DeepSeek论文详解
1. 绪论
DeepSeek在24-25年相交之际一轮爆火,通过强大的模型性能和极低的token价格在众多厂商的大模型中杀出重围,一跃成为LLM圈子里的顶流,大方的技术报告和开源更是进一步增强了其影响力。其实在DeepSeek火爆之际就想好好研读一下他们发布的论文,但是那会忙于流片一直没能抽出时间,只能看一些解读文章,目前相对轻松一些了,遂投入时间好好研究一下论文原文。现根据DeepSeek团队从2024年开始陆续发布的论文/技术报告做一下整理,看看他们是如何一步步走来的。有什么遗漏或者理解错误也欢迎各位读者在评论区斧正。
2. DeepSeek LLM Scaling Open-Source Language Models with Longtermism
这是DeepSeek系列论文的首篇,发表于2024年1月5日[1]。论文开篇即指出,在大语言模型的迅速发展中,关于Scaling Law的结论却各不相同,这成了LLM领域上的一朵乌云(Scaling Law即随着LLM的模型大小、数据集大小和训练计算量的增加,LLM的性能提升遵从幂律扩展,我的理解是,DeepSeek团队认为虽然前面的大量工作确实证实了Scaling Law的存在,但在具体实现时,由于各种因素的影响,实际的LLM工作可能会偏离理论的Scaling Law,因此DeepSeek团队希望对Scaling Law这一LLM的”牛顿定律“进行深入的研究)。
DeepSeek团队在研究Scaling Law的过程中,提出了DeepSeek LLM模型,分为7B和67B一大一小。针对预训练阶段,DeepSeek团队开发了一套2兆(10的12次方)token的数据集。接着,团队在DeepSeek LLM基础模型上进行了监督微调(SFT)和直接偏好优化(DPO),从而得到了DeepSeek Chat模型。在benchmark上DeepSeek 67B超过了LLaMA-2 70B模型,并在开放式评估中展现出了超过GPT-3.5的性能。
在这篇文章我主要关注的insight是针对Scaling Law的深度研究以及DeepSeek团队提出的独特见解,这对他们后续的模型提升反向有着重要的指导意义;因此对本篇的解读会重点关注这个问题,对于一些常规的问题不用太多笔墨。
在研究细节之前先简单看一下DeepSeek的模型架构:

DeepSeek LLM的架构设计整体上follow了LLaMa,采用使用RMSNorm的Pre-Norm架构,并使用SwiGLU作为FFN的激活函数,中间层尺寸为\(\frac{8}{3} d_{model}\)。使用Rotary Embedding作为位置编码。为了优化推理时的开销,67B模型采用了GQA代替传统的MHA。
这里tip一下,GQA是将query head分组去share K和V,是居于MHA和MQA中间的一种平衡模型性能和开销的Attention常用优化手段。
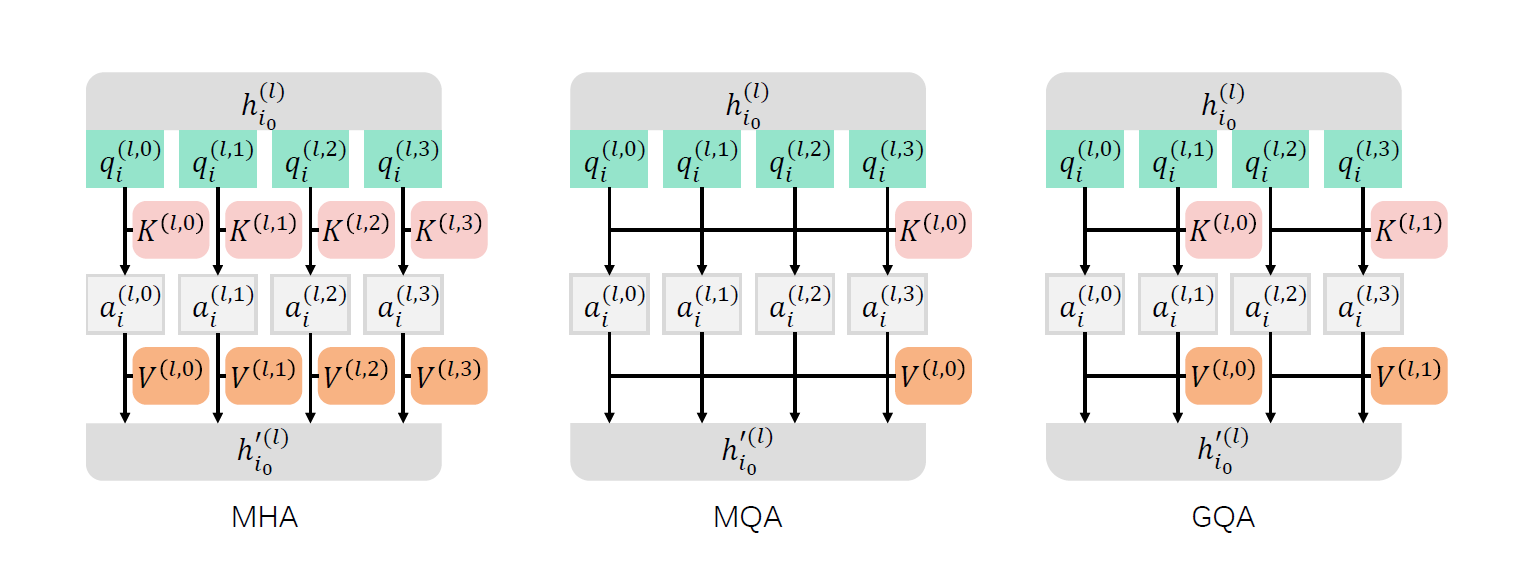
DeepSeek LLM 7B是一个30层的网络,而DeepSeek LLM 67B有95层。和其他采用GQA的工作的区别是,DeepSeek团队重点通过加大网络深度的方式来拓展参数,而非常规的增加FFN的中间层宽度的方式,期望以此提升性能。
接下来来看重点的部分,先从DeepSeek团队对Scaling Law的深入挖掘开始。
Scaling Law拉开了LLM研究的序幕,具体的表述是模型性能随着算力规模\(C\),模型规模\(N\)和数据规模\(D\)的增大而提升。当模型规模\(N\)以模型参数量进行表示,数据规模\(D\)以token数量进行表示的情况下,\(C\)大致满足\(C=6ND\)。因此,在增大算力规模的同时,如何分配模型和数据规模的分配,是Scaling Law中的一个重要研究问题。
尽管在LLM的发展过程中,模型规模的提升带来了模型性能的持续提升,进一步刺激了模型规模的放大,但在早期的研究中,模型规模/数据规模的缩放分配策略展现出了不同的结论,进而引发了针对Scaling Law的泛化性的质疑。此外,这些研究往往没有完整描述超参数的设置,使得难以确定在不同的算力规模下模型是否达到了最优性能。因此DeepSeek团队认为最重要的问题就是重新深入研究Scaling Law来解决这些不确定的问题从而确保他们走在一条正确的缩放模型的路径上,反映了他们的长期主义视角,并且在他们看来这是持续提升模型的关键。
为了确保在不同的算力规模下,模型能够达到最优性能,DeepSeek团队首先研究了超参数对Scaling Law的影响。根据经验,大部分的超参数对于训练过程不会产生太多影响,因此在不同的算力规模下,DeepSeek将这些超参数保持不变,但针对Batch Size和学习率这两个对模型性能影响最大的超参数,DeepSeek团队进行了详细的验证。
早期的工作虽然也提供了一些关于设置Batch Size和学习率的经验,但在DeepSeek团队的初步实验中发现参考价值有限,因此他们通过广泛的实验模拟了算力规模\(C\)和最优Batch Size和学习率之间的关系。这种关系被DeepSeek团队成为超参数的Scaling Law,通过这一关系,可以确保不同算力规模下的模型均可以达到其近乎最优的性能。
接着,DeepSeek团队研究了模型和数据规模比的Scaling Law。为了更准确的表达模型规模,他们使用了一个新的模型规模表示方法,采用非嵌入层\(FLOPs/token\)的参数\(M\)取代之前的模型参数\(N\),并将原来的算力规模近似公式\(C=6ND\)替换为\(C=MD\)。通过实验,他们获得了最优模型/数据规模比分配策略与模型性能预测的insight,并且准确的预测了DeepSeek LLM 7B和67B的模型性能。
此外,在DeepSeek团队研究Scaling Law的过程中,他们所使用的数据经过了多轮迭代。在尝试各种数据集的过程中,他们发现数据的质量也显著影响模型/数据规模的分配策略。当数据质量高时,更多的算力应当被分配给模型规模,这意味着高质量的数据可以驱动更大的模型。因此反过来说,最优的模型/数据规模分配比也可以作为数据质量评估的一个间接方法。DeepSeek团队表示将对数据质量对Scaling Law的影响保持持续关注,并在未来发表更多的分析。
上述的论文内容折射出了DeepSeek团队强大的透过现象看本质的能力,尽管Scaling Law广为人知,但在真正的实践过程中,超参数的设置与模型/数据规模比对模型的性能也有着重大的影响,尽管这种问题属于LLM的基础理论层面的问题,需要投入大量的资源去进行研究,远超简单尝试几次把模型刷到SOTA就可以收工的浮于表面的渐层研究,但只有去深度研究这些问题才能确保自己真正的走在一条正确的路径上,不愧于长期主义之名。
接下来来看针对超参数Scaling Law和模型/数据规模比Scaling Law这两个问题DeepSeek具体的研究成果。
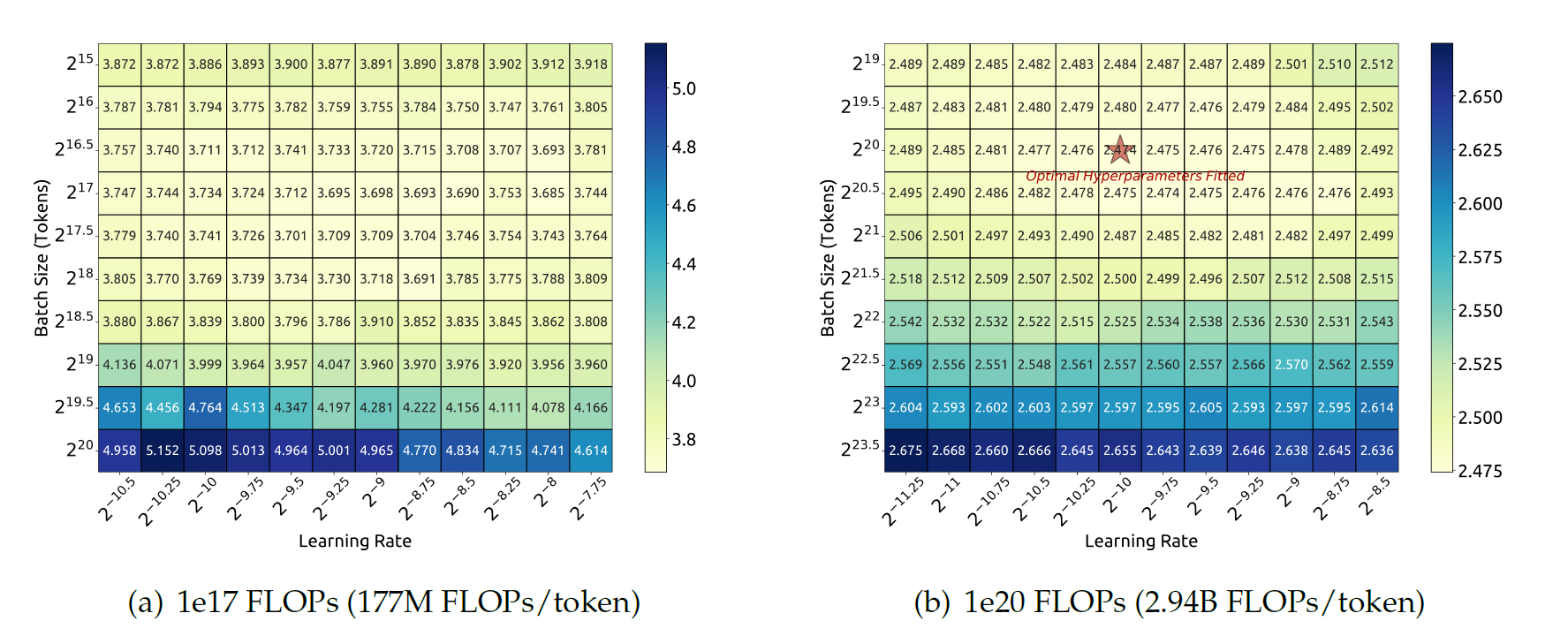
DeepSeek团队最初先在177M \(FLOPs/token\)的小规模实验中研究了Batch Size和学习率的进行了网格搜索,如图(a)所示,结果表明,泛化误差在大量的Batch Size和学习率选择中保持稳定。这表明可以在一个相对广泛的参数空间中接近最优性能。
然后DeepSeek团队使用不同的Batch Size,学习率在\(1e17\)到\(2e19\)的算力规模下训练了多个模型。考虑到参数空间的荣誉,他们考虑了泛化误差不超过最小值0.25%的超参数作为近最优超参数。然后他们拟合了Batch Size大小\(B\)和学习率\(\eta\)与算力规模\(C\)的关系。拟合结果如下图所示。下图揭示了最佳Batch Size随着算力规模\(C\)的增加而增大,而最佳学习率\(\eta\)逐渐降低,这和直觉和经验一致。此外,所有的近最优超参数落在一个宽范围内,在这个区间中选取近最优超参数相对容易。他们最后拟合得到的Batch Size和学习率的公式如下:
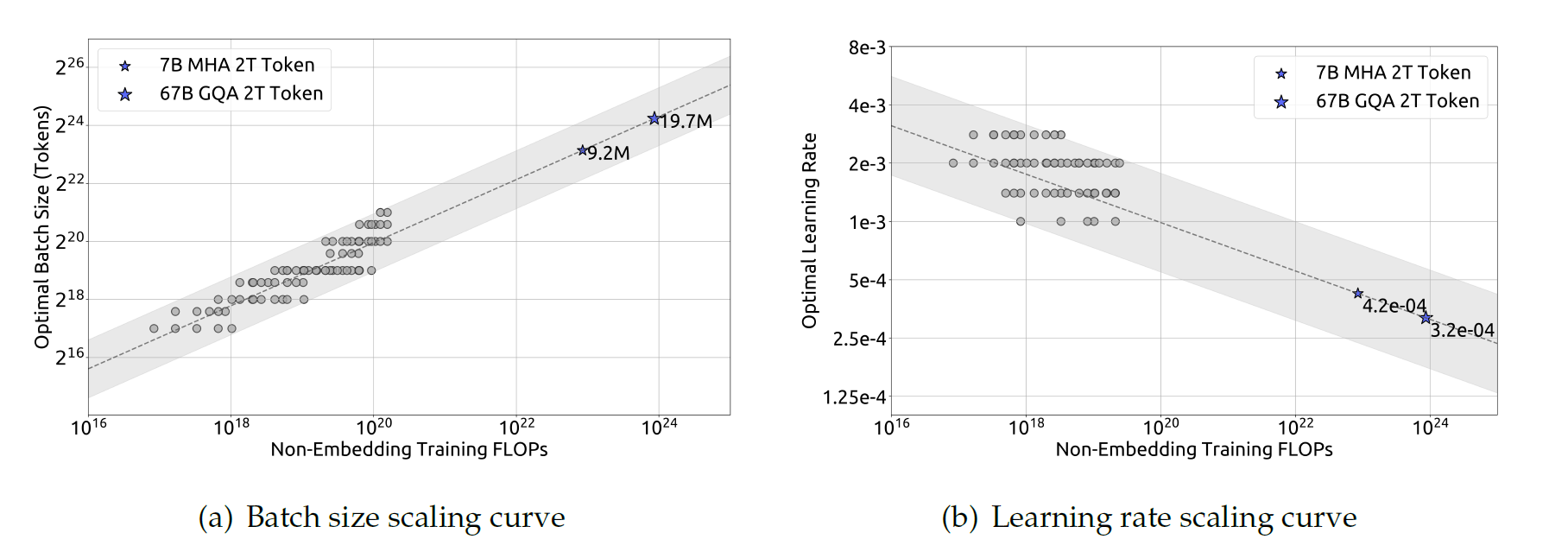
接着他们在一系列\(1e20\)算力规模的模型上验证了公式(一个具体的规模为\(2.94B FLOPs/token\)的模型的结果如上上图(b)所示),结果显示拟合公式计算出的结果在最优参数空间中居中。并且在后续的实验中证明了在DeepSeek LLM 7B和67B模型中,根据拟合公式选择的超参数同样取得了良好的性能。
但一个重点是他们尚未考虑除了算力规模\(C\)之外的其他因素对最优超参数的影响,这与一些早期工作认为最优Batch Size可以建模为泛化误差\(L\)存在不同。此外,他们观察到即使在相同的算力规模下,模型/数据规模比不同时,最优参数空间会略微变化。这表明超参数的选择上仍然有研究空间,他们团队将在未来的工作中继续研究。
接下来继续看DeepSeek团队在模型/数据规模比的Scaling Law上的研究。在确定了近似最优超参数的公式之后,DeepSeek开始拟合曲线,并分析最优的模型/数据规模缩放分配策略。这一策略的主要目的是找到模型缩放指数\(a\)和数据缩放指数\(b\)以满足\(N_{opt}\propto C^a\)以及\(D_{opt}\propto C^b\)。数据规模以数据集中的token数来表示。在之前的工作中,模型的规模通过模型参数量,即通过非嵌入层参数\(N_1\)和完整模型参数\(N_2\)来表示。算力规模\(C\)与模型/数据规模的近似关系可以表示为\(C=6ND\),这意味着我们可以用\(6N_1\)或者\(6N_2\)来近似表示模型规模。然而,由于\(6N_1\)和\(6N_2\)都没有考虑注意力机制的计算开销,并且\(6N_2\)还带上了词表部分的计算,这对模型规模表征的贡献更小了,因此这两种表示都存在着较大的近似误差。
为了消除这一误差,DeepSeek团队引入了一个新的模型规模表示:非嵌入层\(FLOPs/token\) \(M\)。\(M\)包含了注意力操作的计算开销,但是没有包含词表的计算开销。通过用\(M\)来表示模型规模,算力规模\(C\)可以简单的表示为\(C=MD\)。\(6N_1\),\(6N_2\)和\(M\)的具体差异可以见下面的公式:
其中\(n_{layer}\)表示模型的层数,\(d_{model}\)表示了模型的参数,\(n_{vocab}\)是词表的大小,\(l_{seq}\)是序列的长度。DeepSeek团队衡量这三种表示在不同规模的模型下的差异,如下表所示:
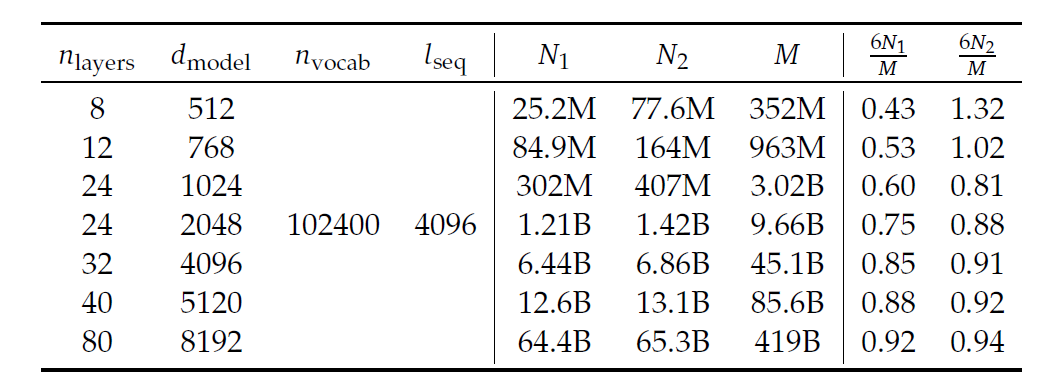
可以看到\(6N_1\)和\(6N_2\)要么低估要么高估了不同尺寸下模型的计算开销。这一误差在小规模模型下有钱显著,误差之大甚至可以达到50%。这一误差会在拟合缩放曲线时引入显著的统计错误。具体的影响可以看下图,对于采用\(6N_1\)和\(6N_2\)的情况,使用拟合的曲线进行预测时,对于DeepSeek 7B和67B模型,\(6N_1\)和\(6N_2\)分别出现了显著的高估和低估的问题,而使用\(M\)作为模型规模去衡量给出的预测精准度是最好的。
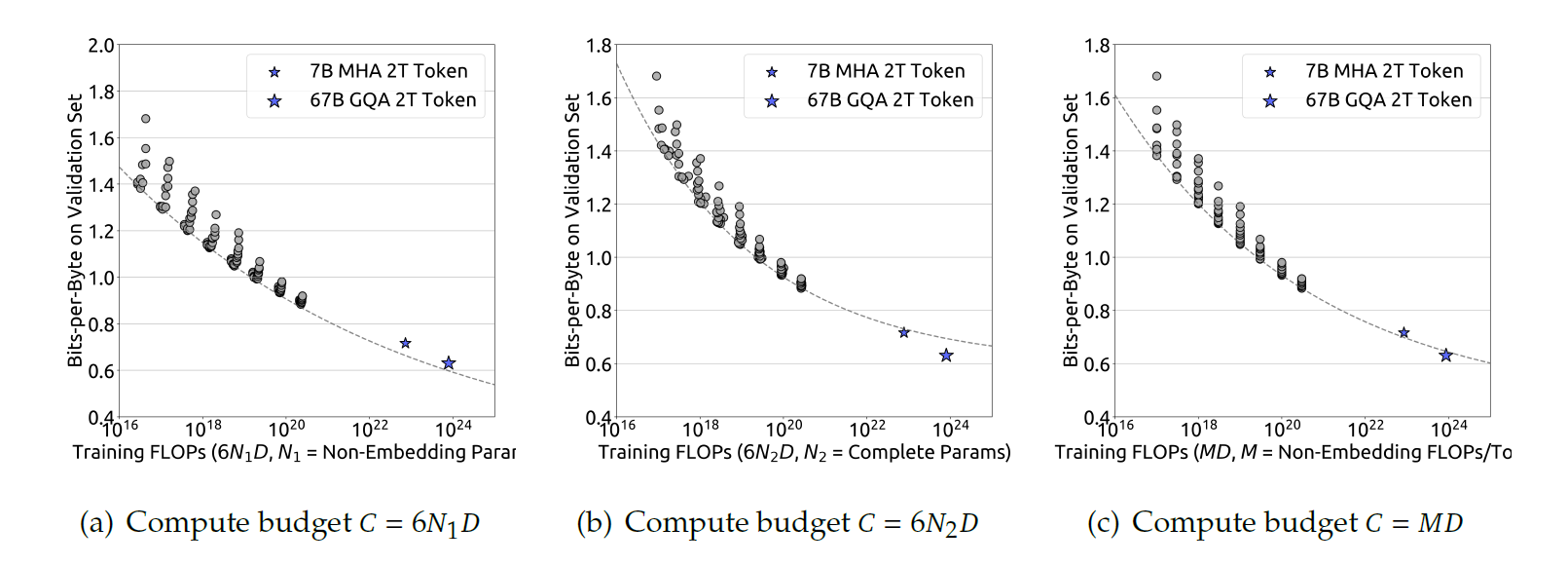
通过采用\(M\)作为模型规模的表示方式之后,我们的研究目标就可以更清楚的表示为:给定算力规模\(C=MD\),找到最优的模型规模\(M_{opt}\)和数据规模\(D_{opt}\)以最小化模型的泛化误差。可以通过公式将这一目标表示为:
在讨论他们的研究结果之前,我觉得有必要分析一下他们这一理论分析的重要性,从动机上来说不难理解,传统的方法中对于模型规模的评估一直采用的是近似的公式(关于具体的公式推导可以参考该文章末尾的部分),这一近似方式究竟对Scaling Law预测的准确性有多大的影响?DeepSeek团队认为这是一个需要正本清源的问题,而不是直接简单的沿用前人工作即可。在实践中也证明了,这一近似确实存在问题,而采用更准确的模型规模公式可以提供更准确的预测结果,更准确的预测对于未来的模型缩放是至关重要的,同时该问题也会很大程度上影响他们接下来对于模型/数据规模比Scaling Law问题分析结果的可靠性,所以这一步是很有意义的。
为了减少实验的开销和拟合难度,DeepSeek团队采用了Chinchilla论文中的IsoFLOP方法,他们选取了从\(1e17\)到\(3e20\)的8个不同算力规模的负载,并为每个负载设计了10个不同的模型/数据规模比。每个负载的超参数选取都采用了之前的近最优超参数选取公式,泛化误差在独立的验证集上计算,其分布近似于训练集,并包含一亿个token。
下图展示了IsoFLOP曲线以及模型/数据规模比曲线,通过每个计算负载上最优的模型/数据规模比进行拟合:
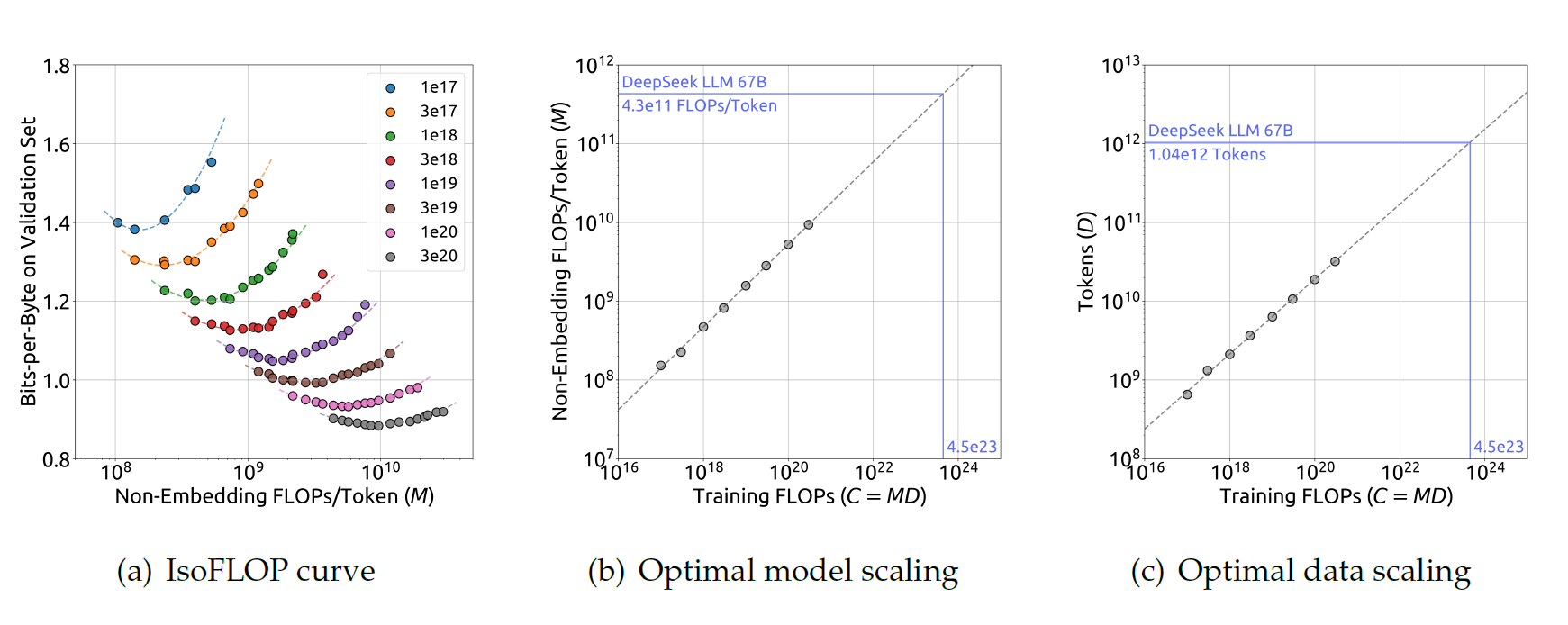
拟合后的最优非嵌入层\(FLOPs/token\) \(M_{opt}\)和最优token数\(D_{opt}\)的具体公式为:
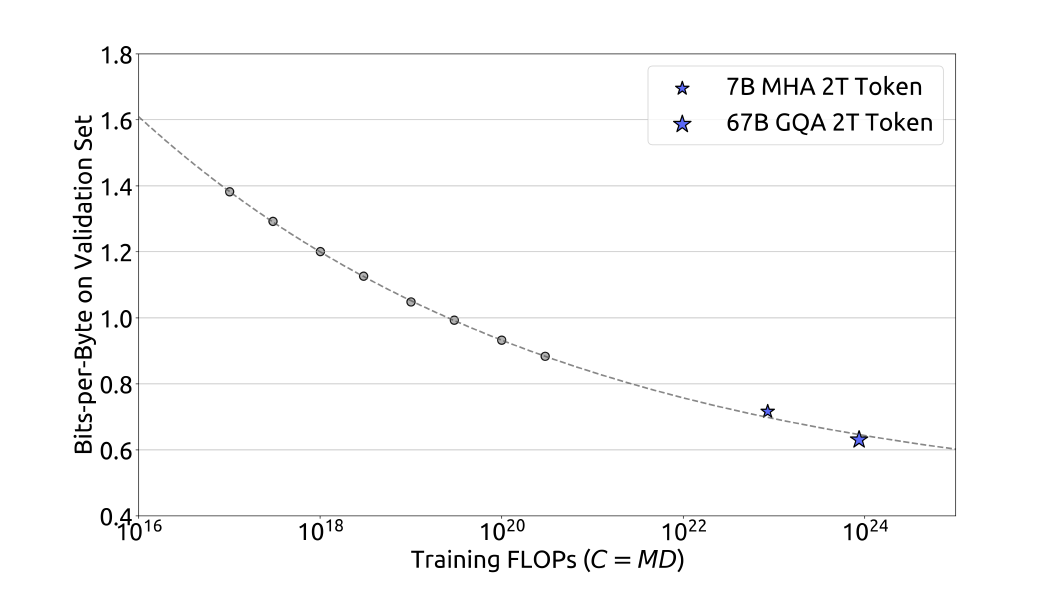
此外他们通过算力规模\(C\)和最优泛化误差拟合了损失缩放曲线,并预测了DeepSeek LLM 7B和67B的泛化误差,如下图所示。结果显示,通过小规模实验获得的结果可以准确地预测1000倍及以上算力规模的模型的性能,这为训练更大规模的模型提供了信心与指导。
在DeepSeek LLM的开发过程中,数据集进行了若干次的迭代,调整不同数据源的比例,并提升整体的质量,这使得DeepSeek团队可以进一步分析不同数据集对Scaling Law的影响。
DeepSeek团队在三个不同的数据集上研究了Scaling Law,分别是早期内部数据,当前内部数据,以及被用于之前Scaling Law研究的OpenWebText2。通过内部分析,他们的当前内部数据质量高于早期内部数据,此外OpenWebText2的数据质量甚至超过了他们的当前内部数据,因为其数据量更小,可以进行更细致的处理。
一个有趣的观察是,通过在这三个数据集上分析最优模型/数据规模比分配策略展现出的结果与数据质量呈现出了关联性。如下表所示,随着数据质量的提升,模型缩放指数\(a\)逐渐增大,而数据缩放指数\(b\)逐渐下降,这一位置算力更多的被分配给了模型而非数据。这一发现或许可以解释在早期Scaling Law研究中最优模型/数据规模比分配出现的显著差异。
