
后缀数组:倍增法和DC3的简单理解
一些定义:设字符串S的长度为n,S[0~n-1]。
子串:设0<=i<=j<=n-1,那么由S的第i到第j个字符组成的串为它的子串S[i,j]。
后缀:设0<=i<=n-1,那么子串S[i,n-1]称作它的后缀,用Suffix[i]表示。
串比较:对于两个串S1,S2,设长度分别为n1,n2。若存在一个位置i,使得对于0<=j<i满足S1[j]=S2[j]且S1[i]<S2[i],那么我们称S1<S2。如果S1是S2的一个前缀,那么也有S1<S2。两个串相等当且仅当长度相同且所有位置的字母都相同。所以,对于S的任意两个不同的后缀Suffix[i],Suffix[j] ,它们一定是不相等的,因为它们的长度都不同。
后缀数组:设我们用数组sa表示S的后缀数组,0<=sa[i]<=n-1,表示将S的n个后缀从小到大排序后,排名第i的后缀的位置是sa[i]。
名次数组:设我们用数组rank表示S的名次数组,0<=rank[i]<=n-1,表示将S的n个后缀从小到大排序后,后缀Suffix[i]的排名是rank[i]。很明显,sa[rank[i]]=i。
现在我们的问题是,给出一个字符串S,长度为n,S[0~n-1],字符集大小为m。求出S的后缀数组sa。有两种方法计算这个sa,倍增法和DC3法。我们设m<=n(一般情况也是这样子的吧。。)。那么倍增法的时间复杂度是O(nlog(n)),DC3的时间复杂度是O(n)。两个方法的空间复杂度都是O(n)。
倍增法
倍增法的思路是:
(1)首先计算S[0],S[1],...,S[n-1]的排名(注意这个单个字符的排序)。比如,对于aabaaaab,排序后为:1,1,2,1,1,1,1,2
(2)计算子串S[0,1],S[1,2],S[2,3],...,S[n-2,n-1],S[n-1,null] 的排名(注意最后一个的第二个字符为空),由于我们知道了单个字符的排名, 那么每个子串可以用一个二元组来表示,比如S[0,1]={1,1},S[1,2]={1,2},S[2,3]={2,1},等等,也就是aa,ab,ba,aa,aa,aa,ab,b$(我们用$表示空)的排名,排序后为:1,2,4,1,1,1,2,3
(3)计算子串S[0,1,2,3],S[1,2,3,4],S[2,3,4,5],...,S[n-4,n-3,n-2,n-1],S[n-3,n-2,n-1,$],S[n-2,n-1,$,$],S[n-1,$,$,$]。方法与上面相同。依次类推,每次使用两个2^(x-1)长度的子串来计算2^x次方长度的子串的排名,直到某一次排序后n个数字各不相同。最后,对于串aabaaaab,如下所示
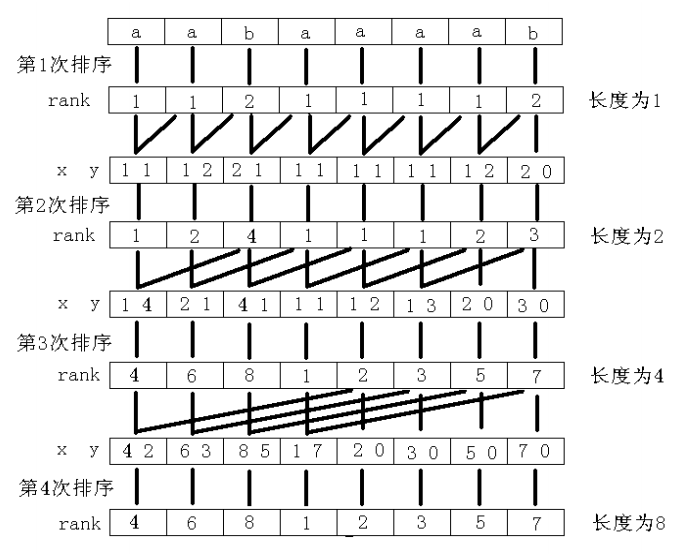
在实现的时候,一般在串的最后加一个空字符。这个字符比其他任何字符都小。下面是一份实现的程序


1 class SuffixArray 2 { 3 private: 4 static const int N=100005; /**字符串最大长度**/ 5 int wa[N],wb[N],wd[N],r[N]; 6 7 bool isSame(int *r,int a,int b,int len) 8 { 9 return r[a]==r[b]&&r[a+len]==r[b+len]; 10 } 11 void da(int *r,int *sa,int n,int m) 12 { 13 int *x=wa,*y=wb,*t; 14 for(int i=0;i<m;i++) wd[i]=0; 15 for(int i=0;i<n;i++) wd[x[i]=r[i]]++; 16 for(int i=1;i<m;i++) wd[i]+=wd[i-1]; 17 for(int