D3D12中同步机制
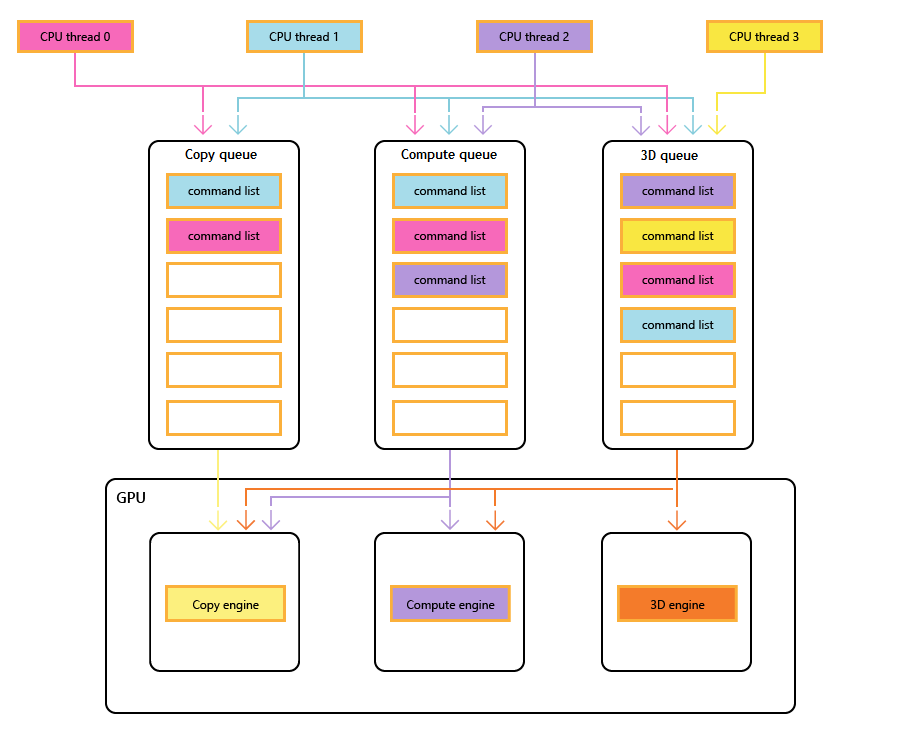
命令列表(Command List)
命令列表(Command List):ID3D12GraphicsCommandList 是 ID3D12CommandList 的子类,其中定义了很多状态设置函数,调用其中的函数,就向命令列表添加一个状态设置命令
有了命令列表可以更好的利用 CPU 多线程能力,应用程序可以启用多个线程,为每个线程创建一个命令列表,每个线程负责一部分命令的记录
例如,可以创建四个线程,每个线程负责场景中 1/4 的模型绘制命令的提交
命令队列(Command Queue)
命令队列(Command Queue):命令列表(Command List)中的命令需要提交到命令队列(Command Queue)中,GPU 才会执行,调用 ID3D12CommandQueue::ExecuteCommandLists 提交命令
命令列表(Command List)也不止一个,有的命令相互之间没有依赖,GPU 可以并行消费这些命令提高效率
D3D12 将 GPU 能并行消费命令的功能抽象为三种引擎:
- 拷贝引擎(Copy Engine):GPU 有一个或多个拷贝引擎,执行数据拷贝命令
- 计算引擎(Compute Engine):GPU 有一个计算引擎,执行计算命令和拷贝命令
- 3D 引擎(3D Engine):GPU 有一个 3D 引擎,能执行图形命令、计算命令和拷贝命令
这三种引擎是同时工作的
需要注意的是命令队列(Command Queue)只是显卡驱动中命令队列的抽象,并不代表设备真的支持那么多队列
通常一种命令队列(3D queue、Compute queue、Copy queue)只创建一个,如果创建多个,然而都只有映射到显卡驱动实际拥有的一个队列,那么多个队列的命令还是需要串行地提交到显卡驱动中,反而可能增加同步的开销
只能在Copy engine上执行命令有:
CopyBufferRegion
CopyTextureRegion
CopyTiles
ResourceBarrier
能在Compute engine上执行命令有:
CopyBufferRegion CopyTextureRegion CopyTiles ResourceBarrier ClearState DiscardResource SetPredication ClearUnorderedAccessViewUint ClearUnorderedAccessViewFloat SetDescriptorHeaps SetComputeRootSignature SetComputeRoot32BitConstant SetComputeRoot32BitConstants SetComputeRootConstantBufferView SetComputeRootShaderResourceView SetComputeRootUnorderedAccessView SetComputeRootDescriptorTable SetPipelineState // 只能设置计算流水线状态对象 Dispatch ExecuteIndrect // 只能间接执行Dispatch EndQuery // 只能查询时间戳类型 ResolveQueryData // 只能解析时间戳类型的查询
在D3D12中,所有的直接命令队列(3D queue)和计算命令队列(Compute queue)被分为一类,称为图形/计算类(3D/Compute)
所有复制命令队列(Copy queue)被分为一类,称为复制类(Copy)
图形/计算类(3D/Compute)和复制类(Copy)都被称为命令队列类,命令队列类有且仅有图形/计算类(3D/Compute)和复制类(Copy)两个实例
不同Command List之间的原子性
即使有多个CPU线程并发地向Command Queue中添加命令,由于只有一个GPU线程从Command Queue中取出数据,一个Command Queue中的各Command List肯定是按顺序串行执行的
注1:一个Command Queue中的命令是严格按照添加进去的顺利来执行的,前面命令执行完,才会执行后面的命令
注2:Command Queue中的命令有6种,其中5种分别对应于ID3D12CommandQueue接口的5个方法(ExecuteCommandLists、Signal、Wait、UpdateTileMapping和CopyTileMappings)
第6种是ISwapChain::Present,该命令在创建交换链时所指定的Command Queue上执行
Command List内部命令的并发性
对于单个Command List中的命令则不一定是按序执行的,而是会发送到GPU的3D engine、Compute engine、Copy engine并发执行的。
使用资源屏障(ResourceBarrier)来控制Command List内部命令的并发性 注:资源屏障(ResourceBarrier)像Fence一样,也可以控制Command Queue中的Command List的同步
Fence(围栏)
Fence可用于控制CPU与GPU的同步,以及不同Command Queue之间的同步,但是Command List内部的并发性对于Fence而言是不可见的
在调用 ID3D12Device::CreateFence 创建围栏时,给它设置一个初始围栏点(围栏点,Fence Point是一个UINT64类型的整数)
在创建之后,CPU线程可调用 ID3D12Fence::Signal 函数给Fence设置新的数值。GPU 命令可以调用 ID3D12CommandQueue::Signal 函数给命令队列给指定Fence设置新的数值
GPU线程可以通过ID3D12CommandQueue::Wait等待某个Fence,直到Fence的值大于或等于某个指定的值时,等待才会结束
CPU线程可以通过ID3D12Fence::SetEventOnCompletion,获取某个Fence的值,配合event内核对象,来做等待控制
GPU等待CPU发起动作才执行后面的命令
