Unity JobSystem使用手册
转载:https://zhuanlan.zhihu.com/p/1944344142680392088
视频:https://www.bilibili.com/video/BV1Njemz2Efx/?spm_id_from=333.1387.favlist.content.click&vd_source=106601ca71b1d910c1ac4aa2466b744c
Job System 是 Unity 提供的一套多线程编程工具。是Dots的重要组成部分。
一、相比C#原生多线程的优势
使用 Unity 的 Job System 相比直接使用 C# 原生多线程(如 System.Threading.Thread 或 System.Threading.Tasks.Task)有几个显著的优势,这些优势主要体现在安全性、性能和对引擎的集成度上。
1.内置的安全检查
- C# 原生多线程:需要自己负责所有线程同步问题(如竞态条件、死锁)。必须手动使用 lock、Mutex、Semaphore 等机制来保护共享数据,这非常容易出错,一个疏忽就会导致极难调试的bug。
- Unity Job System:它自带一套安全系统。这个系统会静态分析我们的 Job 代码,检查是否存在潜在的数据竞争。
- 访问规则:它强制我们使用特定的、线程安全的数据容器(如 NativeArray、NativeList)。
- 所有权概念:它使用“所有权”转移的概念。主线程将数据的所有权“授予”Job后,在主线程的 JobHandle.Complete() 调用之前,主线程不能访问这些数据,从而避免了读写冲突。
- 结论:Job System 通过设计上的限制,极大地降低了因线程同步错误而导致程序崩溃或出现诡异行为的风险,对于游戏开发这种对稳定性要求极高的场景来说,这是无价的。
2.Burst 编译
- C# 原生多线程:代码由标准的 .NET JIT(即时编译器)编译运行。
- Unity Job System:Job 可以与 Burst 编译器 无缝协作。Burst 是一个基于 LLVM 的后端编译器,它有专门为数学计算密集型任务进行优化。
- 生成高度优化的本地代码:Burst 会将 C# Job 代码编译成高度优化的、利用目标平台特定指令集(如 SSE、AVX)的本地机器码,性能提升可达数倍甚至数十倍。
- 无GC分配:Burst 编译的代码通常不会产生垃圾回收(GC)压力。
- 结论:Job + Burst 的组合拳,其性能往往远超手动编写的 C# 多线程代码,甚至可以媲美精心优化的 C++ 代码。
3.负载均衡的线程池
- Unity Job System:它的线程池实现了“工作窃取”算法。
- 负载均衡:如果一个工作线程提前完成了自己的任务,它可以从其他忙碌的线程那里“偷”一些工作来做,从而确保所有 CPU 核心的负载更加均衡,最大限度地利用硬件资源。
- 结论:提供了更高效、更智能的负载分配,减少了线程空闲时间,整体吞吐量更高。
4.隐式的依赖管理和同步
- C# 原生多线程:必须手动管理任务之间的依赖关系。如果 Job B 需要 Job A 的结果,我们必须使用 Task.Wait()、ContinueWith() 等机制来显式地等待。
- Unity Job System:它通过 JobHandle 来管理依赖关系。
- 当我们调度一个 Job 时,它会返回一个 JobHandle。我们可以将这个句柄传递给另一个 Job,作为它开始执行的先决条件(job2.Schedule(job1Handle))。
- 系统会自动处理这些依赖,确保执行顺序正确,而我们无需编写复杂的同步代码。
- 结论:依赖链的构建变得非常直观和易于管理,大大简化了复杂并行任务的编写。
5.与 Unity 引擎的深度集成
- C# 原生多线程:不能在非主线程中调用任何 Unity 的 API(如 Transform.position、GameObject.Instantiate)。几乎所有的 Unity API 都只能在主线程运行,否则会立即抛出异常。
- Unity Job System:虽然 Job 本身也不能调用大多数 Unity API,但 Job System 的设计理念是:
- 在 Job 中执行纯计算:将所有密集的、不涉及引擎核心对象的计算(如位置计算、物理模拟、网格顶点数据修改)放在 Job 中并行处理。
- 在主线程中应用结果:通过 NativeContainer(如 NativeArray)作为桥梁,在 Job 完成后,于主线程的 JobHandle.Complete() 调用之后,安全地将计算结果取回并应用到 Unity 的对象上。
- 结论:Job System 提供了一个标准化的、安全的模式来与主线程交互。 总结 Unity 的 Job System 不是一个通用的多线程解决方案,而是一个专门为游戏循环和高性能计算设计的、安全性极高的领域特定框架。它通过约束和规则,换来了安全性、性能以及开发的便捷性,这是直接使用 C# 原生多线程难以做到的。
