
机器博弈——算法概述及Python实现
机器博弈(Machine Game Playing)是人工智能(AI)领域中的一个重要研究方向,旨在通过算法和策略,使机器在博弈环境中做出最优或接近最优的决策。博弈问题涉及两个或多个智能体在同一环境中相互竞争或合作,因此机器不仅需要具备强大的计算能力,还需要具备复杂的策略规划和决策能力。在完全信息博弈(如国际象棋、围棋)中,机器可以基于状态空间进行深度搜索,通过算法推导最优解。而在不完全信息博弈(如扑克)中,机器则需要推断对手的隐藏信息,采用概率模型或强化学习来优化策略。此外,机器博弈还涉及博弈均衡理论、风险评估、对手建模等复杂问题。近年来,随着蒙特卡洛树搜索(MCTS)、深度强化学习(Deep Reinforcement Learning)和自我对弈(Self-Play)等技术的发展,机器博弈在复杂环境中的表现已接近甚至超越人类水平,成为人工智能发展的重要推动力。
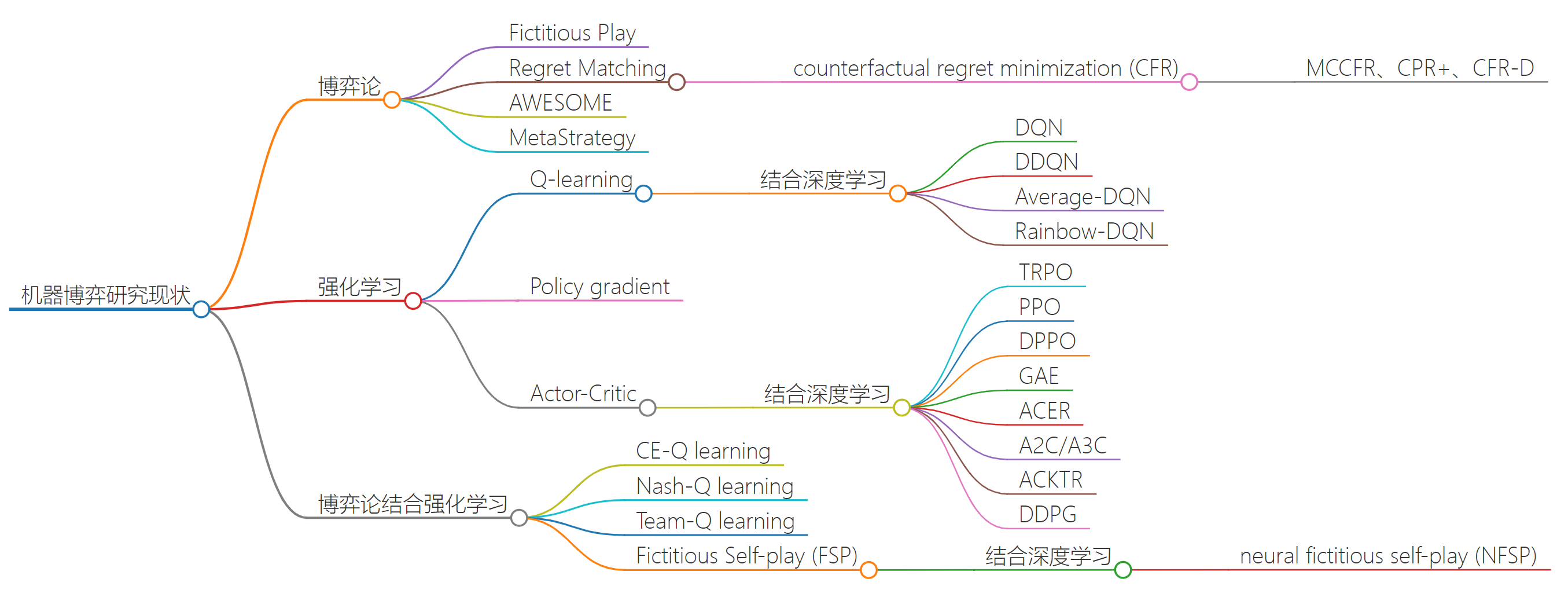
一、机器博弈概述
机器博弈(Machine Game Playing)是人工智能(AI)领域的重要分支,研究如何通过算法和策略使机器在博弈环境中做出最优或接近最优的决策。机器博弈是人工智能与博弈论(Game Theory)相结合的产物,涉及算法设计、策略规划、规则设定等多个层面,已广泛应用于商业竞争、军事对抗、游戏竞技和市场博弈等领域。机器博弈不仅考察机器的计算能力,更涉及策略均衡、信息不完全性、风险控制和动态调整等复杂问题。近年来,随着深度学习和强化学习的迅猛发展,机器博弈在复杂环境中的表现已接近甚至超越人类水平。
1.1 机器博弈的基本框架
机器博弈的研究建立在博弈论和人工智能的理论基础之上。博弈论研究理性个体在不同利益冲突和合作环境下如何做出最优决策,涉及以下基本要素:
- 玩家(Player):参与博弈的个体或智能体。
- 策略(Strategy):玩家在博弈中可以采取的行动方案。
- 收益(Payoff):玩家在博弈中根据自己的策略与其他玩家的策略组合所获得的结果。
- 信息集(Information Set):玩家在做出决策时所拥有的信息集合。
- 均衡(Equilibrium):在其他玩家策略保持不变的情况下,个体玩家采取最优策略所达到的状态。
人工智能通过机器学习、深度学习和强化学习等方法,使机器能够在博弈环境中不断学习和优化策略,提高智能体在复杂博弈场景下的表现。机器博弈的基本框架包括两个核心研究方向:
- 博弈策略的求解:通过算法(如最优策略、均衡求解、强化学习等)来获得不同博弈环境下的最优解。
- 博弈规则的设计:在对抗性环境下,设计博弈规则以引导个体理性行为,确保博弈结果的公平性和有效性。
1.2 机器博弈的理论基础
机器博弈结合了博弈论(Game Theory)与人工智能(AI)方法,构成一个复杂的交叉研究领域。博弈论为理解和建模多个智能体之间的竞争与合作行为提供了坚实的理论框架,而人工智能方法(如深度学习、强化学习和搜索算法)为求解复杂的博弈问题提供了强大的计算工具。
在机器博弈中,纳什均衡(Nash Equilibrium)是一个重要的理论基础。纳什均衡是指在其他玩家的策略保持不变的情况下,任何玩家都无法通过单方面调整策略来提高自身收益。在复杂的多智能体环境中,纳什均衡的存在性和唯一性问题使其成为机器博弈求解的难点之一。
此外,最优反应(Best Response)和遗憾最小化(Regret Minimization)是机器博弈中常用的优化手段。最优反应是指在其他玩家策略给定的条件下,个体采取使自身收益最大化的策略。遗憾最小化通过迭代更新策略,减少历史决策中与最优策略之间的差距,从而在长期博弈中实现收益最大化。
