会员
周边
众包
新闻
博问
闪存
HarmonyOS
Chat2DB
所有博客
当前博客
我的博客
我的园子
账号设置
会员中心
简洁模式
...
退出登录
注册
登录
initial_h
https://github.com/initial-h
博客园
首页
新随笔
管理
随笔分类 -
Reinforcement Learning
上一页
1
2
3
4
5
6
···
9
下一页
reinforcement learning algorithm
Effective Diversity in Population-Based Reinforcement Learning
摘要: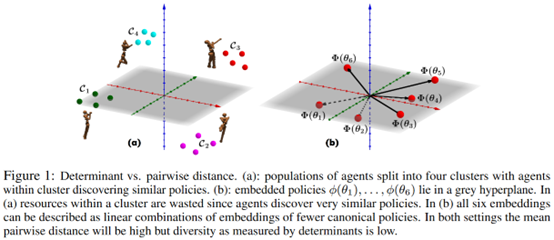 **发表时间:**2020 (NeurIPS 2020) **文章要点:**这篇文章提出了Diversity v
阅读全文
posted @
2023-07-07 08:46
initial_h
阅读(52)
评论(0)
推荐(0)
MODEL-AUGMENTED PRIORITIZED EXPERIENCE REPLAY
摘要: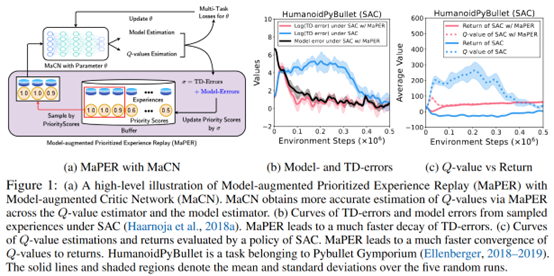 **发表时间:**2022(ICLR 2022) **文章要点:**这篇文章想说Q网络通常会存在under- or
阅读全文
posted @
2023-07-03 11:25
initial_h
阅读(58)
评论(0)
推荐(0)
Remember and Forget for Experience Replay
摘要:**发表时间:**2019(ICML 2019) **文章要点:**这篇文章想说如果replay的经验和当前的policy差别很大的话,对更新是有害的。然后提出了Remember and Forget Experience Replay (ReF-ER)算法,(1)跳过那些和当前policy差别很大
阅读全文
posted @
2023-07-02 12:15
initial_h
阅读(39)
评论(0)
推荐(0)
LEARNING TO SAMPLE WITH LOCAL AND GLOBAL CONTEXTS FROM EXPERIENCE REPLAY BUFFERS
摘要: **发表时间:**2021(ICLR 2021) **文章要点:**这篇文章想说,之前的experience r
阅读全文
posted @
2023-06-25 11:57
initial_h
阅读(31)
评论(0)
推荐(0)
Prioritized Sequence Experience Replay
摘要: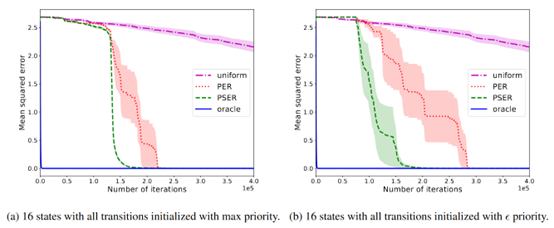 **发表时间:**2020 **文章要点:**这篇文章提出了Prioritized Sequence Exper
阅读全文
posted @
2023-06-23 12:34
initial_h
阅读(103)
评论(0)
推荐(0)
Revisiting Fundamentals of Experience Replay
摘要: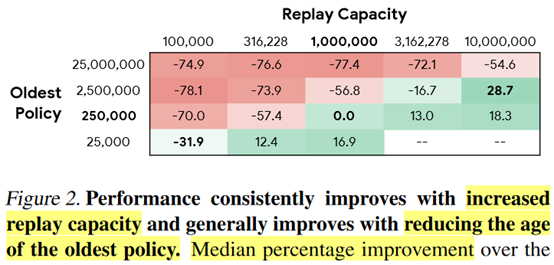 **发表时间:**2020(ICML2020) **文章要点:**这篇文章研究了experience repla
阅读全文
posted @
2023-06-09 12:22
initial_h
阅读(71)
评论(0)
推荐(0)
Revisiting Prioritized Experience Replay: A Value Perspective
摘要: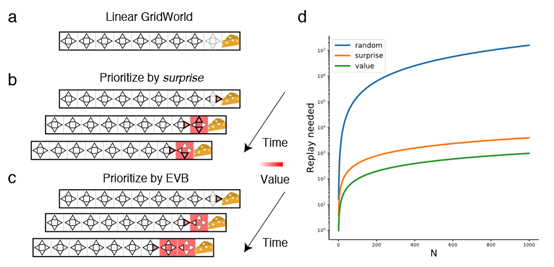 **发表时间:**2021 **文章要点:**这篇文章想说Prioritized experience repla
阅读全文
posted @
