剖析虚幻渲染体系(02)- 多线程渲染
2.1 多线程编程基础
为了更平稳地过渡,在真正进入UE的多线程渲染知识之前,先学习或重温一下多线程编程的基础知识。
2.1.1 多线程概述
多线程(Multithread)编程的思想早在单核时代就已经出现了,当时的操作系统(如Windows95)就已经支持多任务的功能,其原理就是在单核中切换不同的上下文(Context),以便每个进程中的线程都有时间获得执行指令的机会。
但到了2005年,当单核主频接近4GHz时,CPU硬件厂商英特尔和AMD发现,速度也会遇到自己的极限:那就是单纯的主频提升,已经无法明显提升系统整体性能。
随着单核计算频率摩尔定律的缓慢终结,Intel率先于2005年发布了奔腾D和奔腾四至尊版840系列,首次支持了两个物理级别的线程计算单元。此后十多年,多核CPU得到蓬勃发展,由AMD制造的Ryzen 3990X处理器已经拥有64个核心128个逻辑线程。

锐龙(Ryzen)3990X的宣传海报中赫然凸显的核心与线程数量。
硬件的多核发展,给软件极大的发挥空间。应用程序可以充分发挥多核多线程的计算资源,各个应用领域由此也产生多线程编程模型和技术。作为游戏的发动机Unreal Engine等商业引擎,同样可以利用多线程技术,以便更加充分地提升效率和效果。
使用多线程并发带来的作用总结起来主要有两点:
- 分离关注点。通过将相关的代码与无关的代码分离,可以使程序更容易理解和测试,从而减少出错的可能性。比如,游戏引擎中通常将文件加载、网络传输放入独立的线程中,既可以不阻碍主线程,也可以分离逻辑代码,使得更加清晰可扩展。
- 提升性能。人多力量大,这样的道理同样用到CPU上(核多力量大)。相同量级的任务,如果能够分散到多个CPU中同时运行,必然会带来效率的提升。
但是,随着CPU核心数量的提升,计算机获得的效益并非直线提升,而是遵循Amdahl's law(阿姆达尔定律),Amdahl's law的公式定义如下:
公式的各个分量含义如下:
- \(S_{latency}\):整个任务在多线程处理中理论上获得的加速比。
- \(s\):用于执行任务并行部分的硬件资源的线程数量。
- \(p\):可并行处理的任务占比。
举个具体的栗子,假设有8核16线程的CPU用于处理某个任务,这个任务有70%的部分是可以并行处理的,那么它的理论加速比为:
由此可见,多线程编程带来的效益并非跟核心数呈直线正比,实际上它的曲线如下所示:
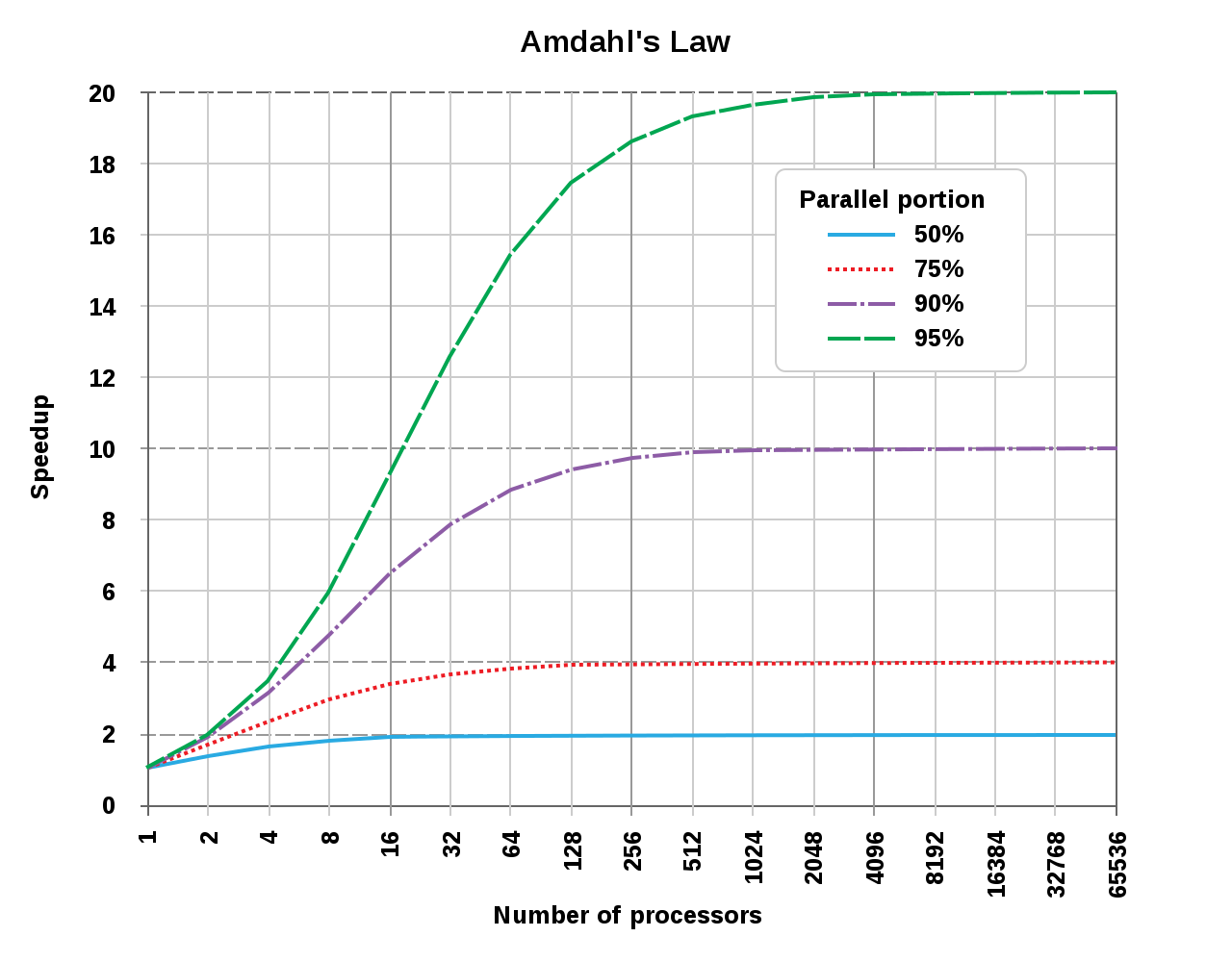
阿姆达尔定律揭示的核心数和加速比图例。由此可见,可并行的任务占比越低,加速比获得的效果越差:当可并行任务占比为50%时,16核已经基本达到加速比天花板,无论后面增加多少核心数量,都无济于事;如果可并行任务占比为95%时,到2048个核心才会达到加速比天花板。
虽然阿姆达尔定律给我们带来了残酷的现实,但是,如果我们能够提升任务并行占比到接近100%,则加速比天花板可以得到极大提升:
如上公式所示,当\(p=1\)(即可并行的任务占比100%)时,理论上的加速比和核心数量成线性正比!!
举个具体的例子,在编译Unreal Engine工程源码或Shader时,由于它们基本是100%的并行占比,理论上可以获得接近线性关系的加速比,在多核系统中将极大地缩短编译时间。
利用多线程并发提高性能的方式有两种:
- 任务并行(task parallelism)。将一个单个任务分成几部分,且各自并行运行,从而降低总运行时间。这种方式虽然看起来很简单直观,但实际操作中可能会很复杂,因为在各个部分之间可能存在着依赖。
- 数据并行(data parallelism)。任务并行的是算法(执行指令)部分,即每个线程执行的指令不一样;而数据并行是指令相同,但执行的数据不一样。SIMD也是数据并行的一种方式。
上面阐述了多线程并发的益处,接下来说说它的副作用。总结起来,副作用如下:
- 导致数据竞争。多线程访问常常会交叉执行同一段代码,或者操作同一个资源,又或者多核CPU的高度缓存同步问题,由此变化带来各种数据不同步或数据读写错误,由此产生了各种各样的异常结果,这便是数据竞争。
- 逻辑复杂化,难以调试。由于多线程的并发方式不唯一,不可预知,所以为了避免数据竞争,常常加入复杂多样的同步操作,代码也会变得离散、片段化、繁琐、难以理解,增加代码的辅助,对后续的维护、扩展都带来不可估量的阻碍。也会引发小概率事件难以重现的BUG,给调试和查错增加了数量级的难度。
- 不一定能够提升效益。多线程技术用得到确实会带来效率的提升,但并非绝对,常和物理核心、同步机制、运行时状态、并发占比等等因素相关,在某些极端情况,或者用得不够妥当,可能反而会降低程序效率。
2.1.2 多线程概念
本小节将阐述多线程编程技术中常涉及的基本概念。
- 进程(Process)
进程(Process)是操作系统执行应用程序的基本单元和实体,它本身只是个容器,通常包含内核对象、地址空间、统计信息和若干线程。它本身并不真正执行代码指令,而是交由进程内的线程执行。
对Windows而言,操作系统在创建进程时,同时也会给它创建一个线程,该线程被称为主线程(Primary thread, Main thread)。
对Unix而言,进程和主线程其实是同一个东西,操作系统并不知道有线程的存在,线程更接近于lightweight processes(轻量级进程)的概念。
进程有优先级概念,Windows下由低到高为:低(Low)、低于正常(Below normal)、正常(Normal)、高于正常(Above normal)、高(High)、实时(Real time)。(见下图)
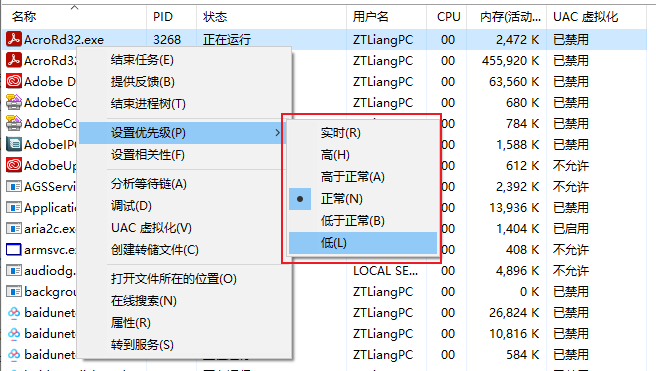
默认情况下,进程的优先级为Normal。优先级高的进程将会优先获得执行机会和时间。
- 线程(Thread)
线程(Thread)是可以执行代码的实体,通常不能独立存在,需要依附在某个进程内部。一个进程可以拥有多个线程,这些线程可以共享进程的数据,以便并行或并发地执行多个任务。
在单核CPU中,操作系统(如Windows)可能会采用轮循(Round robin)的方式进行调度,使得多个线程看起来是同时运行的。(下图)
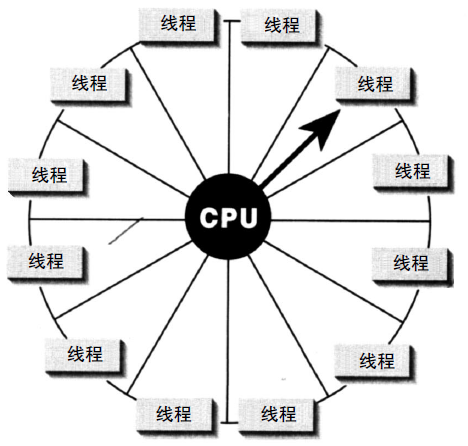
在多核CPU中,线程可能会安排在不同的CPU核心同时运行,从而达到并行处理的目的。
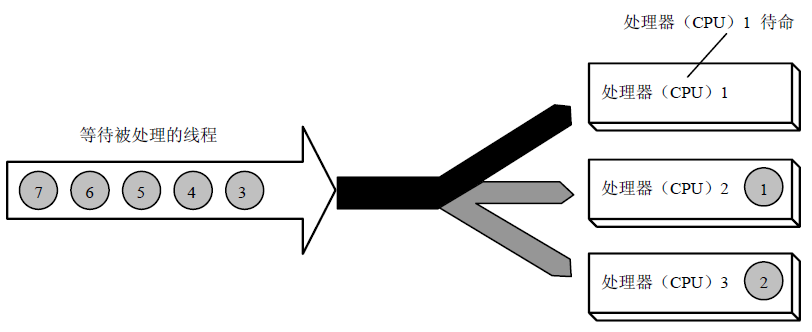
采用SMP的Windows在多核CPU的执行示意图。等待处理的线程被安排到不同的CPU核心。
每个线程可拥有自己的执行指令上下文(如Windows的IP(指令寄存器地址)和SP(栈起始寄存器地址))、执行栈和TLS(Thread Local Storage,线程局部缓存)。
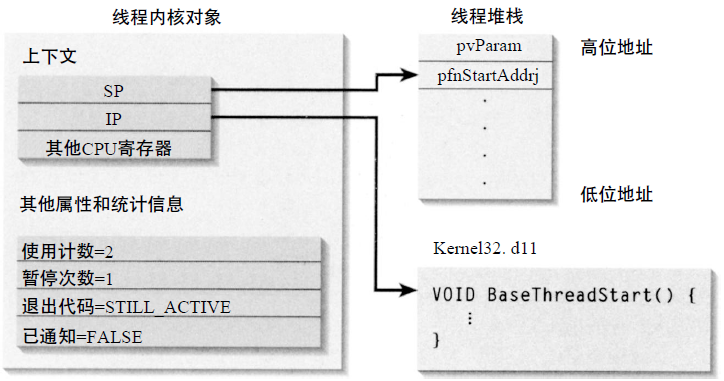
Windows线程创建和初始化示意图。
线程局部存储(Thread Local Storage)是一种存储持续期,对象的生命周期与线程一样,在线程开始时分配,线程结束时回收。每个线程有该对象自己的实例,访问和修改这样的对象不会造成竞争条件(Race Condition)。
线程也存在优先级概念,优先级越高的将优先获得执行指令的机会。
线程的状态一般有运行状态、暂停状态等。Windows可用以下接口切换线程状态:
// 暂停线程
DWORD SuspendThread(HANDLE hThread);
// 继续运行线程
DWORD ResumeThread(HANDLE hThread);
同个线程可被多次暂停,如果要恢复运行状态,则需要调用同等次数的继续运行接口。
- 协程(Coroutine)
协程(Coroutine)是一种轻量级(lightweight)的用户态线程,通常跑在同一个线程,利用同一个线程的不同时间片段执行指令,没有线程、进程切换和调度的开销。从使用者角度,可以利用协程机制实现在同个线程模拟异步的任务和编码方式。在同个线程内,它不会造成数据竞争,但也会因线程阻塞而阻塞。
- 纤程(Fiber)
纤程(Fiber)如同协程,也是一种轻量级的用户态线程,可以使得应用程序独立决定自己的线程要如何运作。操作系统内核不知道纤程的存在,也不会为它进行调度。
- 竞争条件(Race Condition)
同个进程允许有多个线程,这些线程可以共享进程的地址空间、数据结构和上下文。进程内的同一数据块,可能存在多个线程在某个很小的时间片段内同时读写,这就会造成数据异常,从而导致了不可预料的结果。这种不可预期性便造就了竞争条件(Race Condition)。
避免产生竞争条件的技术有很多,诸如原子操作、临界区、读写锁、内核对象、信号量、互斥体、栅栏、屏障、事件等等。
- 并行(Parallelism)
至少两个线程同时执行任务的机制。一般有多核多物理线程的CPU同时执行的行为,才可以叫并行,单核的多线程不能称之为并行。
- 并发(Concurrency)
至少两个线程利用时间片(Timeslice)执行任务的机制,是并行的更普遍形式。即便单核CPU同时执行的多线程,也可称为并发。
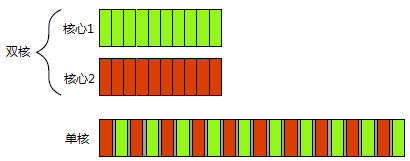
并发的两种形式——上:双物理核心的同时执行(并行);下:单核的多任务切换(并发)。
事实上,并发和并行在多核处理器中是可以同时存在的,比如下图所示,存在双核,每个核心又同时切换着多个任务:
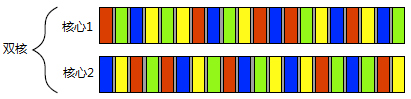
部分参考文献严格区分了并行和并发,但部分文献并不明确指出其中的区别。虚幻引擎的多线程渲染架构和API中,常出现并行和并发的概念,所以虚幻是明显区分两者之间的含义。
- 线程池(Thread Pool)
线程池提供了一种新的任务并发的方式,调用者只需要传入一组可并行的任务和分组的策略,便可以使用线程池的若干线程并发地执行任务,使得调用者无需接直接触线程的调用和管理细节,降低了调用者的成本,也提升了线程的调度效率和吞吐量。
不过,创建一个线程池时,几个关键性的设计问题会影响并发效率,比如:可使用的线程数量,高效的任务分配方式,以及是否需要等待一个任务完成。
线程池可以自定义实现,也可以直接使用C++、操作系统或第三方库提供的API。
2.1.3 C++的多线程
在C++11之前,C++的多线程支持基本为零,仅提供少量鸡肋的volatile等关键字。直到C++11标准,多线程才真正纳入C++标准,并提供了相关关键字、STL标准库,以便使用者实现跨平台的多线程调用。
当然,对使用者来说,多线程的实现可采用C++11的线程库,也可以根据具体的系统平台提供的多线程API自定义线程库,还可以使用诸如ACE、boost::thread等第三方库。使用C++自带的多线程库,有几个优点,一是使用简单方便,依赖少;二是跨平台,无需关注系统底层。
2.1.3.1 C++多线程关键字
- thread_local
thread_local是C++是实现线程局部存储的关键,添加了此关键字的变量意味着每个线程都有自己的一份数据,不会共享同一份数据,避免数据竞争。
C11的关键字_Thread_local用于定义线程局部变量。在头文件<threads.h>定义了thread_local为上述关键词的同义。例如:
#include <threads.h>
thread_local int foo = 0;
C++11引入的thread_local关键字用于下述情形:
1、名字空间(全局)变量。
2、文件静态变量。
3、函数静态变量。
4、静态成员变量。
此外,不同编译器提供了各自的方法声明线程局部变量:
// Visual C++, Intel C/C++ (Windows systems), C++Builder, Digital Mars C++
__declspec(thread) int number;
// Solaris Studio C/C++, IBM XL C/C++, GNU C, Clang, Intel C++ Compiler (Linux systems)
__thread int number;
// C++ Builder
int __thread number;
- volatile
使用了volatile修饰符的变量意味着它在内存中的值可能随时发生变化,也告诉编译器不能做任何优化,每次使用到此变量的值都必须从内存中读取,而不应该直接使用寄存器的值。
举个具体的栗子吧。假设有以下代码段:
int a = 10;
volatile int *p = &a;
int b, c;
b = *p;
c = *p;
若p没有volatile修饰,则b = *p和c = *p只需从内存取一次p的值,那么b和c的值必然是10。
若考虑volatile的影响,假设执行完b = *p语句之后,p的值被其它线程修改了,则执行c = *p会再次从内存中读取p的值,此时c的值不再是10,而是新的值。
但是,volatile并不能解决多线程的同步问题,只适合以下三种情况使用:
1、和信号处理(signal handler)相关的场合。
2、和内存映射硬件(memory mapped hardware)相关的场合。
3、和非本地跳转(setjmp 和 longjmp)相关的场合。
- std::atomic
严格来说atomic并不是关键字,而是STL的模板类,可以支持指定类型的原子操作。
使用原子的类型意味着该类型的实例的读写操作都是原子性的,无法被其它线程切割,从而达到线程安全和同步的目标。
可能有些读者会好奇,为什么对于基本类型的操作也需要原子操作。比如:
int cnt = 0;
auto f = [&]{cnt++;};
std::thread t1{f}, t2{f}, t3{f};
以上三个线程同时调用函数f,该函数只执行cnt++,在C++维度,似乎只有一条执行语句,理论上不应该存在同步问题。然而,编译成汇编指令后,会有多条指令,这就会在多线程中引起线程上下文切换,引起不可预知的行为。
为了避免这种情况,就需要加入atomic类型:
std::atomic<int> cnt{0}; // 给cnt加入原子操作。
auto f = [&]{cnt++;};
std::thread t1{f}, t2{f}, t3{f};
加入atomic之后,所有线程执行后的结果是确定的,能够正常给变量计数。atomic的实现机制与临界区类似,但效率上比临界区更快。
为了更进一步地说明C++的单条语句可能生成多条汇编指令,可借助Compiler Explorer来实时查探C++汇编后的指令:
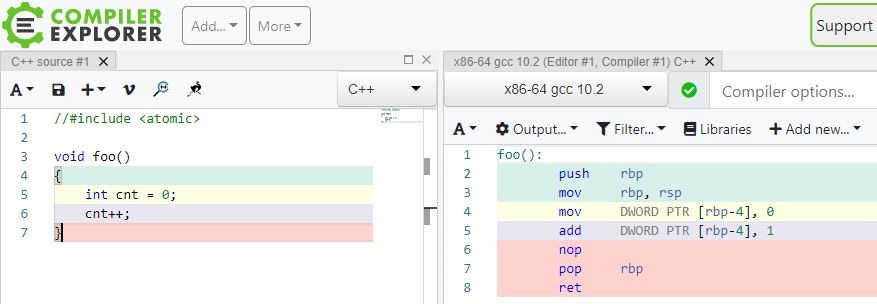
Compiler Explorer动态将左侧C++语句编译出的汇编指令。上图所示的c++代码编译后可能存在一对多的汇编指令,由此印证atomic原子操作的必要性。
充分利用std::atomic的特性和接口,可以实现很多非阻塞无锁的线程安全的数据结构和算法,关于这一点的延伸阅读,强力推荐《C++ Concurrency In Action》。
2.1.3.2 C++线程
C++的线程类型是std::thread,它提供的接口如下表:
| 接口 | 解析 |
|---|---|
| join | 加入主线程,使得主线程强制等待该线程执行完。 |
| detach | 从主线程分离,使得主线程无需等待该线程执行完。 |
| swap | 与另外一个线程交换线程对象。 |
| joinable | 查询是否可加入主线程。 |
| get_id | 获取该线程的唯一标识符。 |
| native_handle | 返回实现层的线程句柄。 |
| hardware_concurrency | 静态接口,返回硬件支持的并发线程数量。 |
使用范例:
#include <iostream>
#include <thread>
#include <chrono>
void foo()
{
// simulate expensive operation
std::this_thread::sleep_for(std::chrono::seconds(1));
}
int main()
{
std::cout << "starting thread...\n";
std::thread t(foo); // 构造线程对象,且传入被执行的函数。
std::cout << "waiting for thread to finish..." << std::endl;
t.join(); // 加入主线程,使得主线程必须等待该线程执行完毕。
std::cout << "done!\n";
}
输出:
starting thread...
waiting for thread to finish...
done!
如果需要在调用线程和新线程之间同步数据,则可以使用C++的std::promise和std::future等机制。示例代码:
#include <vector>
#include <thread>
#include <future>
#include <numeric>
#include <iostream>
void accumulate(std::vector<int>::iterator first,
std::vector<int>::iterator last,
std::promise<int> accumulate_promise)
{
int sum = std::accumulate(first, last, 0);
accumulate_promise.set_value(sum); // Notify future
}
int main()
{
// Demonstrate using promise<int> to transmit a result between threads.
std::vector<int> numbers = { 1, 2, 3, 4, 5, 6 };
std::promise<int> accumulate_promise;
std::future<int> accumulate_future = accumulate_promise.get_future();
std::thread work_thread(accumulate, numbers.begin(), numbers.end(),
std::move(accumulate_promise));
// future::get() will wait until the future has a valid result and retrieves it.
// Calling wait() before get() is not needed
//accumulate_future.wait(); // wait for result
std::cout << "result = " << accumulate_future.get() << '\n';
work_thread.join(); // wait for thread completion
}
输出结果:
result = 21
但是,std::thread的执行并不能保证是异步的,也可能是在当前线程执行。
如果需要强制异步,则可使用std::async。它可以指定两种异步方式:std::launch::async和std::launch::deferred,前者表示使用新的线程异步地执行任务,后者表示在当前线程执行,且会被延迟执行。使用范例:
#include <iostream>
#include <vector>
#include <algorithm>
#include <numeric>
#include <future>
#include <string>
#include <mutex>
std::mutex m;
struct X {
void foo(int i, const std::string& str) {
std::lock_guard<std::mutex> lk(m);
std::cout << str << ' ' << i << '\n';
}
void bar(const std::string& str) {
std::lock_guard<std::mutex> lk(m);
std::cout << str << '\n';
}
int operator()(int i) {
std::lock_guard<std::mutex> lk(m);
std::cout << i << '\n';
return i + 10;
}
};
template <typename RandomIt>
int parallel_sum(RandomIt beg, RandomIt end)
{
auto len = end - beg;
if (len < 1000)
return std::accumulate(beg, end, 0);
RandomIt mid = beg + len/2;
auto handle = std::async(std::launch::async,
parallel_sum<RandomIt>, mid, end);
int sum = parallel_sum(beg, mid);
return sum + handle.get();
}
int main()
{
std::vector<int> v(10000, 1);
std::cout << "The sum is " << parallel_sum(v.begin(), v.end()) << '\n';
X x;
// Calls (&x)->foo(42, "Hello") with default policy:
// may print "Hello 42" concurrently or defer execution
auto a1 = std::async(&X::foo, &x, 42, "Hello");
// Calls x.bar("world!") with deferred policy
// prints "world!" when a2.get() or a2.wait() is called
auto a2 = std::async(std::launch::deferred, &X::bar, x, "world!");
// Calls X()(43); with async policy
// prints "43" concurrently
auto a3 = std::async(std::launch::async, X(), 43);
a2.wait(); // prints "world!"
std::cout << a3.get() << '\n'; // prints "53"
} // if a1 is not done at this point, destructor of a1 prints "Hello 42" here
执行结果:
The sum is 10000
43
Hello 42
world!
53
另外,C++20已经支持轻量级的协程(coroutine)了,相关的关键字:co_await,co_return,co_yield,跟C#等脚本语言的概念和用法如出一辙,但行为和实现机制可能会稍有不同,此文不展开探讨了。
2.1.3.3 C++多线程同步
线程同步的机制有很多,C++支持的有以下几种:
- std::atomic
[2.1.3.1 C++多线程关键字](#2.1.3.1 C++多线程关键字)已经对std::atomic做了详细的解析,可以防止多线程之间共享数据的数据竞险问题。此外,它还提供了丰富多样的接口和状态查询,以便更加精细和高效地同步原子数据,常见接口和解析如下:
| 接口名 | 解析 |
|---|---|
| is_lock_free | 检查原子对象是否无锁的。 |
| store | 存储值到原子对象。 |
| load | 从原子对象加载值。 |
| exchange | 获取原子对象的值,并替换成指定值。 |
| compare_exchange_weak, compare_exchange_strong | 将原子对象的值和预期值(expected)对比,如果相同就替换成目标值(desired),并返回true;如果不同,就加载原子对象的值到预期值(expected),并返回false。weak模式不会卡调用线程,strong模式会卡住调用线程,直到原子对象的值和预期值(expected)相同。 |
| fetch_add, fetch_sub, fetch_and, fetch_or, fetch_xor | 获取原子对象的值,并对其相加、相减等操作。 |
| operator ++, operator --, operator +=, operator -=, ... | 对原子对象响应各类操作符,操作符的意义和普通变量一致。 |
此外,C++20还支持wait, notify_one, notify_all等同步接口。
利用compare_exchange_weak接口可以很方便地实现线程安全的非阻塞式的数据结构。示例:
#include <atomic>
#include <future>
#include <iostream>
template<typename T>
struct node
{
T data;
node* next;
node(const T& data) : data(data), next(nullptr) {}
};
template<typename T>
class stack
{
public:
std::atomic<node<T>*> head; // 堆栈头, 采用原子操作.
public:
// 入栈操作
void push(const T& data)
{
node<T>* new_node = new node<T>(data);
// 将原有的头指针作为新节点的下一节点.
new_node->next = head.load(std::memory_order_relaxed);
// 将新的节点和老的头部节点做对比测试, 如果new_node->next==head, 说明其它线程没有修改head, 可以将head替换成new_node, 从而完成push操作.
