
深度解析:双模态仿真测试解决方案
随着端到端自动驾驶架构的兴起,传统基于规则的仿真测试正面临“真实感不足”与“场景泛化难”的双重挑战。
本文深入解析双模态仿真测试解决方案:一方面依托 aiSim 提供确定性的物理级传感器建模;另一方面通过 World Extractor 实现基于3DGS/NeRF的自动化世界重建。
重点探讨二者如何通过混合渲染(Hybrid Rendering)的技术路线,在保留真实世界视觉保真度的同时,实现动态交通流的泛化,构建可用于闭环验证的数字孪生环境。
一、端到端测试挑战
自动驾驶仿真测试的核心矛盾,长期存在于“物理真实性(Realism)”与“仿真可控性(Controllability)”之间。基于此我们构建了两条既独立又互补的技术路线,形成了完整的工具链生态:
-
物理驱动路线(Model-based): 以 aiSim 仿真平台为核心,基于高精度的3D网格与物理材质系统,提供ISO 26262 ASIL D认证级的确定性仿真,侧重于闭环验证、传感器模型研究与极端边缘场景构造。
-
数据驱动路线(Data-driven): 以 World Extractor 工具链为核心,利用 3DGS 和 NeRF 技术,将真实采集数据自动化重建为高保真数字世界,侧重于解决感知模型的Sim-to-Real Gap(虚实迁移差距)。
这两条路线并非割裂,而是通过混合渲染架构在终端汇聚,为高阶智驾提供“静态环境真实、动态目标可控”的闭环测试能力。
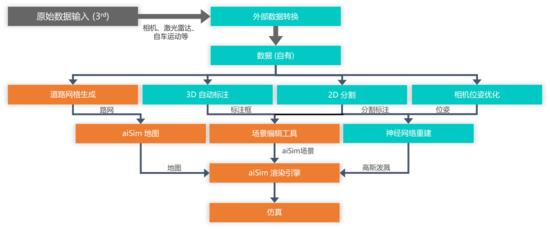
二、aiSim:确定性高保真物理仿真引擎
aiSim 并非仅为神经渲染服务的播放器,而是一款独立的、基于物理的高性能仿真全栈仿真平台,集成了动力学仿真、天气环境系统、物理传感器模型、场景编辑等自动驾驶测试关键功能,并经过 ISO 26262 ASIL D 认证。其核心价值在于为端到端智驾系统提供高保真的确定性输出,并进行有效闭环测试。

1、自研渲染引擎与确定性
不同于基于游戏引擎(如UE/Unity)的方案,aiSim 采用自研的基于 Vulkan API 的渲染管线。
(1)确定性(Determinism): 保证在不同硬件架构(从工作站到云端大规模集群)上,同一帧场景的渲染结果在任意传感器数据层面完全一致,包括像素、点云、动力学信息。这对于回归测试至关重要。
(2)光线追踪(Ray-tracing): 支持对激光雷达(LiDAR)和雷达(Radar)进行多径反射仿真和高斯线束,并基于物理材质属性(PBR)计算反射率,非简单的几何投影。
2、物理级传感器建模
aiSim 并不止步于理想传感器模型,而是深入到物理特性层面:
(1)Camera: 支持从光圈、畸变(F-theta/Mei/Ocam)、CFA(色彩滤光阵列)到ISP后处理的全链路仿真。
(2)LiDAR: 基于辐射测量(Radiometric)而非光度测量,考虑了905nm波长下的材质反射率、大气衰减(雨雾中的Mie散射)以及卷帘门效应(Rolling Shutter)。
(3)Radar: 采用光线追踪模拟多径效应,支持输出RCS、多普勒速度及点云级别的仿真。

