
TensorRtSharp:在 C# 世界中释放 GPU 推理的极致性能
 TensorRtSharp 3.0 是一个为 C# 开发者打造的 TensorRT 封装库,通过 NuGet 一键安装,提供完整的 GPU 推理加速功能。该库基于 TensorRT 10.x 开发,支持 CUDA 11/12,具备类型安全、自动资源管理等特性,显著提升 .NET 环境下的深度学习推理性能(速度提升 2-10 倍,显存降低 50%+)。安装简单,只需添加两个 NuGet 包,并通过环境变量配置原生库路径即可使用。推荐配置为 CUDA 11.6 + TensorRT 10.13.0.35,支持
TensorRtSharp 3.0 是一个为 C# 开发者打造的 TensorRT 封装库,通过 NuGet 一键安装,提供完整的 GPU 推理加速功能。该库基于 TensorRT 10.x 开发,支持 CUDA 11/12,具备类型安全、自动资源管理等特性,显著提升 .NET 环境下的深度学习推理性能(速度提升 2-10 倍,显存降低 50%+)。安装简单,只需添加两个 NuGet 包,并通过环境变量配置原生库路径即可使用。推荐配置为 CUDA 11.6 + TensorRT 10.13.0.35,支持
TensorRtSharp:在 C# 世界中释放 GPU 推理的极致性能
目录
一、前言
1.1 为什么需要 TensorRtSharp?
在深度学习模型部署领域,NVIDIA TensorRT 凭借其卓越的推理性能已成为 GPU 加速的事实标准。根据 NVIDIA 官方数据,使用 TensorRT 进行模型优化和推理加速,通常可以获得:
- 📈 推理速度提升 2-10 倍(相比原生框架)
- 💾 显存占用降低 50% 以上(通过精度优化和层融合)
- ⚡ 延迟降低至毫秒级(满足实时应用需求)
然而,TensorRT 官方仅提供 C++ 和 Python API,这让广大 .NET 开发者面临一个两难的选择:
- 放弃熟悉的 C# 生态,转向 C++ 或 Python
- 通过复杂的互操作层进行调用,开发效率低下
TensorRtSharp 应运而生 —— 这是一个纯 C# 编写的 TensorRT 完整封装库,为 .NET 开发者提供了:
- ✅ 类型安全的 API 接口 - 强类型系统,编译时错误检查
- ✅ 易于使用且性能卓越 - 直观的 API 设计,零性能损失
- ✅ 完整的 TensorRT 功能覆盖 - 支持所有核心功能
- ✅ 自动资源管理 - 基于 RAII 和 Dispose 模式,无需担心内存泄漏
- ✅ 开箱即用 - NuGet 一键安装,无需复杂配置
- ✅ 完善的文档和示例 - 丰富的代码示例和详细的使用说明
1.2 TensorRtSharp 的核心优势
1. 原生 C# 体验
// 简洁直观的 API 设计
using Runtime runtime = new Runtime();
using CudaEngine engine = runtime.deserializeCudaEngineByBlob(data, size);
using ExecutionContext context = engine.createExecutionContext();
context.executeV3(stream);
2. 完整功能覆盖
- ✅ 模型构建(ONNX → Engine)
- ✅ 推理执行(同步/异步)
- ✅ 动态形状支持
- ✅ 多精度推理(FP32/FP16/INT8)
- ✅ 多 GPU 并行推理
1.3 TensorRtSharp 3.0 的重大改进
在前期开发的 TensorRtSharp 1.0 和 2.0 中,使用者需要下载源码编译才能使用,过程繁琐且容易出错。
在最新的 3.0 版本中,我们进行了重大改进:
✅ 一键安装 - 直接将编译好的原生库与托管代码打包至 NuGet 包中
✅ 开箱即用 - 无需配置复杂的构建环境
✅ 版本一致 - 降低因环境差异导致的潜在错误
开发者仅需通过 Visual Studio 的 NuGet 包管理器安装即可直接使用,显著提升了开发效率与部署便捷性!
本文将全面介绍 TensorRtSharp 的设计理念、核心功能和使用方法,助力大家快速上手使用。
二、什么是 TensorRtSharp
2.1 项目简介
TensorRtSharp 3.0 是作者对 NVIDIA TensorRT 官方库的完整 C# 接口封装。通过 P/Invoke 技术,它将 TensorRT 的原生 C++ API 映射为符合 .NET 设计规范的托管代码,让 C# 开发者能够无缝使用 TensorRT 的全部功能。
2.2 核心特性
| 特性 | 说明 |
|---|---|
| 完整的 API 覆盖 | 支持 TensorRT 核心功能,包括模型构建、推理执行、动态形状等 |
| 类型安全 | 强类型系统,编译时错误检查,避免运行时类型错误 |
| 自动资源管理 | 基于 RAII 和 Dispose 模式的资源管理,防止内存泄漏 |
| 跨平台支持 | 支持 Windows、Linux,兼容 .NET 5.0-10.0、.NET Core 3.1、.NET Framework 4.7.1-4.8.1 |
| 高性能异步执行 | 支持 CUDA Stream、多执行上下文并行推理 |
| 开箱即用 | NuGet 包含所有依赖,无需复杂配置 |
2.3 项目信息
| 项目 | 信息 |
|---|---|
| 版本 | 目前最新 NuGet 版本为 0.0.5(持续更新中,建议使用最新版本) |
| GitHub | https://github.com/guojin-yan/TensorRT-CSharp-API |
| 接口 NuGet | JYPPX.TensorRT.CSharp.API |
| Runtime NuGet | JYPPX.TensorRT.CSharp.API.runtime.win-x64.cuda12 或 JYPPX.TensorRT.CSharp.API.runtime.win-x64.cuda11 |
| 编程语言 | C# 10 |
三、安装与配置
3.1 通过 NuGet 安装
安装 TensorRtSharp 非常简单,只需安装两个 NuGet 包:
# 安装接口包
dotnet add package JYPPX.TensorRT.CSharp.API
# 安装运行时包(根据您的 CUDA 版本选择)
# CUDA 12.x 版本
dotnet add package JYPPX.TensorRT.CSharp.API.runtime.win-x64.cuda12
# 或 CUDA 11.x 版本
dotnet add package JYPPX.TensorRT.CSharp.API.runtime.win-x64.cuda11
💡 小贴士:Runtime 包与 CUDA 版本相关,请根据您设备上安装的 CUDA 版本选择对应的包。

3.2 系统要求
| 要求 | 说明 |
|---|---|
| 操作系统 | Windows 10+、Linux(Ubuntu 18.04+)、macOS 10.15+ |
| .NET 版本 | .NET 5.0-10.0、.NET Core 3.1、.NET Framework 4.7.1+ |
| GPU | NVIDIA GPU(支持 CUDA 11.x 或 12.x) |
| 依赖 | NVIDIA TensorRT 10.x、CUDA Runtime |
3.3 重要版本说明
⚠️ 重要提醒:NVIDIA TensorRT 必须是 10.x 系列!!
TensorRtSharp 3.0 基于 TensorRT 10.x 开发,不支持 TensorRT 8.x 或 9.x 版本。
为了防止出现兼容性问题,建议使用与博主相同的配置:
配置 1(推荐):
- CUDA 11.6
- cuDNN 9.2.0
- TensorRT 10.13.0.35
配置 2:
- CUDA 12.3
- cuDNN 9.2.0
- TensorRT 10.11.0.33
3.4 配置原生库
TensorRtSharp 依赖 TensorRT 的原生库(nvinfer.dll)和 CUDA 的原生库(cudart64_*.dll 等)。有两种配置方式:
方式一:拷贝 DLL 到应用程序目录(不推荐)
将 TensorRT 和 CUDA 的所有 DLL 文件拷贝到程序可执行目录下。
缺点:
- 会导致程序目录文件庞大
- 不方便管理与部署
- 不推荐使用此方式
方式二:设置系统 PATH(推荐)
将 TensorRT 的 lib 目录和 CUDA 的 bin 目录路径添加到系统 PATH 环境变量中。
优点:
- 无需复制大量文件
- 保持应用目录整洁
- 便于版本管理和部署维护
配置步骤:
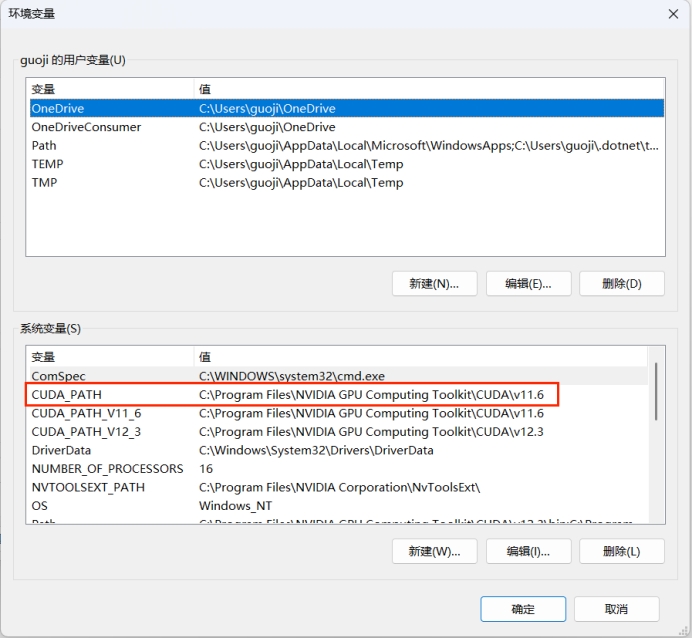
- 设置 CUDA_PATH 环境变量
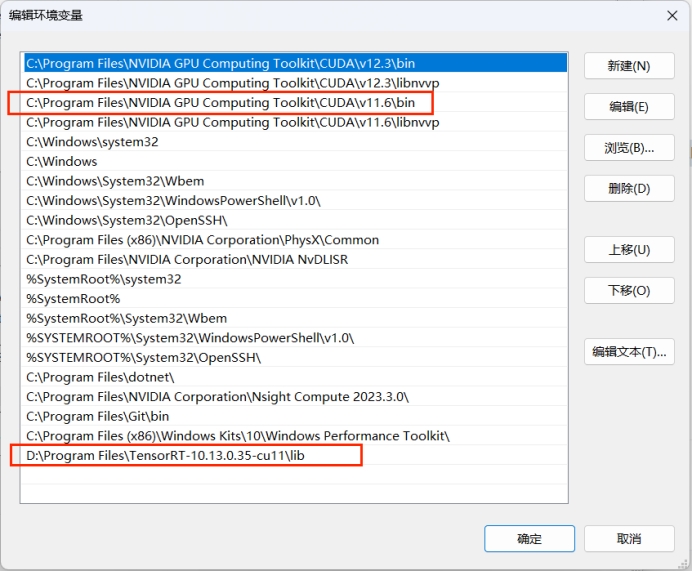
- 设置 PATH 环境变量
将以下路径添加到 PATH:
- CUDA 的 bin 目录(如
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.6\bin) - TensorRT 的 lib 目录(如
C:\TensorRT-10.13.0.35\lib)
💡 建议:优先使用环境变量方式配置,避免因文件冗余导致部署复杂。同时注意不同 CUDA 版本间的兼容性问题。
四、核心架构设计
4.1 三层架构
TensorRtSharp 采用清晰的三层架构设计:
┌─────────────────────────────────────────────────────────┐
│ 业务 API 层 (High-Level API) │
│ Runtime, Builder, CudaEngine, ExecutionContext │
└─────────────────────────────────────────────────────────┘
▲
│
┌─────────────────────────────────────────────────────────┐
│ 资源管理层 (Resource Management) │
│ DisposableTrtObject, DisposableObject, IOvPtrHolder │
└─────────────────────────────────────────────────────────┘
▲
│
┌─────────────────────────────────────────────────────────┐
│ P/Invoke 层 (Native Interop) │
│ NativeMethodsTensorRt*, NativeMethodsCuda* │
└─────────────────────────────────────────────────────────┘
4.2 自动资源管理
TensorRtSharp 实现了完善的资源管理机制,所有 TensorRT 对象都继承自 DisposableTrtObject:
// 所有 TensorRT 对象继承自 DisposableTrtObject
public abstract class DisposableTrtObject : DisposableObject
{
protected IntPtr ptr; // 原生对象指针
public bool IsDisposed { get; protected set; }
// 安全访问原生指针(自动检查释放状态)
public IntPtr TrtPtr
{
get
{
ThrowIfDisposed();
return ptr;
}
}
// 释放非托管资源
protected override void DisposeUnmanaged()
{
if (ptr != IntPtr.Zero)
{
// 调用原生释放函数
NativeDestroy(ptr);
ptr = IntPtr.Zero;
}
}
}
// 使用 using 语句自动释放资源
using Runtime runtime = new Runtime();
using CudaEngine engine = runtime.deserializeCudaEngineByBlob(data, size);
// 离开作用域时自动释放
设计亮点:
- ✅ 采用标准 Dispose 模式,确保资源正确释放
- ✅ 线程安全的资源释放机制(使用
Interlocked.Exchange) - ✅ 自动内存压力通知(
GC.AddMemoryPressure) - ✅ 指针安全访问(
ThrowIfDisposed检查)
五、核心类与 API
5.1 命名空间
在使用 TensorRtSharp 之前,首先引入必要的命名空间:
using JYPPX.TensorRtSharp.Cuda; // CUDA 接口的程序集命名空间
using JYPPX.TensorRtSharp.Nvinfer; // TensorRT 接口的程序集命名空间
5.2 Runtime(推理运行时)
Runtime 是 TensorRT 推理的入口点,负责从序列化的引擎文件创建推理引擎。
// 创建 Runtime 实例
