
统计学(二十四)——贝叶斯统计概述
贝叶斯统计(Bayesian Statistics)作为统计学的重要分支,近年来在理论研究、计算方法以及应用实践等方面取得了诸多突破,逐渐从经典统计方法的有益补充,转变为数据科学、人工智能、医疗健康、金融工程等领域的重要支撑工具。贝叶斯统计以概率作为不确定性的度量手段,通过先验信息与观测数据的有机结合,实现对未知参数、模型及未来预测结果的动态更新,具备直观性强、灵活性高、结果解释清晰的优势。特别是在计算手段和算法工具的持续提升下,贝叶斯方法成功突破了长期以来“理论优美、应用受限”的困境,克服了复杂模型求解困难、计算量庞大等技术障碍,使其在高维数据分析、复杂模型拟合、非参数建模、因果推断以及机器学习等场景中展现出前所未有的实用性和灵活性。伴随开源软件、并行计算、马尔可夫链蒙特卡洛(MCMC)方法和变分推断等技术的发展,贝叶斯统计正逐步成为现代数据分析体系中不可或缺的重要组成部分,发挥着日益突出的作用。
📖 一、贝叶斯统计的理论基础
日出问题:想象一下,有一天早上你醒来,太阳决定休息一天。这不仅(最有可能地)会毁了你的一天,打乱你的生物钟,还会直接改变你对太阳的感觉。你可能会更有可能预测也许第二天太阳也不会升起。或者,如果太阳刚刚度过了糟糕的一天,然后第二天又回来了,那么你对太阳会再休息一天的期望就会比之前高很多。这里发生了什么?基于新的证据,我们改变了对事件发生概率的看法。这是所有贝叶斯统计的关键,并使用一个称为贝叶斯公式来正式描述。
📌 1.1 贝叶斯公式
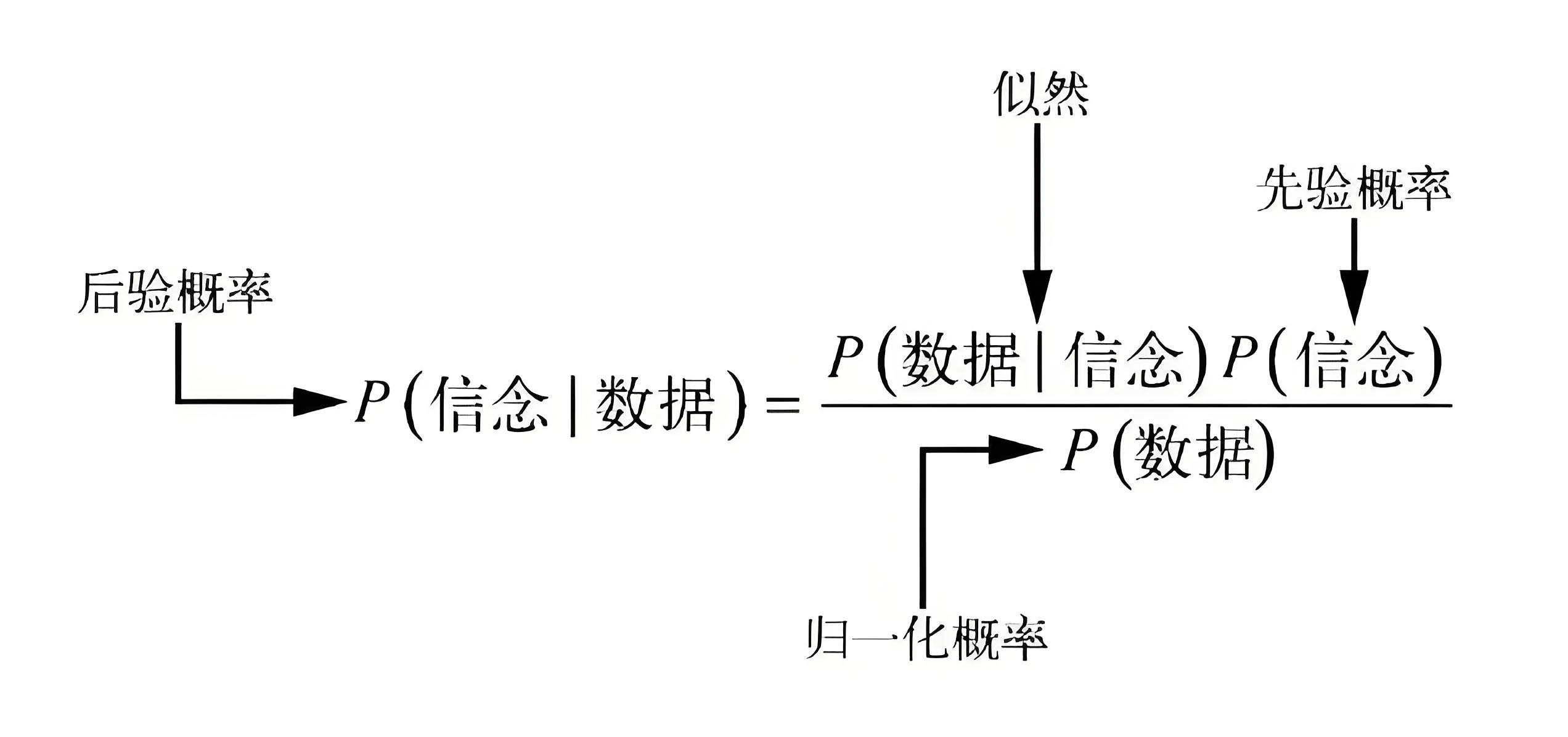
贝叶斯统计的核心基础是贝叶斯公式(Bayes' Theorem),该公式用于根据观测数据 $ D $ 修正对未知参数 $ \theta $ 的信念。数学表达如下:
其中:
- $ P(\theta) $:先验分布(Prior Distribution),表示在观测数据之前,对参数 $ \theta $ 的主观认知或历史知识。
- $ P(D|\theta) $:似然函数(Likelihood Function),表示在给定参数 $ \theta $ 条件下,观测数据 $ D $ 出现的概率。
- $ P(\theta|D) $:后验分布(Posterior Distribution),表示在观测到数据 $ D $ 之后,对参数 $ \theta $ 的新的概率分布。
- $ P(D) $:边际似然或证据项(Marginal Likelihood 或 Evidence),对所有可能的 $ \theta $ 加权后的观测数据概率,起归一化作用:
📌 1.2 核心思想
贝叶斯方法的核心思想是将未知参数视为随机变量,用概率分布表示其不确定性,再通过观测数据不断修正对其的认知。其基本逻辑流程:
- 设定先验分布 $ P(\theta) $,反映主观判断或历史知识。
- 构建似然函数 $ P(D|\theta) $,反映观测数据对参数的支持程度。
- 应用贝叶斯公式,根据观测数据更新先验,得到后验分布:
其中,“$ \propto $” 表示比例关系,实际值需通过 $ P(D) $ 归一化。
这种方法强调 动态学习 和 不确定性刻画,与频率学派假设参数为固定值、关注抽样分布的方法不同,更适用于小样本、不确定性强或需要融入先验信息的复杂环境。
📌 1.3 先验与后验的关系
贝叶斯方法的基本关系可以简化表达为:
即:
含义:
- 似然函数 $ P(D|\theta) $:反映数据对参数的支持程度。