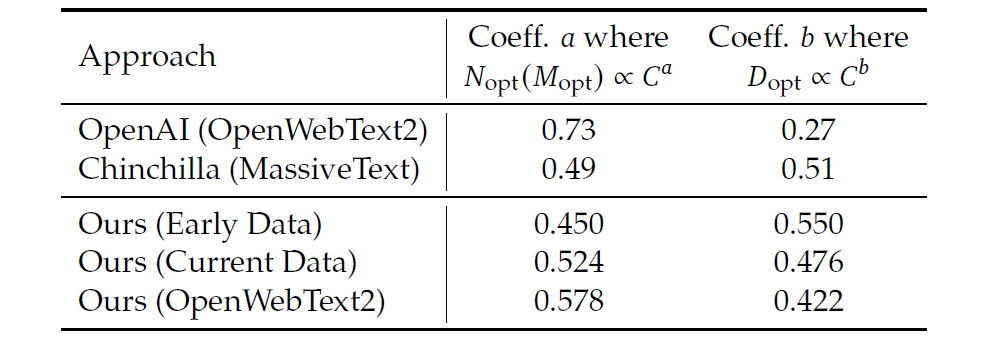
对这一发现的一个直观推测是,高质量的数据通常意味着逻辑清晰,经过充分的训练后,预测难度较小。因此,在增加算力规模时,扩大模型大小更有利。DeepSeek团队表示将继续密切关注数据质量的变化及其对缩放定律的影响,并在未来的工作中提供更多分析。
OK,至此这篇论文中DeepSeek团队对Scaling Law的深入研究与见解的部分全部结束,总结一下是四个重点:
-
定量分析了超参数Batch Size和学习率对Scaling Law的影响,并得到了量化的最优超参数的公式结论
-
定量分析了之前的工作采用模型参数量\(N\)作为模型规模评估指标的缺陷,并提出了新的更准确的非嵌入层\(FLOPs/token\) \(M\)作为新的模型规模评估指标
-
定量分析了模型/数据规模比对Scaling Law的影响,并得到了量化的最优模型规模与数据规模的公式结论
-
通过简单的定量分析发现了模型/数据规模比和数据质量之间的关联性,并提出了在一定的算力规模下,模型规模增长与数据质量的提升呈正相关,数据规模增长与数据质量的提升呈负相关的定性结论
在模型的对齐环节(即对预训练好的LLM进行调优,使其表现更符合人类偏好,例如逻辑性、价值观等),DeepSeek团队收集了大约150万个中文和英文的指令数据,包含了一系列有害和无害的话题。有用数据共包含了120万个实例,其中31.2%是一般语言任务,46.6%是数学问题,22.2%是代码练习。安全数据包含了30万个实例,涵盖了各种敏感话题。
对齐的过程分为两个阶段。第一个阶段是有监督微调(SFT),第二个阶段是直接偏好优化(DPO)。在SFT的阶段,DeepSeek团队对7B模型进行了4轮微调,对67B模型只进行了2轮微调,因为他们观察到67B模型上的过拟合问题更加严重。在GSM8K和HumanEval上,7B模型表现出持续的提升,而67B模型则很快达到了上限。7B和67B模型学习率设置分别为\(1e\mathrm{-}5\)和\(5e\mathrm{-}6\)。除了监控benchmark的精度,DeepSeek团队也分析了聊天模型在调优过程中的重复率问题。他们收集了3868个中文和英文提示词并统计了其中响应失败,出现无法终止的循环重复文本的比例。他们观察到重复率倾向于在数学SFT数据的质量增大时提升。这有可能是因为数学SFT数据偶尔包含相似的分析模式。因此,更弱的模型会在努力捕捉这种重复性分析模式中出现重复响应的问题。为了克服这一问题,DeepSeek团队尝试了两阶段微调和DPO,两种方式都可以在保持住benchmark成绩的同时,减小重复响应的问题。为了进一步提升模型的能力,DeepSeek团队尝试了DPO算法,这一方法被之前的工作证实是一个LLM对齐中简单而有效的方法。他们构建了无害与有害的偏好数据用于DPO训练。对于无害数据,他们收集了多语言提示,涵盖的类别包括创意写作、问答、指导遵循等,然后他们使用DeepSeek Chat模型生成候选响应。类似的操作也被用于有害偏好数据的构建。
他们用DPO进行了一轮训练,学习率为\(5e\mathrm{-}6\),Batch Size为512,使用了学习率预热和余弦学习率调度器。他们发现DPO可以加强模型的开放式生成那里,同时在标准benchmark上的性能表现差异很小。
模型评估方面的细节我这里就不作赘述了,总之就是各种评估中表现得比LLaMA-2和GPT-3.5这两个前辈更好。具体的评估细节感兴趣的读者可以阅读论文原文。
3. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
现在我们开始分析DeepSeek团队于2024年1月11日发表的论文[2]。在这篇论文中,DeepSeek团队详细介绍了DeepSeekMoE,一个高度专家化的混合专家语言模型。
在大语言模型的时代,混合专家架构是一个有效的在增大模型参数规模的同时控制模型计算开销的手段。然而,传统的MoE架构采取从\(N\)个专家中激活top-\(K\)的做法,在确保专家的专业化程度上面临挑战——即每个专家拥有不重叠且聚焦化的知识。因此DeepSeek团队提出了DeepSeekMoE架构来实现高度的专家专业化。其遵从两个基本策略:1. 细粒度的将专家分为\(mN\)个,并从中激活\(mK\)个,从而允许更灵活的激活专家的组合方式;2. 将\(K_s\)专家隔离为共享专家,旨在捕捉共享知识以及消除路由专家中的冗余。
从2B参数量的小规模模型开始,DeepSeek团队首先通过DeepSeekMoE 2B达到了和GShard 2.9B相近的性能,后者的参数量与计算量是前者的1.5倍。此外,DeepSeekMoE 2B的性能接近了相同参数量的等效稠密模型,即MoE模型的性能上限。随后,他们将DeepSeekMoE缩放到了16B参数量,并其在与LLaMA2 7B达到接近性能的同时,只有其40%的计算量。此外,他们进一步努力将DeepSeekMoE缩放到了145B的参数量,以验证其相对于GShard架构的优势,并展现了其能力在接近DeepSeek 67B的同时,只使用了28.5%(甚至可以低到18.2%)的计算量。
这篇工作中,我认为最重要的insight是DeepSeek团队对MoE架构的创造性改变,即对于专家专业化的极致追求。具体来说,他们采用了两个创新手段,一个是改变MoE架构,进行细粒度专家分割,另一个是共享专家隔离。因此整个论文的解读也会重点围绕这两个创新手段来进行。
最近的研究与实践已经证明了,在有着充足训练数据的情况下,通过增加参数量和算力规模的方式可以实现更加强大的语言模型。然而需要承认的是,缩放模型同时也带来了极高的算力开销。考虑到这一问题,混合专家模型开始成为一个流行的解决方案,使用其可以在参数缩放的同时,仍然将计算开销保持在较低的水平。MoE架构已经成功应用在Transformer中,以将模型缩放到更大的规模,同时展现出卓越的性能,这些成果证明了MoE架构的巨大潜力。
然而,尽管MoE架构的潜力是巨大的,现存的MoE架构仍然受到知识混合和知识冗余问题的影响,这些问题限制了专家专业度,即每个专家拥有不重叠且聚焦化的知识。传统的MoE架构将Transformer中的FFN替换为MoE层,每个MoE层由复数个专家组成,每个的结构都和标准FFN一致,每个token都被分配给一位或者两位专家。这一架构带来了两个潜在问题:(1)知识混合:现存的MoE往往只使用非常有限数量的专家(例如8或16个),因此分配给一个专家的token可能会包含多种知识。从而导致专家试图在权重参数中集成大量不同类型的知识,导致难以同时利用。(2)知识冗余:分配给不同专家的token可能需要通用的知识。因此,多个专家可能会在各自的权重参数中重复储存共享知识,从而导致了专家权重参数的冗余。
这两个问题阻碍了当前MoE架构的专家专业化,导致MoE模型难以接近理论的性能上限。
为了解决这两个问题,DeepSeek团队提出了DeepSeekMoE架构来实现高度的专家专业化,其架构采用了两个策略,分别是:(1)细粒度专家分割:在保持参数量固定的情况下,DeepSeek团队通过拆分FFN的中间隐藏层来将专家分割为更细的粒度。从结果上来看,在保持了一个固定的计算开销的情况下,DeepSeek团队能够激活更多细粒度专家,来实现更灵活和更强适应性的专家激活组合。细粒度专家分割是的多种知识可以更细粒度的解耦,并被不同的专家精确的学习,从而使得每个专家有着高度的专业化。激活专家的组合灵活性增加,也有助于更准确和有针对性地获取知识。(2)共享专家隔离:我们将特定的专家隔离出来,作为始终激活的共享专家,旨在不同的上下文中捕获和整合通用知识。通过将通用知识压缩入这些共享专家中,其他路由专家中的冗余性被消除。这可以提高参数效率,并确保每个路由专家通过专注于各自的角度来保持专业化。这些架构创新使得DeepSeekMoE能够训练一个参数高效的MoE模型,其中每个专家都是高度专业化的。
从2B参数量的最小模型开始,DeepSeek团队对DeepSeekMoE架构的优势进行了验证,通过不同任务上的12个zero-shot或者few-shot的benchmark,实验结果显示DeepSeekMoE 2B显著超过了GShard 2B,甚至达到了GShard 2.9B的水平,后者是一个更大的MoE模型,有着1.5倍的专家参数量和计算量。此外,他们发现DeepSeekMoE 2B已经接近了同等参数量的稠密等效模型的性能,后者代表了MoE语言模型的性能上限。为了追求更深的insight,他们对 DeepSeekMoE 的专家专业化进行了详细的消融实验和分析。这些实验和分析验证了细粒度专家分割和共享专家隔离的有效性,并证明了 DeepSeekMoE 可以实现高水平的专家专业化。
基于这一架构,他们进一步将模型缩放到了16B,并在一个2T token的大规模语料库上对DeepSeekMoE 16B进行了训练。评估结果显示仅仅消耗40%计算量的情况下,DeepSeekMoE 16B达到了和DeepSeek 7B接近的性能,后者是同样在2T语料库上训练的稠密模型。他们还将DeepSeekMoE 16B与其他开源模型进行了比较,结果显示DeepSeekMoE 16B在激活参数量接近的情况下性能大幅度超过了这些模型,并且取得了和LLaMA2 7B近似的表现,后者的激活参数量是前者的2.5倍。下图展示了评估的结果:
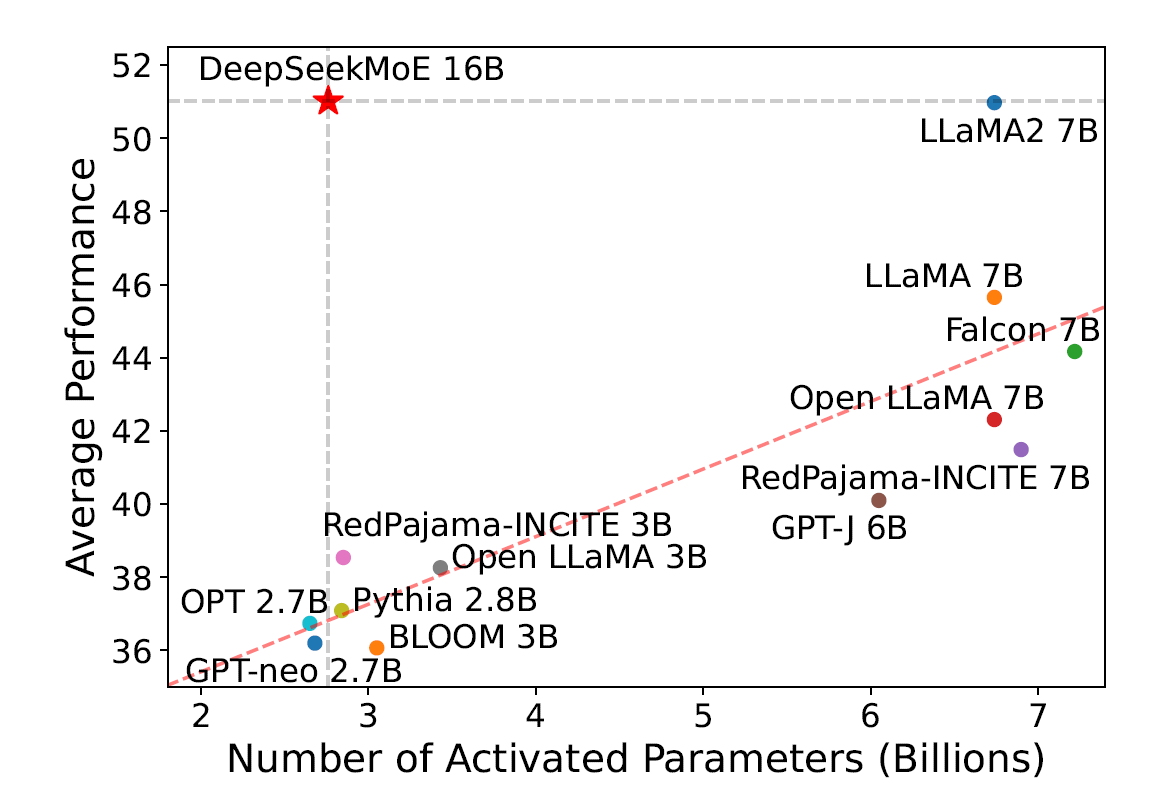
此外,DeepSeek团队对模型做了有监督微调进行对齐,将模型转化为一个聊天模型。评估结果显示在聊天设置下,DeepSeekMoE Chat 16B同样达到了接近DeepSeek Chat 7B和LLaMA2 SFT 7B接近的性能。受到这些结果的激励,他们进一步努力将DeepSeekMoE缩放到了145B参数量。实验结果再次证明了DeepSeekMoE相对于GShard架构的优势。此外,其能力在接近DeepSeek 67B的同时,只使用了28.5%(甚至可以低到18.2%)的计算量。
DeepSeek团队自行总结的主要贡献为:
-
架构创新:他们提出了DeepSeekMoE,该创新的MoE架构旨在达到极高的专家专业度,主要使用了两个策略,分别是细粒度专家分割和共享专家隔离
-
消融验证:他们通过大量的实验消融验证了DeepSeekMoE架构的有效性。实验结果证明了DeepSeekMoE 2B的高度专家化,并且展现出DeepSeekMoE 2B几乎达到了MoE模型的性能上限
-
缩放性:他们将DeepSeekMoE进行缩放,并训练了一个16B的模型,在仅仅使用了40%计算量的情况下,DeepSeekMoE 16B达到了和DeepSeek 7B以及LLaMA2 7B接近的性能。此外他们还努力将DeepSeekMoE缩放到了145B,并再次验证了其相对于GShard架构的优势,且性能接近DeepSeek 67B
-
MoE对齐:他们也成功的对DeepSeekMoE 16B进行了有监督微调以创建一个对齐的聊天模型,展现出了DeepSeekMoE 16B的适应能力和泛化能力
-
公开发表:在开放研究的精神指引下,他们向公众发布了DeepSeekMoE 16B的模型checkpoint,该模型可以直接部署于单张40GB显存的GPU上,且不需要进行量化
至此我们已经基本理解了DeepSeek团队在DeepSeekMoE上的主要创新,接下来我们通过公式的推导来具体理解一下DeepSeekMoE架构的细粒度专家分割和共享专家隔离的实现,以及他们在负载均衡方面做的进一步考量的细节。
首先从基础的Transformer中的混合专家开始,先介绍一个Transformer语言模型中通用的MoE架构。一个标准的Transformer语言模型通过堆叠\(L\)层标准Transformer块来构建,每个块可以表示如下:
其中\(T\)表示序列长度,\(\mathrm{Self}\mathrm{-}\mathrm{Att}(\cdot)\)表示自注意力模块,\(\mathrm{FFN}(\cdot)\)表示FFN,\(\mathbf{u}_{1:T}^{l}\in \mathbf{R}^d\)为经过\(l\)个注意力模块后输出的所有token的隐状态,\(\mathbf{h}_{t}^{l}\in \mathbf{R}^d\)是第\(t\)个token在\(l\)个Transformer块之后输出的隐藏层状态。为简洁起见,省略了上述公式中的层归一化。
构建 MoE 语言模型的典型做法通常是在特定的中间层内用 MoE 层替换 Transformer 中的FFN,MoE层由多个专家组成,每个专家都等效为一个标准FFN。然后,每个token被分配给一个或两个专家,如果第\(l\)层FFN被替换成MoE层,那么其输出的隐状态\(\mathbf{h}_{t}^{l}\)将表达为:
其中\(N\)表示专家的总数,\(FFN_i(\cdot)\)是第\(i\)个专家FFN,\(g_{i,t}\)表示第\(i\)个专家的门控值,\(s_{i,t}\)表示token到专家的亲和度,\(\mathrm{Topk}(\cdot,K)\)表示包含第\(t\)个token和所有\(N\)个专家计算的\(K\)个最高亲和度分数的集合,\(e_i^l\)是第\(l\)层的第\(i\)个专家的质心向量(表示该专家的方向偏向,输入向量与该质心向量做内积然后通过\(\mathrm{Softmax}(\cdot)\)函数计算亲和度)。注意到\(g_{i,t}\)是稀疏的,这意味着在\(N\)个门控值中只有\(K\)个非零。这个稀疏性确保了MoE层中的计算效率,即每个token只会被分配给\(K\)个专家并进行计算。同样,在上面的公式中简化了层归一化以便简洁。
而在DeepSeekMoE中,架构被设计以充分发掘专家专业化的潜力,如下图所示,DeepSeekMoE采用了细粒度专家分割和共享专家隔离两个主要策略,这两个策略都用于提升专家专业度。
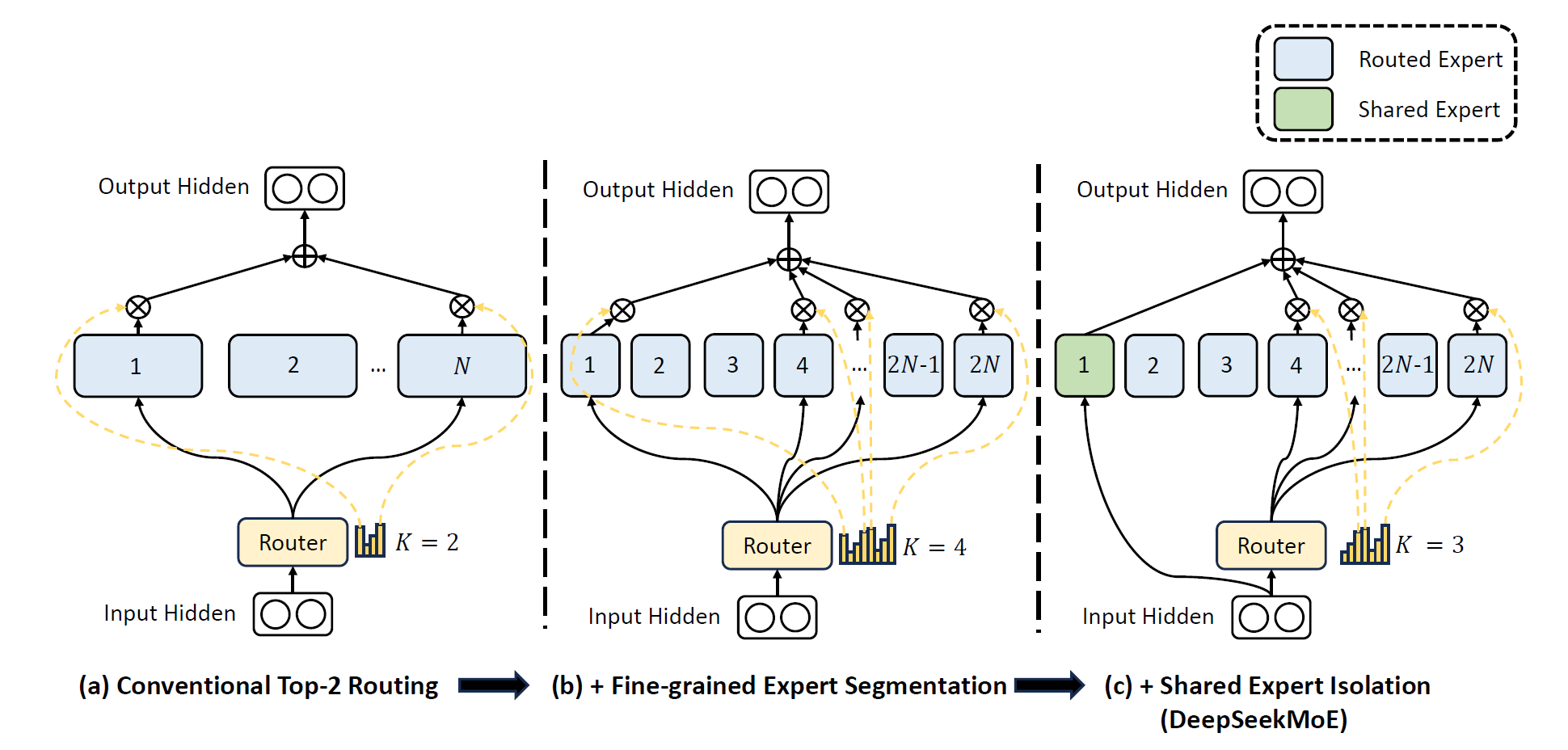
细粒度专家分割:在专家数量有限的情况下,分配给特定专家的token将更有可能涵盖各种类型的知识。因此,指定的专家将试图在其参数中学习截然不同类型的知识,并且很难同时使用它们。但是,如果每个token都可以路由到更多的专家,那么不同的知识将获得分别在不同专家中分解和学习的潜力。在这种情况下,每个专家仍然可以保留高水平的专家专业化,从而有助于在专家之间更集中地分配知识。