Microsoft::WRL::ComPtr<ID3D12Device> md3dDevice; Microsoft::WRL::ComPtr<IDXGISwapChain> mSwapChain; Microsoft::WRL::ComPtr<ID3D12CommandQueue> mCommandQueue; Microsoft::WRL::ComPtr<ID3D12GraphicsCommandList> mCommandList; Microsoft::WRL::ComPtr<ID3D12Fence> m_fence; void Init() { //创建Fence,初始值为5 md3dDevice->CreateFence(5, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&m_fence)); // 鼠标左键按下,触发OnLMouseButtonDown()函数调用 Bind(LMouseButton.Down, OnLMouseButtonDown); } void Render() { // ... ... // 向CommandQueue队列添加一个wait命令,GPU阻塞等待围栏的值达到或超过7,才继续执行 即:m_fence->GetCompletedValue()大于或等于 Value 时,GPU将终止等待 mCommandQueue->Wait(m_fence.Get(), 7);
mCommandList.Close(); ID3D12CommandList* cmdsLists[] = { mCommandList.Get() }; mCommandQueue->ExecuteCommandLists(_countof(cmdsLists), cmdsLists); mSwapChain->Present(0, 0); } void OnLMouseButtonDown() { // CPU线程将fence设置为7,GPU线程结束等待,从而执行Command Queue中的后2个命令 m_fence->Signal(7); }
CPU线程一共向Command Queue中添加3个命令:Wait、ExecuteCommandLists和Present(隐式指定命令队列);GPU由于执行Wait命令而等待,后面2个命令留在命令队列中
执行OnLMouseButtonDown()函数,CPU线程将fence设置为7,使得GPU线程结束等待,从而执行Command Queue中的后2个命令
Present 是 DXGI Swap Chain 的核心方法,它的作用是把后台缓冲区内容“呈现”到前台,让用户看到新一帧
// 返回类型是 HRESULT // 成功:S_OK // 失败:常见错误码 DXGI_ERROR_DEVICE_REMOVED (0x887A0005):设备丢失 XGI_ERROR_INVALID_CALL (0x887A0001):参数或状态非法 E_ABORT (0x80004004):操作被中止(常见于最小化窗口或驱动重启) HRESULT Present( UINT SyncInterval, // 控制帧交换与垂直同步的关系 // 0:立即显示,无垂直同步(允许撕裂,FPS不限,测性能时常用) // 1:等待下一个 VSync,保证不撕裂(大多数游戏/应用默认,FPS上限为显示器刷新率) // n:等待第 n 次 VSync。通常极少用,高帧延时,特殊场景(如视频回放)才会使用 UINT Flags // 控制额外行为 0:正常 Present,最常用 // DXGI_PRESENT_DO_NOT_WAIT:如果上一次 Present 尚未完成,立即返回 // DXGI_PRESENT_TEST:只做显示测试,不真的切换帧(性能调试时用,很少用) // DXGI_PRESENT_RESTART :重启交换链(几乎不用) );
每一帧CPU强制同步等待GPU完成

代码逻辑如下:
Microsoft::WRL::ComPtr<ID3D12Device> md3dDevice; Microsoft::WRL::ComPtr<ID3D12CommandQueue> mCommandQueue; Microsoft::WRL::ComPtr<ID3D12Fence> m_fence; HANDLE m_fenceEvent; void Init() { //创建Fence,初始值为0 md3dDevice->CreateFence(0, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&m_fence)); //创建一个event对象 m_fenceEvent = CreateEvent(nullptr, FALSE, FALSE, nullptr); } void WaitGPUFinish() { // NewFenceValue表示应该设置的新的围栏值,它应该和从GetCompletedValue()获得的旧的围栏值不一样,比如+1。 const UINT64 NewFenceValue = m_fence->GetCompletedValue() + 1; // 向CommandQueue队列添加一个Signal命令,当GPU执行到围栏命令时,表示前面的命令都执行完,此时将围栏设定为新的值 mCommandQueue->Signal(m_fence.Get(), NewFenceValue); // 围栏自己也设定:当它到达新的值时,将会触发m_fenceEvent这个事件 m_fence->SetEventOnCompletion(NewFenceValue, m_fenceEvent); // 让程序无限地等待m_fenceEvent这个事件,直到CommandQueue完成队列 WaitForSingleObject(m_fenceEvent, INFINITE); }
不同GPU Command Queue之间的同步
GPU 命令引擎之间的同步也通过围栏完成
当一个 commandQueue1 需要 commandQueue2 等待它最后一个命令的完成时,可以调用 commandQueue1->Signal 设置围栏,调用 commandQueue2->Wait 等待

代码逻辑如下:
Microsoft::WRL::ComPtr<ID3D12Device> md3dDevice; Microsoft::WRL::ComPtr<ID3D12CommandQueue> m3DCommandQueue; Microsoft::WRL::ComPtr<ID3D12CommandQueue> mComputeCommandQueue; Microsoft::WRL::ComPtr<ID3D12GraphicsCommandList> mComputeCommandList; Microsoft::WRL::ComPtr<ID3D12Fence> m_fence; void Init() { //创建Fence,初始值为0 md3dDevice->CreateFence(0, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&m_fence)); } void Render() { // ... ... // 向3DCommandQueue队列添加一个wait命令,GPU阻塞等待围栏的值达到或超过6,才继续执行 即:m_fence->GetCompletedValue()大于或等于 Value 时,GPU将终止等待 m3DCommandQueue->Wait(m_fence.Get(), 6); // 分派计算着色器到一个线程组 mComputeCommandList->Dispatch(1, 1, 1);
