Python 读取UCI iris数据集分析、numpy基础学习
 python基础、numpy使用、io读取数据集、数据处理转换与简单分析。读取UCI iris数据集中鸢尾花的萼片、花瓣长度数据,进行数据清理,去重,排序,并求出和、累积和、均值、标准差、方差、最大值、最小值。
python基础、numpy使用、io读取数据集、数据处理转换与简单分析。读取UCI iris数据集中鸢尾花的萼片、花瓣长度数据,进行数据清理,去重,排序,并求出和、累积和、均值、标准差、方差、最大值、最小值。
本文章未使用pandas库,若需要pandas+numpy请移步至 [第7天] Python Pandas 基础学习 - 小能日记 (cnblogs.com)
作业要求:读取UCI iris数据集中鸢尾花的萼片、花瓣长度数据,进行数据清理,去重,排序,并求出和、累积和、均值、标准差、方差、最大值、最小值
总共用时:3小时 (代码在后面)
学习内容:python基础、numpy使用、io读取数据集、数据处理转换与简单分析
学习建议:w3school的numpy教程讲的不错,数组连接那部分需要多看看以外,其他都可以一遍过。遇到新问题,多用搜索引擎,大胆尝试。方法名字不知道的要看学习网站总结的文档,具体的使用方式可以搜索引擎单独搜这个方法。
踩过的坑
1、VSCODE 保存PY文件时自动格式化导致过长的单行自动换行:
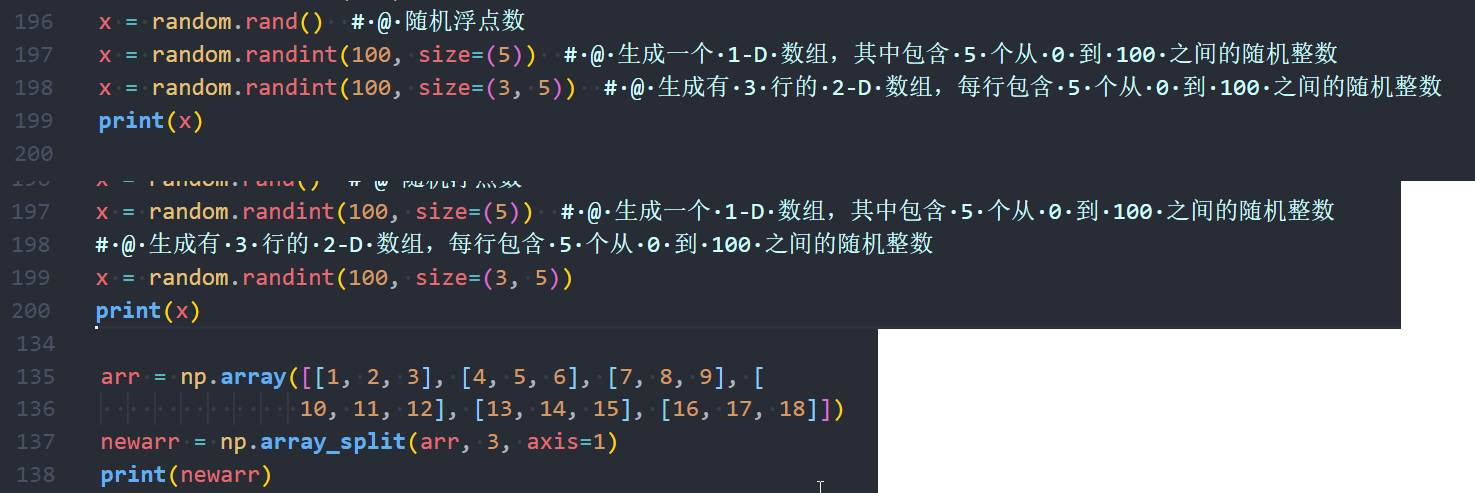
从图中可以看到保存时因为单行过长,导致格式化自动换行
解决方法:
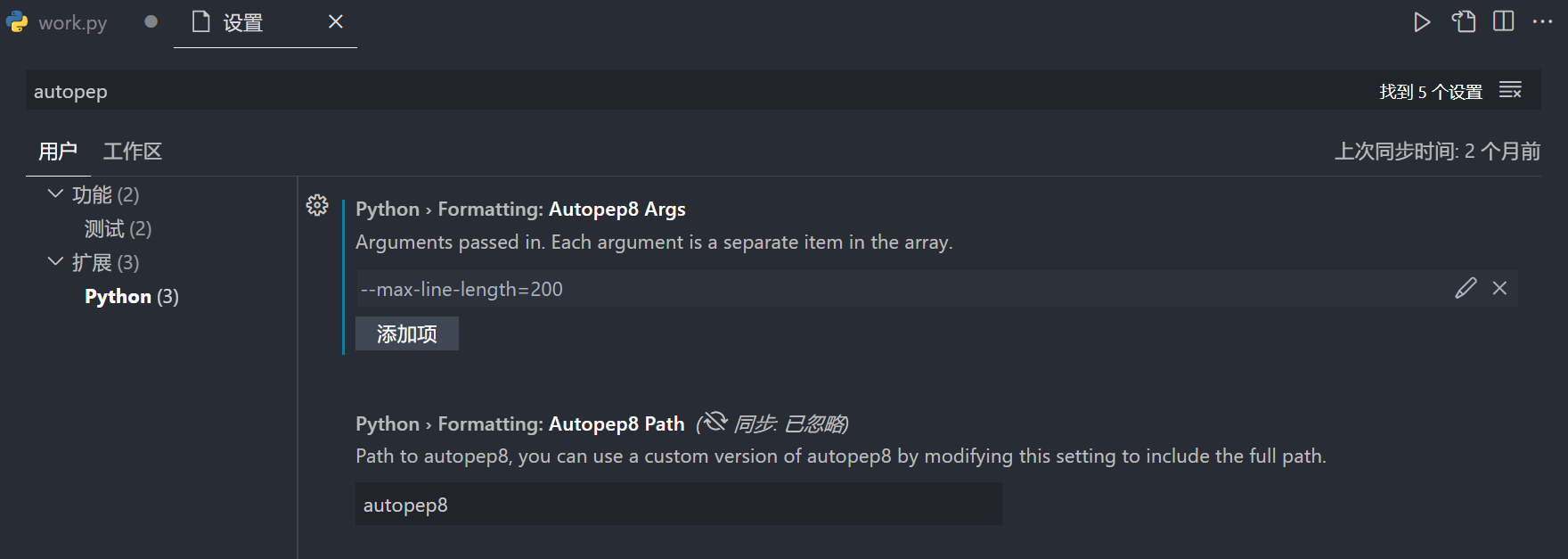
- 打开vscode左下角设置settings(ctrl+,)
- 输入框输入autopep8
- 在python>formatting:Autopep8 Args一栏选择Add Item
- 在添加条目的输入框输入:"--max-line-length=200",如图:
2、python中判断readline读到文件末尾
3、numpy.unique无法对二维数组去重
4、np.sort()函数的作用
5、python for 循环获取index索引
6、在NumPy中如何创建一个空的数组/矩阵?
7、在Numpy中使用自定义结构类型
NumPy 数据类型 | 菜鸟教程 (runoob.com)
Python numpy之结构化数据类型_m0_59235245的博客-CSDN博客_python结构化数据类型
# ^ 去重后转化为 numpy 数组
dt = np.dtype([('sepal_length', 'f4'), ('sepal_width', 'f4'), ('petal_length', 'f4'), ('petal_width', 'f4'), ('category', 'S20')])
res = np.array(list(set(tuple(t) for t in data)), dt)
print(res)
我的代码
注意:不需要手动下载iris.data,运行代码会自动从阿里OSS下载iris.data文件存储在当前目录中
import requests
import numpy as np
import sys
# ^ 阿里云OSS读取数据集文件
content = requests.get("https://xiaonenglife.oss-cn-hangzhou.aliyuncs.com/static/cnblogs/2020_3/iris.data")
if content.status_code != 200:
print("不成功")
sys.exit() # ^ 退出程序
f = open('iris.data', 'w')
f.write(content.text)
f.close
f = open('iris.data', 'r')
# ^ 另一种数据导入方法,字典键名为类别,每个键值对是一个数组,旧方法请看末尾
data = {}
line = f.readline()
while line:
if(len(line) > 1):
values = line.split(',')