- 先验分布 $ P(\theta) $:表示数据之前的主观认知或背景知识。
- 后验分布 $ P(\theta|D) $:结合数据和先验,形成的参数更新认知。
📌 1.4 归一化常数计算
完整后验需要乘以归一化常数,使其积分为1:
其中分母:
是对 $ \theta $ 的积分,确保后验分布为有效概率分布。
通过这种方式,贝叶斯统计提供了一种系统化、动态修正的推断机制,能够灵活地结合现有知识和新观测数据,实现不确定性下的合理推断与决策。
📖 二、贝叶斯统计的新发展
贝叶斯统计在理论方法、计算手段和应用实践等方面取得了显著进展,逐渐从经典方法的补充转变为数据科学与人工智能领域的重要支撑工具。特别是在计算能力提升的推动下,贝叶斯方法突破了长期以来“理论优美、应用受限”的困境,展现出强大的实用性和灵活性。贝叶斯方法凭借其先验整合与后验推断能力,能够全面刻画不确定性,尤其适合小样本和复杂环境下的决策问题。现代贝叶斯计算方法如马尔科夫链蒙特卡洛(MCMC)与变分推断(VI)相继成熟,前者通过抽样方法解决后验积分难题,后者则以优化方法提升大规模计算效率,极大扩展了贝叶斯方法在复杂模型和大数据环境下的应用空间。当前,贝叶斯统计已广泛应用于人工智能、深度学习、医学诊断、生物统计、金融风险评估和因果推断等前沿领域,成为智能化数据分析的重要方法体系。
| 比较维度 | MCMC方法 | 变分推断(VI) |
|---|---|---|
| 基本原理 | 构造收敛于目标后验分布的马尔可夫链,通过抽样逼近 | 将后验分布近似为易计算的分布,优化最小化KL散度 |
| 常用算法 | Metropolis-Hastings、Gibbs采样、Hamiltonian Monte Carlo (HMC) | 均值场变分、Black Box VI、自动微分VI等 |
| 计算方式 | 随机抽样,依赖马尔可夫链长期性质 | 数值优化,转化为确定性优化问题 |
| 优点 | 理论严谨,适用广泛,逼近复杂分布,精度可随样本量提升 | 计算速度快,易于并行,适合大规模数据 |
| 缺点 | 计算耗时,自相关高,需 burn-in 和 thinning,高维下效率差 | 逼近精度依赖分布假设,存在偏差,难拟合多峰后验 |
| 适用场景 | 中小规模模型,高精度要求,复杂后验分布问题 | 大规模数据,贝叶斯深度学习,概率编程 |
| 收敛性质 | 样本数量越多,逼近越准,需判断收敛性 | 优化到局部最优,收敛快但存在偏差 |
| 实现复杂度 | 算法复杂、调参要求高,需处理链相关性问题 | 实现简单,自动化程度高,易与现代框架集成 |
| 代表工具 | Stan、PyMC、JAGS | TensorFlow Probability、Pyro、Edward |
📖 三、贝叶斯统计的应用
📌 3.1 人工智能与机器学习
贝叶斯统计方法逐渐成为人工智能与机器学习领域的重要支撑工具,主要体现在模型优化、不确定性刻画和生成模型构建等方面。其中,贝叶斯优化、贝叶斯神经网络(Bayesian Neural Networks, BNN)和深度生成模型(如VAE)是应用最为广泛的方向。
贝叶斯优化(Bayesian Optimization):
贝叶斯优化是一种基于贝叶斯推断和代理模型的全局优化方法,特别适用于函数评价代价高昂且无解析形式的问题,如机器学习中的超参数调优。其基本思想是利用高斯过程(Gaussian Process, GP)或其他代理模型对目标函数建模,并通过采集函数(如预期改进EI、概率改进PI)指导新点选择,使得在尽可能少的函数评估次数内找到最优解。贝叶斯优化能够有效权衡探索与利用,并显式刻画目标函数的不确定性,已成为AutoML系统的重要组成部分。
