Python Pandas库 初步使用
 用pandas+numpy读取UCI iris数据集中鸢尾花的萼片、花瓣长度数据,进行数据清理,去重,排序,并求出和、累积和、均值、标准差、方差、最大值、最小值
用pandas+numpy读取UCI iris数据集中鸢尾花的萼片、花瓣长度数据,进行数据清理,去重,排序,并求出和、累积和、均值、标准差、方差、最大值、最小值
作业要求:用pandas+numpy读取UCI iris数据集中鸢尾花的萼片、花瓣长度数据,进行数据清理,去重,排序,并求出和、累积和、均值、标准差、方差、最大值、最小值
学习网站:Runoob
Pandas官方文档:pandas-docs
总共用时:1.5小时 (代码在最后面)
学习内容:pandas库基础
踩过的坑
1、关于Python pandas模块输出每行中间省略号问题
关于Python pandas模块输出每行中间省略号问题 - James·Sean - 博客园 (cnblogs.com)
pd.set_option('display.width', None)
pd.set_option('display.max_rows', None)我的代码
work.py
import pandas as pd
import numpy as np
import requests
import sys
import os
path = os.path.dirname(__file__)
# ^ 阿里云OSS读取数据集文件
content = requests.get("https://xiaonenglife.oss-cn-hangzhou.aliyuncs.com/static/cnblogs/2020_3/iris.data")
if content.status_code != 200:
print("不成功")
sys.exit() # ^ 退出程序
f = open(path+'iris.csv', 'w')
f.write(content.text)
f.close()
df = pd.read_csv(path+'iris.csv', names=['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'class'])
print(df)
print('共 {0} 行'.format(df.index.__len__()))
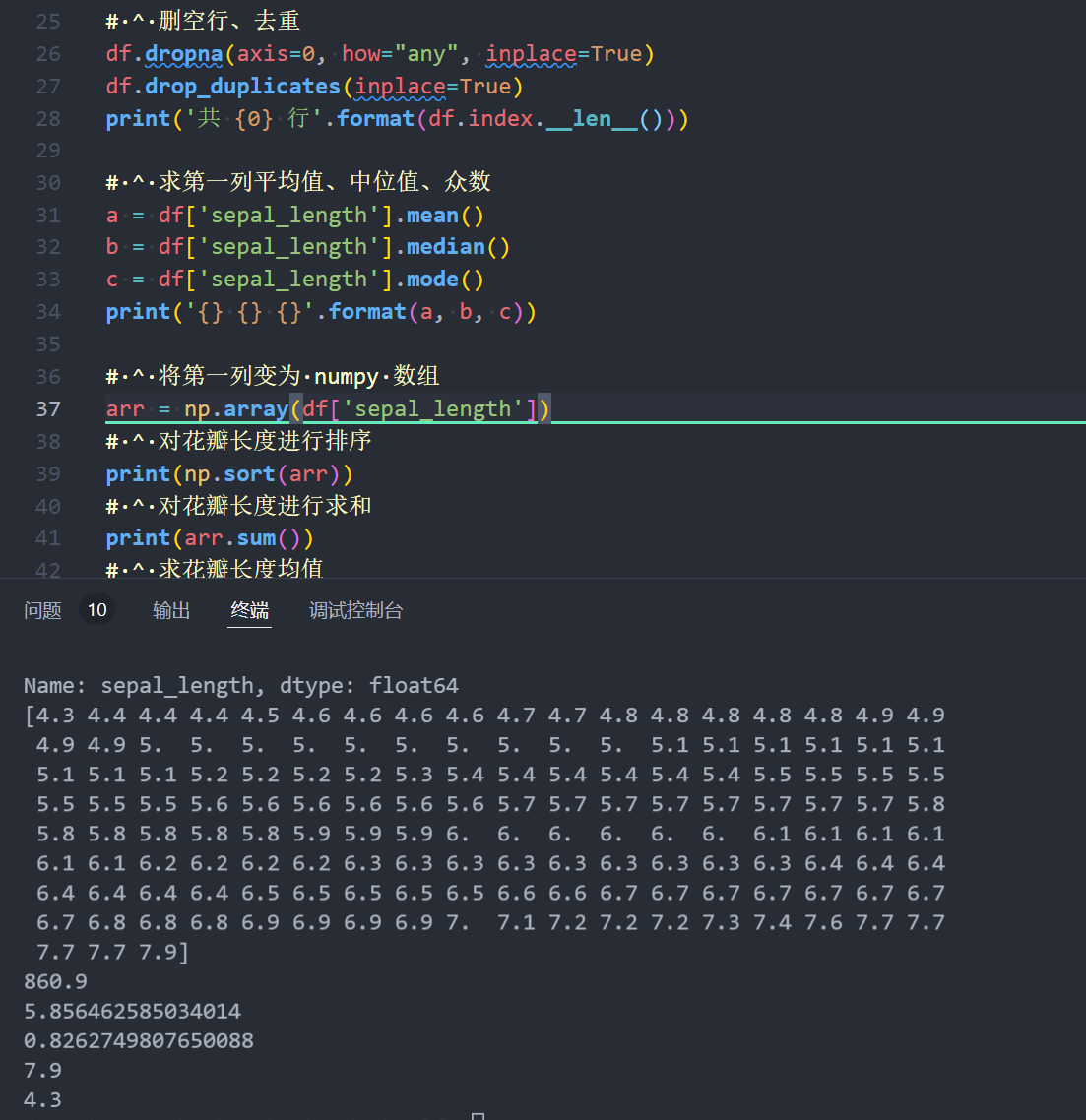
# ^ 删空行、去重
df.dropna(axis=0, how="any", inplace=True)
df.drop_duplicates(inplace=True)
print('共 {0} 行'.format(df.index.__len__()))
# ^ 求第一列平均值、中位值、众数
a = df['sepal_length'].mean()
b = df['sepal_length'].median()
c = df['sepal_length'].mode()
print('{} {} {}'.format(a, b, c))
# ^ 将第一列变为 numpy 数组
arr = np.array(df['sepal_length'])
# ^ 对花瓣长度进行排序
print(np.sort(arr))
# ^ 对花瓣长度进行求和
print(arr.sum())
# ^ 求花瓣长度均值
print(np.mean(arr))
# ^ 求花瓣长度标准差
print(np.std(arr))
# ^ 求花瓣长度最大值
print(np.max(arr))
# ^ 求花瓣长度最小值
print(np.min(arr))
study.py
# pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
import pandas as pd
import json
import os
path = os.path.dirname(__file__)
# f = open(path+'/data.json', 'r', encoding="utf-8")
# data = f.read()
# data = json.loads(data)
# pd.set_option('display.width', None)
# pd.set_option('display.max_rows', None)
# ^ 测试pandas
print(pd.__version__)
data = pd.read_json(path+'/data.json')
print(data)
# ^ Series
a = ["Google", "Runoob", "Wiki"] # @ 数组
myvar = pd.Series(a, index=["x", "y", "z"])
print(myvar)
a = {1: "Google", 2: "Runoob", 3: "Wiki"} # @ 字典
myvar = pd.Series(a)
print(myvar)
# ^ DataFrame
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index=["day1", "day2", "day3"])
print(df.loc["day2"])
data2 = [{'C': 'Google', 'A': 10, 'B': 93.5}, {'C': 'Runoob', 'A': 12, 'B': 89}]
df2 = pd.DataFrame(data2)
print(df2)
# ^ 打开 CSV 文件
df = pd.read_csv(path+'/iris.csv')
print(df.info())
# @ 返回前后 n 行,默认5行
print(df.head())
print(df.tail())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号