
使用 JYPPX.DeploySharp 高效部署 PaddleOCR,解锁多种高性能 OCR 文字识别方案
 本文介绍了基于DeploySharp框架在.NET环境下部署PaddleOCR模型的解决方案。该框架通过统一接口封装了OpenVINO、TensorRT、ONNX Runtime等多种推理引擎,支持百毫秒级文字识别。文章详细解析了PaddleOCR三阶段工作流程(检测-分类-识别)及性能优化策略,阐述了DeploySharp"统一接口、灵活部署"的架构优势。演示程序支持多种推理后端,涵盖CPU/GPU不同硬件场景,提供模型加载、图片推理、性能测试等功能。通过该方案,开发者可根据实际硬件环
本文介绍了基于DeploySharp框架在.NET环境下部署PaddleOCR模型的解决方案。该框架通过统一接口封装了OpenVINO、TensorRT、ONNX Runtime等多种推理引擎,支持百毫秒级文字识别。文章详细解析了PaddleOCR三阶段工作流程(检测-分类-识别)及性能优化策略,阐述了DeploySharp"统一接口、灵活部署"的架构优势。演示程序支持多种推理后端,涵盖CPU/GPU不同硬件场景,提供模型加载、图片推理、性能测试等功能。通过该方案,开发者可根据实际硬件环
使用 JYPPX.DeploySharp 高效部署 PaddleOCR,解锁多种高性能 OCR 文字识别方案
本文介绍如何通过 DeploySharp 框架在 .NET 环境下部署 PaddleOCR 模型,支持 OpenVINO、TensorRT、ONNX Runtime 等多种推理引擎,实现百毫秒级文字识别。
目录
一、前言
OCR(光学字符识别)技术在数字化办公、文档管理、票据识别等场景中发挥着重要作用。百度飞桨开源的 PaddleOCR 作为业界领先的 OCR 框架,以其优异的识别精度和丰富的功能特性深受开发者喜爱。
一年前,我基于自己开发的 OpenVINO C# API 项目,在 .NET 框架下使用 OpenVINO 部署工具部署 PaddleOCR 系列模型,推出了 PaddleOCR-OpenVINO-CSharp 项目。借助 OpenVINO 在 CPU 上的强大推理优化能力,该项目成功实现了在纯 CPU 环境下完成图片文字识别、版面分析及表格识别等功能,推理速度可控制在 300 毫秒以内。
随着项目的发展和应用场景的多样化,单一推理引擎已无法满足所有需求。近期,我将 OpenVINO、TensorRT、ONNX Runtime 等主流推理工具进行了统一封装,推出了 DeploySharp 开源项目。该项目的核心优势在于:
- 统一接口:通过底层接口抽象,实现一套代码适配多种推理引擎
- 灵活部署:开发者可根据实际硬件环境选择最优推理方案
- 性能优化:充分发挥各推理引擎的硬件加速能力
得益于 DeploySharp 底层接口统一的优势,开发者现在可以用同一段代码在 OpenVINO、TensorRT、ONNX Runtime 等多种推理引擎间自由切换。近期,我们完成了 PaddleOCR 模型的支持更新,为 .NET 开发者提供了一套完整的 OCR 解决方案。
目前,PaddleOCR 功能已集成至 DeploySharp 开源项目中(代码已上传至仓库,NuGet 包正在筹备中)。为了让大家快速体验新版 PaddleOCR 的极致性能,我们特别准备了 JYPPX.DeploySharp.OpenCvSharp.PaddleOcr.TestDemo 演示程序,支持即开即用,无需复杂配置。