总结
Unity 的 Job System 不是一个通用的多线程解决方案,而是一个专门为游戏循环和高性能计算设计的、安全性极高的领域特定框架。它通过约束和规则,换来了安全性、性能以及开发的便捷性,这是直接使用 C# 原生多线程难以做到的。
二、JobSystem、Dots和ECS的概念和关系
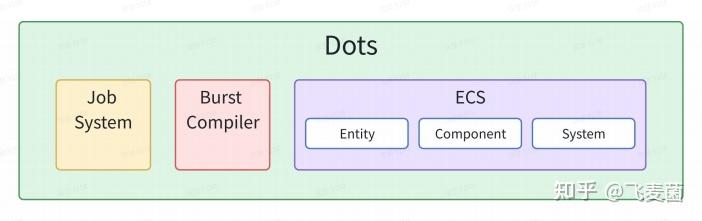
DOTS (Data-Oriented Technology Stack) - 面向数据的技术栈
DOTS是一个技术栈或者说产品方案名称,核心目标是充分利用现代硬件(多核CPU、缓存等)来最大化程序性能。它包含三个主要的技术支柱:
- Job System :用于安全、高效地编写多线程代码的系统。
- The Burst Compiler (Burst编译器):一个基于LLVM的后端编译器,它将C# Job代码编译成高度优化的本地机器码,性能极高。
- The Entity Component System (实体组件系统):就是ECS架构在Unity中的具体实现。
ECS (Entity Component System) - 实体组件系统
ECS 是一种架构模式或设计范式,是一种与传统的面向对象编程(OOP)截然不同的编程架构。它特指 Entity-Component-System 这种组织代码的方式,核心目标是分离数据与行为,并优化内存布局以提升缓存利用率。(Array of Structures vs Structure of Arrays)。
它由三个核心概念组成:
- Entity (实体):它不是一个对象,而是一个唯一的ID。它本身不包含任何数据或逻辑,它只用于标识哪些组件属于同一个“事物”。
- Component (组件):它是纯粹的数据,没有任何方法(函数)。在Unity的DOTS实现中,它是一个实现了
IComponentData接口的struct(结构体)。 - System (系统):它是纯粹的逻辑,不存储任何状态数据。系统会持续遍历拥有特定组件组合的所有实体,并对这些组件的数据执行操作。
例如:一个MovementSystem会遍历所有拥有PositionComponent和VelocityComponent的实体,并在每一帧根据速度更新它们的位置。
Job System - 多线程编程
Job System是Unity提供的专门为游戏循环和高性能计算设计的、安全性极高的领域特定多线程编程框架。
Job System也可以直接在非Dots项目中使用。
概念图
概念图
三、Job System的使用方法
Job System既可以配合ECS工作,也可以单独使用。使用Job System,需要做两件事。
第一步 创建Job结构体
这个结构体可以看作一种模板,调度与执行的时候才会“实例化”出来。
它定义了有哪些输入输出数据,以及执行方法。
1 需要继承特定接口
如IJob,IJobParallelFor,IJobParallelForTransform,IJobFor,…这些接口都继承自 Unity.Jobs.IJob 命名空间,但用途和调度方式有显著不同。
1.1 接口详解与对比
1.1.1 IJob
这是最简单、最基础的 Job 接口。
- 执行模式:单任务。整个
Execute()方法在我们的一个工作线程上仅执行一次。 - 核心方法:
void Execute() - 典型用途:
- 执行一个独立的多线程任务。
- 对
NativeArray或NativeList进行整体的读写操作(注意数据竞争)。 - 不适合处理大量重复的、可并行化的计算。
- 示例:计算两个向量的点积结果。
public struct MyJob : IJob
{
public NativeArray<float> InputA;
public NativeArray<float> InputB;
public NativeArray<float> Result; // 长度为1
public void Execute()
{
Result[0] = 0;
for (int i = 0; i < InputA.Length; i++)
{
Result[0] += InputA[i] * InputB[i];
}
}
}
1.1.2 IJobParallelFor
这是最强大和最常用的并行接口,用于处理可以高度并行化的数据集(如数组、列表)。
- 执行模式:数据并行。我们指定一个数量(
count),Execute(int index)方法会为每个索引(从0到count-1)并行地执行一次。Unity 会自动将工作分割成多个批次,在多个核心上执行。 - 核心方法:
void Execute(int index) - 典型用途:
- 对
NativeArray、NativeSlice中的每个元素进行独立的计算。 - 网格顶点处理、粒子系统更新、大批量数学计算等。
- 关键限制:
- 我们必须确保在
