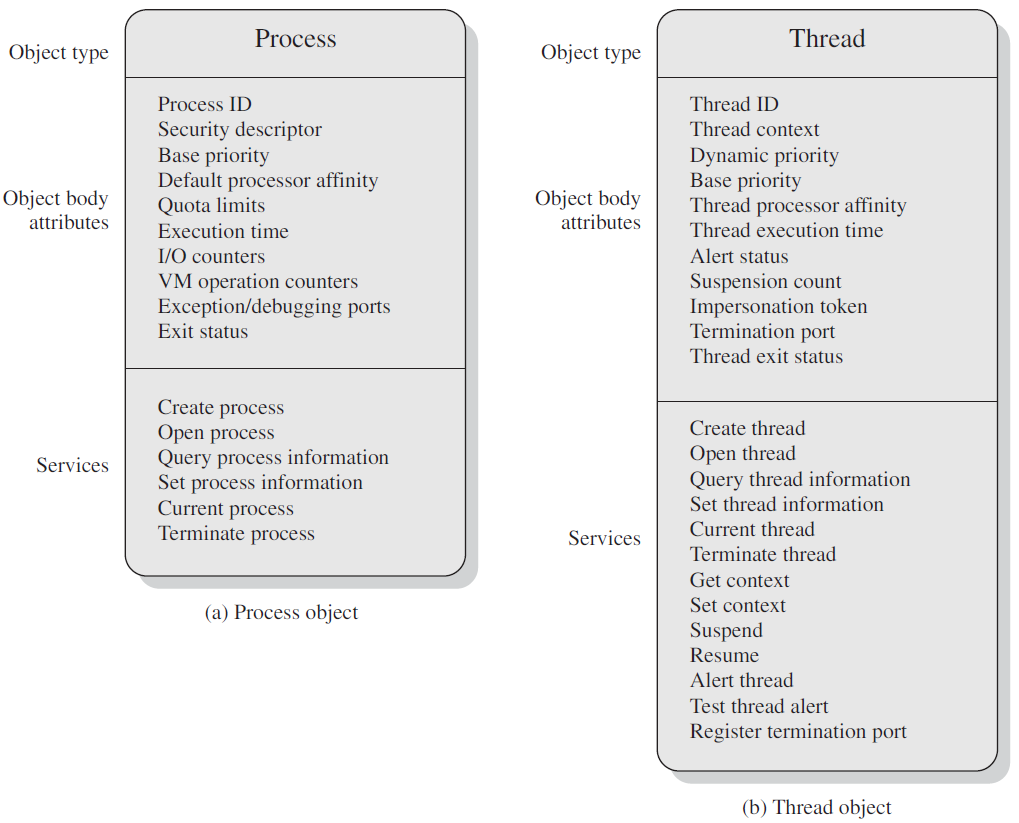
Windows内核公开各种类型的对象,供用户模式进程、内核本身和内核模式驱动程序使用。这些类型的实例是系统(内核)空间中的数据结构,当用户或内核模式代码请求时,由对象管理器(执行程序的一部分)创建和管理。内核对象使用了引用计数,因此只有当对象的最后一个引用被释放时,对象才会被销毁并从内存中释放。
Windows内核支持很多对象类型,可从Sysinternals运行WinObj工具,并找到ObjectTypes目录(下图)。可以根据其可见性和用途进行分类:
- 通过Windows API导出到用户模式的类型。例如:互斥、信号量、文件、进程、线程和计时器。
- 未导出到用户模式,但记录在Windows驱动程序工具包(WDK)中供设备驱动程序编写者使用的类型。例如设备、驱动程序和回调。
- 即使在WDK中也没有记录的类型(至少在编写时),仅由内核本身使用。例如分区、键控事件和核心消息传递。

内核对象的主要属性如下图所示:
某些类型的对象可以具有基于字符串的名称,这些名称可用于使用适当的打开函数按名称打开对象。注意,并非所有对象都有名称,例如进程和线程没有名称——它们有ID。这就是为什么OpenProcess和OpenThread函数需要进程/线程标识符(数字)而不是基于string的名称。
在用户模式代码中,如果不存在具有名称的对象,则调用具有名称的创建函数将创建具有该名称的对象;如果存在,则只打开现有对象。
提供给创建函数的名称不是对象的最终名称。在经典(桌面)进程中,它前面有\Sessions\x\BaseNamedObjects\其中x是调用方的会话ID。如果会话为零,则名称前面只加上\BaseNamedObjects\。如果调用方碰巧在AppContainer(通常是通用Windows平台进程)中运行,则前缀字符串更复杂,由唯一的AppContainerSID: \Sessions\x\AppContaineerNameObjects\组成。
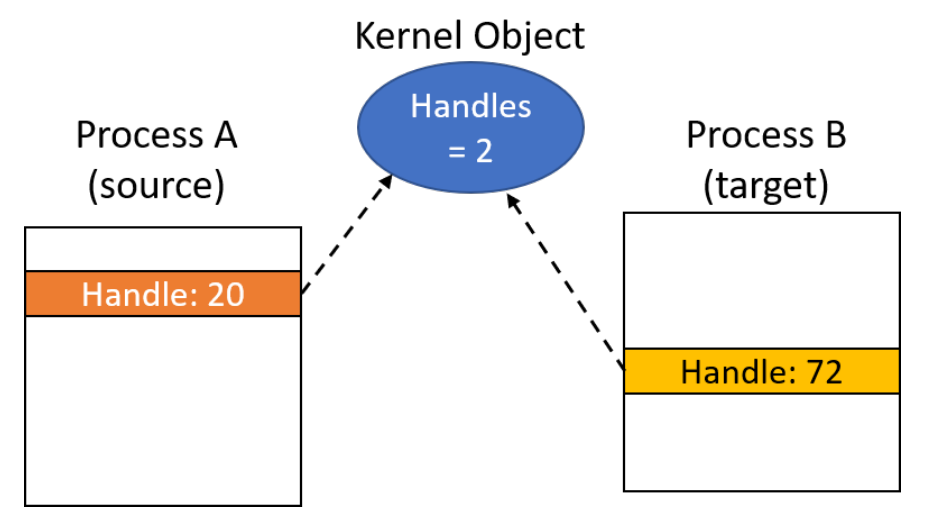
18.3.3 内核对象共享
内核对象的句柄是进程私有的,但在某些情况下,进程可能希望与另一个进程共享内核对象。这样的进程不能简单地将句柄的值传递给其他进程,因为在其他进程的句柄表中,句柄值可能指向其他对象或为空。显然,必须有某种机制来允许这种分享。事实上,有三种分享机制:
-
按名称共享。如果可用,是最简单的方法。“可用”表示所讨论的对象可以有名称,并且确实有名称。典型的场景是,协作进程(2个或更多)将使用相同的对象名调用相应的Create函数。进行调用的第一个进程将创建对象,其他进程的后续调用将为同一对象打开其他句柄。
-
通过句柄继承共享。通常是父进程创建子进程时,传入继承属性和数据而达成。
-
通过复制句柄共享。句柄复制没有固有的限制(除了安全性),几乎可以在任何内核对象上工作,无论是有命字的还是没有名字的,并且可以在任何时间点工作。然而,有一个缺陷,是实践中最困难的分享方式(后面会提及)。Windows通过调用
DuplicateHandle复制句柄。![]()
Windows复制句柄应用案例图示。
18.3.4 句柄
由于内核对象驻留在系统空间中,因此无法直接从用户模式访问它们。应用程序必须使用间接机制来访问内核对象,称为句柄(Handle)。句柄至少具有以下优点:
- 在未来的Windows版本中,对象类型数据结构的任何更改都不会影响任何客户端。
- 可通过安全访问检查控制对对象的访问。
- 句柄是进程私有的,因此在一个进程中拥有特定对象的句柄在另一个进程上下文中没有意义。
内核对象是引用计数的。对象管理器维护句柄计数和指针计数,其和是对象的总引用计数(直接指针可以从内核模式获得)。一旦不再需要用户模式客户端使用的对象,客户端代码应通过调用CloseHandle关闭用于访问该对象的句柄。之后句柄将无效,尝试通过关闭句柄访问对象将失败。在一般情况下,客户端不知道对象是否已被销毁。如果对象的引用降至零,则对象管理器将删除该对象。
句柄值是4的倍数,其中第一个有效句柄是4;零永远不是有效的句柄值,在64位系统上亦是如此。句柄间接指向内核空间中的一个小数据结构,该结构包含句柄的一些信息。下图描述了32位和64位系统的数据结构。

在32位系统上,该句柄条目的大小为8字节,在64位系统上为16字节(从技术上而言,12字节已足够,但为了对齐目的,会扩展为16字节)。每个条目包含以下成分:
- 指向实际对象的指针。由于低位用于标记,并通过地址对齐提高CPU访问时间,因此在32位系统上,对象的地址是8的倍数,在64位系统上是16的倍数。
- 访问掩码,指示可使用此手柄执行的操作。换句话说,访问掩码是句柄的力量。
- 三个标志:继承、关闭时保护和关闭时核验。
访问掩码是位掩码,其中每个“1”位表示可以使用该句柄执行的特定操作。当通过创建对象或打开现有对象创建句柄时,将设置访问掩码。如果创建了对象,则调用者通常具有对该对象的完全访问权。但是,如果对象被打开,调用方需要指定所需的访问掩码,它可能会得到,也可能不会得到。
某些句柄具有特殊值,不可关闭,被称为伪句柄(Pseudo Handles),尽管它们在需要时与任何其他句柄一样使用。在伪句柄上调用CloseHandle总是失败。
当不再需要句柄时,关闭句柄非常重要。如果应用程序未能正确执行此操作,则可能会出现“句柄泄漏”,即如果应用程序打开句柄但“忘记”关闭它们,则句柄的数量将无法控制地增长。帮助代码管理句柄而不忘记关闭它们的一种方法是使用C++实现一个众所周知的习惯用法,称为资源获取即初始化(Resource Acquisition is Initialization,RAII)。其思想是对包装在类型中的句柄使用析构函数,以确保在包装对象被销毁时关闭句柄。下面是一个简单的句柄RAII封装器:
struct Handle
{
explicit Handle(HANDLE h = nullptr)
:_h(h) // 初始化
{}
// 析构函数关闭句柄。
~Handle() { Close(); }
// 删除拷贝构造和拷贝赋值
Handle(const Handle&) = delete;
Handle& operator=(const Handle&) = delete;
// 允许移动(所有权转移)
Handle(Handle&& other) : _h(other._h)
{
other._h = nullptr;
}
Handle& operator=(Handle&& other)
{
if (this != &other)
{
Close();
_h = other._h;
other._h = nullptr;
}
return *this;
}
operator bool() const
{
return _h != nullptr && _h != INVALID_HANDLE_VALUE;
}
HANDLE Get() const
{
return _h;
}
void Close()
{
if (_h)
{
::CloseHandle(_h);
_h = nullptr;
}
}
private:
HANDLE _h;
};
18.3.5 其它内核对象
Windows中还有其他常用内核对象,即用户对象和GDI对象。以下是这些对象的简要描述以及这些对象的句柄。
- 任务管理器。可以通过添加“用户对象”和“GDI对象”列来显示每个进程的此类对象的数量。
- 用户对象。用户对象是窗口(HWND)、菜单(HNU)和挂钩(HHOOK)。这些对象的句柄具有以下属性:
- 无引用计数。第一个销毁用户对象的调用方——它已经消失了。
- 句柄值的范围在窗口工作站(Window Station)下。窗口工作站包含剪贴板、桌面和原子表。例如,意味着这些对象的句柄可以在共享桌面的所有应用程序之间自由传递。
- GDI对象。图形设备接口(GDI)是Windows中的原始图形API,即使有更丰富和更好的API(例如Direct2D)。例如设备上下文(HDC)、笔(HPEN)、画笔(HBRUSH)、位图(HBITMAP)等。以下是它们的属性:
- 无引用计数。
- 句柄仅在创建过程中有效。
- 不能在进程之间共享。
18.3.6 中断
任何操作系统内核的核心职责是管理连接到机器硬盘驱动器和蓝光光盘、键盘和鼠标、3D处理器和无线收音机的硬件。为了履行这一职责,内核需要与机器的各个设备进行通信。考虑到处理器的速度可能比它们与之对话的硬件快几个数量级,内核发出请求并等待明显较慢的硬件的响应是不理想的。相反,由于硬件的响应速度相对较慢,内核必须能够自由地去处理其他工作,只有在硬件实际完成工作之后才处理硬件。
处理器如何在不影响机器整体性能的情况下与硬件一起工作?这个问题的一个答案是轮询(polling),内核可以定期检查系统中硬件的状态并做出相应的响应。然而,轮询会产生开销,因为无论硬件是活动的还是就绪的,轮询都必须重复进行。更好的解决方案是提供一种机制,让硬件在需要注意时向内核发出信号,这种机制称为中断(interrupt)。在本节中,我们将讨论中断以及内核如何响应它们,并使用称为中断处理程序(interrupt handler)的特殊函数。
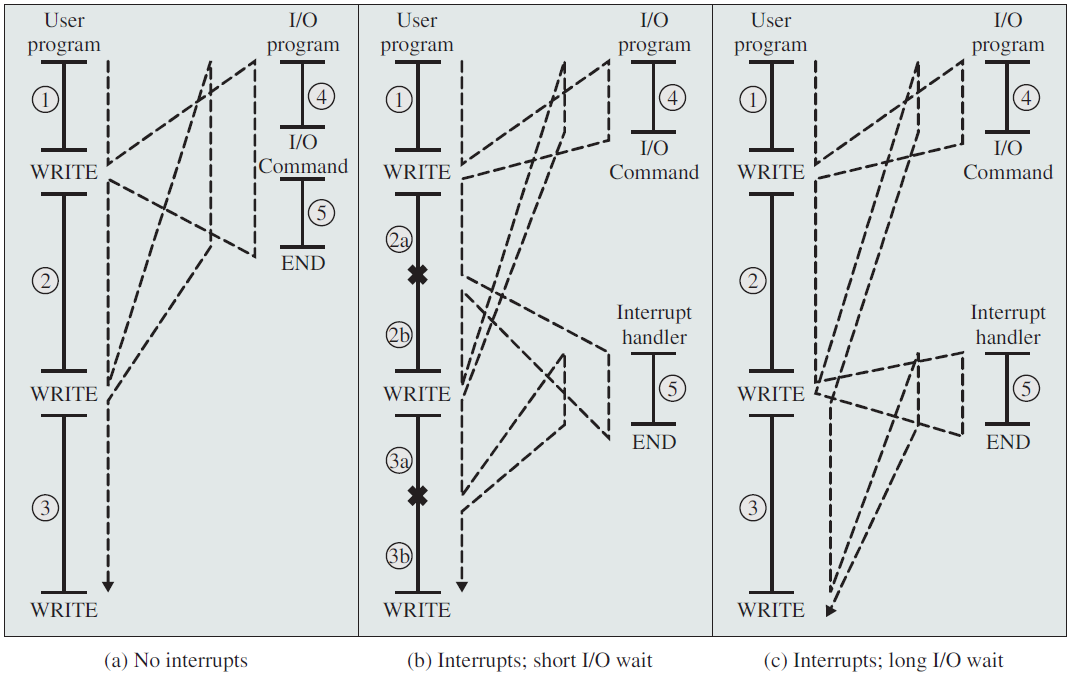
无中断和有中断的程序控制流程。
18.3.6.1 中断概述
中断使硬件能够向处理器发送信号,例如,当用键盘键入时,键盘控制器(管理键盘的硬件设备)向处理器发出电信号,以提醒操作系统新可用的按键,这些电信号就是中断。处理器接收中断并向操作系统发送信号以使操作系统能够响应新数据,硬件设备相对于处理器时钟异步地生成中断,它们可以在任何时间发生。因此,内核可以随时中断以处理中断。
中断是由来自硬件设备的电子信号物理产生的,并被引导到中断控制器的输入引脚,中断控制器是一个简单的多线程芯片,将多条中断线组合成一条到处理器的单线。在接收到中断时,中断控制器向处理器发送信号,处理器检测到该信号并中断其当前执行以处理该中断。然后,处理器可以通知操作系统发生了中断,操作系统可以适当地处理中断。
不同的设备可以通过与每个中断相关联的唯一值与不同的中断相关联,来自键盘的中断与来自硬盘的中断是不同的,使得操作系统能够区分中断并知道哪个硬件设备导致了哪个中断。反过来,操作系统可以使用相应的处理程序为每个中断提供服务。
这些中断值通常称为中断请求(interrupt request,IRQ)线(line)。每个IRQ行都分配了一个数值,例如,在经典PC上,IRQ 0是计时器中断,IRQ 1是键盘中断。然而,并非所有的中断号都是如此严格地定义的,例如,与PCI总线上的设备相关的中断通常是动态分配的。其他非PC架构对中断值具有类似的动态分配,重要的是,一个特定的中断与一个特定设备相关联,内核知道这一点。然后硬件发出中断以引起内核的注意:“嘿,我有新的按键在等待!读取并处理这些坏孩子!”
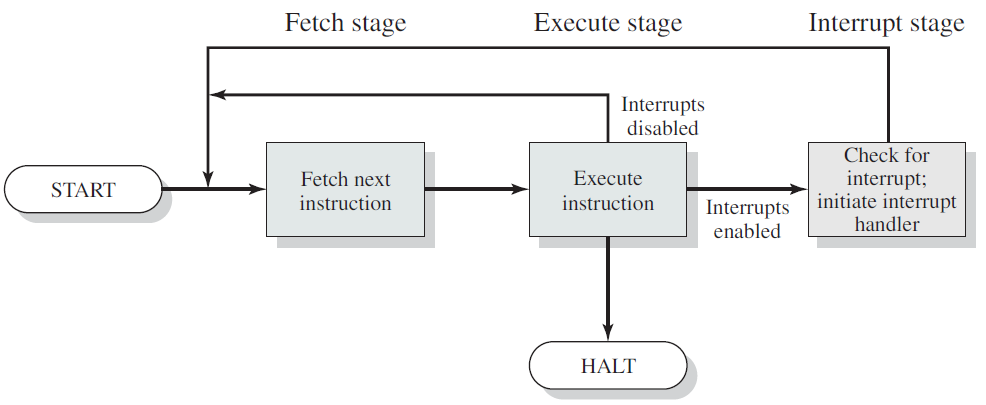
带中断的指令周期。
18.3.6.2 中断请求级别
每个硬件中断都与一个优先级相关联,称为中断请求级别(Interrupt Request Level,IRQL)(注意,不要与称为IRQ的中断物理线混淆),由HAL确定。每个处理器的上下文都有自己的IRQL,就像任何寄存器一样。IRQL可以由CPU硬件实现,也可以不由CPU硬件来实现,但本质上并不重要,IRQL应该像其他CPU寄存器一样对待。
基本规则是处理器执行具有最高IRQL的代码。例如,如果某个CPU的IRQL在某个时刻为零,并且出现了一个IRQL为5的中断,它将在当前线程的内核堆栈中保存其状态(上下文),将其IRQL提升到5,然后执行与该中断相关联的ISR。一旦ISR完成,IRQL将下降到其先前的级别,继续执行先前执行的代码,就像中断不存在一样。当ISR执行时,IRQL为5或更低的其他中断无法中断此处理器。另一方面,如果新中断的IRQL高于5,CPU将再次保存其状态,将IRQL提升到新级别,执行与第二个中断相关联的第二个ISR,完成后,将返回到IRQL 5,恢复其状态并继续执行原始ISR。本质上,提升IRQL会暂时阻止IRQL等于或低于IRQL的代码。中断发生时的基本事件序列如下图所示,下下图显示了中断嵌套的样子。
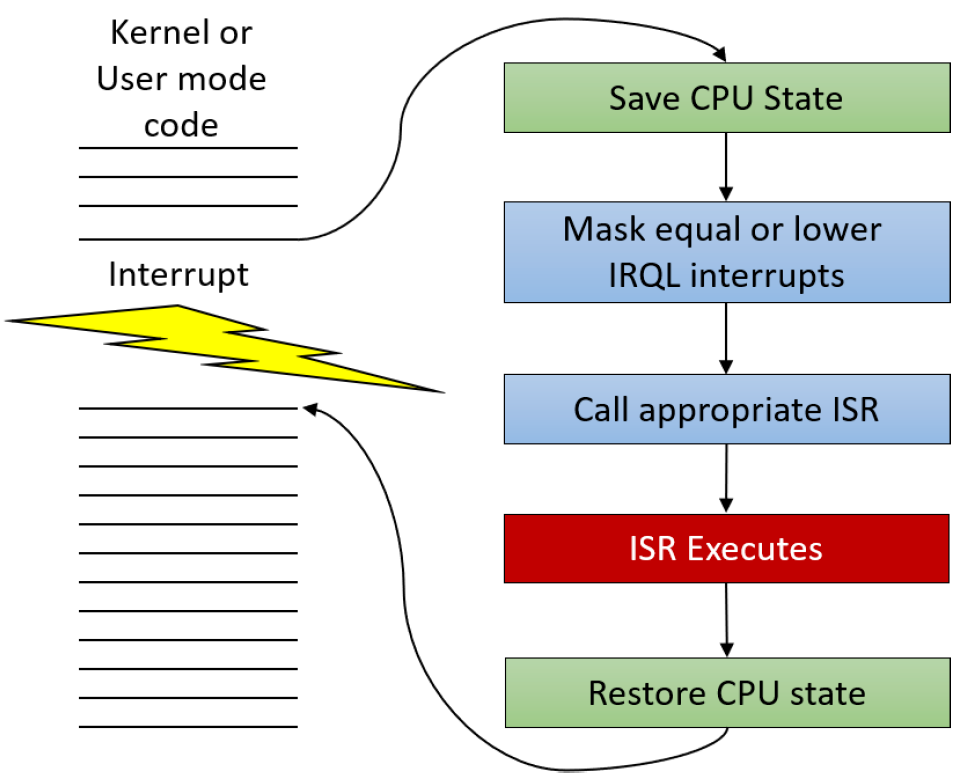
基本中断调度流程。
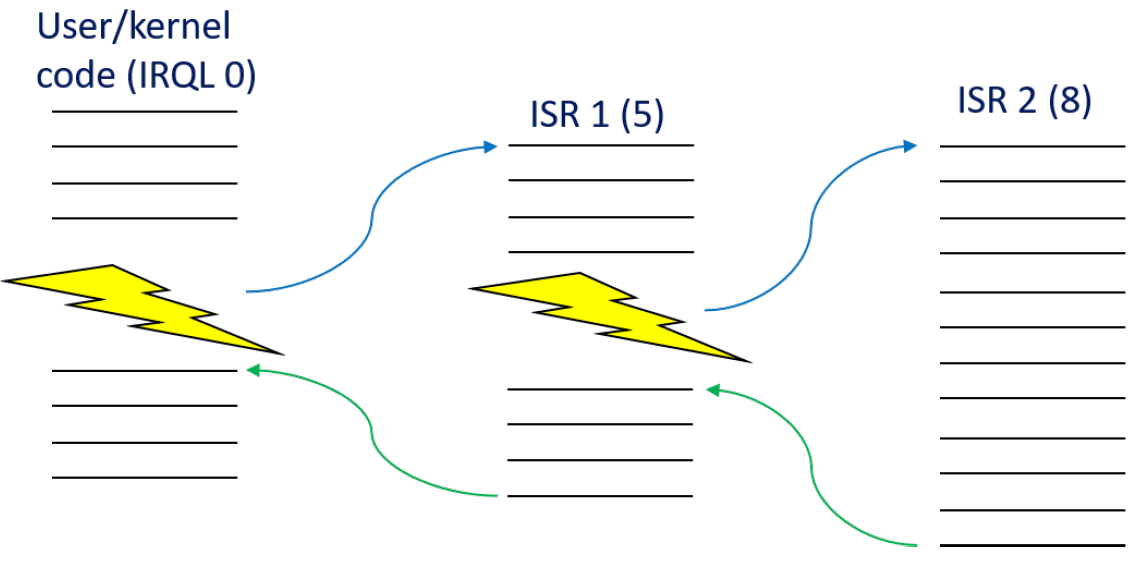
嵌套中断流程。
上两图所示场景的一个重要事实是,所有ISR的执行都是由最初被中断的同一线程完成的。Windows没有处理中断的特殊线程,它们由当时在中断的处理器上运行的任何线程处理。我们很快就会发现,当处理器的IRQL为2或更高时,上下文切换是不可能的,因此在这些ISR执行时,不可能有其他线程潜入。
由于这些“中断”,被中断的线程不会减少其数量。可以说,这不是它的错。
当执行用户模式代码时,IRQL始终为0,这就是为什么在任何用户模式文档中都没有提到IRQL这个术语的原因之一——它总是为0,不能更改。大多数内核模式代码也使用IRQL 0运行,在内核模式下,可以在当前处理器上提升IRQL。
Windows使用API提升或降低IRQL的示例:
// assuming current IRQL <= DISPATCH_LEVEL
KIRQL oldIrql; // typedefed as UCHAR
// 提升IRQL
KeRaiseIrql(DISPATCH_LEVEL, &oldIrql);
NT_ASSERT(KeGetCurrentIrql() == DISPATCH_LEVEL);
// 在IRQL的DISPATCH_LEVEL执行工作。
// 降低IRQ
KeLowerIrql(oldIrql);
18.3.6.3 线程优先级和IRQL
IRQL是处理器的一个属性,优先级是线程的属性,线程优先级仅在IRQL<2时才有意义。一旦执行线程将IRQL提升到2或更高,它的优先级就不再有任何意义了,理论上它拥有无限量程——会一直执行,直到IRQL降低到2以下。
当然,在IRQL>=2上花费大量时间不是一件好事,用户模式代码肯定没有运行,这只是在这些级别上执行代码的能力受到严格限制的原因之一。
Windows任务管理器显示使用称为系统中断的伪进程在IRQL2或更高版本中花费的CPU时间,Process Explorer将其称为“中断”。下图上半部分显示了Task Manager的屏幕截图,下半部分显示了Process Explorer中的相同信息。
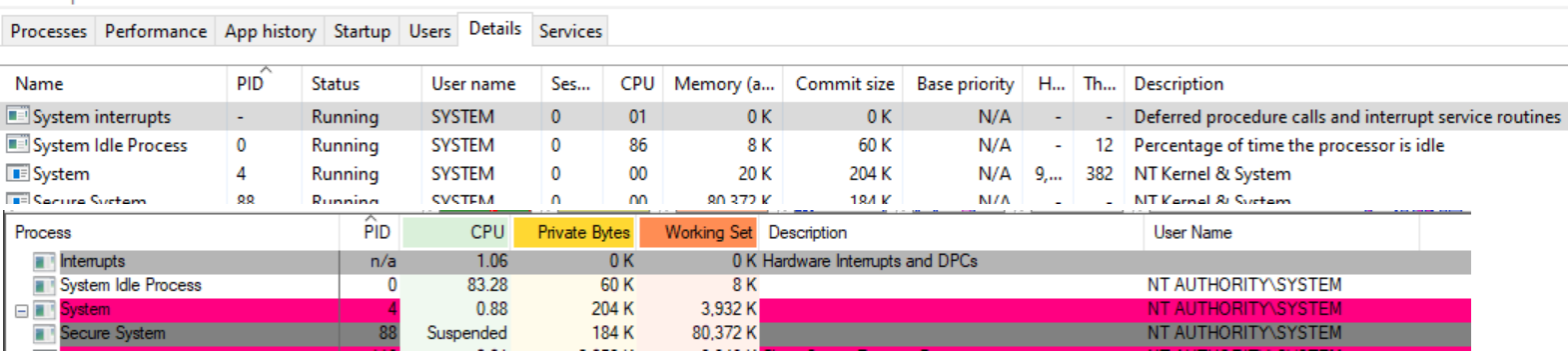
18.3.6.4 中断处理器
内核响应特定中断而运行的函数称为中断处理程序或中断服务例程(interrupt service routine,ISR),每个产生中断的设备都有一个相关的中断处理程序。例如,一个函数处理来自系统计时器的中断,而另一个函数则处理键盘产生的中断。设备的中断处理程序是设备驱动程序(管理设备的内核代码)的一部分。
在Linux中,中断处理程序是正常的C函数。它们匹配一个特定的原型,这使得内核能够以标准方式传递处理程序信息,但除此之外,它们都是普通函数。中断处理程序与其他内核函数的区别在于,内核在响应中断时调用它们,并且它们在一个称为中断上下文(interrupt context)的特殊上下文中运行,这个特殊的上下文有时被称为原子上下文(atomic context),在此上下文中执行的代码不能被阻塞。
因为中断可以在任何时候发生,所以中断处理程序可以在任何时间执行,处理程序必须快速运行,以便尽快恢复被中断代码的执行。因此,虽然操作系统无延迟地为中断提供服务对硬件很重要,但对系统的其余部分来说,中断处理程序在尽可能短的时间内执行也是很重要的。
至少,中断处理程序的工作是向硬件确认中断的接收:“嘿,硬件,我听到了;现在回去工作吧!”然而,中断处理程序通常要执行大量的工作,例如,考虑网络设备的中断处理程序。除了响应硬件之外,中断处理器还需要将网络数据包从硬件复制到内存中,对其进行处理,并将数据包向下推送到适当的协议栈或应用程序。显然,可能需要大量工作,尤其是今天的千兆和10千兆以太网卡。
通过中断传输控制权。
在Linux的驱动程序中,请求中断行并安装处理程序是通过request_irq()完成的:
if(request_irq(irqn, my_interrupt, IRQF_SHARED, "my_device", my_dev))
{
printk(KERN_ERR "my_device: cannot register IRQ %d\n", irqn);
return -EIO;
}
18.3.6.5 中断上下文
执行中断处理程序时,内核处于中断上下文中,进程上下文是内核代表进程执行时的操作模式,例如,执行系统调用或运行内核线程。在进程上下文中,当前宏指向关联的任务。此外,由于进程在进程上下文中耦合到内核,进程上下文可以休眠或以其他方式调用调度器。
另一方面,中断上下文与进程无关,当前宏不相关(尽管它指向被中断的进程)。如果没有后备进程,中断上下文将无法休眠,它将如何重新调度?因此,不能从中断上下文中调用某些函数,如果函数处于休眠状态,则不能从中断处理程序中使用它,这限制了从中断处理函数中调用的函数。
中断上下文是时间关键的,因为中断处理程序会中断其他代码。代码应该快速简单。繁忙的循环是可能的,但不鼓励。请记住,中断处理程序中断了其他代码(甚至可能是另一行上的另一个中断处理程序!)。由于这种异步特性,所有中断处理程序都必须尽可能快和简单。尽可能地,工作应该从中断处理程序中推出,并在下半部分中执行,在更方便的时间运行。
中断处理程序堆栈的设置是一个配置选项,从历史上看,中断处理程序没有收到自己的堆栈,相反,他们将共享中断的进程堆栈。内核堆栈大小为两页,通常在32位体系结构上为8KB,在64位体系结构中为16KB。因为在这种设置中,中断处理程序共享堆栈,所以它们在分配数据时必须格外节约。当然,内核堆栈一开始是有限的,因此所有内核代码都应该谨慎。
在内核进程的早期,可以将堆栈大小从两页减少到一页,在32位系统上只提供4KB的堆栈,此举减少了内存压力,因为系统上的每个进程以前都需要两页连续的、不可扩展的内核内存。为了处理减少的堆栈大小,中断处理程序被赋予了自己的堆栈,每个处理器一个堆栈,一个页面大小,此堆栈称为中断堆栈(interrupt stack)。尽管中断堆栈的总大小是原始共享堆栈的一半,但可用的平均堆栈空间更大,因为中断处理程序可以自己获取整个内存页。
中断处理程序不应该关心正在使用的堆栈设置或内核堆栈的大小,应该始终使用绝对最小的堆栈空间。
18.3.6.6 实现中断处理程序
Linux中中断处理系统的实现依赖于体系结构,实现取决于处理器、使用的中断控制器类型以及体系结构和机器的设计。下图是中断通过硬件和内核的路径图。
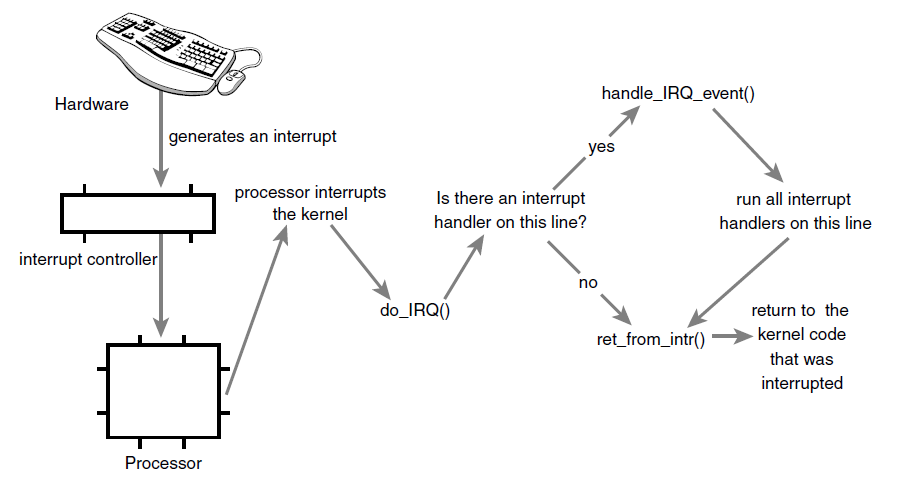
设备通过其总线向中断控制器发送电信号来发出中断,如果中断线被启用,中断控制器将中断发送到处理器。在大多数架构中,通过特殊引脚发送到处理器的电信号来实现。除非中断在处理器中被禁用,否则处理器会立即停止它正在做的事情,禁用中断系统,并跳转到内存中的一个预定义位置并执行位于该位置的代码。这个预定义点由内核设置,是中断处理程序的入口点。
中断在内核中的过程从这个预定义的入口点开始,就像系统调用通过预定义的异常处理程序进入内核一样。对于每个中断行,处理器跳转到内存中的一个唯一位置并执行位于该位置的代码。通过这种方式,内核知道传入中断的IRQ号,初始入口点简单地保存该值并将当前寄存器值(属于中断的任务)存储在堆栈上,则内核调用do_IRQ()。从这里开始,大多数中断处理代码都是用C编写的,然而,它仍然依赖于体系结构。下面是处理IRQ的代码:
/**
* handle_IRQ_event - irq action chain handler
* @irq: the interrupt number
* @action: the interrupt action chain for this irq
*
* Handles the action chain of an irq event
*/
irqreturn_t handle_IRQ_event(unsigned int irq, struct irqaction* action)
{
irqreturn_t ret, retval = IRQ_NONE;
unsigned int status = 0;
if (!(action->flags & IRQF_DISABLED))
local_irq_enable_in_hardirq();
do {
trace_irq_handler_entry(irq, action);
ret = action->handler(irq, action->dev_id);
trace_irq_handler_exit(irq, action, ret);
switch (ret) {
case IRQ_WAKE_THREAD:
/*
* Set result to handled so the spurious check
* does not trigger.
*/
ret = IRQ_HANDLED;
/*
* Catch drivers which return WAKE_THREAD but
* did not set up a thread function
*/
if (unlikely(!action->thread_fn)) {
www.it - ebooks.info
warn_no_thread(irq, action);
break;
}
/*
* Wake up the handler thread for this
* action. In case the thread crashed and was
* killed we just pretend that we handled the
* interrupt. The hardirq handler above has
* disabled the device interrupt, so no irq
* storm is lurking.
*/
if (likely(!test_bit(IRQTF_DIED,
&action->thread_flags))) {
set_bit(IRQTF_RUNTHREAD, &action->thread_flags);
wake_up_process(action->thread);
}
/* Fall through to add to randomness */
case IRQ_HANDLED:
status |= action->flags;
break;
default:
break;
}
retval |= ret;
action = action->next;
} while (action);
if (status & IRQF_SAMPLE_RANDOM)
add_interrupt_randomness(irq);
local_irq_disable();
return retval;
}
18.3.6.7 延迟过程调用
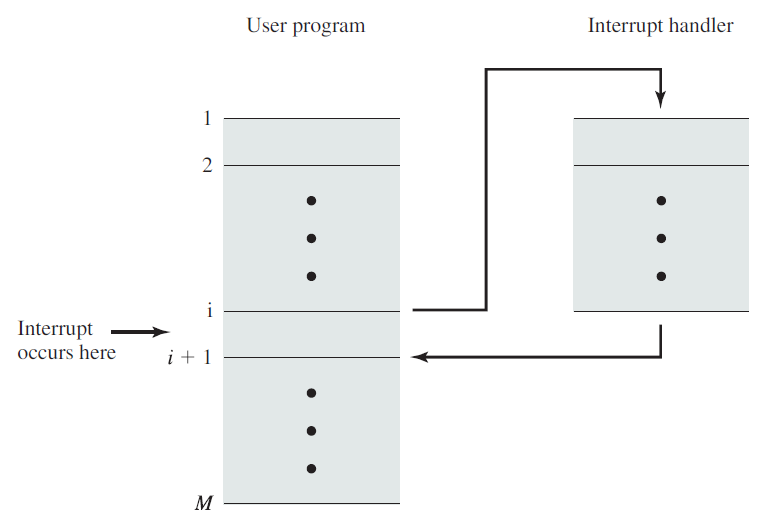
下图显示了客户端调用某些I/O操作时的典型事件序列,在图中,用户模式线程打开文件的句柄,并使用ReadFile函数发出读取操作。由于线程可以进行异步调用,因此它几乎立即重新获得控制权,并可以执行其他工作。接收到此请求的驱动程序将调用文件系统驱动程序(例如NTFS),该驱动程序可能会调用其下面的其他驱动程序,直到请求到达磁盘驱动程序,该磁盘驱动程序将在实际磁盘硬件上启动操作。在这一点上,没有代码需要执行,因为硬件“做它的事情”。
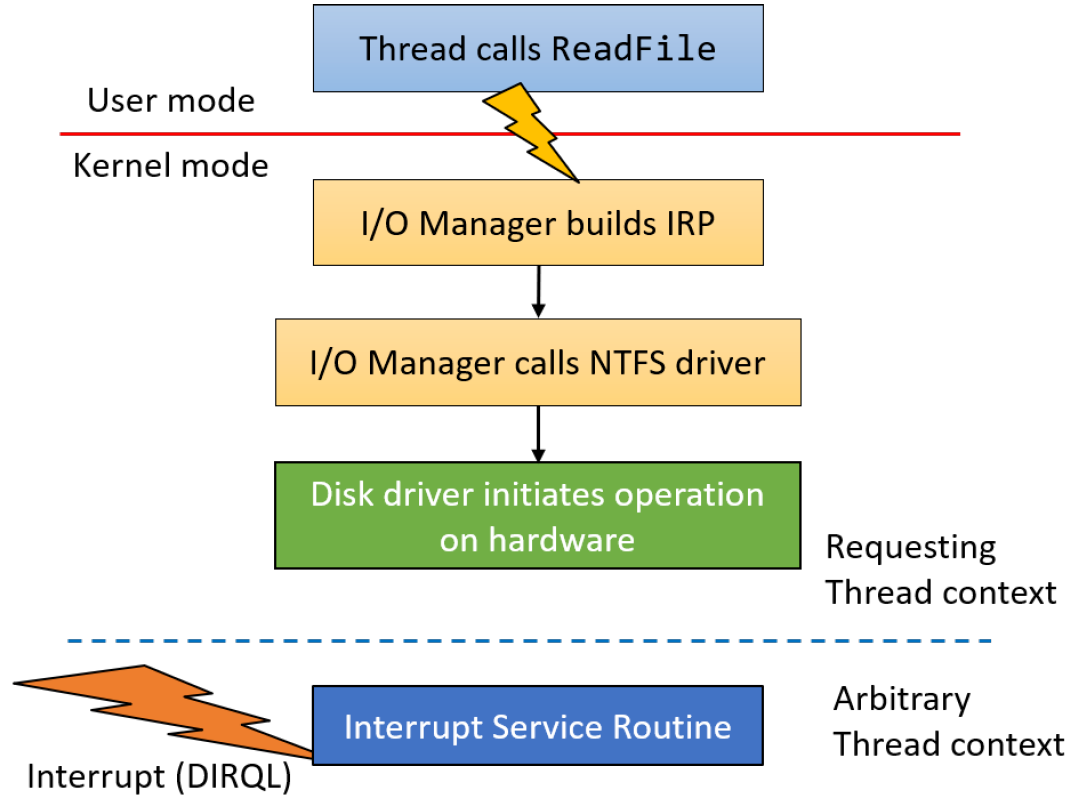
当硬件完成读取操作时,它发出一个中断,导致与中断相关联的中断服务例程在设备IRQL上执行(请注意,处理请求的线程是任意的,因为中断是异步到达的)。典型的ISR访问设备的硬件以获得操作结果,它的最终行动应该是完成最初的请求。
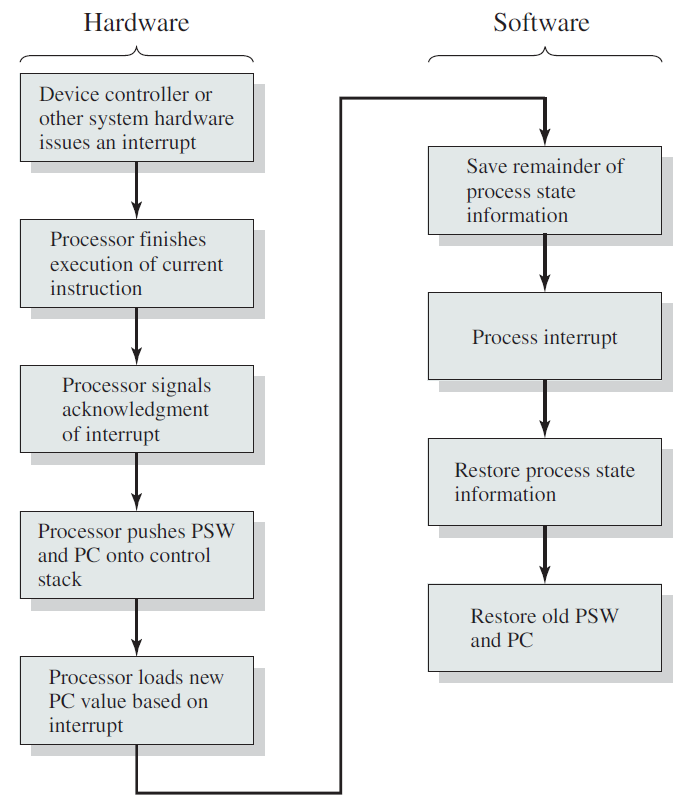
简单的中断处理过程。
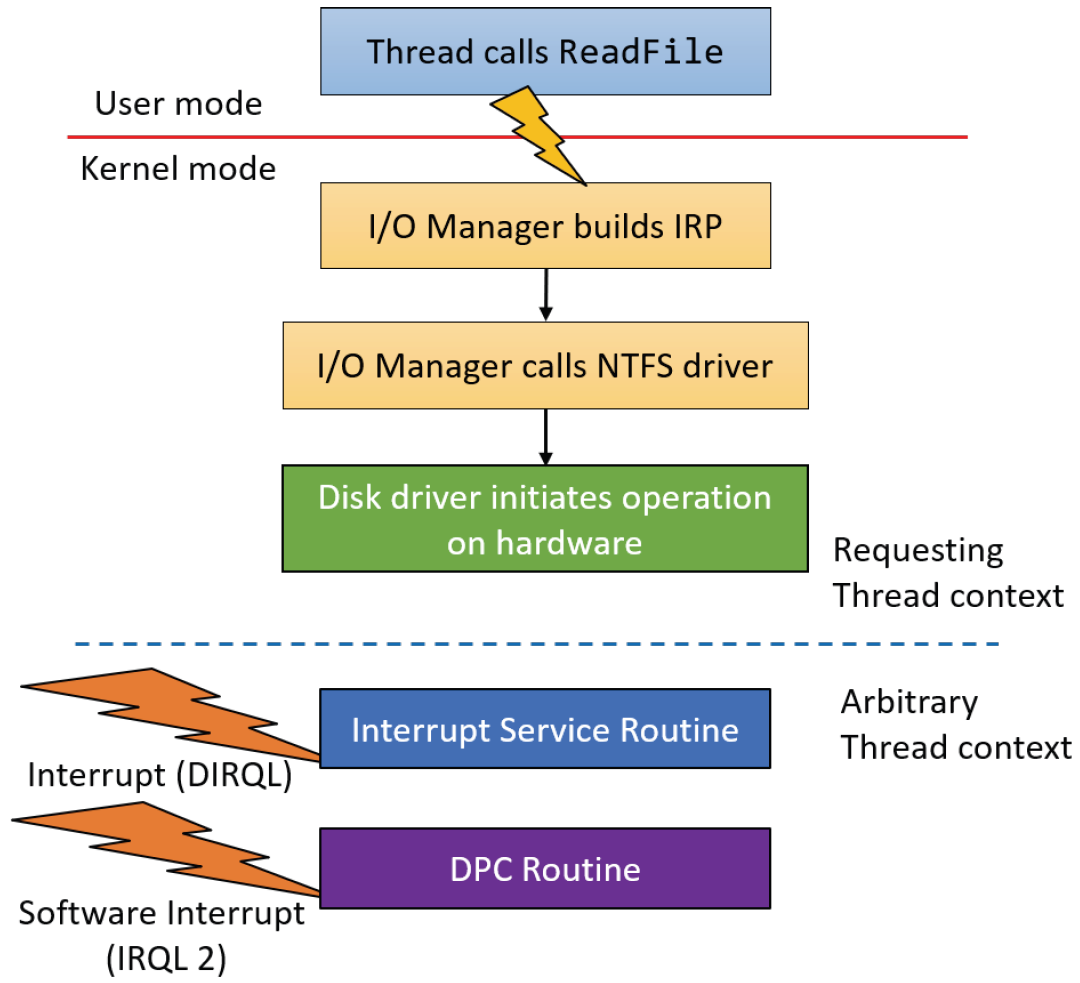
18.3.6.8 异步过程调用
在Windows中,延迟过程调用(DPC)是封装在IRQLDISPATCH_LEVEL调用的函数的对象。就DPC而言,调用线程并不重要。异步过程调用(APC)也是封装要调用的函数的数据结构。但与DPC相反,APC的目标是特定线程,因此只有该线程才能执行该函数,意味着每个线程都有一个与其关联的APC队列。APC有三种类型:
- 用户模式APC。仅当线程进入可报警状态时,这些APC在IRQL PASSIVE_LEVEL的用户模式下执行,通常通过调用API(如SleepEx、WaitForSingleObjectEx、WaitForMultipleObjectsEx和类似API)来完成。这些函数的最后一个参数可以设置为TRUE,以使线程处于可报警状态。在此状态下,它查看其APC队列,如果不是空的,则APC现在执行,直到队列为空。
- 正常内核模式APC。这些APC在IRQL PASSIVE_LEVEL的内核模式下执行,并抢占用户模式代码和用户模式APC。
- 特殊内核APC。这些APC在IRQL APC_LEVEL(1)的内核模式下执行,并抢占用户模式代码、正常内核APC和用户模式APC。I/O系统使用这些APC来完成I/O操作。
18.4 进程
本章将阐述各种操作系统下的进程的概念、特点和技术内幕。
18.4.1 进程模型
在这种模型中,计算机上所有可运行的软件,有时包括操作系统,都被组织成若干顺序进程,或者简称为进程。进程只是执行程序的一个实例,包括程序计数器、寄存器和变量的当前值。从概念上讲,每个进程都有自己的虚拟CPU。当然,在现实中,真正的CPU在进程之间来回切换,但为了理解系统,考虑以(伪)并行方式运行的进程集合要比跟踪CPU如何在程序之间切换容易得多。这种快速的来回切换称为多道程序设计(multiprogramming)。
在下图(a)中,我们看到一台计算机在内存中多道编程四个程序。在下图(b)中,我们看到四个进程,每个进程都有自己的控制流(即自己的逻辑程序计数器),每个进程独立于其他进程运行。当然,只有一个物理程序计数器,因此当每个进程运行时,其逻辑程序计数器被加载到实际程序计数器中。当它完成时(暂时),物理程序计数器保存在内存中进程的存储逻辑程序计数器中。在下图(c)中,我们可以看到,从足够长的时间间隔来看,所有进程都取得了进展,但在任何给定的时刻,只有一个进程实际在运行。
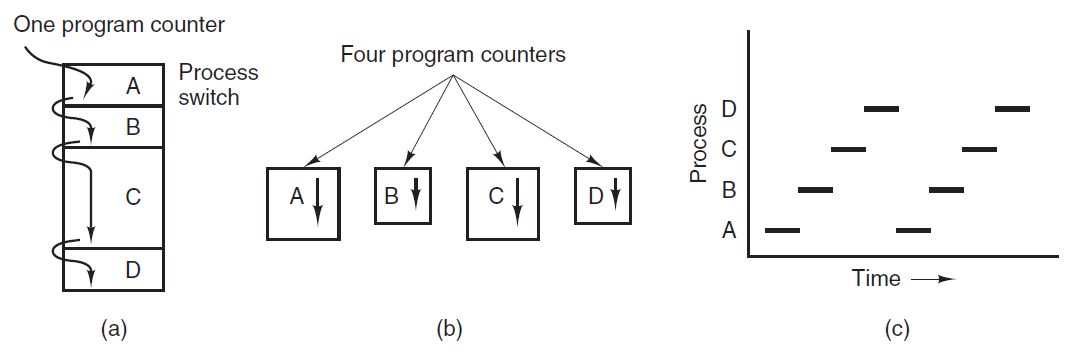
(a) 多道程序设计四个程序。(b) 四个独立、连续进程的概念模型。(c) 一次只有一个程序处于活动状态。
进程或任务是正在执行的程序的实例,进程的执行必须按编程顺序。任何时候最多执行一条指令,包括由程序计数器的值和处理器寄存器的内容表示的当前活动,还包括包含临时数据(如方法参数返回地址和局部变量)的进程堆栈和包含全局变量的数据段。进程还可能包括堆,堆是在进程运行时动态分配的内存。

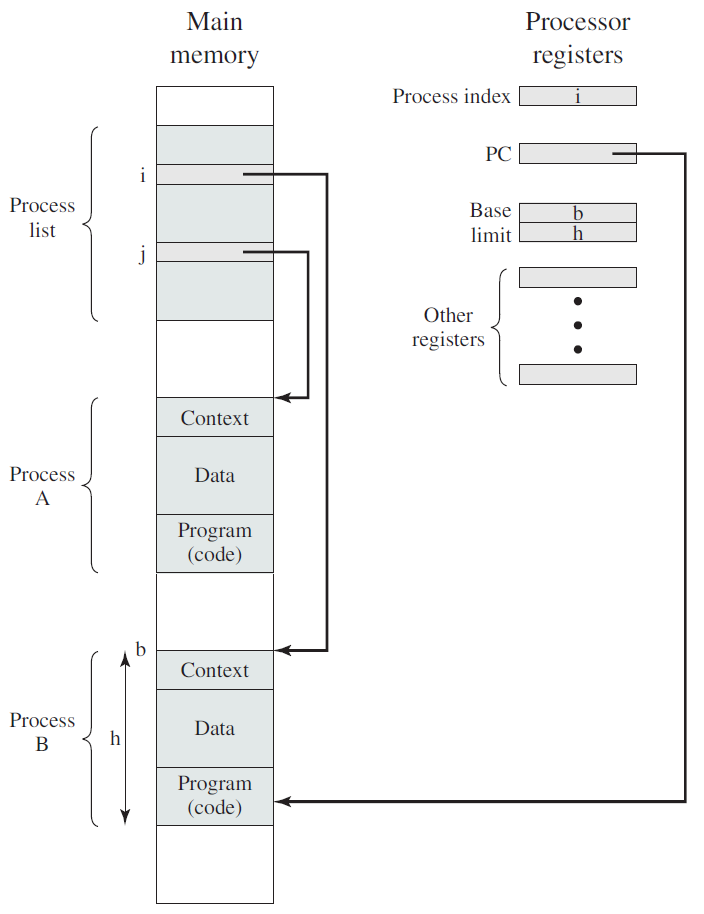
常规的进程实现和内存结构。
进程和程序之间的差异:程序本身不是一个进程,正在执行的程序称为进程。程序是一个被动实体,例如存储在磁盘上的文件的内容,而进程是一个活动实体,有一个程序计数器指定要执行的下一条指令,一组相关的资源可以在多个进程之间共享,使用一些调度算法来确定何时停止一个进程并为另一个进程服务。
当进程执行时,它会改变状态,其状态由该进程的正确活动定义。每个进程可能处于以下状态之一:
- 新建(New):正在创建进程。
- 就绪(Ready):进程正在等待分配给处理器。
- 正在运行(Running Man):正在执行指令。
- 等待(Waiting):进程正在等待某些事件发生。
- 已终止(Terminated:):进程已完成执行。
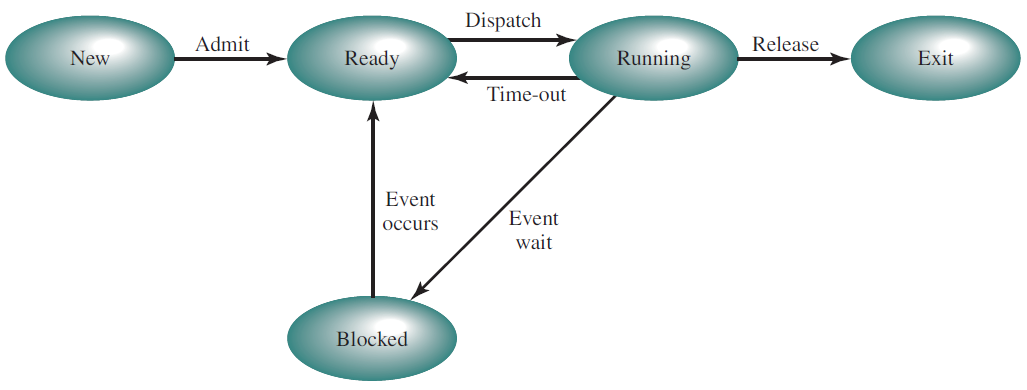
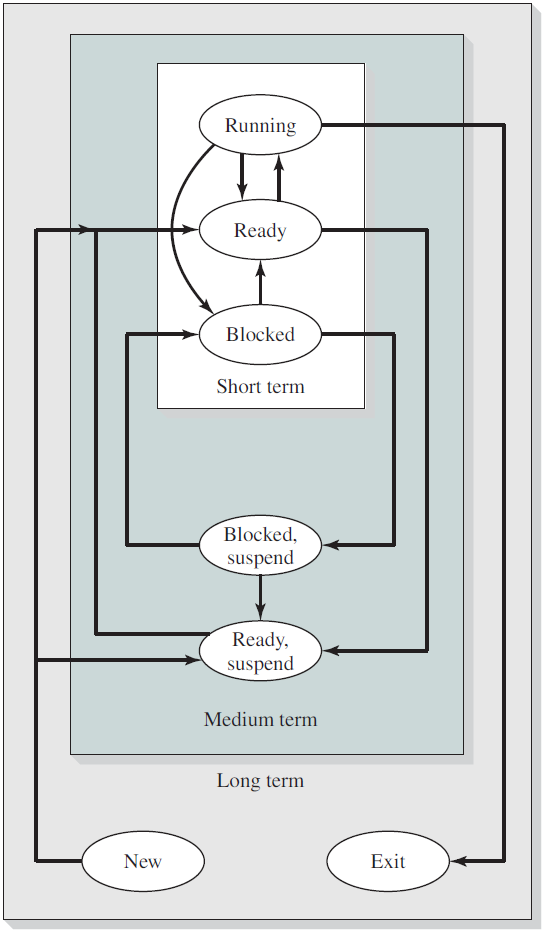
许多进程可能同时处于就绪和等待状态,但在任何一个处理器上,任何时候都只能运行一个进程。下图是进程不同状态之间的切换:
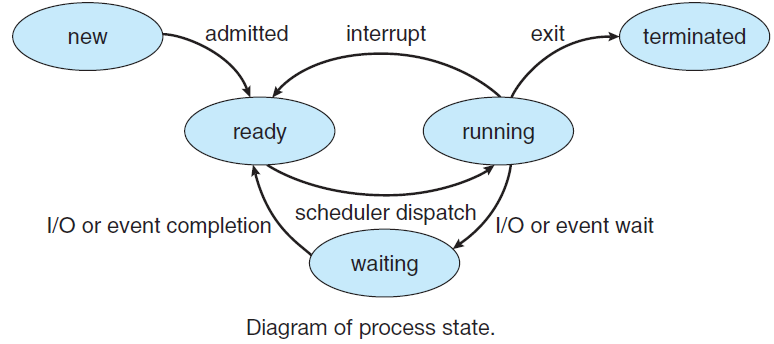
RTOS+的进程状态切换如下:

Linux进程状态切换如下:
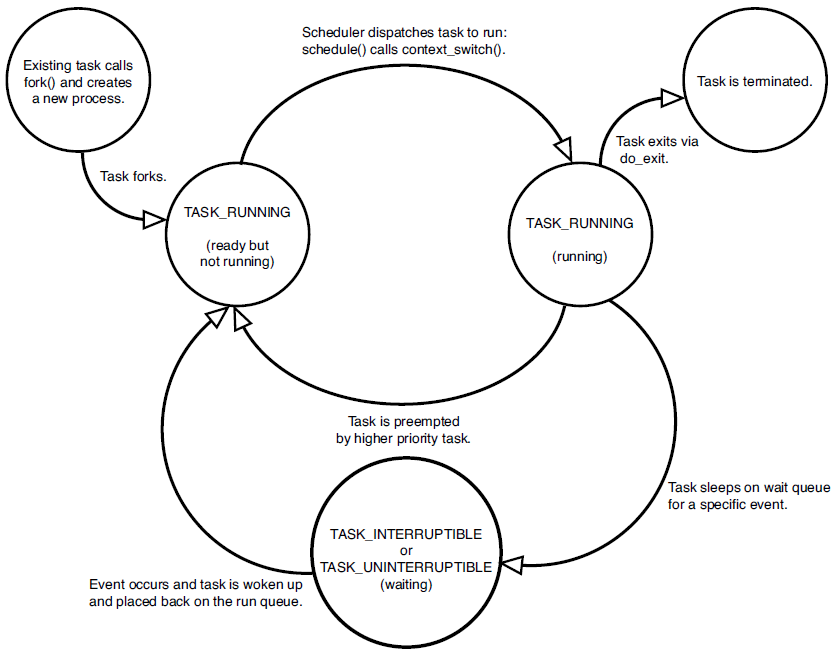
两状态的进程模型:

五状态的进程模型:
进程队列模型样例图:

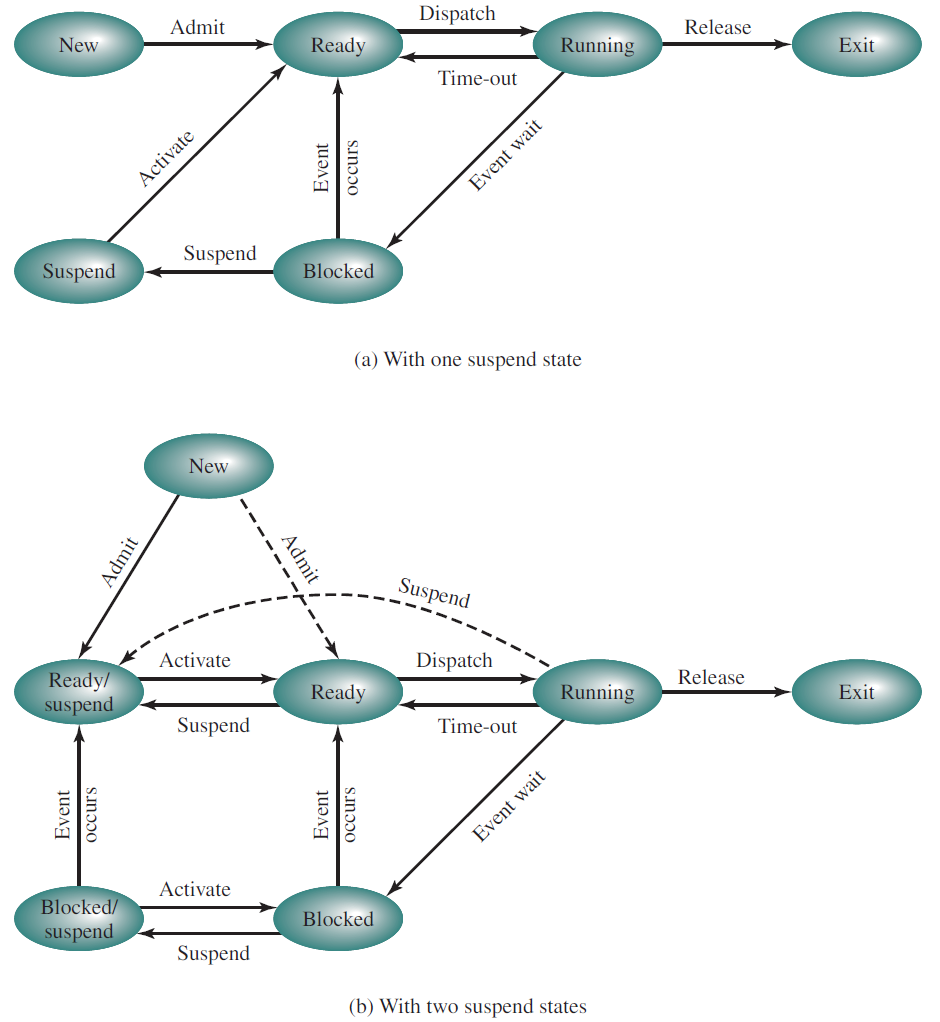
带一个或两个暂停状态的进程状态转换图:
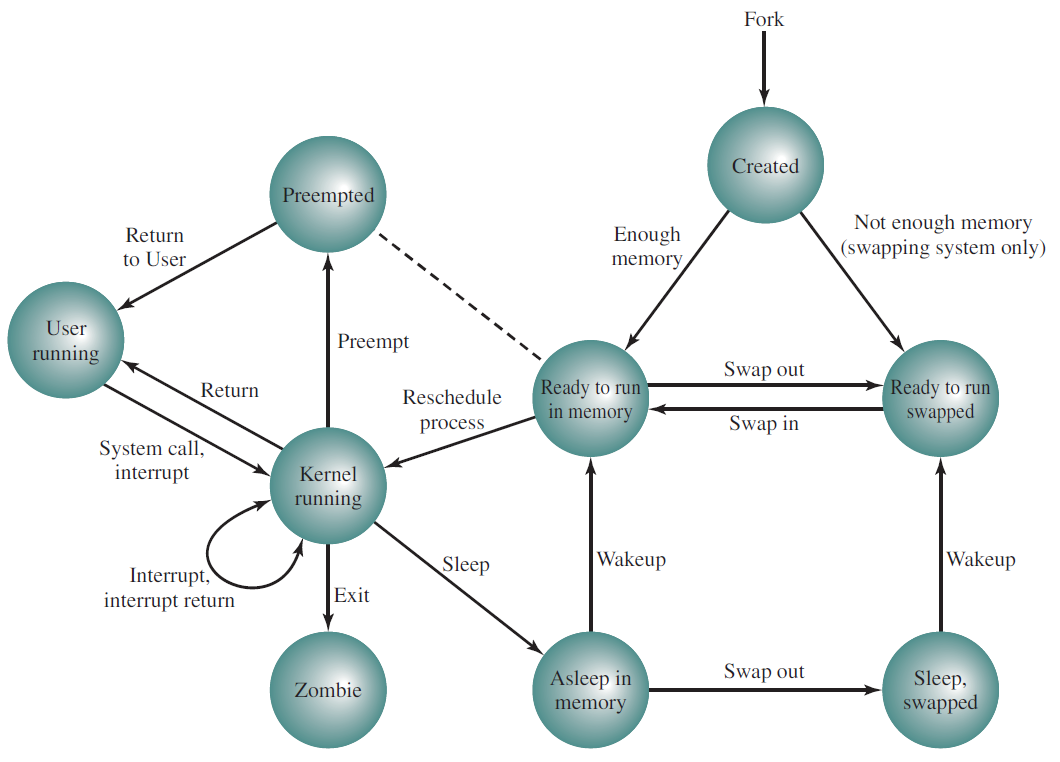
Unix进程状态转换表:
18.4.2 进程控制块
每个进程在操作系统中由进程控制块(Process Control Block,PCB)表示,也由进程控制块控制。进程控制块也称为任务控制块,包含与特定过程相关联的许多信息,包括以下信息:

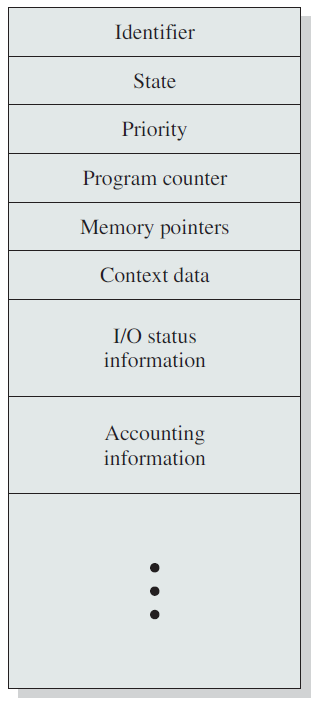
- 进程状态:状态可以是新状态、就绪状态、运行状态、等待状态或终止状态。
- 程序计数器:它指示为此目的执行的下一条指令的地址。
- CPU寄存器:寄存器的数量和类型因计算机架构而异。它包括累加器、索引寄存器、堆栈指针和通用寄存器,加上在发生中断时必须保存的任何条件代码信息,以便在之后正确地继续处理。
- CPU调度信息:此信息包括调度队列的进程优先级指针和任何其他调度参数。
- 内存管理信息:根据操作系统使用的内存系统,该信息可能包括诸如条形和限制寄存器、页面表或段表的值等信息。
- 账号信息:此信息包括CPU数量和实时使用时间、时间限制、帐号、作业或进程编号等。
- I/O状态信息:此信息包括分配给此进程的I/O设备列表、打开的文件列表等,PCB只是用作存储可能因进程而异的任何信息的存储库。
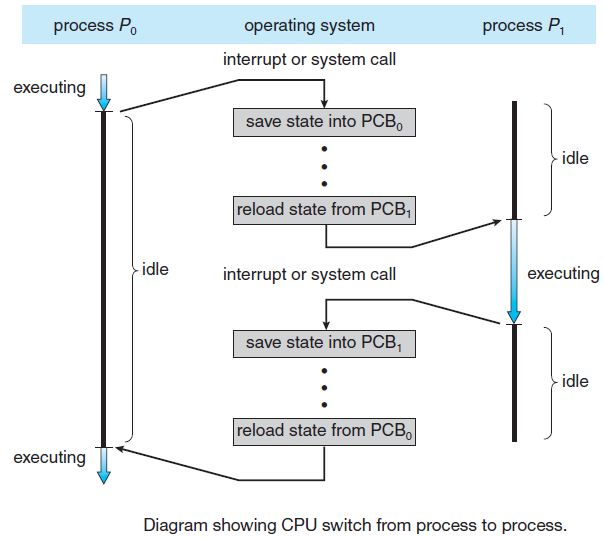
CPU利用PCB来切换进程的执行。
18.4.3 上下文切换
当CPU切换到另一个进程时,系统必须保存旧进程的状态,并加载新进程的保存状态,这个行为称为上下文切换。上下文切换时间开销大,系统在切换时没有做任何有用的工作。切换速度因机器而异,具体取决于内存速度、必须复制的寄存器数量以及特殊指令的存在,典型的速度是几毫秒。上下文切换时间高度依赖于硬件支持。
18.4.4 进程组成
进程是一个包含和管理对象,表示程序的运行实例。以往经常使用的“进程运行”是不准确的,进程实际上不运行——而是进程管理。线程才是执行代码并在技术上运行的载体。从高层次的角度来看,一个进程具有以下特点:
- 一个可执行程序,其中包含用于在进程中执行代码的初始代码和数据。
- 一个私有虚拟地址空间,用于为进程内的代码需要的任何目的分配内存。
- 访问令牌(有时称为主令牌),是存储进程默认安全上下文的对象,由进程内执行代码的线程使用(除非线程通过模拟使用不同的令牌)。
- 执行(内核)对象的私有句柄表,如事件、信号量和文件。
- 一个或多个执行线程。使用一个线程(执行进程的主入口点)创建普通用户模式进程,没有线程的用户模式进程通常是无用的,通常情况下会被内核销毁。

一个进程的重要组成部分。

进程的寻址需求。
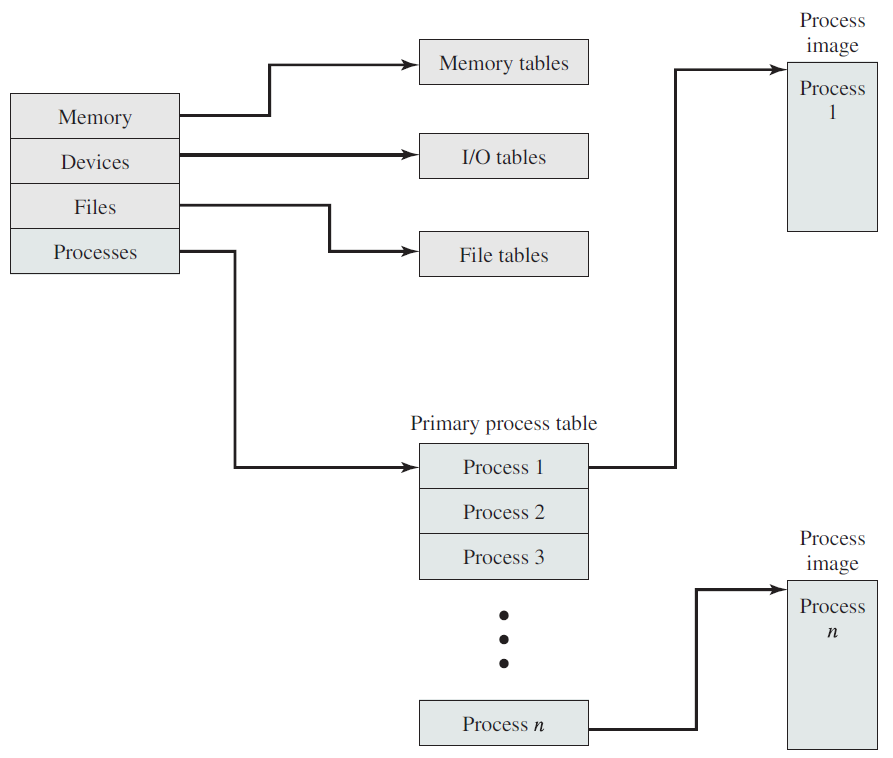
操作系统控制表的常规结构。
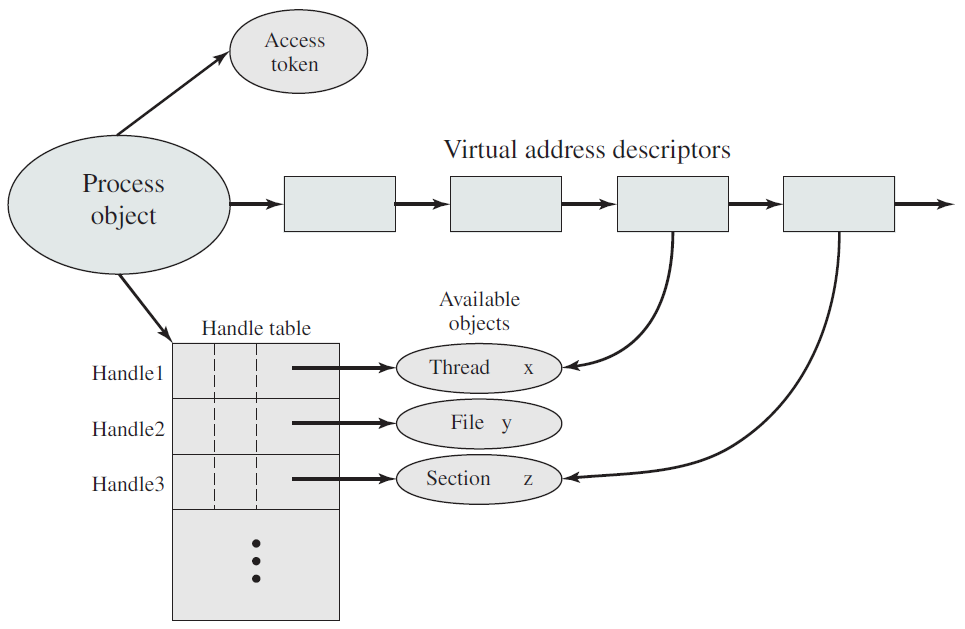
Windows进程和它的资源构成。
进程由其进程ID唯一标识,只要内核进程对象存在,进程ID就保持唯一。一旦它被销毁,相同的ID就可以重新用于新的进程。可执行文件本身不是进程的唯一标识符,例如,Windows的记事本(notepad.exe)可能有5个实例的exe同时运行,每个进程都有自己的地址空间、线程、句柄表、进程ID等。这5个进程都使用相同的镜像文件(notepad.exe)作为其初始代码和数据,但每个实例都有自己的属性。
动态链接库(DLL)是可执行文件,可以包含代码、数据和资源(至少其中之一)。DLL在进程初始化时(称为静态链接)或在显式请求时(动态链接)动态加载到进程中。DLL由于不包含可执行文件等标准主函数,因此无法直接运行。DLL允许在使用同一DLL的多个进程之间共享物理内存中的代码,下图显示使用映射到相同物理(和虚拟)地址的共享DLL的两个进程。

尽管自Windows NT第一次发布以来,进程的基本结构和属性没有改变,但新的进程类型已经引入到具有特殊行为或结构的系统中。以下是当前支持的所有进程类型的快速概述:
- 受保护进程。是在Windows Vista中引入的。创建它们是为了通过防止对呈现受数字版权管理(DRM)保护内容的进程的侵入性访问来支持数字版权管理。例如,没有其他进程(即使以管理员权限运行)可以读取具有受保护进程地址空间的内存,因此DRM保护的数据不能直接被窃取。
- UWP进程。从Windows 8开始可用,承载Windows运行时,通常发布到Microsoft应用商店。UWP进程在AppContainer中执行——是一个沙盒,限制了该进程可以执行的操作。
- 受保护的轻量进程(PPL)。扩展了Vista的保护机制,增加了多个级别的保护,甚至允许第三方服务作为PPL运行,保护它们免受入侵访问和终止,即使是管理级进程。
- 最小化进程(Minimal Process)。是一种真正新的进程形式,其地址空间不包含正常进程所包含的常用图像和数据结构。例如,没有映射到进程地址空间的可执行文件,也没有DLL,进程地址空间实际上是空的。
- 微进程(Pico Process)。这些进程是最小的进程,只有一个附加:微提供程序,它是一个内核驱动程序,可以拦截Linux系统调用并将其转换为等效的Windows系统调用。这些进程用于Windows Subsystem for Linux(WSL),可从Windows 10版本1607获得。
18.4.5 进程调度
几乎所有进程都会交替使用(磁盘或网络)I/O请求进行计算,如下图所示。通常,CPU会运行一段时间而不停止,然后进行系统调用以读取文件或写入文件。当系统调用完成时,CPU会再次计算,直到需要更多数据或必须写入更多数据,依此类推。请注意,一些I/O活动算作计算。例如,当CPU将位复制到视频RAM以更新屏幕时,它是在计算,而不是执行I/O,因为CPU正在使用中。在这种意义上,I/O是指进程进入阻塞状态,等待外部设备完成其工作。

CPU使用的突发与等待I/O的时间交替发生。(a) CPU受限的进程。(b) I/O受限的进程。
关于上图,需要注意的重要一点是,一些进程,如(a)中的进程,花费了大部分时间进行计算,而其他进程,如(b)所示,花费了大量时间等待I/O。
前者称为计算受限或CPU受限;后者称为I/O受限。计算受限的进程通常有较长的CPU突发,因此很少有I/O等待,而I/O受限进程有较短的CPU突发时间,因此频繁的I/O等待。注意,关键因素是CPU突发的长度,而不是I/O突发的长度。I/O受限进程是I/O受限的,因为它们不会在I/O请求之间进行大量计算,而不是因为它们有特别长的I/O请求。发出读取磁盘块的硬件请求需要同样的时间,无论数据到达后处理数据需要多少时间。
值得注意的是,随着CPU的速度越来越快,进程往往会获得更多的I/O受限。出现这种效果是因为CPU的改进速度比磁盘快得多。因此,I/O受限进程的调度在未来可能会成为一个更重要的主题。这里的基本思想是,如果一个I/O受限的进程想要运行,它应该能够很快获得机会,以便发出磁盘请求并保持磁盘繁忙。当进程受到I/O限制时,需要相当多的进程来保持CPU的完全占用。
与进程调度相关的一个关键问题是何时做出进程调度策略。事实证明,在各种情况下都需要调度。首先,创建新进程时,需要决定是运行父进程还是子进程。由于这两个进程都处于就绪状态,这是一个正常的调度决策,可以选择任何一种方式,也就是说,调度程序可以合法地选择下一个运行父进程或子进程。
其次,当进程退出时,必须做出调度决策。该进程无法再运行(因为它不再存在),因此必须从就绪进程集中选择其他进程。如果没有进程就绪,则系统提供的空闲进程通常会运行。
第三,当一个进程在I/O、信号量或其他原因上阻塞时,必须选择另一个进程来运行。有时,阻塞的原因可能会影响选择。例如,如果A是一个重要的进程,它正在等待B退出其关键区域,那么让B接下来运行将允许它退出其关键区,从而让A继续。然而,问题是调度程序通常没有必要的信息来考虑这种依赖关系。
第四,当发生I/O中断时,可以做出调度决策。如果中断来自现已完成其工作的I/O设备,则等待I/O的某些进程可能已准备好运行。由调度程序决定是运行新准备好的进程、中断时正在运行的进程还是第三个进程。
如果硬件时钟以50或60 Hz或其他频率提供周期性中断,则可以在每个时钟中断或每个第k个时钟中断时做出调度决策。调度算法可以根据如何处理时钟中断分为两类。非临时调度算法选择要运行的进程,然后让它运行,直到它阻塞(在I/O上或等待另一个进程)或自动释放CPU。即使它运行了许多小时,也不会被强制暂停。实际上,在时钟中断期间不会做出调度决策。时钟中断处理完成后,中断前运行的进程将恢复,除非高优先级进程正在等待现已满足的超时。
相比之下,抢占式调度算法选择一个进程,并让它最多运行一段固定时间。如果它在时间间隔结束时仍在运行,那么它将被挂起,并且调度程序会选择另一个要运行的进程(如果有的话)。执行抢占式调度需要在时间间隔结束时发生时钟中断,以便将CPU控制权交还给调度程序。如果没有可用的时钟,则非临时调度是唯一的选择。
在不同的环境中,需要不同的调度算法。调度程序应该优化的内容在所有系统中并不相同,值得区别的三种环境是:批次、互动、实时。
为了设计调度算法,有必要了解好的算法应该做什么。有些目标取决于环境(批处理、交互式或实时),但有些目标在所有情况下都是可取的。下面列出了一些目标:
- 所有系统:
- 公平性:给每个进程公平的CPU份额。
- 策略执行:确保所述策略得到执行。
- 平衡:使系统的所有部分保持忙碌。
- 批处理系统:
- 吞吐量:最大化每小时作业数。
- 周转时间:最小化提交和终止之间的时间。
- CPU利用率:使CPU始终处于繁忙状态。
- 交互式系统:
- 响应时间:快速响应请求。
- 比例:满足用户的期望。
- 实时系统:
- 满足最后期限:避免丢失数据。
- 可预测性:避免多媒体系统的质量下降。
在任何情况下,公平都很重要。可比进程应获得可比服务,给一个进程比同等进程多很多CPU时间是不公平的。当然,不同类别的进程可能会有不同的处理方式。与公平相关的是执行系统的策略,如果本地策略是安全控制进程可以在任何时候运行,即使意味着工资单延迟30秒,调度程序也必须确保执行此策略。
另一个总体目标是尽可能使系统的所有部分保持繁忙。如果CPU和所有I/O设备都可以一直运行,那么与某些组件处于空闲状态相比,每秒完成的工作量会更多。例如,在批处理系统中,调度程序可以控制哪些作业进入内存以运行。
在内存中同时使用一些CPU受限进程和一些I/O受限进程比首先加载和运行所有CPU受限作业,然后在它们完成时加载和运行全部I/O受限作业要好。如果使用后一种策略,当CPU受限的进程正在运行时,它们将争夺CPU,磁盘将处于空闲状态。稍后,当I/O受限作业进入时,它们将争夺磁盘,CPU将处于空闲状态。最好通过仔细混合进程来保持整个系统同时运行。
系统在不同调度级别下的状态转换图如下:
调度队列图如下:
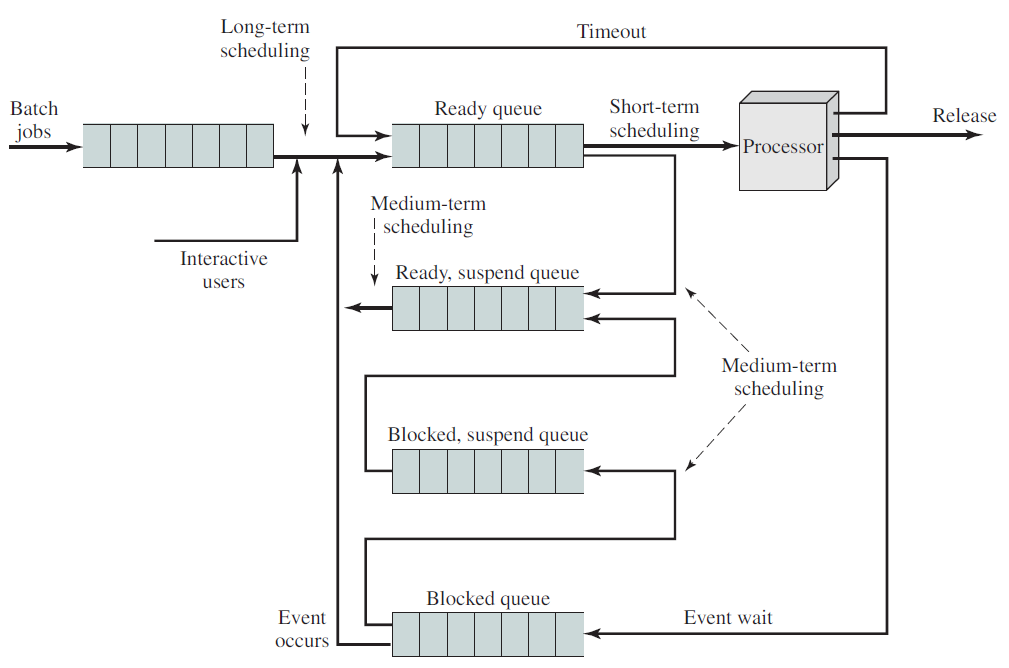
18.4.5.1 调度基础
进程调度是操作系统的基本功能。当一台计算机进行多程序设计时,它有多个进程同时竞争CPU。如果只有一个CPU可用,那么必须选择下一个执行哪个进程。这一决策过程称为调度(scheduling),做出此选择的操作系统部分称为调度程序(scheduler),用于进行此选择的算法称为调度算法(scheduling algorithm)。
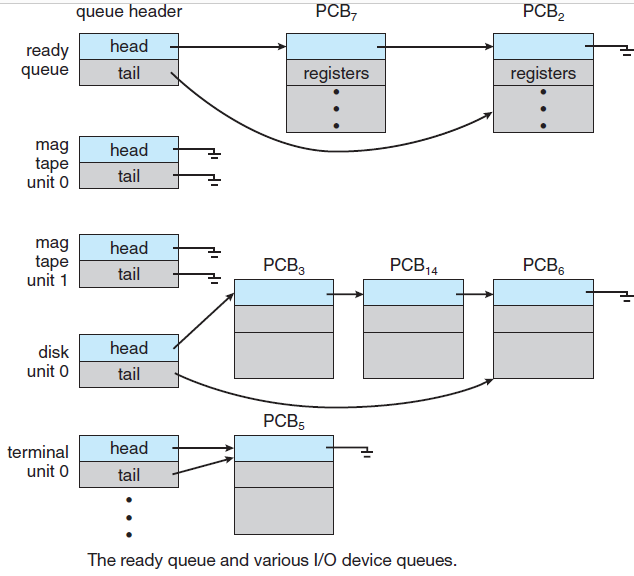
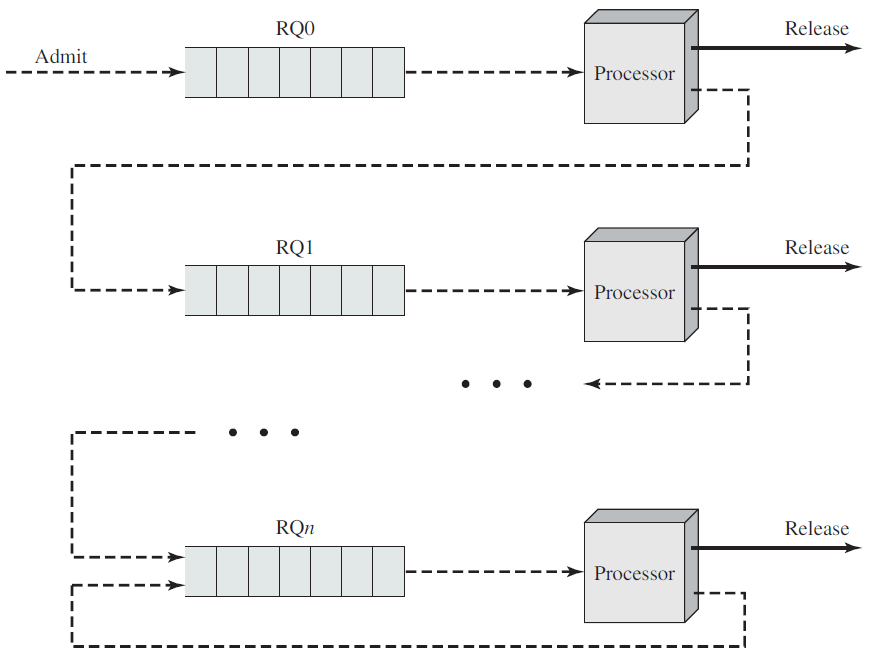
调度队列(Scheduling queue)是进程进入系统时被放入的作业队列,此队列由系统中的所有进程组成,驻留在主存中并已准备好等待执行或保存在名为就绪队列的列表中的进程。
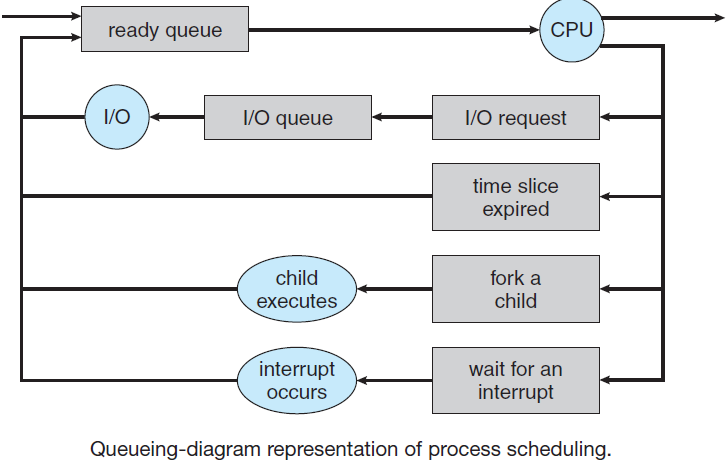
此队列通常存储为链接列表,就绪队列标题包含指向列表中第一个和最后一个PCB的指针,PCB包含一个指向就绪队列中下一个PCB的指针字段。等待特定I/O设备的进程列表保存在名为设备队列的列表中,每个设备都有自己的设备队列。新进程最初被放入就绪队列。它在就绪队列中等待,直到它被选中执行并被赋予CPU。
 0.png)
0.png)
18.4.5.2 调度程序
调度程序的描述如下:
- 进程在其生命周期内在各种调度队列之间迁移。操作系统必须以某种方式从这些队列中选择调度进程。此选择过程由适当的调度程序执行。
- 在批处理系统中,会提交更多进程,然后立即执行。因此,这些进程被假脱机到一个大容量存储设备(如磁盘)中,并保存在那里供以后执行。
调度程序的类型有以下几种:
长期调度程序(Long term scheduler)
长期调度程序从磁盘中选择进程并将其加载到内存中以便执行。它控制多重编程的程度,即内存中进程的数量,执行频率低于其他调度程序。如果多道程序设计的程度是稳定的,那么进程创建的平均速度等于进程离开系统的平均离开速度。因此,仅当进程离开系统时才需要调用长期调度程序。由于执行之间的间隔较长,它可以花费更多的时间来决定应该选择哪个进程来执行。
CPU中的大多数进程要么是I/O密集的,要么是CPU密集的。I/O密集的进程(交互式“C”程序)是一个将大部分时间花在I/O操作上的进程,而不是花在执行I/O操作上,CPU密集的进程在计算上花费的时间比I/O操作(复杂的排序程序)要多。长期调度程序应选择I/O绑定和CPU绑定进程的良好组合,这一点很重要。
短期调度程序(Short term scheduler)
短期调度程序在准备执行的进程中进行选择,并将CPU分配给其中一个进程,这两个调度程序之间的主要区别是它们的执行频率。短期调度程序必须经常为CPU选择新进程,它必须在100毫秒内至少执行一次。由于两次执行之间的时间间隔很短,因此必须非常快。
中期调度程序(Medium term scheduler)
一些操作系统引入了一种称为中期调度程序的额外中间级别的调度,这个调度器背后的主要思想是,有时从内存中删除进程是有利的,从而降低多道程序的程度。然后,该进程可以重新引入内存,并且可以从中断的地方继续执行,称为交换。进程稍后由中期调度程序调出和调入。交换对于改善进程未命中是必要的,或者由于内存需求的某些变化,超出了可用内存限制,这需要释放一些内存。
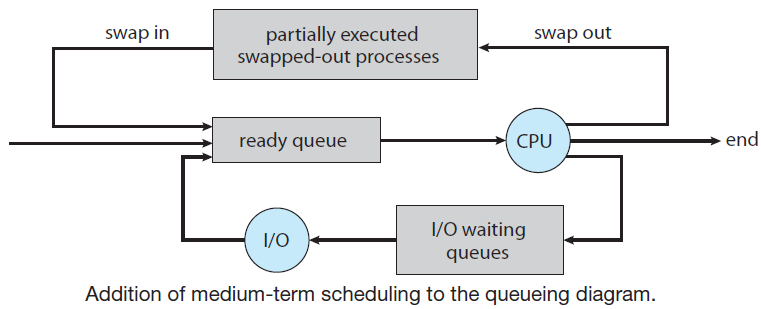
18.4.5.3 调度目标
调度的目标有:
- CPU利用率:使CPU尽可能繁忙。
- 吞吐量:每个时间单位完成其执行的进程数。
- 周转时间:执行特定流程的时间量。
- 等待时间:进程在就绪队列中等待的时间。
- 响应时间:从提交请求到生成第一个响应(而不是输出)所用的时间(对于分时环境)。
调度的总体目标:
- 公平。在任何情况下,公平都很重要。调度程序确保每个进程都能获得其CPU的公平份额,并且没有进程会无限期延迟。
请注意,给予同等或同等的时间是不公平的。想想核电站的安全控制和工资单。 - 政策执行。调度程序必须确保系统的策略得到执行。例如,如果局部策略是安全的,那么安全控制处理必须能够在任何时候运行,即使意味着工资单处理延迟。
- 效率。如果可能的话,调度程序应该使系统(特别是CPU)在百分之几的时间内保持繁忙。如果CPU和所有输入/输出设备可以一直运行,那么与某些组件处于空闲状态时相比,每秒完成的工作更多。
- 响应时间。调度程序应尽量减少交互式用户的响应时间。
- 轮回。调度程序应最小化批处理用户必须等待输出的时间。
- 吞吐量。调度程序应最大化单位时间内处理的作业数。
稍加思考就会发现其中一些目标是相互矛盾的。可以看出,任何支持某类作业的调度算法都会损害另一类作业。毕竟,可用的CPU时间是有限的。
就如何处理时钟中断而言,调度算法可以分为两类:
-
非抢占式调度。如果一个进程一旦被赋予CPU,CPU就不能从该进程中取出,那么调度程序是非抢占性的。以下是非抢占式调度的一些特征:
- 在非抢占式系统中,短作业由长作业等待,但所有进程的总体处理是公平的。
- 在非抢占式系统中,响应时间更容易预测,因为传入的高优先级作业不能取代等待的作业。
- 在非抢占式调度中,调度程序在两种情况下执行作业:1、当进程从运行状态切换到等待状态时;2、当进程终止时。
-
抢占式调度。如果一个进程一旦被给予,CPU就可以被拿走,那么调度规程是优先的。允许逻辑上可运行的进程暂时挂起的策略称为抢占式调度,它与“运行到完成”方法相反。
18.4.5.4 CPU调度算法
CPU调度处理决定就绪队列中的哪些进程将分配给CPU的问题。下面是我们将要研究的一些调度算法。
先到先服务(FCFS)
FCFS是最简单的CPU调度算法。首先请求CPU的进程,即首先分配给CPU的进程。可以通过FIFO队列轻松管理,当进程进入就绪队列时,其PCB链接到队列的后部。但是,FCFS的平均等待时间很长。考虑以下情况:
| 进程 | CPU时间 |
|---|---|
| P1 | 3 |
| P2 | 4 |
| P3 | 2 |
| P4 | 4 |
如果顺序为P1、P2、P3、P4,则使用FCFS算法计算平均等待时间和平均周转时间。解决方案:如果进程以P1、P2、P3、P4的顺序到达,则根据FCFS,甘特图将为:

不同的时间描述如下:
-
进程等待时间:P1 = 0,P2 = 3,P3 = 8,P4 = 10。
-
进程周转(Turnaround)时间:P1 = 0 + 3 = 3,P2 = 3 + 5 = 8,P3 = 8 + 2 = 10,P4 = 10 + 4 =14。
-
平均等待时间:(0 + 3 + 8 + 10) / 4 = 21 / 4 = 5.25。
-
平均周转时间:(3 + 8 + 10 + 14)/4 = 35 / 4 = 8.75。
FCFS算法是非抢占式的,即一旦CPU分配给进程,该进程就会通过终止或请求I/O来保持CPU,直到释放CPU为止。
最短作业优先(SJF)
此算法的另一个名称是下一个最短进程(SPN),如果CPU可用,此算法将与每个进程关联。这种调度也称为最短的下一次CPU迸发(burst),因为调度是通过检查进程的下一个CPU迸发的长度而不是其总长度来完成的。考虑以下情况:
| 进程 | CPU时间 |
|---|---|
| P1 | 3 |
| P2 | 5 |
| P3 | 2 |
| P4 | 4 |
解决方案:根据SJF,甘特图将是:

不同的时间描述如下:
- 进程等待时间:P1 = 0,P2 = 2,P3 = 5,P4 = 9。
- 进程周转时间:P3 = 0 + 2 = 2,P1 = 2 + 3 = 5,P4 = 5 + 4 = 9,P2 = 9 + 5 =14。
- 平均等待时间:(0 + 2 + 5 + 9) / 4 = 16 / 4 = 4。
- 平均周转时间:(2 + 5 + 9 + 14)/4 = 30 / 4 = 7.5。
SJF算法可以是抢占式或非抢占式算法,抢占式的SJF也称为最短剩余时间优先。考虑以下示例:
| 进程 | 到达时间 | CPU时间 |
|---|---|---|
| P1 | 0 | 8 |
| P2 | 1 | 4 |
| P3 | 2 | 9 |
| P4 | 3 | 5 |
此情况的甘特图如下:

进程等待时间:P1 = 10 - 1 = 9,P2 = 1 – 1 = 0,P3 = 17 – 2 = 15,P4 = 5 – 3 = 2。
平均等待时间:(9 + 0 + 15 + 2) / 4 = 26 / 4 = 6.5。
优先级调度
在这个调度中,每个进程都有一个优先级编号(整数),CPU被分配给优先级最高的进程(最小的整数,最高的优先级),可分为抢占式和非抢占式。同等优先级的流程以FCFS方式安排。SJF是一种优先级调度,其中优先级是预测的下一个CPU突发时间。
存在饥饿问题——低优先级进程可能永远不会执行,解决方案是老化——随着时间的推移,进程的优先级增加。
优先级可以在内部或外部定义。内部优先事项的例子有:时间限制、内存要求、文件要求(如打开文件的数量)、CPU与I/O要求。外部定义的优先级由操作系统外部的标准设置,例如进程的重要性、为使用计算机而支付的资金类型或金额、赞助工作的部门、政策。

优先级队列。
考虑以下示例:
| 进程 | 到达时间 | CPU时间 |
|---|---|---|
| P1 | 10 | 3 |
| P2 | 1 | 1 |
| P3 | 2 | 3 |
| P4 | 1 | 4 |
| P5 | 5 | 2 |
根据优先级调度,甘特图将为:

进程等待时间:P1 = 6,P2 = 0,P3 = 16,P4 = 18,P5 = 1。
平均等待时间:(0 + 1 + 6 + 16 + 18) / 5 = 41 / 5 = 8.2。
轮询(Round Robin)
这种算法仅用于分时系统设计,类似于具有抢占条件的FCFS调度,可以在进程之间切换。一个称为量程时间或时间片的小时间单位用于在进程之间切换,轮询制下的平均等待时间很长。考虑以下示例:
| 进程 | CPU时间 |
|---|---|
| P1 | 3 |
| P2 | 5 |
| P3 | 2 |
| P4 | 4 |
时间片 = 1ms,则甘特图为:
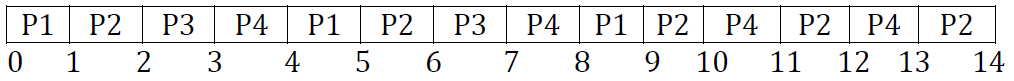
进程等待时间:
- P1 = 0 + (4 – 1) + (8 – 5) = 0 + 3 + 3 = 6
- P2 = 1 + (5 – 2) + (9 – 6) + (11 – 10) + (13 – 12) = 1 + 3 + 3 + 1 + 1 = 9
- P3 = 2 + (6 – 3) = 2 + 3 = 5
- P4 = 3 + (7 – 4) + (10 – 8) + (12 – 11) = 3 + 3 + 2 + 1 = 9
平均等待时间:(6 + 9 + 5 + 9) / 4 = 7.2
最短剩余时间(SRT)
SRT是SJF的抢占式对等物,在分时环境中很有用。在SRT调度中,下一步运行估计运行时间最短的进程,包括新到达的进程。在SJF方案中,一旦作业开始执行,它就会一直运行到完成,一个正在运行的进程可以被一个估计运行时间最短的新到达进程抢占。SRT的开销高于对应的SJF,必须跟踪运行进程的运行时间,并且必须处理偶尔的抢占。在这个方案中,小进程的到达几乎会立即运行,然而,更长的工作意味着更长的等待时间。
最短进程优先(Shortest Process Next)
因为最短的作业首先总是为批处理系统产生最小的平均响应时间,所以如果它也可以用于交互式流程,那就更好了。在一定程度上是可以的。交互进程通常遵循等待命令、执行命令、等待命令、运行命令等模式。如果我们将每个命令的执行视为单独的“作业”,那么我们可以通过先运行最短的一个来最小化总体响应时间,前提是找出当前可运行的进程中最短的进程。
保证调度(Guaranteed Scheduling)
调度的一种完全不同的方法是向用户作出关于性能的真正承诺,然后兑现这些承诺。一个切实可行且易于实现的承诺是:如果在你工作时有n个用户登录,你将获得大约1/n的CPU电量。类似地,在一个运行n个进程的单用户系统上,在所有条件都相同的情况下,每个进程应该获得1/n的CPU周期,这似乎很公平。
为了兑现这一承诺,系统必须跟踪每个进程自创建以来有多少CPU。然后,它计算每个进程有权使用的CPU数量,即自创建以来的时间除以n。由于每个进程实际拥有的CPU时间量也是已知的,因此计算实际消耗的CPU时间与有权使用CPU时间的比率非常简单。比率为0.5意味着一个进程只拥有它应该拥有的一半,比率为2.0意味着进程拥有的是它应有的两倍。然后,算法以最低比率运行该进程,直到其比率超过其最接近的竞争对手的比率。然后选择下一个运行。
彩票调度
虽然向用户作出承诺,然后兑现承诺是一个好主意,但很难实现。然而,可以使用另一种算法以更简单的实现给出类似的可预测结果。这被称为彩票调度(Lottery Scheduling)。
基本思想是为各种系统资源(如CPU时间)提供进程彩票。每当必须做出调度决策时,都会随机选择彩票,持有该彩票的进程将获得资源。当应用于CPU调度时,系统可能每秒举行50次抽奖,每个优胜者都会获得20毫秒的CPU时间作为奖品。
公平调度(Fair-Share Scheduling)
到目前为止,我们假设每个进程都是自己调度的,而不管其所有者是谁。因此,如果用户1启动九个进程,而用户2启动一个进程,并且具有循环或同等优先级,则用户1将获得90%的CPU,用户2仅获得10%的CPU。
为了防止这种情况,一些系统在调度进程之前会考虑哪个用户拥有进程。在这个模型中,每个用户都被分配了CPU的一部分,调度程序以强制执行的方式选择进程。因此,如果向两个用户承诺每人50%的CPU,那么无论他们有多少进程,他们都会得到50%的CPU。
举个例子,考虑一个有两个用户的系统,每个用户承诺占用50%的CPU。用户1有四个进程(A、B、C和D),用户2只有一个进程(E)。如果使用循环调度,则满足所有约束的可能调度序列如下:
A E B E C E D E A E B E C E E D E ...
另一方面,如果用户1有权获得用户2两倍的CPU时间,我们可能会得到:
A B E C D E A B E C D E ...
当然,还有许多其他的可能性,可以利用,取决于公平的概念是什么。
多队列
多级队列调度算法将就绪队列划分为几个单独的队列,例如,在多级队列调度中,进程被永久分配给一个队列。根据进程的某些属性,如内存大小、进程优先级、进程类型,这些进程被永久分配给另一个进程。算法从具有最高优先级的已占用队列中选择进程,然后运行该进程。

多级反馈队列
多级反馈队列调度算法允许进程在队列之间移动,使用许多就绪队列,并将不同的优先级与每个队列相关联。算法从占用的队列中选择优先级最高的进程,并以抢占或非抢占方式运行该进程,如果进程使用了太多CPU时间,它将移动到低优先级队列。类似地,在较低优先级队列中等待时间过长的进程可能会被移动到较高优先级队列,也可能被移动到最高优先级队列。请注意,这种形式的老化可以防止饥饿。例子:
- 进入就绪队列的进程被放置在队列0中。
- 如果未在8毫秒内完成,则会将其移动到队列1的尾部。
- 如果它没有完成,它将被抢占并放入队列2中。
- 队列2中的进程仅在队列0和队列1为空时,在FCFS基础上运行,只有当队列2在FCFS基本队列上运行。
三个队列:Q0–RR,时间量为8毫秒;Q1–RR时间量16毫秒;Q2–FCFS。
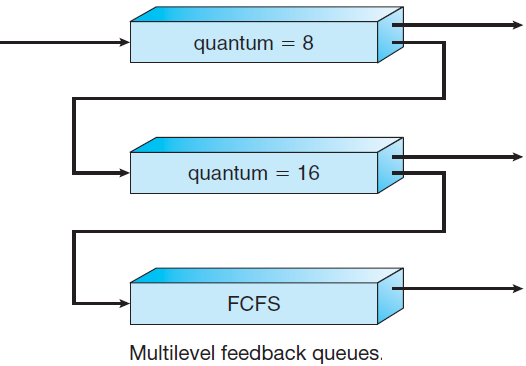
通常,多级反馈队列调度程序定义的参数有:队列数,每个队列的调度算法,用于确定何时将进程升级到更高优先级队列的方法,用于确定何时将进程降级到较低优先级队列的方法,用于确定进程需要服务时将进入哪个队列的方法。
18.4.5.5 调度总结
进程调度在实际运行环境中,需要考量CPU、核心数量、IO等因素的影响,然后通过不同的调度算法来统计其数据,从而得出相对客观且有参考价值的调度数据。评估示意图如下:
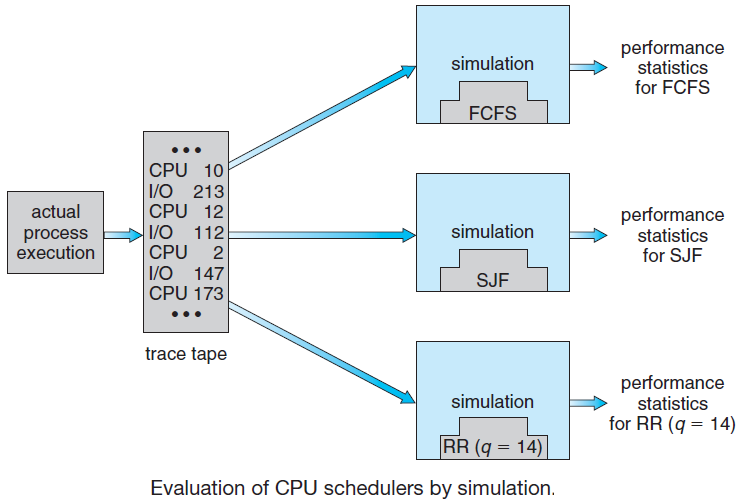
各种调度策略的特点:
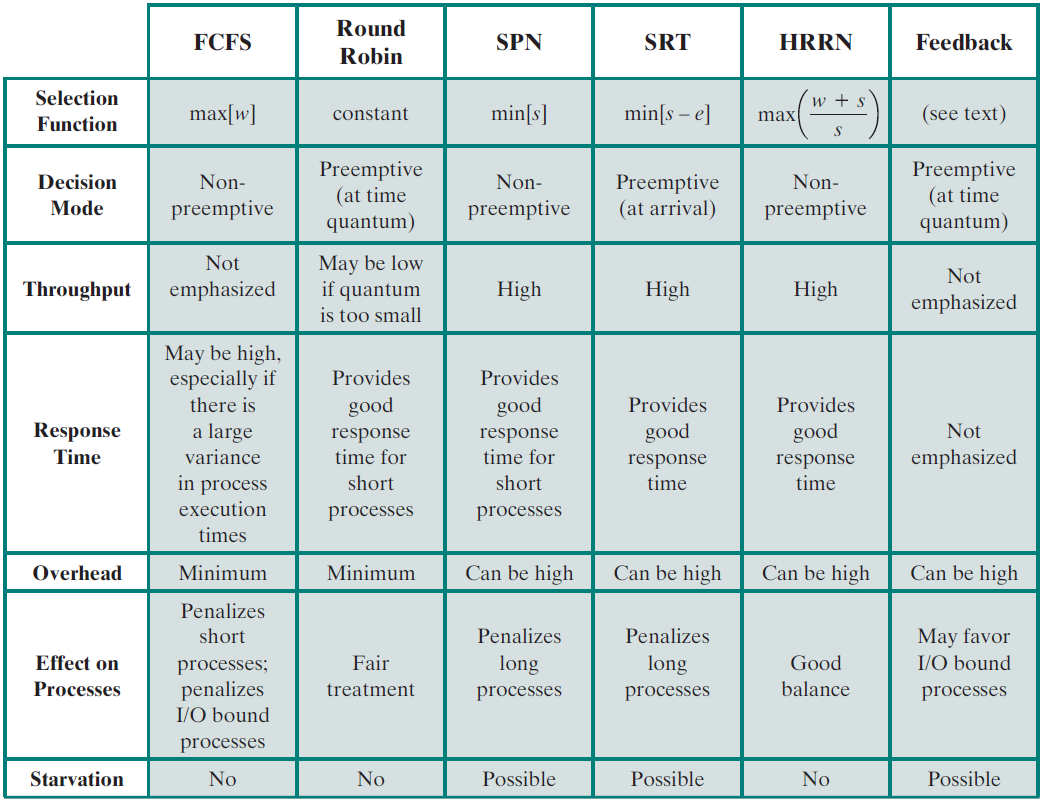
调度策略的时序对比图:
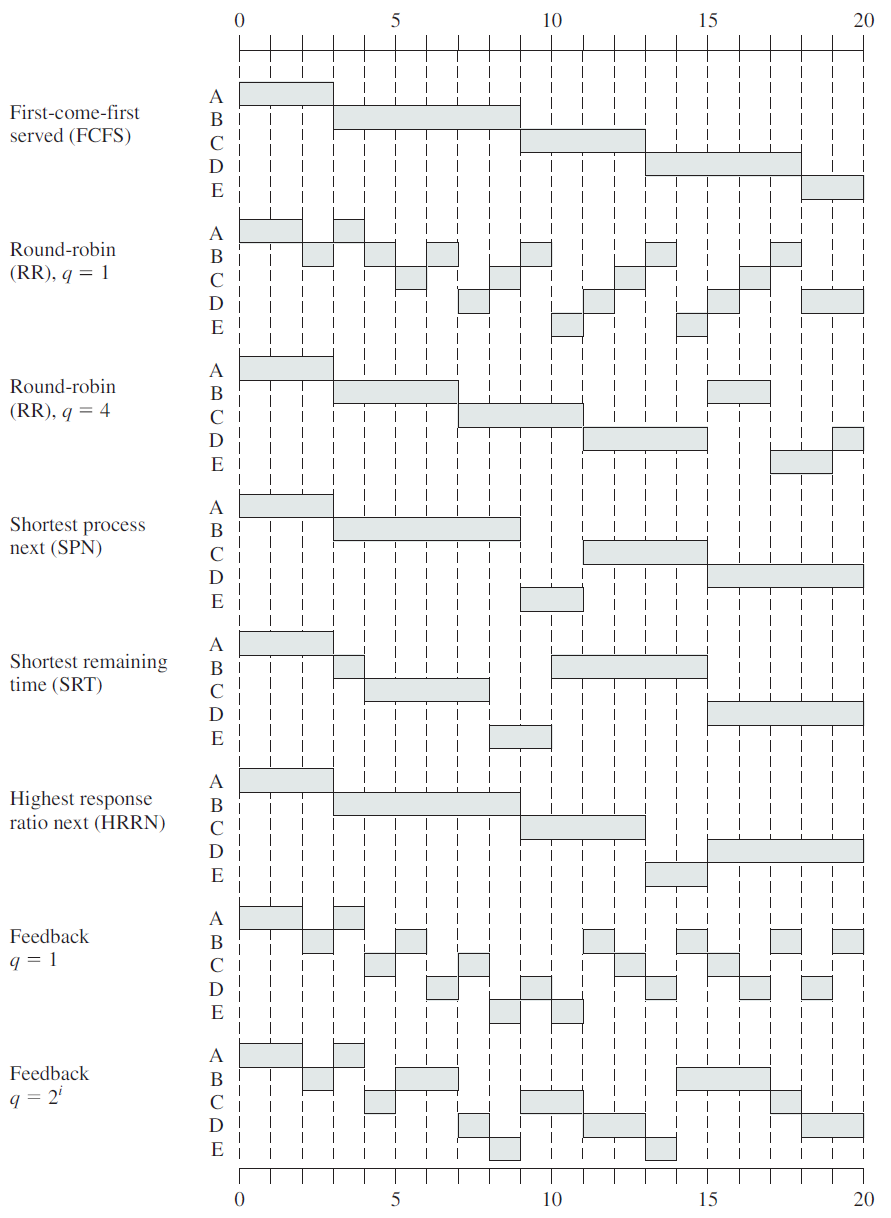
调度策略的综合对比:

除了上述出现的调度算法,实际上还有很多其它调度策略,如适用于实时操作系统的时限调度(Deadline Scheduling)、比率单调调度(Rate Monotonic Scheduling)等。
另外,还存在优先级反转(Priority Inversion),它是一种可能发生在任何基于优先级的抢占式调度方案中的现象,但在实时调度环境中尤其相关。优先级反转的最著名例子涉及火星探路者(Pathfinder)任务,这个漫游机器人于1997年7月4日登陆火星,开始收集大量数据并将其传送回地球。但在任务开始几天之后,着陆器软件开始经历整个系统重置,每次都会导致数据丢失。在建造“探路者”号的喷气推进实验室团队进行了大量努力之后,问题被追溯到优先级反转。
在任何优先级调度方案中,系统应始终以最高优先级执行任务。当系统内的情况迫使较高优先级的任务等待较低优先级的任务时,会发生优先级反转。如果较低优先级的任务锁定了资源(如设备或二进制信号量),而较高优先级的任务试图锁定同一资源,则会发生优先级反转的简单示例。在资源可用之前,优先级较高的任务将处于阻塞状态。如果较低优先级的任务很快完成并释放资源,则较高优先级的任务可能会很快恢复,并且可能不会违反实时约束。
一种更严重的情况称为无限优先级反转(Unbound Priority Inversion),其中优先级反转的持续时间不仅取决于处理共享资源所需的时间,还取决于其他不相关任务的不可预测的操作。Pathfinder软件中经历的优先级反转是无限的,是个很好的例子。
18.4.6 进程属性
Windows进程的常见属性在任务管理器中可以查看,它们的详情如下所述:
-
名字。通常是进程所基于的可执行文件名,但不是进程的唯一标识符。有些进程似乎根本没有可执行名称,例如包括系统、安全系统、注册表、内存压缩、系统空闲进程和系统中断。
- 系统中断(System Interrupt)实际上不是一个进程,只是用来衡量内核服务硬件中断和延迟过程调用所花费的时间。
- 系统空闲进程也不是真正的进程,它的进程ID(PID)始终为零,只是描述了Windows空闲时间——CPU无事可做时的占比。
- 系统进程是一个真正的过程,在技术上也是一个最小化进程,总是有一个4的PID。它代表内核空间中发生的一切——内核和内核驱动程序使用的内存、开放句柄、线程等。
- 安全系统进程仅在Windows 10和Server 2016(及更高版本)系统上可用,这些系统启动时启用了基于虚拟化的安全性。它代表了安全内核中发生的一切。
- 注册表进程是Windows 10版本1803(RS4)中可用的最小化进程,用作管理注册表的“工作区”,而不是像以前版本那样使用分页池。
- 内存压缩进程是Windows 10版本1607上可用的最小化进程,并在其地址空间中保存压缩内存。内存压缩是Windows 10中添加的一项功能,用于保存物理内存(RAM),特别适用于资源有限的设备,如手机和物联网设备。令人困惑的是,任务管理器没有显示此进程,但可被Process Explorer正确显示。
-
PID。进程的唯一ID,是4的倍数,其中最低有效PID值为4(属于系统进程)。一旦进程终止,进程ID将被重用,因此可以看到一个新进程。如果进程需要唯一标识符,则PID和流程启动时间的组合在特定系统上确实是唯一的。
-
状态(Status)。状态可以有三个值之一:运行(Running)、挂起(Suspended)和不响应(Not Responding),根据进程类型总结了它们的含义。
进程类型 运行时的情况 挂起的情况 不响应的情况 GUI进程(非UWP) GUI线程可响应时 进程中的所有线程都挂起 GUI线程至少5秒未检查消息队列 CUI进程(非UWP) 至少有一个线程未挂起 进程中的所有线程都挂起 用不 UWP进程 在后台 在后台 GUI线程至少5秒未检查消息队列 常见的状态转换如下图所示:
![]()
-
用户名。用户名指示进程正在哪个用户下运行。令牌对象附加到进程(称为主令牌),该进程基于用户保存进程的安全上下文。该安全上下文包含用户所属的组、权限等信息。进程可以在特定的内置用户下运行,例如本地系统(在任务管理器中显示为系统)、网络服务和本地服务。这些用户帐户通常用于运行服务。
-
会话ID。进程在其下执行会话的会话号,会话0用于系统进程和服务,会话1及以上用于交互式登录。
-
CPU。显示该进程的CPU消耗百分比,注意它仅显示整数。要获得更好的精度,请使用Process Explorer。
-
内存。与内存相关的列有些棘手,任务管理器显示的默认列是内存(活动专用工作集)或内存(专用工作集,早期版本)。术语工作集是指RAM(物理存储器),私有工作集是进程使用的RAM,不与其他进程共享。共享内存最常见的例子是DLL代码。活动专用工作集与专用工作集相同,但对于当前挂起的UWP进程设置为零。以上两个计数器是否能很好地指示进程使用的内存量?不幸的是,不是。这些指示使用的是专用RAM,但是当前被调出的内存呢?还有另一列——提交大小(Commit Size),用于了解进程内存使用情况的最佳列。任务管理器默认情况下不显示此列。
-
基本优先级。基本优先级列(正式称为优先级类)显示了六个值中的一个,为该进程中执行的线程提供基本调度优先级。与优先级相关联的可能值如下:
- 低(Idle)= 4
- 低于正常 = 6
- 正常(Normal) = 8。最常见(默认)的优先级类别是正常(8)。
- 高于正常 = 10
- 高(High) = 13
- 实时(Real-Time) = 24
-
句柄。显示在特定进程中打开的内核对象的句柄数量。
-
线程。“线程”列显示每个进程中的线程数量。通常至少应该是一个,因为没有线程的进程是无用的。但是,一些进程显示为没有线程。具体来说,安全系统显示为没有线程,因为安全内核实际上使用普通内核进行调度。系统中断伪进程根本不是进程,因此不能有任何线程。最后,系统空闲进程也不拥有线程。此进程显示的线程数是系统上的逻辑处理器数。
进程更详细的属性表如下:
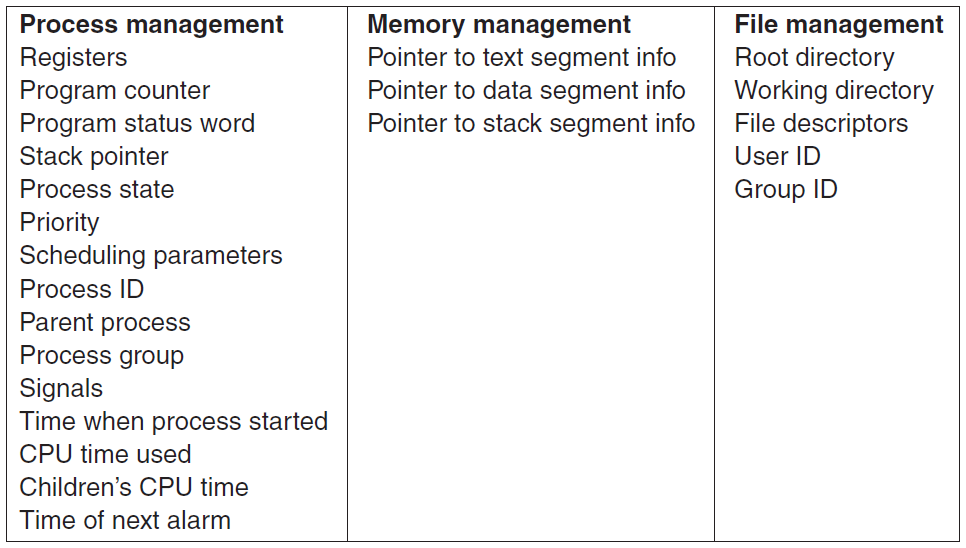
在虚拟内存的用户进程:
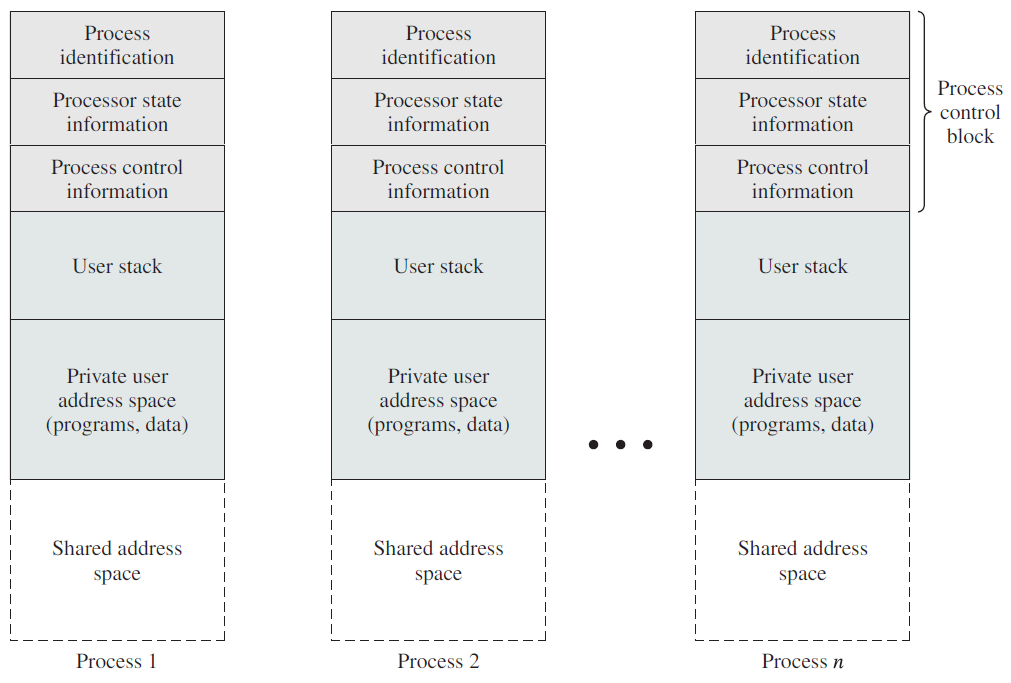
18.4.7 进程操作
进程创建中涉及的主要部分如下图所示。
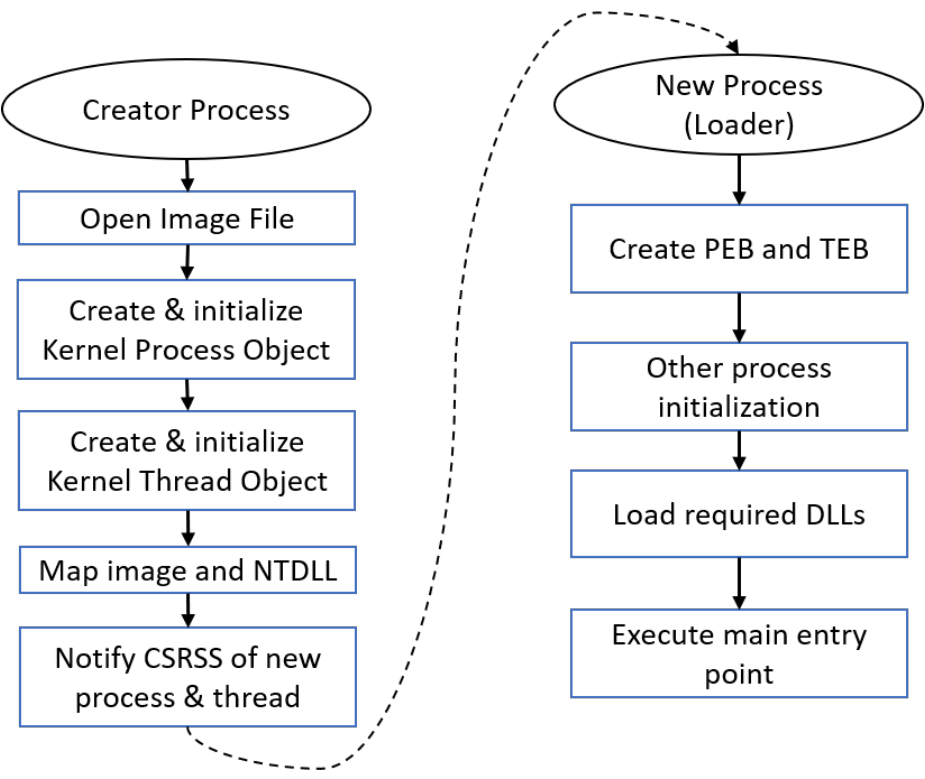
1、Open Image File
内核打开镜像(可执行文件)文件,并验证其是否为可移植可执行文件(PE)的正确格式。文件扩展名并不重要,实际内容才重要。假设各种头文件有效,内核将创建一个新的进程内核对象和一个线程内核对象,因为一个正常进程是由一个线程创建的,最终应该执行主入口点。
2、Create & Initialize Kernel Process Object
此时,内核将映像映射到新进程的地址空间以及NtDll.Dll。NtDll映射到每个进程(最小和微进程除外),因为它在进程创建的最后阶段具有非常重要的职责,并且是调用系统调用的最终阶段。创建进程仍在执行的最后一个主要步骤是通知Windows子系统进程(Csrss.exe)已创建新进程和线程。(Csrss可以被认为是内核管理Windows子系统进程某些方面的助手)。
3、Create & Initialize Kernel Thread Object
此时,从内核的角度来看,进程已经成功创建,因此调用方调用的进程创建函数(通常是CreateProcess)返回成功。然而,新进程尚未准备好执行其初始代码。进程初始化的第二部分必须在新进程的上下文中由新创建的线程执行。
一些开发人员认为,在新流程中运行的第一件事是可执行文件的主要功能。然而,在实际的主函数开始运行之前,还有很多事情要做,最明显的是NtDll,因为目前进程中没有其他操作系统级代码。此时,NtDll有几个职责:
- 首先,它为进程创建用户模式管理对象,称为进程环境块(PEB),并为第一个线程创建用户模式控制对象,称之为线程环境块(TEB)。这些结构部分记录(在<winternl.h>中),正式不应由开发人员直接使用。也就是说,在某些情况下,此结构是有用的,特别是在试图实现难以实现的事情时。
- 然后执行其他一些初始化,包括创建默认进程堆、创建和初始化默认进程线程池等。
- 入口点开始执行之前的最后一个主要部分是加载所需的DLL,通常称为加载器。加载程序查看可执行文件的导入部分,其中包括可执行文件所依赖的所有库。这些通常包括Windows子系统dll,如kernel32.dll、user32.dll,gdi32.dll和advapi32.dll。
实际上,开发人员可以编写四个主要函数,每个函数都有相应的C/C++运行时函数。下表总结了这些名称及其使用时间。
| 开发人员的main | C/C++运行时起点 | 场景 |
|---|---|---|
| main | mainCRTStartup | 使用ASCII字符的控制台应用程序 |
| wmain | wmainCRTStartup | 使用Unicode字符的控制台应用程序 |
| WinMain | WinMainCRTStartup | 使用ASCII字符的GUI应用程序 |
| wWinMain | wWinMainCRTStartup | 使用Unicode字符的GUI应用程序 |
大多数进程将在系统关闭之前的某个时间点终止,有几种方法可以退出或终止进程。需要记住的一点是,无论进程如何终止,内核都会确保进程没有私有的内容:释放所有私有(非共享)内存,并关闭进程句柄表中的所有句柄。如果满足以下任一条件,则过程终止:
1、进程中的所有线程退出或终止。
2、进程中的任何线程调用了ExitProcess。
3、使用TerminateProcess终止进程(通常在外部,但可能是由于未处理的异常)。
编写Windows应用程序的开发者通常会在某个时刻发现执行主函数的线程是“特殊的”,通常称为主线程。可以观察到,无论何时主函数返回,进程都会退出——似乎是上述流程退出原因中未列出的场景。然而,它确实如此,实际是上述的情形2。C/C++运行时库调用main/WinMain,然后执行所需的清理,如调用全局C++析构函数、C运行时清理等,最后调用ExitProcess,导致进程退出。
从内核的角度来看,进程中的所有线程都是相等的,并且没有主线程。当内核中的所有线程退出/终止时,内核会销毁进程,因为没有线程的进程几乎是无用的。实际上,这种情况只能在原生进程(仅依赖于NtDll.dll且没有C/C++运行时的可执行文件)中实现。换句话说,在正常的Windows编程中不太可能发生。
18.4.8 进程补述
18.4.8.1 多程序设计建模
当使用多道程序设计时,CPU利用率可以提高。粗略地说,如果平均进程只计算了它在内存中的20%的时间,那么当五个进程同时在内存中时,CPU应该一直处于繁忙状态。然而,这个模型是不切实际的乐观,因为它默认所有五个进程永远不会同时等待I/O。
一个更好的模型是从概率的角度来看CPU的使用情况。假设一个进程花了一小部分时间等待I/O完成,当内存中同时有\(n\)个进程时,所有\(n\)个进程等待I/O的概率为\(p^n\)(在这种情况下,CPU将处于空闲状态)。CPU利用率由以下公式给出:
下图显示了CPU利用率作为\(n\)的函数——称为多道程序设计的程度。
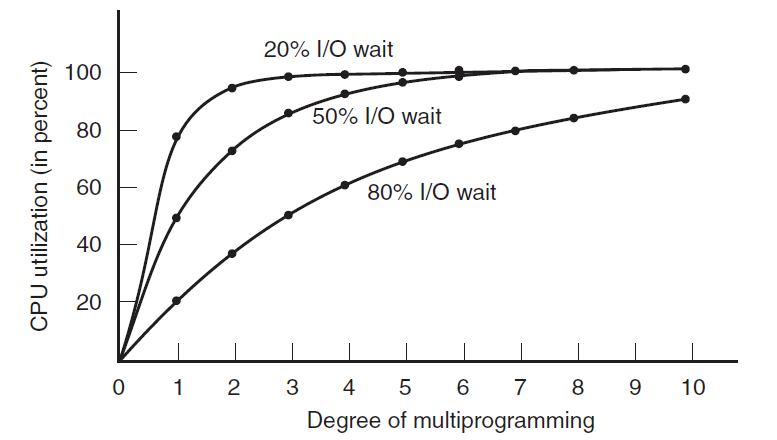
CPU利用率是内存中进程数的函数。
从图中可以明显看出,如果进程花费80%的时间等待I/O,那么必须同时在内存中至少有10个进程才能使CPU浪费低于10%。当你意识到等待用户在终端键入内容(或单击图标)的交互式进程处于I/O等待状态时,应该很清楚,80%以上的I/O等待时间并不罕见。但即使在服务器上,执行大量磁盘I/O的进程通常也会有这个百分比或更多。
为了准确起见,应该指出,刚才描述的概率模型只是一个近似值。它隐式假设所有n个进程都是独立的,意味着内存中有5个进程的系统可以有三个运行,两个等待。但是,对于单个CPU,我们不能同时运行三个进程,因此在CPU繁忙时准备就绪的进程将不得不等待,因此,这些进程不是独立的。使用排队论可以构建更精确的模型,但我们所做的多道程序设计让进程在CPU空闲时使用它,当然,即使上图中的真实曲线与图中所示的曲线略有不同,它仍然有效。
尽管上图中的模型思想简单,但它仍然可以用于对CPU性能进行具体的、尽管是近似的预测。例如,假设一台计算机有8GB内存,操作系统及其表占2GB,每个用户程序也占2GB。这些大小允许三个用户程序同时在内存中,平均I/O等待时间为80%时,CPU利用率(忽略操作系统开销)为\(1− 0.8^3\)或约49%。再增加8GB内存,系统就可以从三路多道程序设计过渡到七路多道编程,从而将CPU利用率提高到79%。换句话说,额外的8GB将提高30%的吞吐量。
再增加8GB只会将CPU利用率从79%提高到91%,因此吞吐量只会再提高12%。使用这个模型,计算机的所有者可能会认为第一次增加内存是一项不错的投资,但第二次不是。
18.4.8.2 加载和链接
创建活动进程的第一步是将程序加载到主内存中并创建进程映像(下图),下下图描述了大多数系统的典型场景。应用程序由多个编译或组装的目标代码形式的模块组成,这些模块被链接以解析模块之间的任何引用,同时,解析对库例程的引用。库例程本身可以合并到程序中或作为共享代码引用,这些代码必须在运行时由操作系统提供。
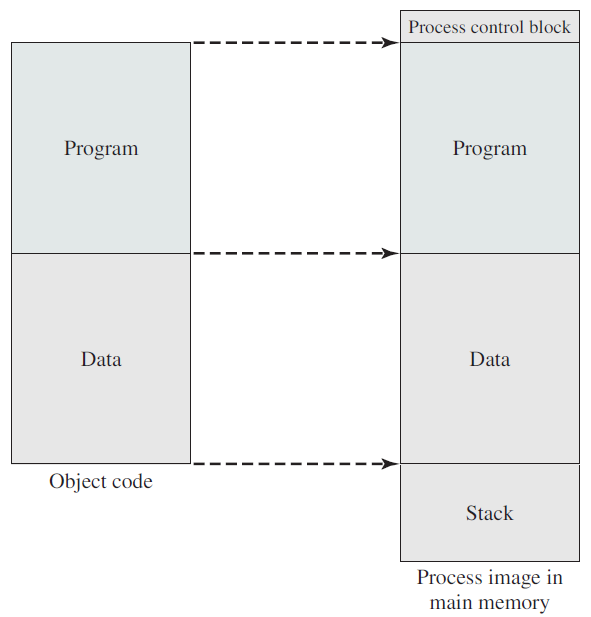
加载函数。
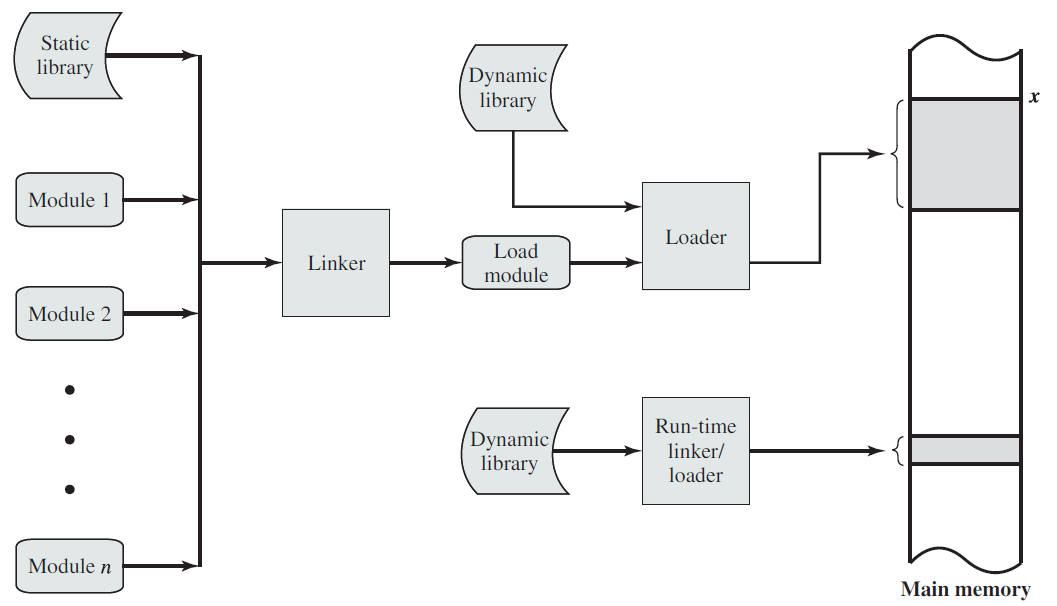
一个加载和链接的场景。
- 加载
在上图中,加载器从位置开始将加载模块放置在主存储器中。在加载程序时,必须满足寻址要求。一般来说,可以采取三种方法:
1、绝对加载。
绝对加载绝对加载程序要求将给定的加载模块始终加载到主内存中的同一位置。因此,在呈现给加载器的加载模块中,所有地址引用都必须指向特定的或绝对的主内存地址。例如,如果上图中的x是位置1024,那么加载模块中指定给该内存区域的第一个字具有地址1024。
将特定地址值分配给程序内的内存引用可以由程序员完成,也可以在编译或汇编时完成。前一种方法有几个缺点,首先,每个程序员都必须知道将模块放入主存的预期分配策略,其次,如果对程序进行了任何修改,涉及到模块主体中的插入或删除,那么所有地址都必须更改。因此,最好允许程序中的内存引用以符号方式表示,然后在编译或汇编时解析这些符号引用,如下图所示,对指令或数据项的每个引用最初都用符号表示,在准备模块输入到绝对加载器时,汇编程序或编译器将把所有这些引用转换为特定地址(在本例中,对于从1024位置开始加载的模块),如下下图b所示。