为了实现目标,在保持一致数量的专家参数和计算成本的同时,DeepSeek团队对专家进行了更精细的细分。更精细的专家细分可实现更灵活和适应性更强的激活专家组合。具体来说,一个典型的MoE的架构如上图中(a)所示,他们将每个专家FFN切分为\(m\)个更小的专家,方式是将FFN的中间隐藏层切分到原尺寸的\(1/m\)倍。由于每个专家变得更小,他们也将激活专家的数量增加了\(m\)倍来保持相同的计算开销,如上图(b)所示。通过细粒度专家分割,MoE层的输出可以表示为:
其中专家参数的重量等于标准FFN的\(N\)倍,\(mN\)表示细粒度专家的总数。通过细粒度专家分割策略,非零门控的总数增加到了\(mK\)。
从组合的角度来看,细粒度专家分割策略显著增强了激活专家的组合灵活性。举一个例子,考虑\(N=16\)的情况,一个典型的top-2路由策略可以得到\(\tbinom{16}{2}=120\)种可能组合。与之相对,如果每个专家被分割为4个更小的专家,细粒度的路由策略可以得到\(\tbinom{64}{8}=4426165368\)种可能组合。组合灵活性的激增增强了获得更准确和有针对性的知识的潜力。
共享专家隔离:使用传统的路由策略,分配给不同专家的token可能需要一些常识或信息。因此,多个专家可能会把共享知识获取到各自的参数中,从而导致专家参数的冗余。但是,如果有共享专家致力于捕获和整合不同上下文中的公共知识,则其他路由专家之间的参数冗余将得到缓解。这种冗余的减少将有助于由更专业的专家构建一个参数效率更高的模型。
为了实现这个目标,在细粒度专家分割的基础上,DeepSeek团队进一步将\(K_s\)专家隔离为共享专家。无论路由模块如何,每个token将确定性地分配给这些共享的专家。为了保持固定的计算成本,其他路由专家中的激活数量将减少\(K_s\),如上图(c)所示。通过使用共享专家隔离,DeepSeekMoE架构的公式如下图所示:
最终,在 DeepSeekMoE 中,共享专家数量为\(K_s\),路由的专家总数是\(mN − K_s\),非零门控的数量是\(mK − K_s\)。
负载均衡考虑:自动学习路由策略可能会遇到负载失衡的问题,带来两个严重的影响。第一,存在路由坍缩的风险,即模型总是只选择少数几个专家,导致其他的专家无法得到充分训练。第二,如果专家分配在不同的石碑上,负载失衡可能会导致出现计算瓶颈。DeepSeek团队采用了两种损失来实现负载均衡。
专家级均衡损失:为了消除路由坍缩的风险,他们采用了专家级均衡损失,均衡损失的计算如下:
其中\(\alpha_1\)是一个称为专家级均衡因子的超参数,\(N^{′}\) 等于 \((mN − Ks)\) ,\(K^{′}\)等于 \((mK − Ks)\) 为简洁起见。\(\mathbb{1}(\cdot )\) 表示指示符功能。
设备级均衡损失:除了专家级均衡损失外,他们还引入了设备级均衡损失。当旨在缓解计算瓶颈时,没有必要在专家级别强制实施严格的均衡约束,因为对负载均衡的过度约束会影响模型性能。相反,他们的主要目标是确保跨设备平衡计算。如果将所有的路由专家分割为\(D\)组\(\{\mathcal{E}_1,\mathcal{E}_2,...,\mathcal{E}_D\}\),并且每组都只分配到一个设备上,那么设备级均衡损失可以计算如下:
其中\(\alpha_2\)是一个称为设备级均衡因子的超参数。在实践中,DeepSeek团队设置了一个小的专家级均衡因子来消除路由坍缩的风险,同时设置了一个大的设备级均衡因子来提升设备间的计算均衡。
至此,论文的重要技术细节部分就已经介绍完了,做一个小的总结,从DeepSeekMoE的工作中可以看出,最重要的insight是DeepSeek团队对MoE架构的创造性改变,即对于专家专业化的极致追求。通过细粒度专家分割和共享专家隔离这两个方法他们实现了这一目标,这可能也代表了MoE架构接下来的发展方向,更多的专家总数和专家激活数实际上为软硬件协同设计带来了更多的挑战,细粒度的专家选择激活组合带来的高灵活性需要软硬件在存储分配、设备通信、调度策略等问题上做出更多考虑,以实现灵活性与效率的最优平衡。
4. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
这篇论文是DeepSeek团队在2024年4月27发表的论文[3],在这篇论文中,DeepSeek团队主要对模型的数学推理能力如何增强进行了探索。并且在这篇文章中,首次提出了对于后续工作具有重要意义的强化学习方法——GRPO。
数学推导由于其复杂和架构化的本质,对于自然语言模型来说是一个很大的挑战。在这篇论文中,DeepSeekMath 7B通过在DeepSeek-Coder-Base-v1.5 7B的基础上,使用120B个来自Common Crawl的数学相关token以及自然语言和代码数据继续预训练。DeepSeekMath 7B在竞赛级MATH benchmark上,不依赖额外工具和投票技巧,达到了令人印象深刻的51.7%的分数,接近Gemini-Ultra和GPT-4的表现。DeepSeekMath 7B在MATH上的64次采样的自一致性达到了60.9%。DeepSeekMath的数学推理能力主要归功于两点因素:首先是DeepSeek团队通过精心的工程数据选择管线,其次是引入了组相对策略优化(GPRO)代替近端策略优化(PPO),从而在加强数学推理能力的同时,优化PPO的内存使用。
这里先补充一下DeepSeek-Coder的tip,其论文发表于24年1月26(DeepSeek-Coder: When the Large Language Model Meets Programming- The Rise of Code Intelligence),DeepSeek-Coder的训练数据集由87%的源代码、10%的与代码相关的英文自然语言语料库以及3%的与代码无关的中文自然语言语料库组成。中文语料库由旨在提高模型理解中文语言能力的高质量文章组成。DeepSeek团队在GitHub上收集了在2023年2月之前创建的公开代码仓库,并仅保留了87种编程语言。初步筛选掉低质量的代码,通过应用一些过滤规则,将数据总量减少到了原始规模的32.8%。通过依赖解析、仓库级去重、质量筛选等步骤提高了数据集质量,并在训练时,除了基本的Predict Next Word之外,还应用了中间填空(FIM)的训练技巧,即将文本随机分为三部分,然后打乱这些部分的顺序,并用特殊字符将它们连接起来。这种方法旨在在训练过程中融入一个填空式的预训练任务。因为DeepSeek-Coder和我们要讲得论文逻辑主线关联性不大,所以这里就不做太多赘述了,感兴趣的读者可以去阅读原文。
DeepSeekMath-7B的表现如下图所示:
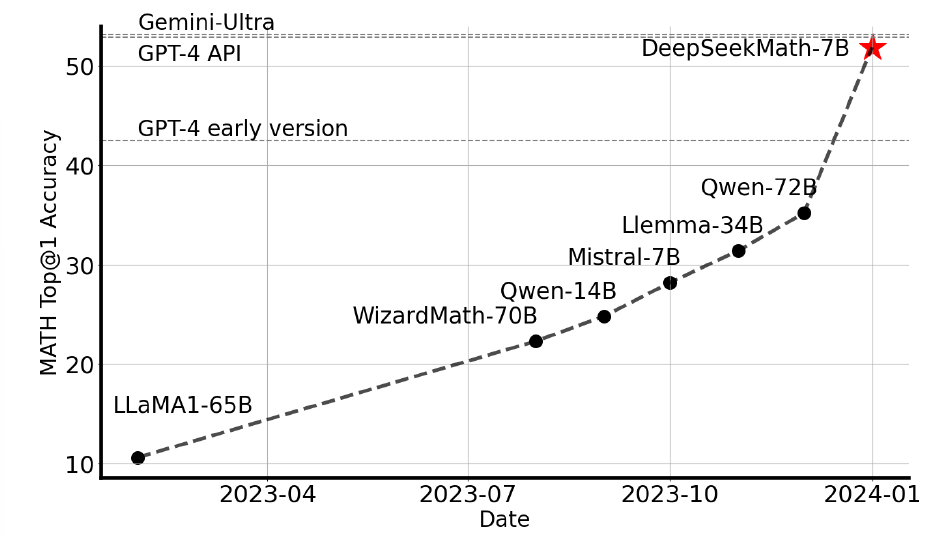
在这篇工作中最重要的insight还是GRPO这一技术,因此本篇的解读会集中在DeepSeek团队对传统PPO强化学习方法的分析,以及GRPO技术的提出上。
大语言模型正在不断增强通过人工智能实现数学推理的能力,并在量化推理benchmark和几何推理benchmark上都取得了重要进展。此外,这些模型也被证明可以有效地辅助人类解决复杂的数学问题。然而,目前的先进模型例如GPT-4,Gemini-Ultra等均为闭源模型,而目前的开源模型在性能上存在显著落后。
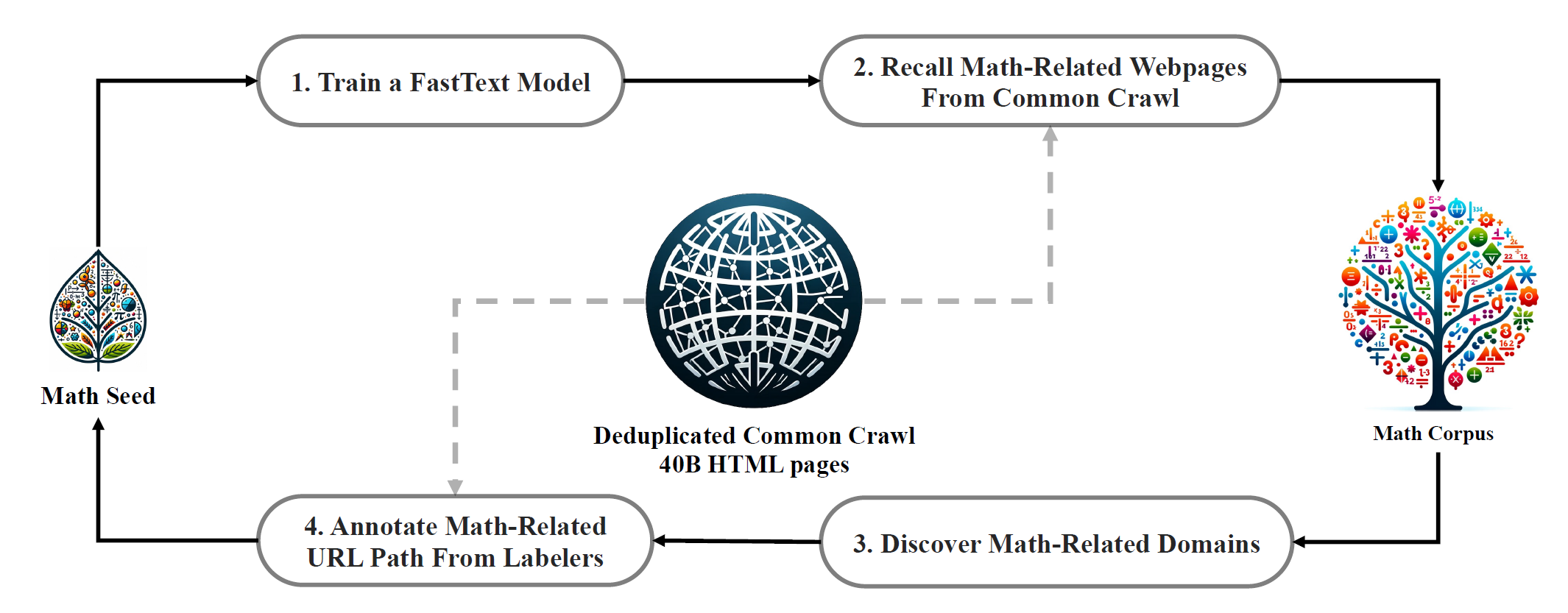
在这项工作中,DeepSeek团队提出了DeepSeekMath,一个在数学能力上远超目前的开源模型,并且在学术benchmark上接近了GPT-4的领域专用语言模型。为了达到这一目标,他们创造了DeepSeek-Math数据集,一个大规模高质量的预训练数据集,有着120B的数学token。这个数据集使用fastText-based分类器从Common Crawl(CC)中抽取而来。在最开始的阶段,分类器使用来自OpenWebMath的实例进行训练作为正样本,同时也是用一系列的其他网页作为负样本。随后,使用分类器来挖掘来自CC的额外的正样本,在通过人工标注进一步优化。分类器通过该强化数据集进行更新并提升性能。评估结果显示大规模数据集有着很高的质量,基础模型DeepSeekMath-Base 7B在GSM8K上达到了64.2%,在竞赛级MATH数据集上达到了36.2%,超过了Minerva 540B。此外,DeepSeekMath数据集是多语言的,所以他们也观察到了在中文数学benchmark上的提升。他们相信在数学数据处理上的经验对于研究社区来说是一个好的起点,并且在未来还有很多提升空间。
整个数据处理管线如下图所示:
DeepSeekMath-Base以DeepSeek-Coder-Base-v1.5 7B为起点,因为DeepSeek团队注意到从代码训练模型上开始相对于通用LLM是一个更好的选择。此外,他们观察到数学训练同样也提升了模型在MMLU benchmark和BBH benchmark上的水平,这意味着不仅增强了模型的数学能力,还进一步放大了通用的推理能力。
在预训练之后,他们应用数学指令对DeepSeekMath-Base使用CoT,程序思维以及工具集成推理数据进行微调。结果是DeepSeekMath-Instruct 7B打败了所有的7B同类模型,并且可以与70B开源指令微调模型相媲美。
更进一步的,他们引入了GRPO算法,一个PPO强化学习算法的变种。GRPO丢弃了Critic模型,取而代之的是从组分数中估计基线,显著减少了训练资源消耗。通过仅仅使用一组英语指令微调数据,GRPO在强大的DeepSeekMath-Instruct上取得了显著的进步,在强化学习过程中,提升出现在了包括了闭领域数据集(GSM8K: 82.9% -> 88.2%,MATH:46.8% -> 51.7%)以及开放领域数据集(CMATH:84.6% -> 88.8%)上。他们还提供了一个通用范例来理解不同的方法,例如拒绝采样微调(RFT),直接偏好优化(DPO),PPO和GRPO。基于这一通用范例,DeepSeek团队发现这些方法都是直接或者简化的强化学习技巧。他们还进行了进一步的实验,例如在线 VS 离线训练,结果 VS 过程监督,单轮 VS 迭代RL等等,以更深入的研究这一范例的基础元素。最后,他们解释了为什么RL能够提升指令微调模型的性能,并进一步总结了基于这一通用范例实现更有效的RL的潜在方向。
在这个过程中,DeepSeek团队将他们的共享主要总结为两点,第一个点是大规模的数学预训练,第二个是对强化学习的分析与探索。
大规模的数学预训练:
- DeepSeek团队的研究充分证明了公开数据集Common Crawl包含了用于数学目的的宝贵信息。通过精心设计的数据选择管线,DeepSeek团队构建了DeepSeekMath数据集,一个高质量的,有着从网页中筛选的120B token的数学内容的数据集,其规模是Minerva使用的数学网页的7倍,OpenWebMath的9倍。
- 预训练基线模型DeepSeekMath-Base 7B达到了可以与Minerva 540B匹配的性能,意味着参数数量并非数学推理能力的关键因素。一个在高质量数据上训练的小模型也可以达到了强大的性能。
- 他们分享了在数学训练过程中的发现。先于数学训练前进行代码训练可以同时提升模型通过/不通过工具解决数学问题的能力。这对于前沿问题:代码训练是否提升了推理能力?提供了一个可能的答案,DeepSeek团队响应这是对的,至少对数学推理来说是这样。
- 尽管使用arXiv论文做训练很常见,尤其是许多与数学相关的论文,但这对本文采用的所有数学基准没有带来显著的改进。
强化学习的分析与探索:
- DeepSeek团队提出了GRPO,一个高效的强化学习算法。GRPO丢弃了Critic模型,取而代之的是来自组分数的基线,相对于PPO显著减少了训练资源消耗。
- 他们展示了GRPO可以显著增强指令微调模型DeepSeekMath-Instruct的性能,且仅仅使用了指令微调数据。此外,在强化学习过程中,他们观察到了开放领域性能表现的提升。
- 他们提供了一个通用的范例来理解不同的方法,例如RFT,DPO,PPO以及GRPO。他们还进行了拓展实验,对比了例如在线 VS 离线训练,结果 VS 过程监督,单轮 VS 迭代RL等等,以更深入的研究这一范例的基础元素。
- 基于这一统一范例,他们探索了强化学习有效性背后的原因,并总结了一些LLM上进行更有效的强化学习的潜在方向。
接下来结合公式详细看一下GRPO的实现细节。
RL已被证明是进一步提升SFT后的LLM的数学推理能力的有效手段,PPO是一个Actor-Critic的RL算法,普遍应用在LLM的微调中。具体来说,其通过最大化以下代理目标来优化LLM:
其中\(\pi_{\theta}\)和\(\pi_{\theta_{old}}\)为当前和旧的策略模型,其中\(q\),\(o\)分别为从问题数据集和旧策略\(\pi_{\theta_{old}}\)的问题和输出。\(\varepsilon\)为PPO中为了稳定训练引入的一个折扣相关的超参数。\(A_t\)为优势,通过基于奖励\(r_{\ge t}\)和学习的价值函数\(V_{\psi}\),应用泛化优势估计(GAE)来计算。因此,在PPO中,价值函数需要和策略模型一起训练来消除建立模型的过优化,标准的方式是向奖励中加入一个来自于每个token的参考模型的KL惩罚,例如:
其中\(r_{\varphi}\)是奖励模型,\(\pi_{ref}\)是参考模型,通常是初始的SFT模型,\(\beta\)是KL惩罚的系数。
由于PPO中使用的价值函数一般是另一个和策略模型相近尺寸的模型,这带来了很大的存储和计算压力。此外,在RL训练时,价值函数被视为计算优势方差缩减的基线。而在LLM上下文中,通常只有最后一个token被奖励函数赋上一个奖励分数,这会使得对于每个token都要精确的价值函数的训练变得复杂。为了解决这个问题,如下图所示:
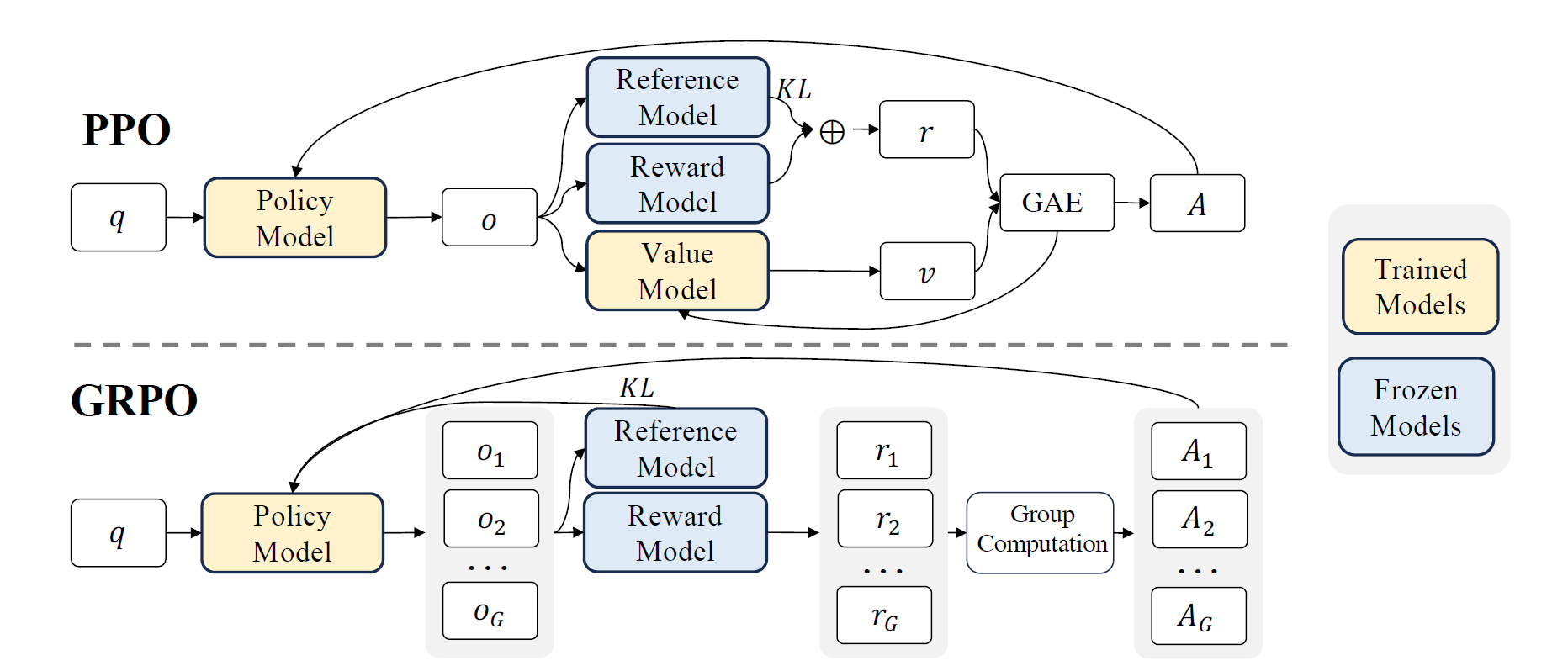
