随笔分类 - Reinforcement Learning
reinforcement learning algorithm
摘要:发表时间:2023(NeurIPS 2023) 文章要点:这篇文章提出,在强化学习里,对于特征向量表示的任务(low-level states),而不是图像表示的任务(image-based tasks),做表征学习也是有必要的。作者认为一个任务的困难在于底层的dynamic,而不是状态空间的大小,
阅读全文
摘要:发表时间:2024(ICLR2024) 文章要点: 文章提出用预训练的视觉语言模型作为zero-shot的reward model(VLM-RMs)。好处在于可以通过自然语言来给定一个具体的任务,通过VLM-RMs让强化学习基于reward学习这个任务(using pretrained vision
阅读全文
摘要:发表时间:2024 文章要点:文章对LLM增强强化学习(LLM-enhanced RL)的现有文献进行了总结。在agent-environment交互的范式下,讨论LLM对RL算法的帮助。 文章先给出LLM-enhanced RL的概念:the methods that utilize the mu
阅读全文
摘要:发表时间:2024(ICLR 2024) 文章要点:文章提出Retroformer,用策略梯度的方式调优prompt,更好的利用环境的reward。大体思路是学习一个retrospective LLM,将之前的轨迹和得分作为输入,得到一个新的prompt,这个prompt综合分析了之前的经验,从而提
阅读全文
摘要:发表时间: 2023 (NeurIPS 2023) 文章要点: 文章提出一个evolvable LLM-based agent框架REMEMBERER,主要思路是给大模型加一个experience memory存储过去的经验,然后用Q-learning的方式计算Q值,再根据任务相似度采样轨迹和对应的
阅读全文
摘要:发表时间:2020 文章要点:这篇文章主要介绍当前offline RL的研究进展,可能的问题以及一些解决方法。 作者先介绍了强化学习的准备知识,比如policy gradients,Approximate dynamic programming,Actor-critic algorithms,Mod
阅读全文
摘要:发表时间:2021(IEEE Transactions on Neural Networks and Learning Systems) 文章要点:这篇文章提出一个新的experience replay的方法,improved SAC (ISAC)。大概思路是先将replay buffer里面好的e
阅读全文
摘要:发表时间:2018(Neural Processing Letters 2019) 文章要点:这篇文章认为之前的experience replay的方法比如PER没有将transition的分布情况考虑在内,于是提出一个新的experience replay的方法,将occurrence frequ
阅读全文
