[计算机/硬件/GPU] 显卡
0 序
-
截至2025年,全球主流的AI大模型满血版的参数量均已突破百亿级,算力需求正以指数级飙升。特别是 DeepSeek 公司旗下的 R1 系列模型的问世,推动了很多中小企业部署私有化模型的需求。
-
然而,面对动辄数十万上百万元的GPU采购成本,选错一块显卡可能让个人或企业付出高昂的试错代价。
1 概述:显卡
显卡/Video Card
- 显卡(Video card、Display card、Graphics card、Video adapter)
- 作为计算机设备的基础组成部分之一
- 其将计算机系统需要的显示信息进行转换驱动显示器,并向显示器提供逐行或隔行扫描信号,控制显示器的正确显示
- 是连接显示器和个人计算机主板的重要组件,是“人机”的重要设备之一,其内置的并行计算能力现阶段也用于AI/深度学习等运算。
- 主要厂商:NVIDIA(英伟达)、AMD(超微半导体)、华为、
NVIDIA显示芯片的显卡称为
N卡,而将采用AMD显示芯片的显卡称为A卡

显示芯片/GPU
- 显示芯片( Video chipset )是显卡的主要处理单元
- 因此,又称为图形处理器(Graphic Processing Unit,
GPU/VPU)GPU是NVIDIA公司在1998年8月发布GeForce 256图形处理芯片(代号:NV10,此核心简称为GeForce,这亦是NVIDIA第1个 "GeForce" 生产线)时首先提出的概念。- 尤其是在处理3D图形时,
GPU使显卡减少了对CPU的依赖,并完成部分原本属于CPU的工作。GPU所采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。- 显卡所支持的各种3D特效由显示芯片的性能决定,采用什么样的显示芯片大致决定了这块显卡的档次和基本性能
比如,NVIDIA的GT系列和AMD的HD系列。
- 衡量一个显卡好坏的方法有很多,除了使用测试软件测试比较外,还有很多指标可供用户比较显卡的性能,影响显卡性能的高低主要有显卡频率、显示存储器等【性能指标】。
CPU vs.GPU
CPU / GPU / NPU
- CPU / GPU / NPU
- 普通服务器:
- 以CPU为核心,擅长逻辑处理与串行计算;
- CPU提供强大通用计算能力,适合处理复杂逻辑任务;
- 适用于Web服务、数据库、邮件服务器等通用IT服务
- CPU能效比相对较低,处理大规模并行计算效率有限
- 价格相对较低,易于扩展CPU、内存等资源
- GPU服务器:
- 配备高性能GPU,专为并行计算与图形处理设计;
- 提供数千至上万计算核心,单精度浮点性能可达数十TFLOPS(每秒万亿次浮点运算),显著优于同等价位CPU
- 专攻AI训练/推理、3D渲染、科学计算、大数据分析等计算密集型任务
- GPU架构高度并行,单位功耗下计算能力强,能效比优势明显
- 初期投入较高,但可通过增加GPU卡实现性能线性提升





HBM : 一款新型的 CPU/GPU 内存芯片
- HBM / GPU / CPU 的关系

“HBM”是一款新型的CPU/GPU内存芯片
2023年,“HBM”由《科创板日报》评选为2023年十大科技热词。
HBM成为 AI 服务器搭载标配,满足海量算力需求。
AI 大模型兴起催生海量算力需求,对芯片内存容量和传输带宽要求更高。
显卡的分类
集成显卡
-
配置核芯显卡的CPU通常价格不高,同时低端核显难以胜任大型游戏。
-
集成显卡是将显示芯片、显存及其相关电路都集成在主板上,与其融为一体的元件;
-
集成显卡的显示芯片有单独的,但大部分都集成在主板的北桥芯片中;
-
一些主板集成的显卡也在主板上单独安装了显存,但其容量较小。
-
集成显卡的显示效果与处理性能相对较弱,不能对显卡进行硬件升级,但可以通过
CMOS调节频率或刷入新BIOS文件实现软件升级来挖掘显示芯片的潜能。 -
集成显卡的优点是功耗低、发热量小,部分集成显卡的性能已经可以媲美入门级的独立显卡
所以很多喜欢自己动手组装计算机的人不用花费额外的资金来购买独立显卡,便能得到自己满意的性能。
- 集成显卡的缺点是性能相对略低,且固化在主板或CPU上,本身无法更换,如果必须换,就只能换主板。
核芯显卡
- 核芯显卡是
Intel产品新一代图形处理核心。
- 和以往的显卡设计不同,
Intel凭借其在处理器制程上的先进工艺以及新的架构设计,将图形核心与处理核心整合在同一块基板上,构成一个完整的处理器。- 智能处理器架构这种设计上的整合大大缩减了处理核心、图形核心、内存及内存控制器间的数据周转时间,有效提升处理效能并大幅降低芯片组整体功耗,有助于缩小核心组件的尺寸,为笔记本、一体机等产品的设计提供了更大选择空间。
-
需要注意的是,核芯显卡和传统意义上的集成显卡并不相同。
-
笔记本平台采用的【图形解决方案】主要有“独立”和“集成”两种:
- 独立显卡拥有单独的图形核心和独立的显存,能够满足复杂庞大的图形处理需求,并提供高效的视频编码应用;
- 集成显卡则将图形核心以单独芯片的方式集成在主板上,并且动态共享部分系统内存作为显存使用
因此能够提供简单的图形处理能力,以及较为流畅的编码应用。
- 相对于前两者,核芯显卡则将图形核心整合在处理器当中,进一步加强了图形处理的效率,并把集成显卡中的“处理器+南桥+北桥(图形核心+内存控制+显示输出)”三芯片解决方案精简为“处理器(处理核心+图形核心十内存控制)十主板芯片(显示输出)”的双芯片模式。
有效降低了核心组件的整体功耗,更利于延长笔记本的续航时间。
-
低功耗是核芯显卡的最主要优势,由于新的精简架构及整合设计,核芯显卡对整体能耗的控制更加优异,高效的处理性能大幅缩短了运算时间,进一步缩减了系统平台的能耗。
-
高性能也是它的主要优势:核芯显卡拥有诸多优势技术,可以带来充足的图形处理能力,相较前一代产品其性能的进步十分明显。
-
核芯显卡可支持
DX10/DX11、SM4.0、OpenGL2.0,以及全高清Full HD MPEG2/H.264/VC-1格式解码等技术,即将加入的性能动态调节更可大幅提升核芯显卡的处理能力,令其完全满足于普通用户的需求。
独立显卡 = { 消费级显卡、专业显卡 }
-
独立显卡是指将显示芯片、显存及其相关电路单独做在一块电路板上,自成一体而作为一块独立的板卡存在,它需占用主板的扩展插槽(
ISA、PCI、AGP或PCI-E)。 -
独立显卡的优点:
- 单独安装有显存,一般不占用系统内存
- 在技术上也较集成显卡先进得多
- 但性能肯定不差于集成显卡
- 容易进行显卡的硬件升级
- 独立显卡的缺点是:
- 功耗有所加大
- 发热量也较大
- 需额外花费购买显卡的资金
- 同时(特别是对笔记本电脑)占用更多空间。
由于显卡性能的不同对于显卡要求也不一样,独立显卡实际分为两类,一类专门为游戏设计的娱乐显卡/消费级显卡,一类则是用于绘图、3D渲染、AI计算的专业显卡。 [4]
显卡的一般结构
-
电容:电容是显卡中非常重要的组成部件,因为显示画质的优劣主要取决于电容的质量,而电容的好坏直接影响到显卡电路的质襞。
-
显存:显卡内存,显存负责存储显示芯片需要处理的各种数据,其容量的大小,性能的高低,直接影响着电脑的显示效果。
新显卡均采用DDR6/DDR5的显存, 主流显存容量一般为2GB ~ 4GB。
-
GPU及风扇:GPU即显卡芯片,它负责显卡绝大部分的计算工作,相当于CPU在电脑中的作用。GPU风扇的作用是给GPU散热。
-
显卡接口:通常被叫做金手指,可分为
PCI、AGP和PCI Express3种
PCI和AGP显卡接口都基本已被淘汰, 市面上主流显卡采用PCI Express的显卡。
-
外设接口:显卡外设接口担负着显卡的输出任务,新显卡包括一个传统VGA模拟接口和一个或多个数字接口(DVI、HDMI和DP)。
-
桥接接口:中高端显卡可支持多块同时工作,它们之间就是通过桥接器连接桥接口。