DeepSeek团队提出了GRPO方法,消除了PPO中所需要的额外的价值函数,取而代之的是使用多次采样输出,即产生于对于相同问题的多次响应的平均奖励,来作为基线。具体的来说,对于每个问题\(q\),GRPO采样一组来自旧策略\(\pi_{\theta_{old}}\)输出的\(\{o_1,o_2,...,o_G\}\),然后通过最大化如下的目标来优化策略模型:
其中\(\varepsilon\)和\(\beta\)是超参数,\(\hat{A}_{i,t}\)是仅根据每组内产出的相对奖励计算的优势,在后文中会详细讨论。GRPO使用的组内相对奖励计算方法和建立模型的本质对齐的很好,因为建立模型一般通过比较在相同的问题上产生的输出进行比较的数据集上训练。同样要注意的是,除了在奖励中增加KL惩罚,GRPO通过将训练策略和参考策略之间的KL散度直接添加到损失中来正则化,避免使\(\hat{A}_{i,t}\)的计算复杂化。
并且与前文中的KL惩罚不同,他们通过下面的无偏估计器来估算KL散度:
以确保为正。
形式上来说,对于每个问题\(q\),一组输出\(\{o_1,o_2,...,o_G\}\)采样自旧策略模型\(\pi_{\theta_{old}}\)。奖励函数随后用于给输出打分,得到\(G\)个奖励\(\mathbf{r}=\{r_1,r_2,...,r_G\}\)。接着,这些奖励通过减去组均值和除以组标准差来归一化。结果监督在每个输出\(o_i\)的末尾提供归一化的奖励,并将输出中的所有token的优势\(\hat{A}_{i,t}\)设置为\(\hat{A}_{i,t}=\widetilde{r}_i=\frac{r_i-\mathrm{mean}(\mathbf{r})}{\mathrm{std}(\mathbf{r})}\),随后通过前面的最大化目标来优化策略。
结果监督仅仅在每个输出的末尾提供一个奖励,这在复杂的数学任务中可能是不充分和不够有效率的。DeepSeek团队探索了过程监督,在每次推理阶段的末尾提供奖励。形式上来说,给定问题\(q\)和\(G\)个采样输出\(\{o_1,o_2,...,o_G\}\),过程建立模型用于给每步的输出打分,产生对应的奖励\(\mathbf{R}=\{\{r_{1}^{index(1)},\cdots,r_{1}^{index(K_{1})}\},\cdots,\{r_{G}^{index(1)},\cdots,r_{G}^{index(K_{G})}\}\}\),其中\(index(j)\)是第\(j\)步末尾的token,\(K_i\)为第\(i\)个输出的中步数。对这些奖励进行均值和标准差的归一化\(\widetilde{r}_i^{\mathrm{index}(j)}=\frac{r_i^{\mathrm{index}(j)}-\mathrm{mean}(\mathbf{R})}{\mathrm{std}(\mathbf{R})}\)。接着过程监督通过求和来自接下来步骤的归一化奖励之和作为优势\(\hat{A}_{i,t}=\sum_{index(j)\geq t}\widetilde{r}_i^{index(j)}\),随后通过前面的最大化目标来优化策略。
由于在强化学习的过程中,旧的奖励模型可能不足以监督当前的策略模型,因此他们探索了GRPO的迭代RL。如下面的算法所示:

在迭代GRPO中,根据策略模型的采样结果为奖励模型生成新的训练集,并使用包含 10% 历史数据的重放机制持续训练旧的奖励模型。然后,将参考模型设置为策略模型,并继续使用新的奖励模型训练策略模型。
DeepSeek团队基于DeepSeekMath-Instruct 7B进行强化学习(RL)。强化学习的训练数据来自监督微调(SFT)数据中与GSM8K和MATH相关的CoT格式问题,共计约14.4万条。他们排除了其他SFT问题,以研究在RL阶段缺乏相关数据的情况下,强化学习对基准测试的影响。他们参考Wang等人的方法构建奖励模型的训练集。并基于DeepSeekMath-Base 7B训练初始奖励模型,学习率设为2e-5。对于GRPO,策略模型的学习率设为1e-6,KL系数为0.04。每个问题采样64个输出,最大长度设为1024,训练批大小为1024。策略模型在每个探索阶段后仅进行一次更新。按照DeepSeekMath-Instruct 7B的评估方式对DeepSeekMath-RL 7B进行基准测试。对于DeepSeekMath-RL 7B,GSM8K和MATH的CoT推理任务可视为闭领域任务,而其他所有基准测试任务可视为开放领域任务。
下表展示了开源和闭源模型在英语和中文基准测试中使用CoT和工具集成推理的性能。
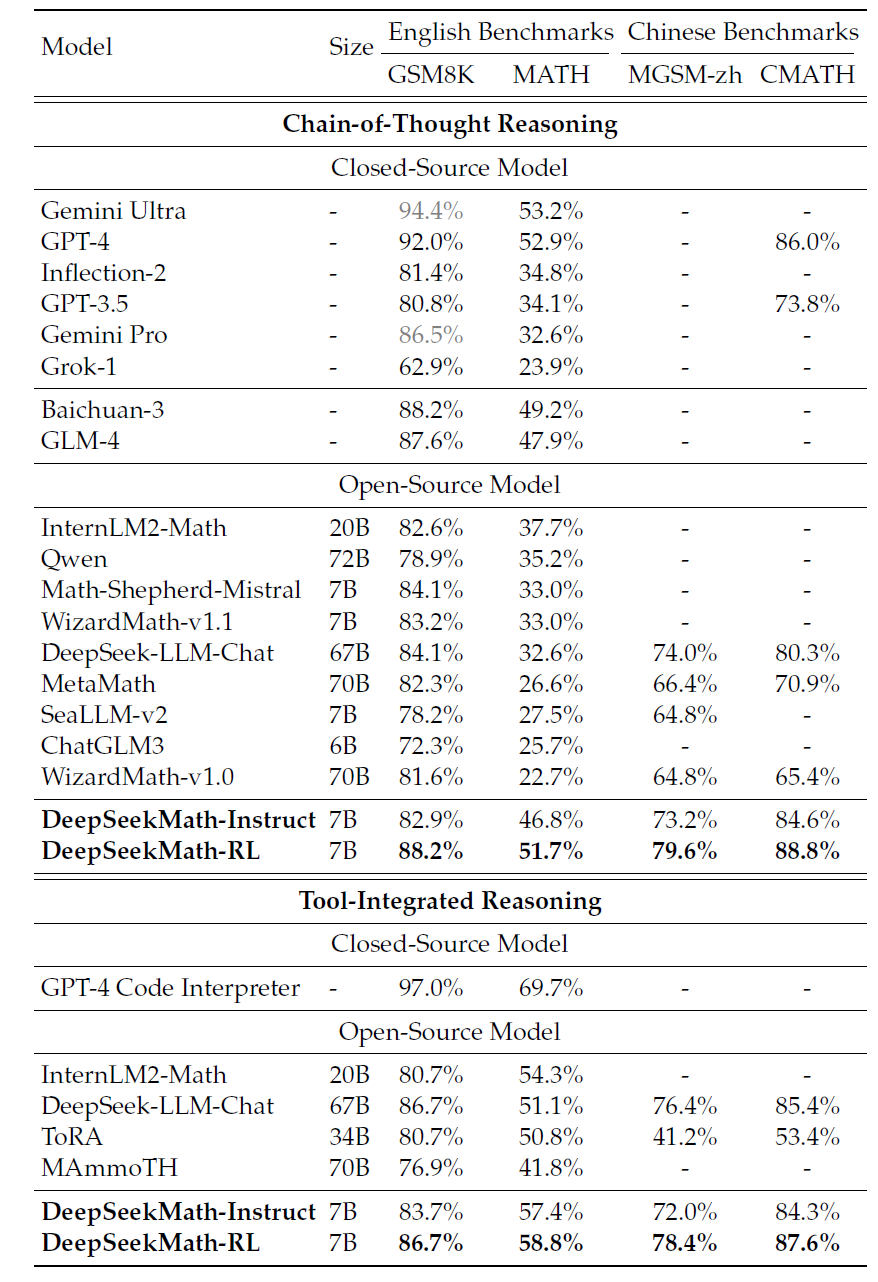
DeepSeek团队发现:
1)DeepSeekMath-RL 7B在GSM8K和MATH上使用CoT推理的准确率分别达到88.2%和51.7%。这一性能超越了所有7B至70B范围的开源模型,以及大多数闭源模型。
2)关键的是,DeepSeekMath-RL 7B仅基于GSM8K和MATH的CoT格式指令微调数据进行训练,并以DeepSeekMath-Instruct 7B为起点。尽管训练数据范围有限,但它在所有评估指标上均优于DeepSeekMath-Instruct 7B,证明了强化学习的有效性。
后续DeepSeek团队还深度讨论了他们构建的一个统一范例来评估RFT,DPO,PPO,GRPO不同方法的效果,以及对强化学习效果和有效性的深度讨论。从结论上来说,RL带来的提升似乎更多归功于从TopK候选中筛选出正确答案,而非模型基础能力的实质性增强。
总体来说,GRPO方法被证明是一个有效的强化学习方法,避免了PPO中需要同时训练策略函数和价值函数的问题,使用多次采样输出取代PPO中的价值模型,从而节省了训练的内存和计算开销。并被积极的应用于他们的后续工作中。
5. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
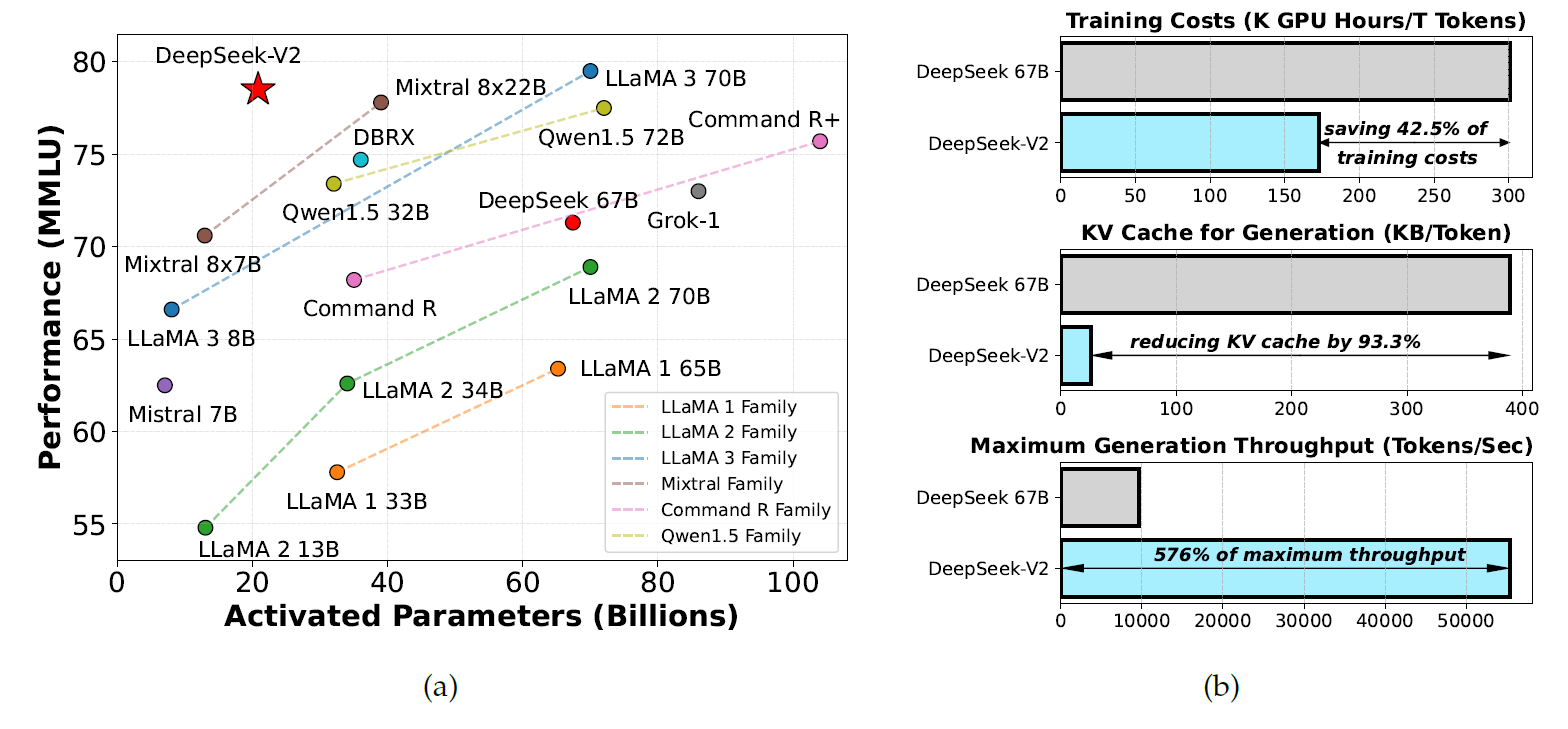
下一篇论文是DeepSeek团队在2024年6月19发布的DeepSeek-V2论文[4],这篇论文介绍了DeepSeek-V2,一个以经济划算的训练和高效的推理为特点的强大混合专家模型。其共包含236B的总参数量,其中每个token会激活21B的参数,并且支持上下文长度为128K token的序列。DeepSeek-V2采用了包括多头潜在注意力(MLA)和DeepSeekMoE的创新架构。MLA通过将键值(KV)缓存压缩为潜在向量的方式显著提升了推理的效率,而DeepSeekMoE通过稀疏计算,使得可以在经济划算的成本下训练强大的模型。与DeepSeek 67B对比,DeepSeek-V2达到了显著的更强大的性能,同时节省了42.5%的训练开销,减少了93.3%的KV缓存,并且将最大的生成吞吐量提升到了5.76倍。作者们在一个高质量且多元的8.1T token数的数据集上进行了预训练,随后进一步进行了有监督微调(SFT)和强化学习(RL)来完全解锁其潜力。评估结果显示,即使仅仅激活21B参数,DeepSeek-V2以及其聊天模型版本仍然达到了开源模型中的顶级性能。
可以看出在DeepSeek-V2中最主要的核心insight就是MLA这个新技术,整体的混合专家模型架构的思路实际上在DeepSeekMoE阶段就已经确立。通过引入MLA,DeepSeek-V2最主要的成就就是在实现了一个强大的模型的同时,在训练开销,KV缓存,最大吞吐等方面相比于前置工作——DeepSeek 67B,取得了极大的提升。因此在后面的解读中,主要就是关注MLA这一技术,与DeepSeekMoE重复的技术部分就不再赘述。
在过去的数年间,LLM经历了快速的发展,使得人们得以对AGI得以一瞥。整体来说,LLM的智能随着参数量的增加而提升,使得其可以在多种任务中展现涌现的能力。但是这一提升伴随而来的是巨大的训练开销,以及推理吞吐率的降低。这些限制对于LLM的大范围使用造成了挑战。为了能够解决这一问题,DeepSeek团队提出了DeepSeek-V2,一个强大的,开源的混合专家(MoE)语言模型,其特征为通过创新的Transformer架构实现经济的训练与高效的推理。其总共有236B的参数量,其中每个token只会激活21B的参数,并且支持128K token的上下文长度。
DeepSeek团队通过MLA和DeepSeekMoE技术分别对Transformer中的注意力模块和FFN层进行了优化。(1)在注意力机制的上下文中,多头注意力(MHA)的KV缓存对于LLM的推理效率造成了很大的影响。很多方式被提出以解决这一问题,包括GQA,MQA等。但是,这些方式经常在减少KV缓存的同时,在性能上做出了一定的拖鞋。为了同时在两者上取得最佳,DeepSeek团队提出了MLA,一个相比于MHA能够取得极佳的性能的技术方案,同时显著减少推理时的KV缓存,并且提升推理效率。(2)对于前馈网络,采用了DeepSeekMoE架构,采用了细粒度专家分割以及共享专家隔离以提升专家专业度。DeepSeekMoE架构相较于其他传统MoE架构,如GShard,展现出了极大的优势,使得DeepSeek团队可以用更小的成本训练更强大的模型。由于在训练时采用了专家并行,他们还我们还设计了控制通信开销和确保负载均衡的补充机制。通过结合这两种技术,DeepSeek-V2同时实现了强大的性能,经济的训练开销以及高效的推理吞吐,如下图所示:
DeepSeek团队在此次工作中构建了一个高质量多元的数据集,包括8.1T个token。对比DeepSeek 67B所使用的数据集,这个新数据集的主要特点是更大的数据量,尤其是中文数据;以及更高的数据质量。他们首先在这个完整的预训练数据集上对DeepSeek-V2就行了初步的预训练。随后,他们手机了1.5M个对话场景,包含了各种领域,例如数学,代码,写作,推理,安全等,来进行DeepSeek-V2 Chat的SFT,得到了DeepSeek-V2 Chat (SFT)。最后,利用DeepSeekMath使用的GRPO技术对模型进行人类偏好对齐,产生了DeepSeek-V2 Chat (RL)。
他们在一系列的中文和英文benchmark下评估了DeepSeek-V2,并将其与其他开源模型进行了比较。结果显示即使只激活了21B的参数,DeepSeek-V2仍然达到了开源模型中的顶级水平,并且成为了最强的开源MoE语言模型。如上图(a)所示,在MMLU中,DeepSeek-V2仅仅通过很少的激活参数,达到了顶级的性能。此外,如上图(b)所示,相较于DeepSeek 67B,DeepSeek-V2节省了42.5%的训练开销,减少了93.3%的KV缓存,并且把最大生成吞吐率提升了5.76倍。他们还进一步在开放benchmark下评估了DeepSeek-V2 Chat (SFT) 和DeepSeek-V2 Chat (RL) 。最终,DeepSeek-V2 Chat (RL)在AlpacaEval 2.0上取得了38.9长度控制获胜率,MT-Bench上获得了8.97总分,AlignBench上获得了7.91的总分。英语开放对话的评估结果显示DeepSeek-V2 Chat (RL)有着开源聊天模型中顶级的性能。此外,在AlignBench上的评估显示,对于中文来说,DeepSeek-V2 Chat (RL)的表现超过了所有开源模型,甚至打败了大部分的闭源模型。
为了能够激发对MLA和DeepSeekMoE的进一步的研究和探索,DeepSeek团队发布了DeepSeek-V2-Lite,一个带有MLA和DeepSeekMoE的小规模模型,给开源社区。其有着15.7B的参数量,每个token激活其中2.4B参数。
总体来说,DeepSeek-V2仍然是Transformer架构,其中每个Transformer块由一个注意力模块和一个FFN构成。但是,对于注意力模块和FFN,DeepSeek团队都进行了架构创新。对于注意力,他们设计了MLA,使用低秩KV联合压缩来减少KV缓存造成的推理时间瓶颈,从而实现高效推理。对于FFN,他们采用了DeepSeekMoE架构,一个高效的,使得强大的模型可以用经济的成本训练的MoE架构。DeepSeek-V2的架构如下图所示,若无特殊说明,否则其他的小细节,例如层归一化以及激活函数等,DeepSeek-V2仍然和DeepSeek 67B保持一致。
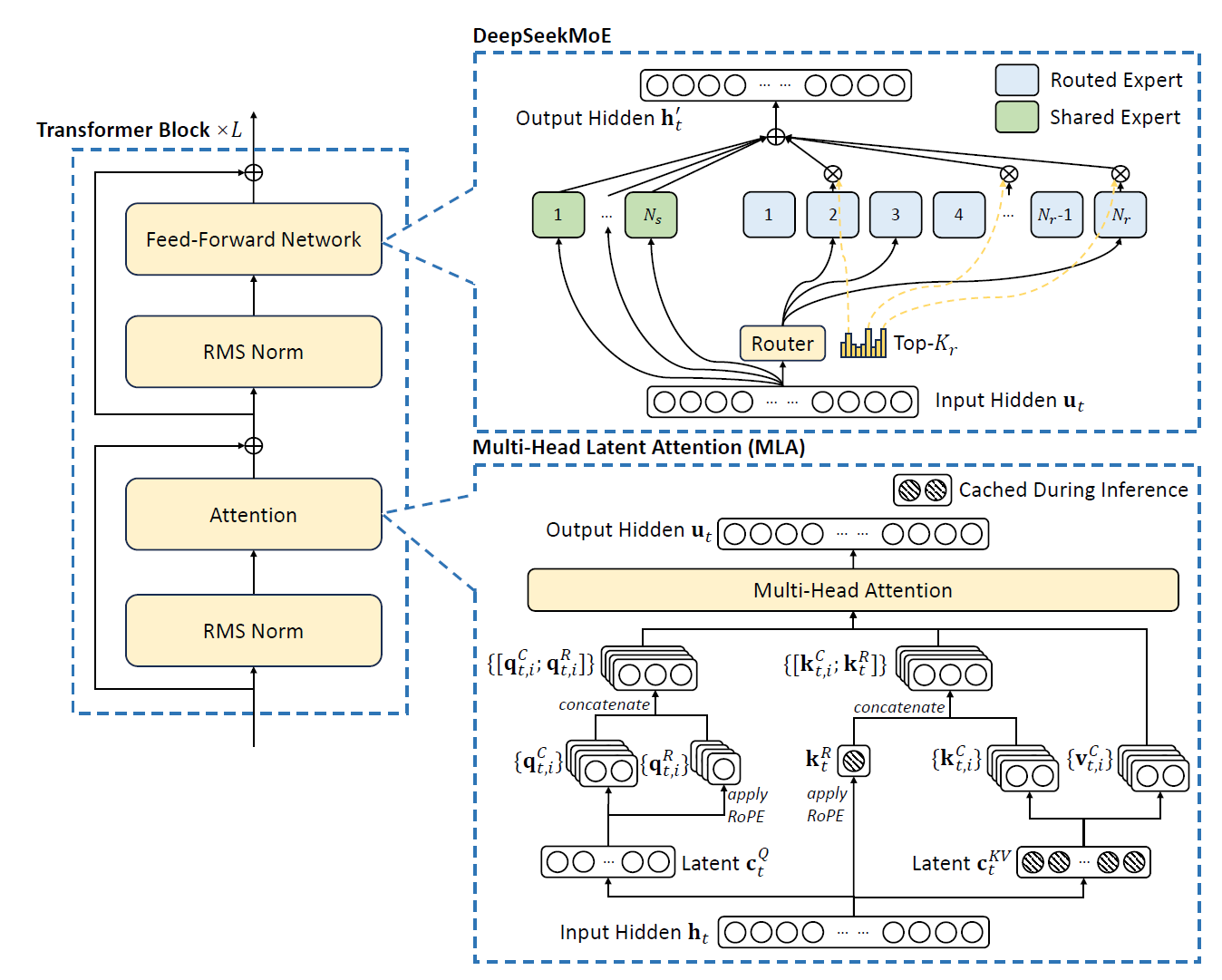
前面的介绍主要是说明了一下DeepSeek-V2的整体pipeline,方便对整个工作有一个全貌的了解,但我们最关心的还是MLA这个关键技术,接下来结合论文原文以及公式来看看这个技术的详细实现。
传统的Transformer模型一般使用MHA,但是在生成过程中,其巨大的KV缓存成为了限制推理效率的瓶颈。为了减少KV缓存,MQA和GQA技术被提出。这些技术的KV缓存更小,但是其性能无法匹配MHA。如下表所示,DeepSeek团队在7B稠密模型上,对MHA,GQA和MQA,在四个benchmark上进行了对比。三个模型均在1.33T token上训练,并且除了注意力模块其他的架构一致。此外,为了公平比较,他们将三个模型的参数都对齐到了7B。从下表中可以看出,MHA在这些benchmark上展现出相对GQA和MQA的显著优势。
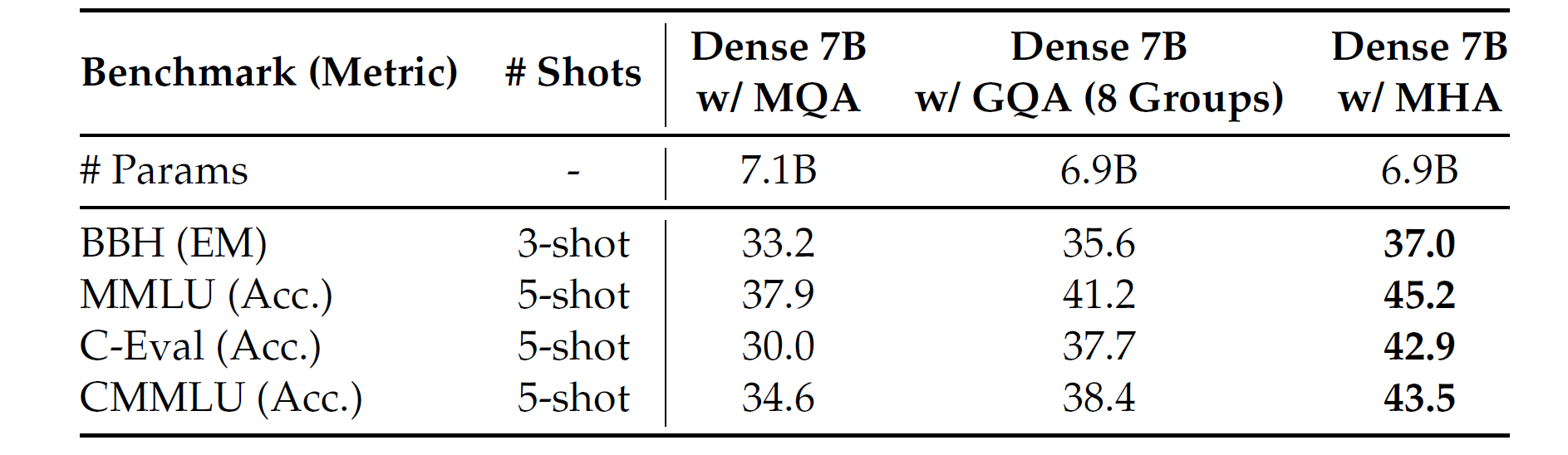
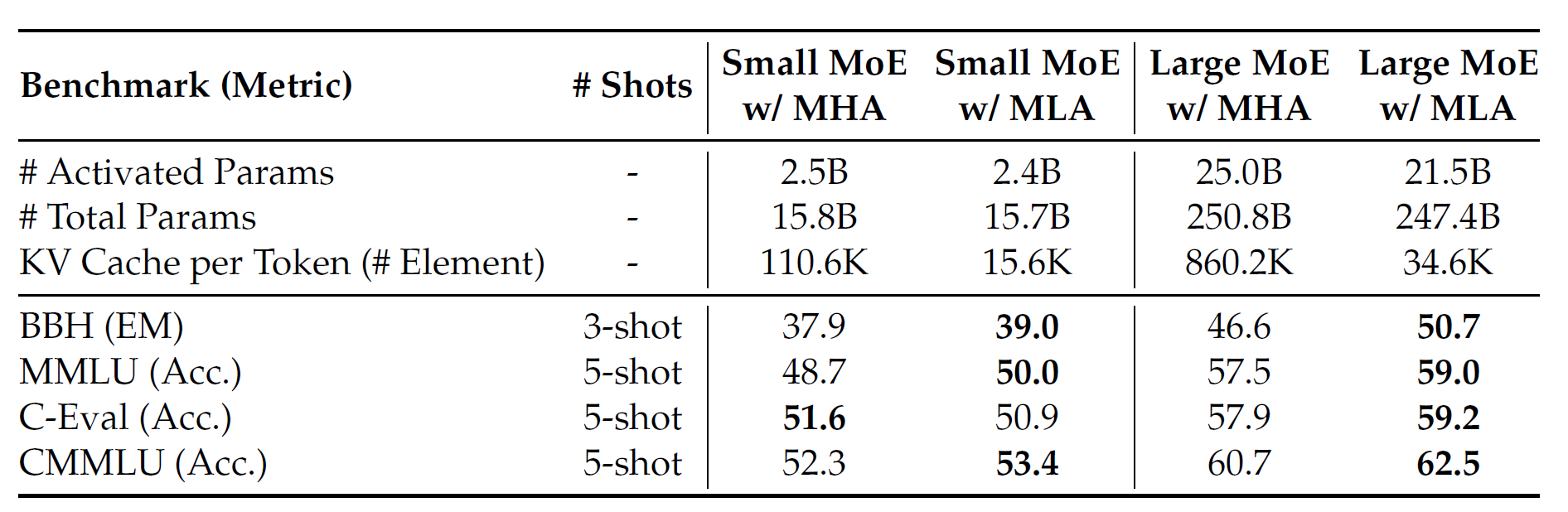
对于DeepSeek-V2,他们设计了一个创新的机制,称为MLA,通过低秩KV联合压缩,MLA达到了比MHA更好的性能,但只需要更少的KV缓存。他们对MLA和MHA的效果进行了对比。在下表中列出了在四个benchmark评估使用MLA和MHA的MoE模型的结果。为了得到明确的结论,DeepSeek团队在两个尺度上进行了训练和评估。两个小的MoE模型共计16B的参数,在1.33T token上训练。两个大的MoE模型共计250B总参数,在420B token上训练。同时,两个小的MoE模型和两个大的MoE模型除了注意力机制之外没有其他的架构差异。从下表中,可以观察到MLA有着比MHA更好的性能。更重要的是,MLA需要的KV缓存远小于MHA。
