经典目标检测论文阅读:从 R-CNN 到 Mask R-CNN
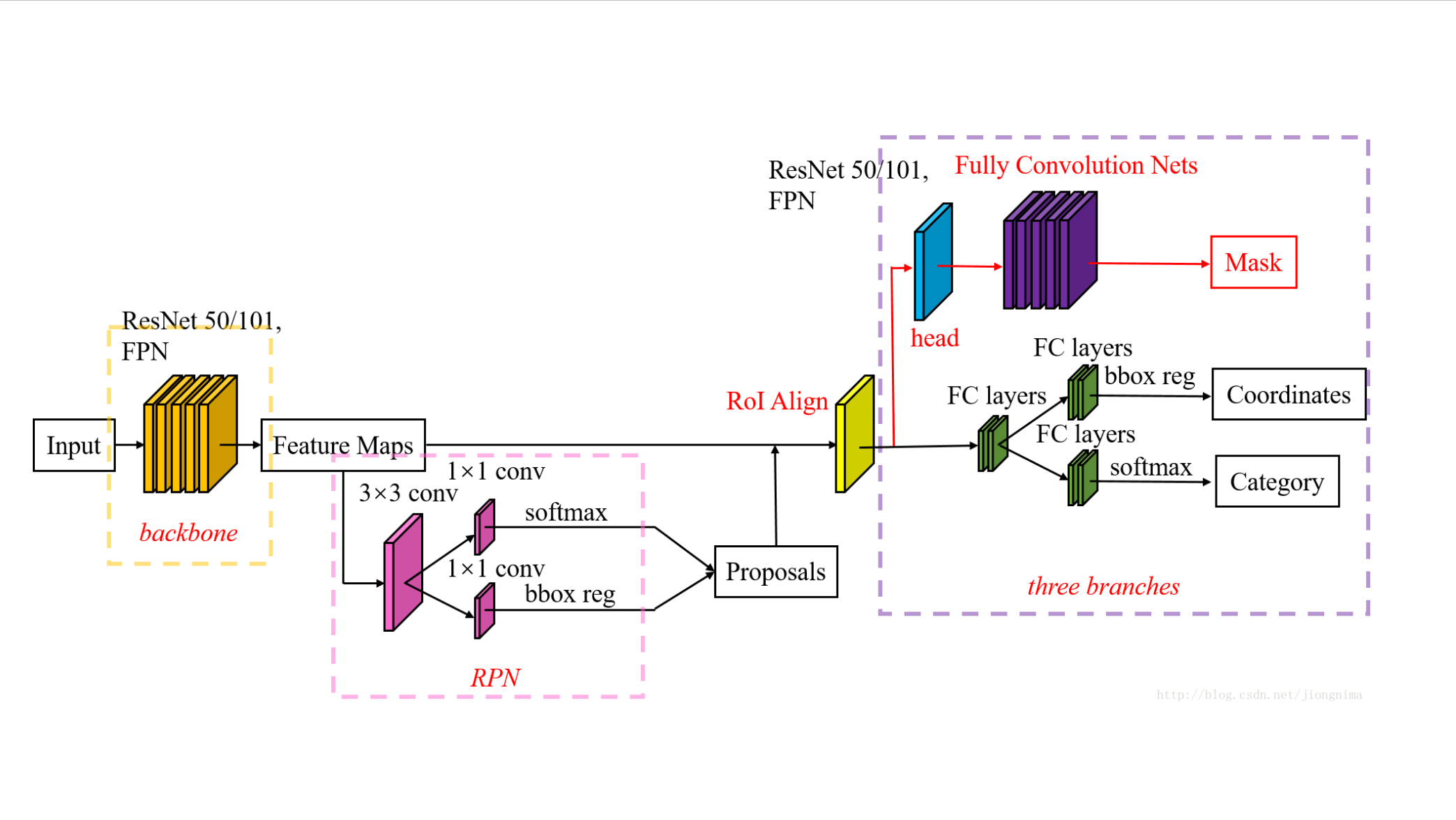 总结了从 R-CNN 到 Mask R-CNN 的目标检测演进历程。
总结了从 R-CNN 到 Mask R-CNN 的目标检测演进历程。
目标检测任务
在目标检测任务中,其定义可以描述为:给定任意一张图像输入给网络,网络需要输出图中是否有目标物体出现?如果有在哪里?是哪类物体?有多大把握确认是这个目标物体?

基于分块 CNN 的目标检测
在早期阶段,CNN(卷积神经网络)主要用于特征提取,常用于分类任务。即输入一张图像,给出图像所属的类别。
因此CNN可以解决图像中是否存在目标物体的这个判断,但位置信息无法给出。于是很多学者提出将图像分块后输入给CNN进行分类,这样每一个图像块都有一个类别,然后将这些类别信息根据图像块的位置进行合并,从而在全图中得到目标的位置矩形框。

这种做法虽然一定程度上可以将分类结果和位置信息结合起来,但是也具有很明显的局限性,那就是分块大小取多大比较合适?分块太大,位置信息不精确,并且图像中可能会存在多个物体叠在一个图像块中的情况,此时分类应该分给谁?而如果分块太小,位置精确但图像内容被拆成许多碎片,分类准确性会降低。
基于 R-CNN 的目标检测
基本原理
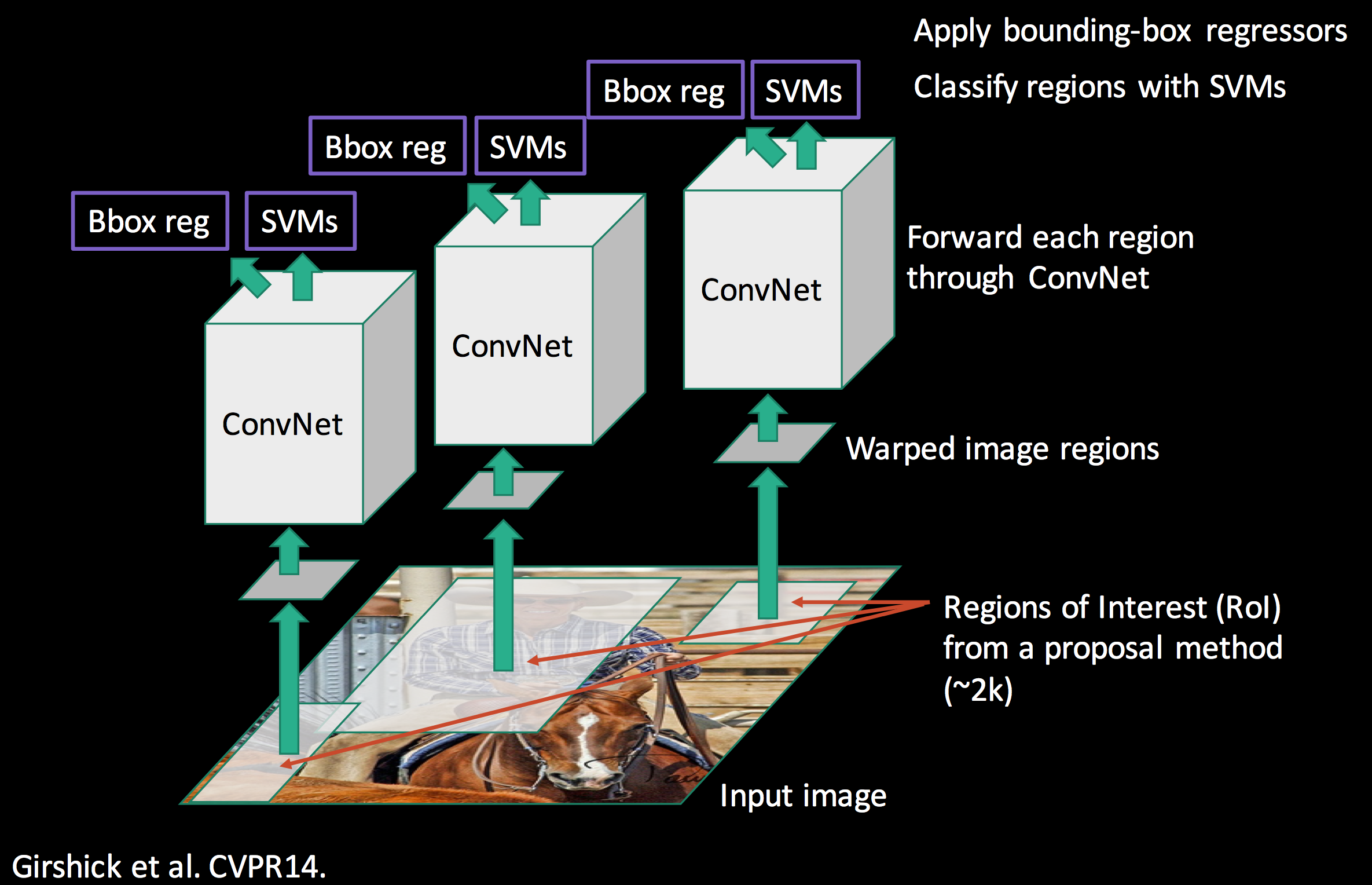
在 R-CNN 中,作者的思路是两阶段方法,即先用 Selective Search 算法生成大量候选框(约2000个),再通过CNN(如AlexNet,VGG)对缩放填充至固定大小的候选框图像(Wraped image regions)进行特征提取,最后对CNN提取到的高维特征分别用 SVM 做物体类别分类,用全连接网络(三层)做矩形框的中心坐标和宽高值进行回归。
