

随笔分类 - Hugging Face 博客
摘要: 这是 让 LLM 来评判 系列文章的第六篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 LLM 评估模型已知偏差及缓解措施: 缺乏内部一致性:同一 prompt 输入评估模型执行多次得到的结果可能不一样 (如果
阅读全文
这是 让 LLM 来评判 系列文章的第六篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 LLM 评估模型已知偏差及缓解措施: 缺乏内部一致性:同一 prompt 输入评估模型执行多次得到的结果可能不一样 (如果
阅读全文
这是 让 LLM 来评判 系列文章的第六篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 LLM 评估模型已知偏差及缓解措施: 缺乏内部一致性:同一 prompt 输入评估模型执行多次得到的结果可能不一样 (如果
阅读全文
摘要: Open R1 项目进展第三期 本次更新带来三大突破性进展: CodeForces-CoTs 数据集: 通过 R1 模型蒸馏生成近 10 万条高质量编程思维链样本,同时包含 C++ 和 Python 双语言解题方案 IOI 基准测试: 基于 2024 国际信息学奥林匹克竞赛 (IOI) 构建的全新挑
阅读全文
Open R1 项目进展第三期 本次更新带来三大突破性进展: CodeForces-CoTs 数据集: 通过 R1 模型蒸馏生成近 10 万条高质量编程思维链样本,同时包含 C++ 和 Python 双语言解题方案 IOI 基准测试: 基于 2024 国际信息学奥林匹克竞赛 (IOI) 构建的全新挑
阅读全文
Open R1 项目进展第三期 本次更新带来三大突破性进展: CodeForces-CoTs 数据集: 通过 R1 模型蒸馏生成近 10 万条高质量编程思维链样本,同时包含 C++ 和 Python 双语言解题方案 IOI 基准测试: 基于 2024 国际信息学奥林匹克竞赛 (IOI) 构建的全新挑
阅读全文
摘要:我们启动 Open R1 项目 已经两周了,这个项目是为了把 DeepSeek R1 缺失的部分补齐,特别是训练流程和合成数据。 这篇文章里,我们很高兴跟大家分享一个大成果: OpenR1-Math-220k,这是我们打造的第一个大规模数学推理数据集! 除此之外,我们还聊聊社区里一些让人兴奋的进展,
阅读全文
摘要: DeepSeek R1 发布已经两周了,而我们启动 open-r1 项目——试图补齐它缺失的训练流程和合成数据——也才过了一周。这篇文章简单聊聊: Open-R1 在模仿 DeepSeek-R1 流程和数据方面的进展 我们对 DeepSeek-R1 的认识和相关讨论 DeepSeek-R1 发布后社
阅读全文
DeepSeek R1 发布已经两周了,而我们启动 open-r1 项目——试图补齐它缺失的训练流程和合成数据——也才过了一周。这篇文章简单聊聊: Open-R1 在模仿 DeepSeek-R1 流程和数据方面的进展 我们对 DeepSeek-R1 的认识和相关讨论 DeepSeek-R1 发布后社
阅读全文
DeepSeek R1 发布已经两周了,而我们启动 open-r1 项目——试图补齐它缺失的训练流程和合成数据——也才过了一周。这篇文章简单聊聊: Open-R1 在模仿 DeepSeek-R1 流程和数据方面的进展 我们对 DeepSeek-R1 的认识和相关讨论 DeepSeek-R1 发布后社
阅读全文
摘要:作者:Thomas Wolf, Hugging Face 联合创始人和首席科学家 发布日期:2025 年 2 月 26 日 原文链接:🔭 The Einstein AI model 几天前,我在一个活动上分享了一个略显争议的观点,后来我决定把它写下来:我担心人工智能无法带来所谓的“压缩的 21 世
阅读全文
