「算法笔记」乱搞小记
2020 年写的(已折叠)
从 613 的课件上摘了一堆。
一、关于乱搞
乱搞:通过一些方式 尝试 得到不该得到的分数。
为什么要写乱搞:1. 正解不会 2. 正解太难写/正解太难调/正解难写又难调 3. 考试时间还有15min 4. 自信感觉能水过去
乱搞包括但不限于:写个非完美算法、写个 O(松) 暴力、瞎搜一通、把几个贪心拼起来、猜想出题人造的数据满足某些性质。
二、非完美算法
适用于大部分最优化问题。
- 退火:正确率高
- 爬山:收敛快
- 遗传(貌似不大行,我也不会 qwq)
如何选取:① 原则:两个都写然后对拍看哪个效果好。② 定性分析:收敛慢的(题目)爬山,收敛快的(题目)退火。
1. 爬山算法
伪代码:
ans=gen(); //随机一个初始解 for t=1 to lim do { int tmp=move(ans); //在当前解的附近随机一个新的解 ans=max(ans,tmp); //打擂 ¿ } print(ans); //输出解
两个问题:
① 正确率过低
- 多次选取初始解运行算法取最优值。
- 改成退火。
- 放弃。
② 如何在解的附近生成新解
-
解是一个数:ans+=rand(-lim,lim),lim*=1-eps。
- 解是一个串:截取子串、循环移位、修改其中一个字符、交换其中两个字符。
- 解是乱七八糟的东西:放弃。
2. 模拟退火
对爬山算法改动一个地方: 若新解劣于当前解,以 (1-eps)t 的概率接受。
伪代码:
data ans=gen(); int p=Rnd_Max; for t=1 to lim do { data tmp=move(ans); if(tmp>ans or rand()>p) ans=tmp; p*=1-eps; } print(ans);
eps 取多少:一般来说 (1-eps)lim 大约取到 1e-5。
收敛慢:eps 改大,在 t 大的时候相当于爬山。
3. 结合两种方法
用退火生成数个初始解,对每个初始解进行爬山以快速收敛。
三、O(松) 暴力
适用于已经存在一个在可观时间内能跑出更大数据范围的代码时。
1. 压位:
A. 把每 32 个位压到一个 int 里去 B. 把每 64 个位压到一个 long long 里去 C. 使用 bitset(速度 B>A>C)
手写 bitset:① 如何 | & ^ >> <<:¿ ② 如何 bitcount:查表 ③ 如何可持久化:分块
2. 缓存优化:A. 大量访问的数组能开多小开多小 B. 滚动数组
3. 内存连续访问优化:矩阵乘法/floyd
4. 循环展开:
//原来: for(i=1;i<=n;i++) do sth; //循环展开后: for(i=1;i<=n;i+=8){ do sth; do sth; do sth; do sth; do sth; do sth; do sth; do sth; } for(;i<=n;i++) do sth;
5. 变量运算速度优化:优化取模,long long 的运算变成 int 运算,struct 封装去掉,临时变量开 register,能三目不要 if
6. 输入输出优化:一般 getchar() 和 putchar() 已经够用了。当然还有 fread 和 fwrite。
读入优化模板(fread 只需把注释去掉即可) :
//#define getchar() (p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<21,stdin),p1==p2)?EOF:*p1++) //char buf[1<<23],*p1=buf,*p2=buf,obuf[1<<23],*O=obuf; template<typename T> inline void read(T& x){ x=0;int f=1; char ch=getchar(); while(!isdigit(ch)){if(ch=='-') f=-1;ch=getchar();} while(isdigit(ch)) x=(x<<3)+(x<<1)+(ch-'0'),ch=getchar(); x*=f; }
四、瞎搜一通
适用于数据范围不大的题目(一般数据范围<20)
- 剪枝:不用多讲,减枝减错掉也问题不大(¿)
- 估价函数:A.严格优于解 B.严格劣于解 C.既不也不 D.等于解(B>A>C)
- 迭代加深:字面意思。“搜索层数”可以灵活加权
五、题目特殊性质
这个就没什么好写的了,主要是(一看数据就很难造的)字符串题。
六、例题
1. 「HAOI 2006」均分数据
题目大意:已知 n 个正整数 a1,a2,...,an。今要将它们分成 m 组,使得各组数据的数值和最平均,即各组的均方差最小。均方差公式如下:
\(\displaystyle\sigma = \sqrt{\frac 1n \sum\limits_{i=1}^n(\overline x - x_i)^2},\overline x = \frac 1n \sum\limits_{i=1}^n x_i\)
其中 σ 为均方差,\(\overline x\) 为各组数据和的平均值,xi 为第 i 组数据的数值和。
Solution:
每组的和越接近越好,于是把每个数加入当前和最小的组里。
每次贪心都把序列打乱,多次运算取最优解。
循环 5e5 次,正确率大大提高。
#include<bits/stdc++.h> #define int long long using namespace std; const int N=30; int n,m,sum,a[N],x[N]; double ans=1e18,tmp,k; double solve(){ memset(x,0,sizeof(x)),tmp=0; for(int i=1;i<=n;i++){ int p=1; for(int j=1;j<=m;j++) if(x[j]<x[p]) p=j; x[p]+=a[i]; } //把每个数加入当前和最小的组里 for(int i=1;i<=m;i++) tmp+=(x[i]-k)*(x[i]-k); return tmp*1.0/m; } signed main(){ scanf("%lld%lld",&n,&m); for(int i=1;i<=n;i++) scanf("%lld",&a[i]),sum+=a[i]; k=1.0*sum/m; for(int i=1;i<=5e5;i++){ random_shuffle(a+1,a+1+n); tmp=solve(),ans=min(ans,tmp); } printf("%.2lf\n",sqrt(ans)); return 0; }
2. 「JSOI 2004」平衡点 / 吊打XXX
题目大意:给出平面中的 n 个点,求这 n 个点的广义费马点(费马点:在三角形内到各个顶点距离之和最小的点)。
Solution:
这道题需要一些物理知识,于是啥都不会的我看懵了(
大概是这样的: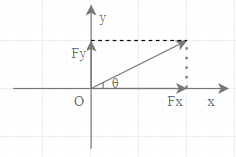
涉及力的正交分解。如图所示,将力 F 沿力 x、y 方向分解,可得:
\( \begin{cases} F_x=F \cos \theta\\ F_y=F \sin \theta \end{cases} \Rightarrow F=\sqrt{F_x^2+F_y^2} \)
(以上只是稍微提一下力的正交分解)
我们可以确定一个原点,将所有的力在这个原点上正交分解,最终得到所有的力的一个合力,而平衡点一定在合力所指向的方向。
每当分得到一个合力之后,将原点在合力的方向上位移一定的距离。
因为绳结不断移动的过程中,系统是不断趋向平衡的,因此每次移动的长度会不断缩小,当移动长度缩小到无法改变最终结果时输出当前位置,结束。
(我也不大懂,反正大概就酱紫了。赶紧去学物理 QwQ)
#include<bits/stdc++.h> #define int long long using namespace std; const int N=1e4+5; int n,x[N],y[N],w[N]; double ansx,ansy,fx,fy,F; void solve(double l){ fx=fy=0; for(int i=1;i<=n;i++){ //将绳结上的力正交分解 double p=sqrt((x[i]-ansx)*(x[i]-ansx)+(y[i]-ansy)*(y[i]-ansy)); if(p==0) continue; fx+=w[i]*(x[i]-ansx)/p; //fx:水平合外力 fy+=w[i]*(y[i]-ansy)/p; //fy:竖直合外力 } F=sqrt(fx*fx+fy*fy); //F:合外力,(fx/F,fy/F)为合外力的方向向量 ansx+=l*fx/F,ansy+=l*fy/F; //向合力方向移动 l } signed main(){ scanf("%lld",&n); for(int i=1;i<=n;i++) scanf("%lld%lld%lld",&x[i],&y[i],&w[i]); for(double l=1e4;l>1e-5;l*=0.79) solve(l); //l:移动长度 printf("%.3lf %.3lf\n",ansx,ansy); return 0; }
3. 「AHOI2014 / JSOI2014」保龄球
题目大意:点此看题
Solution:
每次交换当前排列的两个位置,多次运算取最优解。
循环 5e5 次,正确率大大提高。(事实上 1e5 也能过)