显卡接口 := 金手指 := 总线接口 := 输入接口
- 显卡接口:通常被叫做金手指,可分为
PCI、AGP和PCI Express3种
PCI和AGP显卡接口都基本已被淘汰, 市面上主流显卡采用PCI Express的显卡。
ISA接口 for VGA (已被淘汰)
ISA显卡是以前最普遍使用的VGA显示器所能支持的古老显卡。
VESA接口 (已被淘汰)
VESA是“Video Electronic Standards Association”(视频电子工程标准协会)的缩写,由多家计算机芯片制造商于1989年联合创立。- 1994年底,VESA发表了64位架构的“VESA Local Bus”标准,80486的个人计算机大多采用这一标准的显卡。 [6]
PCI 接口(已被淘汰)
PCI(Peripheral Component Interconnect)显卡,通常被使用于较早期或精简型的计算机中,此类计算机由于将AGP标准插槽移除而必须仰赖PCI接口的显卡。
- 1992年6月,英特尔发明了名为外部链接标准也就是Peripheral Component Interconnect的接口规范,缩写为PCI。 相较上一代 ISA,PCI 有着明显的速度提升,同时还能够自动配置资源,支持即插即用,很快就在各大厂商之间的混战中占领市场。
- 已知被多数的使用于
486到Pentium II早期的时代。- 但直到显示芯片无法直接支持
AGP之前,仍有部分厂商持续制造以AGP转PCI为基底的显卡。
- 已知最新型的
PCI接口显卡,是
GeForce GT 610 PCI(SPARKLE制)型号为GRSP610L1024LCATI HD 4350 PCI(HIS制)HIS HD 5450 PCI(HIS制)- HIS 5450 Silence 512MB DDR3 PCI DVI/HDMI/VGA 产品编号 H545H512P
AGP接口 (基于PCI 2.1扩容、已被淘汰)
AGP(Accelerated Graphics Port)是英特尔(Intel)公司在1996年开发的32位总线接口,用以增进计算机系统中的显示性能。
英特尔于1996年7月正式推出了AGP接口,它是一种显示AGP显卡图片卡专用的局部总线。
严格的说,AGP不能称为总线,它与PCI总线不同,因为它是点对点连接,即连接控制芯片和AGP显示卡,但在习惯上我们依然称其为AGP总线。
AGP接口是基于PCI 2.1 版规范并进行扩充修改而成,工作频率为66MHz。
- 分有AGP 1X、AGP 2X、AGP 4X及最后的AGP 8X,带宽分别为266MB/s、533MB/s、1066MB/s、以及2133 MB/s。
- 其中AGP 4X以后已跟之前电压不兼容。
- 其中3DLABS的“Wildcat4 7210”是最强的专业级AGP图形加速卡,而ATI公司的RadeonHD4670、HD3850,是2007年性能最强的消费级AGP图形加速卡。 [6]
PCI Express(PCI-E) 显卡 (主流)
-
PCI Express(亦称PCI-E)是显卡最新的图形接口,用来取代AGP显卡,面对日后3D显示技术的不断进步,AGP的带宽已经不足以应付庞大的数据运算。 -
性能最高的
PCI-Express显卡是NVIDIA公司的“NVIDIA Titan V”和AMD公司的“Radeon Pro Duo(Fiji)”。 -
现时,2007年后出产的显卡可支持双显卡技术(NVIDIA的SLi及nvlink和AMD的CrossFire)。


- 外接的 PCI Express (PCI-E)显卡
- 用
USB或Thunderbolt高带宽线材连接到外接PCI Express显卡盒,需要用独立电源供应。
外设接口 := 输出接口
- 外设接口:显卡外设接口担负着显卡的输出任务,新显卡包括一个传统VGA模拟接口和一个或多个数字接口(DVI、HDMI和DP)。

VGA 模拟接口 (已被淘汰、低端或工控显示设备)
- VGA:模拟信号接口
- 输出过程:显卡输出的数字信号需要经过数模转换才能通过VGA接口传输,到了显示器端又要进行模数转换。
这种转换过程易导致信号损失,影响显示质量。
- 分辨率与刷新率支持:由于传输的是模拟信号,带宽较低,一般最高只能支持到2048x1536的分辨率,在高分辨率下显示效果不理想
- 应用场景与特点: 曾经是电脑显示器的主要接口,但随着数字接口的发展,逐渐被淘汰。现在主要应用于一些对显示画质要求不高的老旧设备、工业控制设备或一些特殊的显示场景。

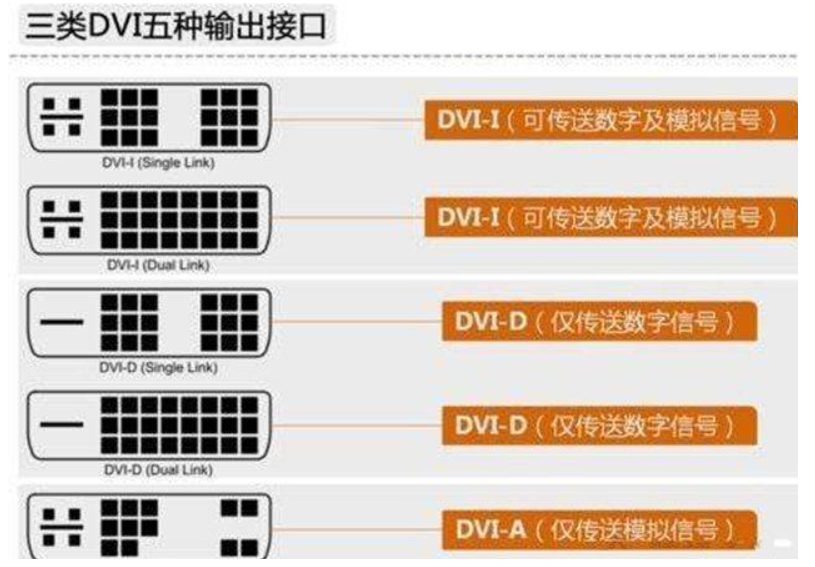
DVI 数字接口(已被淘汰、特定显示设备)
- DVI:数字信号接口。
- 输出过程:其传输的数字信号无需进行数模转换,信号传输的准确性和稳定性较高。
DVI接口分为DVI-D(纯数字信号)、DVI-I(可兼容模拟信号)两种类型。
- 分辨率与刷新率支持:不同类型的DVI接口在带宽和分辨率支持上有所不同。
DVI-D单通道的带宽相对较低,最高支持1920x1200的分辨率;
DVI-D双通道以及DVI-I的带宽较高,可支持2560x1600及以上的分辨率。
- 应用场景与特点: 在一些早期的液晶显示器和显卡上应用较多,但随着
HDMI和DP接口的普及,DVI接口的使用也在逐渐减少。不过在一些专业的显示设备或对显示稳定性要求较高的场景下,仍有一定的应用。
HDMI 数字接口 (目前主流、中高端显示设备)
- HDMI:数字信号接口。
- 输出过程:它可以同时传输高清视频信号和音频信号,实现音视频一线通。
- 分辨率与刷新率支持:不同版本的HDMI接口在带宽和分辨率支持上有所差异。
例如,HDMI 2.0版本支持3840x2160的4K分辨率以及60Hz的刷新率,HDMI 2.1版本则支持更高的8K分辨率和更高的刷新率。
- 应用场景与特点:广泛应用于家庭娱乐设备,如电视、机顶盒、游戏机等,以及一些中高端的电脑显示器和笔记本电脑。它是目前主流的高清音视频传输接口,具有高清传输、音视频一体化、便捷性等特点。

DP 数字接口 (目前主流、高端显示设备)
- DP:数字信号接口。
- 输出过程:它在数字信号传输方面具有更高的带宽和更好的性能。
- 分辨率与刷新率支持:具有较高的带宽,能够轻松支持高分辨率和高刷新率的显示。
例如,DP1.4版本可以支持8K分辨率(7680x4320)的60Hz输出以及4K分辨率的120Hz输出。
- 应用场景与特点: 主要应用于高端显示器、电竞显示器、显卡等设备。它支持高分辨率、高刷新率和高质量的显示需求,是追求高性能显示用户的首选接口。DP接口还具有灵活性高、可适应不同连接方式等特点。