Runtime runtime = new Runtime();
string filePath = "yolov8s-obb.engine";
// 从字节数组反序列化引擎
byte[] data = File.ReadAllBytes(filePath);
using CudaEngine cudaEngine = runtime.deserializeCudaEngineByBlob(data, (ulong)data.Length);
// 从文件流反序列化
using var reader = new FileStreamReader();
reader.open(filePath);
using CudaEngine cudaEngine = runtime.deserializeCudaEngineByFileStreamReader(reader);
// 配置 DLA(深度学习加速器)
runtime.setDLACore(0); // 使用 DLA 核心 0
int dlaCores = runtime.getNbDLACores();
// 设置最大线程数
runtime.setMaxThreads(4);
主要用途:
- 反序列化 TensorRT 引擎文件
- 配置 DLA 加速器
- 加载插件库
5.3 Builder(模型构建器)
Builder 用于从 ONNX 模型构建 TensorRT 引擎。
using Builder builder = new Builder();
// 查询平台能力
bool hasFP16 = builder.platformHasFastFp16(); // 是否支持 FP16
bool hasINT8 = builder.platformHasFastInt8(); // 是否支持 INT8
int maxDLABatch = builder.maxDLABatchSize(); // DLA 最大批大小
// 创建网络定义(显式批处理模式)
using NetworkDefinition network = builder.createNetworkV2(
TrtNetworkDefinitionCreationFlag.kEXPLICIT_BATCH);
// 创建构建器配置
using BuilderConfig config = builder.createBuilderConfig();
// 创建优化配置文件(用于动态形状)
using OptimizationProfile profile = builder.createOptimizationProfile();
// 构建序列化网络
using HostMemory serialized = builder.buildSerializedNetwork(network, config);
// 保存引擎文件
using (FileStream fs = new FileStream("model.engine", FileMode.Create, FileAccess.Write))
{
fs.Write(serialized.getByteData(), 0, (int)serialized.Size);
}
主要用途:
- 创建网络定义和构建配置
- 查询硬件能力(FP16、INT8、DLA)
- 构建 TensorRT 引擎
- 注册自定义插件
5.4 CudaEngine(推理引擎)
CudaEngine 是推理的核心对象,包含优化后的模型计算图。
// 获取张量信息
int numTensors = engine.getNbIOTensors();
string inputName = engine.getIOTensorName(0); // 输入张量名称
string outputName = engine.getIOTensorName(1); // 输出张量名称
Dims inputShape = engine.getTensorShape(inputName);
TrtDataType inputType = engine.getTensorDataType(inputName);
// 创建执行上下文
using ExecutionContext context = engine.createExecutionContext();
using ExecutionContext contextStatic = engine.createExecutionContext(
TrtExecutionContextAllocationStrategy.kSTATIC);
// 序列化引擎
using HostMemory memory = engine.serialize();
// 查询引擎属性
int numLayers = engine.getNbLayers();
string name = engine.getName();
long deviceMemory = engine.getDeviceMemorySize();
主要用途:
- 查询模型输入输出信息
- 创建执行上下文
- 序列化引擎
- 性能分析
5.5 ExecutionContext(执行上下文)
ExecutionContext 管理单次推理的执行环境,支持异步推理和动态形状。
// 绑定张量地址
Cuda1DMemory<float> input = new Cuda1DMemory<float>(3 * 1024 * 1024);
Cuda1DMemory<float> output = new Cuda1DMemory<float>(1 * 20 * 21504);
context.setInputTensorAddress("images", input.get());
context.setOutputTensorAddress("output0", output.get());
// 设置动态形状
context.setinputShape("images", new Dims(1, 3, 1024, 1024));
Dims shape = context.getTensorShape("images");
// 执行推理(异步,使用 CUDA Stream)
using CudaStream stream = new CudaStream();
context.executeV3(stream);
stream.Synchronize(); // 等待完成
// 设置优化配置文件(动态形状)
context.setOptimizationProfileAsync(0, stream);
// 调试功能
context.setDebugSync(true);
主要用途:
- 绑定输入输出张量
- 设置动态形状
- 执行推理(异步)
- 性能分析和调试
5.6 OnnxParser(ONNX 解析器)
OnnxParser 将 ONNX 模型转换为 TensorRT 网络定义。
// 解析 ONNX 文件
using NetworkDefinition network = build.createNetworkV2(TrtNetworkDefinitionCreationFlag.kEXPLICIT_BATCH);
using OnnxParser parser = new OnnxParser(network);
bool success = parser.parseFromFile("yolov8s-obb.onnx", verbosity: 2);
// 检查算子支持
bool supportsConv = parser.supportsOperator("Conv");
// 子图支持
long numSubgraphs = parser.getNbSubgraphs();
bool supported = parser.isSubgraphSupported(0);
long[] nodes = parser.getSubgraphNodes(0);
// 设置解析器标志
parser.setFlag(TrtOnnxParserFlag.kNATIVE_INSTANCENORM);
主要用途:
- 解析 ONNX 模型
- 检查算子支持
- 处理子图
5.7 CUDA 内存管理
(1)设备内存(Cuda1DMemory)
// 创建设备内存
using Cuda1DMemory<float> input = new Cuda1DMemory<float>(1000);
ulong numElements = input.SizeElements;
ulong numBytes = input.SizeBytes;
IntPtr ptr = input.DevicePointer;
// 同步数据传输
float[] hostData = new float[1000];
input.copyFromHost(hostData); // 主机 → 设备
input.copyToHost(hostData); // 设备 → 主机
// 异步数据传输
using CudaStream stream = new CudaStream();
input.copyFromHostAsync(hostData, stream);
input.copyToHostAsync(hostData, stream);
// 内存操作
input.memset(0); // 填充为 0
input.memsetAsync(0, stream); // 异步填充
(2)CUDA 流(CudaStream)
// 创建流(带优先级)
using CudaStream stream = new CudaStream();
using CudaStream streamHigh = new CudaStream(0, -1); // 高优先级
// 同步操作
stream.Synchronize(); // 等待流完成
bool isComplete = stream.Query(); // 查询是否完成
// 事件依赖
using CudaEvent cudaEvent = new CudaEvent();
stream.WaitEvent(cudaEvent); // 等待事件
// 添加回调
stream.AddCallback((streamPtr, statue, userData) =>
{
Console.WriteLine("Stream callback executed");
}, IntPtr.Zero, 0);
// CUDA Graph 捕获
stream.BeginCapture(CudaStreamCaptureMode.Global);
// ... 执行操作 ...
CudaGraph_t graph = stream.EndCapture();
(3)CUDA 设备(CudaDevice)
// 获取系统中启用的 CUDA 兼容设备的数量
int nbDevices = CudaDevice.GetDeviceCount();
// 获取指定设备的属性
CudaDeviceProp properties = CudaDevice.GetDeviceProperties(deviceIdx);
// 设置执行设备
CudaDevice.SetDevice(device);
// 获取有关设备的请求信息
int clockRate = CudaDevice.GetAttribute(CudaDeviceAttr.ClockRate, device);
六、完整使用示例
示例 1:获取和设置设备信息
下面的代码可以获取当前设备的相关信息,同时可以设置推理设备。
using JYPPX.TensorRtSharp.Cuda;
using JYPPX.TensorRtSharp.Nvinfer;
namespace TestDemo
{
internal class Program
{
static void Main(string[] args)
{
// 指定默认使用的 GPU 设备索引
// 在多 GPU 环境下,可以通过修改此变量来选择特定的显卡
int device = 0;
// 记录日志,标记设备信息查询的开始
Logger.Instance.INFO("=== Device Information ===");
// 获取当前系统中可见的 NVIDIA GPU 数量
int nbDevices = CudaDevice.GetDeviceCount();
// 检查系统中是否存在可用的 GPU 设备
if (nbDevices <= 0)
{
Logger.Instance.ERROR("Cannot find any available devices (GPUs)!");
Environment.Exit(0);
}
// 打印所有可用设备的列表
Logger.Instance.INFO("Available Devices: ");
// 遍历系统中的每一个 GPU
for (int deviceIdx = 0; deviceIdx < nbDevices; ++deviceIdx)
{
// 获取索引为 deviceIdx 的 GPU 的详细属性
CudaDeviceProp tempProperties = CudaDevice.GetDeviceProperties(deviceIdx);
// 打印设备 ID、设备名称以及 UUID (唯一标识符)