贝叶斯神经网络(BNN):
贝叶斯神经网络将网络权重视为概率分布而非确定点估计,从而能够自然地表达模型预测的不确定性。在训练过程中,利用贝叶斯推断方法(如变分推断或MCMC)对权重的后验分布进行估计,使得BNN在面对噪声数据、小样本问题或分布外数据时表现出更好的稳健性。与传统神经网络相比,BNN不仅提供预测值,还给出置信区间与不确定性度量,适合医学诊断、金融预测等高风险场景。
Variational Autoencoder (VAE):
VAE是基于变分贝叶斯思想的生成模型,通过引入隐变量和变分推断方法,近似计算复杂后验分布。VAE将观测数据映射到潜在空间,通过优化ELBO(Evidence Lower Bound)逼近真实后验,从而实现图像、文本、语音等数据的生成与重构。
Bayesian GAN:
Bayesian GAN通过在生成对抗网络(GAN)中引入贝叶斯不确定性估计机制,改善GAN在训练过程中的不稳定性和模式崩溃问题。常见做法包括对生成器和判别器参数引入先验分布,基于MCMC或变分推断更新后验分布,使生成模型的结果具有更好的可解释性和不确定性控制能力。
📌 3.2 医学、生物统计与金融
贝叶斯方法因其先验信息整合优势、对不确定性自然建模能力以及在小样本、动态决策环境下的良好表现,已广泛应用于医学、生物统计和金融等实践领域。
小样本条件下疗效分析:
临床试验中常面临样本量有限的困境,传统频率学方法易受样本量不足影响,推断结果稳定性差。贝叶斯方法通过引入先验知识,能够在小样本条件下稳定估计疗效参数。例如,可使用Beta-Binomial模型分析某新药治疗有效率,将历史数据或专家判断转化为先验分布,与现有试验数据联合,得到更稳健的后验估计。
生存分析中的贝叶斯 Cox 模型:
生存分析广泛用于医学预后研究,Cox比例风险模型是最常用方法。贝叶斯Cox模型通过为回归系数设定先验分布,利用MCMC方法采样估计系数后验分布,能够同时提供点估计与可信区间,并对小样本、协变量多重共线性等问题具有更强适应性。此外,可自然引入患者亚组先验、历史试验先验信息,提升模型预测能力。
临床试验动态调整:
贝叶斯方法可根据中期试验数据动态更新参数后验分布,实时调整样本量、分组比例或试验设计。例如,自适应贝叶斯试验设计根据当前后验概率调整治疗组入组比例,加速新疗法优效结论的确认,提高试验效率与伦理性。
风险参数贝叶斯估计:
信用风险、市场风险评估常需估计违约概率、损失率等参数。贝叶斯方法通过将历史数据与专家预判纳入先验,结合当前观测数据,形成后验分布,提升小样本或稀缺事件下的风险评估稳健性,降低极端值波动带来的影响。
不确定性环境中的投资组合优化:
金融市场充满不确定性,贝叶斯方法通过后验分布刻画资产收益率、相关性等参数不确定性,在多期动态投资组合优化中,基于后验均值与方差进行资产配置决策,显著提升投资策略的稳健性与灵活性,适应市场波动变化。
📖 四、贝叶斯因果推断方法
贝叶斯方法不仅在参数估计和预测问题中表现优异,也逐渐成为复杂因果推断领域的重要方法工具。因果推断致力于揭示变量之间的因果关系,超越相关性分析,解决“如果发生了X,结果会如何改变”的问题。而贝叶斯方法凭借其灵活的模型结构、先验整合能力以及不确定性量化特性,为复杂因果关系建模提供了强有力的理论和实践工具。