显存类型
-
显存类型即显卡存储器采用的存储技术类型,市场上主要的显存类型有
SDDR2、GDDR2、GDDR3和GDDR5几种 -
但主流的显卡大都采用了
GDDR3的显存类型,也有一些中高端显卡采用的是GDDR5 -
与
DDR3相比,DDR5类型的显卡拥有更高的频率,性能也更加强大。
HBM(高带宽内存)
-
HBM(高带宽内存)是一种基于3D堆叠技术的DRAM解决方案,具有高带宽、低延迟和低功耗的优势,广泛应用于高性能计算和图形处理领域。
-
HBM显存的定义与特点
- 定义:
HBM全称为High Bandwidth Memory,是一种通过3D堆叠技术实现的动态随机存取内存(DRAM),旨在解决传统内存的【带宽瓶颈】问题。- 工作原理:
HBM通过硅通孔(TSV)和微型凸点(uBump)将多层DRAM芯片垂直堆叠,形成存储堆栈,缩短数据传输路径,从而实现高速数据传输。- 优势:与传统的DDR内存相比,HBM显存具有更高的带宽、更低的延迟和更小的功耗,同时在有限的空间内提供更高的【容量密度】。
HBM与GDDR6的比较
- 带宽与性能:HBM显存在带宽上具有明显优势,例如HBM2的带宽可达1TB/s,而GDDR6的带宽相对较低。这使得HBM在需要大量数据快速读写的高性能计算场景中表现更佳。
- 功耗与面积:HBM显存的功耗相对较低,且由于其3D堆叠设计,占用的PCB面积更小。相比之下,GDDR6显存虽然在频率上有优势,但在功耗和面积上则不及HBM。
- 应用场景:HBM显存主要应用于高性能计算、人工智能、大数据处理和图形处理等领域,而GDDR6则更常见于消费级显卡中。
- HBM显存的应用
HBM显存在AI、大数据、高性能计算(HPC)和图形处理等领域的需求不断攀升,尤其是在需要处理海量数据的应用中,HBM的高带宽能够显著提升数据读取速度,加速模型训练与推理。
尽管HBM显存的成本较高,但其技术优势使其在专业领域仍然占有一席之地。
当前主流显存技术: GDDR6
新一代显存技术:GDDR7 / GDDR6X
- 半导体标准组织 JEDEC 已经在 2024 年 3 月公布了
GDDR7显存规格,确立了新的标准。
GDDR7 的最大优势就是它惊人的速度。
相比 GDDR6 每针脚最高 20Gbps 和 GDDR6X 的 24Gbps,GDDR7 一跃达到了 32Gbps 的峰值速度。
这意味着 GPU 和显存之间的数据传输速度大幅提升,能有效缓解瓶颈问题,即使在处理图形密集型场景时也能保证流畅的帧率。
-
GDDR7是新一代显存技术,旨在全面提升图形性能。它能够提升数据吞吐量、增加带宽,以及改善功耗,让下一代 GPU 比采用 GDDR6 和 GDDR6X 的设备带来显著的性能提升。 -
GDDR6X的最高速度为 24Gbps,GDDR6 为 20Gbps,而 GDDR7 的速度将达到 32Gbps,这是一次巨大的飞跃,性能预计将大幅超越前几代。 -
GDDR7在功耗和散热管理方面取得了显著进步,进一步提升了整体效率:
- 首先,GDDR7 的能效相比 GDDR6 提升了约 20%,可以节省更多能源。
- 其次,GDDR7 的运行电压降低到了 1.20V,明显要低于 GDDR6 和 GDDR6X 常用的 1.35V。更低的电压水平不仅降低了整体功耗,还提升了能效。
- 产品发布计划
目前 GDDR7 的确切发布时间还未公布,预计将在 2024 年底至 2025 年初正式推出。尽管 Nvidia 和 AMD 很可能会采用 GDDR7 显存,但具体的 GPU 配置和容量信息尚未公布。
知名爆料人 Kepler 在社交平台 X 上透露,AMD 即将推出的 RDNA 4 架构(将用于其下一代 GPU)可能仍然会继续使用 GDDR6 显存。如果 Nvidia 从已经非常强大的 GDDR6X 升级到更先进的 GDDR7,AMD 可能会面临更大的劣势。
综合对比
GDDR6 / GDDR6X / GDDR7
| 特性 | GDDR6 | GDDR6X | GDDR7 |
|---|---|---|---|
| 每针脚速率 | 最高 20Gbps | 最高 24Gbps | 最高 32Gbps |
| 芯片密度 | 每芯片最高 32Gb | 每芯片最高 32Gb | 每芯片最高 64Gb |
| 最大存储容量 | 32芯片 512GB | 32芯片 1TB | 32芯片 2TB |
| 数据传输速率 | 32芯片下最高 512 GB/s | 32芯片下最高 672 GB/s | 32芯片下最高 1024 GB/s |
| 信号类型 | 非归零(NRZ) | 4 级脉冲幅度调制(PAM4) | 3 级脉冲幅度调制(PAM3) |
| 电压水平 | 1.35V | 1.35V | 1.20V(核心和 I/O) |
HBM / GDDR6 / GDDR5 / GDDR4 / GDDR3 / SDDR2(DDR2-SDRAM)
| 类型 | 发布时间 | 基础架构 | 传输速率 (Gbps) | 工作电压 (V) | 单芯片容量 (Gb) | 总线位宽 (位) | 典型带宽 (GB/s) | 主要应用 |
|---|---|---|---|---|---|---|---|---|
| GDDR6 | 2018 | DDR4 | 14–16 | 1.35 | ≤16 | 32×N | 448–768 | RTX 30/40 系、RX 6000/7000 系 |
| GDDR5 | 2008 | DDR3 | 5–8 | 1.5 | ≤8 | 32×N | 160–336 | GTX 10 系、RX 400/500 系 |
| GDDR4 | 2006 | DDR3 | 2–4 | 1.5 | ≤2 | 32×N | 64–128 | HD 2900、X1950 |
| GDDR3 | 2004 | DDR2 | 1.6–2.5 | 1.8 | ≤1 | 32×N | 25–64 | 7xxx–9xxx、X8xx |
| SDDR2 | 2003 | DDR1 | 0.8–1.2 | 2.5 | ≤0.5 | 32×N | 6–10 | FX 5xxx、R300 早期卡 |
- “
×N” 表示 GPU 并联多个 32-bit 颗粒形成 256/384-bit 总线。 - 带宽按 256-bit @ 最高速率粗略估算,实际值随位宽与频率变化。
| 指标 | HBM(含 HBM2/2E) | GDDR6 | GDDR5 | GDDR4 | GDDR3 | SDDR2(DDR2-SDRAM) |
|---|---|---|---|---|---|---|
| 典型年份 | 2015 起 | 2018 起 | 2008 起 | 2006 起 | 2004 起 | 2003 起 |
| 架构 | 3D 堆叠(TSV)+ 2.5D 封装 | 2D 平面,独立颗粒 | 2D 平面,独立颗粒 | 2D 平面,独立颗粒 | 2D 平面,独立颗粒 | 2D 平面,独立颗粒 |
| 单颗/堆栈位宽 | 1024-bit(每堆栈 8×128b 通道) | 32-bit | 32-bit | 32-bit | 32-bit | 16-bit(早期 32-bit) |
| 等效速率/引脚 | 2–3.2 Gb/s(HBM2E) | 14–16 Gb/s(PAM16 预加重) | 6–8 Gb/s | 2.5–4 Gb/s | 1.6–2.5 Gb/s | 0.4–1.0 Gb/s |
| 单颗/堆栈带宽 | 256–410 GB/s(每堆栈) | 64 GB/s(16 Gb/s×32b/8) | 28–32 GB/s | 20–32 GB/s | 6–10 GB/s | 1.3–3.2 GB/s |
| 典型电压 | 1.2 V | 1.25–1.35 V | 1.5 V | 1.5–1.8 V | 1.8–2.0 V | 1.8 V |
| 能效 (pJ/bit) | 7–10(低) | 20–25(中高) | 25–30(高) | 30–35(高) | 35–40(高) | 40–50(高) |
| 封装面积 | 极小(与 GPU 同封装) | 较大(需 8–12 颗布板) | 较大 | 较大 | 较大 | 较大 |
| 容量密度/颗粒 | 4–16 GB/堆栈(8-Hi) | 1–2 GB/颗 | 512 Mb–1 GB/颗 | 512 Mb/颗 | 256–512 Mb/颗 | 256 Mb/颗 |
| 扩展/升级 | 难(需换堆栈) | 易(增减颗粒) | 易 | 易 | 易 | 易 |
| 成本 | 高(2.5D+TSV) | 中(量产优化) | 低 | 低 | 低 | 低 |
| 主要应用 | AI/超算/HPC GPU、高端 FPGA | 游戏显卡、推理加速卡 | 老款游戏卡、矿卡 | 早期高端卡 | 中低端旧卡 | 集成显卡/系统内存 |
| 现状态 | 量产(HBM2E),HBM3 试产 | 主流 | 逐步淘汰 | 停产 | 停产 | 停产 |
推荐文献
- [GDDR6、GDDR6X 和 GDDR7:下一代显存技术对比与解读 - 系统极客](
性能指标
制程工艺
- 制程工艺是指制造显卡芯片时的【集成电路精细度】。
- 工艺制程越先进,就能缩小晶体管的【体积】,相同面积的晶圆就能集成更多的晶体管,从而提升性能;
- 同时,有效降低处理器【功耗】和【发热量】,在【架构】上也得到进一步升级。
例如22nm、12nm、7nm(纳米),一般来说这个数字越小代表制造精度越好。
显存位宽
- 【显存位宽】 := 显存在1个时钟周期内所能传送数据的位数 := 一次可以读入的数据量
表示显存(显卡内存)与显示芯片之间交换数据的速度。
位数越大则在周期时间内所能传输的数据量越大,这是显存的重要标准之一。
- 显存位宽的类型
市场上的显存位宽有64、128、192、256、384、448、512(极个别极品高端显卡)位七种。
人们习惯上叫的64位显卡、128位显卡等等就是指其相应的显存位宽。
对于一般的显卡而言,显存位宽越高,性能越好,价格也就越高。
因此,384位等以上位宽的显存更多应用于高端显卡,而主流显卡基本都采用128位显存,更高档次的甜点级显卡则采用256位显存。
- 举例解释
通常说的某个显卡的规格是
2GB 128bit,其中128bit指的就是这块显卡的显存位宽。
显卡频率
- 显卡频率,是指显示核心的工作频率,包含: 核心频率(GPU频率)和显存频率两部分,均以
MHz为单位。
核心频率决定图形渲染与计算效率;显存频率影响数据传输速度,二者需结合显存类型、管线设计等参数综合评估显卡性能。
核心频率在同级别芯片中直接影响性能差异,并作为【超频】主要调整对象;
显存频率与【实际数据传输效率】相关,DDR类显存因双倍传输特性可实现等效频率翻倍。
(1) 核心频率
- 显卡的核心频率是指显示核心的工作频率
- 其工作频率在一定程度上可以反映出显示核心的性能
- 但显卡的性能是由核心频率、流处理器单元、显存频率、显存位宽等多方面的情况所决定的
因此,在显示核心不同的情况下,核心频率高并不代表此显卡性能强劲。
比如,GTS250的核心频率达到了750MHz,要比GTX260+的576MHz高,但在性能上GTX260+绝对要强于GTS250。
-
在同样级别的芯片中,核心频率高的则性能要强一些。
-
