
深度学习——注意力机制(Attention Mechanism)的解构
传统的神经网络(如CNN、RNN)在处理复杂结构的数据时,通常会面临信息冗余、不均衡以及长距离依赖难以建模等问题。而在自然语言处理、图像识别和语音处理等领域,信息的重要性具有强烈的非均质性。例如,在翻译句子时,并非所有的词对当前预测词都有贡献。注意力机制模仿人类视觉聚焦的方式,自动从庞杂的信息中提取关键要素,从而提升神经网络模型的表达能力和泛化能力。

一、引言:注意力机制的产生背景
注意力机制的产生背景源于人类认知科学中的“选择性注意”理论,即个体在面对大量信息时,会优先关注对当前任务最相关的信息。这种机制赋予我们在处理复杂环境中做出快速而准确判断的能力。受到这一启发,研究者试图将类似机制引入神经网络中,以提升模型对关键信息的感知和利用能力。注意力机制最早应用于计算机视觉领域。早在1990年代,研究者就提出模拟人类视觉注意力的方法;但真正使其在深度学习中广泛流行的是2014年Google DeepMind的论文《Recurrent Models of Visual Attention》,该研究首次在图像分类中通过RNN结合注意力机制提升性能。紧接着,Bahdanau等人在2015年的论文《Neural Machine Translation by Jointly Learning to Align and Translate》中将注意力机制引入神经机器翻译任务,实现了对源语言序列与目标语言序列的动态对齐,显著提升了翻译效果,这是注意力机制在NLP领域的重要突破。
2017年,Google发表革命性论文《Attention is All You Need》,提出Transformer结构,完全摒弃RNN,而用自注意力(Self-Attention)机制建模序列内部的关系。这项工作推动了BERT、GPT等大型预训练模型的发展,使注意力机制成为当前自然语言处理和多模态学习的核心技术。
在深度学习的发展早期,神经网络(如CNN和RNN)处理输入数据时往往以固定方式压缩全部信息,无法区分出其中哪些部分更重要。为了解决这个问题,注意力机制(Attention)应运而生。注意力机制的基本思想是为输入数据中的每个部分分配一个权重,表示其对当前任务的重要程度,模型据此加权整合信息,从而实现“聚焦关键”的能力。注意力机制模仿人类视觉聚焦的方式,自动从庞杂的信息中提取关键要素,从而提升神经网络模型的表达能力和泛化能力。
二、注意力机制的基本思想与数学建模
2.1 基本思想
注意力机制(Attention Mechanism)的核心思想来源于人类在感知外部信息时所展现出的“选择性注意”能力。在面对复杂信息或长序列时,人类不会平均地处理所有信息,而是有选择地关注其中对当前任务更关键的部分。深度学习中的注意力机制正是对这一现象的模拟,它使得神经网络在处理序列或结构化数据时,能够动态地调整对不同信息部分的关注程度。传统的神经网络在处理序列输入(如句子)时,往往将所有输入编码成一个固定维度的向量。这种方式在短序列上表现尚可,但在面对长序列时,容易导致关键信息的丢失。注意力机制通过引入可学习的权重,对输入序列中的每一个元素动态赋权,使得模型可以聚焦于与当前预测任务更相关的信息,从而提升表达能力与泛化性能。
2.2 数学表示
注意力机制通常以 Query(查询)、Key(键)和 Value(值)三组向量作为输入,计算出一个加权求和结果作为输出。假设当前的查询向量为 \(\mathbf{q} \in \mathbb{R}^d\),键和值向量分别为 \(\mathbf{k}_i, \mathbf{v}_i \in \mathbb{R}^d\),则注意力的输出定义为:
其中,\(\alpha_i\) 是注意力权重,表示当前查询向量 \(\mathbf{q}\) 对于第 \(i\) 个值向量 \(\mathbf{v}_i\) 的关注程度。权重 \(\alpha_i\) 的计算依赖于查询向量与键向量之间的相似度评分(score),通常经过 softmax 函数归一化:
常用的相似度函数 \(\text{score}(\mathbf{q}, \mathbf{k}_i)\) 包括以下几种:
-
点积(Dot Product Attention):
\[\text{score}(\mathbf{q}, \mathbf{k}_i) = \mathbf{q}^T \mathbf{k}_i \] -
缩放点积(Scaled Dot Product Attention):
\[\text{score}(\mathbf{q}, \mathbf{k}_i) = \frac{\mathbf{q}^T \mathbf{k}_i}{\sqrt{d_k}} \]这里 \(d_k\) 是键向量的维度。该方法通过缩放操作防止内积结果过大,提升数值稳定性,是 Transformer 模型中的默认选择。
-
加性注意力(Additive Attention 或 Bahdanau Attention):
\[\text{score}(\mathbf{q}, \mathbf{k}_i) = \mathbf{v}^T \tanh(W_1 \mathbf{q} + W_2 \mathbf{k}_i) \]其中 \(W_1\) 和 \(W_2\) 是可学习参数矩阵,\(\mathbf{v}\) 是一个权重向量。这种方式通过非线性变换捕捉更复杂的相关性,计算量略高于点积法,常用于 RNN 架构中。
总结来说,注意力机制的数学实质是一个带权平均(Weighted Sum)过程。它将输入值向量 \(\mathbf{v}_i\) 通过权重 \(\alpha_i\) 加权组合,重点突出了与查询向量 \(\mathbf{q}\) 更匹配的键-值对所携带的信息。这种机制赋予了模型灵活的信息检索能力,使其在自然语言处理、图像理解、语音识别等任务中取得了广泛应用与突破。
2.3 注意力机制的分类
随着注意力机制在各类深度学习模型中的广泛应用,研究者针对不同场景与任务需求,发展出了多种不同类型的注意力机制。我们可以从实现方式、信息来源以及计算结构三个维度将其分类为 Soft Attention 与 Hard Attention、Self-Attention 与 Cross-Attention、单头注意力与多头注意力等。
Soft Attention 与 Hard Attention
注意力机制最基本的分类是按其输出方式可导性划分:
Soft Attention:软注意力是当前主流的实现方式,其核心是通过对所有输入位置分配连续权重(即注意力分布),并对所有值向量加权求和得到输出。这种机制是完全可导的,因此可以通过反向传播与梯度下降等常规方法进行训练。Soft Attention 的代表应用包括 Transformer 和图像描述生成模型等。
Hard Attention:硬注意力机制则是对输入进行离散选择,即从所有输入位置中仅选择最关键的一个或几个进行处理。由于离散选择操作不可导,因此通常需要借助强化学习方法(如 REINFORCE)或近似采样算法进行优化。虽然 Hard Attention 更接近人类的认知过程,但在实际训练中不够稳定,应用较少。
Self-Attention 与 Cross-Attention
根据注意力的 Query、Key 和 Value 的来源,可以将注意力机制分为以下两类:
Self-Attention(自注意力):当查询(Query)、键(Key)和值(Value)都来自同一个输入序列时,称为自注意力。该机制可以建模序列内部各位置之间的依赖关系,适用于语言建模、图像处理等任务。Transformer 编码器中的注意力层即为典型的自注意力机制,其中每个词对其它所有词都施加不同程度的关注。