首先先将标准MHA的机制介绍作为背景。令\(d\)为嵌入维度,\(n_h\)为注意力头数量,\(d_h\)为每个头的维度,\(\mathbf{h}_t\in \mathrm{R}^d\)为一个注意力层的第\(t\)个token的注意力输入。标准的MHA首先通过三个矩阵\(W^Q,W^K,W^V\in \mathrm{R}^{d_hn_h}\)产生\(\mathbf{q}_t,\mathbf{k}_t,\mathbf{v}_t,\in \mathrm{R}^d\),即:
随后,\(\mathbf{q}_t,\mathbf{k}_t,\mathbf{v}_t\)接着被切分给\(n_h\),用于多头注意力计算:
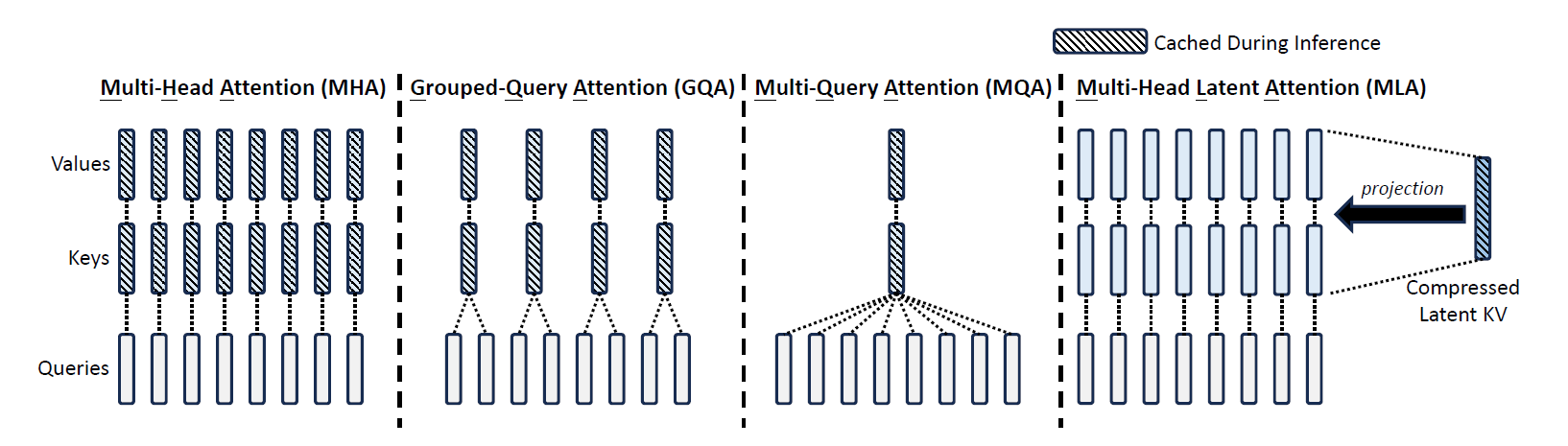
其中\(\mathbf{q}_{t,i},\mathbf{k}_{t,i},\mathbf{v}_{t,i},\in \mathrm{R}^{d_h}\)代表第\(i\)个注意力头的查询、键和值。\(W^O\in\mathrm{R}^{d\times d_hn_h}\)表示输出投影矩阵。在推理时,所有的键值都需要缓存以加速推理,因此MHA对每个token需要缓存\(2n_hd_hl\)个元素。在模型部署时,这个庞大的KV缓存会造成巨大的瓶颈,限制最大的batchsize和序列长度。
MLA的核心是通过对键值低秩联合压缩来减少KV缓存:
其中\(\mathbf{c}_t^{KV}\in\mathrm{R}^{d_c}\)为键值压缩后的潜在向量;\(d_c(\ll d_nn_h)\)为KV压缩维度;\(W^{DKV}\in \mathrm{R}^{d_c\times d}\)为降维投射矩阵;\(W^{UK},W^{UV}\in\mathrm{R^{d_n n_h \times d_c}}\)为键值的升维矩阵。在推理中,MLA仅仅需要缓存\(\mathbf{c}_t^{KV}\),因此其KV缓存仅仅由\(d_c l\)个元素,因此\(l\)是层的数量。此外,在推理中,由于\(W^{UK}\)可以吸收进\(W^Q\),\(W^{UV}\)可以吸收进\(W^O\),因此甚至可以不用在注意力外计算键值。下图展示了MLA中的KV联合压缩如何减少KV缓存。
此外,没了减少训练中的激活存储,DeepSeek团队还对查询进行了低秩压缩,尽管其并不能减少KV缓存:
其中\(\mathbf{c}_t^Q\in \mathrm{R}^{d_c^{'}}\)是查询压缩后的隐向量;\(d_c^{'}(\ll d_hn_h)\)表示查询压缩维度,\(W^{DQ}\in \mathrm{R}^{d_c^{'}\times d}\),\(W^{UQ}\in \mathrm{R^{d_n n_h\times d_c^{'}}}\)分别为查询的降维投影和升维投影矩阵。
和DeepSeek 67B一样,DeepSeek团队试图在DeepSeek-V2中使用旋转位置嵌入(RoPE)。但是RoPE和低秩KV压缩并不匹配。具体来说,RoPE对于键值都是位置敏感的。如果对键\(\mathbf{k}_t^{C}\)应用RoPE,前面公式中的\(W^{UK}\)就会和一个位置敏感的RoPE矩阵耦合。在这种情况下,\(W^{UK}\)在推理时无法被吸收到\(W^Q\)中,因为与当前生成的token相关的RoPE矩阵将位于\(W^Q\)和\(W^{UK}\)之间,而矩阵乘法不遵守交换定律。作为结果,必须在推理过程中重新计算所有前缀token的键,这将严重阻碍推理效率。
这里补充一下小tip,RoPE本质上是利用token之间的相对位置关系,通过对向量乘以旋转矩阵的方式实现位置编码,公式可以表达为:
其中\(\boldsymbol{R}_{\Theta,n-m}^{d}\)就是RoPE旋转矩阵。显然可以看出,如果将键向量改变为\(\mathbf{k}_t^C\),旋转矩阵会插在\(W^Q\)和\(W^{UK}\)之间,导致之前构想的用\(W^Q\)吸收\(W^{UK}\)的方法失效。
因此,DeepSeek团队提出了解耦RoPE策略,使用额外的多头查询\(\mathbf{q}^{R}_{t,i}\in\mathrm{R}^{d_h^R}\)以及共享键\(\mathbf{k}_t^R\in \mathrm{R}^{d_h^R}\)来进行RoPE,其中\(d_h^R\)表示解耦后的查询和键的注意力头维度。通过采用解耦RoPE策略,MLA的计算变为下面的形式:
其中\(W^{QR}\in\mathbb{R}^{d_h^Rn_h\times d_c^{\prime}}\),\(W^{KR}\in\mathbb{R}^{d_h^R\times d}\)分别为产生解耦的查询和键的矩阵。\(\mathrm{RoPE}(\cdot)\)表示应用RoPE矩阵操作;\([\cdot;\cdot]\)表示拼接操作。在推理中,解耦键同样需要缓存,因此DeepSeek-V2的KV缓存总共需要存\((d_c+d_h^R)l\)个元素。
MLA的完整计算过程可见如下的公式:
其中框出的向量是生成过程中需要进行缓存的。在推理中,如果按照原始的公式,需要在计算注意力时从\(\mathbf{c}_t^{KV}\)中恢复出\(\mathbf{k}_t^C\)和\(\mathbf{v}_t^C\)。幸运的是,由于矩阵乘法的结合律,可以把\(W^{UK}\)吸收到\(W^{UQ}\)中,\(W^{UV}\)吸收到\(W^O\)中。因此,不需要为了每个查询再去计算键和值。通过这一优化,可以避免在推理中重新计算\(\mathbf{k}_t^C\)和\(\mathbf{v}_t^C\)带来的计算开销。
至此基本上讨论完了MLA的技术细节,这一技术的核心就在于对KV缓存进行联合低秩压缩,从而大大减小KV缓存的存储与访存开销。尽管低秩分解作为一种压缩技术在网络中非常常用,且之前也有不少工作对Transformer中的低秩压缩问题展开过研究,但对于注意力层巧妙的应用这一技术是DeepSeek团队的独到之处,并且令人惊喜的是MLA不仅大大减小了硬件开销,同时在性能上不仅胜过之前的MQA,GQA方法,而且甚至能够超过原始的MHA。
DeepSeek-V2的核心共享MLA技术就言尽于此,现在再对DeepSeek团队在DeepSeekMoE技术上的一些新内容简单做一下介绍。
首先是在负载均衡的基础上,除了之前介绍过的专家均衡和设备均衡,还进一步加入了通信均衡损失。
DeepSeek团队引入通信均衡损失来确保每个设备的通信是均衡的。虽然设备限定的路由机制保证了每个设备的发送通信是有界的,但如果某个设备接收到的 Token 比其他设备多,实际通信效率也会受到影响。为了缓解此问题,他们设计了如下通信均衡损失:
其中\(\alpha_3\)是一个被称为通信均衡因子的超参数。设备受限的路由机制的工作原理是确保每个设备最多向其他设备传输\(MT\)个隐藏状态。同时,采用通信均衡损失来鼓励每个设备都接收来自其他设备的大概\(MT\)个隐藏状态。通信均衡损失保证了设备之间信息的平衡交换,提高了通信效率。
尽管均衡损失旨在鼓励平衡负载,但重要的是要承认仅靠这一点并不能保证严格的负载均衡。为了进一步减少计算浪费,DeepSeek团队在训练过程中引入了设备级的token丢弃策略。该方法首先计算每个设备的平均计算预算,这意味着每个设备的容量因子等于1.0。然后,受到 Riquelme 的启发,他们在每台设备上丢弃亲和力分数最低的token,直到达到计算预算。此外,他们确保大约10%训练序列的token永远不会被丢弃。这样就可以灵活地决定是否要根据效率要求在推理期间删除token,并始终确保训练和推理之间的一致性。
7. DeepSeek-V3 Technical Report
接下来开始总结DeepSeek团队于2025年2月18日发表的DeepSeek-V3的技术报告[5]。这也是目前DeepSeek团队发布的最先进的模型。DeepSeek也是从V3开始大火,一下获得了全国乃至全世界的瞩目,根本原因在于其通过极低的成本实现了接近甚至部分超越最先进的GPT-4等模型的性能。
DeepSeek-V3是一个强大的MoE语言模型,有着671B总参数,每个token会激活37B的参数。为了实现高效的推理于经济的训练,DeepSeek-V3使用了MLA和DeepSeekMoE架构,这两项技术是之前在DeepSeek-V2中就验证的。此外,DeepSeek-V3开创了一种用于负载均衡的辅助无损策略,并设置了多token预测训练目标以获得更强的性能。DeepSeek团队在14.8 T个多样化且高质量的token上进行了预训练,随后进行了SFT和RL来充分释放潜力。大量的评估显示DeepSeek-V3的性能超越了其他的开源模型,并且达到了媲美先进闭源的水平。尽管其性能卓越,DeepSeek-V3仅仅需要2.788M H800 GPU时做完整训练。此外,其训练过程非常的稳定。在整个训练过程中,DeepSeek团队没有碰到任何不可恢复的损失脉冲,或进行任何回滚。
针对DeepSeek-V3的技术报告,除了算法上的两个新insight——用于负载均衡的辅助无损策略和多token预测训练目标之外,其对于软硬件的协同设计(软件根据硬件Feature进行专门的优化)、以及对硬件的设计建议也是非常精辟,对于做AI芯片设计有着非常好的指导意义,因此在本片中会在讨论算法之余用很多的笔墨好好讨论一下这部分。
首先讲一下算法部分的两个重点:用于负载均衡的辅助无损策略和多token预测训练目标。对于MoE模型来说,非均衡的专家负载会导致路由崩塌,并且损失专家并行下的计算效率。传统的方法一般依赖于辅助损失来避免负载失衡。然而,太大的辅助损失会影响模型的性能。为了取得一个更好的负载均衡和模型性能之间的权衡,DeepSeek团队创新的提出了用于负载均衡的辅助无损策略。具体来说,他们为每个专家引入了偏置项\(b_i\),并将其加入到决定top-K路由的亲和力分数\(s_{i,t}\)中:
注意偏置项仅仅用在路由中。与FFN输出相乘的门控值仍然保持原有的亲和力分数\(s_{i,t}\)。在训练时,需要持续监控每个训练步上的整个批次的专家负载。在每步的末尾,如果对应的专家出现了过载,则将偏置项减少\(\gamma\),如果对应的专家出现了欠载,则将偏置增大\(\gamma\),其中\(\gamma\)是一个被成为偏置更新速度的超参数。通过这一动态调整,DeepSeek-V3在训练时保持了均衡的专家负载,并且相比通过单纯的辅助损失来实现负载均衡的模型取得了更好的性能。
尽管DeepSeek-V3主要依靠用于负载均衡的辅助无损策略,但为了避免单个序列中出现极端的失衡,他们还采用了互补序列辅助损失:
其中均衡因子\(\alpha\)为超参数,在DeepSeek-V3中赋了一个非常小的值;\(\mathbb{1}(\cdot )\) 表示指示符功能;\(T\)表示一个序列中的token数量。互补序列辅助损失鼓励每个序列中专家负载是均衡的。
此外,类似于DeepSeek-V2中采用的设备受限的路由机制,DeepSeek-V3通用也采用了机制来限制训练时的通信开销。简而言之,DeepSeek团队确保每个token被送达至最多\(M\)个节点,根据每个节点上分布的最高的\(\frac{K_r}{M}\)个专家亲和力分数之和进行选取。在这一限制下,MoE训练框架可以几乎达到满的计算-通信重叠。
由于这些有效的负载均衡策略,DeepSeek-V3在其完整训练中保持了一个好的负载均衡,DeepSeek-V3不需要在训练时丢弃任何token。此外,DeepSeek团队也实现的具体的部署策略来确保推理负载均衡,因此DeepSeek-V3同样在推理时不需要丢弃任何token。
接着是DeepSeek-V3的多token预测训练目标,DeepSeek团队调研并为DeepSeek-V3设置了一个多token预测(MTP)目标,将预测对象拓展到了每个位置上的多个未来token。一方面,MTP目标使训练信号更加密集,并可能提高数据效率。另一方面,MTP可能使模型能够预先规划其表示形式,以便更好地预测未来的token。下图展示了MTP的具体实现:
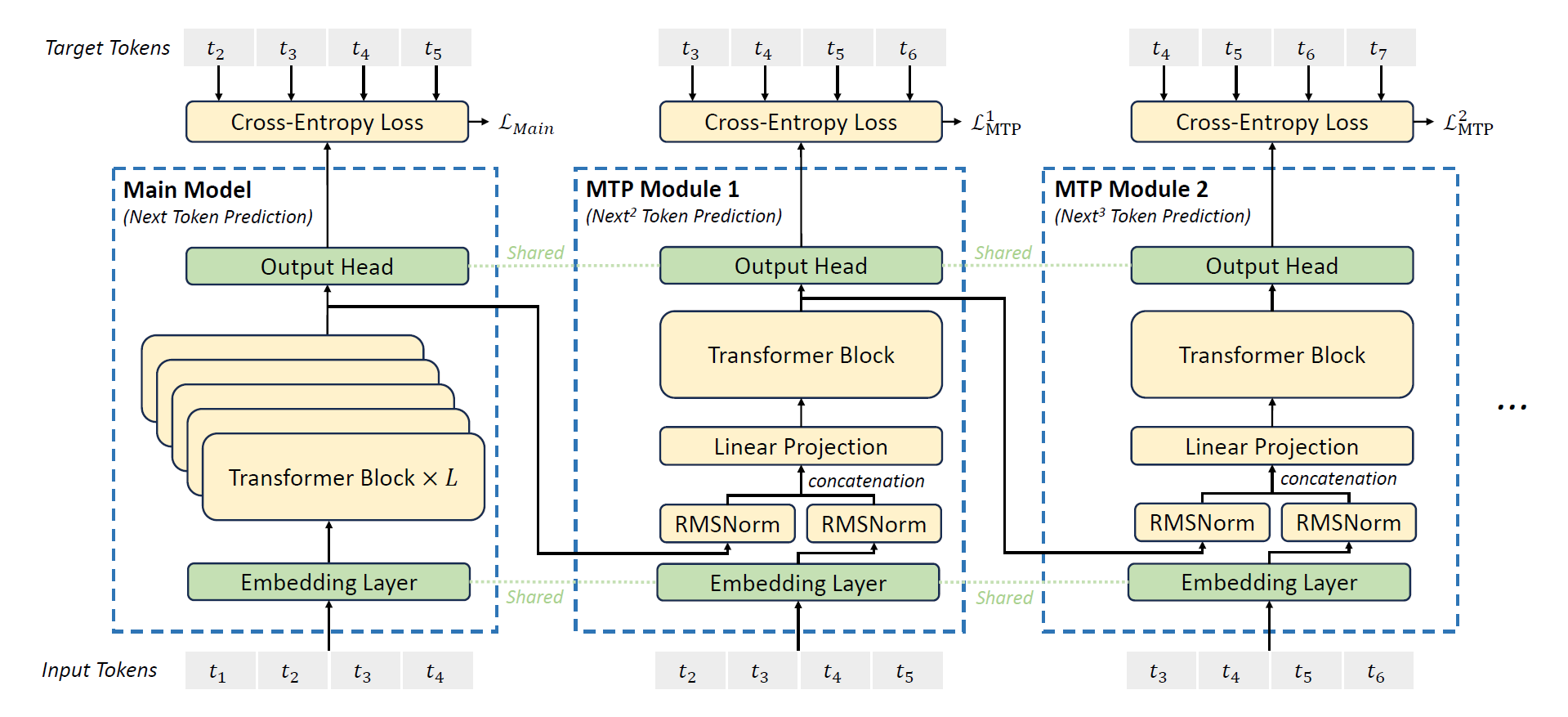
与Gloeckle等人(2024)采用的使用独立输出头并行的预测\(D\)个额外的token的方式不同,DeepSeek团队顺序的预测额外的token,并在每个预测深度保留完整的因果链。接下来将介绍MTP的实现细节。
具体来说,MTP采用\(D\)个顺序模块来预测\(D\)个额外token。第\(k\)个MTP模块由一个贡献嵌入层\(\mathrm{Emb}(\cdot)\),一个贡献输出头\(\mathrm{OutHead}(\cdot)\),一个Transformer块\(\mathrm{TRM}_k(\cdot)\)以及一个投影矩阵\(M_k\in\mathrm{R}^{d\times 2d}\)组成。对于第\(i\)个输入token \(t_i\),在第\(k\)个预测深度,首先拼接组合\((k-1)\)深度的第\(i\)个token的表示\(\mathbf{h}_i^{k-1}\in \mathrm{R}^d\)和\((i+k)\)个token的嵌入\(Emb(t_{i+k})\in \mathrm{R}^d\),然后再进行线性投影:
其中\([\cdot;\cdot]\)表示拼接操作。具体来说,当\(k=1\)时,\(h_i^{k-1}\)代表由主模型输出的表示。注意到对于每个MTP模块,其嵌入层和主模型共享。组合后的\(\mathbf{h}_i^{\prime k}\)作为\(k\)深度的Transformer块的输入,从而产生当前深度的输出表示\(\mathbf{h}_i^k\):
其中\(T\)表示输入序列的长度,$ _{i:j}\(表示切分操作(包括了左侧和右侧边界)。最后,将\)\mathbf{h}_i^k\(作为输入,共享输出头回计算第\)k$哥额外预测token \(P^k_{i+1+k}\in\mathrm{R}^V\)的分布概率,其中\(V\)为词表尺寸:
输出头\(\mathrm{OutHead}(\cdot)\)将表示线性映射成logits,然后运用\(\mathrm{Softmax}(\cdot)\)函数来计算第\(k\)个额外词的预测概率。此外,对于每个MTP模块,其输出头都与主模型共享。DeepSeek团队保持预测因果链的原理与EAGLE类似,但后者的主要目标是推测解码,而他们的目的是提升训练。
对于每个预测深度,都会计算一个交叉熵损失\(\mathcal{L}_{\mathrm{MTP}}^k\):