data.setdefault(values[4].strip('\n'), []) # @ 如果键不存在,则插入这个具有指定值的键
data[values[4].strip('\n')].append([float(values[0]), float(values[1]), float(values[2]),
float(values[3])])
line = f.readline()
print(data)
print(data.keys())
# ^ 去重后转化为 numpy 数组
for key in data:
data[key] = np.array(list(set(tuple(t) for t in data[key])))
print(data)
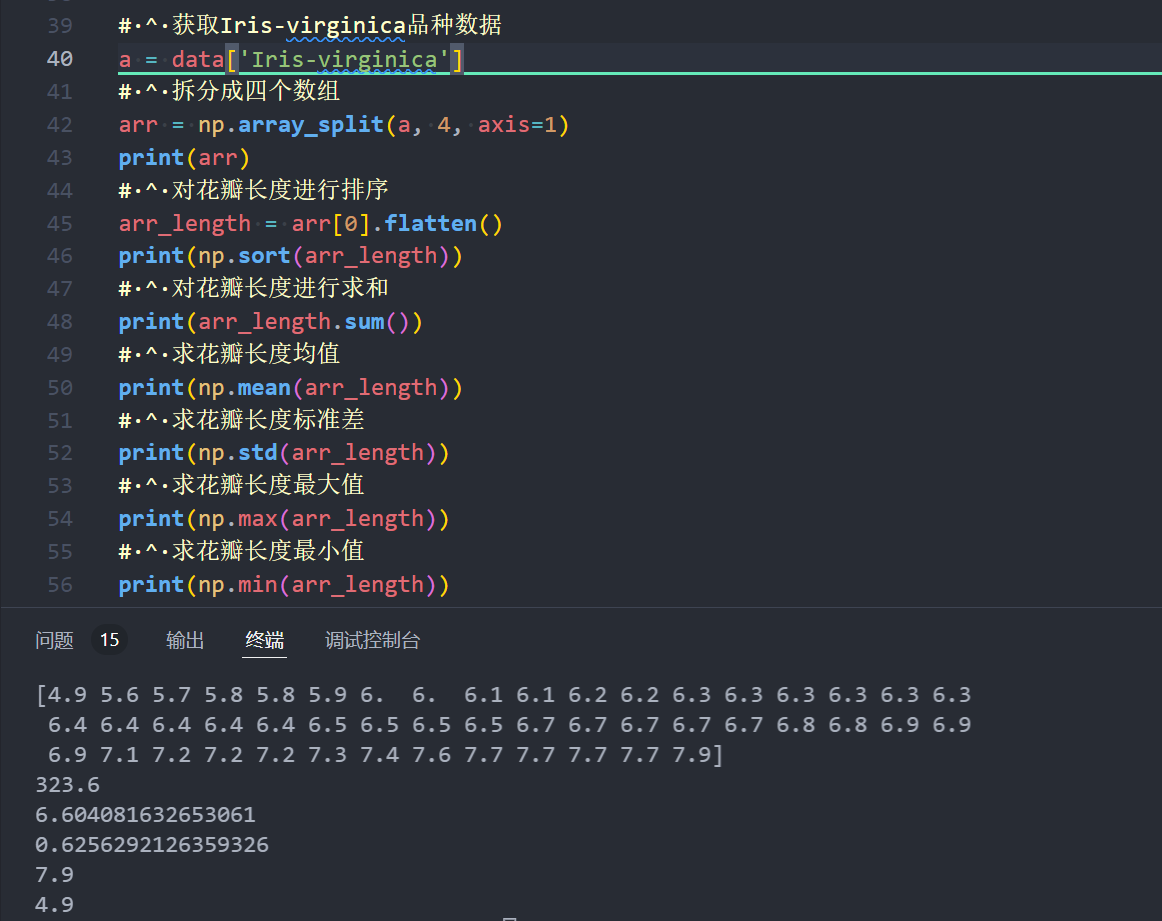
# ^ 获取Iris-virginica品种数据
a = data['Iris-virginica']
# ^ 拆分成四个数组
arr = np.array_split(a, 4, axis=1)
print(arr)
# ^ 对花瓣长度进行排序
arr_length = arr[2].flatten()
print(np.sort(arr_length))
# ^ 对花瓣长度进行求和
print(arr_length.sum())
# ^ 求花瓣长度均值
print(np.mean(arr_length))
# ^ 求花瓣长度标准差
print(np.std(arr_length))
# ^ 求花瓣长度最大值
print(np.max(arr_length))
# ^ 求花瓣长度最小值
print(np.min(arr_length))
"""
# ^ 字典数组方法
iris = []
line = f.readline()
while line:
# ^ print(len(line)) 可以看到最后一行无内容的但有一个空格
if(len(line) > 1):
values = line.split(',')
iris.append(dict(sepal_length=float(values[0]), sepal_width=float(values[1]), petal_length=float(values[2]),
petal_width=float(values[3]), category=values[4].strip('\n')))
line = f.readline()
print(iris, len(iris)) # ^ 输出字典数组
# ^ 数据清理去重
# ^ 把每一个字典转换成一个元组并保存到集合里,再循环集合转化为字典
iris = [dict(t) for t in set([tuple(d.items()) for d in iris])]
print(iris, len(iris))
# ^ 创建 ndarry 数组
# @ 方法二 a = np.zeros(shape=(len(iris), 4))
a = []
for index, item in enumerate(iris):
if item['category'] == "Iris-virginica": # ^ 只针对Iris-virginica品种
a.append([item['sepal_length'], item['sepal_width'], item['petal_length'], item['petal_width']])
a = np.array(a)
# ^ 拆分成四个数组
arr = np.array_split(a, 4, axis=1)
print(arr)
"""
新代码(自定义dt类型)
import requests
import numpy as np
import sys
# ^ 阿里云OSS读取数据集文件
content = requests.get("https://xiaonenglife.oss-cn-hangzhou.aliyuncs.com/static/cnblogs/2020_3/iris.data")
if content.status_code != 200:
print("不成功")
sys.exit() # ^ 退出程序