二、核心技术原理解析
2.1 PaddleOCR 工作流程
PaddleOCR 采用经典的「检测-分类-识别」三阶段流水线架构:
输入图片
│
▼
┌─────────────┐
│ 文本检测 │ → 检测图片中的文本区域位置
│ (Detection) │
└─────────────┘
│
▼
┌─────────────┐
│ 文本方向分类 │ → 判断文本方向(180度翻转等)
│ (Classifier)│
└─────────────┘
│
▼
┌─────────────┐
│ 文本识别 │ → 识别文本区域的具体内容
│ (Recognition)│
└─────────────┘
│
▼
输出识别结果
2.2 三阶段模型详解
| 阶段 | 模型名称 | 输入 | 输出 | 作用 |
|---|---|---|---|---|
| 检测 | PP-OCRv5_det | 原始图片 (3xHxW) | 文本框坐标 | 定位文本区域 |
| 分类 | PP-OCRv5_cls | 裁剪文本框 (3x80x160) | 方向标签 | 纠正文本方向 |
| 识别 | PP-OCRv5_rec | 裁剪文本框 (3x48xL) | 文本内容 | 识别字符序列 |
2.3 性能优化策略
- 模型量化:使用 int8 量化减小模型体积,提升推理速度
- 动态批处理:支持 Batch Size > 1,提高 GPU 利用率
- 并发推理:支持多线程并发处理,充分利用多核性能
- 硬件加速:针对不同硬件选择最优计算后端
三、DeploySharp 架构优势
DeploySharp 的核心设计理念是「统一接口,灵活部署」,其架构如下图所示:
┌─────────────────────────────────────────────────────────┐
│ 应用层 (Application) │
│ PaddleOCR 文字识别 / 其他模型应用 │
└─────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ DeploySharp 抽象接口层 │
│ 统一的模型加载 / 推理执行 / 资源管理接口 │
└─────────────────────────────────────────────────────────┘
│
┌───────────────┼───────────────┐
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ OpenVINO │ │ TensorRT │ │ ONNX Runtime │
│ Engine │ │ Engine │ │ Engine │
│ (CPU 优化) │ │ (GPU 加速) │ │ (跨平台支持) │
└───────────────┘ └───────────────┘ └───────────────┘
│ │ │
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ Intel CPU │ │ NVIDIA GPU │ │ 多种硬件设备 │