2、可重定位加载。
可重定位加载在加载之前将内存引用绑定到特定地址的缺点是,生成的加载模块只能放在主内存的一个区域中。然而,当许多程序共享主内存时,可能不希望提前决定将特定模块加载到内存的哪个区域。最好在加载时做出该决定,因此,我们需要一个可以位于主内存中任何位置的加载模块。
为了满足这个新的要求,汇编程序或编译器生成的不是实际的主存储器地址(绝对地址),而是与某个已知点(例如程序的开始)相关的地址。这种技术如下图c所示。加载模块的开头被分配了相对地址0,并且模块内的所有其他内存引用都是相对于模块的开始来表示的。
由于所有内存引用都以相对格式表示,所以加载器将模块放置在所需的位置就成为一项简单的任务。如果要从位置开始加载模块,则加载程序必须在将模块加载到内存中时简单地添加到每个内存引用中。为了协助该任务,加载模块必须包含告诉加载器地址引用在哪里以及如何解释地址引用的信息(通常相对于程序源,但也可能相对于程序中的其他点,例如当前位置)。这组信息由编译器或汇编程序准备,通常称为重定位字典(relocation dictionary)。
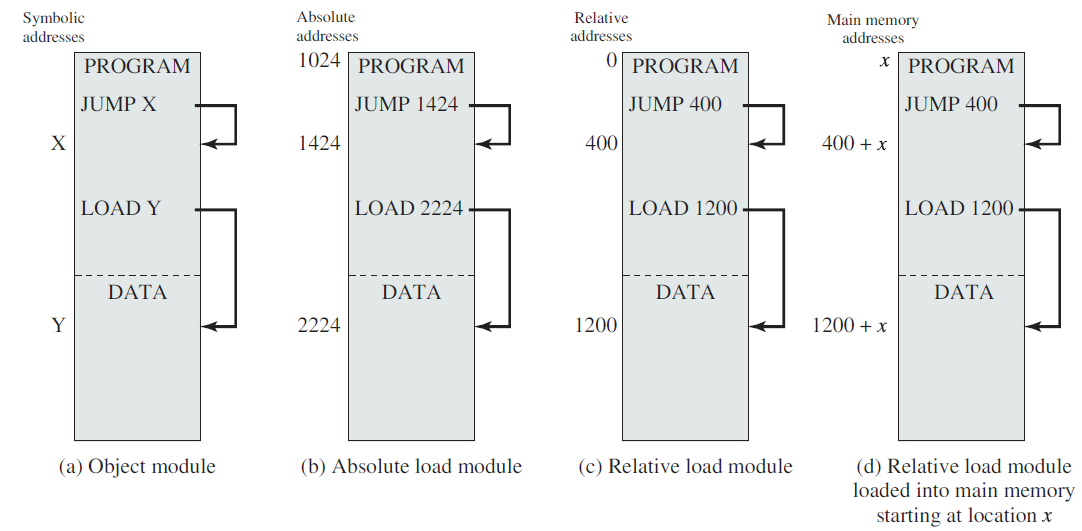
3、动态运行时加载。
重定位加载比较常见,相对于绝对加载,它具有明显的优势。然而,在多道程序设计环境中,即使是不依赖虚拟内存的环境,可重定位的加载方案依然不够。需要在主内存中交换进程映像,以最大限度地提高处理器的利用率。为了最大限度地提高主内存利用率,我们希望能够在不同的时间将进程映像交换回不同的位置。因此,一个程序一旦加载,就可以交换到磁盘上,然后在不同的位置重新交换。如果在初始加载时将内存引用绑定到绝对地址,是不可能的。
另一种方法是推迟绝对地址的计算,直到在运行时实际需要它。为此,加载模块被加载到主内存中,所有内存引用都以相对形式(上图c)。直到实际执行了一条指令,才计算出绝对地址。为了确保此功能不会降低性能,必须通过特殊的程序或硬件而不是软件来完成。
动态地址计算提供了完全的灵活性。程序可以加载到主存储器的任何区域,随后,程序的执行可以被中断,程序可以从主存储器中调出,稍后再调回另一个位置。
- 链接
链接器的功能是将一组目标模块作为输入,并生成一个加载模块,该加载模块由一组集成的程序和数据模块组成,并传递给加载器。在每个对象模块中,可能存在对其他模块中位置的地址引用。每个这样的引用只能在未链接的对象模块中用符号表示。链接器创建一个加载模块,它是所有对象模块的连续连接。每个模块内引用必须从符号地址更改为对整个加载模块内某个位置的引用。例如,图7中的模块A包含模块B的过程调用。当这些模块在加载模块中组合时,对模块B的符号引用将更改为对加载模块中B入口点位置的特定引用。
链接编辑器此地址链接的性质将取决于要创建的加载模块的类型以及链接发生的时间(上表b)。通常情况下,如果需要可重新定位的负载模块,则通常按以下方式进行连接。每个编译或组装的对象模块都是用相对于对象模块开头的引用创建的,所有这些模块都被放在一个单独的可重定位加载模块中,其中包含相对于加载模块原点的所有引用,该模块可以用作可重定位加载或动态运行时加载的输入。
产生可重定位加载模块的链接器通常被称为链接编辑器。下图显示了链接编辑器功能。
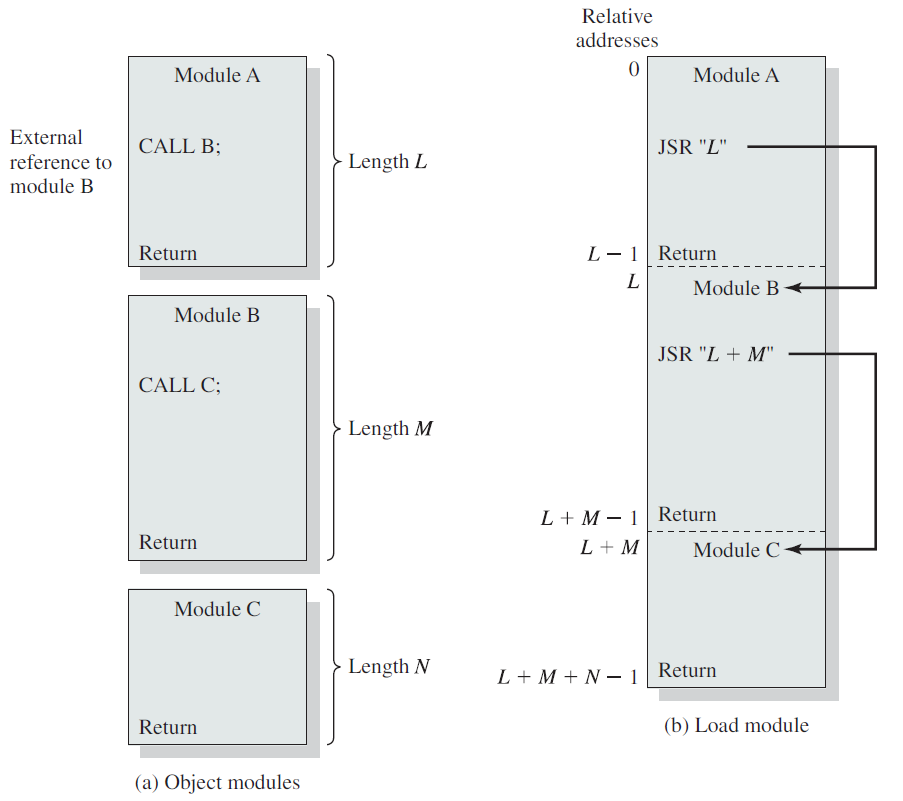
与加载一样,可以延迟某些链接功能。术语动态链接用于指将某些外部模块的链接延迟到加载模块创建之后的做法,因此加载模块包含对其他程序的未解析引用,这些引用可以在加载时或运行时解析。
对于加载时动态链接,需要执行以下步骤。将要加载的加载模块(应用程序模块)读入存储器,对外部模块(目标模块)的任何引用都会导致加载器找到目标模块,加载它,并从应用程序模块的开头将引用更改为内存中的相对地址。与所谓的静态链接相比,动态链接有几个优点:
1、合并目标模块的更改或升级版本变得更容易,目标模块可以是操作系统实用程序或其他通用例程。对于静态链接,对这种支持模块的更改将需要重新链接整个应用程序模块,这不仅效率低下,而且在某些情况下可能是不可能的。例如,在个人计算机领域,大多数商业软件都是以加载模块的形式发布的:源码和对象版本不发布。
2、在动态链接文件中包含目标代码为自动代码共享铺平了道路。操作系统可以识别多个应用程序正在使用相同的目标代码,因为它加载并链接了该代码。它可以使用该信息加载目标代码的单个副本并将其链接到两个应用程序,而不必为每个应用程序加载一个副本。
3、独立软件开发人员更容易扩展广泛使用的操作系统(如Linux)的功能。开发人员可以提出一个对各种应用程序有用的新函数,并将其打包为动态链接模块。
对于运行时动态链接,一些链接被推迟到执行时。目标模块的外部引用保留在加载的程序中。当调用不存在的模块时,操作系统定位该模块,加载该模块,并将其链接到调用模块。这些模块通常是可共享的,在Windows环境中,这些称为动态链接库(DLL)。因此,如果一个进程已经在使用动态链接的共享模块,则该模块位于主内存中,新进程可以简单地链接到已加载的模块。
如果两个或多个进程共享一个DLL模块,但期望该模块的不同版本,则使用DLL可能会导致通常称为DLL地狱(DLL hell)的问题。例如,可能会重新安装应用程序或系统功能,并将较旧版本的DLL文件带入其中。
我们已经看到,动态加载允许整个加载模块到处移动,但是,模块的结构是静态的,在整个进程的执行过程中以及从一个执行到下一个执行都保持不变。但是,在某些情况下,无法在执行之前确定需要哪些对象模块,例如事务处理应用程序(如航空公司预订系统或银行应用程序),事务的性质决定了需要哪些程序模块,它们被适当地加载并与主程序链接。使用这种动态链接器的优点是,除非引用了程序单元,否则不必为程序单元分配内存。此功能用于支持分段系统。
一个额外的细化是可行的:应用程序不需要知道可能被调用的所有模块或入口点的名称。例如,可以编写绘图程序以与各种绘图仪配合使用,每个绘图仪都由不同的驱动程序包驱动。应用程序可以从另一个进程或在配置文件中查找当前安装在系统上的绘图仪的名称,这允许应用程序的用户安装在编写应用程序时不存在的新绘图仪。
18.5 线程
线程是通过进程代码的执行流,有自己的程序计数器、系统寄存器和堆栈,是通过并行提高应用程序性能的一种流行方法。线程有时称为轻量级进程,代表了一种通过减少超线程来提高操作系统性能的软件方法,相当于一个经典的进程。每个线程只属于一个进程,进程外不能存在任何线程,每个线程代表一个单独的控制流。
一些操作系统提供了用户级线程和内核级线程的组合功能,Solaris就是这种组合方法的一个很好的例子。在组合系统中,同一应用程序中的多个线程可以在多个处理器上并行运行,阻塞系统调用不需要阻塞整个进程。
18.5.1 线程和进程
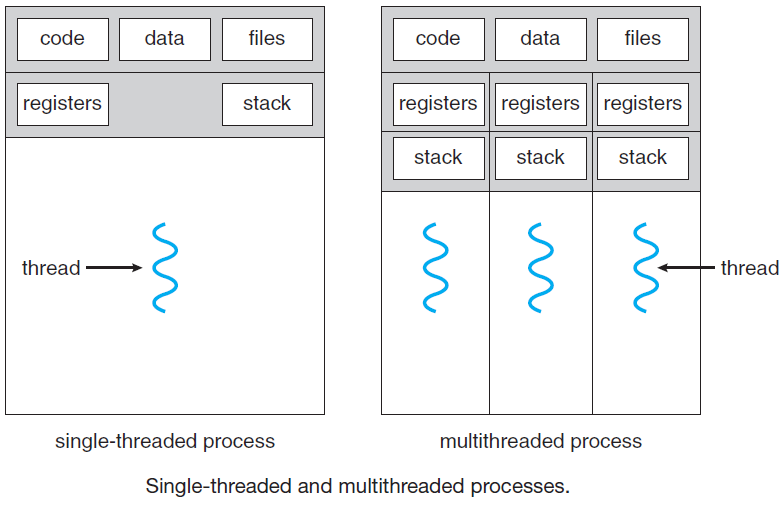
在下图(a)中,我们看到了三个传统进程,每个进程都有自己的地址空间和单个控制线程。相反,在下图(b)中,我们看到一个具有三个控制线程的单个进程。尽管在这两种情况下,我们都有三个线程,但在下图(a)中,每个线程都在不同的地址空间中运行,而在下图(b)中,三个线程共享相同的地址空间。当多线程进程在单个CPU系统上运行时,线程轮流运行。通过在多个进程之间来回切换,系统提供了并行运行的独立顺序进程的错觉。多线程的工作方式相同,CPU在线程之间快速来回切换,提供了线程并行运行的假象,尽管在比实际CPU慢的CPU上运行。在一个进程中有三个计算绑定线程,这些线程看起来是并行运行的,每个线程在一个CPU上的速度是实际CPU的三分之一。
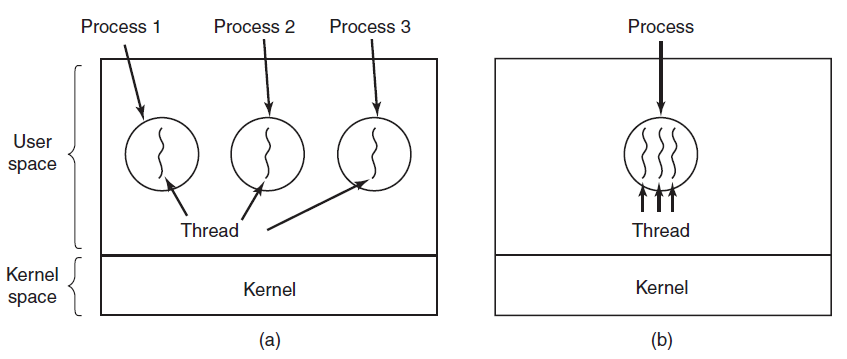
(a) 三个进程,每个进程有一个线程。(b) 一个进程有三个线程。
进程中的不同线程不像不同进程那样独立。所有线程都有完全相同的地址空间,意味着它们也共享相同的全局变量。由于每个线程都可以访问进程地址空间内的每个内存地址,因此一个线程可以读取、写入甚至清除另一个线程的堆栈。线程之间没有保护,原因有二:其一,这是不可能的;其二,不应该有保护。不同的进程可能来自不同的用户,并且可能相互竞争,不同的是,一个进程总是由一个用户拥有,该用户可能创建了多个线程,以便他们能够合作,而不是竞争。除了共享地址空间外,所有线程还可以共享同一组打开的文件、子进程、警报和信号等,如下表所示。因此,当三个进程基本无关时,将使用上图(a)的组织,然而,当三个线程实际上是同一工作的一部分并且相互积极密切合作时,上图(b)是合适的。
| 逐进程数据项 | 逐线程数据项 |
|---|---|
| 地址空间 全局变量 打开文件 子进程 待定报警 信号和信号处理 账号信息 |
程序计数器 寄存器 堆栈 状态 |
第一列中的项目是进程属性,而不是线程属性。例如,如果一个线程打开了一个文件,则该文件对进程中的其他线程可见,并且它们可以读取和写入该文件。这是合乎逻辑的,因为进程是资源管理的单元,而不是线程。如果每个线程都有自己的地址空间、打开的文件、挂起的警报等,那么它将是一个单独的进程。我们试图通过线程概念实现的是多个执行线程共享一组资源的能力,以便它们能够紧密协作来执行某些任务。
Windows进程和线程对比图。
与传统进程(即只有一个线程的进程)一样,线程可以处于以下几种状态之一:运行、阻塞、就绪或终止。正在运行的线程当前具有CPU并且处于活动状态。相反,阻塞的线程正在等待某个事件解除阻塞。例如,当线程执行从键盘读取的系统调用时,它会被阻塞,直到输入被键入为止。线程可以阻止等待某个外部事件发生或其他线程解除阻止。就绪线程计划运行,并在轮到它时立即运行,线程状态之间的转换与进程状态之间的过渡相同。
重要的是要认识到每个线程都有自己的堆栈,如下图所示。每个线程的堆栈包含一个帧,用于每个调用但尚未返回的过程。此帧(frame)包含过程的局部变量和过程调用完成时要使用的返回地址。例如,如果过程X调用过程Y,而Y调用过程Z,那么在执行Z时,X、Y和Z的帧都将位于堆栈上。每个线程通常会调用不同的过程,因此具有不同的执行历史。这就是为什么每个线程都需要自己的堆栈。
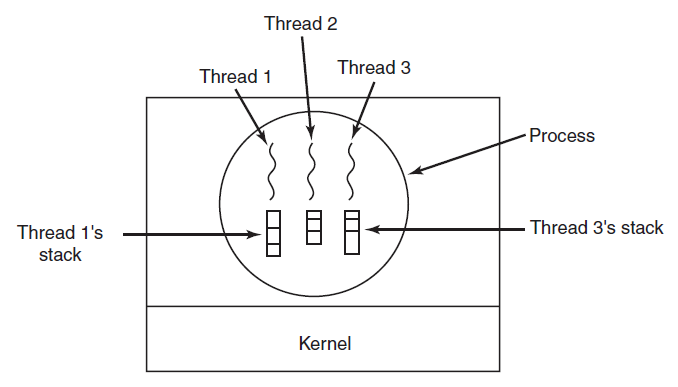
每个线程都有自己的堆栈。
当存在多线程时,进程通常以单个线程开始。此线程能够通过调用库过程(如线程创建)来创建新线程。线程创建的参数指定要运行新线程的过程的名称。没有必要(甚至不可能)指定任何关于新线程地址空间的内容,因为它会自动在创建线程的地址空间中运行。有时线程是分层的,具有父子关系,但通常不存在这种关系,所有线程都是相等的。无论是否具有层次关系,创建线程通常都会返回一个线程标识符,用于命名新线程。
当一个线程完成它的工作时,它可以通过调用库过程来退出,比如线程退出。然后它会消失,不再可调度。在某些线程系统中,一个线程可以通过调用过程等待(特定)线程退出,例如线程联接。此过程将阻塞调用线程,直到(特定)线程退出。在这方面,线程创建和终止与进程创建和终止非常相似,也有大致相同的选项。
另一个常见的线程调用是线程放弃(thread yield),它允许一个线程自愿放弃CPU时间片,让另一个线程运行。这种机制很重要,因为没有时钟中断来实际执行多道程序,就像进程一样。因此,线程要有礼貌,并不时主动放弃CPU,以给其他线程一个运行的机会。其他调用允许一个线程等待另一个线程完成一些工作,等待一个线程宣布它已经完成了一些工作,依此类推。
虽然线程通常很有用,但它们也给编程模型带来了许多复杂性。首先,考虑UNIX fork系统调用的效果。如果父进程有多个线程,那么子进程是否也应该有它们?如果没有,进程可能无法正常运行,因为所有这些可能都是必需的。
但是,如果子进程获得的线程数与父进程相同,那么如果父进程中的线程在读调用(例如从键盘进行的读调用)中被阻塞,会发生什么情况?现在键盘上有两个线程被阻塞了吗?一个在父线程,一个在子线程?当一行被键入时,两个线程都会得到它的副本吗?只有父母?只有孩子?打开的网络连接也存在同样的问题。
另一类问题与线程共享许多数据结构有关。如果一个线程关闭一个文件,而另一个线程仍在读取该文件,会发生什么情况?假设一个线程注意到内存太少,并开始分配更多内存。中途,线程切换发生,新线程还注意到内存太少,并开始分配更多内存,结果内存可能会分配两次。这些问题可以通过一些努力来解决,但要使多线程程序正确工作,需要仔细考虑和设计。
18.5.2 多线程模型
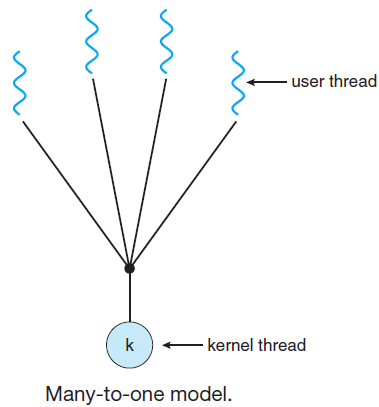
多线程模型有三种类型:
-
多对多关系。在这个模型中,许多用户级线程多路复用到数量较小或相等的内核线程,内核线程的数量可能特定于特定的应用程序或特定的计算机。在这个模型中,开发人员可以根据需要创建任意多个用户线程,相应的内核线程可以在多处理器上并行运行。
![]()
-
多对一关系。多对一模型将多个用户级线程映射到一个内核级线程,线程管理是在用户空间中完成的。当线程进行阻塞系统调用时,整个进程将被阻塞。一次只有一个线程可以访问内核,因此多个线程无法在多处理器上并行运行。如果用户级线程库是在操作系统中实现的,则该系统不支持内核线程使用多对一关系模式。
![]()
-
一对一关系。用户级线程与内核级线程之间存在一对一的关系,此模型比多对一模型提供更多并发性。当一个线程进行阻塞的系统调用时,它允许另一个线程运行,支持在微处理器上并行执行多个线程。
![]()
此模型的缺点是创建用户线程需要相应的内核线程。OS/2、Windows NT和Windows 2000使用一对一关系模型。


18.5.3 多线程优点
多线程编程的好处可以分为四大类:
- 响应性。多线程交互应用程序可以允许程序继续运行,即使部分程序被阻止或正在执行较长的操作,从而提高对用户的响应能力。这种质量在设计用户界面时特别有用。例如,考虑一下当用户单击一个导致执行耗时操作的按钮时会发生什么。在操作完成之前,单线程应用程序将对用户无响应。相反,如果耗时的操作是在单独的线程中执行的,那么应用程序将保持对用户的响应。
- 资源共享。进程只能通过共享内存和消息传递等技术共享资源,这些技术必须由程序员明确调度,但默认情况下,线程共享其所属进程的内存和资源。共享代码和数据的好处是,它允许应用程序在同一地址空间内具有多个不同的活动线程。
- 经济。为进程创建分配内存和资源成本高昂。因为线程共享它们所属进程的资源,所以创建和上下文切换线程更经济。从经验上衡量开销的差异可能很困难,但一般来说,创建和管理进程比线程要花费更多的时间。例如,在Solaris中,创建进程比创建线程慢大约三十倍,上下文切换大约慢五倍。
- 可扩展性。在多处理器体系结构中,多线程的好处甚至更大,其中线程可以在不同的处理核心上并行运行。无论有多少可用处理器,单线程进程只能在一个处理器上运行。
总之,线程的优点/优点是最小化上下文切换时间,提供了进程内的并发性,高效沟通,创建和上下文切换线程更经济。利用多处理器体系结构–多线程的好处可以在多处理器体系架构中大大增加。
18.5.4 用户和内核线程
线程可分为用户级线程和内核级线程。
在用户线程中,线程管理的所有工作都由应用程序完成,内核不知道线程的存在。线程库包含用于创建和销毁线程、在线程之间传递消息和数据、调度线程执行以及保存和恢复线程上下文的代码。应用程序从单个线程开始,并开始在该线程中运行,用户级线程的创建和管理通常很快。
用户级线程相对于内核级线程的优势:线程切换不需要内核模式特权,用户级线程可以在任何操作系统上运行,计划可以是特定于应用程序的,用户级线程的创建和管理速度很快。
用户级线程的缺点:在典型的操作系统中,大多数系统调用都是阻塞的,多线程应用程序无法利用多处理。
在内核级线程中,由内核完成的线程管理。应用程序区域中没有线程管理代码,操作系统直接支持内核线程。任何应用程序都可以编程为多线程,单个进程支持应用程序中的所有线程。
内核维护整个进程以及进程中各个线程的上下文信息,内核的调度是在线程的基础上完成的,内核在内核空间中执行线程创建、调度和管理,内核线程的创建和管理速度通常比用户线程慢。
内核级线程的优点:内核可以在多个进程上同时调度来自同一进程的多个线程,如果进程中的一个线程被阻塞,内核可以调度同一进程的另一个线程。内核例程本身可以多线程。
内核级线程的缺点:内核线程的创建和管理速度通常比用户线程慢,在同一进程中将控制权从一个线程转移到另一个线程需要将模式切换到内核。

用户和内核线程对比图。
线程涉及了复杂的状态转换,以下是操作系统常见的转换图:
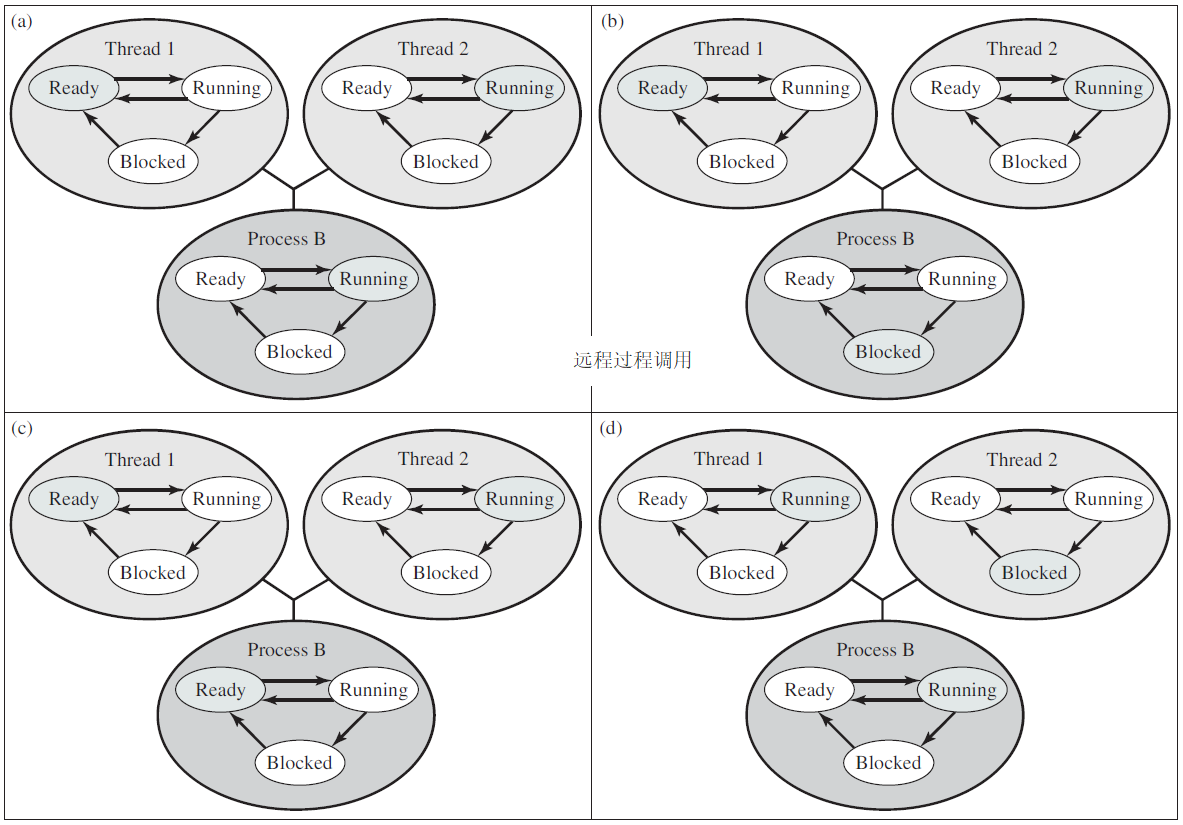
用户级线程状态和进程状态之间的关系示例。
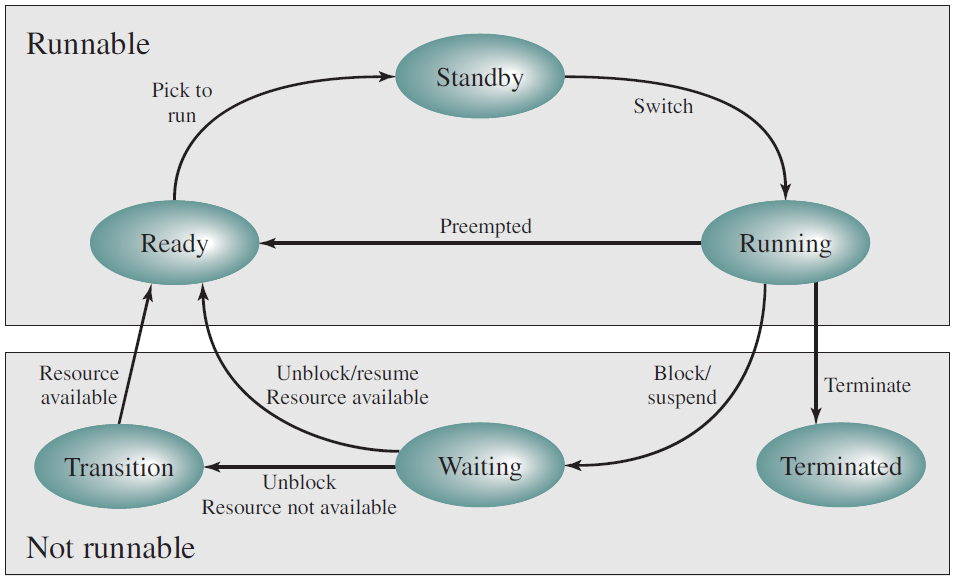
Windows线程状态转换图。
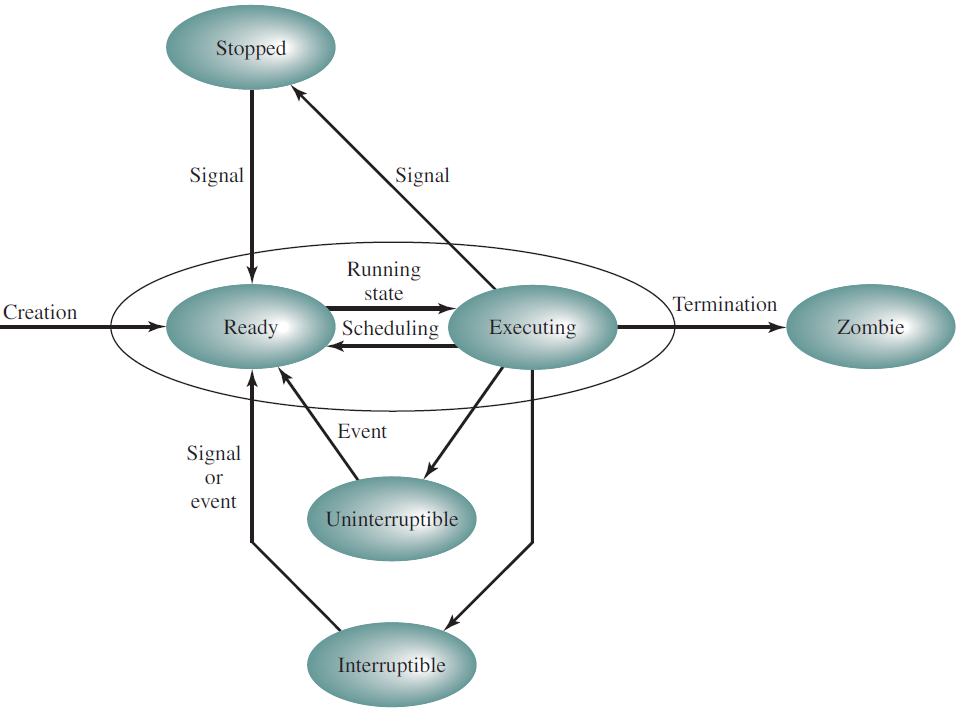
Linux进程、线程模型。
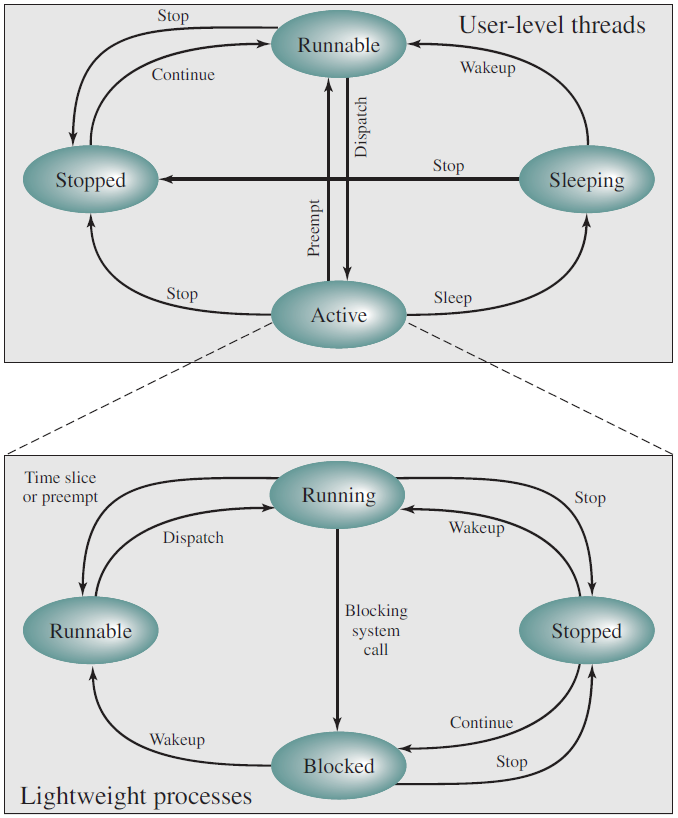
Solaris用户线程和LWP状态。
用户级线程和内核级线程之间的差异如下表:
| 用户线程 | 内核线程 | |
|---|---|---|
| 创建和管理速度 | 更快 | 较慢 |
| 实现方式 | 由用户级的线程库实现 | 操作系统直接支持 |
| 操作系统依赖性 | 可在任何操作系统上运行 | 特定于操作系统 |
| 命名方式 | 在用户级别提供的支持称为用户级别线程 | 内核可能提供的支持称为内核级线程 |
| 多核利用 | 无法利用多处理的优势 | 内核例程本身可以是多线程的 |
进程和线程的区别如下表:
| 进程 | 线程 | |
|---|---|---|
| 量级 | 重量级进程 | 轻量级进程(仅对类Linux) |
| 切换 | 进程切换需要与操作系统交互 | 线程切换不需要调用操作系统并导致内核中断 |
| 共享 | 在多进程中,每个进程执行相同的代码,但有自己的内存和文件资源 | 所有线程共享同一组打开的文件、子进程 |
| 阻塞 | 如果一个服务进程被阻塞,则在它被阻塞之前,无法执行其他服务进程 | 当一个服务线程被阻塞并等待时,同一任务中的第二个线程可以运行 |
| 冗余 | 多冗余进程比多线程进程使用更多资源 | 多线程进程比多冗余进程使用更少的资源 |
| 独立性 | 在多进程中,每个进程都独立于其他进程运行 | 一个线程可以读取、写入甚至完全清除另一个线程堆栈 |
实现线程有两个主要位置:用户空间和内核空间,以及它们的混合实现。下面将描述这些方法及其优缺点。
- 用户空间线程
这种方法将线程包完全放在用户空间中,内核对它们一无所知。就内核而言,它管理的是普通的单线程进程。第一个也是最明显的优点是,用户级线程包可以在不支持线程的操作系统上实现。过去所有的操作系统都属于这一类,甚至现在仍有一些。使用这种方法,线程由库实现。所有这些实现都具有相同的总体结构,如下图所示。线程运行在运行时系统之上,运行时系统是管理线程的进程的集合。
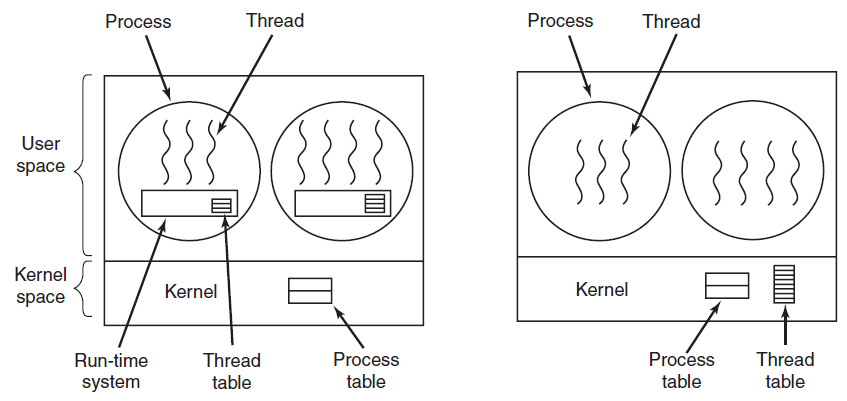
左:用户级线程包。右:由内核管理的线程包。
当在用户空间中管理线程时,每个进程都需要自己的私有线程表来跟踪该进程中的线程。这个表类似于内核的进程表,只是它只跟踪每个线程的属性,例如每个线程的程序计数器、堆栈指针、寄存器、状态等等。线程表由运行时系统管理,当线程移动到就绪状态或阻塞状态时,重新启动线程所需的信息存储在线程表中,与内核在进程表中存储进程信息的方式完全相同。
当一个线程做了一些可能导致其在本地被阻塞的事情时,例如,等待其进程中的另一个线程完成某些工作,它将调用一个运行时系统过程。此过程检查线程是否必须置于阻塞状态。如果是这样,它将线程的寄存器(即它自己的)存储在线程表中,在表中查找准备运行的线程,并用新线程保存的值重新加载机器寄存器。一旦堆栈指针和程序计数器被切换,新线程就会自动重新启动。如果机器恰巧有一条指令存储所有寄存器,另一条指令加载所有寄存器,那么整个线程切换只需几个指令即可完成。这样做线程切换至少比捕获到内核快一个数量级,这是支持用户级线程包的有力论据。
然而,与进程有一个关键区别。当线程暂时完成运行时,例如,当它调用线程放弃时,线程放弃代码可以将线程的信息保存在线程表本身中。此外,它还可以调用线程调度程序来选择要运行的另一个线程。保存线程状态和调度程序的过程只是局部过程,因此调用它们比进行内核调用要高效得多。在其他问题中,不需要陷阱、不需要上下文切换、不需要刷新内存缓存等等。这些特点使得线程调度非常快速。
用户级线程还有其他优点。它们允许每个进程都有自己的定制调度算法。对于某些应用程序,例如,那些具有垃圾收集器线程的应用程序,不必担心线程在不方便的时候被停止。它们的伸缩性也更好,因为内核线程总是需要内核中的一些表空间和堆栈空间,如果有大量线程,可能是一个问题。
尽管它们的性能更好,但用户级线程包仍存在一些主要问题。首先是如何实现阻塞系统调用的问题,假设一个线程在按下任何键之前读取键盘,让线程实际执行系统调用是不可接受的,因为会停止所有线程。首先拥有线程的主要目标之一是允许每个线程使用阻塞调用,但要防止一个阻塞的线程影响其他线程。由于有阻塞系统调用,难以轻松实现这个目标。
系统调用可以全部更改为非阻塞(例如,如果没有缓冲字符,键盘上的读取只会返回0字节),但要求更改操作系统是不可取的。此外,用户级线程的一个论点是,它们可以在现有操作系统上运行。此外,更改read的语义将需要更改许多用户程序。
如果可以提前告知呼叫是否会阻塞,则可以使用另一种方法。在UNIX的大多数版本中,存在一个系统调用select,它允许调用者告诉预期的读取是否会阻塞。当存在此调用时,库过程read可以替换为一个新的过程,该过程首先执行select调用,然后仅在安全时执行read调用(即不会阻塞)。如果读取调用将阻塞,则不进行调用,而是运行另一个线程。下次运行时系统获得控制时,它可以再次检查读取是否现在是安全的。这种方法需要重写系统调用库的部分内容,效率低且不雅观,但别无选择。放置在系统调用周围进行检查的代码称为封套(jacket)或包装器(wrapper)。
与阻塞系统调用的问题类似的是页面错误问题。如果程序调用或跳转到不在内存中的指令,则会发生页错误,操作系统将从磁盘获取丢失的指令(及其邻居),称为页面错误(page fault)。当找到并读入必要的指令时,进程被阻塞。如果线程导致页面错误,内核甚至不知道线程的存在,自然会阻塞整个进程,直到磁盘I/O完成,即使其他线程可能可以运行。
用户级线程包的另一个问题是,如果一个线程开始运行,那么该进程中的其他线程将永远不会运行,除非第一个线程自愿放弃CPU。在单个进程中,没有时钟中断,因此无法以循环方式(轮流)调度进程。除非线程自愿进入运行时系统,否则调度程序永远不会有机会。
线程永远运行的问题的一个可能的解决方案是让运行时系统每秒请求一次时钟信号(中断)来给它控制权,但对程序来说也是粗糙和混乱的。频率较高的周期性时钟中断并不总是可行,即使是这样,总开销也可能很大。此外,线程还可能需要时钟中断,从而干扰运行时系统对时钟的使用。
另一个,也是最具破坏性的,反对用户级线程的论点是,程序员通常希望线程恰好位于线程经常阻塞的应用程序中,例如,在多线程Web服务器中,这些线程不断地进行系统调用。一旦内核出现执行系统调用的陷阱,如果旧的线程被阻塞,内核就几乎不需要再做任何工作来切换线程,并且让内核这样做可以消除不断进行选择系统调用以检查读取系统调用是否安全的需要。对于本质上完全受CPU限制且很少阻塞的应用程序,使用线程有什么意义?没有人会认真建议计算前n个质数或使用线程下棋,因为这样做毫无益处。
- 内核空间线程
现在让我们考虑让内核了解并管理线程。如上图右所示,每个系统都不需要运行时系统。此外,每个进程中都没有线程表。相反,内核有一个线程表来跟踪系统中的所有线程。当线程想要创建新线程或销毁现有线程时,它会进行内核调用,然后通过更新内核线程表来创建或销毁线程。
内核的线程表保存每个线程的寄存器、状态和其他信息。这些信息与用户级线程的信息相同,但现在保存在内核中,而不是用户空间中(在运行时系统中),这些信息是传统内核维护的关于其单线程进程的信息的子集,即进程状态。此外,内核还维护传统的进程表以跟踪进程。
所有可能阻塞线程的调用都被实现为系统调用,其成本远远高于对运行时系统过程的调用。当一个线程阻塞时,内核可以选择运行同一进程中的另一个线程(如果一个线程已就绪)或不同进程中的一个线程。使用用户级线程,运行时系统会从自己的进程中保持线程的运行,直到内核占用CPU(或者没有准备好的线程可以运行)。
由于在内核中创建和销毁线程的成本相对较高,一些系统采用了一种环境正确的方法并回收其线程。当线程被销毁时,它被标记为不可运行,但其内核数据结构不会受到其他方面的影响。稍后,当必须创建新线程时,将重新激活旧线程,从而节省一些开销。用户级线程也可以进行线程回收,但由于线程管理开销要小得多,因此这样做的动机较小。
内核线程不需要任何新的非阻塞系统调用。此外,如果进程中的一个线程导致页面错误,内核可以轻松检查进程是否有其他可运行的线程,如果有,则在等待从磁盘引入所需页面的同时运行其中一个线程。它们的主要缺点是系统调用的成本很高,因此如果线程操作(创建、终止等)很常见,则会产生更多的开销。
虽然内核线程可以解决一些问题,但它们并不能解决所有问题。例如,当多线程进程分叉时会发生什么?新进程是否与旧进程具有相同数量的线程,还是只有一个线程?在许多情况下,最佳选择取决于进程下一步计划做什么。如果它要调用exec来启动一个新程序,可能选择一个线程是正确的,但如果它继续执行,则最好重新生成所有线程。
另一个问题是信号。请记住,至少在经典模型中,信号被发送到进程,而不是线程。当信号传入时,哪个线程应该处理它?线程可能会注册他们对某些信号的兴趣,因此当信号传入时,它会被发送给表示想要它的线程。但是,如果两个或多个线程注册同一信号,会发生什么情况?这些只是线程引入的两个问题,还有更多。
- 混合实现
为了将用户级线程与内核级线程的优点结合起来,已经研究了多种方法。一种方法是使用内核级线程,然后将用户级线程复用到部分或全部线程上,如下图所示。当使用这种方法时,开发人员可以确定要使用多少内核线程,以及每个线程要复用多少用户级线程。该模型提供了最大的灵活性。

将用户级线程多路传输到内核级线程。
使用这种方法,内核只知道内核级别的线程并对其进行调度。其中一些线程可能有多个用户级线程在其上进行多路复用,这些用户级线程的创建、销毁和调度就像在没有多线程功能的操作系统上运行的进程中的用户级线程一样。在这个模型中,每个内核级线程都有一些用户级线程,这些线程轮流使用它。
18.5.5 单线程代码多线程化
许多现有程序都是为单线程进程编写的,将这些转换为多线程比最初看起来要复杂得多。下面,我们将研究几个陷阱。
首先,线程的代码通常由多个过程组成,就像一个进程一样,这些变量可能有局部变量、全局变量和参数。局部变量和参数不会引起任何问题,但对于线程是全局的但对于整个程序不是全局的变量是一个问题。这些变量是全局变量,因为线程中的许多过程都使用它们(因为它们可能使用任何全局变量),但其他线程在逻辑上应该不使用它们。
例如,考虑UNIX维护的errno变量。当进程(或线程)进行失败的系统调用时,错误代码被放入errno。在下图中,线程1执行系统调用访问,以确定它是否有权访问某个文件。操作系统在全局变量errno中返回答案,控制权返回线程1后,但在有机会读取errno之前,调度程序决定线程1目前有足够的CPU时间,并决定切换到线程2。线程2执行一个失败的打开调用,会导致errno被覆盖,线程1的访问代码永远丢失。线程1稍后启动后,将读取错误的值,并且行为不正确。
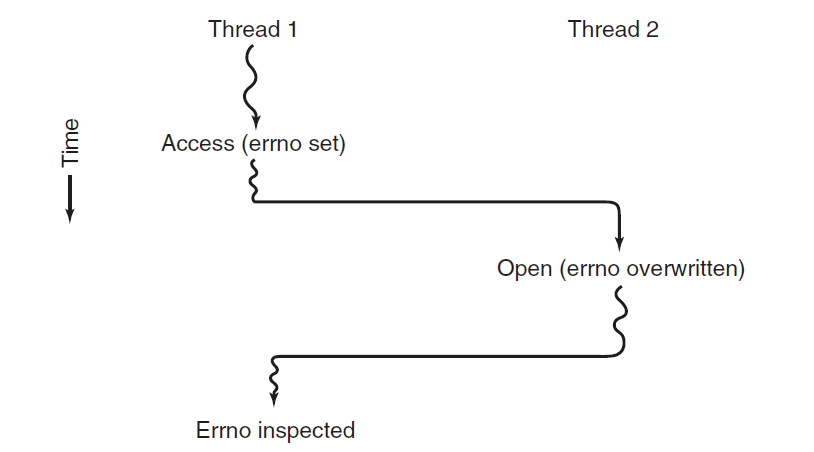
线程之间因使用全局变量而发生冲突。
这个问题有多种解决方案。一是完全禁止全局变量,无论这个理想多么值得,它都与许多现有的软件相冲突。另一种方法是为每个线程分配自己的私有全局变量,如下图所示。这样,每个线程都有自己的errno和其他全局变量的私有副本,从而避免了冲突。实际上,这个决定创建了一个新的作用域级别,变量对线程的所有过程都可见(但对其他线程不可见),此外,变量的现有作用域级别只对一个过程可见,变量在程序中到处可见。
线程可以拥有私有的全局变量。
然而,访问私有全局变量有点棘手,因为大多数编程语言都有表示局部变量和全局变量的方法,但没有中间形式。可以为全局变量分配一块内存,并将其作为额外参数传递给线程中的每个过程。虽然不是一个优雅的方法,但确实有效。或者,可以引入新的库过程来创建、设置和读取这些线程范围的全局变量。第一个调用可能如下所示:
create_global("bufptr");
它在堆上或为调用线程保留的特殊存储区域中为名为bufptr的指针分配存储。无论存储分配到哪里,只有调用线程可以访问全局变量。如果另一个线程创建了一个同名的全局变量,它将获得一个与现有存储位置不冲突的不同存储位置。访问全局变量需要两个调用:一个用于写入,另一个用于读取。写法类似以下代码:
set_global("bufptr", &buf);
它将指针的值存储在之前由创建全局调用创建的存储位置。要读取全局变量,调用可能如下所示:
bufptr = read_global("bufptr");
它返回存储在全局变量中的地址,因此可以访问其数据。
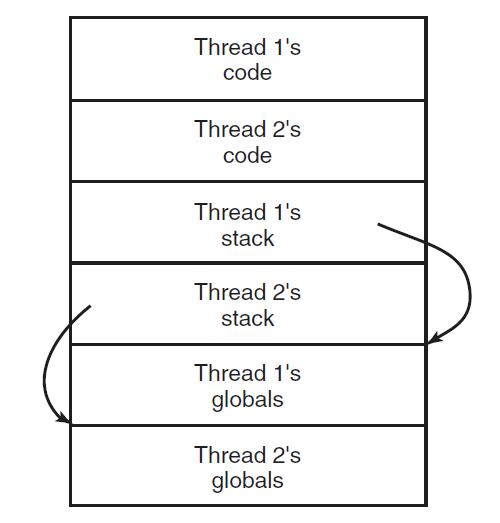
将单线程程序转换为多线程程序的下一个问题是,许多库过程都是不可重入的。也就是说,在前一个调用尚未完成的情况下,它们不会对任何给定过程进行第二次调用。例如,通过网络发送消息很可能被编程为在库内的固定缓冲区中组装消息,然后陷阱到内核发送消息。如果一个线程在缓冲区中组装了它的消息,然后时钟中断强制切换到第二个线程,该线程立即用自己的消息覆盖缓冲区,会发生什么情况?
类似地,内存分配过程(如UNIX中的malloc)维护有关内存使用的关键表,例如可用内存块的链接列表。当malloc忙于更新这些列表时,它们可能暂时处于不一致的状态,指针没有指向任何地方。如果在表不一致时发生线程切换,并且来自不同线程的新调用,则可能会使用无效指针,从而导致程序崩溃。要有效地解决所有这些问题意味着要重写整个库,是一项非常重要的工作,很可能会引入细微的错误。
另一种解决方案是为每个过程提供一个封套(jacket),该封套设置一个位,将库标记为正在使用。当上一个调用尚未完成时,另一个线程使用库过程的任何尝试都将被阻止。虽然这种方法可以工作,但它大大消除了潜在的并行性。
接下来,考虑信号。有些信号在逻辑上是特定于线程的,而其他信号则不是。例如,如果一个线程调用警报,那么产生的信号应该发送给进行调用的线程。然而,当线程完全在用户空间中实现时,内核甚至不知道线程,很难将信号指向正确的线程。如果一个进程一次只能有一个警报挂起,并且多个线程独立调用警报,则会出现额外的复杂性。
其他信号,如键盘中断,不是特定于线程的。谁应该抓住他们?一个指定线程?所有线程?新创建的弹出线程?此外,如果一个线程在不通知其他线程的情况下更改信号处理程序,会发生什么情况?如果一个线程想要捕捉一个特定的信号(例如,用户点击CTRL-C),而另一个线程希望这个信号终止进程,会发生什么?如果一个或多个线程运行标准库过程,而其他线程是用户编写的,则可能会出现这种情况。显然,这些期望是不相容的。通常,信号很难在单线程环境中管理,进入多线程环境并不会使它们更容易处理。
线程引入的最后一个问题是堆栈管理。在许多系统中,当进程的堆栈溢出时,内核只会自动为该进程提供更多堆栈。当一个进程有多个线程时,它也必须有多个堆栈。内核如果不知道所有这些堆栈,就无法在出现堆栈错误时自动增长它们,事实上,它甚至可能没有意识到内存故障与某些线程堆栈的增长有关。
这些问题当然不是不可克服的,但它们确实表明,仅仅将线程引入现有系统而不进行相当实质性的系统重新设计是行不通的。至少,系统调用的语义可能需要重新定义,库需要重写。所有这些事情都必须以这样一种方式进行,即在进程只有一个线程的情况下,保持与现有程序的向后兼容。
18.5.6 Windows线程
进程是管理对象,不直接执行代码。要在Windows上完成任何操作,必须创建线程。用户模式进程是由一个线程创建的,该线程最终执行可执行文件的主入口点。在许多情况下,应用程序可能不需要更多线程。然而,一些应用程序可能会受益于使用进程内执行的多个线程。每个线程都是独立的执行路径,因此可以使用不同的处理器,从而实现真正的并发。
线程是执行代码的实际载体,包含在进程中,使用进程公开的资源进行工作(如虚拟内存和内核对象的句柄)。线程拥有的最重要属性如下:
- 当前访问模式,用户或内核。
- 执行上下文,包括处理器寄存器。
- 堆栈,用于本地变量分配和调用管理。
- 线程本地存储(TLS)数组,提供了一种以统一访问语义存储线程私有数据的方法。
- 基本优先级和当前(动态)优先级。
- 处理器关联,指示允许线程在哪些处理器上运行。
线程最常见的状态是:
- Running(正在运行)。当前正在(逻辑)处理器上执行代码。
- Ready(就绪)。由于所有相关处理器忙或不可用,等待调度执行。
- Waiting(等待)。在继续之前等待某些事件发生,事件发生后,线程将移动到就绪状态。
线程抽象了一个独立的执行路径,从执行的角度来看,它与可能同时处于活动状态的其他线程无关。一旦线程开始执行,它可以执行以下任何操作,直到退出:
- CPU密集操作——依赖CPU操作进行进度的函数计算或调用。
- I/O密集操作——针对I/O设备(如磁盘或网络)执行的操作。在等待I/O操作完成时,线程处于等待状态,不消耗CPU周期。
- 可能导致线程进入等待状态的其他操作,如等待同步原语(互斥体等)。
在进一步研究线程之前,我们必须认识到线程是处理器的抽象。但处理器的定义究竟是什么?在多核构成一个典型CPU的时代,这些术语可能会变得混乱。下图显示了典型CPU的逻辑组成。
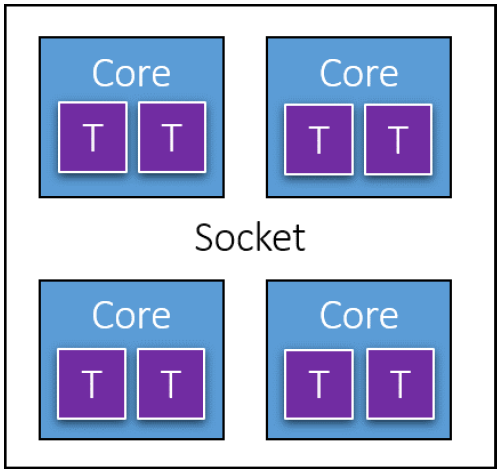
在上图中,有一个插槽(Socket),它是卡在计算机主板上的物理芯片。笔记本电脑和家用电脑通常只有一种,大型服务器计算机可能包含多个插槽。每个插槽都有多个内核,它们是独立的处理器(上图是4个)。
在英特尔处理器上,每个核心可能被分成两个逻辑处理器,由于一种称为超线程(Hyper Threading)的技术,也称为硬件线程。从Windows的角度来看,处理器的数量是逻辑处理器的数量。下图显示博主的笔记本有16个逻辑处理器,意味着在任何给定时刻,最多有16个线程正在运行。任务管理器还显示了插槽、内核和逻辑处理器的数量。
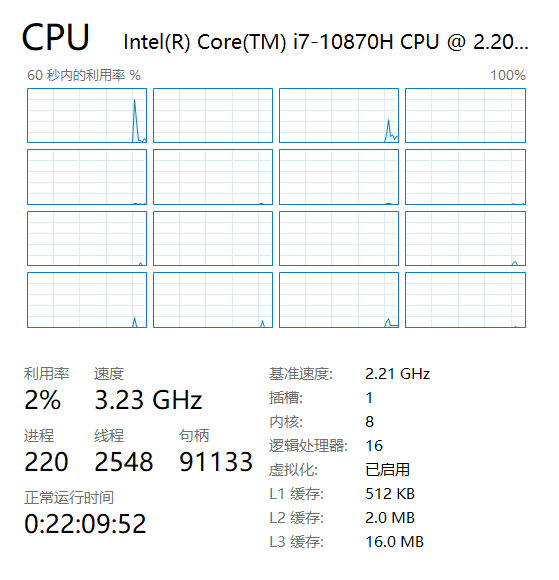
AMD也有类似的技术,称为并发多线程(Simultaneous Multi Threading,SMT)。
可以在BIOS设置中禁用超线程。超线程的潜在缺点是,共享一个核心的每两个逻辑处理器也共享二级缓存,因此可能会相互“干扰”。
18.5.6.1 Fork-Join
下面的示例演示了多线程的复杂用法。PrimeSconter应用程序使用指定数量的线程对一系列数字中的质数进行计数,想法是将工作分成几个线程,每个线程都计算其数字范围内的素数。然后,主线程等待所有工作线程退出,允许它简单地对所有线程的计数求和。如下图所示。
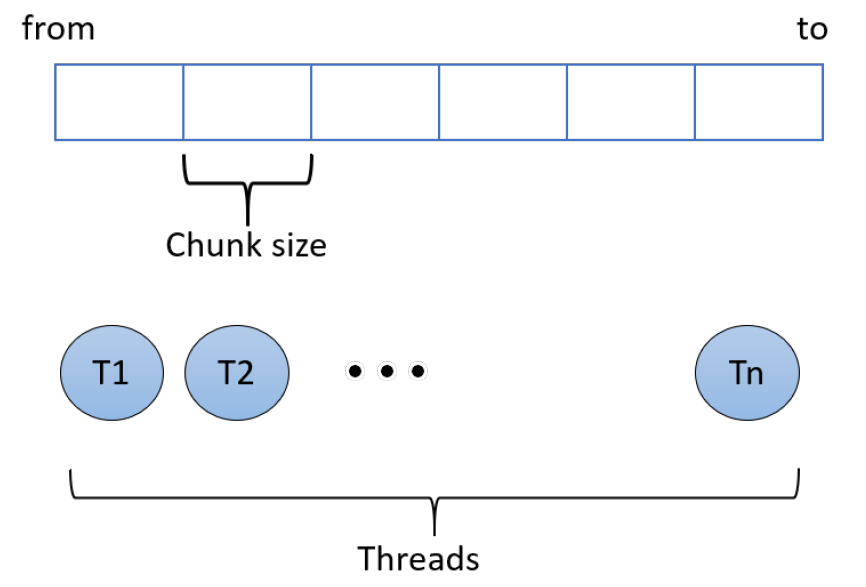
这种创建多个执行某些工作的线程,并等待它们在聚合结果之前退出的想法有时被称为分叉-合并(Fork-Join),因为线程从某个初始线程“分叉”,然后在完成后“连接回”初始线程。
这种模式的另一个名称是结构化并行(Structured Parallelism)。
此应用程序中使用的线程数是算法的参数之一——有趣的问题是,最快完成计算的最佳线程数是多少?
下面代码是上图所示的应用程序PrimeSconter的实现代码:
struct PrimesData
{
int From, To;
int Count;
};
bool IsPrime(int n)
{
if (n < 2)
return false;
if(n == 2)
return true;
int limit = (int)::sqrt(n);
for (int i = 2; i <= limit; i++)
if (n % i == 0)
return false;
return true;
}
DWORD WINAPI CalcPrimes(PVOID param)
{
auto data = static_cast<PrimesData*>(param);
int from = data->From, to = data->To;
int count = 0;
for (int i = from; i <= to; i++)
if (IsPrime(i))
count++;
data->Count = count;
return count;
}
int CalcAllPrimes(int from, int to, int threads, DWORD& elapsed)
{
auto start = ::GetTickCount64();
// allocate data for each thread
auto data = std::make_unique<PrimesData[]>(threads);
// allocate an array of handles
auto handles = std::make_unique<HANDLE[]>(threads);
int chunk = (to - from + 1) / threads;
for (int i = 0; i < threads; i++)
{
auto& d = data[i];
d.From = i * chunk;
d.To = i == threads - 1 ? to : (i + 1) * chunk - 1;
DWORD tid;
handles[i] = ::CreateThread(nullptr, 0, CalcPrimes, &d, 0, &tid);
assert(handles[i]);
printf("Thread %d created. TID=%u\n", i + 1, tid);
}
elapsed = static_cast<DWORD>(::GetTickCount64() - start);
FILETIME dummy, kernel, user;
int total = 0;
for (int i = 0; i < threads; i++)
{
::GetThreadTimes(handles[i], &dummy, &dummy, &kernel, &user);
int count = data[i].Count;
printf("Thread %2d Count: %7d. Execution time: %4u msec\n", i + 1, count, (user.dwLowDateTime + kernel.dwLowDateTime) / 10000);
total += count;
::CloseHandle(handles[i]);
}
return total;
}
int main(int argc, const char* argv[])
{
if (argc < 4)
{
printf("Usage: PrimesCounter <from> <to> <threads>\n");
return 0;
}
int from = atoi(argv[1]);
int to = atoi(argv[2]);
int threads = atoi(argv[3]);
if (from < 1 || to < 1 || threads < 1 || threads > 64)
{
printf("Invalid input.\n");
return 1;
}
DWORD elapsed;
int count = CalcAllPrimes(from, to, threads, elapsed);
printf("Total primes: %d. Elapsed: %d msec\n", count, elapsed);
return 1;
}
以下是相同值范围的一些运行,从使用一个线程的基线开始:
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 1
Thread 1 created (3 to 20000000). TID=29760
Thread 1 Count: 1270606. Execution time: 9218 msec
Total primes: 1270606. Elapsed: 9218 msec
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 2
Thread 1 created (3 to 10000001). TID=22824
Thread 2 created (10000002 to 20000000). TID=41816
Thread 1 Count: 664578. Execution time: 3625 msec
Thread 2 Count: 606028. Execution time: 5968 msec
Total primes: 1270606. Elapsed: 5984 msec
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 4
Thread 1 created (3 to 5000001). TID=52384
Thread 2 created (5000002 to 10000000). TID=47756
Thread 3 created (10000001 to 14999999). TID=42296
Thread 4 created (15000000 to 20000000). TID=34972
Thread 1 Count: 348512. Execution time: 1312 msec
Thread 2 Count: 316066. Execution time: 2218 msec
Thread 3 Count: 306125. Execution time: 2734 msec
Thread 4 Count: 299903. Execution time: 3140 msec
Total primes: 1270606. Elapsed: 3141 msec
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 8
Thread 1 created (3 to 2500001). TID=25200
Thread 2 created (2500002 to 5000000). TID=48588
Thread 3 created (5000001 to 7499999). TID=52904
Thread 4 created (7500000 to 9999998). TID=18040
Thread 5 created (9999999 to 12499997). TID=50340
Thread 6 created (12499998 to 14999996). TID=43408
Thread 7 created (14999997 to 17499995). TID=53376
Thread 8 created (17499996 to 20000000). TID=33848
Thread 1 Count: 183071. Execution time: 578 msec
Thread 2 Count: 165441. Execution time: 921 msec
Thread 3 Count: 159748. Execution time: 1171 msec
Thread 4 Count: 156318. Execution time: 1343 msec
Thread 5 Count: 154123. Execution time: 1531 msec
Thread 6 Count: 152002. Execution time: 1531 msec
Thread 7 Count: 150684. Execution time: 1718 msec
Thread 8 Count: 149219. Execution time: 1765 msec
Total primes: 1270606. Elapsed: 1766 msec
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 16
Thread 1 created (3 to 1250001). TID=50844
Thread 2 created (1250002 to 2500000). TID=9792
Thread 3 created (2500001 to 3749999). TID=12600
Thread 4 created (3750000 to 4999998). TID=52804
Thread 5 created (4999999 to 6249997). TID=5408
Thread 6 created (6249998 to 7499996). TID=42488
Thread 7 created (7499997 to 8749995). TID=49336
Thread 8 created (8749996 to 9999994). TID=13384
Thread 9 created (9999995 to 11249993). TID=41508
Thread 10 created (11249994 to 12499992). TID=12900
Thread 11 created (12499993 to 13749991). TID=39512
Thread 12 created (13749992 to 14999990). TID=3084
Thread 13 created (14999991 to 16249989). TID=52760
Thread 14 created (16249990 to 17499988). TID=17496
Thread 15 created (17499989 to 18749987). TID=39956
Thread 16 created (18749988 to 20000000). TID=31672
Thread 1 Count: 96468. Execution time: 281 msec
Thread 2 Count: 86603. Execution time: 484 msec
Thread 3 Count: 83645. Execution time: 562 msec
Thread 4 Count: 81795. Execution time: 671 msec
Thread 5 Count: 80304. Execution time: 781 msec
Thread 6 Count: 79445. Execution time: 812 msec
Thread 7 Count: 78589. Execution time: 859 msec
Thread 8 Count: 77729. Execution time: 828 msec
Thread 9 Count: 77362. Execution time: 906 msec
Thread 10 Count: 76761. Execution time: 1000 msec
Thread 11 Count: 76174. Execution time: 984 msec
Thread 12 Count: 75828. Execution time: 1046 msec
Thread 13 Count: 75448. Execution time: 1078 msec
Thread 14 Count: 75235. Execution time: 1062 msec
Thread 15 Count: 74745. Execution time: 1062 msec
Thread 16 Count: 74475. Execution time: 1109 msec
Total primes: 1270606. Elapsed: 1188 msec
C:\Dev\Win10SysProg\x64\Release>PrimesCounter.exe 3 20000000 20
Thread 1 created (3 to 1000001). TID=30496
Thread 2 created (1000002 to 2000000). TID=7300
Thread 3 created (2000001 to 2999999). TID=50580
Thread 4 created (3000000 to 3999998). TID=21536
Thread 5 created (3999999 to 4999997). TID=24664
Thread 6 created (4999998 to 5999996). TID=34464
Thread 7 created (5999997 to 6999995). TID=51124
Thread 8 created (6999996 to 7999994). TID=29972
Thread 9 created (7999995 to 8999993). TID=50092
Thread 10 created (8999994 to 9999992). TID=49396
Thread 11 created (9999993 to 10999991). TID=18264
Thread 12 created (10999992 to 11999990). TID=33496
Thread 13 created (11999991 to 12999989). TID=16924
Thread 14 created (12999990 to 13999988). TID=44692
Thread 15 created (13999989 to 14999987). TID=53132
Thread 16 created (14999988 to 15999986). TID=53692
Thread 17 created (15999987 to 16999985). TID=5848
Thread 18 created (16999986 to 17999984). TID=12760
Thread 19 created (17999985 to 18999983). TID=13180
Thread 20 created (18999984 to 20000000). TID=49980
Thread 1 Count: 78497. Execution time: 218 msec
Thread 2 Count: 70435. Execution time: 343 msec
Thread 3 Count: 67883. Execution time: 421 msec
Thread 4 Count: 66330. Execution time: 484 msec
Thread 5 Count: 65366. Execution time: 578 msec
Thread 6 Count: 64337. Execution time: 640 msec
Thread 7 Count: 63798. Execution time: 640 msec
Thread 8 Count: 63130. Execution time: 703 msec
Thread 9 Count: 62712. Execution time: 718 msec
Thread 10 Count: 62090. Execution time: 703 msec
Thread 11 Count: 61937. Execution time: 781 msec
Thread 12 Count: 61544. Execution time: 812 msec
Thread 13 Count: 61191. Execution time: 796 msec
Thread 14 Count: 60826. Execution time: 843 msec
Thread 15 Count: 60627. Execution time: 875 msec
Thread 16 Count: 60425. Execution time: 875 msec
Thread 17 Count: 60184. Execution time: 875 msec
Thread 18 Count: 60053. Execution time: 890 msec
Thread 19 Count: 59681. Execution time: 875 msec
Thread 20 Count: 59560. Execution time: 906 msec
Total primes: 1270606. Elapsed: 1109 msec
执行这些运行的系统具有16个逻辑处理器。以下是来自上述输出的几个有趣的观察结果:
- 随着线程数量的增加,执行时间的改善不是线性的(甚至不接近)。
- 使用比逻辑处理器数量更多的线程减少了执行时间。
为什么我们会得到这些结果?Fork-Join算法中的最佳线程数是多少?答案似乎应该是“逻辑处理器的数量”,因为越来越多的线程会导致上下文切换,因为不是所有线程都可以同时执行,而使用更少的线程肯定会使一些处理器无法使用。
然而,实际并不是那么简单。得到这两个观察结果的唯一原因是:线程之间的工作分配不均等(就执行时间而言)。仅仅是因为所使用的算法:数字越大,需要做的工作越多,因为sqrt函数是单调函数,其输出与其输入成正比。通常是Fork-Join算法的挑战:工作的公平分割。下图演示了四个线程的示例情况。
请注意,在上面的输出中,后面的线程运行时间更长,只是因为它们有更多的工作要做。很明显,即便系统只有16个逻辑处理器,我们也可以使用20个线程获得更好的运行时间。完成的早期线程使处理器空闲,允许那些“额外”线程(16之后)获得处理器,从而推动工作向前。有限制吗?当然,在某种程度上,上下文切换开销,加上线程堆栈内存分配过多可能导致的页面错误,将使情况变得更糟。显然,确定应用程序的最佳处理器数量不是一个容易的问题。更难以回答的是,如果线程需要频繁地进行I/O,这个问题就变得更加困难。
18.5.6.2 线程终止
每个好的(或坏的)线程都必须在某个时刻结束。Windows线程终止有三种方式:
1、线程函数返回(最佳选项)。
2、线程调用ExitThread(最好避免)。
3、线程以TerminateThread终止(通常是个坏主意)。
18.5.6.3 线程堆栈
函数的局部变量和返回地址驻留在线程堆栈上。线程堆栈的大小可以通过CreateThread的第二个参数指定,但实际上有两个值影响线程堆栈:作为堆栈最大大小的保留内存大小和准备使用的初始提交内存大小。保留内存只是将一个连续地址空间范围标记为用于某些目的,因此进程地址空间中的新分配不会从该范围中进行。对于堆栈,此举是必要的,因为堆栈始终是连续的。提交内存意味着实际分配的内存,因此可以使用。
可以立即分配最大堆栈大小,预先提交整个堆栈,但这种做法是一种浪费,因为线程可能不需要整个范围来执行与堆栈相关的工作。内存管理器有一个优化方案:提交较小的内存量,如果堆栈增长超过该量,则触发堆栈扩展,直至达到保留限制。触发是由一个带有特殊标志PAGE_GUARD的页面完成的,如果读写该页面,将导致异常。内存管理器捕获此异常,然后提交一个附加页,将PAGE_GUARD页向下移动一页(请记住,堆栈会增长到较低的地址)。下图显示了这种布置。
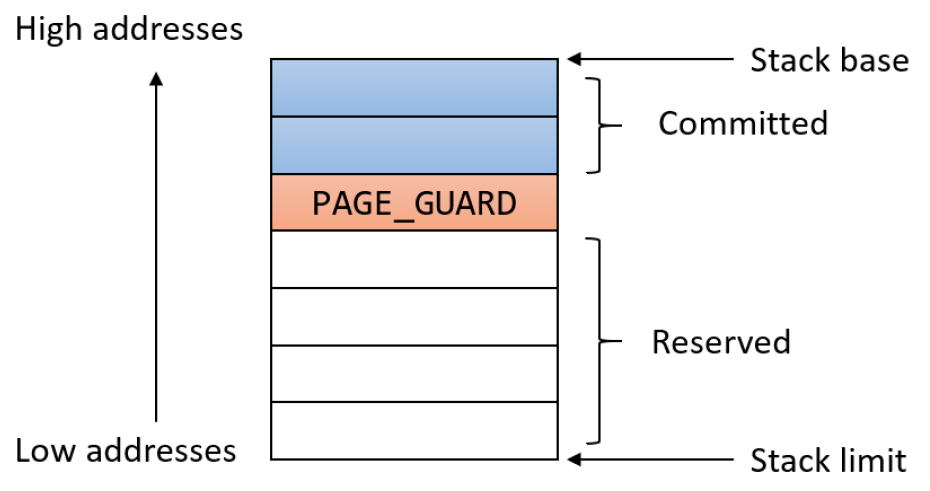
保护页的实际最小值为12KB,即3页,保证了堆栈扩展将允许至少12KB的提交内存可用于堆栈。
Visual Studio允许使用链接器/系统节点下的项目属性更改默认堆栈大小(下图),只是在PE头中设置请求的值。
18.5.7 Windows线程调度
18.5.7.1 优先级
每个线程都有一个相关的优先级,在线程数量比处理器多的情况下十分重要。
线程优先级从0到31,其中31是最高的。线程0是为称为零页线程的特殊线程保留的,该线程是内核内存管理器的一部分,是唯一允许优先级为零的线程。在用户模式下,优先级不能设置为任意值。相反,线程的优先级是进程优先级类(在任务管理器中称为基本优先级)和该基本优先级周围的偏移量的组合。
Windows线程可以使用以下API设置线程优先级:
BOOL SetThreadPriority(_In_ HANDLE hThread, _In_ int nPriority);
nPriority并非绝对优先级,而是相对优先级。其说明如下表:
| 优先级值 | 效果 |
|---|---|
| THREAD_PRIORITY_IDLE (-15) | 优先级降至1(实时优先级类除外),线程优先级降至16 |
| THREAD_PRIORITY_LOWSET (-2) | 优先级相对于优先级类下降2 |
| THREAD_PRIORITY_BELOW_NORMAL (-1) | 优先级相对于优先级类下降1 |
| THREAD_PRIORITY_NORMAL (0) | 优先级设置为进程优先级类值 |
| THREAD_PRIORITY_ABOVE_NORMAL (1) | 优先级相对于优先级类别增加1 |
| THREAD_PRIORITY_HIGHEST (2) | 优先级相对于优先级类别增加2 |
| THREAD_PRIORITY_TIME_CRITICAL (15) | 优先级增加到15,实时优先级类除外,其中线程优先级增加到31 |
在下图中,每个矩形表示基于SetPriorityClass / SetThreadPriority的可能线程优先级值。

下表是按优先级分类的线程优先级:
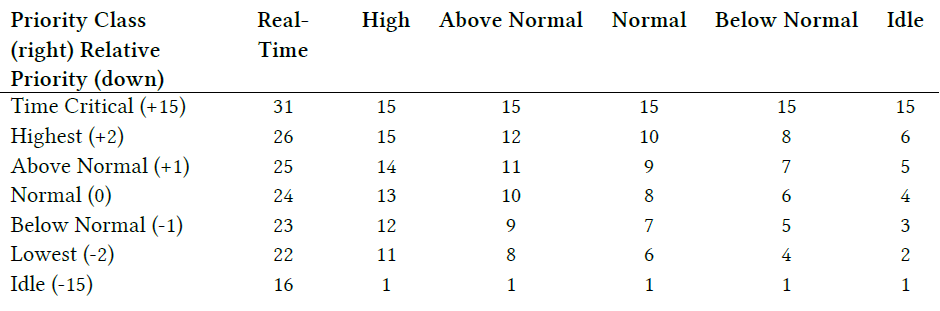 )
)
Windows优先级关系示例:
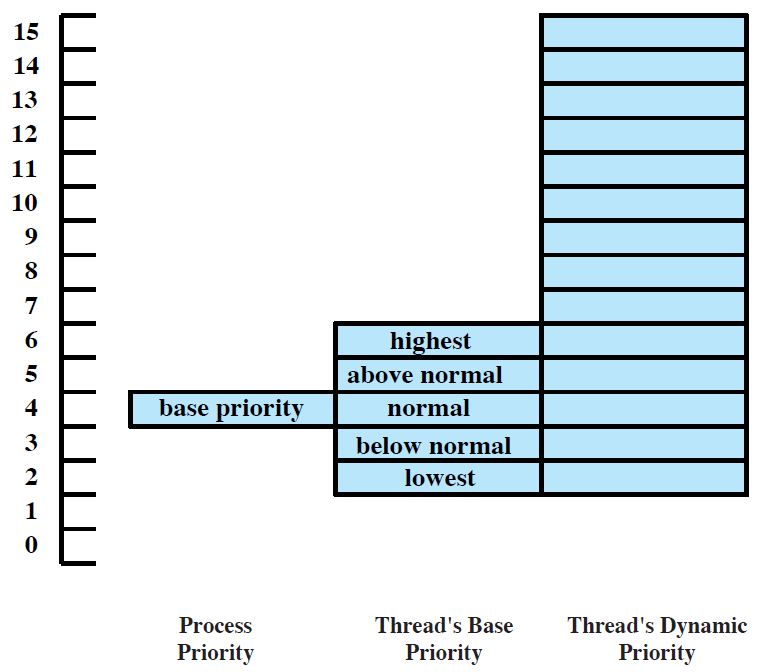
18.5.7.2 单CPU调度
调度通常非常复杂,考虑到几个因素,其中一些因素相互冲突:多处理器、电源管理(一方面希望节省电源,另一方面利用所有处理器)、NUMA(非统一内存架构)、超线程、缓存等。确切的调度算法没有文档记录是有原因的:微软可以在后续的Windows版本和更新中进行修改和调整,而开发人员不需要依赖确切的算法。话虽如此,通过实验可以体验许多调度算法。我们将从最简单的调度开始——当系统上只有一个处理器时,因为它是调度工作的基础。稍后将研究这些算法在多处理系统上的一些变化方式。
调度程序维护一个就绪队列,其中管理要执行(处于就绪状态)的线程。此时不想执行的所有其他线程(处于等待状态)都不会被查看,因为它们不想执行。下图显示了一个示例系统,其中七个线程处于就绪状态,它们根据它们所处的优先级排列在多个队列中。

一个系统上可能有数千个线程,但大多数都处于等待状态,因此调度程序不会考虑这些等待状态的线程。
单CPU的调度算法描述如下。
最高优先级线程首先运行。上图种的线程1和线程2具有最高(且相同)优先级(31),因此优先级为31的队列中的第一个线程运行;假设它是线程1(下图)。
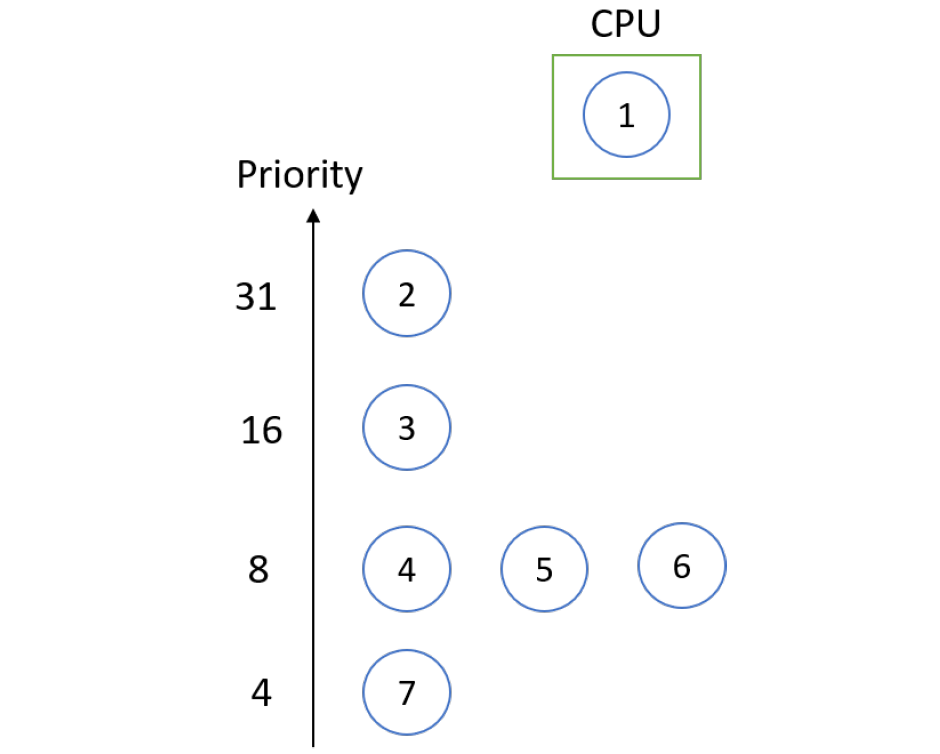
线程1运行一段时间,称为量程(Quantum)。假设线程1有很多事情要做,当它的时间量到期时,调度程序抢占线程1,将其状态保存在内核堆栈中,然后返回到就绪状态(因为它仍然有事情要做)。线程2现在成为正在运行的线程,因为它具有相同的优先级(下图)。
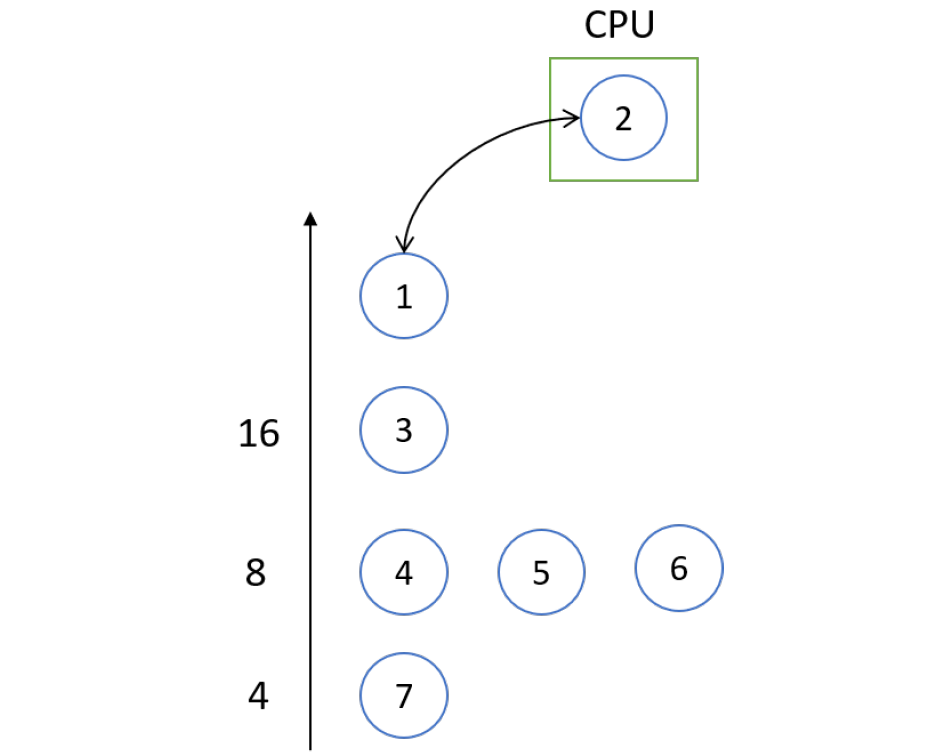
因此,优先级是决定因素。只要线程1和线程2需要执行,它们就会在CPU上循环运行,每个线程运行一段时间。幸运的是,线程通常不会永远运行。相反,它们在某个点进入等待状态。以下是导致线程进入等待状态的几个示例:
- 执行同步I/O操作。
- 等待当前未发出信号的内核对象。
- 当没有UI消息时,等待UI消息。
- 进入自发的睡眠。
一旦线程进入等待状态,它将从调度程序的就绪队列中删除。假设线程1和线程2进入等待状态。现在最高优先级的线程是线程3,它成为运行线程(下图)。
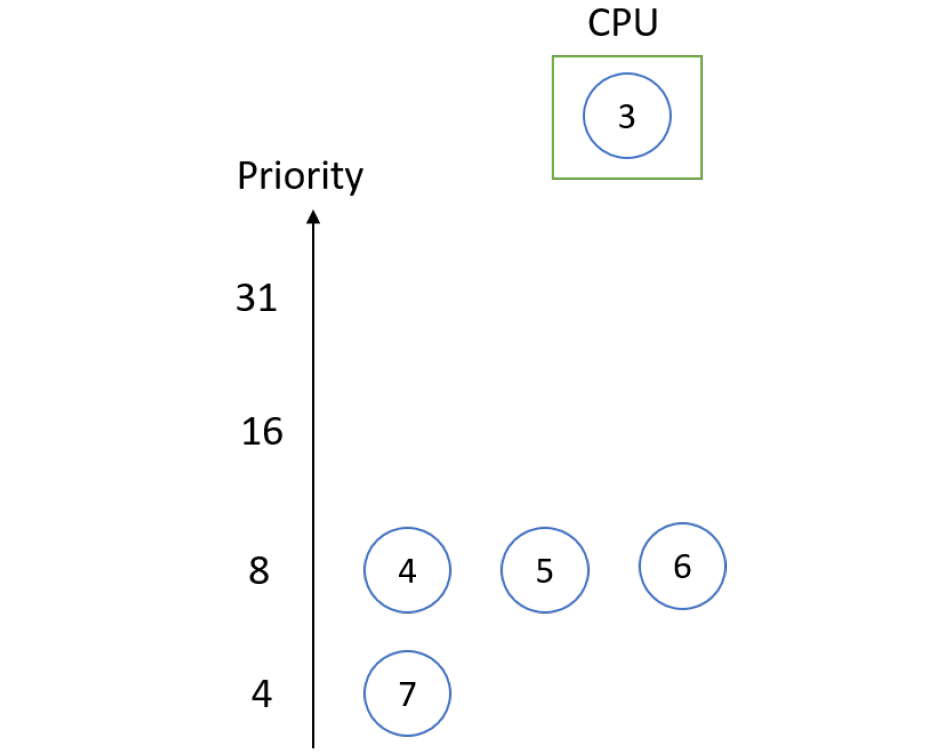
线程3运行一个量程。如果它还有工作要做,它会得到另一个量程,因为它是其优先级中唯一的量程。然而,如果线程1接收到它正在等待的任何内容,它将进入就绪状态并抢占线程3(因为线程1具有更高的优先级),并成为正在运行的线程。线程3返回到就绪状态(下图)。此开关不在线程3的量程末尾,而是在更改时(线程1完成等待)。如果线程3的优先级高于15,则会补充线程3的量程。
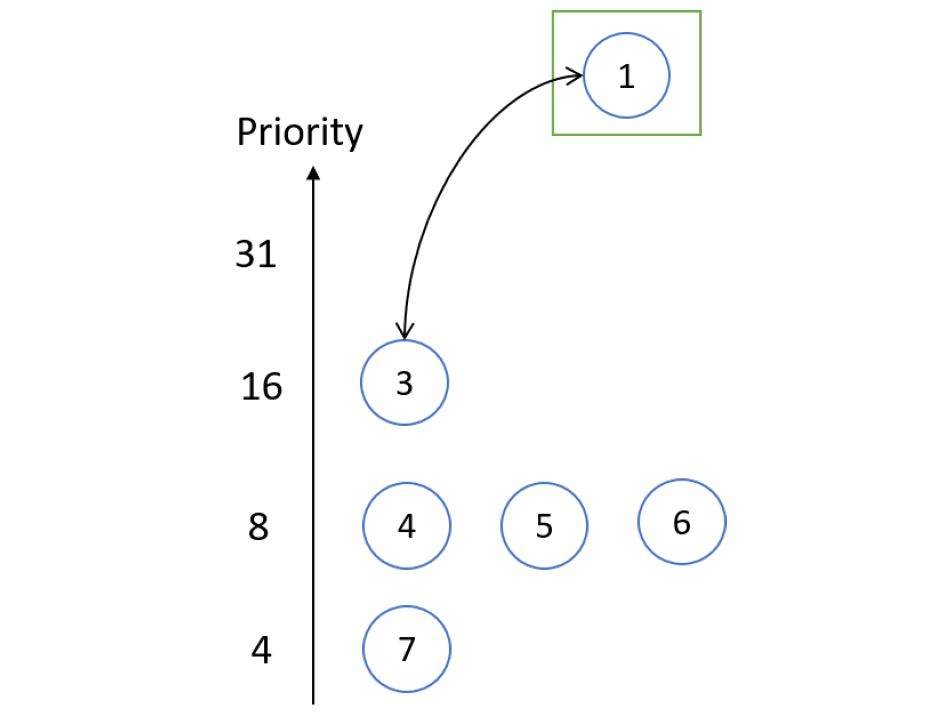
考虑到该算法,如果在就绪状态中没有更高优先级的线程,线程4、5和6将各自具有自己的量运行。
以上是调度的基础。事实上,在实际的单CPU场景中,正是所使用的算法。然而,即使在这种情况下,Windows也试图在某种程度上“公平”。例如,如果较高优先级的线程处于就绪状态,则上述几图中的线程7(优先级为4)可能不会运行,因此它会受到CPU不足的影响。在这样一个系统中,这条线程注定会失败吗?当然不是;系统会将此线程的优先级提高到大约每4秒15次,使其有更好的机会向前推进。此提升持续线程实际执行的一个时间段,然后优先级下降到其初始值。
18.5.7.3 量程
量程(Quantum)在上面被提到了几次,但量程有多长?调度程序以两种正交的方式工作:第一种是使用计时器,默认情况下每15.625毫秒触发一次,可以通过调用GetSystemTimeAdjustment并查看第二个参数来获得。另一种方法是使用SysInternals中的clockres工具:
C:\Users\pavel>clockres
客户端机器(家庭、专业、企业、XBOX等)的默认时间量为2个时钟tick,服务器机器为12个时钟滴答(tick)。换句话说,客户端的时间量为31.25毫秒,服务器为187.5毫秒。
服务器版本获得更长时间量的原因是增加了在单个时间量中完全处理客户端请求的机会。这在客户端机器上不太重要,因为它可能有许多进程,每个进程所做的工作相对较少,其中一些进程的用户界面应该是响应性的,因此短的数量更适合。
调度类值(介于0和9之间)以以下方式设置作为作业一部分的进程中线程的量程:
Quantum = 2 * (TimerInterval) * (SchedulingClass + 1);
18.5.7.4 处理器组
最初的Windows NT设计最多支持32个处理器,其中一个机器字(32位)用于表示系统上的实际处理器,每个位代表一个处理器。当64位窗口出现时,处理器的最大数量自然扩展到64。
从Windows 7(仅限64位系统)开始,微软希望支持64个以上的处理器,因此有一个额外的参数出现:处理器组(Processor Group)。例如,Windows 7和Server 2008 R2最多支持256个处理器,意味着在具有256个处理器的系统上有4个处理器组。
线程可以是一个处理器组的成员,意味着线程可以在属于其当前组的(最多)64个处理器中的一个上调度。创建进程时,会以循环方式为其分配一个处理器组,这样进程就可以跨组“负载平衡”。进程中的线程被分配给进程组,父进程可以通过以下方式之一影响子进程的初始处理器组:
1、父进程可以使用INHERIT_PARENT_AFFINITY标志作为创建进程的标志之一,以指示子进程应该继承其父处理器组,而不是根据系统管理的循环来获取它。如果父进程的线程使用多个关联组,则任意选择其中一个组作为用于子进程组的组。
2、父进程可以使用PROC_THREAD_ATTRIBUTE_GROUP_AFFINITY进程属性来指定期望的默认处理器组。
18.5.7.5 多CPU调度
多处理器调度增加了调度算法的复杂性。Windows唯一能保证的是,要执行的最高优先级线程(如果有多个线程,至少一个)当前正在运行。
通常,可以在任何处理器上调度线程。然而,线程的亲缘性(Affinity),即允许在其上运行的处理器,可以通过多种方式进行控制。
理想的处理器是线程的属性,有时也称为软亲缘性(Soft Affinity)。理想的处理器作为调度程序的提示,在所有其他条件相同的情况下,它是执行该线程代码的首选处理器。默认的理想处理器以循环方式选择,从创建进程时生成的随机数开始。在超线程系统上,下一个理想处理器是从下一个核心中选择的,而不是从下一逻辑处理器中选择的。理想的处理器可以使用Process Explorer工具查看,作为线程选项卡中显示的属性之一(下图)。

虽然理想的处理器可以作为提示和建议线程应该在哪个处理器上执行,但硬亲缘性(Hard Affinity),有时就称为亲缘性,允许为特定线程或进程指定允许执行的处理器。硬亲缘性在两个级别上工作:进程和线程,其中基本规则是线程不能避开其进程设置的亲缘性。
一般来说,设置硬亲缘性约束通常是一个坏主意,限制了调度程序分配处理器的自由度,并可能导致线程获得的CPU时间比没有硬亲缘性约束时少。不过,在一些罕见的情况下,可能会很有用,因为在同一组处理器上运行的线程更有可能获得更好的CPU缓存利用率。对于运行特定已知进程的系统很有用,而不是运行任何东西的随机机器。硬亲缘性的另一个用途是压力测试,例如在某些执行中使用较少的处理器,以查看有限数量处理器的系统在运行相同进程时的行为。
线程的关联不能“逃逸”其进程亲缘性,然而,在某些情况下,让一个线程(或多个线程)使用进程中其他线程禁止使用的处理器是有益的。Windows 10和Server 2016添加了此功能,称为CPU集(CPU Set)。
CPU集表示处理器的抽象视图,其中每个CPU集可能映射到一个或多个逻辑处理器。然而,目前,每个CPU集都精确地映射到单个逻辑处理器。系统有自己的CPU集,默认情况下包括系统上的所有处理器。
CPU集和硬亲缘性可能相互冲突。在这种情况下,硬亲缘性总是胜出,即忽略CPU集。
多处理器(MP)调度很复杂,涉及硬亲缘性、理想处理器、CPU集、电源考虑、游戏模式和其他方面。在MP系统上,每个处理器都有自己的就绪队列。此外,在Windows 8及更高版本上,处理器组有共享就绪队列(目前每组最多4个),允许调度程序在需要为连接到共享就绪队列的就绪线程定位处理器时拥有更多选项(每个CPU就绪队列仍用于具有硬亲缘性的线程)。下图给出了一种改进的、简化的MP调度算法。它假设没有亲和性或CPU集约束,没有功率或其他特殊考虑。

如上图所示,理想的处理器是首选处理器,其次是它运行的最后一个处理器(处理器的缓存可能仍然包含该线程使用的数据)。如果所有处理器都忙,调度器不抢占运行低优先级线程的第一个处理器;这是低效的,因为可能需要搜索许多处理器。相反,线程被放入其理想处理器的(共享)就绪队列中。
在Windows系统,可以使用Windows Performance Recorder (wprui.exe)和Windows Performance Analyzer (WPA)来分析、追踪和监视每个线程的调度情况(下图)。

18.5.7.6 后台模式
有些进程自然比其他进程更重要。例如,如果用户使用Microsoft Word,可能希望自己的交互和Word的使用非常好。另一方面,诸如备份应用程序、反病毒扫描程序、搜索索引器等进程并不重要,不应干扰用户的主要应用程序。
这些后台应用程序限制其影响的一种方法是降低其CPU优先级。此举虽然可行,但CPU只是进程使用的一种资源,其他资源还包括内存和I/O,意味着降低线程的CPU优先级或进程的优先级等级可能不足以降低此类进程的影响。
Windows提供了后台模式(Background Mode)的概念,其中线程的CPU优先级下降到4,内存优先级和I/O优先级也下降。例如,在线程视图的进程资源管理器中查看Windows资源管理器,显示内存和I/O优先级以及CPU优先级(下图)。I/O优先级的默认值为“正常”,内存优先级的默认数值为5(可能值为0到7)。
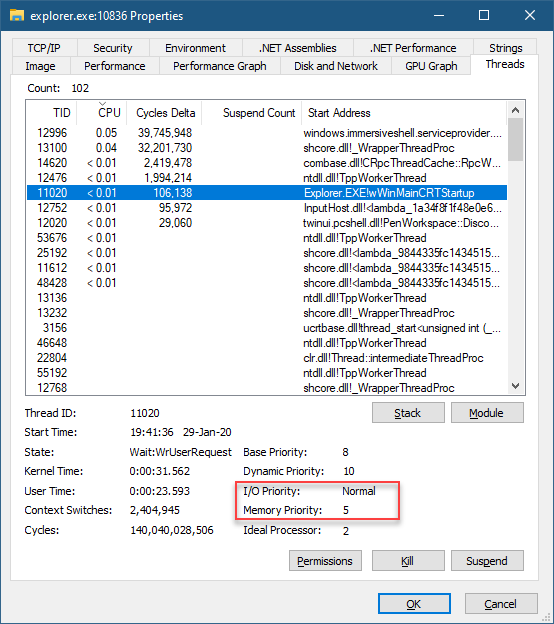
18.5.7.7 优先级提升
优先级是调度的决定因素。然而,Windows对优先级进行了一些调整,称为优先级提升(priority boosts)。这些优先级的临时增加是为了在某种意义上使调度更加“公平”,或者为用户提供更好的体验。
当线程发出同步I/O操作时,它将进入等待状态,直到操作完成。一旦完成,负责I/O操作的设备驱动程序就有机会提高请求线程的优先级,从而提高其运行速度,因为操作最终完成。优先级提升(如果应用)将线程的优先级增加一个由驱动程序决定的量,并且线程管理运行的每个时间段的优先级都会下降一个级别,直到优先级下降到其基本级别。下图显示了该过程的概念视图。
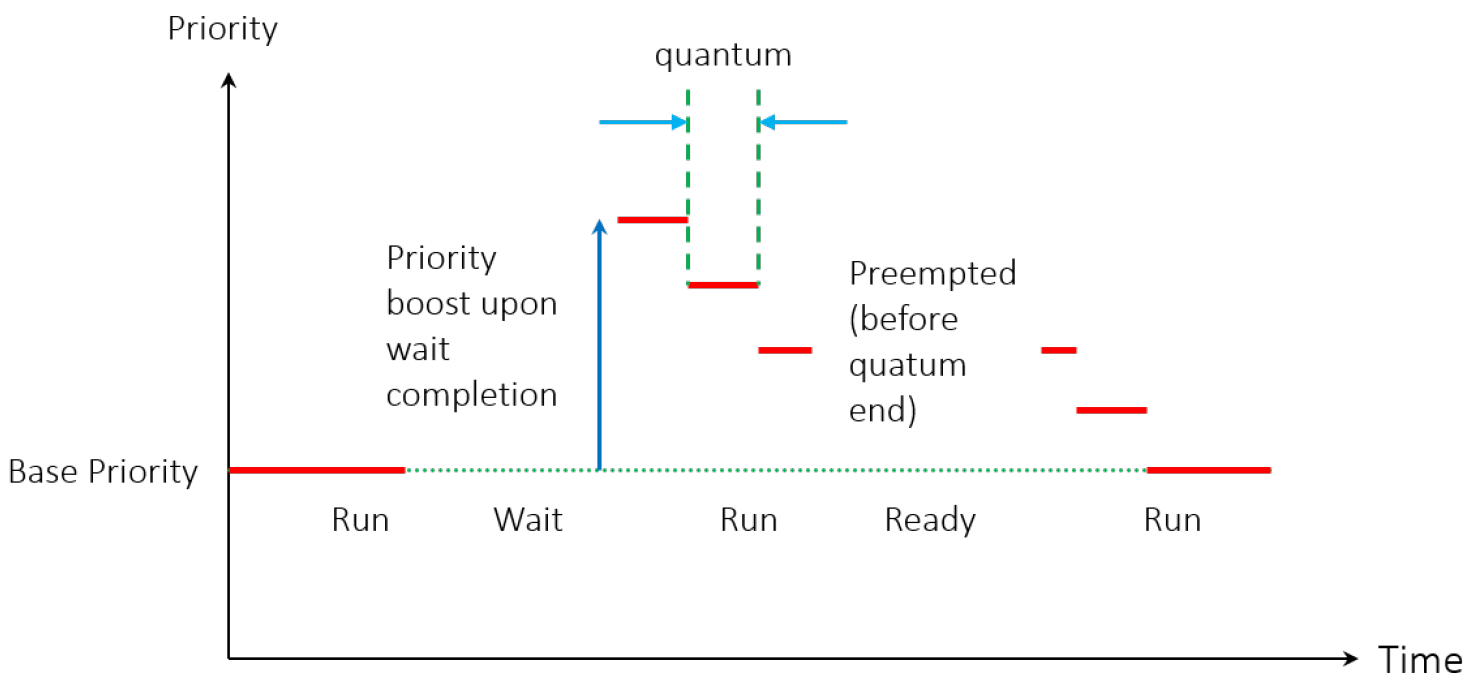
此外,前台进程、GUI线程唤醒、饥饿避免法则等情况也会触发优先级提升。但是,应尽量避免使用优先级提升,因为未来可能被微软抛弃。进程或线程还可以被挂起、继续或睡眠等操作,以执行不同粒度的调度行为。
18.6 同步机制
本章涉及线程和进程间的通信、竞争条件、关键部分、互斥、硬件解决方案、严格交替、彼得森解决方案、生产者-消费者问题、信号量、事件计数器、监视器、消息传递和经典IPC问题,以及死锁的定义、特征、预防、避免等。
利用多线程并发提高性能的方式有两种:
- 任务并行(task parallelism)。将一个单个任务分成几部分,且各自并行运行,从而降低总运行时间。这种方式虽然看起来很简单直观,但实际操作中可能会很复杂,因为在各个部分之间可能存在着依赖。
- 数据并行(data parallelism)。任务并行的是算法(执行指令)部分,即每个线程执行的指令不一样;而数据并行是指令相同,但执行的数据不一样。SIMD也是数据并行的一种方式。
上面阐述了多线程并发的益处,接下来说说它的副作用。总结起来,副作用如下:
- 导致数据竞争。多线程访问常常会交叉执行同一段代码,或者操作同一个资源,又或者多核CPU的高度缓存同步问题,由此变化带来各种数据不同步或数据读写错误,由此产生了各种各样的异常结果,这便是数据竞争。
- 逻辑复杂化,难以调试。由于多线程的并发方式不唯一,不可预知,所以为了避免数据竞争,常常加入复杂多样的同步操作,代码也会变得离散、片段化、繁琐、难以理解,增加代码的辅助,对后续的维护、扩展都带来不可估量的阻碍。也会引发小概率事件难以重现的BUG,给调试和查错增加了数量级的难度。
- 不一定能够提升效益。多线程技术用得到确实会带来效率的提升,但并非绝对,常和物理核心、同步机制、运行时状态、并发占比等等因素相关,在某些极端情况,或者用得不够妥当,可能反而会降低程序效率。
18.6.1 同步基础
18.6.1.1 并行和并发
并行(Parallelism)是至少两个线程同时执行任务的机制。一般有多核多物理线程的CPU同时执行的行为,才可以叫并行,单核的多线程不能称之为并行。
并发(Concurrency)至少两个线程利用时间片(Timeslice)执行任务的机制,是并行的更普遍形式。即便单核CPU同时执行的多线程,也可称为并发。
并发的两种形式——上:双物理核心的同时执行(并行);下:单核的多任务切换(并发)。
事实上,并发和并行在多核处理器中是可以同时存在的,比如下图所示,存在双核,每个核心又同时切换着多个任务:
部分参考文献严格区分了并行和并发,但部分文献并不明确指出其中的区别。虚幻引擎的多线程渲染架构和API中,常出现并行和并发的概念,所以虚幻是明显区分两者之间的含义。
18.6.1.2 阿姆达尔定律
经典的同步是为了避免数据竞争。当两个或多个线程访问同一内存位置,并且其中至少一个线程正在写入该位置时,就会发生数据争用。从同一位置同时读取从来都不是问题。但一旦写入进入图片,所有的赌注都将被关闭。数据可能会损坏,读取可能会被撕毁(一些数据在更改之前读取,一些数据在改变之后读取)。这就是需要同步的地方。
同步会降低性能,因为某些操作必须顺序执行,而不是并发执行。事实上,通过向问题中添加更多线程/CPU可以获得的加速取决于可以并行化的代码的百分比。Amdahl's law(阿姆达尔定律)很好地描述了这一点:
公式的各个分量含义如下:
- \(S_{\text{latency}}(s)\):整个任务在多线程处理中理论上获得的加速比。
- \(s\):用于执行任务并行部分的硬件资源的线程数量。
- \(p\):可并行处理的任务占比。
举个具体的栗子,假设有8核16线程的CPU用于处理某个任务,这个任务有70%的部分是可以并行处理的,那么它的理论加速比为:
由此可见,多线程编程带来的效益并非跟核心数呈直线正比。实际上它的曲线如下所示:
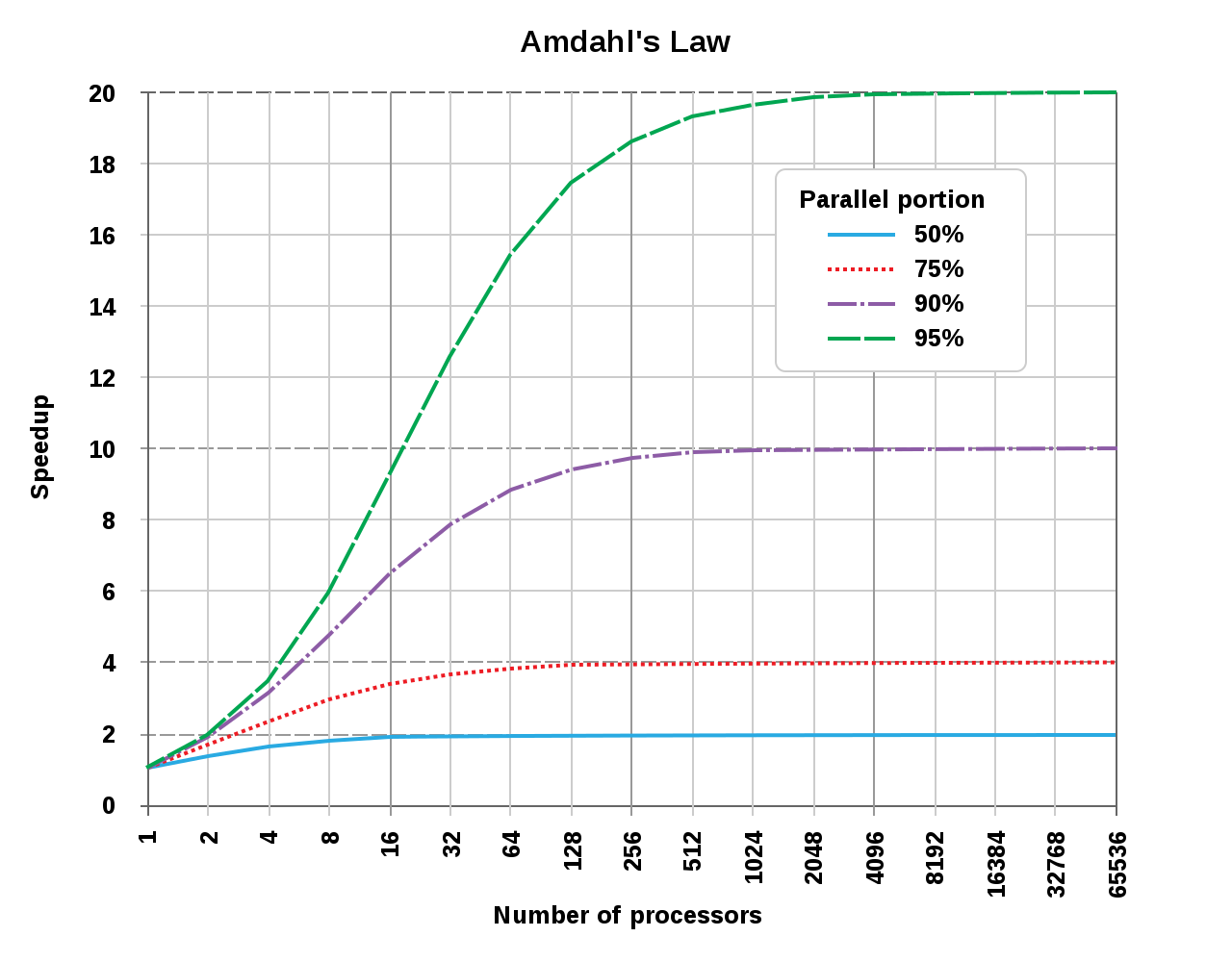
阿姆达尔定律揭示的核心数和加速比图例。由此可见,可并行的任务占比越低,加速比获得的效果越差:当可并行任务占比为50%时,16核已经基本达到加速比天花板,无论后面增加多少核心数量,都无济于事;如果可并行任务占比为95%时,到2048个核心才会达到加速比天花板。
虽然阿姆达尔定律给我们带来了残酷的现实,但是,如果我们能够提升任务并行占比到接近100%,则加速比天花板可以得到极大提升:
如上公式所示,当\(p=1\)(即可并行的任务占比100%)时,理论上的加速比和核心数量成线性正比!举个具体的例子,在编译Unreal Engine工程源码或Shader时,由于它们基本是100%的并行占比,理论上可以获得接近线性关系的加速比,在多核系统中将极大地缩短编译时间。
18.6.1.3 竞争条件
同个进程允许有多个线程,这些线程可以共享进程的地址空间、数据结构和上下文。进程内的同一数据块,可能存在多个线程在某个很小的时间片段内同时读写,这就会造成数据异常,从而导致了不可预料的结果。这种不可预期性便造就了竞争条件(Race Condition)。
在某些操作系统中,协同工作的进程可能共享一些共同的存储,每个进程都可以读写。共享存储可能在主存中(可能在内核数据结构中),也可能是共享文件;共享内存的位置不会改变通信的性质或出现的问题。为了了解进程间通信在实践中是如何工作的,现在让我们考虑一个简单但常见的示例:打印假脱机程序。当一个进程想要打印一个文件时,它会在一个特殊的后台处理程序目录中输入文件名。另一个进程,打印机守护进程,定期检查是否有要打印的文件,如果有,它会打印这些文件,然后从目录中删除它们的名称。
假设我们的后台处理程序目录有大量的插槽,编号为0、1、2…,每个插槽都可以保存一个文件名。还可以想象有两个共享变量,out指向下一个要打印的文件,in指向目录中的下一个空闲插槽。这两个变量很可能保存在所有进程都可以使用的两个字的文件中。在某一时刻,插槽0至3为空(文件已打印),插槽4至6已满(文件名列队打印)。进程A和B或多或少同时决定要将文件排队打印。这种情况如下图所示。
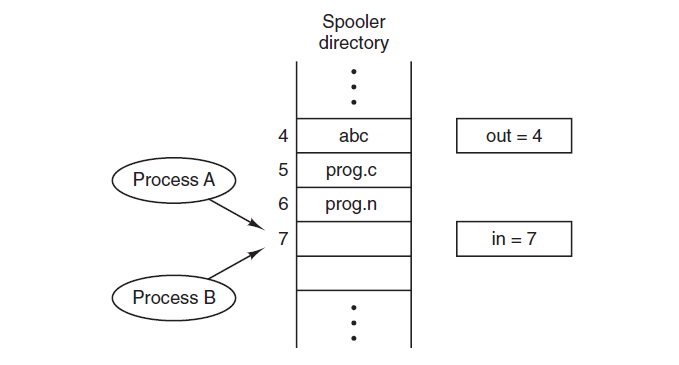
适用于墨菲定律(Murphy’s law),可能会发生以下情况。进程A读入并将值7存储在称为next_free_slot的局部变量中。就在这时,一个时钟中断发生了,CPU决定进程A已经运行了足够长的时间,因此它切换到进程B。进程B也读入并得到一个7,也将其存储在下一个空闲插槽的本地变量中。此时,两个进程都认为下一个可用插槽是7。
进程B现在继续运行,将其文件名存储在插槽7中,并在中更新为8,然后关闭并执行其他操作。
最后,进程A再次运行,从它停止的地方开始,查看下一个空闲插槽,在那里找到一个7,并将其文件名写入插槽7,擦除进程B刚才放在那里的名称。然后计算下一个空闲插槽+1,即8,并设置为8。后台处理程序目录现在在内部是一致的,因此打印机守护程序不会发现任何错误,但进程B永远不会收到任何输出。用户B将在打印机周围徘徊数年,渴望永远不会输出。像这样的情况,两个或多个进程正在读取或写入一些共享数据,最终结果取决于谁在何时运行,称为竞争条件。调试包含竞争条件的程序一点也不有趣。大多数测试运行的结果都很好,但偶尔会发生一些奇怪和无法解释的事情。不幸的是,随着内核数量的增加,并行度也在增加,争用情况变得越来越普遍。
18.6.1.4 互斥实现机制
常见的简单的互斥实现机制包含禁用中断(Disabling Interrupt)、锁变量(Lock Variable)、严格轮换法(Strict Alternation)等。
- 禁用中断
在单处理器系统上,最简单的同步解决方案是让每个进程在进入其关键区域后立即禁用所有中断,并在离开之前重新启用它们。禁用中断时,不会发生时钟中断。毕竟,由于时钟或其他中断,CPU只能从一个进程切换到另一个进程,中断关闭后,CPU将不会切换到其他进程。因此,一旦进程禁用了中断,它就可以检查和更新共享内存,而不用担心任何其他进程会干预。
这种方法通常没有吸引力,因为给用户进程关闭中断的能力是不明智的。如果其中一个这样做了,再也没有打开过呢?可能导致系统崩溃。此外,如果系统是多处理器(具有两个或更多CPU),禁用中断只影响执行禁用指令的CPU。其他的将继续运行,并可以访问共享内存。
另一方面,在更新变量或特别是列表时,内核本身常常可以方便地禁用一些指令的中断。例如,如果在就绪进程列表处于不一致状态时发生中断,则可能会出现争用条件。总之,禁用中断通常是操作系统本身的一项有用技术,但不适合作为用户进程的一般互斥机制。
由于多核芯片的数量不断增加,即使在低端PC中,通过禁用内核内的中断来实现互斥的可能性也越来越小。双核已经很常见,许多机器中有四个,8个、16个或32个也不远。在多核(即多处理器系统)中,禁用一个CPU的中断不会阻止其他CPU干扰第一个CPU正在执行的操作。因此,需要更复杂的方案。
- 锁变量
考虑使用一个共享(锁)变量,初始值为0。当进程想要进入其关键区域时,它首先测试锁。如果锁为0,进程将其设置为1并进入临界区域。如果锁已经是1,进程只会等待,直到它变为0。因此,0表示没有进程处于其关键区域,1表示某些进程处于其临界区域。
不幸的是,这个想法包含了与我们在后台处理程序目录中看到的完全相同的致命缺陷。假设一个进程读取锁并看到它是0,在它可以将锁设置为1之前,另一个进程被调度、运行并将锁设置成1。当第一个进程再次运行时,它也将把锁设置成了1,并且两个进程将同时处于其关键区域。
现在,可能认为我们可以通过先读取锁值,然后在存储到其中之前再次检查它来解决这个问题,但并无实质作用。如果第二个进程在第一个进程完成第二次检查后修改了锁,则会发生争用。
- 严格轮换法
下面代码显示了互斥问题的第三种方法。整数变量轮数(最初为0)跟踪进入关键区域的轮数,并检查或更新共享内存。最初,进程0检查回合,发现它为0,并进入其关键区域。进程1也发现它为0,因此处于一个严密的循环中,不断地测试它何时变为1。不断地测试变量,直到出现某个值,此行为称为忙等待(busy waiting),通常应该避免,因为会浪费CPU时间。只有当有合理的预期等待时间很短时,才会使用繁忙等待,使用繁忙等待的锁称为自旋锁(spin lock)。
// 关键区域问题的建议解决方案。
// 进程0
while (TRUE)
{
while (turn != 0) /* loop */ ;
critical_region();
turn = 1;
noncritical_region();
}
// 进程1
while (TRUE)
{
while (turn != 1) /* loop */ ;
critical_region();
turn = 0;
noncritical_region();
}
- 彼得森的解决方案
通过将轮流思想与锁定变量和警告变量的思想相结合,荷兰数学家T.Dekker是第一个为互斥问题设计不需要严格修改的软件解决方案的人。1981年,G.L.Peterson发现了一种更简单的实现互斥的方法,从而使Dekker的解决方案过时,其算法如下代码所示(忽略原型)。
#define FALSE 0
#define TRUE 1
#define N 2 /* number of processes */
int turn; /* whose turn is it? */
int interested[N]; /* all values initially 0 (FALSE) */
void enter_region(int process); /* process is 0 or 1 */
{
int other; /* number of the other process */
other = 1 − process; /* the opposite of process */
interested[process] = TRUE; /* show that you are interested */
turn = process; /* set flag */
while (turn == process && interested[other] == TRUE) /* null statement */ ;
}
void leave_region(int process) /* process: who is leaving */
{
interested[process] = FALSE; /* indicate departure from critical region */
}
- TSL指令
现在让我们来看一个需要硬件帮助的提案。有些计算机,特别是那些设计有多处理器的计算机,有如下指令:
TSL RX, LOCK
(测试并设置锁定),其工作原理如下。它将内存字锁的内容读入寄存器RX,然后在内存地址锁处存储一个非零值。读字和存储字的操作保证是不可分割的,在指令完成之前,任何其他处理器都不能访问内存字。执行TSL指令的CPU锁定内存总线,以禁止其他CPU访问内存,直到完成。
需要注意的是,锁定内存总线与禁用中断非常不同。禁用中断,然后对内存字执行读操作,然后再执行写操作,不会阻止总线上的第二个处理器访问读操作和写操作之间的字。事实上,禁用处理器1上的中断对处理器2没有任何影响。在处理器1完成之前,保持处理器2不在内存中的唯一方法是锁定总线,需要特殊的硬件设施(基本上是一条总线,声明总线已锁定,除锁定它的处理器外,其他处理器无法使用它)。
要使用TSL指令,我们将使用一个共享变量lock来协调对共享内存的访问。当锁为0时,任何进程都可以使用TSL指令将其设置为1,然后读取或写入共享内存。完成后,进程使用普通的移动指令将锁设置回0。
如何使用此指令来防止两个进程同时进入其关键区域?下图给出了解决方案,图中显示了虚拟(但典型)汇编语言中的四指令子程序。第一条指令将旧的锁值复制到寄存器,然后将锁设置为1。然后将旧的值与0进行比较。如果它不为零,则表示锁已设置,因此程序只需返回到开始处并再次测试它。它迟早会变为0(当当前处于其关键区域的进程完成其关键区域时),子例程返回并设置了锁。清除锁非常简单,程序只将0存储在锁中,不需要特殊的同步指令。
关键区域问题的一个解决方案现在很容易。在进入其关键区域之前,进程调用enter region,它会忙于等待直到锁空闲;然后它获取锁并返回。离开关键区域后,进程将调用leave region,该区域将0存储在锁中。与所有基于关键区域的解决方案一样,进程必须在正确的时间调用进入区域和离开区域,以便方法工作。如果一个进程作弊,互斥将失败。换言之,关键区域只有在进程合作的情况下才能发挥作用。