其中\(T\)表示输入序列长度,\(t_i\)表示第\(i\)个位置的ground-truth token,\(P^k_i[t_i]\)表示\(t_i\)对应的预测概率,由第\(k\)个MTP模块给出。最终,通过计算MTP损失在所有深度上的平均值,并将其与权重因子\(\lambda\)相乘,来得到总的MTP损失\(\mathcal{L}_{\mathrm{MTP}}\),并作为DeepSeek-V3的一个额外的训练目标:
MTP策略的主要目的是提升主模型的性能,因此在推理时可以直接丢弃掉MTP模块,而主模型可以正常独立工作。此外,DeepSeek团队也可以再采用MTP模块进行推测解码,从而降低生成的延迟。
至此算法上的两个insight总结完了,接下来开始重点看看DeepSeek-V3配合GPU硬件所采取的一些技巧,以及他们对硬件发展的一些思路和建议。
DeepSeek-V3在一个2048张NVIDIA H800 GPU的集群上训练。H800的集群每个节点有8张GPU,节点内部通过NVLink和NVSwitch互联。不同的节点之间,使用InfiniBand(IB)进行互联。
DeepSeek-V3的训练由HAI-LLM框架支持,这是一个高效且轻量的训练框架,由DeepSeek自己的工程师团队从头搭建。整体来说,DeepSeek-V3采用16路流水线并行(PP),跨8个节点的64路专家并行(EP),以及ZeRo-1数据并行(DP)。
为了实现DeepSeek-V3的高效训练,DeepSeek团队采用了很多工程优化。首先,他们设计双流水线算法实现高效的流水线并行。与现存的PP方法相比,双流水线算法的流水线气泡更少。更重要的是,其可以重叠前向和反向过程中的计算与通信阶段,从而解决跨节点专家并行带来的大通讯开销的挑战。其次,他们开发了高效的跨节点全到全的通信核来充分利用IB和NVLink的带宽,并且让流式多处理器(SMs)专精于通信。最后,他们精心优化了训练中的内存开销,从而使得DeepSeek-V3可以在不使用高开销的张量并行(TP)的情况下训练。
对于DeepSeek-V3,跨节点专家并行引入的通信开销导致了接近1:1的低效的计算-通信比。为了解决这一挑战,DeepSeek团队设计了一个创新的流水线并行算法——双流水线算法,不仅通过有效的重叠前向和反向的计算-通信阶段从而加速模型训练,同时也减少了流水线气泡。
双流水线算法的核心思想是通过一对独立的前向和反向块来重叠计算与通信。具体来说,他们将每个块切分为四个组件:注意力,全到全分派,多层全连接以及全到全组合。具体来说,对于反向块,注意力和多层全连接进一步分成两块,输入的反向以及权重的反向,类似于ZeroBubble。此外,他们还有一个PP通信模块,如下图所示:

对一对前向和反向块,他们将这些组件进行重拍,并手动调整专精于计算和通信的GPU SMs的比例。在这个重叠策略中,可以确保全到全以及PP通信可以完全隐藏在执行中。基于这一有效的重叠策略,完整的双流水线调度如下图所示:

使用双向流水线调度时,其同时从管道的两端馈送微批次,并且很大一部分通信可以完全重叠。这一重叠同时也确保了,即使模型在未来进一步放大,只有可以保持一个固定的计算-通信比例,就仍然可以跨节点的细粒度专家,并且保持一个接近零的全到全通信开销。
此外,即使是在没有大的通信开销的通用场景中,双流水线仍然展示出了效率优势,如下表所示,DeepSeek团队总结了不同的PP方法中的流水线气泡与内存使用。与ZB1P相比,双流水线显著减少了流水线气泡,同时仅仅把峰值激活内存增大了\(\frac{1}{pp}\)倍。尽管双流水线需要保存两份模型参数,但由于DeepSeek团队在训练中采用了一个大的EP规模,因此这并没有显著增大内存开销。与Chimera相比,双流水线仅仅需要把流水线级和微批次分为两份,而不需要微批次随流水线层级可分。此外,对于双流水线,在微批次数量的增长时,气泡和激活内存都没有增大。

为了确保双流水线充分的计算性能,DeepSeek团队定制了高效的跨节点全到全通信核(包括了分配和组合)来集散后专职于通信的SMs的数量。该核的实现与MoE门控算法和集群的网络拓扑协同设计。具体来说,在集群中,跨节点GPU充分与IB互联,节点内的通信通过NVLink进行。NVLink提供160GB/s的带宽,大概是IB的3.2倍(50GB/s)。为了有效的利用IB和NVLink的不同带宽,他们限制了每个token最多呗分配给4个节点,从而减少IB上的数据传输。对于每个token,当它的路由决策已经确定,它将首先通过IB传输到其目标节点上具有相同节点内索引的 GPU。一旦其抵达目标节点,他们将努力确保它通过NVLink即时转发到托管其目标专家的特定 GPU,而不会被随后到达的token阻塞。通过这种方式,IB和NVLink的通信可以完全重叠,每个token可以有效地为每个节点选择平均3.2名专家,而不会产生NVLink的额外开销。这意味着,尽管DeepSeek-V3实际上只选择8个路由专家,但其可以缩放到最大13名专家(4个节点乘以3.2专家/节点)同时保持同样的通信开销。总体来说,在这样的通信策略中,只用20个SMs就可以充分利用IB和NVLink的带宽。
具体来说,DeepSeek团队采用了卷专用化技术,将20个SMs分成10个通信通道。在分配过程中,(1)IB发送,(2)IB到NVLink发送,(3)NVLink通过专门的卷处理接收。分配到每个通信任务上的卷的数量根据所有SMs上的实际负载进行动态调整。类似的,在组合过程中,(1)NVLink发送,(2)NVLink到IB发送和累加,(3)IB接收和累加同样通过动态调整的卷来处理。此外,分配和组合核与计算流重叠,所以他们也考虑了其对其他SM计算核的影响。具体来说,他们采用自定义的PTX指令并自动调整通信块的尺寸,显著减少了L2 Cache的使用和对其他SMs的干扰。
为了减少训练时的内存开销,DeepSeek团队采用了如下的技巧:
重计算RMSNorm和MLA升维投影 他们在反向传播时重计算所有的RMSNorm操作和MLA升维投影操作,从而减少持续存储其输出激活的需求。通过很小的开销,这个策略显著减少了存储激活的内存需求。
CPU中的指数滑动平均 在训练时,他们保留了模型参数的指数滑动平均(EMA),以便在学习率衰减后对模型性能进行早期评估。EMA参数存储在CPU内存中,并在每个训练步后异步更新。这一方法使得他们可以保存EMA参数,而不需要增加额外的存储或时间开销。
多token预测共享嵌入层与输出头 通过双流水线策略,他们将模型最浅的层(包括嵌入层)和最深的层(包括输出头)部署在同一个PP层次。这一安排使得MTP模组和主模型之间共享的嵌入层和输出头的参数和梯度可以物理共享。这一物理共享机制进一步提升了存储效率。
受到近期低精度训练方面进展的启发,DeepSeek团队还采用了一个细粒度的混合精度框架,使用FP8数据格式来训练DeepSeek-V3。尽管低精度训练很有前景,但其受到激活、权重和梯度中的离群值的限制。尽管在推理量化上已经有一些重大进展,但很少的研究展现了低精度技术在大规模语言模型预训练上的成功应用。为了解决这一问题并有效的拓展FP8格式的动态范围,他们引入了一个细粒度的量化策略:\(1\times N_c\)的分条组和\(N_c\times N_c\)的分块组。相关的反量化开销通过增精度累加过程消除了大部分,这是为了取得精确的FP8 GEMM结果的一个关键方面。此外,为了进一步减少MoE训练时的内存和通信开销,DeepSeek团队缓存并分派FP8格式的激活,同时将低精度优化器状态用BF16存储。他们评估在两个尺度的模型上(分别类似于DeepSeek-V2-Lite和DeepSeek-V2)评估了采用的FP8混合精度框架,使用大概1T tokens进行训练,结果是,与BF16基线相比,FP8训练模型的相对误差保持在大概低0.25%,这是一个在训练随机性下可接受的水平。
在DeepSeek团队提出的细粒度的混合精度框架中,大部分计算密集操作都通过FP8来完成,而一小部分关键的操作仍然保持其原来的数据格式,从而平衡训练效率与数值稳定性,整体的框架如下图所示:
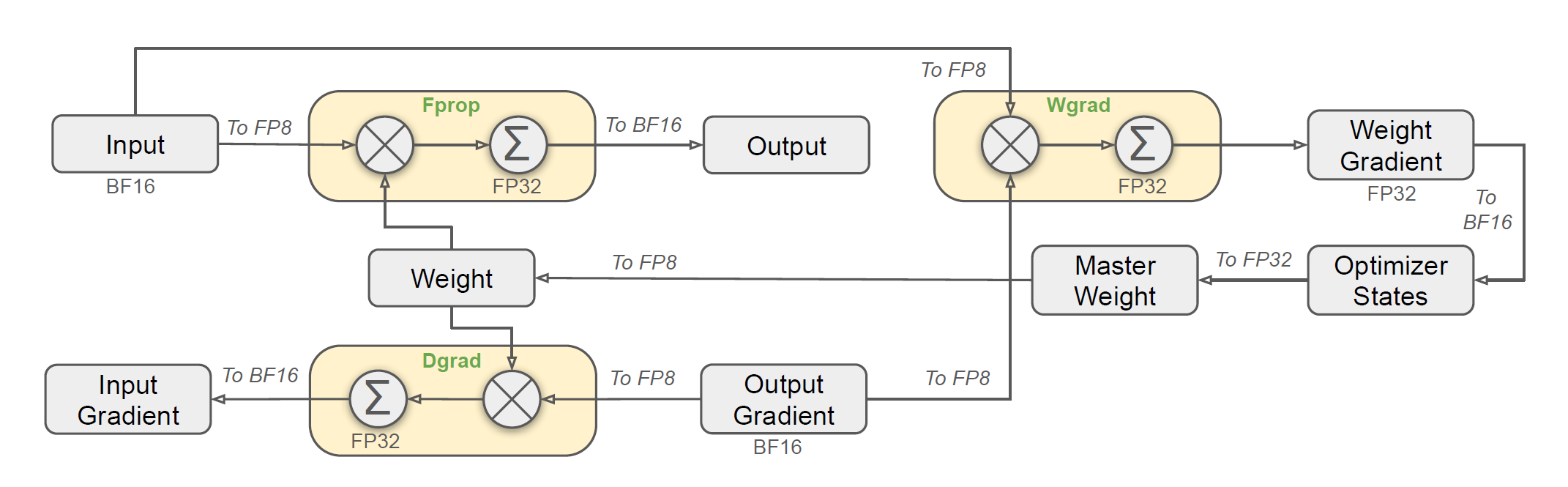
首先,为了加速模型训练,大部分的核心计算核,例如GEMM操作,通过FP8精度实现。这些GEMM操作接受FP8张量作为输入,并产生BF16或FP32的输出。如上图所示,三个GEMMs对应线性操作,分别是Fprop(前向传播),Dgrad(激活反向传播)以及Wgrad(权重反向传播),均通过FP8执行。这一设计理论相比原始的BF16方法,把计算速度增加了两倍。此外,FP8 Wgrad GEMM使得反向传播中的激活可以用FP8格式存储,这显著的减少了内存开销。
尽管FP8格式有着效率优势,但特定算子仍然需要更高的精度,因为其对于低精度计算存在敏感性。此外,一些低开销操作可以使用更高的才做,同时对整体训练的开销不会有多少额外开销。处于这一理由,在仔细的调研后,DeepSeek团队为如下的组件保留了原始精度(BF16或FP32):嵌入模块,输出头,MoE门控模块,归一化算子和注意力算子。这些模块保留高精度确保了DeepSeek-V3稳定的训练。为了进一步确保数值稳定性,他们将主权重,权重梯度和优化器状态用高精度存储。尽管这些高精度组件增加了一些内存开销,但他们的影响可以通过在分布式训练系统中有效的分片到多个DP级中从而将其影响最小化。
基于上述的混合精度FP8框架,DeepSeek团队还引入了一些策略来提升低精度训练的准确率,主要的关注点包括了量化操作以及乘法过程。
细粒度量化 在低精度训练框架中,上溢和下溢是由于FP8格式动态范围有限导致的常见挑战,一般受到其更少的指数位导致的限制。常规操作一般会通过将输入张量的最大绝对值缩放到 FP8 的最大可表示值,输入分布与 FP8 格式的可表示范围保持一致。这一方法使得低精度训练对激活离群值高度敏感,并且可能严重的降低量化精度。为了解决这一问题,他们提出了一个细粒度量化操作,在更细的粒度上应用缩放。如下图(a)所示,(1)对于激活, 他们基于1*128的条带进行分组和缩放(例如每token每128通道)以及(2)对于权重,他们基于128*128的块进行分组和缩放(例如每128输入通道128输出通道)。这一方法确保了量化过程可以更好的通过在更小的元素组上应用缩放来适应离群值。
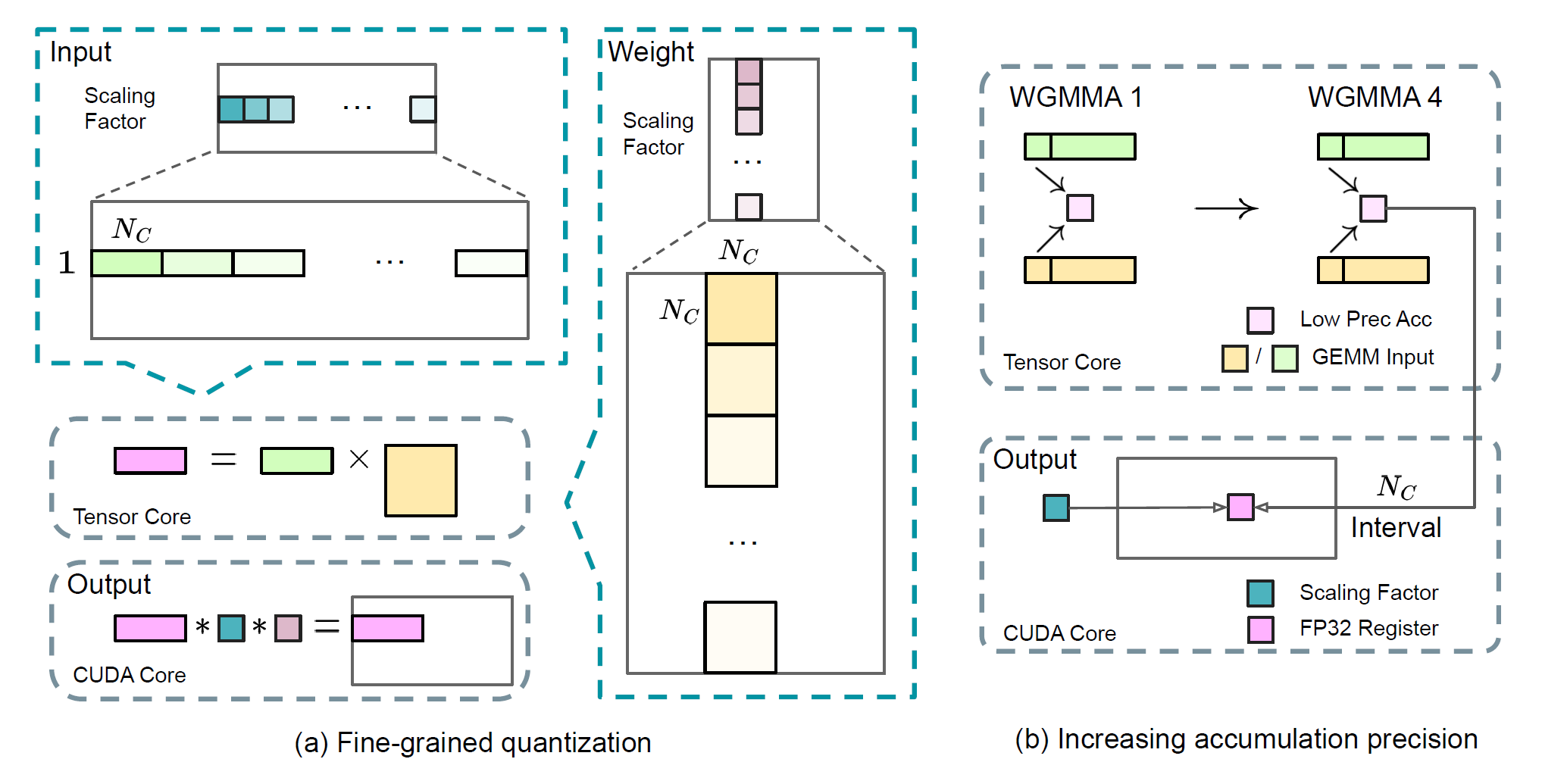
在他们方法中,一个关键改动是沿着GEMM操作的内部维度引入每组缩放因子。这一功能并没有标准FP8 GEMM直接支持。然而,与他们的精确FP32累加策略相结合,这一方法可以得到高效实现。
值得注意的是,DeepSeek团队的细粒度量化策略与microscaling格式的想法高度一致,并且下一代NVIDIA GPUs已经宣布了要支持有着更小量化粒度的microscaling格式。他们希望他们的设计可以作为基于下一代GPU架构的工作的参考。
增加累加精度 低精度GEMM操作经常受到下溢问题的影响,并且其精度很大程度上取决于高精度累加,这一般通过FP32精度来进行。然而,DeepSeek团队观察到NVIDIA H800 GPUs的FP8 GEMM累加精度限制在14位,这显著低于FP32累加精度。这一问题在内部K维度很大时会带来严重的问题,一个大语言模型训练中的典型场景就是批尺寸和模型宽度增大。以GEMM对两个K=4096的随机矩阵做GEMM为例,在他们的测试中,Tensor Cores中有限的精度会导致最大接近2%的相对误差。尽管有这些问题,但FP8的框架中,受限的累加精度仍然是一个默认设置,这严重限制了训练精度。
为了解决这一问题,DeepSeek团队才有了利用CUDA Cores来实现更高精度的策略。这一过程如上图中(b)所示。具体来说,矩阵乘累加(MMA)操作在Tensor Cores上完成,中间结果使用有限位宽进行累加。一旦达到\(N_c\)的间隔,这部分结果会被复制到CUDA Cores的FP32寄存器中,并在其中进行FP32累加。如之前所述,这一细粒度量化操作采用沿着内部维度K的每组缩放因子。这一影响因此可以高效的在CUDA Cores进行相乘从而最小化额外的计算开销。
值得一提的是,这一修改减少了卷级乘累加(WGMMA)对一个单独卷组的指令发射率。然而,在H800架构中,典型情况是两个WGMMA同时进行:当一个卷组执行拓展操作时,另一个能够执行MMA操作。这一设计使得两个操作重叠,从而保持Tensor Cores的高利用率。在DeepSeek团队的实验中,设置\(Nc=128\)个元素,等效于4个WGMMAs,代表最小累加间隔可以显著提升精度,而不需要引入潜在的开销。
尾数与指数 与之前工作采用的混合FP8格式相比,即在Fprop中使用E4M3格式,而在Dgrad和Wgrad中使用E5M2格式,DeepSeek团队全程采用了E4M3格式以实现更高的精度。他们将此事的可行性归功于细粒度量化策略,例如基于条带和块的缩放。通过采用更小的元素组,他们的方法可以在这些组内有效的共享指数位数,消除了有限动态范围的影响。
线上量化 延迟量化被用于张量积量化框架中,保持之前迭代中的最大绝对值的历史来推断当前值。为了确保精确的缩放因子并简化框架,DeepSeek团队在线计算每1*128激活条带和128*128权重块的最大绝对值。基于此,他们得到缩放因子,并在线的将激活和权重量化为FP8格式。
集合他们的FP8训练框架,通过将缓存激活和优化器压缩到更低精度的格式,他们进一步减少了内存开销与通信开销。
低精度优化器状态 DeepSeek团队采用BF16格式而非FP32来跟踪第一个和第二个AdamW优化器的动作,并且没有观察到性能损失。然而,主权重(由优化器存储)和梯度(用于批尺寸累加)仍然保持在FP32来确保训练中的数值稳定性。
低精度激活 如之前所述,Wgrad操作使用FP8来减少内存开销,因此一个自然的选择是将激活以FP8格式缓存,以用于线性层的反向传播。但是,在一些算子上需要为了低开销高精度训练做出一些特殊考虑:
- 注意力算子后的线性层输入。这些激活同样也用于注意力算子的后向传播,使得其对于精度很敏感。他们采用了一个自定义的E5M6数据格式来处理这些激活。此外,这些激活在后向传播中将会从1*128量化条带转换为128*1条带。为了避免引入额外的量化误差,所有的缩放因子都是四舍五入的,例如2的幂积分。