│ │ │ │ │ (CPU/GPU/DML) │
└───────────────┘ └───────────────┘ └───────────────┘
主要优势:
- 零代码切换:更换推理引擎无需修改业务代码
- 资源高效利用:自动管理模型生命周期和计算资源
- 扩展性强:易于添加新的推理引擎支持
- 生产就绪:经过充分测试,可直接用于生产环境
四、支持的推理设备
本演示程序支持多种主流推理后端,覆盖从入门级设备到高性能服务器的各种场景:
| 推理引擎 | 支持设备 | 适用场景 | 性能特点 |
|---|---|---|---|
| OpenVINO | CPU | 无 GPU 环境、Intel 处理器 | CPU 优化,启动快,稳定 |
| TensorRT | CUDA 11/12 | NVIDIA GPU 高性能场景 | GPU 加速,极致性能,需模型转换 |
| ONNX Runtime CPU | CPU | 跨平台部署 | 通用性强,性能中等 |
| ONNX Runtime CUDA | CUDA 12 | NVIDIA GPU 环境部署 | GPU 加速,开箱即用 |
| ONNX Runtime TensorRT | CUDA 12 | NVIDIA GPU 高性能场景 | GPU 加速 + TensorRT 优化 |
| ONNX Runtime DML | DML GPU | Windows 平台多厂商 GPU | 支持 AMD/NVIDIA/Intel GPU |
性能提示:首次加载模型和推理时会较慢,这是正常现象(模型初始化和 JIT 编译)。首次运行时请避免频繁操作,待模型预热完成后性能将显著提升。
五、快速开始指南
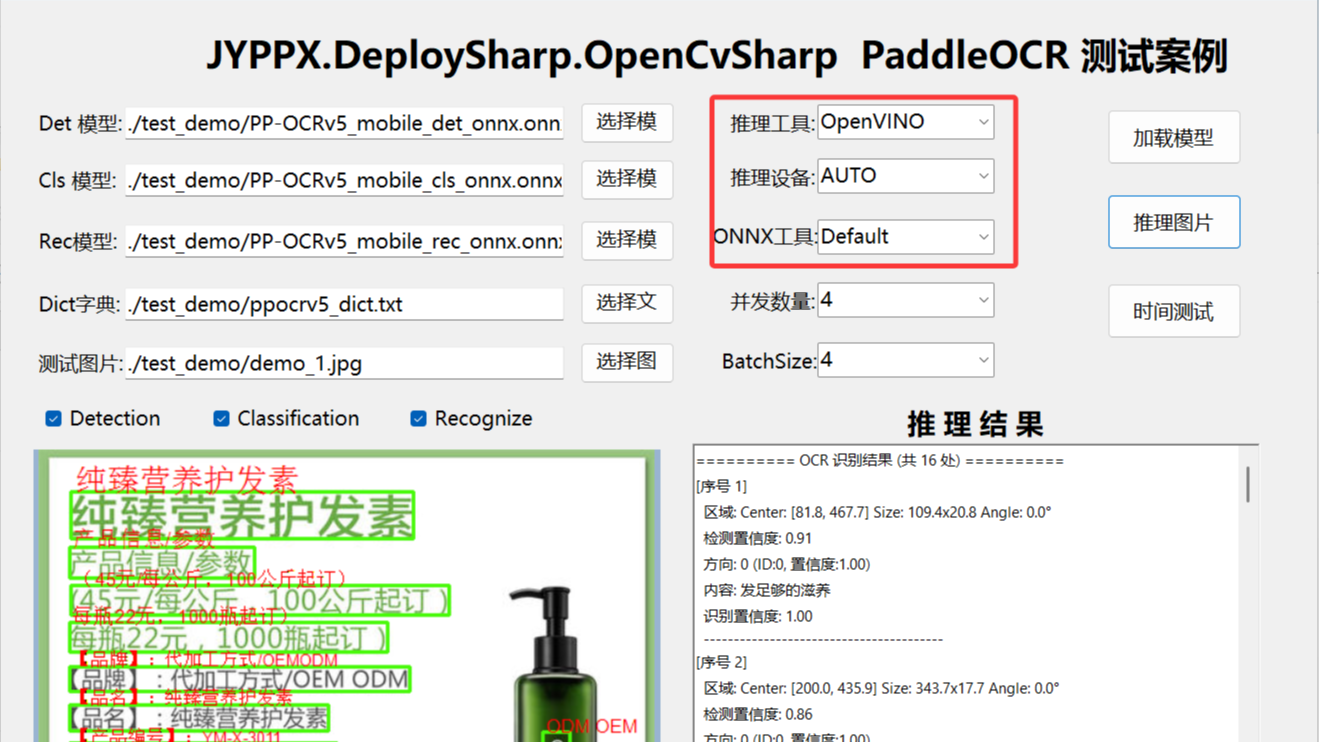
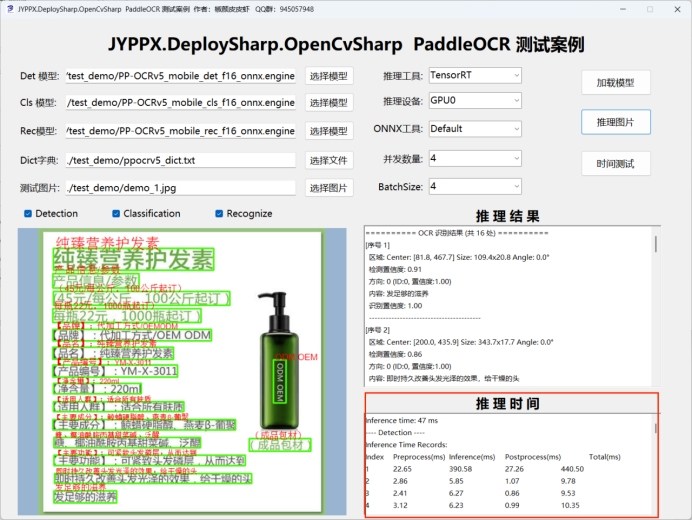
5.1 程序界面概览
运行程序后,主界面如下图所示:
核心操作说明:
| 操作项 | 说明 | 注意事项 |
|---|---|---|
| 推理后端 | 选择使用的推理引擎 | 切换后需重新加载模型 |
| 模型路径 | 预置模型路径,一般无需修改 | 支持自定义模型路径 |
| 图像路径 | 选择待识别的图片 | 支持 JPG/PNG/BMP 等格式 |
| 加载模型 | 加载指定模型到内存 | 首次使用必须执行 |
| 推理图片 | 执行单次图片识别 | 首次需预热 |
| 时间测试 | 连续推理十次并统计平均耗时 | 用于性能评估 |
| 并发数量 | 调整推理并发线程数 | 修改后需重新加载模型 |
| BatchSize | 批量处理大小 | 可动态调整 |
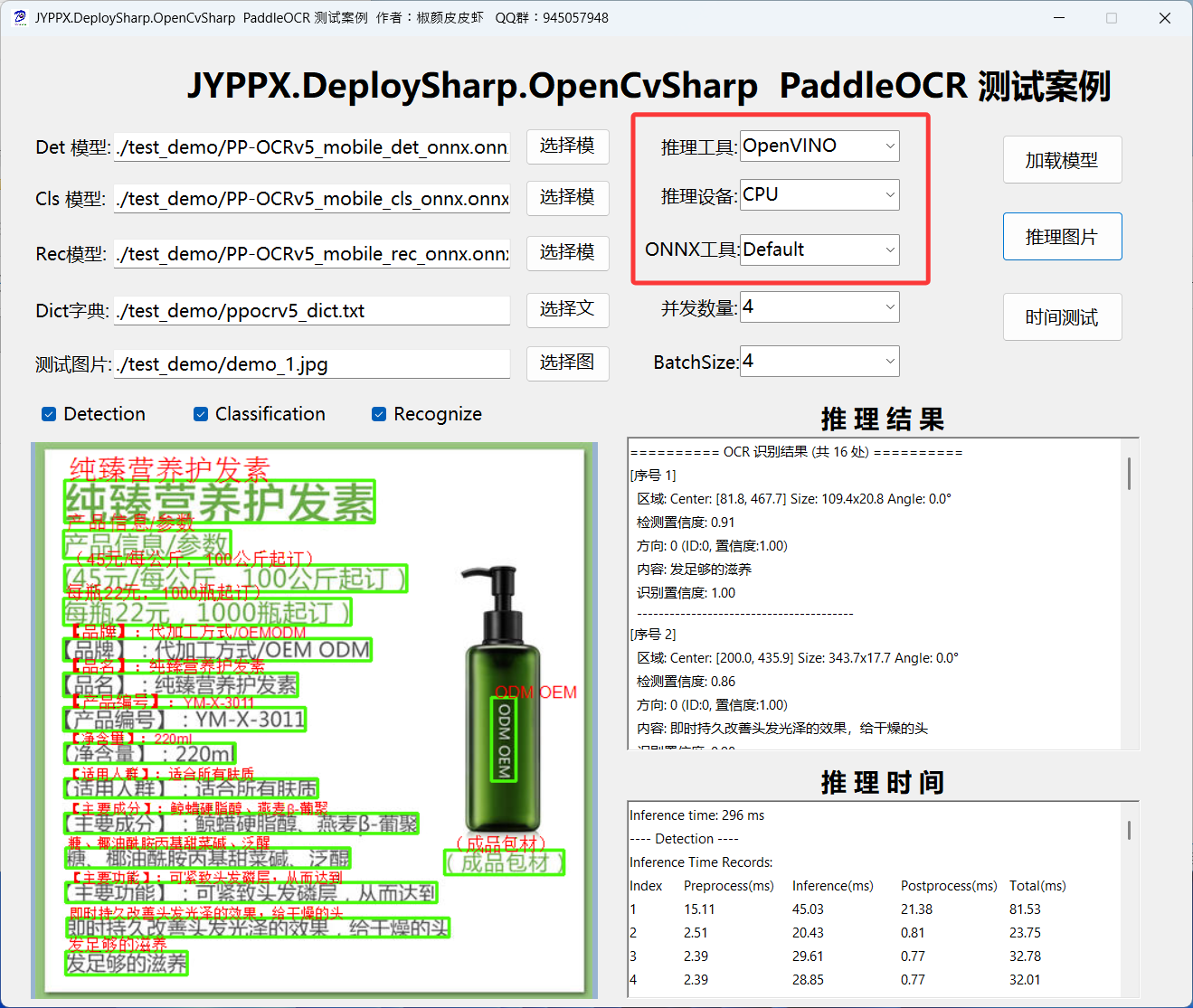
5.2 OpenVINO 推理
OpenVINO 是 Intel 推出的开源工具套件,针对 CPU 和Intel IGPU进行了深度优化,特别适合无 GPU 环境下的高性能推理。
CPU使用步骤:
1.运行程序
2.在「推理后端」下拉框中选择 OpenVINO
3.点击「加载模型」
4.点击「推理图片」开始识别
IGPU使用步骤:
英特尔集显使用流程与上述一致,主要是设备要选择GPU0:
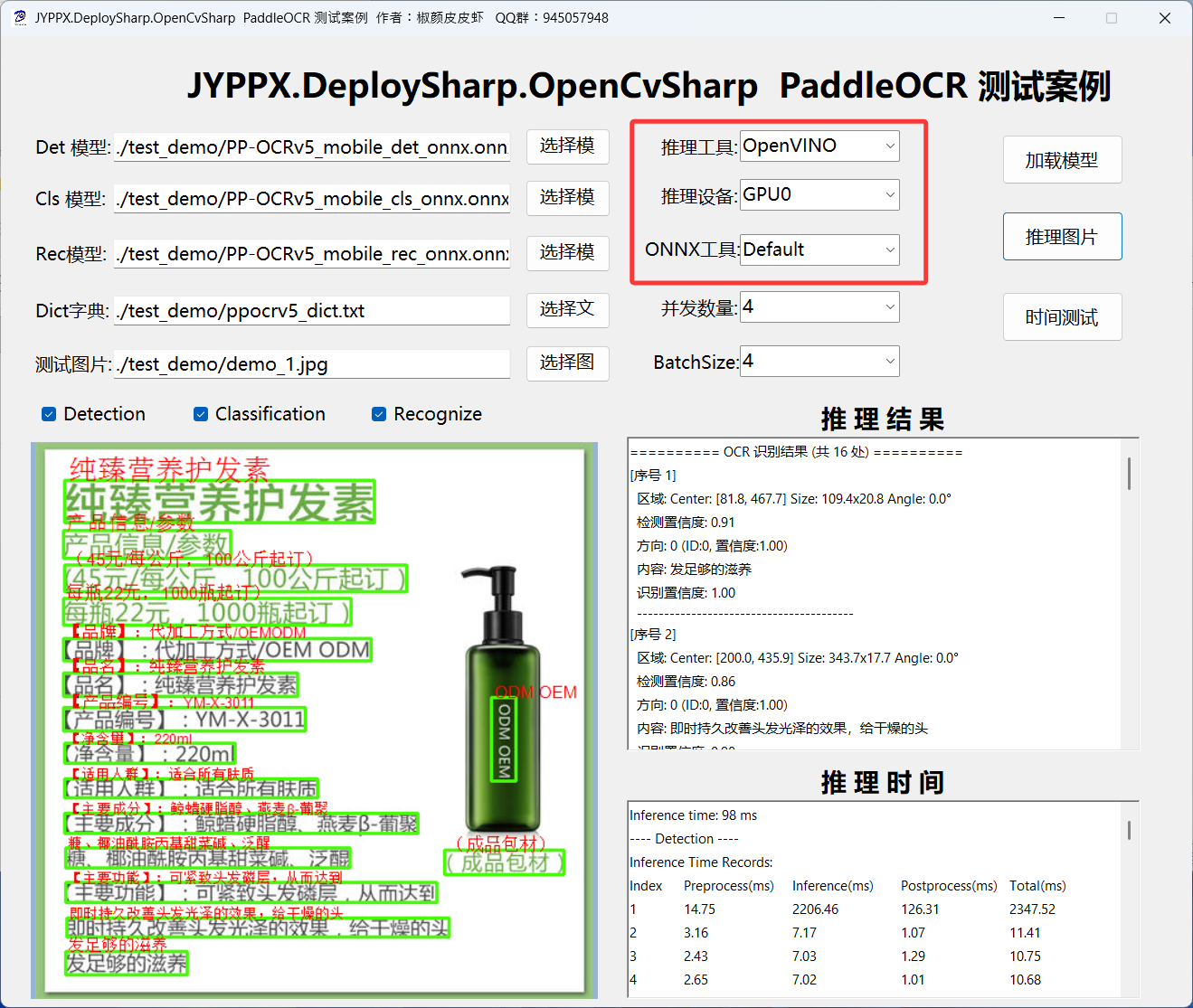
混合设备使用步骤:
英特尔OpenVINO支持CPU+IGPU混合设备推理,即AUTO模式,OpenVINO会根据设备情况自主选择,使用方式与上述一致,主要是设备要选择AUTO:
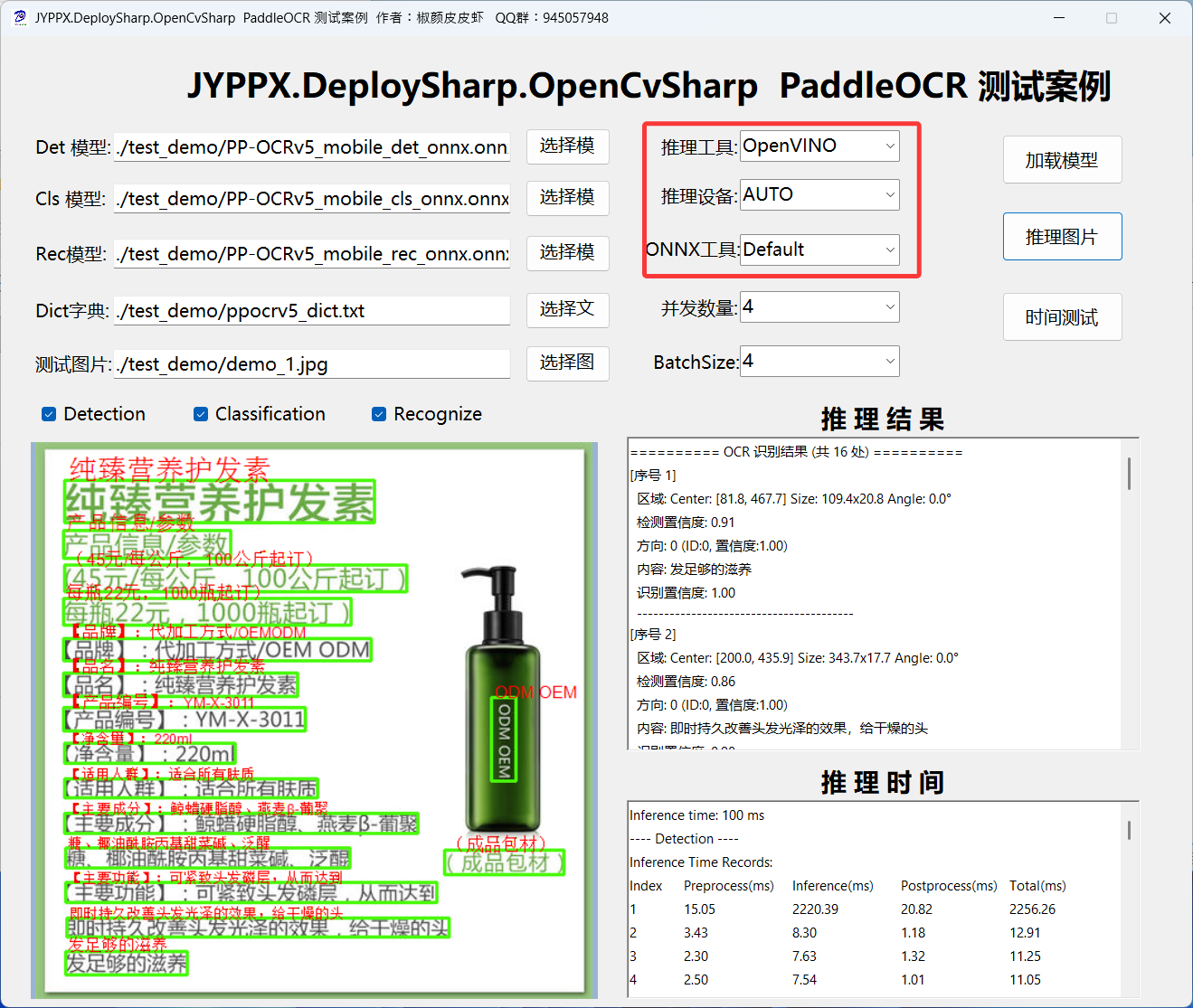
适用场景:
- 服务器环境部署
- 低功耗设备
- Intel CPU 用户
- 对启动速度要求高的场景
5.3 ONNX Runtime CPU 推理
ONNX Runtime 是微软推出的跨平台推理引擎,支持多种硬件加速后端,CPU 模式无需任何依赖即可使用。
使用步骤:
- 运行程序
- 在「推理后端」下拉框中选择 ONNX Runtime CPU
- 点击「加载模型」
- 点击「推理图片」开始识别
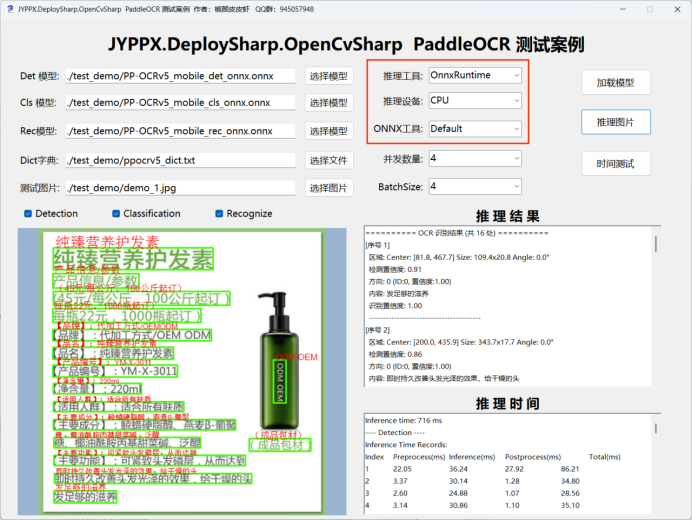
适用场景:
- 跨平台部署需求
- 无 GPU 加速环境
- 需要快速原型验证
5.4 ONNX Runtime CUDA 推理
CUDA 是 NVIDIA 提供的并行计算平台,可充分利用 GPU 的并行计算能力实现显著加速。
配置步骤
-
安装 CUDA 驱动
- 访问 NVIDIA CUDA 官网
- 下载并安装 CUDA 12.x 版本(测试环境:CUDA 12.3)
-
复制依赖文件
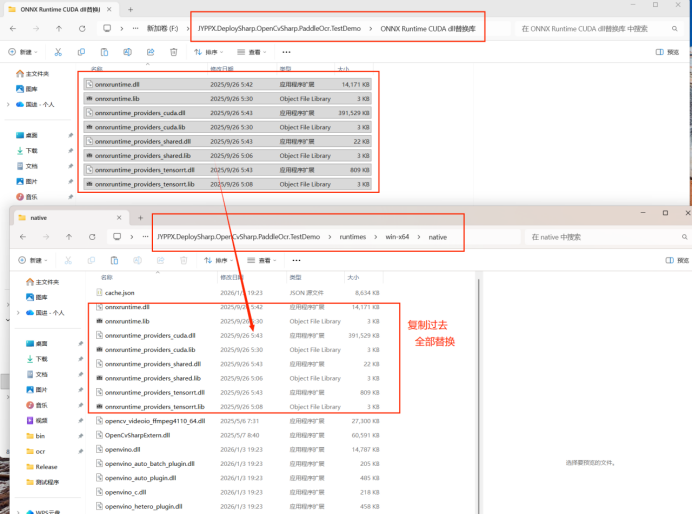
将以下 CUDA 相关 DLL 文件复制到程序运行目录:
![CUDA 依赖文件]()
-
启动推理
运行程序,在「推理后端」下拉框中选择 ONNX Runtime CUDA
![ONNX Runtime CUDA 选择界面]()
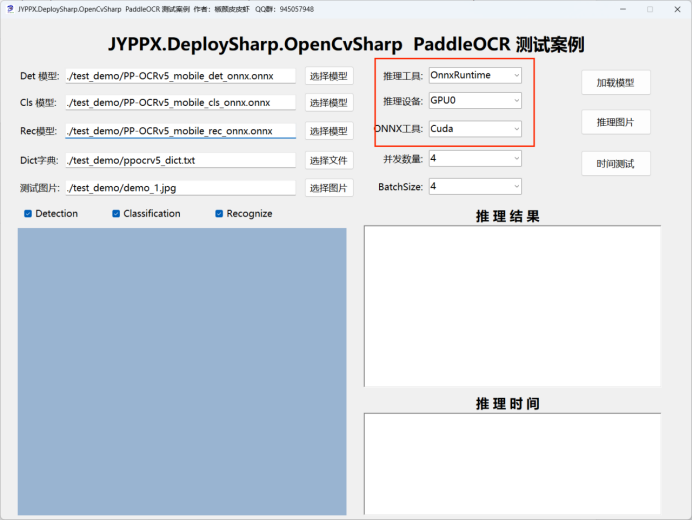
依赖说明:
| NuGet 包名 | 版本 |
|---|---|
| Microsoft.ML.OnnxRuntime.Gpu.Windows | 1.23.0 |
| Microsoft.ML.OnnxRuntime.Managed | 1.23.0 |
适用场景:
- 拥有 NVIDIA 显卡的设备
- 对推理速度有较高要求
- 需要快速部署无需模型转换
5.5 ONNX Runtime TensorRT 推理
TensorRT 是 NVIDIA 推出的高性能深度学习推理优化器,结合 CUDA 加速可达到极致性能。
配置步骤
依赖文件复制方式与 CUDA 模式一致。
使用步骤
- 运行程序
- 在「推理后端」下拉框中选择 ONNX Runtime TensorRT
- 点击「加载模型」
- 点击「推理图片」开始识别
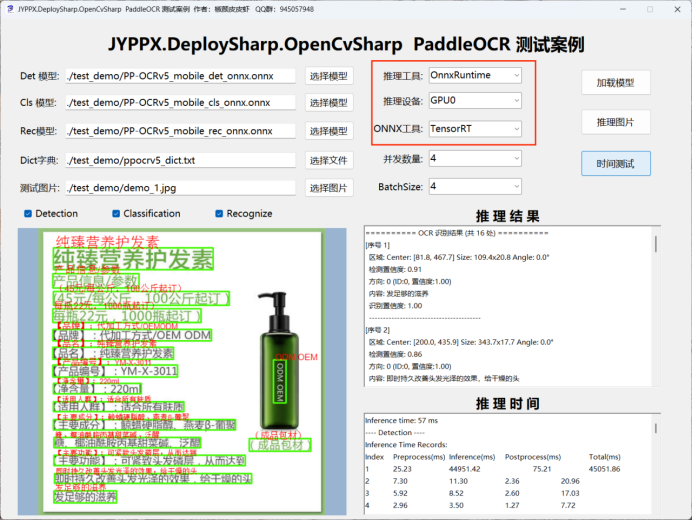
重要提示:首次运行推理时,TensorRT 会自动对 ONNX 模型进行优化编译,此过程可能需要数分钟,请耐心等待。编译后的引擎文件会被缓存,后续推理速度将大幅提升。
依赖说明:
| NuGet 包名 | 版本 |
|---|---|
| Microsoft.ML.OnnxRuntime.Gpu.Windows | 1.23.2 |
| Microsoft.ML.OnnxRuntime.Managed | 1.23.2 |
适用场景:
- 对推理速度要求极高的生产环境
- NVIDIA GPU 设备
- 可接受首次运行较长的编译时间
5.6 ONNX Runtime DML 推理
