
WebApp 开发中的常见问题与 AI 集成实践反思
在 WebApp 从“功能可用”迈向“智能可用”的过程中,开发者面临的挑战早已不再局限于前端布局或后端接口设计。随着大模型与 AI API 被快速引入到 WebApp 中,应用形态看似被极大简化,实则隐藏了更多新的复杂性:模型能力是否与业务匹配?API-Key 如何管理才安全?调用频率、成本、延迟如何平衡?一旦模型更换,系统是否具备足够的可迁移性?尤其是在“所见即所得”的 AI WebApp 开发浪潮下,许多项目在 Demo 阶段运行顺畅,却在真实部署、规模化使用和长期维护中频频踩坑。本篇文章将结合 WebApp 实战经验,系统梳理 WebApp 制作过程中常见的问题,重点聚焦 AI 接入与大模型 API-Key 选择这一关键环节,剖析背后的技术逻辑与设计误区,为后续构建稳定、可持续的智能 Web 应用打下扎实基础。
一、引言:从“能跑起来”到“能长期用”的鸿沟
在生成式 AI 快速演进的背景下,WebApp 的开发范式正在发生深刻变化。过去,一个典型 WebApp 的关注重点更多集中在前端交互、后端接口与数据库设计;而如今,AI 能力的引入,尤其是大模型 API 的接入,使得 WebApp 从“工具型应用”逐渐演化为“智能型系统”。然而,在实际开发过程中,许多 AI WebApp 项目往往会卡在一个尴尬阶段:Demo 能跑,但系统不稳;功能看似完整,但问题频发;用户体验尚可,但维护成本极高。
究其原因,并非模型能力不足,而是 WebApp + AI 的工程复杂度被严重低估。本文结合多个 AI WebApp 项目的实际开发经验,系统梳理 WebApp 制作过程中最容易出现的问题,重点聚焦:
- WebApp 架构层面的隐性风险
- AI 能力集成带来的新型工程问题
- API Key 管理与大模型选择中的典型误区
- 如何从“实验性项目”走向“可长期运行的 AI WebApp”
二、WebApp 制作中的通用工程问题
2.1 架构设计过早复杂化
在 WebApp 的早期开发阶段,最常见、也最容易被忽视的问题之一,就是架构设计过早复杂化。不少项目在功能尚未验证之前,就引入了完整的前后端分离、多层状态管理、复杂的接口抽象,甚至直接规划微服务或多模型协同架构,试图“一次性设计到位”。结果往往适得其反:一方面,开发周期被显著拉长,任何一个简单功能都需要跨多个模块联调;另一方面,当需求发生变化时,原本看似“先进”的架构反而成为束缚,修改成本极高。
