
统计学(十八)——抽样技术概要
抽样调查作为一种基于部分样本对总体特性进行推断的统计方法,具有节省成本、提高效率、便于实施等显著优势。相比全面调查,抽样调查能够在有限的人力、物力和时间条件下,快速获得对总体情况的合理估计,因而在社会调查、市场分析、公共卫生、医学试验、教育评估以及各类科学研究中被广泛应用。合理科学的抽样设计不仅有助于提高估计结果的准确性和精度,避免抽样偏差和系统误差,还能增强研究结论的代表性与外推性,确保调查数据更好地反映总体特征。此外,配合规范的试验设计与样本量控制,抽样调查能够在满足置信水平和精度要求的前提下,优化数据收集与分析流程,为后续的统计推断与决策提供可靠依据。因此,抽样调查不仅是一种高效实用的调查方法,更是现代统计学与数据科学中不可或缺的重要手段。
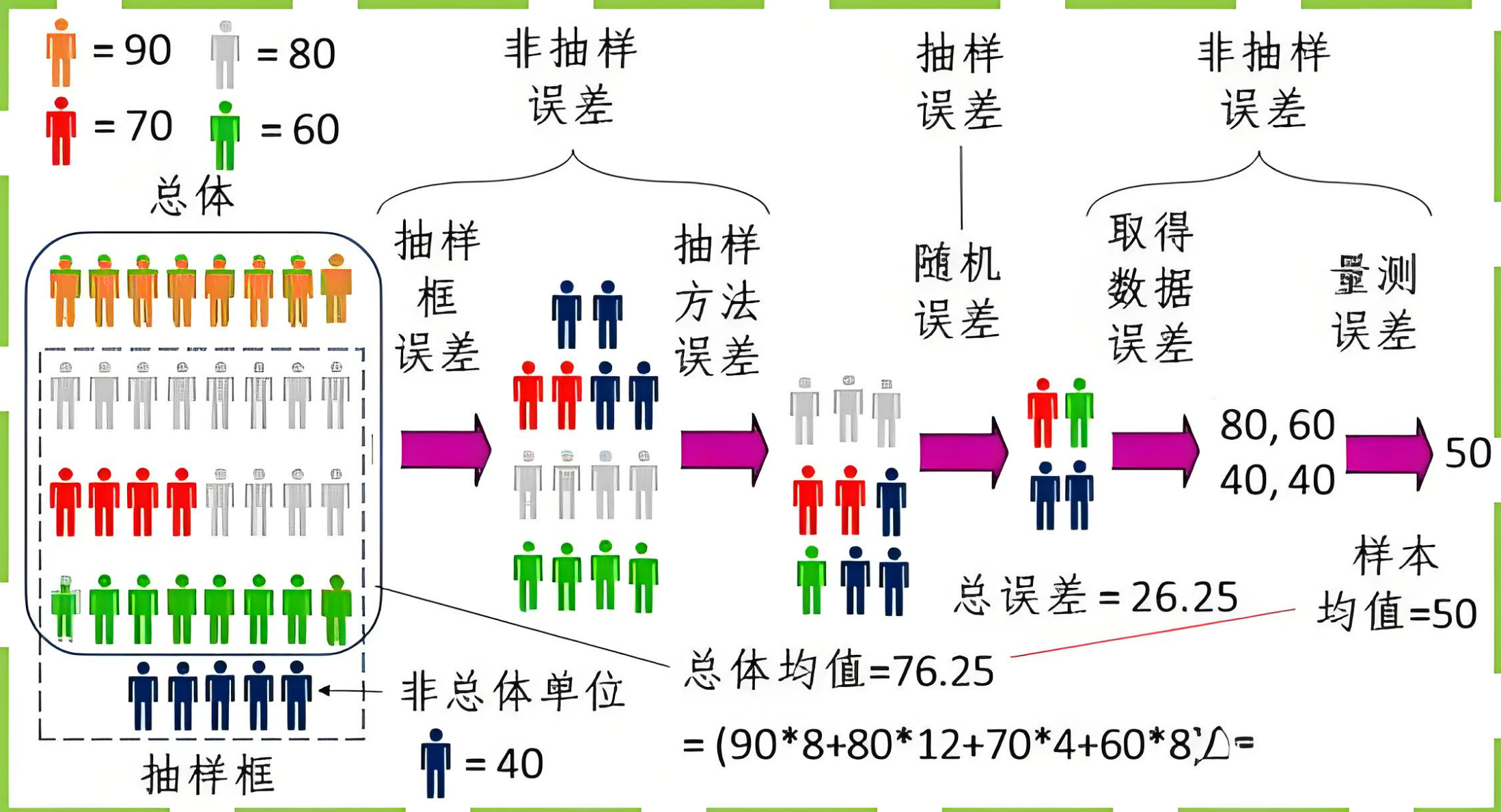
一、抽样方法分类与特点
为了确保抽样调查结果具备良好的代表性和推断性,选择科学合理的抽样方法至关重要。不同的抽样方法适用于不同类型的总体结构和调查需求,各自具备不同的优缺点与应用条件。根据抽取方式和样本分布特征,常见的抽样方法可以分为概率抽样与非概率抽样两大类,其中概率抽样包括简单随机抽样、系统抽样、分层抽样和整群抽样,非概率抽样则包括方便抽样、判断抽样和配额抽样等。
1.1 抽样方法汇总
| 抽样方法 | 特点 | 适用场景 |
|---|---|---|
| 简单随机抽样(Simple Random Sampling) | 每个个体有相等的被抽中机会,方法公平、易于推断,但操作上可能耗时 | 学术研究、人口普查子样本、质量抽检 |
| 系统抽样(Systematic Sampling) | 按固定间隔抽取,操作简便,但若总体有周期性结构可能失真 | 工厂流水线抽检、订单客户抽样 |
| 分层抽样(Stratified Sampling) | 先分层后随机抽样,保证各层充分代表性,提高估计精度 | 不同性别/年龄/地区的市场调研 |
| 整群抽样(Cluster Sampling) | 以群组为单位抽样,成本低、便于操作,但同群内部相关性高 | 学校、社区为单位的教育调查、健康调查 |
| 多阶段抽样(Multistage Sampling) | 分阶段逐层抽样,灵活适应大范围调查,但设计复杂 | 国家级人口普查、农村家庭入户调查 |

| 抽样方法 | 特点 | 适用场景 |
|---|---|---|
| 方便抽样(Convenience Sampling) | 简单、快速、成本低,但代表性差,易产生偏倚 | 试点调查、初步探索性研究、校园问卷、商场随机采访 |
| 判断抽样(Judgmental Sampling) | 灵活、依赖调查者经验,主观性强、代表性依赖判断准确性 | 专家意见调查、典型案例选择、小众市场分析 |
| 配额抽样(Quota Sampling) | 保证结构分布合理,操作简便,但抽取过程不随机,存在偏倚 | 社会调查、媒体调查、广告效果调查 |
| 滚雪球抽样(Snowball Sampling) | 适合隐蔽、难接触群体,样本获取依赖社交网络,偏倚风险高 | 隐性群体调查(吸毒者、地下社团成员) |
| 自愿抽样(Voluntary Sampling) | 简单、成本低,参与者积极性高,但自选性强,代表性差 | 网络调查、公众投票、用户满意度调查 |
1.2 系统抽样
系统抽样 Systematic Sampling 是一种简单且高效的概率抽样方法,常用于大规模、顺序排列的总体中。与简单随机抽样相比,系统抽样操作简便、样本分布均匀,尤其适合抽取生产流水线、名册、问卷等有序总体的样本,广泛应用于社会调查、质量检验、市场研究及医疗统计等领域。