在求解博弈问题中,机器常用的算法包括:
- Minimax 算法:通过模拟最大化与最小化的交替选择,求解最优策略,适用于完全信息博弈(如国际象棋、跳棋)。
- Alpha-Beta 剪枝:对 Minimax 算法进行优化,剪除不必要的分支,显著减少搜索空间和计算复杂度。
- 蒙特卡洛树搜索(MCTS):采用“选择-扩展-模拟-回溯”框架,通过模拟和概率估计,适用于信息不完全的复杂博弈(如围棋)。
Minimax 和 Alpha-Beta 剪枝在国际象棋、跳棋等经典完全信息博弈中取得了巨大成功。MCTS 则在围棋、扑克等复杂环境中展现出强大的实战能力。AlphaGo 通过结合深度学习和 MCTS,在围棋领域取得突破性成就,成为机器博弈领域的重要里程碑。
近年来,强化学习与深度学习的结合推动了机器博弈算法的进一步发展。深度强化学习(Deep Reinforcement Learning)通过策略网络(Policy Network)和价值网络(Value Network)对复杂状态空间进行建模和评估,增强了机器在复杂环境中的适应性和学习能力。
1.3 多智能体系统与协同学习
在机器博弈中,多智能体系统(Multi-Agent System, MAS)是核心研究对象之一。多智能体系统涉及多个自主智能体在共享环境中相互作用,这些智能体之间可能存在竞争(Competitive)关系或合作(Cooperative)关系。
在竞争性博弈中,个体智能体的目标是最大化自身收益,这通常会导致纳什均衡或类似的稳定状态。在合作性博弈中,智能体的目标是最大化整体系统的效率,需要通过共享信息和协调策略来实现全局最优。
常见的多智能体学习模型包括:
- 独立强化学习(Independent Q-Learning):每个智能体独立学习,不考虑其他智能体的策略变化。
- 联合强化学习(Joint Q-Learning):智能体在学习过程中考虑其他智能体的策略,并通过联合策略优化整体收益。
- 对抗性学习(Adversarial Learning):在存在竞争环境的博弈中,智能体通过模拟对手行为,调整自身策略来达到最优结果。
1.4 机器博弈的演化与发展
在复杂的动态环境中,机器博弈常涉及演化博弈(Evolutionary Game Theory, EGT)。演化博弈模拟智能体在环境中的策略变化与适应性,通过“选择、复制、变异”等机制,逐步优化策略。
常见的演化博弈方法包括:
- 遗传算法(Genetic Algorithm)
- 进化策略(Evolutionary Strategy)
- 基因规划(Genetic Programming)
AlphaGo 在围棋领域的突破正是通过将深度学习与演化博弈相结合,实现了在复杂博弈环境中的自我优化。随着强化学习、神经网络和遗憾最小化技术的不断演进,机器博弈将在更多复杂博弈场景(如金融市场、军事对抗、网络安全等)中展现出强大的应用潜力。
二、机器博弈算法
以下是三种最有影响力的机器博弈算法。
2.1 Minimax 算法(极大极小算法)
Minimax 算法是一种在回合制博弈中用于寻找最优策略的决策方法,适用于完全信息博弈(如国际象棋、围棋)。其核心思想是:
- 博弈双方交替行动,一方为“最大化方”(Maximizer),另一方为“最小化方”(Minimizer)。
- 最大化方试图使收益最大化,而最小化方试图使损失最小化。
- 在搜索博弈树的过程中,最大化方选择子节点中的最大值,最小化方选择子节点中的最小值。
极大极小值为:
其中:
- $ s $ 为当前状态
- $ A(s) $ 为状态 $ s $ 下的所有可行动作