Execute方法内,通过index访问数据时是安全的,即不同index之间不能有写入竞争。 - 例如,
array[index] = ...是安全的,因为每个index是唯一的。但array[0] = ...是不安全的,因为所有并行任务都可能尝试写入index 0。 - 示例:并行计算两个数组的对应元素之和。
public struct AddJob : IJobParallelFor
{
[ReadOnly] public NativeArray<float> InputA;
[ReadOnly] public NativeArray<float> InputB;
[WriteOnly] public NativeArray<float> Result;
// index 由系统自动提供
public void Execute(int index)
{
Result[index] = InputA[index] + InputB[index];
}
}
// 调度方式:需要指定数量
var job = new AddJob { ... };
JobHandle handle = job.Schedule(Result.Length, 64); // 64 是每批处理的元素数量
1.1.3 IJobParallelForTransform
这是 IJobParallelFor 的一个特化版本,专门用于并行地处理大量 Transform 组件。
- 执行模式:与
IJobParallelFor相同,是数据并行的。 - 核心方法:
void Execute(int index, TransformAccess transform) - 典型用途:高效地更新成千上万个物体的位置、旋转、缩放。它直接操作底层的
TransformAccess结构,避免了从Component到Transform的昂贵开销和装箱操作。 - 注意事项:
- 我们需要使用
TransformAccessArray而不是NativeArray<Transform>。 - 性能远超在
IJobParallelFor中手动处理Transform。 - 示例:让一堆物体并行地向上移动。
public struct MoveUpJob : IJobParallelForTransform
{
public float DeltaTime;
public float Speed;
public void Execute(int index, TransformAccess transform)
{
transform.position += new float3(0, Speed * DeltaTime, 0);
}
}
// 使用方式
TransformAccessArray transformArray = new TransformAccessArray(transforms);
var job = new MoveUpJob { DeltaTime = Time.deltaTime, Speed = 5f };
JobHandle handle = job.Schedule(transformArray);
1.1.4 IJobFor
这个接口的行为与 IJobParallelFor 完全不同,它不是并行的。
- 执行模式:串行循环。它的
Execute(int index)方法会在单个线程上按顺序(从0到count-1)执行。它通常与ScheduleParallel和Run方法结合使用。 - 核心方法:
void Execute(int index) - 设计目的:主要用于与 Burst Compiler 优化结合。当我们使用
job.ScheduleParallel(handle)时,Burst 可以将整个循环作为一个高效的、编译后的单元来优化,这可能比手写的for循环性能更高,即使是在单线程上。 - 典型用途:需要 Burst 优化但循环迭代间存在数据依赖,无法并行化的计算。
- 示例:一个累积计算,每次迭代依赖于前一次的结果(这种场景无法用
IJobParallelFor)。
public struct CumulativeJob : IJobFor
{
public NativeArray<float> Output;
public void Execute(int i)
{
if (i > 0)
Output[i] = Output[i-1] + 1; // 依赖前一个元素,必须串行
}
}
// 调度方式
var job = new CumulativeJob { Output = outputArray };
JobHandle handle = job.Schedule(outputArray.Length, default(JobHandle));
1.2 选择合适的接口
| 接口 | 执行模式 | 核心方法 | 用途 | 关键点 |
|---|---|---|---|---|