主流显示芯片只有AMD和NVIDIA两家,两家都提供显示核心给第三方的厂商,在同样的显示核心下,部分厂商会适当提高其产品的显示核心频率,使其工作在高于显示核心固定的频率上以达到更高的性能。
(2) 显存频率
- 显存频率一定程度上反应着该显存的速度,显存频率的高低和显存类型有非常大的关系。
- 显存频率与显存时钟周期是相关的,二者成倒数关系
即:显存频率( MHz)=1/显存时钟周期(NS)Xl000
- 但要明白的是,显卡制造时,厂商设定了显存实际工作频率,而实际工作频率不一定等于显存最大频率,此类情况较为常见。
显示存储器/VRAM
- 显示存储器简称显存,也称为帧缓存。
- 顾名思义,其主要功能就是暂时储存显示芯片处理过或即将提取的渲染数据,类似于主板的内存,是衡量显卡的主要性能指标之一。
- 显存与系统内存一样,其容量也是越多越好,图形核心的性能越强,需要的显存也就越大,因为显存越大,可以存储的图像数据就越多,支持的分辨率与颜色数也就越高,游戏运行起来就更加流畅。
- 主流显卡基本上具备的是
6GB容量,一些中高端显卡则配备了6GB、8GB的显存容量
显存带宽 := 显卡内存带宽
-
显卡内存带宽,是显卡性能的重要指标,它决定了【GPU】与【显存】之间的数据传输速率,影响游戏和图形渲染的流畅度和效率。
-
显存带宽的定义
显存带宽是指显卡在单位时间内可以传输的数据量,通常以GB/s为单位。它的计算公式为:
显存带宽=(显存频率)×显存位宽/8
其中,显存频率是显存的工作频率,显存位宽是显存与GPU之间的数据通道宽度。显存带宽越高,意味着显卡在处理数据时的效率越高。
- 显存带宽的重要性
影响性能:在高分辨率游戏或复杂的3D渲染中,显存带宽不足会导致数据传输延迟,从而影响GPU的计算效率,无法充分发挥其性能。
适应高负载:随着游戏画面质量的提升,所需的显存带宽也随之增加。例如,4K分辨率下,显存带宽的不足会显著影响游戏的流畅度。
与显存容量的关系:显存带宽与显存容量密切相关,显存容量决定了显卡可以存储的数据量,而带宽则决定了这些数据的传输速度。两者的平衡对于显卡的整体性能至关重要。
综合对比
| 显卡型号 | 显存类型 | 显存位宽 | 显存频率 | 显存带宽(GB/s) | 备注 |
|---|---|---|---|---|---|
| H100 | HBM3 | 5120-bit | ~3.35 GHz | 3350 | 当前带宽最高的AI计算卡 |
| A100 80GB | HBM2e | 4096-bit | 2.4 GHz | 2460 | 数据中心AI训练卡 |
| RTX 5090 | GDDR7 | 512-bit | 28 Gbps | 1792 | 2025年顶级游戏显卡(32GB) |
| RTX 5080 | GDDR7 | 256-bit | 32 Gbps | 1024 | 新一代高端游戏卡 |
| RTX 4090 | GDDR6X | 384-bit | 21 Gbps | 1008 | 消费级旗舰,8K/AI性能强 |
| RTX 3090 | GDDR6X | 384-bit | 19.5 Gbps | 936 | 上代旗舰,仍具高带宽优势 |
| RTX 5070 Ti Super | GDDR7 | 256-bit | 28 Gbps | 896 | 显存容量提升至 24GB GDDR7(预估 2026年3-5月发布) |
| RTX 5070 Ti | GDDR7 | 256-bit | 28 Gbps | 896 | 支持 PCI Express 第 5 代 显存:16GB 架构:Blackwell CUDA核心:8960 Tensor 核心(AI):第 5 代 1406 AI TOPS 显卡总功耗:300 要求的系统功率 (W):750 |
| RTX 5070 | GDDR7 | 192-bit | 28 Gbps | 672 | 支持 PCI Express 第 5 代 主流级 12GB 显存 架构:Blackwell 显卡总功耗:250 要求的系统功率 (W):650 |
| RX 7800 XT | GDDR6 | 256-bit | 19.5 Gbps | 624 | AMD高端游戏卡 |
| RTX 4070 Ti | GDDR6X | 192-bit | 21 Gbps | 504 | 主流级(12GB 显存),位宽缩减但频率高;架构:Ada Lovelace |
| RTX 4060 Ti | GDDR6 | 128-bit | 18 Gbps | 288 | 入门级,带宽较低 |
| RTX 4060 | GDDR6 | 128-bit | 17 Gbps | 272(估算) | 入门级,1080p 游戏适用 |
| GT 1030 | DDR4 | 64-bit | ~2.1 GHz | ~17 | 入门级亮机卡 |
流处理器单元
-
在
DX10显卡出来以前,并没有“流处理器”这个说法。 -
GPU内部由“管线”构成,分为像素管线和顶点管线,它们的数目是固定的。简单来说:
- 顶点管线主要负责3D建模
- 像素管线负责3D渲染。
由于它们的数量是固定的,这就出现了一个问题:当某个游戏场景需要大量的3D建模而不需要太多的像素处理,就会造成顶点管线资源紧张而像素管线大量闲置,当然也有截然相反的另一种情况。
这都会造成某些资源的【资源紧张】和另一些资源的【闲置浪费】。
在这样的情况下,人们在DX10时代首次提出了“统一渲染架构”,显卡取消了传统的“像素管线”和“顶点管线”,统一改为流处理器单元,它既可以进行顶点运算也可以进行像素运算,这样在不同的场景中,显卡就可以动态地分配进行顶点运算和像素运算的【流处理器数量】,达到资源的充分利用。
- 流处理器的数量的多少已经成为了决定显卡性能高低的一个很重要的指标
NVIDIA和AMD也在不断地增加显卡的流处理器数量使显卡的性能达到跳跃式增长- 值得一提的是,
N卡和A卡GPU架构并不一样,对于流处理器数的分配也不一样。双方没有直接可比性。
著名显卡公司
以下公司曾经或正在生产显示芯片或显卡;包含已经倒闭、退出显卡市场或被并购的公司。
3dfx(已被NVIDIA收购)
3DLABS
Accel Graphics
Avance Logic
AMD(超威)
Appian
Artist Graphics
Ark Logic
ATI(冶天,已被AMD收购)
Canopus(康能普视)
Cirrus Logic(凌云逻辑)
Colorgraphic(彩图)
Creative(创新)
DEC(迪吉多)
Diamond Multimedia(帝盟)
Dynamic Pictures
Everex
Genoa(热那亚)
Headland
Hercules(大力神)
I-O DATA
Intel(英特尔)
Intense3D
IXMicro
Kasan
Lung Hwa(陇华)
MECHREVO(机械革命)
Macronix(旺宏)
Matrox(迈创)
Matsushita(松下)
Motorola(摩托罗拉)
Mpact
NEC(日本电气)
Number Nine
NVIDIA(英伟达)
Orchid(兰花)
OAK
PowerVR
Quantum3D(昆腾3D)
Realtek(瑞昱)
RealVision
Rendition
S3 Graphics
Sigma Designs
SiS(矽统)
STB Systems
STMicroelectronics(意法半导体)
Tandy(坦迪)
Tech Source
Trident(泰鼎)
Tseng Labs(曾氏)
Western Design Center(西方设计中心)
Weitek
XGI(图诚)
ASUS(华硕)
GIGABYTE(技嘉)
MSI(微星)
EVGA(艾维克)
PowerColoer(撼讯)
Galaxy(影驰)
Zotac
2 大牌显卡厂商的解读
Nvidia/英伟达 := N 卡
介绍
- GeForce 系列:英伟达的核心消费级显卡系列,中文名精视。该系列经历了多个架构阶段,如 Kelvin、Rankine、Curie、Tesla、Fermi、Kepler、Maxwell、Pascal、Volta、Turing、Ampere、Ada Lovelace 等。例如基于 Ada Lovelace 架构的 GeForce RTX 40 系列,包括 RTX 4090、RTX 4080 等,具有强大的光线追踪运算、高性能计算和 AI 运算能力。
- Quadro 系列:面向专业用户的显卡系列,主要用于工作站,适用于 3D 建模、动画设计、视频编辑等专业图形应用,具有更高的精度和更广泛的颜色空间。
- 英伟达 P 系列显卡属于 Quadro 系列,是面向专业市场的专业级 GPU 产品线,主要定位于满足专业图形处理和高性能计算需求。
- P 系列显卡具有强大的计算能力,配备了大量的 CUDA 核心,能进行高效的浮点计算,拥有大容量显存和高内存带宽,可满足复杂计算需求和高带宽内存访问需求。
- 其还支持 NVIDIA 的 Quadro Sync II 技术,可用于多路输出、多显示器以及立体显示。
- 此外,P 系列显卡通过了 ISV 认证,与 Adobe Photoshop、Autodesk Maya、SolidWorks 等众多专业软件有良好的兼容性和稳定性。
- 该系列显卡主要应用于计算机辅助设计(CAD)、动画制作、科学计算、虚拟现实、视频编辑等专业领域。
- 具体型号有 P400、P600、P1000、P2000、P4000、P5000、P6000 等,从入门级到高端型号,可满足不同用户和应用场景的需求。
- Tesla 系列:原本是面向高性能计算和数据中心的显卡系列,具有强大的浮点运算能力,但 2020 年英伟达停止使用 “Tesla” 的名称,以避免与电动汽车品牌混淆。
GPU 架构
- Kelvin(开尔文):2001 年问世,首次应用于搭载 NV2A GPU 的 XBOX 游戏主机,GeForce 3 和 GeForce 4 系列 GPU 也基于此架构,它是英伟达在千禧年推出的首个全新 GPU 微架构。
- Rankine(兰金):2003 年推出,是 Kelvin 微架构的后续版本,主要应用于 GeForce 5 系列产品,引入了对顶点和片段程序的支持,还将显存(VRAM)大小扩展至 256MB。
- Curie(居里):2004 年发布,作为 Rankine 微架构的继任者,用于 GeForce 6 和 7 系列 GPU,将显存容量翻倍至 512MB,是支持 PureVideo 视频解码的第一代 NVIDIA GPU。
- Tesla(特斯拉):2006 年发布,取代 Curie 微架构,不仅应用于 GeForce 8、9、100、200 和 300 系列 GPU,还广泛应用于 Quadro 系列 GPU,为 NVIDIA 显卡带来了性能和功能上的创新。
- Fermi(费米):2010 年发布,是 Tesla 的继任者,引入了许多增强功能,如支持 512 个 CUDA 内核、64KB RAM 和分区 L1 缓存 / 共享内存的能力,还支持纠错码(ECC)。
- Kepler(开普勒):2012 年推出,是 Fermi 架构的后继者,引入了全新的流式多处理器架构 SMX,完整支持 TXAA,CUDA 核心数显著增加,达到 1536 个,还实现了更低的功耗效率,支持 GPU 加速自动超频功能和 GPUDirect 技术。