在 AI WebApp 中,这一问题尤为突出。大模型调用本身就具有不确定性,包括响应延迟、输出不稳定、错误难以复现等特征。如果再叠加过度复杂的系统架构,排错路径会迅速失控,开发体验呈指数级恶化。实践经验表明:
AI WebApp 的架构应当遵循“先跑通,再优化”的原则。早期阶段优先采用轻量化方案,如前端直连 API、Serverless 函数、单一模型封装等;待核心功能与交互逻辑稳定后,再逐步抽象服务层与模型层。同时,应有意识地将 AI 调用逻辑与 UI 展示逻辑解耦,为后续模型替换和能力扩展预留空间。
2.2 状态管理混乱
状态管理几乎是所有 WebApp 的难点,而在 AI WebApp 中,这一问题会被进一步放大。典型的 AI 交互流程往往包含:用户操作触发请求、模型异步返回结果、页面根据结果进行多区域更新,这使得状态来源天然呈现出多源、异步、延迟的特点。如果缺乏清晰的状态设计,很容易出现一系列隐蔽但致命的问题,例如旧请求覆盖新结果、页面局部刷新异常、AI 输出与当前参数不匹配等。在 BP 神经网络可视化、训练过程演示、参数调试类应用中,这类错误往往直接破坏用户对结果的信任。常见的工程误区包括:
将 AI 返回结果直接写入全局状态、不对请求进行版本或时间戳校验、忽略用户在请求未完成时修改参数的行为。较为稳妥的做法是:为每一次 AI 请求绑定明确的上下文标识,引入请求版本或任务 ID,对返回结果进行一致性校验;同时将“计算状态”和“展示状态”区分管理,避免异步结果对当前交互造成污染。
2.3 前端渲染性能被低估
相比传统表单型应用,AI WebApp 往往伴随着大量文本输出、动态图表、网络结构可视化与动画效果。许多性能问题并非源自模型调用,而是前端渲染策略被严重低估。在 Canvas、SVG 或 WebGL 场景下,如果每一次状态变化都触发全量重绘,极易导致页面卡顿、内存持续上涨,甚至直接引发浏览器崩溃。这在神经网络结构动态更新、权重变化可视化等场景中尤为常见。成熟的工程经验通常包括:对可视化模块进行分层渲染,将动画与计算逻辑彻底分离,控制重绘频率,并避免将高频变化直接绑定到 React / Vue 的响应式系统中。只有将性能问题前置考虑,AI WebApp 才能在“可演示”之外,真正做到“可长期运行”。
三、AI 集成带来的“新问题”
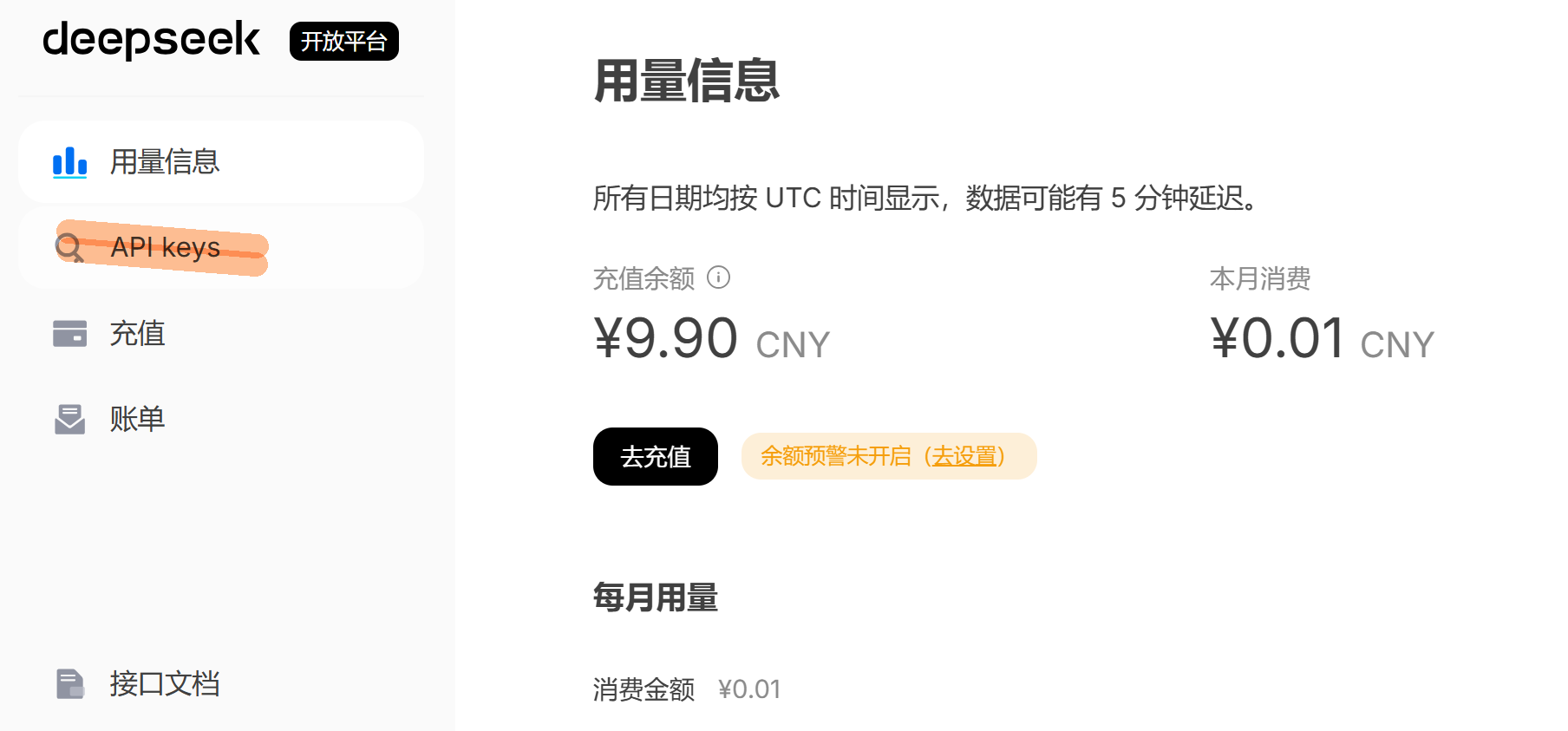
3.0 如何获得API-key
这里以 DeepSeek 为例,简要说明如何获取并使用 API Key,帮助你顺利完成 AI WebApp 的第一步配置。