贡献与不足
R-CNN 贡献在于,首次提出了两阶段的目标检测方法,即先生成候选框,再用CNN进行目标检测。整个过程一共包含四大块算法工作:
- Selective Search 感兴趣区域生成(后续简称“SS”)。
- CNN图像分类网络预训练。
- 基于 SVM 的分类器训练。
- 基于回归模型的边界框精细化。
但以上设计也带来如下问题需要解决:
- 候选框裁剪的图像送入网络时,必须缩放填充至指定大小,这个做法会对目标产生形变。
- 每一张图就会产生2000张左右的小图,这些都要送入给CNN进行特征提取,这无疑增加了训练时的内存占用,降低了推理时的速度,面庞大的数据集工作量将是巨大的!
基于 SPPNet 的目标检测
基本原理
在 SPPNet 中,作者仍然采取的是两阶段方法,先用 Selective Search 算法生成大量候选框(约2000个),然后利用卷积神经网络提取高维特征。在做目标分类和边界框回归时,作者创新新的提出将候选框从原图直接映射到卷积神经网络输出的高维特征图上,相当于直接在高维特征图上进行裁剪。然后再利用金字塔池化操作,将特征图转到指定大小给到全连接层输出。最后再基于全连接层输出进行SVM目标分类,和边界框回归。
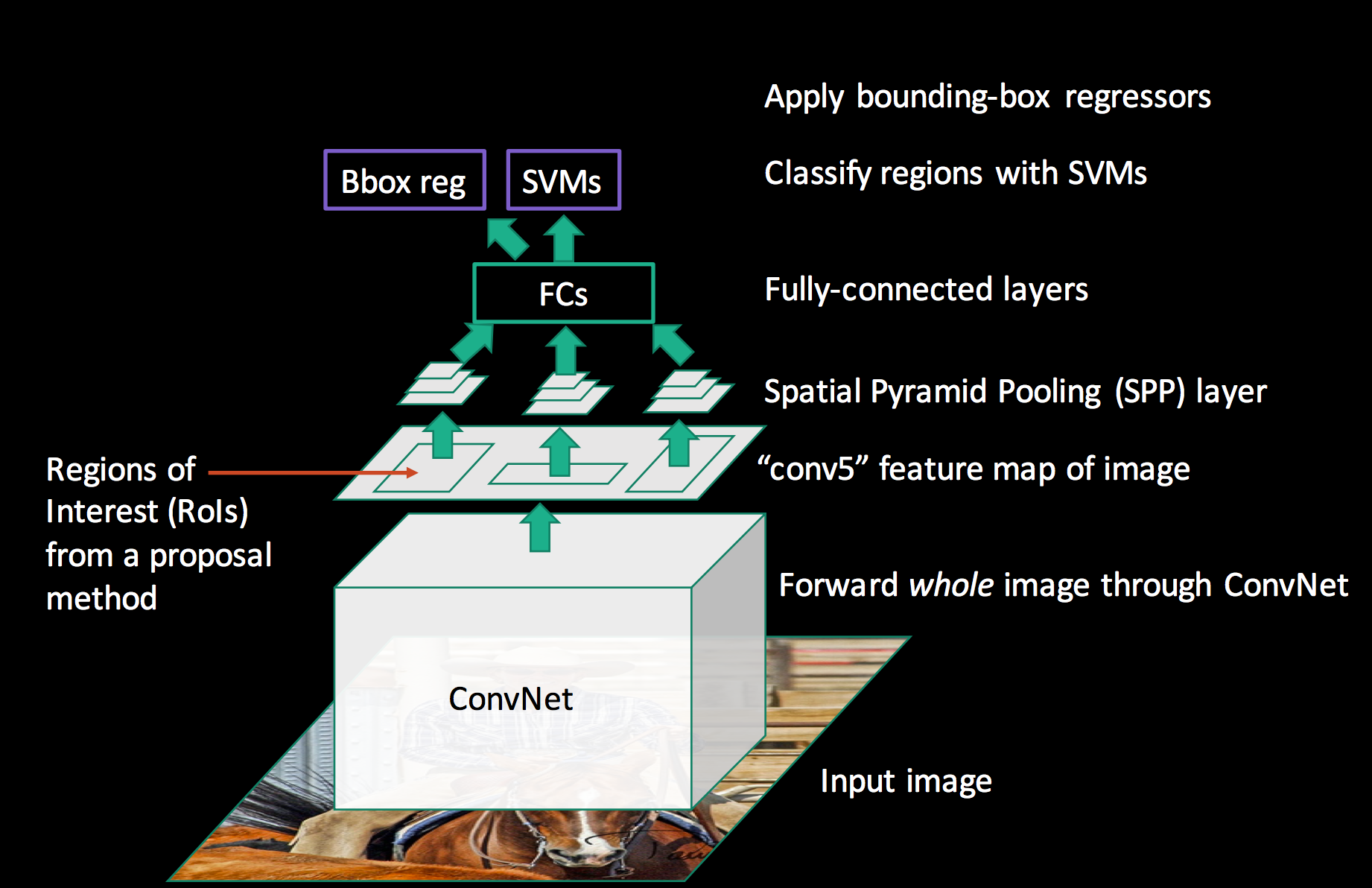
以上改进直接解决了卷积神经网络输入图像必须缩放到固定大小的问题,同时训练时,CNN只需要完成一次前向传播就可以了(ROI映射,直接在高维特征上裁剪),而R-CNN需要 2000次左右(每个小块图像都要卷积)。
金字塔池化(Spatial pyramid pooling)