mComputeCommandList.Close(); // 添加命令列表到CommandQueue命令队列,以便执行 ID3D12CommandList* cmdsLists[] = { mComputeCommandList.Get() }; mComputeCommandQueue->ExecuteCommandLists(_countof(cmdsLists), cmdsLists); // 向CommandQueue队列添加一个Signal命令,当GPU执行到围栏命令时,表示前面的命令都执行完,此时将围栏设定为新的值 mComputeCommandQueue->Signal(m_fence.Get(), 6); }
资源屏障(ResourceBarrier)
同一个资源可能被 CPU/GPU 共享,也可能被 GPU 多个线程共享。为了避免资源访问冲突(Resource Hazard),我们需要对资源进行同步,比如资源在写入未完成时读取,会导致读取错误
过去驱动程序(如D3D11)会跟踪资源的绑定,推测资源状态的变化,同步对资源的访问。跟踪状态对产生额外的 CPU 开销,糟糕的同步点会严重影响效率
所以,新时代图形 API (如D3D12)都将同步的任务交给开发者
这里介绍 GPU 内部多线程对资源访问的同步 —— 资源屏障(Resource Barrier)。在资源状态切换时,设置屏障,同步 GPU 线程对资源的访问
ID3D12GraphicsCommandList::ResourceBarrier函数的形式如下:
void ResourceBarrier( [in] UINT NumBarriers, [in] const D3D12_RESOURCE_BARRIER *pBarriers );
在为资源设置屏障时,需要填写 D3D12_RESOURCE_BARRIER 结构:
typedef struct D3D12_RESOURCE_BARRIER { D3D12_RESOURCE_BARRIER_TYPE Type; D3D12_RESOURCE_BARRIER_FLAGS Flags; union { D3D12_RESOURCE_TRANSITION_BARRIER Transition; D3D12_RESOURCE_ALIASING_BARRIER Aliasing; D3D12_RESOURCE_UAV_BARRIER UAV; }; } D3D12_RESOURCE_BARRIER;
- Type:资源屏障的类型,所有选项由枚举 D3D12_RESOURCE_BARRIER_TYPE 列出,上面介绍的情况设置为D3D12_RESOURCE_BARRIER_TYPE_TRANSITION,表示转换资源屏障
- Flags:表示在资源转换什么时候设置屏障,所有选项由枚举 D3D12_RESOURCE_BARRIER_FLAGS 列出
- Transition:因为是用于资源转换时的屏障,因此选填联合体中的 Transition 成员,D3D12_RESOURCE_TRANSITION_BARRIER,下面时该结构体的成员:
- pResource:表示需要设置屏障的资源指针
- SubResource:子资源如何转换,这里设置为 D3D12_RESOURCE_BARRIER_ALL_SUBRESOURCES ,表示同时转换所有子资源
- StateBefore:资源转换之前的状态,所有选项由枚举 D3D12_RESOURCE_STATES 列出 注:表示需要转换权限的子资源当前的值。如果设置的值与实际中的值不符,可能会导致GPU崩溃。也就是说上层逻辑有义务准确跟踪子资源权限的当前值
- StateAfter:资源转换之后的状态,所有选项由枚举 D3D12_RESOURCE_STATES 列出
任何一种资源(Resource)都是一个子资源(SubResource)的序列,例如:一张256 x 256的2D纹理是由9个mip子资源组成序列的集合

子资源权限
D3D12_RESOURCE_BARRIER中的Transition数据的StateBefore和StateAfter成员指定子资源对命令队列类的权限,用D3D12_RESOURCE_STATES枚举来定义
① 子资源对复制类(Copy)的权限只能是以下3种:
D3D12_RESOURCE_STATE_COMMON = 0 // 公共(可写)
D3D12_RESOURCE_STATE_COPY_DEST = 0x400 // 可作为复制宿(可写)
D3D12_RESOURCE_STATE_COPY_SOURCE = 0x800 // 可作为复制源(只读)
② 子资源对图形/计算类(3D/Compute)的权限可以是任意一种权限,除了以上3种外还有:
D3D12_RESOURCE_STATE_VERTEX_AND_CONSTANT_BUFFER = 0x1 // 可作为顶点或常量缓冲(只读)
D3D12_RESOURCE_STATE_INDEX_BUFFER = 0x2 // 可作为索引缓冲(只读)
D3D12_RESOURCE_STATE_RENDER_TARGET = 0x4 // 可作为渲染目标(可写)
D3D12_RESOURCE_STATE_UNORDERED_ACCESS = 0x8 // 可作为无序访问(可写)
D3D12_RESOURCE_STATE_DEPTH_WRITE = 0x10 // 可作为深度模板(可写)
D3D12_RESOURCE_STATE_DEPTH_READ = 0x20 // 可作为只读深度模板(只读)
D3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCE = 0x40 // 可作为非像素着色器资源(只读)
D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE = 0x80 // 可作为像素着色器资源(只读)
D3D12_RESOURCE_STATE_STREAM_OUT = 0x100 // 可作为流输出(可写)
