【烂笔头系列】小红书推荐系统学习笔记05-重排
重排是精排的后处理操作。
物品多样性
相似度度量
-
基于物品属性标签
-
基于物品向量表征
(1)双塔模型的物品塔,但是因为头部效应问题导致学不好物品向量表征
(2)基于图文内容学习
CLIP - 基于图文内容的物品向量表征
原理
对于图片-文本二元组数据进行对比学习,预测图文是否匹配。优点是:无需人工标注。参考文献《Learning Transferable Visual Models From Natural Language Supervision》和解读文章《对Connecting Text and Images的理解》。
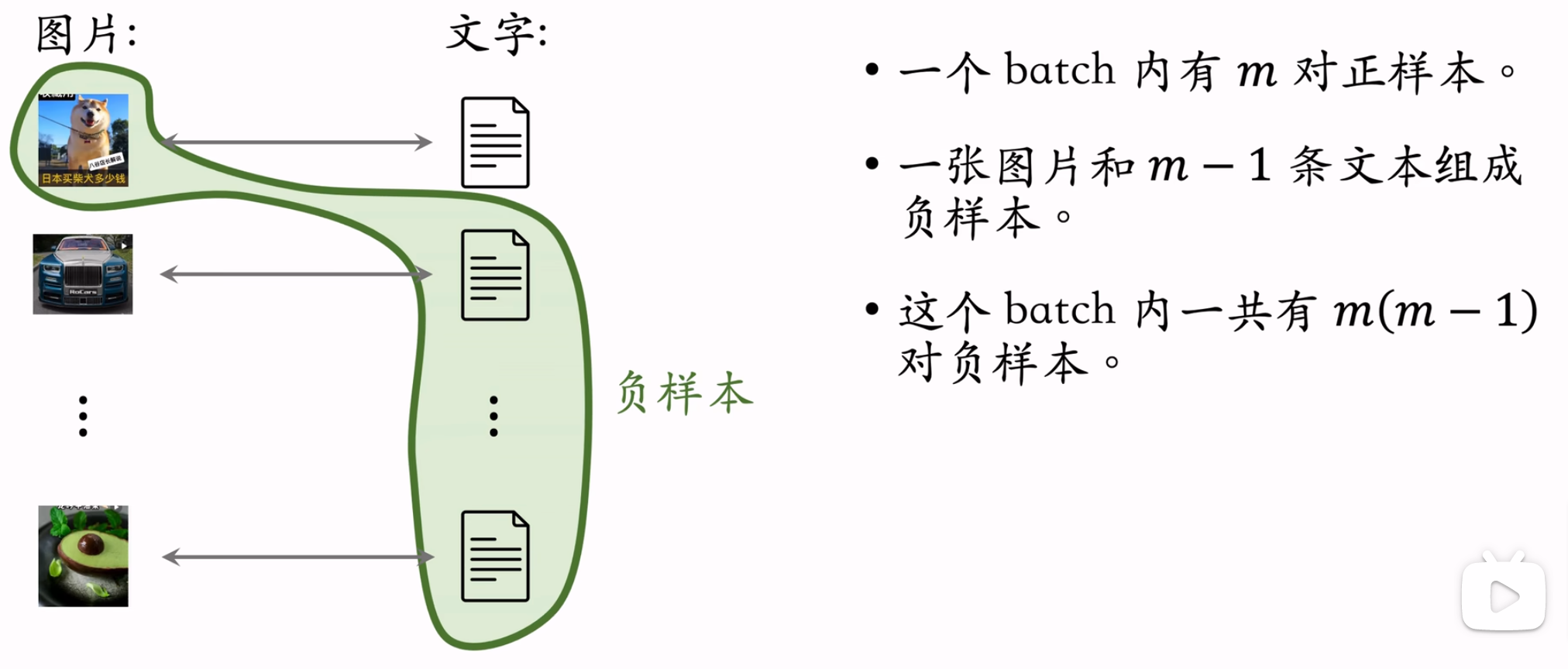
正样本
同一个物品中的图片和文字二元组数据构成正样本。
负样本
同batch内,正样本的图片与其他样本的文字组成的二元组数据构成负样本。