DirectML(DML)是 Windows 平台的高性能硬件加速接口,支持 AMD、NVIDIA 和 Intel 多厂商显卡。
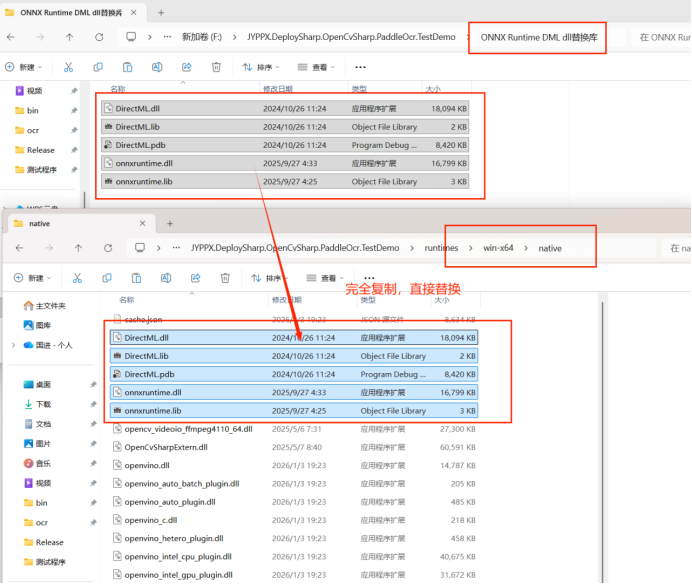
配置步骤
将 DML 相关 DLL 文件复制到程序运行目录:
使用步骤
- 运行程序
- 在「推理后端」下拉框中选择 ONNX Runtime DML
- 点击「加载模型」
- 点击「推理图片」开始识别
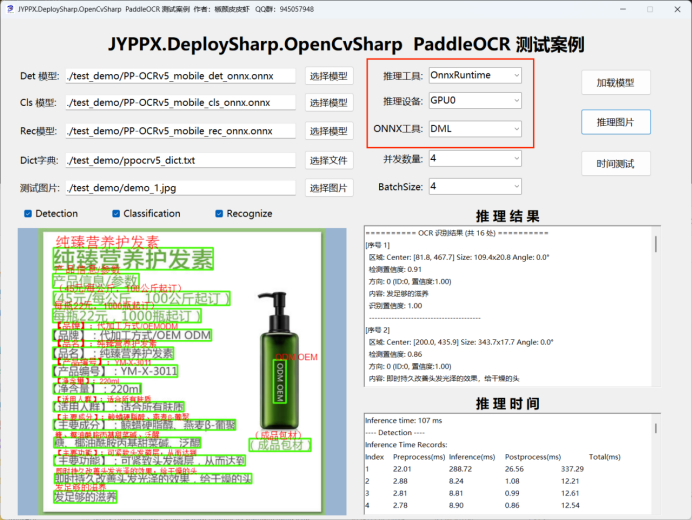
适用场景:
- Windows 平台用户
- AMD 显卡用户
- 需要统一接口支持多品牌显卡
5.7 TensorRTSharp 推理
TensorRTSharp 是对 NVIDIA TensorRT 的 C# 封装,提供原生的 TensorRT 引擎加载和推理能力,支持 FP16 精度进一步提升性能。
环境准备
详细的安装和配置指南请参考:
https://mp.weixin.qq.com/s/D0c6j5MmraJO4Eza7tWm1A
TensorRTSharp 支持 CUDA 11 和 CUDA 12 两个系列,请根据系统安装的 CUDA 版本选择对应的 DLL 文件。
配置步骤
-
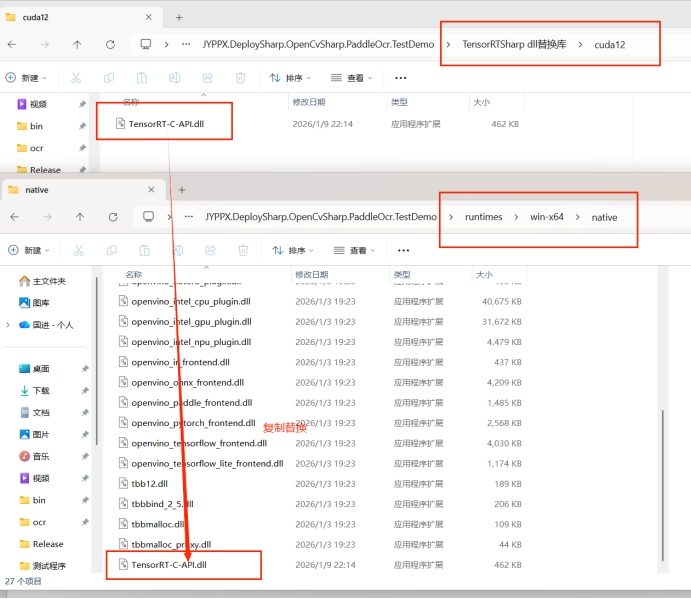
替换 DLL 文件
根据安装的 CUDA 版本,将对应的 TensorRT DLL 文件复制到程序目录:
![TensorRT DLL 文件]()
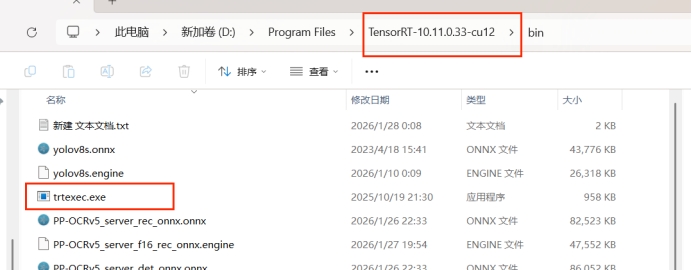
-
模型转换
使用
trtexec工具将 ONNX 模型转换为 TensorRT 引擎文件:![trtexec 转换工具]()
模型转换指令
文本检测模型(Det):
trtexec.exe --onnx=PP-OCRv5_mobile_det_onnx.onnx \
--minShapes=x:1x3x32x32 \
--optShapes=x:4x3x640x640 \
--maxShapes=x:8x3x960x960 \
--fp16 \
--memPoolSize=workspace:1024 \
--sparsity=disable \
--saveEngine=PP-OCRv5_mobile_det_f16_onnx.engine
文本分类模型(Cls):
trtexec.exe --onnx=PP-OCRv5_mobile_cls_onnx.onnx \
--minShapes=x:1x3x80x160 \
--optShapes=x:8x3x80x160 \
--maxShapes=x:64x3x80x160 \
--fp16 \
--memPoolSize=workspace:1024 \
--sparsity=disable \
--saveEngine=PP-OCRv5_mobile_cls_f16_onnx.engine
文本识别模型(Rec):
trtexec.exe --onnx=PP-OCRv5_mobile_rec_onnx.onnx \
--minShapes=x:1x3x48x48 \
--optShapes=x:8x3x48x1024 \
--maxShapes=x:64x3x48x1024 \