D3D12_RESOURCE_STATE_INDIRECT_ARGUMENT = 0x200 // 可作为间接参数(只读)
D3D12_RESOURCE_STATE_RESOLVE_DEST = 0x1000 // 可作为解析宿(可写)
D3D12_RESOURCE_STATE_RESOLVE_SOURCE = 0x2000 // 可作为解析源(只读)
// 。。。 。。。
子资源的权限被分为只读和可写两大类,子资源对命令队列类的权限可以是只有一个可写权限,也可以是同时有多个只读权限
D3D12定义了一个通用读权限D3D12_RESOURCE_STATE_GENERIC_READ,是如下权限的组合:
D3D12_RESOURCE_STATE_GENERIC_READ = D3D12_RESOURCE_STATE_COPY_SOURCE = 0x800 // 可作为复制源(只读) | D3D12_RESOURCE_STATE_INDIRECT_ARGUMENT = 0x200 // 可作为间接参数(只读) | D3D12_RESOURCE_STATE_VERTEX_AND_CONSTANT_BUFFER = 0x1 // 可作为顶点或常量缓冲(只读) | D3D12_RESOURCE_STATE_INDEX_BUFFER = 0x2 // 可作为索引缓冲(只读) | D3D12_RESOURCE_STATE_NON_PIXEL_SHADER_RESOURCE = 0x40 // 可作为非像素着色器资源(只读) | D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE = 0x80 // 可作为像素着色器资源(只读)
每个子资源(SubResource)关联了两份权限,分别对应于图形/计算类(3D/Compute)和复制类(Copy)
子资源对图形/计算类(3D/Compute)的权限在CPU线程执行直接命令队列或计算命令队列中的命令访问子资源时得到体现
同理,子资源对复制类(Copy)的权限在CPU线程执行复制命令队列中的命令访问子资源时得到体现
使用资源屏障(ResourceBarrier)来控制Command List内部命令的并发性
在面向GPU编程时,GPU高速缓存并不一定是相干的,即一个GPU核心对内存的写入并不一定会立即被其他GPU核心察觉到
不同的操作使用不同的GPU高速缓存,GPU完成执行写入操作只是将数据写入到GPU高速缓存中,GPU后续执行的读取操作将无法从内存中访问到相关的数据
资源屏障可以认为是在面向GPU编程时特有的一种内存同步原语,保证了资源屏障之前的GPU命令对内存的写入一定会被资源屏障之后的GPU命令察觉到
举个例子,上面用上传堆更新数据时,需要将数据从上传堆写入默认堆,比如纹理资源。GPU 的像素着色器需要读取纹理。如果拷贝未完成,像素着色器就开始采用纹理,必然会导致结果错误
因此在拷贝开始时,我们调用 ID3D12GraphicsCommandList::ResourceBarrier 为默认堆资源设置一个资源转换屏障,并将它的状态设置为D3D12_RESOURCE_STATE_COPY_DEST ,避免像素着色器读取
当拷贝结束,再将状态设置为D3D12_RESOURCE_STATE_GENERIC_READ ,允许着色器读取
RTT(Render To Texture,渲染到纹理)示例
下面以RTT(Render To Texture,渲染到纹理)为例来做详细说明
具体过程:先把一个彩色三角形渲染到 512x512 的 RTT 纹理,再把该纹理绘制到屏幕(全屏四边形)
其中使用ResourceBarrier函数对ComPtr<ID3D12Resource> rttTexture纹理资源进行状态转换
为了提高性能,GPU内部是高度并发的,如果没有用资源屏障来对纹理资源进行控制,渲染RTT纹理与纹理绘制到屏幕2个命令会同时执行,可能出现纹理没准备好就往屏幕上绘制的情况。
头文件和全局变量
#include <windows.h> #include <d3d12.h> #include <dxgi1_6.h> #include <d3dcompiler.h> #include <DirectXMath.h> #include <wrl.h> using namespace Microsoft::WRL; #pragma comment(lib, "d3d12.lib") #pragma comment(lib, "dxgi.lib") #pragma comment(lib, "d3dcompiler.lib") HWND g_hwnd = nullptr; UINT g_width = 800, g_height = 600; ComPtr<ID3D12Device> device; ComPtr<IDXGISwapChain3> swapChain; ComPtr<ID3D12CommandQueue> cmdQueue; ComPtr<ID3D12CommandAllocator> cmdAlloc; ComPtr<ID3D12GraphicsCommandList> cmdList; ComPtr<ID3D12DescriptorHeap> rtvHeap, srvHeap; ComPtr<ID3D12Resource> backBuffers[2]; UINT rtvDescSize; UINT frameIndex; HANDLE fenceEvent; ComPtr<ID3D12Fence> fence; UINT64 fenceValue = 0; // RTT ComPtr<ID3D12Resource> rttTexture; D3D12_CPU_DESCRIPTOR_HANDLE rttRTV; D3D12_CPU_DESCRIPTOR_HANDLE rttSRV; // PSO/RootSignature ComPtr<ID3D12RootSignature> rootSig; ComPtr<ID3D12PipelineState> rttPSO, blitPSO;
主窗口创建