R-CNN 之所以要求图像必须缩放填充到固定大小后才能输入给CNN,是因为在当时的分类卷积神经网络中,一般要求输入图像大小是固定的,而卷积核大小以及全连接层的大小都是设计好的,每一层的特征维度都是固定大小。但是实际上只有全连接层才是必须固定输入大小,对于CNN输出的特征图,可以通过一定的处理,转换成固定大小的输出。
R-CNN 选择将一张图像裁剪成多个感兴趣区域小图,分别送入CNN训练,造成了训练速度慢的问题。但实际上在感受野概念提出来后,卷积层之间的是能够传递这种ROI大小关系的,输入的ROI在经过若干个卷积后,可以计算出对应的ROI被卷到哪个位置了。
基于以上两个认知前提下,金字塔池化(Spatial pyramid pooling)被提出。

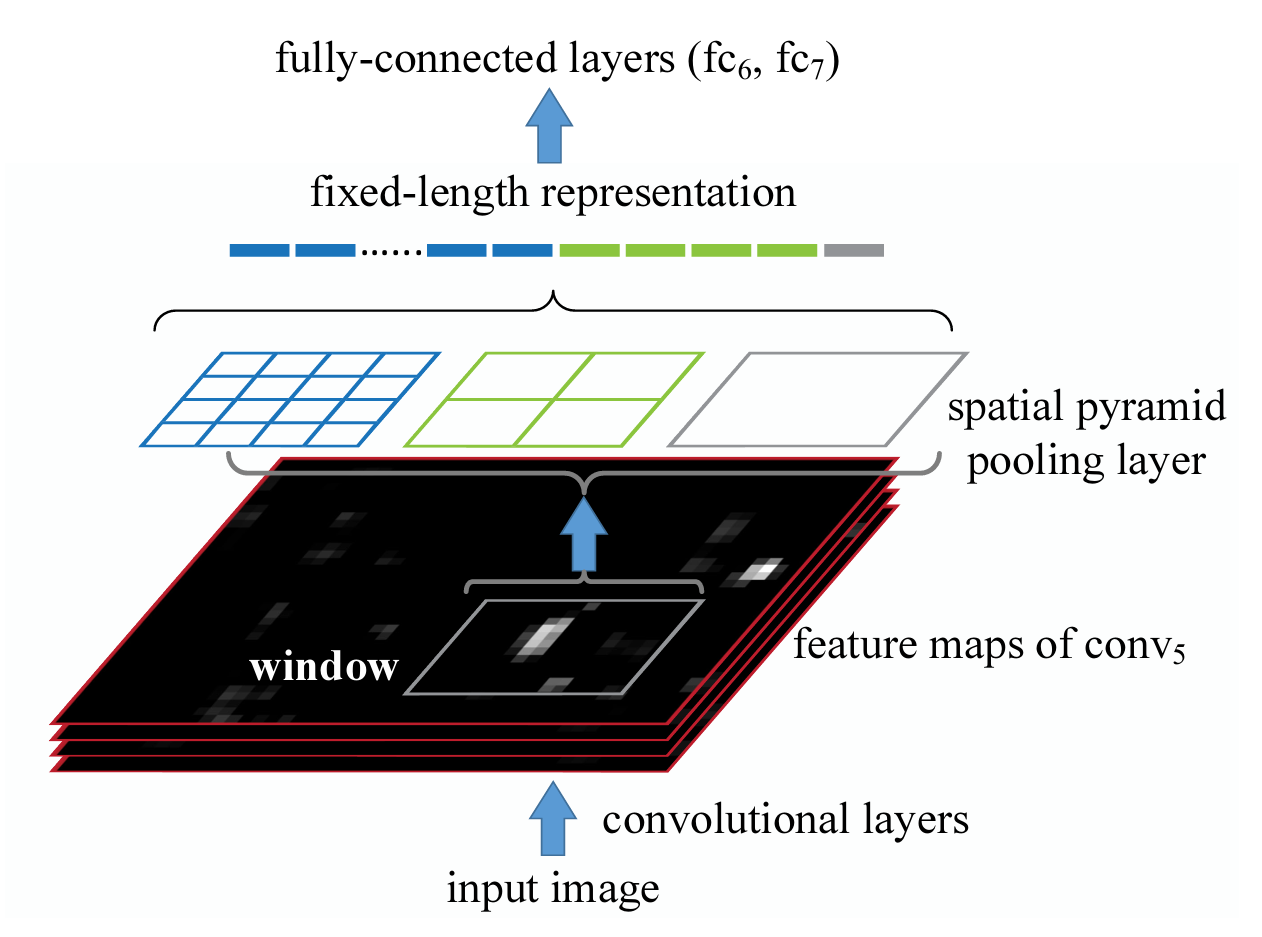
如上图所示,R-CNN选择将图像 crop/warp 后输入给 conv layers,而SPPNet 选择在 conv layers 和 fc layers 之间插入一个 SPP 模块,该模块可以起到将任意大小的特征图,转换为一个固定长度的特征向量,如下图所示:
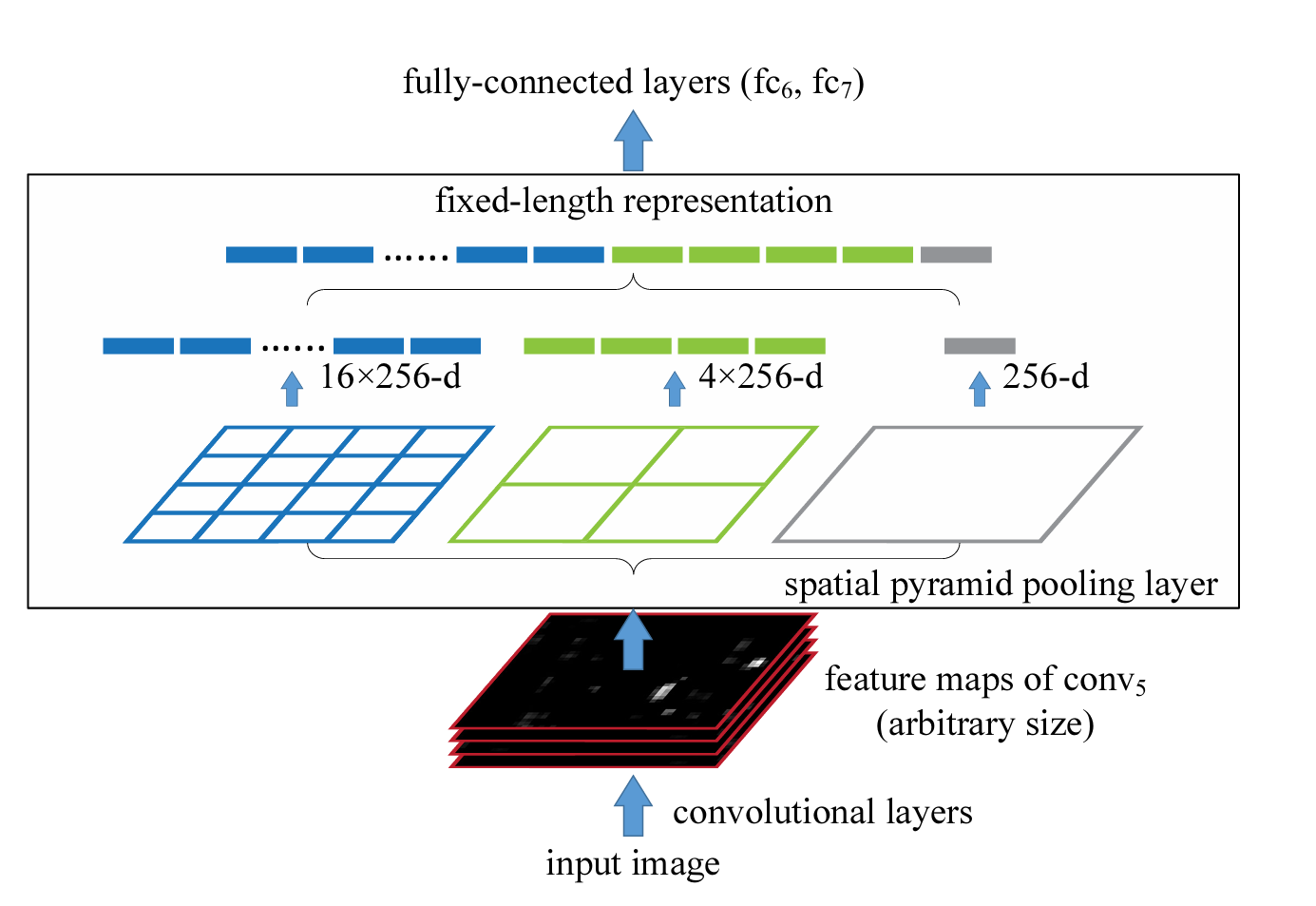
对于输入的特征图,为避免直接池化到一个数值造成特征丢失,可以将特征图分别划分为 1×1,2×2,4×4的网格,对每个网格中的图像做最大池化分别得到 1×1+2×2+4×4 = 21个数值,这些数值拼接到一起,每个通道都拼接到一起,就是一个特征向量了,该向量输入给后续的全连接层做分类或者回归,特征向量的长度只取决于网格划分的大小,而不再取决于输入特征图的大小,这一以来,就可让网络接受任意尺寸的图像输入了。网络可以学到多尺度特征。
而在目标检测时,只需要将候选框ROI映射到高维特征图上,就可以得到这部分ROI产的高维特征了。
ROI映射到特征图