三、World Extractor:自动化重建
针对传统手工建模周期长(月级)、成本高的问题,World Extractor 提供了一套从采集到重建的成熟可用的端到端自动化工具链,将现实世界转化为数字资产。
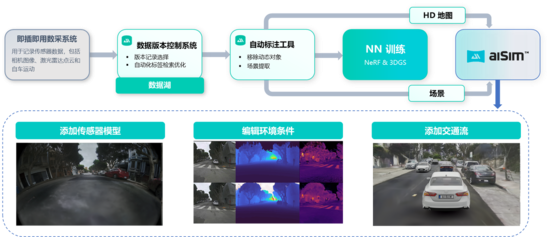
1、严格的硬件采集标准
高质量的重建始于高质量的数据。康谋定义了严格的传感器部署规范以满足神经渲染需求:
(1)覆盖要求: 相机需实现360°全覆盖,相邻视场重叠度需 >10°,以确保特征点匹配。
(2)同步精度: 多传感器(Camera/LiDAR)与GNSS/INS的时间同步精度需<1ms,位置误差需控制在厘米级(RTK/PPK)。
(3)推荐配置: 采用Sony IMX490/728传感器及128线激光雷达,确保高动态范围与点云密度。
2、自动化处理与3DGS训练
采集的数据经过脱敏、清洗后,进入自动化标注与训练流程:
(1)动态物体移除: 这是重建纯净静态世界的关键。工具链利用自动化标注算法(结合2D分割与3D包围盒)识别并剔除路面上的移动车辆与行人,仅保留静态车辆建筑物、路面、植被、等静态元素。
(2)训练新范式:针对传统3DGS在稀疏视角下几何结构崩坏以及外推能力差的问题,提出了NeRF2GS的新路径
-
Step 1 (Teacher): 先训练一个 NeRF 模型。利用 NeRF 在几何连续性上的优势,结合含噪声的 LiDAR 点云进行深度正则化(Depth Regularization)训练。
-
Step 2 (Student): 将 NeRF 生成的高质量深度图和法线图作为监督信号,初始化并训练 3DGS 模型。
-
优势: 这种方法显著修复了路面、天空等弱纹理区域的几何错误,确保了在合成新视角(Novel View Synthesis)时,路面平整、车道线清晰,且无伪影
(3)大规模分块训练:针对城市级大规模场景(>100,000 m²),采用BEV空间动态分块(Block-based)策略,支持多GPU并行训练,通过重叠区域(Overlap)消除块与块之间的渲染接缝。
四、混合渲染以实现闭环测试
这是本方案的核心技术壁垒。单纯的3DGS/NeRF虽然视觉逼真,但本质是“三维录像”,难以修改内容。为了实现闭环测试(Closed-loop Testing),康谋采用了“混合渲染”(Hybrid Rendering)技术。
1、why“静态3DGS + 动态OpenSCENARIO”?
目前学术界存在的4DGS技术虽然能还原动态场景,但缺乏交互性——你无法控制录制视频中车辆的刹车或变道。 康谋的策略是解耦:
(1)背景(Background): 使用World Extractor生成的静态3DGS模型,确保环境的真实(纹理、光照、几何细节)。
(2)前景(Foreground): 使用aiSim物理引擎生成的动态网格(Mesh)物体(车辆、行人),这些物体的行为由 OpenSCENARIO 标准格式驱动,支持泛化和交互。
这种组合既满足了感知算法对分布外(OOD)数据的渴求,又满足了规控算法对交互式测试的需求。

2、深度合成技术
在渲染管线中,如何让“虚拟的车”正确地行驶在“真实的路”上,并被“真实的树”遮挡?这依赖于精确的深度合成(Depth Compositing)技术:
(1)系统实时计算3DGS背景的深度图(Depth Map)与aiSim前景物体的Z-buffer。
(2)遮挡关系: 能够精确处理“虚拟车辆行驶在真实树木后方”的遮挡关系,且边缘无锯齿。
(3)光照融合: 利用从神经场中提取的环境光照信息(IBL),照亮虚拟物体,使其阴影和反射与背景环境浑然一体。

3、多模态一致性
对于 LiDAR 仿真,康谋并未采用简单的深度图投影,而是实现了针对3D高斯球的光线追踪。
(1)机制: 将3D高斯球作为代理几何体(Proxy Geometry)构建加速结构(BVH)。LiDAR 射线直接与这些高斯球进行求交计算。
(2)多模态输出: 不仅能获取距离信息,还能从神经特征中解码出强度(Intensity)信息,从而合成出带有真实反射率特性的点云数据。
(3)保证了Camera与LiDAR在同一时刻、同一视角下的时空强同步。
五、场景泛化与工程落地
基于上述架构,实现了从“复现”到“泛化”的跨越。
1、动态交通流泛化
在重建的高保真静态地图中,测试人员可以通过 OpenSCENARIO 自由配置交通流。例如,在一段空旷的旧金山重建路段中,通过算法生成拥堵场景、Cut-in(切入)场景或事故场景。
这极大地扩展了ODD(运行设计域)的覆盖范围,解决了感知算法在真实路测中难以遇到Corner Case的痛点。
2、广泛的HiL集成
该工具链已在多个OEM及Tier 1中验证,支持与主流域控平台的硬件在环(HiL)集成:
(1)视频注入: 支持通过HDMI/DP或GMSL注入卡,将混合渲染后的视频流直接注入域控制器(如NVIDIA Orin, NVIDIA Thorn, Horizon J6)。
(2)实时性: 在单节点部署下(如4卡仿真图站),即可实现12路相机+激光雷达的高帧率实时仿真,通过分布式集群部署可进一步提升性能表现和渲染质量。
双模态仿真测试解决方案,并非简单的工具堆叠,而是对自动驾驶测试痛点的深刻工程解构。
通过 NeRF2GS 技术,我们将真实世界“搬进”了仿真器;通过 aiSim 物理引擎,我们让这个世界“活”了起来。这种“静态环境高保真,动态场景全泛化”的混合渲染模式,为从感知到规控的端到端闭环验证提供了目前行业内最优的数据底座,显著降低了对高成本路测的依赖。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号