Cross-Attention(交叉注意力):当查询来自一个序列,而键和值来自另一个序列时,称为交叉注意力。此机制常用于需要融合两个不同来源信息的任务中,比如在机器翻译中,解码器使用交叉注意力对编码器的输出进行加权,从而生成目标语言。Transformer 解码器中的第二个注意力层就是典型的 Cross-Attention 实现。
单头注意力与多头注意力
在注意力机制的实际计算结构上,还可以按并行度分为:
单头注意力(Single-Head Attention):最基础的注意力形式,直接对输入执行一次注意力计算。虽然结构简单,但其表征能力较为有限,难以捕捉输入中不同维度或语义层次的信息。
多头注意力(Multi-Head Attention):为提升模型的表达能力,Transformer 中提出了多头注意力机制。它将输入向量分别映射到多个子空间,在每个子空间中并行执行注意力计算,最终将多个头的输出拼接融合。这种机制使得模型能从多个角度理解和关联输入中的不同部分,大幅增强了对复杂模式的建模能力。
2.4 代表性注意力机制模型
注意力机制在深度学习中的不断发展过程中,涌现出多种经典结构。这些模型在机器翻译、自然语言理解、图像处理等多个任务中都起到了关键作用。以下介绍几种具有代表性的注意力机制模型,包括 Bahdanau Attention、Luong Attention、Scaled Dot-Product Attention 以及 Multi-Head Attention。
Bahdanau Attention(Additive Attention)
Bahdanau 等人在 2015 年提出了第一个应用于神经机器翻译中的注意力机制,通常被称为“Additive Attention”。它的关键思想是通过一个可学习的神经网络将查询(Query)和键(Key)进行非线性变换,并使用加性方式计算相似度分数,从而获取注意力权重:
其中,\(\mathbf{q}\) 是当前解码器状态,\(\mathbf{k}_i\) 是编码器第 \(i\) 个隐藏状态,\(W_1\)、\(W_2\)、\(\mathbf{v}\) 是训练中学习的参数。该机制能根据上下文动态对齐源语言与目标语言。
Luong Attention(Dot Product Attention)
Luong 等人随后提出了另一种注意力形式,称为“Dot Product Attention”,相较于 Bahdanau Attention 更为简单高效。它直接对查询和键进行内积计算相似度,不再使用额外的非线性变换:
Luong 注意力在训练速度和性能之间实现了良好的平衡,因此广泛用于早期的序列到序列模型中。
Scaled Dot-Product Attention
Transformer 模型中进一步发展了 Luong 注意力,并引入了“缩放”机制。考虑到在高维空间中,点积值可能过大,影响 softmax 分布,因此使用 \(\sqrt{d_k}\) 进行缩放:
该机制不仅高效可并行,而且作为 Transformer 编码器和解码器的核心单元,展现了强大的建模能力。
Multi-Head Attention
为了增强模型捕捉多粒度特征的能力,Transformer 引入了“多头注意力”机制。其基本思路是将查询、键和值分别线性投影为 \(h\) 个不同的子空间,在每个子空间中独立执行注意力计算,最后将所有头的结果拼接并再次线性变换:
其中每个 head 由如下公式定义:
通过这种结构,模型可以并行地学习输入之间不同层级、不同角度的依赖关系,显著提升了表达能力。
三、最基础的注意力机制原理与Python实现
3.1 注意力机制的原理
注意力机制(Attention Mechanism)最初源于人类在视觉注意中的灵感:我们在观察复杂场景时往往只关注一部分关键区域,忽略其他次要内容。深度学习模型借鉴这一理念,使其能够在处理序列(如语言、图像)时,根据上下文动态分配注意力。