// 反之, 如果new_node->next!=head, 说明其它线程修改了head, 将其它线程修改的head保存到new_node->next, 继续循环检测.
while(!head.compare_exchange_weak(new_node->next, new_node,
std::memory_order_release,
std::memory_order_relaxed))
; // 空循环体
}
};
int main()
{
stack<int> s;
auto r1 = std::async(std::launch::async, &stack<int>::push, &s, 1);
auto r2 = std::async(std::launch::async, &stack<int>::push, &s, 2);
auto r3 = std::async(std::launch::async, &stack<int>::push, &s, 3);
r1.wait();
r2.wait();
r3.wait();
// print the stack's values
node<int>* node = s.head.load(std::memory_order_relaxed);
while(node)
{
std::cout << node->data << " ";
node = node->next;
}
}
输出:
2 3 1
由此可见,利用原子及其接口可以很方便地进行多线程同步,而且由于是多线程异步入栈,栈的元素不一定与编码的顺序一致。
以上代码还涉及内存访问顺序的标记:
- 排序一致序列(sequentially consistent)。
- 获取-释放序列(memory_order_consume, memory_order_acquire, memory_order_release和memory_order_acq_rel)。
- 自由序列(memory_order_relaxed)。
关于这方面的详情可以参看第一篇的内存屏障或者《C++ concurrency in action》的章节5.3 同步操作和强制排序。
- std::mutex
std::mutex即互斥量,它会在作用范围内进入临界区(Critical section),使得该代码片段同时只能由一个线程访问,当其它线程尝试执行该片段时,会被阻塞。std::mutex常与std::lock_guard,示例代码:
#include <iostream>
#include <map>
#include <string>
#include <chrono>
#include <thread>
#include <mutex>
std::map<std::string, std::string> g_pages;
std::mutex g_pages_mutex; // 声明互斥量
void save_page(const std::string &url)
{
// simulate a long page fetch
std::this_thread::sleep_for(std::chrono::seconds(2));
std::string result = "fake content";
// 配合std::lock_guard使用, 可以及时进入和释放互斥量.
std::lock_guard<std::mutex> guard(g_pages_mutex);
g_pages[url] = result;
}
int main()
{
std::thread t1(save_page, "http://foo");
std::thread t2(save_page, "http://bar");
t1.join();
t2.join();
// safe to access g_pages without lock now, as the threads are joined
for (const auto &pair : g_pages) {
std::cout << pair.first << " => " << pair.second << '\n';
}
}
输出:
http://bar => fake content
http://foo => fake content
此外,手动操作std::mutex的锁定和解锁,可以实现一些特殊行为,例如等待某个标记:
#include <chrono>
#include <thread>
#include <mutex>
bool flag;
std::mutex m;
void wait_for_flag()
{
std::unique_lock<std::mutex> lk(m); // 这里采用std::unique_lock而非std::lock_guard. std::unique_lock可以实现尝试获得锁, 如果当前以及被其它线程锁定, 则延迟直到其它线程释放, 然后才获得锁.
while(!flag)
{
lk.unlock(); // 解锁互斥量
std::this_thread::sleep_for(std::chrono::milliseconds(100)); // 休眠100ms,在此期间,其它线程可以进入互斥量,以便更改flag标记。
lk.lock(); // 再锁互斥量
}
}
- std::condition_variable
std::condition_variable和std::condition_variable_any都是条件变量,都是C++标准库的实现,它们都需要与互斥量配合使用。由于std::condition_variable_any更加通用,会在性能上产生更多的开销。故而,应当首先考虑使用std::condition_variable。
利用条件变量的接口,结合互斥量的使用,可以很方便地执行线程间的等待、通知等操作。示例:
#include <iostream>
#include <string>
#include <thread>
#include <mutex>
#include <condition_variable>
std::mutex m;
std::condition_variable cv; // 声明条件变量
std::string data;
bool ready = false;
bool processed = false;
void worker_thread()
{
// 等待直到主线程改变ready为true.
std::unique_lock<std::mutex> lk(m);
cv.wait(lk, []{return ready;});
// 获得了互斥量的锁
std::cout << "Worker thread is processing data\n";
data += " after processing";
// 发送数据给主线程
processed = true;
std::cout << "Worker thread signals data processing completed\n";
// 手动解锁, 以便主线程获得锁.
lk.unlock();
cv.notify_one();
}
int main()
{
std::thread worker(worker_thread);
data = "Example data";
// send data to the worker thread
{
std::lock_guard<std::mutex> lk(m);
ready = true;
std::cout << "main() signals data ready for processing\n";
}
cv.notify_one();
// wait for the worker
{
std::unique_lock<std::mutex> lk(m);
cv.wait(lk, []{return processed;});
}
std::cout << "Back in main(), data = " << data << '\n';
worker.join();
}
输出:
main() signals data ready for processing
Worker thread is processing data
Worker thread signals data processing completed
Back in main(), data = Example data after processing
- std::future
C++的future(期望)是一种可以访问未来的返回值的机制,常用于多线程的同步。可以创建future的类型有: std::async, std::packaged_task, std::promise。
future对象可以执行wait、wait_for、wait_until,从而实现事件等待和同步,示例代码:
#include <iostream>
#include <future>
#include <thread>
int main()
{
// 从packaged_task获取的future
std::packaged_task<int()> task([]{ return 7; }); // wrap the function
std::future<int> f1 = task.get_future(); // get a future
std::thread t(std::move(task)); // launch on a thread
// 从async()获取的future
std::future<int> f2 = std::async(std::launch::async, []{ return 8; });
// 从promise获取的future
std::promise<int> p;
std::future<int> f3 = p.get_future();
std::thread( [&p]{ p.set_value_at_thread_exit(9); }).detach();
// 等待所有future
std::cout << "Waiting..." << std::flush;
f1.wait();
f2.wait();
f3.wait();
std::cout << "Done!\nResults are: " << f1.get() << ' ' << f2.get() << ' ' << f3.get() << '\n';
t.join();
}
输出:
Waiting...Done!
Results are: 7 8 9
2.1.4 多线程实现机制
多线程按并行内容可分为数据并行和任务并行两种。其中数据并行是不同的线程携带不同的数据执行相同的逻辑,最经典的数据并行的应用是MMX指令、SIMD技术、Compute着色器等。任务并行是不同的线程执行不同的逻辑,数据可以相同,也可以不同,例如,游戏引擎经常将文件加载、音频处理、网络接收乃至物理模拟都放到单独的线程,以便它们可以并行地执行不同的任务。
多线程如果按划分粒度和方式,则有线性划分、递归划分、任务类型划分等。
线性划分法的最简单应用就是将连续数组的元素平均分成若干份,每份数据派发到一个线程中执行,例如并行化的std::for_each和UE里的ParallelFor。
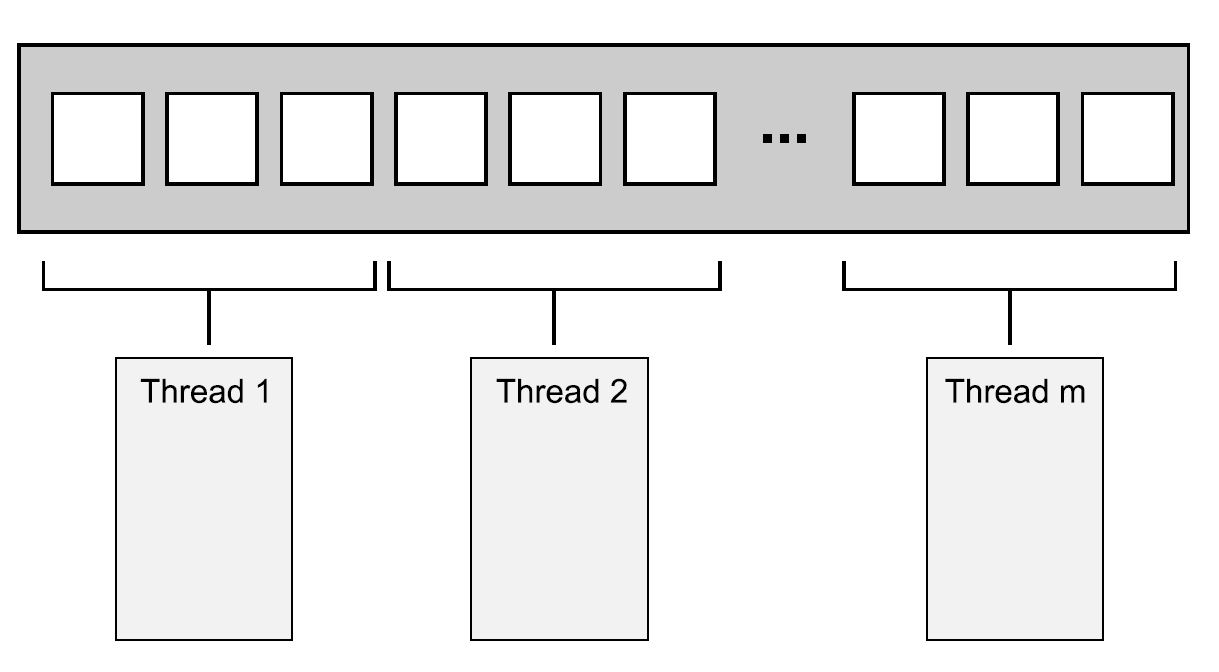
线性划分示意图。连续数据被均分为若干份,接着派发到若干线程中并行地执行。
在线性划分并行执行结束后,通常需要由调用线程合并和同步并行的结果。
递归划分法是将连续数据按照某种规则划分成若干份,每一份又可继续划分成更细粒度,直到某种规则停止划分。常用于快速排序。
快速排序有两个最基本的步骤:将数据划分到中枢(pivot)元素之前或之后,然后对中枢元素之前和之后的两半数组再次进行快速排序。由于只有在一次排序结束后才能知道哪些项在中枢元素之前和之后,所以不能通过对数据的简单(线性)划分达到并行。当要对这种算法进行并行化,很自然的会想到使用递归。每一级的递归都会多次调用quick_sort函数,因为需要知道哪些元素在中枢元素之前和之后。
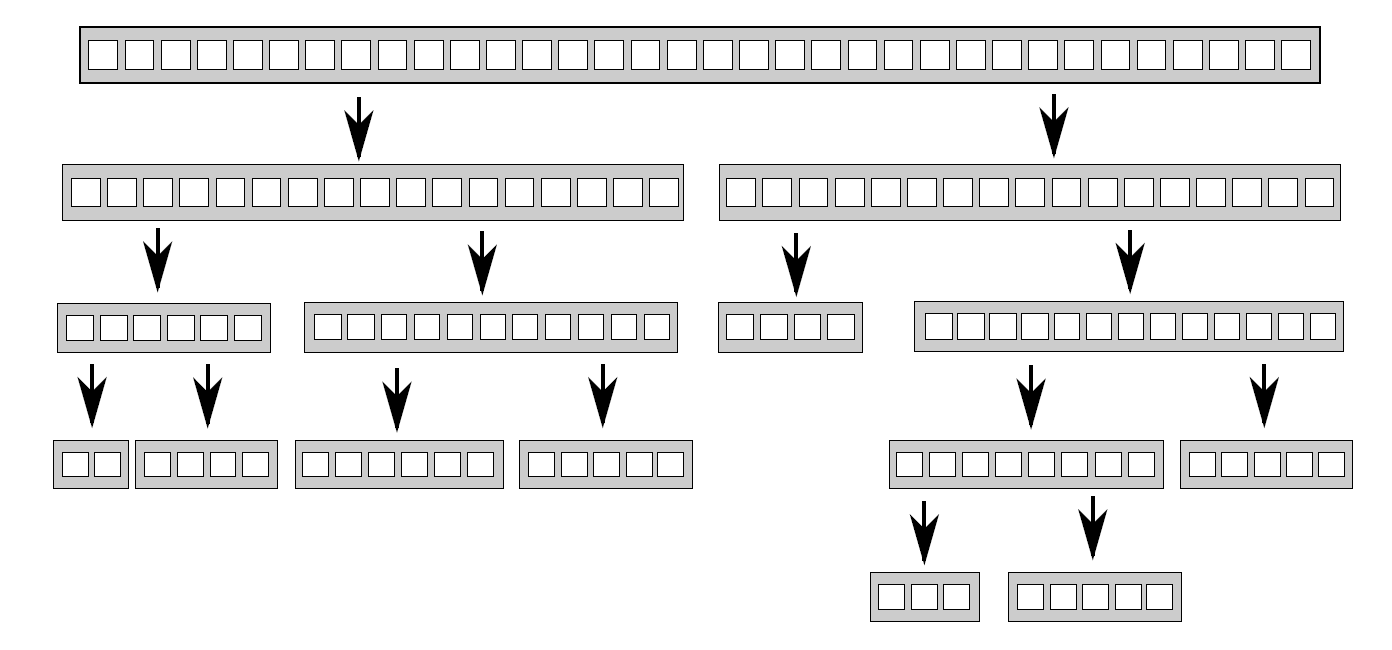
递归划分法示意图。
将一个大框架内的逻辑划分成若干个子任务,它们之间通常保持独立,也可以有一定依赖,每个任务派发到一个线程执行,这就意味着真正意义上的线程独立,每个线程只需要关注自己所要做的事情即可。
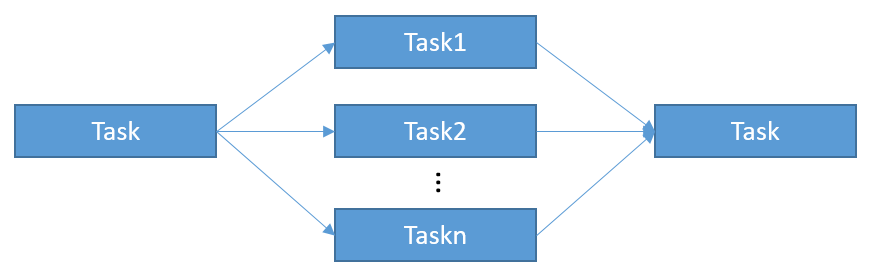
任务划分示意图。
合理地安排和划分子任务,减少它们之间的依赖和等待同步,是提升运行效率的有利武器。不过,要做到这点,往往需要经过精细的设计实现以及反复调试和修改。
上面这种实现机制常被称为Fork-Join(分叉-合并)并行模型,它和串行模型的运行机制对比如下图:
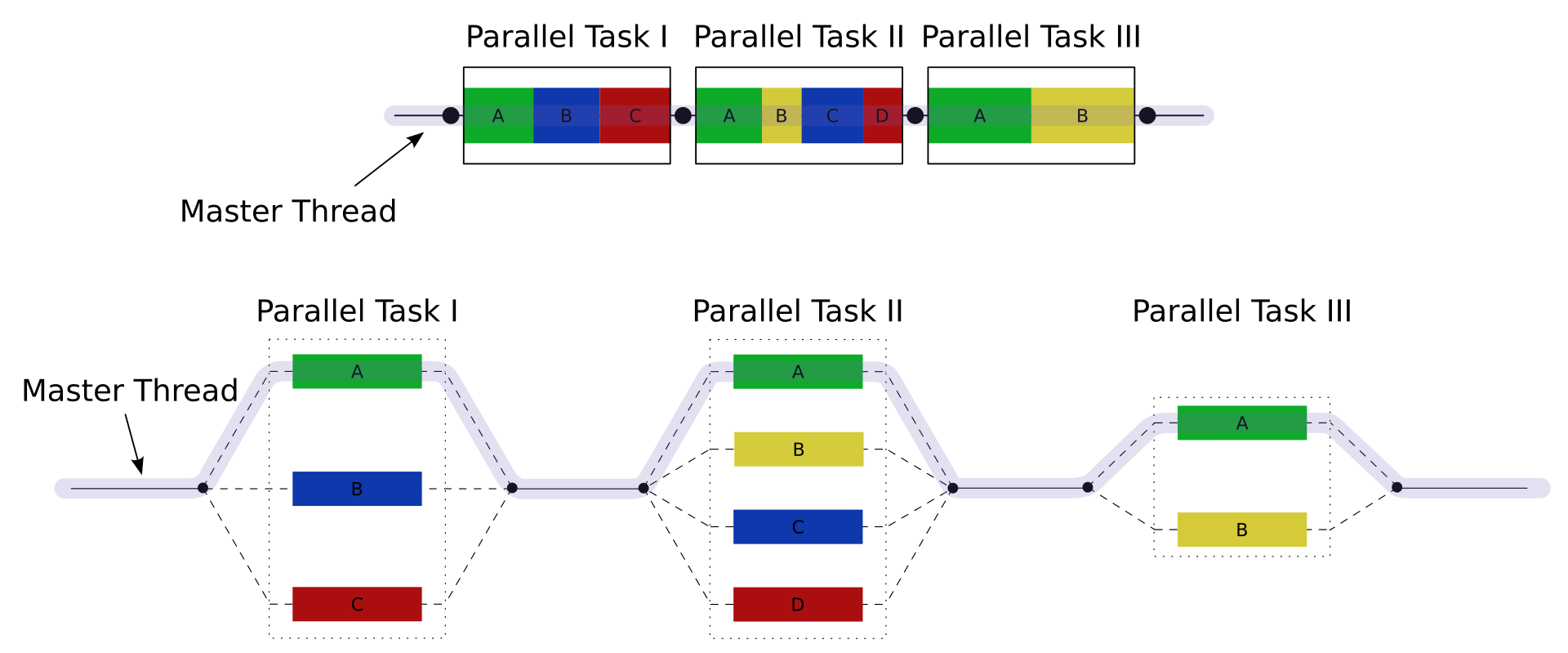
上:串行运行模型;下:Fork-Join并行运行模型。
GDC2010的演讲Task-based Multithreading - How to Program for 100 cores详细阐述了如何采用基于Task的多线程运行机制:

基于Task的多线程比基于线程的架构要好很多,可以更加充分地利用多核优势,使得每个核心都保持忙碌状态:

该文还提到了如何将基于任务的多线程应用于排序、迷宫寻路等实际案例中。
2.2 现代图形API的多线程特性
2.2.1 传统图形API的多线程特性
OpenGL及DirectX10之前版本的图形API,所有的绘制指令是线性和阻塞式的,意味着每次调用Draw接口都不会立即返回,会卡住调用线程。这种CPU和GPU的交互机制在单核时代,对性能的影响不那么突出,但是随着多核时代的到来,这种交互机制显然会严重影响运行性能。
若游戏引擎的渲染器仍然是单线程的,这常常导致CPU的性能瓶颈,阻碍了利用多核计算资源来提高性能或丰富可视化内容。

传统图形API线性执行绘制指令示意图。
单线程渲染器通常会导致单个 CPU 内核满负荷运行,而其他内核保持相对空闲,且性能低于可玩的帧率。
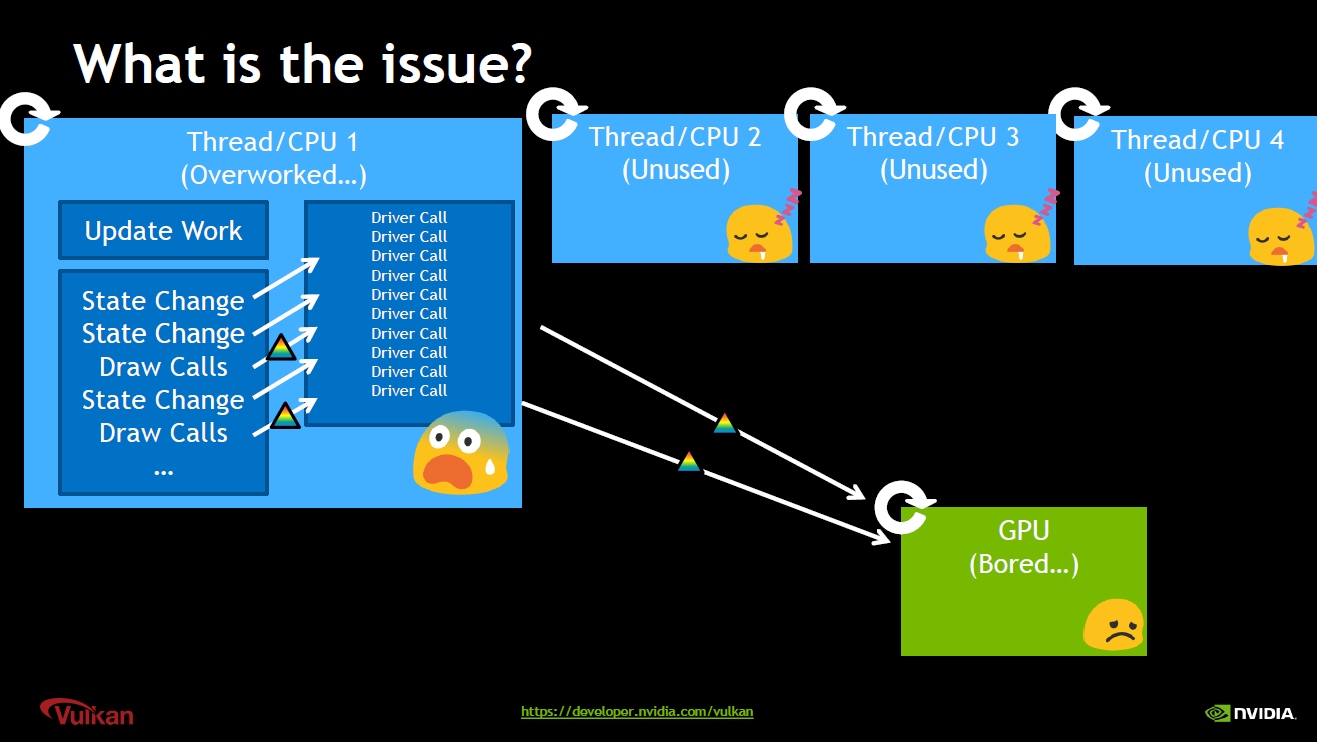
传统图形API在单线程单Context下设置渲染状态调用绘制指令,并且绘制指令是阻塞式的,CPU和GPU无法并行运行,其它CPU核心也会处于空闲等待状态。
在这些传统图形API架构多线程渲染,必须从软件层面着手,开辟多个线程,用于单独处理逻辑和渲染指令,以便解除CPU和GPU的相互等待耦合。早在SIGGraph2008有个Talk(Practical Parallel Rendering with DirectX 9 and 10)专门讲解如何在DirectX9和10实现软件级的多线程渲染,核心部分就是在软件层录制(Playback)D3D的绘制命令(Command)。
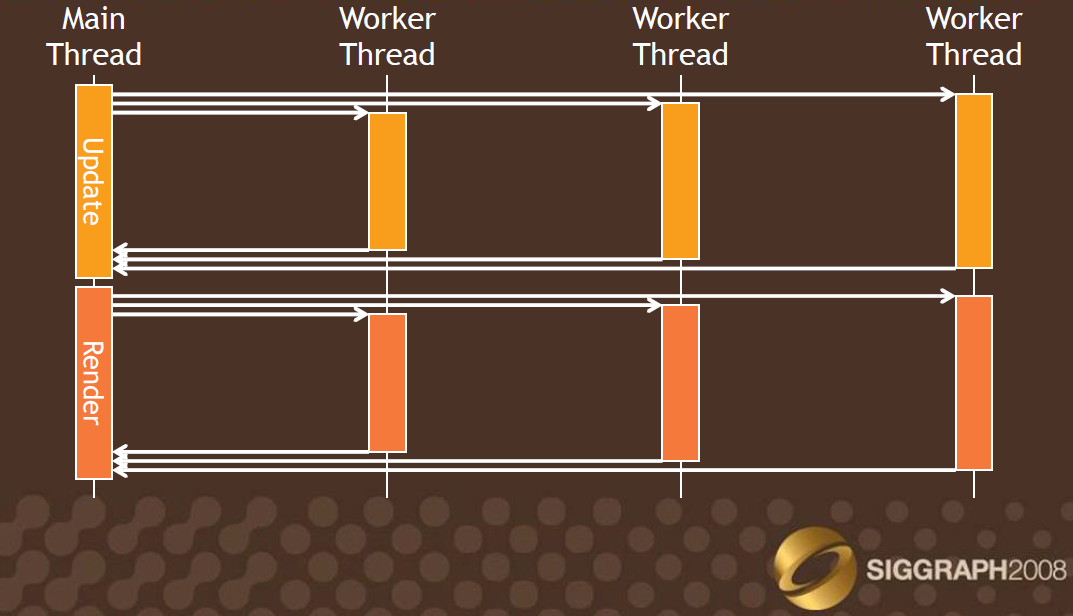
Practical Parallel Rendering with DirectX 9 and 10中提出的一种软件级的多线程渲染架构。
不过,这种软件层面的命令录制存在多种问题,不支持部分图形API(如状态查询),需额外的命令缓存区记录绘制指令,命令阶段无法创建真正的GPU资源等等。
DirectX11尝试从硬件层面解决多线程渲染的问题。它支持了两种设备上下文:即时上下文(Immediate Context)和延迟上下文(Deferred Context)。不同的延迟上下文可以同时在不同的线程中使用,生成将在“即时上下文”中执行的命令列表。这种多线程策略允许将复杂的场景分解成并发任务。
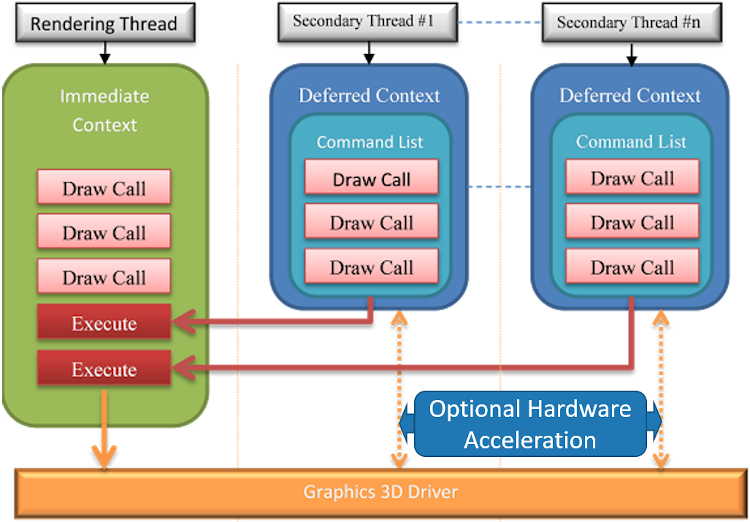
DirectX11的多线程模型。
不同的延迟上下文可以同时在不同的线程中使用,生成将在即时上下文中执行的命令列表。这种多线程策略允许将复杂的场景分解成并发任务。此外,延迟上下文在某些驱动的支持下,可实现硬件级的加速,而不必在即时上下文执行Command List。
为什么使用Deferred Context的Command List提前录制绘制指令会比直接使用Immediate Context调用绘制指令的效率更高?
