随笔分类 - 深度学习
Deep Learning
摘要: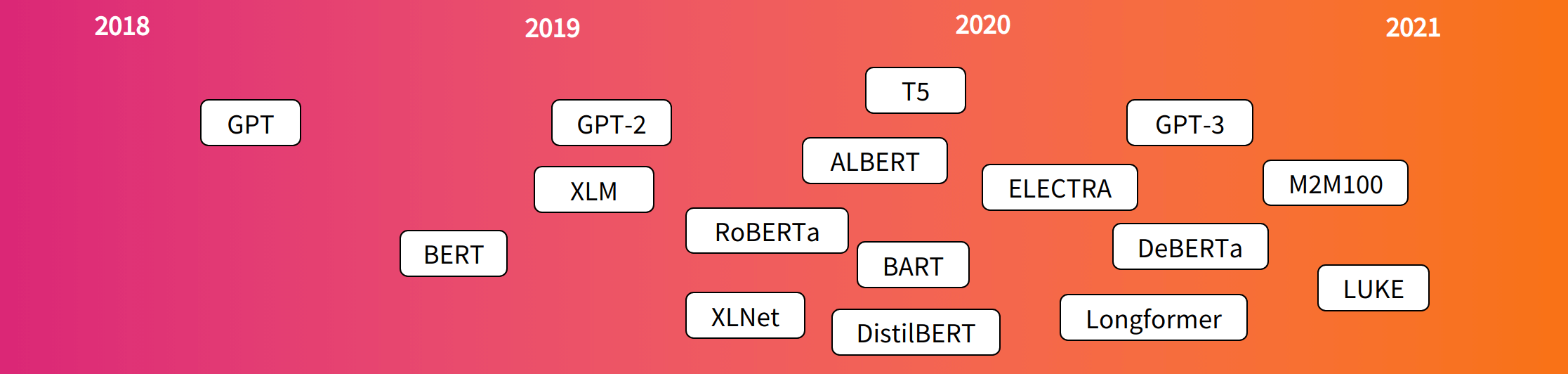 一网打尽十余个Transformer模型。
经典模型:Word2vec, ELMo, Transformer, GPT, BERT, XLNet, UniLM, T5, ALBERT, ELECTRA, DeBERTa, ERNIE.
阅读全文
一网打尽十余个Transformer模型。
经典模型:Word2vec, ELMo, Transformer, GPT, BERT, XLNet, UniLM, T5, ALBERT, ELECTRA, DeBERTa, ERNIE.
阅读全文
一网打尽十余个Transformer模型。
经典模型:Word2vec, ELMo, Transformer, GPT, BERT, XLNet, UniLM, T5, ALBERT, ELECTRA, DeBERTa, ERNIE.
阅读全文
摘要:RNN RNN中循环应用如下公式在每步中处理序列x: \[ \underbrace{h_t}_{新状态}=\underbrace{f_W}_{带参数W的函数}(\underbrace{h_{t-1}}_{旧状态},\underbrace{x_t}_{某step的输入}) \] 在每一步中使用的都是相
阅读全文
摘要:公式推导系列 "线性回归" : 最小二乘, normal equation "逻辑回归" : 最大似然损失函数 "SVM" : 转换为对偶问题,软间隔,核函数,SMO "EM" : 隐变量的后验概率函数(Q函数,最大化下界)与最大似然估计交替优化 "损失函数" : logistic, softmax
阅读全文
摘要:学习率调整方式 初始值通常设置在1e-3, 在学习过程中随着时间降低学习率通常很有用, 以下的学习率衰减方式适用于使用一阶动量的优化算法. 降低学习率的方式有: 递减step decay 每几个epoch降低一次,如每5次降低一半,或每20次降低0.1,视情况而定.可以通过尝试不同的固定的学习率对验
阅读全文
摘要:本文介绍Softmax运算、Softmax损失函数及其反向传播梯度计算, 内容上承接前两篇博文 "损失函数" & "手推反向传播公式" 。 Softmax 梯度 设有K类, 那么期望标签y形如$[0,0,...0,1,0...0]^T$的one hot的形式. softmax层的输出为$[a_1,a
阅读全文
摘要:感受野(receptive field) CNN中,某一层输出结果中一个元素所对应的输入层的区域大小. 感受野计算 从后往前 output field size = ( input field size kernel size + 2 × padding ) / stride + 1,变形之后得到i
阅读全文
摘要:希望本文成为你见过的反向传播理论中最易理解的解释和最简洁形式的公式推导 😃 反向传播是上世纪80年代提出的训练神经网络的一种方法,在每次迭代训练时修改对每个神经元输入的权值,来达到最后一层的输出与期望的输出的总误差最小的目的。反向传播算法可以说是梯度下降在链式法则中的应用。 反向传播与梯度下降 Q
阅读全文
摘要:Mask R CNN 论文Mask R CNN(ICCV 2017, Kaiming He,Georgia Gkioxari,Piotr Dollár,Ross Girshick, arXiv:1703.06870) 这篇论文提出了一个概念简单,灵活,通用的目标实例分割框架,能够同时检测目标并进行实
阅读全文
摘要:R FCN 原理 R FCN作者指出在图片分类网络中具有平移不变性(translation invariance),而目标在图片中的位置也并不影响分类结果;但是检测网络对目标的位置比较敏感.因此Faster R CNN将ROI的特征提取操作放在了最后分类网络中间(靠后的位置)打破分类网络的平移不变性
阅读全文