#include<bits/stdc++.h> #define int long long using namespace std; const int N=60; int n,sum,flag,x,y,tmp,ans; struct data{ int x,y; }a[N]; int solve(){ int sum=0; for(int i=1;i<=n+flag;i++){ sum+=a[i].x+a[i].y; if(a[i-1].x==10) sum+=a[i].x+a[i].y; //全中:下一轮的得分将会被乘2计入总分 else if(a[i-1].x+a[i-1].y==10) sum+=a[i].x; //补中:下一轮中的第一次尝试的得分将会以双倍计入总分 } return sum; } signed main(){ srand(time(0)); scanf("%lld",&n); for(int i=1;i<=n;i++) scanf("%lld%lld",&a[i].x,&a[i].y); if(a[n].x==10) scanf("%lld%lld",&a[n+1].x,&a[n+1].y),flag=1; ans=solve(); for(int i=1;i<=1e5;i++){ x=rand()%(n+flag)+1,y=rand()%(n+flag)+1; while(x==y||(flag&&(x==n||y==n))) x=rand()%(n+flag)+1,y=rand()%(n+flag)+1; swap(a[x],a[y]),tmp=solve(); //每次交换当前排列的两个位置 if(tmp>=ans) ans=tmp; else swap(a[x],a[y]); } printf("%lld\n",ans); return 0; }
4. CF914F Substrings in a String
题目大意:维护一个字符串 S,支持以下操作:
- 修改 S 中一个位置的字符
- 询问串 T 在 S[l..r] 中出现次数
|S|≤105,Σ|T|≤105,字符集 26。
Solution:
时限是 6s,想到可以用暴力的 bitset 维护。
用一个 bitset 的二维数组记录 S 中每个字母的位置信息,再把串 T 中每个字母与 S 的字母进行比较。
#include<bits/stdc++.h> #define int long long using namespace std; const int N=1e5+5,M=30; int q,len,opt,x,l,r; char s[N],c,t[N]; bitset<N>b[M],ans; signed main(){ scanf("%s%lld",s+1,&q),len=strlen(s+1); for(int i=1;i<=len;i++) b[s[i]-'a'][i]=1; //记录每个字母的位置信息 (s[i] 在第 i 位出现过) while(q--){ scanf("%lld",&opt); if(opt==1){ scanf("%lld %c",&x,&c); b[s[x]-'a'][x]=0,b[c-'a'][x]=1,s[x]=c; } else{ scanf("%lld%lld%s",&l,&r,t+1),ans.set(),len=strlen(t+1); //ans.set():将整个 bitset (ans)设置成 1 for(int i=1;i<=len;i++) ans&=b[t[i]-'a']>>(i-1); //比较完一个就右移一位把是否包含该串的信息保存在一个位置 //ans 中有一个 1 就代表以这个位置开头包括一个串 t printf("%lld\n",max(0ll,(int)(1ll*(ans>>l).count()-1ll*(ans>>(r-len+2)).count()))); //计算 l 右边和 r 右边有多少个串 t } } return 0; }
5. CF896E Welcome home, Chtholly
题目大意:维护一个序列,支持以下操作:
- 把一个区间中 >x 的数都减掉 x
- 询问一个区间中有几个 x
n≤105,q≤105,值域 105。
Solution:
暴力+卡常即可。需要亿点点信仰。
#pragma comment(linker,"/stack:200000000") #pragma GCC optimize("Ofast,no-stack-protector") #pragma GCC target("sse,sse2,sse3,ssse3,sse4,popcnt,abm,mmx,avx,tune=native") #include<bits/stdc++.h> #define re register using namespace std; const int N=1e5+5; int n,m,a[N]; float x; int main(){ scanf("%d%d",&n,&m); for(int i=1;i<=n;i++) scanf("%d",&a[i]); while(m--){ re int opt,l,r,ans=0; scanf("%d%d%d%f",&opt,&l,&r,&x); if(opt==1){ for(re int i=l;i<=r;i++) a[i]-=(a[i]>x)?x:0; } else{ for(re int i=l;i<=r;i++) ans+=(a[i]==x); printf("%d\n",ans); } } return 0; }
接下来讲一下正解。(¿)
值域范围小,我们可以直接记录 cnt[i][j] 表示块 i 中值为 j 的数个数。
然后再用并查集把同一块中数值相同的元素缩在一起。
对于第一个操作:首先两边的散块可以暴力修改。
对于中间的块:设 mx 表示该块中的最大值。分以下几种情况:
1. x≥mx,此时不用做任何修改
2. x<mx<2*x,此时可以暴力把区间 [x+1,mx] 和 [1,mx-x] 对应的元素合并
3. 2*x≤mx,我们注意到:第一个操作等价于先把所有元素减 x,然后把小于等于 0 的加 x。所以我们可以设一个 tag[i] 表示块 i 中这种情况减少的总数。对于这种情况,先暴力把区间 [1,x] 和 [x+1,x+x] 对应的元素合并,然后 tag[i]+=x
第二个操作:两边的散块暴力查询,中间的 ans+=cnt[i][x+tag[i]] 即可。
我们发现,对于修改操作:每一块合并的次数不超过 100000 次。所以整体时间复杂度是 O(n1.5)。
6. P4220 [WC2018]通道
先随便找一个根,用这个根 dfs 找到一个点使得三棵树上这个点到根的距离之和最大,然后用这个点继承原来的根,不断更新最大值。
能通过 Luogu 数据:
#include<bits/stdc++.h> #define LL long long using namespace std; const int N=1e5+5; int n,x,y,vis[N]; LL z,mx,tmp,ans; struct graph{ LL dis[N]; vector<pair<int,LL> >v[N]; void add(){ scanf("%d%d%lld",&x,&y,&z); v[x].push_back({y,z}),v[y].push_back({x,z}); } void dfs(int x,int fa){ for(auto p:v[x]){ int y=p.first; if(y!=fa) dis[y]=dis[x]+p.second,dfs(y,x); } } }g1,g2,g3; double used(){ return (double)clock()/CLOCKS_PER_SEC; } signed main(){ scanf("%d",&n); for(int i=1;i<n;i++) g1.add(); for(int i=1;i<n;i++) g2.add(); for(int i=1;i<n;i++) g3.add(); while(used()<3.85){ while(vis[x]&&used()<3.85) x=rand()%n+1; vis[x]=1,g1.dis[x]=g2.dis[x]=g3.dis[x]=mx=0; g1.dfs(x,0),g2.dfs(x,0),g3.dfs(x,0); for(int i=1;i<=n;i++) if((tmp=g1.dis[i]+g2.dis[i]+g3.dis[i])>mx) mx=tmp,x=i; ans=max(ans,mx); } printf("%lld\n",ans); return 0; }
能通过 LOJ 数据:
#include<bits/stdc++.h> #define LL long long using namespace std; const int N=1e5+5; int n,x,y,vis[N]; LL z,mx,tmp,ans; struct graph{ LL dis[N]; vector<pair<int,LL> >v[N]; void add(){ scanf("%d%d%lld",&x,&y,&z); v[x].push_back({y,z}),v[y].push_back({x,z}); } void dfs(int x,int fa){ for(auto p:v[x]){ int y=p.first; if(y!=fa) dis[y]=dis[x]+p.second,dfs(y,x); } } }g1,g2,g3; void calc(int a,int b,int c){ x=rand()%n+1; for(int t=1;t<=10;t++){ vis[x]=1,g1.dis[x]=g2.dis[x]=g3.dis[x]=mx=0; g1.dfs(x,0),g2.dfs(x,0),g3.dfs(x,0); for(int i=1;i<=n;i++){ ans=max(ans,g1.dis[i]+g2.dis[i]+g3.dis[i]); if(!vis[i]&&(tmp=g1.dis[i]*a+g2.dis[i]*b+g3.dis[i]*c)>mx) mx=tmp,x=i; } } } signed main(){ scanf("%d",&n); for(int i=1;i<n;i++) g1.add(); for(int i=1;i<n;i++) g2.add(); for(int i=1;i<n;i++) g3.add(); for(int i=1;i<=10;i++) calc(1,1,1); calc(1,0,0),calc(0,1,0),calc(0,0,1); calc(1,1,0),calc(1,0,1),calc(0,1,1); printf("%lld\n",ans); return 0; }