答案在于Command List内部会对已经录制的指令做高度的优化,执行这些优化后的指令会明显提升效率,比直接单独每条调用图形API会高效得多。
在D3D11中命令列表中的命令是被快速记录下来,而不是立即执行的,直到程序调用ExecuteCommandList方法(调用即返回,不等待)才被GPU真正的执行,此时那些使用延迟渲染设备接口的CPU线程以及主渲染线程又可以去干别的事情了,比如继续下一帧的碰撞检测、物理变换、动画插值、光照准备等等,从而为记录形成新的命令列表做准备。
不过,基于DirectX11的多线程架构,由于硬件层面的加速不是必然支持,所有在Deferred Context记录的指令连同Immediate Context的指令必须由同一个线程(通常是渲染线程)提交给GPU执行。
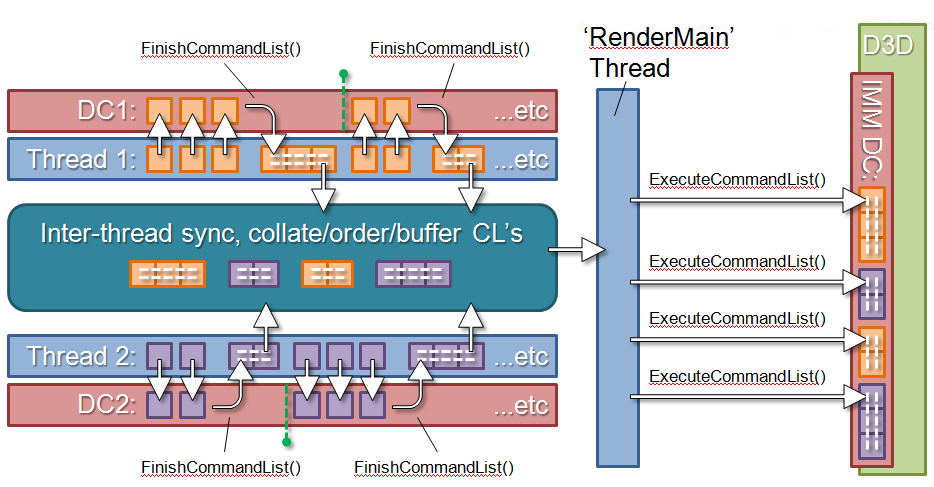
DirectX11下的多线程架构示意图。
这种非硬件支持的多线程渲染只是节省了部分CPU时间(多线程录制指令和绘制同步等待),并不能从硬件层面真正发挥多线程的威力。
2.2.2 DirectX12的多线程特性
相较于DirectX11过渡性的伪多线程模型(称之伪,是因为当时的大多数驱动并不支持DirectX11的硬件级多线程),DirectX 12 多线程则通过显著减少 API 调用额外开销得到了很大的改进,它取消了 DirectX 11 的设备上下文的概念,直接使用Command List来调用 D3D APIs,然后通过命令队列将命令列表提交给 GPU,并且所有 DirectX 12显卡都支持 DirectX 12 多线程的硬件加速。
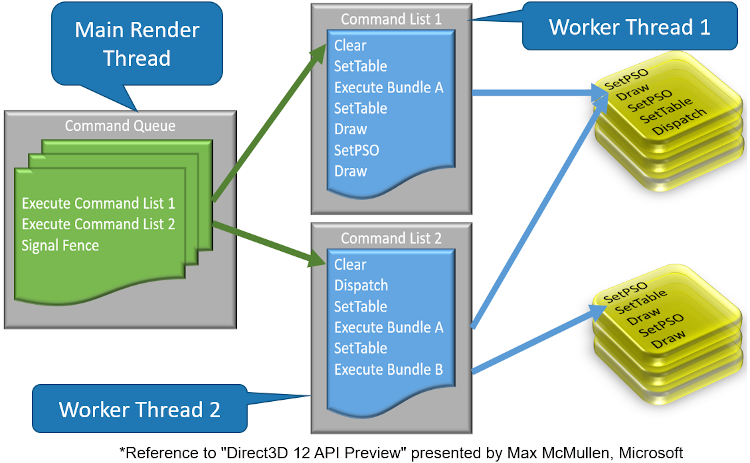
DirectX12的多线程模型。
从原理上来看,DirectX12与DirectX11多线程渲染框架是类似的,都是通过在不同的CPU线程中录制命令列表(Command Lists),最后再统一执行的方式完成多线程渲染。它们都从根本上屏蔽了令人发指的Draw Call同步调用,而改为CPU和GPU完全异步(并行)执行的方式,从而在整体渲染效率和性能上获得巨大的提升。
对于DirectX12,用户层面有3种命令队列(Command Queue):复制队列(Copy Queue)、计算队列(Compute Queue)和3D队列(3D Queue),它们可以并行地执行,并且通过栅栏(Fence)、信号(Signal)或屏障(Barrier)来等待和同步。
GPU硬件层面则有3种引擎:复制引擎(Copy Engine)、计算引擎(Compute Engine)和3D引擎(3D Engine),它们也可以并行地执行,并且通过栅栏(Fence)、信号(Signal)或屏障(Barrier)来等待和同步。
命令队列可驱动GPU硬件的若干引擎,但有一定的限制,更具体地,3D Queue可以驱动GPU硬件的3种引擎,Compute Queue只能驱动Compute Engine和Copy Engine,Copy Queue仅可以驱动Copy Engine。
在CPU层面,可以有若干个线程,每个线程可创建产生若干个命令列表(Command List),每个命令列表可进入3种Command Queue的其中一种。当这些命令被GPU执行时,每种指令列表里的命令会压入不同的GPU引擎,以便它们并行地执行。(下图)

DirectX12中的CPU线程、命令列表、命令队列、GPU引擎之间的运行机制示意图。
2.2.3 Vulkan的多线程特性
作为跨平台图形API的新生代表Vulkan,摒弃了传统图形API的弊端,直面多核时代的优势,从而从设计和架构上发挥了并行渲染的威力。
综合上看,Vulkan和DirectX12是非常接近的,都有着Command Buffer、CommandPool、Command Queue和Fence等核心概念,并行模式也非常相似:在不同的CPU线程并行地生成Command Buffer指令,最后由主线程收集这些Command Buffer并提交至GPU:
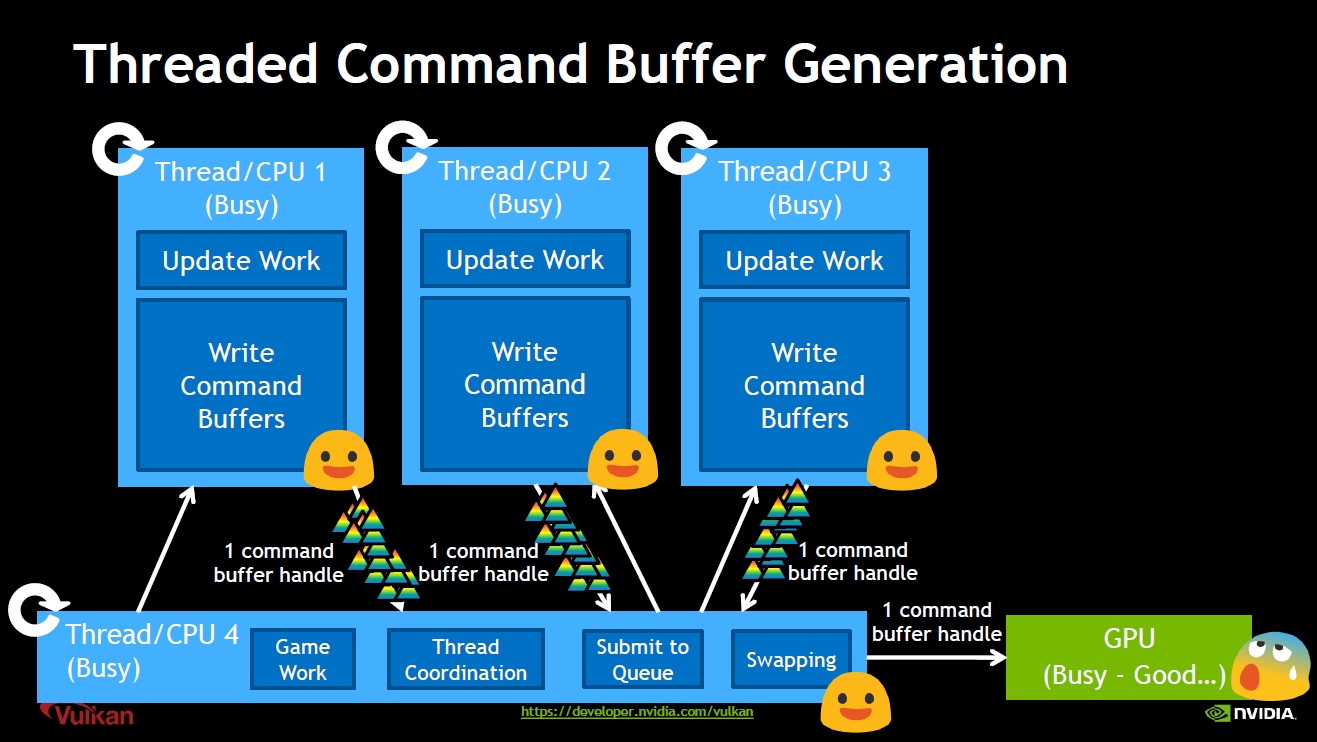
Vulkan图形API并行示意图。
并且,Vulkan的CommandPool可以每帧被不同的线程创建,以便减少同步等待,提升并行效率:

Vulkan中的CommandPool在不同帧之间的并行示意图。
此外,Vulkan也存在着和DirectX12类似的各种同步机制:
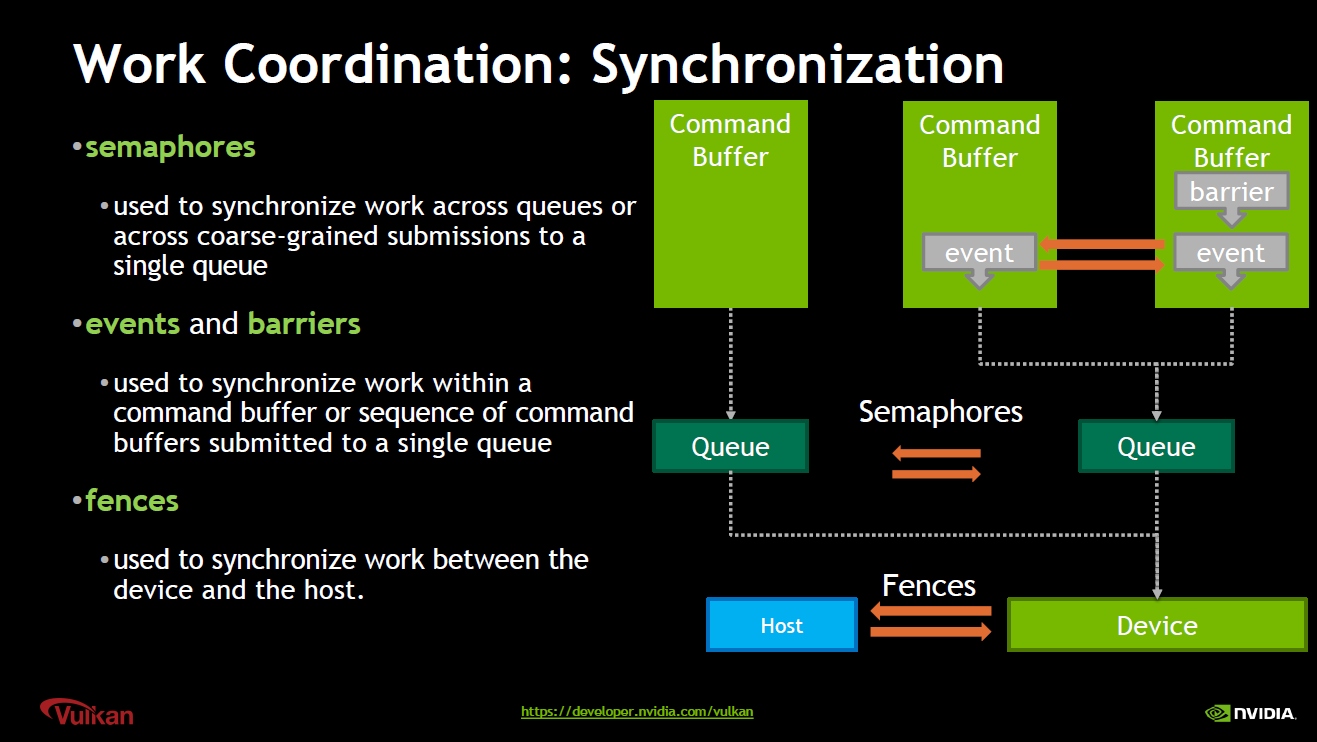
Vulkan同步机制:semaphore(信号)用于同步Queue;Fence(栅栏)用于同步GPU和CPU;Event(事件)和Barrier(屏障)用于同步Command Buffer。
关于Vulkan的更多用法、剖析、对比可参见文献Evaluation of multi-threading in Vulkan。
2.2.4 Metal的多线程特性
Metal作为iOS和MacOS系统的专属图形API,也是新生代的代表,它既兼容OpenGL这种传统的图形API用法,也支持类似Vulkan、DirectX12的新一代图形API理念和架构。从使用者层面来看,Metal是比较友善的,提供了结构更清晰、概念更友好的API。

从OpenGL迁移到新生代图形API的成本和收益对比。横坐标是从OpenGL(或ES)迁移其它图形API的成本,纵坐标是潜在的性能收益。可见Metal的迁移成本较低,但潜在的性能比也没有Vulkan和DirectX12高。
Metal如同Vulkan和DirectX,有着很多相似的概念,诸如Command、Command Buffer、Command Queue及各类同步机制。
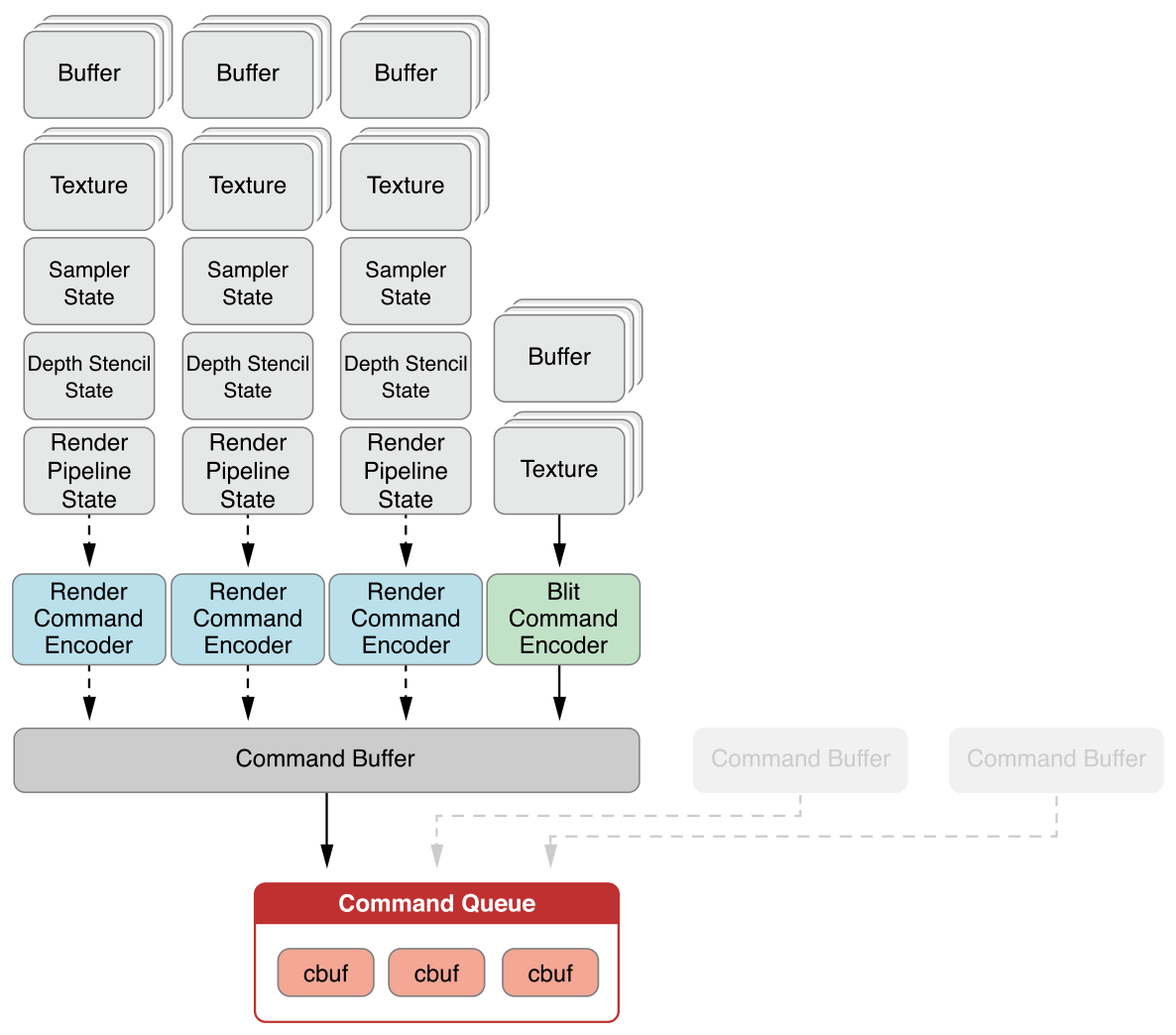
Metal基础概念关系一览表。其中Command Encoder有3种类型:MTLRenderCommandEncoder、MTLComputeCommandEncoder和MTLBlitCommandEncoder。CommandEncoder录制命令之后,塞入Command Buffer,最终进入Command Queue命令队列。
有了类似的概念和机制,Metal同样可以方便地实现多线程录制命令,且从硬件层面支持多线程调度:
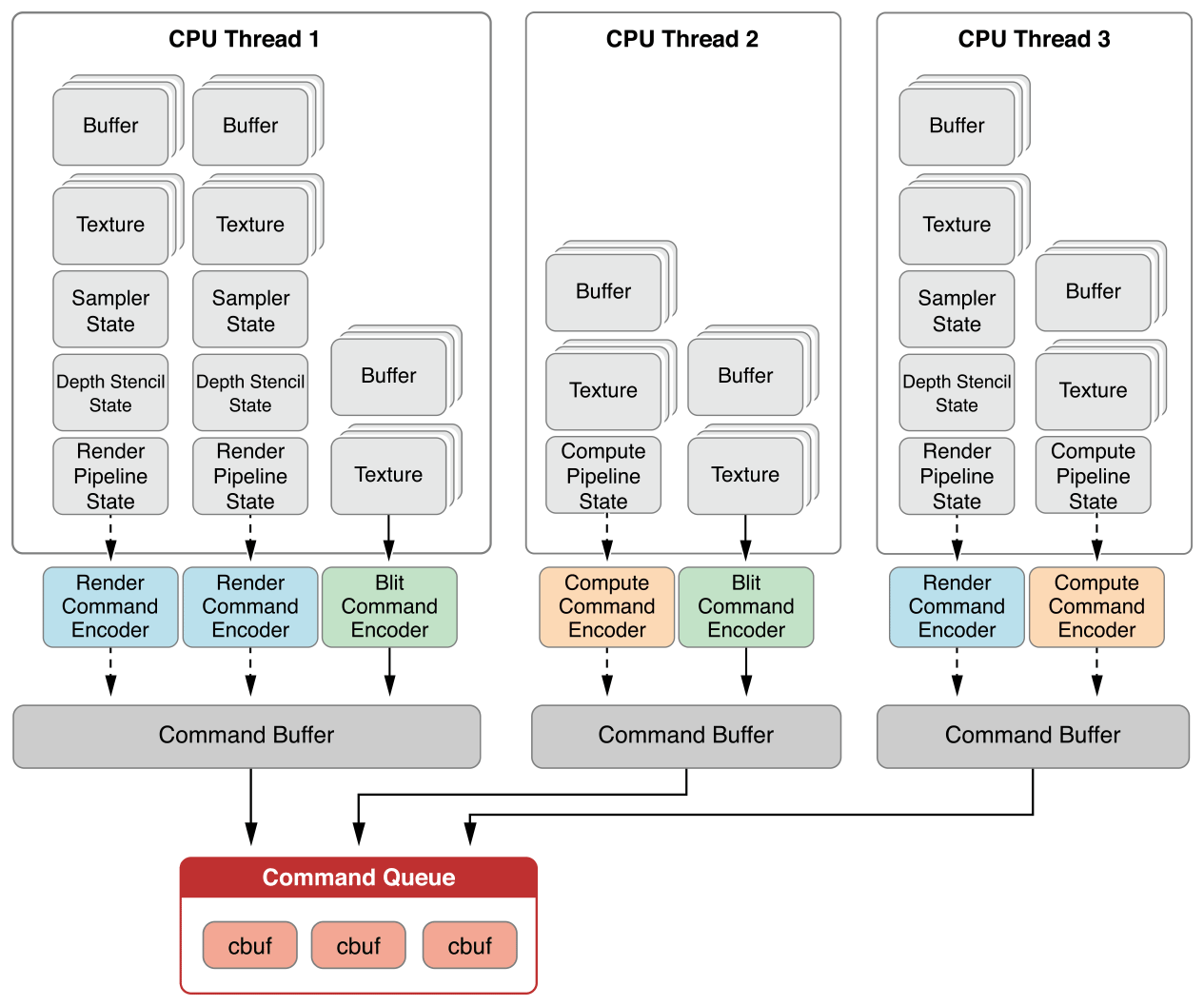
Metal多线程模型示意图。图中显示了3个CPU线程同时录制不同类型的Encoder,每个线程都有专属的Command Buffer,最终这些Command Buffer统一汇入Command Queue交由GPU执行。
2.3 游戏引擎的多线程渲染
在正式讲解UE的多线程渲染之前,先了解一下其它主流商业引擎的多线程架构和设计。
2.3.1 Unity
Unity的渲染体系中有几个核心概念,一个是Client,运行于主线程(逻辑线程),负责产生渲染指令;另一个是Worker Thread,工作线程,用于协助处理主线程或生成渲染指令等各类子工作。Unity的渲染架构中支持以下几种模式:
- Singlethreaded Rendering
单线程渲染模式,此模式下只有单个Client组件,没有工作线程。唯一的Client在主线程中产生所有的渲染命令(rendering command,RCMD),并且拥有图形设备对象,也会在主线程向图形设备产生调用图形API命令(graphics API,GCMD),它的调度示意图如下:

这种模式下,CPU和GPU可能会相互等待,无法充分利用多核CPU,性能比较最差。
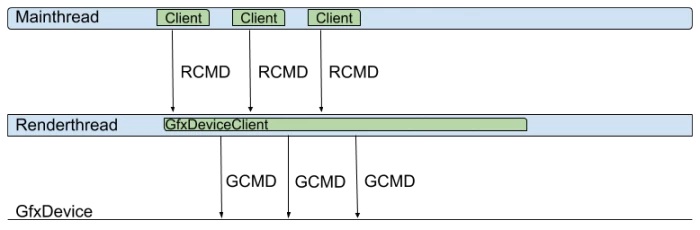
- **Multithreaded Rendering **
多线程渲染模式,这种模式下和单线程对比,就是多了一条工作线程,即用于生成GCMD的渲染线程,其中渲染线程跑的是GfxDeviceClient对象,专用于生成对应平台的图形API指令:
- Jobified Rendering
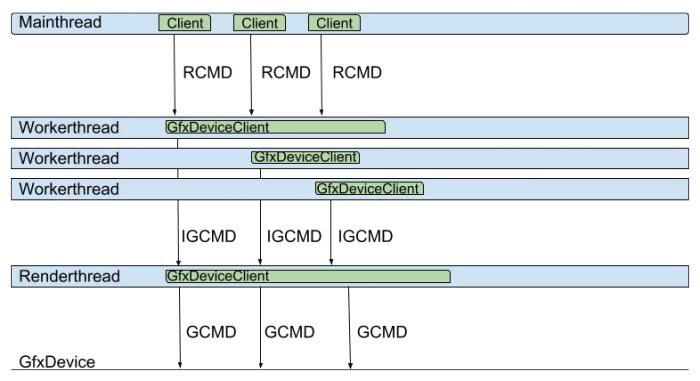
作业化渲染模式,此模式下有多个Client对象,单个渲染线程。此外,有多个作业对象,每个作业对象跑在专用独立的线程,用于生成即时图形命令(intermediate graphics commands,IGCMD)。此外,还有一个工作线程(渲染线程)用于将作业线程生成的IGCMD转换成图形API的GCMD,运行示意图如下:
- Graphics Jobs
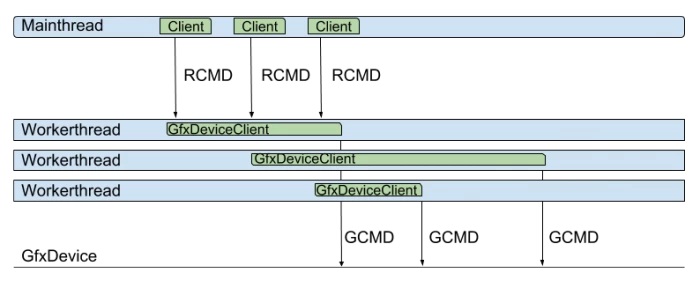
图形化作业渲染模式,此模式下有多个Client,多个工作线程,没有渲染线程。主线程上的多个Client对象驱动工作线程上的对应图形设备对象,直接生成GCMD,从而避免生成Jobified Rendering模式的IGCMD中间指令。只在支持硬件级多线程的图形API上可启用,如DirectX12、Vulkan等。运行示意图如下:
2.3.2 Frostbite
Frostbite(寒霜)引擎在早期的时候,将每一帧分成个步骤:裁剪、构建、渲染,每个步骤所需的数据都放到双缓冲内(double buffer),采用级联方式运行,应用简单的同步流程。它的运行示意图如下:
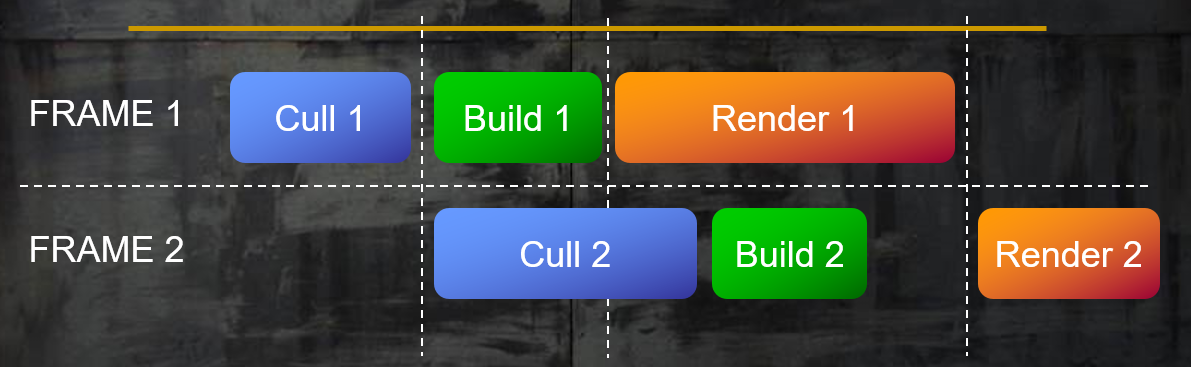
而经过多年的进化,Frostbite在前几年采用了帧图(Frame Graph)的多线程渲染模式。该模式旨在将引擎的各类渲染功能(Feature)和上层渲染逻辑(Renderer)和下层资源(Shader、RenderContext、图形API等)隔离开来,以便做进一步的解耦、优化,其中最重要的优化即开启多线程渲染。

FrameGraph是高层级的Render Pass和资源的代表,包含了一帧中所用到的所有信息。Pass之间可以指定顺序和依赖关系,下图是其中的一个示例:
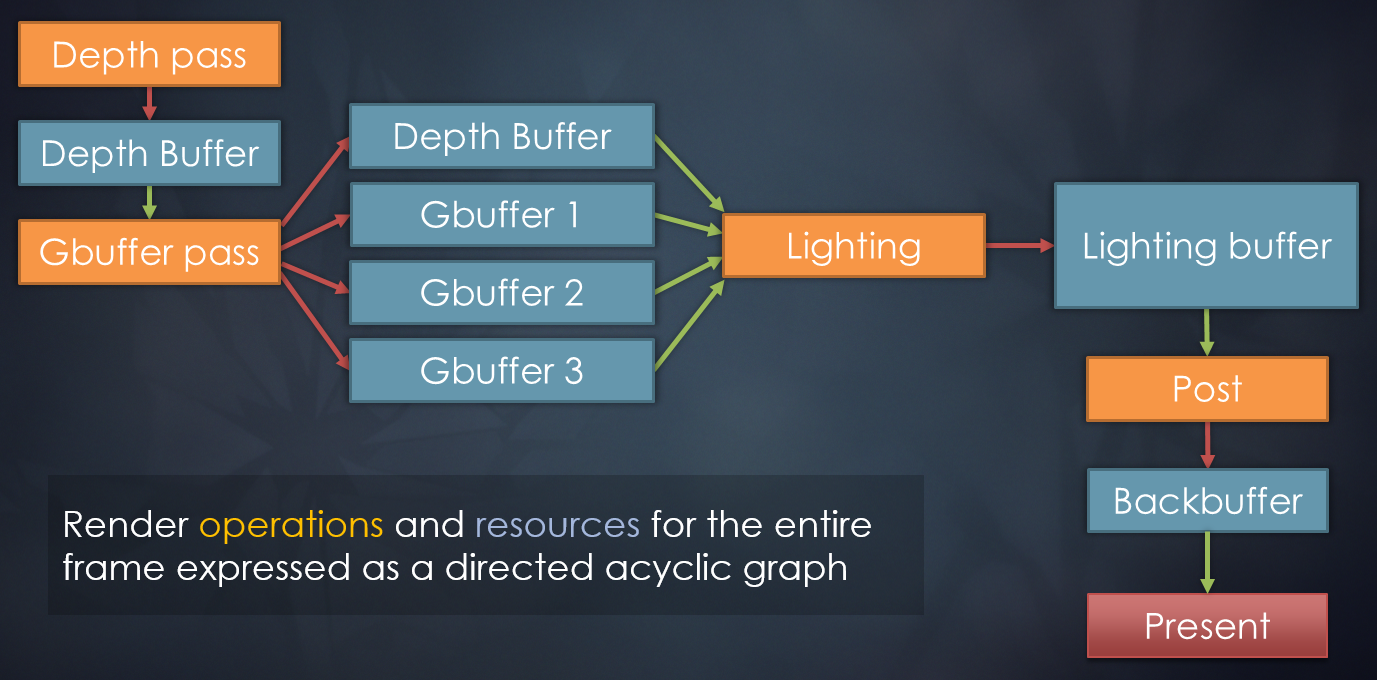
寒霜引擎采用帧图方式实现的延迟渲染的顺序和依赖图。
其中帧图的每一帧信息都有三个阶段:建立(Setup)、编译(Compile)和执行(Execute)。
建立阶段就是创建各个Render Pass、输入纹理、输出纹理、依赖资源等等信息。
编译阶段的工作主要是剔除未使用的Render Pass和资源,计算资源生命周期,以及根据使用标记创建对应的GPU资源,创建GPU资源时又做了大量的优化,诸如:简化显存分配算法,在第一次使用时申请最后一次使用后释放,异步计算外部资源的生命周期,源于绑定标记的精确资源管理,扁平化所有资源的引用以提升GPU高速缓存的命中率等等。编译阶段采用线性遍历所有的RenderPass,遍历时会计算资源引用次数、资源的最初和最后使用者、异步等待点和资源屏障等等。
执行阶段就按照Setup的顺序执行(编译阶段也不会重新排序),只遍历那些未被剔除的Render Pass并执行它们的回调函数。如果是立即模式,则直接调用设备上下文的API。执行阶段才会根据编译阶段生成的handle真正获取GPU资源。
最关键的是整个过程通过依赖图(Dependency Grahp)实现自动化异步计算。异步机制在主时间轴开始,会自动同步在不同Queue里的资源,同时会扩展它们的生命周期,以防意外释放。当然,这个自动化系统也有副作用,如额外增加一定量的内存,可能会引发不可预期的性能瓶颈。所以,寒霜引擎支持手动模式,以便按照预期控制和更改异步运行方式,从而逐Render Pass选择性加入。
下图可以比较简洁明了说明异步计算的运行机制:
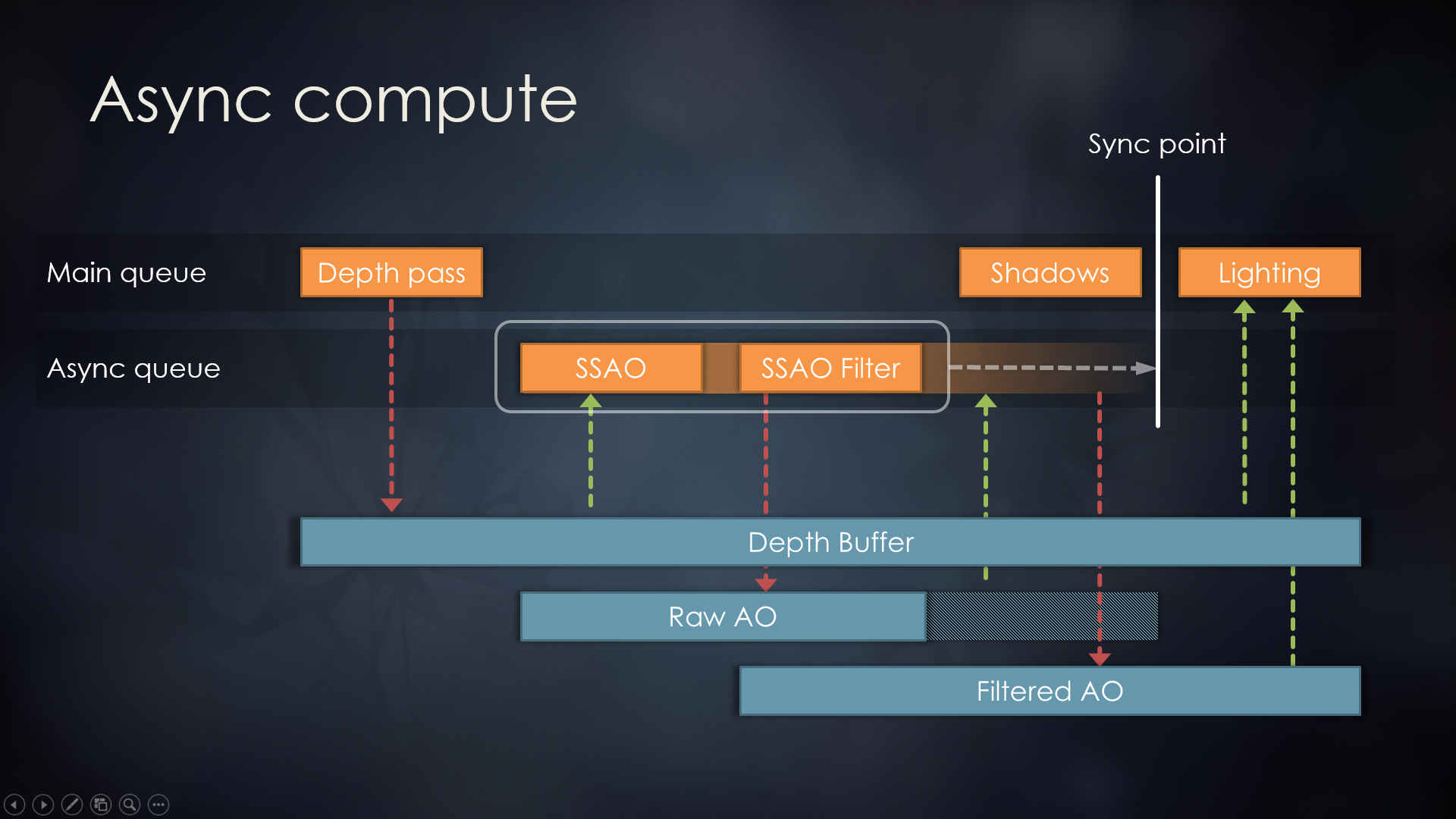
寒霜引擎异步计算示意图。其中SSAO、SSAO Filter的Pass放入到异步队列,它们会写入和读取Raw AO的纹理,即便在同步点之前结束,但Raw AO的生命周期依然会被延长到同步点。
总之,帧图的渲染架构得益于记录了该帧所有的信息,以至于可以通过资源别名(Resource Aliasing)节省大量的内存和显存,可以实现半自动化的异步计算,可以简化渲染管线控制,可以制作出更加良好的可视化和诊断工具。
2.3.3 Naughty Dog Engine
顽皮狗的游戏引擎采用的也是作业系统,允许非GPU端的逻辑代码加入到作业系统。作业直接可以开启和等待其它作业,对调用者隐藏内存管理细节,提供了简洁易用的API,性能优化放在了第二位。
其中作业系统运行于纤程(Fiber),每个纤程类似局部的线程,用户层提供栈空间,其上下文包含少量的纤程状态,以便减少寄存器的占用。实际地运行在线程上,协作型的多线程模型。由于纤程非系统级的线程,切换上下文会非常快,只保存和恢复寄存器的状态(程序计数,栈指针,gpr等),故而开销会很小。
作业系统会开辟若干条工作线程,每条工作线程会锁定到GPU硬件核心。线程是执行单元,纤程是上下文,作业总是在线程的上下文内执行,采用原子计数器来同步。下图是顽皮狗引擎的作业系统架构图:
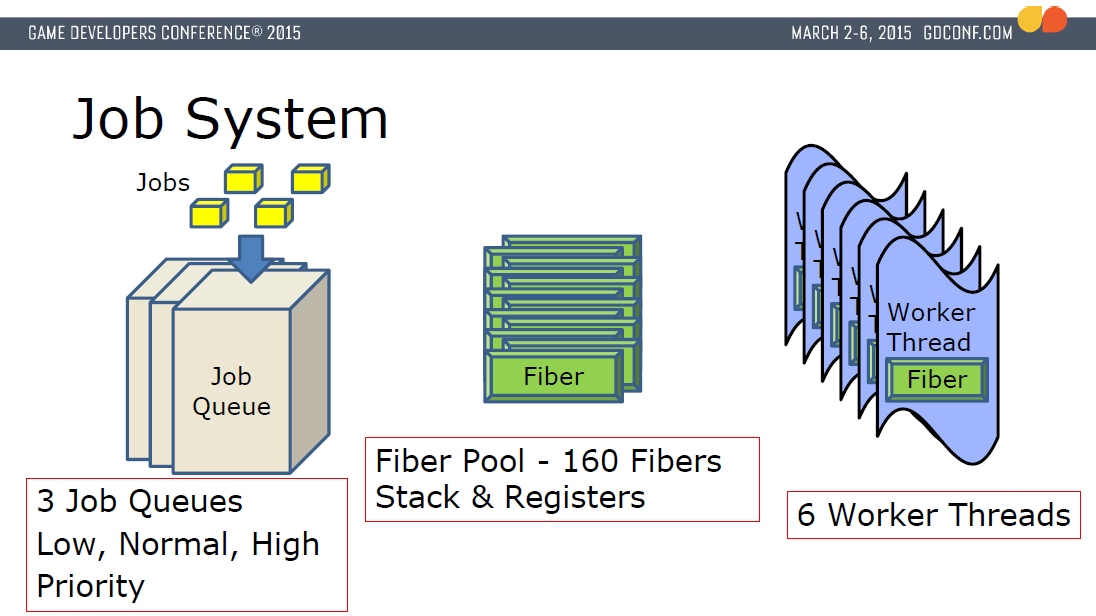
顽皮狗引擎作业系统架构图。拥有6个工作线程,160个纤程,3个作业队列。
作业可以向作业队列添加新的作业,同时等待中的作业会放到专门的等待列表,每个等待中的作业会有引用计数,直到引用计数为0,才会从等待队列中出列,以便继续执行。
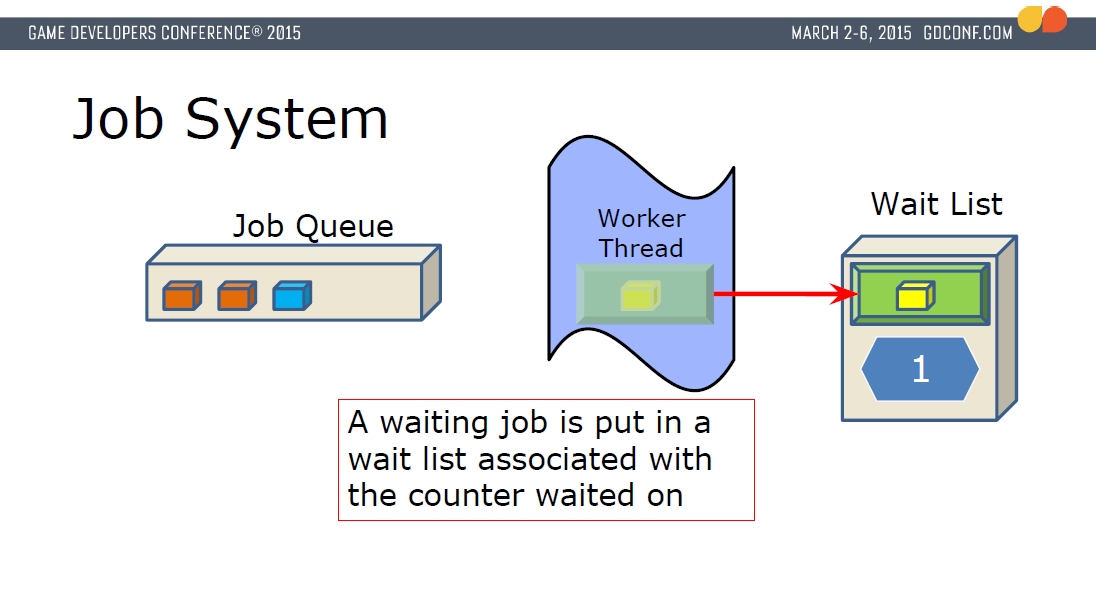
在顽皮狗引擎内,除了IO线程之外的所有东西都是作业,包括游戏物体更新、动作更新和混合、射线检测、渲染命令生成等等。可见将作业系统发挥得淋漓尽致,最大程度提升了并行的比例和效率。
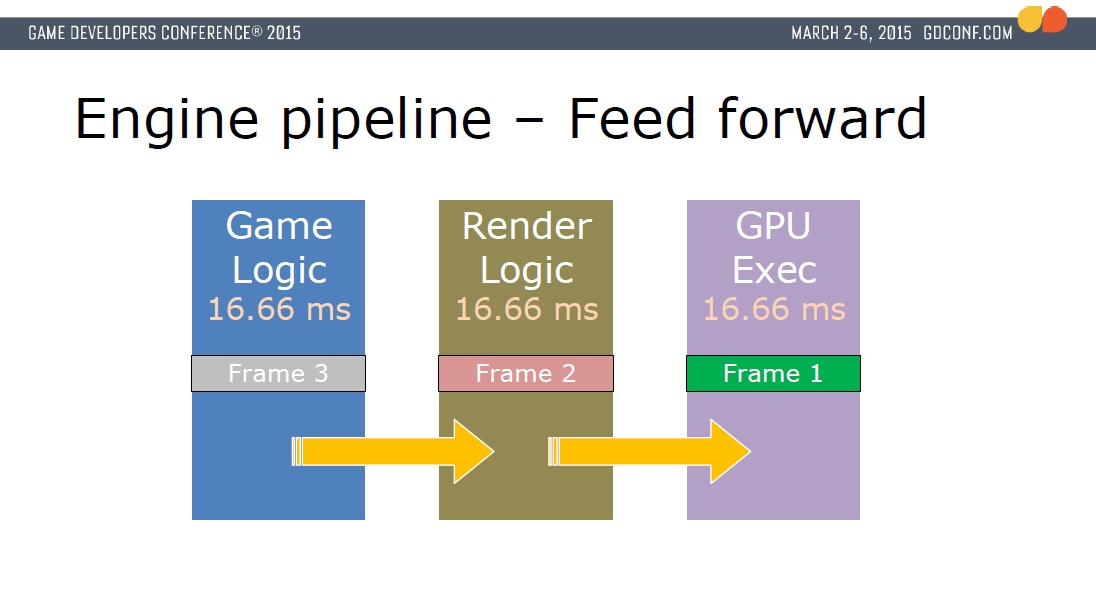
为了提升帧率,将游戏逻辑和渲染逻辑相分离,并行地执行,不过处理的是不同帧的数据,通常游戏数据领先渲染数据一帧,而渲染逻辑又领先GPU数据一帧。
通过这样的机制,可以避免CPU线程之间以及CPU和GPU之间的同步和等待,提升了帧率和吞吐量。
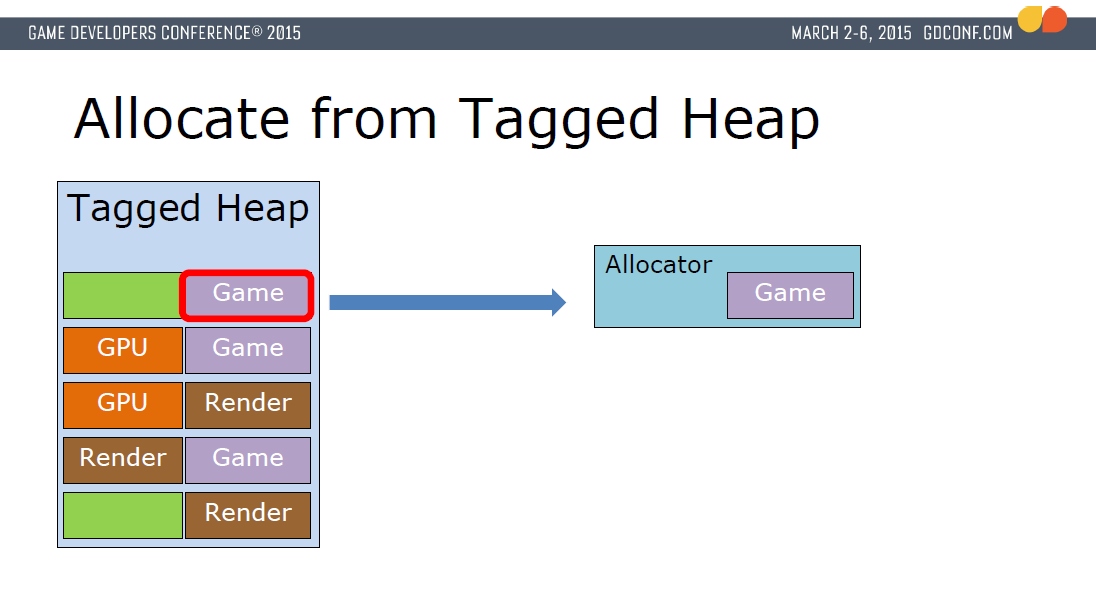
此外,它的内存分配也做了精致的管理,比如引入了带标签的内存堆(Tagged Heap),内存堆以2M为一块(Block),每个Block带有一个标签(Game、Render、GPU之一),分配器分配和释放内存时是在标签堆里执行,避免直接向操作系统获取:
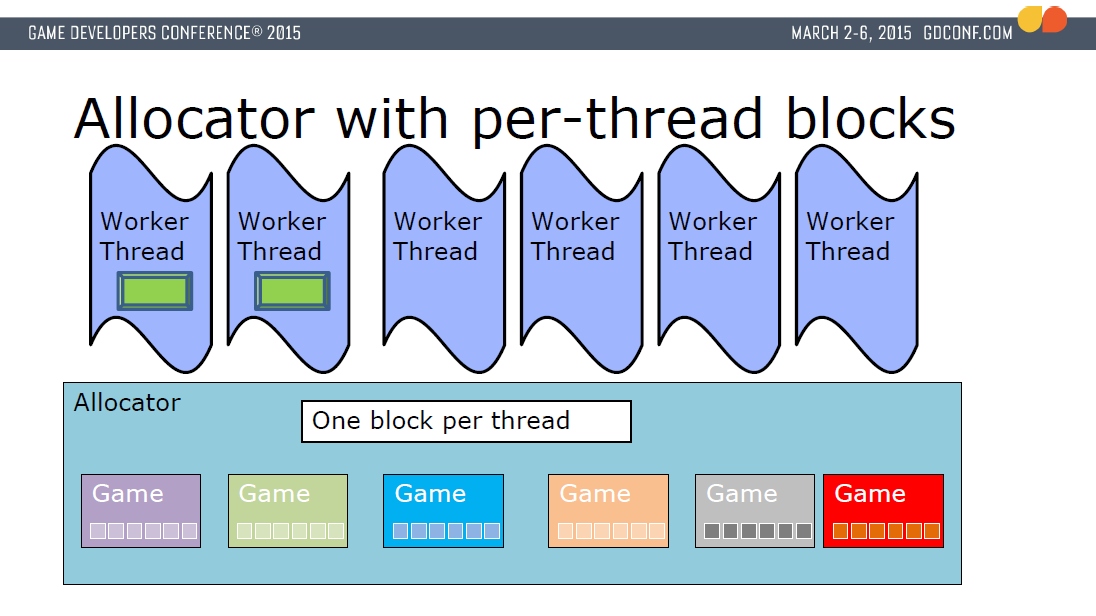
此外,分配器支持为每个工作线程分配一个专属的块(跟TLS类似),避免数据同步和等待的时间,避免数据竞险。
2.3.4 Destiny’s Engine
命运(Destiny)是一款第一人称的动作角色扮演MMORPG,它使用的引擎也被称为命运引擎(Destiny’s Engine)。
命运引擎在多线程架构上,采用的技术有基于任务的并行处理,作业管理设计和同步处理,作业的执行也是在纤程上。作业系统执行作业的优先级是FIFO(先进先出),作业图是异源架构,作业之间存在依赖,但没有栅栏。
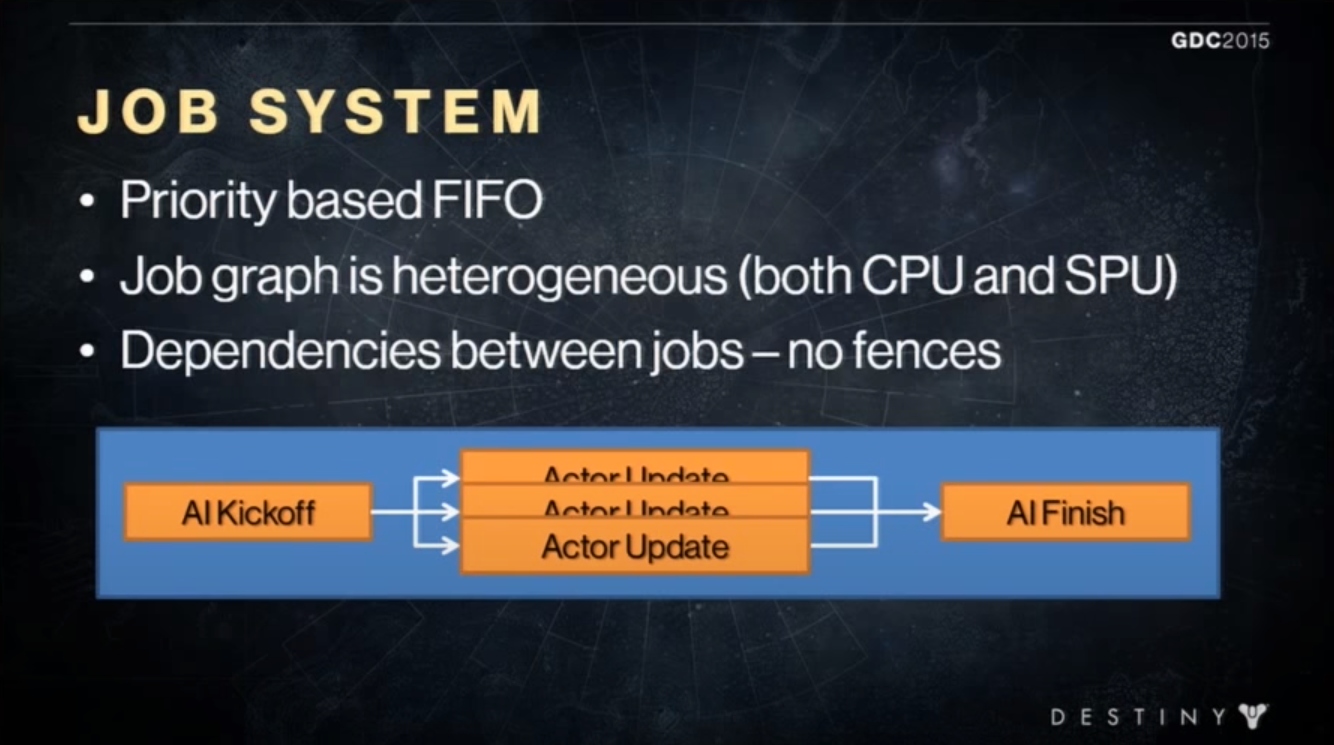
