【烂笔头系列】推荐系统笔记04-推荐系统有哪些可以利用的特征
1. 特征与工程
(1)特征就是对具体行为的抽象,但是抽象过程会造成信息的损失
① 因为具体的推荐行为和场景中包含大量原始的场景、图片和状态信息,保存所有信息的存储空间过大,我们根本无法实现。
② 因为具体的推荐场景中包含大量冗余的、无用的信息,把它们都考虑进来甚至会损害模型的泛化能力。
(2)特征工程原则
① 尽可能地让特征工程抽取出的一组特征,能够保留推荐环境及用户行为过程中的所有“有用“信息,并且尽量摒弃冗余信息
② 在已有的、可获得的数据基础上,“尽量”保留有用信息是现实中构建特征工程的原则
(3)特征处理:没有标准答案
类别、ID类
① one-hot
② multi-hot
数值类
① 归一化:解决特征取值范围不统一的问题,但无法改变特征值的分布
② 分桶:解决特征值分布极不均匀的问题。将样本按照某特征的值从高到低排序,然后按照桶的数量找到分位数,将样本分到各自的桶中,再用桶 ID 作为特征值。
③ 特征交叉:参考YouTube深度推荐模型中的平方、开方等等改变特征分布。
④ Spark MLlib:分别提供了两个转换器 MinMaxScaler 和 QuantileDiscretizer,来进行归一化和分桶的特征处理
(3)常用特征
用户行为数据。
又分为显性反馈行为和隐性反馈行为。在当前的推荐系统特征工程中,隐性反馈行为越来越重要,主要原因是显性反馈行为的收集难度过大,数据量小。
用户关系数据,分为“强关系”和“弱关系”。
用途:
① 作为召回层的一种物品召回方式
② 建立关系图,使用 Graph Embedding 的方法生成用户和物品的 Embedding
③ 直接利用关系数据,通过“好友”的特征为用户添加新的属性特征
④ 直接建立社会化推荐系统
属性、标签类数据。
特征处理方法:
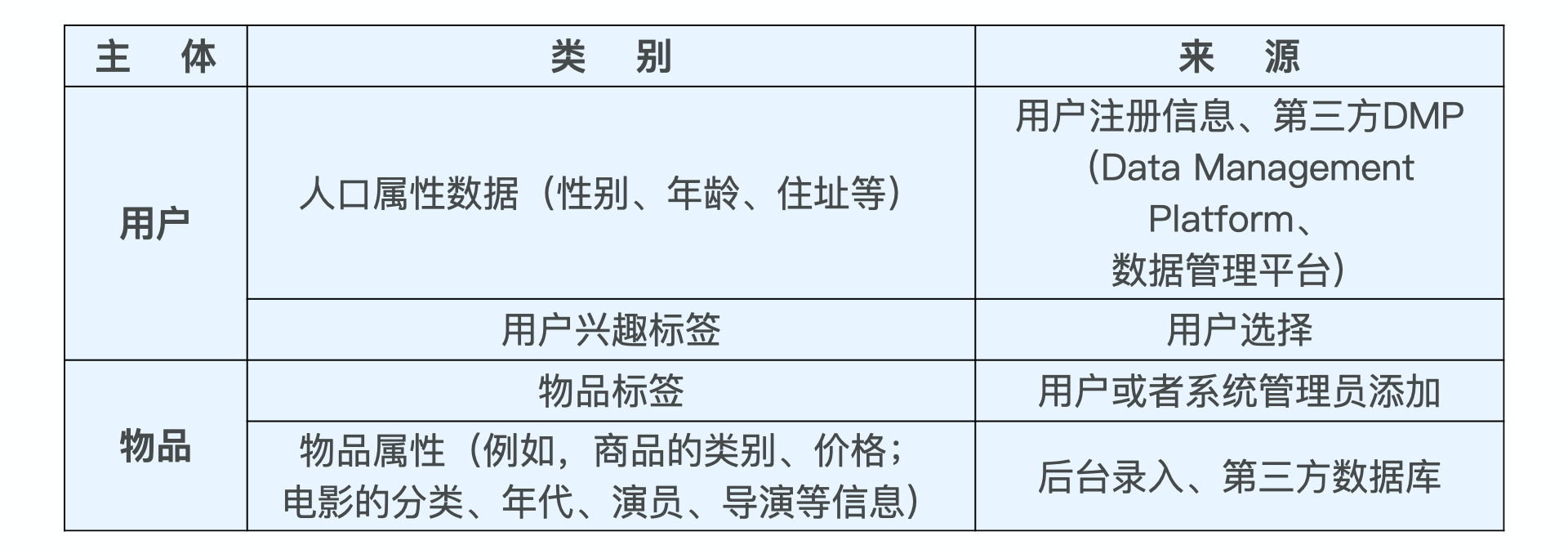
① 通过 Multi-hot 编码的方式将其转换成特征向量
② 重要的属性标签类特征也可以先转换成 Embedding,比如业界最新的做法是将标签属性类数据与其描述主体一起构建成知识图谱(Knowledge Graph),在其上施以 Graph Embedding 或者 GNN(Graph Neural Network,图神经网络)生成各节点的 Embedding
内容类数据,可以看作属性标签型特征的延伸。
① 形式:往往是大段的描述型文字、图片,甚至视频。
② 使用:通过自然语言处理、计算机视觉等技术手段提取关键内容特征转成标签类数据。
场景信息(上下文信息)。
① 形式:时间、地点、当前页面信息、季节、月份、节假日、天气、社会大事件等等
② 任何影响用户决定的因素都可以当作是场景特征的一部分,但实际中更多利用易获取的场景特征
(4)经典问答
1. 问:以音乐APP为例,用户挑选歌曲时的关键信息有哪些?
① 听歌的目的。比如是为了放松,冥想,学习还是运动。目的决定了歌曲是安静还是激昂,舒缓还是节奏感强烈。
② 歌曲或歌单是否受欢迎。定下基调后,我一般会选择收藏或播放量较多的歌曲。这样一般不容易采坑。
③ 歌曲的旋律与当下状态的匹配度。当下的状态可能是心情,情绪或身体的疲劳程度,而旋律与状态的匹配也很重要。
2. 问:音乐APP工程师应该提取哪些关键信息作为特征?
① 用户听歌的目的很难准确预测,但是可以通过“隐性”数据去推测,比如搜索关键词等。
② 歌曲或歌单是否受欢迎,则可以通过歌曲或歌单的播放量、收藏量去建立特征,而具体到人和歌曲的关系时,还可以进一步具体到单曲循环的次数等来细化特定用户对特定歌曲的喜好程度。
③ 当下的状态也很难显性的获得,则可以根据历史听歌记录去推测用户的生理节律,例如夜晚会愿意听舒缓的歌曲,运动会愿意听节奏感强烈的歌曲等等。
参考资料
《深度学习推荐系统实战》 -- 极客时间,王喆

 浙公网安备 33010602011771号
浙公网安备 33010602011771号