| IJob | 单任务 | Execute() | 单一独立任务,整体操作数据 | 最简单,一次执行 |
| IJobParallelFor | 数据并行 | Execute(int index) | 处理大型数组/列表,无数据竞争 | 最常用,高性能,需注意线程安全 |
| IJobParallelForTransform | 数据并行 | Execute(int index, TransformAccess) | 高效并行处理大量Transforms | IJobParallelFor 的特化版,需用 TransformAccessArray |
| IJobFor | 串行循环 | Execute(int index) | 需要Burst优化但存在数据依赖的循环 | 不是并行的,用于Burst优化单线程循环 |
- 只有一个任务要跑 ->
IJob - 要处理几万个完全独立的物体或数据点 ->
IJobParallelFor - 这几万个物体是
GameObject的Transform->IJobParallelForTransform - 循环必须按顺序执行,但又想获得Burst极致优化 ->
IJobFor+ScheduleParallel
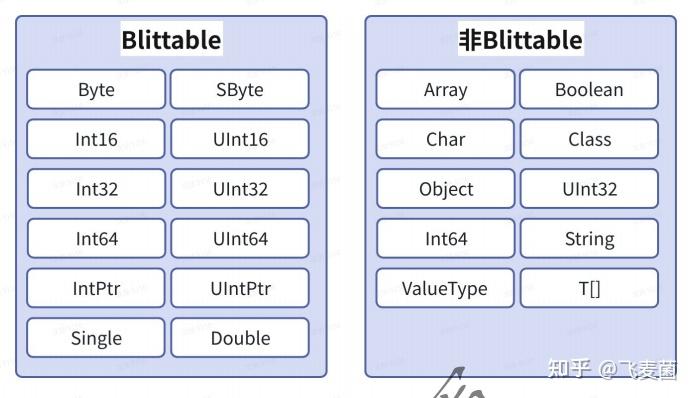
2 需要使用非托管集合,字段必须是Blittable类型
字段必须是Blittable类型,或者是只包含Blittable类型的struct。Blittable类型意味着在托管和原生代码中,内存的表现是一致的。这是一个硬性规定,违反它会导致编译错误或运行时异常。
常见定义字段的方式
[ReadOnly] public NativeArray<float> Input;
[ReadOnly] public float Ratio;
public NativeArray<MyEntityStruct> InputOutput;
- 数据集合的容器推荐使用Unity提供的NativeArray,NativeList,NativeQueue,NativeHashMap等等。
- 可以直接不用数据容器定义Blittable类型的字段。
- 可以加上标签提高性能。 [ReadOnly] [WriteOnly]。
- 可以使用自定义的结构体。但是需要满足,结构体里只能包含Blittable类型,或嵌套其他非托管结构体。嵌套结构体也必须是非托管的。结构体也不能包含Native容器的字段(可以理解成结构体的长度需要是确定的)。
- 常用类型中Vector3并不满足Bilttable,可以使用Unity.Mathematics的float3替代。旋转参数推荐使用quaternion。
math.mul()、math.rotate()等函数代替Vector3操作。 - 使用结构数组的设计模式(SoA)是最佳实践
- 在 Unity.Mathematics 中提供了
bool4、char等替代类型,它们是 Blittable 的。 - 如果一定要用
bool,可以使用byte或int代替。
2.1 tips:JobSystem为什么会限制只能使用Blittable类型?
根本原因在于 JobSystem的工作方式和 内存安全。
- 跨线程内存访问:JobSystem的目的是在多线程(通常是工作线程)上安全地执行任务。这意味着Job结构体的数据需要被完整地拷贝到另一个线程的内存上下文中去执行。
- 无封送处理(No Marshaling):与非托管代码交互(P/Invoke)时,.NET运行时可以进行“封送处理”(Marshaling)来转换非Blittable类型(如
string)。但JobSystem在跨线程传递数据时,没有这种复杂的封送处理机制。它依赖的是最原始、最快的内存块拷贝(memcpy)。 - Blittable类型保证内存布局一致:只有Blittable类型在内存中的二进制表示是明确、固定且连续的。这使得Unity引擎可以简单地将整个Job结构体对应的内存块直接复制到工作线程,工作线程也能用完全相同的布局来解读这块内存,从而安全地访问每一个字段。
- 非Blittable类型的危险:如果一个Job包含了非Blittable类型(如
string),会发生什么? string是引用类型。它的实例存储在托管堆上,而字段本身只是一个指向堆内存的指针(引用)。- 当我们将Job调度到工作线程时,Unity会拷贝这个结构体,也就是拷贝了这个指针值,但不会拷贝指针所指向的堆上的字符串数据。
- 工作线程现在拿到了一个指向主线程托管堆内存的指针。一旦工作线程尝试通过这个指针去访问字符串,就会导致竞态条件(Race Condition),因为主线程可能同时在操作或甚至垃圾回收器(GC)已经移动/释放了那块内存。这会导致无法预测的行为、数据损坏或程序崩溃。
为了彻底杜绝这种危险,Unity在编译期(Burst编译)和调度期(Job.Schedule)都会进行严格的检查。
2.2 tips:非托管,值类型,Blittable类型之间是什么关系?