它将每一帧分成几个步骤:模拟游戏物体、物体裁剪、生成渲染命令、执行GPU相关工作、显示。在线程设计上,会创建6条系统线程,每条线程的内容依次是:模拟循环,其它作业,渲染循环,音频循环,作业核心和调试Log,异步任务、IO等。

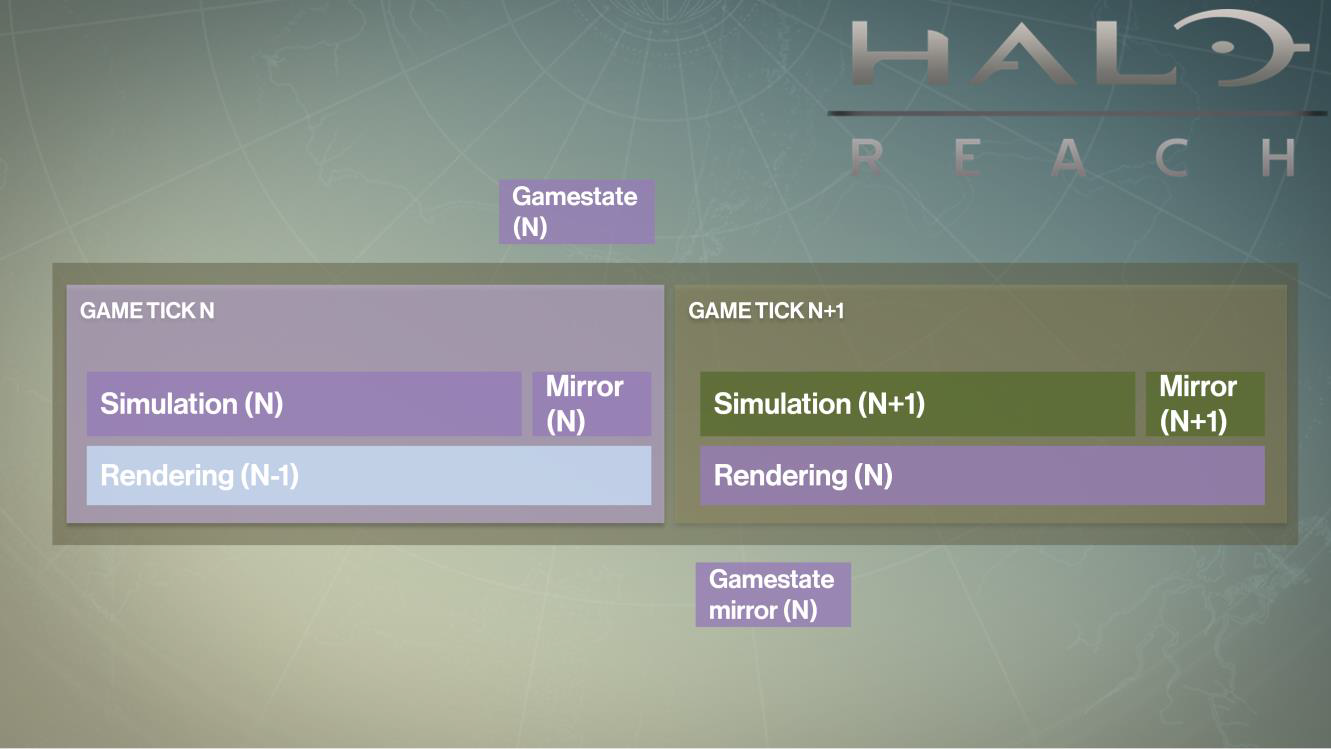
在处理帧之间的数据,也是分离开游戏模拟和渲染逻辑,游戏模拟总是领先渲染一帧。游戏模拟完之后,会将所有数据和状态拷贝一份(镜像,Mirror),以供下一帧的渲染使用:
命运引擎为了最大化CPU和GPU的并行效率,采取了动态加载平衡(dynamic load balancing)和智能作业合批(smart job batching),具体做法是将所有渲染和可见性剔除的工作加入到任务系统,保持低延迟。下图是并行化计算视图作业的图例:

此外,还将模拟逻辑从渲染逻辑中抽离和解耦,采用完全的数据驱动的渲染管线,所有的排序、内存分配、遍历等算法都遵循了高速缓存一致性(结构体小量化,数据对齐,使得单个结构体数据能一次性被加载进高速缓存行)。
2.4 UE的多线程机制
本章节主要剖析一下UE的多线程基础、设计及架构,以便后面更好地切入到多线程渲染。
2.4.1 UE的多线程基础
- TAtomic
UE的原子操作并没有使用C++的Atomic模板,而是自己实现了一套,叫TAtomic。它提供的功能有加载、存储、赋值等操作,在底层实现上,会采用平台相关的原子操作接口实现:
// Engine\Source\Runtime\Core\Public\Templates\Atomic.h
template <typename T>
FORCEINLINE T Load(const volatile T* Element)
{
// 采取平台相关的接口加载原子值.
auto Result = FPlatformAtomics::AtomicRead((volatile TUnderlyingIntegerType_T<T>*)Element);
return *(const T*)&Result;
}
template <typename T>
FORCEINLINE void Store(const volatile T* Element, T Value)
{
// 采取平台相关的接口存储原子值.
FPlatformAtomics::InterlockedExchange((volatile TUnderlyingIntegerType_T<T>*)Element, *(const TUnderlyingIntegerType_T<T>*)&Value);
}
template <typename T>
FORCEINLINE T Exchange(volatile T* Element, T Value)
{
// 采取平台相关的接口交换原子值.
auto Result = FPlatformAtomics::InterlockedExchange((volatile TUnderlyingIntegerType_T<T>*)Element, *(const TUnderlyingIntegerType_T<T>*)&Value);
return *(const T*)&Result;
}
在内存顺序上,不像C++提供了四种模式,UE做了简化,只提供了两种模式:
enum class EMemoryOrder
{
Relaxed, // 顺序松散, 不会引起重排序
SequentiallyConsistent // 顺序一致
};
需要注意的是,TAtomic虽然是模板类,但只对基本类型生效,UE是通过父类TAtomicBaseType_T来达到检测的目的:
template <typename T>
class TAtomic final : public UE4Atomic_Private::TAtomicBaseType_T<T>
{
static_assert(TIsTrivial<T>::Value, "TAtomic is only usable with trivial types");
(......)
}
- TFuture
UE实现了类似C++的Future和Promise对象,是模板类,抽象了返回值类型。以下是TFuture的声明:
// Engine\Source\Runtime\Core\Public\Async\Future.h
template<typename InternalResultType>
class TFutureBase
{
public:
bool IsReady() const;
bool IsValid() const;
void Wait() const
{
if (State.IsValid())
{
while (!WaitFor(FTimespan::MaxValue()));
}
}
bool WaitFor(const FTimespan& Duration) const
{
return State.IsValid() ? State->WaitFor(Duration) : false;
}
bool WaitUntil(const FDateTime& Time) const
{
return WaitFor(Time - FDateTime::UtcNow());
}
protected:
typedef TSharedPtr<TFutureState<InternalResultType>, ESPMode::ThreadSafe> StateType;
const StateType& GetState() const;
template<typename Func>
auto Then(Func Continuation);
template<typename Func>
auto Next(Func Continuation);
void Reset();
private:
/** Holds the future's state. */
StateType State;
};
template<typename ResultType>
class TFuture : public TFutureBase<ResultType>
{
typedef TFutureBase<ResultType> BaseType;
public:
ResultType Get() const
{
return this->GetState()->GetResult();
}
TSharedFuture<ResultType> Share()
{
return TSharedFuture<ResultType>(MoveTemp(*this));
}
};
- TPromise
TPromise通常要和TFuture配合使用,如下所示:
template<typename InternalResultType>
class TPromiseBase : FNoncopyable
{
typedef TSharedPtr<TFutureState<InternalResultType>, ESPMode::ThreadSafe> StateType;
(......)
protected:
const StateType& GetState();
private:
StateType State; // 存储了Future的状态.
};
template<typename ResultType>
class TPromise : public TPromiseBase<ResultType>
{
public:
typedef TPromiseBase<ResultType> BaseType;
public:
// 获取Future对象
TFuture<ResultType> GetFuture()
{
check(!FutureRetrieved);
FutureRetrieved = true;
return TFuture<ResultType>(this->GetState());
}
// 设置Future的值
FORCEINLINE void SetValue(const ResultType& Result)
{
EmplaceValue(Result);
}
FORCEINLINE void SetValue(ResultType&& Result)
{
EmplaceValue(MoveTemp(Result));
}
template<typename... ArgTypes>
void EmplaceValue(ArgTypes&&... Args)
{
this->GetState()->EmplaceResult(Forward<ArgTypes>(Args)...);
}
private:
bool FutureRetrieved;
};
- ParallelFor
ParallelFor是UE内置的支持多线程并行处理任务的For循环,在渲染系统中应用得相当普遍。它支持以下几种并行方式:
enum class EParallelForFlags
{
None, // 默认并行方式
ForceSingleThread = 1, // 强制单线程, 常用于调试.
Unbalanced = 2, // 非任务平衡, 常用于具有高度可变计算时间的任务.
PumpRenderingThread = 4, // 注入渲染线程. 如果是在渲染线程调用, 需要保证ProcessThread空闲状态.
};
支持的ParallelFor调用方式如下:
inline void ParallelFor(int32 Num, TFunctionRef<void(int32)> Body, bool bForceSingleThread, bool bPumpRenderingThread=false);
inline void ParallelFor(int32 Num, TFunctionRef<void(int32)> Body, EParallelForFlags Flags = EParallelForFlags::None);
template<typename FunctionType>
inline void ParallelForTemplate(int32 Num, const FunctionType& Body, EParallelForFlags Flags = EParallelForFlags::None);
inline void ParallelForWithPreWork(int32 Num, TFunctionRef<void(int32)> Body, TFunctionRef<void()> CurrentThreadWorkToDoBeforeHelping, bool bForceSingleThread, bool bPumpRenderingThread = false);
inline void ParallelForWithPreWork(int32 Num, TFunctionRef<void(int32)> Body, TFunctionRef<void()> CurrentThreadWorkToDoBeforeHelping, EParallelForFlags Flags = EParallelForFlags::None);
ParallelFor是基于TaskGraph机制实现的,由于TaskGraph后面才提到,这里就不涉及其实现。下面展示UE的一个应用案例:
// Engine\Source\Runtime\Engine\Private\Components\ActorComponent.cpp
// 并行化增加Primitive到场景的用例.
void FRegisterComponentContext::Process()
{
FSceneInterface* Scene = World->Scene;
ParallelFor(AddPrimitiveBatches.Num(), // 数量
[&](int32 Index) //回调函数, Index返回索引
{
if (!AddPrimitiveBatches[Index]->IsPendingKill())
{
Scene->AddPrimitive(AddPrimitiveBatches[Index]);
}
},
!FApp::ShouldUseThreadingForPerformance() // 是否多线程处理
);
AddPrimitiveBatches.Empty();
}
- 基础模板
UnrealTemplate.h定义了很多基础模板,用于数据转换、拷贝、转移等功能。下面例举部分常见的函数和类型:
| 模板名 | 解析 | stl映射 |
|---|---|---|
| template ReferencedType* IfAThenAElseB(ReferencedType* A,ReferencedType* B) |
返回A ? A : B | - |
| template void Move(T& A,typename TMoveSupportTraits |
释放A,将B的数据替换到A,但不会影响B的数据。 | - |
| template void Move(T& A,typename TMoveSupportTraits |
释放A,将B的数据替换到A,但会影响B的数据。 | - |
| FNoncopyable | 派生它即可实现不可拷贝的对象。 | - |
| TGuardValue | 带作业域的值,可指定一个新值和旧值,作用域内是新值,离开作用域变成旧值。 | - |
| TScopeCounter | 带作用域的计数器,作用域内计数器+1,离开作用域后计数器-1 | - |
| template typename TRemoveReference |
将引用转换成右值,可能会修改源值。 | std::move |
| template T CopyTemp(T& Val) |
强制创建右值的拷贝,不会改变源值。 | - |
| template T&& Forward(typename TRemoveReference |
将引用转换成右值引用。 | std::forward |
| template <typename T, typename ArgType> T StaticCast(ArgType&& Arg) |
静态类型转换。 | static_cast |
2.4.2 UE的多线程实现
UE的多线程实现上并没有采纳C++11标准库的那一套,而是自己从系统级做了封装和实现,包括系统线程、线程池、异步任务、任务图以及相关的通知和同步机制。
2.4.2.1 FRunnable
FRunnable是所有可以在多个线程并行地运行的物体的父类,它提供的基础接口如下:
// Engine\Source\Runtime\Core\Public\HAL\Runnable.h
class CORE_API FRunnable
{
public:
virtual bool Init(); // 初始化, 成功返回True.
virtual uint32 Run(); // 运行, 只有Init成功才会被调用.
virtual void Stop(); // 请求提前停止.
virtual void Exit(); // 退出, 清理数据.