Logger.Instance.INFO($" Device {deviceIdx}: \"{tempProperties.Name}\" UUID: {GetUuidString(tempProperties.Uuid)}");
// 如果当前遍历到的设备 ID 是我们想要使用的目标设备
// 则将该设备的属性保存下来,供后续使用
if (deviceIdx == device)
{
properties = tempProperties;
}
}
// 安全检查:确保请求的目标设备 ID 在有效范围内
if (device < 0 || device >= nbDevices)
{
Logger.Instance.ERROR($"Cannot find device ID {device}!");
Environment.Exit(0);
}
// 将 CUDA 上下文设置到指定的 GPU 设备上
CudaDevice.SetDevice(device);
// 打印选定设备的详细信息
Logger.Instance.INFO($"Selected Device: {properties.Name}");
Logger.Instance.INFO($"Selected Device ID: {device}");
Logger.Instance.INFO($"Selected Device UUID: {GetUuidString(properties.Uuid)}");
Logger.Instance.INFO($"Compute Capability: {properties.Major}.{properties.Minor}");
Logger.Instance.INFO($"SMs: {properties.MultiProcessorCount}");
Logger.Instance.INFO($"Device Global Memory: {(properties.TotalGlobalMem + 20)} MiB");
Logger.Instance.INFO($"Shared Memory per SM: {(properties.SharedMemPerMultiprocessor >> 10)} KiB");
Logger.Instance.INFO($"Memory Bus Width: {properties.MemoryBusWidth} bits (ECC {(properties.ECCEnabled != 0 ? "enabled" : "disabled")})");
// 获取并打印 GPU 核心时钟频率和显存时钟频率
int clockRate = CudaDevice.GetAttribute(CudaDeviceAttr.ClockRate, device);
int memoryClockRate = CudaDevice.GetAttribute(CudaDeviceAttr.MemoryClockRate, device);
Logger.Instance.INFO($"Application Compute Clock Rate: {clockRate / 1000000.0F} GHz");
Logger.Instance.INFO($"Application Memory Clock Rate: {memoryClockRate / 1000000.0F} GHz");
}
/// <summary>
/// 辅助方法:将 CudaUUID 结构体转换为格式化的 GPU UUID 字符串
/// 格式通常为:GPU-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
/// </summary>
public static string GetUuidString(CudaUUID uuid)
{
int kUUID_SIZE = uuid.Bytes.Length;
var ss = new System.Text.StringBuilder();
// 定义 UUID 的分段点,用于插入连字符 "-"
int[] splits = { 0, 4, 6, 8, 10, kUUID_SIZE };
// 添加固定的 "GPU" 前缀
ss.Append("GPU");
// 遍历分段定义,格式化每一部分的字节
for (int splitIdx = 0; splitIdx < splits.Length - 1; ++splitIdx)
{
ss.Append("-");
for (int byteIdx = splits[splitIdx]; byteIdx < splits[splitIdx + 1]; ++byteIdx)
{
ss.AppendFormat("{0:x2}", uuid.Bytes[byteIdx]);
}
}
return ss.ToString();
}
}
}
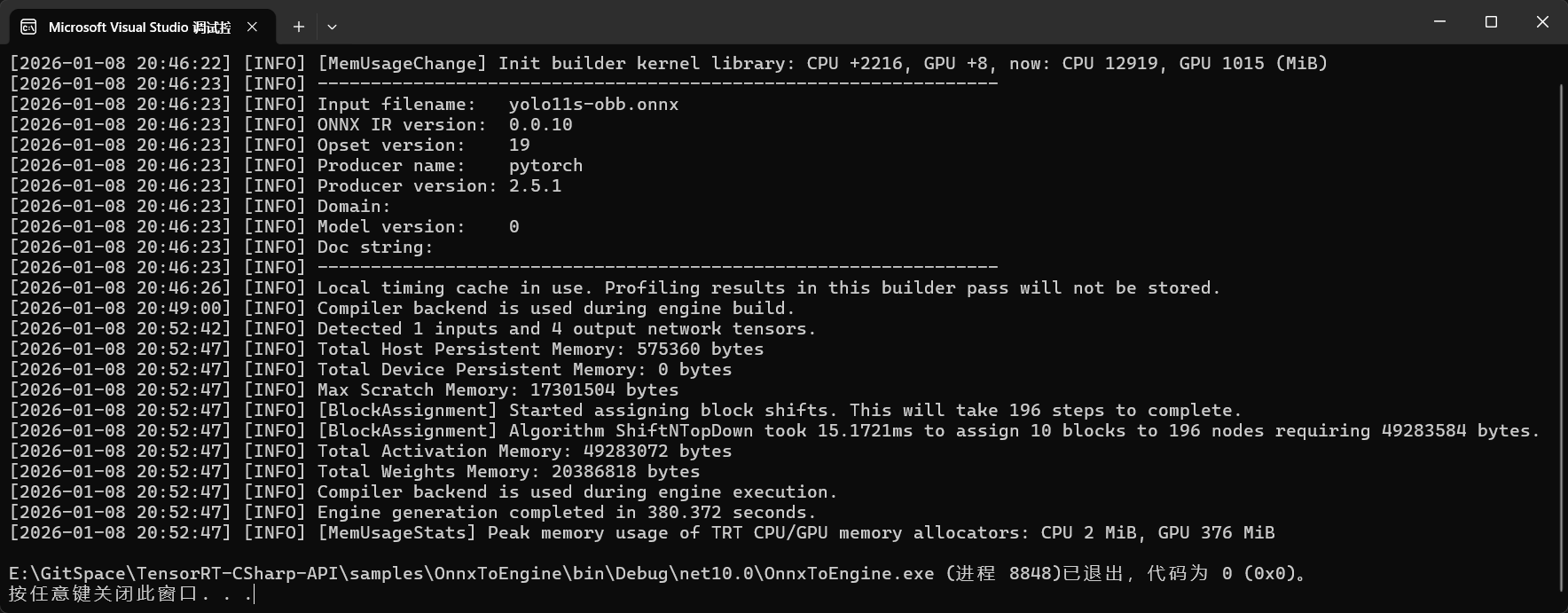
程序运行结果:
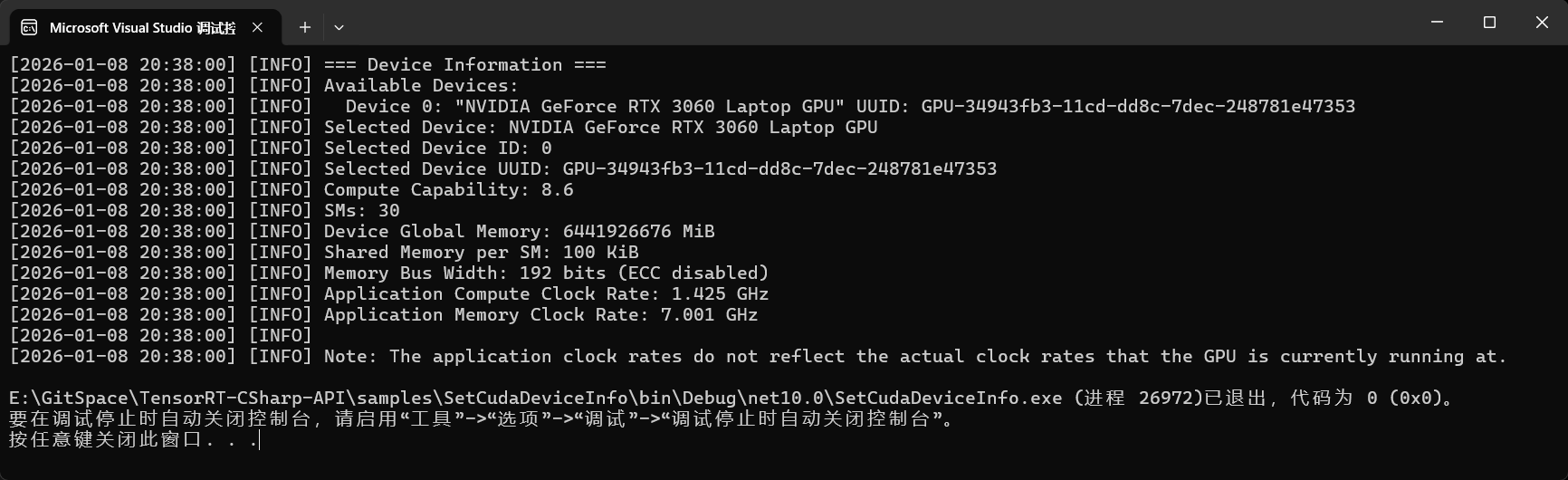
💡 注意:不同的设备输出会有不同,以具体设备输出为准。
🔗程序路径链接:完整程序已经上传到GitHub,请自行下载,链接为:
https://github.com/guojin-yan/TensorRT-CSharp-API/tree/TensorRtSharp3.0/samples/SetCudaDeviceInfo
示例 2:ONNX 转 Engine 模型
下面是按照官方模型转换代码编写的一个简单的转换代码:
using JYPPX.TensorRtSharp.Cuda;
using JYPPX.TensorRtSharp.Nvinfer;
namespace OnnxToEngine
{
internal class Program
{
static void Main(string[] args)
{
// === 配置 TensorRT 日志回调 ===
// 定义一个委托,用于处理 TensorRT 内部产生的日志消息
LogCallbackFunction _callbackDelegate = (message) =>
{
Console.WriteLine(message);
};
// 将自定义的回调函数注册给 TensorRT 的全局 Logger 实例
Logger.Instance.SetCallback(_callbackDelegate);
// 设置日志的严重性级别阈值
// LoggerSeverity.kINFO: 打印信息、警告和错误
Logger.Instance.SetThreshold(LoggerSeverity.kINFO);
// 1. 创建 TensorRT Builder (构建器)
Builder build = new Builder();
// 2. 创建网络定义 (Network Definition)
// 显式批处理 标志表示网络定义中显式包含批处理维度
NetworkDefinition networkDefinition = build.createNetworkV2(TrtNetworkDefinitionCreationFlag.kEXPLICIT_BATCH);
// 3. 创建构建器配置
BuilderConfig builderConfig = build.createBuilderConfig();
// 4. 创建 ONNX 解析器
OnnxParser onnxParser = new OnnxParser(networkDefinition);
// 指定待转换的 ONNX 模型文件路径
string modelpath = "yolo11s-obb.onnx";
// 5. 解析 ONNX 模型文件
// 参数 2: 日志级别 (1=ERROR, 2=WARNING, 3=INFO, 4=VERBOSE)
if (onnxParser.parseFromFile(modelpath, 2) == false)
{
Console.WriteLine($"parse onnx model failed");
return;
}
// 6. 设置构建精度标志
// kFP16: 启用半精度 (FP16) 推理模式
builderConfig.setFlag(TrtBuilderFlag.kFP16);
// 7. 创建 CUDA 流
CudaStream cudaStream = new CudaStream();
// 8. 设置优化配置文件的流
builderConfig.setProfileStream(cudaStream);
// 9. 构建并序列化网络
// 这是一个耗时较长的过程,因为 TensorRT 会进行内核自动调优、层融合等优化
HostMemory hostMemory = build.buildSerializedNetwork(networkDefinition, builderConfig);
// 10. 保存 Engine 到磁盘
string filePath = "yolo11s-obb.engine";
using (FileStream fs = new FileStream(filePath, FileMode.Create, FileAccess.Write))
{
fs.Write(hostMemory.getByteData(), 0, (int)hostMemory.Size);
}
Console.WriteLine("Engine saved successfully!");
}
}
}
程序运行结果:
🔗程序路径链接:完整程序已经上传到GitHub,请自行下载,链接为:
https://github.com/guojin-yan/TensorRT-CSharp-API/tree/TensorRtSharp3.0/samples/OnnxToEngine
💡 使用 trtexec 工具转换模型(推荐)
当前 ONNX 转 Engine 代码由于没有进行优化,转换速度会较慢。建议使用 TensorRT SDK 自带的 trtexec.exe 工具转换模型。
trtexec 使用方式
(1)使用 CMD 切换到工具目录
该工具存放在下载的 TensorRT 库中:
打开 CMD 并切换到该路径:

(2)固定形状模型转换指令
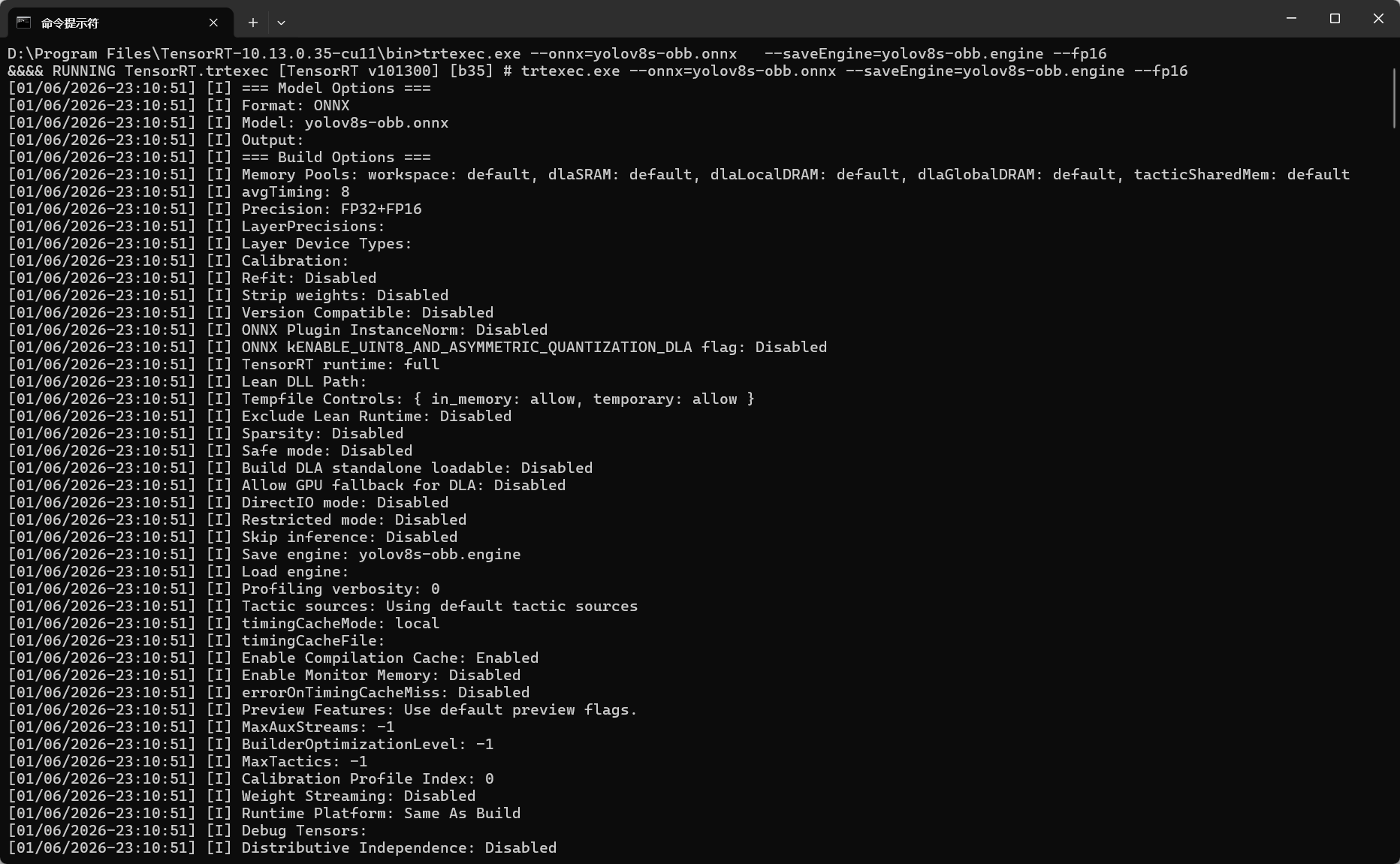
对于形状固定的模型,直接输入常规指令转换即可:
trtexec.exe --onnx=yolov8s-obb.onnx --saveEngine=yolov8s-obb.engine --fp16 --workspace=1024
参数说明:
--onnx=yolov8s-obb.onnx:指定输入的 ONNX 模型文件路径--saveEngine=yolov8s-obb.engine:指定输出的 Engine 文件保存路径--fp16:启用 FP16 精度(可选)--workspace=1024:指定最大工作空间,单位 MB(可选)
(3)动态形状模型转换指令
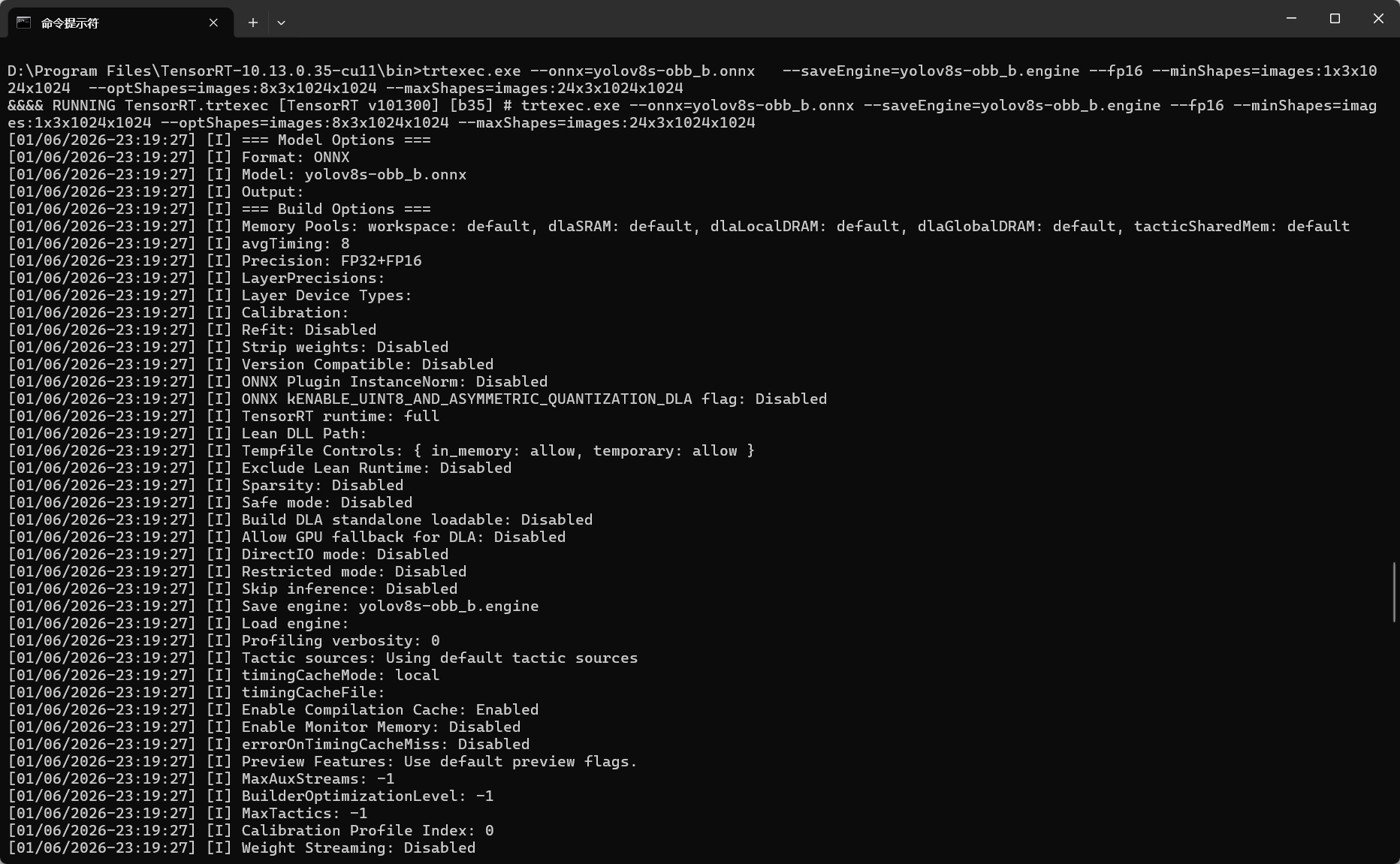
对于输入形状是动态的情况,转换时要设置形状参数:
trtexec.exe --onnx=yolov8s-obb_b.onnx --saveEngine=yolov8s-obb_b.engine --fp16 --minShapes=images:1x3x1024x1024 --optShapes=images:8x3x1024x1024 --maxShapes=images:24x3x1024x1024
参数说明:
--minShapes=images:1x3x1024x1024:最小输入形状--optShapes=images:8x3x1024x1024:最优输入形状(Engine 会为此形状优化)--maxShapes=images:24x3x1024x1024:最大输入形状
多输入模型转换指令:
trtexec --onnx=model.onnx --minShapes=input1:1x3x224x224,input2:1x256 --optShapes=input1:4x3x224x224,input2:4x256 --maxShapes=input1:8x3x224x224,input2:8x256
示例 3:YOLO 目标检测
下面是一个完整的 YOLO 目标检测示例,展示从模型构建到推理的全流程。
⚠️ 由于代码较长,此处仅展示核心思路。完整代码请参考项目示例。
using JYPPX.TensorRtSharp.Cuda;
using JYPPX.TensorRtSharp.Nvinfer;
using OpenCvSharp;
using OpenCvSharp.Dnn;
using System.Diagnostics;
using System.Runtime.InteropServices;
namespace YoloDetInfer
{
internal class Program
{
// ================= 配置参数 =================
// 模型输入尺寸 (宽=高)
private const int InputSize = 640;