它们的关系是一个逐渐缩小的子集关系:
值类型 (Value Types) ⊃ 非托管类型 (Unmanaged Types) ⊃ Blittable 类型 (Blittable Types)
值类型 (Value Types)
这是最广的范畴。
- 定义:值类型是其实例直接包含其数据的类型。它们通常分配在栈上(但也可以是类的字段而被间接分配在堆上)。
- 包括:
- 所有数值类型(
int,float,double,long,byte等) charboolenumstruct(但有条件,见下文)- 特点:赋值操作会进行完整的拷贝。
- 关系中的位置:这是所有后续类型的基础。非托管类型和 Blittable 类型首先必须是值类型
非托管类型 (Unmanaged Types)
这是值类型的一个子集,是 C# 7.3 引入的一个正式概念,主要用于 unsafe 上下文和与非托管代码的交互。
- 定义:一种类型,如果它满足以下所有条件,则它是非托管类型:
- 它必须是值类型(引用类型永远不是非托管的)。
- 它不包含任何引用类型的字段。
- 它的所有字段递归地也都是非托管类型。
关系中的位置:非托管类型是值类型的子集。它排除了那些包含引用类型的值类型(如某些 struct)。
Blittable 类型 (Blittable Types)
这是非托管类型中一个更严格的子集,是与非托管代码互操作(P/Invoke)时最关键的概念。
- 定义:一种数据类型,它在托管内存和非托管内存中具有相同的二进制表示形式(相同的内存布局和位模式)。因此,在互操作时,运行时可以直接进行“位拷贝”(blit)来传递数据,而无需进行任何特殊的转换或封送处理(Marshaling)。
- 包括:
- 大多数基础数值类型:
byte,sbyte,short,ushort,int,uint,long,ulong,single,double。 - 包含“非嵌套”的 Blittable 类型的数组(如
int[])。 - 只包含 Blittable 类型字段的
struct,并且其布局是连续的(通常是[StructLayout(LayoutKind.Sequential)]或默认顺序)。 - 不包括(重要的非 Blittable 类型):
bool: 在C#中占1字节,但在非托管代码中可能是4字节(如Win32 BOOL)。需要封送处理。char: 在C#中是2字节Unicode,在非托管代码中可能是1字节ANSI。需要封送处理。string: 引用类型,且编码不同,必须封送。- 包含
bool或char字段的struct:因为这些字段不是 Blittable 的,所以整个结构体也不是 Blittable 的。
关系中的位置:Blittable 类型是非托管类型的子集。它排除了那些在托管和非托管世界表示形式不一致的非托管类型(主要是 bool 和 char)。
2.3 tips:什么是结构数组(SoA)?
结构数组指的是为每种数据创建平行的、等长的 NativeArray。这是 Data-Oriented Design(面向数据设计)的核心。
- 错误设计 (❌ AoS - Array of Structures):内存布局分散,难以管理。
public struct BadEntityStruct
{
public int Health;
public NativeArray<Vector3> PathPoints; // ❌ 非常糟糕
}
public NativeArray<BadEntityStruct> BadEntities;
JobSystem 和 Burst 的性能优势来自于连续内存块的线性遍历。
如果每个结构体内部都有一个独立的 NativeArray,数据会被分散在内存的各个角落,导致大量的缓存未命中,性能会急剧下降。
- 正确设计 (✅ SoA - Structure of Arrays):内存布局连续,易于批量处理,缓存友好。
public NativeArray<int> EntityHealths;
public NativeArray<Vector3> EntityPositions;
NativeArray<NativeList<Vector3>> EntityPaths;
- 如果需要包含动态数量的数据,正确的做法是:
- 使用平行的数组或列表:
public NativeArray<MyEntityStruct> Entities; // 核心数据
public NativeArray<NativeList<Vector3>> EntityPathLists; // 每个实体的路径点列表
// 确保Entities和EntityPathLists长度一致,索引对应同一个实体
- 使用一个大的扁平化数组 + 偏移量:
public NativeArray<Vector3> AllPathPoints; // 所有实体的所有路径点都塞进这里
public NativeArray<int> EntityPathStartIndex; // 每个实体的路径点在AllPathPoints中的起始索引
public NativeArray<int> EntityPathLength; // 每个实体的路径点数量
2.4 tips:NativeArray<T> 是值类型吗?