};
FRunnable及其子类是可运行于多线程的对象,而与之对立的是只在单线程运行的类FSingleThreadRunnable:
// Engine\Source\Runtime\Core\Public\Misc\SingleThreadRunnable.h
// 多线程禁用下的单线程运行的物体
class CORE_API FSingleThreadRunnable
{
public:
virtual void Tick();
};
FRunnable的子类非常多,以下是常见的部分核心子类及其解析。
-
FRenderingThread:运行于渲染线程上的对象。后面有章节会专门剖析。
-
FRHIThread:运行于RHI线程上的对象。后面有章节会专门剖析。
-
FRenderingThreadTickHeartbeat:运行于心跳渲染线程上的物体。
-
FTaskThreadBase:在线程执行的任务父类,后面会有章节专门解析这部分。
-
FQueuedThread:可存储在线程池的线程父类。提供的接口如下:
// Engine\Source\Runtime\Core\Private\HAL\ThreadingBase.cpp class FQueuedThread : public FRunnable { protected: FEvent* DoWorkEvent; // 任务执行完毕的事件. TAtomic<bool> TimeToDie; // 是否需要超时. IQueuedWork* volatile QueuedWork; // 被执行的任务. class FQueuedThreadPoolBase* OwningThreadPool; // 所在的线程池. FRunnableThread* Thread; // 真正用于执行任务的线程. virtual uint32 Run() override; public: virtual bool Create(class FQueuedThreadPoolBase* InPool,uint32 InStackSize,EThreadPriority ThreadPriority); bool KillThread(); void DoWork(IQueuedWork* InQueuedWork); }; -
TAsyncRunnable:异步地在单独线程运行的任务,是个模板类,声明如下:
// Engine\Source\Runtime\Core\Public\Async\Async.h template<typename ResultType> class TAsyncRunnable: public FRunnable { public: virtual uint32 Run() override; private: TUniqueFunction<ResultType()> Function; TPromise<ResultType> Promise; TFuture<FRunnableThread*> ThreadFuture; }; -
FAsyncPurge:辅助类,提供销毁位于工作线程的UObject对象。
由此可见,FRunnable对象并不能独立存在,总是要依赖线程来真正地执行任务。
另外,还需要特意提出:FRenderingThread、FQueuedThread听名字像是真正的线程,然而并不是,只是用于处理某些特定任务的可运行物体,实际上还是要依赖它们内部FRunnableThread的成员对象来执行。
2.4.2.2 FRunnableThread
FRunnableThread是可运行线程的父类,提供了一组用于管理线程生命周期的接口。它提供的基础接口和解析如下:
// Engine\Source\Runtime\Core\Public\HAL\RunnableThread.h
class CORE_API FRunnableThread
{
static uint32 RunnableTlsSlot; // FRunnableThread的TLS插槽索引.
public:
static uint32 GetTlsSlot();
// 静态类, 用于创建线程, 需提供一个FRunnable对象, 用于线程执行的任务.
static FRunnableThread* Create(FRunnable* InRunnable, const TCHAR* ThreadName, uint32 InStackSize = 0,
EThreadPriority InThreadPri, uint64 InThreadAffinityMask,EThreadCreateFlags InCreateFlags);
// 设置线程优先级.
virtual void SetThreadPriority( EThreadPriority NewPriority );
// 暂停/继续运行线程
virtual void Suspend( bool bShouldPause = true );
// 销毁线程, 通常需要指定等待标记bShouldWait为true, 否则可能引起内存泄漏或死锁!
virtual bool Kill( bool bShouldWait = true );
// 等待执行完毕, 会卡调用线程.
virtual void WaitForCompletion();
const uint32 GetThreadID() const;
const FString& GetThreadName() const;
protected:
FString ThreadName;
FRunnable* Runnable; // 被执行对象
FEvent* ThreadInitSyncEvent; // 线程初始化完成同步事件, 防止线程未初始化完毕就执行任务.
uint64 ThreadAffinityMask; // 亲和标记, 用于线程倾向指定的CPU核心执行.
TArray<FTlsAutoCleanup*> TlsInstances; // 线程消耗时需要一起清理的Tls对象.
EThreadPriority ThreadPriority;
uint32 ThreadID;
private:
virtual void Tick();
};
需要注意的是,FRunnableThread提供了静态创建接口,创建线程时需要指定一个FRunnable对象,作为线程执行的任务。它是一个基础父类,下面是继承自它的部分核心子类及解析:
-
FRunnableThreadWin:Windows平台的线程实现。它的接口和实现如下:
// Engine\Source\Runtime\Core\Private\Windows\WindowsRunnableThread.h class FRunnableThreadWin : public FRunnableThread { HANDLE Thread; // 线程句柄 // 线程回调接口, 创建线程时作为参数传入. static ::DWORD STDCALL _ThreadProc( LPVOID pThis ) { check(pThis); return ((FRunnableThreadWin*)pThis)->GuardedRun(); } uint32 GuardedRun(); uint32 Run(); public: // 转换优先级 static int TranslateThreadPriority(EThreadPriority Priority) { switch (Priority) { case TPri_AboveNormal: return THREAD_PRIORITY_HIGHEST; case TPri_Normal: return THREAD_PRIORITY_HIGHEST - 1; case TPri_BelowNormal: return THREAD_PRIORITY_HIGHEST - 3; case TPri_Highest: return THREAD_PRIORITY_HIGHEST; case TPri_TimeCritical: return THREAD_PRIORITY_HIGHEST; case TPri_Lowest: return THREAD_PRIORITY_HIGHEST - 4; case TPri_SlightlyBelowNormal: return THREAD_PRIORITY_HIGHEST - 2; default: UE_LOG(LogHAL, Fatal, TEXT("Unknown Priority passed to TranslateThreadPriority()")); return TPri_Normal; } } // 设置优先级 virtual void SetThreadPriority( EThreadPriority NewPriority ) override { // Don't bother calling the OS if there is no need ThreadPriority = NewPriority; // Change the priority on the thread ::SetThreadPriority(Thread, TranslateThreadPriority(ThreadPriority)); } virtual void Suspend( bool bShouldPause = true ) override { check(Thread); if (bShouldPause == true) { SuspendThread(Thread); } else { ResumeThread(Thread); } } virtual bool Kill( bool bShouldWait = false ) override { check(Thread && "Did you forget to call Create()?"); bool bDidExitOK = true; // 先停止Runnable对象, 使得其有清理数据的机会 if (Runnable) { Runnable->Stop(); } // 等待线程处理完毕. if (bShouldWait == true) { // Wait indefinitely for the thread to finish. IMPORTANT: It's not safe to just go and // kill the thread with TerminateThread() as it could have a mutex lock that's shared // with a thread that's continuing to run, which would cause that other thread to // dead-lock. (This can manifest itself in code as simple as the synchronization // object that is used by our logging output classes. Trust us, we've seen it!) WaitForSingleObject(Thread,INFINITE); } // 关闭线程句柄 CloseHandle(Thread); Thread = NULL; return bDidExitOK; } virtual void WaitForCompletion( ) override { // Block until this thread exits WaitForSingleObject(Thread,INFINITE); } protected: virtual bool CreateInternal( FRunnable* InRunnable, const TCHAR* InThreadName, uint32 InStackSize = 0, EThreadPriority InThreadPri = TPri_Normal, uint64 InThreadAffinityMask = 0, EThreadCreateFlags InCreateFlags = EThreadCreateFlags::None) override { static bool bOnce = false; if (!bOnce) { bOnce = true; ::SetThreadPriority(::GetCurrentThread(), TranslateThreadPriority(TPri_Normal)); // set the main thread to be normal, since this is no longer the windows default. } check(InRunnable); Runnable = InRunnable; ThreadAffinityMask = InThreadAffinityMask; // 创建初始化完成同步事件. ThreadInitSyncEvent = FPlatformProcess::GetSynchEventFromPool(true); ThreadName = InThreadName ? InThreadName : TEXT("Unnamed UE4"); // Create the new thread { LLM_SCOPE(ELLMTag::ThreadStack); LLM_PLATFORM_SCOPE(ELLMTag::ThreadStackPlatform); // add in the thread size, since it's allocated in a black box we can't track LLM(FLowLevelMemTracker::Get().OnLowLevelAlloc(ELLMTracker::Default, nullptr, InStackSize)); LLM(FLowLevelMemTracker::Get().OnLowLevelAlloc(ELLMTracker::Platform, nullptr, InStackSize)); // 调用Windows API创建线程. Thread = CreateThread(NULL, InStackSize, _ThreadProc, this, STACK_SIZE_PARAM_IS_A_RESERVATION | CREATE_SUSPENDED, (::DWORD *)&ThreadID); } // If it fails, clear all the vars if (Thread == NULL) { Runnable = nullptr; } else { // 加入到线程管理器中. FThreadManager::Get().AddThread(ThreadID, this); ResumeThread(Thread); // Let the thread start up ThreadInitSyncEvent->Wait(INFINITE); SetThreadPriority(InThreadPri); } // 清理同步事件 FPlatformProcess::ReturnSynchEventToPool(ThreadInitSyncEvent); ThreadInitSyncEvent = nullptr; return Thread != NULL; } };从上面代码可看出,Windows平台的线程直接调用Windows API创建和同步信息,从而实现线程的平台抽象,从平台依赖抽离出来。
-
FRunnableThreadPThread:POSIX Thread(简称PThread)的父类,常用于类Unix POSIX 系统,如Linux、Solaris、Apple等。其实现和Windows平台类似,这里就不展开其代码解析了。它的子类有:
-
FRunnableThreadApple:苹果系统(MacOS、iOS)的线程。
-
FRunnableThreadAndroid:安卓系统的线程。
-
FRunnableThreadUnix:Unix系统的线程。
-
-
FRunnableThreadHoloLens:HoloLens系统的线程。
-
FFakeThread:假线程,多线程被禁用后的代替品,实际运行于单个线程。
FRunnable和FRunnableThread是相辅相成的,缺一而不可,一个是运行的载体,一个是运行的内容。下面是它们的一个应用示例:
// 派生FRunnable
class FMyRunnable : public FRunnable
{
bool bStop;
public:
virtual bool Init(void)
{
bStop = false;
return true;
}
virtual uint32 Run(void)
{
for (int32 i = 0; i < 10 && !bStop; i++)
{
FPlatformProcess::Sleep(1.0f);
}
return 0;
}
virtual void Stop(void)
{
bStop = true;
}
virtual void Exit(void)
{
}
};
void TestRunnableAndRunnableThread()
{
// 创建Runnable对象
FMyRunnable* MyRunnable = new FMyRunnable;
// 创建线程, 传入MyRunnable
FRunnableThread* MyThread = FRunnableThread::Create(MyRunnable, TEXT("MyRunnable"));
// 暂停当前线程
FPlatformProcess::Sleep(4.0f);
// 等待线程结束
MyRunnable->Stop();
MyThread->WaitForCompletion();
// 清理数据.
delete MyThread;
delete MyRunnable;
}
细心的同学应该有注意到,创建线程的时候,会将线程加入到FThreadManager中,也就是说所有的线程都由FThreadManager来管理。以下是FThreadManager的声明:
// Engine\Source\Runtime\Core\Public\HAL\ThreadManager.h
class FThreadManager
{
FCriticalSection ThreadsCritical; // 修改线程列表Threads的临界区
static bool bIsInitialized;
TMap<uint32, class FRunnableThread*, TInlineSetAllocator<256>> Threads; // 线程列表, 注意数据结构是Map, Key是线程ID.
public:
void AddThread(uint32 ThreadId, class FRunnableThread* Thread); // 增加线程
void RemoveThread(class FRunnableThread* Thread); // 删除线程
void Tick(); // 帧更新, 只对FFakeThread起作用.
const FString& GetThreadName(uint32 ThreadId);
void ForEachThread(TFunction<void(uint32, class FRunnableThread*)> Func); // 遍历线程
static bool IsInitialized();
static FThreadManager& Get();
};
2.4.2.3 QueuedWork
本节将阐述UE的队列化QueuedWork体系,包含IQueuedWork、TAsyncQueuedWork、FQueuedThreadPool、FQueuedThreadPoolBase等。
- IQueuedWork和TAsyncQueuedWork
IQueuedWork是一组抽象接口,存储着一组队列化的任务对象,会被FQueuedThreadPool线程池对象执行。IQueuedWork的接口如下:
// Engine\Source\Runtime\Core\Public\Misc\IQueuedWork.h
class IQueuedWork
{
public:
virtual void DoThreadedWork() = 0; // 执行队列化的任务.
virtual void Abandon() = 0; // 提前放弃执行, 并通知队列里的所有对象清理数据.
};
由于IQueuedWork只是抽象类,并没有实际执行代码,故而主要子类TAsyncQueuedWork承担了实现代码的任务,以下是TAsyncQueuedWork的声明和实现:
// Engine\Source\Runtime\Core\Public\Async\Async.h
template<typename ResultType>
class TAsyncQueuedWork : public IQueuedWork
{
public:
virtual void DoThreadedWork() override
{
SetPromise(Promise, Function);
delete this;
}
virtual void Abandon() override
{
// not supported
}
private:
TUniqueFunction<ResultType()> Function; // 被执行的函数列表.
TPromise<ResultType> Promise; // 用于同步的对象
};
- FQueuedThreadPool和FQueuedThreadPoolBase
与FRunnable和FRunnableThread类似,TAsyncQueuedWork也不能独立地执行任务,需要依赖FQueuedThreadPool来执行。下面是FQueuedThreadPool的声明:
// Engine\Source\Runtime\Core\Public\Misc\QueuedThreadPool.h
// 执行IQueuedWork任务列表的线程池.
class FQueuedThreadPool
{
public:
// 创建指定数量、栈大小和优先级的线程。
virtual bool Create( uint32 InNumQueuedThreads, uint32 StackSize = (32 * 1024), EThreadPriority ThreadPriority=TPri_Normal ) = 0;
// 销毁线程内的后台线程.
virtual void Destroy() = 0;
// 加入队列化任务. 如果有可用的线程, 则立即执行; 否则会稍后再执行.
virtual void AddQueuedWork( IQueuedWork* InQueuedWork ) = 0;
// 撤销指定队列化任务.
virtual bool RetractQueuedWork( IQueuedWork* InQueuedWork ) = 0;
// 获取线程数量.
virtual int32 GetNumThreads() const = 0;
public:
// 创建线程池对象.
static FQueuedThreadPool* Allocate();
// 重写栈大小.
static uint32 OverrideStackSize;
};
上面可以看出,FQueuedThreadPool是抽象类,只提供接口,并没有实现。实际上,实现是在FQueuedThreadPoolBase中,如下:
// Engine\Source\Runtime\Core\Private\HAL\ThreadingBase.cpp
class FQueuedThreadPoolBase : public FQueuedThreadPool
{
protected:
TArray<IQueuedWork*> QueuedWork; // 需要执行的任务列表
TArray<FQueuedThread*> QueuedThreads; // 线程池内的可用线程
TArray<FQueuedThread*> AllThreads; // 线程池内的所有线程
FCriticalSection* SynchQueue; // 同步临界区
bool TimeToDie; // 超时标记
public:
FQueuedThreadPoolBase()
: SynchQueue(nullptr)
, TimeToDie(0)
{ }
virtual ~FQueuedThreadPoolBase()
{
Destroy();
}
virtual bool Create(uint32 InNumQueuedThreads,uint32 StackSize = (32 * 1024),EThreadPriority ThreadPriority=TPri_Normal) override
{
// 处理同步锁.
bool bWasSuccessful = true;
check(SynchQueue == nullptr);
SynchQueue = new FCriticalSection();
FScopeLock Lock(SynchQueue);
// Presize the array so there is no extra memory allocated
check(QueuedThreads.Num() == 0);
QueuedThreads.Empty(InNumQueuedThreads);
if( OverrideStackSize > StackSize )
{
StackSize = OverrideStackSize;
}
// 创建线程, 注意创建的是FQueuedThread.
for (uint32 Count = 0; Count < InNumQueuedThreads && bWasSuccessful == true; Count++)
{
FQueuedThread* pThread = new FQueuedThread();
// 利用FQueuedThread对象创建真正的线程.
if (pThread->Create(this,StackSize,ThreadPriority) == true)
{
QueuedThreads.Add(pThread);
AllThreads.Add(pThread);
}
else
{
// 创建失败, 清理线程对象.
bWasSuccessful = false;
delete pThread;
}
}
// 创建线程池失败, 清理数据.
if (bWasSuccessful == false)
{
Destroy();
}
return bWasSuccessful;
}
virtual void Destroy() override
{
if (SynchQueue)
{
{
FScopeLock Lock(SynchQueue);
TimeToDie = 1;
FPlatformMisc::MemoryBarrier();
// Clean up all queued objects
for (int32 Index = 0; Index < QueuedWork.Num(); Index++)
{
QueuedWork[Index]->Abandon();
}
// Empty out the invalid pointers
QueuedWork.Empty();
}
// 等待所有线程执行完成, 注意这里并没有使用同步时间, 而是使用类似自旋锁的机制.
while (1)
{
{
// 访问AllThreads和QueuedThreads的数据时先锁定临界区. 防止其它线程修改数据.
FScopeLock Lock(SynchQueue);
if (AllThreads.Num() == QueuedThreads.Num())
{
break;
}
}
FPlatformProcess::Sleep(0.0f); // 切换当前线程时间片, 防止当前线程占用cpu时钟.
}
// 删除所有线程.
{
FScopeLock Lock(SynchQueue);
// Now tell each thread to die and delete those
for (int32 Index = 0; Index < AllThreads.Num(); Index++)
{
AllThreads[Index]->KillThread();
delete AllThreads[Index];
}
QueuedThreads.Empty();
AllThreads.Empty();
}
// 删除同步锁.
delete SynchQueue;
SynchQueue = nullptr;
}
}
int32 GetNumQueuedJobs() const
{
return QueuedWork.Num();
}
virtual int32 GetNumThreads() const
{
return AllThreads.Num();
}
// 加入队列化任务.
void AddQueuedWork(IQueuedWork* InQueuedWork) override
{
check(InQueuedWork != nullptr);
if (TimeToDie)
{
InQueuedWork->Abandon();
return;
}
check(SynchQueue);
FQueuedThread* Thread = nullptr;
{
// 操作线程池里的所有数据前都需要锁定临界区.
FScopeLock sl(SynchQueue);
const int32 AvailableThreadCount = QueuedThreads.Num();
// 没有可用线程, 加入任务队列, 稍后再执行.
if (AvailableThreadCount == 0)
{
QueuedWork.Add(InQueuedWork);
return;
}
// 从可用线程池中获取一个线程, 并将其从可用线程池中删除.
const int32 ThreadIndex = AvailableThreadCount - 1;
Thread = QueuedThreads[ThreadIndex];
QueuedThreads.RemoveAt(ThreadIndex, 1, /* do not allow shrinking */ false);
}
// 执行任务
Thread->DoWork(InQueuedWork);
}
virtual bool RetractQueuedWork(IQueuedWork* InQueuedWork) override
{
if (TimeToDie)
{
return false; // no special consideration for this, refuse the retraction and let shutdown proceed
}
check(InQueuedWork != nullptr);
check(SynchQueue);
FScopeLock sl(SynchQueue);
return !!QueuedWork.RemoveSingle(InQueuedWork);
}
// 如果有可用任务,则获取一个并执行, 否则将线程回归可用线程池. 此接口由FQueuedThread调用.
IQueuedWork* ReturnToPoolOrGetNextJob(FQueuedThread* InQueuedThread)
{
check(InQueuedThread != nullptr);
IQueuedWork* Work = nullptr;
// Check to see if there is any work to be done
FScopeLock sl(SynchQueue);
if (TimeToDie)
{
check(!QueuedWork.Num()); // we better not have anything if we are dying
}
if (QueuedWork.Num() > 0)
{
// Grab the oldest work in the queue. This is slower than
// getting the most recent but prevents work from being
// queued and never done
Work = QueuedWork[0];
// Remove it from the list so no one else grabs it
QueuedWork.RemoveAt(0, 1, /* do not allow shrinking */ false);
}
if (!Work)
{
// There was no work to be done, so add the thread to the pool
QueuedThreads.Add(InQueuedThread);
}
return Work;
}
};
上面的接口ReturnToPoolOrGetNextJob并非FQueuedThreadPoolBase调用,而是由正在执行任务且执行完毕的FQueuedThread对象主动调用,如下所示:
uint32 FQueuedThread::Run()
{
while (!TimeToDie.Load(EMemoryOrder::Relaxed))
{
bool bContinueWaiting = true;
(......)
// 让事件等待.
if (bContinueWaiting)
{
DoWorkEvent->Wait();
}
IQueuedWork* LocalQueuedWork = QueuedWork;
QueuedWork = nullptr;
FPlatformMisc::MemoryBarrier();
check(LocalQueuedWork || TimeToDie.Load(EMemoryOrder::Relaxed)); // well you woke me up, where is the job or termination request?
// 不断地从线程池获取任务并执行, 直到线程池的所有任务执行完毕.
while (LocalQueuedWork)
{
// 执行任务.
LocalQueuedWork->DoThreadedWork();
// 从线程池获取下一个任务.
LocalQueuedWork = OwningThreadPool->ReturnToPoolOrGetNextJob(this);
}
}
return 0;
}
从上面可以看出,FQueuedThreadPool和FQueuedThread的数据和接口巧妙地配合,从而并行化地执行任务。
- GThreadPool
线程池的机制已经讲述完毕,下面讲一下UE的全局线程池GThreadPool的初始化过程,此过程在FEngineLoop::PreInitPreStartupScreen中,1.4.6.1 引擎预初始化已经有提及:
// Engine\Source\Runtime\Launch\Private\LaunchEngineLoop.cpp
int32 FEngineLoop::PreInitPreStartupScreen(const TCHAR* CmdLine)
{
(......)
{
TRACE_THREAD_GROUP_SCOPE("ThreadPool");
// 创建全局线程池
GThreadPool = FQueuedThreadPool::Allocate();
int32 NumThreadsInThreadPool = FPlatformMisc::NumberOfWorkerThreadsToSpawn();
// 如果是纯服务器模式, 线程池只有一个线程.
if (FPlatformProperties::IsServerOnly())
{
NumThreadsInThreadPool = 1;
}
// 创建工作线程相等的线程数量.
verify(GThreadPool->Create(NumThreadsInThreadPool, StackSize * 1024, TPri_SlightlyBelowNormal));
}
(......)
}
如果需要GThreadPool为我们做事,则使用示例如下:
// Engine\Source\Runtime\Engine\Private\ShadowMap.cpp
// 多线程编码纹理
if (bMultithreadedEncode)
{
// 完成的任务计数器.
FThreadSafeCounter Counter(PendingTextures.Num());
// 待编码的纹理任务列表
TArray<FAsyncEncode<FShadowMapPendingTexture>> AsyncEncodeTasks;
AsyncEncodeTasks.Empty(PendingTextures.Num());
// 创建所有任务, 加入到AsyncEncodeTasks列表中.
for (auto& PendingTexture : PendingTextures)
{
PendingTexture.CreateUObjects();
// 创建AsyncEncodeTask
auto AsyncEncodeTask = new (AsyncEncodeTasks)FAsyncEncode<FShadowMapPendingTexture>(&PendingTexture, LightingScenario, Counter, TextureCompressorModule);
// 将AsyncEncodeTask加入全局线程池并执行.
GThreadPool->AddQueuedWork(AsyncEncodeTask);
}
// 如果还有任务未完成, 则让当前线程进入睡眠状态.
while (Counter.GetValue() > 0)
{
GWarn->UpdateProgress(Counter.GetValue(), PendingTextures.Num());
FPlatformProcess::Sleep(0.0001f);
}
}
2.4.2.4 TaskGraph
TaskGraph直译是任务图,使用的图是DAG(Directed Acyclic Graph,有向非循环图),可以指定依赖关系,指定前序和后序任务,但不能有循环依赖。它是UE内迄今为止最为复杂的并行任务系统,涉及的概念、运行机制的复杂度都陡增,本节将花大篇幅描述它们,旨在阐述清楚它们的机制和原理。
- FBaseGraphTask
FBaseGraphTask是运行于TaskGraph的任务,是个基础父类,其派生的具体任务子类才会执行任务。它的声明(节选)如下:
// Engine\Source\Runtime\Core\Public\Async\TaskGraphInterfaces.h
class FBaseGraphTask
{
protected:
FBaseGraphTask(int32 InNumberOfPrerequistitesOutstanding);
// 先决任务完成或部分地完成.
void PrerequisitesComplete(ENamedThreads::Type CurrentThread, int32 NumAlreadyFinishedPrequistes, bool bUnlock = true);
// 带条件(前置任务都已经执行完毕)地执行任务
void ConditionalQueueTask(ENamedThreads::Type CurrentThread)
{
if (NumberOfPrerequistitesOutstanding.Decrement()==0)
{
QueueTask(CurrentThread);
}
}
private:
// 真正地执行任务, 由子类实现.
virtual void ExecuteTask(TArray<FBaseGraphTask*>& NewTasks, ENamedThreads::Type CurrentThread)=0;
// 加入到TaskGraph任务队列中.
void QueueTask(ENamedThreads::Type CurrentThreadIfKnown)
{
checkThreadGraph(LifeStage.Increment() == int32(LS_Queued));
FTaskGraphInterface::Get().QueueTask(this, ThreadToExecuteOn, CurrentThreadIfKnown);
}
ENamedThreads::Type ThreadToExecuteOn; // 执行任务的线程类型
FThreadSafeCounter NumberOfPrerequistitesOutstanding; // 执行任务前的计数器
};
- TGraphTask
FBaseGraphTask的唯一子类TGraphTask承接了完成执行任务的代码。TGraphTask的声明和实现如下:
template<typename TTask>
class TGraphTask final : public FBaseGraphTask
{
public:
// 构造任务的辅助类.
class FConstructor
{
public:
// 创建TTask任务对象, 然后设置TGraphTask任务的数据, 以便在适当时机执行.
template<typename...T>
FGraphEventRef ConstructAndDispatchWhenReady(T&&... Args)
{
new ((void *)&Owner->TaskStorage) TTask(Forward<T>(Args)...);
return Owner->Setup(Prerequisites, CurrentThreadIfKnown);
}
// 创建TTask任务对象, 然后设置TGraphTask任务的数据, 并持有但不执行.
template<typename...T>
TGraphTask* ConstructAndHold(T&&... Args)
{
new ((void *)&Owner->TaskStorage) TTask(Forward<T>(Args)...);
return Owner->Hold(Prerequisites, CurrentThreadIfKnown);
}
private:
TGraphTask* Owner; // 所在的TGraphTask对象.
const FGraphEventArray* Prerequisites; // 先决任务.
ENamedThreads::Type CurrentThreadIfKnown;
};
// 创建任务, 注意返回的是FConstructor对象, 以便对任务执行后续操作.
static FConstructor CreateTask(const FGraphEventArray* Prerequisites = NULL, ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread)
{
int32 NumPrereq = Prerequisites ? Prerequisites->Num() : 0;
if (sizeof(TGraphTask) <= FBaseGraphTask::SMALL_TASK_SIZE)
{
void *Mem = FBaseGraphTask::GetSmallTaskAllocator().Allocate();
return FConstructor(new (Mem) TGraphTask(TTask::GetSubsequentsMode() == ESubsequentsMode::FireAndForget ? NULL : FGraphEvent::CreateGraphEvent(), NumPrereq), Prerequisites, CurrentThreadIfKnown);
}
return FConstructor(new TGraphTask(TTask::GetSubsequentsMode() == ESubsequentsMode::FireAndForget ? NULL : FGraphEvent::CreateGraphEvent(), NumPrereq), Prerequisites, CurrentThreadIfKnown);
}
void Unlock(ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread)
{
ConditionalQueueTask(CurrentThreadIfKnown);
}
FGraphEventRef GetCompletionEvent()
{
return Subsequents;
}
private:
// 执行任务
void ExecuteTask(TArray<FBaseGraphTask*>& NewTasks, ENamedThreads::Type CurrentThread) override
{
(......)
// 处理后续任务.
if (TTask::GetSubsequentsMode() == ESubsequentsMode::TrackSubsequents)
{
Subsequents->CheckDontCompleteUntilIsEmpty(); // we can only add wait for tasks while executing the task
}
// 执行任务
TTask& Task = *(TTask*)&TaskStorage;
{
FScopeCycleCounter Scope(Task.GetStatId(), true);
Task.DoTask(CurrentThread, Subsequents);
Task.~TTask();
checkThreadGraph(ENamedThreads::GetThreadIndex(CurrentThread) <= ENamedThreads::GetRenderThread() || FMemStack::Get().IsEmpty()); // you must mark and pop memstacks if you use them in tasks! Named threads are excepted.