- Maxwell(麦克斯韦尔):2014 年问世,是 Fermi 架构的继任者。首代 Maxwell GPU 在多处理器效率、共享内存容量等方面有优势,每个流式多处理器上的专用共享内存容量增至 64KB,引入了本地共享内存原子操作。
- Pascal(帕斯卡):2016 年取代 Maxwell 架构,引入了支持 NVLink 通信的能力,采用高带宽内存 2(HBM2)技术,实现了计算抢占功能,引入了动态负载均衡机制,在性能和效率方面有显著提升。
- Volta(伏特):2017 年发布,严格针对专业级市场,是第一个使用 Tensor Cores 的微架构,Tensor Cores 用于执行专门的数学计算,支持 AI 和深度学习应用。
- Turing(图灵):2018 年发布,支持 Tensor Cores,并首次加入 RT Core,是 NVIDIA 流行的 Quadro RTX 和 GeForce RTX 系列 GPU 使用的微架构,支持实时光线追踪,对于虚拟现实(VR)等计算量大的应用至关重要。
- Ampere(安培):2020 年 5 月推出,旨在进一步提升光线追踪运算、高性能计算(HPC)和 AI 运算的能力,包括第 3 代 NVLink 和 Tensor Core,结构稀疏性,第二代光线追踪内核,多实例 GPU(MIG)等。
- Ada Lovelace(阿达・洛芙莱斯):2022 年 9 月发布,是 NVIDIA 公司推出的第三代 RTX 架构,被应用于 GeForce RTX 40 系列显卡,所配备的 GPU 流式多处理器拥有高达 83 TFLOPS 的着色器性能,吞吐量相较于前一代产品提升了 2 倍。
- Hopper GPU 架构
- 基本信息:Hopper 架构以美国计算机领域的先驱科学家 Grace Hopper 的名字命名,于 2022 年 3 月 23 日由英伟达宣布推出,取代之前的 Ampere 架构。
- 其首款基于 Hopper 架构的 GPU 为 NVIDIA H100,采用台积电 4nm 工艺,核心面积为 814 平方毫米,集成了 800 亿个晶体管。
- 技术特点:引入新一代流式多处理器的 FP8 张量核心,支持 FP32 和 FP16 累加器以及两种 FP8 输入类型,与 FP16 或 BF16 相比,FP8 将数据存储要求减半,吞吐量翻倍。
- Hopper 架构中的 Transformer 引擎与 FP8 张量核心相结合,在大型 NLP 模型上提供高达 9 倍的 AI 训练速度和 30 倍的 AI 推理速度。
- 此外,Hopper 架构还新增了张量存储加速器,以提高张量核心与全局存储和共享存储的数据交换效率。
- 其他特性:采用第四代 NVLink,每个 GPU 的双向传输速率可达 900GB/s;引入了具有机密计算功能的加速计算平台,确保数据和应用的机密性和完整性;通过多达 7 个 GPU 实例在虚拟化环境中支持多租户、多用户配置,进一步增强了 MIG。
- 架构对比:Ada Lovelace vs. Hopper
- 基本信息:Hopper 架构以美国计算机领域的先驱科学家 Grace Hopper 的名字命名,于 2022 年 3 月 23 日由英伟达宣布推出,取代之前的 Ampere 架构。
1 【架构区别】
核心设计侧重:Ada Lovelace 架构侧重于图形计算,每个 GPC 包含 1 个光栅化引擎等图形相关组件。Hopper 架构则专为数据中心设计,更注重大规模计算和数据处理能力,其核心设计围绕着满足 HPC 和 AI 工作负载的需求。
工艺制程:两者都采用了台积电的 4nm 工艺,Ada Lovelace 架构的 AD102 集成了 763 亿个晶体管,Hopper 架构的 H100 则拥有超过 800 亿个晶体管。
计算核心:Ada Lovelace 架构每个 SM 包含 128 个 FP32 CUDA 核心和 64 个 INT32 CUDA 核心,2 个 FP64 CUDA 核心,相比 Hopper 架构,FP64 核心数量大幅减少。Hopper 架构的 Tensor Core 能够应用混合的 FP8 和 FP16 精度,且将 TF32、FP64、FP16 和 INT8 精度的每秒浮点运算(FLOPS)提高了 3 倍。
显存与互联:Ada Lovelace 架构的显卡通常配备 GDDR6X 显存。Hopper 架构支持 HBM3 显存,带宽达 3TB/s(H100 SXM5),并且采用第四代 NVLink,每个 GPU 的双向传输速率可达 900GB/s。
特殊技术NVIDIA:Ada Lovelace 架构引入了 DLSS 3 技术,通过 AI 驱动的帧生成技术大幅提升游戏性能。Hopper 架构则引入了 DPX 指令,与 CPU 相比将动态编程算法速度提高了 40 倍,还具备机密计算功能,通过保护使用中的数据和应用来确保安全。
2 【适用场景】
Ada Lovelace 架构:主要适用于高端游戏、内容创作领域,如 3D 建模、动画制作、视频编辑等,能够提供出色的光线追踪效果和高效的 AI 加速能力,提升创作效率和画面质量。在 AI 推理方面也有不错的表现,可用于一些对实时性要求较高的推理场景。
Hopper 架构:适用于大规模 AI 训练,尤其是大语言模型等需要处理海量数据和复杂计算的场景,能够显著提高训练速度和效率。同时,在科学计算领域,如气候模拟、分子动力学等,Hopper 架构的高性能和高精度计算能力也能发挥重要作用。
3 【先进性比较】
性能方面:在图形渲染和游戏场景中,Ada Lovelace 架构凭借 DLSS 3 等技术,能够提供更高的帧率和更好的视觉效果,表现更为突出。而在大规模 AI 训练和科学计算任务中,Hopper 架构的强大计算能力和对 FP8 等精度的支持,使其性能远超 Ada Lovelace 架构。
技术创新方面:Ada Lovelace 架构在光线追踪和游戏优化技术上有创新,Hopper 架构则在数据中心互联、机密计算和动态编程算法加速等方面取得了突破。
不能简单地说哪个架构更领先,而是要根据具体的应用场景来判断。如果是游戏玩家或内容创作者,Ada Lovelace 架构的显卡更适合;如果是从事大规模 AI 研究或科学计算的专业人员,Hopper 架构的产品则是更好的选择。
- Blackwell:2024 年 3 月推出,用于 GeForce RTX 50 系列显卡,具备第 4 代 RT Core 和第 5 代 Tensor Core,在性能和能效等方面有进一步提升。
CPU 架构
- Grace CPU 架构
- 诞生时间:2021 年 4 月 12 日,在 GTC 大会上,英伟达发布了其首款基于 Arm 架构的数据中心 CPU 处理器 NVIDIA Grace CPU,该 CPU 采用了 Grace 架构。
- 基本信息:Grace CPU 是一款突破性的 Arm CPU,可与 GPU 紧密结合以增强加速计算能力,也可作为独立 CPU 进行部署,是新一代数据中心的基础。
- 技术特点:采用高性能 Arm Neoverse V2 内核,结合 NVIDIA 可扩展一致性结构 SCF,能最大限度地提升数据中心工作负载的性能和效率。使用带有纠错码 ECC 的 LPDDR5X 显存来实现服务器级可靠性,同时将能效提高 5 倍。NVIDIA NVLink 芯片到芯片 C2C 提供 900GB/s 的双向带宽,比 PCIe Gen 5 快 7 倍。
- 产品组合:包括紧密耦合的 CPU 和 GPU 系统,如适用于加速计算的 Grace Blackwell 和 Grace Hopper,以及采用 Grace CPU 的纯 CPU 解决方案,如 NVIDIA Grace CPU C1,它是一个单插槽高性能服务器平台,针对可扩展平台和边缘平台进行了优化。
它采用高性能Arm Neoverse V2内核,结合NVIDIA可扩展一致性结构(SCF),能够最大限度地提升数据中心工作负载的性能和能效。
Grace CPU使用带有纠错码(ECC)的LPDDR5X显存来实现服务器级可靠性,同时将能效提高5倍。
此外,它还借助NVLink-C2C技术提供900GB/s的双向带宽,比PCIe Gen 5快7倍,可实现CPU与GPU的紧密连接。
基于Grace架构,英伟达推出了Grace CPU、Grace CPU超级芯片、Grace Hopper超级芯片等产品,适用于AI训练和推理、高性能计算(HPC)、数据分析等多种工作负载。
DPU 架构
- BlueField DPU 架构
- 基本信息NVIDIA:BlueField DPU 是一个完全集成的片上数据中心平台,能够为主机处理器卸载和管理数据中心基础设施,实现超级计算机的安全与编排。
- 技术特点:以 BlueField-3 为例,其搭载双 Arm Neoverse V2 CPU 集群与专用 NPU 加速引擎,形成独特的异构计算体系,支持 64 个高性能内核,主频达 3.2GHz,集成 512 个张量核心,FP16 算力达 128TOPS。它实现了 400Gbps 线速转发,TCP/IP 协议栈处理延迟降低至 5μs,在 NVMe-oF 协议支持下,存储 I/O 性能提升 300%,内置硬件级加密引擎,数据加密性能达 320Gbps。
- 功能优势NVIDIA:BlueField DPU 可以托管未受信任的多节点租户,为新调度的租户提供干净的启动镜像,执行完全清理和重新建立信任,虚拟化存储,并授权访问经批准的存储区域。将通讯库从主机 CPU 或 GPU 卸载至 Bluefield DPU,能够针对通信和计算的并行处理创建高度重叠,减少操作系统抖动的负面影响,并显著提高应用程序性能。
CUDA 核心
Tensor 核心
AMD/超微半导体 := A卡
-
Radeon 系列:AMD 的主流消费级显卡系列,俗称 A 卡,如 Radeon RX 7000 系列、RX 6000 系列、RX 5000 系列等。其中,Radeon RX 7900 XT/XTX 基于 RDNA3 架构,性能强悍;Radeon RX 7600 则主打 1080P 高帧率游戏体验。
-
Fire Pro 系列:面向专业用户的显卡系列,提供了针对专业图形应用的优化,如 CAD 设计、数字内容创作等。
寒武纪
- 思元系列:
- 寒武纪的云端智能加速卡系列,基于思元芯片,如思元 100、思元 270、思元 290、思元 370 等。
- 其中,MLU370-X8 智能加速卡搭载双芯片四芯粒思元 370,集成寒武纪 MLU-Link 多芯互联技术,主要面向训练任务,在业界应用广泛的 YOLOv3、Transformer 等训练任务中,8 卡计算系统的并行性能平均达到 350W RTX GPU 的 155%。
华为
- 华为
- 目前主要聚焦于 AI 芯片领域,其昇腾系列芯片如昇腾 910 在计算力方面表现出色。
- 虽然有消息称华为的 2012 实验室研发自己的 GPU 芯片多年,但目前尚未有面向消费级市场的成熟显卡产品系列推出。
平头哥(阿里巴巴)
- 平头哥
- 主要推出了玄铁 RISC - V 系列处理器,广泛应用于边缘计算、无线通讯、工业控制、通用 MCU 等领域,但该系列处理器并非传统意义上的显卡产品系列。
- 其在 2021 年云栖大会上推出的倚天 710 芯片是云芯片,也不属于显卡系列。
3 显卡性能排行
桌面级&&消费级
专业级
AI显卡算力排行榜

