Transformer中的嵌入与位置编码
绝对位置编码与相对位置编码:
- 实验分析非常精彩 | Transformer中的位置嵌入到底改如何看待? - 腾讯云开发者社区-腾讯云 (tencent.com)
- (16条消息) Transformer架构:位置编码_Jayson13的博客-CSDN博客_位置编码
1、Attention Is All You Need (Transformer)
- 嵌入编码
![]()
- 位置编码

2、Improving Language Understanding by Generative Pre-Training (GPT)

我们使用学到的位置嵌入,而不是原始工作中提出的正弦版本。
3、An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (Vision Transformer, ViT)





4、Decision Transformer: Reinforcement Learning via Sequence Modeling (Decision Transformer)

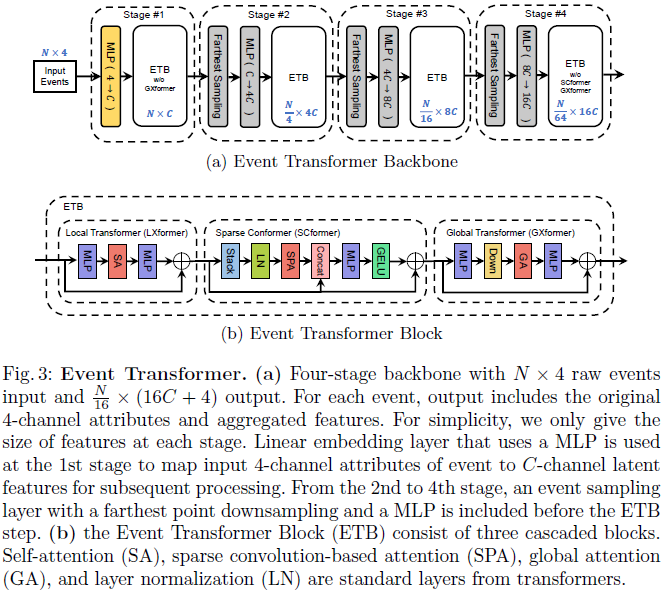

6、Event Transformer. A sparse-aware solution for efficient event data processing
与之前基于帧的方法[1, 4, 19]类似,我们聚合事件数据![]() 在时间窗口Δt期间生成类似帧的表示FH×W×B×2。F 中的每个位置(x, y) | yϵH, xϵW用 B 个桶的两个类似直方图的向量表示,分别用于每个极性pϵ{0, 1}。每个直方图将每个桶中的Δt离散化,并计算相应时段Δt/B中发生的正事件或负事件的数量。最终表示被转换为F' = log(F + 1)以平滑高度激活区域中的极高值。
在时间窗口Δt期间生成类似帧的表示FH×W×B×2。F 中的每个位置(x, y) | yϵH, xϵW用 B 个桶的两个类似直方图的向量表示,分别用于每个极性pϵ{0, 1}。每个直方图将每个桶中的Δt离散化,并计算相应时段Δt/B中发生的正事件或负事件的数量。最终表示被转换为F' = log(F + 1)以平滑高度激活区域中的极高值。
然后将帧表示拆分为大小为P × P的非重叠块。然后,如果每个块包含至少m%的非零元素,即如果至少有m%的像素(x, y),我们将每个块设置为已激活块内已注册事件。激活的块被EvT保留以供进一步处理,而未激活的块被丢弃,从而显著降低了后续计算成本并隐含地减少了环境噪声。如果激活块的数量低于阈值 n,即没有足够的视觉信息需要处理,我们扩展时间窗口Δt并使用新的传入事件增加事件集 ε,重新计算帧表示并提取激活块。重复最后一步,直到我们得到至少 n 个激活的块。作为最后一步,我们将 T 个激活的块展平以创建大小为(P2 × B × 2)的令牌,这是下一节中详细介绍的Transformer主干的输入。
因此,这种基于块的事件表示旨在利用不同的事件数据属性,以便以后更有效地处理事件数据。特别相关的是,时空事件稀疏性通过丢弃非信息块来解决,并且该数据的低延迟通过使用短时间窗(其长度适应事件密度)来解决,这些时间窗口也被二值化以获得更精细表示。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号