📊 抽样思想
系统抽样的基本思想是:将总体单位按照一定顺序排列,从第一个单位起,每隔固定间隔抽取一个样本单位,直到抽取完毕。其核心在于 随机确定起点,按等距抽样,保证样本的随机性和代表性。
设总体容量为\(N\),样本容量为\(n\),则抽样间隔为:
在第 1 到第\(k\)个单位中随机抽取一个作为起始点\(r\),随后依次抽取:
个样本单位,形成所需样本。
📊优缺点
优点:
- 操作简便,便于环境上执行。
- 样本分布均匀,适合顺序排列总体。
- 计算量小,抽样速度快,适合大规模总体。
缺点:
- 若总体存在周期性特征,且周期长度与抽样间隔相互匹配,易导致样本偏差。
- 不适用于无法排序或顺序不固定的总体。
📊 适用条件
系统抽样适用于总体单位可以顺序排列,且总体结构相对均匀、无周期性分布的情况。例如:
- 按学号排列的学生名单
- 工厂流水线产品抽检
- 按时间顺序登记的病人档案
如果总体存在明显周期性,应避免使用系统抽样,或调整抽样间隔,避开周期性影响。
📊 抽样步骤
系统抽样的基本步骤如下:
- 确定总体容量 ( N ) 和所需样本量 ( n )。
- 计算抽样间隔: $$ k = \frac{N}{n} $$
- 随机确定起始点 ( r ),范围在 1 到 ( k ) 之间。
- 依次抽取样本,按:$$r,, r+k,, r+2k,, \cdots,, r+(n-1)k $$
- 完成抽样,形成样本。
📊 示例
假设某高校共有 5000 名学生,需要抽取 100 名学生进行问卷调查。
步骤如下:
- 总体容量 \(N = 5000\),样本量\(n = 100\)
- 计算抽样间隔:\[k = \frac{5000}{100} = 50 \]
- 随机在 1 到 50 之间选取起始点,假设为 20。
- 依次抽取第 20、70、120、170 …… 4970 、 5020(若超出 5000 则循环)编号学生,共 100 人。
📊 与简单随机抽样比较
| 对比内容 | 系统抽样 | 简单随机抽样 |
|---|---|---|
| 执行方式 | 随机选起点,按固定间隔抽取 | 每个个体独立随机抽取 |
| 样本分布 | 样本分布均匀 | 样本分布完全随机 |
| 操作复杂度 | 操作简便,便于执行 | 需依次随机抽取,操作繁琐 |
| 抽样偏差 | 易受总体周期性影响 | 随机性强,抗周期性偏差能力强 |
| 适用情况 | 有序总体,结构均匀,无周期性分布 | 任意总体均适用 |
系统抽样作为一种高效、实用的概率抽样方法,出于操作简便、分布均匀、抽样速度快的优势,广泛应用于多种调查研究与数据抽取场景中。使用时需特别关注总体的周期性结构,合理安排抽样间隔与顺序,避免样本偏差。合理运用系统抽样,有助于提升调查效率,确保调查结果的科学性和代表性。
二、参数估计与样本量确定
在抽样调查与试验设计中,参数估计和样本量确定是确保调查结果科学性与可靠性的核心环节。参数估计旨在通过样本数据对总体特性进行合理推断,而样本量的合理确定则直接关系到估计精度、置信水平以及调查成本之间的平衡。
2.1 参数估计方法
根据总体参数的不同,常用的估计方法包括以下几种:
-
总体均值估计
利用样本均值作为总体均值的无偏估计量,计算公式为:\[\hat{\mu} = \frac{1}{n}\sum x_i \]其中,$ n $ 为样本容量,$ x_i $ 为第 \(i\) 个样本观测值。
-
总体方差估计
采用样本方差作为总体方差的无偏估计量,计算公式为:\[s^2 = \frac{1}{n-1}\sum (x_i-\bar{x})^2 \]其中,$ \bar{x} $ 为样本均值。