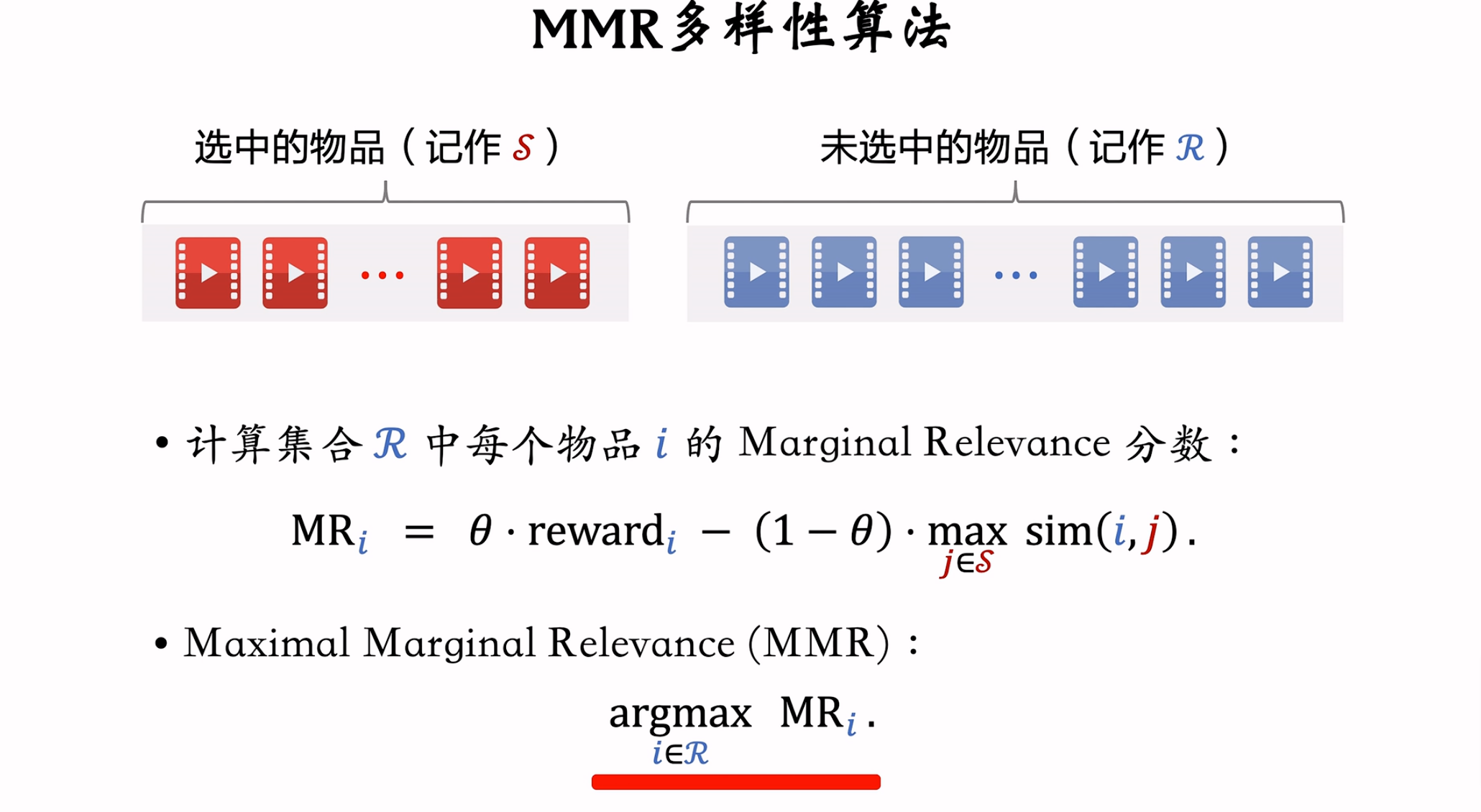
MMR多样性算法
原理
MMR算法中需要计算两个物品的相似度,这个相似度计算就用上一小节提到的CLIP方法学习到的物品Embedding向量的余弦相似度计算即可。
步骤

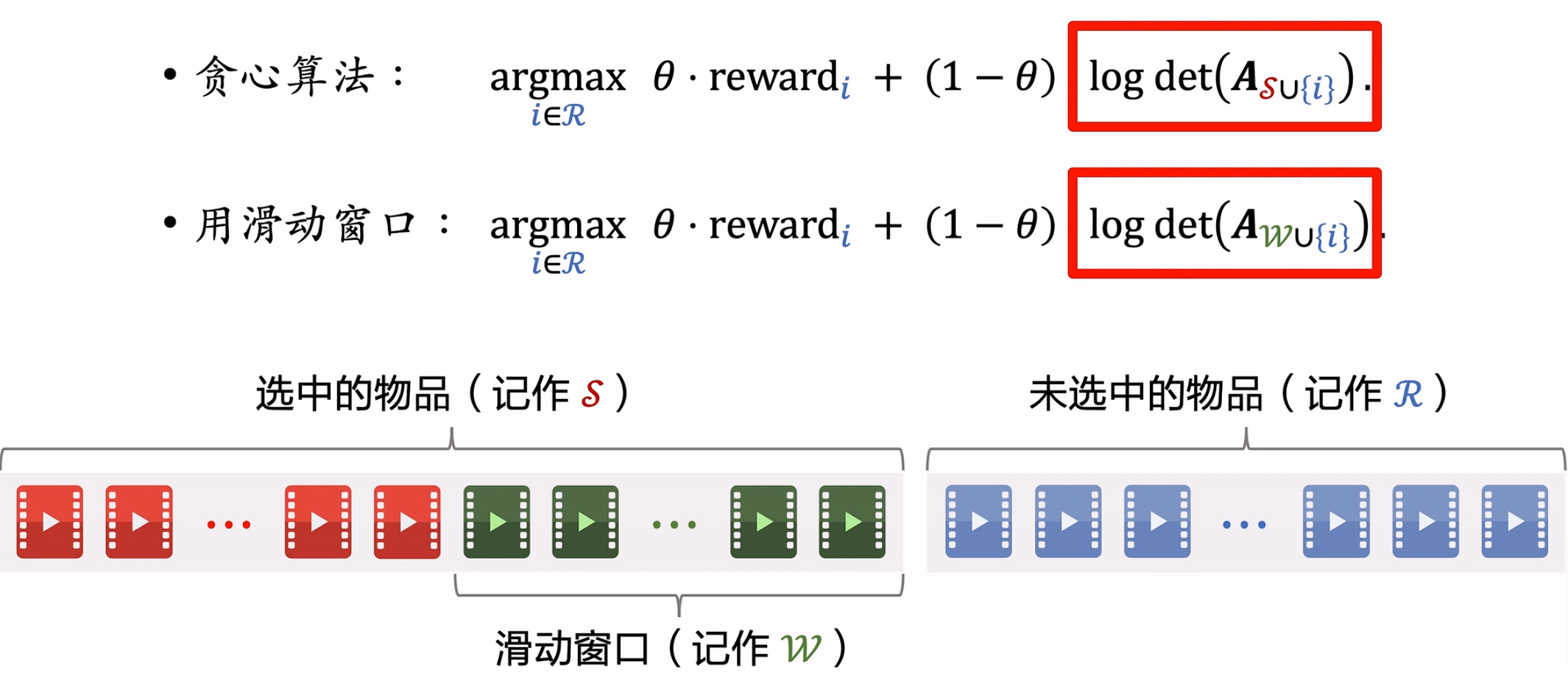
滑动窗口解决S集合过大问题
核心思想就是只考虑待排列表中最后一个窗口范围内的物品无相似(多样性好)即可。