一、模拟退火
类似于物理学上金属退火的过程,随机化求最优解。正确性玄学。
考虑一个较连续的多峰的函数,用模拟退火可以较大几率找到极值。以 找最小值 为例:
- 初始一个温度 \(T\),随机一个点。
- 在与 \(T\) 成正比的步长范围内随机选一个新点(若“点”是一个数组也可以
swap数组中的元素进行扰动),记能量变化量 \(\Delta E\) 为新点值 - 旧点值。- 若 \(\Delta E<0\) 就跳到新点(更优)。
- 否则一定概率跳到新点。这个概率一般取 \(e^{-\frac{\Delta E}{T}}\),即判断 \(rand(0,1)<e^{-\frac{\Delta E}{T}}\) 作为跳不跳的条件。
- 缩小步长 \(T\)(一般乘一个 \(0.99\) 之类的东西),重复步骤 \(2\) 直到步长足够小(在输出精度误差范围内)。
退火其实是有讲究的。技巧:
-
算 \(E\) 要对答案具有更大的包容性,且要保证绝对正确。
-
要保证 \(E\) 的浮动(一直都是一个值怎么退?)。
更好的退火是退一个阈值/退一个坐标,这样对所有情况的考虑会更充分,当作“没有单调性的分治”。这种连续型退火注意要让步长和 \(T\) 正相关。
根据情况多调调参数,想想答案的变动速度。
-
确定答案的大致范围再退火,怎么缩小范围可能会基于一些结论。
-
退火是需要脑子的,建立在更多结论和人类智慧上的退火更强大。
1. P1337 [JSOI2004] 平衡点 / 吊打XXX
给出 \(n\) 个点 \((x_i,y_i)\) 以及其权 \(w_i\),求 \(px,py\) 使得 \(\sum_{i=1}^n \sqrt{(x_i-px)^2+(y_i-py)^2}\cdot w_i\) 最小。
\(1\leq n\leq 1000\),\(-10^4\leq x_i,y_i\leq 10^4\),\(0\leq w_i\leq 1000\)。
#include<bits/stdc++.h>
using namespace std;
const int N=1e3+5;
int n,a[N],b[N],c[N];
double x,y,v,nx,ny,nv,X,Y,ans;
double calc(double x,double y){
double cnt=0;
for(int i=1;i<=n;i++)
cnt+=sqrt((x-a[i])*(x-a[i])+(y-b[i])*(y-b[i]))*c[i];
if(cnt<ans) ans=cnt,X=x,Y=y;
return cnt;
}
double rnd(double x){return (rand()*2-RAND_MAX)*x;}
//随机一个 [-RAND_MAX*t,RAND_MAX*t) 的随机变动距离
void SA(){
v=calc(x=X,y=Y);
for(double t=3e3;t>1e-14;t*=0.993){
nv=calc(nx=x+rnd(t),ny=y+rnd(t));
if(nv<v||rand()<exp(-(nv-v)/t)*RAND_MAX) x=nx,y=ny,v=nv;
}
}
signed main(){
srand(233);
scanf("%d",&n);
for(int i=1;i<=n;i++)
scanf("%d%d%d",&a[i],&b[i],&c[i]),X+=a[i],Y+=b[i];
ans=calc(X/=n,Y/=n);
while(clock()<CLOCKS_PER_SEC*0.8) SA();
printf("%.3lf %.3lf\n",X,Y);
return 0;
}
2. P3878 [TJOI2010]分金币
\(n\) 枚金币,有价值 \(v_i\)。将其分为两部分,要求两部分金币数量之差 \(\leq 1\),求两部分金币价值之差的最小值。
\(1\leq T\leq 20\),\(1\leq n\leq 30\),\(1\leq v_i\leq 2^{30}\)。
“点”是一个数组,每次扰动时交换两个位置,差距不会太大较为连续。
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int N=35;
int t,n,a[N],x,y;
ll v,nv,s[2],ans;
ll calc(){
s[0]=s[1]=0;
for(int i=1;i<=n;i++) s[i<=n/2]+=a[i];
ans=min(ans,abs(s[0]-s[1]));
return abs(s[0]-s[1]);
}
void SA(){
v=calc();
for(double t=3e3;t>1e-14;t*=0.993){
x=rand()%n+1,y=rand()%n+1,swap(a[x],a[y]),nv=calc();
if(nv<v||rand()<exp(-(nv-v)/t)*RAND_MAX) v=nv;
else swap(a[x],a[y]);
}
}
signed main(){
srand(time(0));
scanf("%d",&t);
while(t--){
scanf("%d",&n),ans=1e18;
for(int i=1;i<=n;i++) scanf("%d",&a[i]);
for(int i=1;i<=20;i++) SA();
printf("%lld\n",ans);
}
return 0;
}
3. 工厂
2022.11.3
需要建造 \(n\) 座工厂,每座工厂分别需要 \(1\) 组材料建成。初始 \(n\) 座工厂都尚未建成,且只有 \(1\) 组材料。
当第 \(i\) 座工厂建成后就可以开工:生产周期为 \(a_i\) 天,每个生产周期结束时会产出 \(b_i\) 组材料。一个生产周期结束后开始下一个生产周期。
问建成所有工厂最少需要多少天。建造工厂本身不需要时间,获得 \(1\) 组材料后就可以立即消耗这组材料使工厂落成并开工。
\(1\leq n\leq 16\),\(1\leq a_i\leq 5\times 10^7\),\(1\leq b_i<n\)。
产出材料后肯定就可以建工厂了,set 维护所有开工的工厂中当前生产周期结束时间 \(t\) 最早的 \(x\),用新产出的 \(b_x\) 组材料建工厂,再开启 \(x\) 的下一轮生产周期以及新工厂的第一轮生产周期。
问题在于不知道产出的材料先给哪座工厂。
暴力做法是全排列工厂之间开工的顺序,用模拟退火优化全排列的过程即可。
#include<bits/stdc++.h>
using namespace std;
const int N=20;
int n,a[N],b[N],p[N],ans=1e9;
set<pair<int,int> >s;
mt19937 rnd(time(0));
int calc(){
s.clear(),s.insert({a[p[1]],1});
int t=0,x;
for(int i=2;i<=n;){
auto o=*s.begin(); s.erase(o);
t=o.first,x=o.second,s.insert({t+a[p[x]],x});
for(int j=1;j<=b[p[x]]&&i<=n;j++) s.insert({t+a[p[i]],i}),i++;
}
return ans=min(ans,t),t;
}
void SA(){
int v=calc(),nv;
for(double t=1e3;t>1e-4;t*=0.94){
int x=rand()%n+1,y=rand()%n+1;
swap(p[x],p[y]),nv=calc();
if(nv<v||rnd()<exp(-(nv-v)/t)*RAND_MAX) v=nv;
else swap(p[x],p[y]);
}
}
signed main(){
scanf("%d",&n);
for(int i=1;i<=n;i++)
scanf("%d%d",&a[i],&b[i]),p[i]=i;
for(int i=1;i<=200;i++)
shuffle(p+1,p+1+n,rnd),SA();
printf("%d\n",ans);
return 0;
}
4. 小练习
2023.1.30
给出 \(n\) 个二元组 \((a_i,b_i)\),你可以将其以任意顺序排列,求 \(\min(a_i+i\cdot k)-\max(b_i+i\cdot k)\) 的最大值。
\(1\leq n\leq 10^5\),\(k>0\),\(k\cdot n\leq 10^9\),\(1\leq a_i,b_i\leq 10^9\).