i=n-1;i>=0;i--) sa[--wd[x[i]]]=i; 18 /**基数排序计算长度为1的子串的排名 19 相同的 越靠前 排名越小**/ 20 for(int j=1,p=1;p<n;j<<=1,m=p) 21 { 22 p=0; 23 for(int i=n-j;i<=n-1;i++) y[p++]=i; 24 for(int i=0;i<n;i++) if(sa[i]>=j) y[p++]=sa[i]-j; 25 /**y[i]表示对于组成2^j的所有子串的二元组 26 {pi,qi}来说,第二关键字即qi排名为i的位置为y[i] **/ 27 28 29 for(int i=0;i<m;i++) wd[i]=0; 30 for(int i=0;i<n;i++) wd[x[i]]++; 31 for(int i=1;i<m;i++) wd[i]+=wd[i-1]; 32 for(int i=n-1;i>=0;i--) sa[--wd[x[y[i]]]]=y[i]; 33 /**这里倒着枚举 当两个位置的y[i]和y[j]对应的x 34 相同时,后面的排名大,因为它的第二关键字 35 即y的排名大 而x在外面也决定了排名以第一 36 关键字为主 **/ 37 t=x;x=y;y=t;p=1; 38 x[sa[0]]=0; 39 for(int i=1;i<n;i++) x[sa[i]]=isSame(y,sa[i-1],sa[i],j)?p-1:p++; 40 } 41 } 42 public: 43 /**字符串S,长度n,S[0,n-1],为方便,我们假设它只包含小写字母 44 最后的后缀数组存储在sa[1~n]中 0<=sa[i]<=n-1 45 **/ 46 void calSuffixArray(char *S,int n,int *sa) 47 { 48 for(int i=0;i<n;i++) r[i]=S[i]-'a'+1; 49 r[n++]=0; 50 da(r,sa,n,27); 51 } 52 };
DC3算法
(1)将所有的后缀分成两部分,一部分是模3不等于0的,比如Suffix[1],Suffix[2],Suffix[4],Suffix[7]等,第二部分是模3等于0的后缀,Suffix[0],Suffix[3]等。首先计算第一部分每个后缀的排名(计算的时候假设没有第二部分的这些后缀)。方法是将Suffix[1]和Suffix[2]连起来( 连起来之前要把Suffix[1]和Suffix[2]的长度都变为3的倍数,如果不是,就在后面补上字符集中没有且小于字符集中所有字符的字符,比如0)。对于串S=aabaaaaba,Suffix[1]=abaaaaba,Suffix[2]=baaaaba,分别补成3的倍数,Suffix[1]=abaaaaba0,Suffix[2]=baaaaba00,最后拼成的串为abaaaaba0baaaaba00 。如下所示
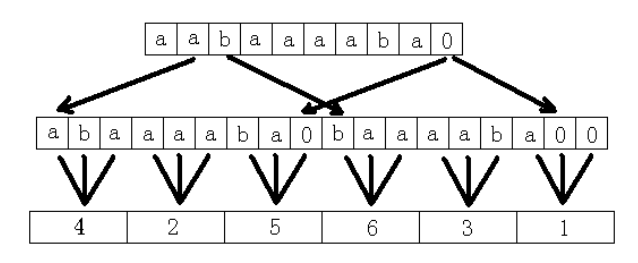
然后从前向后,每三个字符一组,即aba,aaa,ba0,baa,aab,a00,我们发现,他们分别是Suffix[1],Suffix[4],Suffix[7],Suffix[2],Suffix[5],Suffix[8] 的前3个字母。我们求出这六个的排名为4,2,5,6,3,1(注意,如果排序后还有相同的数字,也就是还有两个相同的串,比如3,2,4,5,2,1,那么要继续求,因为两个2之后的数字4大于1,所以第二的位置的2代表的后缀大于第5个位置的2代表的后缀。其实这个问题跟刚才的问题是相同的,所以可以递归求)。这样,我们最后得到了所有模3不等于0的位置的后缀的排名。