2023-06-04 13:12
initial_h
阅读(24)
评论(0)
推荐(0)
Muesli: Combining Improvements in Policy Optimization
摘要: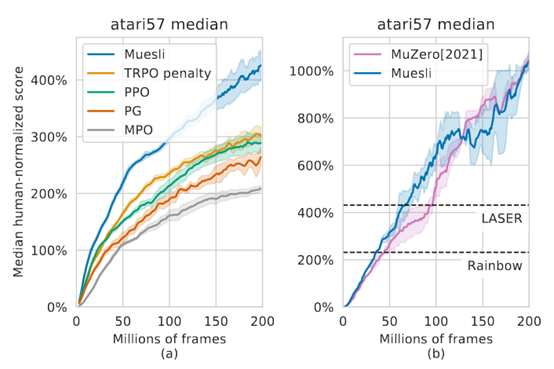 **发表时间:**2021(ICML 2021) **文章要点:**这篇文章提出一个更新policy的方式,结合
阅读全文
posted @
2023-06-02 22:36
initial_h
阅读(29)
评论(0)
推荐(0)
POLICY IMPROVEMENT BY PLANNING WITH GUMBEL
摘要: **发表时间:**2022(ICLR 2022) **文章要点:**AlphaZero在搜索次数很少的时候甚至动
阅读全文
posted @
2023-05-27 21:11
initial_h
阅读(212)
评论(0)
推荐(0)
The Difficulty of Passive Learning in Deep Reinforcement Learning
摘要: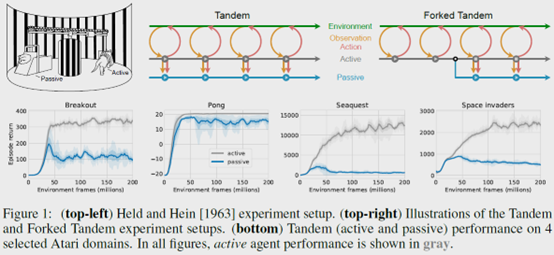 **发表时间:**2021(NeurIPS 2021) **文章要点:**这篇文章提出一个tandem learni
阅读全文
posted @
2023-05-24 22:58
initial_h
阅读(29)
评论(0)
推荐(0)
Off-Policy Deep Reinforcement Learning without Exploration
摘要:**发表时间:**2019(ICML 2019) **文章要点:**这篇文章想说在offline RL的setting下,由于外推误差(extrapolation errors)的原因,标准的off-policy算法比如DQN,DDPG之类的,如果数据的分布和当前policy的分布差距很大的话,那就
阅读全文
posted @
2023-05-21 12:10
initial_h
阅读(191)
评论(0)
推荐(0)
A Deeper Look at Experience Replay
摘要:**发表时间:**2017(Deep Reinforcement Learning Symposium, NIPS 2017) **文章要点:**这篇文章主要研究了replay buffer大小对Q-learning的影响,得出的结论是大的buffer会损害performance,因为采样的样本会更
阅读全文
posted @
2023-05-18 11:53
initial_h
阅读(115)
评论(0)
推荐(0)
DisCor: Corrective Feedback in Reinforcement Learning via Distribution Correction
摘要:**发表时间:**2020 (NeurIPS 2020) **文章要点:**这篇文章想说,对于监督学习来说就算刚开始训的不准,后面的新数据也会给你正确的feedback,这样的话随着训练进行,总会修正之前的错误。但是对于像Q-learning这样的强化学习任务来说,不存在这样的feedback,因为
阅读全文
posted @
2023-05-13 22:44
initial_h
阅读(95)
评论(0)
推荐(0)
DYNAMICS-AWARE UNSUPERVISED DISCOVERY OF SKILLS
摘要:**发表时间:**2020(ICLR2020) **文章要点:**这篇文章提出了一个无监督的model-based的学习算法Dynamics-Aware Discovery of Skills (DADS),可以同时发现可预测的行为以及学习他们的dynamics。然后对于新任务,可以直接用zero-
阅读全文
posted @
2023-05-09 22:41