摘要:发表时间:2021(ICML 2022) 文章要点:这篇文章把experience replay看做一个通过importance sampling来估计梯度的问题,从理论上推导经验回放的最优采样分布,然后提出LaBER (Large Batch Experience Replay)算法来近似这个采样
阅读全文
摘要:发表时间:2016(ICLR 2016) 文章要点:这篇文章提出了很经典的experience replay的方法PER,通过temporal-difference (TD) error来给采样赋权重(Sequences associated with rewards appear to be re
阅读全文
摘要:发表时间:2019 (NeurIPS 2019) 文章要点:这篇文章提出Episodic Backward Update (EBU)算法,采样一整条轨迹,然后从后往前依次更新做experience replay,这种方法对稀疏和延迟回报的环境有很好的效果(allows sparse and dela
阅读全文
摘要: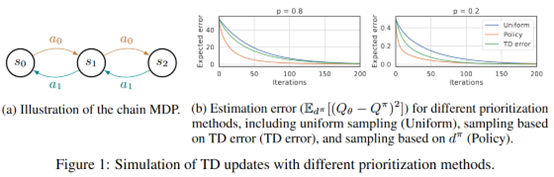 **发表时间:**2020 **文章要点:**这篇文章提出LFIW算法用likelihood作为experienc
阅读全文
摘要: **发表时间:**2020(ICML 2020) **文章要点:**这篇文章基于SAC做简单并且有效的改进来提升
阅读全文
摘要: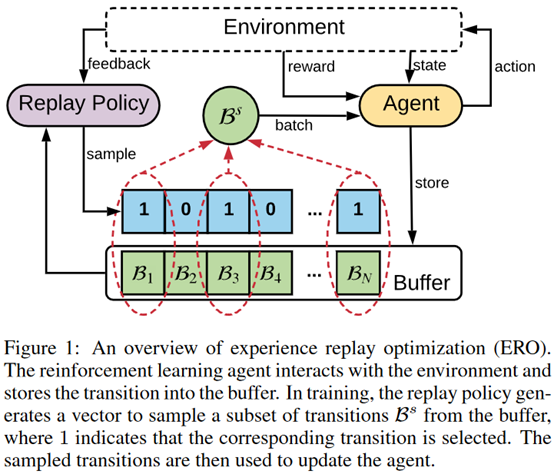 **发表时间:**2019 (IJCAI 2019) **文章要点:**这篇文章提出experience rep
阅读全文
摘要: **发表时间:**2016(IROS 2016) **文章要点:**这篇文章提出了experience repl
阅读全文
摘要: **发表时间:**2015(Deep Reinforcement Learning Workshop, NIPS
阅读全文
摘要: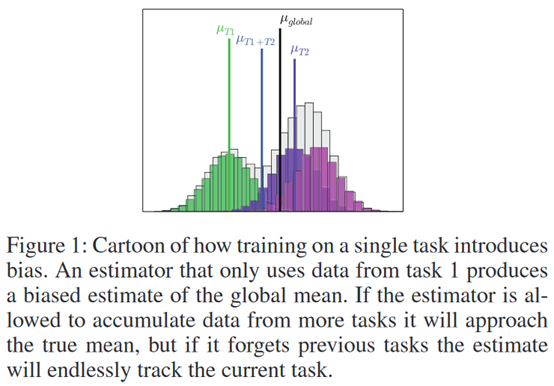 **发表时间:**2018(AAAI 2018) **文章要点:**这篇文章想解决强化学习在学多个任务时候的遗忘
阅读全文
摘要: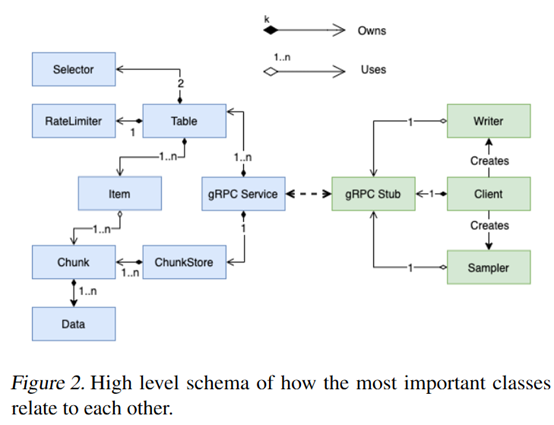 **发表时间:**2021 **文章要点:**这篇文章主要是设计了一个用来做experience replay的框
阅读全文
摘要: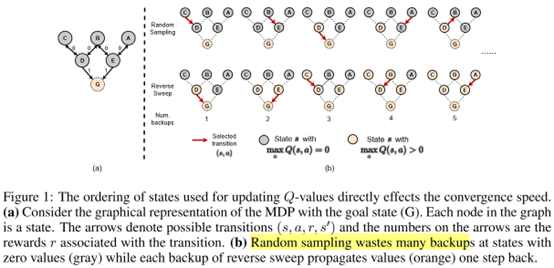 **发表时间:**2022(ICLR 2022) **文章要点:**这篇文章指出根据TD error来采样是低效的
阅读全文
摘要:**发表时间:**2021 (NeurIPS 2021) **文章要点:**理论表明,更高的hindsight TD error,更加on policy,以及更准的target Q value的样本应该有更高的采样权重(The theory suggests that data with highe
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号