由于卷积和池化操作比较复杂,可以简化映射关系为如下表达:
假设每个滤波器在卷积时,若卷积核大小为 \(p\) ,则卷积时外侧padding大小为 \(\lfloor{p/2}\rfloor\) 。则对于特征图中的某个像素点 \((x',y')\) ,其在输入图像中的实际感受野大小为 \((Sx',Sy')\),其中 \(S\) 为当前特征图之前所有层步长的乘积。
于是对于生成的候选框ROI,分别计算左上角和右下角的坐标即可。当padding大小为 \(\lfloor{p/2}\rfloor\) 时,以x坐标为例,左上角x坐标为:
右下角x坐标为:
如果padding大小不为 \(\lfloor{p/2}\rfloor\)时,则需要适当调整上式中 x 的 offset 。
贡献与不足
SPPNet 的贡献在于金字塔池化模块的设计,巧妙地利用特征图按网格划分池化,实现了任意特征图到指定特征向量的映射。解决了以往CNN必须将图像缩放到固定大小训练的问题,也给网络带来了自主学习多尺度特征的机会(输入图像大小变化即为多尺度)。然后基于感受野提出的候选框ROI映射到特征图方法,将一张图的CNN训练次数从2000多次降至1次,极大地提高了训练的效率。
尽管SPPNet解决了以上所说的问题,但所设计的解决方案,仍然是两阶段的,候选框生成、CNN特征提取,SVM分类、边界框回归这几大块仍然是独立,训练过程比较繁琐。
基于 Fast R-CNN 的目标检测
基本原理
在 Fast R-CNN 中,作者仍然采用两阶段方法。先用 Selective Search 算法生成大量候选框(约2000个),让后将整张图输入给CNN进行特征提取。然后借鉴SPPNet,将候选框ROI映射到最后一层输出的特征图上,裁剪得到候选特征图,然后对候选特征图直接按照固定网格大小(7×7)进行最大池化,并拼接到一起得到特征向量。