// 建议根据实际模型动态获取或使用 Netron 查看
private const int OutputSize = 8400;
// 模型类别数 (根据您的具体数据集修改,此处假设为15类)
private const int CategoryNum = 80;
// 置信度阈值
private const float ConfThreshold = 0.25f;
// NMS IOU 阈值
private const float NmsThreshold = 0.3f;
static void Main(string[] args)
{
// ============= 配置 TensorRT 日志回调 =============
// 定义一个委托,用于处理 TensorRT 内部产生的日志消息。
// 这允许我们将 C++ 层面的日志输出到 C# 的控制台。
LogCallbackFunction _callbackDelegate = (message) =>
{
Console.WriteLine(message);
};
// 将自定义的回调函数注册给 TensorRT 的全局 Logger 实例。
Logger.Instance.SetCallback(_callbackDelegate);
// 设置日志的严重性级别阈值。
// LoggerSeverity.kINFO: 打印信息、警告和错误。
// 开发调试阶段通常设为 kINFO 或 kVERBOSE;生产环境可设为 kWARNING 或 kERROR 以减少输出。
Logger.Instance.SetThreshold(LoggerSeverity.kINFO);
string enginePath = "yolov8s.engine";
string imagePath = "bus.jpg";
// ================= 1. 加载 TensorRT Engine =================
// 使用 using 语句确保文件流正确关闭
byte[] engineData;
using (FileStream fs = new FileStream(enginePath, FileMode.Open, FileAccess.Read))
using (BinaryReader br = new BinaryReader(fs))
{
engineData = br.ReadBytes((int)fs.Length);
}
// 反序列化 Engine
// Runtime 必须在 Engine 生命周期内保持存活,通常建议设为全局或静态,或者确保它最后释放
Runtime runtime = new Runtime();
// 创建 CudaEngine (此处使用 using 确保推理完成后引擎被销毁)
using (CudaEngine cudaEngine = runtime.deserializeCudaEngineByBlob(engineData, (ulong)engineData.Length))
{
// ================= 2. 初始化推理上下文与显存 =================
// 创建执行上下文
using (JYPPX.TensorRtSharp.Nvinfer.ExecutionContext executionContext = cudaEngine.createExecutionContext(TrtExecutionContextAllocationStrategy.kSTATIC))
using (CudaStream cudaStream = new CudaStream()) // 创建 CUDA 流用于异步执行
{
// 获取输入维度信息 (用于校验)
Dims inputDims = executionContext.getTensorShape("images");
Logger.Instance.INFO($"Input Shape: {inputDims.d[0]}x{inputDims.d[1]}x{inputDims.d[2]}x{inputDims.d[3]}");
// 计算所需显存大小
// 输入: Batch=1, Channel=3, Height=640, Width=640
ulong inputSizeInBytes = 1 * 3 * InputSize * InputSize;
// 输出: Batch=1, Channels=CategoryNum+4(box)+1(angle), Num=8400
int outputChannels = CategoryNum + 4; // 4坐标 + N类别
ulong outputSizeInBytes = (ulong)(1 * outputChannels * OutputSize);
Stopwatch sw = new Stopwatch();
// 分配 GPU 显存
using (Cuda1DMemory<float> inputGpuMemory = new Cuda1DMemory<float>(inputSizeInBytes))
using (Cuda1DMemory<float> outputGpuMemory = new Cuda1DMemory<float>(outputSizeInBytes))
{
// 绑定显存地址到 TensorRT 上下文
executionContext.setInputTensorAddress("images", inputGpuMemory.get());
executionContext.setOutputTensorAddress("output0", outputGpuMemory.get());
// 预热推理 (可选,但推荐,尤其是首次推理时)
executionContext.executeV3(cudaStream);
cudaStream.Synchronize();
// ================= 3. 图像预处理 =================
Mat img = Cv2.ImRead(imagePath);
if (img.Empty())
{
Logger.Instance.INFO("Image not found!");
return;
}
sw.Start();
float[] inputData = PreProcess(img, out float scale, out int xOffset, out int yOffset);
sw.Stop();
Logger.Instance.INFO($"Pre-processing time: {sw.ElapsedMilliseconds} ms");
// ================= 4. 推理 =================
// 准备主机内存接收结果
float[] outputData = new float[outputChannels * OutputSize];
sw.Restart();
// 将数据从主机 拷贝到设备
inputGpuMemory.copyFromHostAsync(inputData, cudaStream);
// 执行推理 (enqueueV3 是异步的)
executionContext.executeV3(cudaStream);
// 等待推理完成
cudaStream.Synchronize();
// 将结果从设备 拷贝回主机
// 这里的拷贝是同步的,会等待 GPU 计算完成
outputGpuMemory.copyToHostAsync(outputData, cudaStream);
sw.Stop();
Logger.Instance.INFO($"Inference time: {sw.ElapsedMilliseconds} ms");
// ================= 5. 后处理 =================
sw.Restart();
List<DetData> results = PostProcess(outputData, scale, xOffset, yOffset);
sw.Stop();
Logger.Instance.INFO($"Post-processing time: {sw.ElapsedMilliseconds} ms");
// ================= 6. 结果可视化 =================
Mat resultImg = DrawDetResult(results, img);
Cv2.ImShow("YOLO11-DET Result", resultImg);
Cv2.WaitKey(0);
}
}
}
}
/// <summary>
/// 图像预处理:Letterbox 缩放、归一化、HWC 转 CHW
/// </summary>
private static float[] PreProcess(Mat img, out float scale, out int xOffset, out int yOffset)
{
// 转换颜色空间 BGR -> RGB
Mat rgbImg = new Mat();
Cv2.CvtColor(img, rgbImg, ColorConversionCodes.BGR2RGB);
// 计算 Letterbox 缩放比例
int maxDim = Math.Max(rgbImg.Width, rgbImg.Height);
scale = (float)maxDim / InputSize;
// 计算缩放后的尺寸
int newWidth = (int)(rgbImg.Width / scale);
int newHeight = (int)(rgbImg.Height / scale);
// Resize 图像
Mat resizedImg = new Mat();
Cv2.Resize(rgbImg, resizedImg, new Size(newWidth, newHeight));
// 创建黑色背景 Canvas (InputSize x InputSize)
Mat paddedImg = Mat.Zeros(InputSize, InputSize, MatType.CV_8UC3);
// 计算粘贴位置 (居中)
xOffset = (InputSize - newWidth) / 2;
yOffset = (InputSize - newHeight) / 2;
// 将图像拷贝到 Canvas 中央
Rect roi = new Rect(xOffset, yOffset, newWidth, newHeight);
resizedImg.CopyTo(new Mat(paddedImg, roi));
// 归一化 (0-255 -> 0-1) 并转为 float 类型
Mat floatImg = new Mat();
paddedImg.ConvertTo(floatImg, MatType.CV_32FC3, 1.0 / 255.0);
// HWC 转 CHW 并展平为一维数组
Mat[] channels = Cv2.Split(floatImg);
float[] chwData = new float[3 * InputSize * InputSize];
// 拷贝数据:R通道 -> C通道 -> B通道 (OpenCV Split 出来顺序是 B, G, R,对应索引 0, 1, 2)
int channelSize = InputSize * InputSize;
// 将 R, G, B 依次拷入数组
Marshal.Copy(channels[0].Data, chwData, 0, channelSize); // R
Marshal.Copy(channels[1].Data, chwData, channelSize, channelSize); // G
Marshal.Copy(channels[2].Data, chwData, channelSize * 2, channelSize); // B
// 释放临时 Mat
rgbImg.Dispose();
resizedImg.Dispose();
paddedImg.Dispose();
floatImg.Dispose();
foreach (var c in channels) c.Dispose();
return chwData;
}
/// <summary>
/// 后处理:解析 TensorRT 输出、NMS 过滤
/// </summary>
private static List<DetData> PostProcess(float[] result, float scale, int xOffset, int yOffset)
{
List<Rect> boxes = new List<Rect>();
List<float> confidences = new List<float>();
List<int> classIds = new List<int>();
// 遍历所有预测框 (OutputSize)
// 数据布局: [4(box) + 80(classes)] * OutputSize
// 展平数组中,同一属性的数据是连续存储的,例如所有 cx 在一起,所有 cy 在在一起...