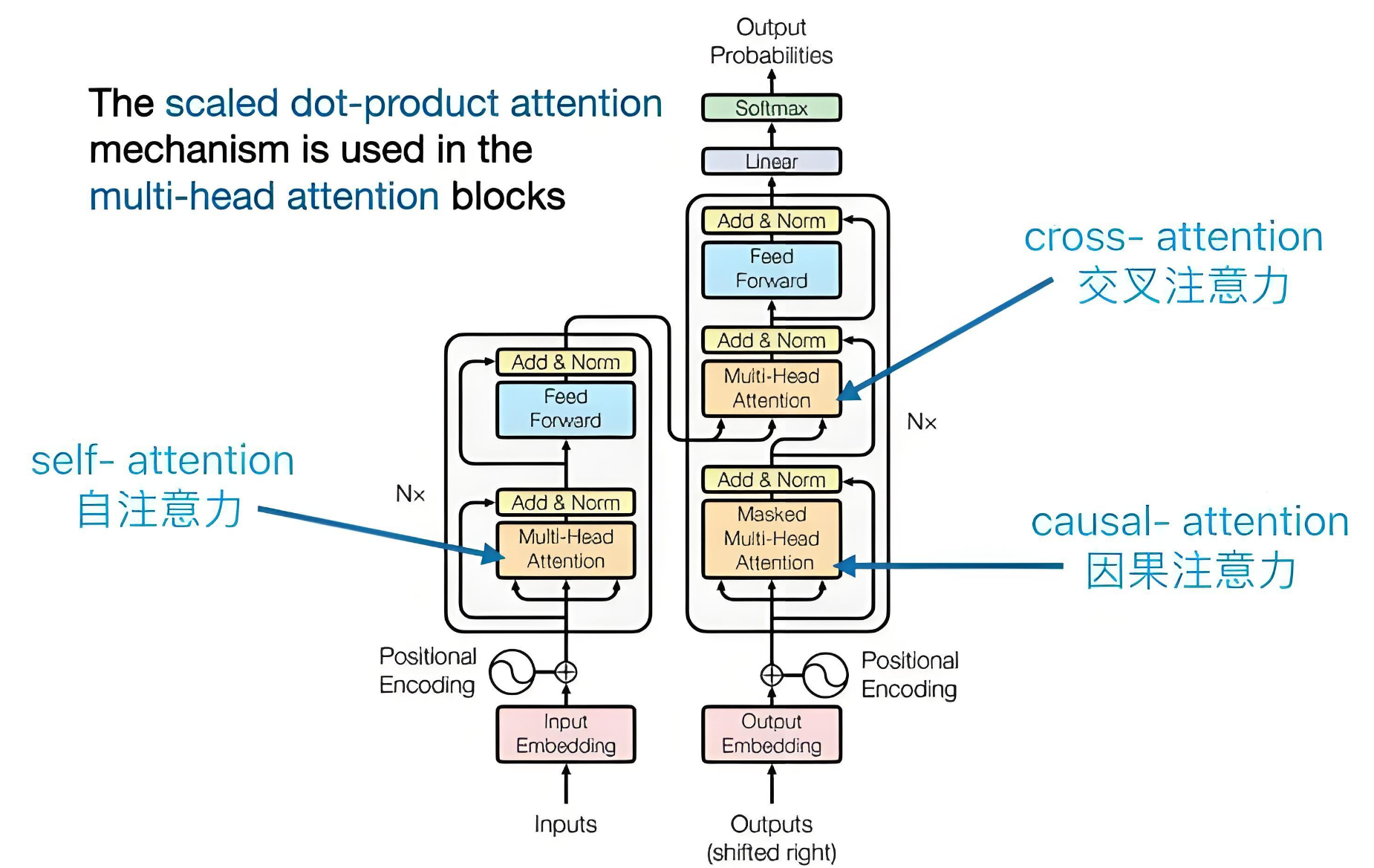
最基础的注意力机制结构可分为以下几个部分:
(1)输入表示
- Query(查询向量):表示当前需要聚焦的信息,一般是目标序列中的某个位置的表示。
- Key(键向量):表示源序列中每个位置的标识,衡量与 Query 的相关程度。
- Value(值向量):是最终被加权求和得到输出的向量。
(2)计算注意力分数
给定一个 Query 和若干个 Key,计算它们之间的相关性分数,表示 Query 应该关注哪个 Key 对应的 Value。常用的打分函数包括:
-
点积(Dot Product):
\[\text{score}(Q, K) = Q \cdot K \] -
缩放点积(Scaled Dot Product):
\[\text{score}(Q, K) = \frac{Q \cdot K}{\sqrt{d_k}} \]其中 $ d_k $ 是 Key 向量的维度,用于防止分数过大导致梯度消失。
-
加性注意力(Additive Attention):
\[\text{score}(Q, K) = v^T \tanh(W_1 Q + W_2 K) \]
(3)归一化注意力权重
使用 softmax 函数将所有打分值转换为归一化的注意力权重:
(4)输出表示
最后将所有 Value 按照注意力权重加权求和,作为最终的注意力输出:
3.2 PyTorch实现基础注意力机制
以下是一个使用 PyTorch 实现的原始点积注意力机制的最小示例,适用于教学和理解:
import torch
import torch.nn.functional as F
from typing import Tuple
def basic_attention(
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
基础注意力机制实现(缩放点积注意力 Scaled Dot-Product Attention)
参数:
- query: (batch_size, query_len, d_k),查询向量
- key: (batch_size, key_len, d_k),键向量
- value: (batch_size, key_len, d_v),值向量
返回:
- output: (batch_size, query_len, d_v),注意力输出结果
- attn_weights: (batch_size, query_len, key_len),注意力权重矩阵
"""
d_k = query.size(-1) # 获取 key/query 的维度
# Step 1: 计算注意力打分矩阵 scores = Q x K^T / sqrt(d_k)
scores = torch.matmul(query, key.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
# Step 2: 对每个 Query 的打分通过 softmax 归一化,获得注意力分数
attn_weights = F.softmax(scores, dim=-1)
# Step 3: 使用注意力分数对 Value 进行加权求和,得到最终的注意力输出
output = torch.matmul(attn_weights, value)
return output, attn_weights
# 示例代码:构造一个简单的输入用于测试
if __name__ == "__main__":
batch_size = 1
seq_len = 4 # 序列长度
d_k = d_v = 8 # 向量维度