LRESULT CALLBACK WndProc(HWND hWnd, UINT msg, WPARAM wParam, LPARAM lParam) { if (msg == WM_DESTROY) PostQuitMessage(0); return DefWindowProc(hWnd, msg, wParam, lParam); } void InitWindow(HINSTANCE hInstance) { WNDCLASS wc = {0}; wc.lpfnWndProc = WndProc; wc.hInstance = hInstance; wc.lpszClassName = L"D3D12RTT"; RegisterClass(&wc); g_hwnd = CreateWindow(wc.lpszClassName, L"D3D12 RTT Demo", WS_OVERLAPPEDWINDOW, CW_USEDEFAULT, CW_USEDEFAULT, g_width, g_height, nullptr, nullptr, hInstance, nullptr); ShowWindow(g_hwnd, SW_SHOW); }
D3D12 初始化(设备、交换链、命令队列等)
void InitD3D() { // 设备 ComPtr<IDXGIFactory4> factory; CreateDXGIFactory1(IID_PPV_ARGS(&factory)); D3D12CreateDevice(nullptr, D3D_FEATURE_LEVEL_11_0, IID_PPV_ARGS(&device)); // 命令队列 D3D12_COMMAND_QUEUE_DESC qDesc = {}; device->CreateCommandQueue(&qDesc, IID_PPV_ARGS(&cmdQueue)); // 交换链 DXGI_SWAP_CHAIN_DESC1 scDesc = {}; scDesc.BufferCount = 2; scDesc.Width = g_width; scDesc.Height = g_height; scDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM; scDesc.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT; scDesc.SwapEffect = DXGI_SWAP_EFFECT_FLIP_DISCARD; scDesc.SampleDesc.Count = 1; ComPtr<IDXGISwapChain1> sc1; factory->CreateSwapChainForHwnd(cmdQueue.Get(), g_hwnd, &scDesc, nullptr, nullptr, &sc1); sc1.As(&swapChain); frameIndex = swapChain->GetCurrentBackBufferIndex(); // 在交换链被创建时,交换链缓冲中的所有子资源对图形/计算类(3D/Compute)的权限都是D3D12_RESOURCE_STATE_COMMON(公共) // 命令分配器/列表 device->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT, IID_PPV_ARGS(&cmdAlloc)); device->CreateCommandList(0, D3D12_COMMAND_LIST_TYPE_DIRECT, cmdAlloc.Get(), nullptr, IID_PPV_ARGS(&cmdList)); cmdList->Close(); // RTV堆 D3D12_DESCRIPTOR_HEAP_DESC rtvHeapDesc = {}; rtvHeapDesc.NumDescriptors = 3; // 2 backbuffer + 1 RTT rtvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_RTV; device->CreateDescriptorHeap(&rtvHeapDesc, IID_PPV_ARGS(&rtvHeap)); rtvDescSize = device->GetDescriptorHandleIncrementSize(D3D12_DESCRIPTOR_HEAP_TYPE_RTV); // SRV堆 D3D12_DESCRIPTOR_HEAP_DESC srvHeapDesc = {}; srvHeapDesc.NumDescriptors = 1; srvHeapDesc.Type = D3D12_DESCRIPTOR_HEAP_TYPE_CBV_SRV_UAV; srvHeapDesc.Flags = D3D12_DESCRIPTOR_HEAP_FLAG_SHADER_VISIBLE; device->CreateDescriptorHeap(&srvHeapDesc, IID_PPV_ARGS(&srvHeap)); // BackBuffer RTV D3D12_CPU_DESCRIPTOR_HANDLE rtvHandle = rtvHeap->GetCPUDescriptorHandleForHeapStart(); for (int i = 0; i < 2; ++i) { swapChain->GetBuffer(i, IID_PPV_ARGS(&backBuffers[i])); device->CreateRenderTargetView(backBuffers[i].Get(), nullptr, rtvHandle); rtvHandle.ptr += rtvDescSize; } }
创建RTT纹理及其RTV和SRV
void CreateRTT() { // 创建一个2D纹理资源作为RTT D3D12_RESOURCE_DESC texDesc = {}; texDesc.Dimension = D3D12_RESOURCE_DIMENSION_TEXTURE2D; texDesc.Width = 512; texDesc.Height = 512; texDesc.DepthOrArraySize = 1; texDesc.MipLevels = 1; texDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM; texDesc.SampleDesc.Count = 1; texDesc.Layout = D3D12_TEXTURE_LAYOUT_UNKNOWN; texDesc.Flags = D3D12_RESOURCE_FLAG_ALLOW_RENDER_TARGET; D3D12_CLEAR_VALUE clearValue = {}; clearValue.Format = DXGI_FORMAT_R8G8B8A8_UNORM; clearValue.Color[0] = 0.0f; clearValue.Color[1] = 0.0f; clearValue.Color[2] = 0.0f; clearValue.Color[3] = 1.0f; device->CreateCommittedResource( &CD3DX12_HEAP_PROPERTIES(D3D12_HEAP_TYPE_DEFAULT), D3D12_HEAP_FLAG_NONE, &texDesc, D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE, // 此参数为资源对图形/计算类(3D/Compute)的权限,即:可作为像素着色器资源(只读)。那么该资源对复制类(Copy)的权限是什么呢?