首先,访问 DeepSeek 官方平台并完成账号注册与登录。登录后进入用户控制台(Console),在左侧或账号设置中找到 API 管理 / API Keys 相关入口。该页面用于集中管理你的模型调用凭证。点击“创建新的 API Key”,系统会自动生成一串唯一密钥。此 Key 即是你在 WebApp 中调用 DeepSeek 大模型服务的核心身份凭证。
需要注意的是,API Key 只会在创建时完整显示一次,务必及时复制并妥善保存。工程实践中,建议将其存放在服务器环境变量或配置文件中,而不是直接写死在前端代码里,以防泄露。此外,不同 Key 往往可绑定调用额度与权限,便于后期成本控制与项目隔离。完成以上步骤后,即可在后端通过 HTTP 请求或 SDK 方式安全接入 DeepSeek 大模型能力。
| 开放平台https://platform.deepseek.com/usage | 创建API-key |
|---|---|
 |
 |
3.1 AI 并不是一个“普通 API”
许多开发者在第一次接入大模型时,往往会下意识地将其等同为一个“返回字符串的 HTTP 接口”,沿用传统 REST API 的设计与调试思路。然而,这种认知在 AI WebApp 中几乎必然导致问题。本质差异在于:AI API 并非确定性函数,而是一个基于概率分布的生成系统。即便输入完全一致,输出内容在长度、结构、语义乃至表达顺序上,都可能出现波动;同时,模型的响应时间也会受到上下文长度、系统负载等因素影响,呈现出明显的不稳定性。如果仍以“请求一次、返回一次、结果必然可用”的方式来设计系统,开发者很快就会遭遇不可复现的 Bug、难以定位的异常,以及测试阶段“一切正常”、上线后却频繁翻车的尴尬局面。因此,在工程层面应当将 AI 调用视为不稳定依赖,在系统设计中预留重试、超时、降级与结果校验机制,而不是把模型当作可靠的计算黑盒。
3.2 Prompt 不是“随便写写”
在 AI WebApp 中,Prompt 实际上承担着远超“参数说明”的角色,它更像是一段隐藏在系统中的业务逻辑。Prompt 的设计方式,直接决定了模型输出的稳定性、可控性与可维护性。常见问题包括:Prompt 随功能不断堆叠,导致上下文臃肿、响应变慢;语义描述模糊,使输出结果难以预测;多个模块复用同一 Prompt,一处修改引发连锁反应。在项目后期,这类 Prompt 往往演变成一堆无法复现、无法调试的“黑箱文本”。更成熟的做法是,将 Prompt 工程化管理:对 Prompt 进行模块拆分,明确输入、输出与约束条件;为关键字段设定格式要求;尽量让 Prompt 的结构像接口文档一样清晰可读。只有当 Prompt 被纳入工程体系,AI WebApp 才具备长期演进的可能。