直接使用枚举法,考虑枚举 \(m=\min(a_i+i\cdot k)\),那么有限制表示第 \(i\) 个元素的位置必须 \(\geq \lceil\frac{m-a_i}{k}\rceil\)。贪心,按 \(b\) 从大到小的顺序将数尽可能往前放,这样就在尽可能优的情况下还给后面留出了后面的位置避免不够放。
确定 \(m\)?考虑确定它的大致范围。
-
按 \(a\) 从大到小排序,按这个顺序可以得到 \(m\) 的最大值 \(mx\),结论是 \(m\) 一定 \(\in(mx-k,mx]\)。
证明:调整法,将 \(m\) 调大 \(k\) 后仍然 \(\leq mx\),只需考虑 \(\max(b_i+i\cdot k)\) 的变化,由于调大后 \(\lceil\frac{m-a_i}{k}\rceil\) 都增加 \(1\),最坏情况是所有位置向右平移(而且不可能实现),所以它至多增加 \(k\)。
根据这个范围再退火,退 \(m=mx-p\) 的 \(p\),每次给 \(p\) 加一个 \([-T,T]\) 中的随机数再对 \(k\) 取模。
总结:看数据范围很难相信这题是退火,直接退一个排列显然不行。通过枚举法和贪心,再通过结论确定答案范围,有了较精确的范围再退火,这体现了退火的讲究。
//O2
#include<bits/stdc++.h>
#define ok clock()<=2.97*CLOCKS_PER_SEC
using namespace std;
const int N=1e6+5;
int n,k,f[N],id[N],p,mx=2e9,ans=-2e9;
struct P{int a,b;}s[N];
int find(int x){return x==f[x]?x:f[x]=find(f[x]);}
int calc(int m){
m=mx-m;
for(int i=1;i<=n+1;i++) f[i]=i;
for(int i=1;i<=n;i++){
int pos=find(max((m-s[i].a+k-1)/k,1));
id[pos]=i,f[pos]=find(pos+1);
}
int mn=2e9,mx=0;
for(int i=1;i<=n;i++)
mn=min(mn,s[id[i]].a+i*k),mx=max(mx,s[id[i]].b+i*k);
return mn-mx; //不直接 m-mx 对答案具有更大的包容性
}
int random(int l,int r){return l+(rand()*rand()+rand())%(r-l+1);} //一个玄学的地方:如果这里的 rand()*rand()+rand() 我改成 mt19937 的 rnd() 就过不了
void SA(){
ans=max(ans,calc(p=0));
for(double t=1e9;t>1&&ok;t*=0.98){
int np=(p+random(-t,t)%k+k)%k,tmp=calc(np);
if(tmp>ans) ans=tmp,p=np;
else if(rand()<exp((tmp-ans)/t)*RAND_MAX) p=np;
}
}
signed main(){
srand(time(0));
scanf("%d%d",&n,&k);
for(int i=1;i<=n;i++)
scanf("%d%d",&s[i].b,&s[i].a);
sort(s+1,s+1+n,[](P x,P y){return x.a>y.a;});
for(int i=1;i<=n;i++) mx=min(mx,s[i].a+i*k);
sort(s+1,s+1+n,[](P x,P y){return x.b^y.b?x.b>y.b:x.a>y.a;}); //b 相同时 a 大的放前面,这样 m 会小,对答案具有更大的包容性
while(ok) SA();
printf("%d\n",ans);
return 0;
}
5. [ABC290Ex] Bow Meow Optimization
2023.3.7
暴力对序列 \(col_i=[i\ 是狗]\) 退火(数据范围 \(300\),每次交换一个 \(col_i=0\) 和 \(col_j=1\)) + 重排不等式(正序和 \(\geq\) 乱序和 \(\geq\) 反序和)。calc 时使用技巧去掉 sort(代码中 c,d 时单谷的,可以双指针)。
#include<bits/stdc++.h>
#define ll long long
#define ok clock()<=1.8*CLOCKS_PER_SEC
using namespace std;
const int N=610;
int n,m,a[N],b[N],p[N],k1,k2,c[N],d[N],col[N];
ll ans=1e18;
unsigned int mx=-1;
mt19937 rnd(time(0));
ll calc(){
for(int i=1;i<=n+m;i++) col[p[i]]=i<=n;
k1=k2=0;
for(int i=1,s0=0,s1=0;i<=n+m;i++){
s0+=!col[i],s1+=col[i];
if(col[i]) c[++k1]=abs((m-s0)-s0);
else d[++k2]=abs((n-s1)-s1);
}
ll v=0;
for(int l=1,r=n,i=1;i<=n;i++)
v+=1ll*a[i]*(c[l]>=c[r]?c[l++]:c[r--]);
for(int l=1,r=m,i=1;i<=m;i++)
v+=1ll*b[i]*(d[l]>=d[r]?d[l++]:d[r--]);
return ans=min(ans,v),v;
}
void SA(){
shuffle(p+1,p+1+(n+m),rnd);
ll v=calc(),nv;
for(double t=1e6;ok;t*=0.9997){
int x=rnd()%n+1,y=rnd()%m+n+1;
swap(p[x],p[y]),nv=calc();
if(nv<v||rnd()<exp(-(nv-v)/t)*mx) v=nv;
else swap(p[x],p[y]);
}
}
signed main(){
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++) scanf("%d",&a[i]);
for(int i=1;i<=m;i++) scanf("%d",&b[i]);
sort(a+1,a+1+n),sort(b+1,b+1+m);
iota(p+1,p+1+(n+m),1),SA();
printf("%lld\n",ans);
return 0;
}
6. CF442E Gena and Second Distance(*3100)
2023.5.12
#include<bits/stdc++.h>
#define db long double
using namespace std;
const int N=1e3+5;
int w,h,n,a[N],b[N];
db ans=-8e18;
mt19937 rnd(time(0));
db calc(db x,db y){
db mn=8e18,mn2=8e18,d;
for(int i=1;i<=n;i++){
d=(x-a[i])*(x-a[i])+(y-b[i])*(y-b[i]);
if(d<=mn) mn2=mn,mn=d;
else mn2=min(mn2,d);
}
return mn2;
}
db rd(db l,db r){
return l+(r-l)*rnd()/rnd.max();
}
void SA(){
db x=rd(0,w),y=rd(0,h),v=calc(x,y);
ans=max(ans,v);
for(db t=0.5;t>1e-12;t*=0.995){
db nx=max((db)0,min((db)w,x+rd(-w,w)*t)),ny=max((db)0,min((db)h,y+rd(-h,h)*t)),nv=calc(nx,ny);
ans=max(ans,nv);
if(nv>v||rnd()<exp((nv-v)/t)*rnd.max()) x=nx,y=ny,v=nv;
}
}
signed main(){
scanf("%d%d%d",&w,&h,&n);
for(int i=1;i<=n;i++) scanf("%d%d",&a[i],&b[i]);
for(int i=1;i<=50;i++) SA();
printf("%.12Lf\n",sqrtl(ans));
return 0;
}
二、随机调整
步骤:1. 若能调整得更优就调整;2. 否则从一样优的里面随机选一个调整。
技巧:
-
注意这种方法得到的答案不降,所以调整方式不能让当前解被局限,必须能通过答案不降的路径调整到最优解/较优解。
-
找到性质中松散/容易满足的那股劲。
若题目中有些限制难以满足,先用智慧把它们满足了,剩下的再交给调整。不要让调整去硬做很严格的限制。
-
找到容易变动且与目标相符的估值。
这一部分有时是简单的(比如不满足的条件个数),有时需要用力对着组合结构构造一下(比如将哈密顿路转化成一些较容易满足的条件)。一般来说,对具体问题需要用具体的估值,不要都转到某个 NPC 硬做。
优化:
- 局部多次调整:避免一个刚被调整过的变量很快又被调整回去导致加大时间开销,可以先固定这个变量调整其他变量,若干轮后再设为不固定。