# 随机生成 Q、K、V
Q = torch.rand(batch_size, seq_len, d_k)
K = torch.rand(batch_size, seq_len, d_k)
V = torch.rand(batch_size, seq_len, d_v)
# 调用注意力函数
output, attn_weights = basic_attention(Q, K, V)
print("注意力输出 (output):")
print(output)
print("\n注意力权重 (attention weights):")
print(attn_weights)
四、Transformer 与注意力机制的结合
Transformer 模型由 Vaswani 等人于 2017 年在论文《Attention is All You Need》中提出,开创了完全基于注意力机制进行序列建模的新时代。与传统基于循环神经网络(RNN)或卷积神经网络(CNN)的方法不同,Transformer 完全摒弃了递归结构,而是通过多层堆叠的自注意力机制来捕捉序列中任意位置之间的依赖关系,极大提高了模型的训练效率和性能。
4.1 Transformer 结构图
Transformer 的基本结构包括两个主要模块:
- 编码器(Encoder)
- 解码器(Decoder)
整个模型结构可以表示为多个编码器层和解码器层的堆叠。每个编码器层由如下子结构组成:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feed Forward Network, FFN)
- 残差连接(Residual Connection)与层归一化(Layer Normalization)
解码器则更加复杂,每个解码器层包括三个子结构:
- Masked 多头自注意力(Masked Multi-Head Self-Attention):防止模型在生成下一个词时看到未来的信息;
- 交叉注意力(Cross-Attention):将当前解码器的 Query 与编码器的 Key 和 Value 进行注意力计算;
- 前馈神经网络 + 残差连接 + 层归一化
其核心机制可以通过以下图示结构理解:
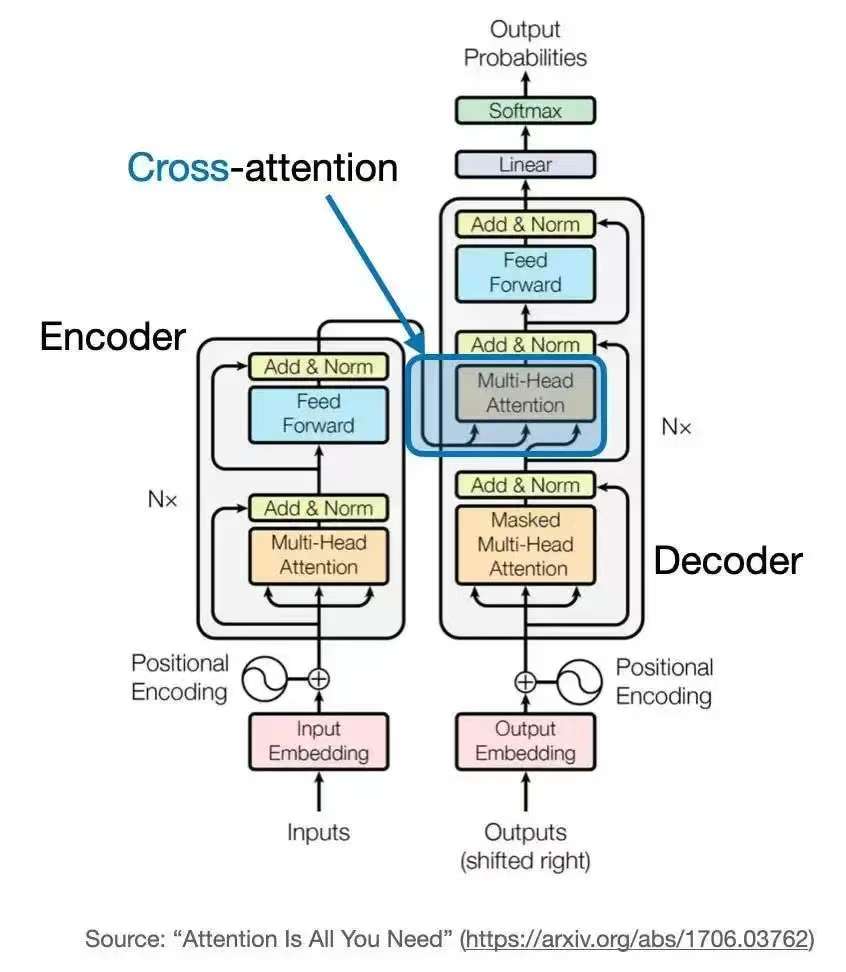
4.2 Transformer 的核心创新
Transformer 的成功来源于多个结构性创新,这些创新共同提升了模型的表达能力和计算效率,尤其适用于处理长距离依赖的序列建模任务。
位置编码(Positional Encoding)
由于 Transformer 中没有递归结构,其本身不具备处理序列中位置信息的能力。为解决这一问题,Transformer 引入了位置编码(Positional Encoding)机制,将每个位置的信息以固定或可学习的方式嵌入进输入向量中。
标准的正余弦位置编码公式如下:
其中:
- $ pos $ 表示序列中位置;
- $ i $ 表示位置向量的维度索引;
- $ d_{\text{model}} $ 是嵌入向量的总维度。
该编码方式具有如下特点:
- 编码结果可加性强,支持位置差的学习;
- 对任意长度序列具备良好泛化能力。
全注意力机制替代 RNN
传统的循环神经网络(RNN)在处理长序列时存在依赖链长、梯度消失等问题,且计算无法并行。而 Transformer 使用完全基于注意力机制的结构建模序列间的依赖关系,显著提升了训练效率。
优点包括:
- 支持并行计算(所有位置可同时计算);
- 长距离依赖关系建模能力强;
- 适用于大规模预训练任务(如 BERT、GPT)。
多头注意力机制(Multi-Head Attention)
