Event Transformer. A sparse-aware solution for efficient event data processing
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

CVPR 2022
Abstract
对于在资源匮乏和具有挑战性的环境中运行的许多应用程序来说,事件摄像机是非常感兴趣的传感器。它们以高时间分辨率和高动态范围记录稀疏的照明变化,同时具有最低的功耗。然而,表现最佳的方法通常会忽略特定的事件数据属性,从而导致开发通用但计算量大的算法。对高效解决方案的努力通常不会在复杂任务中获得最高准确度的结果。这项工作提出了一种新颖的框架,即Event Transformer (EvT)1,它有效地利用了事件数据属性来高效和准确。我们引入了一个新的基于块的事件表示和一个紧凑的类似Transformer的架构来处理它。EvT在不同的基于事件的动作和手势识别基准上进行评估。评估结果显示出与最先进技术更好或相当的准确性,同时需要显著更少的计算资源,这使得EvT能够在GPU和CPU上以最小的延迟工作。
1代码,训练好的模型和补充视频可以在下列网站找到: https://github.com/AlbertoSabater/EventTransformer
1. Introduction
事件相机是仿生传感器,可记录传感器阵列每个像素的强度变化。与传统相机相反,它们以稀疏和异步的方式工作,具有增加的高动态范围和高时间分辨率(以微秒为单位)且功耗最小。这些特征推动了许多基于事件的感知任务的研究,例如动作识别[6, 19]、身体[7, 36]和注视跟踪[2]、深度估计[14, 48]或里程计[24, 35],对于涉及低资源环境和具有挑战性的运动和光照条件的许多应用程序来说很有趣,例如AR/VR或自动驾驶。
处理来自基于事件的相机的信息仍然是一个开放的研究问题。表现最好的方法将事件流转换为类似帧的表示,抛弃它们固有的稀疏性,并使用卷积神经网络[1, 4, 8, 19]或循环层[8, 19]等繁重的处理算法。其他可以更好地利用这种稀疏性的方法,例如类似PointNet的神经网络[47]、图神经网络[6, 10]或脉冲神经网络[23, 39],效率更高,但无法达到相同的精度。因此,需要一种方法来充分利用基于事件的相机的所有潜力,以提高效率和低能耗,同时保持高性能。
这项工作引入了Event Transformer (EvT),这是一种新颖的框架(总结在图1中),旨在解决事件数据稀疏性问题,从而在获得最高准确度结果的同时实现高效。我们提出:1)使用稀疏的基于块的事件数据表示,仅考虑具有注册信息的事件流区域,以及 2)基于自然工作的注意力机制[44]的紧凑Transformer式主干有了这个块信息。与以前的基于帧的方法相比,后者需要最少的计算资源,方法是使用一组潜在内存向量来限制与Transformer架构相关的二次计算复杂度[21, 22],同时也对看到的信息进行编码。
EvT评估在三个不同复杂度的公共真实事件数据基准上运行,用于长事件流和短事件流分类(即动作和手势识别)。结果表明,EvT取得了与最先进技术更好或相当的结果。更重要的是,与之前的工作相比,我们的方法显著降低了计算资源需求,同时节省了相应的功耗,使EvT能够在GPU和CPU中以最小的延迟工作。
2. Related work
本节总结了最常见的事件数据表示方法以及处理它们的基于事件的神经网络架构。它还包括对不同类型的事件数据集的简要描述。
2.1. Event data representation
事件数据表示对与从事件流中提取的时间间隔或时间窗口相关的事件信息进行编码。这些表示可以分为两类:事件级表示通常将事件数据视为图[5, 6, 10, 47]或点云[37, 45],具有最少的预处理并保持事件数据稀疏;不同的是,基于帧的表示将传入事件分组为密集的类似帧的数组,忽略事件数据的稀疏性,但简化了以后的学习过程。我们的工作建立在基于帧的表示之上,我们在其中发现了大量的文献变化。时间表面[25]为每个像素构建编码最后生成的事件的帧。SP-LSTM [32]构建帧,其中每个像素包含一个与时间窗口中事件的存在及其极性相关的值。活动事件的表面[30]构建帧,其中每个像素包含对最后观察到的事件和累积时间开始之间的时间的测量。运动补偿[34, 46]通过根据相机自我运动对齐事件来生成帧。[15]在时间维度上对帧表示进行二值化,获得更好的时间分辨率。TBR [19]将二值化帧表示聚合成单箱帧。M-LSTM [8]使用LSTM网格处理每个像素的传入事件以创建最终的2D表示。