3.3 AI 输出的不确定性如何处理?
AI WebApp 最隐蔽、也最危险的问题之一,并不是模型报错,而是模型自信地给出错误答案。这些结果往往语义通顺、结构完整,极易误导用户。在教学型、科研型或分析型 WebApp 中,如果系统对 AI 输出不做任何校验与约束,错误信息就会被当作“智能结论”直接展示,后果往往比功能失效更加严重。工程实践中,应当将 AI 输出视为“候选结果”,而非最终事实。常见手段包括:对返回结构进行校验、对关键字段缺失或异常设置兜底逻辑、在 UI 层明确标注 AI 建议属性。只有当系统本身具备基本的判断与约束能力,AI 才能真正成为辅助工具,而不是不可控的风险源。
四、API Key 管理中的真实问题
4.1 API Key 暴露风险被严重低估
在 AI WebApp 的实际开发中,API Key 泄露几乎是最常见、也最容易被忽视的安全问题。许多开发者在功能验证阶段,为了快速跑通流程,往往直接将 Key 写入前端代码,或通过简单的配置文件暴露在客户端环境中。
典型的高风险场景包括:
- API Key 明文写在前端 JavaScript 中
- Key 随请求直接暴露在浏览器 Network 面板
- WebApp 被他人 fork 或复制后,Key 被滥用调用
由于大模型 API 通常按调用量计费,一旦 Key 泄露,后果往往立竿见影:轻则调用额度被迅速消耗,重则触发风控策略,导致账号被限流甚至封禁。更严重的是,很多开发者是在账单异常或服务中断后才意识到问题的存在。
4.2 前端直连 vs 后端代理的权衡
在 AI WebApp 架构设计中,是否允许前端直接调用大模型 API,是一个绕不开的选择。
常见的两种方案是:
- 前端直连大模型 API
- 通过后端代理统一调用大模型服务
前端直连的优势在于实现成本低、响应路径短、部署简单,非常适合 Demo、原型验证或个人实验项目;但其最大问题在于 API Key 无法彻底隐藏,安全风险几乎不可避免。后端代理模式则通过服务器统一管理 Key 和请求逻辑,不仅可以隐藏密钥,还能进一步实现缓存、限流、日志审计、请求重试等工程能力。这种方案更符合生产级 WebApp 的设计原则,但也意味着更高的架构复杂度和运维成本。
在教学型或实验型 WebApp 中,常见的折中方案是:
由用户手动输入 API Key,在本地使用,并明确告知潜在风险
这种方式强调“工具属性”而非“平台属性”,在一定程度上平衡了安全性与使用门槛。
4.3 Key 生命周期管理缺失
另一个被普遍忽视的问题是:API Key 的生命周期管理几乎不存在。
许多项目只关注 Key 是否“能用”,却很少考虑:
- Key 是否支持随时更换
- 是否具备多 Key 轮换机制
- 不同模型、不同功能是否应使用不同 Key
随着 WebApp 功能复杂度的提升,单一 Key 往往成为系统的隐性单点风险。一旦 Key 失效或受限,整个应用将被迫停摆。从工程视角看,在 AI WebApp 中,Key 管理本身就是一项基础系统能力,而不是简单的配置项。只有将其纳入整体架构设计,才能支撑长期稳定、可扩展的 AI 应用运行。
五、大模型选择中的典型误区
5.1 并非“模型越大越好”
在 AI WebApp 设计中,一个非常普遍的误区是:
功能一复杂,就直接选择当前最强、参数最大的模型
但在真实的 WebApp 场景中,模型能力与任务需求并非线性匹配关系。不同类型的任务,对模型能力的侧重点完全不同,例如:
- 解释型任务更关注表达清晰度与稳定性
- 结构化输出任务更强调格式遵循能力
- 创意生成任务需要发散性与多样性
- 诊断与分析任务则强调逻辑一致性
如果不加区分地使用“最强模型”,往往会带来一系列副作用:调用成本显著上升、响应时间变长、输出内容过于冗长甚至偏离需求。在高频交互的 WebApp 中,这些问题会被用户迅速放大,直接影响整体体验。
工程实践中,更合理的做法是:模型能力与任务精细匹配,而非一味追求上限。
5.2 忽略模型“风格差异”
即便在能力层面相近,不同大模型在输出风格上的差异依然十分明显。有的模型偏向学术化表述,有的更偏工程说明;有的擅长循序解释,有的则更擅长快速总结。
如果在 WebApp 设计中未充分考虑这种差异,就容易出现一个常见问题:
AI 输出内容与产品整体定位不一致
例如,一个面向初学者的教学型 WebApp,却返回过于抽象、术语密集的回答;或者一个工程诊断工具,却给出过度铺陈、缺乏结论的长文本。这类问题并非“模型不好”,而是模型风格与使用场景不匹配。因此,在模型选型阶段,除了关注能力指标,还应通过实际测试,评估其输出风格是否与应用目标一致。
5.3 多模型共存时的复杂性
当 WebApp 支持多个大模型(如 Gemini、DeepSeek、GPT)时,系统复杂度会显著上升。此时,问题不再只是“用哪个模型”,而是:
- Prompt 是否能够跨模型复用
- 不同模型的输出结构是否一致
- 错误、超时、异常结果如何统一处理