(2)计算模3等于0的位置的排名。这些位置的后缀,可以看做一个字符加上某个第一部分的一个后缀,这也很容易通过一次基数排序(就像倍增法的二元组一样)求得。对于上面的串,模3为0的后缀的排名为Suffix[9]<Suffix[3]<Suffix[0]<Suffix[6]
(3)合并第一部分和第二部分的排名。注意,上面求出的第一部分第二部分的排名都没有考虑另外一部分。合并的时候我们需要比较第一部分的某个后缀和第二部分的某个后缀。分两种情况。第一种是比较Suffix[3*i] 和Suffix[3*j+1],我们把它们看做:
Suffix[3*i]=S[3*i]+Suffix[3*i+1]
Suffix[3*j+1]=S[3*j+1]+Suffix[3*j+2]
Suffix[3*i+1]和Suffix[3*j+2]可以直接比较,因为它们都属于第一部分,而S[3*i]和S[3*j+1]也可以直接比较;
第二种情况是Suffix[3*i] 和Suffix[3*j+2],把它们看做是
Suffix[3*i]=S[3*i]+S[3*i+1]+Suffix[3*i+2]
Suffix[3*j+2]=S[3*j+2]+S[3*j+3]+Suffix[3*(j+1)+1]
Suffix[3*i+2]和Suffix[3*(j+1)+1]可以直接比较,它们都属于第二部分。而 前面是两个单个字符,可以直接比较。这样,就可以合并所有的后缀得到答案。
1 class SuffixArray 2 { 3 private: 4 static const int N=100005; /**字符串最大长度**/ 5 int wa[N*3],wb[N*3],wv[N*3],ws[N*3]; 6 int r[N],sa[N]; 7 8 int c0(int *r,int a,int b) 9 { 10 return r[a]==r[b]&&r[a+1]==r[b+1]&&r[a+2]==r[b+2]; 11 } 12 13 int c12(int k,int *r,int a,int b) 14 { 15 if(k==2) return r[a]<r[b]||r[a]==r[b]&&c12(1,r,a+1,b+1); 16 else return r[a]<r[b]||r[a]==r[b]&&wv[a+1]<wv[b+1]; 17 } 18 19 void sort(int *r,int *a,int *b,int n,int m) 20 { 21 for(int i=0;i<n;i++) wv[i]=r[a[i]]; 22 for(int i=0;i<m;i++) ws[i]=0; 23 for(int i=0;i<n;i++) ws[wv[i]]++; 24 for(int i=1;i<m;i++) ws[i]+=ws[i-1]; 25 for(int i=n-1;i>=0;i--) b[--ws[wv[i]]]=a[i]; 26 } 27 28 void dc3(int *r,int *sa,int n,int m) 29 { 30 #define F(x) ((x)/3+((x)%3==1?0:tb)) 31 #define G(x) ((x)<tb?(x)*3+1:((x)-tb)*3+2) 32 33 int *rn=r+n,*san=sa+n,ta=0,tb=(n+1)/3,tbc=0,p; 34 r[n]=r[n+1]=0; 35 for(int i=0;i<n;i++) if(i%3!