我们的工作引入了基于块的事件表示:我们首先构建一个简单的帧表示(类似于[15]),然后我们将得到的帧划分为不重叠的块网格,灵感来自Visual Transformers [11]。没有足够事件信息的生成块被丢弃,而其余的保留作为最终的事件数据表示。所提出的混合解决方案既受益于事件级表示,因为我们可以在一定程度上解决事件数据的稀疏性,也受益于基于帧的表示的鲁棒性。
2.2. Neural Network architectures for event data
基于深度学习的技术已经显示出与事件相机数据一起使用的有希望的结果。本节讨论处理不同类型事件表示的主要现有架构,以及从多个时间窗口聚合处理后的信息。此外,我们提供了Visual Transformers的简短概述,因为它们实际上是这项工作中提出的用于处理事件的架构的支柱之一。
Architectures for event-representations processing. 旨在处理事件级表示的方法使用利用事件稀疏性的架构处理每个时间窗口内的信息,例如脉冲神经网络[23, 39, 50]、PointNet风格的网络[47]或图神经网络[5, 6, 10]。不同的是,基于帧的方法通常依赖于使用卷积神经网络来处理为每个时间窗口构建的帧[1, 4, 8, 19]。有时也使用Transformers来处理CNN生成的特征之间的远程空间依赖关系[49]。这些方法处理整个帧,即使在该帧的大部分中没有触发任何事件。尽管通常比事件级表示获得更高的准确性,但这种不必要的处理使得基于帧的方法消耗的计算资源比需要的多。
Architectures to aggregate several time-windows data. 旨在分析长事件流的解决方案将它们划分为不同的时间窗口,这些时间窗口用前面描述的方法表示和处理,然后聚合以执行最终的视觉识别任务。这种聚合在相关工作中的执行方式不同,包括使用循环网络[19, 49]、CNN [1, 19]、时间缓冲区[4, 10]或在每个时间窗口的中间结果之间进行投票[19]。
根据聚合策略,我们认为事件处理算法能够执行在线推理,如果它可以在每个时间窗口内增量评估信息,因为它是生成的,然后以最小的延迟执行最终的视觉识别,而不是大批量处理所有捕获的信息。我们的方法通过使用简单的加法操作逐步更新一组潜在记忆向量,并使用简单的分类器处理结果向量来执行在线推理。
Visual Transformers. 最初为自然语言处理[44]引入的Transformer架构最近在视觉识别任务中获得了普及。Vision Transformer,处理由CNN [9]从RGB图像生成的特征,或者更常见的是,直接应用于从输入图像中提取的块[11, 27]。在处理视频数据时,一些方法[3, 28]将来自不同视频帧的块处理在一起,或者将时间信息与LSTM层[18]聚合。与这项工作特别相关的是Perceiver [21, 22],它是一种使用潜在向量来处理输入数据并限制变换器的二次复杂度的Transformer。
在这项工作中,我们使用类似Transformer的架构来分析从事件流中的时间窗口中提取的可变长度的激活块集。受[21, 22]的启发,我们使用潜在向量进行此处理,但不同的是,我们还使用从不同时间窗口中提取的信息逐步改进它们。
2.3. Event dataset recordings