摘要:来源:博客链接 过去两年,开源 AI 社区一直在热烈讨论新 AI 模型的开发。每天都有越来越多的模型在 Hugging Face 上发布,并被用于实际应用中。然而,开发者在使用这些模型时面临的一个挑战是模型格式的多样性。 在本文中,我们将探讨当下常见的 AI 模型格式,包括: GGUF PyTorc
阅读全文
摘要: 一句话总结: SmolVLM 现已具备更强的视觉理解能力📺 SmolVLM2 标志着视频理解技术的根本性转变——从依赖海量计算资源的巨型模型,转向可在任何设备运行的轻量级模型。我们的目标很简单: 让视频理解技术从手机到服务器都能轻松部署。 我们同步发布三种规模的模型 (22 亿/5 亿/2.56
阅读全文
一句话总结: SmolVLM 现已具备更强的视觉理解能力📺 SmolVLM2 标志着视频理解技术的根本性转变——从依赖海量计算资源的巨型模型,转向可在任何设备运行的轻量级模型。我们的目标很简单: 让视频理解技术从手机到服务器都能轻松部署。 我们同步发布三种规模的模型 (22 亿/5 亿/2.56
阅读全文
一句话总结: SmolVLM 现已具备更强的视觉理解能力📺 SmolVLM2 标志着视频理解技术的根本性转变——从依赖海量计算资源的巨型模型,转向可在任何设备运行的轻量级模型。我们的目标很简单: 让视频理解技术从手机到服务器都能轻松部署。 我们同步发布三种规模的模型 (22 亿/5 亿/2.56
阅读全文
摘要: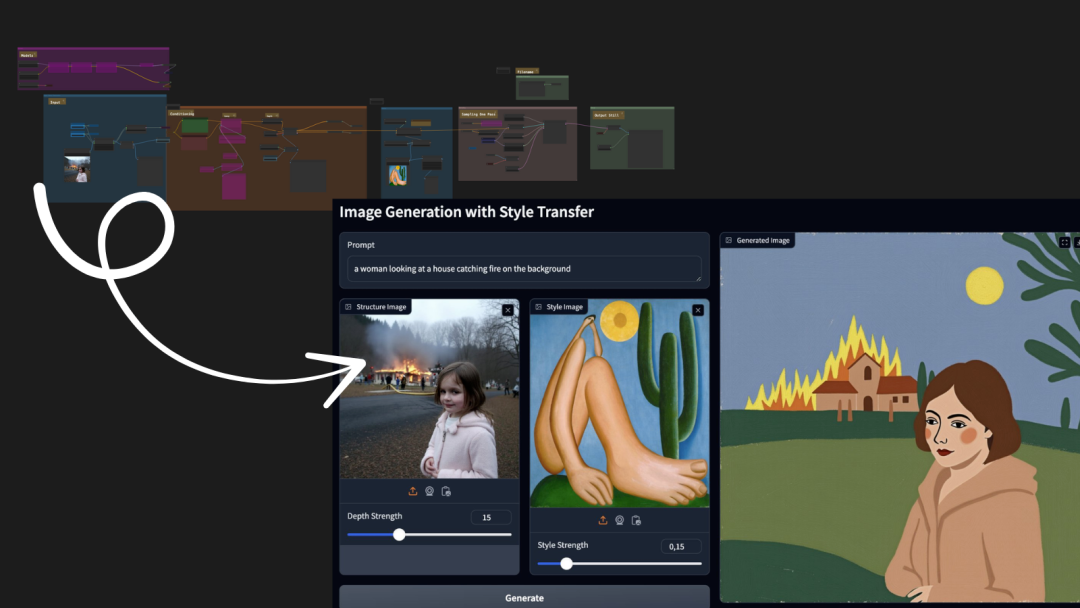 简介 在本教程中,我将逐步指导如何将一个复杂的 ComfyUI 工作流转换为一个简单的 Gradio 应用程序,并讲解如何将其部署在 Hugging Face Spaces 的 ZeroGPU 无服务器架构上,这样可以让它以无服务器的方式免费部署和运行。在本教程中,我们将使用 Nathan Ship
阅读全文
简介 在本教程中,我将逐步指导如何将一个复杂的 ComfyUI 工作流转换为一个简单的 Gradio 应用程序,并讲解如何将其部署在 Hugging Face Spaces 的 ZeroGPU 无服务器架构上,这样可以让它以无服务器的方式免费部署和运行。在本教程中,我们将使用 Nathan Ship
阅读全文
简介 在本教程中,我将逐步指导如何将一个复杂的 ComfyUI 工作流转换为一个简单的 Gradio 应用程序,并讲解如何将其部署在 Hugging Face Spaces 的 ZeroGPU 无服务器架构上,这样可以让它以无服务器的方式免费部署和运行。在本教程中,我们将使用 Nathan Ship
阅读全文
摘要: 介绍 S2S (语音到语音) 是 Hugging Face 社区内存在的一个令人兴奋的新项目,它结合了多种先进的模型,创造出几乎天衣无缝的体验: 你输入语音,系统会用合成的声音进行回复。 该项目利用 Hugging Face 社区中的 Transformers 库提供的模型实现了流水话处理。该流程处
阅读全文
介绍 S2S (语音到语音) 是 Hugging Face 社区内存在的一个令人兴奋的新项目,它结合了多种先进的模型,创造出几乎天衣无缝的体验: 你输入语音,系统会用合成的声音进行回复。 该项目利用 Hugging Face 社区中的 Transformers 库提供的模型实现了流水话处理。该流程处
阅读全文
介绍 S2S (语音到语音) 是 Hugging Face 社区内存在的一个令人兴奋的新项目,它结合了多种先进的模型,创造出几乎天衣无缝的体验: 你输入语音,系统会用合成的声音进行回复。 该项目利用 Hugging Face 社区中的 Transformers 库提供的模型实现了流水话处理。该流程处
阅读全文
摘要: 自推测解码是一种新颖的文本生成方法,它结合了推测解码 (Speculative Decoding) 的优势和大语言模型 (LLM) 的提前退出 (Early Exit) 机制。该方法出自论文 LayerSkip: Enabling Early-Exit Inference and Self-Spec