- $ s' $ 为执行动作 $ a $ 后的状态
优势与不足
✅ 适用于零和博弈,理论基础扎实
✅ 可获得最优解,适用于小规模博弈
❌ 计算复杂度高,扩展到复杂博弈时易出现组合爆炸
示例
| 博弈树 | 算法 |
|---|---|
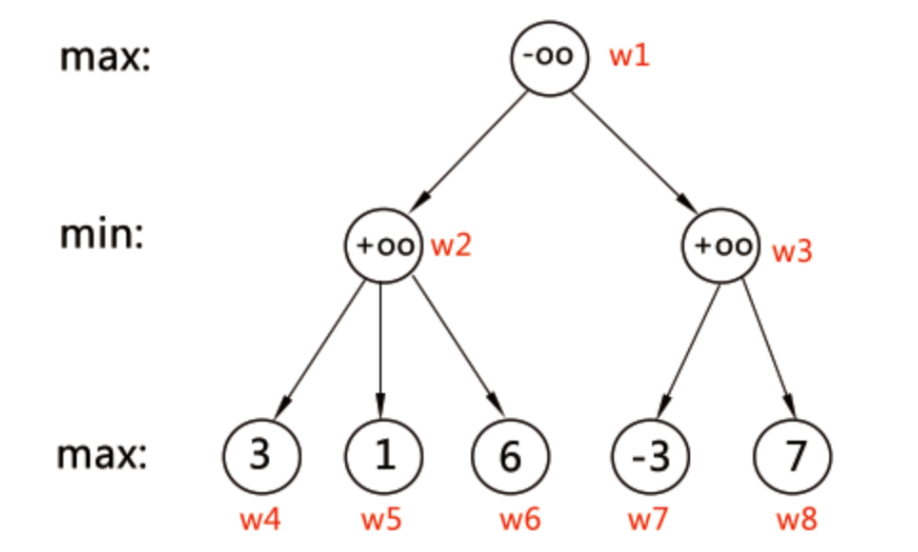 |
最单纯的极大极小算法。 局面估价函数: 我们给每个局面(state)规定一个估价函数值 f,评价它对于己方的有利程度。胜利的局面的估价函数值为 +oo,而失败的局面的估价函数值为–oo。Max 局面: 假设这个局面轮到己方走,有多种决策可以选择,其中每种决策都导致一种子局面(sub-state)。由于决策权在我们手中,当然是选择估价函数值 f 最大的子局面,因此该局面的估价函数值等于子局面 f 值的最大值,把这样的局面称为 max 局面。Min 局面: 假设这个局面轮到对方走,它也有多种决策可以选择,其中每种决策都导致一种子局面(sub-state)。但由于决策权在对方手中,在最坏的情况下,对方当然是选择估价函数值 f 最小的子局面,因此该局面的估价函数值等于子局面 f 值的最小值,把这样的局面称为 min 局面。终结局面: 胜负已分(假设没有和局) |
搜索过程
从根节点 w1 开始搜索。A 是 max 局面,因此需要最大化估值。
搜索 w2 分支
A 选择 w2,B 需要最小化局面:
-
w2 → w4 -
叶子节点,估值为 3。
-
记录:
f(w2) = 3。 -
w2 → w5- 叶子节点,估值为 1。
- 因为 B 是 min 局面,选择较小的估值:
f(w2) = min(3, 1) = 1。
-
w2 → w6- 叶子节点,估值为 6。
- 因为 B 是 min 局面,选择较小的估值:
f(w2) = min(1, 6) = 1。
💡 B 在 w2 局面中会选择估值最小的结果,得到最终 f(w2) = 1。
搜索 w3 分支
A 选择 w3,B 需要最小化局面:
-
w3 → w7- 叶子节点,估值为 -3。
- 记录:
f(w3) = -3。
-
w3 → w8- 叶子节点,估值为 7。
- 因为 B 是 min 局面,选择较小的估值:
f(w3) = min(-3, 7) = -3。
B 在 w3 局面中会选择估值最小的结果,得到最终 f(w3) = -3。
回溯到根节点 w1
A 是 max 局面,需要在 w2 和 w3 的估值中取最大值:
f(w1) = max(1, -3) = 1。
💡 A 在 w1 局面中会选择估值较大的走法,即选择走 w2。
最终推导结果
- ✅
f(w2) = 1 - ✅
f(w3) = -3 - ✅
f(w1) = max(1, -3) = 1 - ✅ A 将在下一步选择走
w2
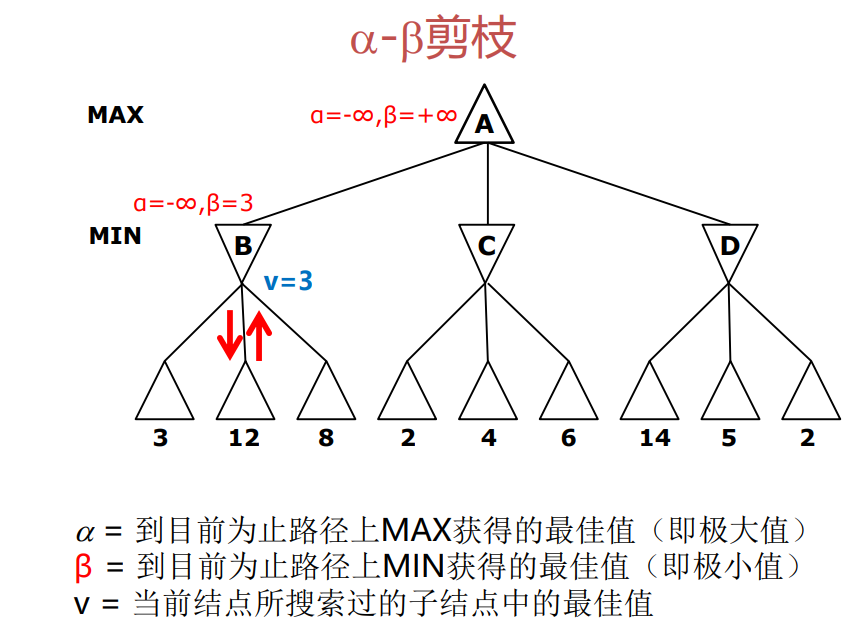
2.2 Alpha-Beta 剪枝算法
Alpha-Beta 剪枝是 Minimax 算法的改进版本,利用界限裁剪来减少搜索空间,从而加速计算。
- 定义两个参数:
- $ \alpha $ —— 最大化方已知的最小可能收益
- $ \beta $ —— 最小化方已知的最大可能损失
- 在搜索过程中,如果某个分支的最大可能收益小于当前已知的最小可能损失,则可以直接剪枝,跳过该分支的进一步探索。
在 Minimax 的基础上增加剪枝条件:
- 若当前节点值 $ v $ 使得 $ v \geq \beta $,则直接返回,不再搜索其他子节点
- 若当前节点值 $ v $ 使得 $ v \leq \alpha $,则直接返回,不再搜索其他子节点
优势与不足
✅ 在不影响结果的前提下大幅减少搜索空间