尽管它们具有广阔的应用前景,但在真实场景中使用这些相机记录的大规模公共数据集仍然不多。因此,一些方法寻求将RGB数据集转换为基于事件的对应物。早期的基于事件的解决方案[6, 16, 26, 33, 38]在LCD监视器中显示RGB数据,并使用事件相机记录这些数据。最近的工作介绍了使用基于学习的模拟器[13, 17, 31]来生成事件数据。尽管如此,这些翻译后的数据集仍不能完全模仿事件数据的性质并引入某些伪影,特别是在它们的稀疏性和延迟方面。发生这种情况是因为事件是由不切实际的光照条件触发的,并且通常取决于监视器的固定低帧速率或相机在静态图像上的移动。为了获得更可靠的评估设置,我们将实验重点放在使用事件相机记录的真实场景数据集上。更具体地说,我们在与动作和手势识别相关的短[5]和长[1, 42]事件流的分类中训练和评估EvT。
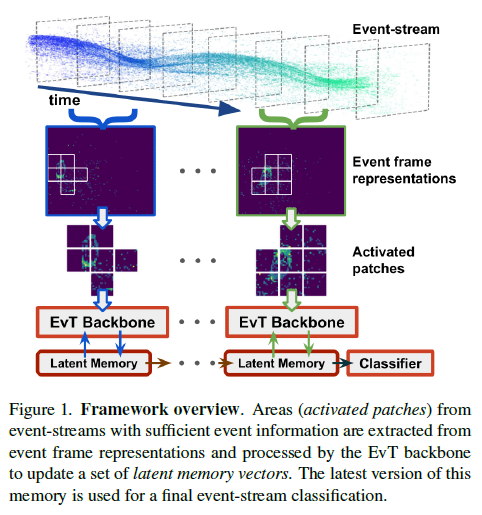
3. Event Transformer framework
与传统的RGB相机不同,事件相机以稀疏和异步的方式记录捕获的视觉信息。每次检测到强度变化时,相机都会触发一个事件e = {x, y, t, p},由其在传感器网格(H × W)空间内的位置(x, y)与事件的时间戳 t (以μs的顺序)及其极性 p (正或负变化)定义。
这项工作为有效的事件数据处理提出了一种新颖的解决方案(图1中的概述)。我们的框架引入了基于块的事件数据表示,该表示提取具有足够记录事件信息的中间帧表示区域。然后,生成的信息由我们提出的Event Transformer (EvT)处理,这是一个紧凑的神经网络,它使用一组潜在的内存向量来处理传入的事件数据以及对目前看到的信息进行编码。这些潜在向量的最终版本被处理以执行最终的视觉识别任务,在我们的例子中是事件流分类。接下来的小节详细介绍了所提出的基于块的事件数据表示和Event Transformer处理,以及如何使用内存向量对事件流进行分类。
3.1. Patch-based event data representation
与之前基于帧的方法[1, 4, 19]类似,我们聚合事件数据![]() 在时间窗口Δt期间生成类似帧的表示FH×W×B×2。F 中的每个位置(x, y) | yϵH, xϵW用 B 个桶的两个类似直方图的向量表示,分别用于每个极性pϵ{0, 1}。每个直方图将每个桶中的Δt离散化,并计算相应时段Δt/B中发生的正事件或负事件的数量。最终表示被转换为F' = log(F + 1)以平滑高度激活区域中的极高值。
在时间窗口Δt期间生成类似帧的表示FH×W×B×2。F 中的每个位置(x, y) | yϵH, xϵW用 B 个桶的两个类似直方图的向量表示,分别用于每个极性pϵ{0, 1}。每个直方图将每个桶中的Δt离散化,并计算相应时段Δt/B中发生的正事件或负事件的数量。最终表示被转换为F' = log(F + 1)以平滑高度激活区域中的极高值。
然后将帧表示拆分为大小为P × P的非重叠块。然后,如果每个块包含至少m%的非零元素,即如果至少有m%的像素(x, y),我们将每个块设置为已激活块内已注册事件。激活的块被EvT保留以供进一步处理,而未激活的块被丢弃,从而显著降低了后续计算成本并隐含地减少了环境噪声。如果激活块的数量低于阈值 n,即没有足够的视觉信息需要处理,我们扩展时间窗口Δt并使用新的传入事件增加事件集 ε,重新计算帧表示并提取激活块。重复最后一步,直到我们得到至少 n 个激活的块。作为最后一步,我们将 T 个激活的块展平以创建大小为(P2 × B × 2)的令牌,这是下一节中详细介绍的Transformer主干的输入。
因此,这种基于块的事件表示旨在利用不同的事件数据属性,以便以后更有效地处理事件数据。特别相关的是,时空事件稀疏性通过丢弃非信息块来解决,并且该数据的低延迟通过使用短时间窗(其长度适应事件密度)来解决,这些时间窗口也被二值化以获得更精细表示。
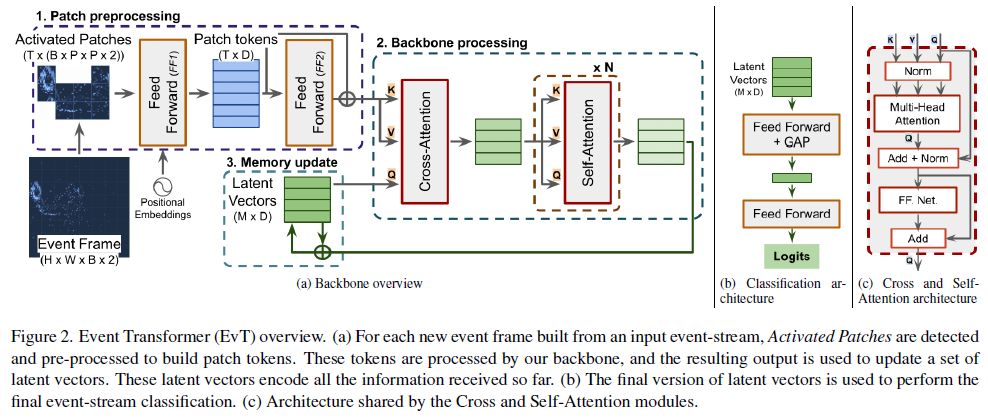
3.2. Event Transformer
Transformers是处理我们提出的基于块的表示的一种自然方式。与其他架构不同,它们能够摄取通过注意力机制处理的可变长度令牌列表。后者与卷积不同,专注于整个输入数据(将其构造为查询(Q)、键(K)和值(V))以捕获局部和长期令牌依赖关系。