- 贝叶斯结构方程模型(Bayesian Structural Equation Model, BSEM)
贝叶斯结构方程模型将传统结构方程模型(SEM)中的参数视为随机变量,引入先验分布,通过贝叶斯方法估计参数后验分布。相比经典SEM,BSEM不仅能够自然纳入参数不确定性和先验知识,还能在小样本、不完全数据及复杂模型场景下保持稳定性。常见应用包括社会科学中的潜变量测量模型、教育评估及心理学研究。- 贝叶斯潜变量模型
潜变量模型用于刻画观测数据背后未直接观测到的潜在因素。贝叶斯潜变量模型通过为潜变量及其参数设定先验,结合观测数据和似然函数,利用MCMC或变分推断求解后验分布,从而估计潜在因素及参数的不确定性。该方法广泛应用于心理测量、生物统计以及市场细分分析。- 贝叶斯DAG模型
DAG(有向无环图)模型是因果推断的重要工具,用于表示变量之间的有向依赖关系。贝叶斯DAG模型通过对DAG结构设定先验(如结构先验、参数先验),依据观测数据更新后验分布,从而推断变量间因果结构。常用方法包括Bayesian Network Structure Learning 和 Causal Discovery。该方法可有效刻画复杂变量关系,并通过贝叶斯模型比较选择最优结构,广泛应用于基因调控网络、社会网络分析和医疗诊断路径推断。
📌 基于贝叶斯DAG模型的医疗诊断路径分析
在实际医疗诊断过程中,患者症状、检查指标、既往病史与最终诊断之间存在复杂的因果关系。传统方法多基于相关性分析,难以全面揭示变量之间的因果机制。而基于贝叶斯DAG模型的方法,能够系统建模各变量间的有向依赖,推断潜在的病因机制与诊断路径。
案例背景
某医院希望分析高血压患者的诊断路径,数据包括:
- 患者既往病史(家族遗传、高盐饮食、肥胖)
- 检查指标(血压、血脂、血糖)
- 症状(头痛、心悸、乏力)
- 最终诊断(是否高血压、病情严重程度)
建模过程
-
变量定义
将上述变量表示为有向无环图(DAG)节点,例如:FamilyHistory→HypertensionObesity→BloodPressure→HypertensionBloodPressure→Symptom
-
设定先验
基于医学文献及临床经验,为各变量关系设定结构先验及参数先验,如:- 遗传因素对高血压有较强先验概率
- 高血压通常导致血压升高和症状表现
-
贝叶斯更新
利用观测到的500名患者数据,通过MCMC方法对DAG结构和参数进行采样,估计后验分布。 -
结构学习与因果推断
- 通过贝叶斯得分(Bayesian Score)选取最优DAG结构。
- 估计因果效应,例如:
P(Hypertension | FamilyHistory=1)= 0.65P(Symptom | BloodPressure=High)= 0.80
-
不确定性分析
- 提供诊断路径概率区间,而非单点值,如:
- 家族史对高血压的影响效应后验均值0.65,95%可信区间[0.58, 0.72]。
应用意义
- 临床辅助诊断:帮助医生明确高血压的主要风险因素,提升诊断的精准度。
- 干预策略设计:通过识别关键中介变量(如肥胖、高盐饮食),为高血压的个性化预防策略提供支持。
- 不确定性量化:通过对模型不确定性的全面量化,提供更加稳健的临床决策依据。
📖 五、贝叶斯估计:药物治疗效果评估
📌 5.1 案例背景
我们希望通过贝叶斯统计方法估计药物治疗的有效率(\(\theta\))。给定以下信息:
- 成功人数(\(x\)) = 20
- 总人数(\(n\)) = 30