主要显卡售价

主流显卡

热门显卡
NVIDIA H100:当前最先进的AI显卡
简介

一般会买8块H100连成一组,也是最贵的显卡,3万美金1块,国内报价30万+,但是买不到
- 英伟达H100芯片是2022年3月22日芯片巨头英伟达在GTC技术大会上公布的一款全新架构的GPU芯片。
这款芯片将会使用台积电最新的四纳米工艺采取新一代的Hopper架构,拥有800亿个晶体管。英伟达,这款芯片于2022年第三季度上市。
- 规格参数
- 使用台积电最新的四纳米工艺,采取新一代的Hopper架构,拥有800亿个晶体管,也是迄今为止该公司推出的最为强大的一款GPU,将取代两年前的Ampere架构。
- H100也将成为全球最大的一款加速芯片。
- 英伟达称这种新技术芯片可以大幅提升人工智能算法的计算速度,未来有望成为人工智能基础设施的核心。
- 相关动态
- 2022年5月,日本一零售商以4745950日元(约合人民币24.16万元)的价格,挂出了NVIDIA最新的H100 Hopper加速计算卡。
参数配置:H100
架构: Hooper
目标: AI训练, HPC
CUDA Core: 16896
Tensor Core: 528
RT Core: 0
GDDR: HBM3 80GB
内存带宽: 3.35TB/s
int4: 0
int8: 3958 TOPS
FP8: 3958 TFLOPS
FP16: 1979 TFLOPS
BF16: 1979 TFLOPS
tf32: 989TFLOPS
fp32: 60TFLOPS
fp64: 1TFLOPS
RT TFLOPS: 0
编解码器: 7 NVDEC, JPEG
多实例GPU(MIG): 最多7 MIGs @ 10GB
基频: 0
boost主频: 0
功耗: 700W
GPU P2P: NVLink 4.0 900GB/s
售价信息
- 20250219
- 京东: H100 80GB : 22.99W
NVIDIA A100:仅次于H100的前最好的AI显卡

