摘要:
EasyEdit2——即插即用的LLM行为控制(Steering)框架: 1、支持广泛的测试时干预,包括安全性、情绪、个性、推理模式、事实性和语言特征。 2、关键模块:转向向量生成器和转向向量应用器。 论文发表于EMNLP 2025 System Demonstrations,Arxiv链接:htt
阅读全文
posted @ 2026-01-01 09:49
颀周
阅读(669)
推荐(0)
摘要:
一篇还未发表的论文,但做了大量实验对熵最小化技巧提升模型推理能力进行了探索。本文训练了13440个大型语言模型,发现熵最小化(EM)只需要一个未标记的数据和10步优化,性能提升就比RL还强。基于两个直接而简单的假设: 生成大型语言模型的采样过程本质上是随机的。 正确答案的熵通常低于错误答案。 EM和
阅读全文
posted @ 2025-12-31 15:36
颀周
阅读(684)
推荐(1)
摘要:
论文发表于NLP顶会EMNLP 2025(原文链接)。大模型CoT产生过短推理,即使简单数学问题也性能下降。本文研究推理长度如何嵌入推理模型的隐藏表示,以影响准确性: 1、发现,推理长度由表示空间中的线性方向决定,从而能沿着该方向引导模型,诱导过短推理。 2、引入权重编辑方法ThinkEdit,缓解
阅读全文
posted @ 2025-12-18 11:27
颀周
阅读(770)
推荐(0)
摘要:
随着大语言模型(LLM)的广泛应用,它们在医疗、金融、教育等关键行业扮演着愈发重要的角色。然而,一个被忽视的现实是:大模型的知识并不会自动更新,更不总是准确。当模型输出过时信息、错误事实甚至自信满满的“胡说八道”时,如何快速、精准、低成本地纠正它?知识编辑(Model Editing)因此成为近年来
阅读全文
posted @ 2025-12-15 16:43
颀周
阅读(1024)
推荐(0)
摘要:
论文发表于人工智能顶会ICLR(原文链接)。基于定位和修改的模型编辑方法(针对ROME和MEMIT等)会破坏LLM中最初保存的知识,特别是在顺序编辑场景。为此,本文提出AlphaEdit: 1、在将保留知识应用于参数之前,将扰动投影到保留知识的零空间上。 2、从理论上证明,这种预测确保了在查询保留的
阅读全文
posted @ 2025-07-10 17:33
颀周
阅读(872)
推荐(1)
摘要:
论文发表于人工智能顶会ICLR(原文链接)。在模型编辑方法中,过去工作主要局限于更新单个事实。因此,基于ROME,本文开发了MEMIT,在大模型GPT-J(6B)和GPT-NeoX(20B)上实现了数千的批量编辑。 阅读本文请同时参考原始论文图表。 方法 模型定义为文中式(1),其中$[x_{[1]
阅读全文
posted @ 2025-07-09 10:26
颀周
阅读(446)
推荐(2)
摘要:
论文发表于自然语言处理顶刊TACL-2024(原文链接)。目前模型编辑方法的评估主要集中在测试单个事实是否被成功注入,以及模型对其它事实的预测是否没有改变。作者认为这样的评估模式有限,因为注入一个事实会产生涟漪效应,模型应该同步更新一系列的额外事实。比如当注入:z是e的母亲时。模型应该同步更新:z的
阅读全文
posted @ 2025-06-11 01:25
颀周
阅读(264)
推荐(0)
摘要:
论文发表于自然语言处理顶会ACL-2022(原文链接)。本文引入知识神经元 (Knowledge Neuron) 的概念,初步研究了预训练Transformer中是如何存储事实知识的: 1、通过研究预训练的BERT,本文发现预训练语言模型的知识是独立存在于中间神经元激活中的 2、可以通过编辑FFN层
阅读全文
posted @ 2025-06-08 13:47
颀周
阅读(306)
推荐(0)
摘要:
论文发表于人工智能顶会ICLR(原文链接)。为了实现大规模编辑,提出基于梯度分解的模型编辑网络(Model Editor Networks with Gradient Decomposition, MEND):训练一个小型辅助编辑网络的集合,对通过微调获得的梯度的低阶分解进行变换,使用变换后的梯度更
阅读全文
posted @ 2025-06-07 12:51
颀周
阅读(330)
推荐(0)
摘要:
论文为大语言模型知识编辑综述,发表于自然语言处理顶会ACL(原文链接)。由于目前存在广泛的模型编辑技术,但一个统一全面的分析评估方法,所以本文: 1、对LLM的编辑方法进行了详尽、公平的实证分析,探讨了它们各自的优势和劣势。 2、构建了一个新的数据集,旨在揭示当前模型编辑方法的缺点,特别是泛化和效率
阅读全文
posted @ 2025-06-07 12:35
颀周
阅读(395)
推荐(0)
摘要:
论文发表于人工智能顶会NeurIPS(原文链接)。当前的模型编辑器会因多次编辑损害模型性能,提出用于连续编辑的通用检索适配器(General Retrieval Adapters for Continual Editing, GRACE):使用一个类似字典的结构(适配器)为需要修改的潜在表示构建新的
阅读全文
posted @ 2025-06-06 12:59
颀周
阅读(246)
推荐(0)
摘要:
论文发表于人工智能顶会NeurIPS(原文链接),研究了GPT(Generative Pre-trained Transformer)中事实关联的存储和回忆,发现这些关联与局部化、可直接编辑的计算相对应。因此: 1、开发了一种因果干预方法,用于识别对模型的事实预测起决定性作用的神经元。 2、为了验证
阅读全文
posted @ 2025-06-05 20:11
颀周
阅读(475)
推荐(0)
摘要:
Wikidata是一个大型结构化开源知识图,为维基百科等项目提供支持。我们可使用SPARQL(Wikidata官方Tutorial)对其进行查询。SPARQL是一种专为 RDF(Resource Description Framework)数据模型设计的查询语言。RDF通过三元组(主语subject
阅读全文
posted @ 2025-03-01 17:50
颀周
阅读(2576)
推荐(0)
摘要:
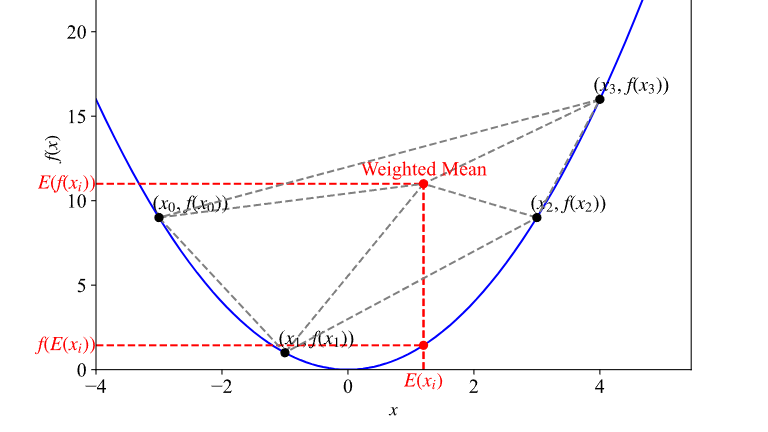
Jenson不等式描述对于一个凸函数,期望值与函数作用后的期望值之间的关系。本文对其进行可视化以获取直观理解。 对于积分为1的非负函数$p(x)$,即 $\displaystyle\int_{-\infty}^{\infty}p(x) dx = 1$ 假设$f(x)$为下凸函数,$g(x)$为任意可
阅读全文
posted @ 2024-12-07 14:53
颀周
阅读(441)
推荐(0)
摘要:
Deep Variational Information Bottleneck (VIB) 变分信息瓶颈 论文阅读笔记。本文利用变分推断将信息瓶颈框架适应到深度学习模型中,可视为一种正则化方法。 变分信息瓶颈 假设数据输入输出对为$(X,Y)$,假设判别模型$f_\theta(\cdot)$有关于$
阅读全文
posted @ 2024-11-28 17:22
颀周
阅读(1391)
推荐(2)
摘要:
本文主要记录研究中用到的与泛函和变分法相关的知识点,推导过程不会严谨考虑所有特殊情况,重在直觉理解。 泛函(Functional) 泛函数(Functional,简称泛函)$J$是以函数为自变量的函数,它将一个定义在某函数空间$Y$中的自变量函数映射到实数域$\mathcal{R}$或复数域$\ma
阅读全文
posted @ 2024-11-24 20:45
颀周
阅读(1782)
推荐(2)
摘要:
使用 python matplotlib 将 LaTex 公式转为 svg,从而方便插入无法打出所需公式的ppt中。 import matplotlib.pyplot as plt plt.rcParams['text.usetex'] = True plt.rcParams['text.latex
阅读全文
posted @ 2024-05-02 12:11
颀周
阅读(287)
推荐(0)
摘要:
在python的多继承中,父类的初始化顺序遵循所谓方法解析顺序(Method Resolution Order,MRO)的机制。python使用C3线性化算法来确定多继承类的MRO: 1. 目标:创建一个一致的线性继承顺序,同时保持父类的相对顺序和子类优先原则。 2. 子类优先:子类总是在其父类之前
阅读全文
posted @ 2024-03-22 15:44
颀周
阅读(165)
推荐(0)
摘要:
以下 from pathlib import Path import hashlib import argparse def file_hash(path: Path, chunk_size: int = 8192) -> str: """计算文件的 SHA256 哈希值""" sha256 = h
阅读全文
posted @ 2024-03-12 15:12
颀周
阅读(55)
推荐(0)
摘要:
一种方法 https://unix.stackexchange.com/questions/116191/give-server-access-to-internet-via-client-connecting-by-ssh 以上方法在我这里不太行。尝试了另一种方式,连上了: 1、远端服务器需要能p
阅读全文
posted @ 2024-02-06 11:57
颀周
阅读(144)
推荐(0)
摘要:
python模块可以相对导入和绝对导入,但这两者是不能随意替换使用的。本文主要讨论工作目录下模块之间的导入规则。其中相对导入前面有一个'.',表示从该脚本所在目录开始索引,而绝对导入前面没有'.',表示从根目录开始索引。首先明确一点,python认为的根目录为当前运行的脚本所在的目录,而不是vsco
阅读全文
posted @ 2023-10-24 12:48
颀周
阅读(599)
推荐(0)
摘要:
训练神经网络模型有时需要观察模型内部模块的输入输出,或是期望在不修改原始模块结构的情况下调整中间模块的输出,pytorch可以用hook回调函数来实现这一功能。主要使用四个hook注册函数:register_forward_hook、register_forward_pre_hook、registe
阅读全文
posted @ 2023-10-07 16:04
颀周
阅读(831)
推荐(0)
摘要:
奇异值分解(Singular Value Decomposition, SVD)可以被看做是方阵特征值分解的推广,适用于任意形状的矩阵。 对于矩阵$A\in \R^{m\times n}$,不失一般性,假设$m\geq n$,奇异值分解期望实现: $A=U\Sigma V^T$ 其中$U,V$分别为
阅读全文
posted @ 2023-09-13 11:18
颀周
阅读(610)
推荐(0)
摘要:
Transformers是著名的深度学习预训练模型集成库,包含NLP模型最多,CV等其他领域也有,支持预训练模型的快速使用和魔改,并且模型可以快速在不同的深度学习框架间(Pytorch/Tensorflow/Jax)无缝转移。以下记录基于HuggingFace官网教程:https://github.
阅读全文
posted @ 2023-08-19 13:54
颀周
阅读(930)
推荐(0)
摘要:
Docker方便一键构建项目所需的运行环境:首先构建镜像(Image)。然后镜像实例化成为容器(Container),构成项目的运行环境。最后Vscode连接容器,方便我们在本地进行开发。下面以一个简单的例子介绍在win10中实现:Docker安装、构建镜像、创建容器、Vscode连接使用。 Doc
阅读全文
posted @ 2023-08-13 21:39
颀周
阅读(546)
推荐(0)
摘要:
github上的项目总喜欢使用argparse + bash来运行,这对于快速运行一个项目来说可能有好处,但在debug的时候是很难受的。因为我们需要在.sh文件中修改传入参数,并且不能使用jupyter。 以下是把parser转换成显式class命名空间的一个代码示例: #%% import ar
阅读全文
posted @ 2023-07-22 17:53
颀周
阅读(106)
推荐(0)
摘要:
定义 子模 (Submodular)、超模 (Supermodular)和模(Modular)函数是组合优化中用到的集合函数概念。函数定义域为某个有限集$\Omega$的幂集$2^\Omega$,值域通常为$R$,即$f:2^\Omega\to R$。 子模函数:对于集合$A\subseteq B\
阅读全文
posted @ 2023-07-08 13:57
颀周
阅读(3050)
推荐(0)
摘要:
机器学习希望最小化模型的期望(泛化)误差$L$,即模型在整个数据分布上的平均误差。然而我们只能在训练集上最小化经验误差$\hat{L}$,我们期望通过最小化经验误差来最小化泛化误差。但是训练数据和数据真实分布之间是有差异的,又根据奥卡姆剃刀原理,在训练误差相同的情况下,模型复杂度越小,泛化性能越好,
阅读全文
posted @ 2023-06-20 19:51
颀周
阅读(586)
推荐(0)
摘要:
核技巧使用核函数直接计算两个向量映射到高维后的内积,从而避免了高维映射这一步。本文用矩阵的概念介绍核函数$K(x,y)$的充分必要条件:对称(半)正定。 对称正定看起来像是矩阵的条件。实际上,对于函数$K(x,y):\R^n\times \R^m\rightarrow \R$,将向量$x\in \R
阅读全文
posted @ 2023-06-19 18:54
颀周
阅读(819)
推荐(0)
摘要:
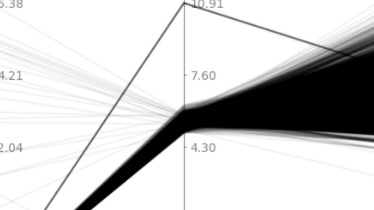
参考自《数据挖掘概念与技术》。 对于有$m$个特征,$n$个样本的数据,平行坐标可视化图中,横轴均匀列出$m$个特征,每个特征生成一个纵轴,其中每个样本就表示为穿越这些纵轴的折线。实现代码如下: import numpy as np import matplotlib.pyplot as plt d
阅读全文
posted @ 2023-04-15 15:10
颀周
阅读(213)
推荐(0)
摘要:
$\Gamma$函数 $\Gamma$函数(Gamma函数)是阶乘函数在实数和复数域的扩展。对于正整数$n$,阶乘函数表示为$n! = 1 \times 2 \times ... \times n$。然而,这个定义仅适用于正整数。Gamma函数的目的是将阶乘扩展到实数和复数域,从而计算实数和复数的“
阅读全文
posted @ 2023-04-14 15:54
颀周
阅读(1121)
推荐(0)
摘要:
ADMM(Alternating Direction Method of Multipliers,交替方向乘子法)是一种优化算法,主要用于解决分布式、大规模和非光滑的凸优化问题。ADMM通过将原始问题分解为多个易于处理的子问题来实现优化。它结合了两种经典优化方法:梯度下降法(gradient des
阅读全文
posted @ 2023-04-10 22:33
颀周
阅读(3089)
推荐(2)
摘要:

孤立森林(Isolation Forest)是经典的异常检测算法(论文网址)。本文用python对其进行实现,以及与常用的异常检测包PyOD进行效果对比。 简单来说,孤立森林(IForest)中包含若干孤立树(ITree),每颗树的创建是独立的,与其它树无关。假设数据集包含$n$个样本,每个样本都包
阅读全文
posted @ 2023-03-22 13:23
颀周
阅读(1208)
推荐(0)
摘要:
找张量积概念的时候,被各种野路子博客引入的各种“积”搞混了,下面仅以Wikipedia为标准记录各种积的概念。 点积(Dot product) https://en.wikipedia.org/wiki/Dot_product 在数学中,点积(Dot product)或标量积(scalar prod
阅读全文
posted @ 2023-03-16 18:08
颀周
阅读(3744)
推荐(1)
摘要:

局部异常因子(Local Outlier Factor, LOF)通过计算样本点的局部相对密度来衡量这个样本点的异常情况,可以算是一类无监督学习算法。下面首先对算法的进行介绍,然后进行实验。 LOF算法 下面介绍LOF算法的每个概念,以样本点集合中的样本点$P$为例。下面的概念名称中都加了一个k-,
阅读全文
posted @ 2023-03-13 16:53
颀周
阅读(2596)
推荐(3)
摘要:
图神经网络(GNN)目前的主流实现方式就是节点之间的信息汇聚,也就是类似于卷积网络的邻域加权和,比如图卷积网络(GCN)、图注意力网络(GAT)等。下面根据GCN的实现原理使用Pytorch张量,和调用torch_geometric包,分别对Cora数据集进行节点分类实验。 Cora是关于科学文献之
阅读全文
posted @ 2023-02-20 21:09
颀周
阅读(1389)
推荐(1)
摘要:
论文网址:https://dl.acm.org/doi/10.1145/3404835.3462961 Arxiv:https://arxiv.org/abs/2104.08419 论文提出一种用增量学习思想做时序知识图谱补全(Temporal Knowledge Graph Completion,
阅读全文
posted @ 2022-12-13 16:45
颀周
阅读(756)
推荐(0)
摘要:
小样本知识图补全——关系学习。论文利用三元组的邻域信息,提升模型的关系表示学习,来实现小样本的链接预测。主要应用的思想和模型包括:GAT(图注意力神经网络)、TransH、SLTM、Model-Agnostic Meta-Learning (MAML)。 论文地址:https://arxiv.org
阅读全文
posted @ 2022-12-09 15:02
颀周
阅读(470)
推荐(1)
摘要:
模型不可知元学习(Model-Agnostic Meta-Learning, MAML)的目标是使模型每次的梯度更新更有效、提升模型的学习效率、泛化能力等,它可以被看做一种对模型进行预训练的方法,适用于小样本学习。 原文:http://proceedings.mlr.press/v70/finn17
阅读全文
posted @ 2022-12-08 16:28
颀周
阅读(1148)
推荐(0)
摘要:
深度学习中,当一块GPU不够用时,我们就需要使用多卡进行并行训练。其中多卡并行可分为数据并行和模型并行。具体区别如下图所示: 由于模型并行比较少用,这里只对数据并行进行记录。对于pytorch,有两种方式可以进行数据并行:数据并行(DataParallel, DP)和分布式数据并行(Distribu
阅读全文
posted @ 2022-10-12 14:13
颀周
阅读(6608)
推荐(4)
 浙公网安备 33010602011771号
浙公网安备 33010602011771号