TSL的另一条指令是XCHG,自动交换两个位置的内容,例如寄存器和内存字。代码如下所示,可以看出,它与TSL的解决方案基本相同。所有Intel x86 CPU都使用XCHG指令进行低级同步。

18.6.2 线程同步
18.6.2.1 原子操作
一些看似简单快捷的操作实际上并不是线程安全的。即使是简单的C变量增量(x++)也不是线程或多处理器安全的。例如,考虑在两个处理器上并行运行的两个线程,它们对同一内存位置执行增量(下图)。
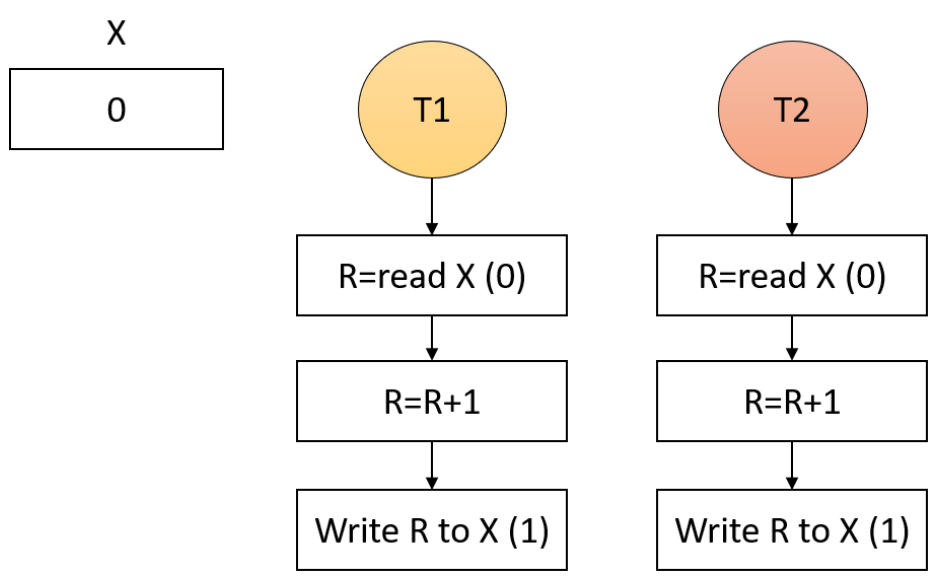
即使是简单的增量也需要读写。在上图中,每个线程可以将初始值(0)读入CPU寄存器,每个线程递增其处理器的寄存器,然后写回结果,写入X的最终结果是1而不是2。该图是一个粗略的简化,因为还有其他因素在起作用,如CPU缓存。但即使忽略这一点,也明显是一场数据争用。事实上,其中一个线程(比如T2)可能被抢占(例如在R递增之后),并且当T1继续递增X时,一旦T2接收到CPU时间,它将1写回X,明显地终止线程T1所做的所有递增。Windows常用的原子操作API如下:
LONG InterlockedIncrement([in, out] LONG volatile *Addend);
SHORT InterlockedIncrement16([in, out] SHORT volatile *Addend);
LONG64 InterlockedIncrement64([in, out] LONG64 volatile *Addend);
LONG InterlockedIncrementNoFence(_Inout_ LONG volatile *Addend);
LONG InterlockedDecrement([in, out] LONG volatile *Addend);
LONG InterlockedDecrement16([in, out] LONG volatile *Addend);
LONG InterlockedDecrement64([in, out] LONG volatile *Addend);
LONG InterlockedOr([in, out] LONG volatile *Destination, [in] LONG Value);
LONG InterlockedExchange([in, out] LONG volatile *Target, [in] LONG Value);
// 将指定的32位变量的值作为原子操作递增(加1), 使用获取内存顺序语义执行。
LONG InterlockedIncrementAcquire(_Inout_ volatile *Addend);
LONG InterlockedIncrementRelease(_Inout_ LONG volatile *Addend);
(...)
18.6.2.2 临界区
对于简单的情况,例如整数增量,互锁函数族非常适用。然而,对于其他操作,需要更通用的机制。临界区(Critical Section)是基于最多一个线程获取锁的经典同步机制。我们需要具备四个条件才能找到一个好的解决方案:
1、临界区域内不可能同时存在两个进程。
2、不能对速度或CPU数量进行假设。
3、在其临界区域之外运行的任何进程都不会阻塞任何进程。
4、任何进程都不应该永远等待进入其关键区域。
抽象地说,我们想要的行为如下图所示。过程A在时间T1进入其临界区,稍后,时间T2,过程B试图进入其临界区域,但失败了,因为另一个过程已经在其临界区,我们一次只允许一个进程。因此,当A离开其临界区域时,B暂时暂停,直到时间T3,允许B立即进入。最终B离开(在T4),我们回到了最初的情况,在其关键区域没有过程。
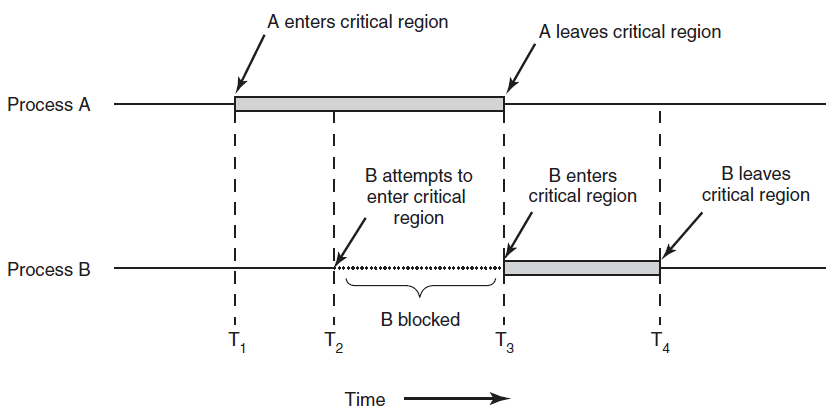
一旦一个线程获得了一个特定的锁,其他线程就无法获得同一个锁,直到首先获得它的线程释放它。只有这样,等待线程中的一个(并且只有一个)才能获得锁。意味着在任何给定时刻,只有一个线程获得了锁。(下图)
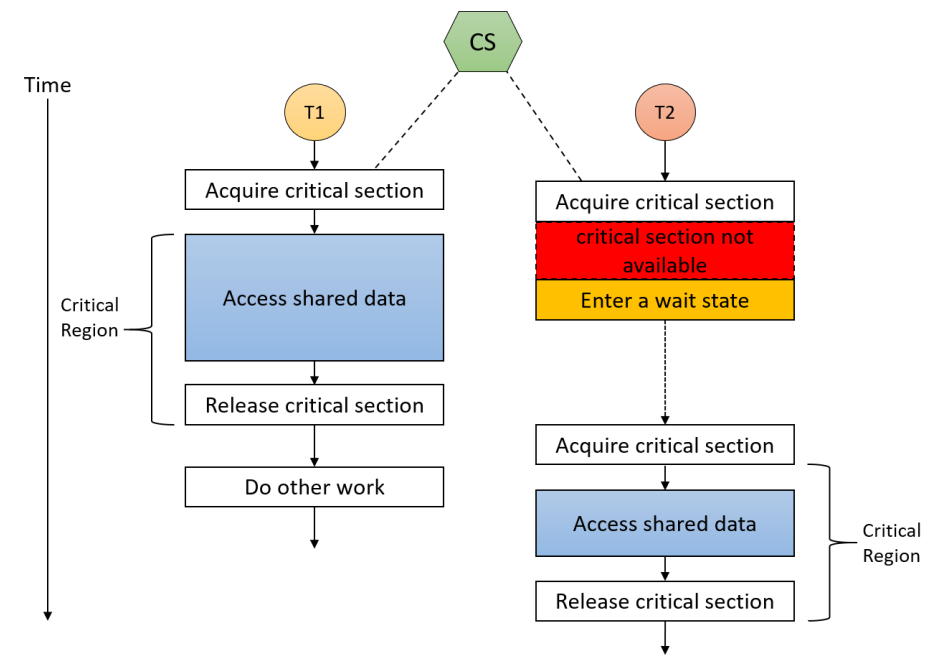
获取锁的线程也是其所有者,意味着两件事:
1、所有者线程是唯一可以释放关键部分的线程。
2、如果所有者线程第二次(递归地)尝试获取临界区,则它会自动成功,并递增内部计数器。意味着所有者线程现在必须释放临界区相同的次数才能真正释放它。
获取锁和释放锁之间的代码称为临界区域(critical region)。
Windows涉及临界区的常用API如下所示:
// 初始化临界区
void InitializeCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
BOOL InitializeCriticalSectionAndSpinCount(LPCRITICAL_SECTION lpCriticalSection, DWORD dwSpinCount);
BOOL InitializeCriticalSectionEx(LPCRITICAL_SECTION lpCriticalSection, DWORD dwSpinCount, DWORD Flags);
// 删除临界区
void DeleteCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
// 进入临界区
void EnterCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
// 离开临界区
void LeaveCriticalSection(LPCRITICAL_SECTION lpCriticalSection);
由于进入和离开临界区必须成对出现,我们可以使用RAII机制来确保这一点,示例代码:
struct AutoCriticalSection
{
AutoCriticalSection(CRITICAL_SECTION& cs)
: _cs(cs)
{
::EnterCriticalSection(&_cs);
}
~AutoCriticalSection()
{
::LeaveCriticalSection(&_cs);
}
// delete copy ctor, move ctor, assignment operators
AutoCriticalSection(const AutoCriticalSection&) = delete;
AutoCriticalSection& operator=(const AutoCriticalSection&) = delete;
AutoCriticalSection(AutoCriticalSection&&) = delete;
AutoCriticalSection& operator=(AutoCriticalSection&&) = delete;
private:
CRITICAL_SECTION& _cs;
};
当然,也可以将临界区封装成一个C++对象,以便提供更友好、安全的访问接口:
class CriticalSection : public CRITICAL_SECTION
{
public:
CriticalSection(DWORD spinCount = 0, DWORD flags = 0)
{
::InitializeCriticalSectionEx(this, (DWORD)spinCount, flags);
}
~CriticalSection()
{
::DeleteCriticalSection(this);
}
void Lock()
{
::EnterCriticalSection(this);
}
void Unlock()
{
::LeaveCriticalSection(this);
}
bool TryLock()
{
return ::TryEnterCriticalSection(this);
}
};
临界区的问题:考虑一个由n个进程(P0,P1,……,Pn-1)组成的系统,每个进程都有一段代码,这段代码称为临界区,其中进程可能会更改公共变量、更新表格、写入文件等。系统的重要特征是,当进程在其临界区执行时,不允许其他进程在其重要部分执行,进程对临界区的执行是相互排斥的。
临界区问题是设计一个协议,进程可以使用该协议来合作,每个进程必须请求许可才能进入其临界区。实现此请求的代码部分是入口区,出口区遵循临界段,剩余的代码是剩余区。
临界区问题的解必须满足以下三个条件:
- 互斥:如果进程Pi在其临界区执行,则任何其他进程都不能在其临界区域执行。互斥要求:
- 必须强制互斥:在具有同一资源或共享对象的临界区的所有进程中,每次只允许一个进程进入其临界区。
- 在非临界区停止的进程必须在不干扰其他进程的情况下停止。
- 要求访问临界区的进程不能无限期延迟:不能出现死锁或饥饿。
- 当没有进程处于临界区时,必须允许任何请求进入其临界区的进程立即进入。
- 没有对相对进程速度或处理器数量进行假设。
- 一个进程只在其临界区内停留有限的时间。
- 进程:如果没有进程正在其临界区执行,并且某些进程希望进入其临界区,那么只有那些未在其剩余区执行的进程才能进入其临界区。
- 限制等待:在进程发出请求后,允许其他进程进入其临界区的次数有限制。
硬件互斥方法如下:
- 中断禁用
在单处理器机器中,并发进程不能重叠,只能交错。此外,进程将继续运行,直到它调用操作系统服务或被中断。因此,为了保证互斥,只要防止进程被中断就足够了。此功能可以以系统内核定义的原语形式提供,用于禁用和启用中断。使用锁解决临界区问题:
do
{
acquire lock
critical section;
release lock
remainder section;
} while (TRUE);
因为临界区不能被中断,所以可以保证互斥。
缺点是它只能在单处理器环境中工作,如果不及时维护,中断可能会丢失,等待进入临界区的进程可能会挨饿。
- 测试和设置指令
它是用于避免相互排斥的特殊机器指令,测试和设置指令可定义如下:
boolean TestAndSet (boolean *target)
{
boolean rv = *target;
*target = TRUE;
return rv:
}
上述功能自动执行。使用TestAndSet的解决方案,共享布尔变量锁已初始化为false:
do
{
while ( TestAndSet (&lock ))
; // do nothing
// critical section
lock = FALSE;
// remainder section
} while (TRUE);
优势:简单易验证,适用于任何数量的进程,可用于支持多个临界区。缺点:可能会出现繁忙等待,可能出现饥饿,可能出现死锁。
- 交换指令
void Swap (boolean *a, boolean *b)
{
boolean temp = *a;
*a = *b;
*b = temp:
}
共享布尔变量锁初始化为FALSE,每个进程都有一个局部布尔变量键:
do
{
key = TRUE;
while( key == TRUE)
Swap(&lock, &key);
// critical section
lock = FALSE;
// remainder section
} while (TRUE);
带TestandSet()的有界等待互斥:
do
{
waiting[i] = TRUE;
key = TRUE;
while (waiting[i] && key)
key = TestAndSet(&lock);
waiting[i] = FALSE;
// critical section
j = (i + 1) % n;
while ((j != i) && !waiting[j])
j = (j + 1) % n;
if (j == i)
lock = FALSE;
else
waiting[j] = FALSE;
// remainder section
} while (TRUE);
彼得森(Peterson)的解决方案:互斥问题是设计一个预协议(或入口协议)和一个后协议(或现有协议),以防止两个或多个线程同时处于其临界区。Tanenbaum研究了临界区问题或互斥问题的建议。问题是当一个进程更新其临界区中的共享可修改数据时,不应允许其他进程进入其临界区。临界区的建议如下:
-
禁用中断(硬件解决方案)。
每个进程在进入其临界区后禁用所有中断,并在离开临界区前重新启用所有中断。中断关闭后,CPU无法切换到其他进程。因此,没有任何其他进程会进入临界区的互斥状态。
禁用中断有时是一种有用的中断,有时是操作系统内核中的一种有用技术,但它不适合作为用户进程的一般互斥机制。原因是,给用户进程关闭中断的权力是不明智的。
-
锁定变量(软件解决方案)。
在这个解决方案中,我们考虑一个单一的共享(锁)变量,初始值为0。当一个进程想要进入其临界区时,它首先测试锁。如果lock为0,进程首先将其设置为1,然后进入临界区。如果锁已经是1,则进程只会等待(lock)变量变为0。因此,0表示其临界区没有进程,1表示某些进程在其临界区。
这个建议中的缺陷可以用例子来解释。假设进程A看到锁为0,在它可以将锁设置为1之前,另一个进程B被调度、运行并将锁设置成1。当进程A再次运行时,它也会将锁设置到1,并且两个进程将同时处于其临界区。
-
严格的替代方案。
在这个建议的解决方案中,整数变量“turn”跟踪谁将进入临界区。最初,进程A检查回合,发现它为0,并进入其临界区。进程B还发现它为0,并处于循环中,不断测试“turn”以查看它何时变为1,不断测试等待某个值出现的变量称为忙碌等待(Busy-Waiting)。
当其中一个进程比另一个慢得多时,轮流进行并不是一个好主意。假设进程0很快完成了它的临界区,所以这两个进程现在都处于非临界区,这种情况违反了上述条件3(限制等待)。
18.6.2.3 读写锁
使用临界区保护共享数据不受并发访问的影响效果很好,但这是一种悲观的机制——最多允许一个线程访问共享数据。在某些情况下,一些线程读取数据,而其他线程写入数据,可以进行优化:如果一个线程读取该数据,则没有理由阻止仅读取数据的其他线程同时执行,亦即“单写入多读取”机制。Windows API提供了表示这种锁的SRWLOCK结构(S表示“Slim”),其定义和相关API如下:
typedef struct _RTL_SRWLOCK
{
PVOID Ptr;
} RTL_SRWLOCK, *PRTL_SRWLOCK;
typedef RTL_SRWLOCK SRWLOCK, *PSRWLOCK;
void InitializeSRWLock(_Out_ PSRWLOCK SRWLock);
void AcquireSRWLockShared(_InOut_ PSRWLOCK SRWLock);
void AcquireSRWLockExclusive(_InOut_ PSRWLOCK SRWLock);
void ReleaseSRWLockShared(_Inout_ PSRWLOCK SRWLock);
void ReleaseSRWLockExclusive(_Inout_ PSRWLOCK SRWLock);
读写锁也可以用RAII封装起来:
class ReaderWriterLock : public SRWLOCK
{
public:
ReaderWriterLock();
ReaderWriterLock(const ReaderWriterLock&) = delete;
ReaderWriterLock& operator=(const ReaderWriterLock&) = delete;
void LockShared();
void UnlockShared();
void LockExclusive();
void UnlockExclusive();
};
struct AutoReaderWriterLockExclusive
{
AutoReaderWriterLockExclusive(SRWLOCK& lock);
~AutoReaderWriterLockExclusive();
private:
SRWLOCK& _lock;
};
struct AutoReaderWriterLockShared
{
AutoReaderWriterLockShared(SRWLOCK& lock);
~AutoReaderWriterLockShared();
private:
SRWLOCK& _lock;
};
// 相关接口的实现
ReaderWriterLock::ReaderWriterLock()
{
::InitializeSRWLock(this);
}
void ReaderWriterLock::LockShared()
{
::AcquireSRWLockShared(this);
}
void ReaderWriterLock::UnlockShared()
{
::ReleaseSRWLockShared(this);
}
void ReaderWriterLock::LockExclusive()
{
::AcquireSRWLockExclusive(this);
}
void ReaderWriterLock::UnlockExclusive()
{
::ReleaseSRWLockExclusive(this);
}
AutoReaderWriterLockExclusive::AutoReaderWriterLockExclusive(SRWLOCK& lock)
: _lock(lock)
{
::AcquireSRWLockExclusive(&_lock);
}
AutoReaderWriterLockExclusive::~AutoReaderWriterLockExclusive()
{
::ReleaseSRWLockExclusive(&_lock);
}
AutoReaderWriterLockShared::AutoReaderWriterLockShared(SRWLOCK& lock)
: _lock(lock)
{
::AcquireSRWLockShared(&_lock);
}
AutoReaderWriterLockShared::~AutoReaderWriterLockShared()
{
::ReleaseSRWLockShared(&_lock);
}
18.6.2.4 条件变量
条件变量(Condition Variable)是另一种同步机制,提供了等待临界区或SRW锁的能力,直到出现某种条件。条件变量的一个经典应用示例是生产者/消费者场景。假设一些线程生成数据项并将它们放置在队列中,每个线程都执行生成项目(item)所需的任何工作,同时,其他线程充当消费者——每个线程从队列中删除一个项目,并以某种方式处理它(下图)。
如果项目的生产速度快于消费者的处理速度,则队列不为空,消费者继续工作。另一方面,如果消费者线程处理所有项目,它们应该进入等待状态,直到生成新的项目,在这种情况下,它们应该被唤醒——正是条件变量提供的行为。与之无关的使用者线程(队列为空)不应自旋(spin),定期检查队列是否变为非空,因为会毫无理由地消耗CPU周期。条件变量允许高效等待(不消耗CPU),直到线程被唤醒(通常由生产者线程唤醒)。
Windows的条件变量由CONDITION_VARIABLE不透明结构表示,使用类似于SRWLOCK,相关API如下:
void InitializeConditionVariable(PCONDITION_VARIABLE ConditionVariable);
BOOL SleepConditionVariableCS(PCONDITION_VARIABLE ConditionVariable, PCRITICAL_SECTION CriticalSection, DWORD dwMilliseconds);
BOOL SleepConditionVariableSRW(PCONDITION_VARIABLE ConditionVariable, PSRWLOCK SRWLock, DWORD dwMilliseconds, ULONG Flags);
VOID WakeConditionVariable (PCONDITION_VARIABLE ConditionVariable);
VOID WakeAllConditionVariable (PCONDITION_VARIABLE ConditionVariable);
线程一旦被唤醒,将重新获取同步对象并继续执行。此时,线程应该重新检查它等待的条件,如果不满足,则再次调用Sleep*函数。如下图所示(使用临界区)。
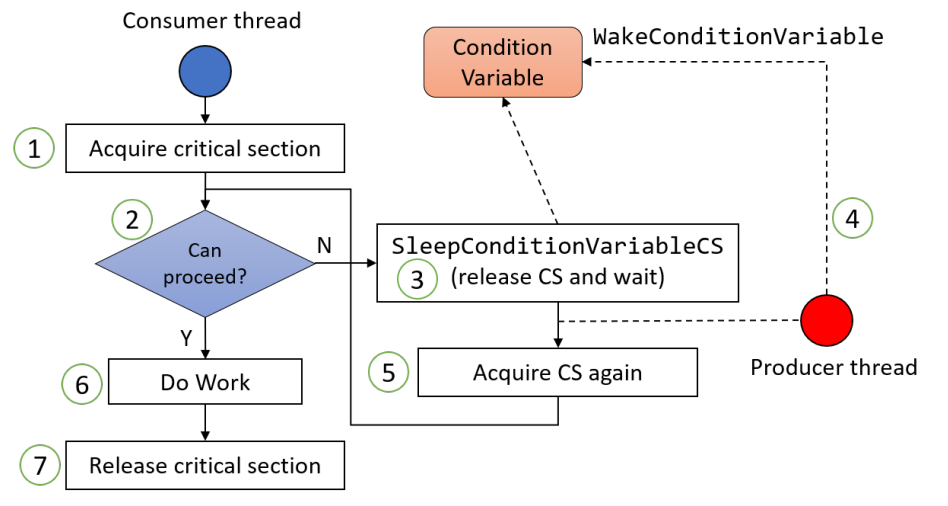
上图涉及的步骤如下:
1、使用者线程获取临界区。
2、线程检查是否可以继续,例如可以检查应该处理的队列是否为空。
3、如果它为空,则线程调用SleepConditionVariableCS,将释放临界区(以便另一个线程可以获取它)并进入睡眠(等待状态)。
4、在某些时候,生产者线程将通过调用WakeConditionVariable来唤醒消费者线程,例如向队列中添加了一个新的项。
5、SleepConditionVariableCS返回,获取临界区并返回检查是否可以继续。如果没有,它将继续等待。
6、现在可以继续了,线程可以执行它的工作(例如从队列中删除项)。临界区仍然保留。
7、最后,工作完成,临界区分必须释放。
18.6.2.5 等待地址
Windows 8和Server 2012添加了另一种同步机制,允许线程高效地等待,直到某个地址的值更改为所需值,然后它可以醒来继续工作。当然可以使用其他同步机制来实现类似的效果,例如使用条件变量,但等待地址(Waiting on Address)更有效,并且不容易死锁,因为没有直接使用临界区(或其他软件同步原语)。线程可以通过调用WaitOnAddress进入等待状态,直到某个值出现在“受监视”数据上,相关API:
BOOL WaitOnAddress(volatile VOID* Address, PVOID CompareAddress, SIZE_T AddressSize, DWORD dwMilliseconds);
VOID WakeByAddressSingle(_In_ PVOID Address);
VOID WakeByAddressAll(_In_ PVOID Address);
18.6.2.6 同步屏障
Windows 8中引入的另一个同步原语是同步屏障(Synchronization Barrier),它允许同步线程,这些线程需要到达工作中的某个点才能继续。例如,假设系统有几个部分,在主应用程序代码可以继续之前,每个部分都需要分两个阶段初始化。实现这一点的一种简单方法是顺序调用每个初始化函数:
void RunApp()
{
// phase 1
InitSubsystem1();
InitSubsystem2();
InitSubsystem3();
InitSubsystem4();
// phase 2
InitSubsystem1Phase2();
InitSubsystem2Phase2();
InitSubsystem3Phase2();
InitSubsystem4Phase2();
// go ahead and run main application code...
}
虽然以上可行,但是如果每个初始化都可以同时进行,那么每个初始化都由不同的线程执行。在所有其他线程完成phase 1之前,每个线程不得继续进行phase 2初始化。当然,可以通过使用其他同步原语的组合来实现这种方案,但已经存在用于这种目的的同步屏障。Windows使用SYNCHRONIZATION_BARRIER不透明结构表示,且使用InitializeSynchronizationBarrier进行初始化,相关API:
BOOL InitializeSynchronizationBarrier(LPSYNCHRONIZATION_BARRIER lpBarrier, LONG lTotalThreads, LONG lSpinCount);
BOOL EnterSynchronizationBarrier(LPSYNCHRONIZATION_BARRIER lpBarrier, DWORD dwFlags);
该函数仅在释放屏障后,对单个线程返回TRUE,对所有其他线程返回FALSE。在前面描述的场景中,以下是在单独线程中运行的初始化函数之一:
DWORD WINAPI InitSubSystem1(PVOID p)
{
auto barrier = (PSYNCHRONIZATION_BARRIER)p;
// phase 1
printf("Subsystem 1: Starting phase 1 initialization (TID: %u)...\n", ::GetCurrentThreadId());
// do work...
printf("Subsystem 1: Ended phase 1 initialization...\n");
// 进入屏障
::EnterSynchronizationBarrier(barrier, 0);
printf("Subsystem 1: Starting phase 2 initialization...\n");
// do work
printf("Subsystem 1: Ended phase 2 initialization...\n");
return 0;
}
phase 1初始化完成后,调用EnterSynchronizationBarrier,等待所有其他线程完成phase 1初始化。主函数可以这样编写:
SYNCHRONIZATION_BARRIER sb;
// 初始化屏障
InitializeSynchronizationBarrier(&sb, 4, -1);
LPTHREAD_START_ROUTINE functions[] = {InitSubSystem1, InitSubSystem2, InitSubSystem3, InitSubSystem4};
printf("System initialization started\n");
HANDLE hThread[4];
int i = 0;
for (auto f : functions)
{
hThread[i++] = ::CreateThread(nullptr, 0, f, &sb, 0, nullptr);
}
// 等待所有屏障
::WaitForMultipleObjects(_countof(hThread), hThread, TRUE, INFINITE);
printf("System initialization complete\n");
// close thread handles...
18.6.3 进程通信和同步
进程间通信(Inter process communication,IPC)是一种允许进程相互通信并同步其操作的机制。这些进程之间的通信可以看作是它们之间合作的一种方法,操作系统中并发执行的进程可以是独立进程,也可以是协作进程。如果一个进程不能影响或不受系统中执行的其他进程的影响,则该进程是独立的,任何不与任何其他进程共享数据的进程都是独立的。如果一个进程可以影响或受到系统中执行的其他进程的影响,那么它就是在合作。显然,任何与其他进程共享数据的进程都是一个协作进程。进程合作的原因:
- 信息共享。由于多个用户可能对同一条信息感兴趣(例如,共享文件),我们必须提供一个允许并发访问此类信息的环境。
- 计算加速。如果我们希望某个特定任务运行得更快,我们必须将其分解为子任务,每个子任务将与其他任务并行执行。请注意,只有当计算机具有多个处理核心时,才能实现这种加速。
- 模块化。我们可能希望以模块化的方式构建系统,将系统功能划分为单独的进程或线程。
- 便利性。即使是单个用户也可以同时处理许多任务。例如,用户可以同时编辑、听音乐和编译。
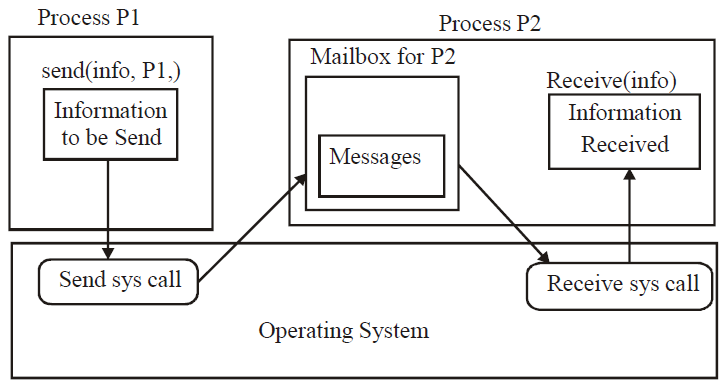
进程间通信机制。
进程间通信有两种基本模型:
- 共享内存。在共享内存模型中,建立了协作进程共享的内存区域。然后,进程可以通过将数据读写到共享区域来交换信息。共享内存可能比消息传递更快,因为消息传递系统通常使用系统调用实现,因此需要更耗时的内核干预任务。
- 消息传递。在消息传递模型中,通信通过协作进程之间交换的消息进行。消息传递对于交换少量数据非常有用,因为不需要避免冲突,在分布式系统中比共享内存更容易实现。
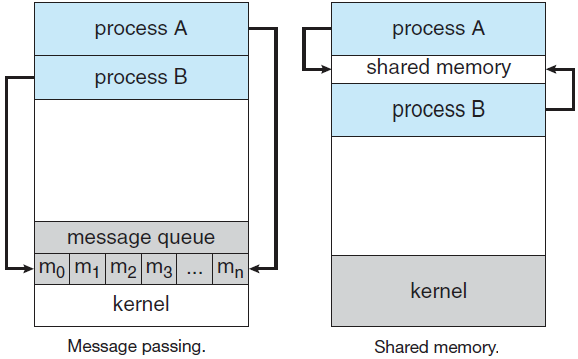
消息传递示例。

Solaris同步数据结构。
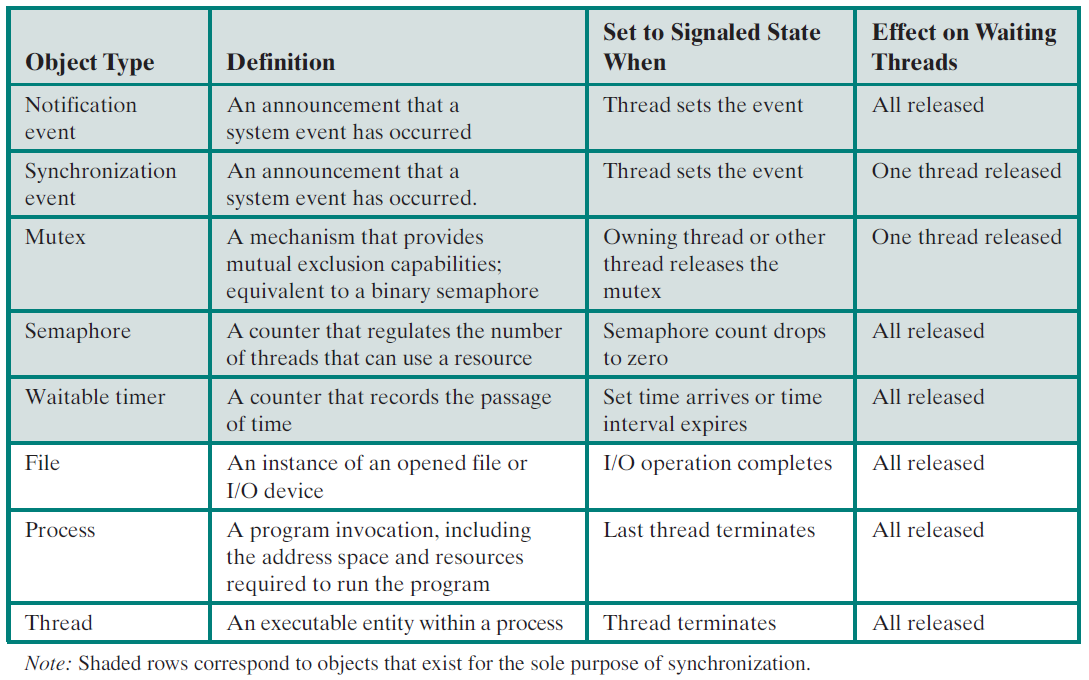
Windows同步对象。
非直接进程通信。
在共享内存系统中,使用共享内存的进程间通信要求通信进程建立共享内存区域。通常,共享内存区域驻留在创建共享内存段的进程的地址空间中。其他希望使用此共享内存段进行通信的进程必须将其连接到其地址空间,通常操作系统会尝试阻止一个进程访问另一个进程的内存。共享内存要求两个或更多进程同意删除此限制。然后,他们可以通过读取和写入共享区域中的数据来交换信息,数据的形式和位置由这些进程决定,不受操作系统的控制。这些进程还负责确保它们不会同时写入同一位置。
竞争条件(Race Condition)的情况是多个进程同时访问和操作相同的数据,执行结果取决于访问发生的特定顺序。假设两个进程P1和P2共享全局变量a,在执行过程中,P1会将a更新为值1,而在执行过程的某个时刻,P2会将a更新为值2,因此,这两个任务正在竞争地写入变量a。在本例中,比赛的“失败者”(最后更新的进程)决定a的最终值。
因此,操作系统关注以下事项:
- 操作系统必须能够跟踪各种进程。
- 操作系统必须为每个活动进程分配和取消分配各种资源。
- 操作系统必须保护每个进程的数据和物理资源免受其他进程的意外干扰。
- 相对于其他并发进程的速度、功能及输出必须独立于其执行速度。
进程交互可以定义为相互之间的不感知、间接感知和直接感知。并发进程在以下情形之一会发生冲突:
- 争夺同一资源的使用。
- 两个或多个进程在执行过程中需要访问资源。
- 每个进程都不知道其他进程的存在。
- 竞争进程之间没有信息交换。
进程经常需要与其他进程进行通信,最好是以结构良好的方式进行,而不是使用中断。简单地说,有三个问题:
1、一个进程如何向另一个进程传递信息。
2、与确保两个或多个进程不会相互妨碍有关,例如,航空公司预订系统中的两个进程,每个进程都试图为不同的客户抢占飞机上的最后一个座位。
3、涉及存在依赖项时的正确排序:如果进程A生成数据,进程B打印它们,B必须等到A生成了一些数据后才能开始打印。
同样重要的是,其中两个问题同样适用于线程。。
18.6.3.1 调度对象
Windows内核对象相关的最重要的几点描述如下:
- 内核对象位于系统(内核)空间,理论上可以从任何进程访问,前提是进程可以获得请求对象的句柄。
- 句柄和进程相关。
- 有三种方法可以跨进程共享对象:句柄继承、名称和句柄复制。
一些内核对象更为特殊,称为调度对象(dispatcher object)或可等待对象(waitable object)。此类对象可以处于两种状态之一:有信号(signaled)或无信号(non-signaled)。有信号和非信号的含义取决于对象的类型,下表总结了常见调度对象的这些状态的含义。
| 对象类型 | 有信号 | 无信号 |
|---|---|---|
| 进程(Process) | Exited/Terminated | Running |
| 线程(Thread) | Exited/Terminated | Running |
| 作业(Job) | 已达到作业结束时间 | 未达到或未设置限制 |
| 互斥体(Mutex) | 免费(无拥有者) | 被拥有 |
| 信号量(Semaphore) | 计数大于0 | 计数等于0 |
| 事件(Event) | 事件被设置 | 事件未被设置 |
| 文件(File) | I/O操作完成 | I/O操作正在进行或未开始 |
| 可等待计时器(Waitable Timer) | 计时器计数已过期 | 计时器计数未过期 |
| I/O完成 | 异步I/O操作已完成 | 异步I/O操作未完成 |
等待对象发出信号通常由以下两个功能之一完成(I/O完成端口除外,该端口具有自己的等待功能):
DWORD WaitForSingleObject(HANDLE hHandle, DWORD dwMilliseconds);
DWORD WaitForMultipleObjects(DWORD nCount, CONST HANDLE* lpHandles, BOOL bWaitAll, DWORD dwMilliseconds);
WaitForSingleObject可能有四个返回值:
- WAIT_OBJECT_0:等待结束,因为对象在超时到期之前发出信号。
- WAIT_TIMEOUT:在线程等待时,对象没有发出信号。如果超时是无限的,则永远不会返回此值。
- WAIT_FAILED:由于某种原因,该功能失败。
- WAIT_ABANDONED:等待在互斥对象上,互斥对象已被放弃。
如果等待函数成功,因为一个或多个对象发出信号,线程将被唤醒并可以继续执行。刚刚发出信号的对象是否仍处于信号状态?取决于对象的类型。某些对象仍保持其信号状态,例如进程和线程。一个进程一旦退出或终止,就会发出信号,并在其剩余生命周期内保持这种状态(当该进程有打开的句柄时)。
某些类型的对象可能在成功等待后改变其信号状态。例如,对互斥体的成功等待会将其返回到无信号状态。另一个在发出信号时表现出特殊行为的对象是自动重置事件。当发出信号时,它会释放一个线程(并且只释放一个),当这种情况发生时,它的状态会自动切换到无信号状态。
如果多个线程等待同一个互斥体,并且它发出信号,会发生什么?只有一个线程可以在互斥体翻转回无信号状态之前获取互斥体。在背后,对象的等待线程存储在先进先出(FIFO)队列中,因此队列中的第一个线程是被唤醒的线程(无论其优先级如何)。但是,不应依赖这种行为。一些内部机制可能会使线程不再等待(例如,如果线程被挂起,例如使用调试器),然后当线程恢复时,它将被推到队列的后面。所以这里的简单规则是,无法确定哪个线程将首先唤醒。该算法可能在未来的Windows版本中随时更改。
18.6.3.2 互斥体
互斥体(mutex,mutual exclusion的缩写)也常被称为互斥锁、互斥量、互斥对象等,提供了与临界区类似的功能,保护共享数据免受并发访问。一次只有一个线程可以成功获取互斥体,并继续访问共享数据。等待互斥体的所有其他线程必须继续等待,直到获取线程释放互斥体。Windows的相关API:
HANDLE CreateMutex(LPSECURITY_ATTRIBUTES lpMutexAttributes, BOOL bInitialOwner, LPCTSTR lpName);
HANDLE CreateMutexEx(LPSECURITY_ATTRIBUTES lpMutexAttributes, LPCTSTR lpName, DWORD dwFlags, DWORD dwDesiredAccess);
HANDLE OpenMutexW(DWORD dwDesiredAccess, BOOL bInheritHandle, LPCWSTR lpName);
BOOL ReleaseMutex(_In_ HANDLE hMutex);
如果拥有互斥的线程退出或终止(无论出于什么原因),会发生什么?由于互斥体的所有者是唯一可以释放互斥体,可能会导致死锁,其他等待互斥的线程永远不会获取它。这种互斥体称为废弃互斥体(abandoned mutex),是由其所有者线程废弃的。
幸运的是,内核知道互斥体的所有权,因此如果看到一个线程在持有互斥体时终止(如果是这样的话,则会有多个),内核会显式释放被放弃的互斥体。这会导致成功获取互斥锁的下一个线程从其WaitForSingleObject调用中取回WAIT_ABANDONED,而不是WAIT_OBJECT_0。意味着线程正常获取互斥体,但特殊返回值用作提示,以指示前一个所有者在终止前没有释放互斥体。
18.6.3.3 信号量
信号量(Semaphore)是一个整数变量,除了初始化之外,只能通过两个标准原子操作访问:wait()和signal()。wait()操作最初称为P,signal()最初称为V。
P和V操作示意图。图中显示了一个任务T0执行的P()函数调用序列,以及另一个任务或ISR对同一信号量执行的V()函数。
信号量作为通用同步工具:
- 计数信号量:整数值可以覆盖非限制域。
- 二进制信号量:整数值的范围只能介于0和1之间。
- 可以更简单地实现。
- 也被称为互斥锁,可以将计数信号量实现为二进制信号量。
- 提供互斥信号量互斥。
// initialized
do
{
wait (mutex);
// Critical Section
signal (mutex);
} while (TRUE);
信号量实现:必须保证没有两个进程可以同时对同一信号量执行wait()和signal()。因此,实现成为临界区问题,其中等待和信号代码放置在临界区。现在可以使用忙碌等待临界区的实现,实现代码很短,如果临界区很少被占用,则很少忙碌等待。请注意,应用程序可能会在临界区花费大量时间,因此不是一个好的解决方案。
无忙碌等待的信号量实现:每个信号量都有一个相关的等待队列,等待队列中的每个条目都有两个数据项:值(整数类型)和指向列表中下一条记录的指针。有两种操作:阻塞——将调用操作的进程放在适当的等待队列中;唤醒——删除等待队列中的一个进程,并将其放入就绪队列。
// 等待实现
wait(semaphore *S)
{
S->value--;
if (S->value < 0)
{
add this process to S->list;
block();
}
}
// 信号实现
signal(semaphore *S)
{
S->value++;
if (S->value <= 0)
{
remove a process P from S->list;
wakeup(P);
}
}
信号量不被硬件支持,但有几个吸引人的特性:
- 信号量与设备无关。
- 信号量易于实现。
- 正确性易于确定。
- 可以有多个不同的临界区和不同的信号量。
- 信号量同时获得许多资源。
信号量的不足:
- 本质上是共享的全局变量。
- 可以从程序中的任何位置访问信号量。
- 无法控制或保证正确使用。
- 信号量和信号量控制访问的数据之间没有语言连接。
- 它们有两个目的:互斥和调度约束。
虽然信号量为进程同步提供了一种方便而有效的机制,但错误地使用它们会导致难以检测的定时错误,因为这些错误只有在发生特定的执行序列时才会发生,而这些序列并不总是发生。
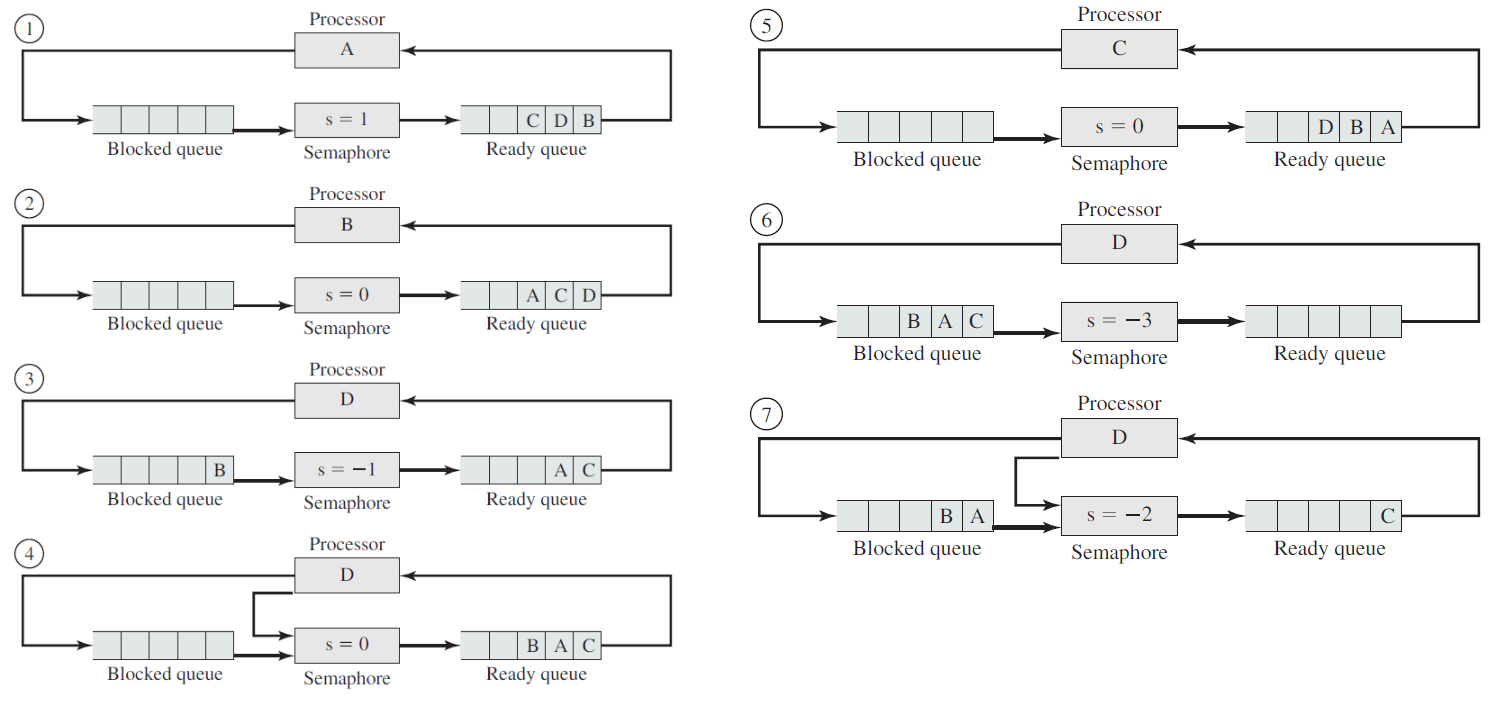
信号量机制示意图。
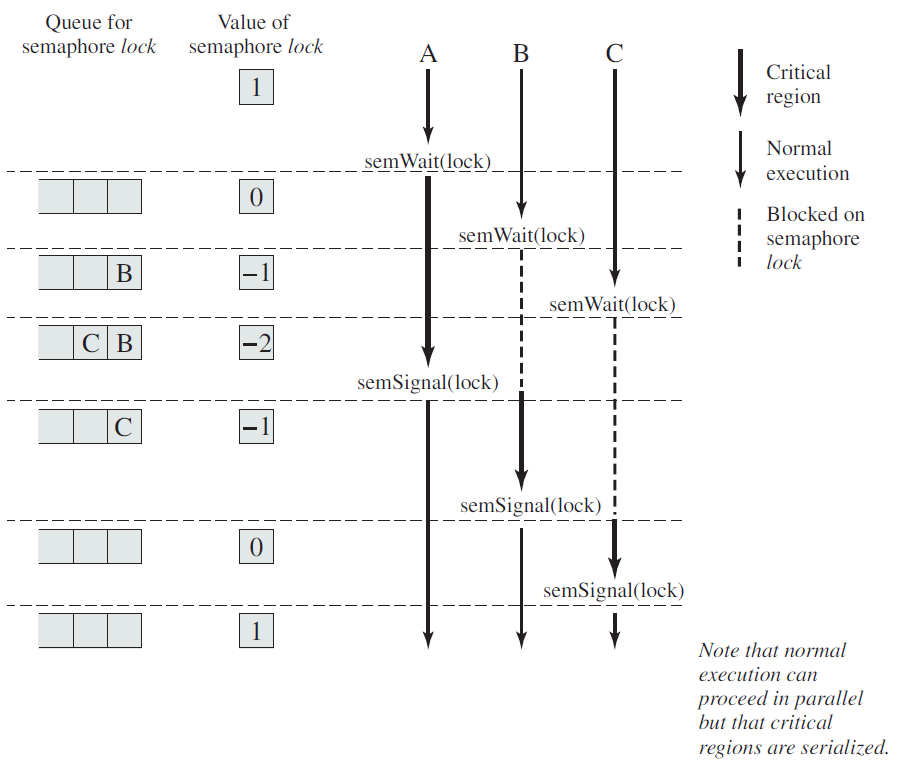
进程访问受信号量保护的共享数据。
监视器是一种编程语言结构,提供与信号量等效的功能,并且更易于控制。监视器结构已经在许多编程语言中实现,包括Concurrent Pascal、Pascal Plus、Modula-2、Modula-3和Java。抽象数据类型或ADT用一组函数封装数据,以对该数据进行操作,这些函数独立于ADT的任何特定实现。监视器类型是一种ADT,包含一组程序员定义的操作,这些操作在监视器中互斥。监视器类型还声明其值定义该类型实例状态的变量,以及操作这些变量的函数体。它也被实现为一个程序库,允许程序员在任何对象上放置监视器锁。监视器语法:
monitor monitor_name
{
/* shared variable declarations */
function P1(...)
{
...
}
function P2 (...)
{
...
}
...
function Pn (...)
{
...
}
initialization code (...)
{
...
}
}
因此,在监控器中定义的函数只能访问监控器中局部声明的变量及其形式参数。类似地,监视器的局部变量只能由局部函数访问。
在Windows中,信号量的作用是以线程安全的方式限制某些东西。信号量用当前和最大计数初始化。只要其当前计数高于零,它就处于信号状态。每当一个线程调用信号量上的WaitForSingleObject并且它处于信号状态时,信号量的计数就会减少,并且允许线程继续。一旦信号量计数达到零,它就变成无信号的,任何试图等待它的线程都将阻塞。相反,想要“释放”一个信号量计数(或更多)的线程调用ReleaseSemaphore,导致信号量计数增加并再次将其设置为有信号状态。
HANDLE CreateSemaphore( LPSECURITY_ATTRIBUTES lpSemaphoreAttributes, ...);
HANDLE CreateSemaphoreEx( LPSECURITY_ATTRIBUTES lpSemaphoreAttributes, ...);
BOOL ReleaseSemaphore( HANDLE hSemaphore, ...);
18.6.3.4 事件
在某种意义上,事件(Event)是最简单的同步原语——它只是一个可以设置(信号状态)或重置(非信号状态)的标志。作为(可能命名的)内核对象,它具有在单个进程内或跨进程工作的灵活性。与事件相关联的复杂性在于有两种类型的事件:手动重置和自动重置。下表总结了它们的特性。
| 事件类型 | 内核名称 | SetEvent效果 |
|---|---|---|
| 手工重置 | 通知 | 将事件置于信号状态,并释放等待它的所有线程,事件保持在信号状态。 |
| 自动重置 | 同步 | 单个线程从等待中释放,然后事件自动返回到无信号状态。 |
Windows相关的API:
HANDLE CreateEvent( LPSECURITY_ATTRIBUTES lpEventAttributes, BOOL bManualReset, BOOL bInitialState, LPCTSTR lpName);
HANDLE CreateEventEx( LPSECURITY_ATTRIBUTES lpEventAttributes, LPCTSTR lpName, DWORD dwFlags, DWORD dwDesiredAccess);
HANDLE OpenEvent( DWORD dwDesiredAccess, BOOL bInheritHandle, LPCTSTR lpName);
BOOL SetEvent(_In_ HANDLE hEvent); // signaled
BOOL ResetEvent(_In_ HANDLE hEvent); // non-signaled
BOOL PulseEvent(_In_ HANDLE hEvent);
18.6.3.5 可等待计时器
Windows API提供了对具有不同语义和编程模型的多个计时器的访问。主要有:
- 对于窗口场景,SetTimer API提供了一个计时器,通过将WM_TIMER消息发布到调用线程的消息队列来工作。此计时器适用于GUI应用程序,因为计时器消息可以在UI线程上处理。
- Windows多媒体API提供了一个用timeSetEvent创建的多媒体计时器,该计时器在优先级为15的单独线程上调用回调函数。计时器可以是一次性的,也可以是周期性的,并且非常精确(其分辨率可由函数设置),分辨率值为零要求系统能够提供最高分辨率。
相关API:
HANDLE CreateWaitableTimer( LPSECURITY_ATTRIBUTES lpTimerAttributes, BOOL bManualReset, LPCTSTR lpTimerName);
HANDLE CreateWaitableTimerEx( LPSECURITY_ATTRIBUTES lpTimerAttributes, LPCTSTR lpTimerName, DWORD dwFlags, DWORD dwDesiredAccess);
HANDLE OpenWaitableTimer( DWORD dwDesiredAccess, BOOL bInheritHandle, LPCTSTR lpTimerName);
BOOL SetWaitableTimer( HANDLE hTimer, const LARGE_INTEGER* lpDueTime, LONG lPeriod, PTIMERAPCROUTINE pfnCompletionRoutine, LPVOID lpArgToCompletionRoutine, BOOL fResume);
BOOL SetWaitableTimerEx( HANDLE hTimer, const LARGE_INTEGER* lpDueTime, LONG lPeriod, PTIMERAPCROUTINE pfnCompletionRoutine, LPVOID lpArgToCompletionRoutine, PREASON_CONTEXT WakeContext, ULONG TolerableDelay);
18.6.3.6 消息传递
消息传递允许进程进行通信并同步其操作,而无需共享相同的地址空间。在分布式环境中特别有用,其中通信进程可能位于通过网络连接的不同计算机上。消息传递设施至少提供两种操作:发送(信息)和接收(消息)。如果P和Q希望通信,他们需要在他们之间建立通信链路,通过发送/接收交换消息。实现通信链路物理(如共享内存、硬件总线)逻辑(如逻辑属性)。
如果是直接通信,进程必须明确命名:
- 发送(P,消息):向进程P发送消息。
- 接收(Q,消息):从进程Q接收消息。
通信链路的属性,自动建立链接,链接只与一对通信进程相关联,每对之间只有一条链路,链接可能是单向的,但通常是双向的。
如果是间接通信,邮件从邮箱(也称为端口)定向和接收,每个邮箱都有唯一的id,进程只有在共享邮箱时才能通信。通信链路的属性,仅当进程共享公共邮箱时才建立链接,链接可能与许多进程关联。每对进程可以共享多个通信链路,链接可以是单向的或双向的。
对应消息的同步,消息传递可以是阻塞的或非阻塞的,阻塞被认为是同步的,阻止发送会阻止发件人,直到收到消息。阻止接收会阻止接收器,直到消息可用,非阻塞被认为是异步的,非阻塞发送让发送方发送消息并继续,非阻塞接收使接收器接收到有效消息或空。
连接到链接的消息队列以三种方式之一实现:
- 零容量:0条消息发送方必须等待接收方(集合)。
- 有限容量:n条消息的有限长度如果链接已满,发送方必须等待。
- 无限容量:无限长度发送程序从不等待。
18.6.3.7 队列
尽管信号量为抢占式多任务提供了最强大的数据结构,但它们只是偶尔显式使用。更常见的是,它们被另一种称为队列的数据结构隐藏。队列也称为FIFO(先进先出),是至少提供两个函数的缓冲区:Put()和Get()。存储在队列中的项目的大小可能会有所不同,因此queue最好作为模板类实现。项目的数量也可能不同,因此类的构造函数将使用所需的长度作为参数。
队列的最简单形式是环形缓冲区(Ring Buffer)。内存的连续部分(称为Buffer)被分配,两个变量GetIndex和PutIndex被初始化为0,从而指向内存空间的开始。对GetIndex和PutIndex执行的唯一操作是递增它们。如果它们碰巧超过了内存的末尾,它们将被重置为开始。这种在结尾处的缠绕将笔直的记忆变成了一个环。当且仅当GetIndex=PutIndex时,缓冲区为空。
否则,PutIndex总是领先于GetIndex(尽管如果PutIndex末尾已经环绕,而GetIndex尚未环绕,则PutIndexe可能小于GetIndex)。在下图中,环形缓冲区显示为直存储器和逻辑环。
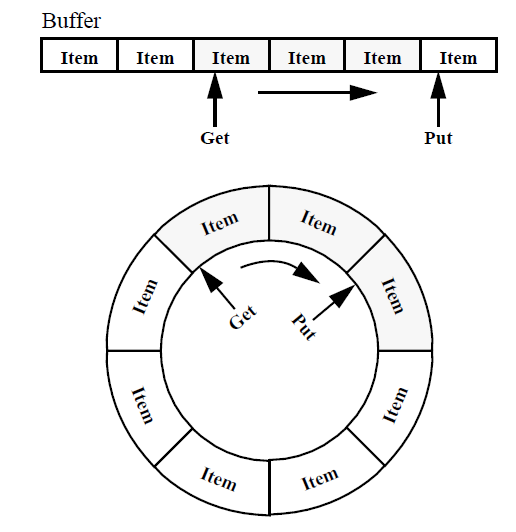
可以使用环形缓冲区来放入或获取信号量,以实现无锁同步。
18.6.3 同步问题
18.6.3.1 死锁
死锁的定义:在多道程序设计环境中,几个进程可能会竞争有限数量的资源。进程请求资源时如果资源不可用,进程将进入等待状态。有时,等待进程再也无法更改状态,因为它请求的资源由其他等待进程持有。这种情况称为死锁(Deadlock)。
死锁场景示意图。
系统可能由有限数量的资源组成,并分布在多个进程中,这些资源被划分为多个实例,每个实例都具有相同的实例。进程必须在使用资源之前请求资源,并且必须在使用后释放资源,可以请求任意数量的资源来执行指定的任务,请求的资源量不得超过可用资源的总数。进程只能按以下顺序使用资源:
- 请求:如果没有立即批准请求,则请求进程必须等待,才能获取资源。
- 使用:进程可以对资源进行操作。
- 释放:进程在使用资源后释放资源。
死锁可能涉及不同类型的资源。示例:考虑一个有一台打印机和一个磁带驱动器的系统。如果进程Pi当前持有打印机,进程Pj持有磁带驱动器。如果进程Pi请求磁带驱动器,而进程Pj请求打印机,则会发生死锁。多线程程序很可能会出现死锁,因为它们会争夺共享资源。
死锁的具体示例。
处理死锁的方法有:
- 使用协议来防止死锁,确保系统永远不会进入死锁状态。
- 允许系统进入死锁状态,检测并从中恢复。
- 忽略这个问题,并假装死锁从未在系统中发生过。包括UNIX在内的大多数操作系统都使用此选项。
为了确保死锁永远不会发生,系统可以使用死锁避免或死锁预防。死锁预防是一套确保至少一种必要条件不会发生的方法。死锁避免要求操作系统提前获得有关进程在其生存期内将请求和使用哪些资源的信息。如果系统不使用死锁避免或死锁预防,则可能会出现死锁情况。在此期间,它可以提供一个算法来检查系统状态,以确定是否发生了死锁,以及从死锁中恢复的算法。未检测到的死锁将导致系统性能下降。
没有死锁的具体示例。
要发生死锁,必须满足以下所有4个必要条件。只要有一个条件不成立,那么我们就可以防止死锁的发生。
-
互斥。适用于不可共享的资源,如一台打印机一次只能由一个进程使用。可共享资源中不可能存在互斥,因此它们不会陷入死锁。只读文件是共享资源的好例子,进程从不等待访问可共享资源。因此,我们不能通过否认不可共享资源中的互斥条件来防止死锁。
-
保留并等待。当进程请求资源(即不可用)时,可以通过强制进程释放其持有的所有资源来消除这种情况。可以使用的一种协议是,每个进程在开始执行之前都会分配其所有资源。例如:考虑一个将数据从磁带机复制到磁盘,对文件进行排序,然后将结果打印到打印机的过程。如果在开始时分配了所有资源,则会将磁带驱动器、磁盘文件和打印机分配给进程。主要问题是它导致资源利用率低,因为最终需要打印机,并且从一开始就分配给它,这样其他进程就无法使用它。
另一个可使用的协议是,当进程没有资源时,允许进程请求资源。例如,进程分配有磁带驱动器和磁盘文件,它执行所需的操作并释放两者,然后,该过程再次请求磁盘文件和打印机,但是可能导致饥饿问题。
-
非抢占式。为了确保这种情况永远不会发生,必须抢占资源。可以使用以下协议:如果一个进程持有某些资源并请求另一个无法立即分配给它的资源,那么请求进程当前持有的所有资源都会被抢占,并添加到其他进程可能正在等待的资源列表中。只有当进程重新获得其请求的旧资源和新资源时,才会重新启动该进程。
当流程请求资源时,我们检查它们是否可用。如果它们可用,我们就分配它们,否则我们会检查它们是否分配给其他等待进程。如果是这样,我们会抢占等待进程中的资源,并将其分配给请求进程。请求进程必须等待。
-
循环等待。死锁的第四个也是最后一个条件是循环等待条件,确保永远不会出现这种情况的一种方法是对所有资源类型强制排序,并且每个进程以递增的顺序请求资源。
避免死锁(仅概念):死锁预防算法可能导致设备利用率低,并降低系统吞吐量。避免死锁需要关于如何请求资源的附加信息。了解请求和发布的完整序列后,我们可以决定每个请求的进程是否应该等待。对于每个请求,它都需要检查当前可用的资源,当前分配给每个进程的资源将处理每个进程的未来请求和释放,以决定是否可以满足当前请求,或者必须等待以避免将来可能出现的死锁。死锁避免算法动态检查资源分配状态,以确保循环等待条件永远不存在。资源分配状态由可用资源和已分配资源的数量以及每个进程的最大需求定义。
安全状态:状态是一种安全状态,其中至少存在一个顺序,所有进程都将完全运行,而不会导致死锁。如果存在安全序列,则系统处于安全状态。如果对于每个Pi,Pi可以请求的资源可以由当前可用的资源满足,则进程序列<P1、P2、…………..Pn>是当前分配状态的安全序列。如果Pi请求的资源当前不可用,则Pi可以获得完成其指定任务所需的所有资源。
安全状态不是死锁状态。每当进程请求资源(即当前可用的资源)时,系统必须决定是否可以立即分配资源,或者进程是否必须等待。只有当分配使系统处于安全状态时,才会批准请求。在这种情况下,如果进程请求资源,即当前可用的资源,则必须等待。因此,资源利用率可能低于没有死锁避免算法的情况。
资源分配图算法:只有当我们有一个资源类型的实例时,才使用此算法。除了请求边缘和赋值边缘外,还使用了一个称为索赔边缘的新边缘。例如,结合下图,其中索赔边缘由虚线表示,索赔边缘Pi->Rj表示流程Pi将来可能会请求Rj。当进程Pi请求资源Rj时,声明边缘将转换为请求边缘。当资源Rj由进程Pi释放时,分配边Rj->Pi被声明边Pi->Rj替换。
当进程Pi请求Rj时,仅当将请求边缘Pi->Rj转换为分配边缘Rj->Pi不会导致循环时,才会批准请求。循环检测算法用于检测循环。如果没有周期,那么要处理的资源分配将使系统处于安全状态。
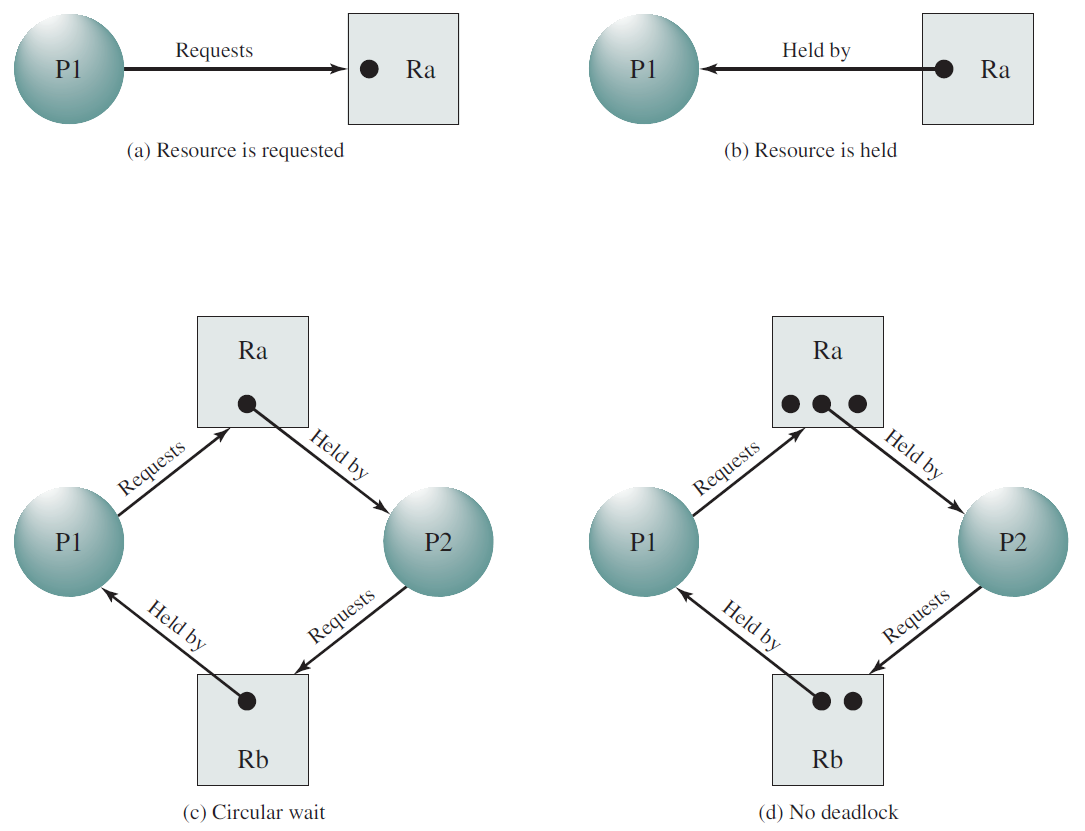
银行家算法适用于具有每个资源类型的多个实例的系统,但其效率低于资源分配图算法。当一个新进程进入系统时,它必须声明它可能需要的最大资源数,此数字不能超过系统中的资源总数。系统必须确定资源分配是否会使系统处于安全状态,如果是这样的话,那么应该等待进程释放足够的资源。使用了几种数据结构来实现银行家算法。设“n”为系统中的进程数,“m”为资源类型数。我们需要以下数据结构:
- 可用:长度为m的矢量表示可用资源的数量。如果Available[i]=k,则资源类型Rj的k个实例可用。
- 最大:nxm矩阵定义了每个进程的最大需求,如果Max[i, j]=k,则Pi最多可以请求k个资源类型Rj的实例。
- 分配:一个nxm矩阵定义了当前分配给每个进程的每种类型的资源数量。如果Allocation[i, j]=k,那么Pi当前是资源类型Rj的k个实例。
- 需求:nxm矩阵表示每个流程的剩余资源需求。如果Need[i, j]=k,那么Pi可能还需要k个资源类型Rj的实例来计算其任务。因此需要[i, j]=最大[i, j]-分配[i]
安全算法用于确定系统是否处于安全状态,伪代码:
// Step 1: 设Work和Finish分别为长度m和n的向量,初始化
Work = Available
For i = 1,2, …, n,
if Allocationi 0, then
Finish[i] = false;
otherwise,
Finish[i] = true
// Step 2: 查找索引i,以便
Finish[i] == false
Requesti <= Work
If no such i exists then
go to step 4
// Step 3:
Work = Work + Allocation
Finish [i] = true
Go to step 2
//Step 4:
If Finish [i] = false
for some i, 1<=i<= n, then
the system is in a deadlock state
Moreover
if Finish[i] = false then
process Pi is deadlocked
安全状态的计算过程。
非安全状态的计算。
资源分配算法:请求=流程Pi的请求向量,如果Requesti[j]=k,则进程Pi需要k个资源类型Rj的实例。
步骤1:若Requesti<=Needi,则转到步骤2。否则,引发错误条件,因为进程已超过其最大声明。
步骤2:如果Requesti<=可用,转至步骤3。否则,由于资源不可用,Pi必须等待。
步骤3:通过如下修改状态,假装将请求的资源分配给Pi:
Available = Available – Request;
Allocationi = Allocationi + Requesti;
Needi = Needi – Requesti;
如果安全的话,资源分配给Pi;如果不安全,Pi必须等待,并恢复旧的资源分配状态。
死锁的检测示例。
从死锁中恢复:中止所有死锁进程,一次中止一个进程,直到消除死锁循环。我们应该选择什么顺序中止?答案是:
- 进程的优先级。
- 进程计算的时间以及完成的时间。
- 进程使用的资源。
- 资源进程需要完成。
- 需要终止多少个进程?
- 进程是交互式的还是批处理的?
资源抢占:选择受害者——将成本降至最低;回滚——返回到某个安全状态,重新启动该状态的进程;饥饿——同一进程可能总是被选为受害者,包括成本因素中的回滚次数。
处理临界区似乎很简单。然而,即使我们使用各种RAII封装器,仍然存在死锁的危险。当拥有锁1的线程A(例如临界区)等待线程B拥有的锁2,而线程B正在等待锁1时,就会发生典型的死锁。
避免死锁的方法另一种简单的方法:总是以相同的顺序获取锁,意味着每个需要多个锁的线程应该总是以相同的顺序获取锁,保证了死锁不会发生(至少不会因为这些锁)。实际问题是如何强制顺序,无需编写任何代码,只需记录顺序,以便将来的代码继续遵守规则。另一种选择是编写一个多锁封装器(multi-lock wrapper),该封装器总是以相同的顺序获取锁,一种简单的实现方法是通过锁在内存中的地址来命令获取。
18.6.3.2 生产者-消费者问题
生产者进程生成消费者进程使用的信息,例如,编译器可以生成汇编程序使用的汇编代码。反过来,汇编程序可能会生成加载程序使用的目标模块。生产者-消费者问题也为客户机-服务器模式提供了一个有用的隐喻。
生产者-消费者问题的一个解决方案是使用共享内存,为了允许生产者和消费者进程同时运行,我们必须有一个项目缓冲区,可以由生产者填充,也可以由消费者清空。该缓冲区将驻留在由生产者和消费者进程共享的内存区域中。生产者可以生产一种商品,而消费者可以消费另一种商品。
生产者和消费者必须同步,以便消费者不会尝试消费尚未生产的数据项。可以使用两种类型的缓冲器:无限缓冲区、有限缓冲区。无限缓冲区对缓冲区的大小没有实际限制,消费者可能不得不等待新产品,但生产者总是可以生产新产品。有限缓冲区假定缓冲区大小固定,在这种情况下,如果缓冲区为空,消费者必须等待。如果缓冲区已满,生产者必须等待。
让我们更仔细地看一下有限缓冲区如何使用共享内存演示进程间通信,以下变量位于生产者和消费者进程共享的内存区域中:
#define BUFFER SIZE 10
typedef struct
{
. . .
} item;
item buffer[BUFFER SIZE];
int in = 0;
int out = 0;
共享缓冲区实现为具有两个逻辑指针的循环数组:in和out,变量in指向缓冲区中的下一个空闲位置,变量out指向缓冲区中的第一个完整位置。
- 当in==out时,缓冲区为空;
- 当((in + 1) % BUFFER SIZE) == out时,缓冲区已满。
生产者进程具有下一个生成的局部变量,其中存储了要生产的新项目。消费者进程有一个局部变量,该变量下一次被使用,存储了要使用的项。
// 使用共享内存的生产者进程。
item next produced;
while (true)
{
/* produce an item in next produced */
while (((in + 1) % BUFFER SIZE) == out)
; /* do nothing */
buffer[in] = next produced;
in = (in + 1) % BUFFER SIZE;
}
// 使用共享内存的消费者进程.
item next consumed;
while (true)
{
while (in == out)
; /* do nothing */
next consumed = buffer[out];
out = (out + 1) % BUFFER SIZE;
/* consume the item in next consumed */
}
编写C程序以实现生产者和消费者问题(信号量):
- 初始化信号量互斥体、full和empty。
- 对于生产者进程:
- 在临时变量中生成项。
- 如果缓冲区中有空空间,请检查互斥量值以进入临界区。
- 如果互斥量值为0,则允许生产者将临时变量中的值添加到缓冲区。
- 对于消费者进程:
- 如果缓冲区为空,则应等待。
- 如果在互斥量值的缓冲区检查中有任何项,如果互斥量==0,则从缓冲区中删除数据项。
- 发出互斥值信号,并将空值减少1。
- 消费数据项。
- 输出结果。
对应的示例代码:
#include<stdio.h>
int mutex=1, full=0, empty=3, x=0;
int n;
void producer();
void consumer();
int wait(int);
int signal(int);
void main()
{
printf("\n 1.producer\n2.consumer\n3.exit\n");
while(1)
{
printf(" \nenter ur choice");
scanf("%d",&n);
switch(n)
{
case 1:
if((mutex==1)&&(empty!=0))
producer();
else
printf("buffer is full\n");
break;
case 2:
if((mutex==1)&&(full!=0))
consumer();
else
printf("buffer is empty");
break;
case 3:
exit(0);
break;
}
}
}
int wait(int s)
{
return(--s);
}
int signal(int s)
{
return (++s);
}
void producer()
{
mutex = wait(mutex);
full = signal(full);
empty = wait(empty);
x++;
printf("\n producer produces the items %d", x);
mutex = signal(mutex);
}
void consumer()
{
mutex = wait(mutex);
full = wait(full);
empty = signal(empty);
printf("\n consumer consumes the item %d", x);
x--;
mutex = signal(mutex);
}
18.6.3.3 经典IPC问题
经典IPC问题几乎用于测试每个新提出的同步方案。在解决这些问题的方法中,我们使用信号量进行同步,因为是呈现此类解决方案的传统方式。然而,这些解决方案的实际实现可以使用互斥锁代替二进制信号量。
有界缓冲区问题
它通常用于说明同步原语的威力。在我们的问题中,生产者和消费者流程共享以下数据结构:
int n;
semaphore mutex = 1;
semaphore empty = n;
semaphore full = 0
假设池由n个缓冲区组成,每个缓冲区可以容纳一个项目。互斥信号量为访问缓冲池提供互斥,并初始化为值1。空信号量和满信号量统计空缓冲区和满缓冲区的数量。信号量empty被初始化为值n,信号量full被初始化为值0。
// 生产者进程的结构
do
{
(...)
/* produce an item in next produced */
(...)
wait(empty);
wait(mutex);
(...)
/* add next produced to the buffer */
(...)
signal(mutex);
signal(full);
} while (true);
// 消费者进程的结果
do {
wait(full);
wait(mutex);
(...)
/* remove an item from buffer to next consumed */
(...)
signal(mutex);
signal(empty);
(...)
/* consume the item in next consumed */
(...)
} while (true);
读取者-写入者问题
假设一个数据库将在多个并发进程之间共享。其中一些进程可能只想读取数据库,而其他进程可能想更新(即读写)数据库。如果两个阅读器同时访问共享数据,则不会产生不利影响。如果写入程序和其他进程(读卡器或写入程序)同时访问数据库,则可能会出现问题,没有读取者应该仅仅因为写入者在等待而等待其他读取者完成。
一旦写入者准备就绪,该写入者将尽快执行其写入。任何一个问题的解决方案都可能导致饥饿。在第一种情况下,写入者可能会挨饿;在第二种情况下,读取者可能会挨饿。在解决第一个写入者问题时,写入者进程共享以下数据结构:
semaphore rw mutex = 1;
semaphore mutex = 1;
int read count = 0;
信号量rw_mutex对于读写器进程都是通用的,互斥信号量用于确保更新变量读取计数时互斥,read_count变量跟踪当前有多少进程正在读取对象,信号量rw_mutex用作编写器的互斥信号量。
// 写入者进程代码
do
{
wait(rw mutex);
(...)
/* writing is performed */
(...)
signal(rw mutex);
} while (true);
// 读取者进程代码
do
{
wait(mutex);
read count++;
if (read count == 1)
wait(rw mutex);
signal(mutex);
(...)
/* reading is performed */
(...)
wait(mutex);
read count--;
if (read count == 0)
signal(rw mutex);
signal(mutex);
} while (true);
如果一个写入者在临界区,n个读取者在等待,则rw_mutex上会有一个读取者排队,n−1个读取者在互斥体上排队。当一个写入者执行signal(rw_mutex)时,我们可以继续执行等待的读取者或单个等待的写入者,由调度程序进行选择。
用餐哲学家问题
用餐哲学家(dining-philosophers)问题被认为是一个经典的同步问题。
想想五位哲学家,他们一生都在思考和吃饭。哲学家们共享一张圆桌,周围有五把椅子,每把椅子都属于一位哲学家,桌子中央是一碗饭,桌子上放着五根筷子。
当哲学家思考时,他不会与同事互动。有时,一位哲学家饿了,试图拿起离他最近的两根筷子(她和左右邻居之间的筷子)。 哲学家一次只能拿起一根筷子,且无法拿起邻居手中的筷子。当一个饥饿的哲学家同时拥有两只筷子时,他吃饭时不会松开筷子。 当吃完饭,他放下两只筷子,开始重新思考。
哲学家试图通过对信号量执行wait()操作来抓住筷子,通过对适当的信号量执行signal()操作来释放筷子。因此,共享数据是筷子的所有元素初始化为1的地方。
semaphore chopstick[5];
do
{
wait(chopstick[i]);
wait(chopstick[(i+1) % 5]);
(...)
/* eat for awhile */
(...)
signal(chopstick[i]);
signal(chopstick[(i+1) % 5]);
(...)
/* think for awhile */
(...)
} while (true);
虽然上述这种解决方案可以保证没有两个邻居同时吃饭,但必须予以拒绝,因为可能会造成死锁。假设五位哲学家同时都饿了,每个人都抓着左边的筷子。此时,筷子的所有元素现在都等于0。当每个哲学家都试图抓住右边的筷子时,他将永远被耽搁。以下是解决死锁问题的几种可能方法:
- 最多允许四位哲学家同时坐在桌子旁。
- 只有当两支筷子都可用时,才允许哲学家拿起筷子(为此,他必须在临界区拿起筷子)。
- 使用非对称解决方案,即奇数哲学家先拿起他的左筷子,然后拿起右筷子,而偶数哲学家则拿起他的右筷子,然后拿起左筷子。
18.6.4 同步总结
除了以上所述的同步方式,Windows还提供了其它诸多方式,完整列表:
- Asynchronous functions
- Condition variable and SRW lock functions
- Critical section functions
- Event functions
- One-time initialization functions
- Interlocked Functions
- Mutex functions
- Private namespace functions
- Semaphore functions
- Singly-linked list functions
- Synchronization barrier functions
- Timer-queue timer functions
- Wait functions
- Waitable-timer functions
此外,C++标准库也提供了同步原语,可以用作Windows API的替代品,特别是对于跨平台代码。通常,这些对象的自定义非常有限,例如:
- std::mutex:它像一个关键部分,不支持递归获取。
- std::recursive_mutex:其作用就像一个关键部分(支持递归获取)。
- std::shared_mutex:类似于SRW锁。
- std::condition_variable:等效于条件变量。
- 其他。
显然,C++中可能缺少一些东西,例如等待地址和同步屏障,但它们可以在未来添加到标准中。在任何情况下,所有C++标准库类型仅在同一进程中工作,无法跨进程使用它们。关于C++的更多同步技术,可以参阅2.1.3.3 C++多线程同步。
18.7 线程高级主题
18.7.1 线程局部存储
线程可以访问其堆栈数据,并处理广泛的全局变量。然而,有时在线程基础上拥有一些存储是很方便的,可以以统一的方式访问。一个经典的例子是我们熟悉的GetLastError函数,尽管任何线程都可以调用GetLastError,但访问的每个线程的结果都不同。处理这种情况的一种方法是存储由线程ID键控的哈希表,然后根据该键查找值。虽然可行,但它有一些缺点:第一,哈希表需要同步,因为多个线程可能同时访问它;第二,搜索正确的线程可能没有预期的那么快。
线程本地存储(Thread Local Storage,TLS)是一种用户模式机制,允许在多线程的基础上存储数据,进程中的每个线程都可以访问,但只能访问自己的数据。但是访问方法是统一的。
TLS使用的另一个经典示例是C/C++标准库。早在20世纪70年代初,C标准库就被构想出来了,当时还没有多线程的概念。因此,C运行时维护一组全局变量作为某些操作的状态。例如,以下经典C代码尝试打开文件并处理可能的错误:
FILE* fp = fopen("somefile.txt", "r");
if(fp == NULL)
{
// something went wrong
switch(errno)
{
case ENOENT: // no such file
break;
case EFBIG:
break;
}
}
任何I/O错误都反映在全局errno变量中。但在多线程应用程序中,是一个问题。假设线程1进行I/O函数调用,导致errno更改。在检查其值之前,线程2也进行I/O调用,再次更改errno,导致线程1检查了由于线程2活动而产生的值。
解决方案是errno不能是全局变量。如今的errno不是一个变量,而是一个宏,它调用一个函数errno(),该函数使用线程本地存储来检索当前线程的值。类似地,I/O函数的实现(如fopen)使用TLS将错误结果存储到当前线程。
18.7.1.1 动态TLS
Windows API为TLS使用提供以下接口:
DWORD TlsAlloc();
BOOL TlsFree(DWORD dwTlsIndex);
BOOL TlsSetValue(DWORD dwTlsIndex, PVOID pTlsValue);
PVOID TlsGetValue(DWORD dwTlsIndex);
TlsAlloc函数返回一个可用的槽索引,并将所有现有线程的所有对应单元格归零。TLS对于DLL非常有用,因为DLL可能希望在每个线程的基础上存储一些信息,因此在加载时会分配大量信息,并在需要时使用。
TLS中的每个单元格都是指针大小的值,因此这里的最佳实践是使用单个插槽,并动态分配所需的任何结构,以保存TLS中需要存储的所有信息,并仅将指向数据的指针存储在插槽本身中。索引可用后,将使用TlsSetValue、TlsGetValue来存储或从槽中检索值。
调用这些函数的线程只能访问特定槽索引中自己的值,没有直接访问另一个线程的TLS插槽的方法——因为会破坏TLS的本意。也意味着访问TLS时不需要同步,因为只有一个线程可以访问内存中的相同地址。TLS数组如下图所示。
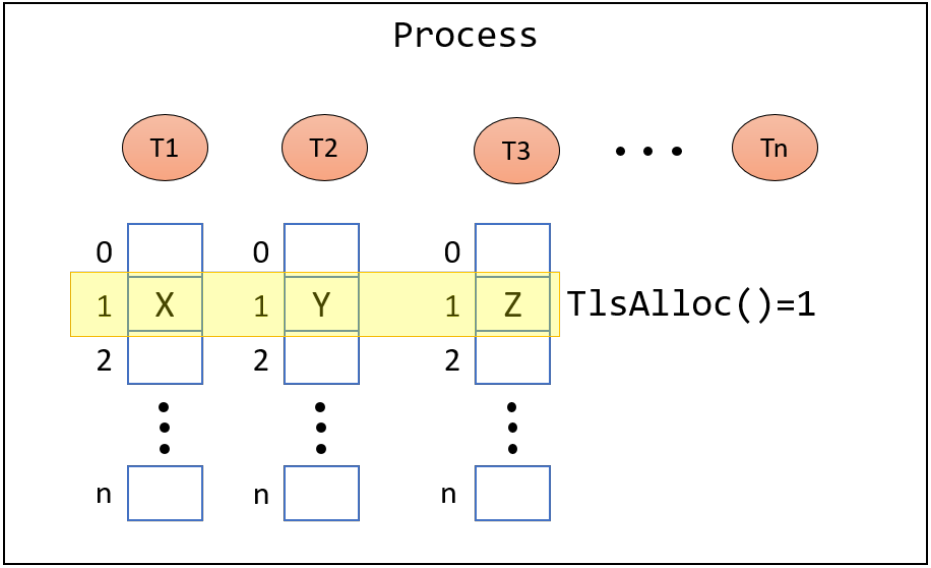
18.7.1.2 静态TLS
线程本地存储也以更简单的形式提供,在全局或静态变量上使用Microsoft扩展关键字,或使用C++11或更高版本的编译器。Windows有两种定义方式,如下所示:
// 方式1:Microsoft特定说明符
__declspec(thread) int counter;
// 方式2:C++标准定义
thread_local int counter;
此TLS是“静态”的——不需要任何分配,并且不能被销毁。在内部,编译器将所有线程局部变量捆绑到一个块(chunk)中,并将信息存储在PE中名为.tls的部分中。进程启动时读取此信息的加载器(NTDLL)调用TlsAlloc来分配一个插槽,并为启动包含所有线程局部变量的内存块的每个线程动态分配。在调用传递给CreateThread的“实”函数之前,每个用户模式线程都在NTDLLProved函数中启动。
18.7.2 远程线程
Windows下可以使用CreateThread函数在当前进程中创建一个线程。然而,在某些情况下,一个进程可能希望在另一个进程中创建线程。典型示例是调试器,当需要强制断点时,例如当用户按下“中断”按钮时,调试器会在目标进程中创建一个线程,并将其指向DebugBreak函数(或发出中断指令的CPU内部函数),从而导致进程中断,并通知调试器。以下API可以创建远程线程:
HANDLE WINAPI CreateRemoteThread(HANDLE hProcess, ...);
HANDLE CreateRemoteThreadEx(HANDLE hProcess, ...);
使用线程来实现远程过程调用(RPC)的示意图如下:
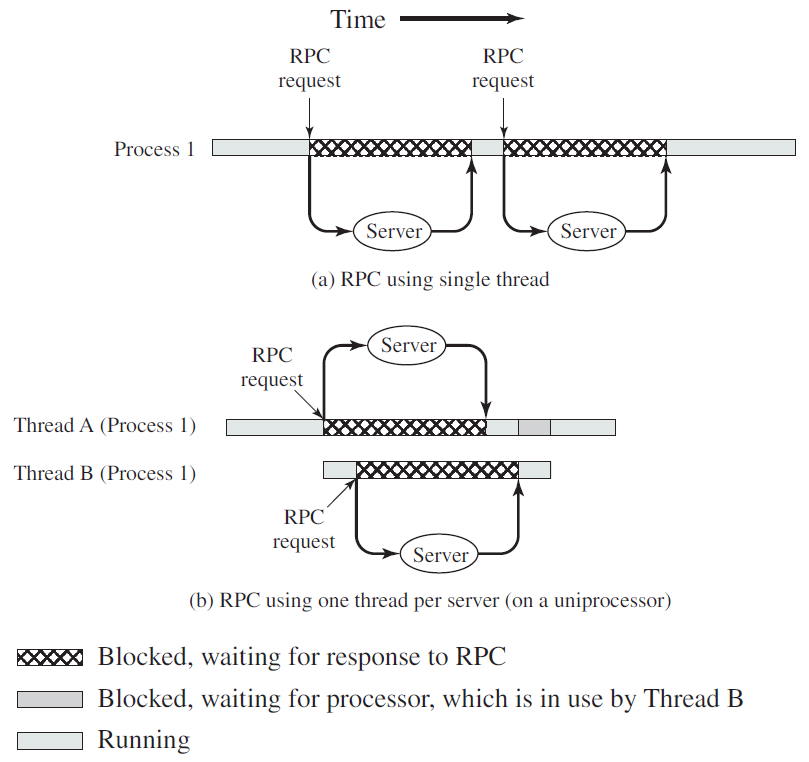
18.7.3 缓存和缓存行
在微处理器的早期,CPU的速度和内存(RAM)的速度是相当的。然后CPU速度上升,内存速度滞后,导致CPU大量停顿(stall),等待内存读取或写入值。为了补偿,CPU和内存之间引入了缓存,如下图所示。


缓存和内存结构图例。
与主内存相比,高速缓存是一种快速内存,允许CPU减少停顿。高速缓存虽然没有主内存那么大,但它的存在在今天的系统中是必不可少的,其重要性不言而喻。举个具体的例子。下面是两种不同的计算矩阵之和的方式:
long long SumMatrix1(const Matrix<int>& m)
{
long long sum = 0;
// 行优先(Row major)
for (int r = 0; r < m.Rows(); ++r)
for (int c = 0; c < m.Columns(); ++c)
sum += m[r][c];
return sum;
}
long long SumMatrix2(const Matrix<int>& m)
{
long long sum = 0;
// 列优先(Col Major)
for (int c = 0; c < m.Columns(); ++c)
for (int r = 0; r < m.Rows(); ++r)
sum += m[r][c];
return sum;
}
Matrix<>类是一维数组的简单包装器。从算法角度来看,两个函数中矩阵元素求和所需的时间应该相同。毕竟,代码一次遍历所有矩阵元素。但实际结果可能令人惊讶。下面是运行一个不同矩阵大小和元素求和所需的时间(都是单线程):
Type Size Sum Time (nsec)
-----------------------------------------------------------------
Row major 256 X 256 2147516416 34 usec
Col Major 256 X 256 2147516416 81 usec
Row major 512 X 512 34359869440 130 usec
Col Major 512 X 512 34359869440 796 usec
Row major 1024 X 1024 549756338176 624 usec
Col Major 1024 X 1024 549756338176 3080 usec
Row major 2048 X 2048 8796095119360 2369 usec
Col Major 2048 X 2048 8796095119360 43230 usec
Row major 4096 X 4096 140737496743936 8953 usec
Col Major 4096 X 4096 140737496743936 190985 usec
Row major 8192 X 8192 2251799847239680 35258 usec
Col Major 8192 X 8192 2251799847239680 1035334 usec
Row major 16384 X 16384 36028797153181696 142603 usec
Col Major 16384 X 16384 36028797153181696 4562040 usec
差异相当大,因为有缓存的存在。当CPU读取数据时,它不会读取单个整数或任何被指示读取的数据,而是读取整个缓存行(通常为64字节),并将其放入内部缓存。然后,当读取内存中的下一个整数时,不需要内存访问,因为该整数已经存在于缓存中。这是最佳的,并且是SumMatrix1的工作方式——它线性遍历内存。另一方面,SumMatrix2读取一个整数(以及缓存行的其余部分),而下一个整数位于更远的另一个缓存行(对于除最小矩阵之外的所有矩阵),需要读取另一缓存行,可能会丢弃可能很快需要的数据,使情况变得更糟。
从技术上讲,在大多数CPU中实现了3个缓存级别。缓存离处理器越近,速度越快,但容量越小。下图显示了4核CPU(采用超线程技术)的典型缓存配置。
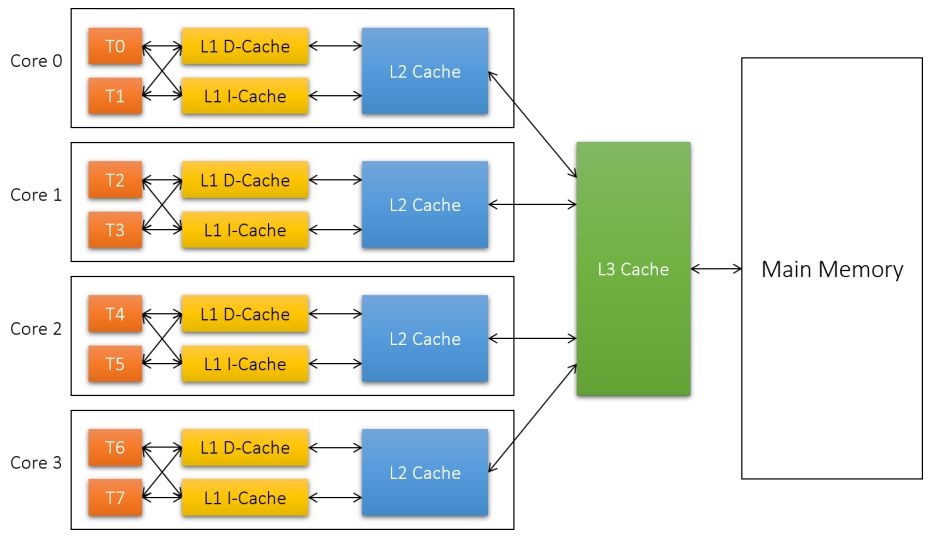
1级缓存由数据缓存(D-cache)和指令缓存(I-cache)组成,每个逻辑处理器有一个。然后是2级缓存,由属于同一核心的逻辑处理器共享。最后,3级缓存是全系统的。这些缓存的大小相当小,大约比主内存小3个数量级。系统上的缓存大小在任务管理器的性能/CPU选项卡中很容易看到,如下图所示。
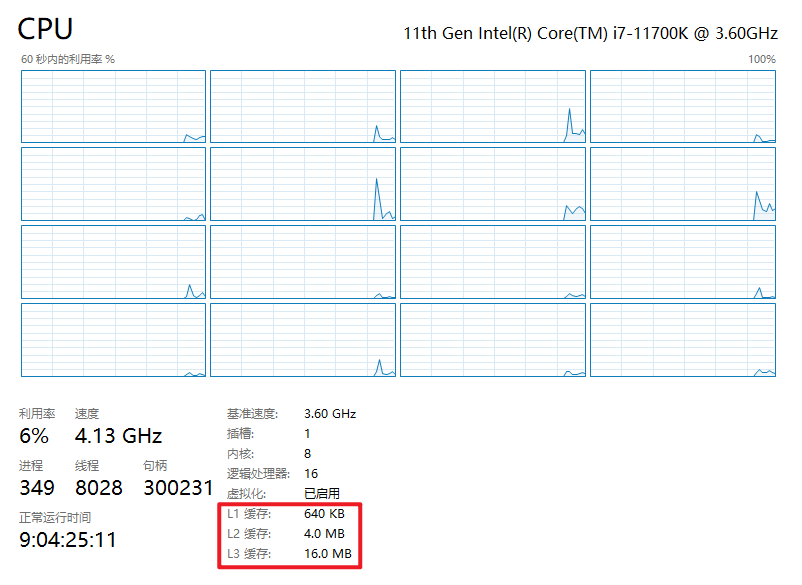
在上图中,3级缓存大小为16 MB(系统范围),2级缓存大小为4MB,但包括所有内核。由于该系统有8个内核,每个2级缓存实际上是4MB/8=512KB。类似地,1级缓存大小为640KB,分布在16个逻辑处理器上,使每个缓存640KB/16=40KB。与主内存大小(以千兆字节为单位)相比,缓存大小较小。

缓存、主内存结构。
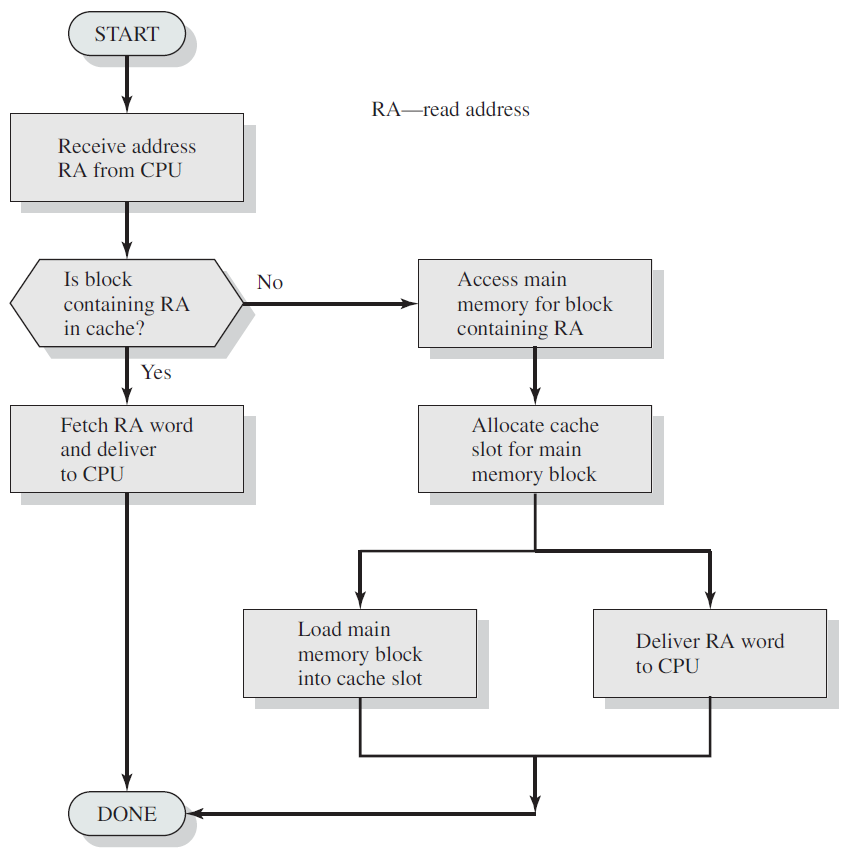
缓存读取操作过程。
让我们看另一个例子,其中缓存和缓存行起着重要(甚至至关重要)的作用。下面的示例演示了如何遍历一个大数组,计算数组中的偶数,它是通过多个线程完成的——每个线程都被分配了数组的一个连续部分。计数本身被放置在另一个数组中,每个单元格由相应的线程修改。下图显示了具有4个线程的这种布置。
下面是计算偶数的第一个版本:
using namespace std;
struct ThreadData
{
long long start, end;
const int* data;
long long* counters;
};
long long CountEvenNumbers1(const int* data, long long size, int nthreads)
{
auto counters_buffer = make_unique<long long[]>(nthreads);
auto counters = counters_buffer.get();
auto tdata = make_unique<ThreadData[]>(nthreads);
long long chunk = size / nthreads;
vector<wil::unique_handle> threads;
vector<HANDLE> handles;
for (int i = 0; i < nthreads; i++)
{
long long start = i * chunk;
long long end = i == nthreads - 1 ? size : ((long long)i + 1) * chunk;
auto& d = tdata[i];
d.start = start;
d.end = end;
d.counters = counters + i;
d.data = data;
wil::unique_handle hThread(::CreateThread(nullptr, 0, [](auto param) -> DWORD
{
auto d = (ThreadData*)param;
auto start = d->start, end = d->end;
auto counters = d->counters;
auto data = d->data;
for (; start < end; ++start)
if (data[start] % 2 == 0)
++(*counters);
return 0;
}, tdata.get() + i, 0, nullptr));
handles.push_back(hThread.get());
threads.push_back(move(hThread));
}
::WaitForMultipleObjects(nthreads, handles.data(), TRUE, INFINITE);
long long sum = 0;
for (int i = 0; i < nthreads; i++)
sum += counters[i];
return sum;
}
启动为每个线程准备数据的循环,并调用CreateThread启动线程循环,看看线程的循环:
for (; start < end; ++start)
if (data[start] % 2 == 0)
++(*counters);
对于每个偶数,计数器指针的内容递增1。注意,这里没有数据竞争——每个线程都有自己的单元,因此最终结果应该是正确的。这段代码的问题在于,当某个线程写入单个计数时,会写入一个完整的缓存行,使其他处理器上查看该内存的任何缓存失效,迫使它们通过再次从主内存读取来刷新缓存——导致性能很慢。这种情况被称为伪共享(false sharing)。
另一种方法是不写与其他线程共享缓存线的单元,至少不是经常写:
// 将统计的中间数据放在局部变量count
size_t count = 0;
for (; start < end; ++start)
if (data[start] % 2 == 0)
count++;
*(d->counters) = count;
主要的区别是将计数保持在局部变量count中,并且仅在循环完成时向结果数组中的单元格写入一次。由于count位于线程的堆栈上,并且堆栈大小至少为4KB,因此它们不可能与其他线程中的其他count变量位于同一缓存行上,大大提高了性能。当然,通常使用局部变量可能比间接访问内存快,因为编译器更容易将该变量缓存在寄存器中。但真正的影响是避免线程之间共享缓存行。主函数使用不同数量的线程测试这两种实现,如下所示:
Initializing data...
Option 1
1 threads count: 2147483647 time: 4843 msec
2 threads count: 2147483647 time: 3391 msec
3 threads count: 2147483647 time: 2468 msec
4 threads count: 2147483647 time: 2125 msec
5 threads count: 2147483647 time: 2453 msec // 线程多了反而降低性能!!
6 threads count: 2147483647 time: 1906 msec
7 threads count: 2147483647 time: 2109 msec // 线程多了反而降低性能!!
8 threads count: 2147483647 time: 2532 msec // 线程多了反而降低性能!!
Option 2
1 threads count: 2147483647 time: 4046 msec
2 threads count: 2147483647 time: 2313 msec
3 threads count: 2147483647 time: 1625 msec
4 threads count: 2147483647 time: 1328 msec
5 threads count: 2147483647 time: 1062 msec
6 threads count: 2147483647 time: 953 msec
7 threads count: 2147483647 time: 859 msec
8 threads count: 2147483647 time: 855 msec
请注意,在选项1中,在某些情况下,更多线程会降低性能。在选项2中,随着线程数量的增加而持续改进性能。
- 缓存性能
主内存缓存机制是计算机架构的一部分,在硬件中实现,通常对操作系统不可见。然而,还有两个两级内存方法的实例,它们也利用了局部性的特性,并且至少部分地在操作系统中实现:虚拟内存和磁盘缓存(下表)。我们将研究所有三种方法中常见的两级内存的一些性能特征。
| 主内存缓存 | 虚拟内存(分页) | 磁盘缓存 | |
|---|---|---|---|
| 常规访问时间比 | 5 : 1 | \(10^6\) : 1 | \(10^6\) : 1 |
| 内存管理系统 | 由特殊硬件实现 | 硬件和系统软件的组合 | 系统软件 |
| 常规块尺寸 | 4 - 128 字节 | 64 - 4096 字节 | 64 - 4096 字节 |
| 处理器访问二级方式 | 直接访问 | 间接访问 | 间接访问 |
下表测量了若干研究者在执行不同语言过程中各种语句类型的外观。
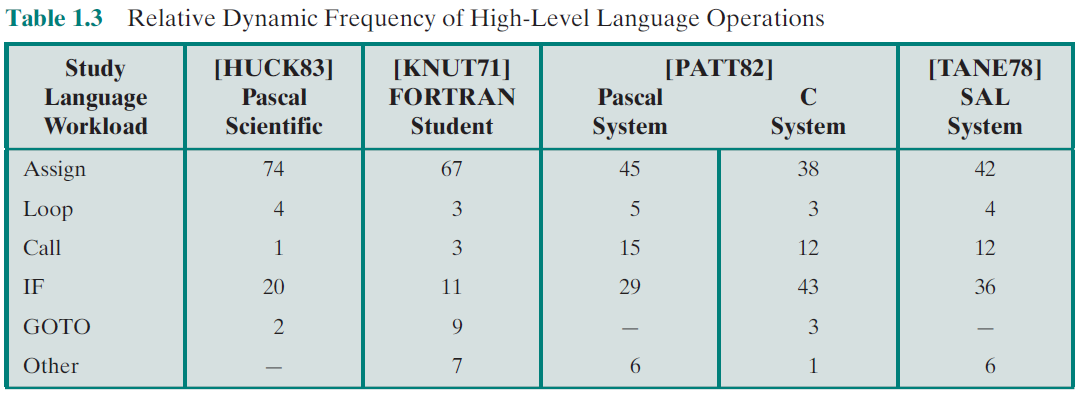
关于断言,PATT85中报告的研究提供了证实(下图),它显示了调用返回行为。每一个调用都由向下和向右移动的行表示,每一个返回都由向上和向右移动行表示。在图中,定义了一个深度等于5的窗口。只有一系列调用和返回,在任意方向上净移动6,才会导致窗口移动。如图所示,正在执行的程序可以长时间保持在一个固定窗口内。
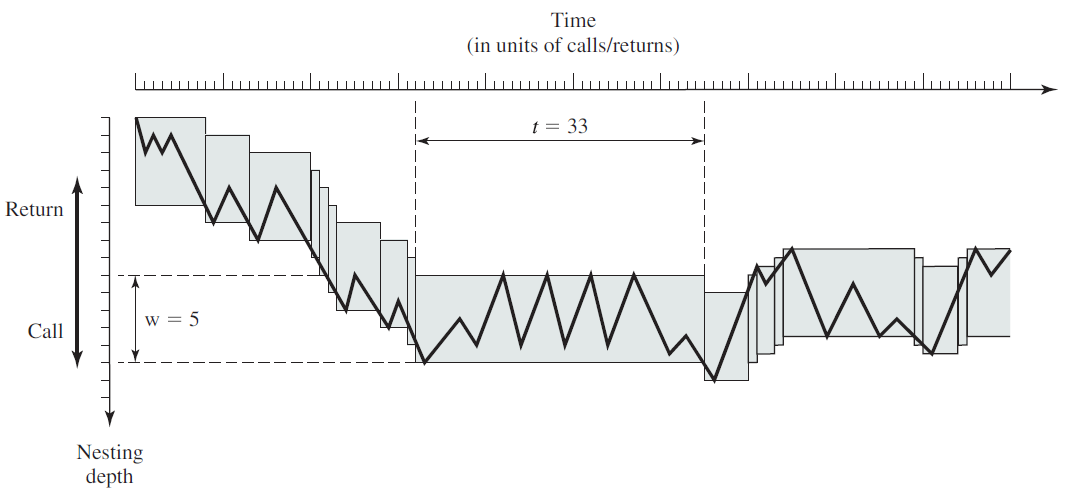
程序的调用返回行为样例。
文献中对空间局部性和时间局部性进行了区分。空间局部性指的是执行过程中涉及多个聚集的内存位置的趋势,反映了处理器按顺序访问指令的趋势,空间位置还反映了程序顺序访问数据位置的趋势,例如在处理数据表时。时间局部性是指处理器访问最近使用的内存位置的趋势,例如,当执行迭代循环时,处理器会重复执行同一组指令。
传统上,通过将最近使用的指令和数据值保存在缓存内存中并利用缓存层次结构来利用时间局部性。空间局部性通常通过使用更大的缓存块和将预取机制(获取预期使用的项)引入缓存控制逻辑来利用。最近,有相当多的研究在改进这些技术以实现更高的性能,但基本策略保持不变。
局部性可以在形成两级内存时加以利用,上层内存(M1)比下层内存(M2)更小、更快、更昂贵(每位)。MI用作较大M2的部分内容的临时存储,当进行内存引用时,将尝试访问MI中的项目,如果成功,则进行快速访问,如果没有,则将一块内存位置从M2复制到MI,然后通过MI进行访问。由于局部性,一旦块被引入,应该会对该块中的位置进行多次访问,从而实现快速的整体服务。为了表示访问一个项目的平均时间,我们不仅要考虑两个级别内存的速度,还要考虑在中找到给定引用的概率:
其中:
- \(T_s\) = 平均(系统)访问时间。
- \(T_1\) = M1的访问时间(如缓存、磁盘缓存)。
- \(T_2\) = M2的访问时间(如主存储器、磁盘)。
- \(H\) = 命中率(在M1中找到的时间相关的比例)。
下图显示了作为命中率函数的平均访问时间。可以看出,对于高命中率,平均总访问时间比M2更接近。
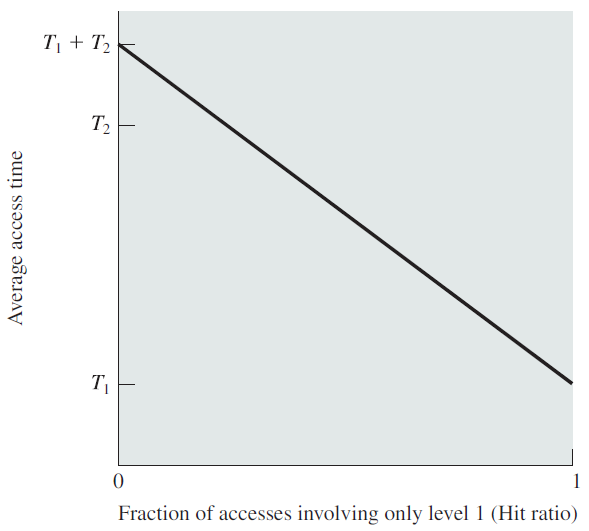
让我们评估两级内存机制相关的一些参数,首先考虑性能,有以下公式:
其中:
- \(C_s\) = 组合两级存储器的平均每位成本。
- \(C_1\) =上级内存M1的每比特的平均成本。
- \(C_2\) = 低级内存M2的每比特平均成本。
- \(S_1\) = M1的尺寸。
- \(S_2\) = M2的尺寸。
我们希望\(C_s \approx C_2\),考虑到\(C_1 >> C_2\),需要\(S_1 << S_2\)。下图显示了它们之间的关联。
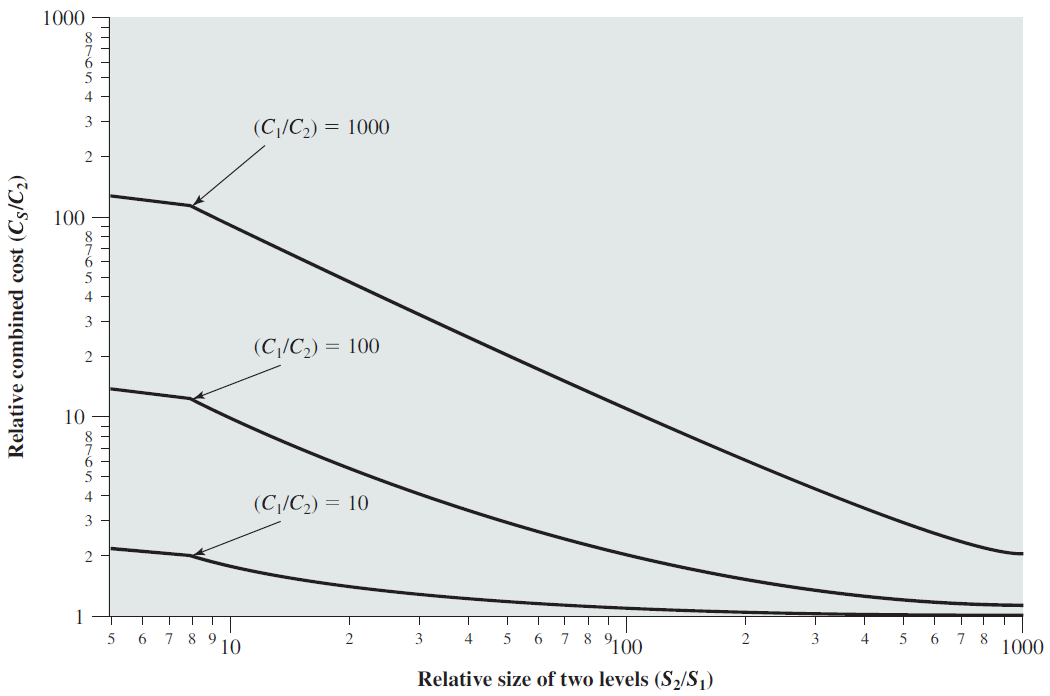
为此,考虑\(T_1 / T_s\)的值,它被称为访问效率,是平均访问时间(\(T_s\))与MI访问时间(\(T_1\))的接近程度的度量:
下图描绘了\(T_1 / T_s\)作为命中率H的函数,其中\(T_1 / T_s\)作为参数。似乎需要0.8至0.9范围内的命中率来满足性能要求。

访问效率作为命中率的函数(r = \(T_1 / T_2\))。
下图显示了局部性对命中率的影响。显然,如果MI的大小与M2相同,那么命中率将为1.0——M2中的所有项目都始终存储在中。现在假设没有局部性:也就是说,引用是完全随机的,在这种情况下,命中率应该是相对内存大小的严格线性函数。例如,如果MI的大小是M2的一半,那么在任何时候,M2中的一半项目也在其中,命中率将为0.5。然而,实际上,引用中存在一定程度的局部性。中等和强局部性的影响如图所示。
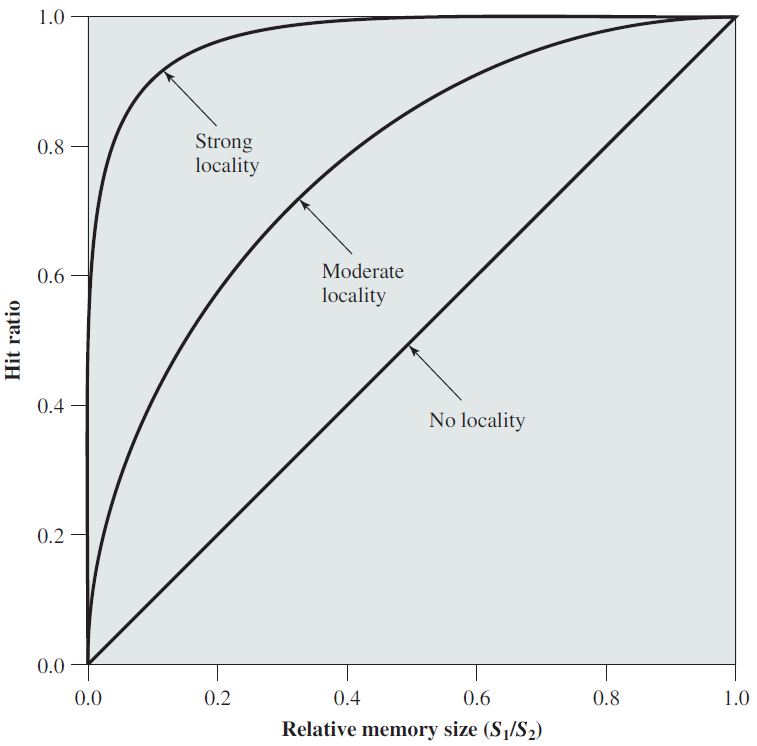
命中率作为相对内存大小的函数。
两个内存的相对大小是否满足成本要求?答案显然是肯定的。如果我们只需要一个相对较小的上层内存来实现良好的性能,那么这两层内存的平均每比特成本将接近较便宜的下层内存。
18.7.4 线程池
Windows提供线程池,是一种允许某些线程从线程池发送操作的机制。与手动创建和管理线程相比,使用线程池的优势如下:
- 客户端代码不进行显式线程创建或终止——线程池管理器会处理。
- 已完成的操作不会销毁工作线程——返回给线程池以服务另一个请求。
- 池中的线程数量可以根据工作项负载动态增长和收缩。
Windows 2000提供了第一个版本的线程池,为每个进程提供了一个线程池。从Windows Vista开始,线程池API得到了显著增强,包括添加了专用线程池,意味着一个进程中可以存在多个线程池。相关API:
PTP_WORK CreateThreadpoolWork(PTP_WORK_CALLBACK pfnwk, PVOID pv, PTP_CALLBACK_ENVIRON pcbe);
void CloseThreadpoolWork(PTP_WORK pwk);
VOID CloseThreadpoolWait(PTP_WAIT pwa);
VOID SubmitThreadpoolWork(PTP_WORK Work);
BOOL TrySubmitThreadpoolCallback(PTP_SIMPLE_CALLBACK pfns, PVOID pv, PTP_CALLBACK_ENVIRON pcbe);
void WaitForThreadpoolWorkCallbacks(PTP_WORK pwk, BOOL fCancelPendingCallbacks);
VOID SetThreadpoolWait(PTP_WAIT pwa, HANDLE h, PFILETIME pftTimeout);
18.7.5 用户模式调度
用户模式和内存模式之间的切换存在大量的基础消耗,所以,减少两者之间的切换可以提升性能。
早期的Windows版本提供纤程,但其存在诸多问题(如TLS未正确传递,线程环境块不符),已被废弃。从Windows 7和Windows 2008 R2开始,Windows支持一种称为用户模式调度(UMS)的替代机制,其中用户模式线程成为各种调度程序,可以从用户模式调度线程,而无需进行用户模式/内核模式转换。该机制是内核已知的,因此UMS不存在纤程的缺点,因为使用的是真正的线程,而不是共享线程的纤程。
不幸的是,但是构建一个使用UMS的真实系统并非易事。微软(自2010年起)提供了一个名为并发运行时的库,缩写为Concrt,发音为“concert”,它在需要并发执行时,在后台使用UMS提供线程的高效使用。
18.7.6 仅初始化一次
许多应用程序中的一个常见模式是使用单例对象。在某些观点中,这是一种反模式。事实上,单例是有用的,有时是必要的。单例的一个常见要求是只初始化一次。在多线程应用程序中,多个线程最初可能同时访问单实例,但单实例必须初始化一次。如何实现这一目标?有几种众所周知的算法,如果实施得当,可以完成任务。Windows API提供了一种内置的方法来调用函数,并保证只调用一次:
INIT_ONCE init = INIT_ONCE_STATIC_INIT;
VOID InitOnceInitialize(_Out_ PINIT_ONCE InitOnce);
BOOL InitOnceExecuteOnce(PINIT_ONCE InitOnce, __callback PINIT_ONCE_FN InitFn, PVOID Parameter, LPVOID* Context);
18.8 作业
18.8.1 作业概述
如果进程处于作业之下,则作业(Job)对象在Process Explorer中间接可见。在这种情况下,作业选项卡出现在进程的属性中(如果进程处于无作业状态,则该选项卡不存在)。另一种收集作业的方法是在选项/配置颜色中启用作业颜色(默认为棕色)…。下图显示了Process Explorer,其中作业颜色可见,所有其他颜色均已移除。
Windows 8引入了将进程与多个作业关联的功能,使得作业比以前有用得多,因为如果希望通过作业控制的进程已经是作业的一部分,则无法将其与其他作业关联。分配了第二个作业的进程会导致创建作业层次结构(如果可能),第二份作业成为第一份工作的子项。基本规则如下:
- 父作业施加的限制会影响作业和所有子作业(以及这些作业中的所有进程)。
- 父作业施加的任何限制不能由子作业删除,但可以更严格。例如,如果父作业将作业范围内的内存限制设置为200MB,则子作业可以将(其进程)限制设置为150MB,但不能设置为250MB。
下图显示了通过调用以下操作(按顺序)创建的作业的层次结构:
1、将进程P1分配给作业J1。
2、将进程P1分配给作业J2,形成层次结构。
3、将进程P2分配给作业J2,进程P2现在受作业J1和J2的影响。
4、将进程P3分配给作业J1。
查看作业层次结构并不容易。例如,Process Explorer显示作业的详细信息,包括显示作业和所有子作业(如果有)的信息。例如,从图上图中查看作业J1的信息,将列出三个进程:P1、P2和P3。此外,由于作业访问是间接的——如果一个进程在作业下,则作业选项卡可用——显示的作业是该进程所属的直接作业,未显示任何父作业。以下代码创建了上图所示的层次结构:
#include <windows.h>
#include <stdio.h>
#include <assert.h>
#include <string>
HANDLE CreateSimpleProcess(PCWSTR name)
{
std::wstring sname(name);
PROCESS_INFORMATION pi;
STARTUPINFO si = { sizeof(si) };
if (!::CreateProcess(nullptr, const_cast<PWSTR>(sname.data()), nullptr, nullptr, FALSE, CREATE_BREAKAWAY_FROM_JOB | CREATE_NEW_CONSOLE, nullptr, nullptr, &si, &pi))
{
return nullptr;
}
::CloseHandle(pi.hThread);
return pi.hProcess;
}
HANDLE CreateJobHierarchy()
{
auto hJob1 = ::CreateJobObject(nullptr, L"Job1");
assert(hJob1);
auto hProcess1 = CreateSimpleProcess(L"mspaint");
auto success = ::AssignProcessToJobObject(hJob1, hProcess1);
assert(success);
auto hJob2 = ::CreateJobObject(nullptr, L"Job2");
assert(hJob2);
success = ::AssignProcessToJobObject(hJob2, hProcess1);
assert(success);
auto hProcess2 = CreateSimpleProcess(L"mstsc");
success = ::AssignProcessToJobObject(hJob2, hProcess2);
assert(success);
auto hProcess3 = CreateSimpleProcess(L"cmd");
success = ::AssignProcessToJobObject(hJob1, hProcess3);
assert(success);
// not bothering to close process and job 2 handles
return hJob1;
}
int main()
{
auto hJob = CreateJobHierarchy();
printf("Press any key to terminate parent job...\n");
::getchar();
::TerminateJobObject(hJob, 0);
return 0;
}
当违反作业限制或发生某些事件时,作业可以通过与作业关联的I/O完成端口通知相关方。I/O完成端口通常用于处理异步I/O操作的完成,但在这种特殊情况下,它们被用作通知某些作业事件发生的机制。
作业是一个调度程序(可等待)对象,当发生CPU时间冲突时发出信号。对于这个简单的情况,线程可以等待WaitForSingleObject(作为一个常见示例),然后处理CPU时间冲突。设置新的CPU时间限制将作业重置为无信号状态。
18.8.2 Silos
Windows 10版本1607和Windows Server 2016引入了称为Silos的作业的增强版本。Silos有两种变体:
- 应用程序Silos。用于使用桌面桥接技术转换为UWP的应用程序,几乎没有服务器Silos那么强大(也不需要)。作业资源管理器有Silos类型列,通过列出作业的类型来指示作业是否实际上是Silos。
- 服务器Silos。仅在Windows Server 2016起的机器上受支持,用于实现Windows容器,即沙盒进程的能力,创建虚拟环境,使进程认为自己在自己的机器上。需要将文件系统、注册表和对象名称空间重定向为特定Silos的一部分,因此内核必须在内部进行重大更改才能感知思洛存储器。
总之,作业提供了许多控制和限制进程的机会,都由内核本身实现。Windows 8中嵌套作业的引入使作业更有用,限制更少。
18.9 内存
内存管理包含的内容有:逻辑和物理地址映射、内存分配、内部和外部碎片和压缩、分页,以及虚拟内存:请求分页、页面替换策略。本章将详细阐述内存相关的概念、技术、原理和机制。
18.9.1 内存基础
今天的现代Intel/AMD处理器在内存方面开始非常有限,最初的8086/8088处理器仅支持1 MB内存(物理内存,因为当时没有其他内存),对内存的每次访问都是段地址和偏移量的组合,在处理器内部使用16位值,但内存访问需要20位(1 MB)。段寄存器的值(16位)乘以16(0x10),然后添加偏移量以达到1MB范围内的地址。这种工作模式现在被称为实模式(Real Mode),并且仍然是当今Intel/AMD处理器的唤醒模式。
随着80386处理器的引入,虚拟内存诞生了,因为它基本上是今天使用的,包括通过只使用偏移量线性访问内存的能力(段寄存器刚刚设置为零),使得内存访问更加方便。虚拟内存意味着每个内存访问都需要转换到物理地址所在的位置,此模式称为保护模式(Protected Mode)。在保护模式下,无法直接访问物理内存,只能通过从虚拟地址到物理地址的映射,此映射必须由操作系统的内存管理器预先准备,因为CPU需要此映射。
在64位系统上,保护模式称为长模式(Long Mode),但本质上是相同的机制,扩展到64位地址。
虚拟地址和物理地址之间的映射,以及操作系统级内存块的管理,都是在称为页面的块中执行的。页面是必要的,因为不可能管理每个字节——管理结构将比该字节大得多。下表列出了Windows支持的所有架构的页面大小。
| 架构 | 小(正常)页 | 大页 | 超大页 |
|---|---|---|---|
| x86 | 4KB | 2MB | N/A |
| x64 | 4KB | 2MB | 1GB |
| ARM | 4KB | 2MB | 2MB |
| ARM64 | 4KB | 2MB | 2MB |
小(正常)页面是默认页面,页面通常表示小页面或正常页面,在所有架构中都是4KB。如果提到不同的页面大小,通常伴随一个前缀:大或巨大。不同的页面大小和页面帧数量,对应的页面错误比率如下:

18.9.2 内存机制
内存管理与管理主内存有关,内存由字节或单词数组组成,每个字节或单词都有自己的地址。CPU根据值程序计数器从内存中提取指令,这些指令可能会导致从特定内存地址进行额外加载和存储。内存单元只看到内存地址流,它不知道它们是如何生成的。程序必须被放入内存并放置在进程中才能运行。输入队列是磁盘上等待进入内存执行的进程的集合。用户程序在运行之前要经过几个步骤。
内存管理功能:跟踪每个内存位置的状态,确定分配策略——内存分配技术和取消分配技术。
内存管理:逻辑和物理地址映射、内存分配、内部和外部碎片和压缩、分页;虚拟内存:请求分页、页面替换策略。
18.9.2.1 地址绑定
程序作为二进制可执行文件存储在辅助存储磁盘上。当程序要执行时,它们被放入主内存并放在一个进程中,磁盘上等待进入主内存的进程集合形成输入队列,将要执行的进程之一从队列中取出并放入主内存中。在执行期间,它从主内存中获取指令和数据,进程终止后,它返回内存空间。在执行过程中,该进程将经历不同的步骤,在每个步骤中,地址以不同的方式表示。在源程序中,地址是符号,编译器将符号地址转换为可重新定位的地址,加载程序将把这个可重新定位的地址转换为绝对地址。
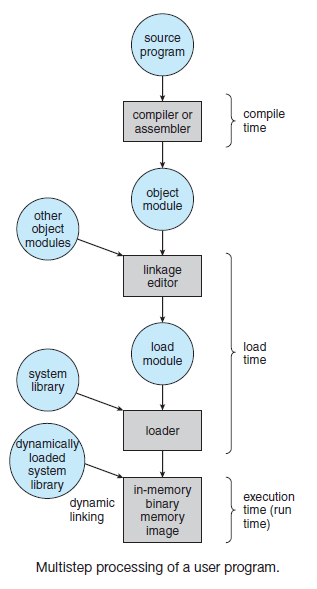
指令和数据的绑定可以在进程中的任何步骤完成:
- 编译时期:如果我们知道进程是否驻留在内存中,那么就可以生成绝对代码。如果静态地址更改,则需要从头重新编译代码。
- 加载时期:如果编译器不知道进程是否驻留在内存中,那么它会生成可重新定位的代码。在这种情况下,绑定被延迟到加载时间。
- 执行时期:如果进程在执行期间从一个内存段移动到另一个,则绑定将延迟到运行时。为此需要使用了特殊硬件,大多数通用操作系统都使用这种方法。
18.9.2.2 逻辑和物理地址
CPU生成的地址称为逻辑地址或虚拟地址。内存单元看到的地址,即加载到内存寄存器的地址,称为物理地址。编译时和加载时地址绑定方法生成一些逻辑地址和物理地址,执行时地址绑定生成不同的逻辑地址和物理地址。
程序生成的逻辑地址空间集是逻辑地址空间,与这些逻辑地址对应的物理地址集是物理地址空间。在运行时,虚拟地址到物理地址的映射是由称为内存管理单元(MMU)的硬件设备完成的。
基址寄存器也称为重定位寄存器,重新定位寄存器的值将添加到用户进程在发送到内存时生成的每个地址。用户程序永远看不到真实的物理地址。下图显示了动态关系,动态关系意味着从虚拟地址空间到物理地址空间的映射,通常在运行时通过一些硬件协助执行。
使用重新定位寄存器的动态重新定位上图显示了动态重新定位,意味着从虚拟地址空间映射到物理地址空间,并由硬件在运行时执行。重新定位由硬件执行,用户无法看到动态重新定位,因此可以将部分执行的进程从内存的一个区域移动到另一个区域,而不会产生影响。具体的例子:
- 如果基数为14000,则用户尝试寻址位置0时会动态重新定位到位置14000,对位置346的访问被映射到位置14346。
- 用户程序永远看不到实际的物理地址。
- 该程序可以创建指向位置346的指针,将其存储在内存中,对其进行操作,并将其与其他地址进行比较,所有这些地址都是数字346。
- 只有当它用作内存地址(可能在间接加载或存储中)时,它才会相对于基址寄存器进行重新定位。
- 用户程序处理逻辑地址。
- 内存映射硬件将逻辑地址转换为物理地址。
- 我们现在有两种不同类型的地址:逻辑地址(范围从0到最大)和物理地址(对于基值R,范围从R+0到R+max)。
- 用户程序只生成逻辑地址,并认为进程在0到最大位置运行。然而,在使用这些逻辑地址之前,必须将其映射到物理地址。
- 逻辑地址空间绑定到单独的物理地址空间的概念是正确的内存管理的核心。
动态加载:对于要执行的进程,应该将其加载到物理内存中,进程的大小仅限于物理内存的大小,动态加载用于获得更好的内存利用率。在动态加载中,除非调用例程或过程,否则不会加载它。每当调用例程时,调用例程首先检查被调用例程是否已加载。如果没有加载,它会导致加载程序将所需的程序加载到内存中,并更新程序地址表,以指示更改和控制传递给新调用的例程。
优势:提供更好的内存利用率,从不加载未使用的例程,不需要特殊的操作系统支持。当在频繁发生的情况下需要处理大量代码时,此方法非常有用。
交换是一种暂时从系统内存中删除非活动程序的技术。进程可以暂时从内存中交换到后备存储,然后再回到内存中继续执行。此过程称为交换。例如:
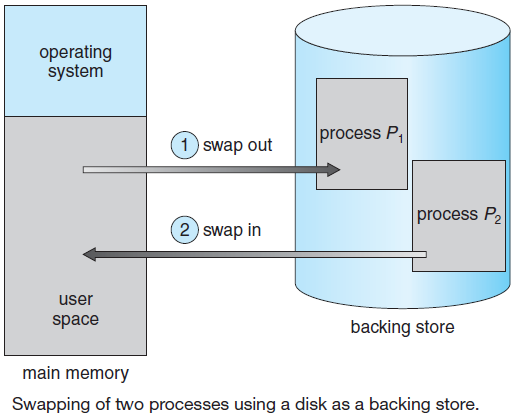
示例:
- 在具有循环CPU调度的多编程环境中,只要时间段到期,刚完成的进程就会被换出,新进程会换入内存以执行。
- 交换的一种变体是基于优先级的调度。当低优先级正在执行时,如果高优先级进程到达,则低优先级将被调出,并允许执行高优先级。此过程也称为推出(Roll out)和推入(Roll in)。
- 通常,被调出的进程将被调回先前占用的相同内存空间,取决于地址绑定。
- 如果绑定是在加载时完成的,那么进程将移动到相同的内存位置。如果绑定是在运行时完成的,那么进程将移动到不同的内存位置。因为物理地址是在运行时计算的。
- 交换需要备份存储,并且它应该足够大,能够容纳所有内存映像的副本。系统维护一个就绪队列,该队列由内存映像位于后备存储或内存中的所有进程组成,这些进程已准备好运行。
交换的决定因素:要交换进程,它应该完全空闲;进程可能正在等待I/O操作;如果I/O异步访问I/O缓冲区的用户内存,则无法交换进程。逻辑地址和物理地址对比如下表:
| 逻辑地址 | 物理地址 |
|---|---|
| CPU生成的地址。 | 存储单元看到的地址。 |
| 程序生成的所有逻辑地址集是一个逻辑地址空间。 | 与这些逻辑地址对应的所有物理地址集是一个物理地址空间。 |
| 逻辑地址(范围从0到最大)。 | 物理地址(对于基本值R,在R+0到R+max的范围内)。 |
| 用户可以查看程序的逻辑地址。 | 用户永远无法查看程序的物理地址。 |
| 用户可以使用逻辑地址访问物理地址。 | 用户可以间接访问物理地址,但不能直接访问。 |
| 逻辑地址是可变的,因此将随系统而变化。 | 该对象的物理地址始终保持不变。 |
连续内存分配:内存分配的最简单方法之一是将内存划分为几个固定分区,主内存通常分为两个分区:常驻操作系统,通常用中断向量保存在低内存中;用户进程,保存在高内存中。每个分区正好包含一个进程,多编程的程度取决于分区的数量。
内存映射和保护:内存保护意味着保护操作系统不受用户进程的影响,保护进程不受其他进程的影响。通过使用带有限制寄存器的重新定位寄存器提供内存保护,重新定位寄存器包含最小物理地址的值,限制寄存器包含逻辑地址的范围。(重新定位=100040,限制=74600)。
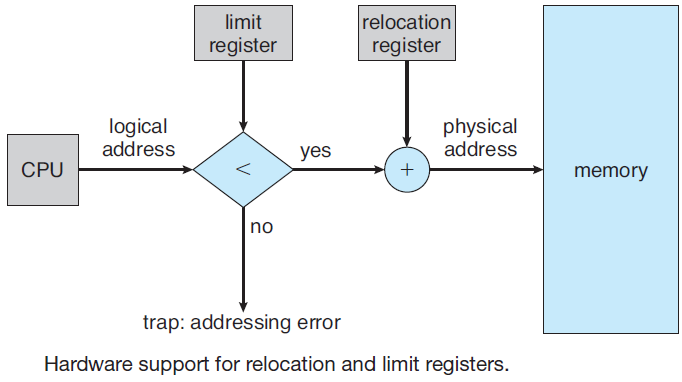
逻辑地址必须小于限制寄存器,MMU通过在重新定位寄存器中添加值来动态映射逻辑地址。当CPU调度程序选择要执行的进程时,作为上下文切换的一部分,调度程序加载具有正确值的重新定位和限制寄存器。由于CPU生成的每个地址都会根据这些寄存器进行检查,因此我们可以保护操作系统和其他用户的程序和数据不被修改。
18.9.2.3 内存分配
多分区分配:
孔洞(hole)是可用内存块,不同大小的孔洞分散在内存中。当进程到达时,会从一个足够容纳它的洞中分配内存。操作系统维护的信息有分配的分区、自由隔板(孔)。一组大小不同的孔,在任何给定的时间分散在内存中。
当一个进程到达并需要内存时,系统会搜索这个集合以查找一个足够大的洞来容纳这个进程。如果孔洞太大,则将其分为两部分:一部分分配给到达进程,另一个返回到孔洞组。
当进程终止时,它会释放内存块,然后将其放回孔洞集。如果新孔洞与其他孔洞相邻,则这些相邻的孔洞将合并为一个较大的孔洞。此过程是一般动态存储分配问题的一个特殊实例,即如何满足空闲孔洞列表中大小为n的请求。
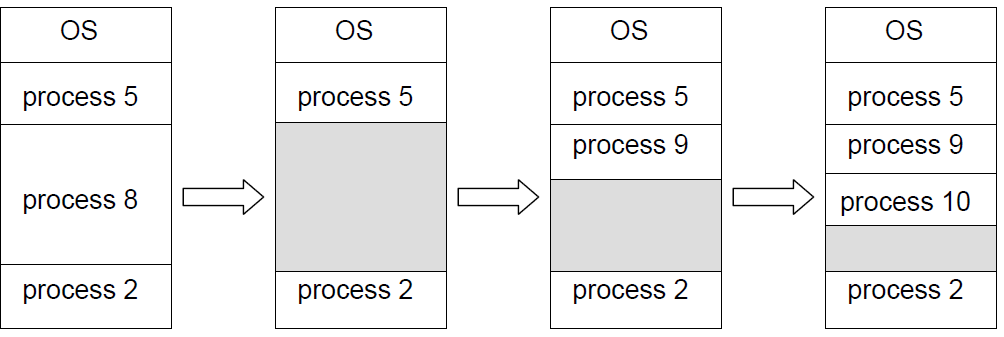
这个问题有很多解决方案。搜索孔洞集以确定最佳分配的孔,首个匹配、最佳匹配和最差匹配策略是用于从可用孔集中选择自由孔的最常用策略。选择自由孔洞的三种策略说明:
- 首个匹配(First fit):分配第一个足够大的孔洞。该算法从一开始就扫描内存,并选择第一个足够大的可用块来保存进程。
- 最佳配合(Best fit):选择尺寸最接近要求的孔洞,分配最小的孔洞,即足够大的孔洞来容纳进程。
- 最差匹配(Worst fit):将最大的孔洞分配给进程请求,搜索整个列表中最大的孔洞。
First-fit和best-fit是最流行的动态内存分配算法,First-fit通常更快,最佳匹配搜索整个列表以查找最小的孔,即足够大的孔。最差匹配会降低最小孔洞的生成速率。所有这些算法都存在碎片化问题。
18.9.2.4 内存碎片和整理
当进程被加载并从内存中删除时,空闲内存空间被分割成小块。一段时间后,我们从内存中删除的进程无法分配,因为内存中有小块内存,内存块仍然未使用。这个问题称为碎片化。
或者,当内存在系统中按顺序/连续分配时,会出现碎片,不同的文件以块的形式存储在内存中,当频繁修改或删除这些文件时,中间会留下间隙/可用空间,称为碎片。
内存碎片可以有两种类型:
-
内部碎片。由于加载的数据块小于分区,因此部分内部存在浪费的空间。这种情况下,可用空间太小,无法容纳任何文件。跟踪可用空间的开销对于操作系统来说太大了,这种便是内部碎片。示例:如果有一个50kb的块,并且进程请求40kb,如果该块被分配给进程,则剩余10kb内存。
-
外部碎片。当存在足够的内存空间来满足请求,但不连续时即存在,即存储被分割成大量的小孔洞。外部碎片可能是小问题,也可能是大问题。如图所示,如果我们想将一个等于释放空间总和的文件放入内存,则不能,因为空间不是连续的。因此,尽管有足够的内存来保存文件,但由于内存分散在不同的位置,我们无法容纳它。这就是外部碎片。
![]()
![]()


克服外部碎片的一个解决方案是压缩(compaction)。目标是将所有空闲内存移动到一起,形成一个大的块。压缩并非总是可行的,如果重新定位是静态的,并且是在装载时完成的,则不可能进行压实。如果重新定位是动态的,并且在执行时完成,则可以进行压缩。

外部碎片问题的另一个可能的解决方案是允许进程的逻辑地址空间是非连续的,从而允许在物理内存可用时为进程分配物理内存。
固定和动态分区方案都有缺点。固定分区方案限制了活动进程的数量,如果可用分区大小和进程大小不匹配,则可能会低效率地使用空间。动态分区方案维护起来更复杂,并且包括压缩的开销。一个有趣的折衷方案是伙伴系统(Buddy System)。
在请求分配大小为k(即\(2^{i-1}<k\le2^i\))的情况下,使用以下递归算法查找大小为\(2^i\)的孔:
void get_hole(int i)
{
if(i==(U+1)) <failure>;
if(<i_list_empty>)
{
get_hole(i+1);
<split hole into buddies>;
<put buddies on i_list>;
}
<take first hole on i_list>;
}
下图给出了使用1M字节初始块的示例。第一个请求A是100K字节,需要128K块,最初的区块分为两个512K伙伴,第一个被分成两个256K的伙伴,其中第一个被分成两个128K伙伴,其中一个分配给A。下一个请求B需要256K块,这样的块已经可用并已分配。该过程继续,根据需要进行拆分和合并。请注意,当释放E时。两个128K好友合并成256K区块,其立即与其伙伴合并。
下图显示了释放B请求后立即的好友分配的二叉树表示,叶节点表示内存的当前分区。如果两个伙伴是叶节点,则必须至少分配一个,否则它们将合并为一个更大的块。

伙伴系统的树表达。

将进程分配给自由帧。
18.9.2.5 分页
大多数虚拟内存系统都使用一种称为分页的技术。在任何计算机上,程序都引用一组内存地址,当程序执行如下指令时:
MOV REG, 1000
这样做是为了将内存地址1000的内容复制到REG(或反之,具体取决于计算机)。地址可以使用索引、基址寄存器、段寄存器和其他方式生成。
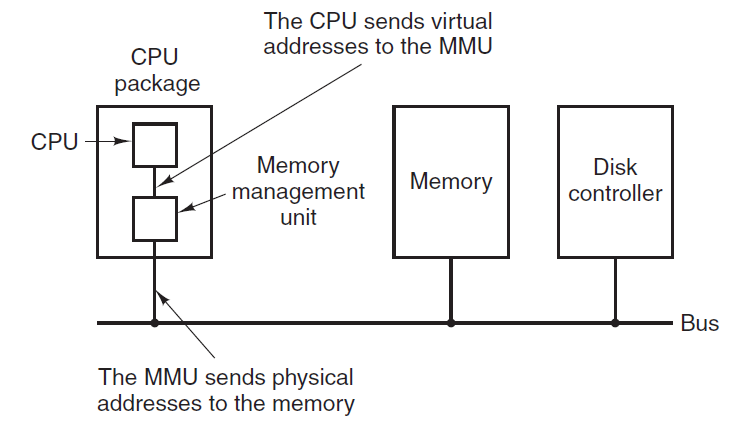
MMU的位置和功能。这里显示的MMU是CPU芯片的一部分,因为它现在很常见。然而,从逻辑上讲,它可能是一个单独的芯片,而且是多年前的事了。
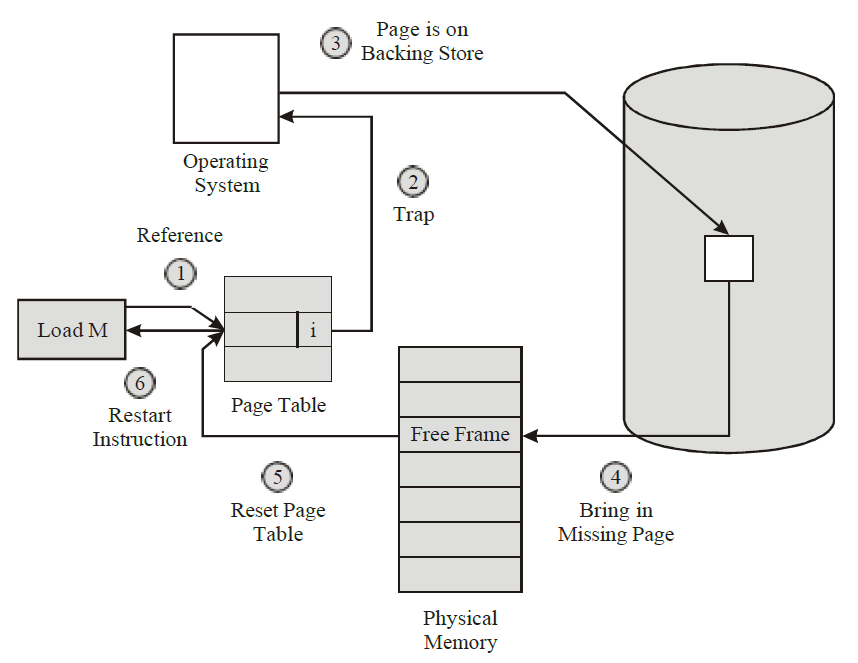
MMU的内部操作。
硬件支持的重分配。
这些程序生成的地址称为虚拟地址,构成虚拟地址空间。在没有虚拟内存的计算机上,虚拟地址直接放在内存总线上,并导致读取或写入具有相同地址的物理内存字。当使用虚拟内存时,虚拟地址不会直接到达内存总线。相反,它们进入MMU(内存管理单元),将虚拟地址映射到物理内存地址,如上图所示。
下图显示了该映射工作原理的一个非常简单的示例。在这个示例中,我们有一台计算机可以生成16位地址,从0到64K− 1,这些是虚拟地址。然而,这台计算机只有32 KB的物理内存。因此,尽管可以编写64KB的程序,但它们不能全部加载到内存中并运行。然而,一个程序核心映像的完整副本(最大为64KB)必须存在于磁盘上,这样才能根据需要放入各个部分。
虚拟地址空间由称为页面的固定大小单元组成。物理内存中的相应单元称为页帧(page frame)。页面和页帧通常大小相同。在本例中,它们是4KB,但实际系统中使用的页面大小从512字节到1GB不等。通过64KB的虚拟地址空间和32KB的物理内存,我们得到了16个虚拟页面和8个页帧。RAM和磁盘之间的传输始终是整页的,许多处理器支持多种页面大小,可以根据操作系统的需要进行混合和匹配。例如,x86-64体系结构支持4-KB、2-MB和1-GB页面,因此我们可以为用户应用程序使用4-KB页面,为内核使用单个1-GB页面。
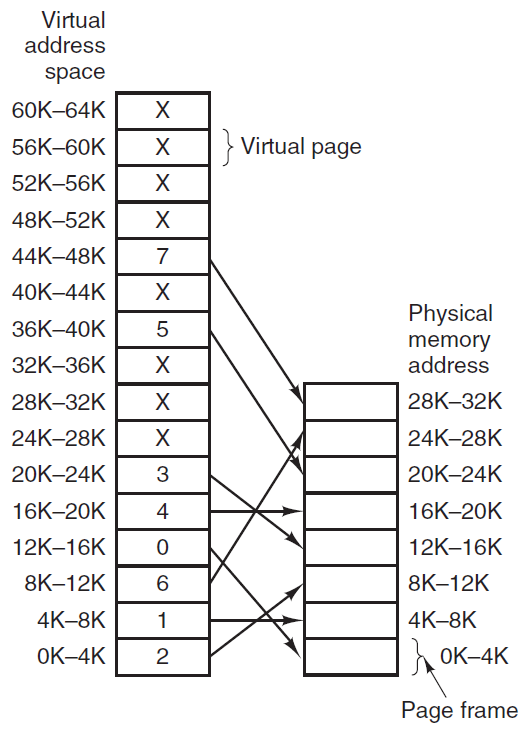
虚拟地址和物理内存地址之间的关系由页表给出。每个页面以4096的倍数开始,以4095个地址结尾,因此4K–8K实际上意味着4096–8191,8K到12K意味着8192–12287。
分页是一种允许进程的物理地址空间不连续的内存管理方案。分页支持由硬件处理,用于避免外部碎片。分页可以避免将不同大小的内存块安装到后备存储上的相当大的问题。当主存储器中的某些代码或日期需要交换时,必须在后备存储器中找到空间。物理内存分为固定大小的块,称为帧(f)。逻辑内存被分成大小相同的块,称为页(p)。当一个进程要执行时,它的页面会从后备存储器加载到可用的帧中。块存储也被划分为与内存帧大小相同的固定大小的块。
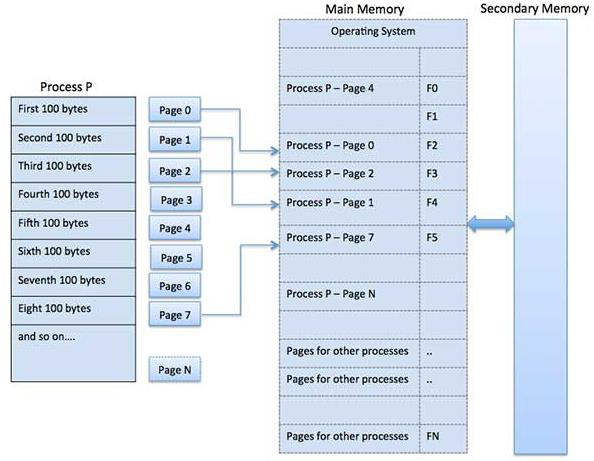
例如,如果操作系统决定退出第1页帧,它将在物理地址4096加载虚拟第8页,并对MMU映射进行两次更改。首先,它将虚拟页1的条目标记为未映射,以捕获将来对4096和8191之间虚拟地址的任何访问。然后,它将用1替换虚拟页8条目中的叉,以便在重新执行捕获的指令时,它将把虚拟地址32780映射到物理地址4108(4096+12)。
现在让我们看看MMU内部,看看它是如何工作的,以及为什么我们选择使用2的幂次方的页面大小。在下图中,我们看到了一个虚拟地址8196(二进制00100000000000100)的示例,它使用MMU映射进行映射。传入的16位虚拟地址被拆分为4位页码和12位偏移量。用4位表示页码,我们可以有16页,用12位表示偏移量,我们可以寻址一页中的所有4096字节。
16个4-KB页面的MMU内部操作。
典型的页表条目。
页码用作页表的索引,生成对应于该虚拟页的页框架的编号。如果当前/缺失位为0,则会导致操作系统陷阱。如果位为1,则页表中找到的页帧编号将与12位偏移量一起复制到输出寄存器的高位3位,12位偏移是从传入虚拟地址原样复制的。它们一起构成了一个15位的物理地址。然后将输出寄存器作为物理内存地址放在内存总线上。
两级层级页表。

两级分页系统的地址转换。
CPU生成的逻辑地址分为两部分:页码(p)和页面偏移量(d)。页码(p)用作页表的索引,页表包含物理内存中每个页的基址。此基址与页偏移量相结合,以定义物理内存,即发送到内存单元。下图显示了分页硬件:
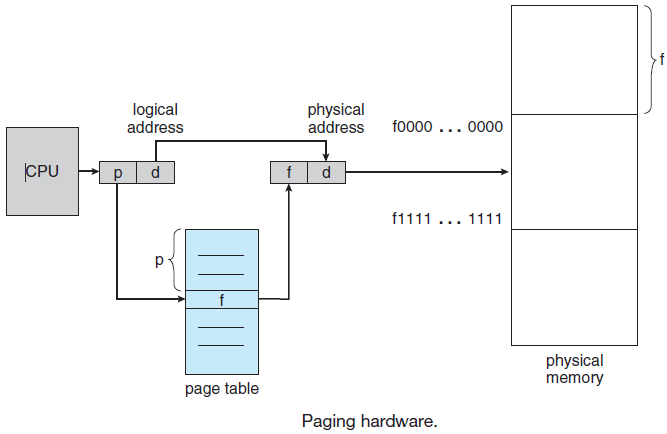
页面大小由硬件定义。2的幂的大小,每页在512字节和10Mb之间变化。如果逻辑地址空间的大小为2m地址单元,页面大小为2n,则高位m-n表示页码,低位n表示页面偏移量。
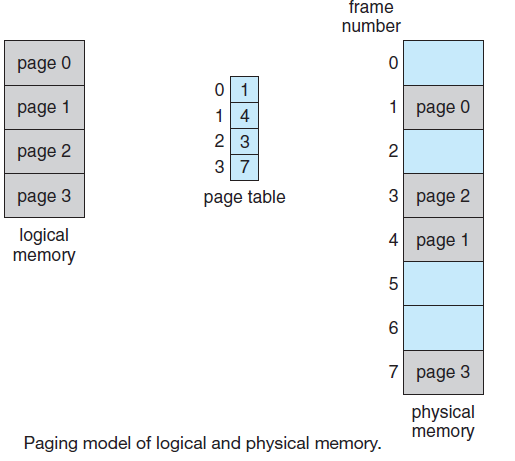
反向页表结构。
示例:结合下图,要显示如何将中的逻辑内存映射到物理内存,请考虑4字节的页面大小和32字节(8页)的物理内存。
- 逻辑地址0是第0页,偏移量为0,第0页在第5帧(frame)中。因此,逻辑地址0映射到物理地址是\([(5*4)+0]=20\)。
- 逻辑地址3是第0页,偏移量3映射到物理地址是\([(5*4) + 3]=23\)。
- 逻辑地址4是第1页,偏移量为0和第1页映射到帧6。因此,逻辑地址4映射到物理地址是\([(6*4)+0]=24\)。
- 逻辑地址13是第3页,偏移量1和第3页映射到帧2。因此,逻辑地址13映射到物理地址是\([(2*4)+1]=9\)。
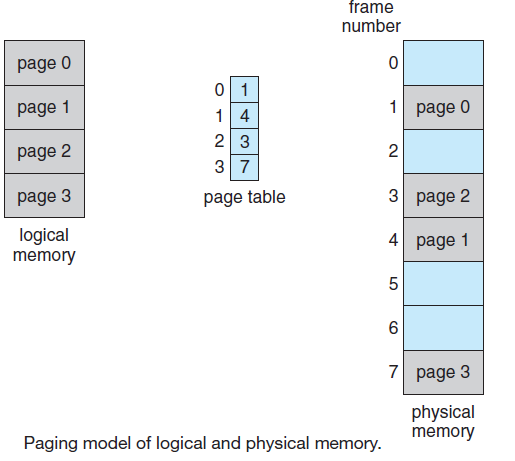
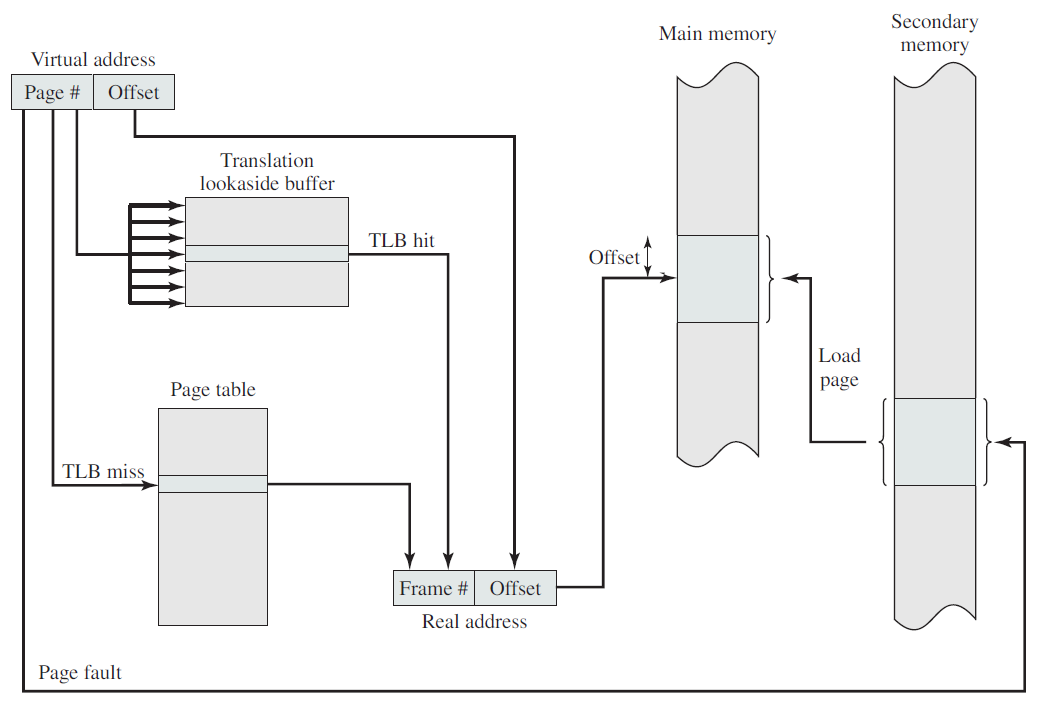
转换后备缓冲区的使用。
当一个进程到达要执行的系统时,将检查其大小(以页表示)。进程的每一页都需要一个帧。因此,如果进程需要n个页面,那么内存中必须至少有n个帧可用。如果n个帧可用,则将它们分配给此到达进程。进程的第一页被加载到一个分配的帧中,帧编号被放入该进程的页表中。下一页被加载到另一个帧中,其帧编号被放入页面表中,依此类推。
由于操作系统正在管理物理内存,因此它必须知道物理内存的分配细节,即分配了哪些帧,哪些帧可用,总共有多少帧,等等。这些信息通常保存在称为帧表的数据结构中。帧表为每个物理页帧都有一个条目,指示后者是空闲的还是已分配的,如果已分配,则指示哪个进程或进程的哪个页面。
分页替换算法有:
- 最优页面替换算法(The Optimal Page Replacement Algorithm)
- 最近未使用的页面替换算法(The Not Recently Used Page Replacement Algorithm)
- 先进先出页面替换算法(The First-In, First-Out Page Replacement Algorithm)
- 第二次机会页面替换算法(The Second-Chance Page Replacement Algorithm)
- 时钟页面替换算法(The Clock Page Replacement Algorithm)
- 最近最少使用(LRU)的页面替换算法(The Least Recently Used Page Replacement Algorithm)
- 软件模拟LRU(Simulating LRU in Software)
- 工作集页面替换算法(The Working Set Page Replacement Algorithm)
- WSClock页面替换算法(The WSClock Page Replacement Algorithm)
页面替换算法总结如下表所示:
| 算法 | 描述 |
|---|---|
| 最佳 | 不可实现,但可用作基准 |
| NRU(最近未使用) | LRU的粗略近似值 |
| FIFO(先进先出) | 可能会抛出重要页面 |
| 第二次机会 | 比FIFO有很大改进 |
| 时钟 | 实时 |
| LRU(最近最少使用) | 非常好,但难以准确实施 |
| NFU(不常用) | 与LRU相当接近 |
| 老化(Aging) | 效率接近LRU |
| 工作环境 | 实施起来有些昂贵 |
| WSClock | 高效算法 |
最佳算法将逐出将来引用最远的页面。不幸的是,无法确定这是哪个页面,因此在实践中无法使用此算法。然而,它可以作为衡量其他算法的基准。
NRU算法根据R和M位的状态将页面分为四类。从编号最低的类中随机选择一页。此算法很容易实现,但很粗糙,有更好的存在。
FIFO通过将页面保存在链接列表中来跟踪页面加载到内存中的顺序。然后删除最旧的页面就变得很简单,但该页面可能仍在使用中,因此FIFO是一个错误的选择。
第二次机会是修改FIFO,在删除页面之前检查页面是否正在使用。如果是,则该页面是空闲的,此修改大大提高了性能。时钟只是第二次机会的不同实现,具有相同的性能属性,但执行算法所需的时间稍短。
LRU是一种很好的算法,但如果没有特殊的硬件就无法实现。如果此硬件不可用,则无法使用。NFU是近似LRU的粗略尝试,不是很好。然而,老化是LRU的一个更好的近似值,可以有效实施,是一个很好的选择。
最后两个算法使用工作集。工作集算法提供了合理的性能,但实现起来有些昂贵。WSClock是一种变体,它不仅提供了良好的性能,而且实现效率也很高。
总之,最好的两种算法是老化和WSClock。它们分别基于LRU和工作集,两者都具有良好的分页性能,并且可以有效地实现。还有其他一些好的算法,但这两个算法在实践中可能是最重要的。
18.9.2.6 地址转换
页面地址称为逻辑地址,由页码和偏移量表示:
Logical Address = Page number + page offset
帧地址称为物理地址,由帧编号和偏移量表示:
Physical Address = Frame number + page offset
称为页映射表的数据结构用于跟踪进程的页与物理内存中的帧之间的关系。
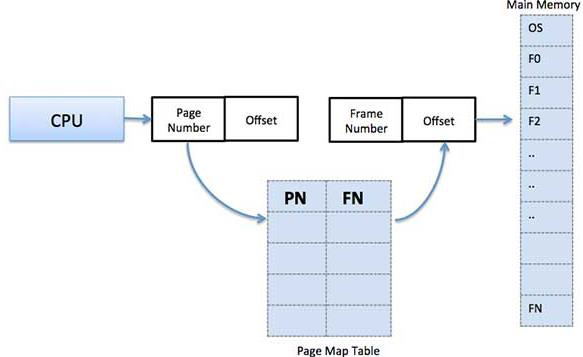
当系统为任何页面分配一个帧时,它会将该逻辑地址转换为物理地址,并在页面表中创建条目,以便在整个程序执行过程中使用。
当一个进程被执行时,它对应的页面被加载到任何可用的内存帧中。假设有一个8Kb的程序,但在给定的时间点,内存只能容纳5Kb,那么分页概念就会出现。当计算机的RAM用完时,操作系统(OS)会将空闲或不需要的内存页移到辅助内存中,以便为其他进程释放RAM,并在程序需要时将其恢复。
在程序的整个执行过程中,操作系统会不断从主内存中删除空闲页面,并将其写入辅助内存,然后在程序需要时将其恢复。
分页的优缺点:
- 分页可以减少外部碎片,但仍会受到内部碎片的影响。
- 分页实现简单,被认为是一种高效的内存管理技术。
- 由于页面和帧的大小相等,交换变得非常容易。
- 页表需要额外的内存空间,因此对于RAM较小的系统可能不太好。
18.9.3 进程地址空间
每个进程都有自己的线性、虚拟和私有地址空间,地址空间开始于地址零,结束于某个最大值,基于操作系统位(32或64)和进程位。下图展示了不同进程在私有内存地址空间下指向的实际物理地址,物理地址包含RAM和磁盘。
进程可以直接访问自己地址空间中的内存,意味着一个进程不能仅仅通过操纵指针来意外或恶意地读取或写入另一个进程的地址空间。可以访问另一个进程的内存,但这需要调用一个函数(ReadProcessMemory或WriteProcessMemority),该函数对目标进程具有足够强的句柄。
进程的地址空间称为虚拟,指的是地址空间只是一个潜在内存映射的空间。每个进程开始时都会非常适度地使用其虚拟地址空间——可执行文件与ntdll.Dll一起映射。然后,加载器(NtDll的一部分)在进程地址空间内分配一些基本结构,例如默认进程堆、进程环境块(PEB)、进程中第一个线程的线程环境块(TEB)。大部分地址空间为空。
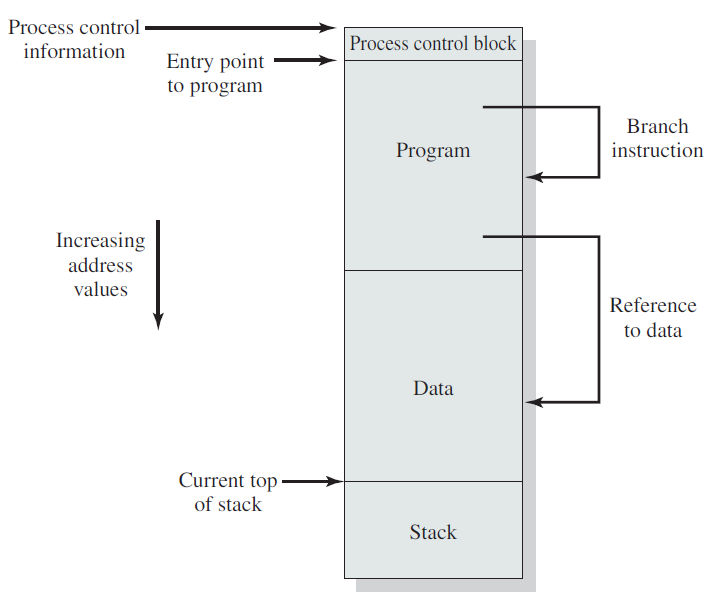
进程的寻址需求。
18.9.3.1 页面状态
虚拟内存中的每个页面可以处于三种状态之一:空闲(free)、提交(committed)和保留(reserved)。
-
空闲页面:未映射,因此尝试访问该页会导致访问冲突异常。进程的大部分地址空间开始时是空闲的。
-
提交页面:与空闲页面相反——是一个映射页面,映射到RAM或文件,访问该页面应成功。如果页面在RAM中,CPU直接访问数据并继续。如果页面不在RAM中(至少CPU查询的表告诉它),CPU会引发一个称为页面错误的异常,由内存管理器捕获。如果页面确实驻留在磁盘上,内存管理器会将其带回RAM,修复转换表以指向RAM中的新地址,并指示CPU重试。从调用线程的角度来看,最终结果是访问成功。如果确实涉及I/O,访问速度会变慢,但调用线程不需要知道这一点,也不需要对它做任何特殊的操作——它是透明的。
提交内存通常称为分配内存。调用C/C++内存分配函数,如malloc、calloc、operator new等,总是提交内存。
-
保留页面:介于空闲和提交之间,类似于空闲页面,因为访问该页面会导致访问冲突——那里没有任何内容。保留页可能稍后提交,保留页范围确保正常内存分配不会使用该范围,因为它是为其他目的保留的,例如管理线程堆栈的。由于线程的堆栈可以增长,并且在虚拟内存中必须是连续的,因此保留了一个页面范围,以便进程中发生的其他分配不使用保留的地址范围。
下表总结了页面的三种状态及特点:
| 页面状态 | 意义 | 如果访问 |
|---|---|---|
| 空闲(free) | 未分配页 | 访问冲突异常 |
| 提交(committed) | 已分配页 | 成功(假设没有页面保护限制) |
| 保留(reserved) | 未分配页,保留供将来使用 | 访问冲突异常 |
18.9.3.2 地址空间布局
下表总结了不同系统的地址空间大小。
| OS类型 | 进程类型 | LARGEADDRESSAWARE清理 | LARGEADDRESSAWARE设置 |
|---|---|---|---|
| 32位启动,不增加UVA | 32位 | 2GB | 2GB |
| 32位启动,增加UVA | 32位 | 2GB | 2GB ~ 3GB |
| 64-bit (Windows 8.1+) | 32位 | 2GB | 4GB |
| 64-bit (Windows 8.1+) | 64位 | 2GB | 128TB |
| 64-bit (up to Windows 8) | 32位 | 2GB | 4GB |
| 64-bit (up to Windows 8) | 64位 | 2GB | 8TB |
在32位系统上,存在两种变体,结合上表,如下图所示。
32位意味着4GB,但为什么进程只能获得2GB?因为高2GB是系统空间(也称为内核空间),是操作系统内核本身所在的位置,包括所有内核设备驱动程序,以及它们在代码和数据方面消耗的内存。
64位系统提供了几个优点,第一个优点是大大增加了地址空间。64位的理论极限是2到64次方,或16EB。大多数现代处理器只支持48位虚拟和物理地址,意味着可以获得的最大地址范围是2到48次方或256TB。也就是说,64位系统的每个进程可以有128TB的地址空间范围,而其他128TB用于系统空间。
18.9.4 Windows内存统计
开发人员通常希望了解他们的进程在内存使用方面的情况。
下表是Windows任务管理(上图)可以看到的内存使用信息:
| 名字 | 描述 |
|---|---|
| 内存使用图 | 显示过去60秒的物理内存(RAM)消耗 |
| 正在使用(压缩) | 当前使用的物理内存(压缩),压缩内存的数量 |
| 提交/提交限制 | 页面文件扩展前的总提交内存/提交内存限制 |
| 内存组成 - 修改 | 尚未写入磁盘的内存 |
| 内存组成 - 空闲 | 空闲页面(大多数是零页面) |
| 缓存 | 如果需要,可以重新利用的内存(备用+修改) |
| 可用 | 可用物理内存(待机+空闲) |
| 分页池/非分页池 | 内核池内存使用 |
关于内存压缩
内存压缩是在Windows 10中添加的,作为一种通过压缩当前不需要的内存来节省内存的方法,特别适用于UWP进程,因为它们不消耗CPU,因此这些进程使用的任何私有物理内存都可以被放弃。相反,内存被压缩,仍然为其他进程留下空闲页。当进程唤醒时,内存将快速解压缩并准备使用,避免了对页面文件的I/O。
在Windows 10的前两个版本中,压缩内存存储在系统进程的用户模式地址空间中,但过于明显且碍眼,所以从Windows 10版本1607开始,一个特殊的进程,内存压缩(一个最小化进程),是保持压缩内存的进程。此外,任务管理器完全没有显示此进程,但其他工具(如Process Explorer)正常显示此进程。
上图中的内存组成条以宽泛的笔划表示物理页面如何在内部管理,“正在使用”部分是当前被视为流程和系统工作集的一部分的页面,备用页是将其备份存储在磁盘上的内存,但与所属进程的关系仍然保留。如果流程现在触及其中一个页面,它们将立即返回其工作集(变为“正在使用中”)。如果这些页面立即被抛出到“空闲”页面堆中,则需要I/O将页面返回RAM。
修改部分表示内容尚未写入备份存储(通常为页面文件)的页面,因此不能丢弃这些页面。如果修改的页面数量过多,或者待机和空闲页面计数过小,则修改的页面将写入其备份文件,并将移动到待机状态。
所有这些转换和管理都旨在减少I/O,这些物理页面列表管理的更精确视图可在Process Explorer的系统信息视图中的内存选项卡中获得,如下图所示。
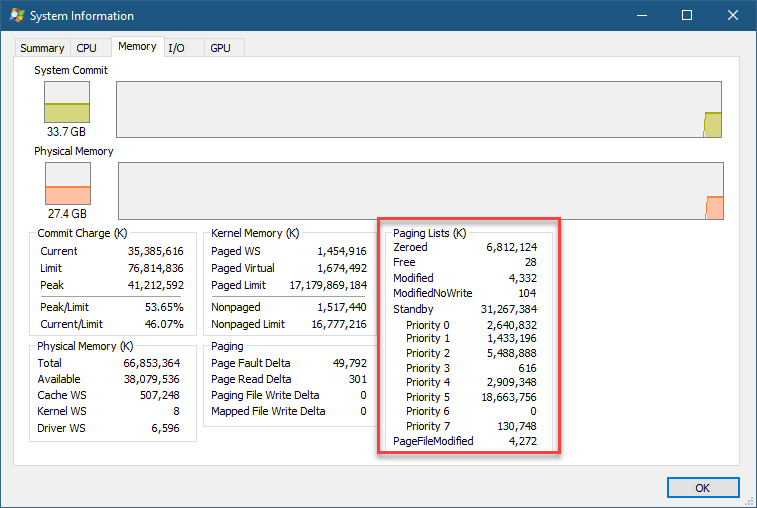
上图的分页列表部分详细说明了执行人员内存管理用于管理物理页面的各种列表。零页面是只包含零的页面,与包含垃圾的空闲页面相比,这些页面占大多数。一个特殊的执行线程称为零页线程,它以优先级0(唯一具有此优先级的线程)运行,是将空闲页归零的线程。零页之所以重要,是为了满足安全要求,即分配的内存永远不能包含属于另一个进程的数据,即使该进程不再存在。上上图中内存组成中的空闲部分包括空闲页和零页的组合。
上图另一个有趣的部分是,根据优先级,没有单一的备用页面列表,但有八个,称为内存优先级,可以在Process Explorer中逐个线程地查看,尽管这也是一个进程属性,默认情况下由每个线程继承。
当由于进程或系统需要物理内存,需要将待机列表中的页移动为空闲页时,使用内存优先级。问题是,哪些页面应该首先释放?一种简单的方法是使用FIFO队列,其中从进程工作集中删除的第一个页面是第一个空闲的页面。然而此法过于简单,假设一个进程在后台工作很多,例如反恶意软件或备份应用程序。这些进程显然使用内存,但它们不像用户直接使用的应用程序那么重要。因此,如果需要物理内存,它们的备用页应该是第一个使用的,即使它们是最近使用的。这就是内存优先级的作用。
默认内存优先级为5。进程和线程的后台模式,其CPU优先级降低到4,内存优先级降低到1,使得该进程使用的备用页更有可能在内存优先级较高的进程之前重用。如果想在不进入后台模式的情况下更改内存优先级,可以使用以下接口:
BOOL SetProcessInformation(HANDLE hProcess, PROCESS_INFORMATION_CLASS ProcessInformationClass, LPVOID ProcessInformation, DWORD ProcessInformationSize);
BOOL SetThreadInformation(HANDLE hThread, THREAD_INFORMATION_CLASS ThreadInformationClass, LPVOID ThreadInformation, DWORD ThreadInformationSize);
18.9.4.1 Windows进程内存统计
任务管理器中与进程相关的内存计数器有些混乱,“详细信息”选项卡中显示的默认内存计数器:内存(专用工作集)或内存(活动专用工作集)。让我们分析这些术语:
- 工作集(Working Set):进程使用的物理内存。
- 专用(Private):进程专用内存(非共享)。
- 活动(Active):不包括后台的UWP进程。
这些计数器的问题在于工作集部分,表示当前在RAM中的专用内存,然而是一个不稳定的计数器,可能会根据流程活动而上下浮动。如果试图确定进程提交(分配)了多少内存,或者进程泄漏了内存,那么这些不是要查看的计数器。
这些计数器仅显示私有内存这一事实通常是一件好事,因为共享内存(如DLL代码使用的内存)是常量,因此任何人都无法对此做任何事情。私有内存是由进程控制的内存。
那么,正确的计数器是什么呢?是提交大小。为了使事情更加混乱,Process Explorer和性能监视器将此计数器称为私有字节。下图显示了任务管理器,它将提交大小和活动私有工作集并排排列,并按提交大小排序。

提交大小也与私有内存有关,所以它与私有工作集处于同等地位,区别在于不在工作集中的内存。如果两个计数器都接近,则表示进程相当活跃,并使用其大部分内存,或者Windows的可用内存不低,因此内存管理器无法快速从工作集中删除页面。
在某些情况下,两个计数器之间的差异可能非常大。在上图中,流程代码(PID 34316)的大部分提交内存不是其工作集的一部分。这就是为什么查看专用工作集计数器会产生误导,看起来这个进程消耗了大约97MB的内存,但实际上它消耗了大约368MB的内存。诚然,目前在RAM中,它仅使用97MB,但提交的内存确实消耗了页表(用于映射提交的内存),并且该内存根据系统的提交限制计数。
使用任务管理器中的提交大小列确定进程的内存消耗,不包括共享内存,但并不重要(在大多数情况下)。在Process Explorer中,提交大小的等效值是私有字节。任务管理器和Process Explorer都包含更多与内存相关的列(Procss Explorer包含多个任务管理器)。特别是一个列没有类似的,即虚拟大小列,如下图所示。
“虚拟大小”列统计所有不处于空闲状态(即已提交和保留)的页面,本质上是进程消耗的地址空间量。对于潜在地址空间为128 TB的64位进程,无关紧要,对于32位进程,可能是个问题。即使提交的内存不太高,但拥有大的保留内存区域会限制新分配的可用地址空间,可能会导致分配失败,即使整个系统可能有足够的空闲内存。
前面描述的计数器不包括保留内存,是有原因的。保留内存成本非常低,因为从CPU的角度来看,它与空闲内存是一样的——不需要页表来描述保留内存。事实上,从Windows 8.1开始,保留内存的成本甚至更低。
上图虚拟大小栏中的一些数字似乎有些令人担忧,一些进程的虚拟大小似乎约为2TB,私有字节列显示的数字要小得多,意味着虚拟大小描述的大部分内存大小都是保留的。一些进程拥有如此巨大的保留块的真正原因是因为Windows 10的安全特性,称为控制流保护(Control Flow Guard,CFG)。可以在Process Explorer中添加CFG列,将看到支持CFG的进程与巨大的2 TB保留区域之间的紧密关联。
18.9.5 进程内存映射
进程的地址空间必须包含进程在内存方面使用的所有内容:可执行代码和全局数据、DLL代码和全局信息、线程堆栈、堆,以及进程提交和/或保留的任何其他内存。下图显示了进程虚拟地址空间的典型示例。
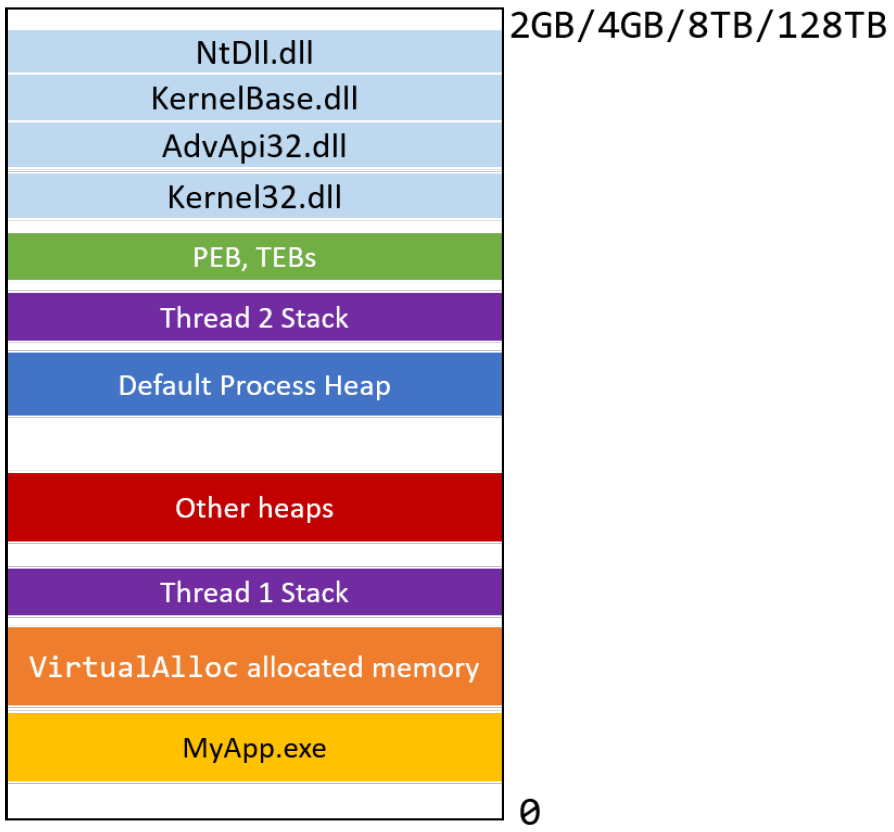
一个典型的进程加载几十个DLL并可能使用许多线程,.NET等框架有自己的DLL和堆,但所有这些看似不同的东西都是由相同的“东西”组成的。
要查看进程的实际内存映射,可以使用系统内部中的VMMap工具。启动VMMap时,会立即显示一个进程选择对话框,可以在其中选择感兴趣的流程(下图)。但是,VMMap仍然限于用户模式访问,无法打开受保护的进程。
一旦选择了一个进程,VMMap的主视图将由三个不同的水平部分填充(下图显示了Explorer.exe的实例)。
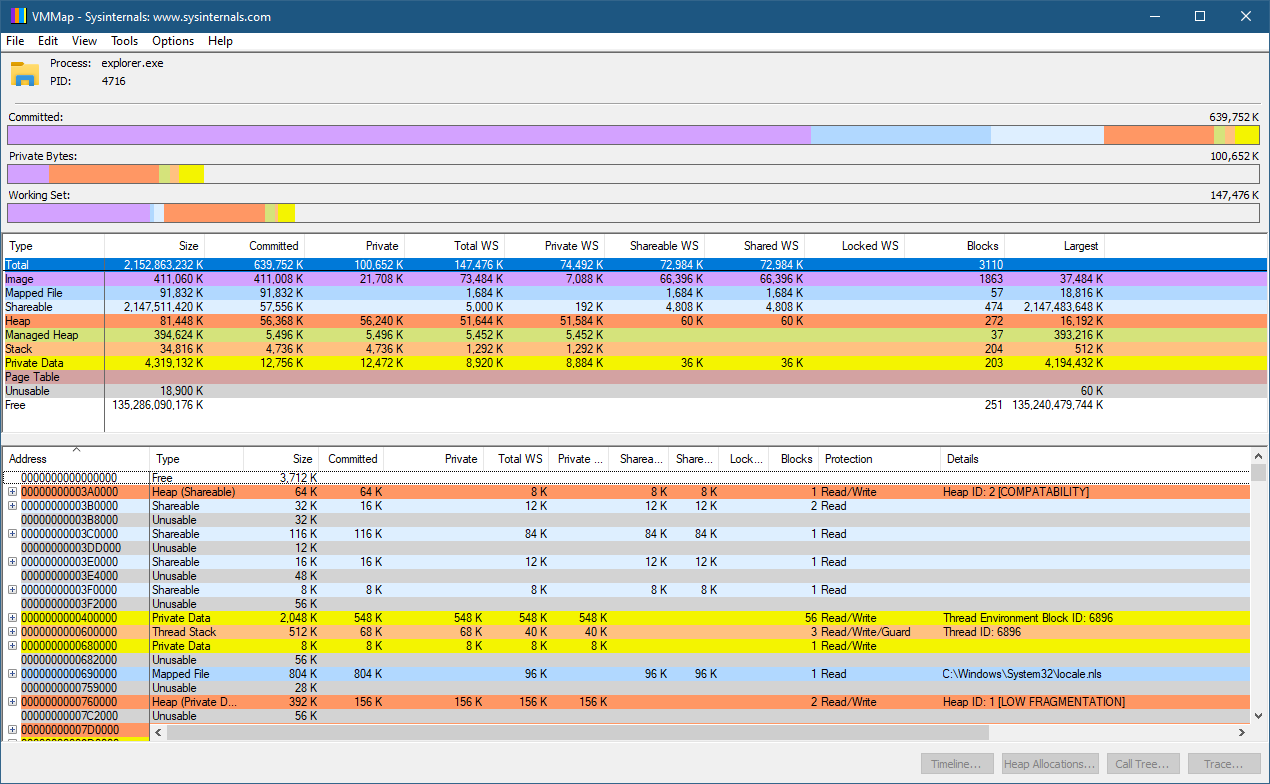
顶部显示三个计数器:
- 提交内存-进程中的总提交内存(包括专用页和共享页)
- 专用字节-专用提交内存
- 工作集-总工作集(专用页和共享页使用的物理内存)
每个计数器都有一个排序直方图,显示该计数器中包含的内存区域的类型,区域类型如第二部分所示。下表总结了VMMap显示的区域类型。
| 类型 | 描述 |
|---|---|
| 镜像(Image) | 映射图像(EXE和DLL) |
| 映射文件(Mapped File) | 映射文件(Image除外) |
| 可共享(Shareable) | 页文件备份的内存映射文件 |
| 堆 | 被堆使用的内存 |
| 托管堆 | 被.NET运行时(CLR或CoreLCR)管理的内存 |
| 栈 | 线程栈使用的内存 |
| 私有数据 | 用VirtualAlloc分配的通用内存 |
| 不可用(Unusable) | 无法使用的内存块(小于64KB分配粒度) |
| 空闲 | 空闲页面 |
如果需要获取进程内存使用情况的摘要视图,PSAPI函数GetProcessMemoryInfo可以提供帮助:
BOOL GetProcessMemoryInfo(HANDLE Process, PPROCESS_MEMORY_COUNTERS ppsmemCounters, DWORD cb);
该函数接受进程句柄,该进程句柄必须具有PROCESS_VM_READ访问掩码,且带有PROCESS_QUERY_LIMITED_INFORMATION或PROCESS_QUERY_INFORMATION。当前进程句柄(GetCurrentProcess)是一个自然的候选,因为它具有完全访问掩码。
18.9.6 页面保护
进程虚拟地址空间中的每个提交页都有保护标志,可以使用VirtualAlloc或VirtualProtect函数设置。下表显示了页面保护属性,可以从中为提交的页面指定一个属性,任何违反页面保护的访问都会导致访问违反异常。
| 保护标记 | 描述 |
|---|---|
| PAGE_NOACCESS | 页面不可访问 |
| PAGE_READONLY | 仅读访问 |
| PAGE_READWRITE | 可读写访问 |
| PAGE_WRITECOPY | 写访问拷贝 |
| PAGE_EXECUTE | 执行访问 |
| PAGE_EXECUTE_READ | 执行和读访问 |
| PAGE_EXECUTE_READWRITE | 所有可能的访问 |
| PAGE_EXECUTE_WRITECOPY | 执行访问和读拷贝 |
除上述值外,还可以添加一些保护常数,如下表所示。
| 保护标记 | 描述 |
|---|---|
| PAGE_GUARD | 保护页。任何访问都会导致页面保护异常 |
| PAGE_NOCACHE | 不可缓存页面。仅当内核驱动程序访问内存并且驱动程序需要时才应使用 |
| PAGE_WRITECOMBINE | 一些内核驱动程序能够使用的优化。不应普遍使用 |
| PAGE_TARGETS_INVALID | 页面是CFG的无效目标 |
| PAGE_TARGETS_NO_UPDATE | 在使用VirtualProtect更改保护时不更新CFG信息 |
18.9.7 共享内存
通常进程具有不混合的单独地址空间,然而在进程之间共享内存有时是有益的。典型的例子是DLL,所有用户模式进程都需要NtDll,最需要的是Kernel32.dll,KernelBase.dll、AdvApi32.dll和许多其他。如果每个进程在物理内存中都有自己的DLL副本,将很快耗尽。事实上,拥有DLL的首要动机之一是共享(至少是代码)的能力。按照惯例,代码是只读的,因此可以安全地共享,来自EXE文件的可执行代码也是如此。如果多个进程基于同一图像文件执行,则没有理由不共享。下图的内核32.dll在两个进程之间共享。
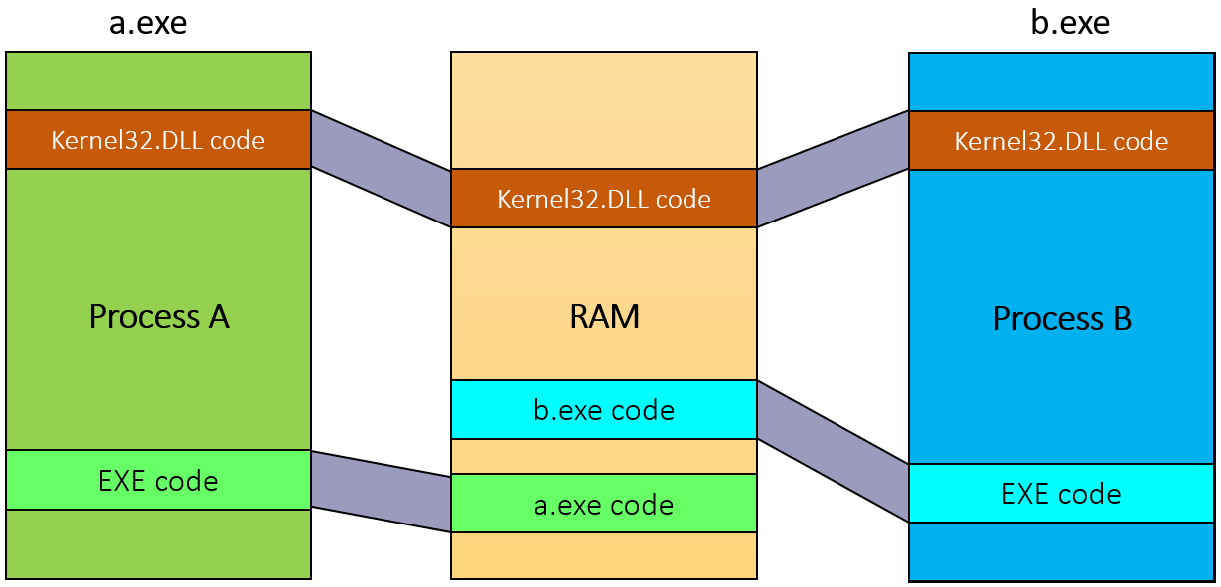
上图共享DLL的所有进程中DLL的虚拟地址相同是必要的,因为并非所有代码都是可重定位的。如果我们在全局范围内声明一个变量,如下所示:
int x;
void main()
{
x++;
//...
}
如果我们运行这个可执行文件的两个实例——第二个实例中的x值是多少?答案是1。x是进程的全局数据,而不是系统的全局数据,与DLL的工作原理相同。如果DLL声明了一个全局变量,则它仅对加载DLL的每个进程是全局的。
在大多数情况下,这正是我们想要的,通过使用名为写时复制(PAGE_WRITECOPY)的页面保护来实现的。其思想是,所有使用相同变量的进程(在可执行文件或这些进程使用的DLL中声明)将该变量所在的页面映射到相同的物理页面(上图)。如果进程更改了该变量的值(下图的进程A),则会引发异常,导致内存管理器创建页面的副本,并将其作为私有页面移交给调用进程,从而删除写时的副本保护(下图中的第3页)。

将任何全局数据复制到每个使用它的进程会更简单,但会浪费物理内存。如果数据未更改,则无需进行复制。在某些情况下,需要在进程之间共享数据。一个相对简单的机制是使用全局变量,但是指定页面应该由普通的PAGE_READWRITE而不是PAGE_WRITECOPY保护。可以通过在可执行文件或DLL中构建新的数据段,并指定其所需的属性来实现。下面代码显示了如何实现这一点:
#pragma data_seg("shared")
int x = 0;
#pragma data_seg()
#pragma comment(linker, "/section:shared,RWS")
data_seg的pragma(编译指示)在PE中创建一个新段,它的名称可以是任何名称(最多8个字符),为了清晰起见,在上面的代码中称为“shared”。然后,应该共享的所有变量都放在该节中,并且必须显式初始化它们,否则它们将不会存储在该节。从技术上讲,如果有几个变量,则只需要明确初始化第一个变量。不过,最好将它们全部初始化。第二个#pragma是指向链接器的指令,用于创建具有属性RWS(读、写、共享)的节。那个小“S”是关键,映像映射后,它将不具有PAGE_WRITECOPY保护,因此在使用相同PE的所有进程之间共享。
18.9.8 页面文件
处理器只能访问物理内存(RAM)中的代码和数据。如果启动了某些可执行文件,Windows会将可执行文件的代码和数据(以及NTdll.dll)映射到进程的地址空间,然后,进程的第一个线程开始执行,会导致它执行的代码(首先在NtDll.dll中,然后是可执行文件)映射到物理内存并从磁盘加载,以便CPU可以执行它。
假设进程的线程都处于等待状态,可能进程有一个用户界面,用户最小化了应用程序的窗口,有一段时间没有使用应用程序。Windows可以将可执行文件使用的RAM重新用于其他需要它的进程。现在假设用户恢复应用程序的窗口——Windows现在必须将应用程序的代码带回RAM。从哪里读取代码?可执行文件本身。
意味着可执行文件和DLL是它们自己的备份。事实上,Windows为可执行文件和DLL创建了一个内存映射文件(这也解释了为什么不能删除这些文件,因为这些文件至少有一个打开的句柄)。
数据呢?如果长时间没有访问某些数据(或者Windows的可用内存不足),内存管理器可以将数据写入磁盘——页面文件(Page File)。页面文件用作专用提交内存的备份,不需要使用页面文件——没有页面文件,Windows也可以正常运行,但减少了一次可以提交的内存量。
此外,Windows最多支持16页文件,它们必须位于不同的磁盘分区中,并命名为pagefile.sys,位于根分区(默认情况下隐藏文件)。如果一个分区太满,或者另一个分区是单独的物理磁盘,那么拥有多个页面文件可能会有好处,会增加I/O吞吐量。
任务管理器中显示的提交限制本质上是RAM的数量加上所有页面文件的当前大小。每个页面文件可以具有初始大小和最大大小。当系统达到其提交限制时,页面文件将增加到其配置的最大值,因此提交限制现在会增加(由于更多I/O,性能可能会降低)。如果提交的内存低于原始提交限制,则页面文件大小将减少回其初始大小。
可以通过进入系统属性,然后选择高级系统设置,然后在性能部分选择设置,然后选择“高级”选项卡,最后在虚拟内存部分选择“更改…”来配置页面文件的大小,结果显示如下图所示的对话框。在单击最后一个按钮之前,请注意,页面文件的当前大小显示在按钮附近。
18.9.9 虚拟内存
传统的虚拟内存包含了虚拟地址、页表入口、段表入口、以及它们的组合等概念和方式:

18.9.9.1 虚拟内存概述
每个进程都有自己的虚拟、私有、线性地址空间,此地址空间开始时为空(或接近空,因为可执行映像和NtDll.Dll通常是第一个映射的)。一旦主(第一个)线程开始执行,可能会分配内存、加载更多DLL等。该地址空间是私有的,意味着其它进程无法直接访问它。地址空间范围从零开始(技术上不能分配第一个64KB的地址),一直到最大值,取决于进程“位”(32或64位)、操作系统“位”和链接器标志,如下所示:
- 对于32位Windows系统上的32位进程,进程地址空间大小默认为2GB。
- 对于32位Windows系统上使用“增加用户地址空间”设置的32位进程,进程地址空间大小可以高达3 GB(取决于具体设置)。要获取扩展地址空间范围,创建进程的可执行文件必须在其头中标记有LargeAddressWare链接器标志。如果不是,它仍将限制在2GB。
- 对于64位进程(自然是在64位Windows系统上),地址空间大小为8TB(Windows 8及更早版本)或128 TB(Windows 7.1及更高版本)。
- 对于64位Windows系统上的32位进程,如果可执行映像与LargeAddressWare标志链接,则地址空间大小为4 GB。否则,大小保持在2GB。
内存本身称为虚拟的,意味着地址范围和它在物理内存(RAM)中的确切位置之间存在间接关系。进程中的缓冲区可以映射到物理内存,也可以临时驻留在文件(如页面文件)中。术语“虚拟”是指从执行角度来看,不需要知道要访问的内存是否在RAM中;如果内存确实映射到RAM,CPU将直接访问数据。否则,CPU将引发页面错误异常,导致内存管理器的页面错误处理程序从适当的文件中提取数据,将其复制到RAM,在映射缓冲区的页面表条目中进行所需的更改,并指示CPU重试。
虚拟内存是一种允许执行可能无法在主内存中编译的进程的技术,它将用户逻辑内存与物理内存分开,这种分离允许在只有小物理内存可用时为程序提供超大内存。虚拟内存使编程任务变得更容易,因为程序员不再需要计算可用或不可用的物理内存量,允许不同进程通过页面共享共享文件和内存,通常由请求分页实现。
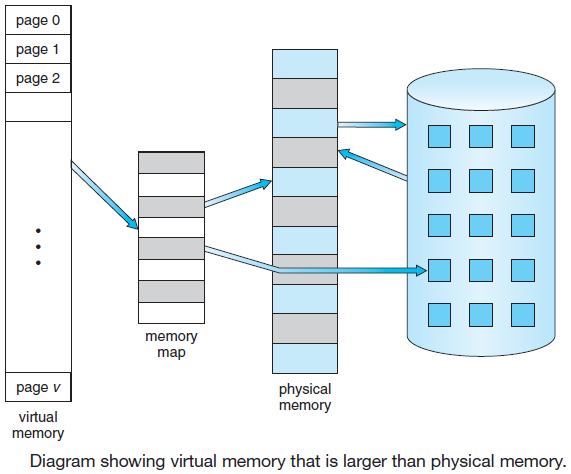
进程的虚拟地址空间是指进程如何存储在内存中的逻辑(或虚拟)视图。通常,此视图表示进程开始于某个逻辑地址,例如地址0,并且存在于连续内存中。
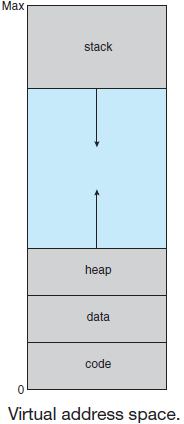
18.9.9.2 分页
请求分页系统类似于具有交换功能的分页系统,当我们想执行一个进程时,我们把它交换到内存中。交换程序操作整个进程,其中分页器(Pager)涉及进程的各个页面,请求分页的概念是使用分页器而不是交换程序。当一个进程要换入时,分页器会猜测在再次换出该进程之前将使用哪些页面,而不是在整个过程中交换,分页器只将那些必要的页面放入内存。分页内存到连续磁盘空间的传输如下图所示。
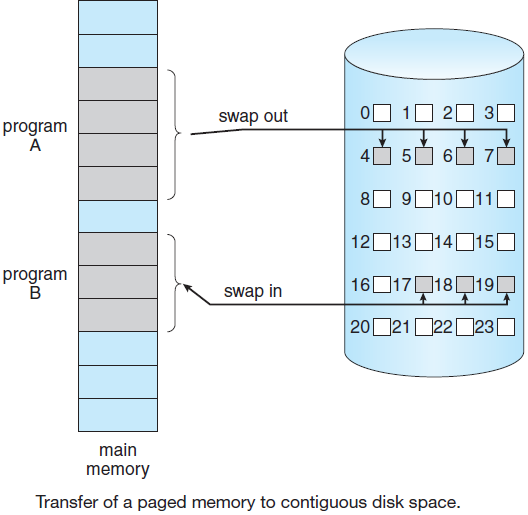
因此,它避免了读取无法使用的内存页,从而减少了交换时间和所需的物理内存量。在这种技术中,我们需要一些硬件支持来区分内存中的页面和磁盘上的页面。为此,硬件使用了有效位和无效位——当该位设置为有效时,表示关联页面在内存中;如果该位设置为无效,则表示页面无效或有效,但当前不在磁盘中。
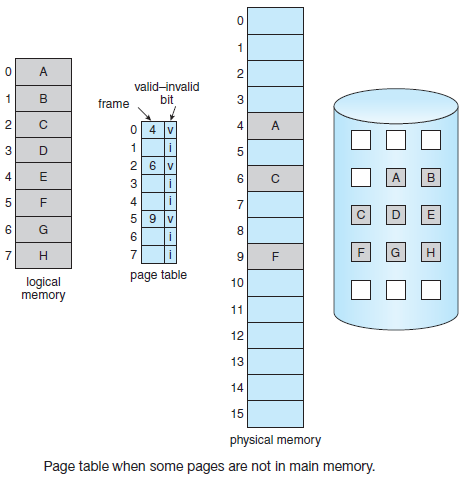
如果进程从未尝试访问页面,则将页面标记为无效将无效。因此,当进程执行并访问驻留在内存中的页面时,执行将正常进行。访问标记为无效的页面会导致页面错误捕捉器(trap),是操作系统无法将所需页面放入内存的结果。
结合下图,如果进程引用的页面不在物理内存中:
1、检查此进程的内部表(页表),以确定引用是否有效。
2、如果引用无效,则终止进程;如果引用有效但尚未引入,则必须从主内存引入。
3、现在在内存中找到一个自由帧。
4、然后,将所需的页面读入新分配的帧。
5、当磁盘读取完成时,修改内部表以指示页面现在在内存中。
6、重新启动被非法地址捕捉器中断的指令。现在,该进程可以像访问内存中的页面一样访问该页面。
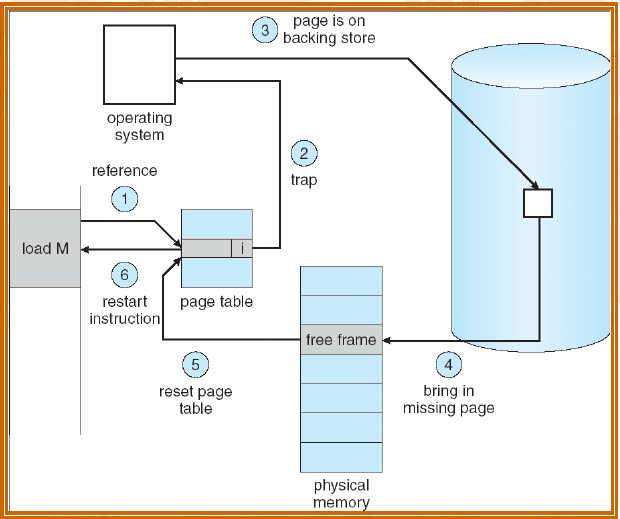
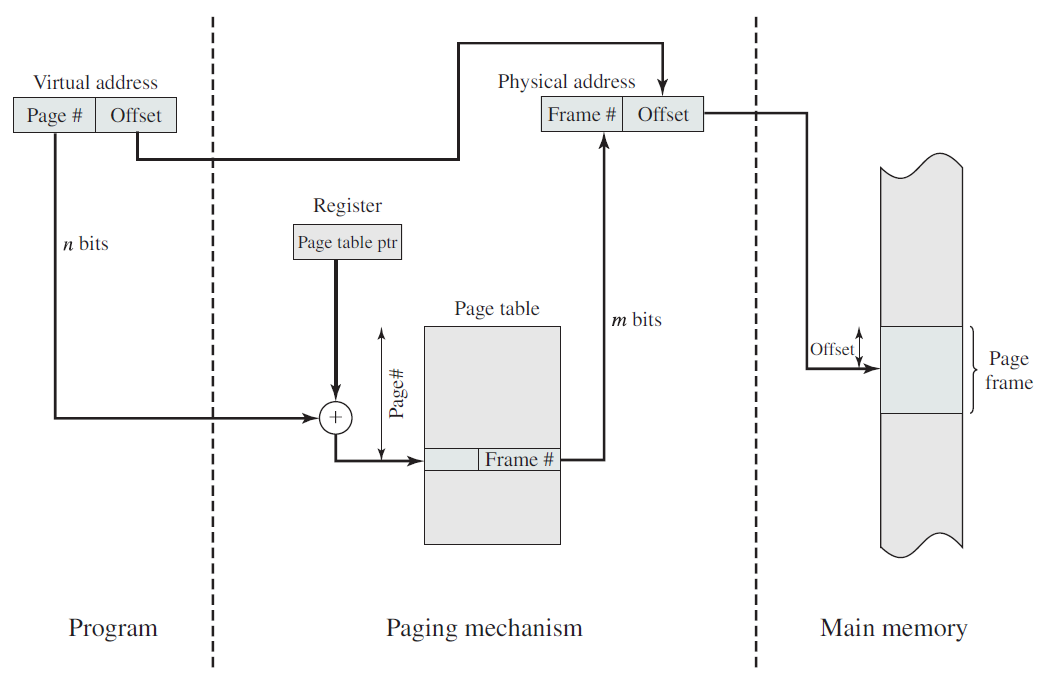
对于请求分页,需要与分页和交换相同的硬件。
- 页表:能够通过有效无效位将条目标记为无效。
- 辅助内存:保存主内存中不存在的页面,是一个高速磁盘。
请求分页会对计算机系统的性能产生重大影响。设P(0<=P<=1)为页面错误的概率,有效访问时间是(1-P) * ma + P * page fault,其中:P=页面故障、ma=内存访问时间。说明有效访问时间与页面故障率成正比。在按需分页中,保持页面错误率低十分重要。
页面错误会导致以下顺序的行为发生:
1、操作系统陷阱。
2、保存用户注册和进程状态。
3、确定中断是页面错误。
4、检查页面引用是否合法,并确定页面在磁盘上的位置。
5、从磁盘向空闲帧发出读取。
6、如果等待,请将CPU分配给其他用户。
7、从磁盘中断。
8、保存其他用户的寄存器和进程状态。
9、确定中断来自磁盘。
10、更正页面表和其他表,以显示所需页面现在在内存中。
11、等待CPU再次分配给该进程。
12、恢复用户寄存器进程状态和新页表,然后恢复中断的指令。
页面替换策略:
- 每个进程都分配了保存进程页面(数据)的帧(内存)。
- 帧根据需要填充页面——称为请求分页。
- 通过修改页面错误服务例程来替换页面,可以防止内存过度分配。
- 页面替换算法的工作是确定哪个页面受到损坏,从而为新页面腾出空间。
- 页面替换完成逻辑内存和物理内存的分离。
结合下图,页面替换的描述如下:
- 请求分页通过不加载从未使用过的页面来共享I/O,还允许在某个时间运行更多进程,从而提高了多道程序设计的程度。
- 页面替换策略处理内存中的页面被必须引入的新页面替换的解决方案。当用户进程执行时,发生页面错误。
- 硬件陷阱指向操作系统,操作系统检查内部表,以确定是页面错误,而不是非法的内存访问。
- 操作系统确定派生页在磁盘上的位置,会发现空闲帧列表中没有空闲帧。
- 当所有帧都在主存中时,需要带一个新的页面来满足页面错误,替换策略与选择当前内存中要替换的页面有关。
- 要删除的第i、e页应该是将来最不可能引用的第i、e页。
- 当用户进程执行时,发生页面错误。操作系统确定所需页面在磁盘上的位置,但发现空闲帧列表中没有空闲帧,即所有内存都在使用中,如上图所示。此时,操作系统有几个选项:可以终止进程,也可以通过释放其所有帧并减少多道程序设计的程度来交换进程。
结合下图,页面替换算法的过程如下:
1、查找磁盘上派生页的位置。
2、查找自由帧。如果有空闲帧,就使用它。 否则,使用替换算法来选择候选页面。将候选页面写入磁盘,相应地更改页面和帧表。
3、将所需页面读入自由帧,更改页面和帧表。
4、重新启动用户进程。
候选页面(Victim Page)是物理内存不足时支持的页面。如果没有空闲帧,则读取两个页面转换(输出和一个输入),将看到有效访问时间。每个页面或帧可能有一个与硬件相关联的脏(修改)位,每当写入页面中的任何单词或字节时,硬件都会设置页面的修改位,表示页面已被修改。当选择要替换的页面时,检查其修改位,如果设置了位,那么页面会因为从磁盘读取而被修改。如果未设置位,则页面自读入内存后未被修改。因此,如果页的副本没有被修改,可以避免将内存页写入磁盘,如果它已经存在的话。但有些页面无法修改。
要实现请求页面,必须解决两个主要问题:
- 必须开发帧分配算法和页面替换算法。
- 如果内存中有多个处理器,必须决定要分配多少帧,并且需要替换页面。
18.9.9.3 页面替换
页面替换算法决定当需要分配内存页时,将交换哪个内存页到页。有3种页面替换算法:
页面错误:内存中不存在CPU要求的页面。
页面命中:内存中存在CPU要求的页面。
1、FIFO(先进先出)算法
FIFO是最简单的页面替换算法,将每个页面放入内存的时间关联起来。当要替换页面时,将选择最旧的页面,把队列放在队列的最前面,当一个页面进入内存时,我们将它插入队列的尾部。示例:考虑以下引用字符串,其帧最初为空。

前三个引用(7,0,1)会出现页面错误,并被放入空帧中。下一个参考页面2取代了第7页,因为第7页是最先引入的。由于0是下一个引用,并且0已经在内存中,因此e没有页面错误。下一个引用3会导致页面0被替换,因此下一个对0的引用会导致页面错误,这将一直持续到字符串结束。总共有15个页面错误。
分析:参考页数 = 20,页面错误数 = 15,页面命中次数 = 5,页面命中率 = 页面命中数/页面引用总数 = (5 / 20)x100 = 25%
,页面错误率 = 页面错误数 / 页面引用总数 = (15 / 20)x100= 75%。
Belady’的Anamoly问题:对于某些页面替换算法,页面错误可能会随着分配的帧数的增加而增加。FIFO替换算法可能会面临此问题。
最佳算法:最优页面替换算法主要是解决Belady的Anamoly问题。理想情况下,我们希望选择一个页面错误率最低的算法,这种算法存在,并被称为最优算法。其过程:替换最长时间(或根本不会)不会使用的页面,即替换参考字符串中向前距离最大的页面。示例:考虑以下引用字符串,其帧最初为空。
前三个引用会导致填充三个空帧的错误,第2页的参考文献取代了第7页,因为只有参考文献18才会使用第7页。第0页将在第5页使用,第1页将在14页使用。只有9个页面错误,最佳替换比有15个错误的FIFO好得多。该算法很难实现,因为它需要知道将来的引用字符串。
分析:参考页数=20,页面错误数=9,页面命中数=11,页面命中率=页面命中数/页面引用总数 = (11 / 20)x100 = 55%,页面错误率=页面错误数/页面引用总数= (9 / 20)x100=45%。
2、LRU(最近最少使用)算法
如果最优算法不可行,则可以近似最优算法。带OPTS和FIFO的主要区别是:FIFO算法使用页面内置的时间,OPT使用页面使用的时间。LRU算法将替换最长时间未使用的页面,将其页面与上次使用该页面的时间相关联。这种策略是向后而不是向前看的最佳页面替换算法。示例:考虑以下引用字符串,其帧最初为空。

前5个错误类似于最佳更换。当引用第4页时,LRU会看到三个帧中的第2页,即最近最少使用的帧。最近使用的页面是第0页,刚好在使用第3页之前。LRU策略通常用作页面替换算法,被认为是不错的选择。
分析:参考页数=20,页面错误数=12,页面命中数=8,页面命中率=页面命中数/页面引用总数= (8 / 20)x100=40%,页面错误率=页面错误数/页面引用总数= (12 / 20)x100=60%。
为了支持超大地址的内存空间,可以使用多级页表,下图a是具有两个页表字段的32位地址,b是两级页表:
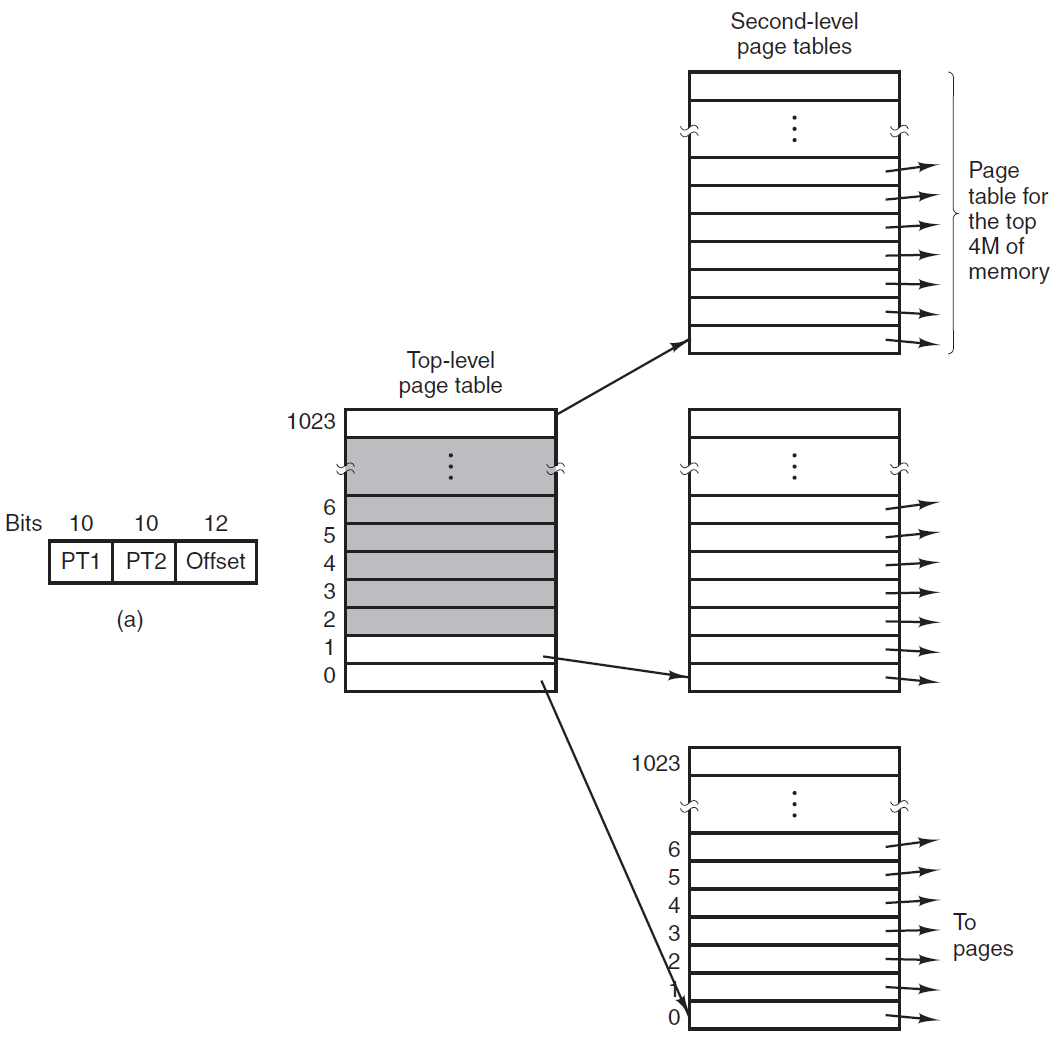
4种常见的页面替换算法的行为对比图:
不同算法在固定分配、局部页面替换算法的比较:

18.9.9.4 分段
前面讨论的虚拟内存是一维的,因为虚拟地址从0到某个最大地址,一个接一个。对于许多问题,拥有两个或多个独立的虚拟地址空间可能比只有一个要好得多。例如,编译器有许多在编译过程中构建的表,可能包括:
- 为打印列表保存的源文本(在批处理系统上)。
- 符号表,包含变量的名称和属性。
- 包含所有使用的整数和浮点常量的表。
- 解析树,包含程序的语法分析。
- 编译器内用于过程调用的堆栈。
随着编译的进行,前四个表中的每个表都在不断增长。最后一个在编译过程中以不可预知的方式增长和收缩。在一维内存中,这些五表必须分配连续的虚拟地址空间块,如下图所示。
考虑一下,如果一个程序的变量数量比平时大得多,但其他所有变量的数量都正常,会发生什么。为符号表分配的地址空间块可能已满,但其他表中可能有很多空间。所需要的是一种方法,让程序员不必管理扩展和收缩表,就像虚拟内存消除了将程序组织成覆盖层的担忧一样。
一个简单而通用的解决方案是为机器提供许多完全独立的地址空间,这些地址空间称为段(Segment)。每个段由一个线性地址序列组成,从0开始,一直到某个最大值。每个段的长度可以是从0到允许的最大地址之间的任意值。不同的段可能(通常)有不同的长度。此外,段长度可能在执行期间发生变化。每当有东西被推到堆栈上时,堆栈段的长度可能会增加,而当有东西从堆栈中弹出时,则会减少。
因为每个段构成一个单独的地址空间,所以不同的段可以独立增长或收缩,而不会相互影响。如果某个段中的堆栈需要更多的地址空间来增长,它的地址空间中没有其他东西可以插入。当然,一个段可能会填满,但段通常非常大,因此这种情况很少发生。要在这个分段或二维内存中指定地址,程序必须提供一个由两部分组成的地址、段号和段内的地址。下图说明了用于前面讨论的编译器表的分段内存,这里显示了五个独立的段。

分段内存允许每个表独立地进行增长或收缩。
段是一个逻辑实体,程序员知道并将其用作逻辑实体。一个段可能包含一个过程、一个数组、一个堆栈或一组标量变量,但通常它不包含不同类型的混合。
分段内存除了简化对增长或收缩的数据结构的处理之外,还有其他优点。如果每个过程占用一个单独的段,以地址0作为起始地址,那么单独编译的过程的链接将大大简化。在编译并连接了构成程序的所有过程之后,对段n中的过程的过程调用将使用由两部分组成的地址(n, 0)来寻址字0(入口点)。
如果随后修改并重新编译了段n中的过程,则不需要更改其他过程(因为没有修改起始地址),即使新版本比旧版本大。在一维内存中,过程被紧紧地挤在一起,彼此之间没有地址空间。因此,更改一个过程的大小可能会影响段中所有其他(不相关)过程的起始地址。反过来,需要修改调用任何移动过程的所有过程,以便合并它们的新起始地址。如果一个程序包含数百个过程,那么此过程可能代价高昂。
分段也有助于在多个进程之间共享程序或数据。一个常见的例子是共享库。运行高级窗口系统的现代工作站通常在几乎每个程序中都有超大的图形库。在分段系统中,图形库可以放在一个段中,由多个进程共享,这样就不需要在每个进程的地址空间中都有图形库。虽然在纯分页系统中也可以有共享库,但它更为复杂。实际上,这些系统是通过模拟分割来实现的。
由于每个段形成程序员所知道的逻辑实体,例如过程或数组,因此不同的段可以有不同的保护类型。过程段可以指定为仅执行,禁止尝试读取或存储过程段。浮点数组可以指定为读/写,但不能执行,跳转到该数组的尝试将被捕获,这种保护有助于捕捉错误。下表比较了分页和分段。
| 问题 | 分页 | 分段 |
|---|---|---|
| 程序员需要知道这项技术正在被使用吗? | 否 | 是 |
| 有多少线性地址空间? | 1 | 很多 |
| 总地址空间能否超过物理内存的大小? | 是 | 是 |
| 程序和数据是否可以区分并单独保护? | 否 | 是 |
| 大小不定的表能很容易地容纳吗? | 否 | 是 |
| 是否促进了用户之间的程序共享? | 否 | 是 |
| 为什么发明这种技术? | 无需购买更多物理内存即可获得较大的线性地址空间 | 允许将程序和数据分解为逻辑独立的地址空间,并帮助共享和保护 |
分段的实现与分页在本质上有所不同:页面大小固定,而分段则不是。下图(a)显示了最初包含五个段的物理内存的示例。现在考虑一下,如果段1被逐出,而较小的段7被放回原处,会发生什么情况。我们得出(b)的存储器配置。段7和段2之间是一个未使用的区域,即一个孔。然后段4替换为段5,如(c)所示,段3替换为段6,如(d)所示。在系统运行一段时间后,内存将被划分为多个块,一些包含段,一些包含孔。这种现象称为棋盘格或外部碎片,会在洞中浪费内存。可以通过压实处理,如(e)所示。

(a)-(d)棋盘的形成。(e) 通过压实移除棋盘格。

动态分区的效果。
下面阐述Intel x86的分页分段技术。直到x86-64,x86的虚拟内存系统在许多方面都与MULTICS相似,包括分段和分页。MULTICS有256K个独立的段,每个段最多64K个36位字,而x86有16K个独立段,每个独立段最多可容纳10亿个32位字。虽然段数较少,但较大的段大小更为重要,因为很少程序需要1000个以上的段,但许多程序需要较大的段。从x86-64开始,分段被认为是过时的,不再受支持,除非是在传统模式下。尽管在x86-64的原生模式中仍然可以使用一些旧的分割机制的残留物,主要是为了兼容性,但它们不再扮演相同的角色,也不再提供真正的分段。
18.9.9.5 虚拟内存转换
虚拟地址转换为物理地址的转换本身是自动的,因此当CPU看到如下指令时:
mov eax, [100000H]
它知道地址0x100000是虚拟的而不是物理的(因为CPU配置为在保护模式/长模式下运行)。CPU现在必须查看内存管理器预先准备的表,这些表描述了页面在RAM中的位置(如果有的话)。如果它不在RAM中(由CPU在转换表中检查的有效位中的零标记),则会引发页面错误异常,由内存管理器适当处理。地址转换涉及的基本组件如下图所示。

CPU被提供虚拟地址作为输入,并且应该输出(和使用)物理地址。由于所有工作都是按照页面工作的,所以地址的低12位(页面内的偏移量)永远不会被转换,并按原样传递到最终地址。
CPU需要上下文进行转换。每个进程都有一个初始结构,它总是驻留在RAM中。对于32位系统,它称为页面目录指针表,对于64位系统,则称为页面映射级别4(Intel术语)。从这个初始结构开始,使用其他结构,包括页面目录和页面表,页表条目是指向物理页地址的条目(如果设置了有效位)。当页面移动到页面文件时,内存管理器将相应的页面表条目标记为无效,以便CPU下次遇到该页面时,将引发页面错误异常。
最后,转换查询缓冲区(Translation Lookaside Buffer,TLB)是最近转换的页面的缓存,因此访问这些页面不需要为了转换目的而通过多层结构。该缓存相对较小,从实用角度来看非常重要。在邻近的时间使用相同范围的内存地址对利用TLB缓存非常有用。
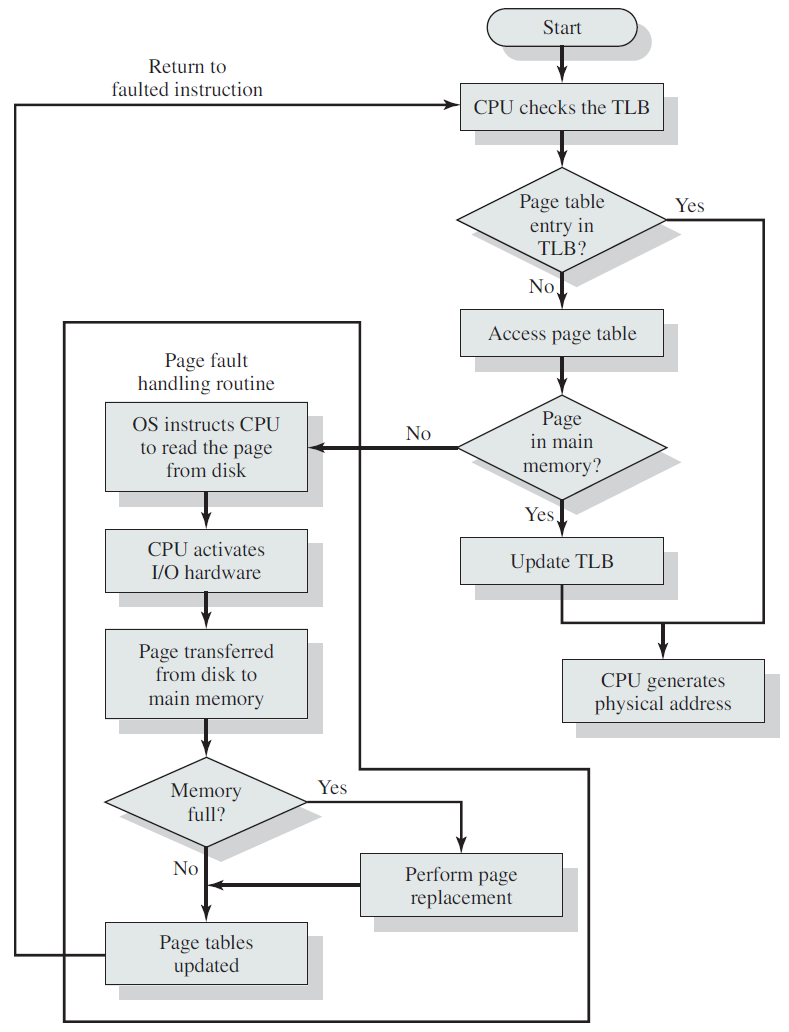
分页和转换后备缓冲器(TLB)的操作。
18.9.10 Windows内存
Windows提供了多组API来处理内存,下图显示了可用集及其依赖关系。
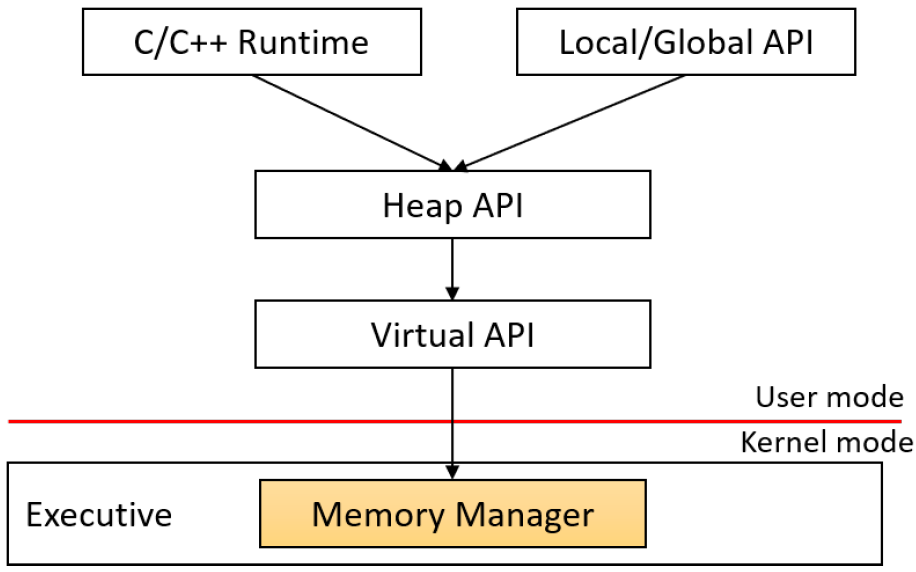
最底层是虚拟API最接近内存管理器,有几个含义:
- 是最强大的API,提供了虚拟内存可以完成的所有功能。
- 始终以页面单位和页面边界为单位工作。
- 高层级的API使用它。
相关虚拟API如下:
LPVOID VirtualAlloc(LPVOID lpAddress, SIZE_T dwSize, DWORD flAllocationType, DWORD flProtect);
LPVOID VirtualAllocEx(HANDLE hProcess, LPVOID lpAddress, SIZE_T dwSize, DWORD flAllocationType, DWORD flProtect);
PVOID VirtualAllocFromApp(PVOID BaseAddress, SIZE_T Size, ULONG AllocationType, ULONG Protection);
BOOL VirtualFree(LPVOID lpAddress, SIZE_T dwSize, DWORD dwFreeType);
BOOL VirtualFreeEx(HANDLE hProcess, LPVOID lpAddress, SIZE_T dwSize, DWORD dwFreeType);
18.9.10.1 工作集
工作集(Working Set)表示在不发生页面错误的情况下可访问的内存。当然,一个进程希望其所有提交的内存都在其工作集中,内存管理器必须平衡一个进程和所有其他进程的需求,长时间未访问的内存可能会从进程的工作集中删除,并不意味着它会被自动丢弃——内存管理器有精心设计的算法,可以将曾经是进程工作集一部分的物理页面保留在RAM中的时间超过可能需要的时间,因此,如果有问题的进程决定访问该内存,它可能会立即发现错误进入工作集(称为软页面故障)。
通过GetProcessMemoryInfo,可以获得进程的当前和峰值工作集:
BOOL GetProcessMemoryInfo(HANDLE Process, PPROCESS_MEMORY_COUNTERS ppsmemCounters, DWORD cb);
进程具有最小和最大工作集。默认情况下,这些限制是软的,因此如果内存充足,进程可以消耗比其最大工作集更多的RAM,如果内存不足,则可以使用比其最小工作集更少的RAM。使用GetProcessWorkingSetSize查询这些限制:
BOOL GetProcessWorkingSetSize(HANDLE hProcess, PSIZE_T lpMinimumWorkingSetSize, PSIZE_T lpMaximumWorkingSetSize);
其它工作集相关的API:
BOOL SetProcessWorkingSetSize(HANDLE hProcess, SIZE_T dwMinimumWorkingSetSize, SIZE_T dwMaximumWorkingSetSize);
BOOL WINAPI EmptyWorkingSet(HANDLE hProcess);
BOOL SetProcessWorkingSetSizeEx(HANDLE hProcess, SIZE_T dwMinimumWorkingSetSize, SIZE_T dwMaximumWorkingSetSize, DWORD Flags);
BOOL GetProcessWorkingSetSizeEx(HANDLE hProcess, PSIZE_T lpMinimumWorkingSetSize, PSIZE_T lpMaximumWorkingSetSize, PDWORD Flags);
18.9.10.2 堆
VirtualAlloc函数集非常强大,因为它们非常接近内存管理器。然而,也有一个缺点。这些函数只在页面块中工作:如果分配10个字节,则返回一个页面。如果再分配10个字节,则会得到不同的页面,对于管理在应用程序中非常常见的小型分配来说太浪费了。这正是堆起作用的地方。
堆管理器是一个在虚拟API之上分层的组件,它知道如何有效地管理小型分配。在此上下文中,堆是由堆管理器管理的内存块,每个进程都从单个堆开始,称为默认进程堆。使用GetProcessHeap获得该堆的句柄:
HANDLE GetProcessHeap();
可以创建更多堆,有了堆,使用HeapAlloc分配(提交)内存:
LPVOID HeapAlloc(HANDLE hHeap, DWORD dwFlags, SIZE_T dwBytes);
其它堆相关的API:
BOOL HeapFree(HANDLE hHeap, DWORD dwFlags, LPVOID lpMem);
HANDLE HeapCreate(DWORD flOptions, SIZE_T dwInitialSize, SIZE_T dwMaximumSize);
BOOL HeapDestroy(HANDLE hHeap);
C/C++内存管理函数(如malloc、calloc、free、C++的new和delete操作符等)的实现取决于编译器提供的库。C/C++运行时使用堆函数来管理它们的分配。以下是malloc的实现,为了清晰起见,删除了一些宏和指令(在malloc.cpp中):
extern "C" void* __cdecl malloc(size_t const size)
{
#ifdef _DEBUG
return _malloc_dbg(size, _NORMAL_BLOCK, nullptr, 0);
#else
return _malloc_base(size);
#endif
}
malloc有两个实现——一个用于调试构建,另一个用于发布构建,以下是发布构建的摘录(在文件malloc_base.cpp中):
extern "C" __declspec(noinline) void* __cdecl _malloc_base(size_t const size)
{
// Ensure that the requested size is not too large:
_VALIDATE_RETURN_NOEXC(_HEAP_MAXREQ >= size, ENOMEM, nullptr);
// Ensure we request an allocation of at least one byte:
size_t const actual_size = size == 0 ? 1 : size;
for (;;)
{
void* const block = HeapAlloc(__acrt_heap, 0, actual_size);
if (block)
return block;
//...code omitted...
}
extern "C" bool __cdecl __acrt_initialize_heap()
{
__acrt_heap = GetProcessHeap();
if (__acrt_heap == nullptr)
return false;
return true;
}
实际上,以上API只是VirtualAlloc的冰山一角,Windows还提供了其它诸多功能的API。
18.9.10.3 非统一内存体系架构(NUMA)
非统一内存体系架构(NUMA)系统涉及一组节点,每个节点持有一组处理器和内存。下图显示了此类系统的拓扑示例。
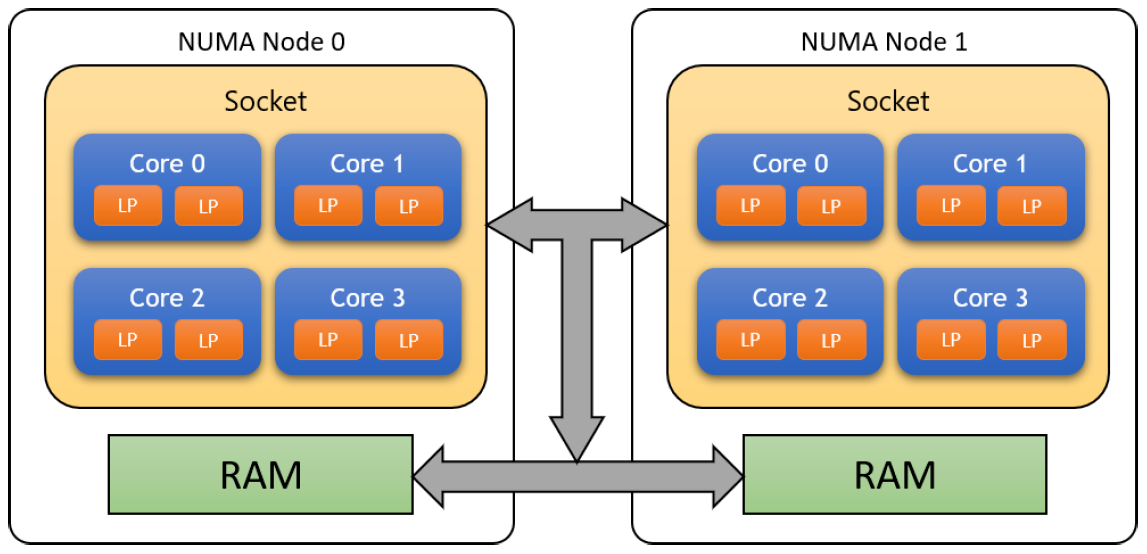
上图显示了具有两个NUMA节点的系统示例,每个节点拥有一个具有4个内核和8个逻辑处理器的套接字。NUMA系统仍然是对称的,因为任何CPU都可以运行任何代码并访问任何节点中的任何内存。然而,从本地节点访问内存要比访问另一个节点中的内存快得多。
Windows知道NUMA系统的拓扑结构。之前讨论的线程调度,调度程序充分利用了这些信息,并尝试在CPU上调度线程,其中线程堆栈位于该节点的物理内存中。NUMA系统通常用于服务器机器,其中通常存在多个套接字。
18.9.10.4 内存映射文件
文件映射对象在Windows中无处不在。加载图像文件(EXE或DLL)时,将使用内存映射文件将其映射到内存。通过这种映射,通过标准指针访问内存,间接访问底层文件。当代码需要在映像内执行时,初始访问会导致页面错误异常,内存管理器在修复用于映射此内存的适当页面表之前,通过从文件读取数据并将其放入物理内存来处理该异常,此时调用线程可以访问代码/数据。这些对应用程序来说是透明的。
一些代码需要在文件中搜索一些数据,而搜索需要在文件内来回跳转。对于I/O API,充其量是不方便的,涉及对ReadFile(预先分配了缓冲区)和SetFilePointer(Ex)的多次调用。另一方面,如果文件的“指针”可用,那么移动和执行文件操作就容易得多:无需分配缓冲区,无需读取文件调用,任何文件指针更改只需转换为指针算术。所有其他常见内存函数,如memcpy、memset等,在内存映射文件中也同样有效。
涉及内存映射文件的常见API有:
HANDLE CreateFileMapping(HANDLE hFile, LPSECURITY_ATTRIBUTES lpFileMappingAttributes, DWORD flProtect, DWORD dwMaximumSizeHigh, DWORD dwMaximumSizeLow, LPCTSTR lpName);
LPVOID MapViewOfFile(HANDLE hFileMappingObject, DWORD dwDesiredAccess, DWORD dwFileOffsetHigh, DWORD dwFileOffsetLow, SIZE_T dwNumberOfBytesToMap);
BOOL UnmapViewOfFile(_In_ LPCVOID lpBaseAddress);
18.9.10.5 共享内存
进程是相互隔离的,因此每个都有自己的地址空间、自己的句柄表等。大多数时候,正是我们想要的。然而,在某些情况下,数据需要在进程之间以某种方式共享。Windows为进程间通信(IPC)提供了许多机制,包括组件对象模型(COM)、Windows消息、套接字、管道、邮件槽、远程过程调用(RPC)、剪贴板、动态数据交换(DDE)等。每种方法都有其优点和缺点,但上述所有方法的共同主题是内存必须从一个进程复制到另一个进程。
内存映射文件是IPC的另一种机制,是所有机制中最快的,因为没有复制(事实上,其他一些IPC机制在同一台机器上的进程之间通信时使用内存映射文件)。一个进程将数据写入共享内存,所有其他具有同一文件映射对象句柄的进程都可以立即看到内存,因为每个进程都将同一内存映射到自己的地址空间,所以不会进行复制。
共享内存基于访问同一文件映射对象的多个进程,对象可以通过三种方式中的任何一种共享,最简单的方法是使用文件映射对象的名称。共享内存本身可以由特定文件(CreateFileMapping的有效文件句柄)备份,在这种情况下,即使在文件映射对象被销毁后,数据仍然可用,或者由分页文件备份,在该情况下,一旦文件映射对象销毁,数据将被丢弃。这两个选项的工作方式基本相同。
文件映射对象在数据一致性方面提供了若干保证:
- 同一数据/文件的多个视图(即使来自多个进程)保证同步,因为不同视图映射到同一物理内存。唯一例外是在网络上映射远程文件时,在这种情况下,来自不同机器的视图可能不会一直同步,但来自同一台机器的视图将继续同步。
- 映射同一文件的多文件映射对象不能保证同步。通常,使用两个或多个文件映射对象映射同一文件不是良好的做法。最好以独占访问方式打开文件,这样就不可能对文件进行其他访问(至少在打算写入的情况下)。
- 如果文件由文件映射对象映射,同时为正常I/O(读文件、写文件等)打开,则I/O操作的更改通常不会立即反映在映射到文件中相同位置的视图中。应避免这种情况。
18.10 动态链接库
18.10.1 DLL概述
动态链接库(DLL)是Windows NT的基本组成部分。DLL存在背后的主要动机是,它们可以在进程之间轻松共享,因此DLL的单个副本位于RAM中,所有需要它的进程都可以共享DLL的代码。在早期,RAM比现在小得多,使得内存节省非常重要。即使在今天,内存节省也非常重要,因为一个典型的进程使用了几十个DLL。
DLL是可移植可执行(PE)文件,可以包含以下一个或多个:代码、数据和资源。每个用户模式进程都使用子系统dll,如kernel32.dll、user32.dll、gdi32.dll和advapi32.dll,实现文档化的Windows API。当然,Ntdll.Dll在每个用户模式进程中都是必需的,包括原生应用程序。
DLL是可以包含函数、全局变量和资源(如菜单、位图和图标)的库。某些函数(和类型)可以通过DLL导出,以便加载DLL的其他DLL或可执行文件可以直接使用它们。DLL可以在进程启动时隐式加载到进程中,也可以在应用程序调用LoadLibrary或LoadLibraryEx函数时显式加载。
18.10.2 显式加载
显式链接到DLL可以更好地控制何时加载和卸载DLL。此外,如果DLL加载失败,进程不会崩溃,因此应用程序可以处理错误并继续。显式DLL链接的一个常见用途是加载语言相关资源。例如,应用程序可能尝试加载带有当前系统区域设置中资源的DLL,如果未找到,则可以加载默认资源DLL,该DLL始终作为应用程序安装的一部分提供。对于显式链接,不使用导入库,因此加载程序不会尝试加载DLL(可能不存在)。这也意味着不能使用#include来获取导出的符号声明,因为链接器将因“未解决的外部”错误而失败。我们如何使用这样的DLL?
第一步是在运行时加载它,通常在需要的地方加载。这是LoadLibrary的工作:
HMODULE LoadLibrary(LPCTSTR lpLibFileName);
LoadLibrary只接受文件名或完整路径。如果只指定了文件名,则搜索DLL的顺序与隐式加载DLL的顺序相同。如果指定了完整路径,则只尝试加载该文件。在实际搜索开始之前,加载器检查是否有一个具有相同名称的模块已加载到进程地址空间中。如果是,则不执行搜索,并返回现有DLL的句柄。例如,如果SimpleDell.Dll已加载(无论从哪个路径),并调用LoadLibrary加载名为SimpleDll.Dll的文件(在任何路径或不带路径的情况下),不会加载其他Dll。
成功加载DLL后,可以使用GetProcAddress从DLL访问导出的函数:
FARPROC GetProcAddress(HMODULE hModule, LPCSTR lpProcName);
函数返回DLL中导出符号的地址。第二个参数是符号的名称,注意,名称必须是ASCII。返回值是一个通用的FARPROC,其中“远”和“近”表示不同的东西。如果符号不存在(或未导出,这是相同的),则GetProcAddress返回NULL。举个例子:
// dll的其中一个函数声明
__declspec(dllexport) bool IsPrime(int n);
// 加载dll,导出上面的函数地址,并调用。
auto hPrimesLib = ::LoadLibrary(L"SimpleDll.dll");
if (hPrimesLib)
{
// DLL found
using PIsPrime = bool (*)(int);
auto IsPrime = (PIsPrime)::GetProcAddress(hPrimesLib, "IsPrime");
if (IsPrime)
{
bool test = IsPrime(17);
printf("%d\n", (int)test);
}
}
这段代码看起来相对简单——DLL已加载。不幸的是,对GetProcAddress的调用失败,GetLastError返回127(找不到指定的进程)。显然,GetProcAddress无法定位导出的函数,即使它已导出。为什么?
原因与函数的名称有关,如果我们使用Dumpbin查探关于SimpleDll.Dll的信息:
0 000111F9 ?IsPrime@@YA_NH@Z = @ILT+500(?IsPrime@@YA_NH@Z)
原因找到了——链接器“弄乱”了要使用的函数的名称:IsPrime@@YA_NH@Z。原因与IsPrime在C++中不够唯一有关。iPrime函数可以是A类、B类以及全局函数,也可能是某个命名空间C的一部分。此外,由于C++函数重载,同一作用域中可能有多个名为IsPrime的函数。因此,链接器为函数提供了一个奇怪的名称,其中包含这些独特的属性。我们可以尝试在前面的代码示例中替换这个损坏的名称,如下所示:
auto IsPrime = (PIsPrime)::GetProcAddress(hPrimesLib, "?IsPrime@@YA_NH@Z");
你会发现它是有效的!然而,这非常无趣且不太实用,我们必须用一种方法来查找损坏的名称,以使其正确。通常的做法是将所有导出的函数转换为C风格的函数。因为C不支持函数重载或类,所以链接器不必进行复杂的修改。下面是一种将函数导出为C的方法:
extern "C" __declspec(dllexport) bool IsPrime(int n);
如果编译C文件,以上将是默认值。
通过此更改,可以简化获取指向IsPrime函数的指针:
auto IsPrime = (PIsPrime)::GetProcAddress(hPrimesLib, "IsPrime");
但是,这种将函数转换为C风格的方案不能用于类中的成员函数——正是使用GetProcAddress访问C++函数不实际的原因,也是大多数用于LoadLibrary/GetProcAddress的DLL仅公开C风格函数的原因。
如果DLL不再需要,可以使用以下API释放之:
BOOL FreeLibrary(HMODULE hLibModule);
系统为每个加载的DLL维护每个进程计数器。如果对同一DLL多次调用LoadLibrary,则需要相同数量的FreeLibrary调用才能从进程地址空间真正卸载DLL。如果需要加载DLL的句柄,则可以使用GetModuleHandle检索它:
HMODULE GetModuleHandle(LPCTSTR lpModuleName);
18.10.3 调用约定
调用约定(Calling Convention)表明函数参数如何传递给函数,以及如果在堆栈上传递,谁负责清理参数。对于x64,只有一个调用约定。对于x86,有几个,最常见的是标准调用约定stdcall和C调用约定cdecl。stdcall和cdecl都使用堆栈传递参数,从右向左推送。它们之间的主要区别在于,对于stdcall,被调用方(函数体本身)负责清理堆栈,而对于cdecl,调用方负责清理堆栈。
stdcall的优点是更小,因为堆栈清理代码只显示一个(作为函数体的一部分)。使用cdecl,对函数的每次调用都必须跟随一条指令,以清除堆栈中的参数。cdecl函数的优点是它们可以接受可变数量的参数(在C/C++中由…指定),因为只有调用方知道传入了多少参数。
Visual C++中用户模式项目中使用的默认调用约定是cdecl,通过在返回类型和函数名之间放置适当的关键字来指定调用约定。为此,Microsoft编译器重新识别__cdecl和__stdcall关键字,使用的关键字也必须在实现中指定,以下是将IsPrime设置为使用stdcall的示例:
extern "C" __declspec(dllexport) bool __stdcall IsPrime(int n);
这也意味着,在定义函数指针以与GetProcAddress一起使用时,还必须指定正确的调用约定,否则我们将得到运行时错误或堆栈损坏:
using PIsPrime = bool (__stdcall *)(int);
// or
typedef bool(__stdcall* PIsPrime)(int);
__stdcall是大多数Windows API使用的调用约定,通常是使用WINAPI、APIENTRY、PASCAL、CALLBACK之一的宏,它们的含义完全相同。
18.10.4 DllMain函数
DLL可以有一个入口点(但不是必须,也可以没有),传统上称为DllMain,必须具有以下原型:
BOOL WINAPI DllMain(HINSTANCE hInsdDll, DWROD reason, PVOID reserved);
hInstance参数是DLL加载到进程中的虚拟地址,如果显式加载DLL,则它与从LoadLibrary返回的值相同。reason参数指示调用DllMain的原因,其值如下表所述:
| Reason值 | 描述 |
|---|---|
| DLL_PROCESS_ATTACH | 当DLL附加到进程时调用 |
| DLL_PROCESS_DETACH | 在从进程卸载DLL之前调用 |
| DLL_THREAD_ATTACH | 在进程中创建新线程时调用 |
| DLL_THREAD_DETACH | 在线程退出进程之前调用 |
18.10.5 Dll注入
在某些情况下,需要将DLL注入另一个进程。注入DLL是指以某种方式强制另一个进程加载特定的DLL,允许DLL在目标进程的上下文中执行代码。这种能力有很多用途,但它们本质上都归结为某种形式的定制或目标进程内操作的拦截。以下是一些具体的例子:
- 反恶意软件解决方案和其他应用程序可能希望在目标进程中挂接API函数。
- 通过子类化窗口或控件自定义窗口的能力,允许对UI进行行为更改。
- 作为目标进程的一部分,可以无限访问该进程中的任何内容。有些是好的,比如监控应用程序行为以定位错误的DLL,但有些是坏的。
18.10.5.1 远程线程注入
通过在加载所需DLL的目标进程中创建线程来注入DLL可能是最广为人知和最直接的技术。其思想是在目标进程中创建一个线程,该线程使用要注入的DLL路径调用LoadLibrary函数。将代码执行到目标进程中的示例代码如下:
int main(int argc, const char* argv[])
{
// 检查命令行参数
if (argc < 3)
{
printf("Usage: injector <pid> <dllpath>\n");
return 0;
}
// 注入器需要目标进程ID和要注入的DLL, 故而打开目标进程的句柄
HANDLE hProcess = ::OpenProcess(PROCESS_VM_WRITE | PROCESS_VM_OPERATION | PROCESS_CREATE_THREAD, FALSE, atoi(argv[1]));
if (!hProcess)
return Error("Failed to open process");
// 准备要加载的DLL路径, 路径字符串本身必须放在目标进程中,因为是执行LoadLibrary的地方. 可以使用VirtualAllocEx函数.
void* buffer = ::VirtualAllocEx(hProcess, nullptr, 1 << 12, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE);
if (!buffer)
return Error("Failed to allocate buffer in target process");
// 使用WriteProcessMemory将DLL路径复制到分配的缓冲区
if (!::WriteProcessMemory(hProcess, buffer, argv[2], ::strlen(argv[2]) + 1, nullptr))
return Error("Failed to write to target process");
// 创建远程线程
DWORD tid;
HANDLE hThread = ::CreateRemoteThread(hProcess, nullptr, 0,
(LPTHREAD_START_ROUTINE)::GetProcAddress(::GetModuleHandle(L"kernel32"), "LoadLibraryA"),
buffer, 0, &tid);
if (!hThread)
return Error("Failed to create remote thread");
// 等待远程线程退出
printf("Thread %u created successfully!\n", tid);
if (WAIT_OBJECT_0 == ::WaitForSingleObject(hThread, 5000))
printf("Thread exited.\n");
else
printf("Thread still hanging around...\n");
// 释放和清理
::VirtualFreeEx(hProcess, buffer, 0, MEM_RELEASE);
::CloseHandle(hThread);
::CloseHandle(hProcess);
}
以上代码中,必须指定DLL的完整路径,因为加载规则是从目标进程的角度,而不是调用方的角度。注入的DLL的DllMain显示了一个简单的消息框:
BOOL APIENTRY DllMain(HMODULE hModule, DWORD reason, PVOID lpReserved)
{
switch (reason)
{
case DLL_PROCESS_ATTACH:
wchar_t text[128];
::StringCchPrintf(text, _countof(text), L"Injected into process %u", ::GetCurrentProcessId());
::MessageBox(nullptr, text, L"Injected.Dll", MB_OK);
break;
}
return TRUE;
}
18.10.5.2 Windows挂钩
Windows挂钩指的是一组与用户界面相关的挂钩,可通过SetWindowsHookEx等API使用:
HHOOK SetWindowsHookEx(int idHook, HOOKPROC lpfn, HINSTANCE hmod, DWORD dwThreadId);
lpfn提供的钩子函数具有以下原型:
typedef LRESULT (CALLBACK* HOOKPROC)(int code, WPARAM wParam, LPARAM lParam);
示例代码:
int main()
{
DWORD tid = FindMainNotepadThread();
if (tid == 0)
return Error("Failed to locate Notepad");
auto hDll = ::LoadLibrary(L"HookDll");
if (!hDll)
return Error("Failed to locate Dll\n");
using PSetNotify = void (WINAPI*)(DWORD, HHOOK);
auto setNotify = (PSetNotify)::GetProcAddress(hDll, "SetNotificationThread");
if (!setNotify)
return Error("Failed to locate SetNotificationThread function in DLL");
auto hookFunc = (HOOKPROC)::GetProcAddress(hDll, "HookFunction");
if (!hookFunc)
return Error("Failed to locate HookFunction function in DLL");
// 设置挂钩。
auto hHook = ::SetWindowsHookEx(WH_GETMESSAGE, hookFunc, hDll, tid);
if (!hHook)
return Error("Failed to install hook");
(...)
}
在DLL(或EXE)中共享变量的技术。注入应用程序在其自身进程的上下文中调用SetNotificationThread,但函数将信息写入共享变量,因此这些变量可用于使用相同DLL的任何进程:
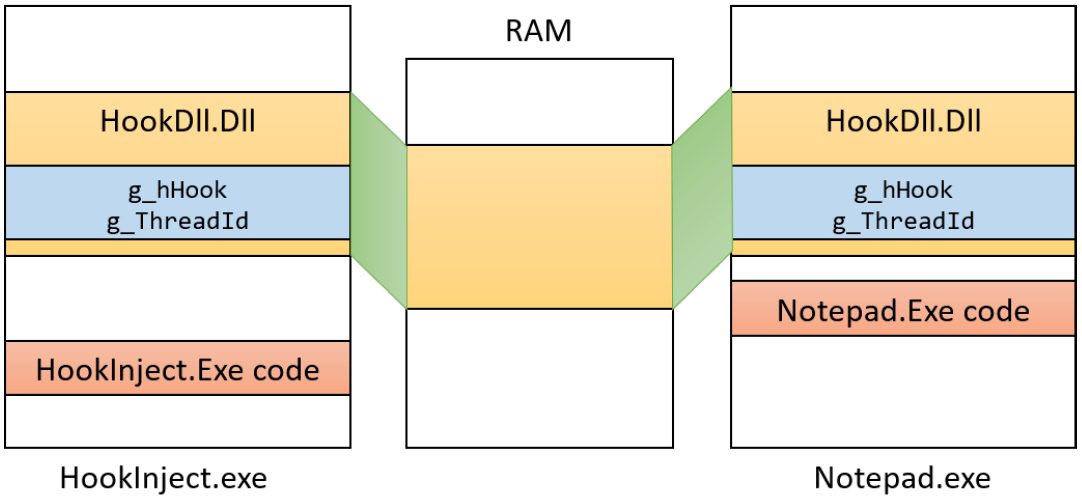
18.10.5.3 API挂钩
API挂钩是指拦截Windows API(或更一般地说,任何外部函数)的行为,以便可以检查其参数并可能改变其行为,是一种非常强大的技术,首先是反恶意软件解决方案所采用的技术,通常将自己的DLL注入每个进程(或大多数进程),并挂接他们关心的某些函数,如VirtualAllocEx和CreateRemoteThread,将它们重定向到DLL提供的备用实现。在该实现中,他们可以检查参数并在向调用方返回错误代码或将调用转发到原始函数之前执行任何需要的操作。
- IAT挂钩
导入地址表(Import Address Table,IAT)挂钩可能是函数挂钩的最简单方法,设置相对简单,不需要任何特定于平台的代码。每个PE映像都有一个导入表,其中列出了它所依赖的DLL以及它从DLL中使用的函数。使用dumpbin或图形工具检查PE文件来查看这些导入,以下是notepad.exe的模块概览:
D:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30133\bin\Hostx64\arm>dumpbin /imports c:\Windows\System32\notepad.exe
Microsoft (R) COFF/PE Dumper Version 14.29.30133.0
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file c:\Windows\System32\notepad.exe
File Type: EXECUTABLE IMAGE
Section contains the following imports:
KERNEL32.dll
1400268B8 Import Address Table
14002D3D8 Import Name Table
0 time date stamp
0 Index of first forwarder reference
2B8 GetProcAddress
DC CreateMutexExW
1 AcquireSRWLockShared
114 DeleteCriticalSection
221 GetCurrentProcessId
2BE GetProcessHeap
281 GetModuleHandleW
10A DebugBreak
387 IsDebuggerPresent
342 GlobalFree
(...)
GDI32.dll
140026800 Import Address Table
14002D320 Import Name Table
0 time date stamp
0 Index of first forwarder reference
34 CreateDCW
39F StartPage
39D StartDocW
366 SetAbortProc
180 DeleteDC
18E EndDoc
(...)
USER32.dll
140026B50 Import Address Table
14002D670 Import Name Table
0 time date stamp
0 Index of first forwarder reference
2AF PostMessageW
28C MessageBoxW
177 GetMenu
43 CheckMenuItem
1C2 GetSubMenu
E9 EnableMenuItem
38D ShowWindow
142 GetDC
2FC ReleaseDC
(...)
Summary
3000 .data
1000 .didat
2000 .pdata
A000 .rdata
1000 .reloc
1000 .rsrc
25000 .text
调用这些导入函数的方式是通过导入地址表,该表包含加载程序(NtDll.Dll)在运行时映射这些函数后这些函数的最终地址。这些地址事先不知道,因为DLL可能不会在其首选地址加载。
IAT挂钩利用了所有调用都是间接调用的事实,在运行时只替换表中的函数地址以指向替代函数,同时保存原始地址,以便在需要时调用实现。这种挂钩可以在当前进程上完成,也可以在另一个进程的上下文中与DLL注入相结合。
必须在所有进程模块中搜索要挂钩的函数,因为每个模块都有自己的IAT。例如,记事本可以调用函数CreateFileW.exe模块本身,但当调用“打开文件”对话框时,ComCtl32.dll也可以调用它。如果只对记事本的调用感兴趣,那么它的IAT是唯一需要连接的。否则,必须搜索所有加载的模块,并且必须替换CreateFileW的IAT条目。
下面的示例代码从User32.Dll中挂接GetSysColor API,并在应用程序中更改一些颜色,而无需接触应用程序的UI代码:
void HookFunctions()
{
auto hUser32 = ::GetModuleHandle(L"user32");
// save original functions
GetSysColorOrg = (decltype(GetSysColorOrg))::GetProcAddress(hUser32, "GetSysColor");
// IAT辅助函数使得挂钩使用变得很简单
auto count = IATHelper::HookAllModules("user32.dll", GetSysColorOrg, GetSysColorHooked);
ATLTRACE(L"Hooked %d calls to GetSysColor\n");
}
18.10.5.4 “迂回”式挂钩
挂接函数的另一种常见方法是执行以下步骤:
- 找到原始函数的地址并保存。
- 用JMP汇编指令替换代码的前几个字节,保存旧代码。
- JMP指令调用挂钩函数。
- 如果要调用原始代码,使用第一步中保存的地址。
- 取消挂钩时,恢复修改的字节。
该方案比IAT挂钩更强大,因为无论是否通过IAT调用,实际函数代码都会被修改。但这种方法有两个缺点:
- 替换的代码是特定于平台的。x86、x64、ARM和ARM64的代码不同,因此更难正确使用。
- 上述步骤必须自动完成。进程中可能有其他线程在程序集字节被替换时调用挂钩函数,可能会导致程序崩溃。
实现这种挂钩很困难,需要复杂的CPU指令和调用约定知识,更不用说上面的同步问题了。有几个开源和免费的库提供此功能,其中一个叫做“Detours”(迂回),来自微软,但也有其他如MinHook和EasyHook。如果需要这种挂钩,优先考虑使用现有的库。以下是Detours挂钩使用示例:
#include <detours.h>
bool HookFunctions()
{
DetourTransactionBegin();
DetourUpdateThread(GetCurrentThread());
DetourAttach((PVOID*)&GetWindowTextOrg, GetWindowTextHooked);
DetourAttach((PVOID*)&GetWindowTextLengthOrg, GetWindowTextLengthHooked);
auto error = DetourTransactionCommit();
return error == ERROR_SUCCESS;
}
Detours与事务的概念一起工作,事务是一组提交以原子方式执行的操作。我们需要保存原始函数,可以在挂接之前使用GetProcAddress完成,也可以使用指针定义完成:
decltype(::GetWindowTextW)* GetWindowTextOrg = ::GetWindowTextW;
decltype(::GetWindowTextLengthW)* GetWindowTextLengthOrg = ::GetWindowTextLengthW;
18.10.6 DLL基地址
每个DLL都有一个首选加载(基)地址,即PE头的一部分,甚至可以使用Visual Studio中的项目属性来指定它(下图)。
默认情况下没有任何内容,使得VisualStudio使用一些默认值。对于32位DLL,这些值为0x10000000;对于64位DLL,它们为0x180000000。可以通过dumping从PE标头信息来验证:
dumpbin /headers HookDll_x64.dll
...
OPTIONAL HEADER VALUES
20B magic # (PE32+)
...
112FD entry point (00000001800112FD) @ILT+760(_DllMainCRTStartup)
1000 base of code
180000000 image base (0000000180000000 to 0000000180025FFF)
...
dumpbin /headers HookDll_x86.dll
...
OPTIONAL HEADER VALUES
10B magic # (PE32)
...
111B8 entry point (100111B8) @ILT+435(__DllMainCRTStartup@12)
1000 base of code
1000 base of data
10000000 image base (10000000 to 1001FFFF)
...
18.10.7 延迟加载DLL
前面研究了链接到DLL的两种主要方式:使用LIB文件的隐式链接(最简单、最方便)和动态链接(显式加载DLL并查找要使用的函数)。事实证明,还有第三种方法,在静态链接和动态链接之间有一种“中间地带”——延迟加载DLL(Delay-Load DLL)。
通过延迟加载,有两个好处:静态链接的便利性和仅在需要时动态加载DLL。要使用延迟加载DLL,需要对使用这些DLL的模块进行一些更改,无论是可执行DLL还是其他DLL。应延迟加载的DLL将添加到输入选项卡中的链接器选项中(下图)。
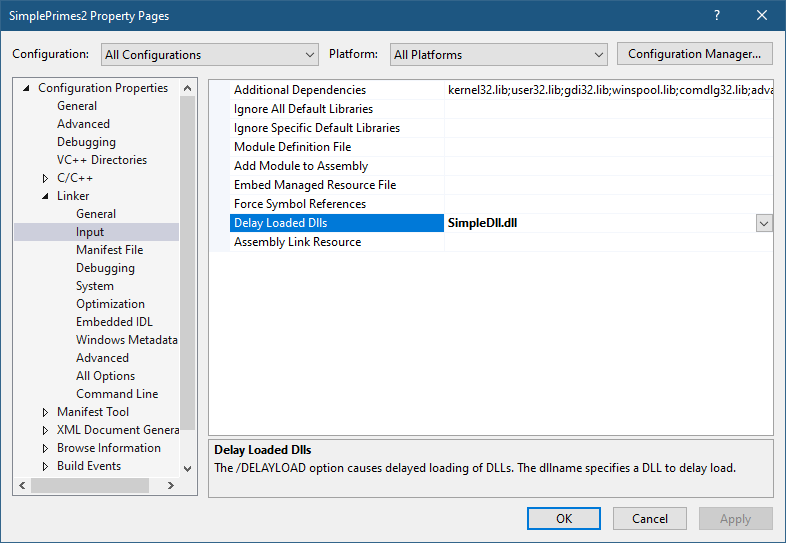
如果要支持动态卸载延迟加载DLL,在“高级链接器”选项卡中添加该选项(“卸载延迟加载的DLL”)。剩下的就是链接DLL的导入库(LIB)文件,并使用导出的功能,就像使用隐式链接的DLL一样。以下是延迟加载DLL示例:
#include "..\SimpleDll\Simple.h"
#include <delayimp.h>
bool IsLoaded()
{
auto hModule = ::GetModuleHandle(L"simpledll");
printf("SimpleDll loaded: %s\n", hModule ? "Yes" : "No");
return hModule != nullptr;
}
int main()
{
IsLoaded();
bool prime = IsPrime(17);
IsLoaded();
printf("17 is prime? %s\n", prime ? "Yes" : "No");
// 卸载dll
__FUnloadDelayLoadedDLL2("SimpleDll.dll");
IsLoaded();
prime = IsPrime(1234567);
IsLoaded();
return 0;
}
输出结果:
SimpleDll loaded: No
SimpleDll loaded: Yes
17 is prime? Yes
SimpleDll loaded: No
SimpleDll loaded: Yes
18.11 文件和I/O
18.11.1 文件和I/O综述
计算机可以操作多种设备,一般类型包括存储设备(磁盘、磁带)、传输设备(网卡、调制解调器)和人机界面设备(屏幕、键盘、鼠标)。设备通过电缆甚至通过空气发送信号来与计算机系统通信,通过一个称为端口(如串行端口)的连接点与机器通信。如果一个或多个设备使用一组公共电线,则该连接称为总线(bus)。
当设备A有一根电缆插入设备B,设备B有一条电缆插入设备C,设备C插入计算机上的端口时,这种安排称为菊花链,通常用作总线。典型的PC总线结构如图所示,PCI总线(通用PC系统总线)将处理器-内存子系统连接到快速设备,扩展总线连接相对较慢的设备,如键盘、串行和USB端口。
在下图的右上部分,四个磁盘在插入SCSI控制器的小型计算机系统接口(SCSI)总线上连接在一起。用于互连计算机主要部件的其他常见总线包括PCI Express(PCIe),其吞吐量高达每秒16 GB,以及Hyper Transport,其吞吐量达每秒25 GB。
计算机系统包含多个I/O设备及其各自的控制器:网卡、图形适配器、磁盘控制器、DVD-ROM控制器、串行端口、通用串口总线、声卡等。控制器是可以操作端口、总线或设备的电子设备的集合。串口控制器是简单设备控制器的一个示例,是计算机中的一个单片机,用于控制串行端口导线上的信号。SCSI总线控制器通常作为一个单独的电路板(主机适配器)插入计算机。它通常包含一个处理器、微码和一些专用内存,以使其能够处理SCSI协议消息。一些设备有自己的内置控制器。
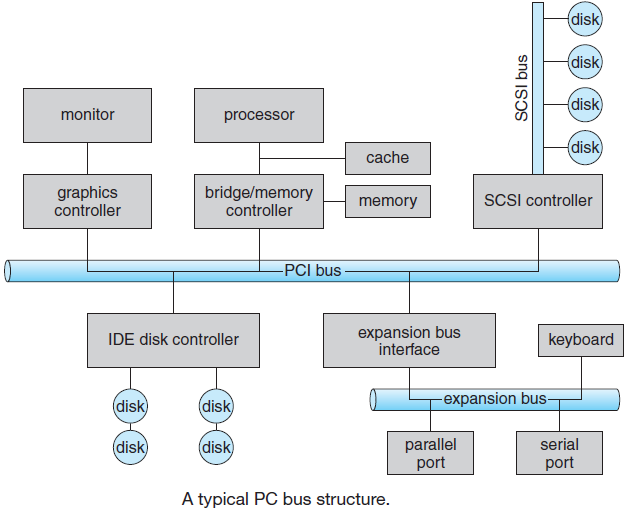
I/O端口通常由四个寄存器组成:状态寄存器、控制寄存器、寄存器中的数据、数据输出寄存器。状态寄存器包含主机可以读取的位,这些位表示的状态:当前命令是否已完成、是否可以从寄存器中的数据读取字节、是否存在设备错误。
主机可以写入控制寄存器来启动命令或更改设备的模式,例如,串行端口控制寄存器中的某个位在全双工和半双工通信之间进行选择,另一个启用奇偶校验,第三位将单词长度设置为7或8位,其他位选择串行端口支持的速度之一。主机读取寄存器中的数据以获取输入,数据输出寄存器由主机写入以发送输出,数据寄存器通常为1至4字节。一些控制器具有FIFO芯片,可以保存几个字节的输入或输出数据,以将控制器的容量扩展到数据寄存器的大小之外。FIFO芯片可以保存少量数据,直到设备或主机能够接收这些数据。
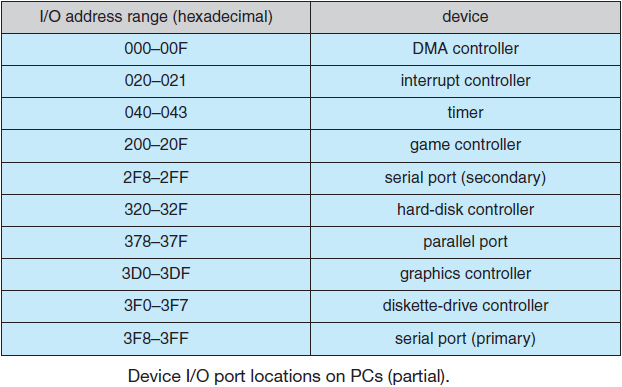
轮询:主机和控制器之间交互的不完整协议可能很复杂,但基本握手概念很简单。控制器通过状态寄存器中的忙位指示其状态(记住,设置位意味着向位中写入1,清除位意味着将0写入位),在忙于工作时设置忙位,并在准备接受下一个命令时清除忙位。主机通过命令寄存器中的命令就绪位发出其愿望。当控制器可以执行命令时,主机设置命令就绪位。在本例中,主机通过端口写入输出,通过如下握手与控制器协调:
1、主机反复读取忙位,直到该位变为清零。
2、主机在命令寄存器中设置写入位,并将一个字节写入数据输出寄存器。
3、主机设置命令就绪位。
4、当控制器注意到命令就绪位已设置时,它将设置为“忙碌”。
5、控制器读取命令寄存器并看到写入命令。
6、它读取数据输出寄存器以获取字节,并对设备进行I/O操作。
7、控制器清除命令就绪位,清除状态寄存器中的错误位以指示设备I/O成功,并清除忙位以指示完成。
主机正忙于等待或轮询:它处于一个循环中,反复读取状态寄存器,直到忙位被清除。如果控制器和设备速度快,则此方法是合理的。但如果等待时间可能很长,主机可能会切换到另一个任务。
I/O设备的类别有:
- 人类可读。适合与计算机用户通信,例如打印机、视频显示终端、键盘等。
- 机器可读。适用于与电子设备通信,例如磁盘和磁带驱动器、传感器、控制器和执行器。
- 通信。适合与远程设备通信,例如数字线路驱动器和调制解调器。
I/O设备之间的差异:
- 数据速率:数据传输速率之间可能存在几个数量级的差异。
- 应用:不同的设备在系统中有不同的用途。
- 控制的复杂性:磁盘要复杂得多,而打印机需要简单的控制界面。
- 传输单元:数据可以作为字节或字符流或更大的块进行传输。
- 数据表示:不同的设备使用不同的数据编码方案。
- 错误条件:错误的性质因设备而异。
直接内存访问(Direct Memory Access,DMA)的描述如下:
- 可以提供一个特殊的控制单元,允许在外部设备和主存储器之间直接传输数据块,而无需处理器的持续干预,这种方法称为直接内存访问(DMA)。
- 可以与轮询或中断软件一起使用。在诸如磁盘之类的设备上特别有用,在这些设备上,可以在单个I/O操作中传输许多字节的信息。当与中断一起使用时,只有在传输了整个数据块后,才会通知CPU。
- 对于传输的每个字节或字,它必须提供存储器地址和控制数据传输的所有总线信号。
- 通过设备驱动程序管理与设备控制器的交互。设备驱动程序是操作系统的一部分,但不一定是操作系统内核的一部分。
- 操作系统为用户应用程序提供了设备的简化视图(例如,UNIX中的字符设备与块设备)。在某些操作系统(例如Linux)中,也可以通过/dev文件系统访问设备。
- 在某些情况下,操作系统会缓冲在设备和用户空间程序(磁盘缓存、网络缓冲区)之间传输的数据。
- 通常会提高性能,但并不总是如此。
I/O系统的主要目的是抽象对物理和逻辑设备的访问,访问任意文件系统中的文件应与访问串行端口、USB摄像头或打印机不同。I/O系统由多个组件组成,一些组件处于用户模式,大多数组件处于内核模式。最重要的部分如下图所示。