int stride = OutputSize; // 步长,不同属性在数组中的偏移量
for (int i = 0; i < OutputSize; i++)
{
// 查找最大类别概率及其索引
float maxConf = 0;
int maxClassId = -1;
// 遍历类别
for (int c = 0; c < CategoryNum; c++)
{
// 数组索引:(坐标/角度偏移量 + 类别偏移) * 框索引
// 注意:原始代码中 result[outputSize * j + i] 这种访问方式基于 Transposed 数据布局
float conf = result[(4 + c) * stride + i];
if (conf > maxConf)
{
maxConf = conf;
maxClassId = c;
}
}
// 置信度过滤
if (maxConf > ConfThreshold)
{
// 提取坐标 (cx, cy, w, h)
float cx = result[0 * stride + i];
float cy = result[1 * stride + i];
float w = result[2 * stride + i];
float h = result[3 * stride + i];
// 还原坐标到原图尺寸
int rx = (int)((cx - xOffset - 0.5 * w) * scale);
int ry = (int)((cy - yOffset - 0.5 * h) * scale);
int rw = (int)(w * scale);
int rh = (int)(h * scale);
boxes.Add(new Rect(rx, ry, rw, rh));
confidences.Add(maxConf);
classIds.Add(maxClassId);
}
}
// 执行 NMS (旋转框 NMS)
// OpenCV 的 NMSBoxes 支持 RotatedRect
int[] indices;
CvDnn.NMSBoxes(boxes, confidences, ConfThreshold, NmsThreshold, out indices);
List<DetData> finalResults = new List<DetData>();
foreach (int idx in indices)
{
finalResults.Add(new DetData
{
index = classIds[idx],
score = confidences[idx],
box = boxes[idx]
});
}
return finalResults;
}
/// <summary>
/// 绘制检测结果(水平矩形框)
/// </summary>
/// <param name="results">检测结果列表</param>
/// <param name="image">原始图像</param>
/// <returns>绘制后的图像</returns>
public static Mat DrawDetResult(List<DetData> results, Mat image)
{
// 克隆图像以免修改原图
Mat mat = image.Clone();
foreach (var item in results)
{
// 1. 绘制矩形框
// Rect 结构包含 X, Y, Width, Height
Cv2.Rectangle(mat, item.box, new Scalar(0, 255, 0), thickness: 2);
// 2. 准备标签文本 (类别ID - 置信度)
string label = $"{item.index} - {item.score:F2}";
// 3. 计算文本的尺寸,用于绘制背景
int baseLine = 1;
Size textSize = Cv2.GetTextSize(label, HersheyFonts.HersheySimplex, 0.6, 1, out baseLine);
// 4. 绘制标签背景(半透明黑色矩形),防止文字与背景混淆
// 位置:矩形左上角略微上移,或者直接贴着左上角
Point labelPosition = new Point(item.box.X, item.box.Y - (int)textSize.Height - 5);
// 确保标签不画出图像边界
if (labelPosition.Y < 0) labelPosition.Y = item.box.Y + (int)textSize.Height + 5;
Rect labelBgRect = new Rect(labelPosition.X,
labelPosition.Y - (int)textSize.Height, // OpenCV GetTextSize 返回的高度是基线到底部的距离,需调整
(int)textSize.Width,
(int)textSize.Height + (int)baseLine);
// 如果背景框也在图像范围内,则绘制
// 注意:这里简化处理,直接画在框上方
Cv2.Rectangle(mat,
new Point(item.box.X, item.box.Y - textSize.Height - 5),
new Point(item.box.X + textSize.Width, item.box.Y),
new Scalar(0, 255, 0),
thickness: -1); // -1 表示填充
// 5. 绘制文本(白色文字)
Cv2.PutText(mat,
label,
new Point(item.box.X, item.box.Y - 5),
HersheyFonts.HersheySimplex,
0.6,
new Scalar(0, 0, 0),
1);
}
return mat;
}
public class DetData
{
public int index;
public float score;
public Rect box;
}
}
}
程序运行结果:
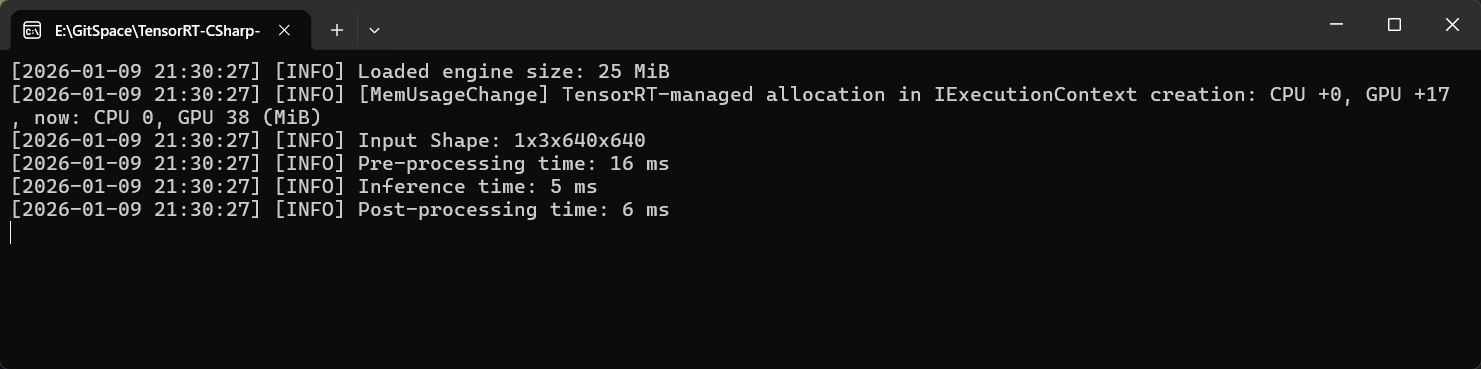

性能测试结果:
| Batch Size | 1 | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 | 22 | 24 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 前处理 (ms) | 9 | 13 | 27 | 38 | 56 | 59 | 63 | 83 | 96 | 105 | 118 | 130 | 144 |
| 模型推理 (ms) | 7 | 15 | 24 | 36 | 48 | 60 | 96 | 84 | 93 | 153 | 120 | 133 | 203 |
| 后处理 (ms) | 25 | 26 | 26 | 26 | 28 | 27 | 27 | 28 | 28 | 28 | 27 | 31 | 29 |
🔗程序路径链接:完整程序已经上传到GitHub,请自行下载,链接为:
https://github.com/guojin-yan/TensorRT-CSharp-API/tree/TensorRtSharp3.0/samples/YoloDetInfer同时也提供了YoloOBB模型的推理程序,请自行下载,链接为:
https://github.com/guojin-yan/TensorRT-CSharp-API/tree/TensorRtSharp3.0/samples/YoloObbInfer
示例 4:动态形状推理
对于输入尺寸可变的模型,需要根据输入的数据配置动态形状。
核心代码:
using JYPPX.TensorRtSharp.Cuda;
using JYPPX.TensorRtSharp.Nvinfer;
using OpenCvSharp;
using OpenCvSharp.Dnn;
using System.Diagnostics;
using System.Runtime.InteropServices;
namespace YoloObbBatchInfer
{
internal class Program
{
// ================= 配置参数 =================
// 模型输入尺寸 (宽=高)
private const int InputSize = 1024;
// 建议根据实际模型动态获取或使用 Netron 查看
private const int OutputSize = 21504;
// 模型类别数 (根据您的具体数据集修改,此处假设为15类)
private const int CategoryNum = 15;
// 置信度阈值
private const float ConfThreshold = 0.25f;
// NMS IOU 阈值
private const float NmsThreshold = 0.3f;
private const int MaxBatchSize = 24;
static void Main(string[] args)
{
// ============= 配置 TensorRT 日志回调 =============
// 定义一个委托,用于处理 TensorRT 内部产生的日志消息。
// 这允许我们将 C++ 层面的日志输出到 C# 的控制台。
LogCallbackFunction _callbackDelegate = (message) =>
{
Console.WriteLine(message);
};
// 将自定义的回调函数注册给 TensorRT 的全局 Logger 实例。
Logger.Instance.SetCallback(_callbackDelegate);
// 设置日志的严重性级别阈值。
// LoggerSeverity.kINFO: 打印信息、警告和错误。
// 开发调试阶段通常设为 kINFO 或 kVERBOSE;生产环境可设为 kWARNING 或 kERROR 以减少输出。
Logger.Instance.SetThreshold(LoggerSeverity.kINFO);
string enginePath = "yolov8s-obb_b.engine";
string[] imagePaths = {
"P0006.png" , "P0016.png", "P0456.png", "P0813.png"};
// ================= 1. 加载 TensorRT Engine =================
// 使用 using 语句确保文件流正确关闭
byte[] engineData;
using (FileStream fs = new FileStream(enginePath, FileMode.Open, FileAccess.Read))
using (BinaryReader br = new BinaryReader(fs))
{
engineData = br.ReadBytes((int)fs.Length);
}
// 反序列化 Engine
// Runtime 必须在 Engine 生命周期内保持存活,通常建议设为全局或静态,或者确保它最后释放
Runtime runtime = new Runtime();
runtime.setMaxThreads(10);
// 创建 CudaEngine (此处使用 using 确保推理完成后引擎被销毁)
using (CudaEngine cudaEngine = runtime.deserializeCudaEngineByBlob(engineData, (ulong)engineData.Length))
{
// ================= 2. 初始化推理上下文与显存 =================
// 创建执行上下文
using (JYPPX.TensorRtSharp.Nvinfer.ExecutionContext executionContext = cudaEngine.createExecutionContext(TrtExecutionContextAllocationStrategy.kSTATIC))
using (CudaStream cudaStream = new CudaStream()) // 创建 CUDA 流用于异步执行
{
// 获取输入维度信息 (用于校验)
Dims inputDims = executionContext.getTensorShape("images");
Logger.Instance.INFO($"Input Shape: {inputDims.d[0]}x{inputDims.d[1]}x{inputDims.d[2]}x{inputDims.d[3]}");
// 计算所需显存大小
// 输入: Batch=1, Channel=3, Height=1024, Width=1024
ulong inputSizeInBytes = MaxBatchSize * 3 * InputSize * InputSize;
// 输出: Batch=1, Channels=CategoryNum+4(box)+1(angle), Num=8400
int outputChannels = CategoryNum + 5; // 4坐标 + 1角度 + N类别
ulong outputSizeInBytes = (ulong)(MaxBatchSize * outputChannels * OutputSize);
Stopwatch sw = new Stopwatch();
// 分配 GPU 显存
using (Cuda1DMemory<float> inputGpuMemory = new Cuda1DMemory<float>(inputSizeInBytes))
using (Cuda1DMemory<float> outputGpuMemory = new Cuda1DMemory<float>(outputSizeInBytes))
{
// 绑定显存地址到 TensorRT 上下文
executionContext.setInputTensorAddress("images", inputGpuMemory.get());
executionContext.setOutputTensorAddress("output0", outputGpuMemory.get());
// 关键一步,修改本次推理的形状
executionContext.setinputShape("images", new Dims(imagePaths.Count(), 3, 1024, 1024));
// 预热推理 (可选,但推荐,尤其是首次推理时)
executionContext.executeV3(cudaStream);
cudaStream.Synchronize();
// ================= 3. 图像预处理 =================
List<Mat> images = new List<Mat>();
foreach (var path in imagePaths)
{
Mat img = Cv2.ImRead(path);
if (img.Empty())
{
Logger.Instance.INFO("Image not found!");
return;
}
images.Add(img);
}
(float[] inputData1, float[] scales1, int[] xOffsets1, int[] yOffsets1) = PreProcessBatch(images);
sw.Start();
(float[] inputData, float[] scales, int[] xOffsets, int[] yOffsets) = PreProcessBatch(images);
sw.Stop();
Logger.Instance.INFO($"Pre-processing time: {sw.ElapsedMilliseconds} ms");
// ================= 4. 推理 =================
// 准备主机内存接收结果
float[] outputData1 = new float[imagePaths.Count() * outputChannels * OutputSize];
// 将数据从主机 拷贝到设备
inputGpuMemory.copyFromHostAsync(inputData, cudaStream);
// 执行推理 (enqueueV3 是异步的)
executionContext.executeV3(cudaStream);
// 等待推理完成
cudaStream.Synchronize();
// 将结果从设备 拷贝回主机
// 这里的拷贝是同步的,会等待 GPU 计算完成
outputGpuMemory.copyToHostAsync(outputData1, cudaStream);
sw.Restart();
// 准备主机内存接收结果
float[] outputData = new float[imagePaths.Count() * outputChannels * OutputSize];
// 将数据从主机 拷贝到设备
inputGpuMemory.copyFromHostAsync(inputData, cudaStream);
// 执行推理 (enqueueV3 是异步的)
executionContext.executeV3(cudaStream);
// 等待推理完成
cudaStream.Synchronize();
// 将结果从设备 拷贝回主机
// 这里的拷贝是同步的,会等待 GPU 计算完成
outputGpuMemory.copyToHostAsync(outputData, cudaStream);
sw.Stop();
Logger.Instance.INFO($"Inference time: {sw.ElapsedMilliseconds} ms");
// ================= 5. 后处理 =================
List<List<ObbData>> results1 = PostProcessBatch(outputData, scales, xOffsets, yOffsets);
sw.Restart();
List<List<ObbData>> results = PostProcessBatch(outputData, scales, xOffsets, yOffsets);
sw.Stop();
Logger.Instance.INFO($"Post-processing time: {sw.ElapsedMilliseconds} ms");
// ================= 6. 结果可视化 =================
List<Mat> resultMats = new List<Mat>();
for(int i = 0; i < results.Count; ++i)
{
resultMats.Add(DrawObbResult(results[i], images[i]));
}
Mat putResultImgs = StitchHorizontalWithPadding(resultMats);
Cv2.ImWrite("YOLO11-OBB Result.png", putResultImgs);
Cv2.ImShow("YOLO11-OBB Result", putResultImgs);
Cv2.WaitKey(0);
}
}
}
}
/// <summary>
/// 图像预处理:Letterbox 缩放、归一化、HWC 转 CHW
/// </summary>
private static (float[], float[] , int[] , int[] ) PreProcessBatch(List<Mat> imgs)
{
int dataLen = 3 * InputSize * InputSize;
float[] chwData = new float[imgs.Count * dataLen];
float[] scales = new float[imgs.Count];
int[] xOffsets = new int[imgs.Count];
int[] yOffsets = new int[imgs.Count];
Parallel.For(0, imgs.Count, i =>
{
Mat img = imgs[i];
// 转换颜色空间 BGR -> RGB
Mat rgbImg = new Mat();
Cv2.CvtColor(img, rgbImg, ColorConversionCodes.BGR2RGB);
// 计算 Letterbox 缩放比例
int maxDim = Math.Max(rgbImg.Width, rgbImg.Height);
scales[i] = (float)maxDim / InputSize;
// 计算缩放后的尺寸
int newWidth = (int)(rgbImg.Width / scales[i]);
int newHeight = (int)(rgbImg.Height / scales[i]);
// Resize 图像
Mat resizedImg = new Mat();
Cv2.Resize(rgbImg, resizedImg, new Size(newWidth, newHeight));
// 创建黑色背景 Canvas (InputSize x InputSize)
Mat paddedImg = Mat.Zeros(InputSize, InputSize, MatType.CV_8UC3);
// 计算粘贴位置 (居中)
xOffsets[i] = (InputSize - newWidth) / 2;
yOffsets[i] = (InputSize - newHeight) / 2;
// 将图像拷贝到 Canvas 中央
Rect roi = new Rect(xOffsets[i], yOffsets[i], newWidth, newHeight);
resizedImg.CopyTo(new Mat(paddedImg, roi));
// 归一化 (0-255 -> 0-1) 并转为 float 类型
Mat floatImg = new Mat();
paddedImg.ConvertTo(floatImg, MatType.CV_32FC3, 1.0 / 255.0);
// HWC 转 CHW 并展平为一维数组
Mat[] channels = Cv2.Split(floatImg);
// 拷贝数据:R通道 -> C通道 -> B通道 (OpenCV Split 出来顺序是 B, G, R,对应索引 0, 1, 2)
int channelSize = InputSize * InputSize;
// 将 R, G, B 依次拷入数组
Marshal.Copy(channels[0].Data, chwData, dataLen * i, channelSize); // R
Marshal.Copy(channels[1].Data, chwData, dataLen * i + channelSize, channelSize); // G
Marshal.Copy(channels[2].Data, chwData, dataLen * i + channelSize * 2, channelSize); // B
// 释放临时 Mat
rgbImg.Dispose();
resizedImg.Dispose();
paddedImg.Dispose();
floatImg.Dispose();
foreach (var c in channels) c.Dispose();
});
return (chwData, scales, xOffsets, yOffsets);
}
/// <summary>
/// 后处理:解析 TensorRT 输出、NMS 过滤
/// </summary>
private static List<List<ObbData>> PostProcessBatch(float[] result, float[] scales, int[] xOffsets, int[] yOffsets)
{
List<ObbData>[] obbDatas = new List<ObbData>[scales.Length];
Parallel.For(0, scales.Length, b =>
{
List<RotatedRect> boxes = new List<RotatedRect>();
List<float> confidences = new List<float>();
List<int> classIds = new List<int>();
// 遍历所有预测框 (OutputSize)
// 数据布局: [4(box) + 15(classes) + 1(angle)] * OutputSize
// 展平数组中,同一属性的数据是连续存储的,例如所有 cx 在一起,所有 cy 在在一起...