业务规则控制多样性
通常是MMR+规则控制多样性
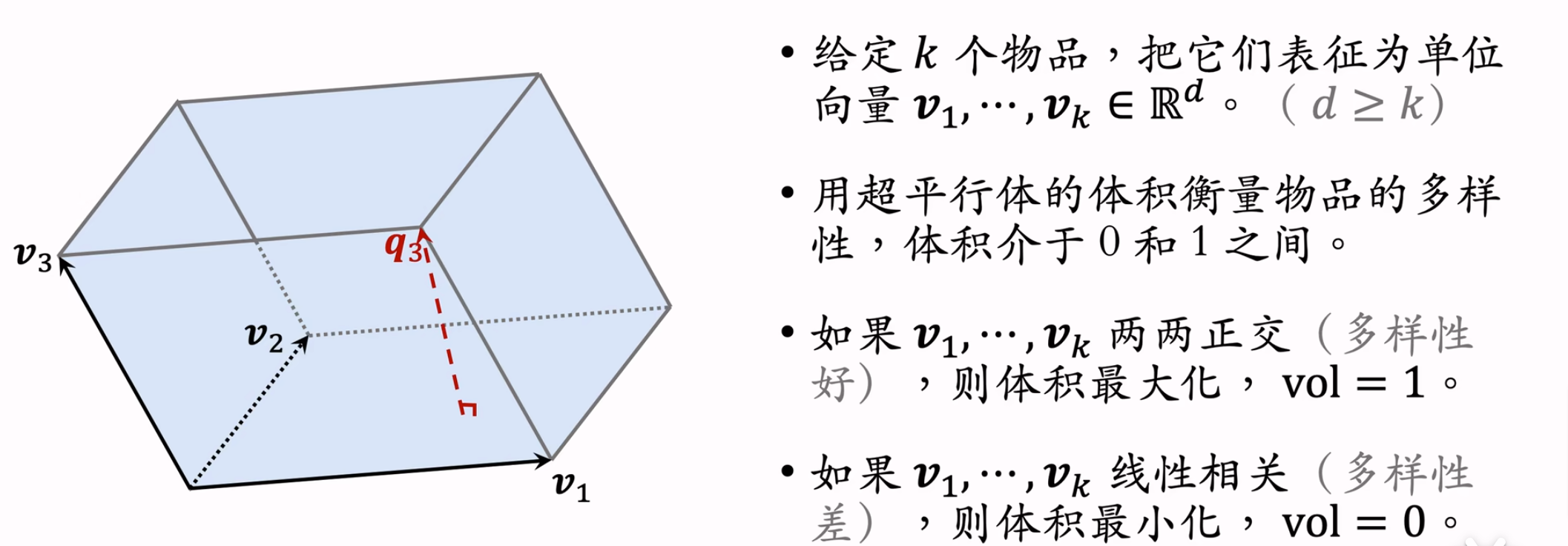
DPP
数学原理
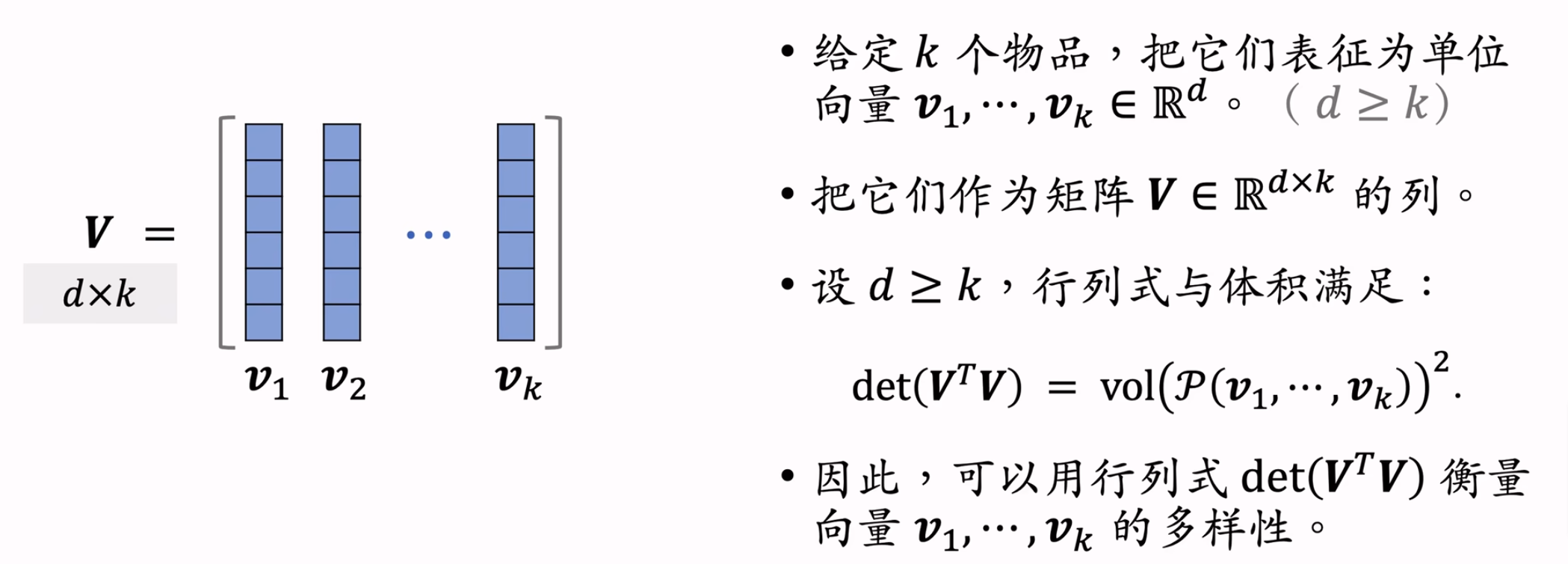
计算思路

求解方法
暴力方法

Hulu方法

DPP+滑动窗口
参考文献
公开课地址:GitHub

 浙公网安备 33010602011771号
浙公网安备 33010602011771号