用户模式进程使用各种Windows API调用I/O系统,内核端的所有文件和设备操作都由I/O管理器启动。通过创建一个称为I/O请求包(IRP)的内核结构来处理请求(如读或写),填充请求的详细信息,然后将其传递给适当的设备驱动程序。对于实际文件,将转到文件系统驱动程序,如NTFS。如下图所示,该过程与正常的系统调用没有本质区别。
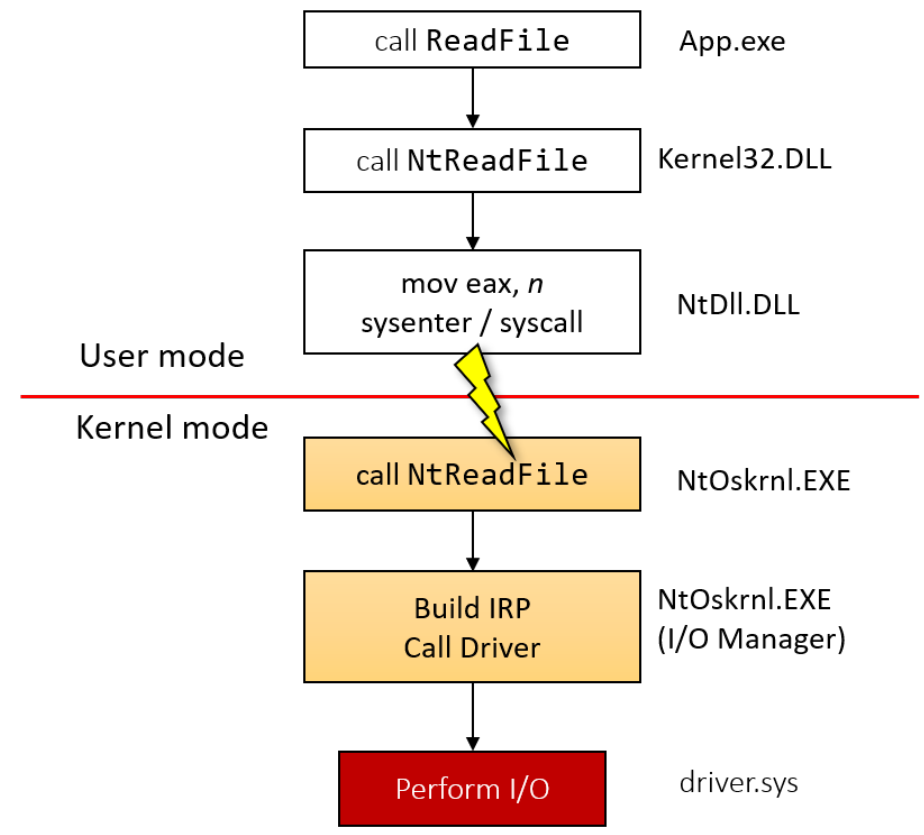
就内核而言,I/O操作总是异步的,意味着驱动程序应该启动操作并尽快返回,以便调用线程可以重新获得控制。但是,原始调用者可以选择同步调用,在这种情况下,I/O管理器代表调用者等待,直到操作完成。从客户的角度来看,这种灵活性非常方便。
下面是不同存储介质的速率对比:
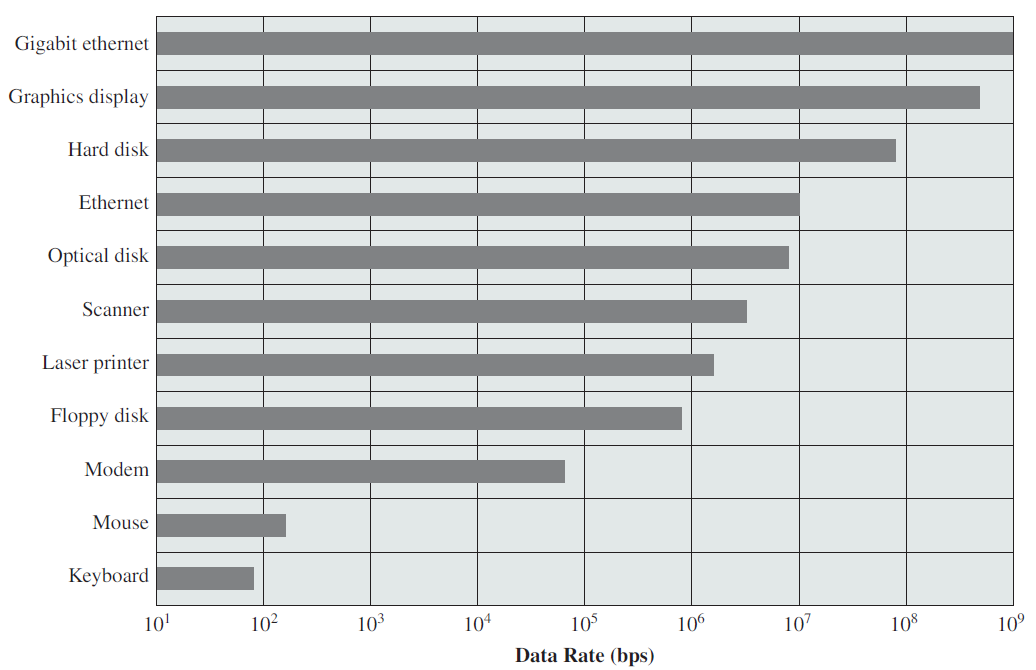
18.11.2 磁盘
18.11.2.1 磁盘结构
磁盘驱动器被寻址为逻辑块(logical block)的大型一维数组,其中逻辑块是最小的传输单元,逻辑块的大小通常为512字节,逻辑块的一维数组按顺序映射到磁盘的扇区,扇区0是最外层圆柱上第一条轨迹的第一扇区。映射依次通过该轨道、该圆柱体中的其余轨道,然后从最外层到最内层通过其余圆柱体,逻辑到物理地址应该很容易,坏扇区除外。通过恒定角速度,每条轨道的扇区数不恒定。
磁盘提供计算机系统的大量辅助存储,可以被视为每台计算机共用的一个I/O设备,有多种尺寸和速度,信息可以用光学或磁性存储。磁带曾被用作早期的辅助存储介质,但存取时间比磁盘慢得多,目前正在使用磁带进行备份。
现代磁盘驱动器被称为逻辑块的大型一维数组,其中逻辑块是最小的传输单元。磁盘I/O操作的实际细节取决于计算机系统、操作系统以及I/O通道和磁盘控制器硬件的性质。信息存储的基本单位是扇区,扇区存储在扁平、圆形的媒体磁盘上,此介质旋转接近一个或多个读/写磁头,磁头可以从磁盘的内部移动到外部。当磁盘驱动器运行时,磁盘以恒定速度旋转,要读或写,磁头必须位于所需磁道和该磁道上所需扇区的开头,轨道选择包括在移动头部系统中移动头部或在固定头部系统中电子选择一个头部。这些特征是软盘、硬盘、CD-ROM和DVD的共同特征。
查看现代硬盘的规格时需要注意的一点是,驱动程序软件所指定和使用的几何图形几乎总是与物理格式不同。在旧磁盘上,每个磁道的扇区数对于所有柱面都是相同的。现代磁盘被划分为多个分区,外部分区上的扇区比内部分区上的多。下图(a)显示了一个有两个区域的小圆盘。外区每条轨道有32个扇区;内部的一条每条轨道有16个扇区。一个真正的磁盘,如WD 3000 HLFS,通常有16个或更多分区,随着从最内层分区到最外层分区的扩展,每个分区的扇区数量增加了大约4%。
(a) 具有两个分区的磁盘的物理几何形状。(b) 此磁盘可能的虚拟几何体。
为了隐藏每个磁道有多少扇区的详细信息,大多数现代磁盘都有一个呈现给操作系统的虚拟几何体。该软件被指示按照每个磁道有x个柱面、y个磁头和z个扇区的方式运行。然后,控制器将(x,y,z)的请求重新映射到实际的圆柱体、封头和扇区。上图(a)中物理磁盘的可能虚拟几何结构如图(b)中所示。在这两种情况下,磁盘都有192个扇区,只有发布的排列与实际的不同。
对于PC,这三个参数的最大值通常为(65535、16和63),因为需要向后兼容原始IBM PC的限制。在这台机器上,16位、4位和6位字段用于指定这些数字,柱面和扇区编号从1开始,磁头编号从0开始。使用这些参数,每个扇区512字节,最大可能磁盘为31.5 GB。为了克服这个限制,所有现代磁盘现在都支持一种称为逻辑块寻址的系统,在这种系统中,磁盘扇区从0开始连续编号,而不考虑磁盘的几何形状。
CPU性能在过去十年中呈指数级增长,大约每18个月翻一番。磁盘性能则不然。随着时间的推移,CPU性能和(硬盘)性能之间的差距变得越来越大,并行处理越来越多地被用于加快CPU性能。多年来,许多人都意识到并行I/O可能也是一个好主意,Patterson等人在其1988年的论文中提出了六种可用于提高磁盘性能和/或可靠性的特定磁盘组织。这些想法很快被业界采纳,并产生了一种新的I/O设备,称为RAID(Redundant Array of Inexpensive Disks,廉价冗余磁盘阵列)。还存在它的反面,就是SLED(Single Large Expensive Disk,单个大型昂贵磁盘)。
RAID级别0到6。备份和奇偶校验驱动器以阴影显示。
磁盘有时会出错,好的扇区可能突然变成坏的扇区,整个驱动器可能会意外损坏。RAID可防止少数扇区出现故障,甚至驱动器出现故障。然而,它们并不能防止写错误,因为首先会留下坏数据,也不能防止在写入损坏原始数据而不替换为新数据时发生崩溃。
对于某些应用程序,即使在磁盘和CPU出现错误的情况下,数据也决不能丢失或损坏。理想情况下,磁盘应该一直工作,没有错误。不幸的是,这是无法实现的。可以实现的是具有以下属性的磁盘子系统:当向其发出写操作时,磁盘要么正确写入数据,要么什么也不做,从而保持现有数据的完整性。这种系统称为稳定存储(stable storage),并用软件实现(Lampon and Sturgis,1979)。目标是不惜一切代价保持磁盘的一致性。
稳定存储使用一对相同的磁盘和相应的块一起工作,形成一个无错误的块。在没有错误的情况下,两个驱动器上的相应块是相同的。任何一个都可以读取以获得相同的结果。为了实现这一目标,定义了以下三种操作:
- 稳定写入。稳定写入包括首先将块写入驱动器1,然后将其读回以验证是否正确写入。如果不是,则会再次执行写入和重新读取,最多可重复n次,直到它们工作为止。在连续n次失败后,该块将重新映射到备用磁盘上,并重复操作,直到成功为止,无论必须尝试多少个备用磁盘。写入驱动器1成功后,会写入并重新读取驱动器2上的相应块,如果需要,可以反复读取,直到最后也成功。在没有CPU崩溃的情况下,当稳定写入完成时,块已正确写入两个驱动器并在两个驱动器上进行验证。
- 读取稳定。稳定读取首先从驱动器1读取块。如果这产生错误的ECC,则再次尝试读取,最多n次。如果所有这些都给出了坏的ECC,则从驱动器2读取相应的块。考虑到成功的稳定写入会留下两个好的块副本,并且我们假设同一块在合理的时间间隔内在两个驱动器上自发损坏的概率可以忽略不计,因此稳定读取总是成功的。
- 崩溃恢复。崩溃后,恢复程序会扫描两个磁盘,并比较相应的块。如果一对块都是好的并且是相同的,那么什么也做不了。如果其中一个出现ECC错误,则坏块将被相应的好块覆盖。如果一对块都是好的但不同的,则驱动器1的块会写入驱动器2。
18.11.2.2 磁盘性能参数
当磁盘驱动器运行时,磁盘以恒定速度旋转。要读或写,磁头必须位于所需磁道和该磁道上所需扇区的开头。轨道选择包括在移动头部系统中移动头部或在固定头部系统中电子选择一个头部,在可移动磁头系统上,磁头在轨道上定位所需的时间称为寻道时间。选择磁道后,磁盘控制器将等待,直到相应的扇区旋转以与磁头对齐,扇区开始到达头部所需的时间称为旋转延迟或旋转延迟。寻道时间(如果有的话)和旋转延迟的总和等于访问时间,即进入读取或写入位置所需的时间。磁头就位后,随着扇区在磁头下方移动,执行读或写操作,这是操作的数据传输部分,转移所需的时间就是转移时间。
寻道时间是将磁盘臂移动到所需轨道所需的时间。事实证明,是一个难以确定的数量。寻道时间由两个关键部分组成:初始启动时间,一旦检修臂达到速度就必须穿过轨道所需的时间,计算公式:
其中:\(T_s\)是寻道时间,\(n\)是轨道遍历时间,\(m\)是取决于磁盘驱动器的常数,\(s\)启动时间。
旋转延时(Rotational Latency)是等待磁盘旋转到磁盘头所需扇区的额外时间。
旋转延迟(Rotational Delay):磁盘(软盘除外)的转速从3600 rpm到15000 rpm不等;在后一速度下,每4毫秒旋转一圈。因此,平均旋转延迟为2毫秒。软盘通常以300至600 rpm的转速旋转。因此,平均延迟将在100到50毫秒之间。
磁盘带宽是传输的总字节数除以第一次请求服务和完成最后一次传输之间的总时间。
传输时间:往返磁盘的传输时间取决于磁盘的以下旋转速度:
其中:\(T\)是传输时间,\(b\)是要传输的字节数,\(r\)是磁道上的字节数,\(N\)是转速,单位为转/秒。因此,总平均访问时间可表示为:
18.11.2.3 磁盘调度
满足一系列I/O请求所需的头数量会影响性能,如果所需的磁盘驱动器和控制器可用,则可以立即处理请求。如果设备或控制器繁忙,任何新的服务请求都将被放入该驱动器的待定请求队列中。当一个请求完成时,操作系统会选择下一个要服务的挂起请求。不同类型的调度算法如下。
- 先到先服务调(FCFS)
最简单的调度形式是先进先出(FIFO)调度,它按顺序处理队列中的项目,将按照收到请求的顺序为请求提供服务。此算法虽然是公平的,但不能提供最快的服务,不需要特别的时间来最小化总寻道时间。
这种策略的优点是公平,因为每一个请求都会得到满足,并且请求会按照收到的顺序得到满足。使用FIFO,如果只有少数几个进程需要访问,并且许多请求都是针对集群文件扇区的,那么可以获得良好的性能。
示例:考虑一个磁盘队列,请求对柱面上的块进行I/O。98, 183, 37, 122, 14, 124, 65, 67。
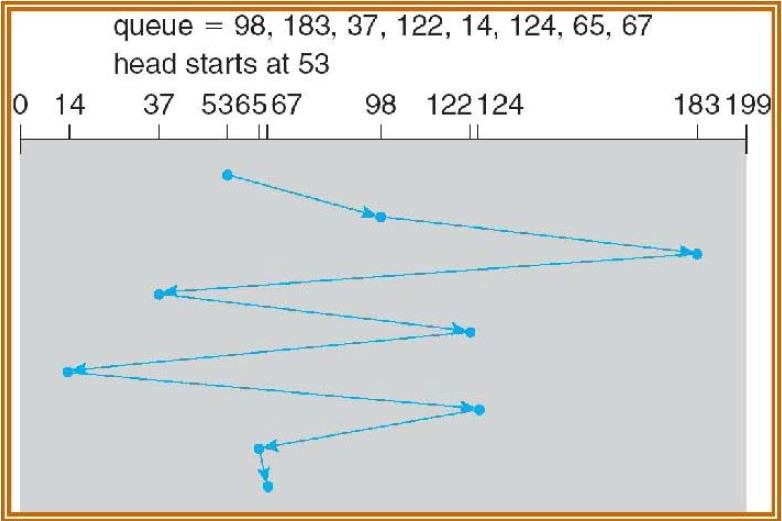
磁头如果最初位于53,将首先从53移动到98,然后再移动到183,然后移动到37、122、14、124、65、67,从而使磁头移动640个圆柱(cylinder)。从122到14,然后再回到124,这说明了这个调度算法的问题。如果cylinder 37和14的请求可以在122和124之前或之后一起处理,则总移动量可以大幅减少,性能可以得到改善。
- 最短寻道时间优先(SSTF)
SSTF首先从当前头部位置选择寻道时间最短的请求,是SJF调度的一种形式,可能会导致某些请求不足。由于寻道时间随头部所经过的cylinder数增加而增加,因此SSTF选择最接近当前cylinder位置的挂起请求,下图显示了236个气缸的缸盖总移动量。示例:考虑一个磁盘队列,请求对柱面上的块进行I/O:98、183、37、122、14、124、65、67。

如果磁头最初位于53,最接近的是cylinder 65,然后是67,然后是37,比98接近67。因此,它服务37,继续服务14、98、122、124,最后服务183,总移动量仅为236个cylinder。
SSTF本质上是SJF的一种形式,可能会导致某些请求的匮乏,是对FCFS的实质性改进,但它不是最优的。
- SCAN
SCAN算法有时称为电梯算法,扫描算法在磁道0处开始扫描,并向编号最高的磁道移动,在磁道通过时为磁道的所有请求提供服务。磁盘臂从磁盘的一端开始,向另一端移动,为请求提供服务,直到它到达磁盘的另一端,此时磁头移动方向相反,服务继续。
下图显示208个cylinder的头部总移动。但请注意,如果请求是均匀密集的,则磁盘另一端的密度最大,等待时间最长。示例:考虑一个磁盘队列,请求对柱面上的块进行I/O:98、183、37、122、14、124、65、67。

如果磁盘磁头最初位于53,并且磁头向0移动,则服务于37,然后服务于14。在cylinder 0处,臂将倒转,并朝着维修65、67、98、122、124和183的磁盘的另一端移动。如果一个请求刚好从头部到达,它将立即得到服务,头部后面的请求将不得不等待,直到手臂到达另一端并反转方向。
它可以始终处理下一个最近的请求,以最小化寻道时间。根据下图的要求,顺序为12、9、16、1、34和36,如图底部的锯齿线所示。按照此顺序,臂运动为1、3、7、15、33和2,总共61个气缸。该算法称为SSF(最短寻道优先),与FCFS相比,它几乎将手臂的总运动量减少了一半。
- 循环扫描(C-SCAN)
C-SCAN是SCAN的变体,旨在提供更均匀的等待时间,其策略将扫描限制在一个方向。与SCAN类似,C-SCAN将磁头从磁盘的末端移动到另一个为请求提供服务的位置,当磁头到达另一端时,它会立即返回到磁盘的开头,而不会在返回时处理任何请求。
C-SCAN将cylinder视为从最终cylinder到第一个cylinder的循环列表,减少了新请求所经历的最大延迟。示例:考虑一个磁盘队列,请求对柱面上的块进行I/O:98、183、37、122、14、124、65、67。
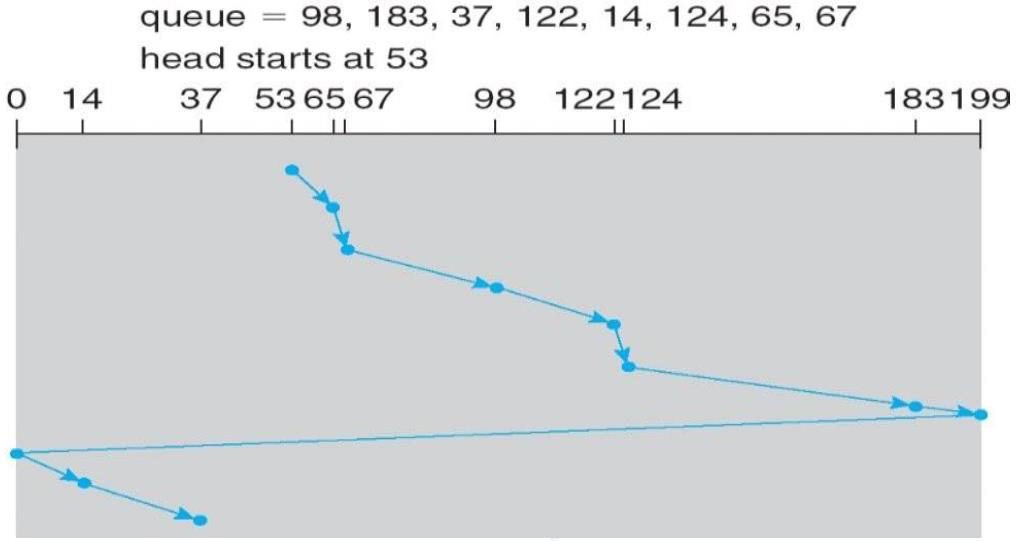
- Look
SCAN和C-SCAN都会在磁盘的整个宽度上移动磁盘臂,开始向一个方向移动头部。当在该方向上没有更多请求时,满足该方向上最近轨迹的请求,磁头正在行驶,反转方向并重复。此算法类似于每条电路上最内侧和最外侧的轨道。实际上,这两种算法都不是以这种方式实现的。手臂在每个方向上只能到达最后的请求。然后它会反转,不会一直到磁盘的末尾。
这些版本的SCAN和CSCAN称为Look和C-Look调度,因为它们在继续向给定方向移动之前会查找请求。示例:考虑一个磁盘队列,请求对柱面上的块进行I/O:98、183、37、122、14、124、65、67。

我们如何在上述几种磁盘调度算法中选择合适的?通用建议如下:
- SSTF很常见,比FCFS提高了性能。
- SCAN和C-SCAN算法更适合于在磁盘上放置重负载的系统,它们的饥饿问题较少。
- SSTF或Look是默认算法的合理选择。
- 调度算法的性能取决于请求的数量和类型。
- 磁盘服务请求可能会受到文件分配方法的影响。
- 磁盘调度算法应作为操作系统的一个单独模块编写,允许在必要时用不同的算法替换。SSTF或LOOK是默认算法的合理选择。
18.11.3 文件
文件是相似记录的集合,除非数据位于文件中,否则无法将其写入辅助存储。文件表示程序和数据,数据可以是数字、字母数字、字母或二进制。许多不同类型的信息可以存储在一个文件中——源程序、目标程序、可执行程序、数字数据、工资记录器、图形图像、录音等。
为了提供存放文件的地方,大多数PC操作系统都有目录的概念,作为将文件分组在一起的一种方式。例如,一个学生可能有一个目录,用于他正在学习的每门课程(用于该课程所需的程序),另一个目录用于他的电子邮件,还有另一个用于他的万维网主页的目录。然后需要系统调用来创建和删除目录。还提供了将现有文件放入目录和从目录中删除文件的调用。目录条目可以是文件或其他目录。该模型还产生了文件系统的层次结构,如下图所示。
文件属性因操作系统而异,常见的文件属性包括:
- 名称:符号文件名是以人类可读形式保存的唯一信息。
- 标识符:唯一标记,通常是一个数字,用于标识文件系统中的文件,是文件的不可读名称。
- 类型:支持不同类型的系统需要此信息。
- 位置:是指向设备和该设备上文件位置的指针。
- 大小:文件的当前大小以及可能的最大允许大小。
- 保护:访问控制信息决定谁可以进行读取、写入、执行等操作。
- 时间、数据和用户标识:必须保存此信息,以备创建、上次修改和上次使用。这些数据有助于保护、安全和使用监控。
| 属性 | 解析 |
|---|---|
| 保护 | 谁可以访问文件以及以何种方式访问 |
| 密码 | 访问文件所需的密码 |
| 创建者 | 文件的人员的创建者ID |
| 所有者 | 当前所有者 |
| 只读标记 | 0表示读/写,1表示只读 |
| 隐藏标记 | 0表示正常,1表示不显示在列表中 |
| 系统标记 | 0表示普通文件,1代表系统文件 |
| 文档标记 | 0已备份,1需要备份 |
| ASCII、二进制标记 | 0表示ASCII文件,1表示二进制文件 |
| 随机访问标记 | 0仅用于顺序访问,1个用于随机访问 |
| 临时标记 | 0表示正常,1用于在进程退出时删除文件 |
| 锁定标记 | 0表示已解锁,非零表示锁定 |
| 记录长度 | 记录中的字节数 |
| 键位置 | 每个记录内键的偏移量 |
| 键长度 | 键字段中的字节数 |
| 创建时间 | 创建文件的日期和时间 |
| 上次访问时间 | 上次访问文件的日期和时间 |
| 上次修改时间 | 上次更改文件的日期和时间 |
| 当前尺寸 | 文件中的字节数 |
| 最大尺寸 | 文件可能增长到的字节数 |
文件根据其类型具有特定的定义结构:
- 文本文件:是按行组织的字符序列。
- 对象文件:是一个字节序列,组织成系统链接器可以理解的块。
- 可执行文件:是加载程序可以放入内存并执行的一系列代码段。
- 源文件:子程序和函数的序列,每一个都进一步组织为声明,后面是可执行语句。
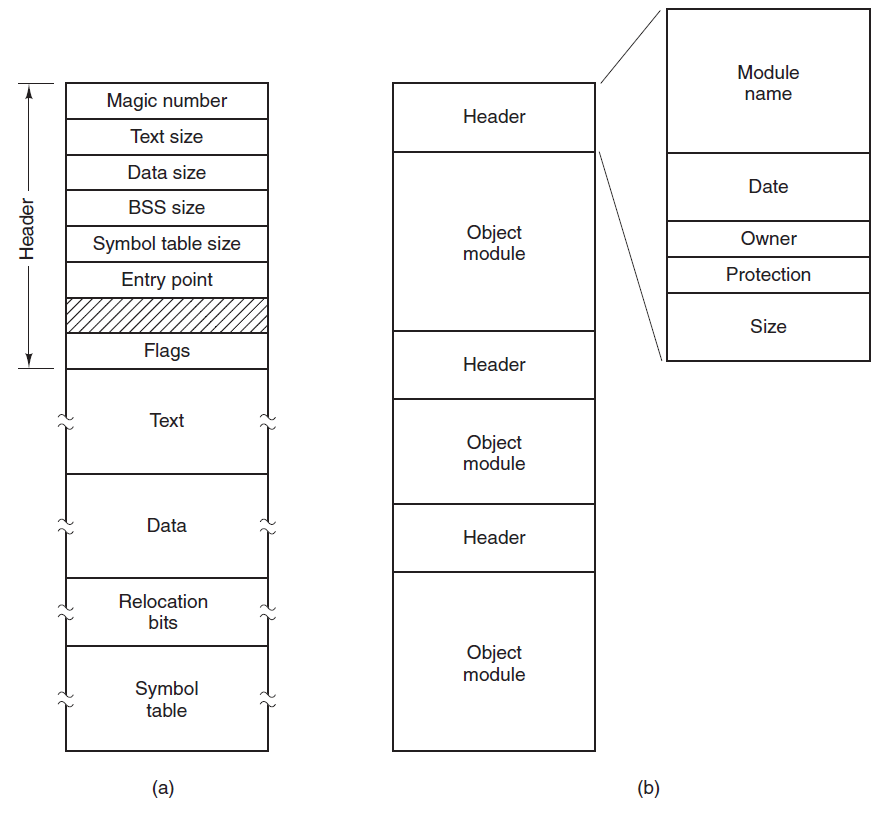
(a) 可执行文件;(b) 文档。
文件是一种抽象数据类型。要定义文件,我们需要考虑可以对文件执行的操作。文件的基本操作是:
- 创建文件:需要两个步骤——首先,在文件系统中找到文件的第一个空间;其次,必须在目录中为新文件创建一个条目,目录条目记录文件名和文件系统中的位置。
- 写入文件:系统调用主要用于写入文件。系统调用指定文件名和信息,即要写入文件的信息,给定名称后,系统将在整个目录中搜索该文件,系统必须保留一个指向文件中下次写入位置的写入指针。
- 读取文件:使用文件系统调用读取文件,需要文件名和内存地址,再次搜索目录以查找关联的目录,系统必须维护指向文件中下次读取位置的读取指针。
- 删除文件:系统将搜索要删除文件的目录。如果找到条目,将释放所有可用空间,该可用空间可以被另一个文件重用。
- 截断文件:-户可能希望删除文件的内容,但保留其属性。截断允许所有属性保持不变,文件长度除外,而不是强制用户删除文件然后重新创建。
- 在文件中重新定位:-索目录以查找适当的条目,并将当前文件位置设置为给定值,在文件中重新定位不需要涉及实际的i/o,文件操作也称为文件查找。
除了这6个操作之外,其他两个操作包括在文件末尾附加新信息和重命名现有文件,这些原语可以组合起来执行其他两个操作。大多数文件操作都涉及在整个目录中搜索与文件关联的条目。为了避免这种情况,操作系统会保留一个小表,其中包含有关打开文件的信息(打开表)。当请求文件操作时,将通过该表中的索引指定该文件。因此,不需要搜索。
打开的文件相关联的信息有:
- 文件指针:在不包括偏移量的读写系统调用的一部分的系统上,系统必须将最后的读写位置作为当前文件位置指针进行跟踪。此指针对于在文件上操作的每个进程都是唯一的。
- 文件打开计数:当文件关闭时,操作系统必须重用其打开的文件表条目,否则可能会耗尽表中的空间。因为多个进程可能会打开一个文件,所以系统必须等待最后一个文件关闭,然后才能删除打开的文件表条目。计数器跟踪打开和关闭的副本数,最后一次关闭时为零。
- 文件的磁盘位置:在磁盘上定位文件所需的信息保存在内存中,以避免每次操作都必须从磁盘读取文件。
- 访问权限:每个进程都以访问模式打开一个文件,此信息存储在每个进程表中,操作系统可以允许操作系统拒绝随后的I/O请求。
可以通过多种方式访问文件中的信息。不同的文件访问方法是:
-
顺序访问。它是最简单的访问方法。文件中的信息是按顺序处理的,一条记录接着一条记录。编辑器和编译器以这种方式访问文件,通常对文件执行读写操作。读取操作读取文件的下一部分,并自动前进文件指针,该指针跟踪下一个i/i轨迹。写入操作附加到文件的末尾,这样的文件可以紧邻开头。顺序访问取决于文件的磁带型号。
![]()
-
直接访问或相对访问。允许随机访问任何文件块,基于文件的磁盘模型,文件由固定长度的逻辑记录组成。它允许程序以任何顺序快速读取和写入记录,允许读取或写入任意块。示例:用户可能需要块13,然后读取块99,然后写入块12。对于搜索具有即时结果的大量信息的记录,直接访问方法是合适的。并非所有操作系统都支持顺序和直接访问,很少有操作系统使用顺序访问,有些操作系统使用直接访问。在直接访问上模拟顺序访问很容易,但反过来效率极低。
索引方法:索引就像一本书末尾的索引,其中包含指向各个块的指针。要在文件中查找记录,我们搜索索引,然后使用指针直接访问文件并查找所需的记录。对于大型文件,索引文件本身可以非常大,以便保存在内存中。一种为索引文件本身创建索引的解决方案。主索引文件将包含指向辅助索引文件的指针,该文件将指向实际数据项。可以使用两种类型的索引:
- 详尽索引:主文件中的每条记录都包含一个条目,索引本身被组织为顺序文件。
- 部分索引:包含记录的条目,其中感兴趣的字段存在可变长度的记录,某些记录将不包含字段。将新记录添加到主文件时,必须更新所有索引文件。
为了跟踪文件,文件系统通常有目录或文件夹,它们本身就是文件。
目录系统的最简单形式是拥有一个包含所有文件的目录。有时它被称为根目录,但因为它是唯一的目录,所以名称并不重要。在早期的个人电脑上,这种系统很常见,部分原因是只有一个用户。有趣的是,世界上第一台超级计算机CDC 6600也只有一个目录存放所有文件,尽管它同时被许多用户使用,此举是为了保持软件设计简单。
下图给出了一个具有一个目录的系统示例,目录包含四个文件,此方案的优点是简单,并且能够快速定位文件,毕竟只有一个地方可以查看。它有时仍用于简单的嵌入式设备,如数码相机和一些便携式音乐播放器。

单级适用于非常简单的专用应用程序(甚至在第一台个人计算机上使用过),但对于拥有数千个文件的现代用户来说,如果所有文件都在一个目录中,则不可能找到任何内容。因此,需要一种方法将相关文件组合在一起——层次结构(即目录树)。使用这种方法,可以有任意多的目录以自然方式对文件进行分组。此外,如果多个用户共享一个公共文件服务器,就像许多公司网络上的情况一样,每个用户都可以为自己的层次结构拥有一个专用根目录。这种方法如下图所示。在这里,根目录中包含的目录A、B和C都属于不同的用户,其中两个用户为他们正在处理的项目创建了子目录。
用户可以创建任意数量的子目录,为用户组织工作提供了强大的结构化工具。因此,几乎所有现代文件系统都是以这种方式组织的。
当文件系统组织为目录树时,需要某种方法来指定文件名。通常使用两种不同的方法。在第一种方法中,每个文件都有一个绝对路径名,由根目录到文件的路径组成。例如,路径/usr/ast/mailbox意味着根目录包含子目录usr,而该子目录又包含子目录ast,其中包含文件mailbox。绝对路径名总是从根目录开始,并且是唯一的。在UNIX中,路径的组件用/分隔,在Windows中,分隔符是\,在MULTICS中,它是>。因此,在这三个系统中,相同的路径名将写入如下:
Windows \usr\ast\mailbox
UNIX /usr/ast/mailbox
MULTICS >usr>ast>mailbox
其中Unix的目录树示例如下:

18.11.3.1 文件系统实现
现在是时候从用户的文件系统视角转向实现者的视角了。用户关心文件的命名方式、允许对其进行哪些操作、目录树的外观以及类似的界面问题。实现者感兴趣的是如何存储文件和目录,如何管理磁盘空间,以及如何使一切高效可靠地工作。下面我们将研究其中的一些领域,以了解问题和权衡。
文件系统软件架构。
文件系统存储在磁盘上。大多数磁盘可以划分为一个或多个分区,每个分区上都有独立的文件系统。磁盘的扇区0称为MBR(主引导记录),用于引导计算机。MBR的末尾包含分区表,此表给出了每个分区的起始地址和结束地址,表中的一个分区被标记为活动分区。当计算机启动时,BIOS读取并执行MBR,MBR程序所做的第一件事是定位活动分区,读取其第一个块(称为引导块),然后执行它。启动块中的程序加载该分区中包含的操作系统。为了一致性,每个分区都从一个引导块开始,即使它不包含可引导的操作系统。此外,将来可能会包含一个。
除了从启动块开始,磁盘分区的布局因文件系统而异。文件系统通常包含下图所示的一些项,第一个是超级块,它包含有关文件系统的所有关键参数,并在计算机启动或首次触摸文件系统时被读入内存,超级块中的典型信息包括用于标识文件系统类型的幻数、文件系统中的块数以及其他关键管理信息。
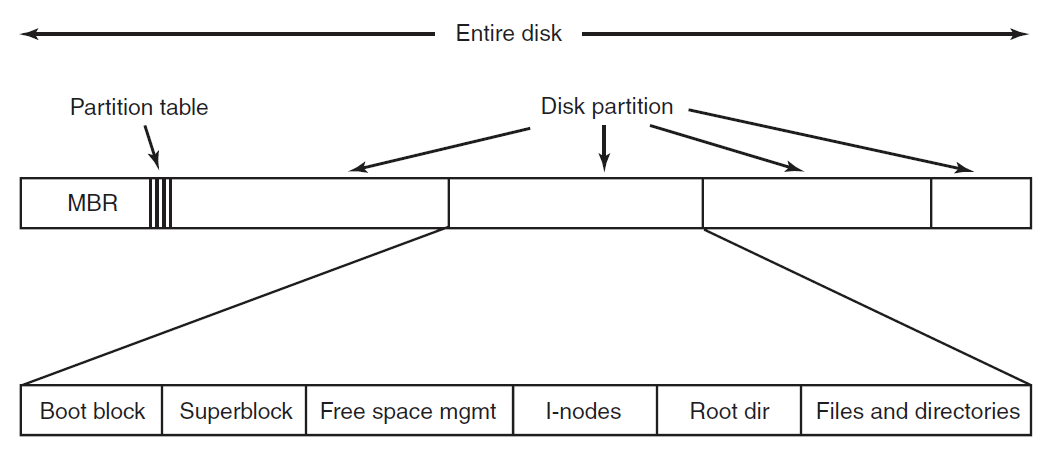
接下来可能会出现有关文件系统中可用块的信息,例如以位图或指针列表的形式。接下来可能是i节点,一组数据结构,每个文件一个,说明文件的所有信息。之后可能是根目录,其中包含文件系统树的顶部。最后,磁盘的其余部分包含所有其他目录和文件。
文件管理元素。
通用文件组织。
Windows支持多种文件系统,包括在Windows 95、MS-DOS和OS/2上运行的文件分配表(FAT)。但Windows的开发人员也设计了一种新的文件系统,即Windows文件系统(NTFS),旨在满足工作站和服务器的高端需求。高端应用示例:
- 客户端/服务器应用程序,如文件服务器、计算服务器和数据库服务器。
- 资源密集型工程和科学应用。
- 大型公司系统的网络应用程序。
NTFS是一个灵活而强大的文件系统,它建立在一个优雅而简单的文件系统模型上。NTFS最值得注意的功能包括:
- 可恢复性:在新Windows文件系统的要求列表中,最重要的是能够从系统崩溃和磁盘故障中恢复。在发生此类故障时,NTFS能够重建磁盘卷并将其恢复到一致状态。它通过使用事务处理模型对文件系统进行更改来实现这一点,每一个重大变化都被视为一个原子行为,要么完全执行,要么根本不执行,失败时正在处理的每个事务随后都会被退出或完成。此外,NTFS对关键文件系统数据使用冗余存储,因此磁盘扇区故障不会导致描述文件系统结构和状态的数据丢失。
- 安全性:NTFS使用Windows对象模型来加强安全性,打开的文件被实现为具有定义其安全属性的安全描述符的文件对象。
- 大磁盘和大文件:与大多数其他文件系统(包括FAT)相比,NTFS更有效地支持非常大的磁盘和非常大的文件。
- 多个数据流:文件的实际内容被视为字节流。在NTFS中,可以为单个文件定义多个数据流,此功能的实用性示例是,它允许远程Macintosh系统使用Windows来存储和检索文件。在Macintosh上,每个文件都有两个组件:文件数据和包含文件信息的资源分叉。NTFS将这两个组件视为两个数据流。
- 通用索引功能:NTFS将属性集合与每个文件相关联。文件管理系统中的一组文件描述被组织为一个关系数据库,以便可以通过任何属性对文件进行索引。
NTFS使用以下磁盘存储概念:
- 扇区(Sector):磁盘上最小的物理存储单元。以字节为单位的数据大小是2的幂,几乎总是512字节。
- 群簇(Cluster):一个或多个连续(在同一轨道上彼此相邻)扇区。扇区中的集群大小是2的幂。
- 卷(Volume):磁盘上的逻辑分区,由一个或多个群集组成,由文件系统用于分配空间。在任何时候,卷都由文件系统信息、文件集合以及卷上可分配给文件的任何其他未分配空间组成。卷可以是单个磁盘的全部或一部分,也可以跨多个磁盘扩展。如果使用硬件或软件RAID 5,则卷由跨越多个磁盘的条带组成。NTFS的最大卷大小为\(2^{64}\)字节。

卷的布局。
NTFS可以在系统崩溃或磁盘故障后将文件系统恢复到一致状态。结合下图,支持可恢复性的关键要素是:
- I/O管理器:包括NTFS驱动程序,用于处理NTFS的基本打开、关闭、读取和写入功能。此外,可以配置软件RAID模块FTDISK以供使用。
- 日志文件服务:维护磁盘写入日志。日志文件用于在系统出现故障时恢复NTFS格式化的卷。
- 缓存管理器:负责缓存文件读写以提高性能。缓存管理器通过使用第11.8节中描述的延迟写入和延迟提交技术来优化磁盘I/O。
- 虚拟内存管理器:NTFS通过将文件引用映射到虚拟内存引用以及读写虚拟内存来访问缓存文件。
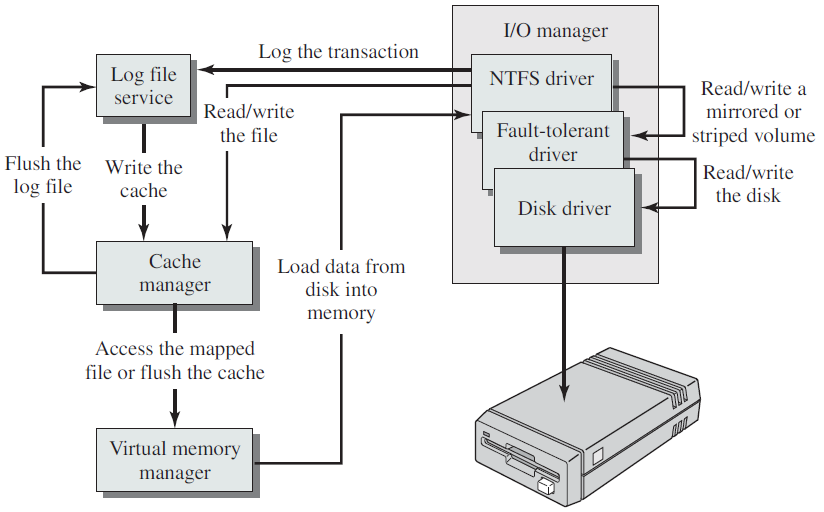
Windows NTFS组件。
18.11.3.2 实现文件
在实现文件存储时,最重要的问题可能是跟踪哪个磁盘块与哪个文件对应,不同的操作系统使用不同的方法。下图是记录块的方法:
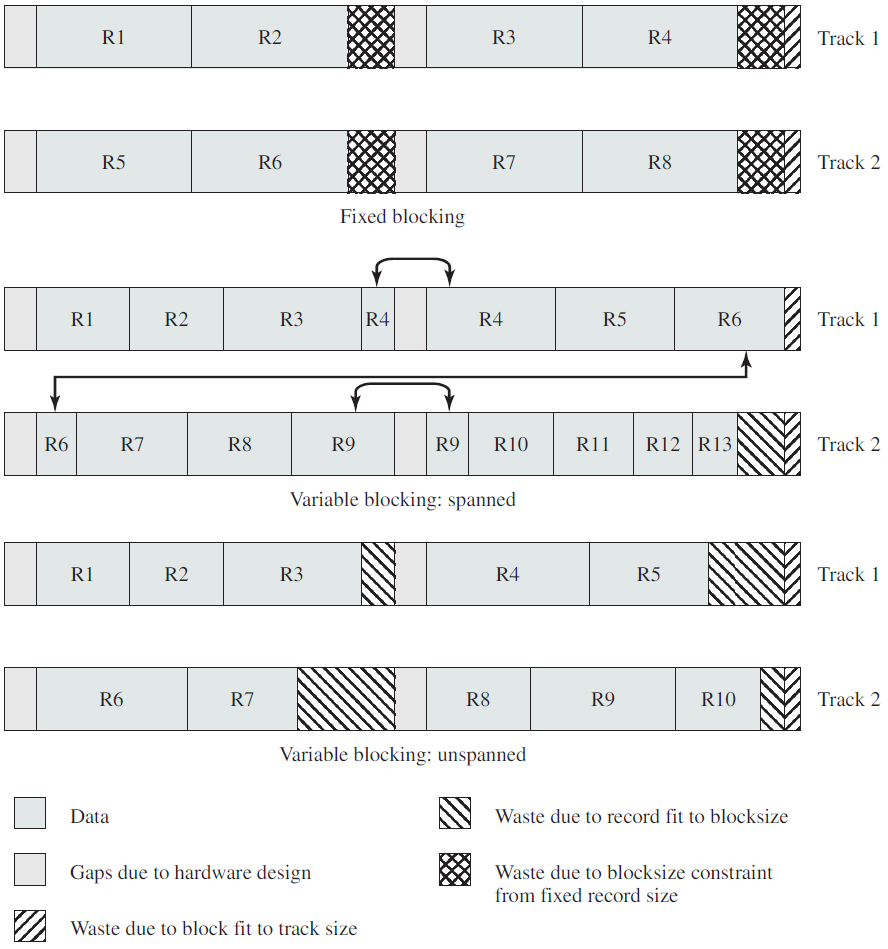
- 连续分配
最简单的分配方案是将每个文件存储为连续运行的磁盘块。因此,在一个具有1-KB块的磁盘上,一个50-KB的文件将被分配50个连续的块。对于2-KB的块,它将被分配25个连续的块。
我们在下图(a)中看到了连续存储分配的示例,显示了前40个磁盘块,从左侧的块0开始。最初,磁盘是空的,然后,从开头(块0)开始,将一个长度为四个块的文件a写入磁盘,之后,一个六块文件B被写入文件a的末尾之后。
请注意,每个文件都从新块的开始处开始,因此如果文件a实际上是3½个块,那么在最后一个块的末尾会浪费一些空间。在图中,总共显示了七个文件,每个文件都从前一个文件的末尾之后的块开始。着色只是为了更容易区分文件,就存储而言,它没有实际意义。

(a) 连续分配七个文件的磁盘空间。(b) 删除文件D和F后磁盘的状态。
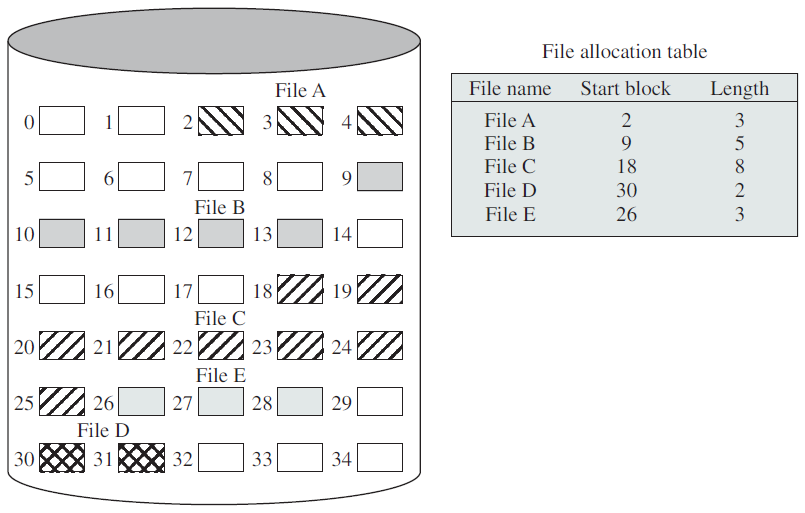
连续文件分配的案例。
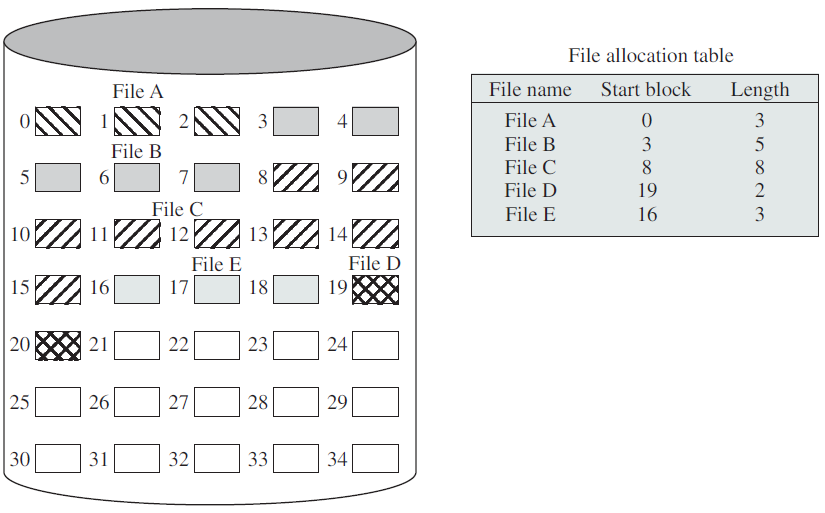
连续文件分配的案例(压缩后)。
连续磁盘空间分配有两个显著的优点。首先,它很容易实现,因为跟踪文件块的位置可以简化为记住两个数字:第一个块的磁盘地址和文件中的块数。给定第一个块的数量,任何其他块的数量都可以通过简单的加法得到。
其次,读取性能非常好,因为整个文件可以在一次操作中从磁盘读取,只需要一个寻道(到第一个块)。此后,不再需要寻道或旋转延迟,因此数据以磁盘的全部带宽进入。因此,连续分配易于实现且具有高性能。
不幸的是,连续分配也有一个非常严重的缺点:随着时间的推移,磁盘会变得支离破碎。要了解这是如何发生的,参看上图(b)。这里删除了两个文件D和F。当一个文件被删除时,它的块会被自然释放,从而在磁盘上留下一段空闲块。磁盘不是当场压实以挤出孔洞,因为这将涉及复制孔后的所有块,可能有数百万块,如果磁盘较大,这将需要数小时甚至数天的时间。因此,磁盘最终由文件和孔洞组成。
最初,这个碎片不是问题,因为每个新文件都可以在磁盘末尾写入,紧跟前一个文件。然而,最终磁盘将被填满,因此有必要压缩磁盘(成本高昂),或者重新使用孔中的可用空间。重复使用空间需要维护孔列表,这是可行的。但是,创建新文件时,需要知道其最终大小,以便选择正确大小的孔来放置文件。
想象一下这种设计的后果。用户启动文字处理器以创建文档,程序首先要问的是最终文档的字节数,必须回答此问题,否则程序将无法继续。如果最终证明给出的数字太小,程序必须提前终止,因为磁盘孔已满,没有地方放置文件的其余部分。如果用户试图通过给出一个不切实际的大数字作为最终大小来避免这个问题,例如1GB,那么编辑器可能无法找到如此大的洞,并宣布无法创建文件。当然,用户可以自由地再次启动程序,并说这次是500MB,以此类推,直到找到合适的漏洞为止。不过,这个方案不太可行。
然而,有一种情况下,连续分配是可行的,而且事实上仍在使用:在CD-ROM上。在这里,所有文件大小都是预先知道的,并且在随后使用CD-ROM文件系统时永远不会改变。而DVD的情况有点复杂。原则上,一部90分钟的电影可以编码为一个长度约为4.5 GB的文件,但使用的文件系统UDF(Universal Disk Format,通用磁盘格式)使用30位数字表示文件长度,将文件限制在1 GB以内。因此,DVD影片通常存储为三个或四个1-GB文件,每个文件都是连续的,单个逻辑文件(电影)的这些物理片段称为扩展数据块。
- 链接列表分配
存储文件的第二种方法是将每个文件保存为磁盘块的链接列表,如下图所示。每个块的第一个字用作指向下一个块的指针。块的其余部分用于数据。
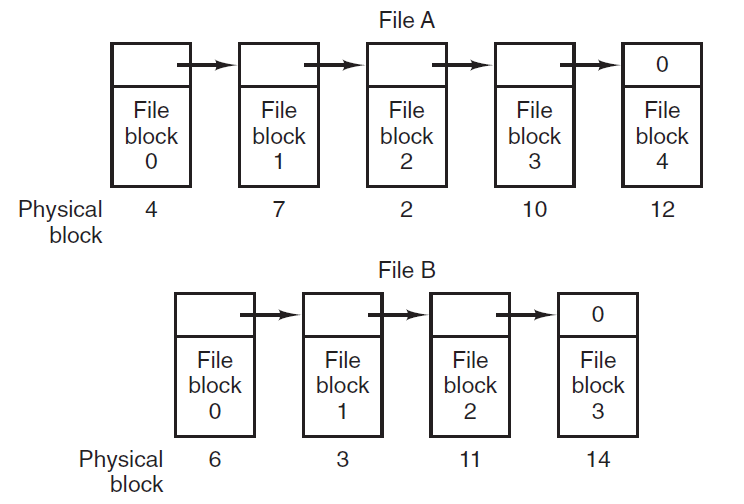
与连续分配不同,此方法可以使用每个磁盘块,磁盘碎片不会丢失空间(最后一个块中的内部碎片除外)。此外,目录条目只存储第一个块的磁盘地址就足够了。其余的可以从那里开始找到。
另一方面,虽然顺序读取文件很简单,但随机访问速度非常慢。要到达块n,操作系统必须从开始处启动并读取n− 之前1个街区,一次一个。显然,读取大量内容时会非常缓慢。
此外,块中的数据存储量不再是2的幂,因为指针占用了几个字节。虽然不是致命的,但具有特殊大小的程序效率较低,因为许多程序读写块的大小是2的幂次方。由于每个块的前几个字节被指向下一个块的指针占用,读取完整块大小需要从两个磁盘块获取并连接信息,这会因复制而产生额外的开销。
- 使用内存中的表分配链接列表
通过从每个磁盘块获取指针字并将其放入内存中的表中,可以消除链表分配的两个缺点。下图显示了上图示例的表格。在两个图中,我们都有两个文件。文件A按顺序使用磁盘块4、7、2、10和12,文件B按顺序使用盘块6、3、11和14。使用下图的表格,我们可以从区块4开始,沿着链条一直走到底,从块6开始也可以这样做。两条链条都用一个特殊标记(例如−1), 但不是有效的块编号。主存储器中的这样一个表称为FAT(File Allocation Table,文件分配表)。

使用主存中的文件分配表分配链接列表。
使用此组织,整个块都可用于数据,随机访问要容易得多。尽管仍必须遵循链来查找文件中的给定偏移量,但链完全在内存中,因此可以在不进行任何磁盘引用的情况下遵循它。与前面的方法一样,目录条目只需保留一个整数(起始块编号)就足够了,而且无论文件有多大,仍然能够定位所有块。
这种方法的主要缺点是,整个表必须始终在内存中才能工作。对于1-TB磁盘和1-KB块大小,该表需要10亿个条目,每个条目对应10亿个磁盘块,每个条目必须至少为3个字节。为了加快查找速度,它们应该是4个字节。因此,该表将始终占用3 GB或2.4 GB的主内存,取决于系统是针对空间还是时间进行了优化,因此不太实用。显然,FAT的想法不能很好地扩展到大型磁盘。它是最初的MS-DOS文件系统,但所有版本的Windows仍然完全支持它。
- I节点
跟踪哪些块属于哪个文件的最后一种方法是将称为I节点(索引节点)的数据结构与每个文件相关联,它列出了文件块的属性和磁盘地址,给定i节点,就可以找到文件的所有块。一个简单的例子如下图所示。
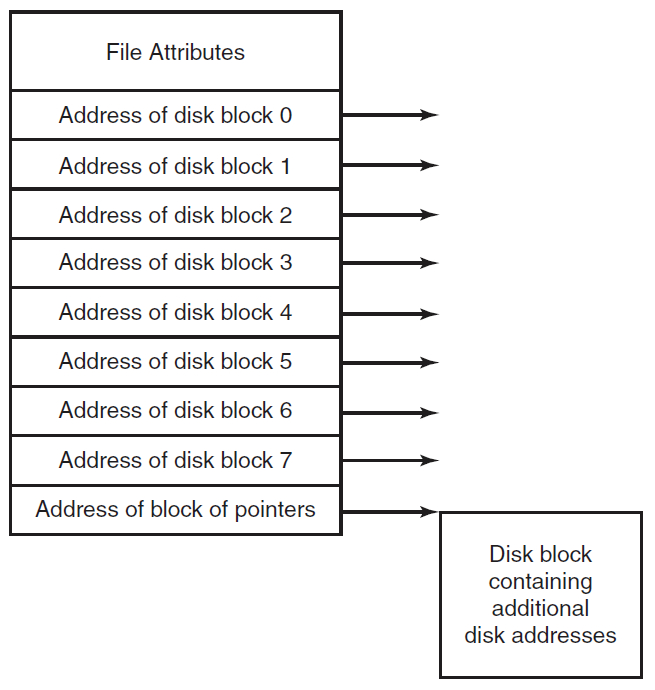
与使用内存中表的链接文件相比,此方案的最大优点是,仅当相应文件打开时,i节点才需要在内存中。如果每个i节点占用n个字节,并且一次最多可以打开k个文件,则保存打开文件的i节点的数组所占用的总内存仅为k*n个字节,只需提前预留这么多空间。
此数组通常远小于上一节中描述的文件表所占用的空间,原因很简单,用于保存所有磁盘块链接列表的表的大小与磁盘本身成比例。如果磁盘有n个块,则表需要n个条目,随着磁盘的增大,此表也会随之线性增长。相反,i-node方案需要内存中的数组,其大小与一次可以打开的最大文件数成正比。磁盘是100 GB、1000 GB还是10000 GB并不重要。
i节点的一个问题是,如果每个节点都有固定数量磁盘地址的空间,那么当文件增长超过此限制时会发生什么情况?一种解决方案是不为数据块保留最后一个磁盘地址,而是为包含更多磁盘块地址的块的地址保留,如上图所示。更高级的方法是两个或多个包含磁盘地址的此类块,甚至是指向其他满有地址的磁盘块的磁盘块。类似地,Windows NTFS文件系统使用了类似的思想,只有更大的i节点也可以包含小文件。
18.11.3.3 实现文件夹
在读取文件之前,必须先将其打开,打开文件时,操作系统使用用户提供的路径名来查找磁盘上的目录项,目录条目提供查找磁盘块所需的信息。根据系统的不同,此信息可能是整个文件的磁盘地址(具有连续分配)、第一个块的编号(两个链表方案)或i节点的编号。在所有情况下,目录系统的主要功能是将文件的ASCII名称映射到查找数据所需的信息上。
一个密切相关的问题是属性应该存储在哪里。每个文件系统都维护各种文件属性,例如每个文件的所有者和创建时间,它们必须存储在某个地方。一种明显的可能性是将它们直接存储在目录条目中,有些系统正是这样做的,该选项如下图(a)所示。在这种简单的设计中,目录由一个固定大小的条目列表组成,每个文件一个,其中包含一个(固定长度)文件名、文件属性的结构,以及一个或多个磁盘地址(最大值),说明磁盘块的位置。
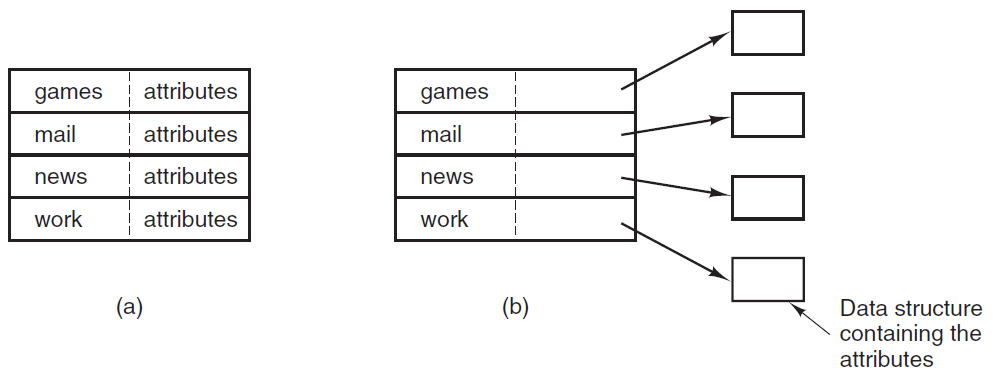
(a) 一个简单的目录,包含固定大小的条目,在目录条目中有磁盘地址和属性。(b) 一种目录,其中的每个条目仅指一个i节点。
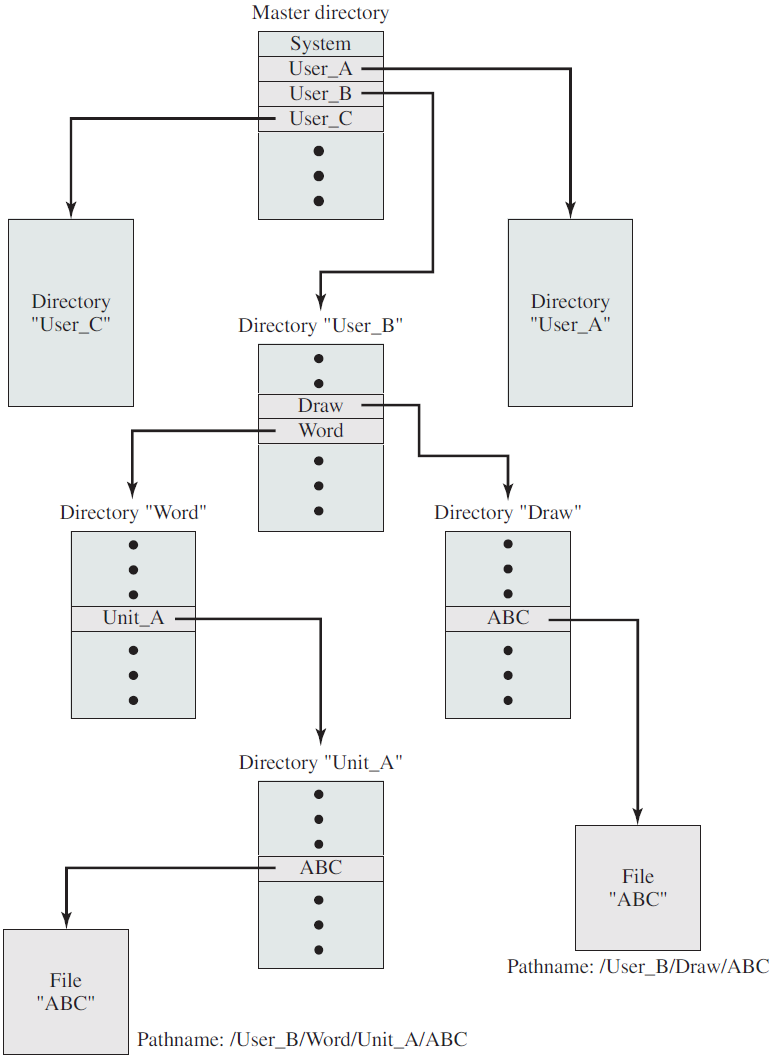
树形结构文件夹的案例。
对于使用i-node的系统,存储属性的另一种可能性是在i-node中,而不是在目录条目中。在这种情况下,目录条目可以更短:只需一个文件名和一个i-node编号,如上图(b)所示。
到目前为止,我们假设文件的名称很短,长度固定。在MS-DOS文件中,基本名称为1-8个字符,扩展名可选为1-3个字符。在UNIX版本7中,文件名为1-14个字符,包括任何扩展名。然而,几乎所有现代操作系统都支持更长、可变长度的文件名。如何实现这些目标?
最简单的方法是设置文件名长度限制,通常为255个字符,然后使用下图的一种设计,为每个文件名保留255个字。这种方法很简单,但浪费了大量目录空间,因为很少有文件具有如此长的名称。出于效率原因,最好采用不同的结构。
一种替代方法是放弃所有目录条目大小相同的想法。使用此方法,每个目录条目都包含一个固定部分,通常从条目的长度开始,然后是固定格式的数据,通常包括所有者、创建时间、保护信息和其他属性。这个固定长度的头后面跟着实际的文件名,不管文件名有多长,如图下图(a)所示,格式为大端格式(例如SPARC)。在这个例子中,我们有三个文件,project-budget、personnel和foo。每个文件名都以一个特殊字符(通常为0)结尾,该字符在图中由一个带叉的框表示。为了允许每个目录条目都从单词边界开始,每个文件名都被填入整数个单词,如图中阴影框所示。
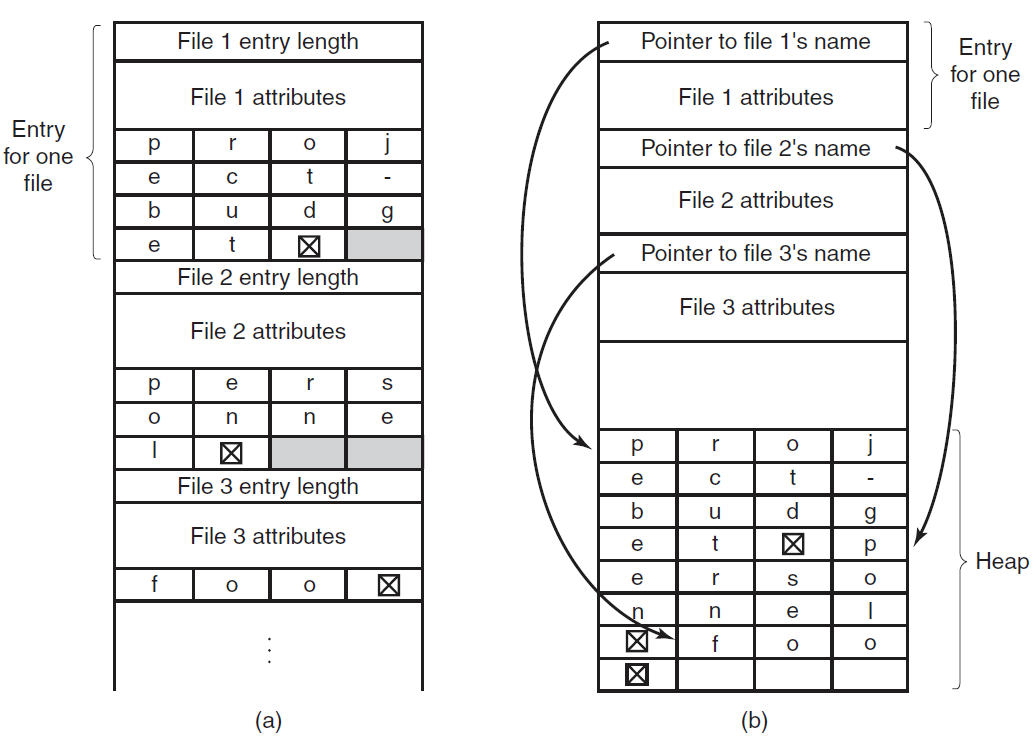
处理目录中长文件名的两种方法。(a) 排成一行。(b) 堆成一堆。
18.11.3.4 共享文件
当多个用户一起处理一个项目时,他们通常需要共享文件。因此,共享文件通常很方便同时出现在属于不同用户的不同目录中。下图显示了包含一个共享文件的文件系统,只有C的一个文件现在也存在于B的一个目录中。B的目录和共享文件之间的连接称为链接。文件系统本身现在是一个有向非循环图(DAG),而不是一棵树。将文件系统作为DAG会使维护变得复杂,但生活正是如此。

包含了一个共享文件的文件系统。
共享文件很方便,但也带来了一些问题。首先,如果目录确实包含磁盘地址,那么在链接文件时,必须在B的目录中创建磁盘地址的副本。如果随后B或C追加到文件中,则新块将仅列在执行追加操作的用户的目录中。其他用户将看不到这些更改,从而破坏了共享的目的。这个问题可以通过两种方式解决:
- 第一种解决方案:磁盘块不列在目录中,而是列在与文件本身相关联的一个小数据结构中,然后目录将只指向小数据结构。这是UNIX中使用的方法(其中小数据结构是i节点)。
- 第二种解决方案:B链接到C的一个文件,方法是让系统创建一个新文件,类型为LINK,然后将该文件输入B的目录中,新文件只包含它链接到的文件的路径名。当B从链接文件中读取时,操作系统会看到正在读取的文件的类型为LINK,查找文件名并读取该文件。这种方法称为符号链接,与传统(硬)链接形成对比。
这些方法都有其缺点。在第一种方法中,当B链接到共享文件时,i-node将文件的所有者记录为C。创建链接不会更改所有权(见下图),但会增加i-node中的链接数,因此系统知道当前有多少目录条目指向该文件。
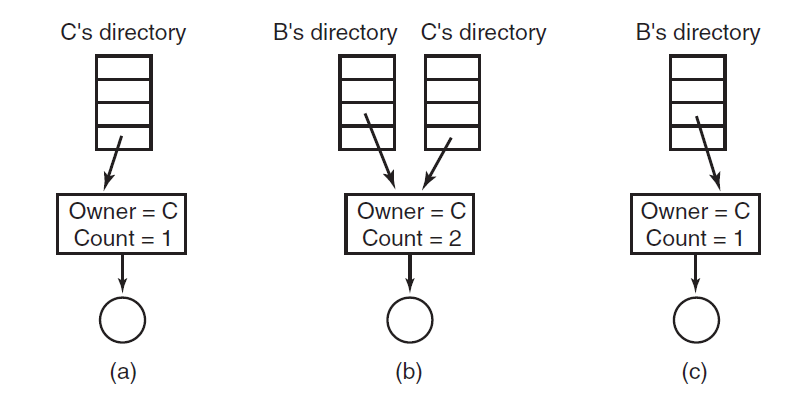
(a) 连接前的情况。(b) 创建链接后。(c) 在原始所有者删除文件后。
如果C随后尝试删除该文件,则系统将面临问题。如果删除文件并清除i-node,B将有一个指向无效i-node的目录条目。如果稍后将i节点重新指定给其他文件,B的链接将指向错误的文件。系统可以从i-node中的计数看出文件仍在使用中,但没有简单的方法可以找到文件的所有目录条目,以便将其删除。指向目录的指针不能存储在索引节点中,因为目录的数量可能不受限制。
唯一要做的是删除C的目录条目,但保留i节点不变,计数设置为1,如上图(C)所示。我们现在有一种情况,B是唯一一个拥有C所拥有文件的目录条目的用户。如果系统进行记帐或有配额,C将继续为该文件计数,直到B决定删除它,如果有,此时计数变为0,文件被删除。
使用符号链接时,不会出现此问题,因为只有真正的所有者才有指向i节点的指针。链接到文件的用户只有路径名,而没有i节点指针。当所有者删除文件时,它将被销毁。当系统无法找到该文件时,后续通过符号链接使用该文件的尝试将失败。删除符号链接根本不会影响文件。
18.11.3.5 日志结构化文件系统
技术的变化给当前的文件系统带来了压力。特别是,CPU的速度越来越快,磁盘越来越大,越来越便宜(但速度并不快),内存的大小呈指数级增长。磁盘寻道时间(固态磁盘除外,固态磁盘没有寻道时间)是一个没有明显改善的参数。
这些因素的组合意味着在许多文件系统中出现了性能瓶颈。伯克利大学的研究试图通过设计一种全新的文件系统LFS(Log-structured
File System,日志结构文件系统)来缓解这个问题。
推动LFS设计的想法是,随着CPU速度的加快和RAM内存的增大,磁盘缓存也在迅速增加。因此,现在可以直接从文件系统缓存满足大部分读取请求,而不需要磁盘访问。从这个观察结果可以看出,在未来,大多数磁盘访问都将是写操作,因此在某些文件系统中用于在需要块之前获取块的预读机制不再能获得太多性能。
更糟糕的是,在大多数文件系统中,写入都是在非常小的块中完成的。小型写入效率很低,因为50微秒的磁盘写入之前通常会有10毫秒的寻道和4毫秒的旋转延迟。使用这些参数,磁盘效率会下降到1%。
要查看所有小写操作的来源,请考虑在UNIX系统上创建一个新文件。要写入此文件,必须写入目录的i节点、目录块、文件的i节点以及文件本身。虽然这些写入可能会延迟,但如果在写入之前发生崩溃,那么这样做会使文件系统面临严重的一致性问题。因此,通常会立即执行i节点写入。
根据这一推理,LFS设计者决定重新实现UNIX文件系统,以实现磁盘的全部带宽,即使面对由大部分小的随机写入组成的工作负载。基本思想是将整个磁盘结构为一个大日志。
定期地,当有特殊需要时,内存中缓冲的所有挂起的写操作都被收集到一个段中,并在日志末尾作为一个连续的段写入磁盘。因此,单个段可能包含混合在一起的i节点、目录块和数据块。每段开头都有一个段摘要,说明段中可以找到什么。如果可以将平均段设置为大约1 MB,则几乎可以利用磁盘的全部带宽。
在这种设计中,i节点仍然存在,甚至具有与UNIX中相同的结构,但它们现在分散在日志中,而不是位于磁盘上的固定位置。然而,在定位i节点时,通常会按常规方式定位块。当然,现在查找i节点要困难得多,因为它的地址不能像在UNIX中那样简单地从i编号计算出来。为了能够找到i节点,将维护一个按i编号索引的i节点映射表。此映射中的条目i指向磁盘上的i节点i。映射表保存在磁盘上,但也会被缓存,因此最常用的部分大部分时间都在内存中。
总结一下我们到目前为止所说的内容,所有写操作最初都在内存中进行缓冲,并且定期将所有缓冲的写操作写入日志末尾的单个段中的磁盘。现在,打开文件包括使用映射表定位文件的i节点。一旦找到i节点,就可以从中找到块的地址。所有块本身都是分段的,位于日志中的某个位置。
如果磁盘无限大,上面的描述就是全部。然而,实际磁盘是有限的,因此日志最终将占据整个磁盘,此时无法向日志写入新的段。幸运的是,许多现有段可能有不再需要的块。例如,如果文件被覆盖,其i节点现在将指向新块,但旧块仍将在以前写入的段中占用空间。
为了解决这个问题,LFS有一个更干净的线程,它花时间循环扫描日志以压缩它。它首先读取日志中第一段的摘要,以查看其中有哪些i节点和文件。然后检查当前的i节点映射表,以查看i节点是否仍然是当前的,文件块是否仍在使用中。否则,该信息将被丢弃。仍在使用的i节点和块进入内存,在下一个段中写出。然后将原始段标记为空闲,以便日志可以将其用于新数据。以这种方式,清洁器沿着日志移动,从后面删除旧段,并将任何实时数据放入内存,以便在下一段中重写。因此,磁盘是一个大的圆形缓冲区,写入线程在前面添加新的段,而清理线程从后面删除旧的段。
这里的记账(bookkeeping)很重要,因为当一个文件块被写回一个新的段时,文件的i节点(在日志中的某个位置)必须被定位、更新并放入内存中,以便在下一段中写出。然后必须更新i节点贴图以指向新副本。尽管如此,仍然可以进行管理,性能结果表明,所有这些复杂性都是值得的。上述论文中给出的测量结果表明,LFS在小写操作方面比UNIX好几个数量级,而在读操作和大写操作方面的性能与UNIX相当或更好。
18.11.3.6 日志文件系统
虽然日志结构文件系统是一个有趣的想法,但它们并没有被广泛使用,部分原因是它们与现有文件系统高度不兼容。然而,它们所固有的一个思想,即面对故障时的健壮性,可以很容易地应用于更传统的文件系统。这里的基本思想是在文件系统执行操作之前保存一个日志,以便如果系统在执行计划的工作之前崩溃,在重新启动系统时,可以查看日志,查看崩溃时发生的情况并完成作业。这种文件系统称为日志文件系统(Journaling File Systems),实际上正在使用中。Microsoft的NTFS文件系统以及Linux ext3和ReiserFS文件系统都使用日志记录,OSX提供日志文件系统作为一个选项。
要了解问题的本质,请考虑一个经常发生的普通操作:删除文件。此操作(在UNIX中)需要三个步骤:
1、从目录中删除文件。
2、将i-node释放到空闲i-node池中。
3、将所有磁盘块返回到可用磁盘块池。
在Windows中,需要类似的步骤。在没有系统崩溃的情况下,采取这些步骤的顺序无关紧要;在发生崩溃的情况下,情况确实如此。假设第一步完成,然后系统崩溃。i节点和文件块将无法从任何文件访问,但也不能用于重新分配,它们只是处于不确定的状态,减少了可用的资源。如果崩溃发生在第二步之后,则仅丢失块。
如果操作顺序发生更改,并且首先释放了i-node,那么在重新启动后,i-node可能会被重新分配,但旧的目录条目将继续指向它,从而指向错误的文件。如果先释放块,则在清除i-node之前发生崩溃意味着有效的目录条目将指向一个i-node,其中列出了当前在空闲存储池中的块,并且很可能很快会被重用,从而导致两个或多个文件随机共享同一块。这些结果都不好。
日志文件系统所做的是首先写入一个日志条目,列出要完成的三个操作。然后将日志条目写入磁盘(为了更好地测量,可能会从磁盘读取,以验证它实际上是否正确写入)。只有在写入日志条目后,才能开始各种操作。操作成功完成后,日志条目将被擦除。如果系统现在崩溃,在恢复时,文件系统可以检查日志以查看是否有任何操作挂起。如果是这样,则可以重新运行所有这些文件(在重复崩溃的情况下多次运行),直到文件被正确删除。
为了使日志记录有效,日志记录的操作必须是幂等的,意味着可以根据需要重复这些操作,而不会造成损害。可以重复执行“更新位图以将i节点k或块n标记为空闲”等操作,直到列回归时没有危险。类似地,搜索目录并删除任何名为foobar的条目也是幂等的。另一方面,将i节点K中新释放的块添加到空闲列表的末尾不是幂等的,因为它们可能已经存在。更昂贵的操作“搜索可用块列表并将块n添加到其中(如果尚未存在)”是幂等的。日志文件系统必须安排其数据结构和可记录操作,以便它们都是幂等的。在这些情况下,可以快速安全地进行崩溃恢复。
为了增加可靠性,文件系统可以引入原子事务的数据库概念。当使用这个概念时,一组操作可以被开始事务和结束事务操作括起来。然后,文件系统知道它必须完成所有括号内的操作,或者不完成任何操作,但不能完成任何其他组合。
NTFS有一个广泛的日志系统,其结构很少因系统崩溃而损坏。自1993年Windows NT首次发布以来,它就一直在开发中。第一个做日志记录的Linux文件系统是ReiserFS,但它的普及受到了阻碍,因为它与当时的标准ext2文件系统不兼容。相反,与ReiserFS相比,ext3是一个不那么雄心勃勃的项目,它在保持与以前的ext2系统兼容的同时也做日志记录。
18.11.3.7 虚拟文件系统
即使对于同一操作系统,在同一台计算机上也经常使用许多不同的文件系统。Windows系统可能有一个主NTFS文件系统,但也有一个旧的FAT-32或FAT-16驱动器或分区,其中包含旧的但仍然需要的数据,有时还需要一个闪存驱动器、旧的CD-ROM或DVD(每个都有自己独特的文件系统)。Windows通过使用不同的驱动器号(如C:、D:等)标识每个文件系统来处理这些不同的文件系统。当进程打开文件时,驱动器号是显式或隐式显示的,因此Windows知道要将请求传递给哪个文件系统。没有尝试将异构文件系统集成到一个统一的整体中。
相比之下,所有现代UNIX系统都在认真尝试将多个文件系统集成到一个结构中。Linux系统可以将ext2作为根文件系统,在/usr上安装ext3分区,在/home上安装ReiserFS文件系统的第二个硬盘,以及在/mnt上临时安装ISO 9660 CD-ROM。从用户的角度来看,存在单个文件系统层次结构。它碰巧包含多个(不兼容)文件系统,这对用户或进程来说是不可见的。
然而,多文件系统的存在对于实现来说是非常明显的,并且自从Sun Microsystems的开创性工作以来,大多数UNIX系统都使用VFS(virtual file system,虚拟文件系统)的概念来尝试将多个文件系统集成到一个有序的结构中。其关键思想是抽象出所有文件系统通用的文件系统部分,并将该代码放在一个单独的层中,该层调用底层的具体文件系统来实际管理数据。总体结构如下图所示。下面的讨论不是针对Linux或FreeBSD或任何其他版本的UNIX,而是介绍了虚拟文件系统在UNIX系统中的工作方式。

虚拟文件系统的位置。
所有与文件相关的系统调用都被定向到虚拟文件系统进行初始处理。这些来自用户进程的调用是标准的POSIX调用,例如open、read、write、lseek等。因此,VFS具有用户进程的“上部”接口,它是众所周知的POSIX接口。
VFS还有一个到具体文件系统的“较低”接口,在上图中标记为VFS接口。该接口由几十个函数调用组成,VFS可以对每个文件系统进行函数调用以完成工作。因此,要创建与VFS一起工作的新文件系统,新文件系统的设计者必须确保它提供了VFS所需的函数调用。此类函数的一个明显示例是从磁盘读取特定块,将其放入文件系统的缓冲区缓存,并返回指向该块的指针。因此,VFS有两个不同的接口:上层接口用于用户进程,下层接口用于具体文件系统。
虽然VFS下的大多数文件系统表示本地磁盘上的分区,但情况并非总是如此。事实上,Sun构建VFS的最初动机是使用NFS(网络文件系统)协议支持远程文件系统。VFS的设计是这样的,只要具体的文件系统提供了VFS所需的功能,VFS就不知道或不关心数据存储在哪里或底层文件系统是什么样的。
在内部,大多数VFS实现本质上是面向对象的,即使它们是用C而不是C++编写的。通常支持几种关键对象类型,包括超级块(描述文件系统)、v节点(描述文件)和目录(描述文件体系目录),每个都有具体文件系统必须支持的关联操作(方法)。此外,VFS有一些内部数据结构供自己使用,包括挂载表和一组文件描述符,用于跟踪用户进程中所有打开的文件。
为了理解VFS是如何工作的,让我们按时间顺序运行一个示例。当系统启动时,根文件系统向VFS注册。此外,当其他文件系统在引导时或操作期间装载时,它们也必须向VFS注册。当一个文件系统注册时,它基本上是提供一个VFS所需函数的地址列表,可以是一个长调用向量(表),也可以是其中的几个,每个VFS对象一个,这是VFS所要求的。因此,一旦文件系统向VFS注册,VFS就知道如何从中读取块,它只需调用文件系统提供的向量中的第四个(或其他)函数。类似地,VFS知道如何执行具体文件系统必须提供的所有其他功能:它只调用文件系统注册时提供地址的函数。
安装文件系统后,可以使用它。例如,如果在/usr上装载了一个文件系统,并且某个进程在解析路径时打开了调用:
open("/usr/include/unistd.h", O_RDONLY)
则VFS会看到一个新的文件系统已装载在/usr上,并通过搜索已装载文件系统的超级块列表来定位其超级块。完成此操作后,它可以找到装载的文件系统的根目录,并查找路径include/unistd.h在那里。然后,VFS创建一个v节点,并调用具体的文件系统来返回文件inode中的所有信息。此信息与其他信息(最重要的是指向函数表的指针)一起复制到v节点(在RAM中)中,以调用v节点上的操作,例如读取、写入、关闭等。
创建v-node后,VFS在文件描述符表中为调用进程创建一个条目,并将其设置为指向新的v-node。最后,VFS将文件描述符返回给调用者,以便它可以使用它来读取、写入和关闭文件。
稍后,当进程使用文件描述符进行读取时,VFS从进程和文件描述符表中找到v节点,并跟随指向函数表的指针,所有这些都是请求文件所在的具体文件系统中的地址。现在将调用处理读取的函数,具体文件系统中的代码将进入并获取请求的块。VFS不知道数据是来自本地磁盘、网络上的远程文件系统、U盘还是其他东西。涉及的数据结构如下图所示。从调用者的进程号和文件描述符开始,依次定位具体文件系统中的v节点、读取函数指针和访问函数。
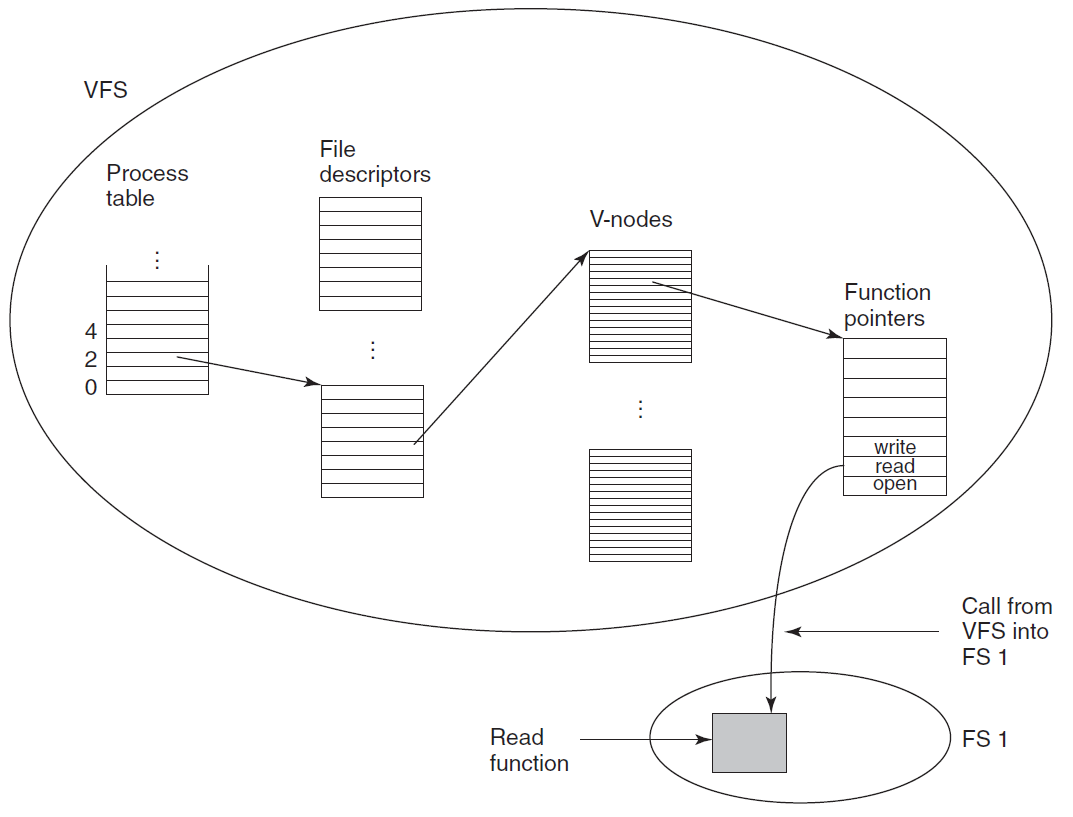
VFS和具体文件系统用于读取的数据结构和代码的简化视图。
通过这种方式,添加新的文件系统变得相对简单。设计人员首先获得VFS期望的函数调用列表,然后编写文件系统来提供所有函数调用。或者,如果文件系统已经存在,那么它们必须提供包装器函数来完成VFS所需的工作,通常是通过对具体文件系统进行一个或多个本地调用。
18.11.3.8 文件系统管理和优化
使文件系统工作是一回事;让它在现实生活中高效、稳健地工作是完全不同的。在以下各节中,我们将讨论管理磁盘所涉及的一些问题。
- 磁盘空间优化
文件通常存储在磁盘上,因此磁盘空间的管理是文件系统设计者的主要关注点。存储一个n字节文件有两种通用策略:分配n个连续字节的磁盘空间,或者将文件分割成多个(不一定)连续的块。在内存管理系统中,纯分段和分页之间也存在相同的折衷。
正如我们所看到的,将文件存储为连续的字节序列有一个明显的问题,即如果文件增长,可能必须将其移动到磁盘上。内存中的段也存在同样的问题,不同的是,与将文件从一个磁盘位置移动到另一个磁盘的位置相比,在内存中移动段是一个相对较快的操作。因此,几乎所有的文件系统都会将文件切成固定大小的块,这些块不需要相邻。
首先考虑的块大小(Block Size)。
一旦决定将文件存储在固定大小的块中,问题就出现了,块应该有多大。考虑到磁盘的组织方式,扇区、磁道和柱面显然是分配单元的候选对象(尽管它们都依赖于设备,这是负数)。在分页系统中,页面大小也是一个主要的竞争者。
拥有较大的块大小意味着每个文件,甚至是一个1字节的文件,都会占用整个柱面,也意味着小文件会浪费大量磁盘空间。另一方面,较小的块大小意味着大多数文件将跨越多个块,因此需要多次寻道和旋转延迟来读取它们,从而降低性能。因此,如果分配单元太大,我们就会浪费空间;如果太小,会浪费时间。
要做出正确的选择,需要掌握一些有关文件大小分布的信息。Tanenbaum等人(2006年)于1984年和2005年分别在一所大型研究型大学(VU)的计算机科学系和一个托管政治网站(www.electroral-vote.com)的商业Web服务器上研究了文件大小分布。结果下图所示,其中,对于两个文件大小的每一次幂,列出了三个数据集中每个数据集小于或等于它的所有文件的百分比。例如,2005年,VU中59.13%的文件小于等于4 KB,90.84%的文件小于或等于64 KB。中间文件大小为2475字节。有些人可能会觉得这种小尺寸令人惊讶。

小于给定大小(以字节为单位)的文件的百分比。
我们可以从这些数据中得出什么结论?首先,对于块大小为1 KB的文件,只有大约30-50%的文件可以放在一个块中,而对于4-KB的文件块,放在一块中的文件百分比可以达到60-70%。本文中的其他数据显示,对于4-KB的块,93%的磁盘块被10%的最大文件使用。这意味着在每个小文件的末尾浪费一些空间几乎无关紧要,因为磁盘被少量大文件(视频)填满,小文件占用的空间总量几乎无关痛痒。即使将最小的90%文件占用的空间加倍,也几乎看不到。
另一方面,使用小块意味着每个文件将由多个块组成。读取每个块通常需要寻道和旋转延迟(固态磁盘除外),因此读取由许多小块组成的文件会很慢。
例如,考虑一个每个磁道有1 MB的磁盘,旋转时间为8.33毫秒,平均寻道时间为5毫秒。读取k字节块的时间(毫秒)就是寻道时间、旋转延迟时间和传输时间的总和:
下图的虚线曲线显示了此类磁盘的数据速率与块大小的函数关系。为了计算空间效率,我们需要假设平均文件大小,为了简单起见,我们假设所有文件都是4KB。虽然这个数字略大于VU测量的数据,但学生可能拥有比企业数据中心中更多的小文件,因此总体上来说,这可能是一个更好的猜测。下图的实心曲线显示了作为块大小函数的空间效率。
这两条曲线可以理解如下。一个块的访问时间完全由寻道时间和旋转延迟决定,因此如果访问一个块要花费9毫秒,那么获取的数据越多越好。因此,数据速率几乎与块大小成线性增长(直到传输时间过长,传输时间开始变得重要)。
现在考虑空间效率。对于4-KB文件和1-KB、2-KB或4-KB块,文件分别使用4、2和1个块,没有浪费。对于8-KB的块和4-KB的文件,空间效率下降到50%,而对于16KB的块,空间效率降低到25%。实际上,很少文件是磁盘块大小的精确倍数,因此文件的最后一个块总是浪费一些空间。
然而,曲线表明,性能和空间利用率之间存在固有的冲突。小数据块对性能不利,但对磁盘空间利用率有利。对于这些数据,没有合理的折衷方案。最接近两条曲线交叉处的大小为64KB,但数据速率仅为6.6MB/秒,空间效率约为7%,两者都不是很好。过去,文件系统选择的大小在1-KB到4-KB之间,但现在磁盘超过1TB,最好将块大小增加到64KB,并接受浪费的磁盘空间。磁盘空间几乎不再短缺。
Vogels在康奈尔大学(Cornell University)对文件进行了测量,以确定Windows NT文件的使用情况是否与UNIX文件的使用有明显不同(Vogels,1999)。他注意到NT文件的使用比在UNIX上更复杂。他写道:当我们在记事本文本编辑器中键入几个字符时,将其保存到文件将触发26个系统调用,包括3次失败的打开尝试、1次文件覆盖和4次额外的打开和关闭序列。
然而,Vogels观察到文件的中值大小(按使用情况加权)为1KB,写文件为2.3KB,读写文件为4.2KB。考虑到不同的数据集测量技术和年份,这些结果与VU结果肯定是兼容的。
接下来阐述跟踪空闲块(Keeping Track of Free Blocks)。
一旦选择了块大小,下一个问题是如何跟踪空闲块。有两种方法被广泛使用,如下图所示。第一种方法包括使用磁盘块的链接列表,每个块都包含尽可能多的可用磁盘块编号。对于1-KB块和32位磁盘块编号,可用列表中的每个块都包含255个可用块。(指向下一个块的指针需要一个插槽。)考虑一个1-TB磁盘,它有大约10亿个磁盘块。要将所有这些地址存储为每个块255个,需要大约400万个块。通常,空闲块用于保存空闲列表,因此存储基本上是空闲的。
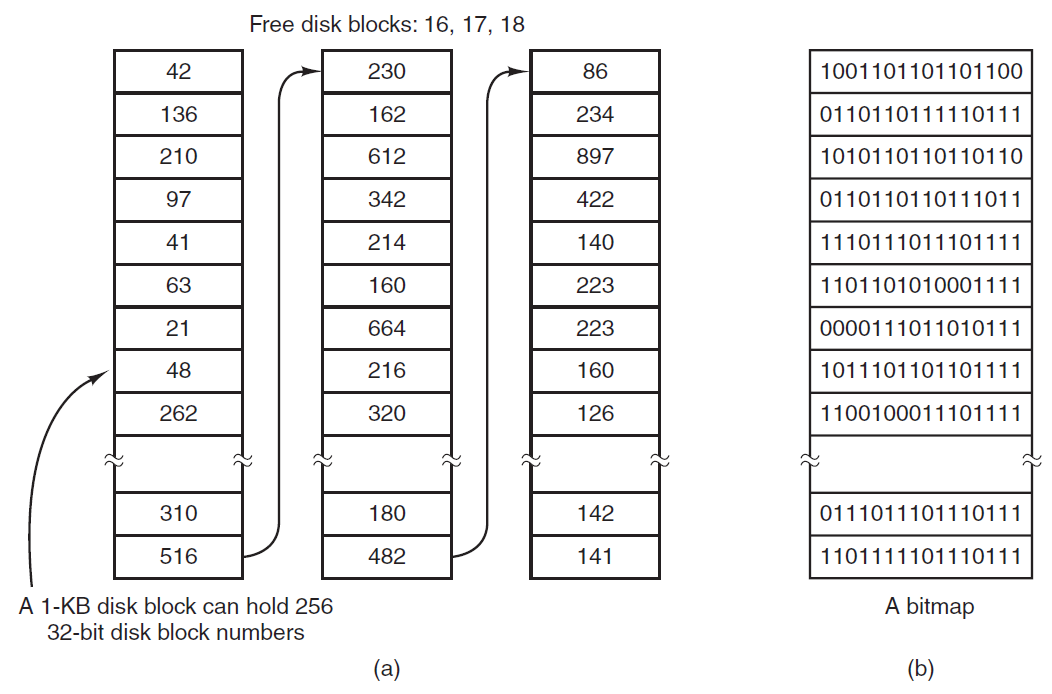
(a) 将空闲列表存储在链接列表中。(b) 位图。
另一种可用空间管理技术是位图。具有n个块的磁盘需要具有n位的位图。在图中,可用块用1表示,分配块用0表示(反之亦然)。对于我们的示例1-TB磁盘,映射需要10亿位,这需要大约130000个1-KB块来存储。位图需要更少的空间并不奇怪,因为它每个块使用1位,而链接列表模型中使用32位。只有当磁盘接近满时(即只有很少的空闲块),链接列表方案所需的块才会少于位图。
如果空闲块倾向于以长时间连续块的形式出现,则可以修改空闲列表系统,以跟踪块的运行而不是单个块的运行。可以将8、16或32位计数与每个块相关联,给出连续可用块的数量。在最好的情况下,一个基本上是空的磁盘可以用两个数字表示:第一个空闲块的地址后面是空闲块的数量。另一方面,如果磁盘严重碎片化,则跟踪运行比跟踪单个块效率低,因为不仅必须存储地址,还必须存储计数。
这个问题说明了操作系统设计者经常遇到的一个问题。有多种数据结构和算法可用于解决问题,但选择最佳数据结构和方法需要设计者没有并且在系统部署和大量使用之前不会拥有的数据。即使如此,数据也可能不可用。例如,在1984年和1995年测量的VU文件大小、网站数据和康奈尔大学数据只是四个样本。虽然比什么都没有要好得多,但不知道它们是否也能代表家用电脑、公司电脑、政府电脑和其他电脑。通过一些努力,我们可能已经能够从其他类型的计算机上获得一些样本,但即使如此,将这些样本外推到所有被测量的计算机上也是愚蠢的。
回到空闲列表方法,只需要在主内存中保留一块指针。创建文件时,所需的块从指针块中获取。当它用完时,会从磁盘中读入一个新的指针块。类似地,当一个文件被删除时,它的块被释放并添加到主内存中的指针块中。当这个块被填满时,它被写入磁盘。
在某些情况下,此方法会导致不必要的磁盘I/O。考虑下图(a)中的情况,内存中的指针块只能再容纳两个条目。如果释放了一个三块文件,指针块溢出,必须写入磁盘,导致(b)所示的情况。如果现在写入了一个三块文件,则必须再次读取完整的指针块,将我们带回(a)。如果刚刚写入的三块文件是一个临时文件,则在释放该文件时,需要另一次磁盘写入才能将整个指针块写回磁盘。简而言之,当指针块几乎为空时,一系列短期临时文件可能会导致大量磁盘I/O。
避免大多数磁盘I/O的另一种方法是分割整个指针块。因此,当释放三个块时,我们不再从下图(a)转到下图。现在,系统可以处理一系列临时文件,而无需执行任何磁盘I/O。如果内存中的块已满,则会将其写入磁盘,并读入磁盘中的半满块。这里的想法是保持磁盘上的大多数指针块已满(以最小化磁盘使用),但保持内存中的指针块约半满,这样它就可以在空闲列表中没有磁盘I/O的情况下处理文件创建和文件删除。
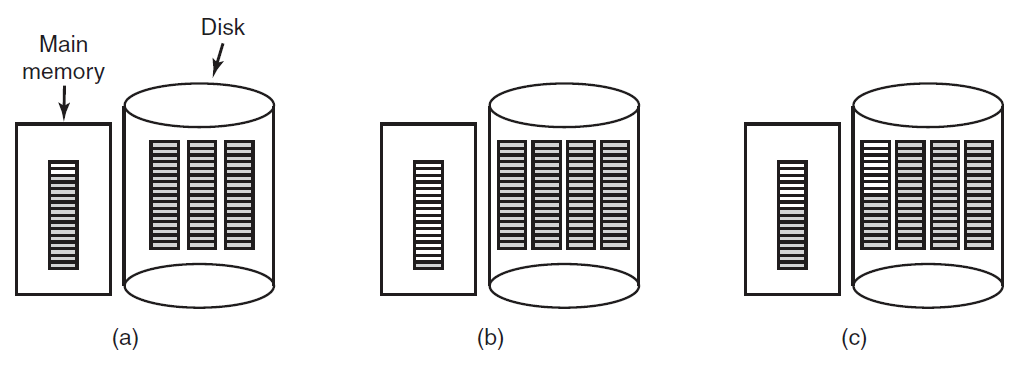
(a) 指向内存中空闲磁盘块的几乎完整的指针块和磁盘上的三个指针块。(b) 释放三个块文件的结果。(c)处理三个空闲块的替代策略。带阴影的条目表示指向可用磁盘块的指针。
使用位图,也可以只保留内存中的一个块,只有当它完全满或空时才将另一个块放入磁盘。这种方法的另一个好处是,通过从位图的单个块进行所有分配,磁盘块将紧密相连,从而最小化磁盘臂运动。由于位图是固定大小的数据结构,如果对内核进行(部分)分页,则可以将位图放在虚拟内存中,并根据需要分页。
接下来阐述磁盘配额(Disk Quotas)。
为了防止人们占用过多的磁盘空间,多用户操作系统通常提供一种强制执行磁盘配额的机制。其思想是,系统管理员为每个用户分配文件和块的最大分配,操作系统确保用户不会超过其配额。下面描述了一个典型的机制。
当用户打开一个文件时,属性和磁盘地址被定位并放入主内存中打开的文件表中。属性中有一个条目,告诉谁是所有者,文件大小的任何增加都将计入所有者的配额。
第二个表包含当前打开文件的每个用户的配额记录,即使该文件是由其他人打开的,此表如下图所示。它是从磁盘上的配额文件中为当前打开文件的用户提取的,关闭所有文件后,记录将被写回配额文件。
当在打开的文件表中创建新条目时,会在其中输入一个指向所有者配额记录的指针,以便于查找各种限制。每次向文件中添加块时,向所有者收取的块总数都会增加,并对硬限制和软限制进行检查。可以超过软限制,但不能超过硬限制。当达到硬块限制时,尝试附加到文件将导致错误。还存在类似的文件数量检查,以防止用户占用所有i节点。
当用户尝试登录时,系统会检查配额文件,以查看用户是否已超过文件数或磁盘块数的软限制。如果违反了任一限制,将显示警告,剩余警告数将减少一。如果计数为零,则用户多次忽略警告,不允许登录。要获得再次登录的权限,需要与系统管理员进行一些讨论。
此方法具有这样的属性,即用户在登录会话期间可能会超出其软限制,前提是他们在注销之前移除超出的限制。不得超过硬限制。
- 文件系统备份
文件系统的破坏通常比计算机的破坏更大。如果一台电脑被火灾、闪电或一杯咖啡泼到键盘上烧毁,会很烦人,也会花很多钱,但通常情况下,可以用最少的麻烦购买一台替代品。便宜的个人电脑甚至可以在一个小时内通过去电脑商店来更换。
如果计算机的文件系统由于硬件或软件而无法挽回地丢失,恢复所有信息将是困难的、耗时的,而且在许多情况下是不可能的。对于那些程序、文档、税务记录、客户文件、数据库、营销计划或其他数据永远消失的人来说,后果可能是灾难性的。虽然文件系统不能提供任何保护,防止设备和介质的物理破坏,但它可以帮助保护信息,非常简单——进行备份,但这并不像听起来那么简单。
大多数人认为备份文件是不值得花时间和精力的,直到有一天他们的磁盘突然损坏,这时他们中的大多数人都经历了一次致命的转换。然而,公司(通常)非常了解其数据的价值,通常每天至少备份一次,通常备份到磁带。现代磁带可容纳数百GB的容量,每GB成本为几美分。然而,备份并不像听起来那么简单,所以我们将在下面研究一些相关问题。磁带备份通常用于处理以下两个潜在问题之一:
1、从灾难中恢复。
2、从愚蠢中恢复过来。
第一种是在磁盘崩溃、火灾、洪水或其他自然灾害后让计算机重新运行。实际上,这些事情并不经常发生,这就是为什么许多人不愿意为备份而烦恼。
第二个原因是用户经常不小心删除了以后再次需要的文件。这个问题经常发生,当一个文件在Windows中被“删除”时,它根本不会被删除,只是被移动到一个特殊的目录,即回收站,这样它就可以很容易地被提取出来并在以后恢复。备份进一步遵循了这一原则,允许从旧备份磁带恢复几天甚至几周前删除的文件。
备份需要很长时间,并且占用大量空间,因此高效、方便地进行备份非常重要。这些考虑提出了以下问题。
首先,应该备份整个文件系统还是只备份其中的一部分?在许多安装中,可执行(二进制)程序保存在文件系统树的有限部分中。如果可以从制造商网站或安装DVD重新安装这些文件,则无需备份这些文件。此外,大多数系统都有一个临时文件目录,通常也没有理由支持它。在UNIX中,所有特殊文件(I/O设备)都保存在目录/dev中。不仅不需要备份这个目录,而且非常危险,因为如果备份程序试图读取每个目录直到完成,它将永远挂起。简而言之,通常只备份特定目录和其中的所有内容,而不是备份整个文件系统。
第二,备份自上次备份以来未更改的文件是浪费的,于是有了增量转储(incremental dumps)的想法。增量转储的最简单形式是定期进行完整转储(备份),例如每周或每月进行一次,并且每天只转储自上次完全转储以来修改过的文件。更好的方法是只转储自上次转储以来发生更改的文件。虽然此方案将转储时间减至最少,但它使恢复更加复杂,因为首先必须恢复最近的完整转储,然后是按相反顺序的所有增量转储。为了便于恢复,通常使用更复杂的增量转储方案。
第三,由于通常会转储大量数据,因此最好在将数据写入磁带之前对其进行压缩。然而,对于许多压缩算法,备份磁带上的一个坏点可能会破坏解压缩算法,使整个文件甚至整个磁带都无法读取。因此,必须仔细考虑压缩备份流的决定。
第四,很难在活动文件系统上执行备份。如果在转储过程中添加、删除和修改文件和目录,则产生的转储可能不一致。然而,由于进行转储可能需要数小时,因此可能需要让系统在晚上的大部分时间离线以进行备份,这并不总是可以接受的。为此,设计了一些算法,通过复制关键数据结构来快速快照文件系统状态,然后要求将来更改文件和目录以复制块,而不是就地更新块(Hutchinson等人,1999)。通过这种方式,文件系统在快照时被有效地冻结,因此可以在以后空闲时进行备份。
第五,也是最后一点,备份会给组织带来许多非技术性问题。如果系统管理员把所有的备份磁盘或磁带放在办公室里,并且在他走下大厅去喝咖啡的时候让它敞开着,没有人看守,那么世界上最好的在线安全系统可能是无用的。间谍所要做的就是闯进来一秒钟,把一张小小的磁盘或磁带放在口袋里,然后兴高采烈地溜走。此外,如果烧毁计算机的火也烧毁了所有备份磁盘,那么每天备份也没有什么用处。因此,备份磁盘应该放在异地,但这会带来更多的安全风险(因为现在必须保护两个站点)。下面我们将讨论只有文件系统备份涉及的技术问题。
可以使用两种策略将磁盘转储到备份磁盘:物理转储或逻辑转储。
物理转储从磁盘的块0开始,按顺序将所有磁盘块写入输出磁盘,并在复制完最后一个磁盘块后停止。这样一个程序非常简单,它可能100%没有bug,可能是任何其他有用的程序都无法做到的。
尽管如此,还是值得对物理转储发表几点意见。首先,备份未使用的磁盘块没有任何价值。如果转储程序可以访问空闲块数据结构,则可以避免转储未使用的块。但是,跳过未使用的块需要在块(或等效块)前面写入每个块的编号,因为备份中的块k不再是磁盘上的块k。
第二个担忧是转储坏块。几乎不可能制造出没有任何缺陷的大型磁盘,总是存在一些坏块。有时,当完成低级格式化时,会检测到坏块,并将其标记为坏块,然后由每个磁道末端为此类紧急情况保留的备用块替换。在许多情况下,磁盘控制器在操作系统甚至不知道的情况下透明地处理坏块替换。
然而,有时块在格式化后会变差,在这种情况下,操作系统最终会检测到它们。通常,它通过创建一个包含所有坏块的“文件”来解决这个问题,只是为了确保它们不会出现在空闲块池中,也不会被分配。不用说,这个文件完全不可读。
如果所有坏块都被磁盘控制器重新映射,并像刚才描述的那样从操作系统中隐藏,那么物理转储可以正常工作。另一方面,如果它们对操作系统可见,并且保存在一个或多个坏块文件或位图中,那么物理转储程序必须能够访问这些信息,并避免转储这些信息,以防止在尝试备份坏块文件时出现无休止的磁盘读取错误。
Windows系统具有在还原时不需要的分页和休眠文件,因此不应首先备份这些文件。特定系统还可能有其他不应备份的内部文件,因此转储程序需要知道这些文件。
物理转储的主要优点是简单和速度快(基本上可以以磁盘的速度运行)。主要缺点是无法跳过选定的目录,进行增量转储,以及根据请求恢复单个文件。由于这些原因,大多数安装都会进行逻辑转储。
逻辑转储从一个或多个指定目录开始,并递归转储在其中找到的自给定基准日期以来发生更改的所有文件和目录(例如,增量转储的上次备份或完整转储的系统安装)。因此,在逻辑转储中,转储磁盘会获得一系列经过仔细识别的目录和文件,这使得根据请求恢复特定文件或目录变得很容易。
由于逻辑转储是最常见的形式,让我们使用下图中的示例来详细检查一种常见算法。大多数UNIX系统都使用此算法。在图中,我们看到一个包含目录(正方形)和文件(圆形)的文件树。阴影项目自基准日期以来已被修改,因此需要转储。无阴影的不需要转储。
要转储的文件系统。正方形是目录,圆形是文件。自上次转储以来,阴影项目已被修改。每个目录和文件都按其i节点编号进行标记。
由于两个原因,此算法还将位于修改文件或目录路径上的所有目录(即使是未修改的目录)转储到修改后的文件或目录。第一个原因是可以将转储的文件和目录恢复到另一台计算机上的新文件系统。这样,转储和恢复程序可以用于在计算机之间传输整个文件系统。
将未修改的目录转储到修改过的文件上的第二个原因是,可以增量恢复单个文件(可能是为了处理愚蠢的恢复)。假设周日晚上进行了完整文件系统转储,周一晚上进行了增量转储。星期二,目录/usr/jhs/proj/nr3及其下的所有目录和文件将被删除。星期三早上,假设用户希望恢复文件/usr/jhs/proj/nr3/plans/summary。但是,不可能只恢复文件摘要,因为没有放置它的位置。必须首先恢复目录nr3和计划。要获得其所有者、模式、时间等信息,即使这些目录自上次完全转储后未被修改,也必须存在于转储磁盘上。
转储算法维护由i节点编号索引的位图,每个i节点有几个位。随着算法的进行,位将在此映射中设置和清除。该算法分四个阶段运行。阶段1从起始目录(本例中的根目录)开始,并检查其中的所有条目。对于每个修改过的文件,其i节点都标记在位图中。每个目录也被标记(无论是否被修改),然后递归检查。
在第1阶段结束时,所有修改的文件和所有目录都已标记在位图中,如下图(a)所示(通过阴影)。阶段2在概念上再次递归遍历树,取消标记任何目录中或目录下没有修改过的文件或目录。此阶段将留下位图,如(b)所示。请注意,目录10、11、14、27、29和30现在没有标记,因为它们下面没有任何修改过的内容。他们不会被抛弃。相比之下,目录5和6将被转储,即使它们本身没有被修改,因为需要它们来将今天的更改恢复到新机器。为了提高效率,阶段1和阶段2可以合并在一个树行走中。
此时,我们知道必须转储哪些目录和文件,如(b)中标记的。阶段3包括按数字顺序扫描i节点并转储所有标记为转储的目录。如(c)所示。每个目录都以目录的属性(所有者、时间等)为前缀,以便可以恢复它们。最后,在第4阶段,(d)中标记的文件也被转储,再次以其属性作为前缀。这便完成了转储。