- 2022年以前最好的 AI显卡
参数配置:A100
架构: Ampere
目标: AI训练, HPC
CUDA Core: 6912
Tensor Core: 432
RT Core: 0
GDDR: HBM2 40GB HBM2e 80GB
内存带宽: 2039GB/s
int4: 0
int8: 624TOPS
FP8: 0
FP16: 312TFLOPS
BF16: 312TFLOPS
tf32: 156TFLOPS
fp32: 19.5TFLOPS
fp64: 9.7TFLOPS
RT TFLOPS: 0
编解码器: 0
多实例GPU(MIG): 最多7 MIGs @ 10GB
基频: 0
boost主频: 1410 MHz
功耗: 400W
GPU P2P: NVLink 3.0 600GB/s
售价信息
- 20250219
- 京东: A100 40GB(原版) : 8.98W / A100 40GB(定制版) : 3.99W / A100 64GB(定制版) : 4.59W / A100 80GB 16.99W
NVIDIA H800,H20,A800:性能受限版的AI显卡
- H800 是H100的中国特供版,限制了 NVLink带宽等参数,目前也不好买。
- H20 是在H800的继续削弱版,性能上再次于H100。
- A800 是A100的中国特供版,限制了 NVLink带宽等参数,性能上稍逊于 A100。
需要注意的是,虽然一割再割,h800和h20等显卡现在也是不好买到的
能买到的还是值得买的
参数配置:H800
架构: Hooper
目标: AI训练, HPC
CUDA Core: 16896
Tensor Core: 528
RT Core: 0
GDDR: HBM3 80GB
内存带宽: 3.35TB/s
int4: 0
int8: 3958 TOPS
FP8: 3958 TFLOPS
FP16: 1979 TFLOPS
BF16: 1979 TFLOPS
tf32: 989TFLOPS
fp32: 60TFLOPS
fp64: 1TFLOPS
RT TFLOPS: 0
编解码器: 7 NVDEC, JPEG
多实例GPU(MIG): 最多7 MIGs @ 10GB
基频: 0
boost主频: 0
功耗: 700W
GPU P2P: NVLink 4.0 400GB/s
售价信息
- 20250219
- 京东 : H800 80GB 23.99W
参数配置:A800
架构: Ampere
目标: AI训练, HPC
CUDA Core: 6912
Tensor Core: 432
RT Core: 0
GDDR: HBM2e 80GB
内存带宽: 2039GB/s
int4: 0
int8: 624TOPS
FP8: 0
FP16: 312TFLOPS
BF16: 312TFLOPS
tf32: 156TFLOPS
fp32: 19.5TFLOPS
fp64: 9.7TFLOPS
RT TFLOPS: 0
编解码器: 0
多实例GPU(MIG): 最多7 MIGs @ 10GB
基频: 0
boost主频: 1410 MHz
功耗: 400W
GPU P2P: NVLink 3.0 400GB/s
售价信息
- 20250219
- 京东 : A800 80G : 15.99W
NVIDIA A30
参数配置:A30
A30
架构: Ampere
目标: AI训练, AI推理
CUDA Core: 3584
Tensor Core: 224
RT Core: 0
GDDR: HBM2 24GB
内存带宽: 933GB/s
int4: 661TOPS
int8: 330TOPS
FP8: 0
FP16: 165TFLOPS
BF16: 165TFLOPS
tf32: 82TFLOPS
fp32: 10.3TFLOPS
fp64: 5.2TFLOPS
RT TFLOPS: 0
编解码器: 1 JPEG decoder, 4 video decoders
多实例GPU(MIG): 4 MIGs @ 6GB, 2 MIGs @ 12GB
基频: 0
boost主频: 1440 MHz
功耗: 165W
GPU P2P: PCIe-G4 64GB/s
售价信息
- 20250219
- 京东 : A30 24GB : 3.56W
NVIDIA A10
参数配置:A10
A10
架构: Ampere
目标: AI推理, 渲染
CUDA Core: 9216
Tensor Core: 288
RT Core: 72
GDDR: GDDR6 24GB
内存带宽: 600GB/s
int4: 500 TOPS
int8: 250TOPS
FP8: 0
FP16: 125TFLOPS
BF16: 125TFLOPS
tf32: 62.5TFLOPS
fp32: 31.2TFLOPS
fp64: 0
RT TFLOPS: yes
编解码器: 1编码器, 2解码器 (+AV1 decode)
多实例GPU(MIG): 0
基频: 0
boost主频: 1695 MHz
功耗: 150W
GPU P2P: PCIe-G4 64GB/s
售价信息
- 20250219
- 京东 : A10 24GB : 1.46W
NVIDIA Tesla V100
参数配置:V100
V100
架构: Volta
目标: AI训练, HPC
CUDA Core: 7680
Tensor Core: 640
RT Core: 0
GDDR: HBM2 32GB
内存带宽: 900GB/s
int4: 0
int8: 60TOPS
FP8: 0
FP16: 125TFLOPS
BF16: 0
tf32: 0
fp32: 15.7TFLOPS
fp64: 7.8TFLOPS
RT TFLOPS: 0
编解码器: 0
多实例GPU(MIG): 0
基频: 0
boost主频: 1530 MHz
功耗: 300W
GPU P2P: NVLink 2.0 300 GB/s
是否禁售: 否
售价信息
- 20250219
- 京东 : V100 16GB : 5289
NVIDIA T4
参数配置:T4
T4
架构: Turing
目标: AI推理, 渲染
CUDA Core: 2560
Tensor Core: 320
RT Core: 40
GDDR: GDDR6 16GB
内存带宽: 300GB/s
int4: 260TOPS
int8: 130TOPS
FP8: 0
FP16: 65TFLOPS
BF16: 0
tf32: 0
fp32: 8.1TFLOPS
fp64: 0
RT TFLOPS: yes
编解码器: NVENC, NVDEC, JPEG decoders
多实例GPU(MIG): 0
基频: 0
boost主频: 1590 MHz
功耗: 70W
GPU P2P: PCIe-G3 32GB/s
是否禁售: 否
售价信息
- 20250219
- 京东 : T4 16GB : 5289
NVIDIA A20
参数配置:A20
H20
架构: Hooper
目标: AI训练, HPC
CUDA Core: 0
Tensor Core: 0
RT Core: 0
GDDR: HBM3 96GB
内存带宽: 4.0TB/s
int4: 0
int8: 296 TOPS
FP8: 296 TFLOPS
FP16: 148 TFLOPS
BF16: 148 TFLOPS
tf32: 74 TFLOPS
fp32: 44 TFLOPS
fp64: 1 TFLOPS
RT TFLOPS: 0
编解码器: 7 NVDEC, 7 NVJPEG
多实例GPU(MIG): 最多7 MIGs
基频: 0
boost主频: 0
功耗: 400W
GPU P2P: NVLink 4.0 900GB/s
是否禁售: 否
NVIDIA L2
参数配置:L2
L2
架构: Ada Lovelace
目标: AI推理, 渲染
CUDA Core: 0
Tensor Core: 0
RT Core: 0
GDDR: GDDR6 24GB
内存带宽: 300 GB/s
int4: 0
int8: 193 TOPS
FP8: 193 TFLOPS
FP16: 96.5TFLOPS
BF16: 96.5TFLOPS
tf32: 48.3TFLOPS
fp32: 24.1TFLOPS
fp64: 0
RT TFLOPS: yes
编解码器: 2 NVENC(+AV1), 4 NVDEC, 4 NVJPEG
多实例GPU(MIG): 0
基频: 0
boost主频: 0
功耗: TBD
GPU P2P: PCIe-G4 64GB/s
是否禁售: 否
NVIDIA L20
参数配置:L20
L20
架构: Ada Lovelace
目标: AI推理, 渲染
CUDA Core: 0
Tensor Core: 0
RT Core: 0
GDDR: GDDR6 48GB
内存带宽: 864GB/s
int4: 0
int8: 239 TOPS
FP8: 239 TFLOPS
FP16: 119.5 TFLOPS
BF16: 119.5 TFLOPS
tf32: 59.8TFLOPS
fp32: 59.8TFLOPS
fp64: 0
RT TFLOPS: yes
编解码器: 3 NVENC(+AV1), 3NVDEC, 4NVJPEG
多实例GPU(MIG): 0
基频: 0
boost主频: 0
功耗: 275W
GPU P2P: PCIe-G4 64GB/s
是否禁售: 否
售价信息
- 20250219
- 京东 : L20 48G / 3.09W
NVIDIA L4
参数配置:L4
L4
架构: Ada Lovelace
目标: AI推理, 渲染
CUDA Core: 7680
Tensor Core: 240
RT Core: 60
GDDR: GDDR6 24GB
内存带宽: 300GB/s
int4: 0
int8: 485TOPS
FP8: 485 TFLOPS
FP16: 242TFLOPS
BF16: 0
tf32: 0
fp32: 120TFLOPS
fp64: 0
RT TFLOPS: yes
编解码器: NVENC, NVDEC, JPEG decoders
多实例GPU(MIG): 0
基频: 0
boost主频: 2040 MHz
功耗: 72W
GPU P2P: PCIe-G4 64GB/s
是否禁售: 否
售价信息
- 20250219
- 京东 : L4 24G : 1.39W
NVIDIA L40
参数配置:L40
L40
架构: Ada Lovelace
目标: AI推理, 渲染
CUDA Core: 18176
Tensor Core: 568
RT Core: 142
GDDR: GDDR6 48GB
内存带宽: 864GB/s
int4: 724TOPS
int8: 362TOPS
FP8: 362 TFLOPS
FP16: 181.05TFLOPS
BF16: 181.05TFLOPS
tf32: 90.5TFLOPS
fp32: 90.5TFLOPS
fp64: 0
RT TFLOPS: 209TFLOPS
编解码器: 3x NVENC, 3x NVDEC (AV1)
多实例GPU(MIG): 0
基频: 0
boost主频: 2490MHz
功耗: 300W
GPU P2P: PCIe Gen4x16 64GB/s
是否禁售: 否
售价信息
- 20250219
- 京东 : L40 48G : 3.69W
NVIDIA L40s
参数配置:L40s
架构: Ada Lovelace
目标: AI训练, AI推理, 渲染
CUDA Core: 18176
Tensor Core: 568
RT Core: 142
GDDR: 48GB GDDR6 with ECC
内存带宽: 864GB/s
int4: 733TOPS
int8: 733TOPS
FP8: 733 TFLOPS
FP16: 362.05TFLOPS
BF16: 362.05TFLOPS
tf32: 183 TFLOPS
fp32: 91.6 TFLOPS
fp64: 0
RT TFLOPS: 212TFLOPS
编解码器: 3x NVENC, 3x NVDEC (AV1)
多实例GPU(MIG): 0
基频: 0
boost主频: 0
功耗: 350W
GPU P2P: PCIe Gen4x16 64GB/s
是否禁售: 否
售价信息
- 20250219
- 京东 : L40s 48G : 5.39W
NVIDIA A40
参数配置: A40
A40
架构: Ampere
目标: AI训练, AI推理, 渲染
CUDA Core: 10752
Tensor Core: 336
RT Core: 84
GDDR: GDDR6 48G
内存带宽: 696 GB/s
int4: 598.7
int8: 299.3
FP8: 0
FP16: 149.7
BF16: 0
tf32: 0
fp32: 37.4
fp64: 0
RT TFLOPS: 0
编解码器: 1x NVENC, 2x NVDEC (AV1 decode)
多实例GPU(MIG): 0
基频: 0
boost主频: 1740MHz
功耗: 300 W
GPU P2P: PCIe-G4 64GB/s
是否禁售: 否
售价信息
- 20250219
- 京东 : A40 48G : 4.69W
NVIDIA RTX5090,RTX4090:性价比之王的AI显卡、尖端家用游戏显卡
- 首先要知道的事:RTX5090,RTX4090的出厂定位是家用游戏显卡
- 它们【不适合】做大模型训练,但是它们适合用来做AI推理
- 通俗的说:
- 你要是训练一个DeepSeek这些显卡做不到
- 但是部署运行一个已训练好的DeepSeek 等模型,这些显卡很值

参数配置:RTX4090
RTX 4090
架构: Ada Lovelace
目标: AI训练, AI推理, 渲染
CUDA Core: 16384
Tensor Core: 512
RT Core: 128
GDDR: GDDR6X 24G
内存带宽: 1008 GB/s
int4: 0
int8: 660.6 TOPS
FP8: 0
FP16: 330.3 TFLOPS
BF16: 0
tf32: 0
fp32: 82.58 TFLOPS
fp64: 1,290 GFLOPS
RT TFLOPS: 191 TFLOPS
编解码器: NVENC, NVDEC, AV1编码, AV1解码
多实例GPU(MIG): 0
基频: 0
boost主频: 2520MHz
功耗: 450W
GPU P2P: PCIe-G4 64GB/s
是否禁售: 否
售价信息
- 20250219
- 京东 : RTX4090 48G(工业包装) : 2.69W / RTX4090 24G(公版): 2.49W /
参数配置:RTX4090D
RTX 4090D
架构: Ada Lovelace
目标: AI训练, AI推理, 渲染
CUDA Core: 14592
Tensor Core: 456
RT Core: 114
GDDR: GDDR6X 24G
内存带宽: 1008 GB/s
int4: 0
int8: 0
FP8: 0
FP16: 0
BF16: 0
tf32: 0
fp32: 73.5 TFLOPS
fp64: 1149 GFLOPS
RT TFLOPS: 0
编解码器: NVENC: 2x 8th Gen, NVDEC: 5th Gen
多实例GPU(MIG): 0
基频: 2280MHz
boost主频: 2520MHz
功耗: 425W
GPU P2P: PCIe-G4 64GB/s
是否禁售: 否
售价信息
- 20250219
- 京东 : RTX4090D 24G(涡轮版) : 1.54W
NVIDIA RTX5070 / 5070Ti
NVIDIA RTX 4060(TI)
售价信息
- 20250219
- 京东 : RTX4060 8G(涡轮卡 : 2539
NVIDIA RTX3090
参数配置:RTX3090
RTX 3090
架构: Ampere
目标: AI训练, AI推理, 渲染
CUDA Core: 10496
Tensor Core: 328
RT Core: 82
GDDR: GDDR6X 24 G
内存带宽: 936.2 GB/s
int4: 0
int8: 0
FP8: 0
FP16: 142
BF16: 0
tf32: 71
fp32: 35.58 TFLOPS
fp64: 556.0 GFLOPS
RT TFLOPS: 35.6 TFLOPS
编解码器: 0
多实例GPU(MIG): 0
基频: 0
boost主频: 1395 MHz
功耗: 350W
GPU P2P: PCIe-G4 64GB/s
是否禁售: 否
售价信息
- 20250219
- 京东 : RTX3090 24G(涡轮卡) : 6689 / 技嘉RTX 3090 24G(涡轮卡) : 6589
NVIDIA RTX 3060(TI)
售价信息
- 20250219
- 京东 : RTX3060 12GB(涡轮卡) : 1889
国产AI显卡
- 现在是不是可以考虑国产显卡跑本地大模型了?
- 可以用了,目前DeepSeek已经有大量的国产厂商发布了适配的新闻。
- 首推【华为昇腾910系列】,细分型号有点复杂。不同渠道有不同的型号
- 具体哪个型号可以,需要的可以自己整理
- 但是[个人(Weixin:数据库工作笔记)]的角度:
- 如果只部署固定的模型例如DeepSeek,可以考虑国产AI显卡
- 如果还要跑其他各种模型和任务
- 目前兼容性还得是英伟达因为cuda的护城河太厚。
- 暂时还是英伟达的方案更优。
AMD显卡
- 同上面的国产显卡
- AMD目前正在努力发展兼容性
- 但是目前坑还是很多
- 非专业人士不建议去踩
K FAQ for 显卡/GPU
Q:在AI领域,非英伟达显卡的劣势?
AMD 显卡被优先排除的原因:(国产显卡也有类似问题)
1、显存类型 ≠ GDDR7(AMD 2025 前仅 GDDR6)
2、架构非 Blackwell(AMD 为 RDNA3 / RDNA4)
3、无 CUDA / Tensor 核心(依赖 ROCm,生态差异大)
4、开源 LLM 部署兼容差(主流框架如 PyTorch、vLLM 对 ROCm 支持有限)
Q: 任一两款显卡的参数对比
- 芯参数网