摘要:之前一篇博文中介绍了 "深度学习中的pooling层" ,在本篇中主要介绍 这种上采样操作。转置卷积也是一种 "卷积" 。 L2 pooling $$ a^l={1\over k}\sqrt{\sum_{j=1}^k(a_j^{l 1})^2} $$ pooling除了仅输出一个值, 也可以输出to
阅读全文
摘要:卷积 卷积是一种定义在两个函数(\(f\) 和 \(g\))上的数学操作,旨在产生一个新的函数。\(f\) 和 \(g\) 的卷积可以写成 \(f\ast g\),数学定义如下: \[ \begin{align} (f*g)(t) &={\int}_{-\infty}^{\infty}f(\tau)
阅读全文
摘要:常见指标 预测出的所有目标中正确的比例 (true positives / true positives + false positives). 被正确定位识别的目标占总的目标数量的比例 (true positives/(true positives + false negatives)). 一般情
阅读全文
摘要:本文逐步介绍YOLO v1~v3的设计历程。 YOLOv1基本思想 YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。 每个格子预测B个bounding box及其置信度(confidence score),以
阅读全文
摘要:生成对抗网络(Generative Adversarial Networks,GANs),由2014年还在蒙特利尔读博士的Ian Goodfellow引入深度学习领域。2016年,GANs热潮席卷AI领域顶级会议,从ICLR到NIPS,大量高质量论文被发表和探讨。Yann LeCun曾评价GANs是
阅读全文
摘要:Highway Networks 论文地址: "arXiv:1505.00387" "cs.LG] (ICML 2015),全文:Training Very Deep Networks( [arXiv:1507.06228" ) 基于梯度下降的算法在网络层数增加时训练越来越困难(并非是梯度消失的问题
阅读全文
摘要:R2CNN 论文Rotational Region CNN for Orientation Robust Scene Text Detection与RRPN(Arbitrary Oriented Scene Text Detection via Rotation Proposals)均提出了检测出任
阅读全文
摘要:Rotation Proposals 论文Arbitrary Oriented Scene Text Detection via Rotation Proposals 这篇论文提出了一个基于Faster R CNN的支持任意角度旋转的场景文字检测框架.在Fast R CNN的部分与论文Rotated
阅读全文
摘要:R CNN系列均训练了Bounding box回归器来对窗口进行校正,其目标是学习一种转换关系将预测得到的窗口P映射为真实窗口G(Ground truth). 变换方式 可以通过简单的仿射变换以及指数变换将当前预测出的Bounding box P向Ground truth纠正: $$ \begin{
阅读全文
摘要:Deformable ConvNets 论文 Deformable Convolutional Networks(arXiv:1703.06211) CNN受限于空间结构,具有较差的旋转不变性,较弱的平移不变性.这篇论文提出了两个可替换原有组件的模块:可变形卷积和RoI pooling.均基于增加空
阅读全文
摘要:" " 是百度 AI 开放平台所推出的可定制专属图像识别模型的平台,只需提供少量标注数据即可完成模型训练。其具备可视化的操作界面,简单几步,便可得到精准的深度学习模型,并能通过 API 进行调用。 step1 上传图片 定制化图像开放平台目前仅支持分类任务,支持上传自己的数据集进行训练,但不支持选择
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号