(这里的操作称作 ROI Pooling,可以理解为只有一个尺寸的SPP)。对于输出的特征向量,这里作者不再将目标分类和边界框回归拆分成两个任务,直接统一使用全连接层线性变换后输出的特征向量,即做目标分类又做边界框回归。
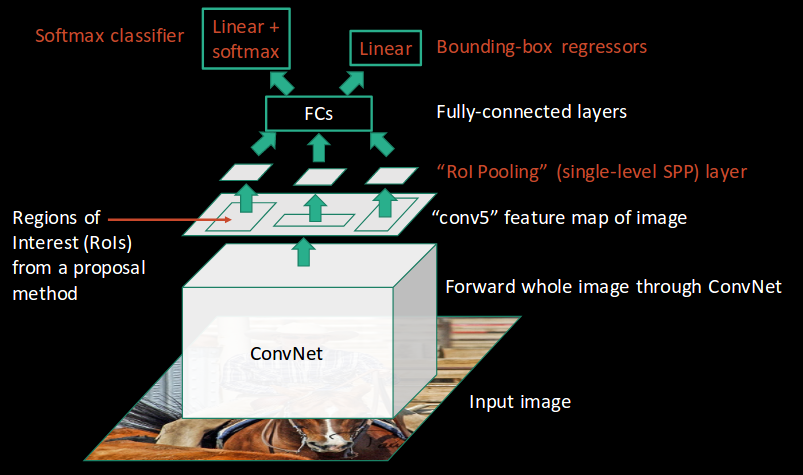
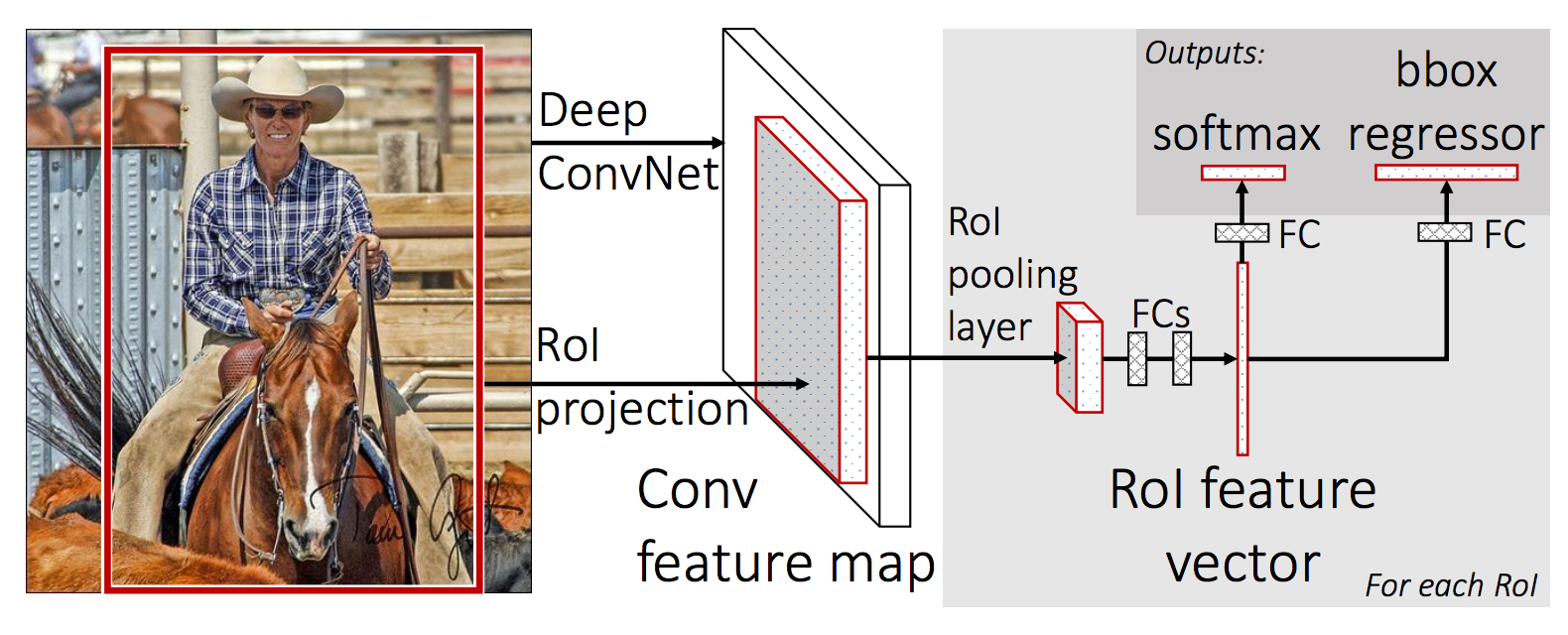
贡献与不足
Fast R-CNN 首次将目标分类和边界框回归这两个任务合并到一起,使得两阶段方法称为纯粹的两阶段,即候选框生成,目标分类和边界框回归。而SPPNet 和 R-CNN都是将CNN特征提取、目标分类、边界回框回归拆分成了三块独立的工作,这使得训练变得繁琐。
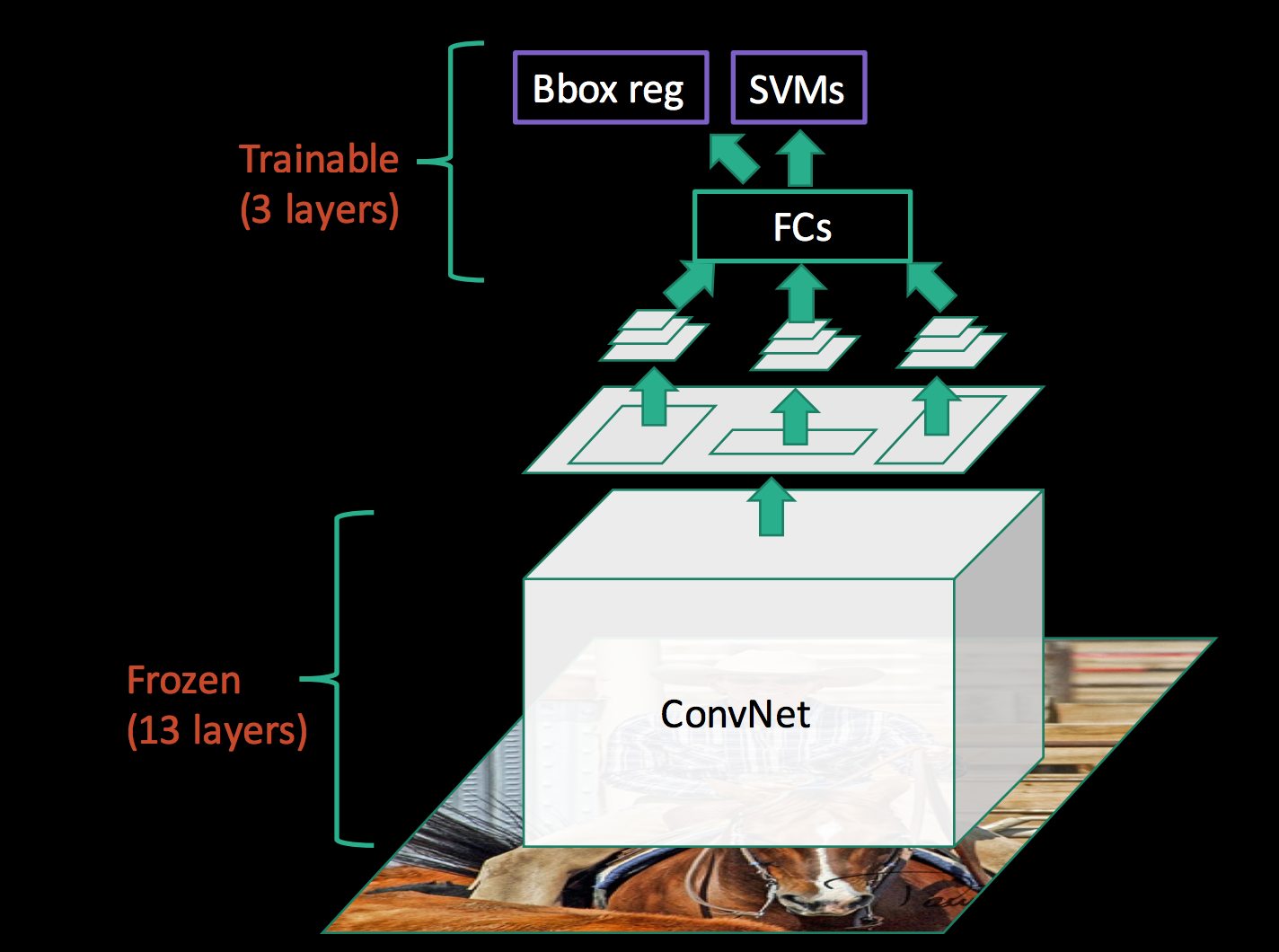
在 SPPNet 中,CNN特征提取网络训练完后,需要冻结。后续的SVM目标分类,边界框回归则可视为一个整体,可独立训练。而在Fast R-CNN中,CNN特征提取和SVM目标分类以及边界框回归三者称为一个大的整体,这使得 CNN 可以微调,而这是SPPNet不具备的(梯度无法从最后传回)。
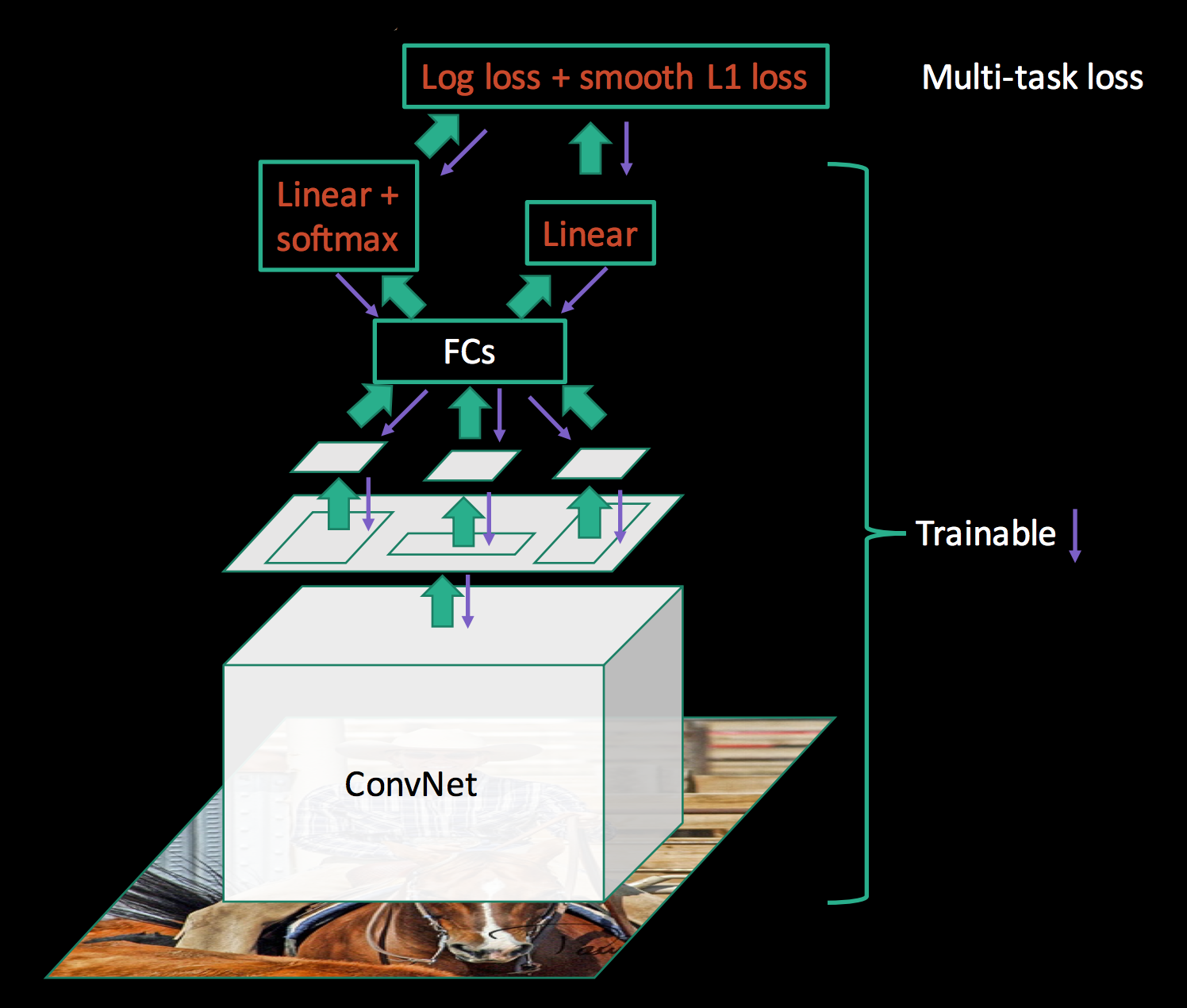
尽管 Fast R-CNN 统一了整个目标分类和边界框回归的网络架构,但仍然是两阶段的做法,候选框生成耗时仍比较长,且两部分工作是分离的。
基于 Faster R-CNN 的目标检测
基本原理
在 Faster R-CNN 中,作者延续了 Fast R-CNN 的总体思路,设计了一个区域建议网络(Region Proposal Network,RPN),来替代Selective Search 选框生成算法。