-
总体比例估计
若总体参数为比例型指标,如支持率、合格率等,可用样本比例估计总体比例,公式为:\[\hat{p} = \frac{x}{n} \]其中,$ x $ 为样本中满足特定条件的个体数量,$ n $ 为样本容量。
-
置信区间计算
为评估估计值的可靠程度,通常需计算置信区间。例如,均值的置信区间为:\[\bar{x} \pm Z_{\alpha/2} \times \frac{s}{\sqrt{n}} \]其中,$ Z_{\alpha/2} $ 为标准正态分布上 \(1-\alpha/2\) 分位点,$ s $ 为样本标准差,$ n $ 为样本容量。
2.2 样本量确定方法
为了在给定置信水平与允许误差条件下保证估计的精度,必须科学合理地确定样本量。常用方法如下:
-
均值估计样本量
\[n = \frac{Z^2 \sigma^2}{d^2} \]其中,$ Z $ 为标准正态分布上相应置信水平的分位点,$ \sigma^2 $ 为总体方差,$ d $ 为允许误差。
-
比例估计样本量
\[n = \frac{Z^2 p(1-p)}{d^2} \]其中,$ p $ 为预估比例值,$ d $ 为允许误差。
-
分层抽样样本量
分层抽样中样本量需根据各层总体占比、层内方差以及总体样本量加权确定。一般遵循 优化分配原则,即:
\[n_h = n \times \frac{N_h S_h}{\sum N_h S_h} \]其中,$ n_h $ 为第 \(h\) 层样本量,$ N_h $ 为第 \(h\) 层总体量,$ S_h $ 为第 \(h\) 层标准差,$ n $ 为总体样本量。
样本量的合理性直接关系到抽样结果的置信度与代表性,过小样本量会导致估计偏差增大,过大则造成资源浪费,因此需综合误差容忍度、总体差异性与调查成本等因素科学确定。
三 分层抽样实战案例:大学生手机使用情况调查设计与分析
📊 背景与目的
在现代高校学生群体中,手机使用时长已成为影响学习效率、生活习惯以及心理健康的重要因素。为了准确了解某高校在校大学生每日手机使用时长的总体均值,并给出合理的区间估计,本研究设计了一个基于分层抽样的调查方案。相较于简单随机抽样,分层抽样能够根据学生年级这一重要变量,合理分层、分配样本,从而提高抽样效率,降低估计方差,增强结果的代表性和可靠性。
📊 分层抽样设计
考虑到大学生在不同年级的学习压力、课程安排、生活方式差异较大,可能导致手机使用习惯存在显著差异,因此将在校5000名学生按照年级划分为4个层次,各层人数如下:
| 年级 | 人数 |
|---|---|
| 大一 | 1500 |
| 大二 | 1400 |
| 大三 | 1200 |
| 大四 | 900 |
| 总计 | 5000 |
📊 样本量分配
本次调查确定总体样本量为171人,采用按层人数比例分配法,即按照各年级人数占总人数比例,计算各层应抽取的样本量,具体计算公式如下:
计算结果如下:
| 年级 | \(N_h\) | \(n_h\) |
|---|---|---|
| 大一 | 1500 | 51 |
| 大二 | 1400 | 48 |
| 大三 | 1200 | 41 |
| 大四 | 900 | 31 |
| 总计 | 5000 | 171 |
该分配方式保证了样本结构与总体结构一致,有助于提高估计的代表性和精度。
📊 分层抽样实施
-
获取名单:在正式抽样前,需将5000名在校学生按照年级分类,整理出包含学生姓名、学号、年级等信息的完整数据表格,命名为student_list。
-
抽取样本:在每个年级内,独立执行简单随机抽样,分别抽取51、48、41、31名学生。为保证随机性和可重复性,设置随机种子。具体R语言实现代码如下:
# 加载 dplyr 包
library(dplyr)
# 设置随机种子,保证结果可重复
set.seed(123)
# 各层样本量
sample_size <- c(51, 48, 41, 31)
grades <- c("大一", "大二", "大三", "大四")
# 各层独立抽样
sample_list <- lapply(1:4, function(i) {
student_list %>%
filter(grade == grades[i]) %>%
sample_n(sample_size[i])
})
# 合并所有层的样本
final_sample <- bind_rows(sample_list)
📊 参数估计与区间计算
根据抽样数据,估计全体学生每日手机使用时长均值为 4.154小时,采用95%置信水平计算置信区间:
得到置信区间:(3.876 小时, 4.432 小时),说明我们有95%的把握认为总体均值位于该区间内。
抽样方差估计公式:
其中,\(s_h^2\) 为各层内样本方差,\(N_h\) 和 \(n_h\) 分别是各层总体和样本容量。
📊 数据可视化与分析
- 各年级均值柱状图
library(ggplot2)
data <- data.frame(
grade = c("大一", "大二", "大三", "大四"),
mean_time = c(4.5, 4.1, 3.9, 4.0)
)
ggplot(data, aes(x=grade, y=mean_time, fill=grade)) +
geom_bar(stat="identity") +
geom_text(aes(label=mean_time), vjust=-0.5) +
labs(title="各年级手机使用时长均值", y="小时") +
theme_minimal()
- 样本量分布饼图
data2 <- data.frame(
grade = c("大一", "大二", "大三", "大四"),
count = c(51, 48, 41, 31)
)
ggplot(data2, aes(x="", y=count, fill=grade)) +
geom_bar(width=1, stat="identity") +
coord_polar("y") +
labs(title="各年级样本分布占比") +
theme_void()
通过本案例,充分体现了分层抽样在提高估计效率、降低方差、增强结论代表性方面的重要作用。按年级分层,使样本更好地反映了总体结构,避免了简单随机抽样在异质总体中的偏差问题。结合R语言实现,快速完成样本抽取、参数估计与图形展示,为学术调研、校园调查提供了清晰、实用的范例。
结论与建议
抽样技术与试验设计是统计学研究和实际应用中至关重要的方法工具。抽样技术通过从总体中科学选取具有代表性的样本,利用样本特性推断总体特征,既节省成本又提高效率。常见方法包括简单随机抽样、系统抽样、分层抽样和整群抽样,各自适用于不同类型的调查对象和场景。合理的样本量确定与抽样方案设计,有助于控制抽样误差,提升推断的准确性和可靠性。试验设计则通过科学安排试验条件与数据收集方式,减少系统误差和随机误差,确保结果具有统计意义。经典设计包括完全随机设计、随机区组设计和析因设计等,广泛应用于自然科学、社会科学和工程管理等领域。两者结合,能够为社会调查、医学研究、市场分析、产品测试等工作提供科学、高效、可靠的数据支撑,是现代研究方法体系中不可或缺的重要组成部分。
参考文献

 浙公网安备 33010602011771号
浙公网安备 33010602011771号