- 换成模拟退火:模拟退火以一定概率接受劣解,不保证调整的单调性,但扩大了调整的状态空间。
1. UOJ#79. 一般图最大匹配
随机一个未匹配点 \(x\):
- 若 \(x\) 有未匹配的邻点,随机一个将它们匹配。
- 否则随机一个已匹配的邻点 \(y\),取消匹配 \((y,mp_y)\) 并匹配 \((x,y)\)。
//97 分
#include<bits/stdc++.h>
using namespace std;
const int N=510;
int n,m,x,y,mp[N],k,id[N],ans;
vector<int>v[N];
mt19937 rnd(time(0));
void work(){
k=0;
for(int i=1;i<=n;i++)
if(!mp[i]) id[++k]=i;
if(!k) return ;
int x=id[rnd()%k+1];
shuffle(v[x].begin(),v[x].end(),rnd);
for(int y:v[x])
if(!mp[y]){mp[x]=y,mp[y]=x,ans++;return ;}
shuffle(v[x].begin(),v[x].end(),rnd);
for(int y:v[x])
if(mp[y]){mp[mp[y]]=0,mp[x]=y,mp[y]=x;return ;}
}
signed main(){
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++)
scanf("%d%d",&x,&y),
v[x].push_back(y),v[y].push_back(x);
while(clock()<=CLOCKS_PER_SEC*0.95) work();
printf("%d\n",ans);
for(int i=1;i<=n;i++) printf("%d ",mp[i]);
return 0;
}
2. CF1168E Xor Permutations(*3100)
2023.1.31 转化 + 随机调整解决隐式匹配问题
给出 \(a_{0\sim 2^k-1}\),构造两个排列 \(p_{0\sim 2^k-1},q_{0\sim 2^k-1}\) 使得 \(\forall i\in[0,2^k-1],p_i\oplus q_i=a_i\),无解输出
Fou。\(2\leq k\leq 12\),\(0\leq a_i<2^k\)。
显然 \((\oplus_{i=1}^np_i)\oplus (\oplus_{i=1}^nq_i)=0\),因此若 \(\oplus_{i=1}^n a_i\neq 0\) 则无解,否则可以证明一定有解。
转化:将 \(p,q\) 匹配到 \(a\) 转化为将 \(p,a\) 匹配到 \(q\),相当于要找一个排列 \(p\) 使得 \(a_i\oplus p_i\) 两两不同。
随机一个还没填到 \(p\) 中的 \(val\):
- 若存在一个 \(p_i=-1\) 使得 \(a_i\oplus val\) 不与别的 \(a_j\oplus p_j\) 冲突,随机其中一个令 \(p_i=val\)。
- 否则随机一个 \(p_i=-1\),并随机一个冲突的位置 \(j\)(即 \(a_i\oplus val=a_j\oplus p_j\) 的 \(j\)),令 \(p_i=val,p_j=-1\)。
#include<bits/stdc++.h>
using namespace std;
const int N=(1<<12)+5;
int n,a[N],sum,p[N],usd[N],k,id[N],vis[N],ans;
vector<int>v;
mt19937 rnd(time(0));
void work(){
k=0;
for(int i=0;i<n;i++) if(!usd[i]) id[++k]=i;
if(!k) return ;
int val=id[rnd()%k+1];
shuffle(v.begin(),v.end(),rnd);
for(int i:v)
if(!~p[i]&&!vis[a[i]^val]){
usd[p[i]=val]=1,vis[a[i]^val]=1,ans++;
return ;
}
shuffle(v.begin(),v.end(),rnd);
for(int i:v) if(!~p[i]){
for(int j:v)
if(~p[j]&&(a[j]^p[j])==(a[i]^val)){
usd[p[j]]=0,p[j]=-1,usd[p[i]=val]=1;
return ;
}
return ;
}
}
signed main(){
scanf("%d",&n),n=1<<n;
for(int i=0;i<n;i++)
scanf("%d",&a[i]),sum^=a[i],
p[i]=-1,v.push_back(i);
if(sum) puts("Fou"),exit(0);
while(clock()<=CLOCKS_PER_SEC*0.95) work();
puts("Shi");
for(int i=0;i<n;i++)
printf("%d ",p[i]); puts("");
for(int i=0;i<n;i++)
printf("%d ",p[i]^a[i]);
return 0;
}
3. U239149 聚会
2023.1.31
给出 \(n,m,x,y,a\),构造一组将 \(1\sim n\times m\) 放置在 \(n\times m\) 的棋盘中的方案,使得相邻位置上的元素互质,且第 \(x\) 行第 \(y\) 列的元素为 \(a\)。
\(2\leq n,m\leq 300\)。
找元素大致分布:首先,\(\lfloor\frac{nm}{2}\rfloor\) 个偶数任意两个不能相邻,将棋盘黑白染色,若 \(nm\) 为偶数则所有偶数的位置集合确定(因为给定了某个位置的奇偶性),否则偶数的位置集合有 \(\lfloor\frac{nm}{2}\rfloor+1\) 种,任意取一种。
然后使用随机调整法,交换两个颜色相同且非 \((x,y)\) 格子上的元素,估值为互质的边数,若交换后估值非严格变大就交换。
优化:用栈维护不合法边集,每次随机其中一条,与栈顶交换后弹出,然后随机找其一个端点与另外某个数交换。
4. 小练习
2023.11.9 随机调整
有 \(n\) 个变量 \(x_{1\sim n}\),你需要保证 \(x_i\geq 0\) 且 \(\sum_{i=1}^n x_i=1\),求 \(\sum_{i=1}^n\sum_{j=i+1}^n w_{i,j}x_ix_j\) 的最大值。
\(1\leq T\leq 20\),\(2\leq n\leq 10\),\(0\leq w_{i,j}\leq 10^3\)。
随机两个变量在它们之间调(一个 \(+d\) 一个 \(-d\)),\(\sum_{i=1}^n\sum_{j=i+1}^n w_{i,j}x_ix_j\) 的改变量,是一个与 \(d\) 有关的二次函数或一次函数,算一下 \(d\) 取什么的时候取最值即可。
#include<bits/stdc++.h>
using namespace std;
const int N=20;
int t,n,w[N][N];
double a[N],sum,ans;
mt19937 rnd(time(0));
void calc(){
sum=0;
for(int i=1;i<=n;i++)
for(int j=i+1;j<=n;j++) sum+=w[i][j]*a[i]*a[j];
ans=max(ans,sum);
}
void work(){
double all=0;
for(int i=1;i<=n;i++) a[i]=rnd()%1000000,all+=a[i];
for(int i=1;i<=n;i++) a[i]/=all;
for(int t=1;t<=2e3;t++){
if(rnd()%128==0) swap(a[rnd()%n+1],a[rnd()%n+1]);
int x=rnd()%n+1,y=rnd()%n+1;
if(x==y) continue;
double sx=0,sy=0,d;
for(int i=1;i<=n;i++)
if(i!=x&&i!=y) sx+=w[x][i]*a[i],sy+=w[y][i]*a[i];
#define f(a,b) (!a?(b>0?1e9:-1e9):-(b)/(2*a))
d=max(-a[x],min(a[y],f(-w[x][y],sx-sy-a[x]*w[x][y]+a[y]*w[x][y])));
if(d) a[x]+=d,a[y]-=d,calc();
}
}
signed main(){
scanf("%d",&t);
while(t--){
scanf("%d",&n),ans=0;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++) scanf("%d",&w[i][j]);
for(int i=1;i<=200;i++) work();
printf("%.10lf\n",ans);
}
return 0;
}
三、shuffle
-
经典结论:随机 \(1,-1\),前缀和最大绝对值 \(\mathcal O(\sqrt n)\)。
-
优化暴力找合法解的过程:shuffle,然后用一些正确率较高的必要条件判断一个范围内是否可能存在解,再去这个范围里找。
-