f = open('iris.data', 'w')
f.write(content.text)
f.close
f = open('iris.data', 'r')
# ^ 采用自定义数据结构类型进行转换
data = []
line = f.readline()
while line:
if(len(line) > 1):
values = line.split(',')
data.append([float(values[0]), float(values[1]), float(values[2]),
float(values[3]), values[4].strip('\n')])
line = f.readline()
# ^ 去重后转化为 numpy 数组
dt = np.dtype([('sepal_length', 'f4'), ('sepal_width', 'f4'), ('petal_length', 'f4'), ('petal_width', 'f4'), ('category', 'S20')])
res = np.array(list(set(tuple(t) for t in data)), dt)
print(res)
# ^ 数组过滤, 获取Iris-virginica品种数据
filter_arr = []
for element in res:
if element[4] == b'Iris-virginica':
filter_arr.append(True)
else:
filter_arr.append(False)
res = res[filter_arr]
# print(len(res), res)
# ^ 取出花瓣长度
arr_length = res["petal_length"]
# ^ 对花瓣长度进行排序
print(np.sort(arr_length))
# ^ 对花瓣长度进行求和
print(arr_length.sum())
# ^ 求花瓣长度均值
print(np.mean(arr_length))
# ^ 求花瓣长度标准差
print(np.std(arr_length))
# ^ 求花瓣长度最大值
print(np.max(arr_length))
# ^ 求花瓣长度最小值
print(np.min(arr_length))
from numpy import random
import numpy as np
def ___():
print("-----------------------------------------")
# ^ 导入模块
print("版本号", np.__version__)
___()
# ^ 使用模块创建标量、一维数组、二维数组、三维数组
arr0 = np.array(11)
arr1 = np.array([1, 2, 3, 4])
arr2 = np.array([[1, 2, 3], [4, 5, 6]])
arr3 = np.array([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [8, 9, 10]]])
print(arr2)
print("arr2 数据类型", type(arr2))
print("arr3 维度为", arr3.ndim)
print("arr2 访问第二维第一个元素", arr2[1, 0])
___()
# ^ 数据类型
arr = np.array([1, 2, 3, 4])
print("arr数据对象类型", arr.dtype)
arr = np.array(['apple', 'banana', 'cherry'])
print("arr数据对象类型", arr.dtype)
# @ 定义数组元素的预期数据类型
arr = np.array([1, 2, 3, 4], dtype="S")
print("arr数据对象类型", arr.dtype)
___()
# @ 数组类型的转换
arr = np.array([1.1, 2.1, 3.1])
newarr = arr.astype('i') # @ newarr = arr.astype(int)
print(newarr, newarr.dtype)