逻辑转储算法使用的位图。
从转储磁盘恢复文件系统非常简单。首先,在磁盘上创建一个空文件系统,然后恢复最近的完整转储。由于目录首先出现在转储磁盘上,因此它们都会首先被还原,从而提供文件系统的框架。然后恢复文件本身,然后重复此过程,在完全转储之后进行第一次增量转储,然后进行下一次,依此类推。
虽然逻辑转储很简单,但有一些棘手的问题。首先,由于空闲块列表不是一个文件,因此它不会被转储,因此在恢复所有转储之后,必须从头重新构建它。这样做始终是可能的,因为空闲块集只是包含在所有合并文件中的块集的补充。
另一个问题是链接。如果一个文件链接到两个或多个目录,那么只恢复一次该文件,并且所有指向该文件的目录都会恢复,这一点很重要。
另一个问题是UNIX文件可能包含漏洞。合法的做法是打开一个文件,写入几个字节,然后查找到远处的文件偏移量,再写入几个字节。中间的块不是文件的一部分,不应转储,也不得还原。核心文件在数据段和堆栈之间通常有数百兆字节的空间。如果处理不当,每个恢复的核心文件将用零填充该区域,因此大小与虚拟地址空间相同(例如,\(2^{32}\)字节,或者更糟的是,\(2^{64}\)字节)。
最后,特殊文件、命名管道等(任何不是真实文件的文件)都不应该转储,无论它们可能出现在哪个目录中(它们不需要局限于/dev)。
- 文件系统一致性
另一个可靠性问题是文件系统一致性。许多文件系统读取块,修改它们,然后将它们写出。如果在写出所有修改的块之前系统崩溃,文件系统可能会处于不一致的状态。如果某些尚未写出的块是i-node块、目录块或包含空闲列表的块,则此问题尤其重要。
为了处理不一致的文件系统,大多数计算机都有一个实用程序来检查文件系统的一致性。例如,UNIX具有fsck,Windows有sfc(和其他)。此实用程序可以在系统启动时运行,特别是在崩溃后。
下面的描述说明了fsck的工作原理。Sfc有些不同,因为它在不同的文件系统上工作,但使用文件系统固有冗余修复它的一般原则仍然有效。所有文件系统检查器都独立于其他文件系统(磁盘分区)来验证每个文件系统。可以进行两种一致性检查:块和文件。为了检查块一致性,程序构建了两个表,每个表包含每个块的计数器,最初设置为0。第一个表中的计数器跟踪每个块在文件中出现的次数;第二个表中的计数器记录每个块出现在空闲列表(或空闲块的位图)中的频率。
然后,程序使用原始设备读取所有i节点,该设备忽略文件结构,只返回从0开始的所有磁盘块。从索引节点开始,可以构建相应文件中使用的所有块编号的列表。读取每个块编号时,第一个表中的计数器递增。然后,程序检查空闲列表或位图以查找所有未使用的块。自由列表中每个块的出现都会导致其在第二个表中的计数器递增。
如果文件系统是一致的,那么每个块在第一个表或第二个表中都会有一个1,如系统(a)所示。然而,由于碰撞,表格可能类似于图(b),其中两个表格中都没有出现方框2。它将被报告为丢失的块。虽然丢失的块不会造成真正的危害,但它们会浪费空间,从而降低磁盘的容量。丢失块的解决方案很简单:文件系统检查器只是将它们添加到空闲列表中。
另一种可能发生的情况如图(c)所示,有一个编号为4的块,在空闲列表中出现了两次。(只有当空闲列表确实是一个列表时,才会出现重复;使用位图是不可能的。)解决方案也很简单:重建空闲列表。
可能发生的最坏情况是,同一数据块存在于两个或多个文件中,如图(d)和块5所示。如果删除其中任何一个文件,块5将被放在空闲列表中,导致同一块同时处于使用和空闲状态。如果两个文件都被删除,则块将被放入空闲列表两次。
文件系统状态。(a) 一致性。(b) 丢失块。(c) 空闲列表中存在重复块。(d) 重复的数据块。
文件系统检查器要采取的适当操作是分配一个空闲块,将块5的内容复制到其中,然后将副本插入其中一个文件。通过这种方式,文件的信息内容保持不变(尽管几乎可以肯定是乱码),但文件系统结构至少保持一致。
应报告错误,以便用户检查损坏情况。除了检查每个块是否都得到了正确的解释之外,文件系统检查器还检查目录系统。它也使用计数器表,但这些计数器是按文件而不是按块计算的。它从根目录开始,递归地下降树,检查文件系统中的每个目录。对于每个目录中的每个i节点,它会为该文件的使用计数增加一个计数器。请记住,由于硬链接,文件可能会出现在两个或多个目录中。符号链接不计数,也不会导致目标文件的计数器递增。
当检查程序全部完成后,它会有一个列表,由i-node编号索引,告诉每个文件包含多少个目录。然后,它将这些数字与存储在i节点本身中的链接计数进行比较。创建文件时,这些计数从1开始,并在每次(硬)链接到文件时递增。在一致的文件系统中,这两种计数将一致。但是,可能会出现两种错误:i节点中的链接计数可能过高,也可能过低。
如果链接计数大于目录条目的数量,那么即使从目录中删除了所有文件,该计数仍将不为零,i-node也不会被删除。此错误并不严重,但如果文件不在任何目录中,则会浪费磁盘空间。应该通过将i节点中的链接计数设置为正确的值来修复此问题。
另一个错误可能是灾难性的。如果两个目录条目链接到一个文件,但i-node表示只有一个,则删除任一目录条目时,i-node计数将变为零。当i节点计数为零时,文件系统会将其标记为未使用,并释放其所有块。此操作将导致其中一个目录现在指向未使用的i-node,其块可能很快会分配给其他文件。同样,解决方案只是将i-node中的链接计数强制为目录条目的实际数量。
出于效率原因,这两种操作(检查块和检查目录)通常是集成在一起的(即,只需要在i节点上进行一次传递)。也可以进行其他检查。例如,目录具有明确的格式,其中包含i节点编号和ASCII名称。如果i节点数大于磁盘上的i节点数,则说明目录已损坏。
此外,每个i-node都有一个模式,其中一些是合法的,但很奇怪,例如0007,它允许所有者及其组根本没有访问权限,但允许外部人员读取、写入和执行文件。至少报告给外部人比所有者更多权利的文件可能会有用。例如,条目超过1000条的目录也是可疑的。位于用户目录中但由超级用户拥有并启用SETUID位的文件是潜在的安全问题,因为此类文件在任何用户执行时都会获得超级用户的权限。只要稍加努力,人们就可以列出一份相当长的技术上合法但仍有可能值得报道的特殊情况的清单。
- 文件系统性能
访问磁盘比访问内存慢得多,读取32位内存字可能需要10纳秒,从硬盘读取可能会以100 MB/秒的速度进行(是每32位字读取速度的四倍),但除此之外,还必须增加5–10毫秒以查找磁道,然后等待所需的扇区到达读取头下方。如果只需要一个字,那么内存访问的速度大约是磁盘访问的一百万倍。由于访问时间的差异,许多文件系统都设计了各种优化以提高性能。下面介绍三种。
第一种提升文件系统性能的方法是缓存。
用于减少磁盘访问的最常见技术是块缓存或缓冲区缓存。在这种情况下,缓存是逻辑上属于磁盘但出于性能原因保留在内存中的块的集合。
可以使用各种算法来管理缓存,但常见的算法是检查所有读取请求,以查看所需的块是否在缓存中。如果是,则无需磁盘访问即可满足读取请求。如果块不在缓存中,则首先将其读入缓存,然后将其复制到需要的位置。缓存可以满足对同一块的后续请求。
高速缓存的操作如下图所示。由于高速缓存中有许多(通常是数千)块,因此需要某种方法来快速确定给定块是否存在。通常的方法是散列设备和磁盘地址,并在散列表中查找结果。具有相同哈希值的所有块都链接在一个链表上,以便可以跟踪冲突链。
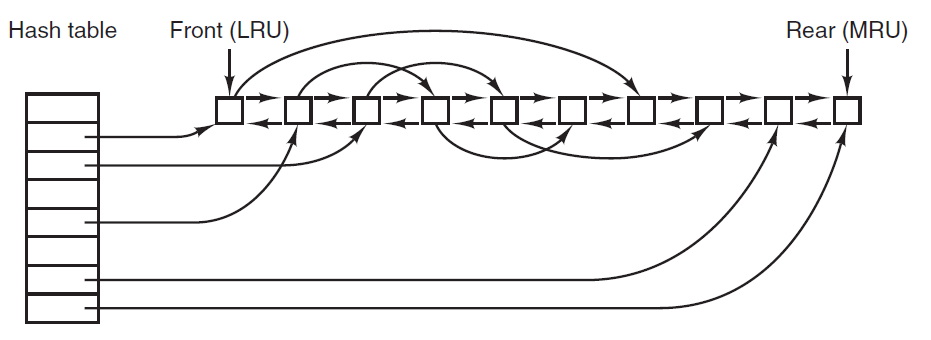
缓冲区缓存数据结构。

IO缓冲方案(输入)。
当一个块必须加载到一个完全缓存中时,必须删除一些块(如果它在引入后被修改,则必须重写到磁盘)。这种情况非常类似于分页,所有常用页面替换算法,如FIFO、二次机会和LRU都适用。分页和缓存之间的一个令人愉快的区别是缓存引用相对较少,因此可以使用链接列表将所有块保持在精确的LRU顺序。
在上图中,我们可以看到,除了从哈希表开始的冲突链之外,还有一个按使用顺序遍历所有块的双向列表,最近最少使用的块位于列表的前面,最近使用的块在末尾。当一个块被引用时,可以将其从双向列表中的位置删除并放在末尾。通过这种方式,可以维持精确的LRU顺序。
不幸的是,这里有一个陷阱。既然我们有可能实现精确LRU的情况,事实证明LRU是不可取的。这个问题与崩溃和文件系统一致性有关。如果将关键块(如i节点块)读入缓存并进行修改,但未重写到磁盘,则崩溃将使文件系统处于不一致状态。如果将i-node块放在LRU链的末端,它可能需要很长时间才能到达前端并被重写到磁盘。
此外,某些块(例如i节点块)很少在短间隔内被引用两次。这些考虑导致修改LRU方案,考虑了两个因素:
1、是否很快会再次需要该区块?
2、块对文件系统的一致性至关重要吗?
对于这两个问题,块可以分为类别,例如i节点块、间接块、目录块、完整数据块和部分完整数据块。很快,可能不再需要的块将放在LRU列表的前面,而不是后面,因此它们的缓冲区将被快速重用。可能很快会再次需要的块,例如正在写入的部分已满的块,位于列表的末尾,因此它们将保留很长时间。
第二个问题独立于第一个问题。如果块对文件系统一致性至关重要(基本上,除了数据块以外的所有内容),并且它已经被修改,则应立即将其写入磁盘,而不必考虑它放在LRU列表的哪一端。通过快速写入关键块,我们大大降低了崩溃破坏文件系统的可能性。
即使使用此措施来保持文件系统完整性不变,也不希望在将数据块写出来之前将其保存在缓存中的时间过长。想想使用个人电脑写书的人的困境。即使我们的编写器定期告诉编辑器将正在编辑的文件写入磁盘,也很有可能所有内容都仍在缓存中,而磁盘上什么也没有。如果系统崩溃,文件系统结构将不会损坏,但一整天的工作将丢失。
系统采用两种方法来处理它。UNIX的方法是使用系统调用sync,它将所有修改的块立即强制放到磁盘上。当系统启动时,一个程序(通常称为update)会在后台启动,在一个无休止的循环中发出同步调用,在调用之间休眠30秒。因此,由于崩溃,损失的工作时间不超过30秒。
虽然Windows现在有一个相当于同步的系统调用,称为Flush File Buffers,但过去它没有。相反,它有一种不同的策略,在某些方面比UNIX方法更好(在某些方面更糟)。它所做的是在每个修改过的块写入缓存后立即将其写入磁盘,所有修改过的块立即写回磁盘的缓存称为直写缓存,与非写缓存相比,它们需要更多的磁盘I/O。
当一个程序一次写入一个1-KB的块时,可以看出这两种方法之间的差异。UNIX将收集缓存中的所有字符,并每隔30秒或每当从缓存中删除块时将其写出一次。对于直写缓存,每个写入的字符都有一个磁盘访问权限。当然,大多数程序都进行内部缓冲,因此它们通常不会写入字符,而是在每个写入系统调用上写入一行或更大的单元。
缓存策略的这种差异导致的结果是,仅从UNIX系统中删除磁盘而不进行同步几乎总是会导致数据丢失,并且通常还会导致文件系统损坏。使用直写缓存不会出现问题。之所以选择这些不同的策略,是因为UNIX是在一个所有磁盘都是硬盘且不可移动的环境中开发的,而第一个Windows文件系统是从软盘世界开始的MS-DOS继承而来的。随着硬盘成为标准,UNIX方法以其更好的效率(但更差的可靠性)成为标准,现在在Windows上也用于硬盘。然而,如前所述,NTFS采取了其他措施(例如日志记录)来提高可靠性。
一些操作系统将缓冲区缓存与页面缓存集成在一起。当支持内存映射文件时,尤其有吸引力。如果一个文件映射到内存,那么它的一些页面可能在内存中,因为它们是按需分页的,这样的页面与缓冲区缓存中的文件块几乎没有区别。在这种情况下,可以以相同的方式处理它们,对文件块和页面都使用一个缓存。
第二种提升文件系统性能的方法是块预读取(Block Read Ahead)。
提高感知文件系统性能的第二种技术是,在需要块来提高命中率之前,尝试将块放入缓存。特别是,许多文件是按顺序读取的。当要求文件系统在文件中生成块k时,它会这样做,但当它完成后,它会在缓存中偷偷检查块k+1是否已经存在。如果不是,它会安排块k+1的读取,希望在需要时,它已经到达缓存。至少,它会在路上。
当然,这种预读策略只适用于实际按顺序读取的文件。如果一个文件正在被随机访问,那么预读取并没有帮助。事实上,它会将磁盘带宽读取捆绑在无用的块中,并从缓存中删除可能有用的块(如果这些块脏了,则可能会捆绑更多的磁盘带宽将其写回磁盘),会造成伤害。为了查看预读是否值得,文件系统可以跟踪每个打开的文件的访问模式。例如,与每个文件关联的位可以跟踪文件是处于“顺序访问模式”还是“随机访问模式”。最初,文件被赋予了怀疑的优势,并被置于顺序访问模式。然而,无论何时完成寻道,位都会被清除。如果再次开始顺序读取,则再次设置位。这样,文件系统就可以合理地猜测是否应该提前读取。如果偶尔出错,这不是灾难,只是浪费了一点点磁盘带宽。
第三种提升文件系统性能的方法是减少圆盘臂运动(Reducing Disk-Arm Motion)。
缓存和预读并不是提高文件系统性能的唯一方法。另一项重要的技术是通过将可能被依次接近的块放置在同一个圆柱体中,来减少磁盘臂的运动量。写入输出文件时,文件系统必须按需一次分配一个块。如果自由块记录在位图中,并且整个位图都在主内存中,那么选择一个尽可能接近前一个块的自由块就足够容易了。有了一个空闲列表(其中一部分位于磁盘上),很难将块紧密地分配在一起。
然而,即使有一个空闲列表,也可以进行一些块聚类。诀窍是不按块跟踪磁盘存储,而是按连续块的组跟踪。如果所有扇区都由512字节组成,则系统可以使用1-KB的块(2个扇区),但以2个块(4个扇区)为单位分配磁盘存储。与拥有2 KB的磁盘块,因为缓存仍将使用1 KB的块,磁盘传输仍将为1 KB,但在空闲的系统上顺序读取文件将减少两倍的寻道数,从而大大提高性能。同一主题的变体是考虑旋转定位,分配块时,系统会尝试将连续块放置在同一圆柱体中的文件中。
在使用i节点或类似节点的系统中,另一个性能瓶颈是,即使读取一个短文件也需要两次磁盘访问:一次用于i节点,另一次用于块。通常的i节点布置如下图(a)所示。这里所有的i节点都靠近磁盘的起点,因此inode和它的块之间的平均距离将是柱面数的一半,需要长时间查找。
一个简单的性能改进是将i节点放在磁盘的中间,而不是开始,从而将i节点和第一个块之间的平均寻道减少了两倍。下图(b)所示的另一个想法是将磁盘划分为圆柱体组,每个圆柱体组都有自己的i节点、块和空闲列表。创建新文件时,可以选择任何i-node,但会尝试在与i-node相同的圆柱体组中查找块。如果没有可用的圆柱体组,则使用附近圆柱体组中的圆柱体组。
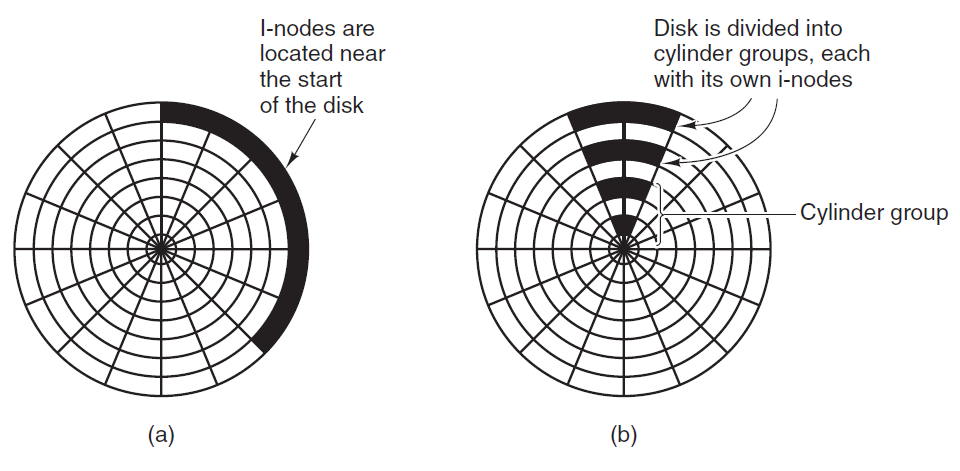
(a) 位于磁盘开头的I节点。(b) 磁盘分为圆柱体组,每个圆柱体组都有自己的块和i节点。
当然,只有当磁盘具有盘臂运动和旋转时间时,它们才相关。越来越多的计算机配备了固态磁盘(SSD),这些固态磁盘没有任何移动部件。对于这些建立在与闪存卡相同技术上的磁盘,随机访问与顺序访问一样快,传统磁盘的许多问题都消失了。不幸的是,出现了新的问题。例如,SSD在读取、写入和删除时具有特殊的属性。特别是,每个块只能写入有限的次数,因此要非常小心地将磨损均匀地分布在磁盘上。
18.11.3.9 磁盘碎片整理
当操作系统最初安装时,它需要的程序和文件从磁盘的开头开始连续安装,每个程序和文件都直接跟在前一个程序和文件之后。所有可用磁盘空间都位于安装文件之后的单个连续单元中。然而,随着时间的推移,文件会被创建和删除,通常磁盘会严重碎片化,到处都是文件和漏洞。因此,当创建新文件时,用于该文件的块可能会分散在整个磁盘上,从而导致性能低下。
通过移动文件使其连续,并将所有(或至少大部分)可用空间放在磁盘上的一个或多个大的连续区域中,可以恢复性能。Windows有一个程序,即碎片整理,它正是这样做的。Windows用户应该定期运行它,但SSD除外。
碎片整理在分区末尾的相邻区域中有大量可用空间的文件系统上效果更好。此空间允许碎片整理程序选择分区开始处附近的碎片文件,并将其所有块复制到可用空间。这样做可以在分区开始处附近释放一个连续的空间块,原始文件或其他文件可以连续放置在其中。然后可以使用下一块磁盘空间等重复该过程。
无法移动某些文件,包括分页文件、休眠文件和日志记录,因为执行此操作所需的管理工作带来的麻烦比实际需要的多。在某些系统中,这些区域是固定大小的连续区域,因此不必进行碎片整理。他们缺乏移动性的一个问题是,他们碰巧在分区的末尾,用户希望减小分区大小。解决此问题的唯一方法是完全删除它们,调整分区大小,然后在以后重新创建它们。
由于磁盘块的选择方式,Linux文件系统(尤其是ext2和ext3)通常比Windows系统受到的碎片整理更少,因此很少需要手动碎片整理。此外,SSD实际上根本不会受到碎片的影响。事实上,对SSD进行碎片整理会适得其反。不仅性能没有提高,SSD也会磨损,因此对它们进行碎片整理只会缩短它们的寿命。
18.11.3.10 文件系统案例
常见的文件系统案例有MS-DOS文件系统、UNIX V7文件系统、CD-ROM文件系统。
甚至UNIX的早期版本也有一个相当复杂的多用户文件系统,因为它是从MULTICS派生而来的。下面我们将讨论V7文件系统,它是使UNIX出名的PDP-11的文件系统。
文件系统的形式是从根目录开始的树,添加了链接,形成了一个有向非循环图(DAG)。文件名最多可以包含14个字符,并且可以包含除/(因为它是路径中组件之间的分隔符)和NUL(因为它用于填充小于14个字符的名称)之外的任何ASCII字符,NUL的数值为0。
UNIX目录条目包含该目录中每个文件的一个条目。每个条目都非常简单,因为UNIX使用i-node方案。目录条目仅包含两个字段:文件名(14字节)和该文件的i-noder数(2字节),如下图所示。这些参数将每个文件系统的文件数限制为64K。
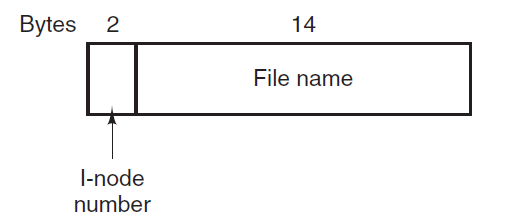
与i节点类似,UNIX i节点包含一些属性。这些属性包含文件大小、三次(创建、上次访问和上次修改)、所有者、组、保护信息以及指向i节点的目录条目数。由于链接,需要后一个字段。每当建立到i节点的新链接时,i节点中的计数就会增加。删除链接时,计数将递减。当它达到0时,将回收i节点,并将磁盘块放回可用列表中。
为了处理非常大的文件,可以跟踪磁盘块。前10个磁盘地址存储在i节点本身,因此对于小文件,所有必要的信息都在i节点中,当文件打开时,这些信息会从磁盘提取到主内存中。对于较大的文件,i节点中的地址之一是称为单个间接块的磁盘块的地址。此块包含其他磁盘地址。如果仍然不够,则i节点中的另一个地址(称为双间接块)包含包含单个间接块列表的块的地址。每个间接块都指向几百个数据块。如果还不够,也可以使用三重间接块。全图如下所示。

打开文件时,文件系统必须使用提供的文件名并定位其磁盘块。让我们考虑如何查找路径名/usr/ast/mbox。我们将以UNIX为例,但算法对于所有分层目录系统基本相同。首先,文件系统定位根目录。在UNIX中,其i节点位于磁盘上的固定位置。从这个i-node中,它可以找到根目录,可以位于磁盘上的任何位置,也可以是块1。
之后,它读取根目录并在根目录中查找路径的第一个组件usr,以查找文件/usr的i-node编号。根据i节点的编号定位i节点很简单,因为每个节点在磁盘上都有一个固定的位置。从这个i-node,系统找到/usr的目录,并在其中查找下一个组件ast。当它找到ast的条目时,它拥有目录/usr/ast的i-node。从这个i节点,它可以找到目录本身并查找mbox。然后将此文件的i节点读入内存并保存在内存中,直到文件关闭。查找过程如下图所示。
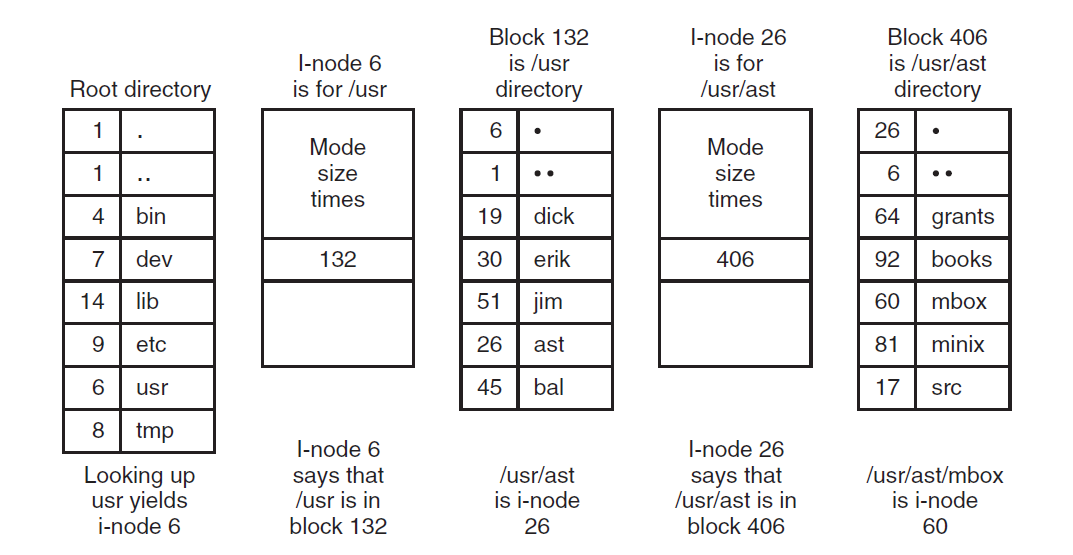
相对路径名的查找方式与绝对路径名相同,只从工作目录开始,而不是从根目录开始。每个目录都有.和..的条目,它们在创建目录时放在那里。条目.具有当前目录的i-node编号,条目..具有父目录的i-node编号。因此,查找../dick/prog的过程。c只需在工作目录中查找..,找到父目录的i-node编号,然后在该目录中搜索dick。处理这些名称不需要特殊的机制,就目录系统而言,它们只是普通的ASCII字符串,与其他名称一样,唯一的技巧是根目录中的..指向自身。
下图是Linux虚拟文件系统上下文:
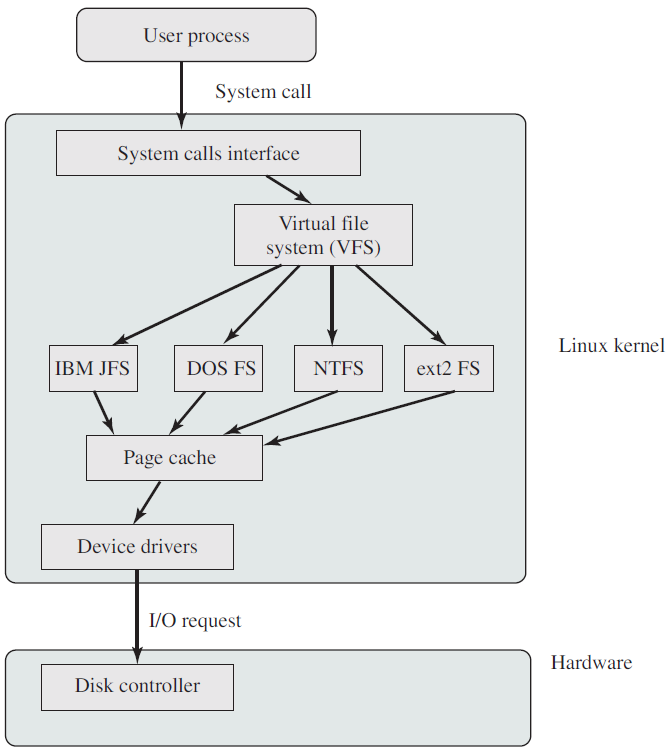
下图是Linux虚拟文件系统概念:
18.11.4 I/O
除了提供诸如进程、地址空间和文件等抽象概念外,操作系统还控制计算机的所有I/O(输入/输出)设备。它必须向设备发出命令、捕获中断和处理错误,还应该在设备和系统其余部分之间提供一个简单易用的接口。在可能的情况下,所有设备的接口应相同(设备独立性)。I/O代码占整个操作系统的很大一部分。
18.11.4.1 I/O硬件原理
不同的人以不同的方式看待I/O硬件。电气工程师从芯片、电线、电源、电机以及构成硬件的所有其他物理组件的角度来看待它,程序员查看呈现给软件的界面—硬件接受的命令、执行的功能以及可以报告的错误。我们应该关注的是I/O设备的编程,而不是设计、构建或维护它们,所以我们的兴趣在于硬件是如何编程的,而不是它内部的工作方式。然而,许多I/O设备的编程通常与其内部操作密切相关。在接下来的内容中,我们将提供与编程相关的I/O硬件的一般背景知识。
I/O设备可以大致分为两类:块设备(block device)和字符设备(character device)。块设备是将信息存储在固定大小的块中的设备,每个块都有自己的地址,公共块大小从512字节到65536字节不等,所有传输都以一个或多个完整(连续)块为单位。块设备的基本特性是可以独立于所有其他块读取或写入每个块,硬盘、蓝光光盘和USB磁盘是常见的块设备。
如果仔细观察,可以块寻址的设备和不可以块寻址设备之间的边界没有很好地定义。每个人都同意磁盘是一个块寻址设备,因为无论臂当前在哪里,总是可以找到另一个圆柱体,然后等待所需的块在头部下方旋转。现在,考虑一下仍在使用的老式磁带机,有时用于进行磁盘备份(因为磁带很便宜)。磁带包含一系列块,如果磁带驱动器收到读取块N的命令,它总是可以倒带并向前走,直到到达块N为止。此操作类似于磁盘执行查找,只是需要更长的时间。此外,在磁带中间重写一个块也许可能,也许不可能。即使有可能将磁带用作随机访问块设备,也在一定程度上拓展了这一点,但它们通常不是这样使用的。
另一种类型的I/O设备是字符设备。字符设备发送或接受字符流,而不考虑任何块结构。它不可寻址,并且没有任何寻道操作。打印机、网络接口、鼠标(用于指向)、鼠标(用于心理实验室实验)以及大多数其他非磁盘设备都可以被视为字符设备。
这个分类方案并不完美,有些设备不适合。例如,时钟不可块寻址,也不生成或接受字符流,所做的只是以明确的间隔引起中断。内存映射屏幕也不适合该模型,触摸屏也不例外。尽管如此,块和字符设备的模型足够通用,可以用作使某些处理I/O设备的操作系统软件独立的基础。例如,文件系统只处理抽象块设备,而将依赖设备的部分留给较低级别的软件。
I/O设备的速度范围很广,给软件带来了相当大的压力,使其在数据速率上的性能超过许多数量级。下表显示了一些常见设备的数据速率。随着时间的推移,这些设备大多会变得更快。
| 设备 | 数据速率(单位:每秒) |
|---|---|
| 键盘 | 10 B |
| 鼠标 | 100 B |
| 56K调制解调器 | 7.0 KB |
| 300dpi扫描仪 | 1.0 MB |
| 数码摄像机 | 3.5 MB |
| 4倍蓝光光盘 | 18.0 MB |
| 802.11n无线 | 37.5 MB |
| USB 2.0 | 60.0 MB |
| FireWire 800 | 100 MB |
| 千兆以太网 | 125 MB |
| SATA 3磁盘驱动器 | 600 MB |
| USB 3.0 | 625 MB |
| SCSI Ultra 5总线 | 640 MB |
| 单通道PCIe 3.0总线 | 985 MB |
| Thunderbolt 2总线 | 2.5 GB |
| SONET OC-768网络 | 5.0 GB |
以下是常见的几种IO组织模型:
设备控制器
I/O单元通常由机械部件和电子部件组成。可以将这两部分分开,以提供更模块化和通用的设计。电子元件称为设备控制器或适配器,在个人计算机上,它通常采用主板上的芯片或可插入(PCIe)扩展插槽的印刷电路卡的形式。机械部件是设备本身。
控制器卡上通常有一个连接器,可以插入通向设备本身的电缆。许多控制器可以处理两个、四个甚至八个相同的设备。如果控制器和设备之间的接口是标准接口,可以是ANSI、IEEE或ISO官方标准,也可以是事实标准,那么公司可以制造适合该接口的控制器或设备。例如,许多公司都生产与SATA、SCSI、USB、Thunderbolt或FireWire(IEEE 1394)接口匹配的磁盘驱动器。
控制器和设备之间的接口通常是非常低级别的接口。例如,一个磁盘可以格式化为2000000个扇区,每个磁道512字节。然而,从驱动器中实际出来的是一个串行位流,从前导码开始,然后是扇区中的4096位,最后是校验和,即ECC(纠错码)。在格式化磁盘时写入前导码,前导码包含柱面和扇区编号、扇区大小、类似数据以及同步信息。
控制器的工作是将串行位流转换为字节块,并执行任何必要的错误纠正,字节块通常首先在控制器内的缓冲区中逐位组装,在校验和经过验证并且块被声明为无错误后,可以将其复制到主内存。
LCD显示器的控制器也可以作为一个同样低电平的位串行设备工作。它从内存中读取包含要显示字符的字节,并生成信号来修改相应像素的背光偏振,以便将其写入屏幕。如果没有显示控制器,操作系统程序员就必须对所有像素的电场进行显式编程。使用控制器,操作系统用一些参数初始化控制器,例如每行的字符或像素数以及每屏的行数,并让控制器负责实际驱动电场。
在很短的时间内,LCD屏幕已经完全取代了旧的CRT(阴极射线管)显示器。CRT显示器将电子束发射到荧光屏上,利用磁场,该系统能够弯曲光束并在屏幕上绘制像素。与LCD屏幕相比,CRT显示器体积庞大、耗电量大且易碎。此外,今天(视网膜)LCD屏幕的分辨率非常好,人眼无法分辨单个像素。今天很难想象,过去的笔记本电脑配备了一个小型CRT屏幕,使其深度超过20厘米,重量约为12公斤。
内存映射I/O
每个控制器都有几个寄存器,用于与CPU通信。通过写入这些寄存器,操作系统可以命令设备发送数据、接收数据、打开或关闭自身,或者执行某些操作。通过读取这些寄存器,操作系统可以了解设备的状态,是否准备接受新命令,等等。
除了控制寄存器外,许多设备还具有操作系统可以读取和写入的数据缓冲区。例如,计算机在屏幕上显示像素的一种常见方式是有一个视频RAM,它基本上只是一个数据缓冲区,可供程序或操作系统写入。
因此,出现了CPU如何与控制寄存器以及设备数据缓冲区通信的问题。有两种选择。在第一种方法中,每个控制寄存器被分配一个I/O端口号,一个8位或16位整数。所有I/O端口的集合构成I/O端口空间,该空间受到保护,因此普通用户程序无法访问它(只有操作系统才能访问)。使用特殊的I/O指令,例如:
IN REG, PORT,
CPU可以读取控制寄存器PORT并将结果存储在CPU寄存器REG中。类似地,使用:
OUT PORT, REG
CPU可以将REG的内容写入控制寄存器。大多数早期的计算机,包括几乎所有的大型机,如IBM360及其所有后续产品,都是这样工作的。在此方案中,内存和I/O的地址空间不同,如下图(a)所示。指令IN R0, 4和MOV R0, 4在这个设计中完全不同。前者读取I/O端口4的内容并将其放入R0,而后者读取内存字4的内容,并将其置于R0。这些示例中的4表示不同且不相关的地址空间。
(a) 分开I/O和内存空间。(b) 内存映射I/O。(c) 混合。
PDP-11引入的第二种方法是将所有控制寄存器映射到内存空间,如上图(b)所示。每个控制寄存器都分配了一个唯一的存储器地址,但没有分配存储器。该系统称为内存映射I/O(Memory-mapped I/O)。在大多数系统中,分配的地址位于或接近地址空间的顶部。上图(c)显示了一种混合方案,该方案具有内存映射I/O数据缓冲区和用于控制寄存器的单独I/O端口。x86使用此体系结构,地址为640K到1M− 除了I/O端口0到64K之外,1是为IBM PC兼容机中的设备数据缓冲区保留的− 1.
这些计划实际上是如何运作的?在所有情况下,当CPU想要从内存或I/O端口读取一个字时,它将所需的地址放在总线的地址线上,然后在总线的控制线上断言一个read信号,第二条信号线用于判断是否需要I/O空间或内存空间。如果是内存空间,内存会响应请求。如果是I/O空间,I/O设备将响应请求。如果只有内存空间(上图(b)),每个内存模块和每个I/O设备都会将地址线与其服务的地址范围进行比较。如果地址在其范围内,它将响应请求。由于从未向内存和I/O设备分配地址,因此没有歧义和冲突。
这两种控制器寻址方案有不同的优缺点。先描述内存映射I/O的优点:
-
首先,如果读写设备控制寄存器需要特殊的I/O指令,那么访问它们需要使用汇编代码,因为无法在C或C++中执行IN或OUT指令,调用这样的过程会增加控制I/O的开销。与此相反,对于内存映射I/O,设备控制寄存器只是内存中的变量,可以用与任何其他变量相同的方式在C中寻址。因此,使用内存映射I/O,I/O设备驱动程序可以完全用C编写。如果没有内存映射I/O的话,就需要一些汇编代码。
-
其次,对于内存映射I/O,不需要特殊的保护机制来阻止用户进程执行I/O。操作系统所要做的就是避免将包含控制寄存器的那部分地址空间放在任何用户的虚拟地址空间中。更好的是,如果每个设备的控制寄存器都位于地址空间的不同页面上,操作系统可以通过简单地将所需页面包含在其页面表中,让用户控制特定设备,而不是其他设备。这样的方案可以将不同的设备驱动程序放置在不同的地址空间中,不仅可以减小内核大小,还可以防止一个驱动程序干扰其他驱动程序。
-
第三,使用内存映射I/O,可以引用内存的每条指令也可以引用控制寄存器。例如,如果有一条指令TEST测试0的内存字,它也可以用于测试0的控制寄存器,可能是设备空闲并可以接受新命令的信号。汇编语言代码可能如下所示:
LOOP: TEST PORT 4 // check if por t 4 is 0 BEQ READY // if it is 0, go to ready BRANCH LOOP // otherwise, continue testing READY:如果不存在内存映射I/O,则必须首先将控制寄存器读入CPU,然后进行测试,便需要两条指令,而不是一条。在上述循环的情况下,必须添加第四条指令,略微降低检测空闲设备的响应速度。
在计算机设计中,实际上一切都涉及权衡,这里也是如此。内存映射I/O也有其缺点:
-
首先,现在大多数计算机都有某种形式的内存字缓存。缓存设备控制寄存器将是灾难性的。考虑上面给出的存在缓存的汇编代码循环。对PORT 4的第一个引用将导致它被缓存。后续引用只会从缓存中获取值,甚至不会询问设备。然后当设备最终准备就绪时,软件将无法发现。相反,循环将永远持续下去。
为了防止内存映射I/O出现这种情况,硬件必须能够选择性地禁用缓存,例如,以每页为基础。此功能增加了硬件和操作系统的额外复杂性,后者必须管理选择性缓存。
-
其次,如果只有一个地址空间,那么所有内存模块和所有I/O设备都必须检查所有内存引用,以查看要响应的内存引用。如果计算机只有一条总线,如下图(a)所示,让每个人都查看每个地址是很简单的。
![]()
然而,现代个人计算机的趋势是拥有专用的高速内存总线,如上图(b)所示。该总线是为优化内存性能而定制的,不会因为I/O设备速度慢而有所妥协。x86系统可以有多条总线(内存、PCIe、SCSI和USB)。
在内存映射机器上使用单独的内存总线的问题是,I/O设备在内存总线上经过时无法看到内存地址,因此无法对其作出响应。同样,必须采取特殊措施使内存映射I/O在具有多条总线的系统上工作。一种可能是首先将所有内存引用发送到内存。如果内存没有响应,则CPU尝试其他总线。这种设计可以工作,但需要额外的硬件复杂性。
第二种可能的设计是在内存总线上放置一个监听设备,将所有呈现的地址传递给潜在感兴趣的I/O设备。这里的问题是I/O设备可能无法以内存所能达到的速度处理请求。
第三种可能的设计,是在内存控制器中过滤地址。在这种情况下,内存控制器芯片包含在引导时预加载的范围寄存器。例如,640K到1M− 1可以标记为非内存范围。属于标记为非内存范围之一的地址被转发到设备而不是内存。此方案的缺点是需要在引导时确定哪些内存地址不是真正的内存地址。因此,每个方案都有支持和反对的理由,所以妥协和权衡是不可避免的。
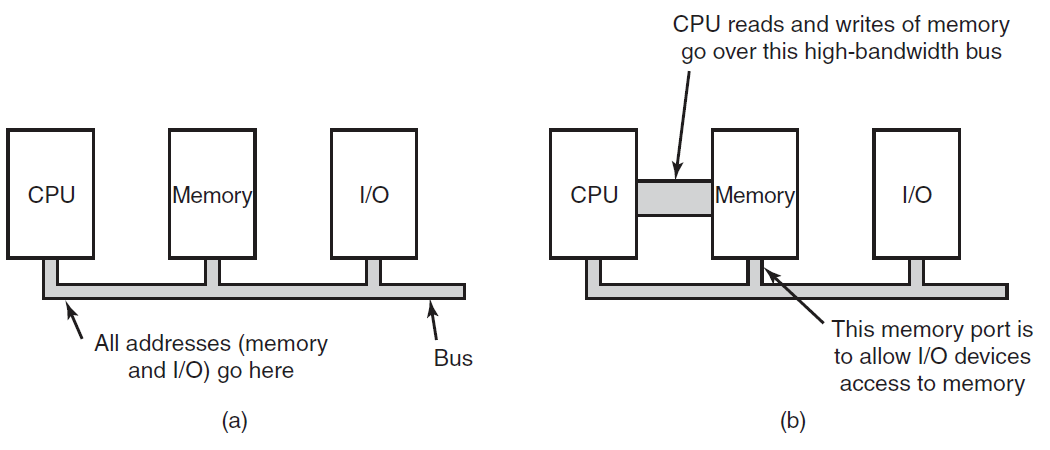
直接内存访问
无论CPU是否具有内存映射I/O,它都需要寻址设备控制器以与它们交换数据。CPU可以一次从I/O控制器请求一个字节的数据,但这样做会浪费CPU的时间,因此通常使用一种不同的方案,称为DMA(Direct Memory Access,直接内存访问)。为了简化解释,我们假设CPU通过连接CPU、内存和I/O设备的单个系统总线访问所有设备和内存,如下图所示。我们已经知道,现代系统中的实际组织更加复杂,但所有原理都是相同的。如果硬件有DMA控制器,操作系统只能使用DMA,而大多数系统都有。有时,该控制器集成到磁盘控制器和其他控制器中,但这种设计要求每个设备都有一个单独的DMA控制器。更常见的情况是,可以使用单个DMA控制器(例如,在主板上)来调节到多个设备的传输,通常是同时进行的。
无论DMA控制器位于何处,它都可以独立于CPU访问系统总线,如下图所示。它包含几个可由CPU写入和读取的寄存器,这些寄存器包括内存地址寄存器、字节计数寄存器和一个或多个控制寄存器,控制寄存器指定要使用的I/O端口、传输方向(从I/O设备读取或写入I/O设备)、传输单元(每次字节或每次字)以及一次突发传输的字节数。
为了解释DMA的工作原理,让我们先看看不使用DMA时磁盘读取是如何发生的。首先,磁盘控制器从驱动器逐位串行读取块(一个或多个扇区),直到整个块位于控制器的内部缓冲区中。接下来,它计算校验和以验证没有发生读取错误。然后控制器导致中断。当操作系统开始运行时,它可以通过执行循环,一次从控制器的缓冲区读取一个字节或一个字的磁盘块,每次迭代从控制器设备寄存器读取一个字符或字,并将其存储在主内存中。
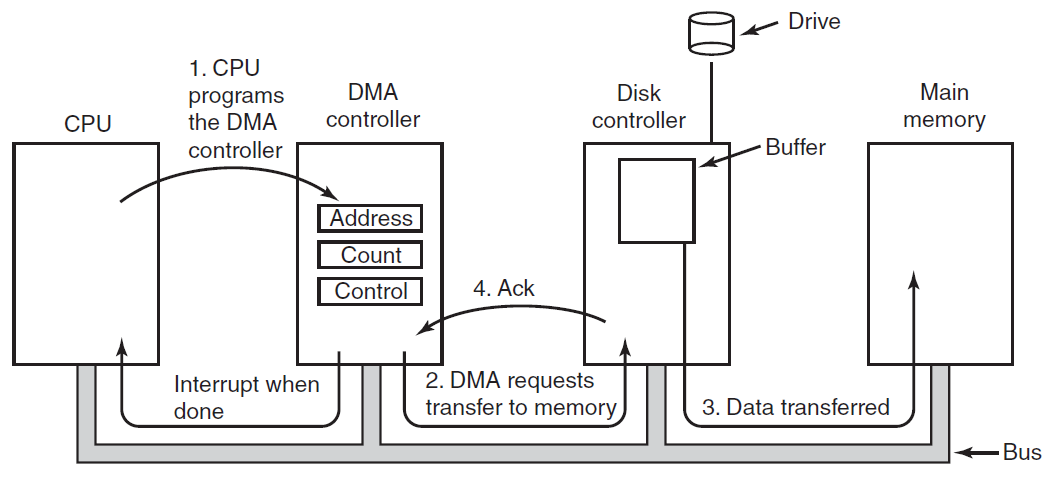
DMA传输的操作。
使用DMA时,过程不同。首先,CPU通过设置其寄存器来编程DMA控制器,以便它知道要将什么传输到哪里(上图中的步骤1)。它还向磁盘控制器发出命令,告诉它将数据从磁盘读取到其内部缓冲区,并验证校验和。当有效数据在磁盘控制器的缓冲区中时,DMA可以开始。
DMA控制器通过总线向磁盘控制器发出读取请求来启动传输(步骤2)。这个读取请求看起来像任何其他读取请求,磁盘控制器不知道(或不关心)它是来自CPU还是来自DMA控制器。通常,要写入的内存地址位于总线的地址行上,因此当磁盘控制器从其内部缓冲区获取下一个字时,它知道将其写入何处。写入内存是另一个标准总线周期(步骤3)。当写入完成时,磁盘控制器也通过总线向DMA控制器发送确认信号(步骤4)。然后,DMA控制器增加要使用的内存地址,并减少字节计数。如果字节计数仍然大于0,则重复步骤2至4,直到计数达到0。此时,DMA控制器中断CPU,让它知道传输现在已完成。当操作系统启动时,不必将磁盘块复制到内存中,因为磁盘块已经在那里了。
DMA控制器的复杂程度差异很大。如上所述,最简单的方法一次处理一个传输。可以对更复杂的程序进行编程,以同时处理多个传输。此类控制器内部有多组寄存器,每个通道一组。CPU首先加载每组寄存器及其传输的相关参数。每次传输必须使用不同的设备控制器。在上图中的每个字被传输后(步骤2到4),DMA控制器决定下一个要服务的设备。它可能被设置为使用循环算法,或者它可能具有优先方案设计,以支持某些设备而不是其他设备。对不同设备控制器的多个请求可能会同时挂起,前提是有明确的方法区分确认。因此,总线上的不同确认线通常用于每个DMA信道。
许多总线可以在两种模式下运行:逐字模式和块模式。一些DMA控制器也可以在这两种模式中运行。在前一种模式中,DMA控制器请求传输一个字并获得它,如果CPU也需要总线,它必须等待。这种机制称为周期窃取(cycle stealing),因为设备控制器会潜入CPU,偶尔从CPU窃取总线周期,稍微延迟一点。在块模式下,DMA控制器告诉设备获取总线,发出一系列传输,然后释放总线。这种操作形式称为突发模式(burst mode)。它比周期窃取更有效,因为获取总线需要时间,并且可以以一条总线的价格传输多个单词。突发模式的缺点是,如果传输长突发,它会在相当长的一段时间内阻塞CPU和其他设备。
在我们讨论的模型中,有时称为飞行模式(fly-by mode),DMA控制器告诉设备控制器将数据直接传输到主存储器。一些DMA控制器使用的另一种模式是让设备控制器将Word发送到DMA控制器,然后DMA控制器发出第二个总线请求,将Word写入应该写入的位置。该方案要求每传输一个字都有额外的总线周期,但更灵活,因为它还可以执行设备到设备的复制,甚至内存到内存的复制(首先对内存进行读取,然后在不同地址对内存进行写入)。
大多数DMA控制器使用物理内存地址进行传输。使用物理地址需要操作系统将预期内存缓冲区的虚拟地址转换为物理地址,并将此物理地址写入DMA控制器的地址寄存器。少数DMA控制器中使用的另一种方案是将虚拟地址写入DMA控制器。
然后DMA控制器必须使用MMU完成虚拟到物理的转换。只有在MMU是内存的一部分(可能,但很少),而不是CPU的一部分的情况下,虚拟地址才能放在总线上。我们前面提到过,在DMA启动之前,磁盘首先将数据读入其内部缓冲区。
为什么控制器在从磁盘获取字节后不直接将其存储在主内存中。换句话说,它为什么需要内部缓冲区?有两个原因。
首先,通过进行内部缓冲,磁盘控制器可以在开始传输之前验证校验和。如果校验和不正确,则发出错误信号,不进行传输。
第二个原因是,一旦磁盘传输开始,无论控制器是否准备就绪,位都会以恒定的速率从磁盘到达。如果控制器试图将数据直接写入内存,则必须通过系统总线传输每个字。如果总线由于其他设备使用而繁忙(例如,在突发模式下),控制器将不得不等待。如果下一个磁盘字在存储前一个之前到达,则控制器必须将其存储在某个地方。如果总线很忙,控制器可能会存储相当多的字,并有很多管理工作要做。当块被内部缓冲时,直到DMA开始时才需要总线,因此控制器的设计要简单得多,因为DMA传输到内存不是时间关键的。(事实上,一些较旧的控制器确实只需要少量内部缓冲就可以直接进入内存,但当总线非常繁忙时,传输可能会因溢出错误而终止。)
并非所有计算机都使用DMA。反对它的理由是,主CPU通常比DMA控制器快得多,并且可以更快地完成工作(当限制因素不是I/O设备的速度时)。如果没有其他工作要做,让(快速)CPU等待(慢速)DMA控制器完成是毫无意义的。此外,去掉DMA控制器并让CPU完成软件中的所有工作可以节省资源,在低端(嵌入式)计算机上很重要。
重新访问中断
在典型的个人计算机系统中,中断结构如下图所示。在硬件级别,中断的工作方式是:当I/O设备完成给它的工作时,它会导致中断(假设操作系统已启用中断)。它通过在分配给它的总线上断言信号来实现这一点,这个信号由主板上的中断控制器芯片检测到,然后由它决定要做什么。
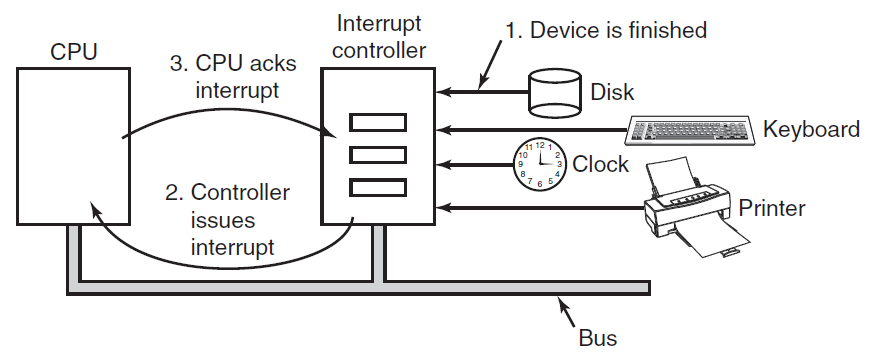
中断是如何发生的。设备和控制器之间的连接实际上使用总线上的中断线,而不是专用线。
如果没有其他中断挂起,中断控制器会立即处理该中断。然而,如果另一个中断正在进行中,或者另一个设备在总线上的高优先级中断请求行上同时发出了请求,则暂时忽略该设备。在这种情况下,它继续在总线上断言中断信号,直到CPU为其提供服务为止。为了处理中断,控制器将一个数字放在地址线上,指定哪个设备需要关注,并断言一个信号来中断CPU。
中断信号使CPU停止正在做的事情,并开始做其他事情。地址行上的数字用作名为中断向量的表的索引,以获取新的程序计数器。该程序计数器指向相应中断服务程序的开始。通常,陷阱和中断从此时起使用相同的机制,通常共享相同的中断向量。中断向量的位置可以硬连接到机器中,也可以在内存中的任何位置,CPU寄存器(由操作系统加载)指向其原点。
在它开始运行后不久,中断服务程序通过向中断控制器的一个I/O端口写入某个值来确认中断。该确认通知控制器可以自由发出另一个中断。通过让CPU延迟此确认,直到它准备好处理下一个中断,可以避免涉及多个(几乎同时)中断的竞争条件。另外,一些(较旧的)计算机没有集中式中断控制器,因此每个设备控制器都请求自己的中断。
硬件总是在开始维修程序之前保存某些信息。保存的信息和保存位置因CPU而异。至少,必须保存程序计数器,以便重新启动中断的进程。在另一个极端,所有可见寄存器和大量内部寄存器也可以保存。
一个问题是在哪里保存这些信息。一种选择是将其放入操作系统可以根据需要读取的内部寄存器中。这种方法的一个问题是,在读取所有潜在相关信息之前,无法确认中断控制器,以免第二个中断覆盖保存状态的内部寄存器。当中断被禁用时,这种策略会导致长时间的死区,并可能导致中断丢失和数据丢失。
因此,大多数CPU将信息保存在堆栈上。然而,这种方法也有问题。首先:谁的堆栈?如果使用当前堆栈,它很可能是用户进程堆栈。堆栈指针甚至可能不是合法的,当硬件试图在指向的地址写入某些字时,会导致致命错误。此外,它可能指向页面的末尾。在多次内存写入之后,可能会超出页面边界并生成页面错误。在硬件中断处理期间发生页面错误会产生一个更大的问题:在哪里保存状态以处理页面错误?
如果使用内核堆栈,则堆栈指针合法并指向固定页面的可能性要大得多。然而,切换到内核模式可能需要更改MMU上下文,并且可能会使大部分或全部缓存和TLB无效。静态或动态重新加载所有这些内容将增加处理中断的时间,从而浪费CPU时间。
精确和不精确中断
另一个问题是,大多数现代CPU都是高度流水线的,而且常常是超标量的(内部并行)。在较旧的系统中,每条指令执行完毕后,微程序或硬件会检查是否有中断挂起。如果是这样,程序计数器和PSW被推到堆栈上,中断序列开始。在中断处理程序运行后,发生了相反的过程,旧的PSW和程序计数器从堆栈中弹出,前一个过程继续。
该模型隐式假设,如果中断发生在某条指令之后,则该指令之前(包括该指令)的所有指令都已完全执行,并且在执行之后根本没有指令。在较旧的机器上,此假设始终有效。在现代设备上可能不是这样。
如果在管道已满时发生中断,通常情况下会发生什么情况?许多指令处于不同的执行阶段。当中断发生时,程序计数器的值可能无法反映已执行指令和未执行指令之间的正确边界。事实上,许多指令可能已部分执行,不同的指令或多或少都已完成。在这种情况下,程序计数器很可能反映要提取并推入管道的下一条指令的地址,而不是执行单元刚刚处理的指令的地址。
在超标量机器上,情况更糟。指令可以分解为微操作,微操作可能会无序执行,取决于内部资源(如功能单元和寄存器)的可用性。在中断时,一些早就开始的指令可能还没有开始,而另一些最近开始的指令几乎已经完成。在发出中断信号时,可能有许多处于不同完整状态的指令,它们与程序计数器之间的关系较小。
使机器处于定义良好状态的中断称为精确中断(precise interrupt),它有四个属性:
1、PC(程序计数器)保存在已知位置。
2、PC所指的指令之前的所有指令均已完成。
3、除PC指示的指令外,没有其他指令完成。
4、PC指向的指令的执行状态是已知的。
请注意,除电脑指示的指令外,没有禁止启动的指令。只是它们对寄存器或内存所做的任何更改都必须在中断发生之前撤消。允许已执行指向的指令。还允许尚未执行。
必须明确哪种情况适用,通常,如果中断是I/O中断,则指令尚未启动。然而,如果中断真的是一个陷阱或页面错误,那么PC通常会指向导致错误的指令,以便稍后重新启动,下图(a)中的情况说明了一个精确的中断。程序计数器(316)之前的所有指令都已完成,而超出它的指令都没有启动(或回滚以撤消其效果)。
不满足这些要求的中断称为不精确中断(imprecise interrupt),它使操作系统编写者的生活最不愉快,他们现在必须弄清楚发生了什么,还有什么事情要发生。下图(b)显示了一个不精确的中断,其中程序计数器附近的不同指令处于不同的完成阶段,旧指令不一定比新指令更完整。具有不精确中断的机器通常会向堆栈中吐出大量内部状态,以使操作系统能够判断出发生了什么。重启机器所需的代码通常非常复杂。此外,在每次中断时都将大量信息保存到内存中,使中断速度变慢,恢复情况更糟。这导致了一种具有讽刺意味的情况,即由于中断速度较慢,速度非常快的超标量CPU有时不适合实时工作。
一些计算机的设计使得某些中断和陷阱是精确的,而另一些则不是。例如,I/O中断是精确的,但由于致命编程错误导致的陷阱是不精确的,这并不是很糟糕,因为在进程被零除后,不需要尝试重新启动正在运行的进程。有些机器有一个位,可以设置为强制所有中断精确。设置这个位的缺点是,它迫使CPU仔细记录正在做的一切,并维护寄存器的影子副本(shadow copies),以便它可以在任何时刻生成精确的中断。所有这些开销都会对性能产生重大影响。
(a) 精确中断;(b) 不精确中断。
一些超标量计算机,如x86系列,具有精确的中断,以允许旧软件正常工作。为与精确中断向后兼容而付出的代价是CPU内极其复杂的中断逻辑,以确保当中断控制器发出信号表示要引起中断时,所有指令在某一点之前都可以完成,超过该点的指令都不允许对机器状态有任何明显的影响。在这里,付出的代价不是时间,而是芯片面积和设计的复杂性。如果向后兼容不需要精确的中断,则此芯片区域可用于更大的片上缓存,从而使CPU更快。另一方面,不精确的中断使操作系统更加复杂和缓慢,因此很难判断哪种方法真正更好。
18.11.4.2 I/O软件原理
本节将阐述I/O的目标,从操作系统的角度来看它的不同实现方式。
I/O软件的目标
I/O软件设计中的一个关键概念是设备独立性,意味着我们应该能够编写可以访问任何I/O设备的程序,而无需事先指定设备。例如,将文件作为输入读取的程序应该能够读取硬盘、DVD或U盘上的文件,而无需针对每个不同的设备进行修改。类似地,应该能够键入以下命令:
sort <input> output
它可以处理来自任何磁盘或键盘的输入,以及发送到任何磁盘或屏幕的输出。这些设备确实不同,需要非常不同的命令序列来读取或写入,取决于操作系统来解决这些问题。
与设备独立性密切相关的是统一命名的目标。文件或设备的名称应仅为字符串或整数,而不应以任何方式依赖于设备。在UNIX中,所有磁盘都可以以任意方式集成到文件系统层次结构中,因此用户无需知道哪个名称对应于哪个设备。例如,可以将USB记忆棒安装在/usr/ast/backup目录的顶部,以便将文件复制到/usr/ast/backup/monday将文件复制至USB记忆棒。这样,所有文件和设备都以相同的方式寻址:通过路径名。
I/O软件的另一个重要问题是错误处理。一般来说,错误的处理应该尽可能靠近硬件。如果控制器发现一个读取错误,如果可以的话,它应该尝试自己更正错误。如果不能,那么设备驱动程序应该处理它,也许只需再次尝试读取块即可。许多错误都是暂时性的,例如读取头上的灰尘斑点导致的读取错误,如果重复操作,这些错误通常会消失。只有当下层无法处理问题时,才应该告诉上层。在许多情况下,错误恢复可以在较低级别透明地完成,而上层甚至不知道错误。
另一个重要问题是同步(阻塞)与异步(中断驱动)传输的比较。大多数物理I/O都是异步的——CPU开始传输,然后去做其他事情,直到中断到来。如果读系统调用后I/O操作阻塞,则用户程序更容易编写,程序会自动挂起,直到数据在缓冲区中可用为止。操作系统应该让中断驱动的操作看起来对用户程序是阻塞的。然而,一些非常高性能的应用程序需要控制I/O的所有细节,因此一些操作系统为它们提供异步I/O。
I/O软件的另一个问题是缓冲。通常,从设备上下来的数据不能直接存储在最终目的地,例如,当数据包从网络中传入时,操作系统直到将数据包存储在某个位置并对其进行检查之后才知道将其放在何处。此外,一些设备具有严重的实时限制(例如数字音频设备),因此必须提前将数据放入输出缓冲区,以将缓冲区填充速率与清空速率解耦,以避免缓冲区不足。缓冲涉及大量复制,通常对I/O性能有重大影响。我们在这里要提到的最后一个概念是共享设备与专用设备。
一些I/O设备(如磁盘)可以由许多用户同时使用,多个用户同时在同一磁盘上打开文件不会导致任何问题。其他设备(如打印机)必须专用于单个用户,直到该用户完成,然后其他用户可以拥有打印机。让两个或两个以上的用户在同一页面上随机混合写入字符肯定不行。引入专用(非共享)设备也会带来各种问题,例如死锁。同样,操作系统必须能够以避免问题的方式处理共享设备和专用设备。
编程输入/输出
有三种根本不同的I/O执行方式,最简单的I/O形式是让CPU完成所有工作,这种方法称为编程I/O(programmed
I/O)。
通过一个例子来说明编程I/O的工作原理是最简单的。考虑一个用户进程,它希望通过串行接口在打印机上打印八个字符的字符串“ABCDEFGH”,软件首先在用户空间的缓冲区中组装字符串,如下图(a)所示。
然后,用户进程通过系统调用打开打印机来获取打印机进行写入。如果打印机当前正由另一个进程使用,则此调用将失败并返回错误代码,或将阻塞,直到打印机可用为止,具体取决于操作系统和调用的参数。一旦拥有打印机,用户进程将进行系统调用,告诉操作系统在打印机上打印字符串。
然后,操作系统(通常)将带有字符串的缓冲区复制到内核空间中的一个数组,例如p,在那里它更容易访问(因为内核可能必须更改内存映射才能获得用户空间)。然后检查打印机当前是否可用,如果没有,它会一直等待,直到打印机可用。一旦打印机可用,操作系统就会使用内存映射I/O将第一个字符复制到打印机的数据寄存器,此操作将激活打印机。
该字符可能尚未出现,因为某些打印机在打印任何内容之前会缓冲一行或一页。然而,在下图(b)中,我们看到第一个字符已经打印出来,并且系统已经将“b”标记为下一个要打印的字符。
一旦将第一个字符复制到打印机,操作系统就会检查打印机是否准备好接受另一个字符。通常,打印机有第二个寄存器,用于显示其状态,写入数据寄存器的行为导致状态变为未就绪。当打印机控制器处理完当前字符后,它通过在状态寄存器中设置一些位或在其中输入一些值来指示其可用性。
此时,操作系统将等待打印机再次就绪。当发生这种情况时,它会打印下一个字符,如下图(c)所示。此循环一直持续到打印完整个字符串,然后控制权返回到用户进程。
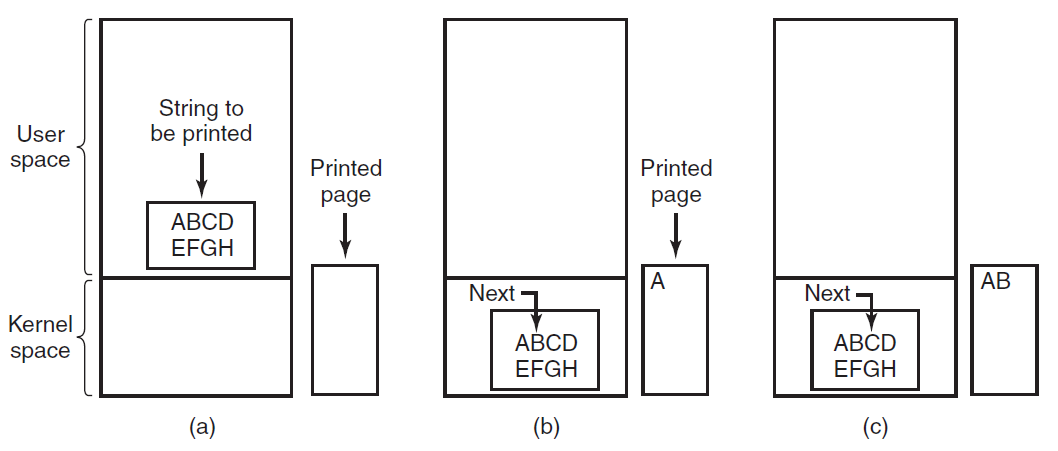
打印字符串的步骤。
下面伪代码简要总结了操作系统执行的操作。首先,将数据复制到内核,然后操作系统进入一个紧密循环,一次输出一个字符。编程I/O的基本行为是,在输出字符后,CPU不断轮询设备,看它是否准备好接受另一个字符。这种行为通常称为轮询(polling)或忙等待(busy waiting)。
copy_from_user(buffer, p,count); /* p is the ker nel buffer */
for (i = 0; i < count; i++) /* loop on every character */
{
while (*printer_status_reg != READY) ; /* loop until ready */
*printer_data_register = p[i]; /* output one character */
}
return_to_user( );
编程I/O很简单,但缺点是在完成所有I/O之前占用CPU的全部时间。如果“打印”字符的时间很短(因为打印机所做的一切都是将新字符复制到内部缓冲区),那么忙等待就可以了。此外,在嵌入式系统中,CPU没有其他事情可做,忙等待也可以。然而,在更复杂的系统中,CPU还有其他工作要做,忙等待效率很低,需要更好的I/O方法。
中断驱动I/O
现在让我们考虑一下在打印机上打印的情况,打印机不缓冲字符,而是在到达时打印每个字符,如果打印机可以打印,例如100个字符/秒,则每个字符需要10毫秒才能打印。这意味着在将每个字符写入打印机的数据寄存器后,CPU将处于空闲循环10毫秒,等待下一个字符的输出。足以进行上下文切换,并在10毫秒内运行其他可能被浪费的进程。
允许CPU在等待打印机就绪时执行其他操作的方法是使用中断。当系统调用打印字符串时,缓冲区被复制到内核空间,如前所示,只要打印机愿意接受字符,就会将第一个字符复制到打印机。此时,CPU调用调度程序,并运行其他一些进程。要求打印字符串的进程被阻止,直到打印完整个字符串。系统调用的工作如下(a)所示。
当打印机打印完字符并准备接受下一个字符时,它会生成一个中断,此中断停止当前进程并保存其状态,然后运行打印机中断服务程序,该代码的粗略版本如下(b)所示。如果没有更多的字符要打印,中断处理程序将采取一些操作取消阻止用户。否则,它输出下一个字符,确认中断,并返回到中断之前运行的进程,该进程从中断处继续。
// 使用中断驱动I/O将字符串写入打印机。
// (a) 执行打印系统调用时执行的代码。
copy_from_user(buffer, p, count);
enable_interrupts();
while (*printer_status_reg != READY) ;
*printer_data_register = p[0];
scheduler();
// (b) 中断打印机的维修程序。
if (count == 0)
{
unblock_user( );
}
else
{
*printer_data_register = p[i];
count = count − 1;
i = i + 1;
}
acknowledge_interrupt();
return_from_interrupt();
使用DMA的I/O
中断驱动I/O的一个明显缺点是每个字符都会发生中断,中断需要时间,因此此方案浪费了一定的CPU时间。解决方案是使用DMA,让DMA控制器一次将字符输入到打印机,而不会影响CPU。本质上,DMA是编程I/O,只有DMA控制器做所有工作,而不是主CPU。此策略需要特殊硬件(DMA控制器),但在I/O期间释放CPU以执行其他工作。代码概要如下所示。
// 使用DMA打印字符串。
// (a) 执行打印系统调用时执行的代码。
copy_from_user(buffer, p, count);
set_up_DMA_controller();
scheduler();
// (b) 中断服务程序。
acknowledge_interrupt();
unblock_user();
return_from_interrupt();
DMA的最大优势是将中断次数从每个字符减少到每个打印缓冲区一个,如果有许多字符并且中断很慢,会有很大的改进。另一方面,DMA控制器通常比主CPU慢得多。如果DMA控制器无法全速驱动设备,或者CPU在等待DMA中断时通常无事可做,那么中断驱动I/O甚至编程I/O可能更好。然而,在大多数情况下,DMA是值得的。
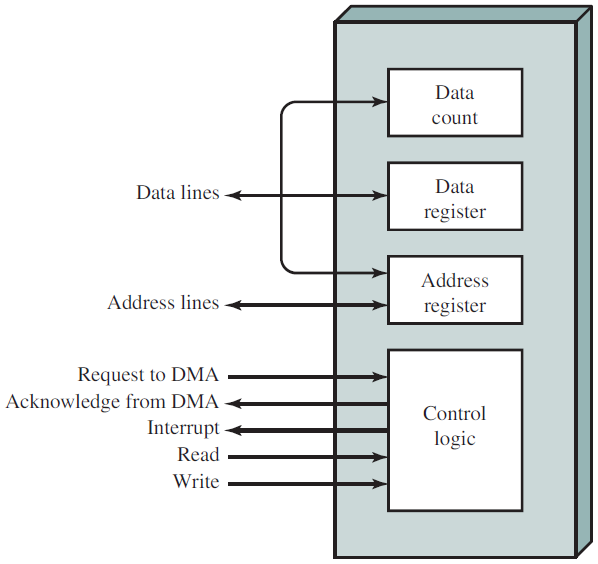
传统DMA块图。
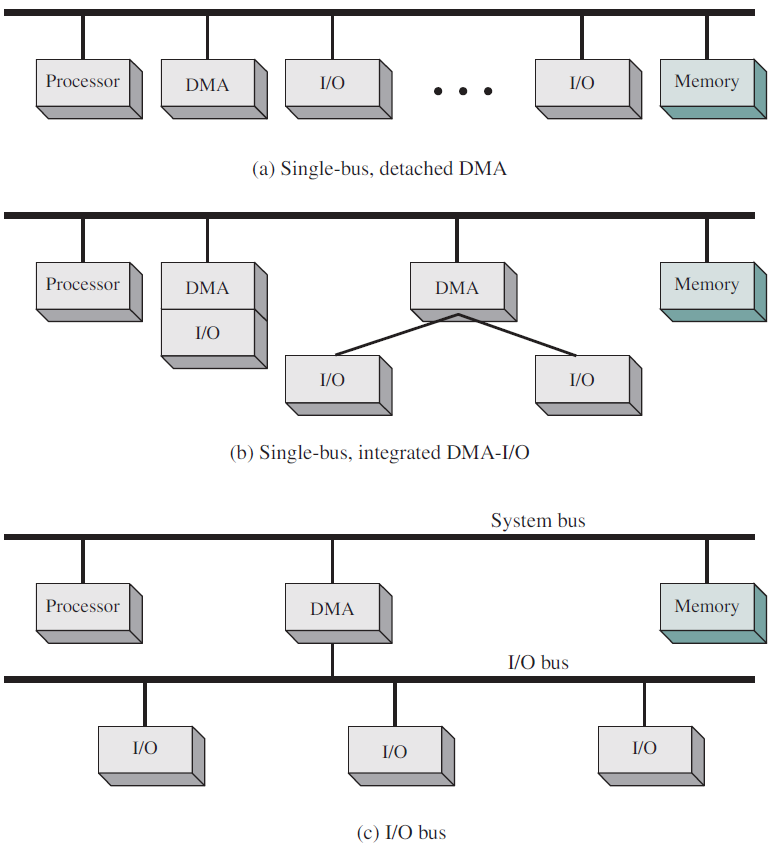
改进后的DMA配置。
18.11.4.3 I/O软件层级
I/O软件通常分为四层,如下图所示。每一层都有一个定义明确的功能来执行,并有一个与相邻层定义明确的接口。功能和接口因系统而异,因此下面的讨论(从底部开始检查所有层)并不针对一台机器。
I/O软件系统的层。
下面阐述这些层。
- 中断处理器
虽然编程I/O偶尔有用,但对于大多数I/O来说,中断是一个令人不快的事实,无法避免。它们应该隐藏在操作系统的内部深处,以便尽可能少的操作系统了解它们。隐藏它们的最佳方法是让驱动程序启动I/O操作块,直到I/O完成并发生中断。驱动程序可以阻塞自身,例如,通过关闭信号量、等待条件变量、接收消息或类似操作。当中断发生时,中断过程会做任何它必须做的事情来处理中断,然后它可以解锁等待它的驱动程序。
在某些情况下,它只会在一个信号量上完成。在其他情况下,它会对监视器中的条件变量发出信号。在其他情况下,它将向被阻止的驱动程序发送消息。在所有情况下,中断的净影响是先前被阻塞的驱动程序现在能够运行。如果驱动程序结构为内核进程,并且有自己的状态、堆栈和程序计数器,则此模型最有效。
当然,现实并不那么简单。处理中断不仅仅是接受中断,对一些信号量执行一个up,然后执行IRET指令以从中断返回到前一个进程。操作系统需要做更多的工作。现在将概述此项工作,作为硬件中断完成后必须在软件中执行的一系列步骤。需要注意的是,这些细节高度依赖于系统,因此在特定机器上可能不需要下面列出的某些步骤,也可能需要未列出的步骤。此外,在某些机器上,确实发生的步骤可能顺序不同。
1、保存中断硬件尚未保存的所有寄存器(包括PSW)。
2、为中断服务过程设置上下文,可能需要设置TLB、MMU和页表。
3、为中断服务过程设置堆栈。
4、确认中断控制器。如果没有集中式中断控制器,则重新启用中断。
5、将寄存器从保存位置(可能是一些堆栈)复制到进程表。
6、运行中断服务程序,它将从中断设备控制器的寄存器中提取信息。
7、选择下一个要运行的进程。如果中断导致某个被阻塞的高优先级进程准备就绪,则可以选择立即运行。
8、为下一个要运行的进程设置MMU上下文。可能还需要一些TLB设置。
9、加载新进程的寄存器,包括其PSW。
10、开始运行新进程。
可以看出,中断处理远不是微不足道的。它还需要相当多的CPU指令,特别是在存在虚拟内存且必须设置页表或存储MMU状态(例如R和M位)的机器上。在某些机器上,在用户模式和内核模式之间切换时,可能还必须管理TLB和CPU缓存,这需要额外的机器周期。
- 设备驱动
前面我们讨论了设备控制器的功能。我们看到,每个控制器都有一些设备寄存器用于发出命令,或者有一些设备注册表用于读取其状态,或者两者都有。设备寄存器的数量和命令的性质因设备而异。例如,鼠标驱动程序必须接受来自鼠标的信息,告诉它移动了多远以及当前按下了哪些按钮。相反,磁盘驱动器可能必须了解扇区、磁道、圆柱体、磁头、臂运动、电机驱动器、磁头固定时间以及使磁盘正常工作的所有其他机制。显然,这些驱动因素将非常不同。
因此,连接到计算机的每个I/O设备都需要一些特定于设备的代码来控制它。此代码称为设备驱动程序,通常由设备制造商编写,并随设备一起交付。由于每个操作系统都需要自己的驱动程序,设备制造商通常为几种流行的操作系统提供驱动程序。
每个设备驱动程序通常处理一种设备类型,或至多一类密切相关的设备。例如,SCSI磁盘驱动程序通常可以处理多个不同大小和速度的SCSI磁盘,也可以处理SCSI蓝光磁盘。另一方面,鼠标和操纵杆如此不同,通常需要不同的驱动程序。然而,一个设备驱动程序控制多个不相关的设备没有技术限制,在大多数情况下都不是一个好主意。
然而,有时不同的设备基于相同的底层技术。最著名的例子可能是USB,它是一种串行总线技术,并非无缘无故被称为“通用”。USB设备包括磁盘、记忆棒、相机、鼠标、键盘、迷你风扇、无线网卡、机器人、信用卡阅读器、充电剃须刀、碎纸机、条形码扫描仪、迪斯科球和便携式温度计。他们都使用USB,但他们做的事情却大相径庭。
诀窍在于USB驱动程序通常是堆叠的,就像网络中的TCP/IP堆栈一样。在底层,通常在硬件中,我们可以找到USB链路层(串行I/O),它处理诸如向USB数据包发送信号和解码信号流之类的硬件。它被用于处理数据包的高层,以及大多数设备共享的USB通用功能。除此之外,最后,我们找到了更高层的API,例如大容量存储接口、摄像头等。因此,我们仍然有单独的设备驱动程序,即使它们共享协议栈的一部分。
实际上,为了访问设备的硬件,也就是控制器的寄存器,设备驱动程序通常必须是操作系统内核的一部分,至少在当前的体系结构中是这样。实际上,可以构造在用户空间中运行的驱动程序,并通过系统调用读取和写入设备寄存器。这种设计将内核与驱动程序隔离开来,并将驱动程序彼此隔离开来,从而消除了以某种方式干扰内核的系统崩溃错误驱动程序的主要来源。对于构建高度可靠的系统,这无疑是一条路。设备驱动程序作为用户进程运行的系统示例是MINIX 3,然而,由于大多数其他桌面操作系统都希望驱动程序在内核中运行,因此我们将在这里考虑这个模型。
由于每个操作系统的设计者都知道外部编写的代码(驱动程序)将被安装在其中,因此需要有一个允许这种安装的体系结构,意味着要有一个定义良好的模型来描述驱动程序的功能以及它如何与操作系统的其余部分交互。设备驱动程序通常位于操作系统其余部分的下方,如下图所示。
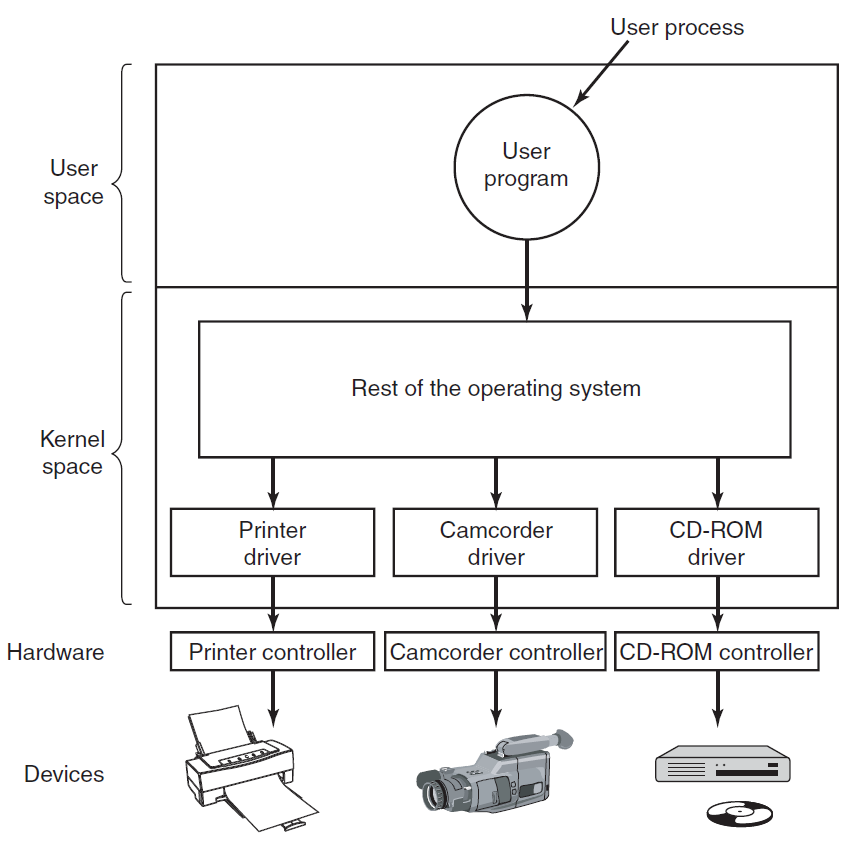
设备驱动程序的逻辑定位。实际上,驱动器和设备控制器之间的所有通信都通过总线进行。
操作系统通常将驱动程序划分为少数类别之一。最常见的类别是块设备(如磁盘),其中包含可以独立寻址的多个数据块,以及字符设备(如键盘和打印机),它们生成或接受字符流。
大多数操作系统定义了所有块驱动程序都必须支持的标准接口和所有字符驱动程序都要支持的第二个标准接口。这些接口由许多过程组成,操作系统的其他部分可以调用这些过程来让驱动程序为其工作。典型的步骤是读取块(块设备)或写入字符串(字符设备)。
在某些系统中,操作系统是一个单一的二进制程序,其中包含它需要编译到其中的所有驱动程序。这种方案多年来一直是UNIX系统的标准,因为它们由计算机中心运行,I/O设备很少更改。如果添加了新设备,系统管理员只需使用新的驱动程序重新编译内核,以构建新的二进制文件。
随着个人计算机及其无数I/O设备的出现,这种模式不再适用。很少有用户能够重新编译或重新链接内核,即使他们有源代码或目标模块,但情况并非总是如此。相反,从MS-DOS开始的操作系统转向了一种模型,在该模型中,驱动程序在执行期间动态加载到系统中。不同的系统以不同的方式处理加载驱动程序。
设备驱动程序具有多个功能。最明显的一种方法是接受来自其上方独立于设备的软件的抽象读写请求,并确保它们得到执行。但它们还必须执行一些其他功能,例如,如果需要,驱动程序必须初始化设备。它可能还需要管理电源要求和记录事件。
许多设备驱动程序具有类似的一般结构。典型的驱动程序首先检查输入参数,看看它们是否有效,如果不是,则返回错误,如果它们有效,可能需要将抽象术语翻译为具体术语。对于磁盘驱动器,可能意味着将线性块编号转换为磁盘几何体的磁头、磁道、扇区和柱面编号。
接下来,驱动程序可能会检查设备当前是否正在使用。如果是,请求将排队等待稍后处理,如果设备处于空闲状态,将检查硬件状态,以查看现在是否可以处理请求。在开始传输之前,可能需要打开设备或启动电机,一旦设备启动并准备就绪,就可以开始实际控制。
控制设备意味着向其发出一系列命令。驱动程序是根据必须执行的操作确定命令序列的位置,在驱动程序知道要发出哪些命令后,它开始将它们写入控制器的设备寄存器。在将每个命令写入控制器后,可能需要检查控制器是否接受该命令并准备接受下一个命令。此序列将继续,直到发出所有命令。一些控制器可以得到一个命令链接列表(内存中),并告诉它们自己读取和处理所有命令,而无需操作系统的进一步帮助。
发出命令后,将应用以下两种情况之一。在许多情况下,设备驱动程序必须等待控制器为其执行某些工作,因此它会阻塞自身,直到中断来解除阻塞。然而,在其他情况下,操作会立即完成,因此驱动无需阻塞。作为后一种情况的示例,滚动屏幕只需要将几个字节写入控制器的寄存器。不需要机械运动,因此整个操作可以在纳秒内完成。
在前一种情况下,被阻塞的驱动程序将被中断唤醒。在后一种情况下,它永远不会睡觉。无论如何,在操作完成后,驱动程序必须检查错误。如果一切正常,驱动程序可能有一些数据要传递给设备独立软件(例如,刚读取的块)。
最后,它返回一些状态信息,以便向调用者报告错误。如果有任何其他请求排队,现在可以选择并启动其中一个请求。如果没有排队,驱动程序将阻塞等待下一个请求。这个简单的模型只是对现实的粗略近似。许多因素使代码更加复杂。首先,I/O设备可能会在驱动程序运行时完成,从而中断驱动程序,中断可能会导致设备驱动程序运行。事实上,它可能会导致当前驱动程序运行,例如,当网络驱动程序正在处理一个传入的数据包时,另一个数据包可能会到达。因此,驱动程序必须是可重入的,意味着运行中的驱动程序必须期望在第一次调用完成之前第二次调用它。
在热插拔系统中,可以在计算机运行时添加或删除设备。因此,当驱动程序忙于读取某个设备时,系统可能会通知它用户突然从系统中删除了该设备。不仅必须在不损坏任何内核数据结构的情况下中止当前的I/O传输,而且对于现在已消失的设备的任何挂起请求也必须从系统及其调用者(如果有坏消息)中优雅地删除。此外,意外添加的新设备可能会导致内核篡改资源(例如中断请求行),将旧设备从驱动程序中删除,并将新设备放在其位置。
驱动程序不允许进行系统调用,但它们通常需要与内核的其余部分进行交互。通常,允许调用某些内核过程。例如,通常会调用分配和取消分配用作缓冲区的内存硬连接页,需要其他有用的调用来管理MMU、定时器、DMA控制器、中断控制器等。
- 独立于设备的I/O软件
虽然一些I/O软件是特定于设备的,但它的其他部分是独立于设备的。驱动程序和独立于设备的软件之间的确切边界取决于系统(和设备),因为出于效率或其他原因,一些可以独立于设备完成的功能实际上可能在驱动程序中完成。下图所示的功能通常在设备独立软件中完成。
| 设备驱动程序的统一接口 |
| 缓冲 |
| 错误报告 |
| 分配和释放专用设备 |
| 提供独立于设备的块大小 |
设备独立软件的基本功能是执行所有设备通用的I/O功能,并为用户级软件提供统一的接口。我们现在将更详细地讨论上述问题。
先阐述设备驱动程序的统一接口。
操作系统中的一个主要问题是如何使所有I/O设备和驱动程序看起来或多或少相同。如果磁盘、打印机、键盘等都以不同的方式连接,那么每次新设备出现时,都必须为新设备修改操作系统。对于每一个新设备,必须对操作系统进行黑客攻击不是一个好主意。
这个问题的一个方面是设备驱动程序和操作系统其余部分之间的接口。在下图(a)中,我们举例说明了一种情况,即每个设备驱动程序都有一个不同的操作系统接口,意味着系统可调用的驱动功能因驱动而异,也可能意味着驱动程序所需的内核函数也因驱动程序而异。总而言之,意味着连接每个新驱动程序需要大量新的编程工作。
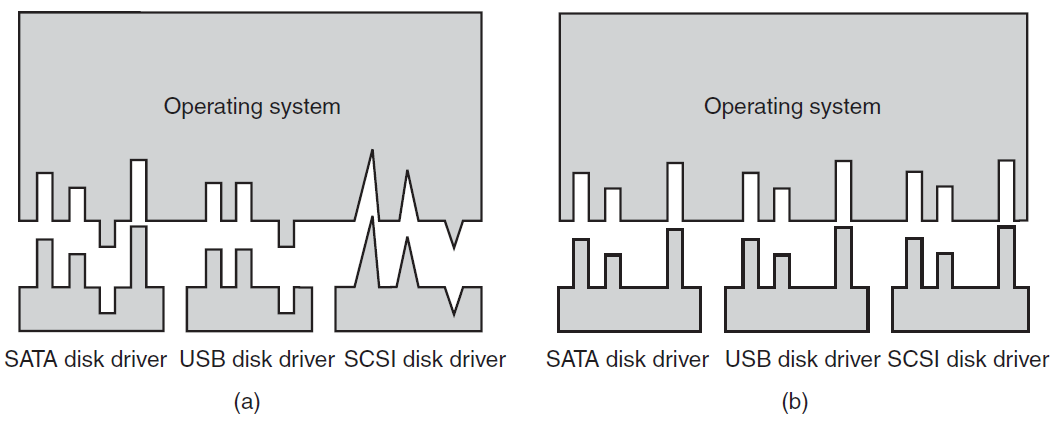
(a) 没有标准的驱动程序接口。(b) 具有标准驱动程序接口。
相反,在上图(b)中,我们展示了一种不同的设计,其中所有驱动程序都具有相同的界面。现在,只要符合驱动程序接口,插入一个新的驱动程序就容易多了,也意味着驱动程序编写者知道对他们的期望是什么。在实践中,并非所有设备都是完全相同的,但通常只有少数设备类型,即使这些设备类型通常也几乎相同。
其工作方式如下。对于每类设备,如磁盘或打印机,操作系统定义了驱动程序必须提供的一组功能。对于磁盘,这些操作自然包括读取和写入,但也包括打开和关闭电源、格式化以及其他磁盘操作。通常,驱动程序持有一个表,其中包含这些函数的指针。加载驱动程序时,操作系统会记录此函数指针表的地址,因此当需要调用其中一个函数时,可以通过此表进行间接调用。此函数指针表定义了驱动程序与操作系统其余部分之间的接口。给定类别的所有设备(磁盘、打印机等)都必须遵守它。
拥有统一接口的另一个方面是如何命名I/O设备。独立于设备的软件负责将符号设备名称映射到正确的驱动程序上。例如,在UNIX中,设备名(如/dev/disk0)唯一地指定了特殊文件的i节点,而此i节点包含用于查找相应驱动程序的主设备号。i节点还包含次要设备编号,该编号作为参数传递给驱动程序,以便指定要读取或写入的单元。所有设备都有主设备号和次设备号,通过使用主设备号选择驱动程序可以访问所有驱动程序。
与命名密切相关的是保护。系统如何阻止用户访问他们无权访问的设备?在UNIX和Windows中,设备在文件系统中显示为命名对象,意味着通常的文件保护规则也适用于I/O设备。然后,系统管理员可以为每个设备设置适当的权限。
接着描述缓冲。
由于各种原因,缓冲也是块和字符设备的一个问题。要查看其中一个,请考虑一个从(ADSL非对称数字用户线路)调制解调器读取数据的过程,许多人在家中使用该调制解调器连接到Internet。处理传入字符的一种可能策略是让用户进程执行读取系统调用并阻塞等待一个字符,每个到达的字符都会导致中断,中断服务过程将字符交给用户进程并解除阻塞。将字符放在某处后,进程读取另一个字符并再次阻塞。该模型如下图(a)所示。
这种业务处理方式的问题是,必须为每个传入字符启动用户进程。允许一个进程在短时间内多次运行很低效,因此这种设计并不好。
改进如下图(b)所示。在方法下,用户进程在用户空间中提供一个n个字符的缓冲区,并读取n个字符。中断服务过程将传入字符放入该缓冲区,直到它完全满为止。只有这样,它才会唤醒用户进程。这个方案比前一个方案效率高得多,但它有一个缺点:如果在字符到达时调出缓冲区,会发生什么情况?缓冲区可以锁定在内存中,但如果许多进程开始任意锁定内存中的页面,可用页面池将缩小,性能将降低。
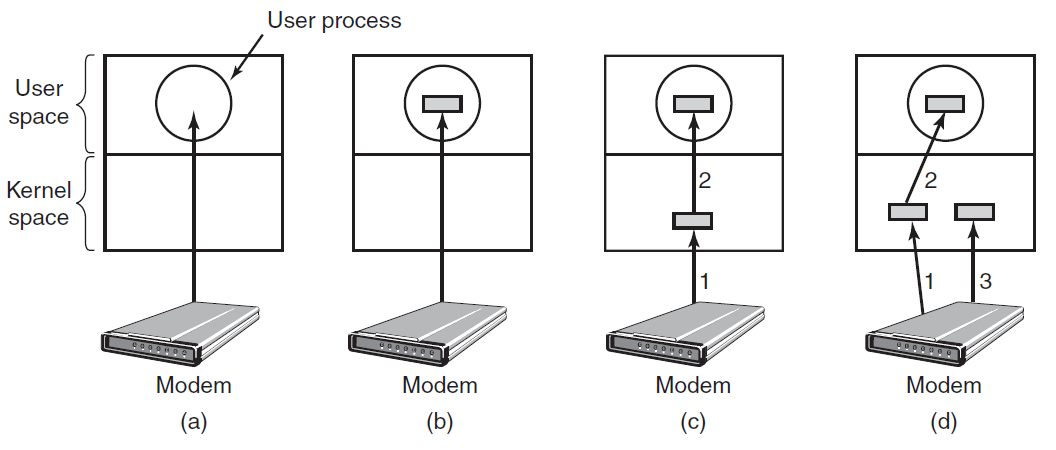
(a) 无缓冲输入。(b) 在用户空间中缓冲。(c) 在内核中进行缓冲,然后复制到用户空间。(d) 内核中的双缓冲。
另一种方法是在内核内创建一个缓冲区,并让中断处理程序将字符放在那里,如上图(c)所示。当此缓冲区已满时,如果需要,将带用户缓冲区的页面放入,并在一次操作中将缓冲区复制到那里。这个方案效率要高得多。
然而,即使是这种改进的方案也存在一个问题:当带有用户缓冲区的页面从磁盘引入时,到达的字符会发生什么?由于缓冲区已满,因此没有放置它们的位置。解决方法是使用第二个内核缓冲区,在第一个缓冲区填满后,但在清空之前,使用第二个缓冲区,如上图(d)所示。当第二个缓冲区填满时,可以将其复制给用户(假设用户已要求),当第二个缓冲区被复制到用户空间时,第一个缓冲区可以用于新字符。这样,两个缓冲区轮流进行:一个缓冲区被复制到用户空间,另一个缓冲区则在积累新的输入。此方案称为双缓冲(double buffering)。
另一种常见的缓冲形式是循环缓冲(circular buffer),由一个内存区域和两个指针组成,一个指针指向下一个可以放置新数据的自由词,另一个指针指向缓冲区中尚未删除的第一个数据字。在许多情况下,硬件在添加新数据(例如,刚从网络中到达)时向前移动第一个指针,而操作系统在删除和处理数据时向前移动第二个指针,两个指针都会环绕——它们到达顶部时会返回底部。
缓冲对输出也很重要。例如,考虑如何使用上图(b)中的模型在不缓冲的情况下输出到调制解调器,用户进程执行写入系统调用以输出n个字符。此时,系统有两种选择:其一,它可以阻止用户直到所有字符都被写入为止,但可能需要很长时间才能通过慢速电话线完成;其二,它还可以立即释放用户,并在用户进行更多计算时执行I/O,但这会导致更严重的问题:用户进程如何知道输出已经完成,并且可以重用缓冲区?系统可以生成信号或软件中断,但这种编程方式很难实现,并且容易出现竞争情况。一个更好的解决方案是内核将数据复制到内核缓冲区,类似于上图(c),并立即解除对调用者的阻塞。此模式的实际I/O何时完成并不重要,用户可以在缓冲区解除阻塞后立即重新使用它。
缓冲是一种广泛使用的技术,但它也有缺点。如果数据缓冲过多,性能就会受到影响。
接下来描述错误报告。
错误在I/O上下文中比在其他上下文中更常见。当它们发生时,操作系统必须尽可能地处理它们。许多错误是特定于设备的,必须由适当的驱动程序处理,但错误处理框架与设备无关。
一类I/O错误是编程错误。当进程要求一些不可能的东西时,就会出现这些错误,例如写入输入设备(键盘、扫描仪、鼠标等)或读取输出设备(打印机、绘图仪等)。其他错误包括提供无效的缓冲地址或其他参数,以及指定无效的设备(例如,当系统只有两个磁盘时,磁盘3),等等。处理这些错误的操作很简单:只需向调用者报告错误代码。
另一类错误是实际的I/O错误,例如,试图写入已损坏的磁盘块或试图读取已关闭的摄像机。在这些情况下,由驱动程序决定要做什么。如果驱动程序不知道要做什么,它可能会将问题传回设备无关软件。
此软件的功能取决于环境和错误的性质。如果是一个简单的读取错误,并且有一个交互式用户可用,它可能会显示一个对话框,询问用户该怎么做。选项可能包括重试一定次数、忽略错误或终止调用进程。如果没有用户可用,可能唯一可行的方法是让系统调用失败并返回错误代码。
但是,有些错误不能用这种方式处理。例如,关键数据结构(如根目录或可用阻止列表)可能已被破坏。在这种情况下,系统可能必须显示错误消息并终止,能做的事情并不多。
接下来阐述分配和释放专用设备。
某些设备(如打印机)在任何给定时刻只能由单个进程使用。由操作系统检查设备使用请求并接受或拒绝它们,具体取决于所请求的设备是否可用。处理这些请求的一种简单方法是要求进程直接打开设备的特殊文件。如果设备不可用,则打开失败。关闭这样的专用设备,然后释放它。
另一种方法是使用特殊机制来请求和释放专用设备。尝试获取不可用的设备会阻止调用方,而不是失败。阻塞的进程被放入队列。请求的设备迟早会可用,队列中的第一个进程可以获取它并继续执行。
不同的磁盘可能具有不同的扇区大小。由独立于设备的软件来隐藏这一事实,并为更高层提供统一的块大小,例如,将几个扇区视为单个逻辑块。这样,高层只处理抽象设备,这些抽象设备都使用相同的逻辑块大小,与物理扇区大小无关。类似地,一些字符设备每次只传送一个字节的数据(例如鼠标),而其他字符设备则以较大的单位传送数据(例如以太网接口)。这些差异也可能被隐藏。
18.11.4.4 用户空间的I/O软件
尽管大多数I/O软件都在操作系统内,但其中一小部分由与用户程序链接在一起的库组成,甚至包括在内核外运行的整个程序。系统调用,包括I/O系统调用,通常由库过程进行。当C程序包含以下调用时:
count = write(fd, buffer, nbytes);
库过程写入可能与程序链接,并包含在运行时内存中的二进制程序中。在其他系统中,库可以在程序执行期间加载。无论如何,所有这些库过程的集合显然是I/O系统的一部分。
虽然这些过程只不过将其参数放在系统调用的适当位置,但其他I/O过程实际上做了真正的工作。特别是,输入和输出的格式化是由库过程完成的。C语言中的一个示例是printf,它接受格式字符串和可能的一些变量作为输入,构建ASCII字符串,然后调用write输出字符串。作为printf的一个例子,考虑下面的语句:
printf("The square of %3d is %6d\n", i, i*i);
它将一个由14个字符组成的字符串“the square of”后跟值i格式化为3个字符的字符串,然后4个字符的串“”是“”,然后\(i^2\)是6个字符,最后是换行符。
并非所有用户级I/O软件都由库程序组成。另一个重要类别是后台打印系统(spooling system),它是多道程序设计系统中处理专用I/O设备的一种方法。考虑一个典型的后台打印设备:打印机。尽管让任何用户进程打开打印机的字符特殊文件在技术上很容易,但假设有一个进程打开了它,然后几个小时内什么也没做,没有其他进程可以打印任何内容。
下图总结了I/O系统,显示了所有层和每个层的主要功能。从底层开始,层是硬件、中断处理程序、设备驱动程序、独立于设备的软件,最后是用户进程。
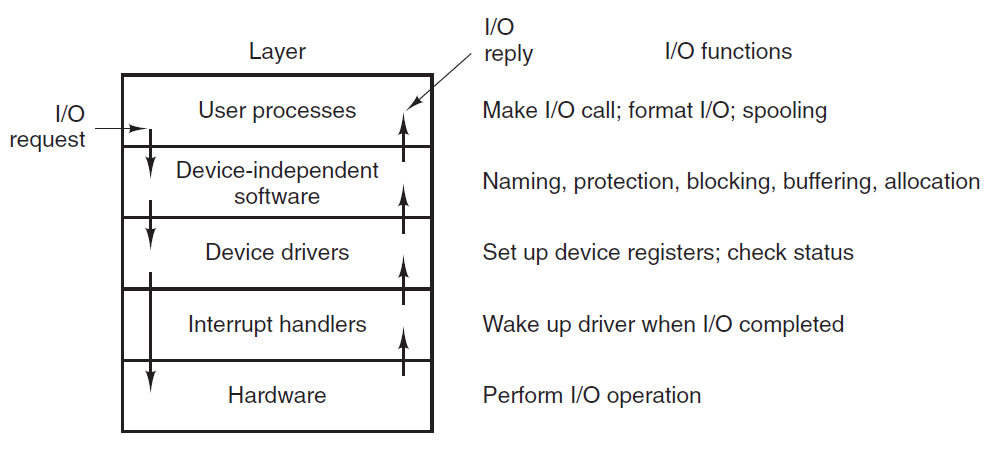
图中的箭头显示了控制流程。例如,当用户程序试图从文件中读取块时,会调用操作系统来执行调用。独立于设备的软件会在缓冲区缓存中查找它。如果所需的块不在那里,它会调用设备驱动程序向硬件发出请求,以便从磁盘获取它。然后,该进程被阻塞,直到磁盘操作完成,并且数据在调用方的缓冲区中安全可用。
当磁盘完成时,硬件生成一个中断。运行中断处理程序是为了发现发生了什么,也就是说,现在哪个设备需要关注。然后,它从设备中提取状态并唤醒休眠进程,以完成I/O请求并让用户进程继续。
18.11.5 Windows I/O
18.11.5.1 同步和同步I/O
异步和同步IO的对比图如下:
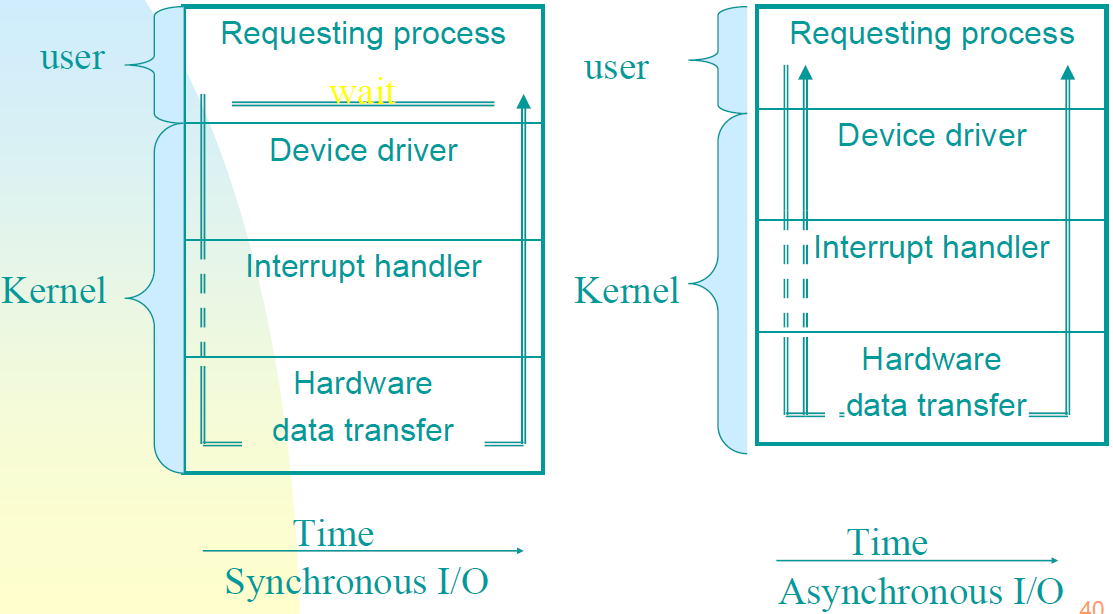
当调用CreateFile而不将FILE_FLAG_OVERLAPPED指定为dwFlagsAndAttributes参数的一部分时,将仅为同步I/O创建文件对象,是最简单的操作,因此我们将首先处理同步I/O。执行I/O的主要功能是ReadFile和WriteFile,它们与任何文件对象一起工作(不一定指向文件系统文件):
BOOL ReadFile(HANDLE hFile, LPVOID lpBuffer, DWORD nNumberOfBytesToRead, LPDWORD lpNumberOfBytesRead, LPOVERLAPPED lpOverlapped);
BOOL WriteFile(HANDLE hFile, LPCVOID lpBuffer, DWORD nNumberOfBytesToWrite, LPDWORD lpNumberOfBytesWritten, LPOVERLAPPED lpOverlapped);
Windows I/O系统本质上是异步的,一旦设备驱动程序向其受控硬件(如磁盘驱动器)发出请求,驱动程序就不需要等待操作完成。相反,它将请求标记为“挂起”,并返回给调用方。当I/O正在进行时,线程可以自由执行其他操作。一段时间后,硬件设备完成I/O操作。设备发出硬件中断,使驱动程序提供的回调运行并完成挂起的请求。
使用同步I/O简单易行,许多情况也足够好。然而,如果要处理大量请求,那么为每个请求创建一个线程来启动I/O操作并等待其完成是效率低下的,且扩展性不好。异步I/O提供了一种解决方案,其中线程启动一个请求,然后返回服务下一个请求等,因为I/O操作在CPU执行其他代码的同时并发运行。这个简化模型中唯一的问题是如何通知线程I/O操作完成。
请求异步操作必须从原始的CreateFile调用开始(始终是同步的),必须将FILE_FLAG_OVERLAPPED标志指定为dwFlagsAndAttributes参数的一部分,将以异步模式打开文件/设备。
打开文件进行异步访问的结果之一是不再有文件指针,意味着每个操作都必须以某种方式提供从文件开始的偏移量来执行操作(大小不是问题,因为它是读/写调用的一部分)。这是重叠结构的任务之一,必须作为最后一个参数传递给ReadFile和WriteFile:
typedef struct _OVERLAPPED
{
ULONG_PTR Internal;
ULONG_PTR InternalHigh;
union
{
struct
{
DWORD Offset;
DWORD OffsetHigh;
};
PVOID Pointer;
};
HANDLE hEvent;
} OVERLAPPED, *LPOVERLAPPED;
该结构包含三条不同的信息:
- 内部和内部高是I/O管理器使用的名称,不应写入。
- 偏移量和偏移量高是要设置的偏移量,指示操作在文件中的开始位置。如果需要64位偏移量,则union的指针成员是这些字段的另一种选择,更容易使用。
- hEvent是内核事件对象的句柄,如果非空,则在操作完成时由I/O管理器发出信号。
此外,Windows还支持手动排队APC(Manually Queued APC)。
18.11.5.2 I/O完成端口
I/O完成端口(I/O Completion Port)有自己的主要部分,因为它们不仅用于处理异步I/O。I/O完成端口与文件对象关联(可以是多个),封装了一个请求队列,以及一个一旦完成就可以为这些请求提供服务的线程列表。每当异步操作完成时,等待完成端口的线程之一应该唤醒并处理完成,可能会启动下一个请求。创建示例:
const int Key = 1;
HANDLE hFile = ::CreateFile(..., FILE_FLAG_OVERLAPPED, ...);
HANDLE hOldCP = ::CreateIoCompletionPort(hFile, hNewCP, Key, 0);
assert(hOldCP == hNewCP);
上述代码可以与其他文件对象重复,所有这些对象都与完成端口相关。下图描述了完成端口的简化图,可以看到绑定的线程是什么,以及所有这一切是如何工作的。
I/O完成端口的目的是允许工作线程处理已完成的I/O操作,这里的“工作线程”可以指绑定到完成端口的任何线程。
18.11.5.3 设备和管道
使用设备(Device,即非文件系统文件)与使用文件系统文件本质上没有什么不同。ReadFile和WriteFile函数适用于任何设备,包括异步,但并非所有设备都支持读写操作。特别是对于设备,还有另一个执行I/O操作的功能——DeviceIoControl:
BOOL DeviceIoControl(HANDLE hDevice, DWORD dwIoControlCode, LPVOID lpInBuffer, DWORD nInBufferSize, LPVOID lpOutBuffer, DWORD nOutBufferSize, LPDWORD lpBytesReturned, LPOVERLAPPED lpOverlapped);
符号链接的其他用途是“软件驱动程序”,即不管理任何硬件,但需要做用户模式下无法完成的事情。一个典型的例子是Process Explorer的驱动程序,它必须公开一个符号链接,以便Process Explorer本身(驱动程序的客户端)可以打开设备的句柄,并对设备进行DeviceIoControl调用,根据驱动程序建立并为Process Explorer所知的通信协议请求各种服务。
管道有两种变体——匿名和命名,匿名管道是一种简单的单向通信机制,仅限于本地机器。使用CreatePipe创建匿名管道对:
BOOL CreatePipe(PHANDLE hReadPipe, PHANDLE hWritePipe, LPSECURITY_ATTRIBUTES lpPipeAttributes, DWORD nSize);
CreatePipe为管道两端创建控制句柄,使用匿名管道的一个典型示例是将输入和/或输出重定向到另一个进程,允许一个进程将数据提供给另一个进程,而另一个过程不知道,也不关心,它只使用标准句柄进行输入/输出。
下图是管道的一个应用案例。创建匿名管道,并与EnumDevices进程共享其写端,EnumDevices进程写入的任何内容都可以使用管道的读取端读取。要使其工作,管道的写入和必须附加到EnumDevices进程的标准输出,因此任何标准输出调用都可以通过管道使用。

18.11.6 时钟
由于各种原因,时钟(也称为计时器)对于任何多道程序系统的运行都是必不可少的。它们维护一天中的时间,并防止一个进程独占CPU等。时钟软件可以采用设备驱动程序的形式,即使时钟既不是磁盘之类的块设备,也不是鼠标之类的字符设备。
计算机中常用两种类型的时钟,它们都与人们使用的时钟和手表大不相同。较简单的时钟系在110或220伏电源线上,在50或60赫兹的每个电压周期上都会造成中断。这些钟过去占主导地位,但现在很少了。
另一种时钟由三个部件组成:晶体振荡器、计数器和保持寄存器,如下图所示。当一块石英晶体在张力下正确切割和安装时,它可以产生非常精确的周期信号,通常在几百兆赫到几兆赫的范围内,具体取决于所选的晶体。使用电子学,这个基本信号可以乘以一个小整数,得到高达几吉赫甚至更多的频率。通常在任何计算机中都至少有一个这样的电路,为计算机的各个电路提供同步信号。这个信号被输入计数器,使它倒数到零。当计数器归零时,会导致CPU中断。
可编程时钟。
可编程时钟通常有几种操作模式。在一次触发模式(one-shot mode)下,当时钟启动时,它将保持寄存器的值复制到计数器中,然后在来自晶体的每个脉冲处递减计数器。当计数器归零时,它会导致中断并停止,直到软件再次明确启动。在方波模式(square-wave mode)下,在归零并导致中断后,保持寄存器自动复制到计数器中,整个过程无限期地重复。这些周期性中断称为时钟信号。
可编程时钟的优点是其中断频率可以由软件控制。如果使用500 MHz晶体,则计数器每2毫微秒脉冲一次。使用(无符号)32位寄存器,中断可以编程为以2纳秒到8.6秒的间隔发生。可编程时钟芯片通常包含两个或三个独立的可编程时钟,并且还有许多其他选项(例如,向上计数而不是向下计数,中断禁用等等)。
为了防止在计算机电源关闭时丢失当前时间,大多数计算机都有一个电池供电的备用时钟,采用了数字手表中使用的低功耗电路。电池时钟可以在启动时读取。如果备份时钟不存在,软件可能会询问用户当前的日期和时间。网络系统还可以通过一种标准方式从远程主机获取当前时间。在任何情况下,时间都会转换为自1970年1月1日凌晨12点UTC(世界协调时间,以前称为格林威治标准时间)以来的时钟节拍数,就像UNIX一样,或者从其他基准时刻开始。Windows的时间起点是1980年1月1日。在每个时钟周期,实时时间都会增加一个计数。通常提供实用程序来手动设置系统时钟和备份时钟,并同步两个时钟。
18.11.7 电源管理
第一台通用电子计算机ENIAC有18000个真空管,耗电14万瓦。结果,它增加了一笔不平凡的电费。晶体管发明后,用电量急剧下降,计算机行业对电力需求失去了兴趣。然而,由于几个原因,如今电源管理再次成为人们关注的焦点,而操作系统在其中扮演着重要角色。
让我们从台式电脑开始。台式电脑通常有一个200瓦的电源(通常效率为85%,即损失15%的输入能量用于加热),如果全世界一次性开启1亿台这样的机器,它们总共需要2万兆瓦的电力,这是20个平均规模的核电站的总产量。如果电力需求能削减一半,我们就可以摆脱10座核电站。从环境角度来看,摆脱10座核电站(或同等数量的化石燃料电站)是一个巨大的胜利,值得追求。
电源是一个大问题的另一个地方是电池供电的计算机,包括笔记本、手持设备和Webpad等。问题的核心是电池不能保持足够的电量,以维持很长时间,最多几个小时。此外,尽管电池公司、计算机公司和消费电子公司进行了大量研究,但进展缓慢。对于一个习惯于每18个月业绩翻番的行业(摩尔定律)来说,毫无进展似乎违反了物理定律。因此,让电脑使用更少的能源,从而延长现有电池的使用寿命,是每个人的重要议程。操作系统在此也扮演着重要角色。
在最低层次上,硬件供应商正在努力提高电子产品的能效。使用的技术包括减小晶体管尺寸、采用动态电压缩放、使用低摆幅和绝热总线以及类似技术。有两种降低能耗的一般方法:
- 第一种是操作系统在计算机的某些部分(主要是I/O设备)不使用时关闭它们,因为关闭的设备消耗很少或没有能量。
- 第二种是应用程序使用更少的能源,可能会降低用户体验的质量,以延长电池时间。
后面将介绍以上方法,但首先介绍一下与电源使用有关的硬件设计。
18.11.7.1 硬件问题
电池有两种类型:一次性电池和充电电池。一次性电池(最常见的是AAA、AA和D电池)可用于运行手持设备,但没有足够的能量为大屏幕明亮的笔记本电脑供电。相比之下,可充电电池可以储存足够的能量,为笔记本电脑供电几个小时。镍镉电池过去在这里占主导地位,但它们让位给了镍金属氢化物电池,后者寿命更长,在最终被丢弃时不会对环境造成严重污染。锂离子电池甚至更好,可以在不完全耗尽的情况下重新充电,但其容量也受到严重限制。
大多数计算机供应商采取的节约电池的一般方法是将CPU、内存和I/O设备设计为具有多个状态:打开、休眠、休眠和关闭。要使用设备,它必须处于打开状态。当设备在短时间内不需要时,可以将其置于休眠状态,从而降低能耗。当它预计不需要更长的时间间隔时,它可以休眠,从而进一步降低能耗。这里的折衷是,让设备脱离休眠状态通常比让它脱离休眠状态需要更多的时间和精力。最后,当设备关闭时,它什么也不做,也不耗电。并非所有设备都具有所有这些状态,但当它们都具有这些状态时,则由操作系统在适当的时候管理状态转换。
有些电脑有两个甚至三个电源按钮。其中之一可能会使整个计算机处于睡眠状态,通过键入字符或移动鼠标可以快速将其唤醒。另一种可能会使计算机进入休眠状态,从休眠状态唤醒所需的时间要长得多。在这两种情况下,这些按钮通常什么也不做,只是向操作系统发送一个信号,操作系统在软件中执行其余操作。
电源管理带来了操作系统必须处理的许多问题。其中许多与资源休眠有关,有选择地暂时关闭设备,或者至少在设备空闲时降低其功耗。必须回答的问题包括:哪些设备可以控制?它们是开/关,还是有中间状态?在低功率状态下可以节省多少电力?重启设备是否需要消耗能量?进入低功耗状态时必须保存一些上下文吗?恢复满功率需要多长时间?当然,这些问题的答案因设备而异,因此操作系统必须能够处理各种可能性。
不同的研究人员已经对笔记本电脑进行了研究,以确定电源的去向。Li等人、Lorch和Smith(1998)在笔记本电脑设备上进行了测量,得出了如下图中所示的结果。Weiser等人(1994年)也进行了测量但没有公布数值,只是简单地说,前三个电量消耗依次是显示器、硬盘和CPU。虽然这些数字不太一致,可能是因为所测量的不同品牌的计算机确实有不同的能源需求,但显然显示器、硬盘和CPU是节能的明显目标。在智能手机等设备上,可能还有其他耗电设备,如收音机和GPS。
| 设备 | Li等人(1994) | Lorch和Smith (1998) |
|---|---|---|
| 显示器 | 68% | 39% |
| CPU | 12% | 18% |
| 硬盘 | 20% | 12% |
| 调制解调器 | - | 6% |
| 声音 | - | 2% |
| 内存 | 0.5% | 1% |
| 其它 | - | 22% |
笔记本电脑各部件的功耗。
18.11.7.2 操作系统问题
操作系统在能源管理中起着关键作用,控制着所有的设备,所以它必须决定关闭什么以及何时关闭。如果它关闭了一个设备,并且很快又需要该设备,那么在重新启动时可能会出现恼人的延迟。另一方面,如果等待时间过长而无法关闭设备,则会无谓地浪费能量。
诀窍是找到算法和启发式,让操作系统能够就什么时候关闭以及什么时候关闭做出良好的决定。问题是“好”是高度主观的。一个用户可能会发现,在不使用计算机30秒后,它需要2秒来响应击键,这是可以接受的。在相同的条件下,另一个用户可能会连续一闪而过。在没有音频输入的情况下,计算机无法区分这些用户。
- 显示器
显示器而是能源预算的大户,要获得清晰明亮的图像,屏幕必须背光,需要大量的能量。许多操作系统试图通过在几分钟内没有活动时关闭显示器来节省能源。通常,用户可以决定关机时间间隔,从而在频繁关闭屏幕和快速耗尽电池电量之间进行权衡(用户可能真的不需要)。关闭显示器是一种睡眠状态,因为当按下任何键或移动定点设备时,几乎可以立即(从视频RAM)重新生成显示器。
Flinn和Satyanarayanan(2004年)提出了一个可能的改进方案。他们建议让显示器由一些区域组成,这些区域可以独立通电或断电。在下图中,用虚线分隔了16个区域。当光标位于窗口2中时,如(a)所示,只有右下角的四个区域必须亮起。其他12个可以是暗的,节省了3/4的屏幕电量。
当用户将光标移动到窗口1时,窗口2的区域可以变暗,窗口1后面的区域可以打开。但是,因为窗口1跨越了9个区域,所以需要更多电源。如果窗口管理器可以感知正在发生的事情,它可以自动将窗口1移动到四个区域,并以一种捕捉到区域的动作,如(b)所示。为了实现从9/16全功率到4/16全功率的降低,窗口管理器必须了解电源管理或能够接受来自其他系统的指令。更复杂的是能够部分照亮未完全填满的窗户(例如,包含短行文字的窗户右侧可以保持黑暗)。
使用区域背光显示。(a) 选择窗口2时,它不会移动。(b) 选择窗口1后,它会移动以减少照亮的区域数。
- 磁盘
对于硬盘,即使没有通道,保持高速旋转也需要大量的能量。许多计算机,尤其是笔记本电脑,在空闲一定时间后会降低磁盘转速。当下次需要时,它会再次旋转。不幸的是,停止的磁盘正在蛰伏(hibernating),而不是休眠(sleeping),因为它需要几秒钟才能再次启动,会导致用户明显的延迟。
此外,重新启动磁盘会消耗大量能量。因此,每个磁盘都有一个特征时间\(T_d\),即盈亏平衡点,通常在5到15秒之间。假设下一次磁盘访问预计在未来的某个时间t到来。如果t<\(T_d\),保持磁盘旋转所需的能量会更少,而不是先将其向下旋转,然后再快速将其向上旋转。如果t>\(T_d\),节省的能量使磁盘值得先向下旋转,然后再向上旋转。如果能够做出良好的预测(例如,基于过去的访问模式),操作系统可以做出良好的关机预测并节省能源。实际上,大多数系统都是保守的,只有在几分钟不活动后才会停止磁盘。
另一种节省磁盘能量的方法是在RAM中拥有大量磁盘缓存。如果所需的块在缓存中,则不必重新启动空闲磁盘来满足读取。类似地,如果对磁盘的写入可以在缓存中缓冲,则停止的磁盘不必重新启动即可处理写入。磁盘可以保持关闭状态,直到缓存填满或发生读取未命中。
避免不必要的磁盘启动的另一种方法是,操作系统通过向正在运行的程序发送消息或信号,使其了解磁盘状态。有些程序具有可跳过或延迟的任意写入。例如,可以设置文字处理器,每隔几分钟将正在编辑的文件写入磁盘。如果此时它会正常写入文件,则文字处理器知道磁盘已关闭,它可以延迟此写入,直到打开为止。
- CPU
管理CPU也可以节省能源。笔记本电脑CPU可以在软件中休眠,从而将功耗降至几乎为零。在这种状态下,它唯一能做的就是在发生中断时唤醒。因此,每当CPU空闲时,无论是等待I/O还是因为没有工作可做,它都会进入休眠状态。
在许多计算机上,CPU电压、时钟周期和电源使用之间存在关系。在软件中,CPU电压通常可以降低,这样既节省了能源,又缩短了时钟周期(近似线性)。由于消耗的功率与电压的平方成正比,将电压减半会使CPU的速度减半,但只有1/4的功率。
此属性可用于具有明确期限的程序,例如必须每隔40毫秒解压缩并显示一帧的多媒体查看器,但如果速度更快,则会变为空闲。假设CPU在全速运行40毫秒时使用x焦耳,而x/4焦耳以半速运行。如果多媒体查看器可以在20毫秒内解压缩并显示帧,则操作系统可以满功率运行20毫秒,然后关闭20毫秒,总能耗为x/2焦耳。或者,它可以半功率运行,只需在截止日期前完成,但只需使用x/4焦耳。下图显示了在一段时间间隔内以全速和全功率运行,以及以半速和四分之一功率运行两倍时间的对比。在这两种情况下,都做了相同的功,但在(b)中,只消耗了一半的能量。
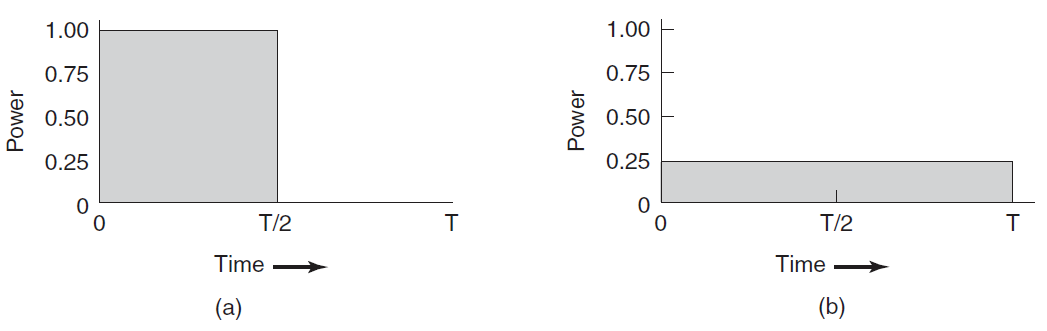
(a) 以全速运行。(b) 电压降低两倍,时钟速度减少两倍,功耗减少四倍。
类似地,如果用户以每秒1个字符的速度键入,但处理字符所需的工作需要100毫秒,那么操作系统最好检测到长空闲时间,并将CPU速度降低10倍。简而言之,慢速运行比快速运行更节能。
有趣的是,CPU内核的缩减并不总是意味着性能的降低。Hruby等人(2013)表明,有时网络堆栈的性能会随着内核速度的降低而提高。其解释是,核心可能太快而不利于自身。例如,假设一个CPU有几个快速内核,其中一个内核代表运行在另一个内核上的生产者负责传输网络数据包。生产商和网络堆栈通过共享内存直接通信,它们都在专用内核上运行。生产者执行了相当多的计算,无法完全跟上网络堆栈的核心。在典型的运行中,网络将传输它必须传输的所有内容,并在一定时间内轮询共享内存,以查看是否真的没有更多数据要传输。最后,它会放弃并进入休眠状态,因为连续轮询对功耗非常不利。不久之后,生产者提供了更多数据,但现在网络堆栈处于快速休眠状态。唤醒堆栈需要时间并降低吞吐量。一个可能的解决方案是永远不要休眠,但这也不具有吸引力,因为这样做会增加功耗,而这恰恰与我们试图实现的相反。一个更具吸引力的解决方案是在较慢的内核上运行网络堆栈,这样它就可以一直处于繁忙状态(因此从不休眠),同时还可以降低功耗。如果小心放慢网络核心的速度,其性能将优于所有核心都快得惊人的配置。
- 内存
内存有两种可能的节能选项。首先,可以刷新缓存,然后关闭缓存。它始终可以从主内存重新加载,而不会丢失信息。重新加载可以动态快速完成,因此关闭缓存将进入休眠状态。
一个更激烈的选择是将主内存的内容写入磁盘,然后关闭主内存本身。这种方法是休眠的,因为几乎所有的电源都可以被切断而占用大量的重新加载时间,特别是在磁盘也关闭的情况下。当内存被切断时,CPU要么也必须被切断,要么必须从ROM中执行。如果CPU被切断,唤醒它的中断必须使它跳转到ROM中的代码,以便在使用之前可以重新加载内存。尽管有这么多开销,如果几秒钟内重新启动比从磁盘重新启动操作系统(通常需要一分钟或更长时间)更可取,那么长时间(如数小时)关闭内存可能是值得的。
- 无线通信
越来越多的便携式计算机可以无线连接到外部世界(如互联网)。所需的无线电发射机和接收机通常是一流的电源插座。特别是,如果无线电接收器始终打开以收听传入的电子邮件,电池可能会很快耗尽。另一方面,如果收音机在空闲1分钟后关闭,则可能会错过传入的信息,这显然是不可取的。
Kravets和Krishnan(1998)提出了一个有效的解决方案,利用移动计算机与具有大内存和磁盘且无电源限制的固定基站通信这一事实。他们建议让移动计算机在即将关闭无线电时向基站发送消息,从那时起,基站在其磁盘上缓冲传入的消息。移动计算机可以明确指示它计划休眠多长时间,或者在它再次打开无线电时简单地通知基站。此时,任何累积的消息都可以发送给它。
收音机关闭时生成的传出消息在移动计算机上进行缓冲。如果缓冲区可能已满,则会打开收音机,并将队列传输到基站。收音机应该什么时候关掉?一种可能性是让用户或应用程序决定。另一种方法是在空闲几秒钟后将其关闭。什么时候应该再次打开?同样,用户或程序可以决定,也可以定期打开它来检查入站流量并传输任何排队消息。当然,它也应该在输出缓冲区接近满时打开。其他各种启发方法也是可能的。
在802.11(“WiFi”)网络中可以找到支持这种电源管理方案的无线技术的示例。在802.11中,移动计算机可以通知接入点它将要休眠,但它会在基站发送下一个信标帧之前唤醒。接入点定期发送这些帧,此时,接入点可以告诉移动计算机它有待处理的数据。如果没有此类数据,移动计算机可以再次休眠,直到下一个信标帧。
- 热量管理
一个稍有不同但仍与能源相关的问题是热量管理(Thermal Management)。现代CPU由于其高速而变得异常热,台式机通常有一个内部电风扇,用于将热空气吹出机箱。由于降低功耗通常不是台式机的驱动问题,因此风扇通常一直处于开启状态。
笔记本电脑的情况有所不同。操作系统必须连续监测温度,当温度接近最大允许温度时,操作系统可以选择。它可以打开风扇,这会产生噪音并消耗电力。或者,它可以通过减少屏幕背光、降低CPU速度、更积极地降低磁盘转速等方式来降低功耗。
用户的一些输入可能有价值,可以作为指导。例如,用户可以事先指定风扇的噪音令人反感,因此该操作系统反而会降低功耗。
- 电量管理
在过去,电池只是提供电流,直到完全耗尽,然后停止,再也没有了。移动设备现在使用智能电池,可以与操作系统通信。根据操作系统的请求,它们可以报告最大电压、电流电压、最大充电、电流充电、最大漏电流率、电流漏电流率等信息。大多数移动设备都有可以运行的程序来查询和显示所有这些参数,还可以指示智能电池在操作系统的控制下更改各种操作参数。
有些笔记本电脑有多个电池。当操作系统检测到一个电池即将用完时,它必须安排一个优雅的切换到下一个电池,而不会在转换过程中造成任何故障。当最后一块电池即将耗尽时,操作系统将向用户发出警告,然后有序关闭,例如确保文件系统未损坏。
- 设备接口
一些操作系统有一种称为ACPI(Advanced Configuration and Power Interface,高级配置和电源接口)的精细电源管理机制。操作系统可以发送任何一致的驱动程序命令,要求它报告其设备的功能及其当前状态。当与即插即用结合时,此功能尤其重要,因为在启动后,操作系统甚至不知道存在哪些设备,更不用说它们的能耗或电源管理属性了。
它还可以向驱动发送命令,指示他们降低功率水平(当然,取决于它之前学到的能力)。另外还有一些传输信号,特别是,当键盘或鼠标等设备在闲置一段时间后检测到活动时,这是系统返回(接近)正常操作的信号。
18.11.7.3 应用程序问题
到目前为止,我们已经研究了操作系统如何减少各种设备的能耗。但还有另一种方法:告诉程序使用更少的能源,即使更差的用户体验(当电池耗尽和灯熄灭时,糟糕的体验比没有体验要好)。通常,当电池电量低于某个阈值时,会传递此信息。然后由程序决定是降低性能以延长电池寿命,还是保持性能和能源耗尽风险。
这里出现的一个问题是,程序如何降低性能以节省能源。Flinn和Satyanarayanan(2004)研究了这个问题,他们提供了四个性能降低如何节省能源的例子。在此研究种,信息以各种形式呈现给用户。当不存在退化时,将提供尽可能好的信息。当出现降级时,呈现给用户的信息的保真度(准确性)比本来的要差。
为了测量能源使用量,Flinn和Satyanarayanan设计了一种称为PowerScope的软件工具,它所做的是提供程序的电源使用配置文件。要使用它,计算机必须通过软件控制的数字万用表连接到外部电源。使用万用表,软件能够读取电源输入的毫安数,从而确定计算机消耗的瞬时功率。PowerScope所做的是定期对程序计数器和电源使用情况进行采样,并将这些数据写入文件。程序终止后,对文件进行分析,以给出每个过程的能量使用情况,这些测量结果构成了他们观察的基础。还采用了硬件节能措施,并形成了衡量性能下降的基线。
测量的第一个节目是视频播放器。在未分级模式下,它以全分辨率和彩色播放30帧/秒。降级的一种形式是放弃颜色信息,以黑白显示视频。另一种形式的降级是降低帧速率,会导致闪烁,并给电影带来显著降低的质量。还有一种退化形式是通过降低空间分辨率或缩小显示图像来减少两个方向上的像素数。这种措施节省了大约30%的能源。
第二个程序是语音识别器。它对麦克风进行采样,以构造波形,这个波形可以在笔记本电脑上分析,也可以通过无线链路发送到固定电脑上进行分析。此举可以节省CPU能量,但会消耗无线电能量。降级是通过使用更小的字和更简单的声学模型来完成的,节省率约为35%。
下一个例子是通过无线电链接获取地图的地图查看器。降级包括将地图裁剪成较小的尺寸,或告诉远程服务器忽略较小的道路,从而减少传输的比特数。这里再次实现了约35%的收益。
第四个实验是将JPEG图像传输到Web浏览器。JPEG标准允许使用各种算法,将图像质量与文件大小进行权衡,平均增益只有9%。总之,实验表明,通过接受一些质量下降,用户可以在给定的电池上运行更长的时间。
18.12 多处理器系统
电子(或光学)组件之间的所有通信最终归结为在它们之间发送定义良好的比特串,不同之处在于所涉及的时间尺度、距离尺度和逻辑组织。一个极端是共享内存多处理器,其中大约有两到1000个CPU通过共享内存进行通信。在这个模型中,每个CPU都有对整个物理内存的平等访问权,并且可以使用LOAD和STORE指令读取和写入单个字,访问一个存储字通常需要1-10纳秒。正如我们将看到的,现在通常在一个CPU芯片上放置多个处理核心,这些核心共享对主存储器的访问(有时甚至共享缓存)。换而言之,共享内存多计算机的模型可以使用物理上分离的CPU、单个CPU上的多个内核或以上两者的组合来实现。虽然下图(a)所示的这个模型听起来很简单,但实际并非如此,通常需要在幕后传递大量信息。

