摘要:  OpenVINO™ C# API 3.3 全新发布!这次升级的重点,是把 OpenVINO GenAI 正式带进 C#/.NET 生态。开发者可以在 C# 项目中直接调用本地 LLM 文本生成、Whisper 语音识别、VLM 图文问答等能力,不再必须绕 Python 服务或外部脚本。
3.3 继续保持传统 OpenVINO 推理能力稳定,老项目可以平滑升级;需要 GenAI 时,再按平台引入 JYPPX.OpenVINO.GenAI.runtime.*。同时新增 samples/GenAI 示例体系和系列教程,覆盖文本生成、语音识别、多模态问答、runtime 包选择与迁移实践。C# 本地 AI 开发,正在变得更完整、更工程化。 阅读全文
OpenVINO™ C# API 3.3 全新发布!这次升级的重点,是把 OpenVINO GenAI 正式带进 C#/.NET 生态。开发者可以在 C# 项目中直接调用本地 LLM 文本生成、Whisper 语音识别、VLM 图文问答等能力,不再必须绕 Python 服务或外部脚本。
3.3 继续保持传统 OpenVINO 推理能力稳定,老项目可以平滑升级;需要 GenAI 时,再按平台引入 JYPPX.OpenVINO.GenAI.runtime.*。同时新增 samples/GenAI 示例体系和系列教程,覆盖文本生成、语音识别、多模态问答、runtime 包选择与迁移实践。C# 本地 AI 开发,正在变得更完整、更工程化。 阅读全文
OpenVINO™ C# API 3.3 全新发布!这次升级的重点,是把 OpenVINO GenAI 正式带进 C#/.NET 生态。开发者可以在 C# 项目中直接调用本地 LLM 文本生成、Whisper 语音识别、VLM 图文问答等能力,不再必须绕 Python 服务或外部脚本。
3.3 继续保持传统 OpenVINO 推理能力稳定,老项目可以平滑升级;需要 GenAI 时,再按平台引入 JYPPX.OpenVINO.GenAI.runtime.*。同时新增 samples/GenAI 示例体系和系列教程,覆盖文本生成、语音识别、多模态问答、runtime 包选择与迁移实践。C# 本地 AI 开发,正在变得更完整、更工程化。 阅读全文
posted @ 2026-06-11 09:41
椒颜皮皮虾
阅读(347)
评论(0)
推荐(2)
 最新的英特尔® 酷睿™ Ultra 处理器(第二代)让我们能够在台式机、移动设备和边缘中实现大多数 AI 体验,将 AI 加速提升到新水平,在 AI 时代为边缘计算提供动力。英特尔® 酷睿™ Ultra 处理器提供了一套全面的专为 AI 定制的集成计算引擎,包括 CPU、GPU 和 NPU,提供高达 99 总平台 TOPS。近期,YOLO系列模型发布了YOLOv12, 对 YOLO 框架进行了全面增强,特别注重集成注意力机制,同时又不牺牲 YOLO 模型所期望的实时处理能力,是 YOLO 系列的一次进化,突破了人工视觉的极限。本文中,我们将使用英特尔® 酷睿™ Ultra 处理器AI PC设备,结合OpenVINO™ C# API 使用最新发布的OpenVINO™ 2025.0 部署YOLOv11 和 YOLOv12 目标检测模型,并在AIPC设备上,进行速度测试。
最新的英特尔® 酷睿™ Ultra 处理器(第二代)让我们能够在台式机、移动设备和边缘中实现大多数 AI 体验,将 AI 加速提升到新水平,在 AI 时代为边缘计算提供动力。英特尔® 酷睿™ Ultra 处理器提供了一套全面的专为 AI 定制的集成计算引擎,包括 CPU、GPU 和 NPU,提供高达 99 总平台 TOPS。近期,YOLO系列模型发布了YOLOv12, 对 YOLO 框架进行了全面增强,特别注重集成注意力机制,同时又不牺牲 YOLO 模型所期望的实时处理能力,是 YOLO 系列的一次进化,突破了人工视觉的极限。本文中,我们将使用英特尔® 酷睿™ Ultra 处理器AI PC设备,结合OpenVINO™ C# API 使用最新发布的OpenVINO™ 2025.0 部署YOLOv11 和 YOLOv12 目标检测模型,并在AIPC设备上,进行速度测试。  重磅发布!OpenVINO™ C# API 3.2 来了!