arr = np.array([1, 0, 3])
newarr = arr.astype(bool)
print(newarr, newarr.dtype)
___()
# ^ 副本与视图
"""
副本拥有数据,对副本所做的任何更改都不会影响原始数组,对原始数组所做的任何更改也不会影响副本。
视图不拥有数据,对视图所做的任何更改都会影响原始数组,而对原始数组所做的任何更改都会影响视图。
"""
# @ 副本
arr = np.array([1, 2, 3, 4, 5])
x = arr.copy()
arr[0] = 61
print(arr)
print(x)
___()
# @ 视图
arr = np.array([1, 2, 3, 4, 5])
y = arr.view()
arr[0] = 61
print(arr)
print(y)
___()
# @ 检查副本与视图是否拥有数据 如果数组拥有数据, base 属性返回 None。否则,base 属性将引用原始对象。
print(x.base)
print(y.base)
___()
# ^数组形状
arr = np.array([[1, 2, 3], [4, 5, 6]])
print("arr 数组形状", arr.shape)
# ^数组重塑
arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
newarr = arr.reshape(4, 3)
print("将12个元素一维转为二维\n", newarr)
newarr = arr.reshape(2, 3, 2)
print("将12个元素一维转为三维\n", newarr)
print("重塑返回的是视图", newarr.base) # IMPORTANT
___()
# ^ 展平数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
newarr = arr.reshape(-1)
print(newarr)
# ^ 使用迭代器遍历三维数组
arr = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
for x in np.nditer(arr):
print(x)
# @ 迭代并修改数据类型,需要额外空间
for x in np.nditer(arr, flags=['buffered'], op_dtypes=['S']):
print(x)
# @ 以不同的步长迭代
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
for x in np.nditer(arr[:, ::2]):
print(x)
# @ 枚举迭代
arr = np.array([[1, 2, 3, 4], [5, 6, 7, 8]])
for idx, x in np.ndenumerate(arr):
print(idx, x)
___()
# ^ 数组连接
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
arr = np.concatenate((arr1, arr2))
print(arr)
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[5, 6], [7, 8]])
arr = np.concatenate((arr1, arr2), axis=1)
print(arr)
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
arr = np.stack((arr1, arr2), axis=1)
print(arr)
___()
# ^ 数组分割
arr = np.array([1, 2, 3, 4, 5, 6])
newarr = np.array_split(arr, 3)
print(newarr)
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9], [
10, 11, 12], [13, 14, 15], [16, 17, 18]])