随机化贪心:shuffle 后从前往后按某种方式贪心,多次随机选最优解。
技巧:
-
结合多种不同的贪心规则“拼盘”。
-
加入 权重:给直观感受上更优的点提高更高的权重,更有几率排在序列前面。
若某个点存在多个相关量,将相关量分类,类间关联性较小,类间的权值用加法,同类的量用 比值定义法,越重要的量就在上面加次方。
-
1. LOJ#3603.「PA 2021」Poborcy podatkowi
2023.1.20
给出一棵 \(n\) 个节点的树,边有边权(可能为负),你需要选出一些不交的包含恰好 \(4\) 条边的路径,使得边权和最大,输出这个最大值。
\(2\leq n\leq 2\times 10^5\),\(-10^9\leq a_i\leq 10^9\)。
设 \(f_{x,i}\) 表示子树 \(x\) 中,选了一些长度为 \(4\) 的链,剩下一条以 \(x\) 为根长度为 \(i\) 的链,此时的最大边权和。
合并各个儿子的信息:将一些长度为 \(1\) 和 \(3\) 的匹配,长度为 \(2\) 的两两匹配,然后选择至多一条链延伸上去。
最后有两种情况:\(2\) 的个数为偶数,\(1\) 和 \(3\) 的个数差 \(\leq 1\);或者 \(2\) 的个数为奇数,\(1\) 和 \(3\) 的个数相同。于是需要记录长度为 \(2\) 的链的奇偶性(即选的),以及当前的选择里 \(1\) 比 \(3\) 多了多少。
将儿子们 random_shuffle 一下,第二维就限制在 \(\mathcal O(\sqrt n)\) 了。时间复杂度 \(\mathcal O(n\sqrt n)\)。
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int N=2e5+5,M=450;
int n,x,y,z,cur=1,pre;
ll dp[N][4],f[2][2][2*M+5],w;
vector<pair<int,int> >v[N];
mt19937 rnd(time(0));
void upd(ll &x,ll y){x=max(x,y);}
void dfs(int x,int fa){
for(auto p:v[x]){
int y=p.first;
if(y!=fa) dfs(y,x);
}
memset(f,-0x3f,sizeof(f)),f[cur][0][0+M]=0;
shuffle(v[x].begin(),v[x].end(),rnd);
for(auto p:v[x]){
int y=p.first,z=p.second;
if(y!=fa){
swap(cur,pre);
for(int i=0;i<2;i++)
for(int j=-M;j<=M;j++){
w=f[pre][i][j+M];
upd(f[cur][i][j+M],w+max(dp[y][0],dp[y][3]+z)); //不选 / 长度为 4 的链
upd(f[cur][i^1][j+M],w+dp[y][1]+z); //长度为 2 的链
if(j<M) upd(f[cur][i][j+1+M],w+dp[y][0]+z); //长度为 1 的链
if(j>-M) upd(f[cur][i][j-1+M],w+dp[y][2]+z); //长度为 3 的链
}
}
}
dp[x][0]=f[cur][0][0+M],dp[x][1]=f[cur][0][1+M],
dp[x][2]=f[cur][1][0+M],dp[x][3]=f[cur][0][-1+M];
}
signed main(){
scanf("%d",&n);
for(int i=1;i<n;i++){
scanf("%d%d%d",&x,&y,&z);
v[x].push_back({y,z}),v[y].push_back({x,z});
}
dfs(1,0),printf("%lld\n",dp[1][0]);
return 0;
}
四、随机 xor & 随机权值
1. 甜甜圈
2021.11.13 同 P5987 [PA2019]Terytoria
给出一张 \(X\times Y\) 的左右、上下分别连通的网格,上面钦定了 \(n\) 个矩形的两个对顶点(坐标从 \(0\) 开始标号),求被这 \(n\) 个矩形都覆盖的格子数量的最大值。
\(n\leq 5\times 10^5\),\(2\leq X,Y\leq 10^9\)。
发现两维独立,分别做再将答案相乘即可。
转化为:有 \(n\) 个区间,每次取一个区间或这个区间的补集,求被 \(n\) 个区间同时覆盖的点数最大值。
-
给每个区间一个 ull 随机数 \(a_i\),令这个区间内的数异或上它,众数即为答案。
原因:考虑一个位置上的数是一堆 \(a_i\) 的异或和,代表了一个操作序列,异或上的 \(a_i\) 表示取这个区间,没异或上的表示取这个区间的补集。两个位置的数相同说明存在同样的决策方式使得它们同时被覆盖,不同就不行。
#include<bits/stdc++.h>
#define ull unsigned long long
#define getchar() (p1==p2&&(p2=(p1=buf)+fread(buf,1,1<<21,stdin),p1==p2)?EOF:*p1++)
using namespace std;
char buf[1<<23],*p1=buf,*p2=buf,obuf[1<<23],*O=obuf;
template<typename T>
inline void read(T& x){
x=0;int f=1;
char ch=getchar();
while(!isdigit(ch)){if(ch=='-') f=-1;ch=getchar();}
while(isdigit(ch)) x=(x<<3)+(x<<1)+(ch-'0'),ch=getchar();
x*=f;
}
using namespace std;
const int N=1e6+5;
int n,x,y,x1[N],Y1[N],x2[N],y2[N],cnt,a[N],sum,ans;
ull t;
pair<ull,int>s[N];
mt19937_64 rnd(time(0));
int calc(int l[N],int r[N],int v){
sum=ans=cnt=0,a[++cnt]=0,a[++cnt]=v;
for(int i=1;i<=n;i++){
if(l[i]>r[i]) swap(l[i],r[i]);
a[++cnt]=l[i],a[++cnt]=r[i];
}
sort(a+1,a+1+cnt),cnt=unique(a+1,a+1+cnt)-a-1;
for(int i=1;i<=cnt;i++) s[i]={0,0};
for(int i=1;i<=n;i++){
l[i]=lower_bound(a+1,a+1+cnt,l[i])-a,r[i]=lower_bound(a+1,a+1+cnt,r[i])-a;
t=rnd(),s[l[i]].first^=t,s[r[i]].first^=t;
}
for(int i=1;i<cnt;i++) s[i].first^=s[i-1].first,s[i].second=a[i+1]-a[i];
sort(s+1,s+cnt);
for(int i=1;i<=cnt;i++){
if(s[i].first==s[i-1].first) sum+=s[i].second;
else ans=max(ans,sum),sum=s[i].second;
}
return ans;
}
signed main(){
read(n),read(x),read(y);
for(int i=1;i<=n;i++) read(x1[i]),read(Y1[i]),read(x2[i]),read(y2[i]);
printf("%lld\n",1ll*calc(x1,x2,x)*calc(Y1,y2,y));
return 0;
}
2. 集合哈希
判断两个集合是否相同:xor 哈希,给每个值一个 ull 随机数 \(val_i\),判断 \(\oplus_{i\in S}val_i\) 是否相同。
出现在了 ZR#2523 的 \(25\) 分部分分。
3. 小练习
2023.2.2 主席树 + xor 哈希
给出 \(n\) 个开区间 \((l_i,r_i)\),定义 \(S(x)=\{i\mid x\in(l_i,r_i)\}\)。
定义集合族 \(T=\{S(x)\mid x\in \mathbb R,S(x)\neq\varnothing\}\)。求 \(T\) 中字典序第 \(k\) 小的集合。
\(1\leq n\leq 2\times 10^5\),\(0\leq l_i<r_i\leq 10^9\),\(1\leq k\leq 10^9\)。
扫描线,只有 \(\mathcal O(n)\) 个不同的 \(S(x)\),主席树维护 \(S(x),S(y)\) 字典序比较:左区间有不一样的就去左区间找,否则去右区间找,这样找到 \([i\in S(x)]\neq [i\in S(y)]\) 的最小的 \(i\)。分哪个是 \(1\) 哪个是 \(0\) 简单讨论一下即可。
判断不一样:xor 哈希,给每个区间 \(i\) 一个 ull 随机数 \(val_i\),主席树上 \(seg_{l,r}=\oplus_{i\in[l,r]}[i\in S(x)]val_i\)。
#include<bits/stdc++.h>