Q: 中小企业、家庭用户在购买显卡的注意事项
-
明确需求和预算
需求定位:根据使用场景选择显卡。例如,家庭用户主要用于游戏或轻量级办公,可以选择中低端显卡;中小企业用于图形设计或视频编辑,则需要中高端显卡。
预算规划:显卡价格从几百元到上万元不等。例如,预算在2000-3000元的用户可以选择NVIDIA RTX 4060 Ti或AMD RX 7600,这些显卡性价比高,能满足大多数游戏和图形处理需求。 -
性能指标
核心性能:核心数量和频率越高,显卡性能越强。
显存容量和类型:显存容量应至少为8GB,推荐选择GDDR6或更高版本的显存。
支持技术:如果需要光线追踪或AI加速功能,建议选择支持DLSS或类似技术的显卡。 -
兼容性
硬件兼容性:确保显卡与主板的PCIe插槽兼容(如PCIe 3.0或4.0),并确认电源功率足够支持显卡运行。
软件兼容性:检查显卡是否支持所需的操作系统和软件。 -
散热和功耗
散热设计:良好的散热系统可以防止显卡过热,确保性能稳定。建议选择多风扇或液冷散热的显卡。
功耗:高性能显卡功耗较大,需确认电源是否能满足需求。 -
品牌和售后服务
品牌选择:优先选择知名品牌,如华硕、微星、技嘉等,这些品牌的产品质量更有保障。
售后服务:关注保修政策,如保修期长短、是否支持个人送保等。 -
其他注意事项
显卡尺寸:确保显卡能适配机箱,特别是小机箱用户。
接口类型:检查显卡的输出接口(如HDMI、DisplayPort)是否与显示器兼容。
防坑技巧:购买后录制开箱视频,检查显卡是否有使用痕迹或损坏,确保SN码与包装一致。
- 推荐型号
- 预算有限:NVIDIA RTX 3050、AMD RX 6500 XT
- 中端需求:NVIDIA RTX 4060 Ti、AMD RX 7600
- 高性能需求:NVIDIA RTX 4070、AMD RX 7700 XT
综合考虑以上因素,可以帮助用户在众多显卡产品中找到最适合自己的型号。
Q: 英伟达显卡后面的“Ti”是指?
Ti通常代表该显卡是加强版或高级版。
NVIDIA显卡中的“Ti”标识表示该显卡是性能加强版。
Ti是“Titanium”的缩写,意味着这些显卡在性能上有所提升,通常比不带Ti的版本拥有更高的CUDA核心数量、更快的显存、更高的GPU频率或其他方面的性能增强。Ti版本通常是基于相同系列的普通版本但经过一定的强化,适用于追求极致性能的用户
- 在NVIDIA的产品线中,无论是中端还是顶级旗舰显卡,都可能看到Ti的身影。Ti版本代表着该系列中的佼佼者,是追求高性能玩家的首选
例如,GTX 1080 Ti比GTX 1080拥有更多的CUDA核心、更高的频率和更快的显存带宽,因此在游戏、专业图形工作和计算任务中表现更为出色
- 以 RTX 3060 和 RTX 3060TI 为例
- 核心规格和性能差异
>> + 流处理器数量:3060 Ti拥有4864个流处理器,而3060仅有3584个,这使得3060 Ti在处理复杂图形任务时表现出更强的能力。
>> + 显存容量:3060 Ti的显存为8GB,而3060为12GB。尽管3060的显存看似更大,但在实际使用中,3060 Ti通常能以更高的频率处理游戏数据,从而提升整体性能。
>> + 功耗:3060 Ti的TDP(热设计功耗)为200W,而3060为170W。这意味着使用3060 Ti可能需要更高功率的电源,但其性能回报也更为显著。
- 游戏性能对比
在2K分辨率下,3060 Ti比3060强约30%。
具体游戏测试中,如《瘟疫传说安魂曲》、《最后生还者1》、《霍格沃兹遗产》和《赛博朋克2077》,3060 Ti在最高画质下的帧率普遍高于3060,提升幅度在20%左右。
- 适用场景
- 3060:适合预算有限的用户,尤其是在1080P分辨率下表现优秀,适合日常使用和轻量级游戏。
- 3060 Ti:适合追求高分辨率(如2K)和高帧率的游戏玩家,以及需要进行复杂图形处理的专业创作者。其性能提升在高端市场上更为显著。
Q: NVIDIA A100、H100、RTX 4090、RTX 4060 和 RTX 3060 的对比
- 数据中心级GPU(A100/H100/A800/H800):
- A100 和 H100 是高性能计算核心,适用于AI训练、超算等场景。H100的第四代Tensor Core和FP8支持使其在生成式AI中表现突出14。
- A800 和 H800 是针对中国市场限制的调整版本,主要削减互联带宽(如NVLink),但算力基本保留,价格因供需失衡可能更高8。
- 消费级GPU(RTX 4060 Ti/3060 Ti):
- RTX 4060 Ti:凭借Ada架构和DLSS 3技术,在1080p下性能领先3060 Ti约18%,但显存位宽(128bit)和带宽(288GB/s)低于3060 Ti(256bit/448GB/s)1116。
- RTX 3060 Ti:性价比仍较高,适合预算有限的玩家,但功耗较高且不支持DLSS 3212。
- 价格与市场:
- 数据中心级GPU价格受出口限制和供需影响波动较大(如H800现货价格曾达13万元人民币)8。
- 消费级显卡中,RTX 4060 Ti因显存容量和架构升级,适合追求新技术的用户,但需关注降价空间
基于公开参数及评测数据整理:
| 参数/型号 | NVIDIA A100 | NVIDIA H100 | RTX 4090 | RTX 4060 | RTX 3060 |
|---|---|---|---|---|---|
| 定位 | 数据中心/深度学习 | 数据中心/高性能计算 | 消费级旗舰(游戏/创作) | 消费级主流(游戏/轻度创作) | 消费级甜品(游戏/入门级创作) |
| 架构 | Ampere | Hopper | Ada Lovelace | Ada Lovelace | Ampere |
| CUDA 核心数 | 6912 | 16896 (TPC集群) | 16384 | 3072 | 3584 |
| 显存容量 | 40/80GB HBM2e | 80GB HBM3 | 24GB GDDR6X | 8GB GDDR6 | 12GB GDDR6 |
| 显存位宽 | 5120-bit | 5120-bit | 384-bit | 128-bit | 192-bit |
| 显存带宽 | 1.5TB/s (HBM2e) | 3.35TB/s (HBM3) | 1008 GB/s | 272 GB/s | 360 GB/s |
| FP32 浮点性能 | 19.5 TFLOPS | 51 TFLOPS | 82.58 TFLOPS | 15.11 TFLOPS | 12.7 TFLOPS |
| Tensor Core | 第三代(支持TF32/BF16) | 第四代(支持FP8) | 第四代(支持DLSS 3) | 第四代(支持DLSS 3) | 第三代(支持DLSS 2) |
| 功耗(TDP) | 250W-400W | 700W (SXM5) | 450W | 115W | 170W |
| 应用场景 | AI训练/推理、HPC | 超大规模AI模型、超级计算 | 4K游戏、8K渲染、专业创作 | 1080P/2K游戏、轻量级创作 | 1080P游戏、入门级设计 |
| 价格(参考) | ~$10,000+ | ~$30,000+ | ~¥15,000+ | ¥2399(首发) | ¥2100(当前均价) |
补充说明
-
性能差异:
- A100/H100:专为数据中心设计,支持大规模并行计算,A100在深度学习训练中表现远超消费级显卡(如RTX 4090的FP32性能虽高,但缺少专用AI优化)。
- RTX 4090:消费级旗舰,适合高分辨率游戏和渲染,但显存带宽和容量低于专业卡。
- RTX 4060:1080P游戏表现比RTX 3060提升约15%,但显存位宽和容量缩减可能影响高分辨率表现。
- RTX 3060:12GB大显存适合部分专业应用,但核心性能落后于4060。
-
能效比:
- RTX 4060的115W功耗显著低于RTX 3060(170W),适合ITX小机箱和笔记本。
- A100/H100的高功耗需搭配专用散热和供电系统,适用于服务器环境。
-
性价比建议:
- 游戏用户:预算充足选RTX 4090,追求性价比可考虑RTX 4060或二手RTX 3060 Ti。
- AI开发者:A100/H100是行业标杆,但成本极高;RTX 4090可用于小规模实验或推理任务。
-
显存与光追:
- RTX 40系支持DLSS 3,帧生成技术显著提升光追游戏帧率(如赛博朋克2077开启DLSS 3后性能翻倍)。
- RTX 3060的12GB显存在某些场景(如AI绘图)优于RTX 4060的8GB。
注:价格和性能数据可能因市场波动和驱动更新变化,建议参考最新评测。
Q: AMD显卡 vs NIVDIA 显卡?



Y 推荐文献
-
京东商城: 深图师 NVDIA 店铺
X 参考文献

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号