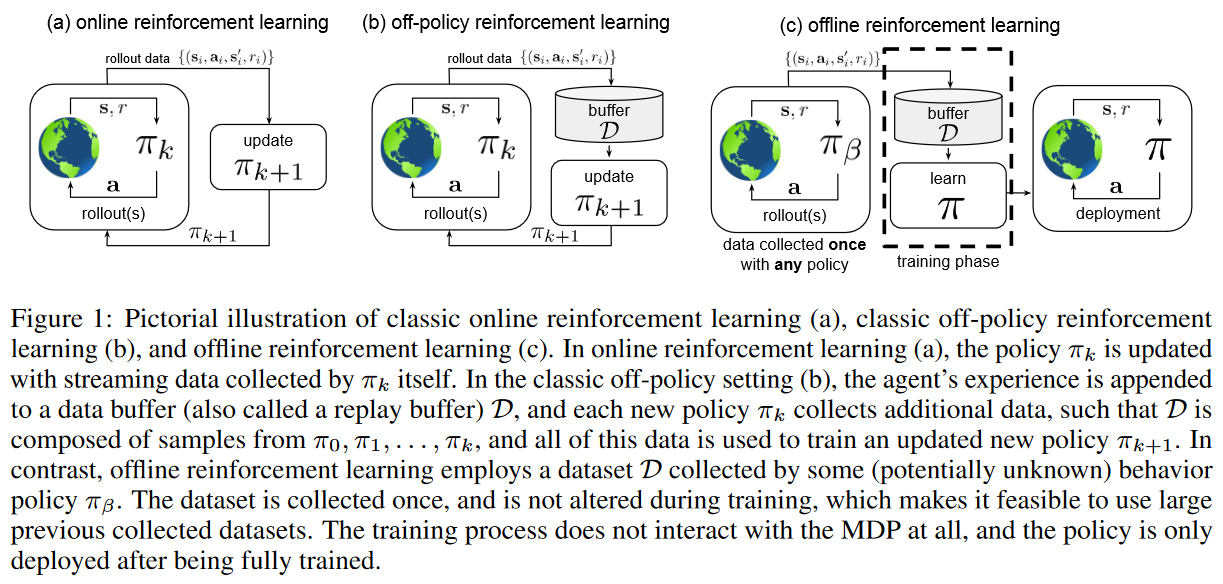
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
发表时间:2020
文章要点:这篇文章主要介绍当前offline RL的研究进展,可能的问题以及一些解决方法。
作者先介绍了强化学习的准备知识,比如policy gradients,Approximate dynamic programming,Actor-critic algorithms,Model-based reinforcement learning,这里不具体说了。接着开始说offline RL,和online相比,主要的区别就是我们只能有一个static dataset,并且不能和环境交互获得新数据,所以offline RL排除了exploration,只能基于这个dataset来学策略。这种设定和很多实际应用相关,比如文中提到的Decision making in health care,Learning goal-directed dialogue policies,Learning robotic manipulation skills等等。接着说一下每个章节大概在说什么。
2.4 What Makes Offline Reinforcement Learning Difficult
文章提到offline面临的一些问题,其中distribution shift是offline RL里一个主要的挑战。这个问题是说在训练policy最大化return的过程中,agent训练得到的policy和收集数据的policy是不一样的,是有偏移的(distributional shift: while our function approximator (policy, value function, or model) might be trained under one distribution, it will be evaluated on a different distribution, due both to the change in visited states for the new policy and, more subtly, by the act of maximizing the expected return.)。
作者还理论说了下即使在有optimal action label的情况下,offline RL的error和time horizon的平方成正比,而online的时候是线性的。

通常的解决办法是约束the learned policy和behavior policy的距离,不要差太多。
3 Offline Evaluation and Reinforcement Learning via Importance Sampling
接着作者介绍了importance sampling在offline RL里面的作用,这里主要是针对policy gradient方法的。
首先是,Offline Evaluation,通常要学一个policy就需要知道怎么评估策略,评估完了后就可以知道哪个策略最好了。其中一个方式是importance sampling,

接着作者介绍了几个减少方差的方法,不细说了。
另一个用处是Off-Policy Policy Gradient,就是直接用policy gradient结合importance sampling在static dataset上面学policy,