- MoE中SwiGLU算子的输入。为了进一步减少内存开销,他们将SwiGLU算子的输入缓存,并在后向传播时重新计算其输出。这些激活值同样用细粒度量化方法的FP8格式存储,达到了一个计算准确率和存储效率之间的平衡。
低精度通信 通信带宽是训练MoE模型时的一个重要瓶颈。为了解决这一挑战,他们在MoE升维度投影前把激活量化到FP8,然后使用分派组件。与MoE升投影中的FP8 Fprop兼容。类似于注意力算子后的线性层的输入,这些激活值的缩放因子是2的幂积分。类似的策略被应用于MoE降投影前的激活梯度。对于前向和前向和反向的组合组件,他们将其保持在BF16来保持训练管线中关键部分的训练精度。
基于在实现全到全通信和FP8训练过程中的实践,DeepSeek团队为AI硬件提供商们给出如下的芯片设计建议:
通信硬件 在DeepSeek-V3中,他们实现了计算与通信的重叠,来隐藏计算过程中的通信延迟。相比于串行的计算与开销,这显著减少了对通信带宽的依赖。然而,当前的通信实现依赖于昂贵的SMs开销(例如他们为了这一目的,使用了H800 GPU上可用的132 SMs中的20个),这限制了计算的吞吐率。此外,使用SMs来进行通信会导致显著的低效,例如其Tensor Cores利用率极其低下。
当前,这些SMs主要为了全到全通信做如下的任务:
- 在IB和NVLink域之间转发数据,同时从单个GPU聚合发往同一节点内多个GPU的IB流量。
- 在RDMA缓冲区(已注册的GPU内存区域)和输入/输出缓冲区之间传输数据。
- 为全到全组合执行归约算子。
- 在向IB和NVLink域中的多个专家传输分块数据期间管理精细的内存布局。
他们期待未来硬件提供商们能够开发硬件,将这些通信任务从宝贵的计算单元SM上卸载下来,作为一个GPU协处理器或者一个类似NVIDIA SHARP的网络协处理器。此外,为了减少应用中的编程复杂度,他们希望这一硬件可以从计算单元的角度统一IB(横向拓展)和NVLink(纵向拓展)网络。通过这一统一接口,计算单元可以简单的完成类似于跨整个IB-NVLink统一域的读、写、多播、归约,并且仅仅需要简单的发送通信请求即可。
Tensor Cores中更高的FP8 GEMM累加精度 在当前NVIDIA Hopper架构中的Tensor Core实现中,FP8 GEMM受到累加精度首先的影响。通过最大指数完成32个位数乘积的右移对齐后,Tensor Core对每个尾数乘积仅仅提供最大14位尾数用于加法,并且截取超出这一范围的比特。这一加法结果在寄存器中的累加仍然使用14比特精度。他们通过将128 FP8*FP8的乘法结果在CUDA Core的寄存器中通过FP32精度累加的方式暂时解决这一限制。尽管这一做法可以有效的实现成功的FP8训练,但其本质上是一个对Hopper架构FP8 GEMM累加精度的硬件低效的妥协。因此他们希望未来的芯片可以采用更高的精度。
支持基于条带和块的量化 当前的GPU仅支持张量基的量化,缺少对细粒度量化,例如条带和块基量化的原生支持,在当前的实现中,一旦达到\(N_c\)的间隔,部分和需要从Tensor Cores中复制到CUDA Cores中,与缩放因子相乘,并与CUDA Cores中的FP32寄存器相加。尽管这一反量化的开销可以通过与DeepSeek团队提出的精确FP32累加策略相结合来减小,但Tensor Cores和Cuda Cores中频繁的数据移动仍然限制了计算效率。因此,他们建议未来的芯片能够在Tensor Cores中支持细粒度量化来接受缩放因子并实现带有组缩放的MMA。通过这种方式,整个部分和累加和反向量化可以全部在Tensor Cores内完成,直到整个结果产生,避免了频繁的数据移动。
支持在线量化 根据他们的研究,当前的芯片难以高效地支持在线量化。在当前的过程中,他们需要从HBM读取128个BF16个激活值(之前计算的输出)来量化,而量化后的FP8值随后要写回HBM,仅仅为了再次读出用于MMA。为了解决这一低效性,他们建议未来的芯片将FP8映射和TMA(张量内存加速器)访问集成到一个融合算子中,从而量化可以在从全局存储向共享存储中传输中即可完成,避免了频繁的存储读写。他们还建议支持一个卷级别的映射指令用于加速,从而进一步实现层归一化与FP8映射之间更好的融合。此外,可以使用近存计算方法,其中计算逻辑被放置在靠近HBM的位置。在这种情况下,BF16可以直接在他们从HBM向GPU读出时就完成向FP8的映射,从而大概减少50%的片外访存。
支持转置GEMM操作 当前的架构在融合矩阵转置和GEMM操作上非常的笨重。在他们的工作流中,前向过程中的激活被量化成1*128 FP8条带并存储。在反向过程中,这个矩阵需要被读出,反量化,转置,然后重量化成128*1的条带,然后存储到HBM中。为了减少内存操作,他们建议未来的芯片对于那些训练和推理中都会使用的精度,可以直接支持矩阵在MMA前从共享存储中的转置读出。结合与FP8格式转换与TMA访问的融合,这一做法会极大的加速量化工作流。
DeepSeek-V3论文的解读至此告一段落了。做个总结,DeepSeek-V3主要引入了用于负载均衡的辅助无损策略和多token预测训练目标两个重要的算法改进。此外,他们在如何高效的利用硬件方面也投入了大量的精力,并介绍了双流水线算法,高效的跨节点全到全通信核和基于FP8的细粒度的混合精度框架三个重要技术。最后,他们还根据自身实现中的亲身体会,为未来的AI芯片设计提出了详细的建议。总体来说这是一篇软硬件贯通的好文章,非常值得精读。
8. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
最后介绍一下DeepSeek团队在2025年1月22日发表的DeepSeek-R1[6]。
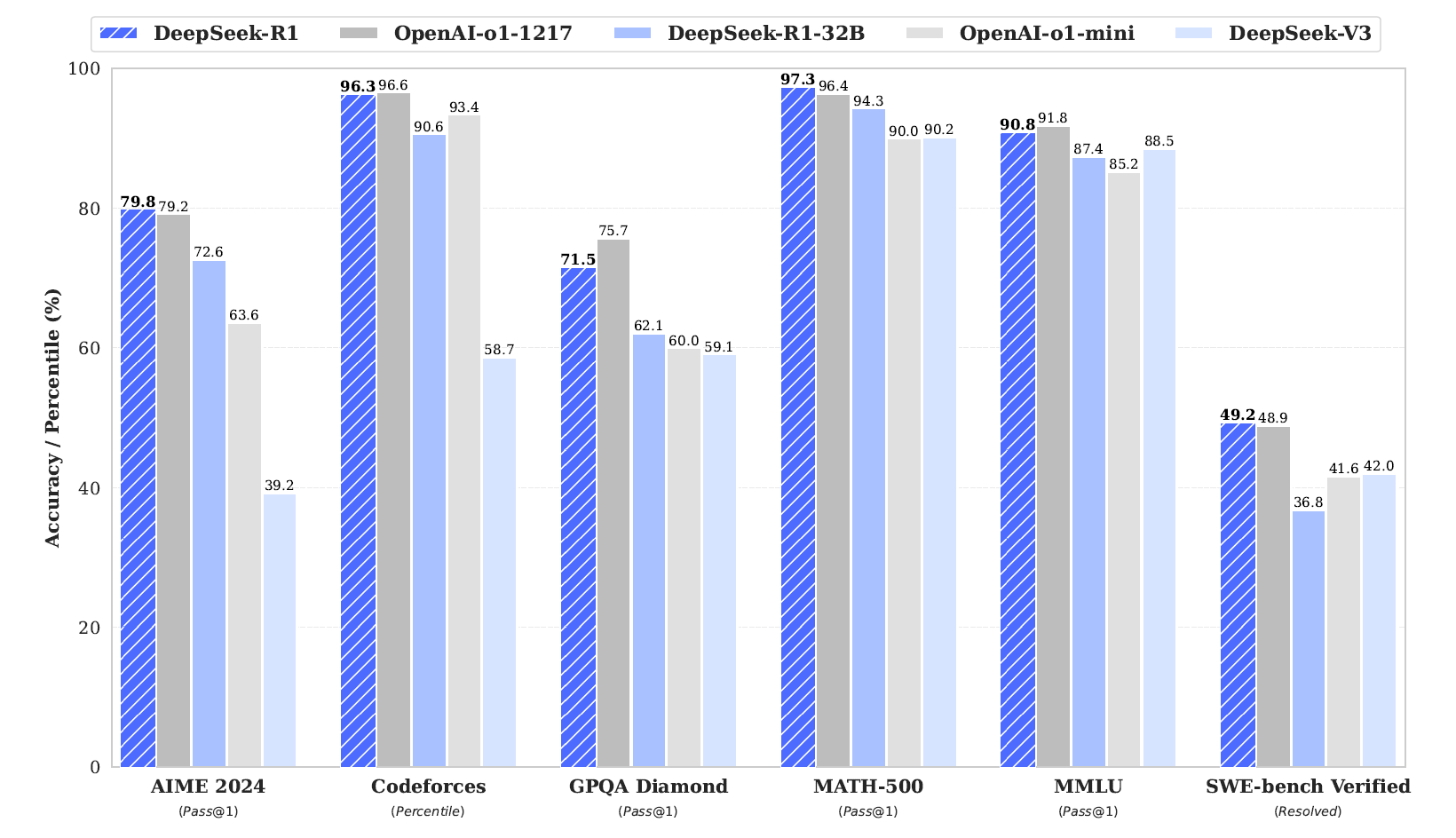
这是DeepSeek团队发布的第一个生成推理模型,DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1-Zero是一个不经过SFT,直接使用RL进行训练的模型。其展示出了优秀的推理能力。通过RL,DeepSeek-R1-Zero自然的显现出了强大的推理能力。然而,其遇到了诸如生成结果可读性差,多种语言混合的问题。为了解决这些问题并进一步增强推理能力,他们推出了DeepSeek-R1,包含了多阶段训练以及RL前的冷启动数据。DeepSeek-R1在推理任务中达到了媲美OpenAI-o1-1217的性能。为了支持研究社区,他们开源了DeepSeek-R1-Zero,DeepSeek-R1以及6个(1.5B,7B,8B,14B,32B,70B)基于Qwen和Llama在DeepSeek-R1上蒸馏的稠密模型。
在这一工作中,最主要的核心insight是跳过SFT直接使用RL训练,以及通过蒸馏增强小模型推理能力。因此在解读文章时会主要关注DeepSeek团队在这一过程中的发现,以及DeepSeek-R1-Zero和DeepSeek-R1这两个模型围绕RL训练和模型蒸馏提出一些重要技术。
近些年,LLMs正在经历快速的迭代和进化。近期,后训练已经成为完整训练管线中的一个重要组件。其已经展现了增强推理任务精度,对齐社会价值,适应用户偏好等作用,并且后训练所需要的计算开销相对于预训练很小。在文本内推理能力方面,OpenAI的o1系列模型首先引入了推理时间缩放,即增加CoT推理过程。这一方式在各种推理任务上取得了显著的进展,例如数学,代码以及科学推理。然而,高效的推理时间缩放仍然对于研究社区来说是一个开放的问题。之前的工作已经探索了各种方式,包括基于过程的奖励模型,强化学习和搜索算法(例如蒙特卡洛树搜索和柱搜索)。然而,这些方法均没有达到可以与OpenAI o1系列模型可以比肩的通用推理性能。
在这一论文中,DeepSeek团队迈出了单纯使用RL来提升语言模型推理能力的第一步。他们的目标是探索LLMs在不适用任何监督数据的情况下增强推理能力的潜力,主要聚焦于在一个纯RL过程中他们的自我进化。具体来说,他们使用DeepSeek-V3-Base作为基础模型,并应用GRPO作为RL框架来提升模型的推理能力。在训练时,DeepSeek-R1-Zero自然的涌现了许多强大且有趣的推理行为。在数千个RL步后,DeepSeek-R1-Zero展现了在推理benchmark下的超强表现。例如,在AIME 2024上的pass@1分数从15.6%增加到了71.0%,通过最大投票,分数进一步提升到了86.7%,达到了OpenAI-o1-0912的性能。
然而,DeepSeek-R1-Zero遇到了诸如可读性差,语言混合的挑战。为了解决这些挑战并进一步增强推理能力,DeepSeek团队提出了DeepSeek-R1,其利用了少量的冷启动数据以及多阶段训练管线。具体来说,他们通过收集数千个冷启动数据来微调DeepSeek-V3-Base模型作为开始。随后,他们进行类似DeepSeek-R1-Zero的推理聚焦的RL。在RL过程中接近收敛时,他们根据RL检查点中的拒绝采样构建新的SFT数据,结合来自DeepSeek-V3在诸如写作,真实QA和自我认知等领域的监督数据,然后重新训练DeepSeek-V3-Base模型。在通过新数据微调后,检查点再经历新一轮的RL,并使用来自所有场景的提示词。经过这些步之后,他们得到了DeepSeek-R1,其性能可以对标OpenAI-o1-1217。
他们进一步探索了从DeepSeek-R1到更小的稠密模型上的蒸馏。使用Qwen2.5-32B作为基础模型,直接使用DeepSeek-R1进行蒸馏的性能超过了在上面应用RL。这代表着更大的基础模型发现的推理模式对于提升推理能力很重要。他们开源了蒸馏的Qwen和Llama系列。需要注意的是,他们蒸馏的14B模型大大超过了当前开源的QwQ-32B-Preview,而蒸馏的32B和70B模型在所有稠密模型中取得了推理benchmark的新纪录。
接着是DeepSeek团队总结的他们的主要贡献:
后训练:在基础模型上进行大规模强化学习:
- 他们直接在基础模型上应用RL,而不依赖SFT作为基础步。这一方式使得模型可以探索CoT来解决复杂问题,并带来了DeepSeek-R1-Zero上的进步。DeepSeek-R1-Zero展现出了例如自我验证,反射以及生成CoT,标志着研究社区的一个重要的里程碑。需要注意的是,这是首个开放的研究验证了LLMs的推理能力可以完全通过RL引发,而不需要SFT。这一突破为未来该领域的继续发展开辟了道路。
- 他们引入了新的管线来开发DeepSeek-R1。该管线包含了两个RL阶段,目标是探索提升推理方式并与人类偏好对齐,同时还有两个SFT阶段作为模型的推理和非推理能力的种子。他们相信该管线可以帮助产业界创造更好的模型。
蒸馏:小模型也可以变得很强大:
- 他们展示了大模型的推理方式可以蒸馏到小模型中,从而使得小模型可以达到比通过RL发现推理方式更好的性能。开源模型DeepSeek-R1以及其API将会帮助研究社区在未来蒸馏出更好的小模型。
- 使用DeepSeek-R1产生的推理数据,他们微调了一些目前研究社区广泛使用的稠密模型。评估结果显示蒸馏稠密小模型在benchmark上表现得很好。DeepSeek-R1-Distill-Qwen-7B在AIME 2024上达到55.5%,超过了QwQ-32B-Preview。此外,DeepSeek-R1-Distll-Qwen-32B在AIME 2024上达到了72.6%,MATH-500上达到了94.3%,LiveCodeBench达到了57.2%。这些结果显著超过了之前的开源模型,并且可以达到o1-mini的水平。他们向社区开源了基于Qwen2.5和Llama3系列的1.5B,7B,8B,14B,32B和70B的检查点。
接下来我们开始讨论DeepSeek-R1-Zero和DeepSeek-R1的技术细节。
之前的工作高度依赖大量的监督数据来提升模型性能。在该研究中,Deepseek团队展示了推理能力可以通过大规模RL来显著提高,即使在没有SFT作为冷启动的前提下。此外,性能可以通过包含少量的冷启动数据进一步提高。接下来将会展示(1)DeepSeek-R1-Zero,直接在基础模型上不适用任何SFT数据直接使用RL,(2)DeepSeek-R1,在一个通过数千个长CoT例子上微调的检查点上开始应用RL,(3)从DeepSeek-R1向小稠密模型上蒸馏推理能力。
之前他们的工作展示了强化学习在推理任务上有着极高的有效性。但是,这些工作高度依赖于有监督数据,而收集这些数据非常耗时。因此他们探索LLMs不使用任何监督数据开发推理能力的潜能,聚焦于它们在纯强化学习过程中的自我进化。
DeepSeek团队采用的仍然是之前介绍过的GRPO强化学习算法。在奖励建模方面,奖励是训练信号的源头,直接决定了RL的优化方向。为了训练DeepSeek-R1-Zero,他们采用了一个基于规则的奖励系统,主要由两种奖励组成:
- 准确性奖励:准确性奖励模型评估响应是否正确。例如,在有确定结果的数学问题中,模型需要以特定的格式提供最终答案(例如,在一个盒子里),从而产生可靠的基于规则的正确性验证。类似的,对于LeetCode问题,编译器可以基于预定义的测试用例来产生反馈。
- 格式奖励:除了准确性奖励模型,他们还使用了格式奖励模型,来强制模型将其思考放在'<think>'和'</think>'标签之间。
他们并没有在开发DeepSeek-R1-Zero中输出或使用神经网络奖励模型,因为他们发现神经网络奖励模型可能在大规模强化学习过程中受到奖励黑客的影响,并且保持神经网络奖励模型需要额外的训练资源,且使得整个训练管线变得更加复杂。
为了训练DeepSeek-R1-Zero,他们设计了一个直接模板来引导模型遵守特定指令。如下表所示,该模板要求DeepSeek-R1-Zero首先产生一个推理过程,然后再是最终答案。他们可以限制了对于这一结构形式的限制,避免任何具体内容偏置——例如强制进行反思推理或推广特定的问题解决策略,以确保能够在RL过程中准确观察模型的自然进展。

对DeepSeek-R1-Zero的评估过程不作太多赘述,但一个有趣的点是模型训练过程中出现的“啊哈”时刻:
在训练DeepSeek-R1-Zero时,一个值得纪念的点是“啊哈”时刻的出现,如下表所示:

出现在模型的一个中间版本。在这一阶段,DeepSeek-R1-Zero学会了在一个问题上对它的初始方法分配更多的思考时间。这一行为不仅是对模型增长的推理能力的验证,同样也是一个代表性的例子,证明了强化学习可以带来非预期的复杂的输出。