✅ 时间复杂度由 \(O(bd)\) 降至 \(O(b^{d/2})\)(\(b\) 为分支因子,\(d\) 为深度)
❌ 在博弈树结构不对称时,效果会有所下降
2.3 蒙特卡洛树搜索(MCTS)
MCTS 是近年来在复杂博弈(如围棋、扑克)中广泛应用的算法,核心思路是基于随机模拟和树搜索来逐步优化策略。
MCTS 主要包括以下四个步骤:
- 选择(Selection):使用 UCT(Upper Confidence Bound for Trees)公式选择当前最优分支。
- 扩展(Expansion):在未完全展开的节点中增加新的节点。
- 模拟(Simulation):从新节点开始进行随机模拟,得到博弈结果。
- 回溯(Backpropagation):将模拟结果沿着路径向上传递,更新节点的胜率和访问次数。
在选择节点时,采用 UCT 公式平衡探索与开发:
其中:
- $ w_i $ = 节点 $ i $ 的胜利次数
- $ n_i $ = 节点 $ i $ 的访问次数
- $ N $ = 当前节点总访问次数
- $ c $ = 调整探索与开发平衡的常数
优势与不足
✅ 适用于信息不完全的复杂博弈(如围棋、德州扑克)
✅ 在大规模搜索空间中具有良好效果
❌ 模拟结果对算法性能影响大,模拟次数不足会导致策略不稳定
2.4 综合对比
| 算法 | 核心思路 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|
| Minimax | 通过最大化与最小化交替选择最优策略 | 理论基础扎实,最优解 | 计算复杂度高 | 完全信息博弈(如国际象棋) |
| Alpha-Beta 剪枝 | 在 Minimax 基础上进行搜索剪枝,减少搜索空间 | 加速搜索,减少无效搜索 | 适用范围有限 | 完全信息博弈(如国际象棋) |
| MCTS | 通过随机模拟和树搜索进行决策优化 | 适用于复杂和不完全信息博弈 | 需要大量模拟才能稳定 | 不完全信息博弈(如围棋、扑克) |
Minimax 和 Alpha-Beta 剪枝在国际象棋、跳棋等经典博弈中取得了巨大成功,而 MCTS 在围棋等复杂博弈中展现出强大的实战能力。尤其是 AlphaGo 采用了基于深度学习改进的 MCTS 算法,成为机器博弈领域的里程碑。
三、极大极小算法案例
Minimax是一种悲观算法,即假设对手每一步都会将我方引入从当前看理论上价值最小的格局方向,即对手具有完美决策能力。因此我方的策略应该是选择那些对方所能达到的让我方最差情况中最好的,也就是让对方在完美决策下所对我造成的损失最小。
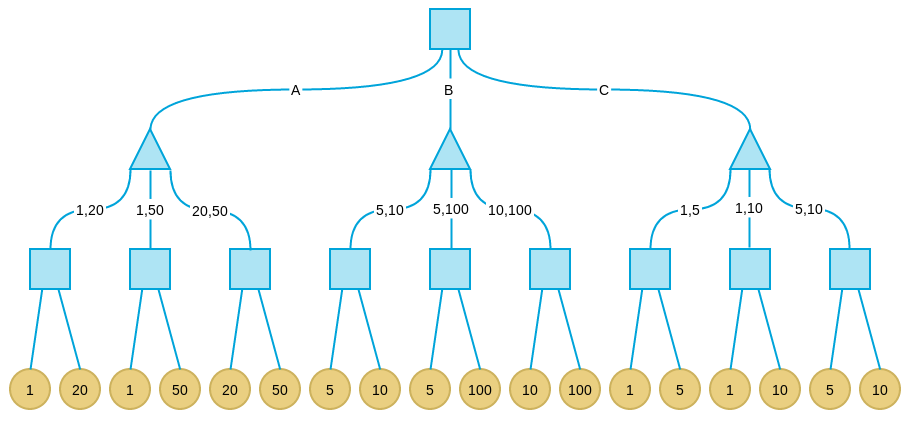
3.1 博弈规则
考虑这样一个游戏:有三个盘子A、B和C,每个盘子分别放有三张纸币。A放的是1、20、50;B放的是5、10、100;C放的是1、5、20。单位均为“元”。有甲、乙两人,两人均对三个盘子和上面放置的纸币有可以任意查看。游戏分三步:
- 甲从三个盘子中选取一个。
- 乙从甲选取的盘子中拿出两张纸币交给甲。
- 甲从乙所给的两张纸币中选取一张,拿走。其中甲的目标是最后拿到的纸币面值尽量大,乙的目标是让甲最后拿到的纸币面值尽量小。
3.2 问题建模
状态空间:
甲从三个盘子中选择一个(A、B、C)。
乙从所选盘子中选择两张纸币给甲。
甲从乙给出的两张纸币中选择一张,获得最终收益。
效用函数:
甲的收益 = 甲最终选择的纸币面值。
乙的收益 = - 甲的收益(零和博弈)。
博弈树结构:
根节点:甲选择盘子
第二层节点:乙从所选盘子中选两张纸币
叶子节点:甲选择纸币,形成最终收益
🏆 求解方法