--fp16 \
--memPoolSize=workspace:1024 \
--sparsity=disable \
--saveEngine=PP-OCRv5_mobile_rec_f16_onnx.engine
开始推理
模型转换完成后,在程序中选择对应的 .engine 文件即可开始推理:
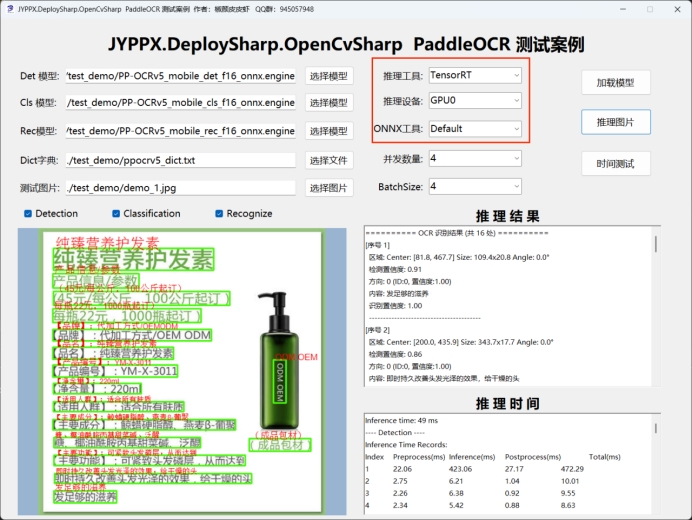
适用场景:
- 追求极致推理性能
- NVIDIA GPU 环境
- 允许离线模型转换
六、性能测试与分析
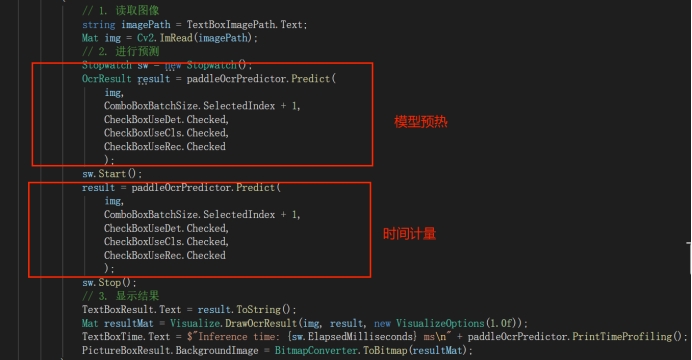
6.1 性能测试工具
演示程序内置了完整的性能测试工具,支持两种测试模式:
- 整体耗时统计:计算从图片输入到结果输出的完整端到端耗时
- 详细阶段分析:记录预处理、推理、后处理各阶段的具体耗时
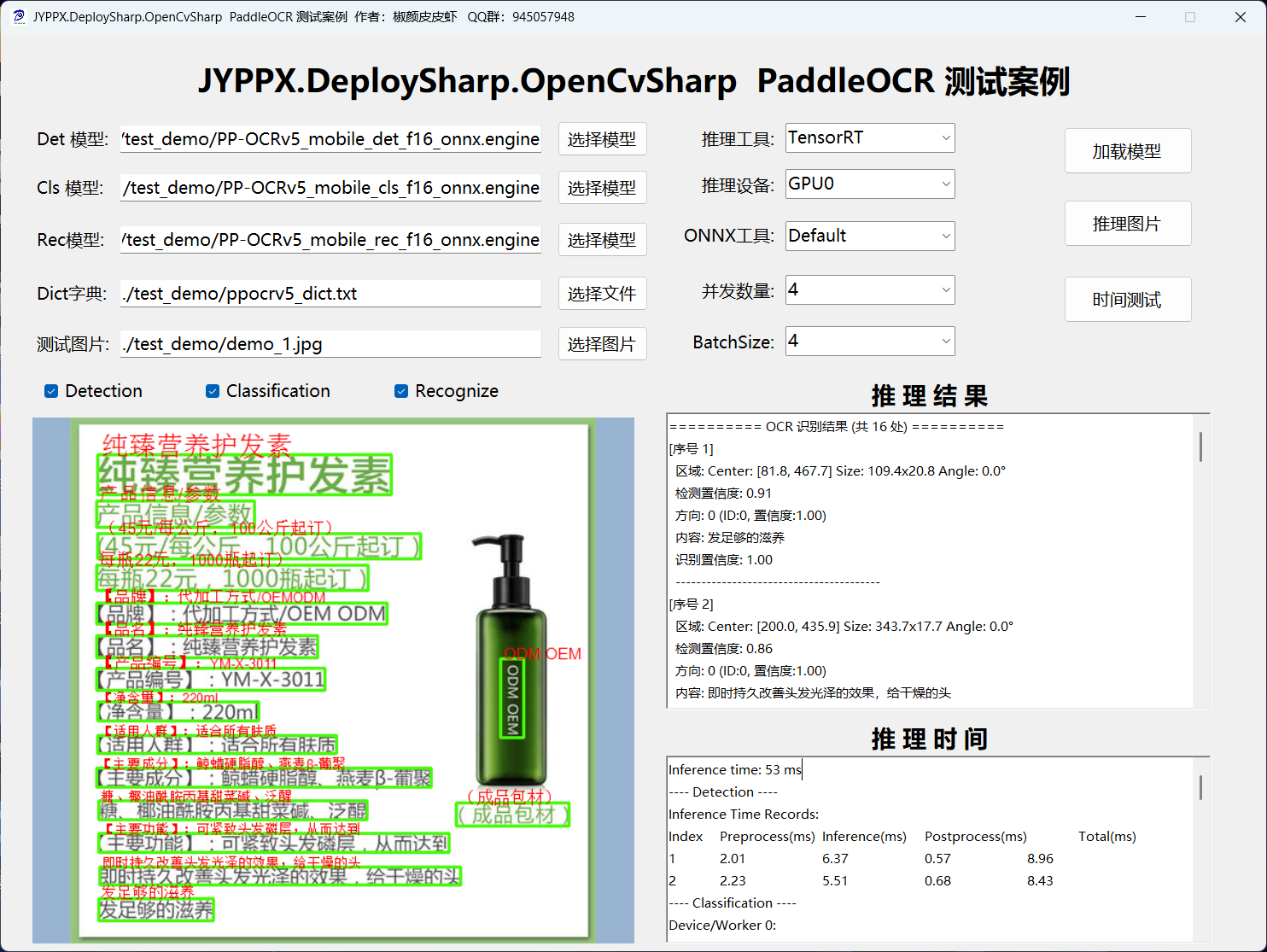
6.2 TensorRTSharp 性能示例
以下为使用 TensorRTSharp 在 4 并发配置下的性能测试数据:
Inference time: 53 ms
---- Detection ----
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 2.01 6.37 0.57 8.96
2 2.23 5.51 0.68 8.43
---- Classification ----
Device/Worker 0:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 1.84 6.89 0.00 8.73
2 1.99 6.97 0.01 8.96
Device/Worker 1:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 1.79 6.66 0.00 8.46
2 1.66 7.60 0.00 9.26
Device/Worker 2:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 1.61 5.31 0.00 6.92
2 1.51 8.01 0.00 9.53
Device/Worker 3:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 1.24 7.73 0.00 8.98
2 1.82 8.35 0.00 10.17
---- Recognition ----
Device/Worker 0:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 0.00 41.97 1.42 43.39
2 0.00 14.50 2.30 16.81
Device/Worker 1:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 0.00 47.40 6.81 54.21
2 0.00 19.42 2.76 22.18
Device/Worker 2:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 0.00 38.10 3.42 41.52