}
TaskConstructed = false;
// 执行后序任务.
if (TTask::GetSubsequentsMode() == ESubsequentsMode::TrackSubsequents)
{
FPlatformMisc::MemoryBarrier();
Subsequents->DispatchSubsequents(NewTasks, CurrentThread);
}
// 释放任务对象数据.
if (sizeof(TGraphTask) <= FBaseGraphTask::SMALL_TASK_SIZE)
{
this->TGraphTask::~TGraphTask();
FBaseGraphTask::GetSmallTaskAllocator().Free(this);
}
else
{
delete this;
}
}
// 设置先决任务.
void SetupPrereqs(const FGraphEventArray* Prerequisites, ENamedThreads::Type CurrentThreadIfKnown, bool bUnlock)
{
checkThreadGraph(!TaskConstructed);
TaskConstructed = true;
TTask& Task = *(TTask*)&TaskStorage;
SetThreadToExecuteOn(Task.GetDesiredThread());
int32 AlreadyCompletedPrerequisites = 0;
if (Prerequisites)
{
for (int32 Index = 0; Index < Prerequisites->Num(); Index++)
{
check((*Prerequisites)[Index]);
if (!(*Prerequisites)[Index]->AddSubsequent(this))
{
AlreadyCompletedPrerequisites++;
}
}
}
PrerequisitesComplete(CurrentThreadIfKnown, AlreadyCompletedPrerequisites, bUnlock);
}
// 设置任务数据.
FGraphEventRef Setup(const FGraphEventArray* Prerequisites = NULL, ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread)
{
FGraphEventRef ReturnedEventRef = Subsequents; // very important so that this doesn't get destroyed before we return
SetupPrereqs(Prerequisites, CurrentThreadIfKnown, true);
return ReturnedEventRef;
}
// 持有任务数据.
TGraphTask* Hold(const FGraphEventArray* Prerequisites = NULL, ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread)
{
SetupPrereqs(Prerequisites, CurrentThreadIfKnown, false);
return this;
}
// 创建任务.
static FConstructor CreateTask(FGraphEventRef SubsequentsToAssume, const FGraphEventArray* Prerequisites = NULL, ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread)
{
if (sizeof(TGraphTask) <= FBaseGraphTask::SMALL_TASK_SIZE)
{
void *Mem = FBaseGraphTask::GetSmallTaskAllocator().Allocate();
return FConstructor(new (Mem) TGraphTask(SubsequentsToAssume, Prerequisites ? Prerequisites->Num() : 0), Prerequisites, CurrentThreadIfKnown);
}
return FConstructor(new TGraphTask(SubsequentsToAssume, Prerequisites ? Prerequisites->Num() : 0), Prerequisites, CurrentThreadIfKnown);
}
TAlignedBytes<sizeof(TTask),alignof(TTask)> TaskStorage; // 被执行的任务对象.
bool TaskConstructed;
FGraphEventRef Subsequents; // 后续任务同步对象.
};
- TAsyncGraphTask
上面可知TGraphTask虽然是任务,但它执行的实际任务是TTask的模板类,UE的注释里边给出了TTask的基本形式:
class FGenericTask
{
TSomeType SomeArgument;
public:
FGenericTask(TSomeType InSomeArgument) // 不能用引用, 可用指针代替之.
: SomeArgument(InSomeArgument)
{
// Usually the constructor doesn't do anything except save the arguments for use in DoWork or GetDesiredThread.
}
~FGenericTask()
{
// you will be destroyed immediately after you execute. Might as well do cleanup in DoWork, but you could also use a destructor.
}
FORCEINLINE TStatId GetStatId() const
{
RETURN_QUICK_DECLARE_CYCLE_STAT(FGenericTask, STATGROUP_TaskGraphTasks);
}
[static] ENamedThreads::Type GetDesiredThread()
{
return ENamedThreads::[named thread or AnyThread];
}
void DoTask(ENamedThreads::Type CurrentThread, const FGraphEventRef& MyCompletionGraphEvent)
{
// The arguments are useful for setting up other tasks.
// Do work here, probably using SomeArgument.
MyCompletionGraphEvent->DontCompleteUntil(TGraphTask<FSomeChildTask>::CreateTask(NULL,CurrentThread).ConstructAndDispatchWhenReady());
}
};
然而,我们如果需要定制自己的任务,直接使用或派生TAsyncGraphTask类即可,无需另起炉灶。TAsyncGraphTask和其父类FAsyncGraphTaskBase声明如下:
// Engine\Source\Runtime\Core\Public\Async\Async.h
// 后序任务模式
namespace ESubsequentsMode
{
enum Type
{
TrackSubsequents, // 追踪后序任务
FireAndForget // 无需追踪任务依赖, 可以避免线程同步, 提升执行效率.
};
}
class FAsyncGraphTaskBase
{
public:
TStatId GetStatId() const
{
return GET_STATID(STAT_TaskGraph_OtherTasks);
}
// 任务后序模式.
static ESubsequentsMode::Type GetSubsequentsMode()
{
return ESubsequentsMode::FireAndForget;
}
};
template<typename ResultType>
class TAsyncGraphTask : public FAsyncGraphTaskBase
{
public:
// 构造任务, InFunction就是需要执行的代码段.
TAsyncGraphTask(TUniqueFunction<ResultType()>&& InFunction, TPromise<ResultType>&& InPromise, ENamedThreads::Type InDesiredThread = ENamedThreads::AnyThread)
: Function(MoveTemp(InFunction))
, Promise(MoveTemp(InPromise))
, DesiredThread(InDesiredThread)
{ }
public:
// 执行任务
void DoTask(ENamedThreads::Type CurrentThread, const FGraphEventRef& MyCompletionGraphEvent)
{
SetPromise(Promise, Function);
}
ENamedThreads::Type GetDesiredThread()
{
return DesiredThread;
}
TFuture<ResultType> GetFuture()
{
return Promise.GetFuture();
}
private:
TUniqueFunction<ResultType()> Function; // 被执行的函数对象.
TPromise<ResultType> Promise; // 同步对象.
ENamedThreads::Type DesiredThread; // 期望执行的线程类型.
};
- FTaskThreadBase
FTaskThreadBase是执行任务的线程父类,定义了一组设置、操作任务的接口,声明如下:
class FTaskThreadBase : public FRunnable, FSingleThreadRunnable
{
public:
FTaskThreadBase()
: ThreadId(ENamedThreads::AnyThread)
, PerThreadIDTLSSlot(0xffffffff)
, OwnerWorker(nullptr)
{
NewTasks.Reset(128);
}
// 设置数据.
void Setup(ENamedThreads::Type InThreadId, uint32 InPerThreadIDTLSSlot, FWorkerThread* InOwnerWorker)
{
ThreadId = InThreadId;
check(ThreadId >= 0);
PerThreadIDTLSSlot = InPerThreadIDTLSSlot;
OwnerWorker = InOwnerWorker;
}
// 从当前线程初始化.
void InitializeForCurrentThread()
{
// 设置平台相关的TLS.
FPlatformTLS::SetTlsValue(PerThreadIDTLSSlot, OwnerWorker);
}
ENamedThreads::Type GetThreadId() const;
// 用于带名字的线程处理任务直到线程空闲或RequestQuit被调用.
virtual void ProcessTasksUntilQuit(int32 QueueIndex) = 0;
// 用于带名字的线程处理任务直到线程空闲或RequestQuit被调用.
virtual uint64 ProcessTasksUntilIdle(int32 QueueIndex);
// 请求退出. 会导致线程空闲时退出到调用者. 如果是带名字的线程, 在ProcessTasksUntilQuit中用以返回给调用者; 无名线程则直接关闭.
virtual void RequestQuit(int32 QueueIndex) = 0;
// 入队任务, 假设this线程和当前线程一样. 如果是带名字的线程, 会直接进入私有的队列.
virtual void EnqueueFromThisThread(int32 QueueIndex, FBaseGraphTask* Task);
// 入队任务, 假设this线程和当前线程不一样.
virtual bool EnqueueFromOtherThread(int32 QueueIndex, FBaseGraphTask* Task);
// 唤醒线程.
virtual void WakeUp();
// 查询任务是否在处理中.
virtual bool IsProcessingTasks(int32 QueueIndex) = 0;
// 单线程帧更新
virtual void Tick() override
{
ProcessTasksUntilIdle(0);
}
// FRunnable API
virtual bool Init() override
{
InitializeForCurrentThread();
return true;
}
virtual uint32 Run() override
{
check(OwnerWorker); // make sure we are started up
ProcessTasksUntilQuit(0);
FMemory::ClearAndDisableTLSCachesOnCurrentThread();
return 0;
}
virtual void Stop() override
{
RequestQuit(-1);
}
virtual void Exit() override
{
}
virtual FSingleThreadRunnable* GetSingleThreadInterface() override
{
return this;
}
protected:
ENamedThreads::Type ThreadId; // 线程id(线程索引)
uint32 PerThreadIDTLSSlot; // TLS槽.
FThreadSafeCounter IsStalled; // 阻塞计数器. 用于触发阻塞信号.
TArray<FBaseGraphTask*> NewTasks; // 待处理的任务列表.
FWorkerThread* OwnerWorker; // 所在的工作线程对象.
};
FTaskThreadBase只是抽象类,具体的实现由子类FNamedTaskThread和FTaskThreadAnyThread完成。
其中FNamedTaskThread处理带名字线程的任务:
// 带名字的任务线程.
class FNamedTaskThread : public FTaskThreadBase
{
public:
// 用于带名字的线程处理任务直到线程空闲或RequestQuit被调用.
virtual void ProcessTasksUntilQuit(int32 QueueIndex) override
{
check(Queue(QueueIndex).StallRestartEvent); // make sure we are started up
Queue(QueueIndex).QuitForReturn = false;
verify(++Queue(QueueIndex).RecursionGuard == 1);
// 不断地循环处理队列任务, 直到退出、关闭或平台不支持多线程。
do
{
ProcessTasksNamedThread(QueueIndex, FPlatformProcess::SupportsMultithreading());
} while (!Queue(QueueIndex).QuitForReturn && !Queue(QueueIndex).QuitForShutdown && FPlatformProcess::SupportsMultithreading()); // @Hack - quit now when running with only one thread.
verify(!--Queue(QueueIndex).RecursionGuard);
}
// 用于带名字的线程处理任务直到线程空闲或RequestQuit被调用.
virtual uint64 ProcessTasksUntilIdle(int32 QueueIndex) override
{
check(Queue(QueueIndex).StallRestartEvent); // make sure we are started up
Queue(QueueIndex).QuitForReturn = false;
verify(++Queue(QueueIndex).RecursionGuard == 1);
uint64 ProcessedTasks = ProcessTasksNamedThread(QueueIndex, false);
verify(!--Queue(QueueIndex).RecursionGuard);
return ProcessedTasks;
}
// 处理任务.
uint64 ProcessTasksNamedThread(int32 QueueIndex, bool bAllowStall)
{
uint64 ProcessedTasks = 0;
(......)
TStatId StallStatId;
bool bCountAsStall = false;
(......)
while (!Queue(QueueIndex).QuitForReturn)
{
// 从队列首部获取任务.
FBaseGraphTask* Task = Queue(QueueIndex).StallQueue.Pop(0, bAllowStall);
TestRandomizedThreads();
if (!Task)
{
if (bAllowStall)
{
{
FScopeCycleCounter Scope(StallStatId);
Queue(QueueIndex).StallRestartEvent->Wait(MAX_uint32, bCountAsStall);
if (Queue(QueueIndex).QuitForShutdown)
{
return ProcessedTasks;
}
TestRandomizedThreads();
}
continue;
}
else
{
break; // we were asked to quit
}
}
else // 任务不为空
{
// 执行任务.
Task->Execute(NewTasks, ENamedThreads::Type(ThreadId | (QueueIndex << ENamedThreads::QueueIndexShift)));
ProcessedTasks++;
TestRandomizedThreads();
}
}
return ProcessedTasks;
}
virtual void EnqueueFromThisThread(int32 QueueIndex, FBaseGraphTask* Task) override
{
checkThreadGraph(Task && Queue(QueueIndex).StallRestartEvent); // make sure we are started up
uint32 PriIndex = ENamedThreads::GetTaskPriority(Task->ThreadToExecuteOn) ? 0 : 1;
int32 ThreadToStart = Queue(QueueIndex).StallQueue.Push(Task, PriIndex);
check(ThreadToStart < 0); // if I am stalled, then how can I be queueing a task?
}
virtual void RequestQuit(int32 QueueIndex) override
{
// this will not work under arbitrary circumstances. For example you should not attempt to stop threads unless they are known to be idle.
if (!Queue(0).StallRestartEvent)
{
return;
}
if (QueueIndex == -1)
{
// we are shutting down
checkThreadGraph(Queue(0).StallRestartEvent); // make sure we are started up
checkThreadGraph(Queue(1).StallRestartEvent); // make sure we are started up
Queue(0).QuitForShutdown = true;
Queue(1).QuitForShutdown = true;
Queue(0).StallRestartEvent->Trigger();
Queue(1).StallRestartEvent->Trigger();
}
else
{
checkThreadGraph(Queue(QueueIndex).StallRestartEvent); // make sure we are started up
Queue(QueueIndex).QuitForReturn = true;
}
}
virtual bool EnqueueFromOtherThread(int32 QueueIndex, FBaseGraphTask* Task) override
{
TestRandomizedThreads();
checkThreadGraph(Task && Queue(QueueIndex).StallRestartEvent); // make sure we are started up
uint32 PriIndex = ENamedThreads::GetTaskPriority(Task->ThreadToExecuteOn) ? 0 : 1;
int32 ThreadToStart = Queue(QueueIndex).StallQueue.Push(Task, PriIndex);
if (ThreadToStart >= 0)
{
QUICK_SCOPE_CYCLE_COUNTER(STAT_TaskGraph_EnqueueFromOtherThread_Trigger);
checkThreadGraph(ThreadToStart == 0);
TASKGRAPH_SCOPE_CYCLE_COUNTER(1, STAT_TaskGraph_EnqueueFromOtherThread_Trigger);
Queue(QueueIndex).StallRestartEvent->Trigger();
return true;
}
return false;
}
virtual bool IsProcessingTasks(int32 QueueIndex) override
{
return !!Queue(QueueIndex).RecursionGuard;
}
private:
// 线程任务队列.
struct FThreadTaskQueue
{
FStallingTaskQueue<FBaseGraphTask, PLATFORM_CACHE_LINE_SIZE, 2> StallQueue; // 阻塞的任务队列.
uint32 RecursionGuard; // 防止循环(递归)调用.
bool QuitForReturn; // 是否请求退出.
bool QuitForShutdown; // 是否请求关闭.
FEvent* StallRestartEvent; // 当线程满载时的阻塞事件.
};
FORCEINLINE FThreadTaskQueue& Queue(int32 QueueIndex)
{
checkThreadGraph(QueueIndex >= 0 && QueueIndex < ENamedThreads::NumQueues);
return Queues[QueueIndex];
}
FORCEINLINE const FThreadTaskQueue& Queue(int32 QueueIndex) const
{
checkThreadGraph(QueueIndex >= 0 && QueueIndex < ENamedThreads::NumQueues);
return Queues[QueueIndex];
}
FThreadTaskQueue Queues[ENamedThreads::NumQueues]; // 带名字线程专用的任务队列.
};
FTaskThreadAnyThread用于处理无名线程的任务,由于无名线程有很多个,所以处理任务时和FNamedTaskThread有所不同:
class FTaskThreadAnyThread : public FTaskThreadBase
{
public:
virtual void ProcessTasksUntilQuit(int32 QueueIndex) override
{
if (PriorityIndex != (ENamedThreads::BackgroundThreadPriority >> ENamedThreads::ThreadPriorityShift))
{
FMemory::SetupTLSCachesOnCurrentThread();
}
check(!QueueIndex);
do
{
// 处理任务
ProcessTasks();
} while (!Queue.QuitForShutdown && FPlatformProcess::SupportsMultithreading()); // @Hack - quit now when running with only one thread.
}
virtual uint64 ProcessTasksUntilIdle(int32 QueueIndex) override
{
if (!FPlatformProcess::SupportsMultithreading())
{
// 处理任务
return ProcessTasks();
}
else
{
check(0);
return 0;
}
}
(......)
private:
#if UE_EXTERNAL_PROFILING_ENABLED
static inline const TCHAR* ThreadPriorityToName(int32 PriorityIdx)
{
PriorityIdx <<= ENamedThreads::ThreadPriorityShift;
if (PriorityIdx == ENamedThreads::HighThreadPriority)
{
return TEXT("Task Thread HP"); // 高优先级的工作线程
}
else if (PriorityIdx == ENamedThreads::NormalThreadPriority)
{
return TEXT("Task Thread NP"); // 普通优先级的工作线程
}
else if (PriorityIdx == ENamedThreads::BackgroundThreadPriority)
{
return TEXT("Task Thread BP"); // 后台优先级的工作线程
}
else
{
return TEXT("Task Thread Unknown Priority");
}
}
#endif
// 此处的处理任务与FNamedTaskThread有区别, 在于获取任务的方式不一样, 是从TaskGraph系统中的无名任务队列获取任务的.
uint64 ProcessTasks()
{
LLM_SCOPE(ELLMTag::TaskGraphTasksMisc);
TStatId StallStatId;
bool bCountAsStall = true;
uint64 ProcessedTasks = 0;
(......)
verify(++Queue.RecursionGuard == 1);
bool bDidStall = false;
while (1)
{
// 从TaskGraph系统中的无名任务队列获取任务的.
FBaseGraphTask* Task = FindWork();
if (!Task)
{
(......)
TestRandomizedThreads();
if (FPlatformProcess::SupportsMultithreading())
{
FScopeCycleCounter Scope(StallStatId);
Queue.StallRestartEvent->Wait(MAX_uint32, bCountAsStall);
bDidStall = true;
}
if (Queue.QuitForShutdown || !FPlatformProcess::SupportsMultithreading())
{
break;
}
TestRandomizedThreads();
(......)
continue;
}
TestRandomizedThreads();
(......)
bDidStall = false;
Task->Execute(NewTasks, ENamedThreads::Type(ThreadId));
ProcessedTasks++;
TestRandomizedThreads();
if (Queue.bStallForTuning)
{
{
FScopeLock Lock(&Queue.StallForTuning);
}
}
}
verify(!--Queue.RecursionGuard);
return ProcessedTasks;
}
// 任务队列数据.
struct FThreadTaskQueue
{
FEvent* StallRestartEvent;
uint32 RecursionGuard;
bool QuitForShutdown;
bool bStallForTuning;
FCriticalSection StallForTuning; // 阻塞临界区
};
// 从TaskGraph系统中获取任务.
FBaseGraphTask* FindWork()
{
return FTaskGraphImplementation::Get().FindWork(ThreadId);
}
FThreadTaskQueue Queue; // 任务队列, 只有第一个用于无名线程.
int32 PriorityIndex;
};
- ENamedThreads
在理解TaskGraph的实现和使用之前,有必要理解ENamedThreads相关的机制。ENamedThreads是一个命名空间,此空间内提供了编解码线程、优先级的操作。它的声明和解析如下:
namespace ENamedThreads
{
enum Type : int32
{
UnusedAnchor = -1,
// ----专用(带名字的)线程----
#if STATS
StatsThread, // 统计线程
#endif
RHIThread, // RHI线程
AudioThread, // 音频线程
GameThread, // 游戏线程
ActualRenderingThread = GameThread + 1, // 实际渲染线程. GetRenderingThread()获取的渲染可能是实际渲染线程也可能是游戏线程.
AnyThread = 0xff, // 任意线程(未知线程, 无名线程)
// ----队列索引和优先级----
MainQueue = 0x000, // 主队列
LocalQueue = 0x100, // 局部队列
NumQueues = 2,
ThreadIndexMask = 0xff,
QueueIndexMask = 0x100,
QueueIndexShift = 8,
// ----队列任务索引、优先级----
NormalTaskPriority = 0x000, // 普通任务优先级
HighTaskPriority = 0x200, // 高任务优先级
NumTaskPriorities = 2,
TaskPriorityMask = 0x200,
TaskPriorityShift = 9,
// ----线程优先级----
NormalThreadPriority = 0x000, // 普通线程优先级
HighThreadPriority = 0x400, // 高线程优先级
BackgroundThreadPriority = 0x800, // 后台线程优先级
NumThreadPriorities = 3,
ThreadPriorityMask = 0xC00,
ThreadPriorityShift = 10,
// 组合标记
#if STATS
StatsThread_Local = StatsThread | LocalQueue,
#endif
GameThread_Local = GameThread | LocalQueue,
ActualRenderingThread_Local = ActualRenderingThread | LocalQueue,
AnyHiPriThreadNormalTask = AnyThread | HighThreadPriority | NormalTaskPriority,
AnyHiPriThreadHiPriTask = AnyThread | HighThreadPriority | HighTaskPriority,
AnyNormalThreadNormalTask = AnyThread | NormalThreadPriority | NormalTaskPriority,
AnyNormalThreadHiPriTask = AnyThread | NormalThreadPriority | HighTaskPriority,
AnyBackgroundThreadNormalTask = AnyThread | BackgroundThreadPriority | NormalTaskPriority,
AnyBackgroundHiPriTask = AnyThread | BackgroundThreadPriority | HighTaskPriority,
};
struct FRenderThreadStatics
{
private:
// 存储了渲染线程,注意是原子操作类型。
static CORE_API TAtomic<Type> RenderThread;
static CORE_API TAtomic<Type> RenderThread_Local;
};
// ----设置和获取渲染线程接口----
Type GetRenderThread();
Type GetRenderThread_Local();
void SetRenderThread(Type Thread);
void SetRenderThread_Local(Type Thread);
extern CORE_API int32 bHasBackgroundThreads; // 是否有后台线程
extern CORE_API int32 bHasHighPriorityThreads; // 是否有高优先级线程
// ----设置和获取线程索引、线程优先级、任务优先级接口----
Type GetThreadIndex(Type ThreadAndIndex);
int32 GetQueueIndex(Type ThreadAndIndex);
int32 GetTaskPriority(Type ThreadAndIndex);
int32 GetThreadPriorityIndex(Type ThreadAndIndex);
Type SetPriorities(Type ThreadAndIndex, Type ThreadPriority, Type TaskPriority);
Type SetPriorities(Type ThreadAndIndex, int32 PriorityIndex, bool bHiPri);
Type SetThreadPriority(Type ThreadAndIndex, Type ThreadPriority);
Type SetTaskPriority(Type ThreadAndIndex, Type TaskPriority);
}
- FTaskGraphInterface
上面提到了很多任务类型,本节才真正涉及这些任务的管理器和工厂FTaskGraphInterface。FTaskGraphInterface就是任务图的管理者,提供了任务的操作接口:
class FTaskGraphInterface
{
virtual void QueueTask(class FBaseGraphTask* Task, ENamedThreads::Type ThreadToExecuteOn, ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread) = 0;
public:
// FTaskGraphInterface对象操作接口
static CORE_API void Startup(int32 NumThreads);
static CORE_API void Shutdown();
static CORE_API bool IsRunning();
static CORE_API FTaskGraphInterface& Get();
// 线程操作接口.
virtual ENamedThreads::Type GetCurrentThreadIfKnown(bool bLocalQueue = false) = 0;
virtual int32 GetNumWorkerThreads() = 0;
virtual bool IsThreadProcessingTasks(ENamedThreads::Type ThreadToCheck) = 0;
virtual void AttachToThread(ENamedThreads::Type CurrentThread)=0;
virtual uint64 ProcessThreadUntilIdle(ENamedThreads::Type CurrentThread)=0;
// 任务操作接口.
virtual void ProcessThreadUntilRequestReturn(ENamedThreads::Type CurrentThread)=0;
virtual void RequestReturn(ENamedThreads::Type CurrentThread)=0;
virtual void WaitUntilTasksComplete(const FGraphEventArray& Tasks, ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread)=0;
virtual void TriggerEventWhenTasksComplete(FEvent* InEvent, const FGraphEventArray& Tasks, ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread, ENamedThreads::Type TriggerThread = ENamedThreads::AnyHiPriThreadHiPriTask)=0;
void WaitUntilTaskCompletes(const FGraphEventRef& Task, ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread);
void TriggerEventWhenTaskCompletes(FEvent* InEvent, const FGraphEventRef& Task, ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread, ENamedThreads::Type TriggerThread = ENamedThreads::AnyHiPriThreadHiPriTask);
virtual void AddShutdownCallback(TFunction<void()>& Callback) = 0;
static void BroadcastSlow_OnlyUseForSpecialPurposes(bool bDoTaskThreads, bool bDoBackgroundThreads, TFunction<void(ENamedThreads::Type CurrentThread)>& Callback);
};
FTaskGraphInterface的实现是在FTaskGraphImplementation类中,FTaskGraphImplementation采用了特殊的线程对象WorkerThreads(工作线程)来作为执行的载体,当然如果是专用的(带名字的线程,如GameThread、RHI、ActualRenderingThread)线程,则会进入专用的任务队列。由于它的实现细节很多,后面再展开讨论。
- FTaskGraphImplementation
FTaskGraphImplementation继承并实现了FTaskGraphInterface的接口,部分接口和实现如下:
// Engine\Source\Runtime\Core\Private\Async\TaskGraph.cpp
class FTaskGraphImplementation : public FTaskGraphInterface
{
public:
static FTaskGraphImplementation& Get();
// 构造函数, 计算任务线程数量, 创建专用线程和无名线程等.
FTaskGraphImplementation(int32)
{
bCreatedHiPriorityThreads = !!ENamedThreads::bHasHighPriorityThreads;
bCreatedBackgroundPriorityThreads = !!ENamedThreads::bHasBackgroundThreads;
int32 MaxTaskThreads = MAX_THREADS; // 最大任务线程数量默认是83.
int32 NumTaskThreads = FPlatformMisc::NumberOfWorkerThreadsToSpawn(); // 根据硬件核心数量获取任务线程数量.
// 处理不能支持多线程的平台.
if (!FPlatformProcess::SupportsMultithreading())
{
MaxTaskThreads = 1;
NumTaskThreads = 1;
LastExternalThread = (ENamedThreads::Type)(ENamedThreads::ActualRenderingThread - 1);
bCreatedHiPriorityThreads = false;
bCreatedBackgroundPriorityThreads = false;
ENamedThreads::bHasBackgroundThreads = 0;
ENamedThreads::bHasHighPriorityThreads = 0;
}
else
{
LastExternalThread = ENamedThreads::ActualRenderingThread;
}
// 专用线程数量
NumNamedThreads = LastExternalThread + 1;
// 计算工作线程集数量, 与是否开启线程高优先级、是否创建后台优先级线程有关。
NumTaskThreadSets = 1 + bCreatedHiPriorityThreads + bCreatedBackgroundPriorityThreads;
// 计算真正需要的任务线程数量, 最大不超过83个.
NumThreads = FMath::Max<int32>(FMath::Min<int32>(NumTaskThreads * NumTaskThreadSets + NumNamedThreads, MAX_THREADS), NumNamedThreads + 1);
NumThreads = FMath::Min(NumThreads, NumNamedThreads + NumTaskThreads * NumTaskThreadSets);
NumTaskThreadsPerSet = (NumThreads - NumNamedThreads) / NumTaskThreadSets;
ReentrancyCheck.Increment(); // just checking for reentrancy
PerThreadIDTLSSlot = FPlatformTLS::AllocTlsSlot();
// 创建所有任务线程.
for (int32 ThreadIndex = 0; ThreadIndex < NumThreads; ThreadIndex++)
{
check(!WorkerThreads[ThreadIndex].bAttached); // reentrant?
// 根据是否专用线程分别创建线程.
bool bAnyTaskThread = ThreadIndex >= NumNamedThreads;
if (bAnyTaskThread)
{
WorkerThreads[ThreadIndex].TaskGraphWorker = new FTaskThreadAnyThread(ThreadIndexToPriorityIndex(ThreadIndex));
}
else
{
WorkerThreads[ThreadIndex].TaskGraphWorker = new FNamedTaskThread;
}
WorkerThreads[ThreadIndex].TaskGraphWorker->Setup(ENamedThreads::Type(ThreadIndex), PerThreadIDTLSSlot, &WorkerThreads[ThreadIndex]);
}
TaskGraphImplementationSingleton = this; // 赋值this到TaskGraphImplementationSingleton, 以便外部可获取.
// 设置无名线程的属性.
for (int32 ThreadIndex = LastExternalThread + 1; ThreadIndex < NumThreads; ThreadIndex++)
{
FString Name;
const ANSICHAR* GroupName = "TaskGraphNormal";
int32 Priority = ThreadIndexToPriorityIndex(ThreadIndex);
EThreadPriority ThreadPri;
uint64 Affinity = FPlatformAffinity::GetTaskGraphThreadMask();
if (Priority == 1)
{
Name = FString::Printf(TEXT("TaskGraphThreadHP %d"), ThreadIndex - (LastExternalThread + 1));
GroupName = "TaskGraphHigh";
ThreadPri = TPri_SlightlyBelowNormal; // we want even hi priority tasks below the normal threads
// If the platform defines FPlatformAffinity::GetTaskGraphHighPriorityTaskMask then use it
if (FPlatformAffinity::GetTaskGraphHighPriorityTaskMask() != 0xFFFFFFFFFFFFFFFF)
{
Affinity = FPlatformAffinity::GetTaskGraphHighPriorityTaskMask();
}
}
else if (Priority == 2)
{
Name = FString::Printf(TEXT("TaskGraphThreadBP %d"), ThreadIndex - (LastExternalThread + 1));
GroupName = "TaskGraphLow";
ThreadPri = TPri_Lowest;
// If the platform defines FPlatformAffinity::GetTaskGraphBackgroundTaskMask then use it
if ( FPlatformAffinity::GetTaskGraphBackgroundTaskMask() != 0xFFFFFFFFFFFFFFFF )
{
Affinity = FPlatformAffinity::GetTaskGraphBackgroundTaskMask();
}
}
else
{
Name = FString::Printf(TEXT("TaskGraphThreadNP %d"), ThreadIndex - (LastExternalThread + 1));
ThreadPri = TPri_BelowNormal; // we want normal tasks below normal threads like the game thread
}
// 计算线程栈大小.
#if WITH_EDITOR
uint32 StackSize = 1024 * 1024;
#elif ( UE_BUILD_SHIPPING || UE_BUILD_TEST )
uint32 StackSize = 384 * 1024;
#else
uint32 StackSize = 512 * 1024;
#endif
// 真正地创建工作线程的执行线程.