甲采用最大化策略,尽量使最终收益最大。
乙采用最小化策略,尽量压低甲的收益。
3.3 Python求解
import itertools
# 定义三个盘子中的纸币
plates = {
'A': [1, 20, 50],
'B': [5, 10, 100],
'C': [1, 5, 20]
}
# 极大极小搜索算法
def minimax(plate, maximizing_player):
if maximizing_player:
# 甲选择最大化
max_eval = float('-inf')
for pair in itertools.combinations(plates[plate], 2):
choice = max(pair)
max_eval = max(max_eval, choice)
return max_eval
else:
# 乙选择最小化
min_eval = float('inf')
for pair in itertools.combinations(plates[plate], 2):
choice = max(pair) # 乙交出两张纸币后,甲最大化选择
min_eval = min(min_eval, choice)
return min_eval
# 甲选择的最优策略
def find_best_strategy():
best_plate = None
best_value = float('-inf')
for plate in plates:
value = minimax(plate, False)
if value > best_value:
best_value = value
best_plate = plate
return best_plate, best_value
if __name__ == "__main__":
plate, value = find_best_strategy()
print(f"甲选择的最佳盘子是: {plate}, 期望收益为: {value}")
甲选择的最佳盘子是: A, 期望收益为: 20

四、库恩扑克(Kuhn's Poker)的蒙特卡洛树搜索
库恩扑克(Kuhn's Poker)是由哈罗德·库恩(Harold Kuhn)在1950年提出的一个简化的双人零和博弈模型,用于研究不完全信息博弈中的最优策略和纳什均衡。
4.1 库恩扑克(Kuhn's Poker)博弈
游戏规则
- 玩家人数:2名玩家。
- 牌型:三张牌(例如0、1、2),玩家各发一张,自己可见,牌面大小决定牌力。
- 行动顺序:
- 玩家1先行动,可以下注(Bet)或让牌(Pass)。
- 玩家2根据玩家1的选择,可以选择跟注(Call)或弃牌(Fold)。
- 胜负规则:
- 若双方都弃牌或都让牌,持有更高牌值的玩家获胜。
- 若玩家2弃牌,玩家1获胜;若玩家2跟注,则比较牌面大小,牌大者获胜。
支付结构
- 初始底池为 1 单位。
- 下注或跟注需要额外支付 1 单位。
- 如果最终形成比牌,赢家获得总底池(2 或 4 单位)。
这个模型展示了在不完全信息博弈下的策略平衡和博弈最优解,是研究强化学习和博弈论的重要模型。
4.2 Python程序
import numpy as np
import random
from collections import defaultdict
class KuhnPokerMCTS:
def __init__(self, n_iter=10000):
self.n_iter = n_iter
self.strategy = defaultdict(lambda: np.array([0.5, 0.5]))