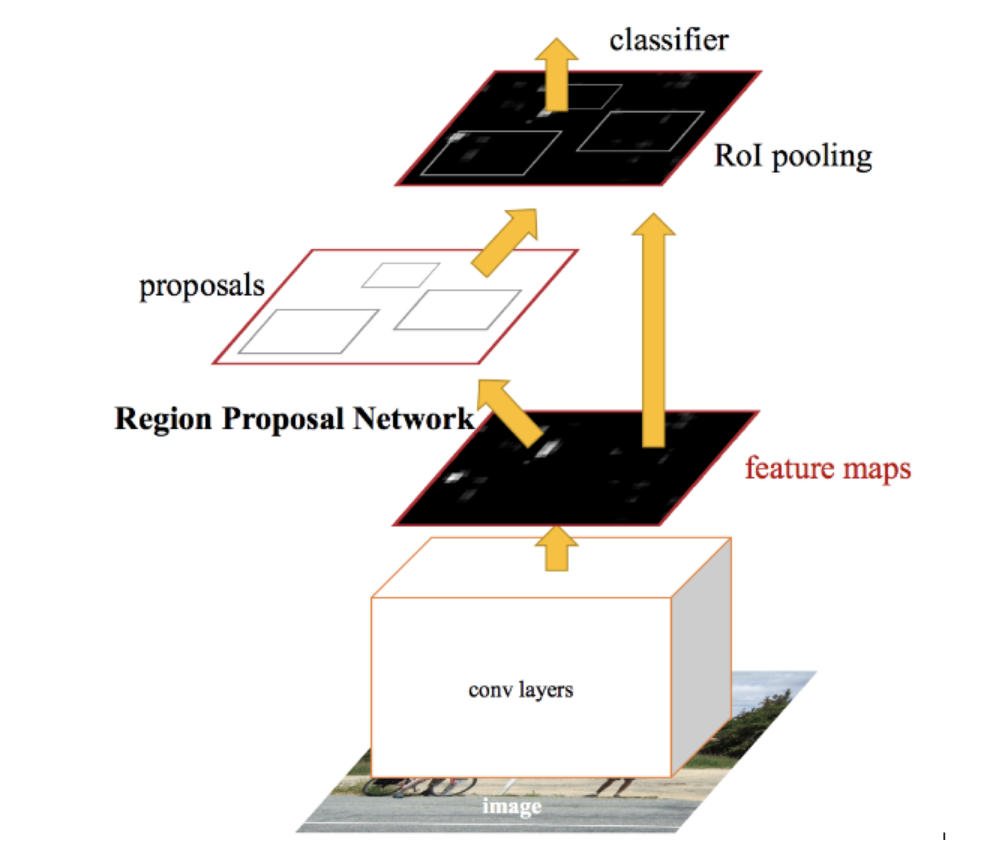
整体流程:输入图像经CNN卷积后输出高维特征图,然后分两路,一路给RPN网络做特征提取,输出候选框,这部分候选框生成被单独监督;另一路则在候选框生成后,延续Fast R-CNN的做法,通过候选框ROI裁剪特征图,做ROI Pooling,以及后续操作(与Fast R-CNN一样)。
在这样的设计下,目标检测终于可称得上是端到端的训练了。网络的训练同时监督候选框生成,又监督目标分类以及边界框回归。
区域建议网络(RPN)
矩形框生成
在 RPN 网络中,输入的是特征提网络的 “conv5” 特征图。在该特征图上,使用 3×3 的卷积核进行特征提取(padding为1,stride为1),得到同样大小的特征图。此时对于每个像素,其沿深度方向构成一个 n×1×1的一维向量,该向量分别送入到两个全连接网络(也可以是1×1卷积)中进行计算,其中一个全连接网络负责预测预测该窗口对应的前景和背景概率(相加为1),另一个全连接网络则负责回归当前的窗口下边界框的坐标信息。而对于每一个像素,都对应绑定k个矩形框,即两个全连接层输出的是k个矩形框配套的信息(2k 个概率scores,4k个边界框坐标)。假设特征图的大小是 w×h×d,则一共会产生 w×h×k 个矩形框。
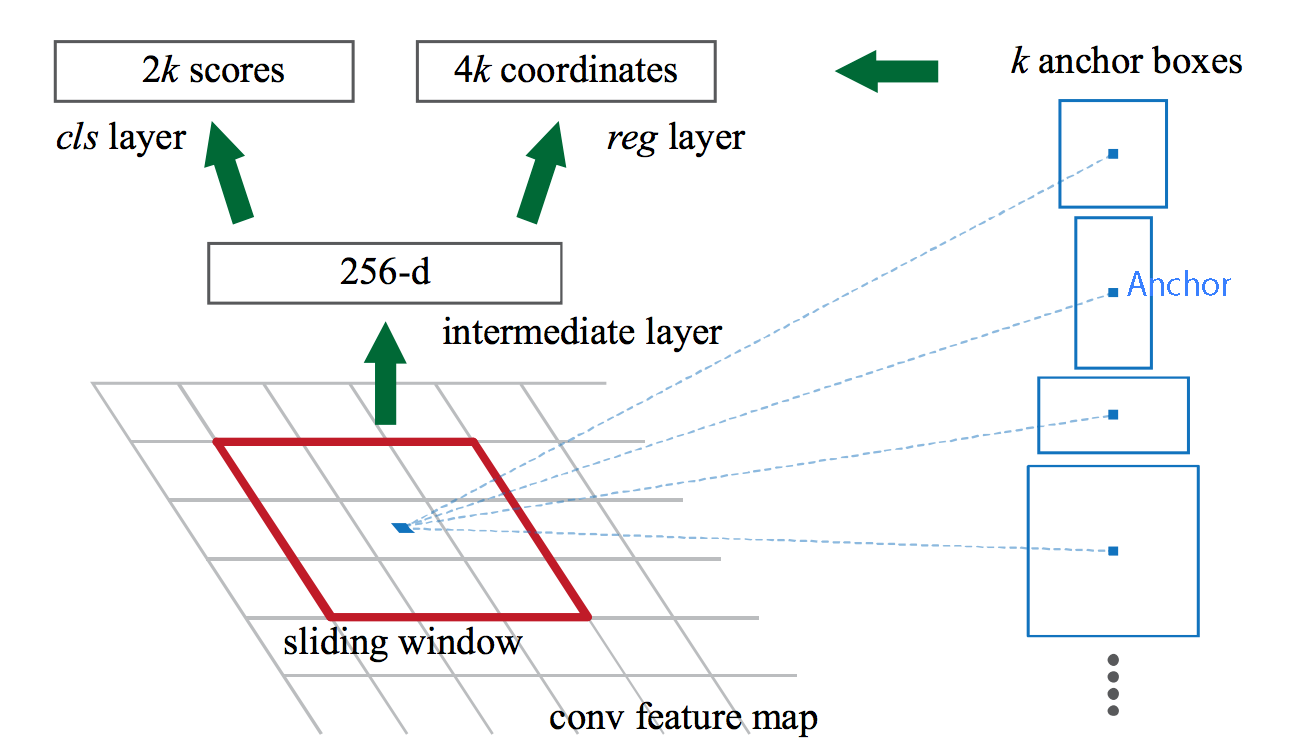
其中 \(k=9\) ,这9个矩形框的产生逻辑是这样的:
以特征图像素点为中心,映射到输入图像中,则该像素点为中心,按照三种长宽比例:1:1, 2:1, 1:2,三种面积比例 128×128,256×256,512×512,排列组合,产生一共9种矩形框。
矩形框滤除