int stride = OutputSize; // 步长,不同属性在数组中的偏移量
int resultDataOffset = OutputSize * (CategoryNum + 5) * b;
for (int i = 0; i < OutputSize; i++)
{
// 查找最大类别概率及其索引
float maxConf = 0;
int maxClassId = -1;
// 遍历类别
for (int c = 0; c < CategoryNum; c++)
{
// 数组索引:(坐标/角度偏移量 + 类别偏移) * 框索引
// 注意:原始代码中 result[outputSize * j + i] 这种访问方式基于 Transposed 数据布局
float conf = result[(4 + c) * stride + i + resultDataOffset];
if (conf > maxConf)
{
maxConf = conf;
maxClassId = c;
}
}
// 置信度过滤
if (maxConf > ConfThreshold)
{
// 提取坐标 (cx, cy, w, h)
float cx = result[0 * stride + i + resultDataOffset];
float cy = result[1 * stride + i + resultDataOffset];
float w = result[2 * stride + i + resultDataOffset];
float h = result[3 * stride + i + resultDataOffset];
// 提取角度 (通常在第 5 个位置,即类别之前)
float angleRad = result[(CategoryNum + 4) * stride + i + resultDataOffset];
// 还原坐标到原图尺寸
float rx = (cx - xOffsets[b]) * scales[b];
float ry = (cy - yOffsets[b]) * scales[b];
float rw = w * scales[b];
float rh = h * scales[b];
// 将弧度转换为角度
// Normalize angle to [-π/2, π/2] range
// 将角度归一化到[-π/2, π/2]范围
if (angleRad >= Math.PI && angleRad <= 0.75 * Math.PI)
{
angleRad -= (float)Math.PI;
}
float angleDeg = angleRad * (float)(180f / Math.PI); // Convert to degrees/转换为角度制
boxes.Add(new RotatedRect(new Point2f(rx, ry), new Size2f(rw, rh), angleDeg));
confidences.Add(maxConf);
classIds.Add(maxClassId);
}
}
// 执行 NMS (旋转框 NMS)
// OpenCV 的 NMSBoxes 支持 RotatedRect
int[] indices;
CvDnn.NMSBoxes(boxes, confidences, ConfThreshold, NmsThreshold, out indices);
List<ObbData> finalResults = new List<ObbData>();
foreach (int idx in indices)
{
finalResults.Add(new ObbData
{
index = classIds[idx],
score = confidences[idx],
box = boxes[idx]
});
}
obbDatas[b] = finalResults;
});
return obbDatas.Select(x => x?.ToList() ?? new List<ObbData>()).ToList();
}
/// <summary>
/// 绘制旋转检测结果
/// </summary>
public static Mat DrawObbResult(List<ObbData> results, Mat image)
{
// 克隆图像以免修改原图
Mat mat = image.Clone();
foreach (var item in results)
{
// 获取旋转矩形的四个顶点
Point2f[] points = item.box.Points();
// 绘制多边形框
for (int j = 0; j < 4; j++)
{
Cv2.Line(mat, (Point)points[j], (Point)points[(j + 1) % 4],
new Scalar(0, 255, 0), 2);
}
// 绘制标签 (类别 - 置信度)
string label = $"{item.index} - {item.score:F2}";
Point2f textPos = points[0]; // 左上角
Cv2.PutText(mat, label, (Point)textPos, HersheyFonts.HersheySimplex, 0.8,
new Scalar(255, 0, 0), 2);
}
return mat;
}
public class ObbData
{
public int index;
public float score;
public RotatedRect box;
}
/// <summary>
/// 智能水平拼接:自动处理高度不一致的图片
/// </summary>
/// <param name="images">图片列表</param>
/// <param name="backgroundColor">填充背景颜色,默认为黑色</param>
/// <returns>拼接后的 Mat</returns>
public static Mat StitchHorizontalWithPadding(List<Mat> images, Scalar? backgroundColor = null)
{
if (images == null || images.Count == 0)
return new Mat();
// 1. 找到所有图片中的最大高度
int maxHeight = images.Max(img => img.Rows);
// 计算总宽度
int totalWidth = images.Sum(img => img.Cols);
// 2. 准备结果画布
Mat result = new Mat(maxHeight, totalWidth, images[0].Type(), backgroundColor ?? Scalar.Black);
// 3. 将每一张图片复制到画布的对应位置
int currentX = 0; // 当前 X 轴偏移量
foreach (var img in images)
{
if (img.Empty()) continue;
// 计算当前图片需要垂直偏移多少(底部对齐逻辑)
// 如果想顶部对齐,yOffset = 0
// 如果想居中,yOffset = (maxHeight - img.Rows) / 2
int yOffset = maxHeight - img.Rows;
// 定义 ROI (感兴趣区域)
Rect roi = new Rect(currentX, yOffset, img.Cols, img.Rows);
// 将原图片拷贝到结果图的 ROI 区域
img.CopyTo(new Mat(result, roi));
// 移动 X 轴指针
currentX += img.Cols;
}
return result;
}
}
}
下图为上述程序运行后的输出,模型输入形状为 -1x3x1024x1024,其中Batch Size为动态输入;项目示例使用了四张图片进行同时推理,开启并行处理后,四张图像预处理时间仅用21ms,推理时间为25ms,后处理时间为26ms,累计时间为72ms.
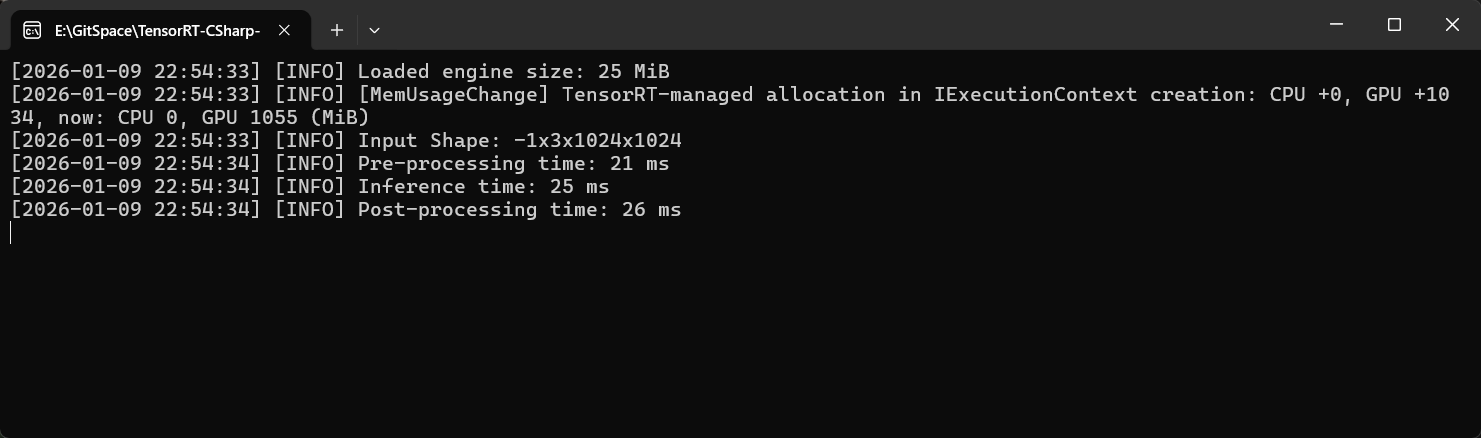
下图为推理结果展示:

性能测试(不同 Batch Size):
为了探究不同Batch Size推理时间差异,此处对不同Batch Size进行了测试,测试结果如下:
| Batch Size | 1 | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 | 22 | 24 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 前处理 (ms ) | 9 | 13 | 27 | 38 | 56 | 59 | 63 | 83 | 96 | 105 | 118 | 130 | 144 |
| 模型推理 (ms) | 7 | 15 | 24 | 36 | 48 | 60 | 96 | 84 | 93 | 153 | 120 | 133 | 203 |
| 后处理 (ms) | 25 | 26 | 26 | 26 | 28 | 27 | 27 | 28 | 28 | 28 | 27 | 31 | 29 |
🔗程序路径链接:完整程序已经上传到GitHub,请自行下载,链接为:
https://github.com/guojin-yan/TensorRT-CSharp-API/tree/TensorRtSharp3.0/samples/YoloObbBatchInfer
示例 5:并行推理
使用一个 Runtime 创建多执行上下文,实现多并行推理。
核心代码:
using JYPPX.TensorRtSharp.Cuda;
using JYPPX.TensorRtSharp.Nvinfer;
using OpenCvSharp;
using OpenCvSharp.Dnn;
using System.Diagnostics;
using System.Runtime.InteropServices;
using static OpenCvSharp.FileStorage;
namespace YoloDetParallelInfer
{
internal class Program
{
// ================= 配置参数 =================
// 模型输入尺寸 (宽=高)
private const int InputSize = 640;
// 建议根据实际模型动态获取或使用 Netron 查看
private const int OutputSize = 8400;
// 模型类别数 (根据您的具体数据集修改,此处假设为15类)
private const int CategoryNum = 80;
// 置信度阈值
private const float ConfThreshold = 0.25f;
// NMS IOU 阈值
private const float NmsThreshold = 0.3f;
static void Main(string[] args)
{
// ============= 配置 TensorRT 日志回调 =============
// 定义一个委托,用于处理 TensorRT 内部产生的日志消息。
// 这允许我们将 C++ 层面的日志输出到 C# 的控制台。
LogCallbackFunction _callbackDelegate = (message) =>
{
Console.WriteLine(message);
};
// 将自定义的回调函数注册给 TensorRT 的全局 Logger 实例。
Logger.Instance.SetCallback(_callbackDelegate);
// 设置日志的严重性级别阈值。
// LoggerSeverity.kINFO: 打印信息、警告和错误。
// 开发调试阶段通常设为 kINFO 或 kVERBOSE;生产环境可设为 kWARNING 或 kERROR 以减少输出。
Logger.Instance.SetThreshold(LoggerSeverity.kINFO);
string enginePath = "yolov8s.engine";
string imagePath = "bus.jpg";
Mat img = Cv2.ImRead(imagePath);
if (img.Empty())
{
Logger.Instance.INFO("Image not found!");
return;
}
// ================= 1. 加载 TensorRT Engine =================
// 使用 using 语句确保文件流正确关闭
byte[] engineData;
using (FileStream fs = new FileStream(enginePath, FileMode.Open, FileAccess.Read))
using (BinaryReader br = new BinaryReader(fs))
{
engineData = br.ReadBytes((int)fs.Length);
}
// 反序列化 Engine
// Runtime 必须在 Engine 生命周期内保持存活,通常建议设为全局或静态,或者确保它最后释放
Runtime runtime = new Runtime();
runtime.setMaxThreads(6);
// 创建 CudaEngine (此处使用 using 确保推理完成后引擎被销毁)
using (CudaEngine cudaEngine = runtime.deserializeCudaEngineByBlob(engineData, (ulong)engineData.Length))
{
// ================= 2. 初始化推理上下文与显存 =================
Stopwatch totalSw = new Stopwatch();
totalSw.Start();
Parallel.For(0, 24, b =>
{
// 创建执行上下文
using (JYPPX.TensorRtSharp.Nvinfer.ExecutionContext executionContext = cudaEngine.createExecutionContext(TrtExecutionContextAllocationStrategy.kSTATIC))
using (CudaStream cudaStream = new CudaStream()) // 创建 CUDA 流用于异步执行
{
// 获取输入维度信息 (用于校验)
Dims inputDims = executionContext.getTensorShape("images");
Logger.Instance.INFO($"Input Shape: {inputDims.d[0]}x{inputDims.d[1]}x{inputDims.d[2]}x{inputDims.d[3]}");
// 计算所需显存大小
// 输入: Batch=1, Channel=3, Height=640, Width=640
ulong inputSizeInBytes = 1 * 3 * InputSize * InputSize;
// 输出: Batch=1, Channels=CategoryNum+4(box)+1(angle), Num=8400
int outputChannels = CategoryNum + 4; // 4坐标 + N类别
ulong outputSizeInBytes = (ulong)(1 * outputChannels * OutputSize);
Stopwatch sw = new Stopwatch();
// 分配 GPU 显存
using (Cuda1DMemory<float> inputGpuMemory = new Cuda1DMemory<float>(inputSizeInBytes))
using (Cuda1DMemory<float> outputGpuMemory = new Cuda1DMemory<float>(outputSizeInBytes))
{
// 绑定显存地址到 TensorRT 上下文
executionContext.setInputTensorAddress("images", inputGpuMemory.get());
executionContext.setOutputTensorAddress("output0", outputGpuMemory.get());
// 预热推理 (可选,但推荐,尤其是首次推理时)
executionContext.executeV3(cudaStream);
cudaStream.Synchronize();
// ================= 3. 图像预处理 =================
sw.Start();
float[] inputData = PreProcess(img, out float scale, out int xOffset, out int yOffset);
sw.Stop();
Logger.Instance.INFO($"Channel {b}: Pre-processing time: {sw.ElapsedMilliseconds} ms");
// ================= 4. 推理 =================
// 准备主机内存接收结果
float[] outputData = new float[outputChannels * OutputSize];
sw.Restart();
// 将数据从主机 拷贝到设备
inputGpuMemory.copyFromHostAsync(inputData, cudaStream);
// 执行推理 (enqueueV3 是异步的)
executionContext.executeV3(cudaStream);
// 等待推理完成
cudaStream.Synchronize();
// 将结果从设备 拷贝回主机
// 这里的拷贝是同步的,会等待 GPU 计算完成
outputGpuMemory.copyToHostAsync(outputData, cudaStream);
sw.Stop();
Logger.Instance.INFO($"Channel {b}: Inference time: {sw.ElapsedMilliseconds} ms");
// ================= 5. 后处理 =================
sw.Restart();
List<DetData> results = PostProcess(outputData, scale, xOffset, yOffset);
sw.Stop();
Logger.Instance.INFO($"Channel {b}: Post-processing time: {sw.ElapsedMilliseconds} ms");
// ================= 6. 结果可视化 =================
//Mat resultImg = DrawDetResult(results, img);
//Cv2.ImShow("YOLO11-DET Result", resultImg);
//Cv2.WaitKey(0);
}
}
});
totalSw.Stop();
Logger.Instance.INFO($"Total time for 8 inferences: {totalSw.ElapsedMilliseconds} ms");
}
}
/// <summary>
/// 图像预处理:Letterbox 缩放、归一化、HWC 转 CHW
/// </summary>
private static float[] PreProcess(Mat img, out float scale, out int xOffset, out int yOffset)
{
// 转换颜色空间 BGR -> RGB
Mat rgbImg = new Mat();
Cv2.CvtColor(img, rgbImg, ColorConversionCodes.BGR2RGB);
// 计算 Letterbox 缩放比例
int maxDim = Math.Max(rgbImg.Width, rgbImg.Height);
scale = (float)maxDim / InputSize;
// 计算缩放后的尺寸
int newWidth = (int)(rgbImg.Width / scale);
int newHeight = (int)(rgbImg.Height / scale);
// Resize 图像
Mat resizedImg = new Mat();
Cv2.Resize(rgbImg, resizedImg, new Size(newWidth, newHeight));
// 创建黑色背景 Canvas (InputSize x InputSize)
Mat paddedImg = Mat.Zeros(InputSize, InputSize, MatType.CV_8UC3);
// 计算粘贴位置 (居中)
xOffset = (InputSize - newWidth) / 2;
yOffset = (InputSize - newHeight) / 2;
// 将图像拷贝到 Canvas 中央
Rect roi = new Rect(xOffset, yOffset, newWidth, newHeight);
resizedImg.CopyTo(new Mat(paddedImg, roi));
// 归一化 (0-255 -> 0-1) 并转为 float 类型
Mat floatImg = new Mat();
paddedImg.ConvertTo(floatImg, MatType.CV_32FC3, 1.0 / 255.0);
// HWC 转 CHW 并展平为一维数组
Mat[] channels = Cv2.Split(floatImg);
float[] chwData = new float[3 * InputSize * InputSize];
// 拷贝数据:R通道 -> C通道 -> B通道 (OpenCV Split 出来顺序是 B, G, R,对应索引 0, 1, 2)
int channelSize = InputSize * InputSize;
// 将 R, G, B 依次拷入数组
Marshal.Copy(channels[0].Data, chwData, 0, channelSize); // R
Marshal.Copy(channels[1].Data, chwData, channelSize, channelSize); // G
Marshal.Copy(channels[2].Data, chwData, channelSize * 2, channelSize); // B
// 释放临时 Mat
rgbImg.Dispose();
resizedImg.Dispose();
paddedImg.Dispose();
floatImg.Dispose();
foreach (var c in channels) c.Dispose();
return chwData;
}
/// <summary>
/// 后处理:解析 TensorRT 输出、NMS 过滤
/// </summary>
private static List<DetData> PostProcess(float[] result, float scale, int xOffset, int yOffset)
{
List<Rect> boxes = new List<Rect>();
List<float> confidences = new List<float>();
List<int> classIds = new List<int>();
// 遍历所有预测框 (OutputSize)
// 数据布局: [4(box) + 80(classes)] * OutputSize
// 展平数组中,同一属性的数据是连续存储的,例如所有 cx 在一起,所有 cy 在在一起...