WorkerThreads[ThreadIndex].RunnableThread = FRunnableThread::Create(&Thread(ThreadIndex), *Name, StackSize, ThreadPri, Affinity); // these are below normal threads so that they sleep when the named threads are active
WorkerThreads[ThreadIndex].bAttached = true;
if (WorkerThreads[ThreadIndex].RunnableThread)
{
TRACE_SET_THREAD_GROUP(WorkerThreads[ThreadIndex].RunnableThread->GetThreadID(), GroupName);
}
}
}
// 入队任务.
virtual void QueueTask(FBaseGraphTask* Task, ENamedThreads::Type ThreadToExecuteOn, ENamedThreads::Type InCurrentThreadIfKnown = ENamedThreads::AnyThread) final override
{
TASKGRAPH_SCOPE_CYCLE_COUNTER(2, STAT_TaskGraph_QueueTask);
if (ENamedThreads::GetThreadIndex(ThreadToExecuteOn) == ENamedThreads::AnyThread)
{
TASKGRAPH_SCOPE_CYCLE_COUNTER(3, STAT_TaskGraph_QueueTask_AnyThread);
// 多线程支持下的处理.
if (FPlatformProcess::SupportsMultithreading())
{
// 处理优先级.
uint32 TaskPriority = ENamedThreads::GetTaskPriority(Task->ThreadToExecuteOn);
int32 Priority = ENamedThreads::GetThreadPriorityIndex(Task->ThreadToExecuteOn);
if (Priority == (ENamedThreads::BackgroundThreadPriority >> ENamedThreads::ThreadPriorityShift) && (!bCreatedBackgroundPriorityThreads || !ENamedThreads::bHasBackgroundThreads))
{
Priority = ENamedThreads::NormalThreadPriority >> ENamedThreads::ThreadPriorityShift; // we don't have background threads, promote to normal
TaskPriority = ENamedThreads::NormalTaskPriority >> ENamedThreads::TaskPriorityShift; // demote to normal task pri
}
else if (Priority == (ENamedThreads::HighThreadPriority >> ENamedThreads::ThreadPriorityShift) && (!bCreatedHiPriorityThreads || !ENamedThreads::bHasHighPriorityThreads))
{
Priority = ENamedThreads::NormalThreadPriority >> ENamedThreads::ThreadPriorityShift; // we don't have hi priority threads, demote to normal
TaskPriority = ENamedThreads::HighTaskPriority >> ENamedThreads::TaskPriorityShift; // promote to hi task pri
}
uint32 PriIndex = TaskPriority ? 0 : 1;
check(Priority >= 0 && Priority < MAX_THREAD_PRIORITIES);
{
TASKGRAPH_SCOPE_CYCLE_COUNTER(4, STAT_TaskGraph_QueueTask_IncomingAnyThreadTasks_Push);
// 将任务压入待执行队列, 且获得并执行可执行的任务索引(可能无).
int32 IndexToStart = IncomingAnyThreadTasks[Priority].Push(Task, PriIndex);
if (IndexToStart >= 0)
{
StartTaskThread(Priority, IndexToStart);
}
}
return;
}
else
{
ThreadToExecuteOn = ENamedThreads::GameThread;
}
}
// 以下是不支持多线程的处理.
ENamedThreads::Type CurrentThreadIfKnown;
if (ENamedThreads::GetThreadIndex(InCurrentThreadIfKnown) == ENamedThreads::AnyThread)
{
CurrentThreadIfKnown = GetCurrentThread();
}
else
{
CurrentThreadIfKnown = ENamedThreads::GetThreadIndex(InCurrentThreadIfKnown);
checkThreadGraph(CurrentThreadIfKnown == ENamedThreads::GetThreadIndex(GetCurrentThread()));
}
{
int32 QueueToExecuteOn = ENamedThreads::GetQueueIndex(ThreadToExecuteOn);
ThreadToExecuteOn = ENamedThreads::GetThreadIndex(ThreadToExecuteOn);
FTaskThreadBase* Target = &Thread(ThreadToExecuteOn);
if (ThreadToExecuteOn == ENamedThreads::GetThreadIndex(CurrentThreadIfKnown))
{
Target->EnqueueFromThisThread(QueueToExecuteOn, Task);
}
else
{
Target->EnqueueFromOtherThread(QueueToExecuteOn, Task);
}
}
}
virtual int32 GetNumWorkerThreads() final override;
virtual ENamedThreads::Type GetCurrentThreadIfKnown(bool bLocalQueue) final override;
virtual bool IsThreadProcessingTasks(ENamedThreads::Type ThreadToCheck) final override;
// 将当前线程导入到指定Index.
virtual void AttachToThread(ENamedThreads::Type CurrentThread) final override;
// ----处理任务接口----
virtual uint64 ProcessThreadUntilIdle(ENamedThreads::Type CurrentThread) final override;
virtual void ProcessThreadUntilRequestReturn(ENamedThreads::Type CurrentThread) final override;
virtual void RequestReturn(ENamedThreads::Type CurrentThread) final override;
virtual void WaitUntilTasksComplete(const FGraphEventArray& Tasks, ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread) final override;
virtual void TriggerEventWhenTasksComplete(FEvent* InEvent, const FGraphEventArray& Tasks, ENamedThreads::Type CurrentThreadIfKnown = ENamedThreads::AnyThread, ENamedThreads::Type TriggerThread = ENamedThreads::AnyHiPriThreadHiPriTask) final override;
virtual void AddShutdownCallback(TFunction<void()>& Callback);
// ----任务调度接口----
// 开启指定优先级和索引的任务线程.
void StartTaskThread(int32 Priority, int32 IndexToStart);
void StartAllTaskThreads(bool bDoBackgroundThreads);
FBaseGraphTask* FindWork(ENamedThreads::Type ThreadInNeed);
void StallForTuning(int32 Index, bool Stall);
void SetTaskThreadPriorities(EThreadPriority Pri);
private:
// 获取指定索引的任务线程引用.
FTaskThreadBase& Thread(int32 Index)
{
checkThreadGraph(Index >= 0 && Index < NumThreads);
checkThreadGraph(WorkerThreads[Index].TaskGraphWorker->GetThreadId() == Index);
return *WorkerThreads[Index].TaskGraphWorker;
}
// 获取当前线程索引.
ENamedThreads::Type GetCurrentThread();
int32 ThreadIndexToPriorityIndex(int32 ThreadIndex);
enum
{
MAX_THREADS = 26 * (CREATE_HIPRI_TASK_THREADS + CREATE_BACKGROUND_TASK_THREADS + 1) + ENamedThreads::ActualRenderingThread + 1,
MAX_THREAD_PRIORITIES = 3
};
FWorkerThread WorkerThreads[MAX_THREADS]; // 所有工作线程(任务线程)对象数组.
int32 NumThreads; // 实际上被使用的线程数量.
int32 NumNamedThreads; // 专用线程数量.
int32 NumTaskThreadSets;// 任务线程集合数量.
int32 NumTaskThreadsPerSet; // 每个集合拥有的任务线程数量.
bool bCreatedHiPriorityThreads;
bool bCreatedBackgroundPriorityThreads;
ENamedThreads::Type LastExternalThread;
FThreadSafeCounter ReentrancyCheck;
uint32 PerThreadIDTLSSlot;
TArray<TFunction<void()> > ShutdownCallbacks; // 销毁前的回调.
FStallingTaskQueue<FBaseGraphTask, PLATFORM_CACHE_LINE_SIZE, 2> IncomingAnyThreadTasks[MAX_THREAD_PRIORITIES];
};
总结起来,TaskGraph会根据线程优先级、是否启用后台线程创建不同的工作线程集合,然后创建它们的FWorkerThread对象。入队任务时,会将任务Push到任务列表IncomingAnyThreadTasks(类型是FStallingTaskQueue,线程安全的无锁的链表)中,并取出可执行的任务索引,根据任务的属性(希望在哪个线程执行、优先级、任务索引)启用对应的工作线程去执行。
TaskGraph涉及的工作线程FWorkerThread声明如下:
struct FWorkerThread
{
FTaskThreadBase* TaskGraphWorker; // 所在的FTaskThread对象(被FTaskThread对象拥有)
FRunnableThread* RunnableThread; // 真正执行任务的可运行线程.
bool bAttached; // 是否附加的线程.(一般用于专用线程)
};
由此可见,TaskGraph最终也是借助FRunnableThread来执行任务。TaskGraph系统总算是和FRunnableThread联系起来,形成了闭环。
至此,终于将TaskGraph体系的主干脉络阐述完了,当然,还有很多技术细节(如同步事件、触发细节、调度算法、无锁链表以及部分概念)并没有涉及,这些就留给读者自己去研读UE源码探索了。
2.5 UE的多线程渲染
前面做了大量的基础铺垫,终于回到了主题,讲UE的多线程渲染相关的知识。
2.5.1 UE的多线程渲染基础
2.5.1.1 场景和渲染模块主要类型
UE的场景和渲染模块涉及到概念非常多,主要类型和解析如下:
| 类型 | 解析 |
|---|---|
| UWorld | 包含了一组可以相互交互的Actor和组件的集合,多个关卡(Level)可以被加载进UWorld或从UWorld卸载。可以同时存在多个UWorld实例。 |
| ULevel | 关卡,存储着一组Actor和组件,并且存储在同一个文件。 |
| USceneComponent | 场景组件,是所有可以被加入到场景的物体的父类,比如灯光、模型、雾等。 |
| UPrimitiveComponent | 图元组件,是所有可渲染或拥有物理模拟的物体父类。是CPU层裁剪的最小粒度单位, |
| ULightComponent | 光源组件,是所有光源类型的父类。 |
| FScene | 是UWorld在渲染模块的代表。只有加入到FScene的物体才会被渲染器感知到。渲染线程拥有FScene的所有状态(游戏线程不可直接修改)。 |
| FPrimitiveSceneProxy | 图元场景代理,是UPrimitiveComponent在渲染器的代表,镜像了UPrimitiveComponent在渲染线程的状态。 |
| FPrimitiveSceneInfo | 渲染器内部状态(描述了FRendererModule的实现),相当于融合了UPrimitiveComponent and FPrimitiveSceneProxy。只存在渲染器模块,所以引擎模块无法感知到它的存在。 |
| FSceneView | 描述了FScene内的单个视图(view),同个FScene允许有多个view,换言之,一个场景可以被多个view绘制,或者多个view同时被绘制。每一帧都会创建新的view实例。 |
| FViewInfo | view在渲染器的内部代表,只存在渲染器模块,引擎模块不可见。 |
| FSceneViewState | 存储了有关view的渲染器私有信息,这些信息需要被跨帧访问。在Game实例,每个ULocalPlayer拥有一个FSceneViewState实例。 |
| FSceneRenderer | 每帧都会被创建,封装帧间临时数据。下派生FDeferredShadingSceneRenderer(延迟着色场景渲染器)和FMobileSceneRenderer(移动端场景渲染器),分别代表PC和移动端的默认渲染器。 |
2.5.1.2 引擎模块和渲染模块代表
UE为了结构清晰,减少模块之间的依赖,加速迭代速度,划分了很多模块,最主要的有引擎模块、渲染器模块、核心、RHI、插件等等。上一小节提到了很多概念和类型,它们有些存在于引擎模块(Engine Module),有些存在于渲染器模块(Renderer Module),具体如下表:
| Engine Module | Renderer Module |
|---|---|
| UWorld | FScene |
| UPrimitiveComponent / FPrimitiveSceneProxy | FPrimitiveSceneInfo |
| FSceneView | FViewInfo |
| ULocalPlayer | FSceneViewState |
| ULightComponent / FLightSceneProxy | FLightSceneInfo |
2.5.1.3 游戏线程和渲染线程代表
游戏线程的对象通常做逻辑更新,在内存中有一份持久的数据,为了避免游戏线程和渲染线程产生竞争条件,会在渲染线程额外存储一份内存拷贝,并且使用的是另外的类型,以下是UE比较常见的类型映射关系(游戏线程对象以U开头,渲染线程以F开头):
| Game Thread | Rendering Thread |
|---|---|
| UWorld | FScene |
| UPrimitiveComponent | FPrimitiveSceneProxy / FPrimitiveSceneInfo |
| - | FSceneView / FViewInfo |
| ULocalPlayer | FSceneViewState |
| ULightComponent | FLightSceneProxy / FLightSceneInfo |
游戏线程代表一般由游戏游戏线程操作,渲染线程代表主要由渲染线程操作。如果尝试跨线程操作数据,将会引发不可预料的结果,产生竞争条件。
/** SceneProxy在注册进场景时,会在游戏线程中被构造和传递数据。 */
FStaticMeshSceneProxy::FStaticMeshSceneProxy(UStaticMeshComponent* InComponent):
FPrimitiveSceneProxy(...),
Owner(InComponent->GetOwner()) <======== 此处将AActor指针被缓存
...
/** SceneProxy的DrawDynamicElements将被渲染器在渲染线程中调用 */
void FStaticMeshSceneProxy::DrawDynamicElements(...)
{
if (Owner->AnyProperty) <========== 将会引发竞争条件! 游戏线程拥有AActor、UObject的所有状态!!并且UObject对象可能被GC掉,此时再访问会引起程序崩溃!!
}
部分代表比较特殊,如FPrimitiveSceneProxy、FLightSceneProxy ,这些场景代理本属于引擎模块,但又属于渲染线程专属对象,说明它们是连接游戏线程和渲染线程的桥梁,是线程间传递数据的工具人。
2.5.2 UE的多线程渲染总览
默认情况下,UE存在游戏线程(Game Thread)、渲染线程(Render Thread)、RHI线程(RHI Thread),它们都独立地运行在专门的线程上(FRunnableThread)。
游戏线程通过某些接口向渲染线程的Queue入队回调接口,以便渲染线程稍后运行时,从渲染线程的Queue获取回调,一个个地执行,从而生成了Command List。
渲染线程作为前端(frontend)产生的Command List是平台无关的,是抽象的图形API调用;而RHI线程作为后端(backtend)会执行和转换渲染线程的Command List成为指定图形API的调用(称为Graphical Command),并提交到GPU执行。这些线程处理的数据通常是不同帧的,譬如游戏线程处理N帧数据,渲染线程和RHI线程处理N-1帧数据。
但也存在例外,比如渲染线程和RHI线程运行很快,几乎不存在延迟,这种情况下,游戏线程处理N帧,而渲染线程可能处理N或N-1帧,RHI线程也可能在转换N或N-1帧。但是,渲染线程不能落后游戏线程一帧,否则游戏线程会卡住,直到渲染线程处理所有指令。
除此之外,渲染指令是可以并行地被生成,RHI线程也可以并行地转换这些指令,如下所示:
UE4并行生成Command list示意图。
开启多线程渲染带来的收益是帧率更高,帧间变化频率降低(帧率更稳定)。以Fortnite(堡垒之夜)移动端为例,在开启RHI线程之前,渲染线程急剧地上下波动,而加了RHI线程之后,波动平缓许多,和游戏线程基本保持一致,帧率也提升不少:
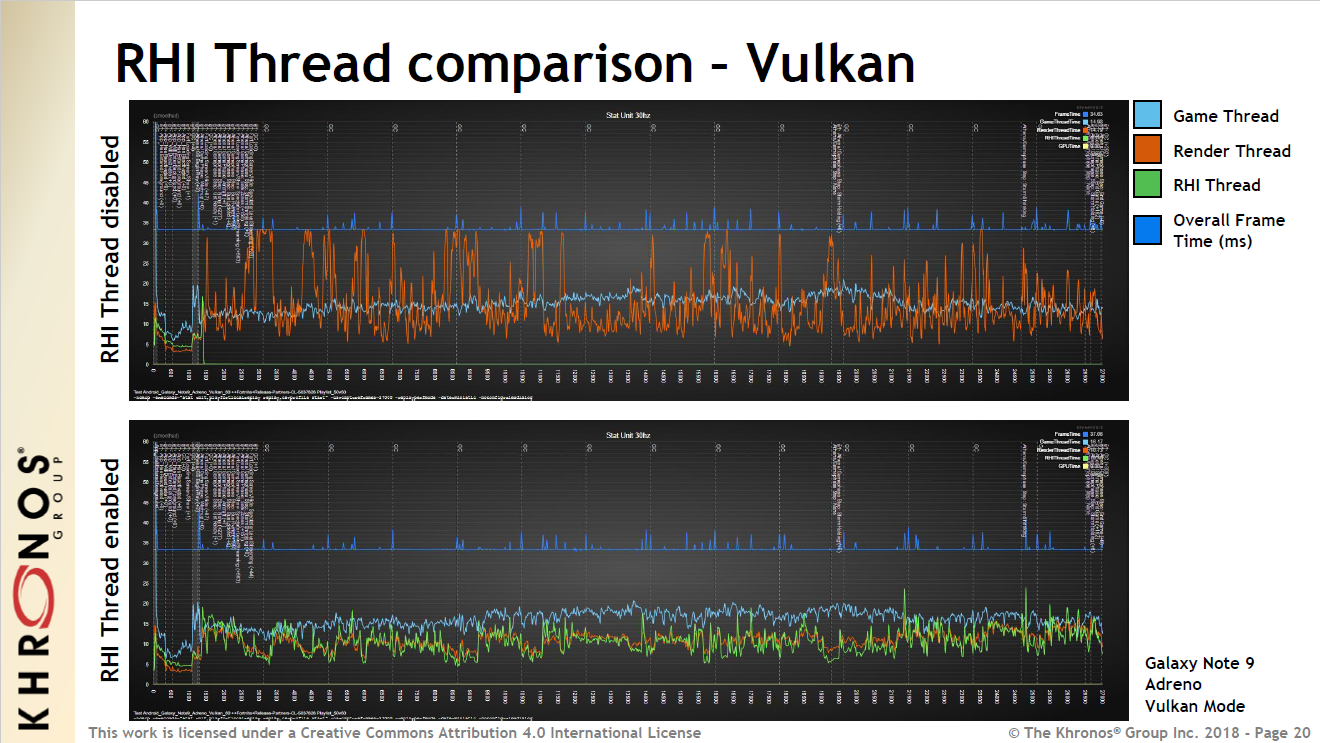
2.5.3 游戏线程和渲染线程的实现
2.5.3.1 游戏线程的实现
游戏线程被称为主线程,是引擎运行的心脏,承载主要的游戏逻辑、运行流程的工作,也是其它线程的数据发起者。
游戏线程的创建是运行程序入口的线程,由系统启动进程时被同时创建的(因为进程至少需要一个线程来工作),在引擎启动时直接存储到全局变量中,且稍后会设置到TaskGraph系统中:
// Engine\Source\Runtime\Launch\Private\LaunchEngineLoop.cpp
int32 FEngineLoop::PreInitPreStartupScreen(const TCHAR* CmdLine)
{
(......)
// 获取当前线程id, 存储到全局变量中.
GGameThreadId = FPlatformTLS::GetCurrentThreadId();
GIsGameThreadIdInitialized = true;
FPlatformProcess::SetThreadAffinityMask(FPlatformAffinity::GetMainGameMask());
// 设置游戏线程数据(但很多平台都是空的实现体)
FPlatformProcess::SetupGameThread();
(......)
if (bCreateTaskGraphAndThreadPools)
{
SCOPED_BOOT_TIMING("FTaskGraphInterface::Startup");
FTaskGraphInterface::Startup(FPlatformMisc::NumberOfCores());
// 将当前线程(主线程)附加到TaskGraph的GameThread命名插槽中. 这样主线程便和TaskGraph联动了起来.
FTaskGraphInterface::Get().AttachToThread(ENamedThreads::GameThread);
}
}
以上代码也说明:主线程、游戏线程和TaskGraph系统的ENamedThreads::GameThread其实是一回事,都是同一个线程!
经过上面的初始化和设置后,其它地方就可以通过TaskGraph系统并行地处理任务了,也可以访问全局变量,以便判断游戏线程是否初始化完,当前线程是否游戏线程:
bool IsInGameThread()
{
return GIsGameThreadIdInitialized && FPlatformTLS::GetCurrentThreadId() == GGameThreadId;
}
2.5.3.2 渲染线程的实现
渲染线程与游戏不同,是一条专门用于生成渲染指令和渲染逻辑的独立线程。RenderingThread.h声明了全部对外的接口,部分如下:
// Engine\Source\Runtime\RenderCore\Public\RenderingThread.h
// 是否启用了独立的渲染线程, 如果为false, 则所有渲染命令会被立即执行, 而不是放入渲染命令队列.
extern RENDERCORE_API bool GIsThreadedRendering;
// 渲染线程是否应该被创建. 通常被命令行参数或ToggleRenderingThread控制台参数设置.
extern RENDERCORE_API bool GUseThreadedRendering;
// 是否开启RHI线程
extern RENDERCORE_API void SetRHIThreadEnabled(bool bEnableDedicatedThread, bool bEnableRHIOnTaskThreads);
(......)
// 开启渲染线程.
extern RENDERCORE_API void StartRenderingThread();
// 停止渲染线程.
extern RENDERCORE_API void StopRenderingThread();
// 检查渲染线程是否健康(是否Crash), 如果crash, 则会用UE_Log输出日志.
extern RENDERCORE_API void CheckRenderingThreadHealth();
// 检查渲染线程是否健康(是否Crash)
extern RENDERCORE_API bool IsRenderingThreadHealthy();
// 增加一个必须在下一个场景绘制前或flush渲染命令前完成的任务.
extern RENDERCORE_API void AddFrameRenderPrerequisite(const FGraphEventRef& TaskToAdd);
// 手机帧渲染前序任务, 保证所有渲染命令被入队.
extern RENDERCORE_API void AdvanceFrameRenderPrerequisite();
// 等待所有渲染线程的渲染命令被执行完毕. 会卡住游戏线程, 只能被游戏线程调用.
extern RENDERCORE_API void FlushRenderingCommands(bool bFlushDeferredDeletes = false);
extern RENDERCORE_API void FlushPendingDeleteRHIResources_GameThread();
extern RENDERCORE_API void FlushPendingDeleteRHIResources_RenderThread();
extern RENDERCORE_API void TickRenderingTickables();
extern RENDERCORE_API void StartRenderCommandFenceBundler();
extern RENDERCORE_API void StopRenderCommandFenceBundler();
(......)
RenderingThread.h还有一个非常重要的宏ENQUEUE_RENDER_COMMAND,它的作用是向渲染线程入队渲染指令。下面是它的声明和实现:
// 向渲染线程入队渲染指令, Type指明了渲染操作的名字.
#define ENQUEUE_RENDER_COMMAND(Type) \
struct Type##Name \
{ \
static const char* CStr() { return #Type; } \
static const TCHAR* TStr() { return TEXT(#Type); } \
}; \
EnqueueUniqueRenderCommand<Type##Name>
上面最后一句使用了EnqueueUniqueRenderCommand命令,继续追踪之:
// TSTR是渲染命令名字, LAMBDA是回调函数.
template<typename TSTR, typename LAMBDA>
FORCEINLINE_DEBUGGABLE void EnqueueUniqueRenderCommand(LAMBDA&& Lambda)
{
typedef TEnqueueUniqueRenderCommandType<TSTR, LAMBDA> EURCType;
// 如果在渲染线程内直接执行回调而不入队渲染命令.
if (IsInRenderingThread())
{
FRHICommandListImmediate& RHICmdList = GetImmediateCommandList_ForRenderCommand();
Lambda(RHICmdList);
}
else
{
// 需要在独立的渲染线程执行
if (ShouldExecuteOnRenderThread())
{
CheckNotBlockedOnRenderThread();
// 从GraphTask创建任务且在适当时候入队渲染命令.
TGraphTask<EURCType>::CreateTask().ConstructAndDispatchWhenReady(Forward<LAMBDA>(Lambda));
}
else // 不在独立的渲染线程执行, 则直接执行.
{
EURCType TempCommand(Forward<LAMBDA>(Lambda));
FScopeCycleCounter EURCMacro_Scope(TempCommand.GetStatId());
TempCommand.DoTask(ENamedThreads::GameThread, FGraphEventRef());
}
}
}
上面说明如果是有独立的渲染线程,最终会将渲染命令入队到TaskGraph的任务Queue中,等待合适的时机在渲染线程中被执行。其中TEnqueueUniqueRenderCommandType就是专用于渲染命令的特殊TaskGraph任务类型,声明如下:
class RENDERCORE_API FRenderCommand
{
public:
// 所有渲染指令都必须在渲染线程执行.
static ENamedThreads::Type GetDesiredThread()
{
check(!GIsThreadedRendering || ENamedThreads::GetRenderThread() != ENamedThreads::GameThread);
return ENamedThreads::GetRenderThread();
}
static ESubsequentsMode::Type GetSubsequentsMode()
{
return ESubsequentsMode::FireAndForget;
}
};
template<typename TSTR, typename LAMBDA>
class TEnqueueUniqueRenderCommandType : public FRenderCommand
{
public:
TEnqueueUniqueRenderCommandType(LAMBDA&& InLambda) : Lambda(Forward<LAMBDA>(InLambda)) {}
// 正在执行任务.
void DoTask(ENamedThreads::Type CurrentThread, const FGraphEventRef& MyCompletionGraphEvent)
{
TRACE_CPUPROFILER_EVENT_SCOPE_ON_CHANNEL_STR(TSTR::TStr(), RenderCommandsChannel);
FRHICommandListImmediate& RHICmdList = GetImmediateCommandList_ForRenderCommand();
Lambda(RHICmdList);
}
(......)
private:
LAMBDA Lambda; // 缓存渲染回调函数.
};
为了更好理解入队渲染命令操作,举个具体的例子,以增加灯光到场景为例:
void FScene::AddLight(ULightComponent* Light)
{
(......)
// Send a command to the rendering thread to add the light to the scene.
FScene* Scene = this;
FLightSceneInfo* LightSceneInfo = Proxy->LightSceneInfo;
// 这里入队渲染指令, 以便在渲染线程将灯光数据传递到渲染器.
ENQUEUE_RENDER_COMMAND(FAddLightCommand)(
[Scene, LightSceneInfo](FRHICommandListImmediate& RHICmdList)
{
CSV_SCOPED_TIMING_STAT_EXCLUSIVE(Scene_AddLight);
FScopeCycleCounter Context(LightSceneInfo->Proxy->GetStatId());
Scene->AddLightSceneInfo_RenderThread(LightSceneInfo);
});
}
将ENQUEUE_RENDER_COMMAND(FAddLightCommand)代入前面解析过的宏和模板,并展开,完整的代码如下:
struct FAddLightCommandName
{
static const char* CStr() { return "FAddLightCommand"; }
static const TCHAR* TStr() { return TEXT("FAddLightCommand"); }
};
EnqueueUniqueRenderCommand<FAddLightCommandName>(
[Scene, LightSceneInfo](FRHICommandListImmediate& RHICmdList)
{
CSV_SCOPED_TIMING_STAT_EXCLUSIVE(Scene_AddLight);
FScopeCycleCounter Context(LightSceneInfo->Proxy->GetStatId());
Scene->AddLightSceneInfo_RenderThread(LightSceneInfo);
})
{
typedef TEnqueueUniqueRenderCommandType<FAddLightCommandName, LAMBDA> EURCType;
// 如果在渲染线程内直接执行回调而不入队渲染命令.
if (IsInRenderingThread())
{
FRHICommandListImmediate& RHICmdList = GetImmediateCommandList_ForRenderCommand();
Lambda(RHICmdList);
}
else
{
// 需要在独立的渲染线程执行
if (ShouldExecuteOnRenderThread())
{
CheckNotBlockedOnRenderThread();
// 从GraphTask创建任务且在适当时候入队渲染命令.
TGraphTask<EURCType>::CreateTask().ConstructAndDispatchWhenReady(Forward<LAMBDA>(Lambda));
}
else // 不在独立的渲染线程执行, 则直接执行.
{
EURCType TempCommand(Forward<LAMBDA>(Lambda));
FScopeCycleCounter EURCMacro_Scope(TempCommand.GetStatId());
TempCommand.DoTask(ENamedThreads::GameThread, FGraphEventRef());
}
}
}
FRenderingThread承载了渲染线程的主要工作,它的部分接口和实现代码如下:
// Engine\Source\Runtime\RenderCore\Private\RenderingThread.cpp
class FRenderingThread : public FRunnable
{
private:
bool bAcquiredThreadOwnership; // 当没有独立的RHI线程时, 渲染线程将被其它线程捕获.
public:
FEvent* TaskGraphBoundSyncEvent; // TaskGraph同步事件, 以便在主线程使用渲染线程之前就将渲染线程绑定到TaskGraph体系中.
FRenderingThread()
{
bAcquiredThreadOwnership = false;
// 获取同步事件.
TaskGraphBoundSyncEvent = FPlatformProcess::GetSynchEventFromPool(true);
RHIFlushResources();
}
// FRunnable interface.
virtual bool Init(void) override
{
// 获取当前线程ID到全局变量GRenderThreadId, 以便其它地方引用.
GRenderThreadId = FPlatformTLS::GetCurrentThreadId();
// 处理线程捕获关系.
if (!IsRunningRHIInSeparateThread())
{
bAcquiredThreadOwnership = true;
RHIAcquireThreadOwnership();
}
return true;
}
(......)
virtual uint32 Run(void) override
{
// 设置TLS.
FMemory::SetupTLSCachesOnCurrentThread();
// 设置渲染线程平台相关的数据.
FPlatformProcess::SetupRenderThread();
(......)
{
// 进入渲染线程主循环.
RenderingThreadMain( TaskGraphBoundSyncEvent );
}
FMemory::ClearAndDisableTLSCachesOnCurrentThread();
return 0;
}
};
可见它在运行之后会进入渲染线程逻辑,这里再进入RenderingThreadMain代码一探究竟:
void RenderingThreadMain( FEvent* TaskGraphBoundSyncEvent )
{
LLM_SCOPE(ELLMTag::RenderingThreadMemory);
// 将渲染线程和局部线程线程插槽设置成ActualRenderingThread和ActualRenderingThread_Local.
ENamedThreads::Type RenderThread = ENamedThreads::Type(ENamedThreads::ActualRenderingThread);
ENamedThreads::SetRenderThread(RenderThread);
ENamedThreads::SetRenderThread_Local(ENamedThreads::Type(ENamedThreads::ActualRenderingThread_Local));
// 将当前线程附加到TaskGraph的RenderThread插槽中.