我们工作的处理核心Event Transformer (EvT)就是受到这些想法的启发。这个主干处理,具有注意机制和一组 M 学到的潜在向量,块令牌列表(其长度取决于事件数据的稀疏性)。这些潜在向量也可用作内存,通过处理从事件流中的连续时间窗口计算的激活块,如第3.1节中所述,该内存会逐步细化。最终版本的精化潜在向量通过一个简单的分类器进行处理,以执行最终的事件流分类。整个过程(详见图2)分为以下几个步骤:
Patch pre-processing. T个输入激活的块中的每一个都映射到一个维度为 D 的向量。这个向量长度 D 在整个网络中是恒定的。该转换(FF1)由初始单层前馈网络(FF)、二维感知位置嵌入的串联和最后一个单层FF网络组成。需要使用位置嵌入来增加块信息,因为与CNN不同,Transformer不能隐式知道输入数据的位置。在被我们的主干核心处理之前,转换后的块,即块令牌,会经历另一个由双层前馈网络和跳过连接组成的转换(FF2),以实现更精细的表示,同时保留关于其的信息局部性。
Backbone processing. 我们骨干网的核心由共享相同架构的单个Cross-Attention和 N 个Self-Attention模块组成(详见图2c)。与之前的Transformer相关工作[3, 22, 44]类似,它由Multi-Head Attention层[44]、归一化层、跳过连接和前馈层组成。我们的主干首先根据块令牌信息K-V (Cross-Attention)处理潜在记忆向量Q,然后将得到的向量精炼为没有外部信息的Q-K-V (Self-Attention)。
Memory update. 一旦主干处理了块标记 T 和潜在向量,则通过简单的求和运算将本次迭代中生成的潜在向量与现有的内存潜在向量组合。这种潜在向量的增强版本编码了更广泛的时空信息,并将用于处理来自以下时间窗口的激活块。
Classification output. 我们提出的框架的最终输出是通过处理最新版本的潜在记忆向量获得的,其中包含迄今为止看到的事件流的关键时空信息。在我们的例子中,我们通过简单地使用两个前馈层和全局平均池(GAP)处理潜在向量来执行多类分类,如图2b所示。
4. Experiments
本节包括所提出的Event Transformer (EvT)的实现和训练细节,以及实验验证。我们在两个任务(动作和手势识别的长和短事件流分类)中评估EvT,分析其效率,并通过彻底的消融研究证明EvT设计选择的合理性。
4.1. Implementation and training details
Patch-based event representation.
Event Transformer.
Training details.
4.2. Evaluation
4.2.1 Long event-stream classification
4.2.2 Short event-stream classification
4.2.3 Event sparsity and model efficiency analysis
4.3. Ablation study
5. Conclusions
目前的工作介绍了一种用于事件数据处理的新颖框架,Event Transformer(EvT)。EvT有效地利用事件数据属性来最大限度地减少其计算和资源需求,同时实现最佳性能。EvT引入了一种新的基于稀疏块的事件数据表示,该表示仅考虑具有足够记录信息的部分流,以及一种高效且紧凑的类似Transformer的架构,可以自然地处理它。EvT在不同的动作和手势识别基准上实现了比当前最先进的更好或相当的准确性。最重要的是,我们的解决方案需要的计算资源比以前的工作要少得多,能够在CPU和GPU中以最小的延迟执行推理,从而促进其在低消耗硬件和实时应用程序上的使用。
基于所呈现的结果,我们认为基于块的表示和Transformer是有效事件数据处理的有前途的研究方向。该框架还为其他基于事件的感知任务(如身体跟踪或深度估计)以及不同类型的稀疏数据(如LiDAR数据)提供了有希望的好处。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号