using namespace std;
const int N=4e5+5,M=N<<5;
int n,k,l,r,cnt,num,tot,rt[N],lc[M],rc[M],id[N];
long long val[N],s[M];
mt19937_64 rnd(time(0));
vector<int>ans;
struct P{
double x;
int id;
}a[N];
int modify(int p,int l,int r,int pos,int v){
int x=++tot,mid=(l+r)/2;
s[x]=s[p]^v;
if(l==r) return x;
if(pos<=mid) lc[x]=modify(lc[p],l,mid,pos,v),rc[x]=rc[p];
else lc[x]=lc[p],rc[x]=modify(rc[p],mid+1,r,pos,v);
return x;
}
bool cmp(int x,int y,int l,int r,int xr,int yr){ //诶我好像把 ll xr,ll yr 写成 int 了诶
if(l==r) return (!s[x]&&s[y]&&!xr)||(s[x]&&!s[y]&&yr);
int mid=(l+r)/2;
if(s[lc[x]]!=s[lc[y]])
return cmp(lc[x],lc[y],l,mid,xr^s[rc[x]],yr^s[rc[y]]);
return cmp(rc[x],rc[y],mid+1,r,xr,yr);
}
void get(int p,int l,int r){
if(!p) return ;
if(l==r){
if(s[p]) ans.push_back(l);
return ;
}
int mid=(l+r)/2;
get(lc[p],l,mid),get(rc[p],mid+1,r);
}
signed main(){
scanf("%d%d",&n,&k);
for(int i=1;i<=n;i++)
scanf("%d%d",&l,&r),val[i]=rnd(),
a[++cnt]={l+0.1,i},a[++cnt]={r,i};
sort(a+1,a+1+cnt,[](P x,P y){return x.x<y.x;});
for(int i=1;i<=cnt;i++){
if(a[i].x!=a[i-1].x) num++,rt[num]=rt[num-1],id[num]=num;
rt[num]=modify(rt[num],1,n,a[i].id,val[a[i].id]);
}
stable_sort(id+1,id+1+num,[](int x,int y){return cmp(rt[x],rt[y],1,n,0,0);}); //卡常
for(int i=1;i<=num;i++)
if(!(k-=s[rt[id[i]]]!=s[rt[id[i-1]]])){ //去重
get(rt[id[i]],1,n);
printf("%d\n",(int)ans.size());
for(int j:ans) printf("%d ",j);
exit(0);
}
return 0;
}
4. CF799F Beautiful fountains rows(*3500)
2023.2.18
一个 \(n\times m\) 的矩阵 \(a\),给出 \(l_i,r_i\),\(a_{i,j}=[j\in[l_i,r_i]]\)。
求符合以下条件的 \(L,R\) 的 \(R-L+1\) 之和:整个矩阵的第 \(L\) 列到第 \(R\) 列存在 \(1\),并且每行的第 \(L\) 列到第 \(R\) 列要么没有 \(1\) 要么有奇数个 \(1\)。
\(1\leq n,m\leq 2\times 10^5\),\(1\leq l_i\leq r_i\leq m\)。
-
给每个区间 \([l_i,r_i]\) 一个 ull 随机数 \(a_i\),令 \([l_i+1,r_i]\) 内的数异或上它,可以认为 \(L,R\) 满足限制 2 当且仅当区间 \([L,R]\) 内的数异或和为 \(0\)。
原因:单独考虑某个 \(i\) 对区间 \([L,R]\) 异或和的影响,只有 \([l_i+1,r_i]\cap [L,R]\) 的长度为偶数时影响为 \(\oplus 0\)。当所有 \(i\) 的影响都为 \(\oplus 0\) 时就满足限制 2。由于 ull 随机所以若干个 \(>0\) 的随机数异或成 \(0\) 的概率极小。
由 \([l_i+1,r_i]\) 来异或而不是 \([l_i,r_i]\) 的好处是,异或与偶数更相配,\(0\) 比 \(>0\) 更容易处理。
-
对于限制 2,求出异或前缀和 \(s_i\),就转化成有多少 \(L,R\) 使得 \(s_R=s_{L-1}\) 了,
map维护。对于限制 1,只要去掉全为 \(0\) 的贡献即可。
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int N=2e5+5;
int n,m,l,r,a[N];
ll v,s[N],ans;
map<ll,pair<int,ll> >mp;
mt19937_64 rnd(time(0));
signed main(){
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++)
scanf("%d%d",&l,&r),a[l]++,a[r+1]--,
v=rnd(),s[l+1]^=v,s[r+1]^=v;
for(int i=1;i<=m;i++)
a[i]+=a[i-1],s[i]^=s[i-1];
for(int i=1;i<=m;i++){
s[i]^=s[i-1];
mp[s[i]].first++,mp[s[i]].second+=i;
ans+=1ll*mp[s[i]].first*(i+1)-mp[s[i]].second;
}
for(int i=1,cur=0;i<=m;i++){
if(!a[i]) cur++;
else cur=0;
ans-=1ll*cur*(cur+1)/2;
}
printf("%lld\n",ans);
return 0;
}
5. QOJ#5254. Differences
2023.3.20
给出 \(n\) 个长度为 \(m\) 的字符串 \(s_{1\sim n}\),已知恰好有一个字符串和其他所有字符串都恰好有 \(k\) 个位置不等,你需要找到它是哪个。
\(2\leq n,m\leq 10^5\),\(1\leq k\leq m\),\(nm\leq 2\times 10^7\)。
从必要条件入手:对于一个串 \(s_i\),求出 \(s_i\) 与其他字符串的不等位置之和(从前往后考虑每一位,加上有多少字符串这一位与 \(s_i\) 不同),不等位置之和必须是 \((n-1)k\)。
加上随机:随机一个包含 \(s_i\) 的集合干这个事情,不等位置之和必须是 \((sz-1)k\)。
主要问题是无法分辨不等位置属于哪个串,注意到上述过程相当于给每个字符串加权 \(0\) 或 \(1\) 很废,考虑改为给每个字符串随机一个 ull 权值 \(w_i\),要求 \(\sum_{j\neq i}(s_j\ 与\ s_i\ 不等位置数)w_j=\sum_{j\neq i}w_j\times k\)。
#include<bits/stdc++.h>
#define ll long long
#define id(i,j) (i-1)*m+j
using namespace std;
const int N=2e7+5;
int n,m,k,c;
ll w[N],all,sum,buc[5],tot[N];
char s[N];
mt19937_64 rnd(time(0));
signed main(){
scanf("%d%d%d",&n,&m,&k);
for(int i=1;i<=n;i++) w[i]=rnd(),all+=w[i];
for(int i=1;i<=n;i++){
getchar();
for(int j=1;j<=m;j++) s[id(i,j)]=getchar();
}
for(int j=1;j<=m;j++){
fill(buc,buc+4,0),sum=0;
for(int i=1;i<=n;i++)
c=s[id(i,j)]-'A',buc[c]+=w[i],sum+=w[i];
for(int i=1;i<=n;i++)
tot[i]+=sum-buc[s[id(i,j)]-'A'];
}
for(int i=1;i<=n;i++)
if(tot[i]==(all-w[i])*k) printf("%d\n",i);
return 0;
}
6. 功夫派
2023.12.12 随机 xor + 分块
给出 \(a_{1\sim n}\),问有多少区间 \([l,r]\) 满足:
- 对于所有在 \(a_{l\sim r}\) 出现过的数,它们的出现次数都是奇数次。
\(1\leq n\leq 3\times 10^4\),\(1\leq a_i\leq 10^6\)。
-
给每种数 \(x\) 随机一个 ull \(w_x\),则 \(a_{l\sim r}\) 中每种数出现奇数次 \(\Leftrightarrow\) ”\(\oplus_{i=l}^r w_{a_i}=\oplus_{x\in a_{l\sim r}}w_x\)“。
-