如果这些问题未在架构层面提前规划,多模型支持很容易演变为维护灾难:大量条件分支、重复 Prompt、难以调试的边缘错误层出不穷。从工程角度看,多模型共存不是简单的“多接几个 API”,而是一项需要明确抽象边界与规范接口的系统设计工作。只有在充分评估收益与成本之后,引入多模型策略才是理性的选择。
六、AI WebApp 中的“用户预期管理”
6.1 用户容易高估 AI 能力
AI WebApp 往往通过简洁的界面、即时的反馈和流畅的交互,给用户一种“系统非常智能、结果高度可靠”的直观印象。但在实际运行中,大模型仍然存在明显局限,例如:可能给出语义模糊或模棱两可的回答,可能误判上下文或忽略隐含前提,甚至在逻辑上出现自洽却错误的推断。如果产品层面未主动揭示这些不确定性,用户一旦发现 AI 输出与预期不符,反而会产生更强烈的失望感。特别是在教学、科研或分析类 WebApp 中,用户往往默认 AI 具备“专业判断能力”,这种认知偏差一旦被放大,体验下降会非常明显。
6.2 必须明确“AI 是辅助,而非裁决者”
因此,在 AI WebApp 的交互设计中,必须通过明确的文案、提示和信息层级,反复强调一个核心原则:AI 的角色是辅助工具,而非最终裁决者。AI 给出的结论应被定位为参考建议,而不是不可质疑的答案。在工程实现上,可以通过标注“AI 生成结果”“仅供参考”等方式弱化权威感;在产品层面,应为用户保留判断空间,鼓励对关键结论进行复核和验证。对于涉及公式推导、实验结论或决策建议的场景,更应强调结果的可追溯性与可解释性。良好的用户预期管理,并不是削弱 AI 的价值,而是帮助用户在合理边界内使用 AI,从而建立长期、稳定的信任关系。
七、从工程角度反思 AI WebApp 的正确姿势
综合前述各类工程与安全问题,构建一个可持续、可维护的 AI WebApp,需要从系统架构、模型调用、安全管理和用户体验多个维度进行设计。首先,架构应保持简洁但具备可扩展性,初期可采用轻量方案验证功能,后期再逐步引入微服务、缓存与异步处理,避免早期过度复杂化带来的维护负担。其次,AI 能力应模块化设计、可替换,包括不同大模型调用、Prompt 管理及结果校验等模块,确保系统在模型升级或更换时不会影响整体逻辑。同时,Prompt 必须工程化管理,明确输入输出规范,避免因文本模糊或随意修改而产生不可控行为。在安全层面,API Key 的使用必须可控,优先采用临时 Key、本地或后端安全存储,并在使用后及时删除或轮换,以防泄露和滥用。最后,在产品体验上,应明确 AI 的能力边界,教育用户理解 AI 输出只是辅助结果而非最终结论,确保用户在决策或操作时保持理性判断。总的来说,AI 不应被神化为“魔法”,而应成为被理解、被约束、被管理的工具。只有将技术、工程和用户预期统一纳入设计视野,才能构建既安全可靠,又高效可控的 AI WebApp,实现长期可持续发展。
八、总结与展望
WebApp 与 AI 的结合,正在不断拓展应用边界,为用户带来前所未有的交互体验和智能服务。然而,这种结合同时也引入了新的不确定性与工程挑战。一个成熟的 AI WebApp,并非仅仅“接上大模型即可完成”,而是在复杂多变的环境中,设计出可控、可预测的系统行为。随着大模型能力进一步增强,开发者必须更加注重 AI 的工程化能力,包括 Prompt 管理、模块化调用、API 安全以及多模型协作;同时需要关注输出的可解释性和用户预期管理,确保 AI 结果在教育、科研、决策等场景中具有可靠参考价值;还要考虑系统长期运行的稳定性,防止性能瓶颈或异常调用影响整体体验;更重要的是,明确人与 AI 的合理分工,让 AI 作为辅助工具而非替代者,真正发挥智能加持作用。
只有将技术、工程与用户体验有机结合,AI WebApp 才能超越原型演示,发展成为可长期使用、可持续演进的智能系统。
参考文献
- Brown, T., Mann, B., Ryder, N., et al. (2020). Language Models are Few-Shot Learners. Advances in Neural Information Processing Systems, 33, 1877–1901. 本文系统介绍了大规模语言模型的能力与局限,为 WebApp 中模型选择提供理论基础。
- Google AI. (2025). Gemini AI Studio Documentation. Retrieved from https://ai.google.com/studio/gemini. 提供 Gemini AI Studio 的官方接口说明、API 管理及工程实践案例,是开发者实现安全调用的重要参考。
- Chollet, F. (2017). Deep Learning with Python. Manning Publications. 介绍深度学习模型构建、训练与调优方法,为 AI WebApp 中模型集成、可视化和性能优化提供理论支撑。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号