为了让learned policy和behavior policy不要差太远,还可以加一些约束,比如KL-divergence, entropy regularizer等等。
因为policy gradient需要基于轨迹来做importance sampling(per-action importance weights),再加上数据集的样本有限,这样会加剧方差的问题。一个可能的解决办法是Approximate Off-Policy Policy Gradients,将对轨迹的修正转变为对state distribution的采样,甚至把importance sampling去掉,这样会有误差,但是实践表明一点误差是可以接受的,而且最后效果不错。
如果不想引入误差,另一个方式是Marginalized Importance Sampling,直接估计state-marginal importance ratio而不是per-action importance weighting
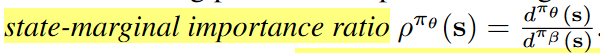
这部分的主要问题还是importance sampling带来的方差,这个问题在offline下会更严重。the maximum improvement that can be reliably obtained via importance sampling is limited by (i) the suboptimality of the behavior policy; (ii) the dimensionality of the state and action space; (iii) the effective horizon of the task.
4 Offline Reinforcement Learning via Dynamic Programming
下一个内容是Dynamic Programming,这个主要是针对Q-learning。这里遇到的主要问题就是distributional shift,通常方法包括policy constraint methods和uncertainty-based methods。前者约束learned policy和behavior policy的距离,后者估计Q-value的uncertainty,从而用来检测是否存在distributional shift的问题。
文章先说了value estimation的方法,这部分和online区别不大,比如Bellman residual minimization,Least-squares fixed point approximation,Least squares temporal difference Q-learning (LSTD-Q),Least squares policy iteration (LSPI)。
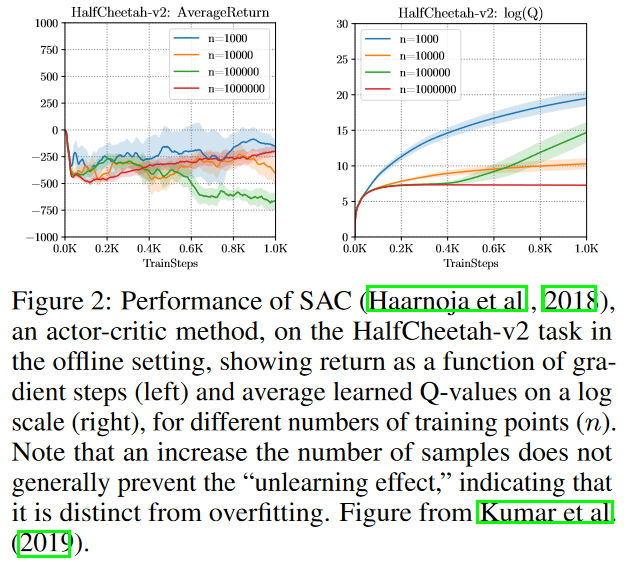
接着具体说了distributional shift,作者想说因为learned policy和behavior policy差太多,学到的policy通常都在没见过的state上选动作,这就导致policy的性能无法保证。作者进一步用一个实验来说明,即使增大数据量,这个问题还是没有被缓解。这说明这个问题不是因为overfitting造成的
接着就介绍了policy constraint的方法,explicit f-divergence constraints,implicit f-divergence constraints,integral probability metric (IPM) constraints,这些方式可以直接加policy constraints或者通过添加reward的方式做policy penalty。这里有个直觉的准则,Intuitively, an effective policy constraint should prevent the learned policy \(\pi(a|s)\) from going outside the set of actions that have a high probability in the data, but would not prevent it from concentrating around a subset of high-probability actions.
之前的方式都是约束policy的距离,这个方式不利于学到一个好的policy。另一个方式是约束两个policy的support,这个support是说我不需要policy很近,我只需要大家的策略动作都出现在data里面,所以只需要约束OOD的概率

接着说了uncertainty的方式,大概做法就是在估计Q的时候考虑uncertainty

另一个方式是加正则项,比如加个penalty
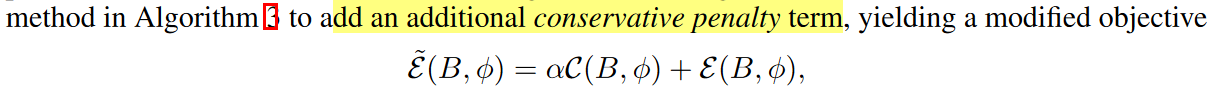
这里面存在的问题有,uncertainty不好估计,可能会导致过分保守的估计或者过分宽松的估计。
5 Offline Model-Based Reinforcement Learning
这章主要说了下Model-Based的情况。首先主要的问题还是Model Exploitation and Distribution Shift,之前model-free的话就是value exploitation。主要的解决方式还是搞一个constraint或者penalty,估计model uncertainty等等。
6 Applications and Evaluation
这章就讲了下应用和benchmark。Benchmark主要说了D4RL,应用说了Robotics,Healthcare,Autonomous Driving,Advertising and Recommender Systems,Language and Dialogue。
总结:对这个方向的了解还是不够深刻,看起来这篇文章写了很多,但是读下来没有醍醐灌顶的感觉,还没摸到文章的逻辑在哪。
疑问:感觉写的挺难的,有些结论都没看明白,讲forward/backward bellman equation那里完全没看明白。
里面的章节顺序其实有点看不明白,有的地方感觉内容重复了,可能还没真正理解为啥要这么划分,比如3,4章里面讲具体方法的地方。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号