newarr = np.array_split(arr, 3, axis=1)
print(newarr)
___()
# ^ 数组搜索
arr = np.array([1, 2, 3, 4, 5, 4, 4])
x = np.where(arr == 4)
print(x)
arr = np.array([6, 7, 8, 9])
x = np.searchsorted(arr, 7)
print(x)
arr = np.array([6, 7, 8, 9])
x = np.searchsorted(arr, 7, side='right')
print(x)
___()
# ^ 数组排序
arr = np.array([3, 2, 0, 1])
print(np.sort(arr))
# @ 此方法返回数组的副本,而原始数组保持不变。
arr = np.array(['banana', 'cherry', 'apple'])
print(np.sort(arr))
arr = np.array([[3, 2, 4], [5, 0, 1]])
print(np.sort(arr))
___()
# ^ 数组过滤
arr = np.array([61, 62, 63, 64, 65])
x = [True, False, True, False, True]
newarr = arr[x]
print(newarr)
# @ 创建过滤器
arr = np.array([61, 62, 63, 64, 65])
# 创建一个空列表
filter_arr = []
# 遍历 arr 中的每个元素
for element in arr:
# 如果元素大于 62,则将值设置为 True,否则为 False:
if element > 62:
filter_arr.append(True)
else:
filter_arr.append(False)
# IMPORTANT 简写为 filter_arr = arr > 62
# STEP 如 filter_arr = arr % 2 == 0
newarr = arr[filter_arr]
print(filter_arr)
print(newarr)
# ^ 生成随机数
x = random.randint(100)
x = random.rand() # @ 随机浮点数
x = random.randint(100, size=(5)) # @ 生成一个 1-D 数组,其中包含 5 个从 0 到 100 之间的随机整数
x = random.randint(100, size=(3, 5)) # @ 生成有 3 行的 2-D 数组,每行包含 5 个从 0 到 100 之间的随机整数
x = random.choice([3, 5, 7, 9])
x = random.choice([3, 5, 7, 9], size=(3, 5))
print(x)
___()
# ^ 请使用 NumPy mean() 方法确定平均:
speed = [99, 86, 87, 88, 111, 86, 103, 87, 94, 78, 77, 85, 86]
x = np.mean(speed)
print(x)
# ^ 请使用 NumPy median() 方法找到中间值:
x = np.median(speed)
print(x)
# ^ 使用 NumPy std() 方法查找标准差:
x = np.std(speed)
print(x)
# ^ 使用 NumPy var() 方法确定方差:
speed = [32, 111, 138, 28, 59, 77, 97]
x = np.var(speed)
print(x)
# ^ 使用 NumPy percentile() 方法查找百分位数
ages = [5, 31, 43, 48, 50, 41, 7, 11, 15, 39, 80, 82, 32, 2, 8, 6, 25, 36, 27, 61, 31]
x = np.percentile(ages, 75)
print(x)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号