这是一次由 AI 大模型驱动的全面进化——基于老版本代码库,通过 Kimi、GPT-4 等 AI 工具深度重构,带来更清晰的架构、更强劲的性能、更完善的测试体系。
✨ 核心亮点: 🚀 AI 大模型优化重构,代码质量全面提升 🎯 支持 .NET 4.6 到 10.0,全框架无缝兼容 ⚡ Span
重磅发布!OpenVINO™ C# API 3.2 来了!
这是一次由 AI 大模型驱动的全面进化——基于老版本代码库,通过 Kimi、GPT-4 等 AI 工具深度重构,带来更清晰的架构、更强劲的性能、更完善的测试体系。
✨ 核心亮点: 🚀 AI 大模型优化重构,代码质量全面提升 🎯 支持 .NET 4.6 到 10.0,全框架无缝兼容 ⚡ Span 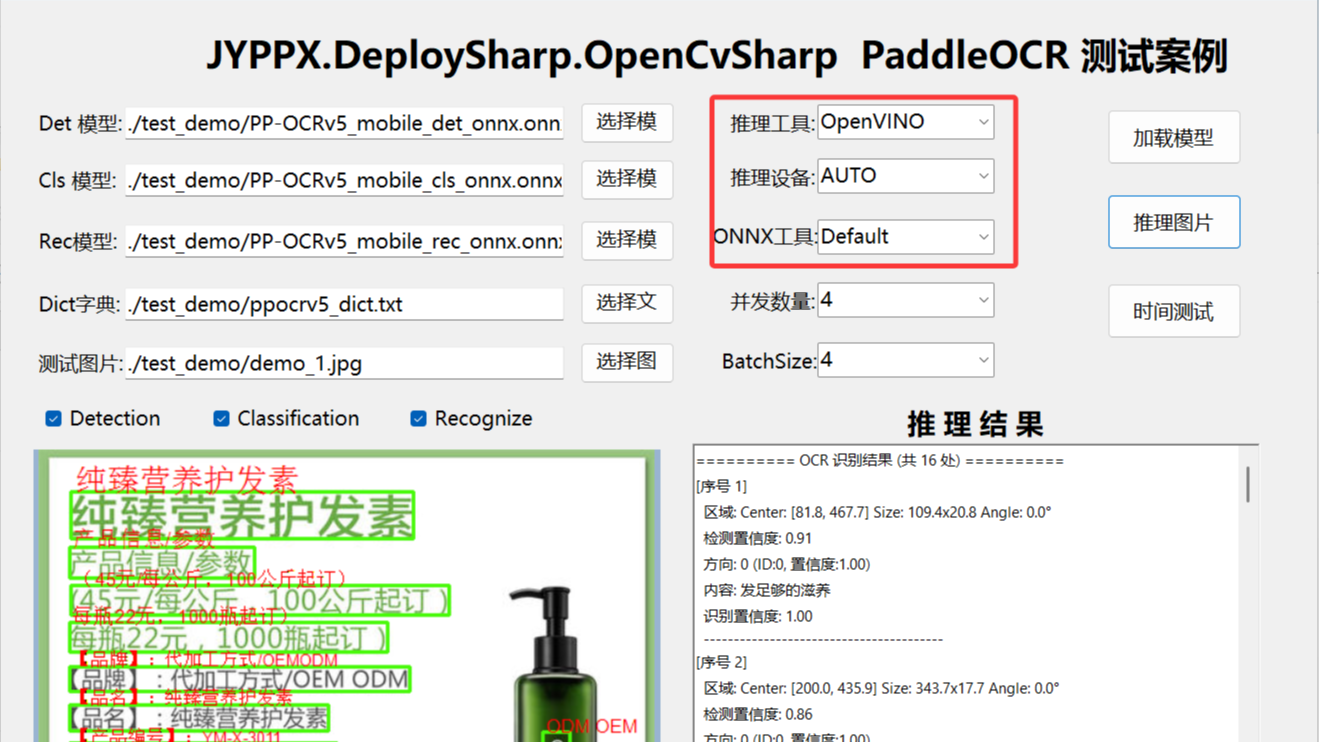 本文介绍了基于DeploySharp框架在.NET环境下部署PaddleOCR模型的解决方案。该框架通过统一接口封装了OpenVINO、TensorRT、ONNX Runtime等多种推理引擎,支持百毫秒级文字识别。文章详细解析了PaddleOCR三阶段工作流程(检测-分类-识别)及性能优化策略,阐述了DeploySharp"统一接口、灵活部署"的架构优势。演示程序支持多种推理后端,涵盖CPU/GPU不同硬件场景,提供模型加载、图片推理、性能测试等功能。通过该方案,开发者可根据实际硬件环
本文介绍了基于DeploySharp框架在.NET环境下部署PaddleOCR模型的解决方案。该框架通过统一接口封装了OpenVINO、TensorRT、ONNX Runtime等多种推理引擎,支持百毫秒级文字识别。文章详细解析了PaddleOCR三阶段工作流程(检测-分类-识别)及性能优化策略,阐述了DeploySharp"统一接口、灵活部署"的架构优势。演示程序支持多种推理后端,涵盖CPU/GPU不同硬件场景,提供模型加载、图片推理、性能测试等功能。通过该方案,开发者可根据实际硬件环  DeploySharp是一个专为C#开发者设计的跨平台模型部署框架,全面支持YOLOv26系列模型,包括目标检测、实例分割、姿态估计和旋转框检测。该框架提供多引擎支持(OpenVINO/ONNX Runtime/TensorRT)、两种图像处理库选择(ImageSharp/OpenCvSharp)以及跨平台运行时兼容性。通过模块化架构和NuGet包生态,开发者可以快速部署YOLOv26模型,实现从模型加载到推理执行的端到端解决方案。项目开源且支持多种硬件设备,为计算机视觉应用落地提供高效工具。