NativeArray<T> 是一个结构体(struct),因此它属于值类型。
这是一个非常重要的特性,也是它能在 JobSystem 中安全使用的关键原因之一。但是,它的行为与简单的值类型(如 int、float)有本质区别,理解这一点至关重要。
为什么 NativeArray<T> 是值类型,却又如此特殊?
简单来说:NativeArray<T> 是一个包装器或智能指针。它的结构体内部并不直接存储数据数组,而是包含了一个指向Unity内存管理系统(Allocator)中分配的非托管内存块的指针和一些管理元数据(如长度、版本号等)。
这种设计带来的行为特性:
1.值类型的拷贝语义:
- 当我们将一个
NativeArray变量赋值给另一个变量,或者作为参数传递给方法时,发生的是值类型的拷贝。这意味着m_Buffer、m_Length等内部字段的值被复制了一份。 - 关键点:复制的是指针(
m_Buffer),而不是指针所指向的数据。因此,两个NativeArray变量(arrayA和arrayB)将指向同一块非托管内存数据。
2.“浅拷贝”而非“深拷贝”:
- 对
arrayA[0]进行修改,会直接反映在arrayB[0]上,因为它们操作的是同一片内存。 - 这种行为类似于引用类型,但其本质是值类型(结构体)包含了一个指针。
为什么Unity要这样设计?
- 性能:避免在Job之间传递数据时进行昂贵的内存拷贝。Job可以高效地读写同一块内存,从而实现线程间通信。
- 与JobSystem协同工作:作为值类型,
NativeArray可以完美地嵌入到IJob结构体中,满足Job参数必须是Blittable类型的要求。因为它只包含指针和整数等原始类型,整个结构体的内存布局是固定的和明确的。 - 内存安全:虽然数据是共享的,但Unity的安全系统(通过
AtomicSafetyHandle)会跟踪NativeArray的生命周期和访问权限。例如,它会在我们尝试在Schedule的Job仍在执行时Dispose()数组,或者在一个写入权限不匹配的Job中写入数据时抛出异常,从而防止内存损坏和数据竞争。
总结
- NativeArray<T> 是一个值类型的struct。
- 它进行的是浅拷贝,只复制内部的指针和元数据,多个变量共享同一份底层数据。
- 它的内存布局只包含原生类型(如指针、int),可以被安全地直接拷贝到工作线程。
- 必须管理它的生命周期。因为它管理着非托管内存,必须在使用完毕后调用 Dispose() 方法来释放内存,否则会导致内存泄漏。
- 多个 NativeArray 变量可能指向同一块内存,修改一个会影响另一个。这可能导致难以察觉的 Bug,尤其是在多个 Job 中共享数据时。
3 需要实现执行方法
Job结构体里需要实现Execute方法,根据接口的不同,传入参数会有所不同。
具体可以看之前介绍的 接口详解与对比 的案例。
请使用Burst.Compatible的数学库以便使用Brust编译,http://math.xxx。https://docs.unity3d.com/Packages/com.unity.mathematics@1.3/api/Unity.Mathematics.math.html
第二步 调度与执行
Job可以在代码的任意位置开启执行,无论是Start,Update,LateUpdate都可以。
假设我们已经有一个写好的job结构
// 简单任务:为数组中的每个元素加一
public struct AddOneJob : IJob
{
public NativeArray<float> InputOutput;
public void Execute()
{
for (int i = 0; i < InputOutput.Length; i++)
{
InputOutput[i] = InputOutput[i] + 1;
}
}
}
想要它真正执行,还需要以下几个步骤。
void Start()
{
var data = new NativeArray<float>(1000, Allocator.TempJob);
for (int i = 0; i < data.Length; i++)
data[i] = i;
var job = new AddOneJob { InputOutput = data };
JobHandle handle = job.Schedule();
DoOtherWork();
handle.Complete();
Debug.Log($"Result: {data[0]}");
data.Dispose();
}
1.分配内存
var data = new NativeArray<float>(1000, Allocator.TempJob);
为我们需要参与计算的数据划分一块内存,需要使用正确的Allocator(分配器)。
Unity 主要提供了三种我们需要关心的 Allocator,它们都在 Unity.Collections 命名空间下:
Allocator.Temp(临时分配器)。仅在当前帧的、调用它的函数范围内有效。绝对不能在 Job 中使用Allocator.TempJob(临时任务分配器)Job最常用分配器。必须在主线程显式调用Dispose。Allocator.Persistent(持久化分配器)分配的内存会一直存在,直到你显式调用.Dispose()。- (
Allocator.None用于特殊场景,通常不主动使用)
总结
- 默认选择
TempJob:凡是需要给 Job 传递数据的,无脑先选Allocator.TempJob。 - 牢记
Dispose:对于TempJob和Persistent,必须有清晰的分配和释放配对逻辑。通常使用using块或在MonoBehaviour的OnDestroy或自定义的Dispose方法中释放。 Temp仅用于主线程瞬时操作:把它想象成stackalloc,绝不跨帧、绝不给Job。- 慎用
Persistent:把它当作最后的手段,而不是首选。问问自己:“这个数据真的需要存活那么久吗?用TempJob每帧分配一次是否可行?” - 依赖检查器:在 Unity Editor 中开启 Jobs > Safety Check 选项,它可以帮助你捕获许多分配和访问错误(如忘记 Dispose、竞态条件等)。
| 特性 | Allocator.Temp | Allocator.TempJob | Allocator.Persistent |
|---|---|---|---|
| 生命周期 | 极短(当前函数/帧) | 较短(至少4帧或Job完成后) | 永久(直到手动释放) |
| 性能 | 最快 | 快 | 最慢 |
| 线程安全 | 仅主线程 | 可用于Job(多线程) | 可用于Job(多线程) |
| 需要手动 Dispose | 是 | 是 | 是 |
| 主要使用场景 | 同一函数块内的临时计算 | JobSystem 数据传递(默认选择) | 跨场景/模式的长期缓存 |
| 内存泄漏风险 | 低(但错误使用会导致崩溃) | 中(忘记Dispose会报错) | 极高(忘记就真泄漏了) |
| 错误使用后果 | 崩溃(Job中使用) | 内存泄漏报错 | 严重内存泄漏 |
2.初始化数据
为上一步分配的内存,填充工作数据。
for (int i = 0; i < data.Length; i++)
data[i] = i;
3.创建并设置 Job
实例化Job结构体出来,并且将之前分配好的数据赋值给Job的字段。
var job = new AddOneJob { InputOutput = data };
4.调度Job
4.1简单调用IJob
如果只有一个IJob的话,可以简单的写JobHandle handle = job.Schedule();
这段代码并没有立刻阻塞主线程,你仍然可以执行其他操作DoOtherWork();
直到这段代码,主线程才会开始阻塞,直到所有Job完成。 handle.Complete();
4.2调用并行的IJobParallelFor
不太一样的地方是,job.Schedule的时候,需要传递数据长度,和批处理大小JobHandle handle = job.Schedule(vectors.Length, 64);
依然等待完成即可handle.Complete();
4.3依赖关系与链式调度
Job 之间可以建立依赖关系,确保执行顺序:
public struct JobA : IJob { /* ... */ }
public struct JobB : IJob { /* ... */ }
public struct JobC : IJobParallelFor { /* ... */ }
void ScheduleJobChain()
{
var jobA = new JobA();
var jobB = new JobB();
var jobC = new JobC();
// JobB 依赖 JobA
JobHandle handleA = jobA.Schedule();
JobHandle handleB = jobB.Schedule(handleA); // 传入依赖句柄
// JobC 依赖 JobB,并行处理1000个元素,每批32个
JobHandle handleC = jobC.Schedule(1000, 32, handleB);
// 只需等待最后一个 Job
handleC.Complete();
}
4.4Transform相关的调用
TransformAccessArray transformArray = new TransformAccessArray(transforms);
var job = new MoveUpJob { DeltaTime = Time.deltaTime, Speed = 5f };
JobHandle handle = job.Schedule(transformArray);请注意,每帧new TransformAccessArray是一个非常消耗性能的事情,特别是长度高的时候。