self.regret_sum = defaultdict(lambda: np.array([0.0, 0.0]))
self.strategy_sum = defaultdict(lambda: np.array([0.0, 0.0]))
def get_strategy(self, info_set):
regret = self.regret_sum[info_set]
strategy = np.maximum(regret, 0)
normalizing_sum = sum(strategy)
if normalizing_sum > 0:
strategy /= normalizing_sum
else:
strategy = np.array([0.5, 0.5])
self.strategy_sum[info_set] += strategy
return strategy
def get_average_strategy(self, info_set):
normalizing_sum = sum(self.strategy_sum[info_set])
if normalizing_sum > 0:
return self.strategy_sum[info_set] / normalizing_sum
else:
return np.array([0.5, 0.5])
def simulate(self, history, p0, p1):
plays = len(history)
player = plays % 2
opp = 1 - player
if plays > 1:
terminal_pass = history[-1] == 'p'
double_bet = history[-2:] == 'bb'
is_player_card_higher = self.cards[player] > self.cards[opp]
if terminal_pass:
if history == "pp":
return 1 if is_player_card_higher else -1
else:
return 1
elif double_bet:
return 2 if is_player_card_higher else -2
info_set = f"{self.cards[player]}{history}"
strategy = self.get_strategy(info_set)
action = np.random.choice([0, 1], p=strategy)
next_history = history + ('p' if action == 0 else 'b')
if player == 0:
value = self.simulate(next_history, p0 * strategy[action], p1)
else:
value = self.simulate(next_history, p0, p1 * strategy[action])
regret = value * (1 if player == 0 else -1)
regret_values = np.array([value if action == i else -value for i in range(2)])
self.regret_sum[info_set] += p1 * regret_values if player == 0 else p0 * regret_values
return value
def train(self):