FTaskGraphInterface::Get().AttachToThread(RenderThread);
FPlatformMisc::MemoryBarrier();
// 触发同步事件, 通知主线程渲染线程已经附加到TaskGraph, 已经准备好接收任务.
if( TaskGraphBoundSyncEvent != NULL )
{
TaskGraphBoundSyncEvent->Trigger();
}
(......)
// 渲染线程不同阶段的处理.
FCoreDelegates::PostRenderingThreadCreated.Broadcast();
check(GIsThreadedRendering);
FTaskGraphInterface::Get().ProcessThreadUntilRequestReturn(RenderThread);
FPlatformMisc::MemoryBarrier();
check(!GIsThreadedRendering);
FCoreDelegates::PreRenderingThreadDestroyed.Broadcast();
(......)
// 恢复线程线程到游戏线程.
ENamedThreads::SetRenderThread(ENamedThreads::GameThread);
ENamedThreads::SetRenderThread_Local(ENamedThreads::GameThread_Local);
FPlatformMisc::MemoryBarrier();
}
不过这里还留有一个很大的疑问,那就是FRenderingThread只是获取当前线程作为渲染线程并附加到TaskGraph中,并没有创建线程。那么是哪里创建的渲染线程呢?继续追踪,结果发现是在StartRenderingThread()接口中创建了FRenderingThread实例,它的实现代码如下(节选):
// Engine\Source\Runtime\RenderCore\Private\RenderingThread.cpp
void StartRenderingThread()
{
(......)
// Turn on the threaded rendering flag.
GIsThreadedRendering = true;
// 创建FRenderingThread实例.
GRenderingThreadRunnable = new FRenderingThread();
// 创建渲染线程!!
GRenderingThread = FRunnableThread::Create(GRenderingThreadRunnable, *BuildRenderingThreadName(ThreadCount), 0, FPlatformAffinity::GetRenderingThreadPriority(), FPlatformAffinity::GetRenderingThreadMask(), FPlatformAffinity::GetRenderingThreadFlags());
(......)
// 开启渲染命令的栅栏.
FRenderCommandFence Fence;
Fence.BeginFence();
Fence.Wait();
(......)
}
如果继续追踪,会发现StartRenderingThread()是在FEngineLoop::PreInitPostStartupScreen中调用的。
至此,渲染线程的创建、初始化以及主要接口的实现都剖析完了。
2.5.3.3 RHI线程的实现
RHI线程的工作是转换渲染指令到指定图形API,创建、上传渲染资源到GPU。它的主要逻辑在FRHIThread中,实现代码如下:
// Engine\Source\Runtime\RenderCore\Private\RenderingThread.cpp
class FRHIThread : public FRunnable
{
public:
FRunnableThread* Thread; // 所在的RHI线程.
FRHIThread()
: Thread(nullptr)
{
check(IsInGameThread());
}
void Start()
{
// 开始时创建RHI线程.
Thread = FRunnableThread::Create(this, TEXT("RHIThread"), 512 * 1024, FPlatformAffinity::GetRHIThreadPriority(),
FPlatformAffinity::GetRHIThreadMask(), FPlatformAffinity::GetRHIThreadFlags()
);
check(Thread);
}
virtual uint32 Run() override
{
LLM_SCOPE(ELLMTag::RHIMisc);
// 初始化TLS
FMemory::SetupTLSCachesOnCurrentThread();
// 将FRHIThread所在的RHI线程附加到askGraph体系中,并指定到ENamedThreads::RHIThread。
FTaskGraphInterface::Get().AttachToThread(ENamedThreads::RHIThread);
// 启动RHI线程,直到线程返回。
FTaskGraphInterface::Get().ProcessThreadUntilRequestReturn(ENamedThreads::RHIThread);
// 清理TLS.
FMemory::ClearAndDisableTLSCachesOnCurrentThread();
return 0;
}
// 单例接口。
static FRHIThread& Get()
{
static FRHIThread Singleton; // 使用了局部静态变量,可以保证线程安全。
return Singleton;
}
};
可见RHI线程不同于渲染线程,是直接在FRHIThread对象内创建实际的线程。而FRHIThread的创建也是在StartRenderingThread()中:
void StartRenderingThread()
{
(......)
if (GUseRHIThread_InternalUseOnly)
{
FRHICommandListExecutor::GetImmediateCommandList().ImmediateFlush(EImmediateFlushType::DispatchToRHIThread);
if (!FTaskGraphInterface::Get().IsThreadProcessingTasks(ENamedThreads::RHIThread))
{
// 创建FRHIThread实例并启动它.
FRHIThread::Get().Start();
}
DECLARE_CYCLE_STAT(TEXT("Wait For RHIThread"), STAT_WaitForRHIThread, STATGROUP_TaskGraphTasks);
// 创建RHI线程拥有者捕获任务, 让游戏线程等待.
FGraphEventRef CompletionEvent = TGraphTask<FOwnershipOfRHIThreadTask>::CreateTask(NULL, ENamedThreads::GameThread).ConstructAndDispatchWhenReady(true, GET_STATID(STAT_WaitForRHIThread));
QUICK_SCOPE_CYCLE_COUNTER(STAT_StartRenderingThread);
// 让游戏线程或局部线程等待RHI线程处理(捕获了线程拥有者, 大多数图形API为空)完毕.
FTaskGraphInterface::Get().WaitUntilTaskCompletes(CompletionEvent, ENamedThreads::GameThread_Local);
// 存储RHI线程id.
GRHIThread_InternalUseOnly = FRHIThread::Get().Thread;
check(GRHIThread_InternalUseOnly);
GIsRunningRHIInDedicatedThread_InternalUseOnly = true;
GIsRunningRHIInSeparateThread_InternalUseOnly = true;
GRHIThreadId = GRHIThread_InternalUseOnly->GetThreadID();
GRHICommandList.LatchBypass();
}
(......)
}
那么渲染线程如何向RHI线程入队任务呢?答案就在RHICommandList.h中:
// Engine\Source\Runtime\RHI\Public\RHICommandList.h
// RHI命令父类
struct FRHICommandBase
{
FRHICommandBase* Next = nullptr; // 指向下一条RHI命令.
// 执行RHI命令并销毁.
virtual void ExecuteAndDestruct(FRHICommandListBase& CmdList, FRHICommandListDebugContext& DebugContext) = 0;
};
// RHI命令结构体
template<typename TCmd, typename NameType = FUnnamedRhiCommand>
struct FRHICommand : public FRHICommandBase
{
(......)
void ExecuteAndDestruct(FRHICommandListBase& CmdList, FRHICommandListDebugContext& Context) override final
{
(......)
TCmd *ThisCmd = static_cast<TCmd*>(this);
ThisCmd->Execute(CmdList);
ThisCmd->~TCmd();
}
};
// 向RHI线程发送RHI命令的宏.
#define FRHICOMMAND_MACRO(CommandName) \
struct PREPROCESSOR_JOIN(CommandName##String, __LINE__) \
{ \
static const TCHAR* TStr() { return TEXT(#CommandName); } \
}; \
struct CommandName final : public FRHICommand<CommandName, PREPROCESSOR_JOIN(CommandName##String, __LINE__)>
RHI线程的相关实现机制跟渲染线程类型,且更加简洁。以下是它的使用示范:
// Engine\Source\Runtime\RHI\Public\RHICommandList.h
FRHICOMMAND_MACRO(FRHICommandDrawPrimitive)
{
uint32 BaseVertexIndex;
uint32 NumPrimitives;
uint32 NumInstances;
FORCEINLINE_DEBUGGABLE FRHICommandDrawPrimitive(uint32 InBaseVertexIndex, uint32 InNumPrimitives, uint32 InNumInstances)
: BaseVertexIndex(InBaseVertexIndex)
, NumPrimitives(InNumPrimitives)
, NumInstances(InNumInstances)
{
}
RHI_API void Execute(FRHICommandListBase& CmdList);
};
// Engine\Source\Runtime\RHI\Public\RHICommandListCommandExecutes.inl
void FRHICommandDrawPrimitive::Execute(FRHICommandListBase& CmdList)
{
RHISTAT(DrawPrimitive);
INTERNAL_DECORATOR(RHIDrawPrimitive)(BaseVertexIndex, NumPrimitives, NumInstances);
}
由此可见,所有的RHI指令都是预先声明并实现好的,目前存在的RHI渲染指令类型达到近百种(如下),渲染线程创建这些声明好的RHI指令即可在合适的被推入RHI线程队列并被执行。
FRHICOMMAND_MACRO(FRHICommandUpdateGeometryCacheBuffer)
FRHICOMMAND_MACRO(FRHISubmitFrameToEncoder)
FRHICOMMAND_MACRO(FLocalRHICommand)
FRHICOMMAND_MACRO(FRHISetSpectatorScreenTexture)
FRHICOMMAND_MACRO(FRHISetSpectatorScreenModeTexturePlusEyeLayout)
FRHICOMMAND_MACRO(FRHISyncFrameCommand)
FRHICOMMAND_MACRO(FRHICommandStat)
FRHICOMMAND_MACRO(FRHICommandRHIThreadFence)
FRHICOMMAND_MACRO(FRHIAsyncComputeSubmitList)
FRHICOMMAND_MACRO(FRHICommandWaitForAndSubmitSubListParallel)
FRHICOMMAND_MACRO(FRHICommandWaitForAndSubmitSubList)
FRHICOMMAND_MACRO(FRHICommandWaitForAndSubmitRTSubList)
FRHICOMMAND_MACRO(FRHICommandSubmitSubList)
FRHICOMMAND_MACRO(FRHICommandBeginUpdateMultiFrameResource)
FRHICOMMAND_MACRO(FRHICommandEndUpdateMultiFrameResource)
FRHICOMMAND_MACRO(FRHICommandBeginUpdateMultiFrameUAV)
FRHICOMMAND_MACRO(FRHICommandEndUpdateMultiFrameUAV)
FRHICOMMAND_MACRO(FRHICommandSetGPUMask)
FRHICOMMAND_MACRO(FRHICommandWaitForTemporalEffect)
FRHICOMMAND_MACRO(FRHICommandBroadcastTemporalEffect)
FRHICOMMAND_MACRO(FRHICommandSetStencilRef)
FRHICOMMAND_MACRO(FRHICommandDrawPrimitive)
FRHICOMMAND_MACRO(FRHICommandDrawIndexedPrimitive)
FRHICOMMAND_MACRO(FRHICommandSetBlendFactor)
FRHICOMMAND_MACRO(FRHICommandSetStreamSource)
FRHICOMMAND_MACRO(FRHICommandSetViewport)
FRHICOMMAND_MACRO(FRHICommandSetStereoViewport)
FRHICOMMAND_MACRO(FRHICommandSetScissorRect)
FRHICOMMAND_MACRO(FRHICommandSetRenderTargets)
FRHICOMMAND_MACRO(FRHICommandBeginRenderPass)
FRHICOMMAND_MACRO(FRHICommandEndRenderPass)
FRHICOMMAND_MACRO(FRHICommandNextSubpass)
FRHICOMMAND_MACRO(FRHICommandBeginParallelRenderPass)
FRHICOMMAND_MACRO(FRHICommandEndParallelRenderPass)
FRHICOMMAND_MACRO(FRHICommandBeginRenderSubPass)
FRHICOMMAND_MACRO(FRHICommandEndRenderSubPass)
FRHICOMMAND_MACRO(FRHICommandBeginComputePass)
FRHICOMMAND_MACRO(FRHICommandEndComputePass)
FRHICOMMAND_MACRO(FRHICommandBindClearMRTValues)
FRHICOMMAND_MACRO(FRHICommandSetGraphicsPipelineState)
FRHICOMMAND_MACRO(FRHICommandAutomaticCacheFlushAfterComputeShader)
FRHICOMMAND_MACRO(FRHICommandFlushComputeShaderCache)
FRHICOMMAND_MACRO(FRHICommandDrawPrimitiveIndirect)
FRHICOMMAND_MACRO(FRHICommandDrawIndexedIndirect)
FRHICOMMAND_MACRO(FRHICommandDrawIndexedPrimitiveIndirect)
FRHICOMMAND_MACRO(FRHICommandSetDepthBounds)
FRHICOMMAND_MACRO(FRHICommandClearUAVFloat)
FRHICOMMAND_MACRO(FRHICommandClearUAVUint)
FRHICOMMAND_MACRO(FRHICommandCopyToResolveTarget)
FRHICOMMAND_MACRO(FRHICommandCopyTexture)
FRHICOMMAND_MACRO(FRHICommandResummarizeHTile)
FRHICOMMAND_MACRO(FRHICommandTransitionTexturesDepth)
FRHICOMMAND_MACRO(FRHICommandTransitionTextures)
FRHICOMMAND_MACRO(FRHICommandTransitionTexturesArray)
FRHICOMMAND_MACRO(FRHICommandTransitionTexturesPipeline)
FRHICOMMAND_MACRO(FRHICommandTransitionTexturesArrayPipeline)
FRHICOMMAND_MACRO(FRHICommandClearColorTexture)
FRHICOMMAND_MACRO(FRHICommandClearDepthStencilTexture)
FRHICOMMAND_MACRO(FRHICommandClearColorTextures)
FRHICOMMAND_MACRO(FRHICommandSetGlobalUniformBuffers)
FRHICOMMAND_MACRO(FRHICommandBuildLocalUniformBuffer)
FRHICOMMAND_MACRO(FRHICommandBeginRenderQuery)
FRHICOMMAND_MACRO(FRHICommandEndRenderQuery)
FRHICOMMAND_MACRO(FRHICommandCalibrateTimers)
FRHICOMMAND_MACRO(FRHICommandPollOcclusionQueries)
FRHICOMMAND_MACRO(FRHICommandBeginScene)
FRHICOMMAND_MACRO(FRHICommandEndScene)
FRHICOMMAND_MACRO(FRHICommandBeginFrame)
FRHICOMMAND_MACRO(FRHICommandEndFrame)
FRHICOMMAND_MACRO(FRHICommandBeginDrawingViewport)
FRHICOMMAND_MACRO(FRHICommandEndDrawingViewport)
FRHICOMMAND_MACRO(FRHICommandInvalidateCachedState)
FRHICOMMAND_MACRO(FRHICommandDiscardRenderTargets)
FRHICOMMAND_MACRO(FRHICommandDebugBreak)
FRHICOMMAND_MACRO(FRHICommandUpdateTextureReference)
FRHICOMMAND_MACRO(FRHICommandUpdateRHIResources)
FRHICOMMAND_MACRO(FRHICommandCopyBufferRegion)
FRHICOMMAND_MACRO(FRHICommandCopyBufferRegions)
FRHICOMMAND_MACRO(FRHICommandClearRayTracingBindings)
FRHICOMMAND_MACRO(FRHICommandRayTraceOcclusion)
FRHICOMMAND_MACRO(FRHICommandRayTraceIntersection)
FRHICOMMAND_MACRO(FRHICommandRayTraceDispatch)
FRHICOMMAND_MACRO(FRHICommandSetRayTracingBindings)
FRHICOMMAND_MACRO(FClearCachedRenderingDataCommand)
FRHICOMMAND_MACRO(FClearCachedElementDataCommand)
2.5.4 游戏线程和渲染线程的交互
本节将讲述各个线程之间的数据交换机制和实现细节。首先看看游戏线程如何将数据传递给渲染线程。
游戏线程在Tick时,会通过UGameEngine、FViewport、UGameViewportClient等对象,才会进入渲染模块的调用:
void UGameEngine::Tick( float DeltaSeconds, bool bIdleMode )
{
UGameEngine::RedrawViewports()
{
void FViewport::Draw( bool bShouldPresent)
{
void UGameViewportClient::Draw()
{
// 计算ViewFamily、View的各种属性
ULocalPlayer::CalcSceneView();
// 发送渲染命令
FRendererModule::BeginRenderingViewFamily()
{
World->SendAllEndOfFrameUpdates();
// 创建场景渲染器
FSceneRenderer* SceneRenderer = FSceneRenderer::CreateSceneRenderer(ViewFamily, ...);
// 向渲染线程发送绘制场景指令.
ENQUEUE_RENDER_COMMAND(FDrawSceneCommand)(
[SceneRenderer](FRHICommandListImmediate& RHICmdList)
{
RenderViewFamily_RenderThread(RHICmdList, SceneRenderer)
{
(......)
// 调用场景渲染器的绘制接口.
SceneRenderer->Render(RHICmdList);
(......)
}
FlushPendingDeleteRHIResources_RenderThread();
});
}
}}}}
前面章节也提到,渲染线程使用的是SceneProxy和SceneInfo等对象,那么游戏的Actor组件是如何跟场景代理的数据联系起来的呢?又是如何更新数据的?
先弄清楚游戏组件向SceneProxy传递数据的机制,答案就藏在FScene::AddPrimitive:
// Engine\Source\Runtime\Renderer\Private\RendererScene.cpp
void FScene::AddPrimitive(UPrimitiveComponent* Primitive)
{
(......)
// 创建图元的场景代理
FPrimitiveSceneProxy* PrimitiveSceneProxy = Primitive->CreateSceneProxy();
Primitive->SceneProxy = PrimitiveSceneProxy;
if(!PrimitiveSceneProxy)
{
return;
}
// 创建图元场景代理的场景信息
FPrimitiveSceneInfo* PrimitiveSceneInfo = new FPrimitiveSceneInfo(Primitive, this);
PrimitiveSceneProxy->PrimitiveSceneInfo = PrimitiveSceneInfo;
(......)
FScene* Scene = this;
ENQUEUE_RENDER_COMMAND(AddPrimitiveCommand)(
[Params = MoveTemp(Params), Scene, PrimitiveSceneInfo, PreviousTransform = MoveTemp(PreviousTransform)](FRHICommandListImmediate& RHICmdList)
{
FPrimitiveSceneProxy* SceneProxy = Params.PrimitiveSceneProxy;
(......)
SceneProxy->CreateRenderThreadResources();
// 在渲染线程中将SceneInfo加入到场景中.
Scene->AddPrimitiveSceneInfo_RenderThread(PrimitiveSceneInfo, PreviousTransform);
});
}
上面有个关键的一句Primitive->CreateSceneProxy()即是创建组件对应的PrimitiveSceneProxy,在PrimitiveSceneProxy的构造函数中,将组件的所有数据都拷贝了一份:
FPrimitiveSceneProxy::FPrimitiveSceneProxy(const UPrimitiveComponent* InComponent, FName InResourceName)
:
CustomPrimitiveData(InComponent->GetCustomPrimitiveData())
, TranslucencySortPriority(FMath::Clamp(InComponent->TranslucencySortPriority, SHRT_MIN, SHRT_MAX))
, Mobility(InComponent->Mobility)
, LightmapType(InComponent->LightmapType)
, StatId()
, DrawInGame(InComponent->IsVisible())
, DrawInEditor(InComponent->GetVisibleFlag())
, bReceivesDecals(InComponent->bReceivesDecals)
(......)
{
(......)
}
拷贝数据之后,游戏线程修改的是PrimitiveComponent的数据,而渲染线程修改或访问的是PrimitiveSceneProxy的数据,彼此不干扰,避免了临界区和锁的同步,也保证了线程安全。不过这里还有疑问,那就是创建PrimitiveSceneProxy的时候会拷贝一份数据,但在创建完之后,PrimitiveComponent是如何向PrimitiveSceneProxy更新数据的呢?
原来是ActorComponent有几个标记,只要这几个标记被标记为true,便会在适当的时机调用更新接口,以便得到更新:
// Engine\Source\Runtime\Engine\Classes\Components\ActorComponent.h
class ENGINE_API UActorComponent : public UObject, public IInterface_AssetUserData
{
protected:
// 以下接口分别更新对应的状态, 子类可以重写以实现自己的更新逻辑.
virtual void DoDeferredRenderUpdates_Concurrent()
{
(......)
if(bRenderStateDirty)
{
RecreateRenderState_Concurrent();
}
else
{
if(bRenderTransformDirty)
{
SendRenderTransform_Concurrent();
}
if(bRenderDynamicDataDirty)
{
SendRenderDynamicData_Concurrent();
}
}
}
virtual void CreateRenderState_Concurrent(FRegisterComponentContext* Context)
{
bRenderStateCreated = true;
bRenderStateDirty = false;
bRenderTransformDirty = false;
bRenderDynamicDataDirty = false;
}
virtual void SendRenderTransform_Concurrent()
{
bRenderTransformDirty = false;
}
virtual void SendRenderDynamicData_Concurrent()
{
bRenderDynamicDataDirty = false;
}
private:
uint8 bRenderStateDirty:1; // 组件的渲染状态是否脏的
uint8 bRenderTransformDirty:1; // 组件的变换矩阵是否脏的
uint8 bRenderDynamicDataDirty:1; // 组件的渲染动态数据是否脏的
};
上面protected的接口就是用于刷新组件的数据到对应的SceneProxy,具体的组件子类可以重写它,以定制自己的更新逻辑,比如ULightComponent的变换矩阵更新逻辑如下:
// Engine\Source\Runtime\Engine\Private\Components\LightComponent.cpp
void ULightComponent::SendRenderTransform_Concurrent()
{
// 将变换信息更新到场景.
GetWorld()->Scene->UpdateLightTransform(this);
Super::SendRenderTransform_Concurrent();
}
而场景的UpdateLightTransform会将组件的数据组装起来,并将数据发送到渲染线程执行:
// Engine\Source\Runtime\Renderer\Private\RendererScene.cpp
void FScene::UpdateLightTransform(ULightComponent* Light)
{
if(Light->SceneProxy)
{
// 组装组件的数据到结构体(注意这里不能将Component的地址传到渲染线程,而是将所有要更新的数据拷贝一份)
FUpdateLightTransformParameters Parameters;
Parameters.LightToWorld = Light->GetComponentTransform().ToMatrixNoScale();
Parameters.Position = Light->GetLightPosition();
FScene* Scene = this;
FLightSceneInfo* LightSceneInfo = Light->SceneProxy->GetLightSceneInfo();
// 将数据发送到渲染线程执行.
ENQUEUE_RENDER_COMMAND(UpdateLightTransform)(
[Scene, LightSceneInfo, Parameters](FRHICommandListImmediate& RHICmdList)
{
FScopeCycleCounter Context(LightSceneInfo->Proxy->GetStatId());
// 在渲染线程执行数据更新.
Scene->UpdateLightTransform_RenderThread(LightSceneInfo, Parameters);
});
}
}
void FScene::UpdateLightTransform_RenderThread(FLightSceneInfo* LightSceneInfo, const FUpdateLightTransformParameters& Parameters)
{
(......)
// 更新变换矩阵.
LightSceneInfo->Proxy->SetTransform(Parameters.LightToWorld, Parameters.Position);
(......)
}
至此,组件如何向场景代理更新数据的逻辑终于理清了。
需要特别提醒的是,FScene、FSceneProxy等有些接口在游戏线程调用,而有些接口(一般带有_RenderThread的后缀)在渲染线程调用,切记不能跨线程调用,否则会产生竞争条件,甚至引发程序崩溃。
2.5.5 游戏线程和渲染线程的同步
前面也提到,游戏线程不可能领先于渲染线程超过一帧,否则游戏线程会等待渲染线程处理完。它们的同步机制涉及两个关键的概念:
// Engine\Source\Runtime\RenderCore\Public\RenderCommandFence.h
// 渲染命令栅栏
class RENDERCORE_API FRenderCommandFence
{
public:
// 向渲染命令队列增加一个栅栏. bSyncToRHIAndGPU是否同步RHI和GPU交换Buffer, 否则只等待渲染线程.
void BeginFence(bool bSyncToRHIAndGPU = false);
// 等待栅栏被执行. bProcessGameThreadTasks没有作用.
void Wait(bool bProcessGameThreadTasks = false) const;
// 是否完成了栅栏.
bool IsFenceComplete() const;
private:
mutable FGraphEventRef CompletionEvent; // 处理完成同步的事件
ENamedThreads::Type TriggerThreadIndex; // 处理完之后需要触发的线程类型.
};
// Engine\Source\Runtime\Engine\Public\UnrealEngine.h
class FFrameEndSync
{
FRenderCommandFence Fence[2]; // 渲染栅栏对.
int32 EventIndex; // 当前事件索引
public:
// 同步游戏线程和渲染线程. bAllowOneFrameThreadLag是否允许渲染线程一帧的延迟.
void Sync( bool bAllowOneFrameThreadLag )
{
Fence[EventIndex].BeginFence(true); // 开启栅栏, 强制同步RHI和GPU交换链的.
bool bEmptyGameThreadTasks = !FTaskGraphInterface::Get().IsThreadProcessingTasks(ENamedThreads::GameThread);
// 保证游戏线程至少跑过一次任务.
if (bEmptyGameThreadTasks)
{
FTaskGraphInterface::Get().ProcessThreadUntilIdle(ENamedThreads::GameThread);
}
// 如果允许延迟, 交换事件索引.
if( bAllowOneFrameThreadLag )
{
EventIndex = (EventIndex + 1) % 2;
}
(......)
// 开启栅栏等待.
Fence[EventIndex].Wait(bEmptyGameThreadTasks);
}
};
而FFrameEndSync的使用是在FEngineLoop::Tick中:
// Engine\Source\Runtime\Launch\Private\LaunchEngineLoop.cpp
void FEngineLoop::Tick()
{
(......)
// 在引擎循环的帧末尾添加游戏线程和渲染线程的同步事件.
{
static FFrameEndSync FrameEndSync; // 局部静态变量, 线程安全.
static auto CVarAllowOneFrameThreadLag = IConsoleManager::Get().FindTConsoleVariableDataInt(TEXT("r.OneFrameThreadLag"));
// 同步游戏和渲染线程, 是否允许一帧的延迟可由控制台命令控制. 默认是开启的.
FrameEndSync.Sync( CVarAllowOneFrameThreadLag->GetValueOnGameThread() != 0 );
}
(......)
}
2.6 多线程渲染结语
并行计算架构已然成为现代引擎的标配,UE的多线程渲染是随着多核CPU和新一代图形API诞生而必然的产物。但就目前而言,渲染线程很多时候还是单条的(虽然可以借助TaskGraph部分地并行)。理想情况下,是多条渲染线程并行且不依赖地生成渲染命令,并且不需要主线程来驱动,任何线程都可作为工作线程(亦即没有UE的命名线程),任何线程都可发起计算任务,避免操作系统级别的功能线程。而这需要操作系统、图形API、计算机语言共同地不断演化才可达成。
最近发布的UE4.26已经在普及RDG,RDG可以自动裁剪、优化渲染Pass和资源,是提升引擎整体并行处理的一大利器。
这篇文章原本预计2个月左右完成,然而实际上花了3个多月,几乎耗尽了笔者的所有业余时间。原本还有很多技术章节需要添加,但篇幅和时间都超限了,只好作罢。希望此系列文章对学习UE的读者们有帮助,感谢关注和收藏。
特别说明
- 感谢所有参考文献的作者,部分图片来自参考文献和网络,侵删。
- 本系列文章为笔者原创,只发表在博客园上,欢迎分享本文链接,但未经同意,不允许转载!
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
- 系列文章,未完待续,完整目录请戳内容纲目。
参考文献
- Unreal Engine 4 Sources
- Unreal Engine 4 Documentation
- Rendering and Graphics
- Materials
- Graphics Programming
- Unreal Engine 4 Rendering
- Threaded Rendering
- 《大象无形-虚幻引擎程序设计浅析》
- 《房燕良-虚幻4渲染系统架构解析》
- UE4 Render System Sheet
- Inside UE4
- Exploring in UE4
- 《游戏引擎架构》
- C++ reference
- 《C++面向对象多线程编程》
- 《Win32多线程程序设计》
- 《Windows核心编程(第5版)》
- 《Effective C++》
- 《C++ Concurrency In Action》
- 《Modern Concurrency in Depth》
- 《Multithreaded Programming Guide》
- Windows 95
- 多核处理器
- Amdahl's law
- Thread-local storage
- Covering Multithreading Basics
- Multi-Threaded Programming: C++11
- 深入理解Coroutine(协程)及其原理以及Coroutine in Kotlin
- C++11 多线程
- C++ 的可移植性和跨平台开发[6]:多线程
- volatile (computer programming)
- 谈谈 C/C++ 中的 volatile
- Practical Parallel Rendering with DirectX 9 and 10
- Multi-engine synchronization
- Understanding DirectX Multithreaded Rendering Performance by Experiments
- Performance, Methods, and Practices of DirectX 11 Multithreaded Rendering
- Introduction to Multithreaded rendering and the usage of Deferred Contexts in DirectX 11
- Practical Parallel Rendering with DirectX 9 and 10
- D3D11和D3D12多线程渲染框架的比较
- Render graphs and Vulkan — a deep dive
- DirectX 12: Performance Comparison Between Single- and Multithreaded Rendering when Culling Multiple Lights
- Vulkan - 高性能渲染
- Vulkan 多线程渲染
- Vulkan Multi-Threading
- 新一代图形API VULKAN 对 AR、VR 的影响
- Fork-Join Model
- Fiber (computer science)
- Evaluation of multi-threading in Vulkan
- Metal: Command Organization and Execution Model
- Task-based Multithreading - How to Program for 100 cores
- Multi-Threaded Game Engine Design
- 游戏引擎随笔 0x04:并行计算架构
- Multithreaded Rendering & Graphics Jobs 多线程渲染与图形Jobs
- Optimizing Graphics in Unity
- Frostbite Rendering Architecture and Real-time Procedural Shading & Texturing Techniques (GDC 2007)
- FrameGraph: Extensible Rendering Architecture in Frostbite
- Parallelizing the Naughty Dog engine using fibers
- Destiny’s Multi-threaded Renderer Architecture talk
- Multithreading the Entire Destiny Engine
- Everything You Need to Know About Multithreaded Rendering in Fortnite
- bgfx
- 虚幻4 Task Graph System 介绍
- UE4中TaskGraph系统的简单分析
- Directed acyclic graph
- Scalability for All: Unreal Engine* 4 with Intel
- UE高级性能剖析技术
- UE4 关于主循环的资料
- Intel® ISPC User's Guide
- 多线程渲染
- UE4里的渲染线程
- UE4主线程与渲染线程同步
- Bringing Fortnite to Mobile with Vulkan and OpenGL ES

 浙公网安备 33010602011771号
浙公网安备 33010602011771号