最佳实践是写一个EntityMoveSystem,持有一个私有字段,创建一个固定长度的数组,动态扩容。_transformAccessArray = new TransformAccessArray(transforms);
这里的transform作为了移动的载具,可以作为父节点分配给需要被移动的物体,然后物体被回收时也同时被回收。
测试结论是当物体数量1000以下时,基本不需要考虑用Job优化。当物体数量在2000以上时,仅消耗传统方法1/5的时间。
非常有趣的情况是,如果我们设置了
Physics.autoSimulation = false;
Physics.autoSyncTransforms = false;
并且在FixedUpdate里Physics.Simulate(fixedDeltaTime);
在LateUpdate里Physics.SyncTransforms();
unity内部其实也是自动使用了IJobParallelForTransform来并行处理。
5.使用处理后的数据
将Job处理好后的数据传给感兴趣的其他模块。
6.手动释放内存
必须为第1步分配的非托管集合手动释放内存。data.Dispose();
第三步 使用Burst编译
[BurstCompile] 是一个属性标记,用于触发 Burst 编译器。
把它放在一个结构体(如 IJob 结构体)或一个静态方法上,就是在告诉 Unity 的 Burst 编译器:“请把这个代码编译成极度优化的、平台特定的本地机器码。”
使用Burst编译的好处
极高的性能:
- 向量化(SIMD):这是最大的亮点。Burst 能将我们的循环操作编译成 SSE/AVX 等 CPU 指令,使得一条指令可以同时对多个数据(如4个float)进行操作,而不是一次一个。这对于数学计算密集型任务(如动画、物理、粒子模拟)是效率极高的。
- 低级优化:Burst 编译器比标准的 .NET JIT(即时编译器)激进得多,它会进行循环展开、常量传播、内联等各种底层优化,生成堪比手动编写 C++ 代码效率的机器码。
避免托管代码开销:
- 生成的代码直接是本地码,运行时不经过 .NET 虚拟机的 JIT 编译和垃圾回收(GC)管理,避免了相关的性能开销。
跨平台优化:
- Burst 会为我们的目标平台(Windows, macOS, Android, iOS等)生成特定的指令集,确保在每个平台上都能获得最佳性能。
需注意代码必须符合 Burst 的安全子集(避免使用托管类型、异常等)。
using Unity.Burst;
[BurstCompile] // 添加此特性让 Burst 编译器优化
public struct OptimizedJob : IJobParallelFor
{
public NativeArray<float> Data;
public void Execute(int index)
{
Data[index] = math.abs(Data[index]);
}
}
请尽量使用Burst.Compatible的数学库以便Brust编译出高效的机器码,http://math.xxx
第四步 调试与诊断
1.使用 Profiler 分析 Job 执行
Window > Analysis > Profiler > Job Details
2.增加日志
使用 UnityEngine.Debug.Log 会报错
使用 Unity.Collections.LowLevel.Unsafe.UnsafeUtility 中的方法
Job 中不能抛出异常,否则会导致 Silent Failure(静默失败)。建议:
- 使用
NativeArray<int>或NativeQueue<Exception>收集错误信息。 - 在
Complete()后检查并处理。
3.使用 Safety Checks
在 Player Settings 中启用/禁用安全检测,开发阶段启用,发布时禁用以提升性能。
4. Job 的依赖关系图可视化
Unity Profiler 中的 Job Dependency Viewer,帮助可视化 Job 之间的依赖关系和执行时间。
5.Job 中常用性能分析标记
using Unity.Profiling;
var marker = new ProfilerMarker("MyJob.Execute");
public void Execute(int index)
{
using (marker.Auto())
{
// job code
}
}
四、Job System的使用场景
推荐使用场景
- 大规模数学运算(矩阵、向量、物理)
- 网格/顶点数据处理
- 动画骨骼计算
- 大规模状态更新(如1000+实体位置更新)
- 寻路、视野、碰撞、挤压等算法
不推荐场景
- 简单、轻量级的计算(开销可能大于收益)
- 需要频繁访问 Unity API 的操作
- 逻辑复杂、分支众多的算法
- 需要每帧分配内存的操作

 浙公网安备 33010602011771号
浙公网安备 33010602011771号