2 0.00 22.36 3.37 25.73
Device/Worker 3:
Inference Time Records:
Index Preprocess(ms) Inference(ms) Postprocess(ms) Total(ms)
1 0.00 109.94 4.58 114.52
2 0.00 26.59 4.55 31.14
6.3 性能对比总结
下表为使用洗发水图片,跑10次的平均时间测试:
| 推理引擎 | 设备 | 平均耗时 | 设备类型 |
|---|---|---|---|
| OpenVINO | CPU | 288ms | Intel(R) Core(TM) Ultra 9 288V 8核 |
| OpenVINO | IGPU | 99ms | Intel(R) Arc(TM) 140V GPU (16GB) |
| OpenVINO | 混合 AUTO:IGPU+CPU | 100ms | Intel(R) Core(TM) Ultra 9 288V 8核 Intel(R) Arc(TM) 140V GPU (16GB) |
| ONNX Runtime | CPU | 656ms | AMD Ryzen 7 5800H with Radeon Graphics 8核 |
| ONNX Runtime DML | GPU | 114ms | NVIDIA GeForce RTX 3060 Laptop GPU |
| ONNX Runtime DML | IGPU | 331ms | Intel(R) Arc(TM) 140V GPU (16GB) |
| ONNX Runtime CUDA | GPU | 93ms | NVIDIA GeForce RTX 3060 Laptop GPU |
| ONNX Runtime TensorRT | GPU | 52ms | NVIDIA GeForce RTX 3060 Laptop GPU |
| TensorRTSharp | GPU | 51ms | NVIDIA GeForce RTX 3060 Laptop GPU |
性能测试征集:我们欢迎广大开发者分享各自的测试数据。请在评论区提供您的测试配置(硬件型号、并发数、Batch Size)和实测耗时,后续我们将整理成性能基准对比表。
七、常见问题解答
Q1: 首次推理为什么特别慢?
A: 首次推理时需要进行以下操作:
- 模型加载到内存
- 推理引擎初始化
- JIT 编译(部分引擎)
这是正常现象,后续推理速度会显著提升。
Q2: 如何选择合适的推理引擎?
A: 根据硬件环境和需求选择:
| 场景 | 推荐引擎 |
|---|---|
| 无 GPU,有Intel CPU,追求稳定性 | OpenVINO |
| 有Intel GPU,需要跨平台 | OpenVINO |
| 无 GPU,需要跨平台 | ONNX Runtime CPU |
| 有 NVIDIA 显卡,快速部署 | ONNX Runtime CUDA |
| 有 NVIDIA 显卡,追求性能 | ONNX Runtime TensorRT / TensorRTSharp |
| Windows 平台,AMD 显卡 | ONNX Runtime DML |
Q3: 切换推理引擎时为什么需要重新加载模型?