在上述矩形框生成方法下,将会产生上万个矩形框,例如一张 1000×600×3 的图像,将会产生 60×40×9 (20k) 个矩形框,对于部分超出图像边界的矩形,将其忽略,则剩下约 6k 个。剩下的矩形框彼此之间还可能产生大量重叠,基于候选框的目标概率得分排序,以及非极大值抑制,IOU是否大于0.7来进行筛选,最终剩下约 2k 个矩形框。
贡献与不足
Faster R-CNN 首次提出使用深度学习方法产生候选矩形框,虽然理解上较为复杂,但正是因为该设计的存在,才使得目标检测网络能够做到端到端,为后续研究提供了参考。
RPN网络生成了大量的矩形框,因此带来了巨大的计算量,整个网络无法做到实时检测。
基于 Mask R-CNN 的目标检测
在 Mask R-CNN 中,作者主要做了两点改进:
- 对 Faster R-CNN 中的 ROI Pooling 操作改进为 ROI Align操作;
- 在 Faster R-CNN 加了一个分支,用于输出目标框中目标的分割结果。
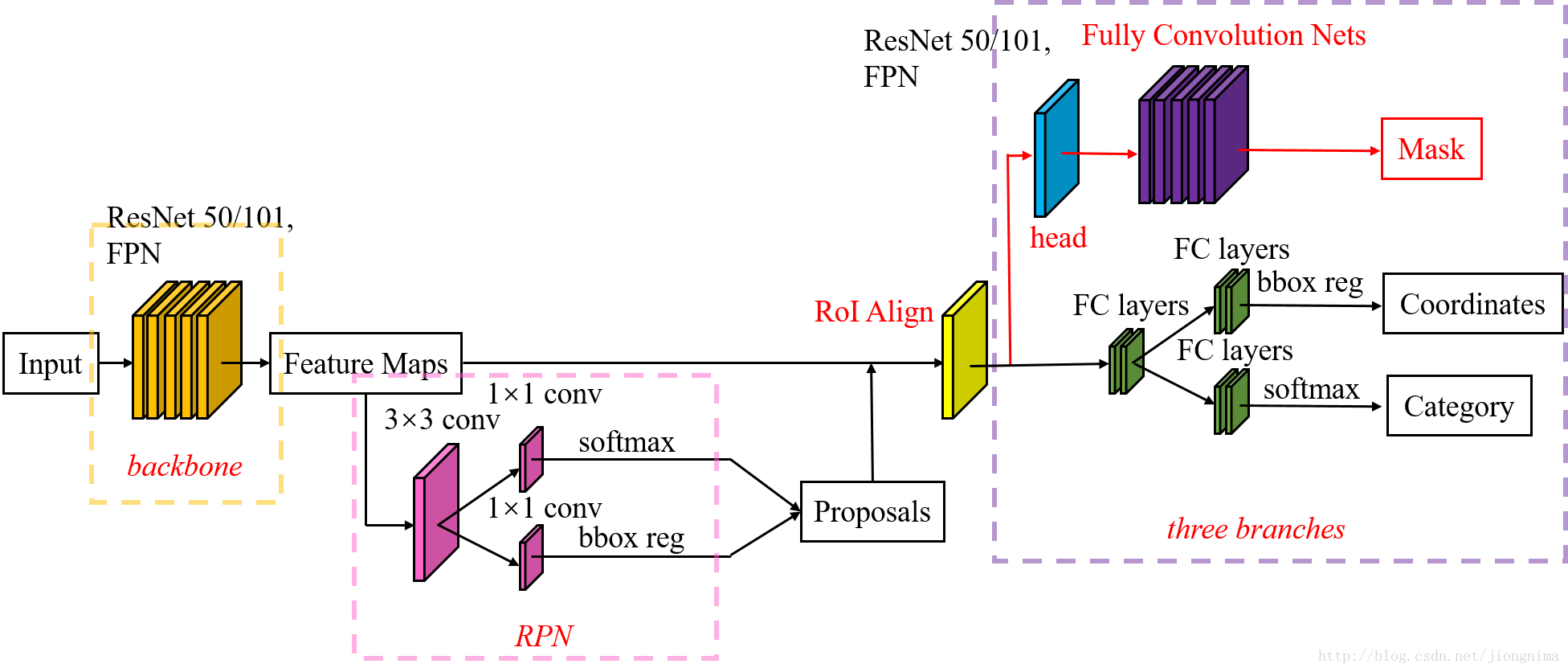
ROI Align
作者希望做图像分割,当然会在意像素的精度了。在研究ROI Pooling操作时,发现Faster R-CNN作者在这些步骤中运用许多取整的运算,这些会导致像素误差,具体表现在:
- 从特征图中提取候选框特征图时,使用了四舍五入取整
- 在对候选框特征图进行网格划分时,使用了向下取整
这样处理下来,作者认为会影响逐项像素预测的任务,而对于分类任务影响不大,于是提出使用双线性插值来更精确地找到每个块对应的特征。
分割分支