Transformer 引入多头注意力(Multi-Head Attention)机制,将输入映射为多个不同子空间,并在每个子空间上并行执行注意力操作,然后再将多个头的结果拼接起来:
其中每个注意力头的定义为:
优点:
- 每个头可学习不同类型的关系(如语法、语义);
- 提高模型捕捉多层次特征的能力;
- 增强模型的非线性和表达能力。
这些创新使 Transformer 成为自然语言处理、语音识别、图像理解等多种任务中的通用架构,为后续模型(如 BERT、T5、GPT 系列)提供了坚实的基础。
五、应用场景:注意力机制在各领域的实践
注意力机制因其“选择性关注”与“动态聚焦”的能力,在多个人工智能领域取得了广泛应用,成为现代深度学习模型中的核心组件。以下介绍其在自然语言处理、计算机视觉及多模态融合等领域的具体实践与价值。
5.1 自然语言处理(NLP)
在自然语言处理中,注意力机制极大地改进了序列建模能力。尤其是在 Seq2Seq 架构中引入注意力后,模型不再受限于固定长度的编码表示,而是可以针对解码时刻动态查阅不同的编码部分。
- 机器翻译:经典的神经机器翻译模型(如 Bahdanau Attention)通过计算当前译词与源语言词之间的注意力权重,实现了对源句不同位置的动态对齐,从而提升了长句翻译的准确性。
- 文本摘要:在自动摘要任务中,注意力机制能够聚焦于文本的关键句或关键词,增强模型提取关键信息的能力,特别适用于抽取式摘要和生成式摘要模型。
- 情感分析:在情感分类任务中,注意力可以突出文本中带有情感倾向的词语(如“非常好”、“令人失望”),从而使模型更有效地区分情绪类别。
此外,在预训练语言模型(如 BERT、GPT)中,Transformer 的自注意力机制贯穿始终,使模型能建模不同词之间的上下文依赖,推动了 NLP 多个子任务的性能突破。
5.2 计算机视觉(CV)
在计算机视觉领域,注意力机制也在不断演进,并逐渐成为增强卷积神经网络(CNN)表示能力的重要方式。
- 图像分类:空间注意力(Spatial Attention)和通道注意力(Channel Attention)通过识别图像中更重要的区域或通道,帮助模型从复杂背景中提取有效特征。例如,SE-Net 采用通道注意力自适应调整特征图的重要性权重。
- 目标检测:注意力机制用于强化目标区域的特征表达,同时抑制背景干扰,提高检测精度。经典模块如 CBAM(Convolutional Block Attention Module)将空间与通道注意力结合,实现轻量且有效的增强。
- 图像描述生成(Image Captioning):视觉注意力机制可用于引导模型在生成描述词时关注图像的不同局部区域,实现从图像到语言的有效对齐,如 Show, Attend and Tell 模型。
5.3 多模态融合
在涉及图像、文本、语音等多种模态信息的任务中,注意力机制提供了一种高效的跨模态对齐与融合方法。
- 图文匹配与检索:Cross-Attention 能够将图像区域与文本片段进行动态对应,使得模型能理解“图中哪个部分对应哪句话”;
- 语音识别与音频处理:注意力用于对语音流中重要音素进行聚焦,增强语音到文本转换的准确性;
- 视频问答与多模态生成:在 VQA(Visual Question Answering)任务中,注意力机制能够结合问题内容,定位视频帧中相关区域,实现跨模态的精准回答。
六、注意力机制的优势、挑战与发展方向
注意力机制作为深度学习中的核心模块,已广泛应用于自然语言处理、计算机视觉、多模态学习等多个领域。其强大的表达能力和灵活的结构为模型性能的提升提供了重要支持。然而,注意力机制的发展过程中也面临一些挑战,并催生出多种创新改进。以下从三个方面进行整理归纳。
6.1 优势分析