int stride = OutputSize; // 步长,不同属性在数组中的偏移量
for (int i = 0; i < OutputSize; i++)
{
// 查找最大类别概率及其索引
float maxConf = 0;
int maxClassId = -1;
// 遍历类别
for (int c = 0; c < CategoryNum; c++)
{
// 数组索引:(坐标/角度偏移量 + 类别偏移) * 框索引
// 注意:原始代码中 result[outputSize * j + i] 这种访问方式基于 Transposed 数据布局
float conf = result[(4 + c) * stride + i];
if (conf > maxConf)
{
maxConf = conf;
maxClassId = c;
}
}
// 置信度过滤
if (maxConf > ConfThreshold)
{
// 提取坐标 (cx, cy, w, h)
float cx = result[0 * stride + i];
float cy = result[1 * stride + i];
float w = result[2 * stride + i];
float h = result[3 * stride + i];
// 还原坐标到原图尺寸
int rx = (int)((cx - xOffset - 0.5 * w) * scale);
int ry = (int)((cy - yOffset - 0.5 * h) * scale);
int rw = (int)(w * scale);
int rh = (int)(h * scale);
boxes.Add(new Rect(rx, ry, rw, rh));
confidences.Add(maxConf);
classIds.Add(maxClassId);
}
}
// 执行 NMS (旋转框 NMS)
// OpenCV 的 NMSBoxes 支持 RotatedRect
int[] indices;
CvDnn.NMSBoxes(boxes, confidences, ConfThreshold, NmsThreshold, out indices);
List<DetData> finalResults = new List<DetData>();
foreach (int idx in indices)
{
finalResults.Add(new DetData
{
index = classIds[idx],
score = confidences[idx],
box = boxes[idx]
});
}
return finalResults;
}
/// <summary>
/// 绘制检测结果(水平矩形框)
/// </summary>
/// <param name="results">检测结果列表</param>
/// <param name="image">原始图像</param>
/// <returns>绘制后的图像</returns>
public static Mat DrawDetResult(List<DetData> results, Mat image)
{
// 克隆图像以免修改原图
Mat mat = image.Clone();
foreach (var item in results)
{
// 1. 绘制矩形框
// Rect 结构包含 X, Y, Width, Height
Cv2.Rectangle(mat, item.box, new Scalar(0, 255, 0), thickness: 2);
// 2. 准备标签文本 (类别ID - 置信度)
string label = $"{item.index} - {item.score:F2}";
// 3. 计算文本的尺寸,用于绘制背景
int baseLine = 1;
Size textSize = Cv2.GetTextSize(label, HersheyFonts.HersheySimplex, 0.6, 1, out baseLine);
// 4. 绘制标签背景(半透明黑色矩形),防止文字与背景混淆
// 位置:矩形左上角略微上移,或者直接贴着左上角
Point labelPosition = new Point(item.box.X, item.box.Y - (int)textSize.Height - 5);
// 确保标签不画出图像边界
if (labelPosition.Y < 0) labelPosition.Y = item.box.Y + (int)textSize.Height + 5;
Rect labelBgRect = new Rect(labelPosition.X,
labelPosition.Y - (int)textSize.Height, // OpenCV GetTextSize 返回的高度是基线到底部的距离,需调整
(int)textSize.Width,
(int)textSize.Height + (int)baseLine);
// 如果背景框也在图像范围内,则绘制
// 注意:这里简化处理,直接画在框上方
Cv2.Rectangle(mat,
new Point(item.box.X, item.box.Y - textSize.Height - 5),
new Point(item.box.X + textSize.Width, item.box.Y),
new Scalar(0, 255, 0),
thickness: -1); // -1 表示填充
// 5. 绘制文本(白色文字)
Cv2.PutText(mat,
label,
new Point(item.box.X, item.box.Y - 5),
HersheyFonts.HersheySimplex,
0.6,
new Scalar(0, 0, 0),
1);
}
return mat;
}
public class DetData
{
public int index;
public float score;
public Rect box;
}
}
}
为了方便编写代码,上述并行处理即使时间包括了推理上下文的创建、推理预热等步骤,所以实际时间会偏长,上述程序运行后输出如下所示:
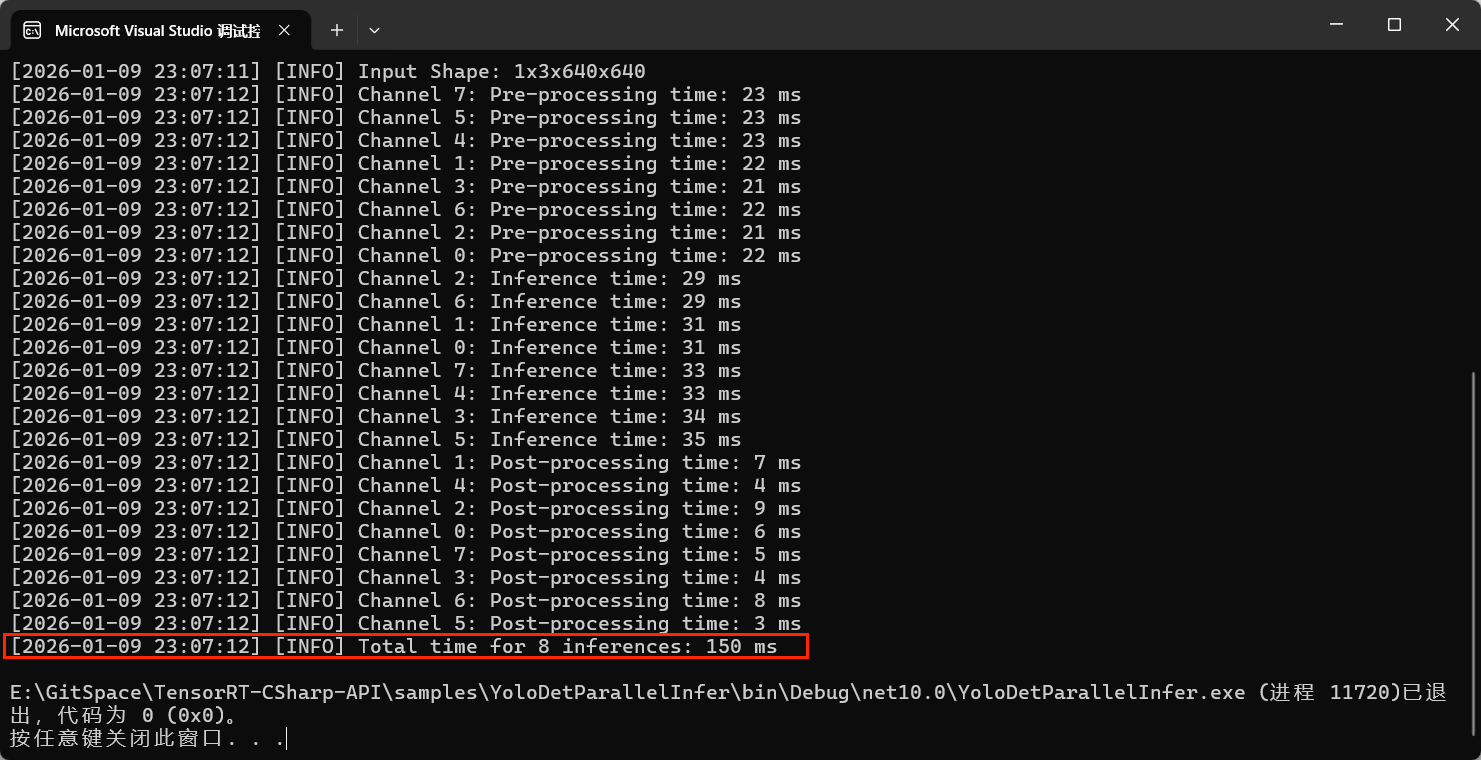
并行测试结果:
同时为了比较不同并行数,测试了从1到24不同并行数的情况,推理总时间如下:
| 并行数 | 1 | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 | 22 | 24 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 推理总时间 (ms) | 80 | 85 | 95 | 115 | 130 | 155 | 180 | 210 | 230 | 255 | 270 | 285 | 310 |
🔗程序路径链接:完整程序已经上传到GitHub,请自行下载,链接为:
https://github.com/guojin-yan/TensorRT-CSharp-API/tree/TensorRtSharp3.0/samples/YoloObbBatchInfer
七、异常处理
TensorRtSharp 提供了完善的异常处理机制。
try
{