// 答:当该值为COPY_DEST 可作为复制宿(可写)、COPY_SOURCE 可作为复制源(只读)、VERTEX_AND_CONSTANT_BUFFER 可作为顶点或常量缓冲(只读)、INDEX_BUFFER 可作为索引缓冲(只读)、
// NON_PIXEL_SHADER_RESOURCE 可作为非像素着色器资源(只读)、PIXEL_SHADER_RESOURCE 可作为像素着色器资源(只读)、UNORDERED_ACCESS 可作为无序访问(可写)时,
// 该资源对复制类(Copy)的权限为D3D12_RESOURCE_STATE_COMMON(公共),否对复制类(Copy)的权限是不可见的
// 注:不可见是复制类(Copy)特有的概念,图形/计算类(3D/Compute)不存在这样的概念。子资源对复制类不可见是指资源永远不可能被复制类(Copy)命令队列所对应的GPU线程访问到 &clearValue, IID_PPV_ARGS(&rttTexture) ); // RTT的RTV rttRTV = rtvHeap->GetCPUDescriptorHandleForHeapStart(); rttRTV.ptr += 2 * rtvDescSize; // 第3个 device->CreateRenderTargetView(rttTexture.Get(), nullptr, rttRTV); // RTT的SRV rttSRV = srvHeap->GetCPUDescriptorHandleForHeapStart(); D3D12_SHADER_RESOURCE_VIEW_DESC srvDesc = {}; srvDesc.Format = DXGI_FORMAT_R8G8B8A8_UNORM; srvDesc.ViewDimension = D3D12_SRV_DIMENSION_TEXTURE2D; srvDesc.Shader4ComponentMapping = D3D12_DEFAULT_SHADER_4_COMPONENT_MAPPING; srvDesc.Texture2D.MipLevels = 1; device->CreateShaderResourceView(rttTexture.Get(), &srvDesc, rttSRV); }
创建RootSignature对象
void CreateRootSignature() { // 一个SRV CD3DX12_DESCRIPTOR_RANGE range; range.Init(D3D12_DESCRIPTOR_RANGE_TYPE_SRV, 1, 0); CD3DX12_ROOT_PARAMETER param; param.InitAsDescriptorTable(1, &range, D3D12_SHADER_VISIBILITY_PIXEL); CD3DX12_ROOT_SIGNATURE_DESC desc; desc.Init(1, ¶m, 0, nullptr, D3D12_ROOT_SIGNATURE_FLAG_ALLOW_INPUT_ASSEMBLER_INPUT_LAYOUT); ComPtr<ID3DBlob> sigBlob, errBlob; D3D12SerializeRootSignature(&desc, D3D_ROOT_SIGNATURE_VERSION_1, &sigBlob, &errBlob); device->CreateRootSignature(0, sigBlob->GetBufferPointer(), sigBlob->GetBufferSize(), IID_PPV_ARGS(&rootSig)); }
创建RTT的PSO对象
void CreateRTTPSO() { const char* szRttVS = R"( struct VSOut { float4 pos : SV_Position; float4 color : COLOR; }; VSOut main(uint id : SV_VertexID) { float2 pos[3] = { float2(0,0.5), float2(0.5,-0.5), float2(-0.5,-0.5) }; float3 col[3] = { float3(1,0,0), float3(0,1,0), float3(0,0,1) }; VSOut o; o.pos = float4(pos[id], 0, 1); o.color = float4(col[id],1); return o; } )"; const char* szRttPS = R"( float4 main(float4 pos:SV_Position, float4 color:COLOR) : SV_Target { return color; } )"; ComPtr<ID3DBlob> vsRTTBlob, psRTTBlob; D3DCompile(rttVS, strlen(szRTTVS), nullptr, nullptr, nullptr, "main", "vs_5_0", 0, 0, &vsRTTBlob, nullptr); D3DCompile(rttPS, strlen(szRTTPS), nullptr, nullptr, nullptr, "main", "ps_5_0", 0, 0, &psRTTBlob, nullptr); D3D12_INPUT_ELEMENT_DESC inputLayoutRTT[] = {}; // PSO for RTT D3D12_GRAPHICS_PIPELINE_STATE_DESC psoRTTDesc = {}; psoRTTDesc.pRootSignature = rootSig.Get(); psoRTTDesc.VS = { vsRTTBlob->GetBufferPointer(), vsRTTBlob->GetBufferSize() }; psoRTTDesc.PS = { psRTTBlob->GetBufferPointer(), psRTTBlob->GetBufferSize() }; psoRTTDesc.BlendState = CD3DX12_BLEND_DESC(D3D12_DEFAULT); psoRTTDesc.SampleMask = UINT_MAX; psoRTTDesc.RasterizerState = CD3DX12_RASTERIZER_DESC(D3D12_DEFAULT); psoRTTDesc.DepthStencilState.DepthEnable = FALSE; psoRTTDesc.DepthStencilState.StencilEnable = FALSE; psoRTTDesc.InputLayout = { inputLayoutRTT, 0 }; psoRTTDesc.PrimitiveTopologyType = D3D12_PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE; psoRTTDesc.NumRenderTargets = 1; psoRTTDesc.RTVFormats[0] = DXGI_FORMAT_R8G8B8A8_UNORM; psoRTTDesc.SampleDesc.Count = 1; device->CreateGraphicsPipelineState(&psoRTTDesc, IID_PPV_ARGS(&rttPSO)); }
创建Blit到BackBuffer的PSO对象
void CreateBlitPSO() { const char* szBlitVS = R"( struct VSOut { float4 pos : SV_Position; float2 uv : TEXCOORD; }; VSOut main(uint id : SV_VertexID) { float2 pos[4] = { float2(-1,1), float2(1,1), float2(-1,-1), float2(1,-1) }; float2 uv[4] = { float2(0,0), float2(1,0), float2(0,1), float2(1,1) }; VSOut o; o.pos = float4(pos[id],0,1); o.uv = uv[id]; return o; } )"; const char* szBlitPS = "( Texture2D tex0 : register(t0); SamplerState sam0 : register(s0); float4 main(float4 pos:SV_Position, float2 uv:TEXCOORD) : SV_Target { return tex0.Sample(sam0, uv); } )"; D3DCompile(szBlitVS, strlen(szBlitVS), nullptr, nullptr, nullptr, "main", "vs_5_0", 0, 0, &vsBlitBlob, nullptr); D3DCompile(szBlitPS, strlen(szBlitPS), nullptr, nullptr, nullptr, "main", "ps_5_0", 0, 0, &psBlitBlob, nullptr); D3D12_INPUT_ELEMENT_DESC inputLayoutBlit[] = {}; D3D12_GRAPHICS_PIPELINE_STATE_DESC psoBlitDesc = {}; psoBlitDesc.pRootSignature = rootSig.Get(); psoBlitDesc.VS = { vsRTTBlob->GetBufferPointer(), vsRTTBlob->GetBufferSize() }; psoBlitDesc.PS = { psRTTBlob->GetBufferPointer(), psRTTBlob->GetBufferSize() }; psoBlitDesc.BlendState = CD3DX12_BLEND_DESC(D3D12_DEFAULT); psoBlitDesc.SampleMask = UINT_MAX; psoBlitDesc.RasterizerState = CD3DX12_RASTERIZER_DESC(D3D12_DEFAULT); psoBlitDesc.DepthStencilState.DepthEnable = FALSE; psoBlitDesc.DepthStencilState.StencilEnable = FALSE; psoBlitDesc.InputLayout = { inputLayoutBlit, 0 }; psoBlitDesc.PrimitiveTopologyType = D3D12_PRIMITIVE_TOPOLOGY_TYPE_TRIANGLE; psoBlitDesc.NumRenderTargets = 1; psoBlitDesc.RTVFormats[0] = DXGI_FORMAT_R8G8B8A8_UNORM; psoBlitDesc.SampleDesc.Count = 1; device->CreateGraphicsPipelineState(&psoBlitDesc, IID_PPV_ARGS(&blitPSO)); }
渲染循环
void WaitForGPU() { fenceValue++; cmdQueue->Signal(fence.Get(), fenceValue); if (fence->GetCompletedValue() < fenceValue) { fence->SetEventOnCompletion(fenceValue, fenceEvent); WaitForSingleObject(fenceEvent, INFINITE); } } void Render() { cmdAlloc->Reset(); cmdList->Reset(cmdAlloc.Get(), nullptr); // ---------- Pass 1: 渲染到RTT ---------- // 资源状态转换: SRV->RT 注:将rttTexture纹理资源从SRV转换为RenderTarget cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition( rttTexture.Get(), D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE, D3D12_RESOURCE_STATE_RENDER_TARGET) );