注意力机制的最大优势在于其对长距离依赖关系的建模能力。与传统的循环神经网络相比,Self-Attention 可以在一次计算中并行捕捉序列中任意位置之间的依赖,有效避免了梯度消失和传播缓慢的问题。其次,注意力机制通过为不同部分赋予不同权重,具备了信息选择性过滤能力,能够自动聚焦关键特征区域,从而提升了模型的泛化能力并减少冗余信息。最后,注意力机制本质上是一种可视化友好的结构,其注意力权重矩阵可以直接展示模型在决策过程中关注的位置,具备较强的可解释性,有助于模型结果的分析与优化。
6.2 挑战与局限
尽管注意力机制优势明显,但其在实际应用中也暴露出一些问题。首先是计算资源开销较大。尤其在处理长序列时,Self-Attention 的时间复杂度为 \(O(n^2)\),对内存和计算能力提出较高要求。其次,注意力机制本身缺乏位置感知能力,无法自动感知序列的顺序信息,需要依赖额外的位置编码机制(如正余弦编码或可学习位置嵌入)来弥补这一缺陷。此外,多头注意力机制虽然增强了表示能力,但也存在注意力冗余问题。研究发现,部分注意力头在训练后贡献甚微,甚至处于“无效”状态,可能导致模型参数浪费。
6.3 发展方向与改进探索
为解决上述问题,研究者提出了多个改进方案。首先,稀疏注意力机制(如 Longformer、BigBird、Sparse Transformer)通过限制注意力计算范围,显著降低了长序列的计算复杂度,使得注意力机制可扩展至百万级输入长度。其次,动态注意力机制与可学习掩码策略允许模型在不同输入或任务条件下动态调整注意力区域,提高了模型的灵活性与泛化能力。在图像与多模态任务中,多尺度注意力机制逐渐兴起,它通过在不同尺度上施加注意力,有效整合全局与局部特征,提升了图像分类、检测等任务的性能。最后,注意力机制也在图神经网络中大放异彩。**图注意力网络(GAT)**采用节点间的可学习注意力权重对邻居信息进行加权聚合,有效提升了图结构数据建模的能力。
总结与展望
意力机制的引入,使深度学习模型具备了类似“聚焦”的能力,能够自主判断并强化对关键信息的关注,从而提升模型的表现与解释性。这一机制已成为当前主流架构(如 Transformer)的核心组成部分,广泛应用于自然语言处理、计算机视觉、语音识别、多模态融合等任务中。随着研究的深入,注意力机制也不断在结构设计、计算效率与表达能力方面取得优化,逐步扩展到更复杂的任务类型与模态环境。
注意力机制的发展将呈现出多元化趋势。其中一个重点方向是高效注意力结构的设计,以应对长序列处理中的计算瓶颈;其次,跨模态注意力融合将促进图像、文本、音频等多种信息源之间的深度交互;此外,提升注意力机制的可解释性对于建立可信赖的人工智能系统也至关重要。另一个值得关注的方向是将注意力机制与强化学习、元学习等先进方法相结合,以实现更灵活、适应性更强的智能系统。通过这些方向的推进,注意力机制将在未来智能模型中发挥更加核心和广泛的作用。
参考文献:
- Vaswani et al. (2017), Attention is All You Need
- Bahdanau et al. (2015), Neural Machine Translation by Jointly Learning to Align and Translate
- Lin et al. (2017), A Structured Self-Attentive Sentence Embedding
- Dosovitskiy et al. (2020), An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
- Zhang et al. (2019), Self-Attention Generative Adversarial Networks
- Beltagy et al. (2020), Longformer: The Long-Document Transformer

 浙公网安备 33010602011771号
浙公网安备 33010602011771号