(a) 共享内存的多处理器。(b) 通过消息传递的多计算机。(c) 广域分布式系统。
接下来是上图(b)的系统,其中CPU存储器对通过高速互连连接,这种系统称为消息传递多计算机。每个内存都是单个CPU的本地内存,只能由该CPU访问。CPU通过互连发送多字消息进行通信。有了良好的互连,短消息可以在10–50微秒内发送,但仍比图8-1(a)中的内存访问时间长得多。此设计中没有共享全局内存。多计算机(即消息传递系统)比(共享内存)多处理器更容易构建,但它们更难编程。因此,每种类型都有自己的粉丝。
第三种模型如上图(c)所示,通过广域网(如互联网)连接完整的计算机系统,形成分布式系统。每一个都有自己的内存,系统通过消息传递进行通信。(b)和(c)之间唯一真正的区别是,在后者中,使用的是完整的计算机,消息时间通常为10–100毫秒。这种长延迟迫使这些松散耦合系统以不同于(b)中紧密耦合系统的方式使用。这三种类型的系统在延迟方面相差大约三个数量级,这就是一天和三年之间的差异。
共享内存多处理器(或此后仅为多处理器)是一种计算机系统,其中两个或多个CPU共享对公共RAM的完全访问。在任何CPU上运行的程序都会看到一个正常的(通常是分页的)虚拟地址空间。这个系统唯一不寻常的特性是,CPU可以将一些值写入内存字,然后读回该字并获得不同的值(因为另一个CPU已经更改了它)。当组织正确时,此属性构成处理器间通信的基础:一个CPU将一些数据写入内存,另一个CPU读取数据。
在大多数情况下,多处理器操作系统是正常的操作系统,它们处理系统调用、进行内存管理、提供文件系统和管理I/O设备。然而,在某些领域,它们具有独特的特点,包括进程同步、资源管理和调度。
18.12.1 多处理器硬件
尽管所有多处理器都具有每个CPU都可以寻址所有内存的特性,但有些多处理器还具有每个内存字都可以像其他内存字一样快地读取的附加特性。这些机器被称为UMA(Uniform Memory Access,统一内存访问)多处理器。相反,NUMA(非统一内存访问)多处理器没有此属性。
18.12.1.1 基于总线架构的UMA多处理器
最简单的多处理器基于单个总线,如下图(a)所示,两个或更多CPU和一个或更多内存模块都使用相同的总线进行通信。当CPU想要读取一个内存字时,它首先检查总线是否繁忙。如果总线空闲,CPU将它想要的字的地址放在总线上,断言一些控制信号,并等待直到存储器将想要的字放在总线。
如果CPU想读或写内存时总线正忙,那么CPU只需等待直到总线空闲,这正是问题所在。使用两个或三个CPU,总线的争用将是可管理的,如果是32或64,那将是难以忍受的。系统将完全受到总线带宽的限制,大多数CPU将在大部分时间处于空闲状态。

三种基于总线的多处理器。(a) 没有缓存。(b) 使用缓存。(c) 有缓存和私有内存。
解决方案是向每个CPU添加一个缓存,如上图(b)所示。高速缓存可以位于CPU芯片内部、CPU芯片旁边、处理器板上,或者这三者的组合。由于现在可以从局部缓存中满足许多读取,因此总线流量将大大减少,系统可以支持更多的CPU。通常,缓存不是基于单个字,而是基于32或64字节块。当一个字被引用时,它的整个块(称为缓存行)将被提取到接触它的CPU的缓存中。
每个缓存块被标记为只读(在这种情况下,它可以同时存在于多个缓存中)或读写(在这种情形下,它可能不存在于任何其他缓存中)。如果CPU试图写入一个或多个远程高速缓存中的字,总线硬件将检测到该写入,并在总线上发出信号,通知所有其他高速缓存该写入。如果其他缓存具有“干净”副本,即内存中的内容的精确副本,则它们可以丢弃副本,并让写入程序在修改缓存块之前从内存中获取缓存块。如果某个其他缓存具有“无效”(即已修改)副本,则必须先将其写回内存,然后才能继续写入,或通过总线将其直接传输到写入器。这组规则称为缓存一致性协议(cache-coherence protocol),是众多规则之一。
另一种可能性是上图(c)的设计,其中每个CPU不仅有一个高速缓存,而且还有一个通过专用(专用)总线访问的局部专用内存。为了最佳地使用此配置,编译器应该将所有程序文本、字符串、常量和其他只读数据、堆栈和局部变量放在私有内存中。然后,共享内存仅用于可写共享变量。在大多数情况下,这种谨慎的布局将大大减少总线流量,但它确实需要编译器的积极配合。
18.12.1.2 使用交叉开关的UMA多处理器
即使有最好的缓存,使用单一总线也会将UMA多处理器的大小限制在大约16或32个CPU。除此之外,还需要一种不同类型的互连网络。将n个CPU连接到k个存储器的最简单电路是交叉开关(crossbar switch),如下图所示。交叉开关在电话交换交换机中已经使用了几十年,以任意方式将一组输入线连接到一组输出线。
在水平(输入)线和垂直(输出)线的每个交点处都是交叉点(crosspoint),交叉点是一个小的电子开关,可以根据水平线和垂直线是否连接而电动打开或关闭。在下图(a)中,我们看到三个交叉点同时闭合,允许(CPU、内存)对(010000)、(101101)和(110010)同时连接,还有许多其他的组合。事实上,组合的数量等于8路可以安全放置在棋盘上的不同方式的数量。
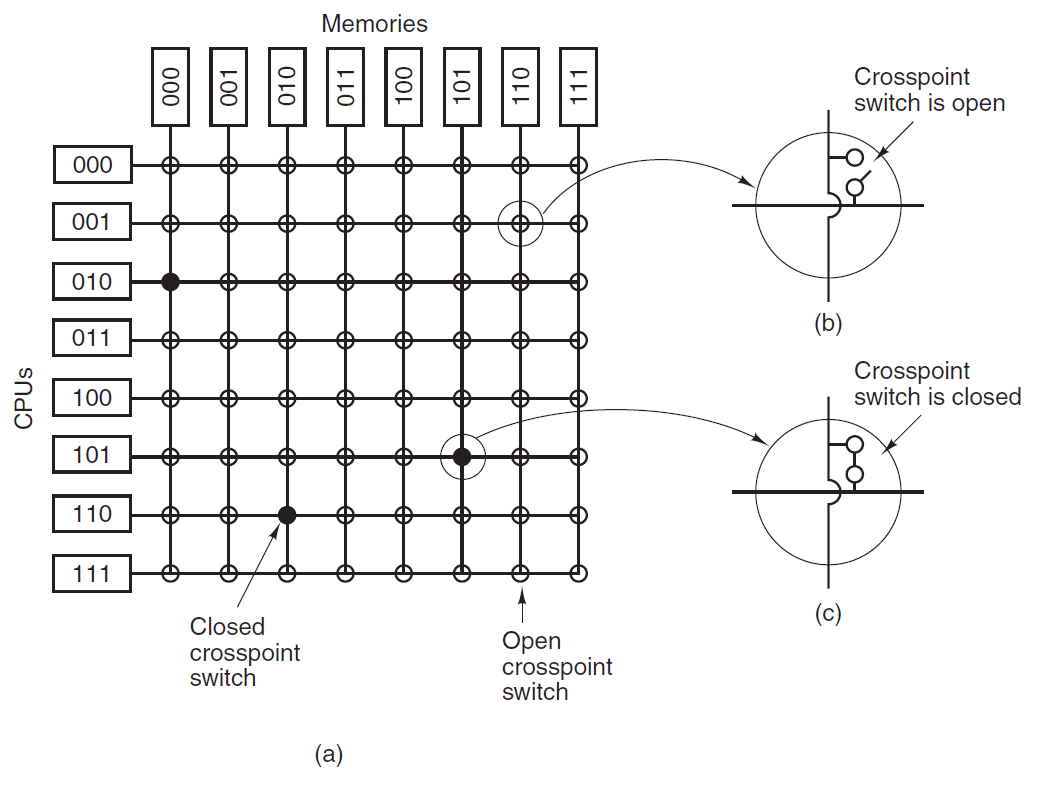
(a) 8×8交叉开关。(b) 打开的交叉点。(c) 闭合的交叉点。
交叉开关的一个最好的特性是它是一个非阻塞网络,意味着没有CPU因为某些交叉点或线路已被占用而被拒绝连接(假设内存模块本身可用),并非所有互连都具有这种优良特性。此外,不需要提前规划,即使已经设置了七个任意连接,也始终可以将剩余的CPU连接到剩余的内存。
当然,如果两个CPU想要同时访问同一个模块,那么争用内存仍然存在。然而,通过将内存划分为n个单元,与上上图的模型相比,争用减少了n倍。
交叉开关最糟糕的特性之一是交叉点的数量随着\(n^2\)而增加,例如1000个CPU和1000个内存的系统需要100万个交叉点,如此大的交叉开关不可行。然而,对于中型系统,交叉设计是可行的。
18.12.1.3 使用多级交换网络的UMA多处理器
一种完全不同的多处理器设计基于下图(a)所示的普通2×2,此开关有两个输入和两个输出,到达任一输入行的消息可以切换到任一输出行。出于我们的目的,消息最多包含四个部分,如下图(b)所示。Module(模块)字段指示要使用的内存,地址指定一个Module内的地址,操作码提供操作,如READ或WRITE。最后,可选的Value字段可能包含一个操作数,例如要写入WRITE的32位字。开关检查模块字段,并使用该字段确定消息应在X或Y上发送。
(a) 具有两条输入线a和B以及两条输出线X和Y的2×2开关。(B)消息格式。
18.12.1.4 NUMA多处理器
单总线UMA多处理器通常限制在不超过几十个CPU,交叉或交换多处理器需要大量(昂贵)硬件,并且没有那么大。要获得超过100个CPU,必须付出一些代价,通常,所有内存模块都有相同的访问时间,这种让步导致了NUMA多处理器的思想,如上所述。与UMA类似,它们在所有CPU上提供单一地址空间,但与UMA机器不同,访问本地内存模块比访问远程内存模块更快。因此,所有的UMA程序都将在NUMA机器上运行而无需更改,但性能将比在UMA机器上更差。
NUMA机器有三个关键特征,区别于其他多处理器:
1、所有CPU都有一个可见的地址空间。
2、通过LOAD和STORE指令访问远程存储器。
3、访问远程内存比访问本地内存慢。
当对远程内存的访问时间没有隐藏(因为没有缓存)时,系统称为NC-NUMA(非缓存一致NUMA)。当缓存一致时,系统称为CC-NUMA(缓存一致NUMA)。
构建大型CC-NUMA多处理器的一种流行方法是基于目录的多处理器。其想法是维护一个数据库,告诉每个缓存行的位置及其状态。当引用缓存行时,会查询数据库,以找出它的位置以及它是干净的还是脏的。由于该数据库在每一条涉及内存的指令上都会被查询,因此它必须保存在速度极快的专用硬件中,该硬件可以在总线周期的一小部分内做出响应。
为了使基于目录的多处理器的思想更加具体,让我们考虑一个简单的(假设的)示例,一个256节点系统,每个节点由一个CPU和16MB RAM组成,通过本地总线连接到CPU。总内存为\(2^{32}\)字节,分为\(2^{26}\)个缓存行,每个缓存行64字节。内存在节点之间静态分配,节点0中为0–16M,节点1中为16M–32M,等等。节点通过互连网络连接,如下图(a)所示。每个节点还保存包含其\(2^{24}\)字节存储器的218个64字节高速缓存行的目录条目。目前,我们假设一行最多可以保存在一个缓存中。
(a) 基于256节点目录的多处理器。(b) 将32位内存地址划分为字段。(c) 节点36处的目录。
18.12.1.5 多内核(Multicore Chips)
随着芯片制造技术的进步,晶体管越来越小,越来越多的晶体管可以放在芯片上,这种规律被称为摩尔定律,是英特尔联合创始人戈登·摩尔(Gordon Moore)第一次注意到的。1974年,Intel 8080包含2000多个晶体管,而Xeon Nehalem EX CPU拥有20多亿个晶体管。
一个显而易见的问题是:这些晶体管的作用是什么?一个选项是向芯片添加兆字节的缓存,具有4个32MB片上缓存的芯片很常见,但在某些时候,增加缓存大小可能会使命中率仅从99%提高到99.5%,并不会大幅提高应用程序的性能。
另一种选择是将两个或多个完整的CPU(通常称为核心)放在同一芯片上(从技术上讲,放在相同的芯片上)。双核、四核和八核芯片已经很常见,甚至可以购买数百核的芯片。毫无疑问,更多的核心正在蓬勃发展。缓存仍然至关重要,遍布整个芯片,例如,Intel Xeon 2651有12个物理超线程内核,提供24个虚拟内核。12个物理核中的每一个具有32KB的L1指令缓存和32KB的L2数据缓存,每个都有256KB的二级缓存,12个内核共享30MB的L3缓存。
虽然CPU可能共享或不共享缓存,但它们始终共享主内存,并且在每个内存字都有唯一值的意义上,此内存是一致的。特殊的硬件电路确保,如果一个字存在于两个或多个高速缓存中,并且其中一个CPU修改了该字,则该字将自动从所有高速缓存中原子化删除,以保持一致性。这个过程称为窥探(snooping)。
这种设计的结果是多核芯片只是非常小的多处理器。事实上,多核芯片有时被称为CMP(Chip MultiProcessors,芯片多处理器)。从软件的角度来看,CMP与基于总线的多处理器或使用交换网络的多处理器并没有太大区别。然而,依然存在一些差异。首先,在基于总线的多处理器上,每个CPU都有自己的缓存,常为AMD使用。共享缓存设计被英特尔在其许多处理器中使用,在其他多处理器中不存在。共享的二级或三级缓存可能会影响性能。如果一个内核需要大量的缓存内存,而另一个则不需要,那么这种设计可以让缓存占用者获取它需要的任何东西。另一方面,共享缓存也使得贪婪的内核有可能伤害其他内核。
CMP不同于其较大的同类的一个领域是容错。由于CPU之间的连接如此紧密,共享组件中的故障可能会同时导致多个CPU性能损耗,这在传统的多处理器中不太可能发生。
除了所有核都相同的对称多核芯片之外,多核芯片的另一个常见类别是片上系统(System On a Chip,SoC)。这些芯片有一个或多个主CPU,但也有专用核心,如视频和音频解码器、密码处理器、网络接口等,从而在芯片上形成完整的计算机系统。
18.12.1.6 多核芯片(Manycore Chips)
多核(Multicore)只是指“不止一个核”,但当核的数量远远超出手指计数的范围时,我们使用另一个名称。多核芯片(Manycore)是包含数十、数百甚至数千核的多核芯片。虽然Multicore成为Manycore并没有硬阈值,但一个简单的区别是,如果你不再在乎失去一两个核,你可能会拥有多核。
像Intel的Xeon Phi这样的加速器插件卡拥有超过60个x86内核,其他供应商已经用不同种类的核心突破了100核心的障碍,一千个通用核可能正在研制,很难想象如何处理一千个内核,更不用说如何对它们进行编程了。
大量内核的另一个问题是,保持其缓存一致性所需的机器变得非常复杂和昂贵。许多工程师担心缓存一致性可能无法扩展到数百个内核。有些人甚至主张我们应该完全放弃它。他们担心,硬件中一致性协议的成本将非常高,以至于所有这些闪亮的新内核都不会对性能有太大帮助,因为处理器太忙了,无法将缓存保持在一致状态。更糟糕的是,它需要在(快速)目录上花费太多的内存才能做到这一点。这就是所谓的相干墙(coherency wall)。
例如,考虑我们上面讨论的基于目录的缓存一致性解决方案。如果每个目录条目都包含一个位向量来指示哪些内核包含特定的缓存行,那么具有1024个内核的CPU的目录条目将至少128字节长。由于缓存行本身很少大于128字节,导致目录条目大于它跟踪的缓存行的尴尬情况。可能不是我们想要的。
一些工程师认为,唯一能够扩展到大量处理器的编程模型是采用消息传递和分布式存储器的编程模型,也是我们在未来多核芯片中应该期待的。像Intel的48核SCC这样的实验处理器已经降低了缓存一致性,并提供了更快的消息传递的硬件支持。另一方面,其他处理器即使在大的内核计数下也能提供一致性。混合模式也是可能的,例如,一个1024核芯片可以被划分为64个岛(island),每个岛有16个缓存一致性核,同时放弃岛之间的缓存一致性。
数以千计的核已经不再那么特别了。今天最常见的许多核心,图形处理单元,几乎可以在任何没有嵌入式和有监视器的计算机系统中找到。GPU是一个具有专用内存和数千个小内核的处理器,与通用处理器相比,GPU在执行计算的电路上花费了更多的晶体管预算,而在缓存和控制逻辑上花费的更少。它们非常适合并行进行许多小计算,比如在图形应用程序中渲染多边形。它们不擅长连续任务,也很难编程。虽然GPU对操作系统很有用(例如,加密或处理网络流量),但操作系统本身不太可能在GPU上运行。
其他计算任务越来越多地由GPU处理,特别是在科学计算中常见的计算要求较高的任务。用于GPU上的通用处理的术语是你猜到的——GPGPU。不幸的是,对GPU进行高效编程非常困难,需要特殊的编程语言,如OpenGL或NVIDIA的专有CUDA。编程GPU和编程通用处理器之间的一个重要区别是,GPU本质上是“单指令多数据”机器,意味着大量内核执行完全相同的指令,但数据不同。这种编程模型非常适合数据并行,但对于其他编程风格(如任务并行)并不总是很方便。
18.12.1.7 异构多核(Heterogeneous Multicores)
一些芯片在同一芯片上集成了GPU和多个通用内核。类似地,除了一个或多个专用处理器之外,许多SoC还包含通用核。在单个芯片中集成多个不同种类处理器的系统统称为异构多核处理器。异构多核处理器的一个例子是IXP网络处理器系列,最初由Intel于2000年推出,并定期更新最新技术。网络处理器通常包含一个通用控制核心(例如,运行Linux的ARM处理器)和几十个高度专业化的流处理器,这些处理器非常擅长处理网络数据包,而其他处理器则不多,通常用于网络设备,如路由器和防火墙。另一方面,高速网络高度依赖于对内存的快速访问(读取数据包),流处理器有特殊的硬件来实现这一点。
IXP上的流处理器和控制处理器是完全不同的,具有不同的指令集,GPU和通用内核也是如此。然而,在保持相同指令集的同时,也可能引入异构性。例如,一个CPU可以有少量的“大”内核,具有深的流水线和可能高的时钟速度,以及更多的“小”内核,这些内核更简单、更不强大,并且可能在较低的频率下运行。强大的内核是运行需要快速顺序处理的代码所必需的,而小内核对于可以高效并行执行的任务是有用的,例如ARM的big.LITTLE处理器系列。
18.12.2 多处理器操作系统类型
现在让我们从多处理器硬件转向多处理器软件,特别是多处理器操作系统。各种方法是可能的,下面将研究其中的三个。请注意,所有这些都同样适用于多核系统以及具有离散CPU的系统。
18.12.2.1 逐CPU的操作系统
组织多处理器操作系统的最简单可能的方法是将内存静态地划分为尽可能多的分区,并为每个CPU提供自己的私有内存和操作系统的私有副本。实际上,n个CPU然后作为n个独立的计算机运行。一个明显的优化是允许所有CPU共享操作系统代码,并仅对操作系统数据结构进行私有拷贝,如下图所示。

在四个CPU之间划分多处理器内存,但共享操作系统代码的单个副本。标记为Data的框是每个CPU的操作系统专用数据。
这种方案仍然比有n台单独的计算机要好,因为它允许所有的计算机共享一组磁盘和其他I/O设备,还允许灵活地共享内存。例如,即使使用静态内存分配,一个CPU也可以获得额外大的内存,这样它就可以有效地处理大型程序。此外,进程可以通过允许生产者将数据直接写入内存,并允许消费者从生产者写入数据的地方获取数据,从而有效地相互通信。然而,从操作系统的角度来看,让每个CPU都有自己的操作系统是最原始的。
值得一提的是,这种设计的四个方面可能并不明显。
首先,当一个进程进行系统调用时,系统调用会在它自己的CPU上使用操作系统表中的数据结构进行捕获和处理。
第二,由于每个操作系统都有自己的表,它也有自己的进程集,可以自己调度。没有共享进程。如果用户登录到CPU1,他的所有进程都在CPU1上运行。因此,当CPU2加载工作时,CPU1可能处于空闲状态。
第三,没有共享物理页面。当CPU2连续分页时,CPU1可能有空闲页。由于内存分配是固定的,CPU 2无法从CPU 1借用一些页面。
第四,也是最糟糕的一点,如果操作系统维护最近使用的磁盘块的缓冲区缓存,那么每个操作系统都会独立于其他操作系统执行此操作。因此,可能会发生某个磁盘块同时存在于多个缓冲区缓存中,并且是脏的,从而导致不一致的结果。避免此问题的唯一方法是消除缓冲区缓存。这样做并不难,但会严重影响性能。
由于这些原因,该模型很少再用于生产系统。如果每个处理器的所有状态都保持在该处理器的本地,那么很少或没有共享会导致一致性或锁定问题。相反,如果多个处理器必须访问和修改同一个进程表,锁定会很快变得复杂(并且对性能至关重要)。
18.12.2.2主从式多处理器
第二个模型如下图所示,操作系统及其表的一个副本存在于CPU1上,而不是其他任何一个。所有系统调用都被重定向到CPU1进行处理,如果剩余CPU时间,CPU 1也可以运行用户进程。这种模型被称为主从式(master-slave),因为CPU 1是主,而其它CPU是从。
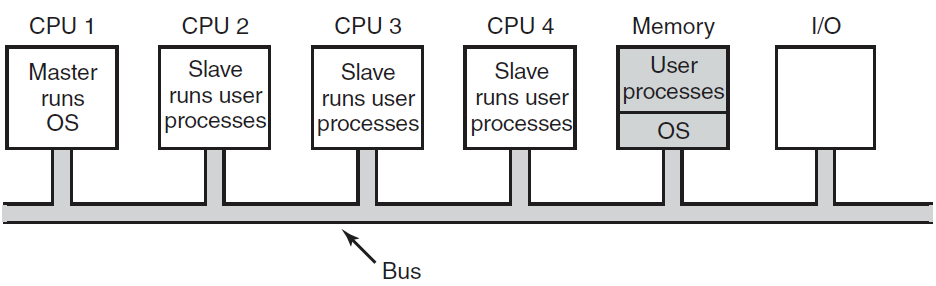
主从式多处理器模型。
主从模型解决了第一个模型的大部分问题。有一个单独的数据结构(例如,一个列表或一组优先级列表),用于跟踪就绪进程。当CPU空闲时,它要求CPU 1上的操作系统运行一个进程,并分配一个进程。因此,永远不会发生一个CPU空闲而另一个CPU过载的情况。类似地,页面可以在所有进程之间动态分配,并且只有一个缓冲区缓存,因此不会发生不一致。
这个模型的问题是,对于许多CPU,主CPU将成为一个瓶颈,因为它必须处理来自所有CPU的所有系统调用。例如,如果所有时间的10%都用于处理系统调用,那么10个CPU将使主机几乎饱和,而20个CPU将完全过载。因此,这个模型对于小型多处理器来说是简单可行的,但对于大型多处理器来说,则不可行。
18.12.2.3 对称多处理器
第三种模型SMP(Symmetric Multiprocessors,对称多处理器)消除了这种不对称性。内存中有一个操作系统副本,但任何CPU都可以运行它。当进行系统调用时,进行系统调用的CPU捕获内核并处理系统调用。SMP模型如下图所示。

SMP架构案例1。

SMP架构案例2。
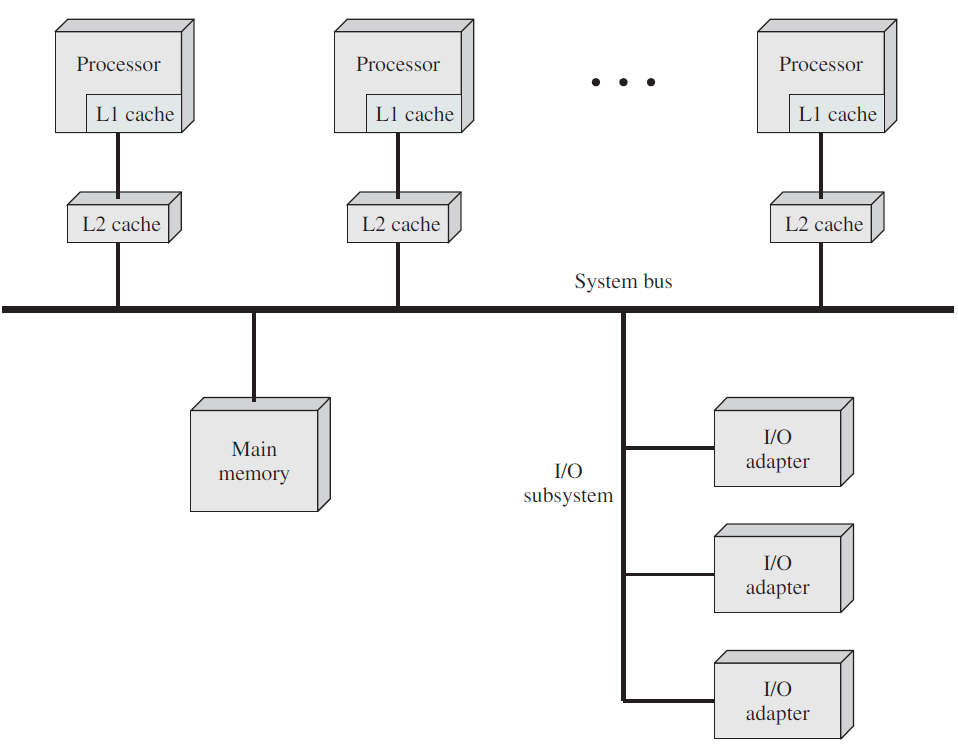
SMP架构案例3。
该模型动态平衡进程和内存,因为只有一组操作系统表,还消除了主CPU瓶颈,因为没有主CPU。但它引入了自己的问题,特别是,如果两个或多个CPU同时运行操作系统代码,很可能会导致灾难,想象两个CPU同时选择相同的进程运行或要求相同的空闲内存页。解决这些问题的最简单方法是将互斥体(即锁)与操作系统相关联,使整个系统成为一个大的关键区域。当CPU想要运行操作系统代码时,它必须首先获取互斥体。如果互斥锁被锁定,它只会等待。这样,任何CPU都可以运行操作系统,但一次只能运行一个。这种方法叫做大内核锁(big kernel lock)。
这种模式很有效,但几乎和主从模式一样糟糕。同样,假设所有运行时间的10%花费在操作系统内部。有了20个CPU,将有很长的CPU队列等待进入。幸运的是,它很容易改进,操作系统的许多部分彼此独立,例如,一个CPU运行调度程序,另一个CPU处理文件系统调用,第三个CPU处理页面错误,这没有问题。
这种观察导致将操作系统拆分为多个独立的关键区域,这些区域彼此不交互。每个关键区域都有自己的互斥体保护,因此一次只能有一个CPU执行它。通过这种方式,可以实现更多的并行性。然而,很可能会发生一些表(如进程表)被多个关键区域使用的情况。例如,进程表不仅用于调度,还用于fork系统调用和信号处理。多个关键区域可能使用的每个表都需要自己的互斥体,这样,每个关键区域一次只能由一个CPU执行,每个关键表一次只能被一个CPU访问。
大多数现代多处理机都使用这种调度,为这样的机器编写操作系统的困难之处并不在于实际代码与常规操作系统有很大的不同,事实并非如此。最困难的部分是将其划分为关键区域,这些区域可以由不同的CPU同时执行,而不会相互干扰,甚至不会以微妙的、间接的方式。此外,两个或多个关键区域使用的每个表都必须由互斥体单独保护,并且使用该表的所有代码都必须正确使用互斥体。
此外,必须非常小心地避免死锁。如果两个关键区域都需要表A和表B,并且其中一个首先获取A,另一个先获取B,那么迟早会发生死锁,没有人会知道原因。理论上,所有的表都可以分配整数值,所有的关键区域都可以按递增的顺序获取表。这种策略避免了死锁,但它要求程序员非常仔细地考虑每个关键区域需要哪些表,并按照正确的顺序发出请求。
随着代码的不断发展,关键区域可能需要一个以前不需要的新表。如果程序员是新手,并且不理解系统的全部逻辑,那么诱惑将是在需要的时候抓住表上的互斥体,并在不再需要时释放它。无论这看起来多么合理,它都可能导致死锁,用户会认为这是系统冻结。要做到这一点并不容易,面对不断变化的程序员,要在一段时间内保持这一点是非常困难的。
18.12.3 多处理器同步
多处理器中的CPU经常需要同步,前面看到内核关键区域和表必须由互斥体保护的情况,下面看看这种同步在多处理器中是如何工作的。
首先,确实需要适当的同步原语。如果单处理器机器(只有一个CPU)上的进程进行了需要访问某个关键内核表的系统调用,那么内核代码可以在访问该表之前禁用中断。然后,它就可以完成工作了,因为它知道在完成之前,它将能够在不需要任何其他过程的情况下完成工作。在多处理器上,禁用中断只影响执行禁用操作的CPU。其他CPU继续运行,仍然可以触及关键表。因此,所有CPU必须使用并遵守适当的互斥协议,以确保互斥工作。
任何实用互斥协议的核心都是一条特殊指令,它允许在一个不可分割的操作中检查和设置内存字,可以使用TSL(测试和设置锁定)来实现关键区域,如前所述,TSL的作用是读取一个内存字并将其存储在寄存器中。同时,它将1(或其他非零值)写入内存字。当然,执行内存读取和内存写入需要两个总线周期。在单处理器上,只要指令不能中途中断,TSL总是按预期工作。
现在想想在多处理器上会发生什么。在下图中,我们看到了最坏的定时,其中用作锁的内存字1000最初为0。在步骤1中,CPU 1读取该字并获得0。在第2步中,在CPU 1有机会将该字重写为1之前,CPU 2进入并将该字作为0读出。在第3步中,CPU将1写入该字。在步骤4中,CPU 2还将1写入字。两个CPU都从TSL指令中得到了0,因此它们现在都可以访问关键区域,互斥失败。
如果无法锁定总线,TSL指令可能会失败。这四个步骤显示了一系列事件,其中显示了故障。
为了防止这个问题,TSL指令必须首先锁定总线,防止其他CPU访问它,然后执行两次内存访问,然后解锁总线。通常,通过使用通常的总线请求协议请求总线,然后断言(即设置为逻辑1值)某些特殊总线,直到两个循环都完成,从而锁定总线。只要这条特殊线路被断言,其他CPU就不会被授予总线访问权。此指令只能在具有使用它们所需线路和(硬件)协议的总线上实现。现代总线都有这些设施,但在早期没有这些设施的总线上,不可能正确实施TSL。这就是彼得森协议被发明的原因:完全在软件中同步。
如果TSL得到正确的实施和使用,它保证了互斥可以发挥作用。然而,这种互斥方法使用自旋锁,因为请求的CPU只是处于一个严密的循环中,尽可能快地测试锁。它不仅完全浪费了请求CPU(或多个CPU)的时间,而且还可能给总线或内存带来大量负载,严重减慢了所有其他CPU正常工作的速度。
乍一看,缓存的存在似乎应该消除总线争用的问题,但事实并非如此。理论上,一旦请求CPU读取了锁字,它应该在缓存中获得一个副本。只要没有其他CPU尝试使用锁,请求的CPU应该能够耗尽其缓存。当拥有锁的CPU向其写入0以释放它时,缓存协议会自动使远程缓存中的所有副本无效,要求再次获取正确的值。
问题是高速缓存在32或64字节的块中运行。通常,锁周围的单字是由持有锁的CPU所需要的,由于TSL指令是写(因为它修改了锁),它需要对包含锁的缓存块进行独占访问。因此,每个TSL都会使锁持有者缓存中的块无效,并为请求的CPU获取一个专用的、独占的副本。一旦锁持有者接触到与锁相邻的单字,缓存块就会移动到其机器上。因此,包含锁的整个缓存块不断地在锁所有者和锁请求者之间穿梭,产生的总线流量甚至超过了对锁字的单独读取。
如果能够消除请求端的所有TSL引发的写入,就可以显著减少缓存抖动(thrashing),可通过让请求的CPU首先进行一次纯读取来查看锁是否空闲来实现。只有当锁看起来是空闲的时,它才会执行TSL来实际获取它。这个小变化的结果是,大多数轮询变成了都是读而不是写。如果持有锁的CPU仅读取同一缓存块中的变量,则它们可以在共享只读模式下各自拥有缓存块的副本,从而消除所有缓存块传输。
当锁最终被释放时,所有者进行写操作,这需要独占访问,从而使远程缓存中的所有副本无效。请求CPU下次读取时,将重新加载缓存块。请注意,如果两个或多个CPU正在争夺同一个锁,可能会发生两个CPU都看到它同时空闲,两个CPU同时执行TSL以获取它。只有其中一个会成功,因此这里没有竞争条件,因为真正的获取是由TSL指令完成的,并且是原子的。看到锁是免费的,然后尝试用TSL立即获取它并不能保证你获得它。但对于算法的正确性,谁获得它并不重要。纯读取的成功只是暗示,将是尝试获取锁的好时机,但并不能保证获取成功。
另一种减少总线流量的方法是使用众所周知的以太网二进制指数退避算法(Ethernet binary exponential backoff algorithm),使用连续轮询可以在轮询之间插入延迟环路。最初,延迟是一条指令,如果锁仍然繁忙,延迟将加倍到两条指令,然后是四条指令,以此类推,直到达到最大值。低的最大值在释放锁时提供快速响应,但在缓存抖动上浪费更多的总线周期。高的最大值可以减少缓存抖动,但代价是不会注意到很快释放的锁。二进制指数回退可以与TSL指令之前的纯读取一起使用,也可以不使用。
一个更好的想法是让每个希望获取互斥锁的CPU都有自己的私有锁变量进行测试,如下图所示。变量应位于其他未使用的缓存块中,以避免冲突。该算法的工作原理是让无法获取锁的CPU分配一个锁变量,并将其自身附加到等待锁的CPU列表的末尾。当当前锁持有者退出关键区域时,它释放列表中第一个CPU正在测试的私有锁(在其自己的缓存中)。然后,该CPU进入临界区域。完成后,它会释放其后继者正在使用的锁,以此类推。尽管协议有点复杂(为了避免两个CPU同时连接到列表的末尾),但它是高效且无饥饿的。
使用多个锁来避免缓存抖动。
18.12.3.1自旋与切换
到目前为止,我们假设需要锁定互斥锁的CPU只是通过连续轮询、间歇轮询或将其自身附加到等待的CPU列表来等待它。有时,请求的CPU除了等待之外别无选择。例如,假设某个CPU处于空闲状态,需要访问共享就绪列表以选择要运行的进程。如果就绪列表被锁定,CPU不能决定暂停正在执行的操作并运行另一个进程,因为这样做需要读取就绪列表。它必须等待,直到它可以获取就绪列表。
然而,在其他情况下,有一个选择。例如,如果CPU上的某个线程需要访问文件系统缓冲区缓存,并且该缓存当前被锁定,则CPU可以决定切换到其他线程而不是等待,是自旋还是切换线程的问题一直是一个研究的问题。请注意,这个问题在单处理器上不会发生,因为当没有其他CPU释放锁时,自旋没有多大意义。如果一个线程试图获取一个锁,但失败了,它总是被阻塞,以给锁所有者一个运行和释放锁的机会。
假设自旋和执行线程切换都是可行的选项,权衡如下。自旋直接浪费CPU周期,反复测试锁不是一件有成效的工作。但是,切换也会浪费CPU周期,因为必须保存当前线程的状态,必须获取就绪列表上的锁,必须选择线程,必须加载其状态,并且必须启动线程。此外,CPU缓存将包含所有错误的块,因此当新线程开始运行时,会发生许多昂贵的缓存未命中。TLB也可能发生故障。最终,必须切换回原始线程,随后会有更多的缓存未命中。执行这两个上下文切换所花费的周期加上所有缓存未命中都被浪费了。
如果已知互斥体通常保持50微秒,并且从当前线程切换需要1毫秒,稍后再切换需要1秒,那么只在互斥体上自旋更有效。另一方面,如果平均互斥体保持10毫秒,那么进行两个上下文切换是值得的。问题是关键区域的持续时间可能会有很大的差异,那么哪种方法更好呢?
一种设计是总是自旋,第二种设计是始终切换,但第三种设计是在每次遇到锁定的互斥体时做出单独的决定。在必须做出决定的时候,不知道是自旋还是切换更好,但对于任何给定的系统,都可以跟踪所有活动,并在稍后离线分析。回想起来,哪一个决定是最好的,在最好的情况下浪费了多少时间。然后,这种事后发现的算法成为衡量可行算法的基准。
几十年来,研究人员一直在研究这个问题。大多数研究都使用一个模型,在该模型中,未能获取互斥体的线程会在一段时间内自旋。如果超过此阈值,则切换。在某些情况下,阈值是固定的,通常是切换到另一个线程然后再切换回来的已知开销。在其他情况下,它是动态的,取决于所观察到的等待互斥体的历史。
当系统跟踪最后几次观察到的自旋时间并假设这一次与之前的自旋时间相似时,就可以获得最佳结果。例如,假设再次进行1毫秒的上下文切换,线程将自旋最多2毫秒,但观察它实际自旋的时间。如果它无法获取锁,并且发现在前三次运行中它平均等待了200微秒,那么它应该在切换前自旋2毫秒。然而,如果它看到它在前一次尝试中自旋了整整2毫秒,它应该立即切换,而不是自旋。
一些现代处理器,包括x86,提供了特殊的指令,使等待在降低功耗方面更加高效。例如,x86上的MONITOR/MWAIT指令允许程序阻塞,直到其他处理器修改之前定义的内存区域中的数据。具体来说,MONITOR指令定义了一个地址范围,应该监视该地址范围的写入。然后,MWAIT指令阻塞线程,直到有人写入该区域。实际上,线程正在自旋,但没有不必要地消耗许多周期。
18.12.4 多处理器调度
在查看如何在多处理器上进行调度之前,有必要确定正在调度什么。在过去,当所有进程都是单线程的时候,进程都是调度的,没有其他可调度的。所有现代操作系统都支持多线程进程,使得调度更加复杂。
线程是内核线程还是用户线程都很重要。如果线程是由用户空间库完成的,并且内核对线程一无所知,那么调度将按每个进程进行,就像它一直做的那样。如果内核甚至不知道线程的存在,它就很难对线程进行调度。
对于内核线程,情况就不同了,内核知道所有线程,并且可以在属于进程的线程中进行选择。在这些系统中,趋势是内核选择要运行的线程,它所属的进程在线程选择算法中只扮演一个小角色(或者可能没有)。下面我们将讨论调度线程,但当然,在具有单线程进程或在用户空间中实现线程的系统中,调度的是进程。
进程与线程不是唯一的调度问题。在单处理器上,调度是一维的。唯一必须(反复)回答的问题是:“下一个应该运行哪个线程?”在多处理器上,调度有两个维度,调度程序必须决定运行哪个线程以及在哪个CPU上运行,额外的维度使多处理器上的调度变得非常复杂。另一个复杂的因素是,在一些系统中,所有线程都是相互关联的,属于不同的进程,彼此之间没有任何关系。在其他应用程序中,它们是分组的,属于同一个应用程序并一起工作。前一种情况的一个例子是独立用户启动独立进程的服务器系统,不同进程的线程是不相关的,每一个进程都可以在不考虑其他进程的情况下进行调度。
后一种情况的例子经常出现在程序开发环境中。大型系统通常由一些头文件组成,其中包含宏、类型定义和实际代码文件使用的变量声明。更改头文件时,必须重新编译包含它的所有代码文件。程序make通常用于管理开发,当make被调用时,它只开始编译那些由于头文件或代码文件的更改而必须重新编译的代码文件,仍然有效的对象文件不会重新生成。
make的原始版本按顺序运行,但为多处理器设计的较新版本可以同时启动所有编译。如果需要10个编译,那么安排其中9个编译立即运行并将最后一个编译保留到很晚的时间是没有意义的,因为用户在最后一个完成之前不会感觉到工作已经完成。在这种情况下,将执行编译的线程视为一个组,并在调度它们时考虑到这一点则有意义。
有时,调度广泛通信的线程比较有用,例如以生产者-消费者的方式,不仅在同一时间,而且在空间上紧密地联系在一起,它们可能会从共享缓存中受益。同样,在NUMA体系结构中,如果它们访问附近的内存,可能会有所帮助。
常见的调度算法有时间分享、空间分享、成组调度等。由于时间分享前面已经介绍过,下面只介绍后两种。
18.12.4.1 空间分享
当线程以某种方式相互关联时,可以使用多处理器调度的另一种通用方法。前面我们提到了并行make的例子。通常情况下,一个进程有多个线程一起工作。例如,如果进程的线程经常通信,那么让它们同时运行是很有用的。跨多个CPU同时调度多个线程称为空间共享(space sharing)。
最简单的空间共享算法是这样工作的。假设一次创建了一组相关线程,在创建它时,调度器会检查空闲CPU是否与线程一样多。如果有,每个线程都有自己的专用(即非多程序)CPU,它们都会启动。如果没有足够的CPU,不会启动任何线程。每个线程都会占用它的CPU,直到它终止,这时CPU会被放回可用CPU池中。如果一个线程在I/O上阻塞,它将继续保持CPU,直到线程唤醒为止,CPU一直处于空闲状态。当下一批线程出现时,将应用相同的算法。
在任何时刻,CPU集都会被静态地划分为若干个分区,每个分区都运行一个进程的线程。在下图中,有大小为4、6、8和12个CPU的分区,例如,有2个未分配的CPU。随着时间的推移,分区的数量和大小将随着新线程的创建和旧线程的完成和终止而改变。
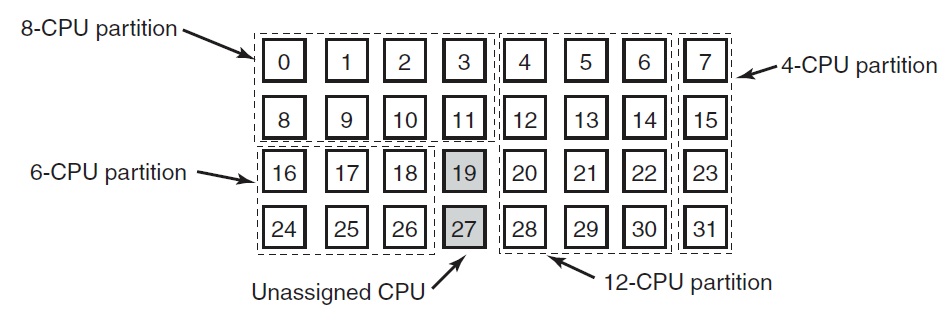
一组32个CPU分成四个分区,有两个可用CPU。
必须定期做出调度决定。在单处理器系统中,最短作业优先是一种众所周知的批调度算法。多处理器的类似算法是选择需要最少CPU周期数的进程,即CPU计数×运行时间最小的线程。然而,在实践中,这种信息很少可用,因此算法很难实现。事实上,研究表明,在实践中,先到先得很难做到。
在这个简单的分区模型中,一个线程只需要一些CPU,然后要么得到它们,要么等待它们可用。另一种方法是线程主动管理并行度。管理并行性的一种方法是使用一个中央服务器来跟踪哪些线程正在运行,哪些线程想要运行,以及它们的最小和最大CPU需求是多少。每个应用程序定期轮询中央服务器,询问它可能使用多少CPU。然后,它向上或向下调整线程数以匹配可用的线程数。
例如,一个Web服务器可以有5个、10个、20个或任何其他数量的线程并行运行。如果它目前有10个线程,并且突然对CPU的需求增加,并且它被告知减少到5个线程,那么当下一个5个线程完成其当前工作时,它们被告知退出,而不是被赋予新的工作。该方案允许分区大小动态变化,以比上图的固定系统更好地匹配当前工作负载。
18.12.4.2 分组调度
空间共享的一个明显优势是消除了多道程序设计,从而消除了上下文切换开销。然而,一个同样明显的缺点是,当CPU阻塞并且在再次准备就绪之前没有任何事情可做时,会浪费时间。因此,人们一直在寻找能够同时在时间和空间上进行调度的算法,尤其是那些创建多个线程的线程,这些线程通常需要相互通信。
要了解进程的线程独立调度时可能出现的问题,请考虑一个系统,其中线程A0和A1属于进程a,线程B0和B1属于进程B;线程A1和B1在CPU 1上分时,线程A0和A1需要经常通信。通信模式是A0向A1发送一条消息,A1随后向A0发送一个回复,然后是另一个这样的序列,这在客户机-服务器情况下很常见。假设幸运的是A0和B1首先开始,如下图所示。
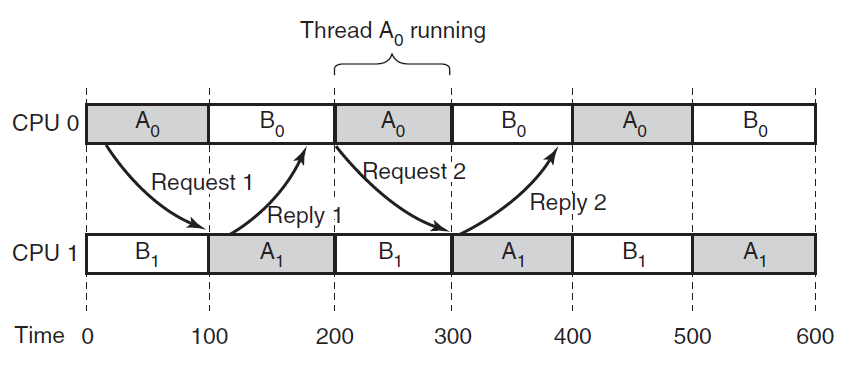
属于线程A的两个线程之间的异相通信。
在时间片0中,A0向A1发送一个请求,但A1直到在时间片1中以100毫秒开始运行时才收到请求。它立即发送回复,但A0直到在200毫秒再次运行时才收到回复。最后结果是每200毫秒一个请求-应答序列,性能不是很好。
这个问题的解决方案是分组调度(gang scheduling),是联合调度的产物,它包括三个部分:
1、相关线程组被安排为一个单元,一个组。
2、一个帮派的所有成员同时在不同的分时CPU上运行。
3、所有帮派成员一起开始和结束他们的时间片。
使分组调度工作的诀窍是,所有CPU都是同步调度的,意味着时间被划分为离散的量子,如上图所示。在每个新量子开始时,所有CPU都被重新调度,每个CPU上都会启动一个新线程。在下一个时间段开始时,会发生另一个调度事件。在这两者之间,不进行调度。如果线程阻塞,它的CPU将保持空闲状态,直到时间段结束。
下图给出了分组调度工作的一个例子,有一个多处理器,有六个CPU,由五个进程a到e使用,总共有24个就绪线程。在时隙0期间,线程A0到A6被调度和运行。在时隙1期间,调度并运行线程B0、B1、B2、C0、C1和C2。在时隙2期间,D的五个线程和E0开始运行。属于线程E的其余六个线程在时隙3中运行。然后循环重复,时隙4与时隙0相同,以此类推。
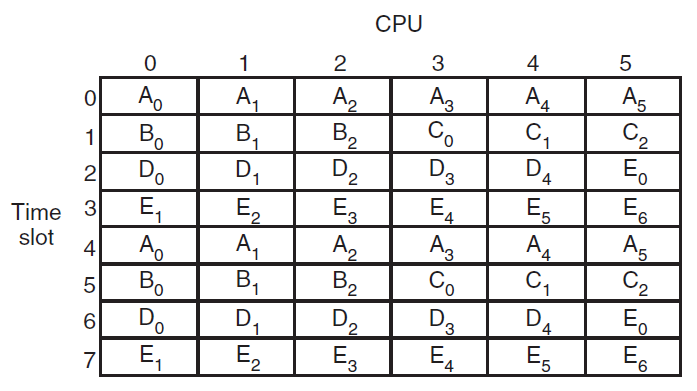
分组调度的思想是让一个进程的所有线程同时在不同的CPU上运行,这样,如果其中一个线程向另一个线程发送请求,它将几乎立即收到消息,并且能够几乎立即回复。在上图中,由于所有A线程都在一起运行,在一个时间段内,它们可以在一个量子段内发送和接收大量消息,从而消除了上上图的问题。
18.12.5 多核和多线程
使用多核系统来支持具有多线程的单个应用程序,例如工作站、视频游戏控制台或运行处理器密集型应用程序的个人计算机上可能出现的应用程序,会带来性能和应用程序设计问题。在本节中,我们阐述一下多核系统上多线程应用程序的一些性能影响。
多核组织的潜在性能优势取决于有效利用应用程序可用的并行资源的能力,性能参数遵循Amdahl定律,下面两图展示了多核的性能影响曲线图:

除了通用服务器软件之外,许多应用程序类别也直接受益于随内核数量扩展吞吐量的能力,以下是其中的几个示例:
-
多线程原生应用程序:多线程应用程序的特点是具有少量高线程进程,示例包括Lotus Domino或Siebel CRM(客户关系经理)。
-
多进程应用程序:多进程应用的特点是存在许多单线程进程,示例包括Oracle数据库、SAP和PeopleSoft。
-
Java应用程序:Java应用程序以一种基本的方式拥抱线程。Java语言不仅极大地促进了多线程应用程序,而且Java虚拟机是一个多线程进程,为Java应用程序提供调度和内存管理。可以直接从多核资源中受益的Java应用程序包括应用程序服务器,如Sun的Java application Server、BEA的Weblogic、IBM的Websphere和开源Tomcat应用程序服务器。所有使用Java 2 Platform,Enterprise Edition(2EE平台)应用服务器的应用程序都可以立即从多核技术中受益。
-
多实例应用程序:即使单个应用程序不能扩展以利用大量线程,也可以通过并行运行应用程序的多个实例从多核架构中获益。如果多个应用程序实例需要某种程度的隔离,则可以使用虚拟化技术(针对操作系统的硬件)为每个应用程序实例提供各自独立的安全环境。
下图显示了游戏引擎Source的渲染模块的线程结构。在这种层次结构中,高级线程根据需要生成低级线程。渲染模块依赖于Source引擎的关键部分,即世界列表,它是游戏世界中视觉元素的数据库表示。第一个任务是确定世界上需要渲染的区域,下一个任务是确定从多个角度观看时场景中的对象,然后是处理器密集型工作。渲染模块必须从多个视角(例如玩家视角、电视显示器的视角和水中反射的视角)来渲染每个对象。

18.13 Android
Android是一个相对较新的操作系统,设计用于在移动设备上运行。它基于Linux内核,Android仅向Linux内核本身引入了一些新概念,使用了大多数Linux设施(进程、用户ID、虚拟内存、文件系统、调度等),有时方式与最初的意图完全不同。
自推出以来,Android已成为应用最广泛的智能手机操作系统之一。它的普及带动了智能手机的爆炸式增长,移动设备制造商可以免费在其产品中使用它。它也是一个开源平台,使其可针对各种设备进行定制。它不仅在第三方应用生态系统有利的以消费为中心的设备(如平板电脑、电视、游戏系统和媒体播放器)中广受欢迎,而且越来越多地被用作需要图形用户界面(GUI)的专用设备的嵌入式操作系统,如VOIP电话、智能手表、汽车仪表板、医疗设备和家用电器。
大量的Android操作系统是用高级语言(Java编程语言)编写的。内核和大量低级库是用C和C++编写的。然而,大部分系统都是用Java编写的,除了一些小的例外,整个应用程序API也是用Java编写和发布的。用Java编写的Android部分倾向于遵循一种非常面向对象的设计,这正是该语言所鼓励的。
18.13.1 Android和Google
Android是一个不同寻常的操作系统,它将开源代码与封闭源代码的第三方应用程序结合在一起。Android的开源部分被称为Android开源项目(AOSP),是完全开放的,任何人都可以自由使用和修改。
Android的一个重要目标是支持一个丰富的第三方应用程序环境,需要有一个稳定的实现和API来运行应用程序。然而,在一个开放源码的世界里,每个设备制造商都可以随心所欲地定制平台,兼容性问题很快就会出现。需要有某种方法来控制这种冲突。
针对Android的部分解决方案是CDD(兼容性定义文档),它描述了Android必须如何与第三方应用程序兼容,文档本身描述了兼容Android设备的要求。然而,如果没有某种方式来加强这种兼容性,它往往会被忽略,需要一些额外的机制来实现这一点。
Android通过允许在开源平台之上创建额外的专有服务来解决这个问题,提供平台本身无法实现的(通常是基于云的)服务。由于这些服务是专有的,它们可以限制允许哪些设备包含它们,因此需要这些设备的CDD兼容性。
谷歌实现了Android,以支持各种专有云服务,谷歌的一系列服务是典型的例子:Gmail、日历和联系人同步、云到设备消息传递以及许多其他服务,有些对用户可见,有些则不可见。在提供兼容应用程序方面,最重要的服务是Google Play。
Google Play是Google的Android应用程序在线商店。通常,当开发者创建Android应用程序时,他们会使用Google Play发布。由于Google Play(或任何其他应用程序商店)是将应用程序交付给Android设备的渠道,该专有服务负责确保应用程序在其交付的设备上运行。
Google Play使用两种主要机制来确保兼容性。第一个也是最重要的一个要求是,根据CDD,随附的任何设备必须是兼容的Android设备,确保了所有设备的行为基线。此外,Google Play必须了解应用程序所需的设备的任何功能(例如有GPS用于执行地图导航),因此应用程序无法在缺少这些功能的设备上使用。
18.13.2 Android的历史
谷歌在2000年代中期开发了Android,在其开发初期收购了一家初创公司Android。今天存在的Android平台的几乎所有开发都是在谷歌的管理下完成的。
18.13.2.1 早期开发
Android股份有限公司是一家软件公司,成立的目的是开发软件以创造更智能的移动设备。最初是针对相机,但由于智能手机的潜在市场更大,人们的目光很快转向了智能手机。最初的目标是通过在Linux之上构建一个可以广泛使用的开放平台来解决当时为移动设备开发的困难。
在此期间,实现了平台用户界面的原型,以展示其背后的想法。为了支持丰富的应用程序开发环境,平台本身瞄准了三种关键语言:JavaScript、Java和C++。
谷歌于2005年7月收购了Android,提供了必要的资源和云服务支持,以继续将Android作为一个完整的产品进行开发。在此期间,一小部分工程师紧密合作,开始为平台开发核心基础设施,并为更高级别的应用程序开发奠定基础。
2006年初,计划发生了重大变化:该平台将完全专注于Java编程语言,而不是支持多种编程语言,用于其应用程序开发。这是一个艰难的改变,因为最初的多语言方法表面上让每个人都对“世界上最好的”感到满意;对于喜欢其他语言的工程师来说,专注于一种语言就像是倒退了一步。
然而,试图让每个人都快乐,很容易让任何人都快乐。构建三套不同的语言API比专注于一种语言需要付出更多的努力,从而大大降低了每种语言的质量。专注于Java语言的决定对于平台的最终质量和开发团队满足重要截止日期的能力至关重要。
随着开发的进展,Android平台与最终将在其上发布的应用程序密切相关。谷歌已经拥有各种各样的服务,包括Gmail、地图、日历、YouTube,当然还有将在Android上提供的搜索服务。在早期平台上实现这些应用程序所获得的知识被反馈到其设计中。这种应用程序的迭代过程允许在开发早期解决平台中的许多设计缺陷。
大多数早期应用程序开发都是在很少有底层平台可供开发人员使用的情况下完成的。该平台通常在一个进程内运行,通过一个“模拟器”,将所有系统和应用程序作为一个进程在主机上运行。事实上,今天仍然有一些旧实现的残留物,比如应用程序。onTerminate方法仍然存在于SDK(软件开发工具包)中,Android程序员使用它编写应用程序。
2006年6月,两个硬件设备被选定为计划产品的软件开发目标。第一款代号为“Sooner”,基于现有的智能手机,配有QWERTY键盘和屏幕,无需触摸输入,该设备的目标是通过利用现有硬件尽快推出初始产品。第二个目标设备代号为“Dream”,是专为Android设计的,可以完全按照设想运行。它包括一个大(当时)触摸屏、滑出式QWERTY键盘、3G收音机(用于更快的网络浏览)、加速计、GPS和指南针(用于支持谷歌地图)等。
随着软件进度计划越来越清晰,两个硬件进度计划显然没有意义。等到Sooner有可能发布的时候,硬件已经过时了,Sooner的努力正在推出更重要的Dream设备。为了解决这个问题,它决定放弃Sooner作为目标设备(尽管该硬件的开发持续了一段时间,直到新的硬件准备就绪),并完全专注于Dream。
18.13.2.2 Android 1.0
Android平台的首次公开发布是2007年11月发布的预览SDK,包括一个运行完整Android设备系统映像和核心应用程序的硬件设备模拟器、API文档和开发环境。在这一点上,核心设计和实现已经到位,并且在大多数方面与我们将要讨论的现代Android系统架构非常相似。该公告包括在Sooner和Dream硬件上运行的平台的视频演示。
Android的早期开发是在一系列季度演示里程碑下完成的,以推动和展示持续的过程。SDK版本是该平台的第一个更正式的版本。它需要将迄今为止为应用程序开发而拼凑起来的所有部分,清理并记录它们,并为第三方开发人员创建一个内聚的开发环境。
开发现在沿着两条轨道进行:接收关于SDK的反馈以进一步完善和最终确定API,以及完成和稳定交付Dream设备所需的实现。在此期间,SDK进行了多次公开更新,最终于2008年8月发布了0.9版本,其中包含了几乎最后的API。
该平台本身一直在快速发展,2008年春季,重点转向稳定,以便梦想得以实现。此时,Android包含了大量从未作为商业产品发布的代码,从C库的一部分一直到Dalvik解释器(运行应用程序)、系统和应用程序。
Android还包含了一些以前从未有过的新颖设计思想,目前尚不清楚它们将如何实现。所有这些都需要作为一个稳定的产品组合在一起,团队花了几个月的时间,想知道所有这些东西是否真的组合在一起并按预期工作。
最后,在2008年8月,该软件稳定并准备发货。产品进入工厂并开始在设备上闪现。9月,Android 1.0在Dream设备上发布,现在称为T-Mobile G1。
18.13.2.3 后续开发
在Android 1.0发布后,开发继续快速进行。在接下来的5年中,该平台进行了大约15次重大更新,从最初的1.0版本中添加了大量新功能和改进。
最初的兼容性定义文件基本上只允许与T-Mobile G1非常相似的兼容设备使用。在接下来的几年中,兼容设备的范围将大大扩大。这一过程的关键点是:
- 2009年,Android版本1.5到2.0引入了软键盘,以消除对物理键盘的要求,更广泛的屏幕支持(尺寸和像素密度)适用于较低的QVGA设备,以及新的更大和更高密度的设备,如WVGA Motorola Droid,以及一个新的“系统功能”设施,用于设备报告它们支持哪些硬件功能,以及应用程序指示它们需要哪些硬件功能。后者是Google Play用来确定应用程序与特定设备的兼容性的关键机制。
- 2011年,Android版本3.0至4.0在平台中引入了10英寸及更大平板电脑的新核心支持。核心平台现在完全支持从小型QVGA手机到智能手机和更大的“平板电脑”、7英寸平板电脑和更大平板电脑,再到10英寸以上的设备屏幕尺寸。
- 由于该平台为更多样的硬件提供了内置支持,不仅支持更大的屏幕,而且支持带或不带鼠标的非触摸设备,因此出现了更多类型的Android设备。这包括谷歌电视、游戏设备、笔记本电脑、相机等电视设备。
重要的开发工作也进入了一些不那么明显的领域:将谷歌的专有服务与Android开源平台进行更清晰的分离。
对于Android 1.0,已经投入了大量工作来创建一个干净的第三方应用程序API和一个不依赖于专有谷歌代码的开源平台。然而,谷歌专有代码的实现往往还没有清理干净,依赖于平台的内部部分,通常,该平台甚至没有谷歌专有代码所需的设施来与之进行良好的集成。为解决这些问题,很快开展了一系列项目:
- 2009年,Android 2.0版引入了一种体系结构,第三方可以将自己的同步适配器插入联系人数据库等平台API。Google用于同步各种数据的代码被转移到这个定义良好的SDK API。
- 2010年,Android 2.2版包含了谷歌专有代码的内部设计和实现工作。这种“伟大的分离”干净地实现了许多核心谷歌服务,从提供基于云的系统软件更新到“云到设备的消息传递”和其他后台服务,这样它们就可以与平台分开交付和更新。
- 2012年,一个新的Google Play服务应用程序交付给了设备,其中包含Google专有非应用程序服务的更新和新功能。这是2010年分拆工作的成果,允许谷歌全面交付和更新云到设备消息和地图等专有API。
18.13.3 Android设计目标
Android平台在开发过程中出现了许多关键设计目标:
1、为移动设备提供完整的开源平台。Android的开源部分是一个自下而上的操作系统堆栈,包括各种应用程序,可以作为一个完整的产品发布。
2、通过强大而稳定的API,强力支持专有的第三方应用程序。如前所述,维护一个既真正开源又足够稳定的平台,以供专有第三方应用程序使用,是一项挑战。Android使用混合的技术解决方案(指定一个定义良好的SDK以及公共API和内部实现之间的划分)和政策要求(通过CDD)来解决这一问题。
3、允许所有第三方应用程序,包括来自谷歌的应用程序,在公平的竞争环境中竞争。Android开源代码被设计为尽可能中立于构建在其之上的高级系统功能,从访问云服务(如数据同步或云到设备的消息API),到库(如谷歌的映射库)和应用商店等丰富服务。
4、提供一种应用程序安全模型,在该模型中,用户不必深深信任第三方应用程序。操作系统必须保护用户免受应用程序的不当行为,不仅是可能导致其崩溃的有缺陷的应用程序,而且还要保护用户对设备和设备上用户数据的更微妙的滥用。用户越不需要信任应用程序,他们就越有自由尝试和安装应用程序。
5、支持典型的移动用户交互:在许多应用程序中花费很短的时间。移动体验往往涉及与应用程序的简短互动:浏览新收到的电子邮件、接收和发送短信或即时消息、联系联系人拨打电话等;Android的目标通常是200毫秒,以冷启动基本应用程序。
6、为用户管理应用程序流程,简化应用程序的用户体验,以便用户在完成应用程序时不必担心关闭应用程序。移动设备也倾向于在没有交换空间的情况下运行,当当前运行的应用程序集需要比实际可用的RAM更多的RAM时,交换空间允许操作系统更优雅地发生故障。为了满足这两个需求,系统需要采取更积极的态度来管理进程,并决定何时启动和停止进程。
7、鼓励应用程序以丰富和安全的方式进行互操作和协作。在某些方面,移动应用程序是对shell命令的回归:它们不是越来越大的桌面应用程序的单一设计,而是针对特定需求而设计的。为了帮助支持这一点,操作系统应该为这些应用程序提供新类型的设施,以便它们协同工作,创建一个更大的整体。
8、创建一个完整的通用操作系统。移动设备是通用计算的一种新表现形式,比我们的传统桌面操作系统更简单。Android的设计应该足够丰富,可以发展到至少与传统操作系统一样的能力。
18.13.4 Android架构
Android是在标准Linux内核之上构建的,只有几个对内核本身的重要扩展。然而,一旦进入用户空间,它的实现就与传统的Linux发行版大不相同,并且以非常不同的方式使用了许多Linux特性。
与传统的Linux系统一样,Android的第一个用户空间进程是init,它是所有其他进程的根。然而,守护进程Android的init进程启动不同,它更多地关注低级细节(管理文件系统和硬件访问),而不是更高级的用户设施,比如调度cron作业。Android还有一个额外的进程层,运行Dalvik的Java语言环境,负责执行用Java实现的系统的所有部分。
下图展示了Android的基本进程结构。首先是init进程,它产生了许多低级守护进程。其中一个是zygote,它是高级Java语言进程的根。
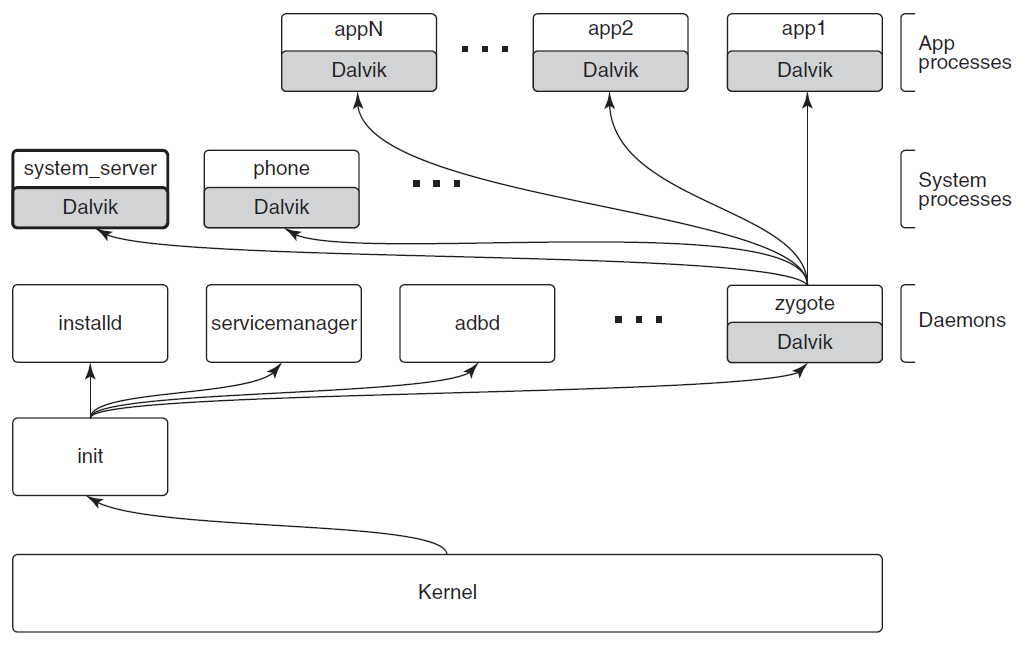
Android进程层次结构。
Android的init不会以传统方式运行shell,因为典型的Android设备没有用于shell访问的本地控制台。相反,守护进程adbd侦听请求shell访问的远程连接(例如通过USB),根据需要为它们分叉shell进程。
由于大多数Android都是用Java语言编写的,所以zygote守护进程及其启动的进程是系统的核心。总是启动的第一个进程称为系统服务器,它包含所有核心操作系统服务,其中的关键部分是电源管理器、包管理器、窗口管理器和活动管理器。
其他进程将根据需要从zygote中创建。其中一些是作为基本操作系统一部分的“持久”进程,例如电话进程中的电话堆栈,必须始终运行。系统运行时,将根据需要创建和停止其他应用程序进程。
应用程序通过调用操作系统提供的库与操作系统交互,这些库共同构成了Android框架(Android framework)。其中一些库可以在该进程中执行其工作,但许多库需要与其他进程(通常是系统服务器进程中的服务)执行进程间通信。
下图显示了与系统服务交互的Android框架API的典型设计,在本例中为包管理器。包管理器提供了一个框架API,供应用程序在本地进程中调用,这里是PackageManager类。在内部,此类必须获得到系统服务器中相应服务的连接。为了实现这一点,在启动时,系统服务器在服务管理器(由init启动的守护进程)中以定义良好的名称发布每个服务。应用程序进程中的PackageManager使用相同的名称检索从服务管理器到其系统服务的连接。
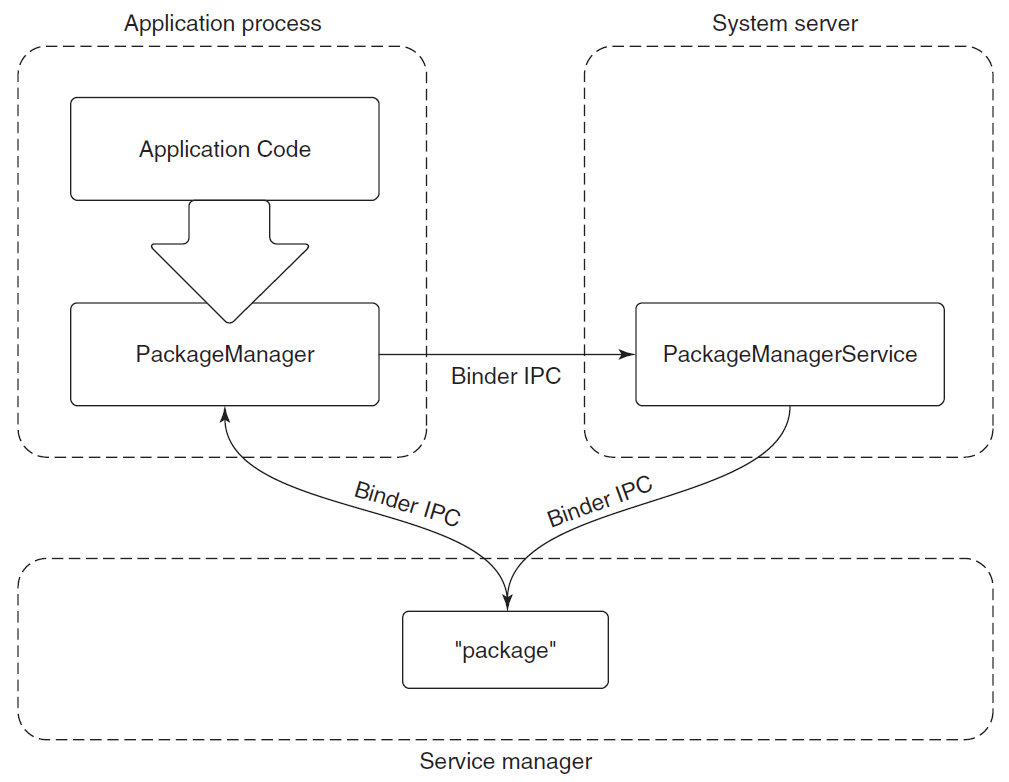
发布并与系统服务交互。
一旦PackageManager与其系统服务连接,它就可以对其进行调用。大多数对PackageManager的应用程序调用都使用Android的Binder IPC机制实现为进程间通信,在这种情况下,调用系统服务器中的PackageManagerService实现。PackageManagerService的实现仲裁所有客户端应用程序之间的交互,并维护多个应用程序所需的状态。
18.13.5 Linux扩展
大部分情况下,Android包括一个提供标准Linux功能的Linux内核。作为操作系统,Android最有趣的方面是如何使用现有的Linux功能。然而,Android系统也依赖于Linux的一些重要扩展。
18.13.5.1 唤醒锁(Wake Lock)
移动设备上的电源管理与传统计算系统不同,因此Android为Linux添加了一个新功能,称为唤醒锁(也称为挂起阻止程序),用于管理系统如何进入睡眠状态。
在传统的计算系统上,系统可能处于两种电源状态之一:正在运行并准备好用户输入,或者处于深度睡眠状态,在没有外部中断(如按下电源键)的情况下无法继续执行。运行时,可以根据需要打开或关闭辅助硬件,但CPU本身和硬件的核心部分必须保持通电状态,以处理传入的网络流量和其他此类事件。进入低功耗睡眠状态相对来说很少发生:要么是通过用户明确地将系统置于睡眠状态,要么是由于用户不活动的时间间隔较长而进入睡眠状态。要退出此睡眠状态,需要来自外部源的硬件中断,例如按下键盘上的按钮,此时设备将醒来并打开屏幕。
移动设备用户有不同的期望。尽管用户可以以一种看起来像让设备进入睡眠的方式关闭屏幕,但传统的睡眠状态实际上并不理想。当设备的屏幕关闭时,设备仍然需要能够工作:它需要能够接收电话、接收和处理传入聊天消息的数据,以及许多其他事情。
与传统电脑相比,人们对移动设备屏幕的开启和关闭要求也更高。移动交互往往会在一天中出现很多短时间:你收到一条消息,打开设备查看它,也许会发送一句话的回复,你遇到朋友遛狗,打开设备给她拍照。在这种典型的移动使用中,从拉出设备到准备好使用的任何延迟都会对用户体验产生显著的负面影响。
考虑到这些要求,一个解决方案是,当设备的屏幕关闭时,不要让CPU进入睡眠状态,这样它就可以随时重新打开。毕竟,内核确实知道什么时候没有为任何线程安排工作,Linux(以及大多数操作系统)将自动使CPU空闲,在这种情况下使用更少的功率。然而,空闲CPU与真正的睡眠不同。例如:
1、在许多芯片组上,空闲状态比真正的睡眠状态使用的功率要多得多。
2、如果某些工作碰巧可用,即使该工作不重要,空闲的CPU也可以随时唤醒。
3、仅仅让CPU空闲并不意味着你可以关闭真正睡眠中不需要的其他硬件。
Android上的唤醒锁允许系统进入更深层次的睡眠模式,而无需像关闭屏幕这样的明确用户操作。带有唤醒锁的系统的默认状态是设备处于睡眠状态。当设备运行时,为了防止它重新进入睡眠状态,需要保持唤醒锁。
当屏幕打开时,系统始终保持一个唤醒锁,防止设备进入睡眠状态,因此它将保持运行,正如我们预期的那样。然而,当屏幕关闭时,系统本身通常不会保持唤醒锁,因此只有当其他东西保持唤醒锁时,系统才会保持睡眠状态。当没有更多的唤醒锁时,系统进入睡眠状态,并且只有在硬件中断的情况下才能退出睡眠。
一旦系统进入睡眠状态,硬件中断将再次唤醒它,就像在传统操作系统中一样。这种中断的一些来源是基于时间的警报、来自蜂窝无线电的事件(例如来电)、传入的网络流量以及按下某些硬件按钮(例如电源按钮)。这些事件的中断处理程序需要对标准Linux进行一次更改:它们需要获得一个初始唤醒锁,以便在系统处理中断后保持系统运行。
中断处理程序获取的唤醒锁必须保持足够长的时间,以便将控制权从堆栈向上转移到内核中的驱动程序,该驱动程序将继续处理事件。然后,内核驱动程序负责获取自己的唤醒锁,之后可以安全地释放中断唤醒锁,而不会有系统返回睡眠的风险。
如果驱动程序随后要将此事件传递到用户空间,则需要进行类似的握手。驱动必须确保其继续保持唤醒锁,直到将事件传递给等待的用户进程,并确保有机会获得自己的唤醒锁。该流也可以在用户空间中的子系统中继续;只要有东西持有唤醒锁,我们就继续执行所需的处理以响应事件。然而,一旦不再保持唤醒锁,整个系统就会返回睡眠状态,所有处理都会停止。
18.13.5.2 内存不足杀手
Linux包括一个内存不足杀手(Out-Of-Memory Killer),它试图在内存极低时恢复。现代操作系统内存不足的情况是模糊的。使用分页和交换,应用程序本身很少会出现内存不足的故障。然而,内核仍然会遇到这样一种情况,即它在需要时无法找到可用的RAM页面,这不仅是为了新的分配,而且是在交换或分页当前正在使用的某个地址范围时。
在这样一个内存不足的情况下,标准的Linux内存不足杀手是寻找RAM的最后手段,这样内核就可以继续它正在做的任何事情。这是通过给每个进程分配一个“坏”级别来完成的,并简单地杀死被认为是最坏的进程。进程的好坏取决于进程使用的RAM数量、运行时间以及其他因素;目标是杀死希望不是关键的大型进程。
Android给内存不足杀手带来了特别的压力。它没有交换空间,因此在内存不足的情况下更常见:除了从最近使用的存储中删除映射的干净RAM页面之外,没有办法缓解内存压力。即便如此,Android使用标准的Linux配置来过度提交内存,也就是说,允许在RAM中分配地址空间,而不保证有可用的RAM来支持它。过度提交是优化内存使用的一个非常重要的工具,因为它通常用于mmap大型文件(如可执行文件),只需要将该文件中的全部数据的一小部分加载到RAM中。
在这种情况下,现有的Linux内存不足杀手并不能很好地发挥作用,因为它更多的是作为最后的手段,而且很难正确识别要杀死的好进程。事实上,Android在很大程度上依赖于定期运行的内存不足杀手来获取进程并做出正确的选择。
为了解决这个问题,Android向内核引入了自己的内存不足杀手,具有不同的语义和设计目标。Android内存不足杀手运行得更为积极:每当RAM变得“低”时低RAM由一个可调参数标识,该参数指示内核中有多少可用的空闲和缓存RAM是可接受的。当系统低于该限制时,内存不足杀手会运行以从其他地方释放RAM。目标是确保系统永远不会进入糟糕的分页状态,这可能会在前台应用程序争夺RAM时对用户体验产生负面影响,因为由于不断的分页输入和输出,它们的执行速度会变慢。
Android的内存不足杀手并没有试图猜测应该杀死哪些进程,而是非常严格地依赖用户空间提供给它的信息。传统的Linux内存不足杀手有一个逐进程的oom_adj参数,可以用来通过修改进程的总体不良分数来引导它走向最佳的进程。Android的内存不足杀手使用相同的参数,但作为一个严格的顺序:具有较高oom_adj的进程总是在具有较低的进程之前被杀死。
18.13.6 Dalvik
Dalvik在Android上实现Java语言环境,负责运行应用程序及其大部分系统代码。从包管理器到窗口管理器,再到活动管理器,几乎所有系统服务进程都是用Dalvik执行的Java语言代码实现的。
然而,Android并不是传统意义上的Java语言平台。Android应用程序中的Java代码是以Dalvik的字节码格式提供的,基于注册机,而不是Java传统的基于堆栈的字节码。Dalvik的字节码格式允许更快的解释,同时仍然支持JIT(Just-in-Time,实时)编译。通过使用字符串池和其他技术,Dalvik字节码在磁盘和RAM中的空间效率也更高。
在编写Android应用程序时,源代码是用Java编写的,然后使用传统Java工具编译成标准Java字节码。然后,Android引入了一个新步骤:将Java字节码转换为Dalvik更紧凑的字节码表示。它是应用程序的Dalvik字节码版本,打包为最终的应用程序二进制文件,并最终安装在设备上。
Android的系统架构在很大程度上依赖于Linux的系统原语,包括内存管理、安全性和跨安全边界的通信。它不使用Java语言作为核心操作系统概念,几乎没有试图抽象出底层Linux操作系统的这些重要方面。
特别值得注意的是Android对进程的使用。Android的设计不依赖Java语言实现应用程序和系统之间的隔离,而是采用传统的操作系统进程隔离方法。这意味着每个应用程序都在其自己的Linux进程中运行,并有自己的Dalvik环境,系统服务器和其他用Java编写的平台核心部分也是如此。
使用进程进行这种隔离允许Android利用Linux的所有功能来管理进程,从内存隔离到进程离开时清理与进程相关的所有资源。除了进程之外,Android完全依赖于Linux的安全特性,而不是使用Java的SecurityManager架构。
Linux进程和安全性的使用大大简化了Dalvik环境,因为它不再负责系统稳定性和健壮性的这些关键方面。不巧的是,它还允许应用程序在实现中自由使用本机代码,这对于通常使用基于C++的引擎构建的游戏尤为重要。
像这样混合进程和Java语言确实会带来一些挑战。即使是在现代移动硬件上,创建一个全新的Java语言环境也需要一秒钟的时间。回想一下Android的设计目标之一,即能够以200毫秒的目标快速启动应用程序。要求为这个新应用程序启动一个新的Dalvik进程将远远超出预算。即使不需要初始化新的Java语言环境,在移动硬件上也很难实现200毫秒的启动。
这个问题的解决方案是我们前面简要提到的合子本地守护进程。Zygote负责启动和初始化Dalvik,直到它可以开始运行用Java编写的系统或应用程序代码。所有新的基于Dalvik的进程(系统或应用程序)都是从合子派生出来的,允许它们在已经准备好的环境中开始执行。
Zygote带来的不仅仅是Dalvik,还预加载了系统和应用程序中常用的Android框架的许多部分,以及加载资源和其他经常需要的东西。
请注意,从Zygote创建新进程需要一个Linux fork,但没有exec调用。新的进程是原始Zygote进程的复制品,其所有的预初始化状态都已设置好并准备就绪。下图说明了一个新的Java应用程序进程如何与原始的Zygote进程相关。在fork之后,新进程有自己独立的Dalvik环境,尽管它通过写页面上的拷贝与Zygote共享所有预加载和初始化的数据。现在剩下的就是让新运行的进程准备就绪,给它正确的标识(UID等),完成需要启动线程的Dalvik初始化,并加载要运行的应用程序或系统代码。
除了发射速度,Zygote还带来了另一个好处。因为只有一个fork用于从中创建进程,所以初始化Dalvik和预加载类和资源所需的大量脏RAM页面可以在Zygote及其所有子进程之间共享。这种共享对于Android环境尤其重要,因为在Android环境中无法进行交换;可以从“磁盘”(闪存)按需分页清理页面(如可执行代码)。然而,任何脏页必须在RAM中保持锁定,无法将它们调出到“磁盘”。
18.13.7 Binder IPC
Android的系统设计主要围绕应用程序之间以及系统本身不同部分之间的进程隔离进行。这需要大量的进程间通信来协调不同进程之间的关系,可能需要大量的工作来实现和正确处理。Android的Binder进程间通信机制是一个丰富的通用IPC工具,大多数Android系统都是建立在它之上的。
Binder架构分为三层,如下图所示。堆栈底部是一个内核模块,它实现了实际的跨进程交互,并通过内核的ioctl函数将其公开,ioctl是一个通用内核调用,用于向内核驱动程序和模块发送自定义命令。在内核模块之上是一个基本的面向对象用户空间API,允许应用程序通过IBinder和Binder类创建IPC端点并与之交互。顶部是一个基于接口的编程模型,其中应用程序声明了它们的IPC接口,而不需要担心IPC在底层如何发生的细节。

Binder IPC架构。
18.13.7.1 Binder内核模块
Binder没有使用现有的LinuxIPC工具,例如管道,而是包含一个特殊的内核模块,它实现了自己的IPC机制。BinderIPC模型与传统的Linux机制有很大的不同,因此它不能在用户空间中高效地在它们之上实现。此外,Android不支持大多数用于跨进程交互的System V原语(信号量、共享内存段、消息队列),因为它们不提供从错误或恶意应用程序中清除资源的强大语义。
Binder使用的基本IPC模型是RPC(远程过程调用)。也就是说,发送进程向内核提交完整的IPC操作,该操作在接收进程中执行;发送方可以在接收方执行时阻塞,从而允许从调用返回结果。(发送方可以选择指定它们不应阻塞,继续与接收方并行执行。)因此,绑定IPC是基于消息的,就像System V消息队列一样,而不是基于Linux管道中的流。Binder中的消息被称为事务,在更高级别上可以被视为跨进程的函数调用。
用户空间提交给内核的每个事务都是一个完整的操作:它标识了操作的目标、发送者的身份以及正在传递的完整数据。内核确定接收该事务的适当进程,并将其传递给进程中的等待线程。
下图说明了交易的基本流程。发起进程中的任何线程都可以创建一个标识其目标的事务,并将其提交给内核。内核生成事务的副本,并将发送者的身份添加到其中。它确定哪个进程负责事务的目标,并唤醒进程中的线程以接收它。一旦接收进程执行,它将确定事务的适当目标并交付它。
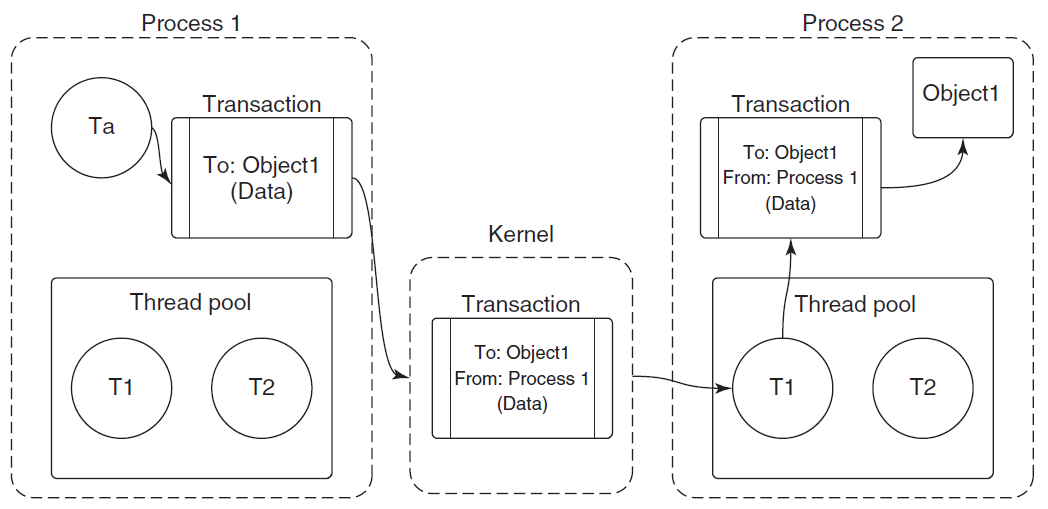
基本绑定IPC事务。
对于这里的讨论,我们将事务数据在系统中的移动方式简化为两个副本,一个副本到内核,一个到接收进程的地址空间。实际的实现在一个副本中完成。对于每个可以接收事务的进程,内核都会创建一个共享内存区域。在处理事务时,它首先确定将接收该事务的进程,并将数据直接复制到该共享地址空间中。
请注意,上图中的每个进程都有一个“线程池”,是由用户空间创建的一个或多个线程,用于处理传入事务。内核将把每个传入的事务分派给当前正在该进程的线程池中等待工作的线程。然而,从发送进程调用内核并不需要来自线程池,进程中的任何线程都可以自由启动事务,如图中的Ta。
我们已经看到,给内核的事务标识了一个目标对象;然而,内核必须确定接收进程。为了实现这一点,内核跟踪每个进程中的可用对象,并将它们映射到其他进程,如下图所示,在这里看到的对象只是该进程地址空间中的位置。内核只跟踪这些对象地址,没有任何意义;它们可以是C数据结构、C++对象或位于该进程地址空间中的任何其他对象的位置。
对远程进程中对象的引用由整数句柄标识,很像Linux文件描述符。例如,考虑进程2中的Object2a,内核知道它与进程2关联,并且内核在进程1中为它分配了句柄2。因此,进程1可以将事务提交给目标为其句柄2的内核,内核可以从中确定该事务正在发送给进程2,特别是该进程中的Object2b。
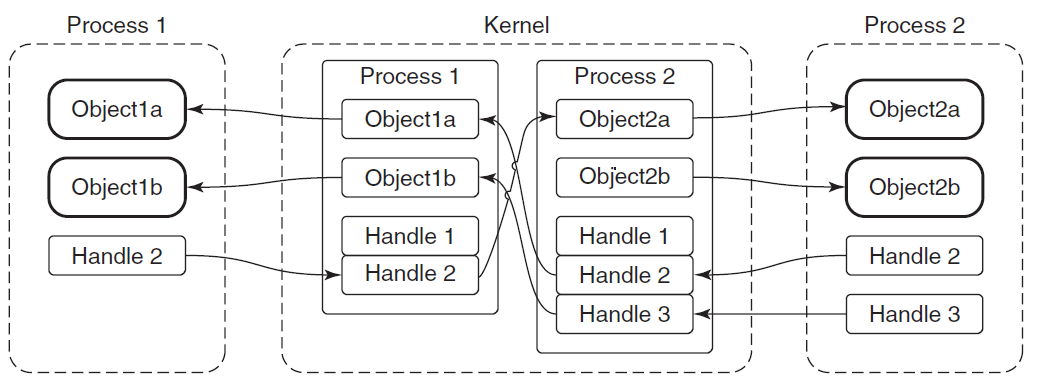
绑定跨进程对象映射。
与文件描述符一样,一个进程中句柄的值与另一个进程的值的含义不同。例如,在上图中,我们可以看到,在进程1中,句柄值2表示Object2a;然而,在进程2中,相同的句柄值2标识Object1a。此外,如果内核没有为另一个进程分配句柄,一个进程就不可能访问另一个过程中的对象。同样在上图中,我们可以看到内核知道进程2的Object2b,但没有为进程1分配句柄。因此,进程1没有访问该对象的路径,即使内核为其他进程分配了句柄。
这些句柄到对象的关联首先是如何建立的?与Linux文件描述符不同,用户进程不直接请求句柄。相反,内核根据需要为进程分配句柄。该过程如下图所示。在这里,我们将查看上一图中从进程2到进程1对Object1b的引用是如何产生的。关键是交易如何在系统中流动,从图底部的左到右。下图所示的关键步骤是:
1、进程1创建包含本地地址Object1b的初始事务结构。
2、进程1向内核提交事务。
3、内核查看事务中的数据,找到地址Object1b,并为其创建一个新条目,因为它以前不知道这个地址。
4、内核使用事务的目标Handle 2来确定这是针对进程2中的Object2a的。
5、内核现在重写事务头以适合进程2,将其目标更改为地址Object2a。
6、内核同样重写目标进程的事务数据;这里它发现进程2还不知道Object1b,因此为它创建了一个新的句柄3。
7、重写的事务被传送到进程2以供执行。
8、在接收到事务后,进程发现有一个新的句柄3,并将其添加到其可用句柄表中。
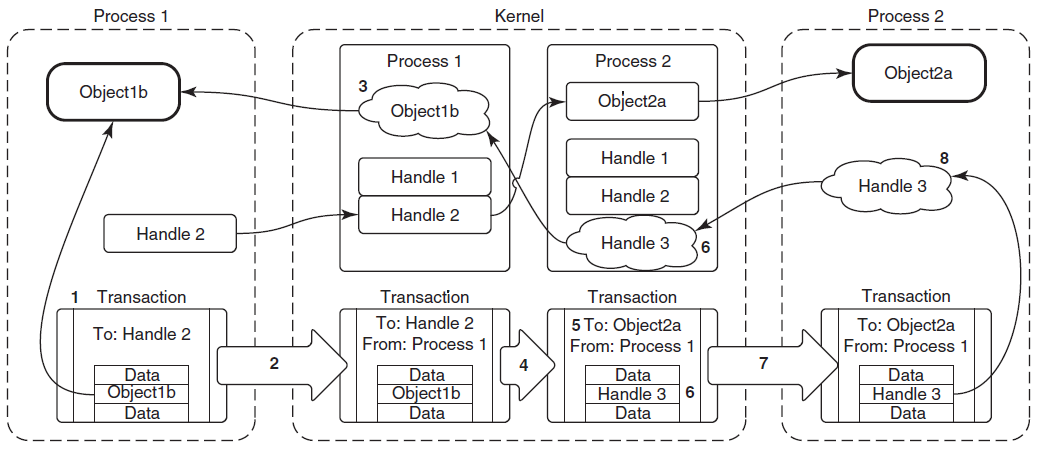
在进程之间传输Binder对象。
如果一个事务中的一个对象已经为接收进程所知,那么这个流程是相似的,除了现在内核只需要重写该事务,以便它包含先前分配的句柄或接收进程的本地对象指针。这意味着多次将同一个对象发送到进程将始终导致相同的标识,而不像Linux文件描述符那样,多次打开同一个文件将每次分配不同的描述符。当这些对象在进程之间移动时,Binder IPC系统保持唯一的对象标识。
Binder架构本质上为Linux引入了一个基于能力的安全模型。每个Binder对象都是一种功能。将对象发送到另一个进程将授予该进程该能力。然后,接收过程可以利用对象提供的任何特征。一个进程可以将一个对象发送到另一个进程,然后从任何进程接收一个对象,并识别接收到的对象是否与它最初发送的对象完全相同。
18.13.7.2 Binder用户空间API
大多数用户空间代码不会直接与Binder内核模块交互。相反,有一个用户空间面向对象的库,它提供了一个更简单的API。这些用户空间API的第一级相当直接地映射到我们迄今为止所讨论的内核概念,以三个类的形式:
1、IBinder是Binder对象的抽象接口。它的关键方法是transaction,它将事务提交给对象。接收事务的实现可以是本地进程或另一进程中的对象,如果它在另一个进程中,将通过前面讨论的绑定器内核模块传递给它。
2、Binder是一个具体的Binder对象。实现Binder子类为您提供了一个可由其他进程调用的类,关键方法是onTransact,它接收发送给它的事务。Binder子类的主要职责是查看它在这里接收的事务数据并执行适当的操作。
3、Parcel是用于读取和写入Binder事务中的数据的容器。它有读取和写入类型化数据整数、字符串和数组的方法,但最重要的是,它可以读取和写入对任何IBinder对象的引用,使用适当的数据结构让内核理解并跨进程传输该引用。
下图描述了这些类是如何协同工作的,这里我们看到Binder1b和Binder2a是具体的Binder子类的实例。为了执行IPC,进程现在创建一个包含所需数据的Parcel,并通过另一个我们尚未看到的类BinderProxy发送它。每当进程中出现新句柄时,都会创建该类,从而提供IBinder的实现,该实现的transaction方法为调用创建适当的事务并将其提交给内核。
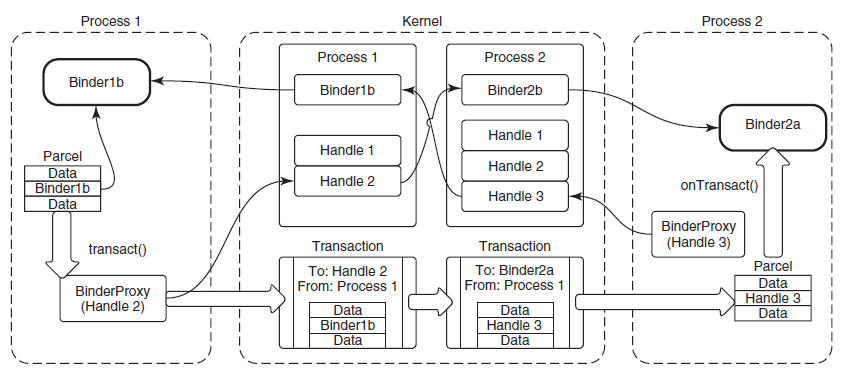
因此,我们之前看到的内核事务结构在用户空间API中被分割:目标由BinderProxy表示,其数据保存在Parcel中。正如我们前面所看到的,事务通过内核,在接收过程中出现在用户空间中时,它的目标用于确定适当的接收绑定器对象,而Parcel是根据其数据构建的,并传递给该对象的onTransact方法。这三个类现在使编写IPC代码变得相当容易:
1、来自Binder的子类。
2、实现onTransact来解码和执行传入调用。
3、实现相应的代码以创建可传递给该对象的事务处理方法的Parcel。
这项工作的大部分在最后两个步骤中,是解组(unmarshalling)和编组(marshalling)代码,需要将我们希望使用简单方法调用编程的方式转换为执行IPC所需的操作。
18.13.7.3 Binder接口和AIDL
BinderIPC的最后一部分是最常用的,一个基于高级接口的编程模型。这里我们不再处理绑定对象和地块数据,而是从接口和方法的角度来思考。
该层的主要部分是一个名为AIDL(用于Android接口定义语言)的命令行工具。这个工具是一个接口编译器,它对接口进行抽象描述,并从中生成定义该接口所需的源代码,并实现对其进行远程调用所需的适当编组和解编组代码。
下面代码显示了AIDL中定义的接口的一个简单示例,这个接口称为IExample,包含一个方法print,接受一个String参数。
package com.example
interface IExample
{
void print(Str ing msg);
}
上述代码中的接口描述由AIDL编译,生成下图中所示的三个Java语言类:
1、IExample提供了Java语言接口定义。
2、IExample.Stub是此接口实现的基类。它继承自Binder,这意味着它可以是IPC调用的接收者;它继承了IExample,因为这是正在实现的接口。此类的目的是执行解组:将传入的onTransact调用转换为IExample的适当方法调用。然后它的子类只负责实现IExample方法。
3、IExample.Proxy是IPC调用的另一端,负责执行调用的编组。它是IExample的一个具体实现,实现它的每个方法,将调用转换为适当的Parcel内容,并通过与之通信的IBinder上的事务调用将其发送出去。
基于AIDL的绑定IPC的完整路径如下图所示:
18.13.8 Android应用程序
Android提供的应用程序模型与Linux shell中的正常命令行环境,甚至是从图形用户界面启动的应用程序非常不同。应用程序不是具有主入口点的可执行文件,它是组成该应用程序的所有东西的容器:它的代码、图形资源、关于它对系统是什么的声明以及其他数据。
按照惯例,Android应用程序是一个扩展名为apk的文件,适用于Android Package。这个文件实际上是一个普通的zip存档,包含了应用程序的所有内容。apk的重要内容包括:
1、描述应用程序是什么、它做什么以及如何运行它的清单。清单必须提供应用程序的包名称、Java风格的范围字符串(例如com.android.app.calculator),
其唯一地标识它。
2、应用程序所需的资源,包括它向用户显示的字符串、布局和其他描述的XML数据、图形位图等。
3、代码本身,可以是Dalvik字节码以及原生库代码。
4、签名信息,安全地识别作者。
应用程序的关键部分是它的清单(manifest)——显示为一个名为AndroidManifest.xml的预编译XML文件,在apk的zip命名空间的根中。假设电子邮件应用程序的完整清单声明示例如下图所示:它允许您查看和撰写电子邮件,还包括将本地电子邮件存储与服务器同步所需的组件,即使用户当前不在应用程序中。
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android" package="com.example.email">
<application>
<activity android:name="com.example.email.MailMainActivity">
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category="" android:name="android.intent.categor y.LAUNCHER" />
</intent-filter>
</activity>
<activity android:name="com.example.email.ComposeActivity">
<intent-filter>
<action android:name="android.intent.action.SEND" />
<category="" android:name="android.intent.categor y.DEFAULT" />
<data android:mimeType="*/*" />
</intent-filter>
</activity>
<service="" android:name="com.example.email.SyncSer vice">
</service>
<receiver android:name="com.example.email.SyncControlReceiver">
<intent-filter>
<action android:name="android.intent.action.DEVICE STORAGE LOW" />
</intent-filter>
<intent-filter>
<action android:name="android.intent.action.DEVICE STORAGE OKAY" />
</intent-filter>
</receiver>
<provider android:name="com.example.email.EmailProvider" android:author="" ities="com.example.email.provider.email">
</provider>
</application>
</manifest>
Android应用程序没有一个简单的主入口点,当用户启动它们时就会执行。相反,它们在清单的<application>标签下发布各种入口点,描述应用程序可以做的各种事情。这些入口点表示为四种不同的类型,定义了应用程序可以提供的核心行为类型:活动、接收者、服务和内容提供者。我们展示的示例显示了一些活动和其他组件类型的一个声明,但应用程序可能声明其中的任何一个或多个。
应用程序可以包含的四种不同组件类型中的每一种在系统中具有不同的语义和用途。在所有情况下,android:name属性都提供实现该组件的应用程序代码的Java类名,系统将在需要时对其进行实例化。
包管理器(package manager)是Android的一部分,用于跟踪所有应用程序包。它解析每个应用程序的清单,收集并索引在其中找到的信息。有了这些信息,它就为客户机提供了查询当前安装的应用程序并检索相关信息的工具。它还负责安装应用程序(为应用程序创建存储空间并确保apk的完整性)以及卸载所需的一切(清理与先前安装的应用程序相关的一切)。
应用程序在清单中静态声明它们的入口点,这样它们就不需要在安装时执行向系统注册它们的代码。这种设计使系统在许多方面更加健壮:安装应用程序不需要运行任何应用程序代码,应用程序的顶级功能始终可以通过查看清单来确定,没有必要保留一个单独的数据库来存储可能与应用程序的实际功能不同步(例如跨更新)的应用程序信息,并且它保证在卸载应用程序后不会留下任何有关应用程序的信息。这种去中心化的方法是为了避免Windows的集中注册表导致的许多此类问题。
将应用程序分解为细粒度组件也有助于我们的设计目标,即支持应用程序之间的互操作和协作。应用程序可以发布提供特定功能的自身片段,其他应用程序可以直接或间接使用这些片段。
在包管理器之上是另一个重要的系统服务——活动管理器(activity manager)。虽然包管理器负责维护所有已安装应用程序的静态信息,但活动管理器确定这些应用程序应在何时、何处以及如何运行。尽管有它的名字,它实际上负责运行所有四种类型的应用程序组件,并为每种组件实现适当的行为。
18.13.8.1 活动(Activity)
活动是通过用户界面直接与用户交互的应用程序的一部分。当用户在其设备上启动应用程序时,实际上是应用程序内部的一个活动,该活动已被指定为此类主入口点,应用程序在其活动中实现负责与用户交互的代码。
上面xml代码所示的示例电子邮件清单包含两个活动。第一个是主邮件用户界面,允许用户查看他们的邮件,第二个是用于编写新消息的单独接口,第一个邮件活动被声明为应用程序的主要入口点,即当用户从主屏幕启动它时将启动的活动。
由于第一个活动是主活动,因此它将作为用户可以从主应用程序启动器启动的应用程序显示给用户。如果他们这样做,系统将处于下图所示的状态,左侧的活动管理器在其流程中创建了一个内部ActivityRecord实例,以跟踪活动。这些活动中的一个或多个被组织到称为任务的容器中,这些容器大致对应于用户作为应用程序的体验。此时,活动管理器已启动电子邮件应用程序的进程和MainMailActivity的实例,以显示其主UI,该UI与相应的ActivityRecord关联。此活动处于称为“已恢复”的状态,因为它现在位于用户界面的前台。
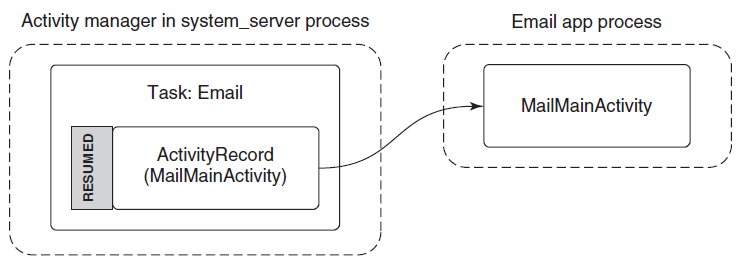
如果用户现在要离开电子邮件应用程序(不退出它)并启动相机应用程序拍照,我们将处于下图所示的状态。请注意,我们现在有一个新的相机进程正在运行相机的主要活动,它在活动管理器中有一个关联的ActivityRecord,是恢复的活动。以前的电子邮件活动也发生了一些有趣的事情:它现在停止了,ActivityRecord保存了该活动的保存状态,而不是恢复。
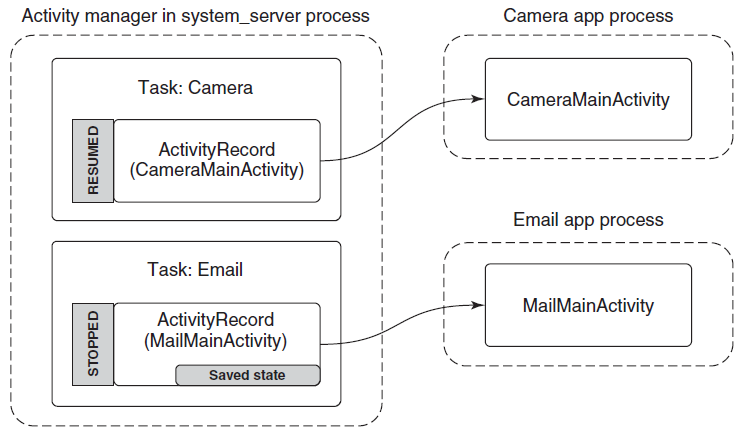
当一个活动不再在前台时,系统会要求它“保存其状态”这涉及到应用程序创建表示用户当前看到的内容的最少数量的状态信息,并将这些信息返回给活动管理器,并存储在系统服务器进程中与该活动关联的ActivityRecord中。活动的保存状态通常很小,例如包含在电子邮件中滚动的位置,但不包含消息本身,应用程序会将其存储在持久存储中的其他位置。
回想一下,尽管Android确实需要分页,它可以从磁盘上的文件(如代码)映射干净的RAM中进行分页,但它并不依赖交换空间,意味着应用程序进程中的所有脏RAM页都必须留在RAM中。将电子邮件的主要活动状态安全地存储在活动管理器中,可以使系统在处理交换提供的内存时恢复一些灵活性。
例如,如果相机应用程序开始需要大量RAM,系统可以简单地摆脱电子邮件进程,如下图所示。ActivityRecord及其宝贵的保存状态仍被活动管理器安全地保存在系统服务器进程中。由于系统服务器进程承载了Android的所有核心系统服务,因此它必须始终保持运行,因此保存在这里的状态将在我们需要的时候一直保持。
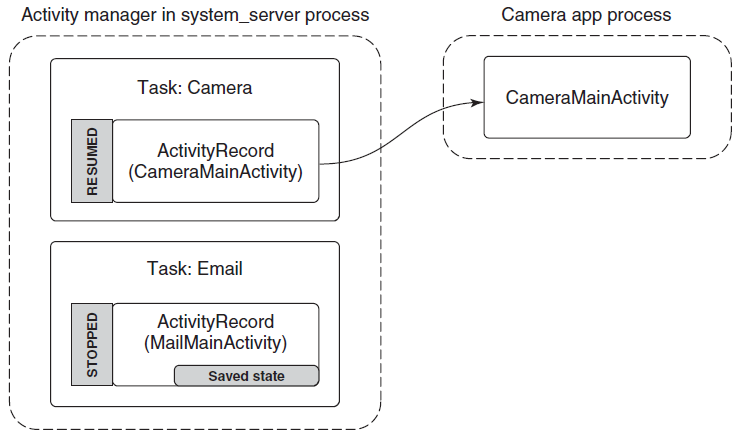
我们的示例电子邮件应用程序不仅具有主UI的活动,而且还包括另一个ComposeActivity。应用程序可以声明任意数量的活动,可以帮助组织应用程序的实现,但更重要的是,它可以用于实现跨应用程序交互。例如,这是Android跨应用程序共享系统的基础,这里的ComposeActivity正在参与其中。如果用户在使用相机应用程序时决定要共享她拍摄的照片,我们的电子邮件应用程序的ComposeActivity是它拥有的共享选项之一。如果选择此选项,将启动该活动并提供要共享的图片。
在上图所示的活动状态下执行该股票期权将导致下图所示的新状态。有一些重要事项需要注意:
1、必须重新启动电子邮件应用程序的进程,才能运行其ComposeActivity。
2、但是,旧的MailMainActivity此时不会启动,因为它不需要。这减少了RAM的使用。
3、摄像机的任务现在有两条记录:我们刚刚进入的原始CameraMainActivity和现在显示的新ComposeActivity。对于用户来说,这些仍然是一个有凝聚力的任务:通过电子邮件发送图片是当前与他们交互的相机。
4、新的ComposeActivity位于顶部,因此恢复;先前的CameraMainActivity不再位于顶部,因此其状态已保存。如果其他地方需要RAM,此时我们可以安全地退出其进程。
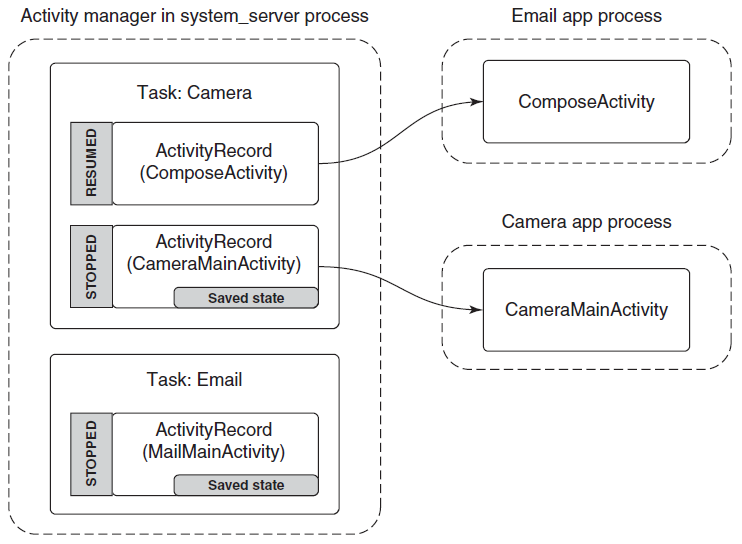
最后,让我们看看,如果用户在最后一个状态(即撰写电子邮件以共享图片)下离开相机任务并返回到电子邮件应用程序,会发生什么情况。下图显示了系统将处于的新状态。请注意,我们已将电子邮件任务及其主要活动带回前台,使得MailMainActivity成为前台活动,但应用程序进程中当前没有运行它的实例。
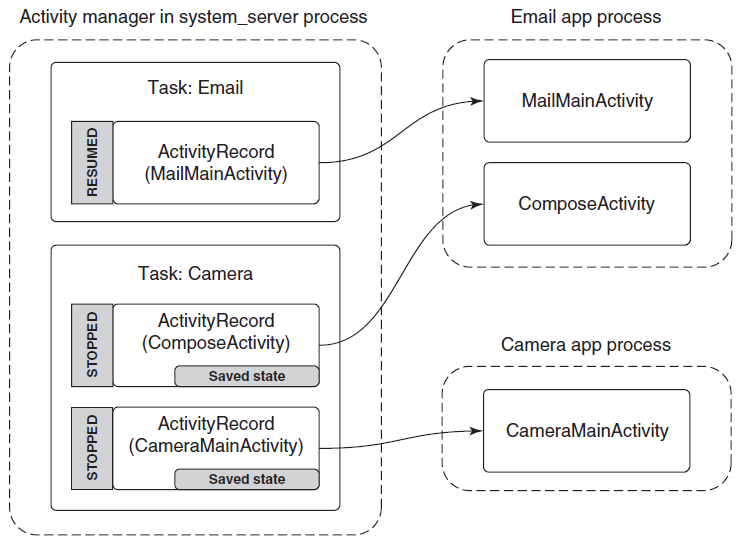
为了返回到上一个活动,系统创建一个新实例,将其返回到旧实例提供的先前保存的状态。此将活动从其保存状态恢复的操作必须能够将活动恢复到用户上次离开时的相同视觉状态。为此,应用程序将在其保存状态中查找用户所在的消息,从其持久存储中加载该消息的数据,然后应用任何已保存的滚动位置或其他用户界面状态。
18.13.8.2 服务(Service)
服务有两个不同的身份:
1、它可以是一个独立的长时间运行的后台操作。以这种方式使用服务的常见示例包括:执行背景音乐播放、在用户处于其他应用程序中时保持活动网络连接(例如与IRC服务器)、在后台下载或上传数据等。
2、它可以作为其他应用程序或系统与应用程序进行丰富交互的连接点。应用程序可以使用它为其他应用程序提供安全API,例如执行图像或音频处理、将文本转换为语音等。
前面所示的示例电子邮件清单包含一个用于执行用户邮箱同步的服务。一个常见的实现将安排服务以固定的间隔运行,例如每15分钟运行一次,在该运行时启动服务,并在完成时停止自身。
这是第一种服务风格的典型使用,即长时间运行的后台操作。下图显示了这种情况下系统的状态,这非常简单。活动管理器创建了一个ServiceRecord来跟踪服务,注意到它已经启动,因此在应用程序的进程中创建了它的SyncService实例。在此状态下,服务处于完全活动状态(如果不持有唤醒锁,则禁止整个系统进入睡眠状态),并且可以自由地做它想做的事情。在这种状态下,应用程序的进程可能会离开,例如,如果进程崩溃,但活动管理器将继续维护其ServiceRecord,并可以在需要时决定重新启动服务。
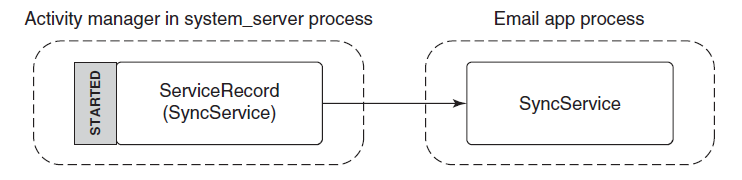
为了了解如何将服务用作与其他应用程序交互的连接点,我们假设我们希望扩展现有的SyncService,使其具有允许其他应用程序控制其同步间隔的API。我们需要为这个API定义一个AIDL接口,如下所示:
package com.example.email
interface ISyncControl
{
int getSyncInterval();
void setSyncInterval(int seconds);
}
要使用此功能,另一个进程可以绑定到我们的应用程序服务,从而访问其接口,将在两个应用程序之间创建连接,如下图所示。此过程的步骤如下:
1、客户端应用程序告诉活动管理器它希望绑定到服务。
2、如果服务尚未创建,活动管理器将在服务应用程序的进程中创建它。
3、服务将其接口的IBinder返回给活动管理器,活动管理器现在将该IBinder保存在其ServiceRecord中。
4、现在,活动管理器拥有了服务IBinder,可以将其发送回原始客户端应用程序。
5、现在具有服务的IBinder的客户端应用程序可以继续在其接口上进行它想要的任何直接调用。
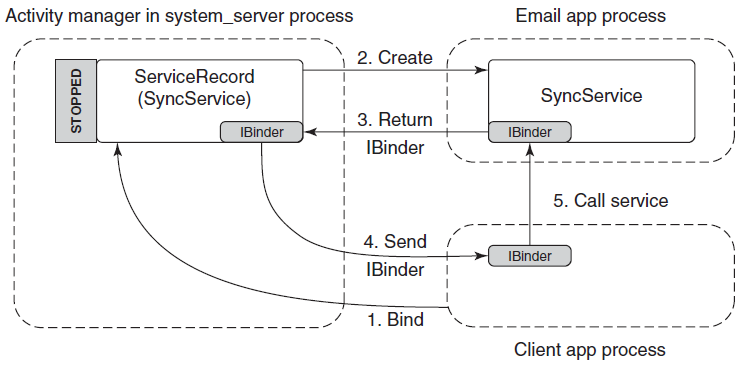
18.13.8.3 接收者(Receiver)
接收者是发生的(通常是外部)事件的接收者,通常在后台和正常用户交互之外。接收器在概念上与应用程序在发生有趣的事情(警报响起、数据连接更改等)时显式注册回调相同,但不要求应用程序运行以接收事件。
上述所示的示例电子邮件清单包含一个接收器,应用程序可以在设备的存储空间变低时发现该接收器,以便停止同步电子邮件(这可能会消耗更多存储空间)。当设备的存储量变低时,系统将发送存储量低的广播代码,以发送给对事件感兴趣的所有接收器。
下图说明了活动管理器如何处理此类广播,以便将其发送给感兴趣的接收者。它首先向包管理器请求对事件感兴趣的所有接收者的列表,该列表被放置在表示该广播的广播记录中。然后,活动管理器将继续遍历列表中的每个条目,让每个相关应用程序的进程创建并执行相应的接收方类。