Runtime runtime = new Runtime();
byte[] data = File.ReadAllBytes("model.engine");
using CudaEngine engine = runtime.deserializeCudaEngineByBlob(data, (ulong)data.Length);
}
catch (TrtException ex)
{
// TensorRT 特定错误
Console.WriteLine($"TensorRT Error: {ex.ErrMsg}");
Console.WriteLine($"Status: {ex.Status}");
}
catch (CudaException ex)
{
// CUDA 运行时错误
Console.WriteLine($"CUDA Error: {ex.Message}");
Console.WriteLine($"Status: {ex.Status}");
}
catch (InitException ex)
{
// 初始化错误
Console.WriteLine($"Initialization Failed: {ex.Message}");
Console.WriteLine($"Status: {ex.Status}");
}
异常类型说明:
| 异常类型 | 说明 |
|---|---|
TrtException |
TensorRT API 错误(20+ 错误码) |
CudaException |
CUDA 运行时错误(40+ 错误码) |
InitException |
库初始化错误 |
八、日志系统
TensorRtSharp 提供了单例日志系统。
// 获取日志实例
Logger logger = Logger.Instance;
// 设置日志级别
logger.SetThreshold(LoggerSeverity.kINFO); // INFO、WARNING、ERROR
// 设置自定义回调
logger.SetCallback((message) =>
{
Console.WriteLine($"[TensorRT] {message}");
});
// 记录日志
logger.INFO("Engine building started...");
logger.WARNING("FP16 not supported, falling back to FP32");
logger.ERROR("Failed to parse ONNX model");
// 静默模式
logger.SetThreshold(LoggerSeverity.kINTERNAL_ERROR); // 仅严重错误
九、与其他库的对比
| 特性 | TensorRtSharp | ML.NET | ONNX Runtime |
|---|---|---|---|
| 编程语言 | C# | C# | C++/Python |
| API 类型 | 托管封装 | 托管库 | 原生绑定 |
| 性能 | 原生速度 | 中等 | 原生速度 |
| 易用性 | 高 | 高 | 中等 |
| TensorRT 支持 | 完整 | 无 | 有限 |
| 自定义算子 | 支持 | 困难 | 支持 |
| 动态形状 | 支持 | 有限 | 支持 |
| 多 GPU | 支持 | 有限 | 支持 |
十、常见问题
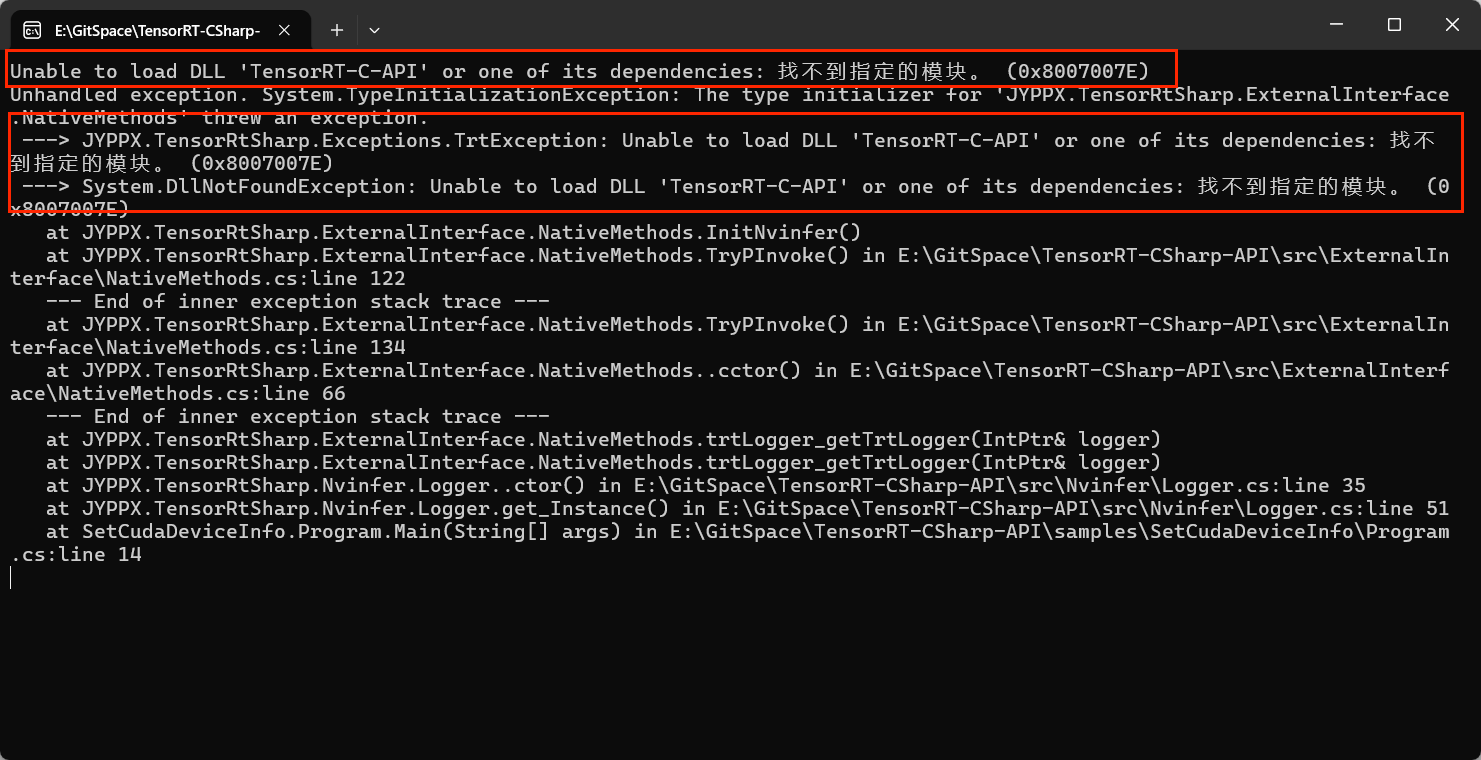
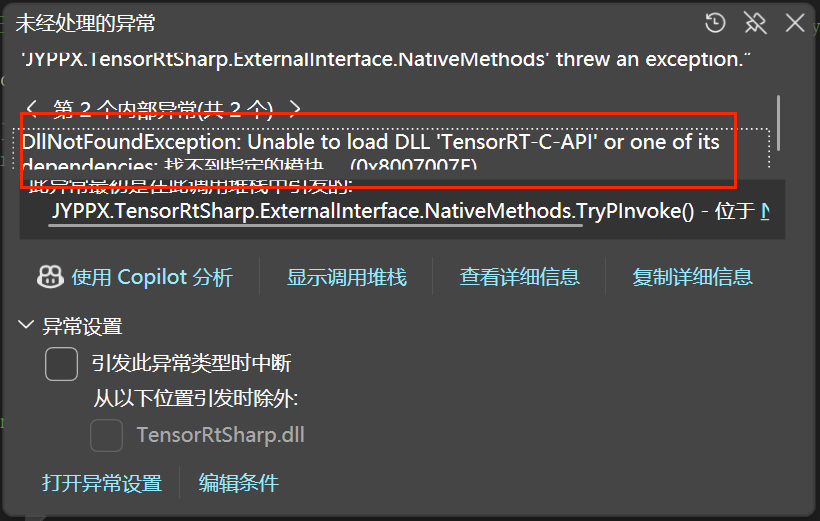
问题一:找不到 DLL 模块
错误信息:
Unable to load DLL 'TensorRT-C-API' or one of its dependencies: 找不到指定的模块。
解决方案:
- 检查是否安装了对应版本的 Runtime NuGet 包
- 确认系统 PATH 环境变量中包含 TensorRT 的 lib 目录和 CUDA 的 bin 目录
- 确认 TensorRT 版本为 10.x 系列
错误截图:
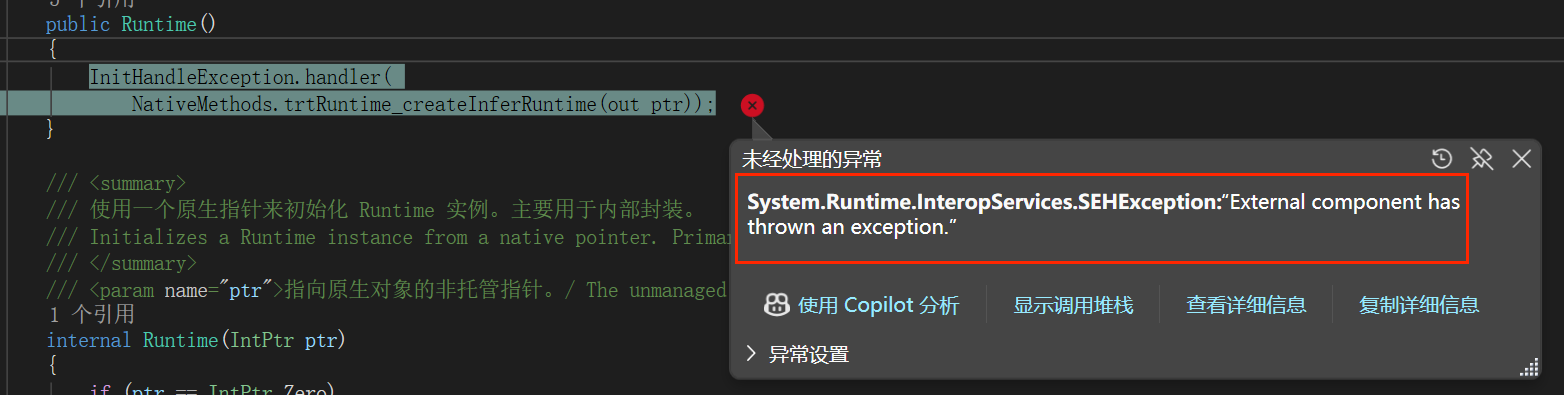
问题二:SEHException 异常
错误信息:
System.Runtime.InteropServices.SEHException: "External component has thrown an exception."
可能原因:
- TensorRT 版本不匹配(必须使用 10.x)
- CUDA 版本不兼容
- 模型文件损坏
解决方案:
- 确认 TensorRT 版本为 10.x
- 检查 CUDA 版本是否匹配
- 重新生成 Engine 文件
错误截图:
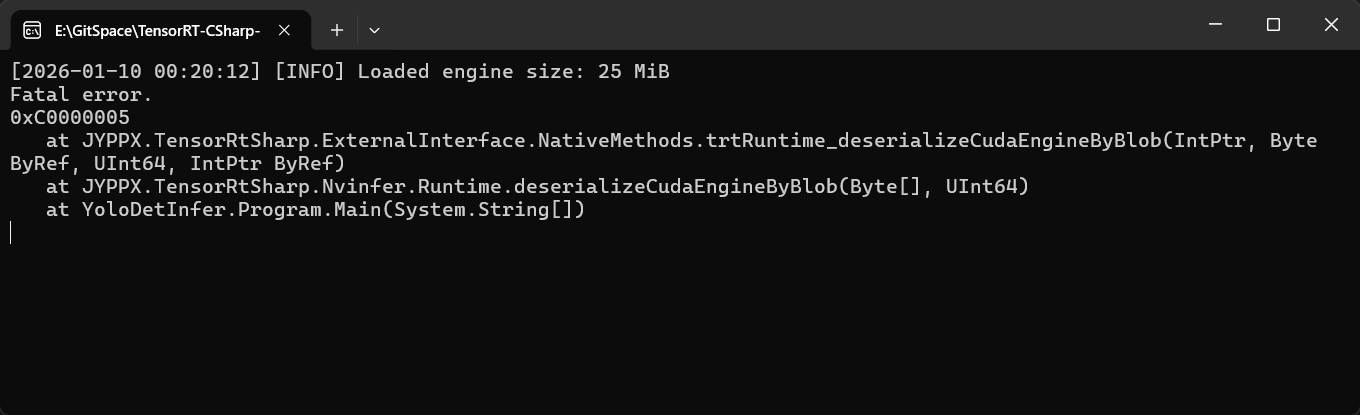
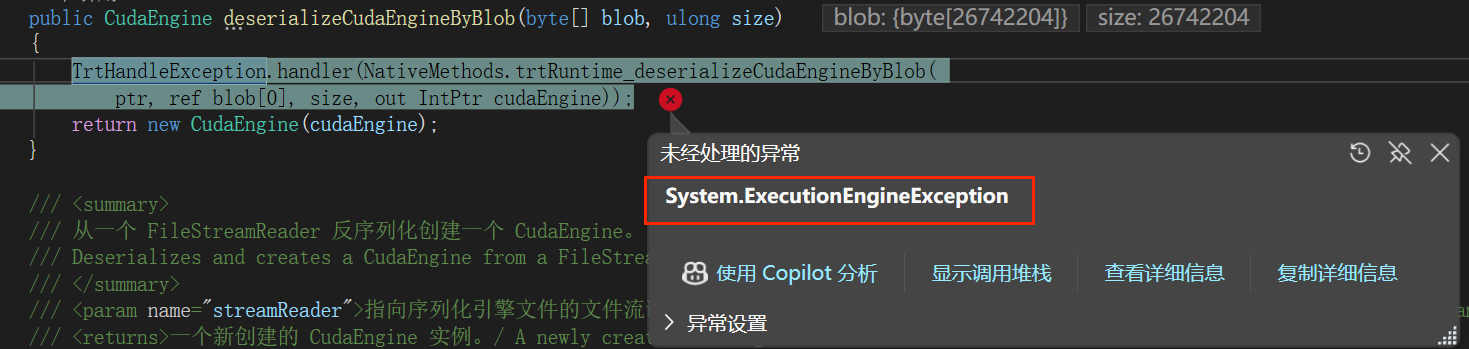
问题三:System.ExecutionEngineException 异常
错误信息:
System.ExecutionEngineException
可能原因:
- 模型文件与设备不匹配
解决方案:
- 在当前设备上重新生成模型文件
错误截图:
十一、总结
TensorRtSharp 是一个功能完整、设计精良的 TensorRT C# 封装库,它填补了 .NET 生态在高性能深度学习推理方面的空白。通过提供类型安全的 API、自动资源管理和完善的异常处理,TensorRtSharp 让 C# 开发者能够充分发挥 GPU 的计算能力,而无需面对复杂的原生代码。
核心优势
✅ 完整的 API 覆盖:支持 TensorRT 核心功能
✅ 类型安全:强类型系统,编译时错误检查
✅ 自动资源管理:RAII + Dispose 模式
✅ 高性能:异步执行、多流并行
✅ 易用性:直观的 API、详细注释
✅ 跨平台:支持 Windows/Linux
✅ 开箱即用:NuGet 包含所有依赖
适用场景
无论您是构建以下类型的应用,TensorRtSharp 都是您的理想选择:
- 🎯 实时视觉应用:目标检测、图像分割、姿态估计
- 🎤 语音处理:语音识别、语音合成
- 🚀 边缘计算:嵌入式设备推理
立即开始
安装命令:
dotnet add package JYPPX.TensorRT.CSharp.API
dotnet add package JYPPX.TensorRT.CSharp.API.runtime.win-x64.cuda12
GitHub 仓库:
https://github.com/guojin-yan/TensorRT-CSharp-API
立即安装并体验 C# 世界中的 GPU 推理极致性能吧!
技术支持
如有问题或建议,欢迎通过以下方式交流:
- 📧 GitHub Issues:在项目仓库提 Issue 或 Pull Request
- 💬 QQ 交流群:加入 945057948,回复更方便更快哦

作者:Guojin Yan
版本:0.0.5
最后更新:2026年1月
【文章声明】
本文主要内容基于作者的研究与实践,部分表述借助AI工具进行了辅助优化。由于技术局限性,文中可能存在错误或疏漏之处,恳请各位读者批评指正。如果内容无意中侵犯了您的权益,请及时通过公众号后台与我们联系,我们将第一时间核实并妥善处理。感谢您的理解与支持!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号