for _ in range(self.n_iter):
self.cards = random.sample([0, 1, 2], 2)
self.simulate('', 1, 1)
def get_final_strategy(self):
final_strategy = {}
for info_set in self.strategy_sum:
strategy = self.get_average_strategy(info_set)
final_strategy[info_set] = np.round(strategy, 2) # 保留2位小数
return final_strategy
# 训练MCTS模型
mcts = KuhnPokerMCTS(n_iter=100000)
mcts.train()
strategy = mcts.get_final_strategy()
# 输出最终策略(格式化为2位小数)
for k, v in sorted(strategy.items()):
print(f"{k}: {v}")
4.3 库恩扑克(Kuhn’s Poker) MCTS 结果解释
0: [1. 0.]
0b: [1. 0.]
0p: [1. 0.]
0pb: [1. 0.]
1: [1. 0.]
1b: [1. 0.]
1p: [0. 1.]
1pb: [0. 1.]
2: [0. 1.]
2b: [0.5 0.5]
2p: [0. 1.]
2pb: [0.5 0.5]
- 0, 1, 2 表示玩家的初始手牌(0 = 最小,2 = 最大)。
[1. 0.]表示玩家在该信息集下采取行动的概率:- 第一个数字是
pass(弃牌)的概率,第二个是bet(下注)的概率。 - 如
0: [1. 0.]表示拿到0号牌时,100%选择弃牌。
- 第一个数字是
0b, 0p, 0pb等表示不同历史行动后的策略:0b= 初始牌为0,选择下注后的策略。0p= 初始牌为0,选择弃牌后的策略。
2b和2pb为[0.5, 0.5],说明策略尚未收敛,或在某些情况下存在策略不确定性。
解释汇总:
- 弃牌(pass)在弱牌(0、1)下为最优策略。
- 强牌(2)下注和弃牌策略未完全确定,显示为 50%-50%。
- 策略已在大部分情况下收敛,符合MCTS预期。
总结
机器博弈(Machine Game Playing)是人工智能(AI)领域的重要分支,研究如何通过算法和策略使机器在博弈环境中做出最优或接近最优的决策。博弈问题涉及多方竞争或合作,机器需要在有限或不完全的信息条件下,基于策略规划、博弈均衡和风险评估来优化决策。机器博弈的核心算法包括 Minimax 算法、Alpha-Beta 剪枝和蒙特卡洛树搜索(MCTS)。
Minimax 算法通过最大化与最小化交替选择最优策略,适用于完全信息博弈(如国际象棋、跳棋),但计算复杂度高,容易出现“组合爆炸”。Alpha-Beta 剪枝是 Minimax 的改进版本,通过在搜索过程中设置界限,剪除不必要的分支,显著减少计算量,提高搜索效率。蒙特卡洛树搜索(MCTS)则采用“选择-扩展-模拟-回溯”框架,通过随机模拟和概率估计来优化策略,尤其适用于复杂和不完全信息博弈(如围棋、扑克)。Minimax 和 Alpha-Beta 剪枝在国际象棋、跳棋等经典博弈中取得巨大成功,而 MCTS 在围棋等复杂博弈中展现出强大的实战能力。特别是 AlphaGo 结合深度学习与 MCTS,在围棋博弈中击败人类顶尖棋手,成为机器博弈领域的里程碑。
参考文献

 浙公网安备 33010602011771号
浙公网安备 33010602011771号