这个时刻不仅是模型的“啊哈”时刻,也是研究者们观察其行为的“啊哈”时刻。它强调了强化学习的力量和美感:不是明确地教模型如何解决问题,而是简单地为其提供正确的激励措施,然后它就会自主开发高级问题解决策略。“啊哈”时刻有力地提醒研究者们,RL有可能在人工系统中解锁新的智能水平,为未来更加自主和自适应的模型铺平道路。
受到DeepSeek-R1-Zero的结果的启发,有两个问题自然而然地出现了:(1)推理能力能否通过引入少量的高质量数据作为冷启动来进一步提升?(2)如何训练一个用户友好的模型,不仅能够产生清楚且一致的CoT,同时也能展现出很强的泛化能力?为了解决这些问题,DeepSeek团队设计了一个管线来训练DeepSeek-R1,该管线由四个阶段组成,如下所述。
冷启动 与DeepSeek-R1-Zero不同,为了避免从基础模型开始RL训练的早期不稳定的冷启动阶段,他们为DeepSeek-R1构建并收集了少量的长CoT数据微调模型作为初始的RL actor。为了收集这种数据,他们探索了几种途径:使用有着长CoT的few-shot提示词作为样例,直接提示模型来生成带有反射和验证的详细回答,收集DeepSeek-R1-Zero的输出并整理成刻度格式,以及通过人类标注者对结果进行调优。
在该工作中,他们收集了数千个冷启动数据来微调DeepSeek-V3-Base作为RL的启动点。与DeepSeek-R1-Zero相比,冷启动数据的优势包括:
- 可读性:DeepSeek-R1-Zero的一个主要限制就是其内容经常不适合阅读。响应可能会混杂多种语言,或者缺乏markdown格式来给用户高亮回答。相对的,DeepSeek-R1通过冷启动创建,他们创建了可读的格式,包括了每个响应的结束进行总结,并滤除掉对于读者不友好的响应。此处,他们将输出格式定义为 |special_token|<reasoning_process>|special_token|<summary>,其中推理过程是查询的CoT,总结用于汇总推理结果。
- 潜力:通过进行的设计有着人类偏好的冷启动数据格式,他们观察到相比DeepSeek-R1-Zero有更好的性能。也让他们确信迭代训练是对推理模型来说更好的方式。
聚焦推理的强化学习 基于冷启动数据微调DeepSeek-V3-Base后,他们应用于DeepSeek-R1-Zero相同的大规模强化学习训练过程。这一阶段专注于强化模型的推理能力,尤其是集中推理型的任务,例如代码,数学,科学和逻辑推理,包含了有着清晰解决方案的明确定义的问题。在这一训练阶段中,他们观察到CoT经常展现出语言混合,尤其是当RL的提示包含了多种语言时。为了解决语言混合的问题,他们在RL训练时引入了语言一致性奖励,通过CoT中目标语言的比例进行计算。尽管笑容实验展示这种对齐会导致模型性能上的略微下降,当这一奖励对齐了人类偏好,使得其更具有可读性。最终,他们将推理任务以及语言一致性的奖励通过直接相加来组合形成最终奖励。随后他们在微调模型上应用RL训练知道其达到推理任务上的收敛。
拒绝采样和监督微调 在推理聚焦任务收敛后,他们为接下来的训练使用结果检查点来收集SFT数据。与初始的冷启动数据不同,冷启动数据主要聚焦在推理,而这一阶段使用其他领域的数据来增强模型在写作、角色扮演以及其他通用任务上的能力。具体来说,他们采用了如下的数据生成和模型微调方法:
- 推理数据:DeepSeek团队通过从上述强化学习训练的检查点进行拒绝采样,精心设计推理提示并生成推理轨迹。在前期阶段,仅包含可通过基于规则的奖励进行评估的数据。而在当前阶段,通过纳入更多数据来扩展数据集,其中部分数据通过将标准答案和模型预测输入DeepSeek-V3进行判断,采用生成式奖励模型进行评估。此外,由于模型输出有时存在混乱难读的情况,他们已过滤掉混合语言、冗长段落和代码块的思维链内容。针对每个提示,他们会采样多个响应,并仅保留正确答案。最终,他们收集了约60万条与推理相关的训练样本。
- 非推理数据:对于非推理类数据(如写作、事实问答、自我认知和翻译任务),他们采用DeepSeek-V3处理流程,并复用部分DeepSeek-V3的SFT数据集。针对特定非推理任务,他们会通过提示要求DeepSeek-V3在回答问题前先生成潜在的思维链。但对于简单查询(例如"你好"这类问候),则不会提供思维链响应。最终,他们共收集约20万条与推理无关的训练样本。
他们对模型使用上述数据集大概80万条采用进行微调。
面向全场景的强化学习 为了进一步让模型与人类偏好对齐,他们实施了第二阶段的强化学习,旨在提升模型的有用性和无害性,同时优化其推理能力。具体来说,他们结合奖励信号和多样化的提示分布来训练模型。对于推理数据,他们遵循DeepSeek-R1-Zero中概述的方法,使用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。对于通用数据,他们采用奖励模型来捕捉复杂和微妙场景中的人类偏好。他们基于DeepSeek-V3的流程,采用了类似的偏好对和训练提示分布。在有用性方面,他们只关注最终的回答总结,确保评估重点放在回应对用户的实用性和相关性上,同时最小化对底层推理过程的干扰。在无害性方面,他们评估模型的完整响应,包括推理过程和总结,以识别和减轻生成过程中可能出现的任何潜在风险、偏见或有害内容。最终,通过整合奖励信号和多样化的数据分布,他们训练出了一个在保持有用性和无害性的同时,也擅长推理的模型。
为了让更高效的小模型也能具备类似DeepSeek-R1的推理能力,他们直接使用DeepSeek-R1整理的80万样本对Qwen和Llama等开源模型进行了微调。实验结果表明,这种直接的蒸馏方法能显著提升小模型的推理能力。他们使用的基础模型包括Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B以及Llama-3.3-70B-Instruct。选择Llama-3.3是因为其推理能力略优于Llama-3.1。
对于蒸馏后的模型,他们仅SFT,没有加入强化学习RL阶段——虽然引入RL可能会大幅提升模型性能。他们在此的主要目的是验证蒸馏技术的有效性,而将RL阶段的探索留给更广泛的研究社区。
至此对DeepSeek-R1的工作进行一下总结。总体来说,DeepSeek团队通过DeepSeek-R1-Zero验证了直接进行大规模强化学习可以有效地增强模型推理能力,为了进一步增强模型的推理能力,以及解决DeepSeek-R1-Zero存在的输出可读性差等问题,他们通过冷启动与多阶段训练技术实现了DeepSeek-R1。最后,通过实验,他们证明了大模型的强大推理能力可以通过蒸馏的方式传给小模型,从而显著提升小模型的推理能力。
8. 总结
流片结束后边读边写了大概两个月,终于填完了这个坑哈哈。拢共3w多字,每次填这种长坑都是意志力和时间管理能力的双重挑战。
首先通过一个表格来总结一下DeepSeek各个论文的关键技术点以及沿革关系吧:
| Model Name | Key Innovation | Relationship |
|---|---|---|
| DeepSeek LLM | 1. 定量分析了超参数Batch Size和学习率对Scaling Law的影响,并得到了量化的最优超参数的公式结论 2. 定量分析了之前的工作采用模型参数量\(N\)作为模型规模评估指标的缺陷,并提出了新的更准确的非嵌入层\(FLOPs/token\) \(M\)作为新的模型规模评估指标 3. 定量分析了模型/数据规模比对Scaling Law的影响,并得到了量化的最优模型规模与数据规模的公式结论 4. 通过简单的定量分析发现了模型/数据规模比和数据质量之间的关联性,并提出了在一定的算力规模下,模型规模增长与数据质量的提升呈正相关,数据规模增长与数据质量的提升呈负相关的定性结论 |
构建了稠密结构的标准模型,为后续研究提供基础,并详细和深入的探索了Scaling Law,为未来的大规模训练提供了可靠的理论指导 |
| DeepSeek MoE | 1. 提出了DeepSeekMoE架构,该创新的MoE架构旨在达到极高的专家专业度 2. 提出了细粒度专家分割策略,增强了专家获得更准确和有针对性的知识的潜力 3. 提出了共享专家隔离策略,避免了多个专家可能会把共享知识获取到各自的参数中,从而导致专家参数的冗余 4. 引入了专家级均衡损失和设备级均衡损失,来实现避免MoE训练时出现路由坍缩以及负载失衡的问题 |
构建了重要的基础MoE模型,并在后续的模型中持续沿用,并与之前的稠密模型DeepSeek LLM进行对比,验证了MoE架构可以在减少计算量的情况下增加性能 |
| DeepSeekMath | 1. 通过精心设计的数据处理管线,得到了DeepSeek-Math数据集,一个大规模,高质量的数学问题数据集,从而实现了大规模的数学预训练 2. 提出了新的强化学习算法GRPO取代之前被广泛使用的PPO算法,在减少开销的同时,实现了更好的模型性能 |
首创的GRPO强化学习算法被持续应用在DeepSeek-V2,DeepSeek-V3,DeepSeek-R1等后续工作的后训练过程中 |
| DeepSeek-V2 | 1. 引入MLA技术,对KV缓存进行联合低秩压缩,从而大大减小KV缓存的存储与访存开销,同时相比于之前的MQA和GQA方法,完美的保持了模型的性能,甚至超过了MHA的基线方法 2. 进一步引入了通信均衡损失和设备级的token丢弃策略来确保每个设备的通信是均衡的 |
延续了DeepSeek MoE中的MoE架构,引入的MLA技术在后续的DeepSeek-V3等工作中持续使用 |
| DeepSeek-V3 | 1. 提出用于负载均衡的辅助无损策略,避免负载均衡辅助损失对模型影响造成影响,采用了互补序列辅助损失来避免单个序列中出现极端的失衡 2. 引入了双流水线算法实现高效的流水线并行,并大大减少了流水线气泡 3. 定制了高效的跨节点全到全通信核以确保双流水线充分的计算性能 4. 提出了细粒度的混合精度框架,将部分计算密集型算子采用FP8格式进行计算,并通过细粒度量化减少带来的上溢和下溢问题 |
集大成者,延续了DeepSeek MoE提出的MoE架构与DeepSeek-V2提出的MLA技术,并完整的介绍了DeepSeek团队的AI Infra情况以及针对硬件特性采取的一些巧妙的软件优化技巧 |
| DeepSeek-R1 | 1. 验证了大模型可以不经过SFT,直接使用大规模RL训练来增强推理能力 2. 通过冷启动数据以及多阶段训练管线进一步提升了模型的推理能力,并增强了模型输出可读性和通用问题能力 3. 通过对小模型的蒸馏实验,验证了大模型的推理能力可以通过蒸馏方式传递到小模型上,从而增强小模型的推理能力 |
开拓者,以DeepSeek-V3为基础,探索了与之前不同的,以大规模的RL训练为核心的后训练技术,验证了RL对模型推理能力提升的有效性 |
然后来谈点读论文时的感触。我一直有个观点,好的论文可以看到论文背后作者的精神,而DeepSeek的一系列论文传递给我的精神就是保持高质量的insight和长期主义。一方面,他们每一篇的论文都提出了非常精妙的创新点,既有强大的Innovation,又通过详实的实验充分证明了这些Innovation并非好看的花架子,而是实在的、有效的;另一方面,他们的工作具有非常好的延续性,并不是打一枪换一个地方,而是在很清晰的思考下,保留已验证过的良好技术,并在其基础上进一步提升。这对于做研究的人来说非常具有参考价值和启发性,对于如何把一项研究做好,DeepSeek的路径清晰可循——先研究领域的底层规律,为未来之路指明方向,然后在推进过程中,对现存的问题保持深度的思考并提出可靠的解决方案,并通过不断的积累,最终实现真正的巨大突破。
DeepSeek的成功固然有时势造英雄的成分——美国对中国先进算力与AI领域的持续打压,很大程度上影响了民众和领域学者们的心态,而中国的AI领域需要这样的一个英雄角色站出来,证明即使在这样的不利条件下,中国仍然有能力做出达到国际领先水平的基础AI模型,进而引发了国民级的轰动效应。但更不可忽视的是,DeepSeek团队在成名之前,迈着踏实稳健的步伐一步一步的向前追赶。实际上DeepSeek团队很大一部分的组成都是年轻人,有着扎实的AI领域学术基础,而从学术投向产业时,他们表现出的勇于创新和务实精神是非常值得学习的。
最后作为搞硬件的,再谈谈自己的一点想法,DeepSeek的出现带来了很好的机会,尽管目前来看NVIDIA在AI Infra领域仍然是支配的态势,但由于国际局势的变化,中国也需要有自己优秀的AI Infra公司,而DeepSeek通过高质量的模型,以及国民级的认知,扩大了国内模型服务的市场,从而使得AI Infra的需求得到了增强;另一方面,DeepSeek慷慨的开源,也增强了国内基础模型方面的软件实力,为未来可能的通过软硬件协同方式,实现强大、高效的AI系统开辟了道路。
不积跬步,无以至千里;不积小流,无以成江海。让我们期待未来!
Reference
DeepSeek LLM Scaling Open-Source Language Models with Longtermism https://arxiv.org/abs/2401.02954 ↩︎
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models https://arxiv.org/abs/2401.06066 ↩︎
Deepseekmath:Pushing the limits of mathematical reasoning in open language models https://arxiv.org/pdf/2402.03300 ↩︎
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model https://arxiv.org/abs/2405.04434 ↩︎
DeepSeek-V3 Technical Report https://arxiv.org/abs/2412.19437 ↩︎
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning https://arxiv.org/abs/2501.12948 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号