接收器仅作为一次性操作运行。当一个事件发生时,系统会发现任何对它感兴趣的接收者,并将该事件传递给他们,一旦他们消费了该事件,他们就完成了。没有像我们在其他应用程序组件中看到的那样的ReceiverRecord,因为特定的接收器在单个广播期间只是一个临时实体。每次向接收器组件发送新广播时,都会创建该接收器类的新实例。
18.13.8.4 内容提供者(Content Provider)
我们的最后一个应用程序组件,内容提供者,是应用程序用来相互交换数据的主要机制。与内容提供者的所有交互都是通过使用content:scheme的URI进行的;URI的权限用于找到要与之交互的正确内容提供者实现。
例如,在图10-51的电子邮件应用程序中,内容提供商指定其权限为com.example.email.provider.email。因此,在此内容提供商上运行的URI将从content://com.example.email.provider.email/开始,URI的后缀由提供者自己解释,以确定正在访问其中的哪些数据。在这里的示例中,一个常见的约定是URI:content://com.example.email.provider.email/messages,表示所有电子邮件的列表,而content://com.example.email.provider.email/messages/1提供对键号1处的单个消息的访问。
要与内容提供者交互,应用程序总是要经过一个名为ContentResolver的系统API,其中大多数方法都有一个初始URI参数,指示要操作的数据。最常用的ContentResolver方法之一是query,它对给定的URI执行数据库查询,并返回一个Cursor以检索结构化结果。例如,检索所有可用电子邮件的摘要如下所示:
query("content://com.example.email.provider.email/messages")
尽管这在应用程序中看起来不一样,但当他们使用内容提供者时,实际发生的事情与绑定到服务有许多相似之处。下图说明了系统如何处理我们的查询示例:
1、应用程序调用ContentResolver。查询以启动操作。
2、URI的权限被交给活动管理器,以便它(通过包管理器)找到适当的内容提供者。
3、如果内容提供商尚未运行,则会创建它。
4、一旦创建,内容提供者将其IBinder返回给活动管理器,实现系统的IContentProvider接口。
5、将内容提供者的绑定返回到ContentResolver。
6、内容解析器现在可以通过调用AIDL接口上的适当方法来完成初始查询操作,并返回游标结果。

18.13.8.5 意图(Intent)
在前面所示的应用程序清单中,我们尚未讨论的一个细节是活动和接收方声明中包含的<intent-filter>标记。这是Android的意图功能的一部分,是不同应用程序如何识别彼此以便能够交互和协同工作的基石。
意图是Android用来发现和识别活动、接收者和服务的机制。它在某些方面类似于Linuxshell的搜索路径,shell使用该路径查找多个可能的目录,以便找到与给定的命令名匹配的可执行文件。
意向有两种主要类型:显性和隐性。显式意图是直接标识单个特定应用程序组件的意图;在Linux shell术语中,它相当于为命令提供绝对路径。这种意图的最重要部分是一对命名组件的字符串:目标应用程序的包名和该应用程序中组件的类名。现在回到应用程序前面所示中的活动,该组件的明确意图将是包名为com.example的组件,电子邮件和类名com.example.email.MailMainActivity。
显式意图的包和类名足以唯一标识目标组件,例如上面提及的主要电子邮件活动。从包名称中,包管理器可以返回应用程序所需的所有信息,例如在哪里找到代码。从类名中,我们知道要执行代码的哪一部分。
隐含意图是描述所需组件的特性,而不是组件本身的特性;在Linux shell术语中,这相当于向shell提供一个命令名,shell将其与搜索路径一起用于查找要运行的具体命令。找到与隐含意图匹配的组件的过程称为意图解析。
18.13.9 应用程序沙盒
传统上,在操作系统中,应用程序被视为代表用户作为用户执行的代码。此行为是从命令行继承的,在命令行中,运行ls命令,并期望它作为身份(UID)运行,具有与你在系统上相同的访问权限。同样,当使用图形用户界面启动你想要玩的游戏时,该游戏将有效地作为你的身份运行,可以访问你的文件和许多其他可能不需要的东西。
然而,这并不是我们今天主要使用电脑的方式。我们运行从一些不太受信任的第三方来源获得的应用程序,这些应用程序具有广泛的功能,可以在其环境中执行我们几乎无法控制的各种任务。操作系统支持的应用程序模型与实际使用的应用程序之间存在断开。可以通过一些策略来缓解,例如区分正常用户权限和“管理员”用户权限,并在首次运行应用程序时发出警告,但这些策略并没有真正解决潜在的断开问题。
换言之,传统的操作系统非常擅长保护用户免受其他用户的侵害,但不擅长保护用户不受自身的侵害。所有程序都是靠用户的力量运行的,如果其中任何一个程序行为不当,它都会对用户造成伤害。想想看:在UNIX环境中,你会造成多大的损害?可能会泄露用户可访问的所有信息。你可以执行rm-rf*,为自己提供一个漂亮的、空的主目录。如果这个程序不仅有漏洞,而且是恶意的,它可以加密所有的文件以换取赎金。用“你的力量”运行一切是危险的!
Android试图以一个核心前提来解决这一问题:应用程序实际上是在用户设备上作为来宾运行的应用程序的开发者。因此,应用程序不受任何未经用户明确批准的敏感信息的信任。
在Android的实现中,这一理念相当直接地通过用户ID来表达。安装Android应用程序时,会为其创建一个新的唯一Linux用户ID(或UID),其所有代码都以该“用户”身份运行因此,Linux用户ID为每个应用程序创建一个沙盒,在文件系统中有自己的隔离区域,就像它们为桌面系统上的用户创建沙盒一样。换句话说,Android在Linux中使用了一个现有的功能,但方式新颖。结果是更好的隔离。
18.13.10 进程模型
Linux中的传统进程模型是创建一个新进程的fork,然后是一个exec,用要运行的代码初始化该进程,然后开始执行。shell负责驱动此执行,根据需要fork和执行进程以运行shell命令。当这些命令退出时,Linux将删除该进程。
Android使用的进程略有不同。正如前面关于应用程序的部分所讨论的,活动管理器是Android中负责管理正在运行的应用程序的一部分。它协调新应用程序进程的启动,确定将在其中运行什么,以及何时不再需要它们。
18.13.10.1 期待进程
为了启动新流程,活动经理必须与zygote沟通。当活动管理器第一次启动时,它会创建一个带有合子的专用套接字,当它需要启动一个进程时,通过它发送一个命令。该命令主要描述要创建的沙盒:新进程应作为其运行的UID以及将应用于它的任何其他安全限制。因此,Zygote必须以root身份运行:当它分叉时,它会为运行时的UID进行适当的设置,最后删除root权限并将进程更改为所需的UID。
回想一下在我们之前关于Android应用程序的讨论中,活动管理器维护关于活动执行、服务、广播和内容提供商的动态信息。它使用这些信息来驱动应用程序进程的创建和管理,例如,当应用程序启动程序以新的意图调用系统以启动活动时,活动管理器负责运行新的应用程序。
在新进程中启动活动的流程如下图所示,图中每个步骤的详细信息如下:
1、一些现有进程(如应用程序启动程序)调用活动管理器,目的是描述它想要启动的新活动。
2、活动管理器要求包管理器将意图解析为显式组件。
3、活动管理器确定应用程序的进程尚未运行,然后向合子请求具有适当UID的新进程。
4、Zygote执行一个分叉,创建一个自己的克隆的新进程,删除特权并为应用程序的沙盒适当设置其UID,并在该进程中完成Dalvik的初始化,以便Java运行时完全执行。例如,它必须在分叉后像垃圾收集器一样启动线程。
5、新进程现在是一个完全启动并运行Java环境的zygote克隆,它调用活动管理器,问“我应该做什么?”
6、活动管理器返回有关它正在启动的应用程序的完整信息,例如在哪里找到它的代码。
7、新进程加载正在运行的应用程序的代码。
8、活动管理器向新进程发送任何挂起的操作,在本例中为“启动活动X”。
9、新进程接收启动活动的命令,实例化适当的Java类并执行它。
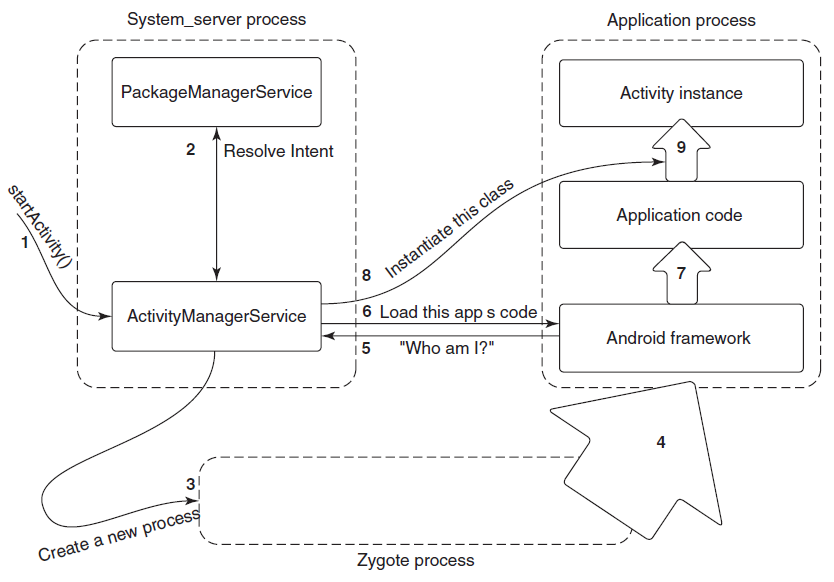
请注意,当我们开始此活动时,应用程序的进程可能已经在运行。在这种情况下,活动管理器将简单地跳到最后,向进程发送一个新命令,告诉它实例化并运行适当的组件,可能导致在应用程序中运行额外的活动实例(如果合适的话)。
18.13.10.2 进程生命周期
活动管理器还负责确定何时不再需要进程,它跟踪进程中运行的所有活动、接收者、服务和内容提供商,由此可以确定进程的重要性(或不重要)。
回想一下,Android内核中的内存不足杀手使用一个进程的作为一个严格的顺序来确定应该首先杀死哪些进程。活动管理器负责根据进程的状态,通过将其划分为主要使用类别,适当设置每个进程的oom_adj。下表显示了主要类别,最重要的类别排在第一位,最后一列显示了分配给此类进程的典型oom_adj值。
| 分类 | 描述 | oom_adj |
|---|---|---|
| SYSTEM | 系统和守护进程进程 | −16 |
| PERSISTENT | 始终运行应用程序进程 | -12 |
| FOREGROUND | 当前与用户交互 | 0 |
| VISIBLE | 对用户可见 | 1 |
| PERCEPTIBLE | 用户知道的东西 | 2 |
| SERVICE | 运行后台服务 | 3 |
| HOME | 主页/启动器进程 | 4 |
| CACHED | 未使用的进程 | 5 |
现在,当RAM变低时,系统已经配置了进程,以便内存不足杀手首先杀死缓存的进程,以尝试回收足够的所需RAM,然后是主页、服务等等。在一个特定的oom调整级别内,它会先杀死内存占用较大的进程,然后再杀死内存占用较小的进程。
我们现在看到了Android是如何决定何时启动进程的,以及它如何根据重要性对这些进程进行分类的。现在我们需要决定何时退出进程,对吗?或者我们真的需要在这里做更多的事情吗?答案是,我们没有。在Android上,应用程序进程永远不会干净地退出。系统只留下不需要的进程,依靠内核根据需要获取它们。
缓存进程在许多方面取代了Android缺少的交换空间。由于其他地方需要RAM,缓存进程可以从活动RAM中抛出。如果应用程序稍后需要再次运行,则可以创建一个新进程,将其恢复到用户上次离开时所需的任何先前状态。在幕后,操作系统正在根据需要启动、终止和重新启动进程,因此重要的前台操作仍在运行,只要缓存的进程的RAM不会在其他地方得到更好的使用,它们就会被保留。
18.13.10.3 进程依赖
目前,我们对如何管理单个Android进程有一个很好的概述。然而,还有一个更复杂的问题:进程之间的依赖关系。
举个例子,考虑一下我们之前的相机应用程序,它保存着已经拍摄的照片。这些图片不是操作系统的一部分,它们由相机应用中的内容提供商实现。其他应用程序可能希望访问该图片数据,成为相机应用程序的客户端。
进程之间的依赖关系可以发生在内容提供者(通过对提供者的简单访问)和服务(通过绑定到服务)之间。无论哪种情况,操作系统都必须跟踪这些依赖关系并适当地管理进程。
进程依赖性影响两个关键因素:何时创建进程(以及其中创建的组件),以及进程的oom_adj重要性。请记住,进程的重要性是其中最重要的组成部分,它的重要性也是依赖它的最重要进程的重要性。
例如,在相机应用程序的情况下,其进程和内容提供商不正常运行。它将在其他进程需要访问该内容提供商时创建。当访问摄像机的内容提供商时,摄像机进程将被认为至少与使用它的进程一样重要。
为了计算每个进程的最终重要性,系统需要维护这些进程之间的依赖关系图。每个进程都有当前运行的所有服务和内容提供商的列表,每个服务和内容提供商本身都有使用它的每个进程的列表。(这些列表保存在活动管理器内的记录中,因此应用程序不可能对它们撒谎。)遍历进程的依赖关系图涉及遍历其所有内容提供者和服务以及使用它们的进程。
下图说明了一个典型的状态进程,考虑到它们之间的依赖关系。此示例包含两个依赖项,基于使用相机内容提供商向电子邮件添加图片附件。第一个是当前前台电子邮件应用程序,它使用相机应用程序加载附件,将相机进程提升到与电子邮件应用程序相同的重要性。第二种是类似的情况,音乐应用程序使用服务在后台播放音乐,并且在这样做的同时依赖于访问用户音乐媒体的媒体进程。
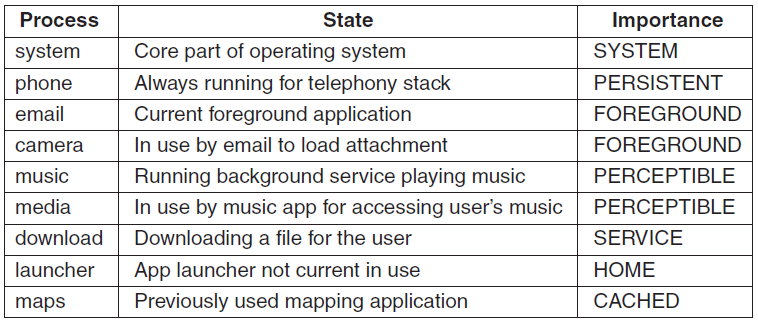
考虑如果上图的状态发生变化,使得电子邮件应用程序完成了附件加载,并且不再使用相机内容提供商,会发生什么情况。下图说明了进程状态将如何改变。请注意,不再需要相机应用程序,因此它已脱离前景重要性,并降至缓存级别,使相机缓存也使旧地图应用程序在缓存的LRU列表中下降了一步。
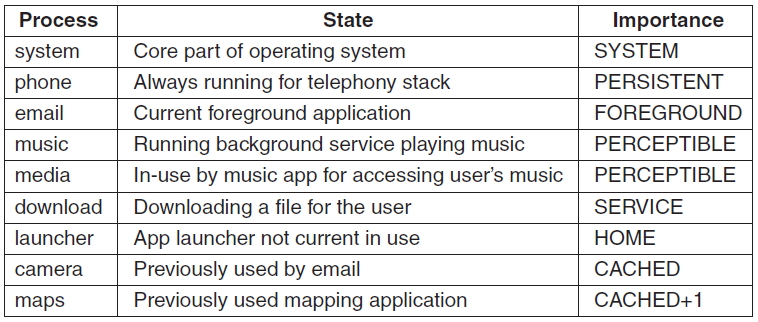
这两个示例最终说明了缓存进程的重要性。如果电子邮件应用程序再次需要使用相机提供程序,则该提供程序的进程通常已作为缓存进程保留。再次使用它只需要将进程设置回前台,并重新连接到已经在那里初始化数据库的内容提供商。
18.14 UE Platform
前面章节详细阐述了操作系统相关的概念、原理和运行机制,本章将阐述UE对操作系统的封装。本篇以UE5.0.5的源码进行分析。
18.14.1 UE Platform概述
UE的操作系统相关接口封装在了Core文件夹下,具体见下图:
以上文件中,有部分是通用接口层,如HAL、Memory等。这其中最重要的类非FGenericPlatformMisc莫属,它抽象了大多数平台的通用接口。后面章节会详细阐述之。
18.14.2 FGenericPlatformMisc
FGenericPlatformMisc是UE跨平台的重要类型,抽象了大多数操作系统的操作接口,以便其它模块实现平台无关的操作。当然,FGenericPlatformMisc只是声明了一组接口,具体实现由不同的子类实现。FGenericPlatformMisc的主要接口如下所示:
// GenericPlatformMisc.h
struct CORE_API FGenericPlatformMisc
{
// 平台生命周期
static void PlatformPreInit();
static void PlatformInit();
static void PlatformTearDown();
static void RequestExit( bool Force );
static void RequestExitWithStatus( bool Force, uint8 ReturnCode );
static bool RestartApplication();
static bool RestartApplicationWithCmdLine(const char* CmdLine);
static void TearDown();
// 窗口/UI
static void PlatformHandleSplashScreen(bool ShowSplashScreen);
static void HidePlatformStartupScreen();
static EAppReturnType::Type MessageBoxExt( EAppMsgType::Type MsgType, const TCHAR* Text, const TCHAR* Caption );
static void ShowConsoleWindow();
static int GetMobilePropagateAlphaSetting();
// 调试/错误
static void SetGracefulTerminationHandler();
static void SetCrashHandler(void (* CrashHandler)(const FGenericCrashContext& Context));
static bool SupportsFullCrashDumps();
static uint32 GetLastError();
static void SetLastError(uint32 ErrorCode);
static void RaiseException( uint32 ExceptionCode );
static void LowLevelOutputDebugString(const TCHAR *Message);
static void VARARGS LowLevelOutputDebugStringf(const TCHAR *Format, ... );
static void SetUTF8Output();
static void LocalPrint( const TCHAR* Str );
static bool IsLocalPrintThreadSafe();
static bool HasSeparateChannelForDebugOutput();
static const TCHAR* GetSystemErrorMessage(TCHAR* OutBuffer, int32 BufferCount, int32 Error);
static void PromptForRemoteDebugging(bool bIsEnsure);
// 环境变量、路径
static FString GetEnvironmentVariable(const TCHAR* VariableName);
static void SetEnvironmentVar(const TCHAR* VariableName, const TCHAR* Value);
FORCEINLINE static int32 GetMaxPathLength();
static const TCHAR* GetPathVarDelimiter();
static bool IsValidAbsolutePathFormat(const FString& Path);
static void NormalizePath(FString& InPath);
static void NormalizePath(FStringBuilderBase& InPath);
static const TCHAR* GetDefaultPathSeparator();
static const TCHAR* RootDir();
static TArray<FString> GetAdditionalRootDirectories();
static void AddAdditionalRootDirectory(const FString& RootDir);
static const TCHAR* EngineDir();
static const TCHAR* LaunchDir();
static void CacheLaunchDir();
static const TCHAR* ProjectDir();
static FString CloudDir();
static bool HasProjectPersistentDownloadDir();
static bool CheckPersistentDownloadStorageSpaceAvailable( uint64 BytesRequired, bool bAttemptToUseUI );
static const TCHAR* GamePersistentDownloadDir();
static const TCHAR* GeneratedConfigDir();
static void SetOverrideProjectDir(const FString& InOverrideDir);
// 设备/硬件
static FString GetDeviceId();
static FString GetUniqueAdvertisingId();
static void SubmitErrorReport( const TCHAR* InErrorHist, EErrorReportMode::Type InMode );
static bool IsRemoteSession();
FORCEINLINE static bool IsDebuggerPresent();
static EProcessDiagnosticFlags GetProcessDiagnostics();
static FString GetCPUVendor();
static uint32 GetCPUInfo();
static bool HasNonoptionalCPUFeatures();
static bool NeedsNonoptionalCPUFeaturesCheck();
static FString GetCPUBrand();
static FString GetCPUChipset();
static FString GetPrimaryGPUBrand();
static FString GetDeviceMakeAndModel();
static struct FGPUDriverInfo GetGPUDriverInfo(const FString& DeviceDescription);
static void PrefetchBlock(const void* InPtr, int32 NumBytes = 1);
static void Prefetch(void const* x, int32 offset = 0);
static const TCHAR* GetDefaultDeviceProfileName();
FORCEINLINE static int GetBatteryLevel();
FORCEINLINE static void SetBrightness(float bBright);
FORCEINLINE static float GetBrightness();
FORCEINLINE static bool SupportsBrightness();
FORCEINLINE static bool IsInLowPowerMode();
static float GetDeviceTemperatureLevel();
static inline int32 GetMaxRefreshRate();
static inline int32 GetMaxSyncInterval();
static bool IsPGOEnabled();
static TArray<uint8> GetSystemFontBytes();
static bool HasActiveWiFiConnection();
static ENetworkConnectionType GetNetworkConnectionType();
static bool HasVariableHardware();
static bool HasPlatformFeature(const TCHAR* FeatureName);
static bool IsRunningOnBattery();
static EDeviceScreenOrientation GetDeviceOrientation();
static void SetDeviceOrientation(EDeviceScreenOrientation NewDeviceOrientation);
static int32 GetDeviceVolume();
// OS相关
static void GetOSVersions( FString& out_OSVersionLabel, FString& out_OSSubVersionLabel );
static FString GetOSVersion();
static bool GetDiskTotalAndFreeSpace( const FString& InPath, uint64& TotalNumberOfBytes, uint64& NumberOfFreeBytes );
static bool GetPageFaultStats(FPageFaultStats& OutStats, EPageFaultFlags Flags);
static bool GetBlockingIOStats(FProcessIOStats& OutStats, EInputOutputFlags Flags=EInputOutputFlags::All);
static bool GetContextSwitchStats(FContextSwitchStats& OutStats, EContextSwitchFlags Flags=EContextSwitchFlags::All);
static bool CommandLineCommands();
static bool Is64bitOperatingSystem();
static bool OsExecute(const TCHAR* CommandType, const TCHAR* Command, const TCHAR* CommandLine = NULL);
static bool Exec(class UWorld* InWorld, const TCHAR* Cmd, FOutputDevice& Out);
static bool GetSHA256Signature(const void* Data, uint32 ByteSize, FSHA256Signature& OutSignature);
static FString GetDefaultLanguage();
static FString GetDefaultLocale();
static FString GetTimeZoneId();
static TArray<FString> GetPreferredLanguages();
static const TCHAR* GetUBTPlatform();
static const TCHAR* GetUBTTarget();
static void SetUBTTargetName(const TCHAR* InTargetName);
static const TCHAR* GetUBTTargetName();
static const TCHAR* GetNullRHIShaderFormat();
static IPlatformChunkInstall* GetPlatformChunkInstall();
static IPlatformCompression* GetPlatformCompression();
static void GetValidTargetPlatforms(TArray<FString>& TargetPlatformNames);
static FPlatformUserId GetPlatformUserForUserIndex(int32 LocalUserIndex);
static int32 GetUserIndexForPlatformUser(FPlatformUserId PlatformUser);
// 消息/事件
static bool SupportsMessaging();
static bool SupportsLocalCaching();
static bool AllowLocalCaching();
static void BeginNamedEvent(const struct FColor& Color, const TCHAR* Text);
static void BeginNamedEvent(const struct FColor& Color, const ANSICHAR* Text);
template<typename CharType>
static void StatNamedEvent(const CharType* Text);
static void TickStatNamedEvents();
static void LogNameEventStatsInit();
static void EndNamedEvent();
static void CustomNamedStat(const TCHAR* Text, float Value, const TCHAR* Graph, const TCHAR* Unit);
static void CustomNamedStat(const ANSICHAR* Text, float Value, const ANSICHAR* Graph, const ANSICHAR* Unit);
static void BeginEnterBackgroundEvent(const TCHAR* Text) ;
static void EndEnterBackgroundEvent();
static void BeginNamedEventFrame();
static void RegisterForRemoteNotifications();
static bool IsRegisteredForRemoteNotifications();
static void UnregisterForRemoteNotifications();
static void PumpMessagesOutsideMainLoop();
static void PumpMessagesForSlowTask();
static void PumpEssentialAppMessages();
// 内存
static void MemoryBarrier();
static void SetMemoryWarningHandler(void (* Handler)(const FGenericMemoryWarningContext& Context));
static bool HasMemoryWarningHandler();
// I/O
static void InitTaggedStorage(uint32 NumTags);
static void ShutdownTaggedStorage();
static void TagBuffer(const char* Label, uint32 Category, const void* Buffer, size_t BufferSize);
static bool SetStoredValues(const FString& InStoreId, const FString& InSectionName, const TMap<FString, FString>& InKeyValues);
static bool SetStoredValue(const FString& InStoreId, const FString& InSectionName, const FString& InKeyName, const FString& InValue);
static bool GetStoredValue(const FString& InStoreId, const FString& InSectionName, const FString& InKeyName, FString& OutValue);
static bool DeleteStoredValue(const FString& InStoreId, const FString& InSectionName, const FString& InKeyName);
static bool DeleteStoredSection(const FString& InStoreId, const FString& InSectionName);
static TArray<FCustomChunk> GetOnDemandChunksForPakchunkIndices(const TArray<int32>& PakchunkIndices);
static TArray<FCustomChunk> GetAllOnDemandChunks();
static TArray<FCustomChunk> GetAllLanguageChunks();
static TArray<FCustomChunk> GetCustomChunksByType(ECustomChunkType DesiredChunkType);
static void ParseChunkIdPakchunkIndexMapping(TArray<FString> ChunkIndexRedirects, TMap<int32, int32>& OutMapping);
static int32 GetChunkIDFromPakchunkIndex(int32 PakchunkIndex);
static int32 GetPakchunkIndexFromPakFile(const FString& InFilename);
static FText GetFileManagerName();
static bool IsPackagedForDistribution();
static FString LoadTextFileFromPlatformPackage(const FString& RelativePath);
static bool FileExistsInPlatformPackage(const FString& RelativePath);
static bool Expand16BitIndicesTo32BitOnLoad();
static void GetNetworkFileCustomData(TMap<FString,FString>& OutCustomPlatformData);
static bool SupportsBackbufferSampling();
// 线程/作业/异步
static bool UseRenderThread();
static bool AllowAudioThread();
static bool AllowThreadHeartBeat();
static int32 NumberOfCores();
static const FProcessorGroupDesc& GetProcessorGroupDesc();
static int32 NumberOfCoresIncludingHyperthreads();
static int32 NumberOfWorkerThreadsToSpawn();
static int32 NumberOfIOWorkerThreadsToSpawn();
static struct FAsyncIOSystemBase* GetPlatformSpecificAsyncIOSystem();
static const TCHAR* GetPlatformFeaturesModuleName();
static bool SupportsMultithreadedFileHandles();
// 交互
static bool GetUseVirtualJoysticks();
static bool SupportsTouchInput();
static bool SupportsForceTouchInput();
static bool ShouldDisplayTouchInterfaceOnFakingTouchEvents();
static bool DesktopTouchScreen();
static bool FullscreenSameAsWindowedFullscreen();
static bool GetVolumeButtonsHandledBySystem();
static void SetVolumeButtonsHandledBySystem(bool enabled);
static void PrepareMobileHaptics(EMobileHapticsType Type);
static void TriggerMobileHaptics();
static void ReleaseMobileHaptics();
// 系统信息
static FString GetLoginId();
static FString GetEpicAccountId();
static FString GetOperatingSystemId();
static EConvertibleLaptopMode GetConvertibleLaptopMode();
static bool SupportsDeviceCheckToken();
static bool RequestDeviceCheckToken(...);
// 引擎
static const TCHAR* GetEngineMode();
static bool ShouldDisablePluginAtRuntime(const FString& PluginName);
static bool UseHDRByDefault();
static void ChooseHDRDeviceAndColorGamut(uint32 DeviceId, uint32 DisplayNitLevel, int32& OutputDevice, int32& ColorGamut);
// 其它
static void CreateGuid(struct FGuid& Result);
static void TickHotfixables();
static FString GetLocalCurrencyCode();
static FString GetLocalCurrencySymbol();
static void ShareURL(const FString& URL, const FText& Description, int32 LocationHintX, int32 LocationHintY);
(...)
};
由上可知,FGenericPlatformMisc不仅包含OS相关的接口,还包含了设备、硬件、应用程序、输入输出、UI、交互、多线程、路径等相关的接口。下图是它的继承体系图:
下面小节将抽取部分平台的部分接口进行分析。
18.14.2.1 FWindowsPlatformMisc
FWindowsPlatformMisc实现了Windows平台的相关接口,部分接口分析如下:
// WindowsPlatformMisc.cpp
void FWindowsPlatformMisc::PlatformPreInit()
{
FGenericPlatformMisc::PlatformPreInit();
(...)
// 使用自己的处理程序来调用纯虚拟对象。
DefaultPureCallHandler = _set_purecall_handler( PureCallHandler );
const int32 MinResolution[] = {640, 480};
if ( ::GetSystemMetrics(SM_CXSCREEN) < MinResolution[0] || ::GetSystemMetrics(SM_CYSCREEN) < MinResolution[1] )
{
FMessageDialog::Open( EAppMsgType::Ok, NSLOCTEXT("Launch", "Error_ResolutionTooLow", "The current resolution is too low to run this game.") );
FPlatformMisc::RequestExit( false );
}
// 初始化文件SHA哈希映射
InitSHAHashes();
}
void FWindowsPlatformMisc::PlatformInit()
{
FGenericPlatformMisc::LogNameEventStatsInit();
(...)
// 将睡眠粒度等设置为1毫秒。
timeBeginPeriod( 1 );
(...)
// 获取cpu信息.
const FPlatformMemoryConstants& MemoryConstants = FPlatformMemory::GetConstants();
UE_LOG(LogInit, Log, TEXT("CPU Page size=%i, Cores=%i"), MemoryConstants.PageSize, FPlatformMisc::NumberOfCores() );
UE_LOG(LogInit, Log, TEXT("High frequency timer resolution =%f MHz"), 0.000001 / FPlatformTime::GetSecondsPerCycle() );
// 在游戏线程上注册。
FWindowsPlatformStackWalk::RegisterOnModulesChanged();
}
// 获取OS版本.
void FWindowsPlatformMisc::GetOSVersions( FString& OutOSVersionLabel, FString& OutOSSubVersionLabel )
{
// OS初始化器.
static struct FOSVersionsInitializer
{
FOSVersionsInitializer()
{
OSVersionLabel[0] = 0;
OSSubVersionLabel[0] = 0;
GetOSVersionsHelper( OSVersionLabel, UE_ARRAY_COUNT(OSVersionLabel), OSSubVersionLabel, UE_ARRAY_COUNT(OSSubVersionLabel) );
}
TCHAR OSVersionLabel[128];
TCHAR OSSubVersionLabel[128];
} OSVersionsInitializer;
OutOSVersionLabel = OSVersionsInitializer.OSVersionLabel;
OutOSSubVersionLabel = OSVersionsInitializer.OSSubVersionLabel;
}
// 获取磁盘的总量和空闲空间.
bool FWindowsPlatformMisc::GetDiskTotalAndFreeSpace( const FString& InPath, uint64& TotalNumberOfBytes, uint64& NumberOfFreeBytes )
{
const FString ValidatedPath = FPaths::ConvertRelativePathToFull(InPath).Replace(TEXT("/"), TEXT("\\"));
bool bSuccess = !!::GetDiskFreeSpaceEx( *ValidatedPath, nullptr, reinterpret_cast<ULARGE_INTEGER*>(&TotalNumberOfBytes), reinterpret_cast<ULARGE_INTEGER*>(&NumberOfFreeBytes));
return bSuccess;
}
// 获取页面错误信息.
bool FWindowsPlatformMisc::GetPageFaultStats(FPageFaultStats& OutStats, EPageFaultFlags Flags/*=EPageFaultFlags::All*/)
{
bool bSuccess = false;
if (EnumHasAnyFlags(Flags, EPageFaultFlags::TotalPageFaults))
{
PROCESS_MEMORY_COUNTERS ProcessMemoryCounters;
FPlatformMemory::Memzero(&ProcessMemoryCounters, sizeof(ProcessMemoryCounters));
::GetProcessMemoryInfo(::GetCurrentProcess(), &ProcessMemoryCounters, sizeof(ProcessMemoryCounters));
OutStats.TotalPageFaults = ProcessMemoryCounters.PageFaultCount;
bSuccess = true;
}
return bSuccess;
}
// 获取IO阻塞状态.
bool FWindowsPlatformMisc::GetBlockingIOStats(FProcessIOStats& OutStats, EInputOutputFlags Flags/*=EInputOutputFlags::All*/)
{
bool bSuccess = false;
IO_COUNTERS Counters;
FPlatformMemory::Memzero(&Counters, sizeof(Counters));
// Ignore flags as all values are grabbed at once
if (::GetProcessIoCounters(::GetCurrentProcess(), &Counters) != 0)
{
OutStats.BlockingInput = Counters.ReadOperationCount;
OutStats.BlockingOutput = Counters.WriteOperationCount;
OutStats.BlockingOther = Counters.OtherOperationCount;
OutStats.InputBytes = Counters.ReadTransferCount;
OutStats.OutputBytes = Counters.WriteTransferCount;
OutStats.OtherBytes = Counters.OtherTransferCount;
bSuccess = true;
}
return bSuccess;
}
FString FWindowsPlatformMisc::GetOperatingSystemId()
{
FString Result;
QueryRegKey(HKEY_LOCAL_MACHINE, TEXT("Software\\Microsoft\\Cryptography"), TEXT("MachineGuid"), Result);
return Result;
}
void FWindowsPlatformMisc::PumpMessagesOutsideMainLoop()
{
TGuardValue<bool> PumpMessageGuard(GPumpingMessagesOutsideOfMainLoop, true);
// 处理挂起的窗口消息,在某些情况下,D3D将窗口消息(来自IDXGISwapChain::Present)发送到主线程拥有的视口窗口,是渲染线程所必需的。
MSG Msg;
PeekMessage(&Msg, NULL, 0, 0, PM_NOREMOVE | PM_QS_SENDMESSAGE);
return;
}
18.14.2.2 FAndroidMisc
FAndroidMisc实现了Android平台的相关接口,部分接口分析如下:
// AndroidPlatformMisc.cpp
void FAndroidMisc::RequestExit( bool Force )
{
#if PLATFORM_COMPILER_OPTIMIZATION_PG_PROFILING
// 在完全关闭时写入PGO配置文件。
extern void PGO_WriteFile();
if (!GIsCriticalError)
{
PGO_WriteFile();
// 立即退出,以避免在AndroidMain退出时可能发生的第二次PGO写入。
Force = true;
}
#endif
UE_LOG(LogAndroid, Log, TEXT("FAndroidMisc::RequestExit(%i)"), Force);
if(GLog)
{
GLog->FlushThreadedLogs();
GLog->Flush();
}
// 强制退出.
if (Force)
{
#if USE_ANDROID_JNI
AndroidThunkCpp_ForceQuit();
#else
exit(1);
#endif
}
else
{
RequestEngineExit(TEXT("Android RequestExit"));
}
}
// 初始化
void FAndroidMisc::PlatformInit()
{
extern void AndroidSetupDefaultThreadAffinity();
AndroidSetupDefaultThreadAffinity();
(...)
// 初始化JNI环境.
#if USE_ANDROID_JNI
InitializeJavaEventReceivers();
AndroidOnBackgroundBinding = FCoreDelegates::ApplicationWillEnterBackgroundDelegate.AddStatic(EnableJavaEventReceivers, false);
AndroidOnForegroundBinding = FCoreDelegates::ApplicationHasEnteredForegroundDelegate.AddStatic(EnableJavaEventReceivers, true);
#endif
// 初始化cpu温度传感器.
InitCpuThermalSensor();
(...)
}
// 销毁
void FAndroidMisc::PlatformTearDown()
{
auto RemoveBinding = [](FCoreDelegates::FApplicationLifetimeDelegate& ApplicationLifetimeDelegate, FDelegateHandle& DelegateBinding)
{
if (DelegateBinding.IsValid())
{
ApplicationLifetimeDelegate.Remove(DelegateBinding);
DelegateBinding.Reset();
}
};
RemoveBinding(FCoreDelegates::ApplicationWillEnterBackgroundDelegate, AndroidOnBackgroundBinding);
RemoveBinding(FCoreDelegates::ApplicationHasEnteredForegroundDelegate, AndroidOnForegroundBinding);
}
// 是否使用渲染线程
bool FAndroidMisc::UseRenderThread()
{
// 如果由于命令行等原因,我们通常不想使用渲染线程.
if (!FGenericPlatformMisc::UseRenderThread())
{
return false;
}
// 检查DeviceProfiles配置中的DisableThreadedRendering CVar,未来任何需要禁用线程渲染的设备都应该得到一个设备配置文件并使用此CVar.
const IConsoleVariable *const CVar = IConsoleManager::Get().FindConsoleVariable(TEXT("r.AndroidDisableThreadedRendering"));
if (CVar && CVar->GetInt() != 0)
{
return false;
}
// 英伟达tegra双核处理器,即optimus 2x和xoom在运行多线程时发生崩溃。使用lg optimus 2x和motorola xoom测试的opengl(错误)无法处理多线程。
if (FAndroidMisc::GetGPUFamily() == FString(TEXT("NVIDIA Tegra")) && FPlatformMisc::NumberOfCores() <= 2 && FAndroidMisc::GetGLVersion().StartsWith(TEXT("OpenGL ES 2.")))
{
return false;
}
// 带有2.x驱动程序的Vivante GC1000存在渲染线程问题
if (FAndroidMisc::GetGPUFamily().StartsWith(TEXT("Vivante GC1000")) && FAndroidMisc::GetGLVersion().StartsWith(TEXT("OpenGL ES 2.")))
{
return false;
}
// 使用opengl在kindlefire(第1代)上使用多线程呈现缓冲区存在问题.
if (FAndroidMisc::GetDeviceModel() == FString(TEXT("Kindle Fire")))
{
return false;
}
// 在使用opengl的多线程的三星s3 mini上,启动时swapbuffer排序存在问题.
if (FAndroidMisc::GetDeviceModel() == FString(TEXT("GT-I8190L")))
{
return false;
}
return true;
}
// 触发奔溃处理
void FAndroidMisc::TriggerCrashHandler(ECrashContextType InType, const TCHAR* InErrorMessage, const TCHAR* OverrideCallstack)
{
if (InType != ECrashContextType::Crash)
{
// 不会在致命信号期间刷新日志,malloccrash会导致死锁。
if (GLog)
{
GLog->PanicFlushThreadedLogs();
GLog->Flush();
}
if (GWarn)
{
GWarn->Flush();
}
if (GError)
{
GError->Flush();
}
}
FAndroidCrashContext CrashContext(InType, InErrorMessage);
if (OverrideCallstack)
{
CrashContext.SetOverrideCallstack(OverrideCallstack);
}
else
{
CrashContext.CaptureCrashInfo();
}
if (GCrashHandlerPointer)
{
GCrashHandlerPointer(CrashContext);
}
else
{
// 默认处理器.
DefaultCrashHandler(CrashContext);
}
}
// 设置崩溃处理器.
void FAndroidMisc::SetCrashHandler(void(*CrashHandler)(const FGenericCrashContext& Context))
{
#if ANDROID_HAS_RTSIGNALS
GCrashHandlerPointer = CrashHandler;
FFatalSignalHandler::Release();
FThreadCallstackSignalHandler::Release();
// 通过-1将使这些恢复,并且不会困住它们.
if ((PTRINT)CrashHandler == -1)
{
return;
}
FFatalSignalHandler::Init();
FThreadCallstackSignalHandler::Init();
#endif
}
// 是否有Vulkan驱动支持.
bool FAndroidMisc::HasVulkanDriverSupport()
{
#if !USE_ANDROID_JNI
VulkanSupport = EDeviceVulkanSupportStatus::NotSupported;
VulkanVersionString = TEXT("0.0.0");
#else
// 此版本不检查VulkanRHI或被cvars禁用!
if (VulkanSupport == EDeviceVulkanSupportStatus::Uninitialized)
{
// 假设没有
VulkanSupport = EDeviceVulkanSupportStatus::NotSupported;
VulkanVersionString = TEXT("0.0.0");
// 检查libvulkan.so
void* VulkanLib = dlopen("libvulkan.so", RTLD_NOW | RTLD_LOCAL);
if (VulkanLib != nullptr)
{
// 如果是Nougat,我们可以检查Vulkan版本
if (FAndroidMisc::GetAndroidBuildVersion() >= 24)
{
extern int32 AndroidThunkCpp_GetMetaDataInt(const FString& Key);
int32 VulkanVersion = AndroidThunkCpp_GetMetaDataInt(TEXT("android.hardware.vulkan.version"));
if (VulkanVersion >= UE_VK_API_VERSION)
{
// 最后检查,尝试初始化实例
VulkanSupport = AttemptVulkanInit(VulkanLib);
}
}
else
{
// 否则,我们需要尝试初始化实例
VulkanSupport = AttemptVulkanInit(VulkanLib);
}
dlclose(VulkanLib);
if (VulkanSupport == EDeviceVulkanSupportStatus::Supported)
{
UE_LOG(LogAndroid, Log, TEXT("VulkanRHI is available, Vulkan capable device detected."));
return true;
}
(...)
#endif
return VulkanSupport == EDeviceVulkanSupportStatus::Supported;
}
// Vulkan是否可用
bool FAndroidMisc::IsVulkanAvailable()
{
(...)
// 不存在VulkanRHI模块.
if (!FModuleManager::Get().ModuleExists(TEXT("VulkanRHI")))
{
UE_LOG(LogAndroid, Log, TEXT("Vulkan not available as VulkanRHI not present."));
}
// 没有bSupportsVulkan或bSupportsVulkanSM5,Vulka不能作为打包的项目提供。
else if (!(bSupportsVulkan || bSupportsVulkanSM5))
{
UE_LOG(LogAndroid, Log, TEXT("Vulkan not available as project packaged without bSupportsVulkan or bSupportsVulkanSM5."));
}
// Vulkan API检测由命令行选项禁用。
else if (bVulkanDisabledCmdLine)
{
UE_LOG(LogAndroid, Log, TEXT("Vulkan API detection is disabled by a command line option."));
}
// Vulkan可用,但在AndroidRuntimeSettings中bDetectVulkanByDefault=False禁用了检测。使用-detectvulkan覆盖。
else if (!bDetectVulkanByDefault && !bDetectVulkanCmdLine)
{
UE_LOG(LogAndroid, Log, TEXT("Vulkan available but detection disabled by bDetectVulkanByDefault=False in AndroidRuntimeSettings. Use -detectvulkan to override."));
}
else
{
CachedVulkanAvailable = 1;
}
return CachedVulkanAvailable == 1;
}
// 检测是否该使用Vulkan
bool FAndroidMisc::ShouldUseVulkan()
{
static int CachedShouldUseVulkan = -1;
if (CachedShouldUseVulkan == -1)
{
(...)
// 如果Vulkan可用且控制台变量没有禁用Vulkan, 则可用.
if (bVulkanAvailable && !bVulkanDisabledCVar)
{
CachedShouldUseVulkan = 1;
UE_LOG(LogAndroid, Log, TEXT("VulkanRHI will be used!"));
}
(...)
}
return CachedShouldUseVulkan == 1;
}
// 是否该使用桌面Vulkan.
bool FAndroidMisc::ShouldUseDesktopVulkan()
{
(...)
// 如果VulkanSM5开启且VulkanSM5没有被禁用, 则可以.
if (bVulkanSM5Enabled && !bVulkanSM5Disabled)
{
CachedShouldUseDesktopVulkan = 1;
UE_LOG(LogAndroid, Log, TEXT("Vulkan SM5 RHI will be used!"));
}
(...)
}
// 获取Vulkan版本号.
FString FAndroidMisc::GetVulkanVersion()
{
check(VulkanSupport != EDeviceVulkanSupportStatus::Uninitialized);
return VulkanVersionString;
}
void FAndroidMisc::GetOSVersions(FString& out_OSVersionLabel, FString& out_OSSubVersionLabel)
{
out_OSVersionLabel = TEXT("Android");
out_OSSubVersionLabel = AndroidVersion;
}
FString FAndroidMisc::GetOSVersion()
{
return AndroidVersion;
}
// 获取磁盘信息.
bool FAndroidMisc::GetDiskTotalAndFreeSpace(const FString& InPath, uint64& TotalNumberOfBytes, uint64& NumberOfFreeBytes)
{
extern FString GExternalFilePath;
struct statfs FSStat = { 0 };
FTCHARToUTF8 Converter(*GExternalFilePath);
int Err = statfs((ANSICHAR*)Converter.Get(), &FSStat);
if (Err == 0)
{
TotalNumberOfBytes = FSStat.f_blocks * FSStat.f_bsize;
NumberOfFreeBytes = FSStat.f_bavail * FSStat.f_bsize;
}
(...)
return (Err == 0);
}
18.14.2.3 FIOSPlatformMisc
FIOSPlatformMisc实现了iOS平台的相关接口,部分接口分析如下:
// IOSPlatformMisc.cpp
// 预初始化.
void FIOSPlatformMisc::PlatformPreInit()
{
FGenericPlatformMisc::PlatformPreInit();
GIOSAppInfo.Init();
// 关闭SIGPIPE崩溃
signal(SIGPIPE, SIG_IGN);
}
// 初始化.
void FIOSPlatformMisc::PlatformInit()
{
// 启动创建帧缓冲区的UI线程,要求“r.MobileContentScaleFactor”在创建之前可用,因此需要立即缓存该值。
[[IOSAppDelegate GetDelegate] LoadMobileContentScaleFactor];
FAppEntry::PlatformInit();
// 增加同时打开的文件的最大数量.
struct rlimit Limit;
Limit.rlim_cur = OPEN_MAX;
Limit.rlim_max = RLIM_INFINITY;
int32 Result = setrlimit(RLIMIT_NOFILE, &Limit);
check(Result == 0);
(...)
// 内存
const FPlatformMemoryConstants& MemoryConstants = FPlatformMemory::GetConstants();
GStartupFreeMemoryMB = GetFreeMemoryMB();
// 创建Documents/<GameName>/Content目录,以便我们可以将其从iCloud备份中排除
FString ResultStr = FPaths::ProjectContentDir();
ResultStr.ReplaceInline(TEXT("../"), TEXT(""));
(...)
NSURL* URL = [NSURL fileURLWithPath : ResultStr.GetNSString()];
if (![[NSFileManager defaultManager] fileExistsAtPath:[URL path]])
{
[[NSFileManager defaultManager] createDirectoryAtURL:URL withIntermediateDirectories : YES attributes : nil error : nil];
}
// 标记为不上传.
NSError *error = nil;
BOOL success = [URL setResourceValue : [NSNumber numberWithBool : YES] forKey : NSURLIsExcludedFromBackupKey error : &error];
if (!success)
{
NSLog(@"Error excluding %@ from backup %@",[URL lastPathComponent], error);
}
(...)
}
// 退出.
void FIOSPlatformMisc::RequestExit(bool Force)
{
if (Force)
{
FApplePlatformMisc::RequestExit(Force);
}
else
{
[[IOSAppDelegate GetDelegate] ForceExit];
}
}
void FIOSPlatformMisc::RequestExitWithStatus(bool Force, uint8 ReturnCode)
{
if (Force)
{
FApplePlatformMisc::RequestExit(Force);
}
else
{
(...)
[[IOSAppDelegate GetDelegate] ForceExit];
}
}
// 获取平台特性.
bool FIOSPlatformMisc::HasPlatformFeature(const TCHAR* FeatureName)
{
if (FCString::Stricmp(FeatureName, TEXT("Metal")) == 0)
{
return [IOSAppDelegate GetDelegate].IOSView->bIsUsingMetal;
}
return FGenericPlatformMisc::HasPlatformFeature(FeatureName);
}
// 获取设备配置名.
const TCHAR* FIOSPlatformMisc::GetDefaultDeviceProfileName()
{
static FString IOSDeviceProfileName;
if (IOSDeviceProfileName.Len() == 0)
{
IOSDeviceProfileName = TEXT("IOS");
FString DeviceIDString = GetIOSDeviceIDString();
TArray<FString> Mappings;
if (ensure(GConfig->GetSection(TEXT("IOSDeviceMappings"), Mappings, GDeviceProfilesIni)))
{
for (const FString& MappingString : Mappings)
{
FString MappingRegex, ProfileName;
if (MappingString.Split(TEXT("="), &MappingRegex, &ProfileName))
{
const FRegexPattern RegexPattern(MappingRegex);
FRegexMatcher RegexMatcher(RegexPattern, *DeviceIDString);
if (RegexMatcher.FindNext())
{
IOSDeviceProfileName = ProfileName;
break;
}
}
(...)
}
}
}
return *IOSDeviceProfileName;
}
// 获取默认的栈大小.
int FIOSPlatformMisc::GetDefaultStackSize()
{
return 512 * 1024;
}
// 系统版本.
void FIOSPlatformMisc::GetOSVersions(FString& out_OSVersionLabel, FString& out_OSSubVersionLabel)
{
#if PLATFORM_TVOS
out_OSVersionLabel = TEXT("TVOS");
#else
out_OSVersionLabel = TEXT("IOS");
#endif
NSOperatingSystemVersion IOSVersion;
IOSVersion = [[NSProcessInfo processInfo] operatingSystemVersion];
out_OSSubVersionLabel = FString::Printf(TEXT("%ld.%ld.%ld"), IOSVersion.majorVersion, IOSVersion.minorVersion, IOSVersion.patchVersion);
}
// 磁盘信息.
bool FIOSPlatformMisc::GetDiskTotalAndFreeSpace(const FString& InPath, uint64& TotalNumberOfBytes, uint64& NumberOfFreeBytes)
{
bool GetValueSuccess = false;
NSNumber *FreeBytes = nil;
NSURL *URL = [NSURL fileURLWithPath : NSHomeDirectory()];
GetValueSuccess = [URL getResourceValue : &FreeBytes forKey : NSURLVolumeAvailableCapacityForImportantUsageKey error : nil];
if (FreeBytes)
{
NumberOfFreeBytes = [FreeBytes longLongValue];
}
NSNumber *TotalBytes = nil;
GetValueSuccess = GetValueSuccess &&[URL getResourceValue : &TotalBytes forKey : NSURLVolumeTotalCapacityKey error : nil];
if (TotalBytes)
{
TotalNumberOfBytes = [TotalBytes longLongValue];
}
if (GetValueSuccess && (NumberOfFreeBytes > 0) && (TotalNumberOfBytes > 0))
{
return true;
}
(...)
}
// 工程版本.
FString FIOSPlatformMisc::GetProjectVersion()
{
NSDictionary* infoDictionary = [[NSBundle mainBundle] infoDictionary];
FString localVersionString = FString(infoDictionary[@"CFBundleShortVersionString"]);
return localVersionString;
}
// 构建数字.
FString FIOSPlatformMisc::GetBuildNumber()
{
NSDictionary* infoDictionary = [[NSBundle mainBundle]infoDictionary];
FString BuildString = FString(infoDictionary[@"CFBundleVersion"]);
return BuildString;
}
// 设置存储值.
bool FIOSPlatformMisc::SetStoredValue(const FString& InStoreId, const FString& InSectionName, const FString& InKeyName, const FString& InValue)
{
NSUserDefaults* UserSettings = [NSUserDefaults standardUserDefaults];
NSString* StoredValue = [NSString stringWithFString:InValue];
[UserSettings setObject:StoredValue forKey:MakeStoredValueKeyName(InSectionName, InKeyName)];
return true;
}
// 获取存储值.
bool FIOSPlatformMisc::GetStoredValue(const FString& InStoreId, const FString& InSectionName, const FString& InKeyName, FString& OutValue)
{
NSUserDefaults* UserSettings = [NSUserDefaults standardUserDefaults];
NSString* StoredValue = [UserSettings objectForKey:MakeStoredValueKeyName(InSectionName, InKeyName)];
if (StoredValue != nil)
{
OutValue = StoredValue;
return true;
}
return false;
}
// 设置崩溃处理器.
void FIOSPlatformMisc::SetCrashHandler(void (* CrashHandler)(const FGenericCrashContext& Context))
{
SCOPED_AUTORELEASE_POOL;
GCrashHandlerPointer = CrashHandler;
if (!FIOSApplicationInfo::CrashReporter && !FIOSApplicationInfo::CrashMalloc)
{
// 配置崩溃处理程序malloc区域,为其自身保留少量内存.
FIOSApplicationInfo::CrashMalloc = new FIOSMallocCrashHandler(4*1024*1024);
PLCrashReporterConfig* Config = [[[PLCrashReporterConfig alloc] initWithSignalHandlerType: PLCrashReporterSignalHandlerTypeBSD symbolicationStrategy: PLCrashReporterSymbolicationStrategyNone crashReportFolder: FIOSApplicationInfo::TemporaryCrashReportFolder().GetNSString() crashReportName: FIOSApplicationInfo::TemporaryCrashReportName().GetNSString()] autorelease];
FIOSApplicationInfo::CrashReporter = [[PLCrashReporter alloc] initWithConfiguration: Config];
PLCrashReporterCallbacks CrashReportCallback = {
.version = 0,
.context = nullptr,
.handleSignal = PLCrashReporterHandler
};
[FIOSApplicationInfo::CrashReporter setCrashCallbacks: &CrashReportCallback];
NSError* Error = nil;
if ([FIOSApplicationInfo::CrashReporter enableCrashReporterAndReturnError: &Error])
{
// 无操作.
}
else
{
// 崩溃处理器.
struct sigaction Action;
FMemory::Memzero(&Action, sizeof(struct sigaction));
// 保存崩溃处理器.
Action.sa_sigaction = PlatformCrashHandler;
sigemptyset(&Action.sa_mask);
Action.sa_flags = SA_SIGINFO | SA_RESTART | SA_ONSTACK;
sigaction(SIGQUIT, &Action, NULL);
sigaction(SIGILL, &Action, NULL);
sigaction(SIGEMT, &Action, NULL);
sigaction(SIGFPE, &Action, NULL);
sigaction(SIGBUS, &Action, NULL);
sigaction(SIGSEGV, &Action, NULL);
sigaction(SIGSYS, &Action, NULL);
sigaction(SIGABRT, &Action, NULL);
}
}
}
需要注意的是,苹果的操作系统(Mac、iOS)混合使用了C++和Object C,所以上面的有些语句跟C++差异比较明显,不要对此感到奇怪,也不要觉得是语法错误。
18.14.2.4 FUnixPlatformMisc
FUnixPlatformMisc实现了Unix系统的接口,部分代码分析如下:
// UnixPlatformMisc.cpp
// 预初始化
void FUnixPlatformMisc::PlatformPreInit()
{
FGenericPlatformMisc::PlatformPreInit();
UnixCrashReporterTracker::PreInit();
}
void FUnixPlatformMisc::PlatformInit()
{
// 安装特定于平台的信号处理程序.
InstallChildExitedSignalHanlder();
// IsFirstInstance()不仅仅用于日志记录,实际上是第一个.
bool bFirstInstance = FPlatformProcess::IsFirstInstance();
bool bIsNullRHI = !FApp::CanEverRender();
bool bPreloadedModuleSymbolFile = FParse::Param(FCommandLine::Get(), TEXT("preloadmodulesymbols"));
UnixPlatForm_CheckIfKSMUsable();
FString GPUInfo = GetGPUInfo();
(...)
FPlatformTime::PrintCalibrationLog();
(...)
if (bPreloadedModuleSymbolFile)
{
UnixPlatformStackWalk_PreloadModuleSymbolFile();
}
if (FPlatformMisc::HasBeenStartedRemotely() || FPlatformMisc::IsDebuggerPresent())
{
// 立即打印输出
setvbuf(stdout, NULL, _IONBF, 0);
}
if (FParse::Param(FCommandLine::Get(), TEXT("norandomguids")))
{
SysGetRandomSupported = 0;
}
// 此符号用于调试,但在启用LTO的情况下,会被剥离,因为没有任何东西在使用它让我们在这里使用它来记录它在VeryVerbose设置下是否有效.
extern uint8** GNameBlocksDebug;
if (GNameBlocksDebug)
{
UE_LOG(LogInit, VeryVerbose, TEXT("GNameBlocksDebug Valid - %i"), !!GNameBlocksDebug);
}
}
// 销毁.
void FUnixPlatformMisc::PlatformTearDown()
{
// 我们请求关闭信号,因此无法打印。
if (GDeferedExitLogging)
{
uint8 OverriddenErrorLevel = 0;
if (FPlatformMisc::HasOverriddenReturnCode(&OverriddenErrorLevel))
{
UE_LOG(LogCore, Log, TEXT("FUnixPlatformMisc::RequestExit(bForce=false, ReturnCode=%d)"), OverriddenErrorLevel);
}
else
{
UE_LOG(LogCore, Log, TEXT("FUnixPlatformMisc::RequestExit(false)"));
}
}
UnixPlatformStackWalk_UnloadPreloadedModuleSymbol();
FPlatformProcess::CeaseBeingFirstInstance();
}
// 低级别输出调试信息.
void FUnixPlatformMisc::LowLevelOutputDebugString(const TCHAR *Message)
{
static_assert(PLATFORM_USE_LS_SPEC_FOR_WIDECHAR, "Check printf format");
fprintf(stderr, "%s", TCHAR_TO_UTF8(Message)); // there's no good way to implement that really
}
// OS版本信息.
void FUnixPlatformMisc::GetOSVersions(FString& out_OSVersionLabel, FString& out_OSSubVersionLabel)
{
out_OSVersionLabel = FString(TEXT("GenericLinuxVersion"));
out_OSSubVersionLabel = GetKernelVersion();
TMap<FString, FString> OsInfo = ReadConfigurationFile(TEXT("/etc/os-release"));
if (OsInfo.Num() > 0)
{
FString* VersionAddress = OsInfo.Find(TEXT("PRETTY_NAME"));
if (VersionAddress)
{
FString* VersionNameAddress = nullptr;
if (VersionAddress->Equals(TEXT("Linux")))
{
VersionNameAddress = OsInfo.Find(TEXT("NAME"));
if (VersionNameAddress != nullptr)
{
VersionAddress = VersionNameAddress;
}
}
out_OSVersionLabel = FString(*VersionAddress);
}
}
(...)
}
// OS标识符.
FString FUnixPlatformMisc::GetOperatingSystemId()
{
(...)
int OsGuidFile = open("/etc/machine-id", O_RDONLY);
if (OsGuidFile != -1)
{
char Buffer[PlatformMiscLimits::MaxOsGuidLength + 1] = {0};
ssize_t ReadBytes = read(OsGuidFile, Buffer, sizeof(Buffer) - 1);
if (ReadBytes > 0)
{
CachedResult = UTF8_TO_TCHAR(Buffer);
}
close(OsGuidFile);
}
(...)
}
// 获取磁盘信息.
bool FUnixPlatformMisc::GetDiskTotalAndFreeSpace(const FString& InPath, uint64& TotalNumberOfBytes, uint64& NumberOfFreeBytes)
{
struct statfs FSStat = { 0 };
FTCHARToUTF8 Converter(*InPath);
int Err = statfs((ANSICHAR*)Converter.Get(), &FSStat);
if (Err == 0)
{
TotalNumberOfBytes = FSStat.f_blocks * FSStat.f_bsize;
NumberOfFreeBytes = FSStat.f_bavail * FSStat.f_bsize;
}
(...)
return (Err == 0);
}
// 设置存储值.
bool FUnixPlatformMisc::SetStoredValues(const FString& InStoreId, const FString& InSectionName, const TMap<FString, FString>& InKeyValues)
{
const FString ConfigPath = FString(FPlatformProcess::ApplicationSettingsDir()) / InStoreId / FString(TEXT("KeyValueStore.ini"));
FConfigFile ConfigFile;
ConfigFile.Read(ConfigPath);
for (auto const& InKeyValue : InKeyValues)
{
FConfigSection& Section = ConfigFile.FindOrAdd(InSectionName);
FConfigValue& KeyValue = Section.FindOrAdd(*InKeyValue.Key);
KeyValue = FConfigValue(InKeyValue.Value);
}
ConfigFile.Dirty = true;
return ConfigFile.Write(ConfigPath);
}
值得一提的是,Linux平台的实现和Unix完全一样,未作任何的额外修改。
18.14.2.5 FPlatformMisc
有着UE开发经验或者细心的同学肯定发现了,我们在使用平台相关的接口时,使用的是FPlatformMisc而不是FGenericPlatformMisc,那么它们的关系是怎样的呢?为了解开谜底,还需要从以下代码中获取答案:
// PreprocessorHelpers.h
#define COMPILED_PLATFORM_HEADER(Suffix) PREPROCESSOR_TO_STRING(PREPROCESSOR_JOIN(PLATFORM_HEADER_NAME/PLATFORM_HEADER_NAME, Suffix))
// PlatformMisc.h
#include "GenericPlatform/GenericPlatformMisc.h"
#include COMPILED_PLATFORM_HEADER(PlatformMisc.h)
从上面的代码片段可以看出,UE使用了COMPILED_PLATFORM_HEADER(PlatformMisc.h)的宏生成了当前系统对应的文件路径,例如:
Windows: "Windows/WindowsPlatformMisc.h"
Android: "Android/AndroidPlatformMisc.h"
IOS : "IOS/IOSPlatformMisc.h"
Unix : "Unix/UnixPlatformMisc.h"
Mac : "Mac/MacPlatformMisc.h"
然后每个平台的XXXPlatformMisc.h中都有一句typedef FXXXPlatformMisc FPlatformMisc,例如:
// WindowsPlatformMisc.h
typedef FWindowsPlatformMisc FPlatformMisc;
// AndroidPlatformMisc.h
typedef FAndroidMisc FPlatformMisc;
// IOSPlatformMisc.h
typedef FIOSPlatformMisc FPlatformMisc;
// LinuxPlatformMisc.h
typedef FLinuxPlatformMisc FPlatformMisc;
有了以上类型重定义,从而实现了FGenericPlatformMisc的不同子类使用统一的FPlatformMisc类型,其它模块就可以使用统一的类型FPlatformMisc访问OS相关的接口,实现跨平台的目的。
顺带提一下,COMPILED_PLATFORM_HEADER()还用于跨平台的其它文件或模块中:
#include COMPILED_PLATFORM_HEADER(PlatformAGXConfig.h)
#include COMPILED_PLATFORM_HEADER(PlatformApplicationMisc.h)
#include COMPILED_PLATFORM_HEADER(PlatformSplash.h)
#include COMPILED_PLATFORM_HEADER(PlatformSurvey.h)
#include COMPILED_PLATFORM_HEADER(PlatformModuleDiagnostics.h)
#include COMPILED_PLATFORM_HEADER(CriticalSection.h)
#include COMPILED_PLATFORM_HEADER(PlatformCompilerPreSetup.h)
#include COMPILED_PLATFORM_HEADER(PlatformCompilerSetup.h)
#include COMPILED_PLATFORM_HEADER(Platform.h)
#include COMPILED_PLATFORM_HEADER(PlatformAffinity.h)
#include COMPILED_PLATFORM_HEADER(PlatformAtomics.h)
#include COMPILED_PLATFORM_HEADER(PlatformCrashContext.h)
#include COMPILED_PLATFORM_HEADER(PlatformFile.h)
#include COMPILED_PLATFORM_HEADER(PlatformMath.h)
#include COMPILED_PLATFORM_HEADER(PlatformMemory.h)
#include COMPILED_PLATFORM_HEADER(PlatformOutputDevices.h)
#include COMPILED_PLATFORM_HEADER(PlatformProcess.h)
#include COMPILED_PLATFORM_HEADER(PlatformProperties.h)
#include COMPILED_PLATFORM_HEADER(PlatformStackWalk.h)
#include COMPILED_PLATFORM_HEADER(PlatformString.h)
#include COMPILED_PLATFORM_HEADER(PlatformTime.h)
#include COMPILED_PLATFORM_HEADER(PlatformTLS.h)
#include COMPILED_PLATFORM_HEADER(PlatformHttp.h)
#include COMPILED_PLATFORM_HEADER(PlatformBackgroundHttp.h)
#include COMPILED_PLATFORM_HEADER(OpenGLDrvPrivate.h)
#include COMPILED_PLATFORM_HEADER_WITH_PREFIX(Apple/Platform, PlatformDynamicRHI.h)
#include COMPILED_PLATFORM_HEADER(StaticShaderPlatform.inl)
#include COMPILED_PLATFORM_HEADER(StaticFeatureLevel.inl)
#include COMPILED_PLATFORM_HEADER(DataDrivenShaderPlatformInfo.inl)
#include COMPILED_PLATFORM_HEADER_WITH_PREFIX(Framework/Text, PlatformTextField.h)
涉及了进程、原子操作、临界区、堆栈遍历、TLS、内存、文件、崩溃上下文、亲缘性、编译器、应用程序、数学、HTTP、Shader、RHI等等模块。后续小节会对部分重要模块进行分析。
18.14.3 FGenericPlatformApplicationMisc
FGenericPlatformApplicationMisc的跨平台和实现机制和FGenericPlatformMisc类似,下面看看它的声明:
// GenericPlatformApplicationMisc.h
struct APPLICATIONCORE_API FGenericPlatformApplicationMisc
{
// App声明周期.
static class GenericApplication* CreateApplication();
static void PreInit();
static void Init();
static void PostInit();
static void TearDown();
// 模块/上下文/设备
static void LoadPreInitModules();
static void LoadStartupModules();
static FOutputDeviceConsole* CreateConsoleOutputDevice();
static FOutputDeviceError* GetErrorOutputDevice();
static FFeedbackContext* GetFeedbackContext();
static bool IsThisApplicationForeground();
static void RequestMinimize();
static bool RequiresVirtualKeyboard();
static void PumpMessages(bool bFromMainLoop);
// 屏幕/窗口
static void PreventScreenSaver();
static bool IsScreensaverEnabled();
static bool ControlScreensaver(EScreenSaverAction Action);
static struct FLinearColor GetScreenPixelColor(const FVector2D& InScreenPos, float InGamma);
static bool GetWindowTitleMatchingText(const TCHAR* TitleStartsWith, FString& OutTitle);
static void SetHighDPIMode();
static float GetDPIScaleFactorAtPoint(float X, float Y);
static bool IsHighDPIAwarenessEnabled();
static bool AnchorWindowWindowPositionTopLeft();
static EScreenPhysicalAccuracy GetPhysicalScreenDensity(int32& OutScreenDensity);
static EScreenPhysicalAccuracy ComputePhysicalScreenDensity(int32& OutScreenDensity);
static EScreenPhysicalAccuracy ConvertInchesToPixels(T Inches, T2& OutPixels);
static EScreenPhysicalAccuracy ConvertPixelsToInches(T Pixels, T2& OutInches);
// 控制器
static void SetGamepadsAllowed(bool bAllowed);
static void SetGamepadsBlockDeviceFeedback(bool bAllowed);
static void ResetGamepadAssignments();
static void ResetGamepadAssignmentToController(int32 ControllerId);
static bool IsControllerAssignedToGamepad(int32 ControllerId);
static FString GetGamepadControllerName(int32 ControllerId);
static class UTexture2D* GetGamepadButtonGlyph(...);
static void EnableMotionData(bool bEnable);
static bool IsMotionDataEnabled();
// 其它操作
static void ClipboardCopy(const TCHAR* Str);
static void ClipboardPaste(class FString& Dest);
(...)
};
由此可见,FGenericPlatformApplicationMisc主要是对应用程序的声明周期、窗口、屏幕、设备、控制器等提供统一的接口,而具体的实现由不同的平台子类实现。下面小节分析部分平台的部分接口。
18.14.3.1 FWindowsPlatformApplicationMisc
FWindowsPlatformApplicationMisc实现Windows平台应用程序的接口:
// WindowsPlatformApplicationMisc.cpp
// 创建应用程序
GenericApplication* FWindowsPlatformApplicationMisc::CreateApplication()
{
HICON AppIconHandle = LoadIcon( hInstance, MAKEINTRESOURCE( GetAppIcon() ) );
if( AppIconHandle == NULL )
{
AppIconHandle = LoadIcon( (HINSTANCE)NULL, IDI_APPLICATION );
}
// 创建窗口应用程序.
return FWindowsApplication::CreateWindowsApplication( hInstance, AppIconHandle );
}
void FWindowsPlatformApplicationMisc::PreInit()
{
FApp::SetHasFocusFunction(&FWindowsPlatformApplicationMisc::IsThisApplicationForeground);
}
void FWindowsPlatformApplicationMisc::LoadStartupModules()
{
FModuleManager::Get().LoadModule(TEXT("HeadMountedDisplay"));
(...)
}
class FFeedbackContext* FWindowsPlatformApplicationMisc::GetFeedbackContext()
{
(...)
return FPlatformOutputDevices::GetFeedbackContext();
}
// 注入消息.
void FWindowsPlatformApplicationMisc::PumpMessages(bool bFromMainLoop)
{
const bool bSetPumpingMessages = !GPumpingMessages;
if (bSetPumpingMessages)
{
GPumpingMessages = true;
}
ON_SCOPE_EXIT
{
if (bSetPumpingMessages)
{
GPumpingMessages = false;
}
};
if (!bFromMainLoop)
{
FPlatformMisc::PumpMessagesOutsideMainLoop();
return;
}
GPumpingMessagesOutsideOfMainLoop = false;
WinPumpMessages();
// 确定应用程序是否具有焦点.
bool bHasFocus = FApp::HasFocus();
static bool bHadFocus = false;
(...)
#if !UE_SERVER
// 对于非编辑器客户端,记录活动窗口是否处于焦点.
if( bHadFocus != bHasFocus )
{
FGenericCrashContext::SetEngineData(TEXT("Platform.AppHasFocus"), bHasFocus ? TEXT("true") : TEXT("false"));
}
#endif
bHadFocus = bHasFocus;
// 如果是我们的窗口,允许声音,否则应用乘数.
FApp::SetVolumeMultiplier( bHasFocus ? 1.0f : FApp::GetUnfocusedVolumeMultiplier() );
}
// 设置高DPI模式.
void FWindowsPlatformApplicationMisc::SetHighDPIMode()
{
if (IsHighDPIAwarenessEnabled())
{
if (void* ShCoreDll = FPlatformProcess::GetDllHandle(TEXT("shcore.dll")))
{
typedef enum _PROCESS_DPI_AWARENESS {
PROCESS_DPI_UNAWARE = 0,
PROCESS_SYSTEM_DPI_AWARE = 1,
PROCESS_PER_MONITOR_DPI_AWARE = 2
} PROCESS_DPI_AWARENESS;
// 从shcore.dll获取SetProcessDpiAwarenessProc接口地址.
typedef HRESULT(STDAPICALLTYPE *SetProcessDpiAwarenessProc)(PROCESS_DPI_AWARENESS Value);
SetProcessDpiAwarenessProc SetProcessDpiAwareness = (SetProcessDpiAwarenessProc)FPlatformProcess::GetDllExport(ShCoreDll, TEXT("SetProcessDpiAwareness"));
GetDpiForMonitor = (GetDpiForMonitorProc)FPlatformProcess::GetDllExport(ShCoreDll, TEXT("GetDpiForMonitor"));
typedef HRESULT(STDAPICALLTYPE *GetProcessDpiAwarenessProc)(HANDLE hProcess, PROCESS_DPI_AWARENESS* Value);
GetProcessDpiAwarenessProc GetProcessDpiAwareness = (GetProcessDpiAwarenessProc)FPlatformProcess::GetDllExport(ShCoreDll, TEXT("GetProcessDpiAwareness"));
if (SetProcessDpiAwareness && GetProcessDpiAwareness && !IsRunningCommandlet() && !FApp::IsUnattended())
{
PROCESS_DPI_AWARENESS CurrentAwareness = PROCESS_DPI_UNAWARE;
GetProcessDpiAwareness(nullptr, &CurrentAwareness);
if (CurrentAwareness != PROCESS_PER_MONITOR_DPI_AWARE)
{
UE_LOG(LogInit, Log, TEXT("Setting process to per monitor DPI aware"));
HRESULT Hr = SetProcessDpiAwareness(PROCESS_PER_MONITOR_DPI_AWARE); // 如果我们处于任何无头显模式,则不在乎警告
if (Hr != S_OK)
{
UE_LOG(LogInit, Warning, TEXT("SetProcessDpiAwareness failed. Error code %x"), Hr);
}
}
}
FPlatformProcess::FreeDllHandle(ShCoreDll);
}
else if (void* User32Dll = FPlatformProcess::GetDllHandle(TEXT("user32.dll")))
{
// user32.dll获取SetProcessDpiAware接口地址.
typedef BOOL(WINAPI *SetProcessDpiAwareProc)(void);
SetProcessDpiAwareProc SetProcessDpiAware = (SetProcessDpiAwareProc)FPlatformProcess::GetDllExport(User32Dll, TEXT("SetProcessDPIAware"));
if (SetProcessDpiAware && !IsRunningCommandlet() && !FApp::IsUnattended())
{
UE_LOG(LogInit, Log, TEXT("Setting process to DPI aware"));
BOOL Result = SetProcessDpiAware();
if (Result == 0)
{
UE_LOG(LogInit, Warning, TEXT("SetProcessDpiAware failed"));
}
}
FPlatformProcess::FreeDllHandle(User32Dll);
}
}
}
// 获取显示器DPI.
int32 FWindowsPlatformApplicationMisc::GetMonitorDPI(const FMonitorInfo& MonitorInfo)
{
int32 DisplayDPI = 96;
if (IsHighDPIAwarenessEnabled())
{
if (GetDpiForMonitor)
{
RECT MonitorDim;
MonitorDim.left = MonitorInfo.DisplayRect.Left;
MonitorDim.top = MonitorInfo.DisplayRect.Top;
MonitorDim.right = MonitorInfo.DisplayRect.Right;
MonitorDim.bottom = MonitorInfo.DisplayRect.Bottom;
HMONITOR Monitor = MonitorFromRect(&MonitorDim, MONITOR_DEFAULTTONEAREST);
if (Monitor)
{
uint32 DPIX = 0;
uint32 DPIY = 0;
// 获取显示器DPI.
if (SUCCEEDED(GetDpiForMonitor(Monitor, 0, &DPIX, &DPIY)))
{
DisplayDPI = DPIX;
}
}
}
else
{
HDC Context = GetDC(nullptr);
DisplayDPI = GetDeviceCaps(Context, LOGPIXELSX);
ReleaseDC(nullptr, Context);
}
}
return DisplayDPI;
}
// 获取点的DPI比例因子
float FWindowsPlatformApplicationMisc::GetDPIScaleFactorAtPoint(float X, float Y)
{
float Scale = 1.0f;
if (IsHighDPIAwarenessEnabled())
{
if (GetDpiForMonitor)
{
POINT Position = { static_cast<LONG>(X), static_cast<LONG>(Y) };
HMONITOR Monitor = MonitorFromPoint(Position, MONITOR_DEFAULTTONEAREST);
if (Monitor)
{
uint32 DPIX = 0;
uint32 DPIY = 0;
if (SUCCEEDED(GetDpiForMonitor(Monitor, 0, &DPIX, &DPIY)))
{
Scale = (float)DPIX / 96.0f;
}
}
}
else
{
HDC Context = GetDC(nullptr);
int32 DPI = GetDeviceCaps(Context, LOGPIXELSX);
Scale = (float)DPI / 96.0f;
ReleaseDC(nullptr, Context);
}
}
return Scale;
}
18.14.3.2 FAndroidApplicationMisc
FAndroidApplicationMisc实现Android平台应用程序的接口:
// AndroidPlatformApplicationMisc.cpp
void FAndroidApplicationMisc::LoadPreInitModules()
{
FModuleManager::Get().LoadModule(TEXT("OpenGLDrv"));
#if USE_ANDROID_AUDIO
FModuleManager::Get().LoadModule(TEXT("AndroidAudio"));
FModuleManager::Get().LoadModule(TEXT("AudioMixerAndroid"));
#endif
}
class FFeedbackContext* FAndroidApplicationMisc::GetFeedbackContext()
{
static FAndroidFeedbackContext Singleton;
return &Singleton;
}
class FOutputDeviceError* FAndroidApplicationMisc::GetErrorOutputDevice()
{
static FAndroidErrorOutputDevice Singleton;
return &Singleton;
}
GenericApplication* FAndroidApplicationMisc::CreateApplication()
{
return FAndroidApplication::CreateAndroidApplication();
}
void FAndroidApplicationMisc::SetGamepadsAllowed(bool bAllowed)
{
if (FAndroidInputInterface* InputInterface = (FAndroidInputInterface*)FAndroidApplication::Get()->GetInputInterface())
{
InputInterface->SetGamepadsAllowed(bAllowed);
}
}
// 计算物理屏幕的密度.
ScreenPhysicalAccuracy FAndroidApplicationMisc::ComputePhysicalScreenDensity(int32& OutScreenDensity)
{
FString MyDeviceModel = FPlatformMisc::GetDeviceModel();
TArray<FString> DeviceStrings;
GConfig->GetArray(TEXT("DeviceScreenDensity"), TEXT("Devices"), DeviceStrings, GEngineIni);
TArray<FScreenDensity> Devices;
for ( const FString& DeviceString : DeviceStrings )
{
FScreenDensity DensityEntry;
if ( DensityEntry.InitFromString(DeviceString) )
{
Devices.Add(DensityEntry);
}
}
for ( const FScreenDensity& Device : Devices )
{
if ( Device.IsMatch(MyDeviceModel) )
{
OutScreenDensity = Device.Density * GetWindowUpscaleFactor();
return EScreenPhysicalAccuracy::Truth;
}
}
// JNI模式
#if USE_ANDROID_JNI
extern FString AndroidThunkCpp_GetMetaDataString(const FString& Key);
FString DPIStrings = AndroidThunkCpp_GetMetaDataString(TEXT("unreal.displaymetrics.dpi"));
TArray<FString> DPIValues;
DPIStrings.ParseIntoArray(DPIValues, TEXT(","));
float xdpi, ydpi;
LexFromString(xdpi, *DPIValues[0]);
LexFromString(ydpi, *DPIValues[1]);
OutScreenDensity = ( xdpi + ydpi ) / 2.0f;
if ( OutScreenDensity <= 0 || OutScreenDensity > 2000 )
{
return EScreenPhysicalAccuracy::Unknown;
}
OutScreenDensity *= GetWindowUpscaleFactor();
return EScreenPhysicalAccuracy::Approximation;
#else
return EScreenPhysicalAccuracy::Unknown;
#endif
}
18.14.3.3 FIOSPlatformApplicationMisc
FIOSPlatformApplicationMisc实现IOS平台应用程序的接口:
// IOSPlatformApplicationMisc.cpp
void FIOSPlatformApplicationMisc::LoadPreInitModules()
{
FModuleManager::Get().LoadModule(TEXT("IOSAudio"));
FModuleManager::Get().LoadModule(TEXT("AudioMixerAudioUnit"));
}
class FFeedbackContext* FIOSPlatformApplicationMisc::GetFeedbackContext()
{
static FIOSFeedbackContext Singleton;
return &Singleton;
}
class FOutputDeviceError* FIOSPlatformApplicationMisc::GetErrorOutputDevice()
{
static FIOSErrorOutputDevice Singleton;
return &Singleton;
}
// 创建应用程序.
GenericApplication* FIOSPlatformApplicationMisc::CreateApplication()
{
CachedApplication = FIOSApplication::CreateIOSApplication();
return CachedApplication;
}
void FIOSPlatformApplicationMisc::EnableMotionData(bool bEnable)
{
FIOSInputInterface* InputInterface = (FIOSInputInterface*)CachedApplication->GetInputInterface();
return InputInterface->EnableMotionData(bEnable);
}
bool FIOSPlatformApplicationMisc::IsMotionDataEnabled()
{
const FIOSInputInterface* InputInterface = (const FIOSInputInterface*)CachedApplication->GetInputInterface();
return InputInterface->IsMotionDataEnabled();
}
// 剪切板
void FIOSPlatformApplicationMisc::ClipboardCopy(const TCHAR* Str)
{
#if !PLATFORM_TVOS
CFStringRef CocoaString = FPlatformString::TCHARToCFString(Str);
UIPasteboard* Pasteboard = [UIPasteboard generalPasteboard];
[Pasteboard setString:(NSString*)CocoaString];
#endif
}
void FIOSPlatformApplicationMisc::ClipboardPaste(class FString& Result)
{
#if !PLATFORM_TVOS
UIPasteboard* Pasteboard = [UIPasteboard generalPasteboard];
NSString* CocoaString = [Pasteboard string];
if(CocoaString)
{
TArray<TCHAR> Ch;
Ch.AddUninitialized([CocoaString length] + 1);
FPlatformString::CFStringToTCHAR((CFStringRef)CocoaString, Ch.GetData());
Result = Ch.GetData();
}
else
{
Result = TEXT("");
}
#endif
}
18.14.3.4 FLinuxPlatformApplicationMisc
FLinuxPlatformApplicationMisc实现Linux平台应用程序的接口:
// LinuxPlatformApplicationMisc.cpp
GenericApplication* FLinuxPlatformApplicationMisc::CreateApplication()
{
return FLinuxApplication::CreateLinuxApplication();
}
void FLinuxPlatformApplicationMisc::PreInit()
{
MessageBoxExtCallback = MessageBoxExtImpl;
FApp::SetHasFocusFunction(&FLinuxPlatformApplicationMisc::IsThisApplicationForeground);
}
void FLinuxPlatformApplicationMisc::Init()
{
// skip for servers and programs, unless they request later
bool bIsNullRHI = !FApp::CanEverRender();
if (!IS_PROGRAM && !bIsNullRHI)
{
InitSDL();
}
FGenericPlatformApplicationMisc::Init();
UngrabAllInputCallback = UngrabAllInputImpl;
}
void FLinuxPlatformApplicationMisc::LoadPreInitModules()
{
#if WITH_EDITOR
FModuleManager::Get().LoadModule(TEXT("OpenGLDrv"));
#endif // WITH_EDITOR
}
void FLinuxPlatformApplicationMisc::LoadStartupModules()
{
#if !IS_PROGRAM && !UE_SERVER
FModuleManager::Get().LoadModule(TEXT("AudioMixerSDL")); // added in Launch.Build.cs for non-server targets
FModuleManager::Get().LoadModule(TEXT("HeadMountedDisplay"));
#endif // !IS_PROGRAM && !UE_SERVER
#if defined(WITH_STEAMCONTROLLER) && WITH_STEAMCONTROLLER
FModuleManager::Get().LoadModule(TEXT("SteamController"));
#endif // WITH_STEAMCONTROLLER
#if WITH_EDITOR
FModuleManager::Get().LoadModule(TEXT("SourceCodeAccess"));
#endif //WITH_EDITOR
}
void FLinuxPlatformApplicationMisc::TearDown()
{
FGenericPlatformApplicationMisc::TearDown();
if (GInitializedSDL)
{
UE_LOG(LogInit, Log, TEXT("Tearing down SDL."));
SDL_Quit();
GInitializedSDL = false;
MessageBoxExtCallback = nullptr;
UngrabAllInputCallback = nullptr;
}
}
// 注入消息.
void FLinuxPlatformApplicationMisc::PumpMessages( bool bFromMainLoop )
{
if (GInitializedSDL && bFromMainLoop)
{
if( LinuxApplication )
{
LinuxApplication->SaveWindowPropertiesForEventLoop();
SDL_Event event;
while (SDL_PollEvent(&event))
{
LinuxApplication->AddPendingEvent( event );
}
LinuxApplication->CheckIfApplicatioNeedsDeactivation();
LinuxApplication->ClearWindowPropertiesAfterEventLoop();
}
else
{
// 没有要向其发送事件的应用程序, 只需清除队列。
SDL_Event event;
while (SDL_PollEvent(&event))
{
// noop
}
}
bool bHasFocus = FApp::HasFocus();
// 如果是我们的窗口,允许声音,否则应用乘数.
FApp::SetVolumeMultiplier( bHasFocus ? 1.0f : FApp::GetUnfocusedVolumeMultiplier() );
}
}
18.14.3.5 FPlatformApplicationMisc
FPlatformApplicationMisc、FGenericPlatformApplicationMisc之间的关系、实现和用法于FPlatformMisc、FGenericPlatformMisc类似,不再累述。
18.14.4 进程、线程和同步
18.14.4.1 FRunnableThread
FRunnableThread是UE封装了各个操作系统下的线程基类,它的定义如下:
// RunnableThread.h
class CORE_API FRunnableThread
{
public:
// 创建
static FRunnableThread* Create(FRunnable* InRunnable, const TCHAR* ThreadName, uint32 InStackSize = 0, ...);
// 线程状态转换.
virtual void Suspend( bool bShouldPause = true ) = 0;
virtual bool Kill( bool bShouldWait = true ) = 0;
virtual void WaitForCompletion() = 0;
// 线程属性
// 线程类型.
enum class ThreadType
{
Real,
Fake,
Forkable,
};
virtual FRunnableThread::ThreadType GetThreadType() const;
static uint32 GetTlsSlot();
virtual void SetThreadPriority( EThreadPriority NewPriority ) = 0;
virtual bool SetThreadAffinity( const FThreadAffinity& Affinity );
const uint32 GetThreadID() const;
const FString& GetThreadName() const;
EThreadPriority GetThreadPriority() const;
protected:
void SetTls();
void FreeTls();
static FRunnableThread* GetRunnableThread();
private:
static uint32 RunnableTlsSlot; // FRunnableThread指针的TLS插槽索引.
static void SetupCreatedThread(...);
virtual void Tick();
virtual void OnPostFork();
void PostCreate(EThreadPriority ThreadPriority);
(...)
};
由此可知,UE抽象了线程的若干接口和数据,包含创建、销毁、转换状态及设置堆栈大小、优先级、亲缘性、TLS等接口。继承自它的子类是实现各个平台的类,继承树如下:
上图显示了Windows直接继承自FRunnableThread,而Android、Apple、Unix等系统源自Unix系统的POSIX thread(PThread)机制。
POSIX线程库是用于C/C++的基于标准的线程API,允许生成一个新的并发进程流,在多处理器或多核系统上最有效,在这些系统中,进程可以被安排在另一个处理器上运行,从而通过并行或分布式处理提高速度。线程比“分叉”或生成新进程需要更少的开销,因为系统不会为进程初始化新的系统虚拟内存空间和环境。
虽然在多处理器系统上最有效,但在利用I/O延迟和其他可能停止进程执行的系统功能的单处理器系统上也可以获得收益。(一个线程可能在另一个线程等待I/O或其他系统延迟时执行。)并行编程技术(如MPI和PVM)用于分布式计算环境,而线程仅限于单个计算机系统。进程中的所有线程共享相同的地址空间,通过定义一个函数及其将在线程中处理的参数来生成线程。在软件中使用POSIX线程库的目的是更快地执行软件。
本质上,PThread是进程,但和普通的进程更轻量,也常被称为轻量化进程,适合用来模拟线程。它是Unix系的系统才有的概念,Windows不存在。
在UE体系中,FRunnableThread只提供了基础的跨平台线程功能,在实际应用中,需要结合ThreadManager、Runnable、Task、Queue、TaskGraph等类型进行交互,从而形成完整的并发体系。更多技术细节可参阅2.4 UE的多线程机制,本篇不再累述。
18.14.4.2 FPlatformProcess
FPlatformProcess是对FGenericPlatformProcess的类型重定义,机制和FGenericPlatformMisc类似,封装和代表了各个操作系统的进程。下面是FGenericPlatformProcess的定义:
// GenericPlatformProcess.h
struct CORE_API FGenericPlatformProcess
{
// 信号量
struct FSemaphore
{
const TCHAR* GetName() const;
virtual void Lock() = 0;
virtual bool TryLock(uint64 NanosecondsToWait) = 0;
virtual void Unlock() = 0;
protected:
enum Limits
{
MaxSemaphoreName = 128
};
TCHAR Name[MaxSemaphoreName];
};
// dll/模块
static void* GetDllHandle( const TCHAR* Filename );
static void FreeDllHandle( void* DllHandle );
static void* GetDllExport( void* DllHandle, const TCHAR* ProcName );
static void AddDllDirectory(const TCHAR* Directory);
static void PushDllDirectory(const TCHAR* Directory);
static void PopDllDirectory(const TCHAR* Directory);
static void GetDllDirectories(TArray<FString>& OutDllDirectories);
static const TCHAR* GetModulePrefix();
static const TCHAR* GetModuleExtension();
// 进程/应用程序
static FProcHandle CreateProc( const TCHAR* URL, const TCHAR* Parms, ...);
static FProcHandle OpenProcess(uint32 ProcessID);
static bool IsProcRunning( FProcHandle & ProcessHandle );
static void WaitForProc( FProcHandle & ProcessHandle );
static void CloseProc( FProcHandle & ProcessHandle );
static void TerminateProc( FProcHandle & ProcessHandle, bool KillTree = false );
static EWaitAndForkResult WaitAndFork();
static bool GetProcReturnCode( FProcHandle & ProcHandle, int32* ReturnCode );
static bool IsApplicationRunning( uint32 ProcessId );
static bool IsApplicationRunning( const TCHAR* ProcName );
static FString GetApplicationName( uint32 ProcessId );
static bool GetApplicationMemoryUsage(uint32 ProcessId, SIZE_T* OutMemoryUsage);
static bool ExecProcess(const TCHAR* URL, const TCHAR* Params,...);
static bool ExecElevatedProcess(const TCHAR* URL, ...);
static void LaunchURL( const TCHAR* URL, const TCHAR* Parms, FString* Error );
static bool CanLaunchURL(const TCHAR* URL);
static bool LaunchFileInDefaultExternalApplication( const TCHAR* FileName, ...);
static void Sleep( float Seconds );
static void SleepNoStats( float Seconds );
static void SleepInfinite();
static void YieldThread();
static void Yield();
static void YieldCycles(uint64 Cycles);
static ENamedThreads::Type GetDesiredThreadForUObjectReferenceCollector();
static void ModifyThreadAssignmentForUObjectReferenceCollector( int32& NumThreads, i... );
static void ConditionalSleep(TFunctionRef<bool()> Condition, float SleepTime = 0.0f);
static void SetRealTimeMode();
static bool Daemonize();
static bool IsFirstInstance();
static void TearDown();
static bool SkipWaitForStats();
// 进程属性
static uint32 GetCurrentProcessId();
static uint32 GetCurrentCoreNumber();
static const TCHAR* ComputerName();
static const TCHAR* UserName(bool bOnlyAlphaNumeric = true);
static bool SetProcessLimits(EProcessResource::Type Resource, uint64 Limit);
static const TCHAR* ExecutableName(bool bRemoveExtension = true);
// 线程/池/同步
static void SetThreadAffinityMask( uint64 AffinityMask );
static void SetThreadPriority( EThreadPriority NewPriority );
static void SetThreadName( const TCHAR* ThreadName );
static uint32 GetStackSize();
static void DumpThreadInfo( const TCHAR* MarkerName );
static void SetupGameThread();
static void SetupRenderThread();
static void SetupRHIThread();
static void SetupAudioThread();
static void TeardownAudioThread();
static class FEvent* GetSynchEventFromPool(bool bIsManualReset = false);
static void FlushPoolSyncEvents();
static void ReturnSynchEventToPool(FEvent* Event);
static class FRunnableThread* CreateRunnableThread();
// 管道
static void ClosePipe( void* ReadPipe, void* WritePipe );
static bool CreatePipe(void*& ReadPipe, void*& WritePipe, bool bWritePipeLocal = false);
static FString ReadPipe( void* ReadPipe );
static bool ReadPipeToArray(void* ReadPipe, TArray<uint8> & Output);
static bool WritePipe(void* WritePipe, const FString& Message, FString* OutWritten = nullptr);
static bool SupportsMultithreading();
// 进程间通信(IPC)
static FSemaphore* NewInterprocessSynchObject(const FString& Name, bool bCreate, uint32 MaxLocks = 1);
static FSemaphore* NewInterprocessSynchObject(const TCHAR* Name, bool bCreate, uint32 MaxLocks = 1);
static bool DeleteInterprocessSynchObject(FSemaphore * Object);
// 目录/路径
static bool ShouldSaveToUserDir();
static const TCHAR* BaseDir();
static const TCHAR* UserDir();
static const TCHAR *UserSettingsDir();
static const TCHAR *UserTempDir();
static const TCHAR *UserHomeDir();
static const TCHAR* ApplicationSettingsDir();
static const TCHAR* ShaderDir();
static void SetShaderDir(const TCHAR*Where);
static void SetCurrentWorkingDirectoryToBaseDir();
static FString GetCurrentWorkingDirectory();
static const FString ShaderWorkingDir();
static void CleanShaderWorkingDir();
static const TCHAR* ExecutablePath();
static FString GenerateApplicationPath( const FString& AppName, EBuildConfiguration BuildConfiguration);
static const TCHAR* GetBinariesSubdirectory();
static const FString GetModulesDirectory();
// 其它
static FString GetGameBundleId();
static void ExploreFolder( const TCHAR* FilePath );
(...)
};
以上可得知,UE的进程基础封装了很多接口,包含进程生命周期、应用程序操作、线程管理、线程同步、进程间通信和同步、目录和路径、DLL模块等。
FGenericPlatformProcess的继承体系和实现与FGenericPlatformMisc类似,本文不再累述,有兴趣的童鞋自行阅读UE源码。
18.14.4.3 同步对象
UE为了满足各种各样的跨线程、跨进程之间的通信和同步,封装了很多同步对象。下面抽取部分重要的类型进行简要分析。
- FCriticalSection和FSystemWideCriticalSection
FCriticalSection是使用操作系统的临界区机制,是用户空间的概念和机制,而FSystemWideCriticalSection是使用了操作系统的内核对象Mutex(互斥体)。它们的常见接口如下(以Windows为例):
// WindowsCriticalSection.h
class FWindowsCriticalSection
{
public:
void Lock();
bool TryLock();
void Unlock();
(...)
};
class FWindowsSystemWideCriticalSection
{
public:
bool IsValid() const;
void Release();
private:
// 使用Windows的Mutex内核对象实现.
Windows::HANDLE Mutex;
(...)
};
FCriticalSection不涉及用户和内核态的转换,效率更高,但只能用于线程间的同步,而不能用于进程间同步。
FSystemWideCriticalSection涉及到了用户和内核态的转换,效率比FCriticalSection低很多,但可以用作进程间同步。
- FRWLock
FRWLock提供非递归读/写(或共享独占)访问,常用于多线程访问同一个数据块。它的特殊之处在于,如果只是读,则允许多个线程同时读,但如果有一个线程是写,则该线程必须独占数据块,带写入完毕,才允许其它线程读或写,以保证安全。其定义如下(以Windows为例):
// WindowsCriticalSection.h
class FWindowsRWLock
{
public:
FWindowsRWLock(uint32 Level = 0);
~FWindowsRWLock();
void ReadLock();
void WriteLock();
void ReadUnlock();
void WriteUnlock();
private:
Windows::SRWLOCK Mutex;
};
- FPlatformAtomics
FPlatformAtomics封装了各个操作系统的原子操作,接口如下(以Windows为例):
// GenericPlatformAtomics.h
struct CORE_API FWindowsPlatformAtomics : public FGenericPlatformAtomics
{
// Increment
static int8 InterlockedIncrement( volatile int8* Value );
static int16 InterlockedIncrement( volatile int16* Value );
static int32 InterlockedIncrement( volatile int32* Value );
static int64 InterlockedIncrement( volatile int64* Value );
// Decrement
static int8 InterlockedDecrement( volatile int8* Value );
static int16 InterlockedDecrement( volatile int16* Value );
static int32 InterlockedDecrement( volatile int32* Value );
static int64 InterlockedDecrement( volatile int64* Value );
// Add
static int8 InterlockedAdd( volatile int8* Value, int8 Amount );
static int16 InterlockedAdd( volatile int16* Value, int16 Amount );
static int32 InterlockedAdd( volatile int32* Value, int32 Amount );
static int64 InterlockedAdd( volatile int64* Value, int64 Amount );
// Exchange
static int8 InterlockedExchange( volatile int8* Value, int8 Exchange );
static int16 InterlockedExchange( volatile int16* Value, int16 Exchange );
static int32 InterlockedExchange( volatile int32* Value, int32 Exchange );
static int64 InterlockedExchange( volatile int64* Value, int64 Exchange );
static void* InterlockedExchangePtr( void*volatile* Dest, void* Exchange );
static int8 InterlockedCompareExchange( volatile int8* Dest, int8 Exchange, int8 Comparand );
static int16 InterlockedCompareExchange( volatile int16* Dest, int16 Exchange, int16 Comparand );
static int32 InterlockedCompareExchange( volatile int32* Dest, int32 Exchange, int32 Comparand );
static int64 InterlockedCompareExchange( volatile int64* Dest, int64 Exchange, int64 Comparand );
// And
static int8 InterlockedAnd(volatile int8* Value, const int8 AndValue);
static int16 InterlockedAnd(volatile int16* Value, const int16 AndValue);
static int32 InterlockedAnd(volatile int32* Value, const int32 AndValue);
static int64 InterlockedAnd(volatile int64* Value, const int64 AndValue);
// Or / Xor
static int8 InterlockedOr(volatile int8* Value, const int8 OrValue);
static int16 InterlockedOr(volatile int16* Value, const int16 OrValue);
static int32 InterlockedOr(volatile int32* Value, const int32 OrValue);
static int64 InterlockedOr(volatile int64* Value, const int64 OrValue);
static int8 InterlockedXor(volatile int8* Value, const int8 XorValue);
static int16 InterlockedXor(volatile int16* Value, const int16 XorValue);
static int32 InterlockedXor(volatile int32* Value, const int32 XorValue);
static int64 InterlockedXor(volatile int64* Value, const int64 XorValue);
// Read
static int8 AtomicRead(volatile const int8* Src);
static int16 AtomicRead(volatile const int16* Src);
static int32 AtomicRead(volatile const int32* Src);
static int64 AtomicRead(volatile const int64* Src);
// Read Relaxed
static int8 AtomicRead_Relaxed(volatile const int8* Src);
static int16 AtomicRead_Relaxed(volatile const int16* Src);
static int32 AtomicRead_Relaxed(volatile const int32* Src);
static int64 AtomicRead_Relaxed(volatile const int64* Src);
// Store
static void AtomicStore(volatile int8* Src, int8 Val);
static void AtomicStore(volatile int16* Src, int16 Val);
static void AtomicStore(volatile int32* Src, int32 Val);
static void AtomicStore(volatile int64* Src, int64 Val);
// Store Relaxed
static void AtomicStore_Relaxed(volatile int8* Src, int8 Val);
static void AtomicStore_Relaxed(volatile int16* Src, int16 Val);
static void AtomicStore_Relaxed(volatile int32* Src, int32 Val);
static void AtomicStore_Relaxed(volatile int64* Src, int64 Val);
#if PLATFORM_HAS_128BIT_ATOMICS
static bool InterlockedCompareExchange128( volatile FInt128* Dest, const FInt128& Exchange, FInt128* Comparand );
static void AtomicRead128(const volatile FInt128* Src, FInt128* OutResult);
#endif
static void* InterlockedCompareExchangePointer( void*volatile* Dest, void* Exchange, void* Comparand );
static bool CanUseCompareExchange128();
protected:
static void HandleAtomicsFailure( const TCHAR* InFormat, ... );
};
- FPlatformTLS
TLS全称是Thread Local Storage,意为线程局部存储,顾名思义,就是可以给每个线程存储独有的数据,从而避免多线程之间的竞争,提升性能。
UE提供了FPlatformTLS,以为上层模块提供统一而简洁的TLS操作接口。其定义如下(以Windows为例):
// WindowsPlatformTLS.h
struct FWindowsPlatformTLS : public FGenericPlatformTLS
{
// TLS对应的线程id。
static uint32 GetCurrentThreadId(void);
// TLS对应的插槽。
static uint32 AllocTlsSlot(void);
static void FreeTlsSlot(uint32 SlotIndex);
// TLS值操作。
static void SetTlsValue(uint32 SlotIndex,void* Value);
static void* GetTlsValue(uint32 SlotIndex);
};
使用示例之一是LockFreeList实现:
// LockFreeList.cpp
class LockFreeLinkAllocator_TLSCache : public FNoncopyable
{
public:
LockFreeLinkAllocator_TLSCache()
{
check(IsInGameThread());
TlsSlot = FPlatformTLS::AllocTlsSlot();
check(FPlatformTLS::IsValidTlsSlot(TlsSlot));
}
~LockFreeLinkAllocator_TLSCache()
{
FPlatformTLS::FreeTlsSlot(TlsSlot);
TlsSlot = 0;
}
private:
FThreadLocalCache& GetTLS()
{
checkSlow(FPlatformTLS::IsValidTlsSlot(TlsSlot));
FThreadLocalCache* TLS = (FThreadLocalCache*)FPlatformTLS::GetTlsValue(TlsSlot);
if (!TLS)
{
TLS = new FThreadLocalCache();
FPlatformTLS::SetTlsValue(TlsSlot, TLS);
}
return *TLS;
}
uint32 TlsSlot;
(...)
};
- FPlatformNamedPipe
FPlatformNamedPipe是对操作系统的命名管道通信的封装,提供了以下接口:
// GenericPlatformNamedPipe.h
class FGenericPlatformNamedPipe
{
public:
virtual bool Create(const FString& PipeName, bool bServer, bool bAsync);
virtual bool Destroy();
virtual bool OpenConnection();
virtual bool BlockForAsyncIO();
virtual bool UpdateAsyncStatus();
virtual bool IsCreated() const;
virtual bool HasFailed() const;
virtual bool IsReadyForRW() const;
virtual bool WriteBytes(int32 NumBytes, const void* Data);
inline bool WriteInt32(int32 In);
virtual bool ReadBytes(int32 NumBytes, void* OutData);
inline bool ReadInt32(int32& Out);
virtual const FString& GetName() const;
protected:
FString* NamePtr;
};
UE用到FPlatformNamedPipe的是着色器编译模块:
// XGEControlWorker.cpp
class FXGEControlWorker
{
const FString PipeName;
FProcHandle XGConsoleProcHandle;
// 输入、输出命名管道。
FPlatformNamedPipe InputNamedPipe;
FPlatformNamedPipe OutputNamedPipe;
(...)
};
- FPlatformStackWalk
FPlatformStackWalk是大多数平台下对堆栈遍历的通用实现,定义如下:
// GenericPlatformStackWalk.h
struct FGenericPlatformStackWalk
{
// 初始化
static void Init();
static bool InitStackWalking();
static bool InitStackWalkingForProcess(const FProcHandle& Process);
// 程序计数器
static bool ProgramCounterToHumanReadableString( int32 CurrentCallDepth, ... );
static void ProgramCounterToSymbolInfo( uint64 ProgramCounter, ...);
static void ProgramCounterToSymbolInfoEx( uint64 ProgramCounter, ...);
// 符号信息
static bool SymbolInfoToHumanReadableString( const FProgramCounterSymbolInfo& SymbolInfo, ... );
static bool SymbolInfoToHumanReadableStringEx( const FProgramCounterSymbolInfoEx& SymbolInfo, ... );
static TArray<FProgramCounterSymbolInfo> GetStack(int32 IgnoreCount, ...);
// 捕获堆栈
static uint32 CaptureStackBackTrace( uint64* BackTrace, uint32 MaxDepth, ... );
static uint32 CaptureThreadStackBackTrace(uint64 ThreadId, ...);
// 遍历
static void StackWalkAndDump( ANSICHAR* HumanReadableString, ... );
static void ThreadStackWalkAndDump(ANSICHAR* HumanReadableString, ...);
static void StackWalkAndDumpEx( ANSICHAR* HumanReadableString, ... );
// 获取接口.
static int32 GetProcessModuleCount();
static int32 GetProcessModuleSignatures(FStackWalkModuleInfo *ModuleSignatures, ...);
static TMap<FName, FString> GetSymbolMetaData();
(...)
};
FPlatformStackWalk的应用之一是程序崩溃时的调用堆栈打印和分析:
// CrashReportClientMainWindows.cpp
void SaveCrcCrashException(EXCEPTION_POINTERS* ExceptionInfo)
{
// 如果会话已创建,请尝试在适当的字段中写入异常代码。递增计数器的第一个崩溃线程赢得了竞争,并可以编写其异常代码。
static volatile int32 CrashCount = 0;
if (FPlatformAtomics::InterlockedIncrement(&CrashCount) == 1)
{
FCrashReportAnalyticsSessionSummary::Get().OnCrcCrashing(ExceptionInfo->ExceptionRecord->ExceptionCode);
if (ExceptionInfo->ExceptionRecord->ExceptionCode != STATUS_HEAP_CORRUPTION)
{
// 尝试让异常调用堆栈记录,以找出CRC崩溃的原因,但是不可靠,因为它在崩溃的进程中运行,并分配内存/使用调用堆栈,但我们仍然可以获得一些有用的数据。
if (FPlatformStackWalk::InitStackWalkingForProcess(FProcHandle()))
{
FPlatformStackWalk::StackWalkAndDump(CrashStackTrace, UE_ARRAY_COUNT(CrashStackTrace), 0);
if (CrashStackTrace[0] != 0)
{
FCrashReportAnalyticsSessionSummary::Get().LogEvent(ANSI_TO_TCHAR(CrashStackTrace));
}
}
}
}
}
18.14.5 其它Platform模块
18.14.5.1 FPlatformMemory
FPlatformMemory封装抽象了各个操作系统下对内存的统一操作接口:
// GenericPlatformMemory.h
struct FGenericPlatformMemory
{
static bool bIsOOM; // 是否内存不足
static uint64 OOMAllocationSize; // 设置为触发内存不足的分配大小,否则为零.
static uint32 OOMAllocationAlignment; // 设置为触发内存不足的分配对齐,否则为零。
static void* BackupOOMMemoryPool; // 内存不足时要删除的预分配缓冲区。用于OOM处理和崩溃报告。
static uint32 BackupOOMMemoryPoolSize; // BackupOOMMemoryPool的大小(字节)。
// 可用于内存统计的各种内存区域。枚举的确切含义相对依赖于平台,尽管一般的(物理、GPU)很简单。一个平台可以添加更多的内存,并且不会影响其他平台,除了StatManager跟踪每个区域的最大可用内存(使用数组FPlatformMemory::MCR_max big)所需的少量内存之外.
enum EMemoryCounterRegion
{
MCR_Invalid, // not memory
MCR_Physical, // main system memory
MCR_GPU, // memory directly a GPU (graphics card, etc)
MCR_GPUSystem, // system memory directly accessible by a GPU
MCR_TexturePool, // presized texture pools
MCR_StreamingPool, // amount of texture pool available for streaming.
MCR_UsedStreamingPool, // amount of texture pool used for streaming.
MCR_GPUDefragPool, // presized pool of memory that can be defragmented.
MCR_PhysicalLLM, // total physical memory including CPU and GPU
MCR_MAX
};
// 使用的分配器.
enum EMemoryAllocatorToUse
{
Ansi, // Default C allocator
Stomp, // Allocator to check for memory stomping
TBB, // Thread Building Blocks malloc
Jemalloc, // Linux/FreeBSD malloc
Binned, // Older binned malloc
Binned2, // Newer binned malloc
Binned3, // Newer VM-based binned malloc, 64 bit only
Platform, // Custom platform specific allocator
Mimalloc, // mimalloc
};
static EMemoryAllocatorToUse AllocatorToUse;
enum ESharedMemoryAccess
{
Read = (1 << 1),
Write = (1 << 2)
};
// 共享内存区域的通用表示
struct FSharedMemoryRegion
{
TCHAR Name[MaxSharedMemoryName];
uint32 AccessMode;
void * Address;
SIZE_T Size;
};
// 内存操作.
static void Init();
static void OnOutOfMemory(uint64 Size, uint32 Alignment);
static void SetupMemoryPools();
static uint32 GetBackMemoryPoolSize()
static FMalloc* BaseAllocator();
static FPlatformMemoryStats GetStats();
static uint64 GetMemoryUsedFast();
static void GetStatsForMallocProfiler( FGenericMemoryStats& out_Stats );
static const FPlatformMemoryConstants& GetConstants();
static uint32 GetPhysicalGBRam();
static bool PageProtect(void* const Ptr, const SIZE_T Size, const bool bCanRead, const bool bCanWrite);
// 分配.
static void* BinnedAllocFromOS( SIZE_T Size );
static void BinnedFreeToOS( void* Ptr, SIZE_T Size );
static void NanoMallocInit();
static bool PtrIsOSMalloc( void* Ptr);
static bool IsNanoMallocAvailable();
static bool PtrIsFromNanoMalloc( void* Ptr);
// 虚拟内存块及操作.
class FBasicVirtualMemoryBlock
{
protected:
void *Ptr;
uint32 VMSizeDivVirtualSizeAlignment;
public:
FBasicVirtualMemoryBlock(const FBasicVirtualMemoryBlock& Other) = default;
FBasicVirtualMemoryBlock& operator=(const FBasicVirtualMemoryBlock& Other) = default;
FORCEINLINE uint32 GetActualSizeInPages() const;
FORCEINLINE void* GetVirtualPointer() const;
void Commit(size_t InOffset, size_t InSize);
void Decommit(size_t InOffset, size_t InSize);
void FreeVirtual();
void CommitByPtr(void *InPtr, size_t InSize);
void DecommitByPtr(void *InPtr, size_t InSize);
void Commit();
void Decommit();
size_t GetActualSize() const;
static FPlatformVirtualMemoryBlock AllocateVirtual(size_t Size, ...);
static size_t GetCommitAlignment();
static size_t GetVirtualSizeAlignment();
};
// 数据和调试
static bool BinnedPlatformHasMemoryPoolForThisSize(SIZE_T Size);
static void DumpStats( FOutputDevice& Ar );
static void DumpPlatformAndAllocatorStats( FOutputDevice& Ar );
static EPlatformMemorySizeBucket GetMemorySizeBucket();
// 内存数据操作.
static void* Memmove( void* Dest, const void* Src, SIZE_T Count );
static int32 Memcmp( const void* Buf1, const void* Buf2, SIZE_T Count );
static void* Memset(void* Dest, uint8 Char, SIZE_T Count);
static void* Memzero(void* Dest, SIZE_T Count);
static void* Memcpy(void* Dest, const void* Src, SIZE_T Count);
static void* BigBlockMemcpy(void* Dest, const void* Src, SIZE_T Count);
static void* StreamingMemcpy(void* Dest, const void* Src, SIZE_T Count);
static void* ParallelMemcpy(void* Dest, const void* Src, SIZE_T Count, EMemcpyCachePolicy Policy = EMemcpyCachePolicy::StoreCached);
(...)
};
更多详情可参阅1.4.3 内存分配。
18.14.5.2 FPlatformMath
FPlatformMath封装了一组依赖于操作系统的高效数学运算,定义如下:
// GenericPlatformMath.h
struct FGenericPlatformMath
{
static float LoadHalf(const uint16* Ptr);
static void StoreHalf(uint16* Ptr, float Value);
static void VectorLoadHalf(float* RESTRICT Dst, const uint16* RESTRICT Src);
static void VectorStoreHalf(uint16* RESTRICT Dst, const float* RESTRICT Src);
static void WideVectorLoadHalf(float* RESTRICT Dst, const uint16* RESTRICT Src);
static void WideVectorStoreHalf(uint16* RESTRICT Dst, const float* RESTRICT Src);
static inline uint32 AsUInt(float F);
static inline uint64 AsUInt(double F);
static int32 TruncToInt(float F);
static int32 TruncToInt(double F);
static float TruncToFloat(float F);
static int32 FloorToInt(float F);
static int32 FloorToInt(double F);
static float FloorToFloat(float F);
static int32 RoundToInt(float F);
static int32 RoundToInt(double F);
static float RoundToFloat(float F);
static int32 CeilToInt(float F);
static int32 CeilToInt(double F);
static float CeilToFloat(float F);
static float Fractional(float Value);
static float Frac(float Value);
static float Modf(const float InValue, float* OutIntPart);
static float Pow( float A, float B );
static float Exp( float Value );
static float Loge( float Value );
static float LogX( float Base, float Value );
static uint32 FloorLog2(uint32 Value);
static float Sqrt( float Value );
static float InvSqrt( float F );
static float InvSqrtEst( float F );
static bool IsNaN( float A );
static bool IsNaN(double A);
static bool IsFinite( float A );
static bool IsFinite(double A);
static bool IsNegative(float A);
static float Fmod(float X, float Y);
static float Sin( float Value );
static float Asin( float Value );
static float Sinh(float Value);
static float Cos( float Value );
static float Acos( float Value );
static float Tan( float Value );
static float Atan( float Value );
static int32 Rand();
static void RandInit(int32 Seed);
static float FRand();
static void SRandInit( int32 Seed );
static int32 GetRandSeed();
static float SRand();
(...)
};
18.14.5.3 IPlatformFile
IFileHandle是UE对各个系统下的单个文件的封装,IPlatformFile是UE对各个系统下的文件的封装,而FPlatformFileManager是对IPlatformFile链的管理。
先看看IFileHandle的核心继承图:
除了上图显示的文件类型,还有FAsyncBufferedFileReaderWindows、FLoggedFileHandle、FManagedStorageFileWriteHandle、FRegisteredFileHandle、FNetworkFileHandle、FStreamingNetworkFileHandle、FPakFileHandle、FStorageServerFileHandle等文件类型。
再看看IPlatformFile的核心UML图:
当然,还有很多非常规的文件类型继承自IPlatformFile:
- FCachedReadPlatformFile:缓存文件。
- FLoggedPlatformFile:日志文件。
- FPlatformFileOpenLog:打开日志文件。
- FNetworkPlatformFile:网络文件。
- FPakPlatformFile:Pak包体内文件。
- FSandboxPlatformFile:沙盒文件。
- FStorageServerPlatformFile:存储服务器文件。
- FConcertSandboxPlatformFile:音乐会沙盒文件。
下面看看IFileHandle和IPlatformFile的定义:
// GenericPlatformFile.h
class IFileHandle
{
public:
virtual int64 Tell() = 0;
virtual bool Seek(int64 NewPosition) = 0;
virtual bool SeekFromEnd(int64 NewPositionRelativeToEnd = 0) = 0;
virtual bool Read(uint8* Destination, int64 BytesToRead) = 0;
virtual bool Write(const uint8* Source, int64 BytesToWrite) = 0;
virtual bool Flush(const bool bFullFlush = false) = 0;
virtual bool Truncate(int64 NewSize) = 0;
virtual void ShrinkBuffers()
virtual int64 Size();
};
class IPlatformFile
{
public:
static IPlatformFile& GetPlatformPhysical();
static const TCHAR* GetPhysicalTypeName();
virtual void SetSandboxEnabled(bool bInEnabled)
virtual bool IsSandboxEnabled() const
virtual bool ShouldBeUsed(IPlatformFile* Inner, const TCHAR* CmdLine) const
virtual bool Initialize(IPlatformFile* Inner, const TCHAR* CmdLine) = 0;
virtual void InitializeAfterSetActive()
virtual void InitializeAfterProjectFilePath()
virtual void MakeUniquePakFilesForTheseFiles(const TArray<TArray<FString>>& InFiles)
virtual void InitializeNewAsyncIO();
virtual void AddLocalDirectories(TArray<FString> &LocalDirectories)
virtual void BypassSecurity(bool bInBypass)
virtual void Tick();
virtual IPlatformFile* GetLowerLevel() = 0;
virtual void SetLowerLevel(IPlatformFile* NewLowerLevel) = 0;
virtual const TCHAR* GetName() const = 0;
virtual bool FileExists(const TCHAR* Filename) = 0;
virtual int64 FileSize(const TCHAR* Filename) = 0;
virtual bool DeleteFile(const TCHAR* Filename) = 0;
virtual bool IsReadOnly(const TCHAR* Filename) = 0;
virtual bool MoveFile(const TCHAR* To, const TCHAR* From) = 0;
virtual bool SetReadOnly(const TCHAR* Filename, bool bNewReadOnlyValue) = 0;
virtual FDateTime GetTimeStamp(const TCHAR* Filename) = 0;
virtual void SetTimeStamp(const TCHAR* Filename, FDateTime DateTime) = 0;
virtual FDateTime GetAccessTimeStamp(const TCHAR* Filename) = 0;
virtual FString GetFilenameOnDisk(const TCHAR* Filename) = 0;
virtual IFileHandle* OpenRead(const TCHAR* Filename, bool bAllowWrite = false) = 0;
virtual IFileHandle* OpenReadNoBuffering(const TCHAR* Filename, bool bAllowWrite = false)
virtual IFileHandle* OpenWrite(const TCHAR* Filename, bool bAppend = false, bool bAllowRead = false) = 0;
virtual bool DirectoryExists(const TCHAR* Directory) = 0;
virtual bool CreateDirectory(const TCHAR* Directory) = 0;
virtual bool DeleteDirectory(const TCHAR* Directory) = 0;
virtual FFileStatData GetStatData(const TCHAR* FilenameOrDirectory) = 0;
// 仅使用名称的文件和目录访问者的基类。
class FDirectoryVisitor
{
public:
virtual bool Visit(const TCHAR* FilenameOrDirectory, bool bIsDirectory) = 0;
FORCEINLINE bool IsThreadSafe() const
EDirectoryVisitorFlags DirectoryVisitorFlags;
};
typedef TFunctionRef<bool(const TCHAR*, bool)> FDirectoryVisitorFunc;
// 获取所有统计数据的文件和目录访问者的基类.
class FDirectoryStatVisitor
{
public:
virtual bool Visit(const TCHAR* FilenameOrDirectory, const FFileStatData& StatData) = 0;
};
typedef TFunctionRef<bool(const TCHAR*, const FFileStatData&)> FDirectoryStatVisitorFunc;
virtual bool IterateDirectory(const TCHAR* Directory, FDirectoryVisitor& Visitor) = 0;
virtual bool IterateDirectoryStat(const TCHAR* Directory, FDirectoryStatVisitor& Visitor) = 0;
virtual IAsyncReadFileHandle* OpenAsyncRead(const TCHAR* Filename);
virtual void SetAsyncMinimumPriority(EAsyncIOPriorityAndFlags MinPriority)
virtual IMappedFileHandle* OpenMapped(const TCHAR* Filename)
virtual void GetTimeStampPair(const TCHAR* PathA, const TCHAR* PathB, FDateTime& OutTimeStampA, FDateTime& OutTimeStampB);
virtual FDateTime GetTimeStampLocal(const TCHAR* Filename);
virtual bool IterateDirectory(const TCHAR* Directory, FDirectoryVisitorFunc Visitor);
virtual bool IterateDirectoryStat(const TCHAR* Directory, FDirectoryStatVisitorFunc Visitor);
virtual bool IterateDirectoryRecursively(const TCHAR* Directory, FDirectoryVisitor& Visitor);
virtual bool IterateDirectoryStatRecursively(const TCHAR* Directory, FDirectoryStatVisitor& Visitor);
virtual bool IterateDirectoryRecursively(const TCHAR* Directory, FDirectoryVisitorFunc Visitor);
virtual bool IterateDirectoryStatRecursively(const TCHAR* Directory, FDirectoryStatVisitorFunc Visitor);
virtual void FindFiles(TArray<FString>& FoundFiles, const TCHAR* Directory, const TCHAR* FileExtension);
virtual void FindFilesRecursively(TArray<FString>& FoundFiles, const TCHAR* Directory, const TCHAR* FileExtension);
virtual bool DeleteDirectoryRecursively(const TCHAR* Directory);
virtual bool CreateDirectoryTree(const TCHAR* Directory);
virtual bool CopyFile(const TCHAR* To, const TCHAR* From, EPlatformFileRead ReadFlags = EPlatformFileRead::None, EPlatformFileWrite WriteFlags = EPlatformFileWrite::None);
virtual bool CopyDirectoryTree(const TCHAR* DestinationDirectory, const TCHAR* Source, bool bOverwriteAllExisting);
virtual FString ConvertToAbsolutePathForExternalAppForRead( const TCHAR* Filename );
virtual FString ConvertToAbsolutePathForExternalAppForWrite( const TCHAR* Filename );
// 用于向文件服务器函数发送/接收数据的帮助程序类.
class IFileServerMessageHandler
{
public:
virtual ~IFileServerMessageHandler() { }
virtual void FillPayload(FArchive& Payload) = 0;
virtual void ProcessResponse(FArchive& Response) = 0;
};
virtual bool SendMessageToServer(const TCHAR* Message, IFileServerMessageHandler* Handler)
virtual bool DoesCreatePublicFiles()
virtual void SetCreatePublicFiles(bool bCreatePublicFiles)
};
IFileHandle、IPlatformFile和FPlatformFileManager的UML关系如下(忽略它们各自的子类):
FPlatformFileManager对外提供了平台无关的文件操作接口,定义如下:
// PlatformFileManager.h
class FPlatformFileManager
{
public:
static FPlatformFileManager& Get( );
IPlatformFile& GetPlatformFile( );
IPlatformFile* GetPlatformFile( const TCHAR* Name );
IPlatformFile* FindPlatformFile( const TCHAR* Name );
void SetPlatformFile( IPlatformFile& NewTopmostPlatformFile );
void TickActivePlatformFile();
void InitializeNewAsyncIO();
void RemovePlatformFile(IPlatformFile* PlatformFileToRemove);
private:
IPlatformFile* TopmostPlatformFile;
};
使用案例如下:
// CrashReportClientApp.cpp
static void HandleAbnormalShutdown(FSharedCrashContext& CrashContext, uint64 ProcessID, ...)
{
(...)
// 获取平台文件对象。
IPlatformFile& PlatformFile = FPlatformFileManager::Get().GetPlatformFile();
// 创建临时崩溃目录
const FString TempCrashDirectory = FPlatformProcess::UserTempDir() / FString::Printf(TEXT("UECrashContext-%d"), ProcessID);
FCString::Strcpy(CrashContext.CrashFilesDirectory, *TempCrashDirectory);
if (PlatformFile.CreateDirectory(CrashContext.CrashFilesDirectory))
{
// 将日志文件复制到临时目录
const FString LogDestination = TempCrashDirectory / FPaths::GetCleanFilename(CrashContext.UserSettings.LogFilePath);
PlatformFile.CopyFile(*LogDestination, CrashContext.UserSettings.LogFilePath);
// 此崩溃不是真正的崩溃,而是在异常终止时捕获编辑器日志的崩溃。
FCrashReportAnalyticsSessionSummary::Get().LogEvent(TEXT("SyntheticCrash"));
(...)
// 删除临时崩溃目录。
PlatformFile.DeleteDirectoryRecursively(*TempCrashDirectory);
(...)
}
}
18.15 本篇总结
本篇主要阐述了操作系统的相关知识,包含线程、进程、同步、通信、内存、磁盘等等,以及UE对OS相关模块的封装和实现,使得读者对操作系统模块有着大致的理解,至于更多技术细节和原理,需要读者自己去研读UE源码发掘。
特别说明
- 感谢所有参考文献的作者,部分图片来自参考文献和网络,侵删。
- 本系列文章为笔者原创,只发表在博客园和知乎上。欢迎分享本文链接,但未经同意,不允许转载!
- 系列文章,未完待续,完整目录请戳剖析虚幻渲染体系-开篇说明。
- 关于某“大厂”的“技术砖家”对博主造谣的回应
参考文献
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- Operating Systems: Internals and Design Principles
- Game Engines
- Windows 10 System Programming, Part 1
- Windows 10 System Programming, Part 2
- Windows核心编程
- Windows Kernel Programming
- Windows Kernel Programming : Yosifovich, Pavel
- THE WINDOWS OPERATING SYSTEM
- [Linux Kernel Development Third Edition]( https://www.doc-developpement-durable.org/file/Projets-informatiques/cours-&-manuels-informatiques/Linux/Linux Kernel Development ,%203rd%20Edition.pdf)
- Linux Kernel Module Programming Guide
- The Linux Kernel Module Programming Guide
- Linux System Programming
- The Linux Kernel: Architecture and Programming
- Modern Operating Systems (4th Edition)
- A Comprehensive Study of Kernel (Issues and Concepts) in Different Operating Systems
- The Operating System and the Kernel
- A High Performance Kernel-Less Operating System Architecture
- A caching model of operating system kernel functionality
- Exokernel: An Operating System Architecture for Application-Level Resource Management
- Synchronization Functions
- Introduction to Operating System
- Operating System Component and Structure
- OPERATING SYSTEM BSc IV SEMESTER
- Time Sharing Operating System
- Types of Software
- A caching model of operating system kernel functionality
- A High Performance Kernel-Less Operating System Architecture
- Operating Systems by Yingxu Wang
- Realtime Operating Systems
- Operating System: The Basics
- History of Unix
- Introduction to computing, architecture and the UNIX OS
- [Linux Kernel Development (3rd Edition)](https://www.doc-developpement-durable.org/file/Projets-informatiques/cours-&-manuels-informatiques/Linux/Linux Kernel Development, 3rd Edition.pdf)
- [Linux System Programming](https://doc.lagout.org/programmation/unix/Linux System Programming Talking Directly to the Kernel and C Library.pdf)
- [Module 1: Introduction to Operating System](https://archive.nptel.ac.in/content/storage2/courses/106108101/pdf/Lecture_Notes/Mod 1_LN.pdf)
- Operating Systems
- Operating System Concepts
- Modern Operating System
- The Linux Kernel Module Programming Guide
- [Professional Linux Kernel Architecture](https://doc.lagout.org/operating system /linux/Professional Linux Kernel Architecture.pdf)
- The operating system kernel
- operating systems - internals and design principles
- Operating Systems: Three Easy Pieces
- Operating Systems in geeksforgeeks
- 硬核操作系统讲解
- POSIX thread (pthread) libraries

 浙公网安备 33010602011771号
浙公网安备 33010602011771号