initial_h
阅读(78)
评论(0)
推荐(0)
Heuristic-Guided Reinforcement Learning
摘要:**发表时间:**2021 (NeurIPS 2021) **文章要点:**这篇文章提出了一个Heuristic-Guided Reinforcement Learning (HuRL)的框架,用domain knowledge或者offline data构建heuristic,将问题变成一个sho
阅读全文
posted @
2023-05-06 23:30
initial_h
阅读(133)
评论(0)
推荐(1)
Teachable Reinforcement Learning via Advice Distillation
摘要:**发表时间:**2021 (NeurIPS 2021) **文章要点:**这篇文章提出了一种学习policy的监督范式,大概思路就是先结构化advice,然后先学习解释advice,再从advice中学policy。这个advice来自于外部的teacher,相当于一种human-in-the-l
阅读全文
posted @
2023-05-02 23:41
initial_h
阅读(42)
评论(0)
推荐(1)
Deep Dynamics Models for Learning Dexterous Manipulation
摘要:**发表时间:**2019 (CoRL 2019) **文章要点:**文章提出了一个online planning with deep dynamics models (PDDM)的算法来学习Dexterous multi-fingered hands,大概意思就是学习拟人的灵活的手指操控技巧。大概
阅读全文
posted @
2023-04-30 13:34
initial_h
阅读(84)
评论(0)
推荐(0)
EXPLORING MODEL-BASED PLANNING WITH POLICY NETWORKS
摘要:**发表时间:**2020(ICLR 2020) **文章要点:**这篇文章说现在的planning方法都是在动作空间里randomly generated,这样很不高效(其实瞎扯了,很多不是随机的方法啊)。作者提出在model based RL里用policy网络来做online planning
阅读全文
posted @
2023-04-27 23:02
initial_h
阅读(61)
评论(0)
推荐(0)
Learning Off-Policy with Online Planning
摘要:**发表时间:**2021(CoRL 2021) **文章要点:**这篇文章提出Off-Policy with Online Planning (LOOP)算法,将H-step lookahead with a learned model和terminal value function learne
阅读全文
posted @
2023-04-23 12:56
initial_h
阅读(43)
评论(0)
推荐(0)
The Second Type of Uncertainty in Monte Carlo Tree Search
摘要:**发表时间:**2020 **文章要点:**MCTS里通常通过计算访问次数来做探索,这个被称作count-derived uncertainty。这篇文章提出了第二种uncertainty,这种uncertainty来源于子树的大小,一个直觉的想法就是,如果一个动作对应下的子树小,那就不用探索那么
阅读全文
posted @
2023-04-20 23:14
initial_h
阅读(53)
评论(0)
推荐(0)
上一页
1
2
3
4
5
6
···
9
下一页
公告

 浙公网安备 33010602011771号
浙公网安备 33010602011771号