A: 不同推理引擎对模型格式的内部表示和优化策略不同,因此需要重新解析和加载模型。点击「加载模型」即可完成切换。
Q4: BatchSize 和并发数量有什么区别?
A: 两个参数的作用不同:
- BatchSize:单次推理处理的图片数量,提升 GPU 利用率
- 并发数量:同时运行的推理引擎数量,设置几个就会生成几个推理引擎进行同时推理,提升多核/CPU 利用率
调整 BatchSize 不需要重新加载模型,但调整并发数量后需要重新加载。
Q5: TensorRT 模型转换失败怎么办?
A: 检查以下几点:
- 确保 CUDA 版本与 TensorRT 版本匹配
- 检查 ONNX 模型文件是否完整
- 确认
trtexec参数中输入尺寸范围合理 - 如显存不足,减小
--memPoolSize参数
Q6: 推理结果为空或识别不准确怎么办?
A: 常见原因和解决方法:
- 图片质量:检查图片是否模糊、倾斜或光照不足
- 输入尺寸:确保图片尺寸符合模型输入要求
- 语言支持:确认模型是否支持目标语言
- 模型版本:尝试使用不同版本的 PaddleOCR 模型
八、软件获取
8.1 源码下载
DeploySharp 项目已完全开源,可通过以下方式获取:
主仓库:
https://github.com/guojin-yan/DeploySharp.git
PaddleOCR 演示程序:
https://github.com/guojin-yan/DeploySharp/tree/DeploySharpV1.0/applications/JYPPX.DeploySharp.OpenCvSharp.PaddleOcr
8.2 可执行程序
如需直接获取编译好的可执行程序,请加入技术交流群,从群文件下载最新版本。
九、技术支持
9.1 反馈与交流
- GitHub Issues:在项目仓库提交 Issue 或 Pull Request
- QQ 交流群:加入 945057948,获取实时技术支持

9.2 相关资源
- PaddleOCR 官方项目:https://github.com/PaddlePaddle/PaddleOCR
- OpenVINO 官方文档:https://docs.openvino.ai/
- TensorRT 官方文档:https://docs.nvidia.com/deeplearning/tensorrt/
- ONNX Runtime 官方文档:https://onnxruntime.ai/docs/
结语
通过 DeploySharp 框架,我们成功实现了 PaddleOCR 在 .NET 环境下的高效部署。无论是纯 CPU 环境下的稳定运行,还是 GPU 加速下的极致性能,开发者都可以根据实际需求灵活选择。
未来,我们将持续优化框架性能,支持更多模型类型和推理引擎,为 .NET 开发者提供更完善的 AI 模型部署解决方案。
作者:Guojin Yan
最后更新:2026年1月
【文章声明】
本文主要内容基于作者的研究与实践,部分表述借助 AI 工具进行了辅助优化。由于技术局限性,文中可能存在错误或疏漏之处,恳请各位读者批评指正。如果内容无意中侵犯了您的权益,请及时通过公众号后台与我们联系,我们将第一时间核实并妥善处理。感谢您的理解与支持!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号