阅读全文
自推测解码是一种新颖的文本生成方法,它结合了推测解码 (Speculative Decoding) 的优势和大语言模型 (LLM) 的提前退出 (Early Exit) 机制。该方法出自论文 LayerSkip: Enabling Early-Exit Inference and Self-Spec
阅读全文
自推测解码是一种新颖的文本生成方法,它结合了推测解码 (Speculative Decoding) 的优势和大语言模型 (LLM) 的提前退出 (Early Exit) 机制。该方法出自论文 LayerSkip: Enabling Early-Exit Inference and Self-Spec
阅读全文
摘要:Hugging Face 在 Git LFS 仓库 中存储了超过 30 PB 的模型、数据集和 Spaces。由于 Git 在文件级别进行存储和版本控制,任何文件的修改都需要重新上传整个文件。这在 Hub 上会产生高昂的成本,因为平均每个 Parquet 和 CSV 文件大小在 200-300 MB
阅读全文
摘要:设计你自己的评估 prompt 这是 让 LLM 来评判 系列文章的第三篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 通用 prompt 设计建议 我总结的互联网上通用 prompt 的通用设计原则如下: 任
阅读全文
摘要:创刊号 🎉 AI 领域的发展速度令人惊叹,回想一年前我们还在为生成正确手指数量的人像而苦苦挣扎的场景,恍如隔世 😂。 过去两年对开源模型和艺术创作工具而言具有里程碑意义。创意表达的 AI 工具从未像现在这般触手可及,然而这仅仅是冰山一角。让我们共同回顾 2024 年 AI 艺术领域的关键突破与创
阅读全文
摘要: 奖励模型相关内容 这是 让 LLM 来评判 系列文章的第五篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 什么是奖励模型? 奖励模型通过学习人工标注的成对 prompt 数据来预测分数,优化目标是对齐人类偏好。
阅读全文
奖励模型相关内容 这是 让 LLM 来评判 系列文章的第五篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 什么是奖励模型? 奖励模型通过学习人工标注的成对 prompt 数据来预测分数,优化目标是对齐人类偏好。
阅读全文
奖励模型相关内容 这是 让 LLM 来评判 系列文章的第五篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 什么是奖励模型? 奖励模型通过学习人工标注的成对 prompt 数据来预测分数,优化目标是对齐人类偏好。
阅读全文
摘要:欢迎来到 Physical AI 的最前沿!Seeed x LeRobot 具身智能黑客松现邀请所有对在机器人领域训练模仿学习策略,并实时进行推理部署感兴趣的人,共同创造具有影响力的创新解决方案。在这里,你可以与志同道合的开发者一起实践前沿机器人技术,获取免费硬件支持和独家资源,并快速在真实机器人系
阅读全文
摘要: 评估你的评估结果 这是 让 LLM 来评判 系列文章的第三篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 在生产中或大规模使用 LLM 评估模型之前,你需要先评估它在目标任务的表现效果如何,确保它的评分跟期望的
阅读全文
评估你的评估结果 这是 让 LLM 来评判 系列文章的第三篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 在生产中或大规模使用 LLM 评估模型之前,你需要先评估它在目标任务的表现效果如何,确保它的评分跟期望的
阅读全文