=0) wa[tbc++]=i; 36 37 sort(r+2,wa,wb,tbc,m); 38 sort(r+1,wb,wa,tbc,m); 39 sort(r,wa,wb,tbc,m); 40 41 rn[F(wb[0])]=0; p=1; 42 for(int i=1;i<tbc;i++) rn[F(wb[i])]=c0(r,wb[i-1],wb[i])?p-1:p++; 43 44 if(p<tbc) dc3(rn,san,tbc,p); 45 else for(int i=0;i<tbc;i++) san[rn[i]]=i; 46 /**以上是第一部分计算完毕*/ 47 48 for(int i=0;i<tbc;i++) if(san[i]<tb) wb[ta++]=san[i]*3; 49 if(n%3==1) wb[ta++]=n-1; 50 sort(r,wb,wa,ta,m); 51 /**以上是第二部分计算完毕*/ 52 53 /**合并*/ 54 for(int i=0;i<tbc;i++) wv[wb[i]=G(san[i])]=i; 55 int i=0,j=0; 56 for(p=0;i<ta&&j<tbc;p++) 57 { 58 sa[p]=c12(wb[j]%3,r,wa[i],wb[j])?wa[i++]:wb[j++]; 59 } 60 while(i<ta) sa[p++]=wa[i++]; 61 while(j<tbc) sa[p++]=wb[j++]; 62 63 #undef F(x) 64 #undef G(x) 65 } 66 67 public: 68 /**字符串S,长度n,S[0,n-1],为方便,我们假设它只包含小写字母 69 最后的后缀数组存储在SA[1~n]中 0<=SA[i]<=n-1 70 **/ 71 void calSuffixArray(char *S,int n,int *SA) 72 { 73 for(int i=0;i<n;i++) r[i]=S[i]-'a'+1; 74 r[n+1]=0; 75 dc3(r,sa,n+1,27); 76 for(int i=1;i<=n;i++) SA[i]=sa[i]; 77 } 78 };
到此位置,这就是求后缀数组sa的两种方式。 下面,来介绍一个新的数组height。
在求出sa数组之后,我们定义一个新的数组height,height[i]表示Suffix[sa[i-1]]与Suffix[sa[i]]的最长公共前缀,也就是排名为i和排名为i-1的两个后缀的最长公共前缀。如果我们求出了height数组,那么对于任意两个位置i,j,我们不妨设rank[i]小于rank[j],它们的最长公共前缀就是height[rank[i]+1],height[rank[i]+2],...,height[rank[j]]的最小值。比如字符串为aabaaaab,我们求后缀Suffix[1]=abaaaab和Suffix[4]=aaab的最长公共前缀,如下图所示

那么如何计算height?我们定义h[i]=height[rank[i]],也就是Suffix[i]和它前一名的最长公共前缀,那么很明显有h[i]>=h[i-1]-1。因为h[i-1]是Suffix[i-1]和它前一名的最长公共前缀,设为Suffix[k],那么Suffix[i]和Suffix[k+1] 的最长公共前缀为h[i-1]-1,所以h[i]至少是h[i-1]-1。所以我们可以按照求h[1],h[2],h[3] 顺序计算所有的height。代码如下
1 const int N=100005; 2 int Rank[N]; 3 4 void calHeight(int *r,int *sa,int n,int *height) 5 { 6 int i,j,k=0; 7 for(int i=1;i<=n;i++) Rank[sa[i]]=i; 8 for(int i=0;i<n;i++) 9 { 10 if(k) k--; 11 j=sa[Rank[i]-1]; 12 while(i+k<n&&j+k<n&&r[i+k]==r[j+k]) k++; 13 height[Rank[i]]=k; 14 } 15 }