记 \(s_r=\oplus_{i=1}^r w_{a_i}\)。扫描线 \(r\),要算有多少个 \(l\) 满足 \(s_{l-1}\oplus(\oplus_{x\in a_{l\sim r}}w_x)=s_r\)。
考虑扫 \(r\) 时对每个 \(l\) 实时维护 \(val_l=s_{l-1}\oplus(\oplus_{x\in a_{l\sim r}w_x})\)。每次 \(r-1\to r\) 时,\(a_r\) 在 \(l\in[pre_r+1,r]\) 的 \([l,r]\) 中从未出现变成了出现,于是对 \(l\in[pre_r+1,r]\) 令 \(val_l'\gets val_l\oplus w_{a_r}\) 即可。
-
需要支持:区间异或,查询区间某个值的出现次数。
分块,对每个块开个 map 分别维护块内每种值的出现次数。区间异或时,散块暴力,整块打 tag。
时间复杂度 \(\mathcal O(n\sqrt n)\)(假如手写哈希表)。
#include<bits/stdc++.h>
#include<ext/pb_ds/assoc_container.hpp>
#include<ext/pb_ds/hash_policy.hpp>
#define ll long long
using namespace std;
const int N=3e4+5,M=180,V=1e6+5;
int n,a[N],len,num,bl[N],l[M],r[M],lst[V],ans;
ll w[V],s[N],val[N],tg[M];
mt19937_64 rnd(time(0));
__gnu_pbds::gp_hash_table<ll,int>mp[M];
void upd(int x,int y,ll v){
auto upd=[&](int i){
mp[bl[i]][val[i]]--,mp[bl[i]][val[i]^=v]++;
};
if(bl[x]==bl[y]){
for(int i=x;i<=y;i++) upd(i);
return ;
}
for(int i=bl[x]+1;i<bl[y];i++) tg[i]^=v;
for(int i=x;i<=r[bl[x]];i++) upd(i);
for(int i=l[bl[y]];i<=y;i++) upd(i);
}
int qry(int x,int y,ll v){
int ans=0;
auto qry=[&](int i){
ans+=(val[i]^tg[bl[i]])==v;
};
if(bl[x]==bl[y]){
for(int i=x;i<=y;i++) qry(i);
return ans;
}
for(int i=bl[x]+1;i<bl[y];i++) ans+=mp[i][v^tg[i]];
for(int i=x;i<=r[bl[x]];i++) qry(i);
for(int i=l[bl[y]];i<=y;i++) qry(i);
return ans;
}
signed main(){
scanf("%d",&n),len=sqrt(n),num=(n-1)/len+1;
for(int i=1;i<=n;i++)
scanf("%d",&a[i]),bl[i]=(i-1)/len+1;
for(int i=1;i<=num;i++)
l[i]=(i-1)*len+1,r[i]=min(n,i*len);
for(int i=1;i<=n;i++){
if(!lst[a[i]]) w[a[i]]=rnd();
s[i]=s[i-1]^w[a[i]];
mp[bl[i]][val[i]=s[i-1]]++;
upd(lst[a[i]]+1,i,w[a[i]]),ans+=qry(1,i,s[i]),lst[a[i]]=i;
}
printf("%d\n",ans);
return 0;
}
五、多次随机取众数
概率分析,随机出于答案有关的某个东西的概率比随机出其他东西的概率高,那么随机很多次取出现次数最多的那次,就知道与答案有关的那个东西是什么了。
1. CF1438F Olha and Igor(*3000)
六、随机增量法
科学革命
2023.3.28
给出一个 \(n\times n\) 的矩阵 \(a\),要求构造一个排列 \(p_{1\sim n}\),使得对于所有 \(i\neq j\) 都有 \(d(\gcd(p_i,p_j))=a_{i,j}\)。
\(1\leq n\leq 10^3\)。
随机增量法,随机一个顺序将数加进去。
加上必要条件:如果 \(p_i=v\),那么 \(i\neq j,a_{i,j}\) 组成的集合必须等于 \(v\neq j,d(\gcd(v,j))\) 组成的集合。
#include<bits/stdc++.h>
using namespace std;
const int N=1e3+5;
int n,d[N],a[N][N],p[N],vis[N],bad;
long long w[N],wpos[N],wval[N];
vector<int>tmp;
mt19937_64 rnd(time(0));
bool ok(int i,int v){
for(int j=1;j<=n;j++)
if(p[j]&&d[__gcd(v,p[j])]!=a[i][j]) return 0;
return 1;
}
signed main(){
scanf("%d",&n);
for(int i=1;i<=n;i++){
w[i]=rnd(),tmp.push_back(i);
for(int j=i;j<=n;j+=i) d[j]++;
}
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++){
scanf("%d",&a[i][j]);
if(i!=j) wpos[i]+=w[a[i][j]],wval[i]+=w[d[__gcd(i,j)]];
}
while(1){
bad=0,shuffle(tmp.begin(),tmp.end(),rnd);
for(int i=1;i<=n;i++) vis[i]=p[i]=0;
for(int i=1;i<=n;i++){
for(int v:tmp)
if(!vis[v]&&wpos[i]==wval[v]&&ok(i,v)){vis[p[i]=v]=1;break;}
if(!p[i]){bad=1;break;}
}
if(!bad) break;
}
for(int i=1;i<=n;i++) printf("%d\n",p[i]);
return 0;
}
七、其他
1. POJ3318 Matrix Multiplication
2023.3.2
给出 \(n\times n\) 的矩阵 \(A,B,C\),问是否有 \(A\times B=C\)。
\(n\leq 500\),\(|a_{i,j}|,|b_{i,j}|\leq 100\),\(|c_{i,j}|\leq 10^7\),保证 \(\mathcal O(n^3)\) 超时。
随机一个 \(n\times 1\) 的矩阵 \(R\),check 是否有 \(A\times B\times R=C\times R\)。而 \(A\times(B\times R),C\times R\) 都可以 \(\mathcal O(n^2)\) 算。
#include<algorithm>
#include<cstdio>
using namespace std;
const int N=510;
int n;
struct mat{
int n,m,x[N][N];
void init(){
n=m=::n;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++) scanf("%d",&x[i][j]);
}
friend mat operator*(mat a,mat b){
mat c;
c.n=a.n,c.m=b.m;
for(int i=1;i<=a.n;i++)
for(int j=1;j<=b.m;j++){
c.x[i][j]=0;
for(int k=1;k<=a.n;k++) c.x[i][j]+=a.x[i][k]*b.x[k][j];
}
return c;
}
bool operator==(mat a){
if(n!=a.n||m!=a.m) return 0;
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++)
if(x[i][j]!=a.x[i][j]) return 0;
return 1;
}
}a,b,c,r;
signed main(){
scanf("%d",&n),a.init(),b.init(),c.init();
r.n=n,r.m=1;
bool ok=1;
for(int t=0;t<5;t++){
for(int i=1;i<=n;i++) r.x[i][1]=rand()%100+1;
ok&=a*(b*r)==c*r;
}
puts(ok?"YES":"NO");
return 0;
}
2. QOJ#5156. Going in Circles
2023.7.16

随机一个比较长的 \(01\) 串,比如长度为 \(25\)。然后将当前的若干车厢灯的状态改为这个 \(01\) 串,接着不断向后走直到再次遇到这个串就能求出 \(n\) 了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号