评估你的评估结果 这是 让 LLM 来评判 系列文章的第三篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 在生产中或大规模使用 LLM 评估模型之前,你需要先评估它在目标任务的表现效果如何,确保它的评分跟期望的
阅读全文
摘要: 基础概念 这是 让 LLM 来评判 系列文章的第一篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 什么是评估模型? 评估模型 (Judge models) 是一种 用于评估其他神经网络的神经网络。大多数情况下它
阅读全文
基础概念 这是 让 LLM 来评判 系列文章的第一篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 什么是评估模型? 评估模型 (Judge models) 是一种 用于评估其他神经网络的神经网络。大多数情况下它
阅读全文
基础概念 这是 让 LLM 来评判 系列文章的第一篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 什么是评估模型? 评估模型 (Judge models) 是一种 用于评估其他神经网络的神经网络。大多数情况下它
阅读全文
摘要:基础概念 这是 让 LLM 来评判 系列文章的第一篇,敬请关注系列文章: 基础概念 选择 LLM 评估模型 设计你自己的评估 prompt 评估你的评估结果 奖励模型相关内容 技巧与提示 什么是评估模型? 评估模型 (Judge models) 是一种 用于评估其他神经网络的神经网络。大多数情况下它
阅读全文
摘要: 一些评估测试集 这是 自动评估基准 系列文章的第三篇,敬请关注系列文章: 基础概念 设计你的自动评估任务 一些评估测试集 技巧与提示 如果你感兴趣的任务已经得到充分研究,很可能评估数据集已经存在了。 下面列出了一些近年来开发构建的评估数据集。需要注意的是: 大部分数据集有些 “过时”,因为它们是在
阅读全文
一些评估测试集 这是 自动评估基准 系列文章的第三篇,敬请关注系列文章: 基础概念 设计你的自动评估任务 一些评估测试集 技巧与提示 如果你感兴趣的任务已经得到充分研究,很可能评估数据集已经存在了。 下面列出了一些近年来开发构建的评估数据集。需要注意的是: 大部分数据集有些 “过时”,因为它们是在
阅读全文
一些评估测试集 这是 自动评估基准 系列文章的第三篇,敬请关注系列文章: 基础概念 设计你的自动评估任务 一些评估测试集 技巧与提示 如果你感兴趣的任务已经得到充分研究,很可能评估数据集已经存在了。 下面列出了一些近年来开发构建的评估数据集。需要注意的是: 大部分数据集有些 “过时”,因为它们是在
阅读全文
摘要: 过去几年,大语言模型 (LLM) 的进程主要由训练时计算缩放主导。尽管这种范式已被证明非常有效,但预训练更大模型所需的资源变得异常昂贵,数十亿美元的集群已经出现。这一趋势引发了人们对其互补方法的浓厚兴趣, 即推理时计算缩放。推理时计算缩放无需日趋庞大的预训练预算,而是采用动态推理策略,让模型能够对难
阅读全文
过去几年,大语言模型 (LLM) 的进程主要由训练时计算缩放主导。尽管这种范式已被证明非常有效,但预训练更大模型所需的资源变得异常昂贵,数十亿美元的集群已经出现。这一趋势引发了人们对其互补方法的浓厚兴趣, 即推理时计算缩放。推理时计算缩放无需日趋庞大的预训练预算,而是采用动态推理策略,让模型能够对难
阅读全文
过去几年,大语言模型 (LLM) 的进程主要由训练时计算缩放主导。尽管这种范式已被证明非常有效,但预训练更大模型所需的资源变得异常昂贵,数十亿美元的集群已经出现。这一趋势引发了人们对其互补方法的浓厚兴趣, 即推理时计算缩放。推理时计算缩放无需日趋庞大的预训练预算,而是采用动态推理策略,让模型能够对难
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号