DeploySharp是一个专为C#开发者设计的跨平台模型部署框架,全面支持YOLOv26系列模型,包括目标检测、实例分割、姿态估计和旋转框检测。该框架提供多引擎支持(OpenVINO/ONNX Runtime/TensorRT)、两种图像处理库选择(ImageSharp/OpenCvSharp)以及跨平台运行时兼容性。通过模块化架构和NuGet包生态,开发者可以快速部署YOLOv26模型,实现从模型加载到推理执行的端到端解决方案。项目开源且支持多种硬件设备,为计算机视觉应用落地提供高效工具。  TensorRtSharp 3.0 是一个为 C# 开发者打造的 TensorRT 封装库,通过 NuGet 一键安装,提供完整的 GPU 推理加速功能。该库基于 TensorRT 10.x 开发,支持 CUDA 11/12,具备类型安全、自动资源管理等特性,显著提升 .NET 环境下的深度学习推理性能(速度提升 2-10 倍,显存降低 50%+)。安装简单,只需添加两个 NuGet 包,并通过环境变量配置原生库路径即可使用。推荐配置为 CUDA 11.6 + TensorRT 10.13.0.35,支持
TensorRtSharp 3.0 是一个为 C# 开发者打造的 TensorRT 封装库,通过 NuGet 一键安装,提供完整的 GPU 推理加速功能。该库基于 TensorRT 10.x 开发,支持 CUDA 11/12,具备类型安全、自动资源管理等特性,显著提升 .NET 环境下的深度学习推理性能(速度提升 2-10 倍,显存降低 50%+)。安装简单,只需添加两个 NuGet 包,并通过环境变量配置原生库路径即可使用。推荐配置为 CUDA 11.6 + TensorRT 10.13.0.35,支持  NVIDIA ® TensorRT ™ 是一款用于高性能深度学习推理的 SDK,包含深度学习推理优化器和运行时,可为推理应用程序提供低延迟和高吞吐量。YOLOv10是清华大学研究人员近期提出的一种实时目标检测方法,通过消除NMS、优化模型架构和引入创新模块等策略,在保持高精度的同时显著降低了计算开销,为实时目标检测领域带来了新的突破。 在本文中,我们将演示如何使用NVIDIA TensorRT C++ API 部署YOLOv10目标检测模型,实现模型推理加速。
NVIDIA ® TensorRT ™ 是一款用于高性能深度学习推理的 SDK,包含深度学习推理优化器和运行时,可为推理应用程序提供低延迟和高吞吐量。YOLOv10是清华大学研究人员近期提出的一种实时目标检测方法,通过消除NMS、优化模型架构和引入创新模块等策略,在保持高精度的同时显著降低了计算开销,为实时目标检测领域带来了新的突破。 在本文中,我们将演示如何使用NVIDIA TensorRT C++ API 部署YOLOv10目标检测模型,实现模型推理加速。  浙公网安备 33010602011771号
浙公网安备 33010602011771号