- 先验分布:\(\text{Beta}(1, 1)\)
📌 5.2 理论推导
-
先验分布:
\[\theta \sim \text{Beta}(\alpha, \beta) \]在此案例中,先验为 \(\text{Beta}(1, 1)\),即均匀分布。
-
似然函数:
由二项分布给出:$$ P(D|\theta) \propto \theta^x (1 - \theta)^{n - x} $$
其中,\(x\) 为成功人数,\(n\) 为总人数。 -
后验分布:
根据贝叶斯定理,后验分布为:$$ P(\theta|D) \propto \theta^{x + \alpha - 1} (1 - \theta)^{n - x + \beta - 1}$$
代入数据后得到后验分布:$$ \theta|D \sim \text{Beta}(21, 11)$$
📌 5.3 R语言实现
install.packages("ggplot2")
library(ggplot2)
a <- 1
b <- 1
x <- 20
n <- 30
a_post <- a + x
b_post <- b + n - x
theta <- seq(0, 1, length=1000)
posterior <- dbeta(theta, a_post, b_post)
data <- data.frame(theta, posterior)
ggplot(data, aes(x=theta, y=posterior)) +
geom_line(color='blue', size=1) +
labs(title='Beta(21,11) 后验分布', x='θ', y='密度')
📌 5.4 结果分析
-
后验均值:
\[E(\theta | D) = \frac{a_{post}}{a_{post} + b_{post}} = \frac{21}{32} \approx 0.656 \] -
95% 后验区间:
qbeta(c(0.025, 0.975), a_post, b_post)
本案例展示了如何使用贝叶斯方法估计药物治疗的有效率,主要步骤包括:
- 理论推导:从先验分布、似然函数到后验分布的推导。
- 实现过程:通过R和Python代码实现贝叶斯估计,绘制后验分布图。
- 后验分析:计算后验均值和区间估计。
这种方法特别适用于药效评估,尤其是在样本量较小的情况下,能够通过后验分布全面估计药物效果,并为临床决策提供有力支持。
📖 总结
贝叶斯统计凭借其将先验知识与观测数据有机整合,并基于后验分布进行推断与决策的能力,成为现代统计分析体系中极具优势的推断工具。与经典频率学派方法相比,贝叶斯统计能够在小样本、数据不完全或存在较大不确定性的环境下,充分利用先验信息,有效提高推断的稳健性和解释性,特别适用于高风险、复杂系统中的实时决策与不确定性管理。近年来,贝叶斯统计已广泛应用于人工智能、机器学习、医学诊断、生物统计、金融风险评估、市场预测等领域,发挥着核心作用。依托于现代计算手段的发展,特别是马尔可夫链蒙特卡洛(MCMC)、变分贝叶斯(VB)、集成采样与高性能并行计算平台,贝叶斯统计正朝着可扩展化、自动化和智能化方向迅速演进,能够灵活适配高维、大数据和复杂动态模型分析需求。未来,贝叶斯方法有望在强化学习、智能医疗、量化金融、政策决策等场景中,展现更加广阔的应用前景和学术价值。
参考文献

 浙公网安备 33010602011771号
浙公网安备 33010602011771号