// CPU在调用ClearRenderTargetView函数之前,必须要调用ResourceBarrier函数将StateAfter成员变量设置为D3D12_RESOURCE_STATE_RENDER_TARGET
// 使得当GPU线程执行直接命令队列的命令列表中的ClearRenderTargetView命令时,作为渲染目标的资源,对图形/计算类(3D/Compute)的权限必须有可作为渲染目标(D3D12_RESOURCE_STATE_RENDER_TARGET) // 设置RTT为渲染目标 cmdList->OMSetRenderTargets(1, &rttRTV, FALSE, nullptr); FLOAT clearColor[4] = {0.1f, 0.1f, 0.1f, 1.0f}; cmdList->ClearRenderTargetView(rttRTV, clearColor, 0, nullptr); D3D12_VIEWPORT viewport = {0,0,512,512,0,1}; D3D12_RECT scissorRect = {0,0,512,512}; cmdList->RSSetViewports(1, &viewport); cmdList->RSSetScissorRects(1, &scissorRect); cmdList->SetPipelineState(rttPSO.Get()); cmdList->SetGraphicsRootSignature(rootSig.Get()); cmdList->IASetPrimitiveTopology(D3D_PRIMITIVE_TOPOLOGY_TRIANGLELIST); cmdList->DrawInstanced(3, 1, 0, 0); // 资源状态转换: RT->SRV 注:将rttTexture纹理资源从RenderTarget转换为SRV cmdList->ResourceBarrier(1, &CD3DX12_RESOURCE_BARRIER::Transition( rttTexture.Get(), D3D12_RESOURCE_STATE_RENDER_TARGET, D3D12_RESOURCE_STATE_PIXEL_SHADER_RESOURCE)); // ---------- Pass 2: 渲染到屏幕 ---------- D3D12_CPU_DESCRIPTOR_HANDLE bbRTV = rtvHeap->GetCPUDescriptorHandleForHeapStart(); bbRTV.ptr += frameIndex * rtvDescSize; cmdList->OMSetRenderTargets(1, &bbRTV, FALSE, nullptr); FLOAT clearColor2[4] = {0.2f, 0.2f, 0.2f, 1.0f}; cmdList->ClearRenderTargetView(bbRTV, clearColor2, 0, nullptr); D3D12_VIEWPORT viewport2 = {0,0,(float)g_width,(float)g_height,0,1}; D3D12_RECT scissorRect2 = {0,0,(LONG)g_width,(LONG)g_height}; cmdList->RSSetViewports(1, &viewport2); cmdList->RSSetScissorRects(1, &scissorRect2); cmdList->SetPipelineState(blitPSO.Get()); cmdList->SetGraphicsRootSignature(rootSig.Get()); ID3D12DescriptorHeap* heaps[] = { srvHeap.Get() }; cmdList->SetDescriptorHeaps(1, heaps); cmdList->SetGraphicsRootDescriptorTable(0, srvHeap->GetGPUDescriptorHandleForHeapStart()); cmdList->IASetPrimitiveTopology(D3D_PRIMITIVE_TOPOLOGY_TRIANGLESTRIP); cmdList->DrawInstanced(4, 1, 0, 0); // 提交 cmdList->Close(); ID3D12CommandList* lists[] = { cmdList.Get() }; cmdQueue->ExecuteCommandLists(1, lists); swapChain->Present(1, 0); // GPU线程在执行命令队列中的IDXGISwapChain::Present命令时,交换链缓冲中的所有子资源对图形/计算类(3D/Compute)的权限必须有D3D12_RESOURCE_STATE_COMMON(公共) WaitForGPU(); frameIndex = swapChain->GetCurrentBackBufferIndex(); }
主程序入口
int WINAPI WinMain(HINSTANCE hInstance, LPSTR, int) { InitWindow(hInstance); InitD3D(); CreateRTT(); CreateRootSignature(); CreateRTTPSO(); CreateBlitPSO(); // Fence device->CreateFence(0, D3D12_FENCE_FLAG_NONE, IID_PPV_ARGS(&fence)); fenceEvent = CreateEvent(nullptr, FALSE, FALSE, nullptr); // 主循环 MSG msg = {}; while (msg.message != WM_QUIT) { if (PeekMessage(&msg, nullptr, 0, 0, PM_REMOVE)) { TranslateMessage(&msg); DispatchMessage(&msg); } else { Render(); } } return 0; }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号