在分割分支中,RoI Align之后有一个"head"部分,主要作用是将RoI Align的输出维度扩大,这样在预测Mask时会更加精确。在Mask Branch的训练环节,作者没有采用FCN式的SoftmaxLoss,反而是输出了K个Mask预测图(为每一个类都输出一张),并采用average binary cross-entropy loss训练,当然在训练Mask branch的时候,输出的K个特征图中,也只是对应ground truth类别的那一个特征图对Mask loss有贡献。
参考资料
- Fast R-CNN and Faster R-CNN
- https://ispz.github.io/2019/12/02/从RCNN到MSRCNN
- Introduction to Object Detection Algorithms using cnn | Analytics Vidhya
- PowerPoint Presentation
- 深度学习目标检测算法之Faster R-CNN算法-CSDN博客
- https://www.bilibili.com/video/BV1af4y1m7iL
- RPN-区域生成网络-Region Proposal Network(Faster-RCNN) - 知乎
- 【机器学习】FRCNN rpn部分 - Jolyne123 - 博客园
- RPN之generate_anchor - 知乎
- Mask RCNN 超详细图文入门(含代码+原文)_mask rcnn代码-CSDN博客
- 实例分割模型Mask R-CNN详解:从R-CNN,Fast R-CNN,Faster R-CNN再到Mask R-CNN-CSDN博客
- 【Faster R-CNN论文讲解_3】 【精准空降到 07:24】
- Deep Learning for Generic Object Detection: A Survey

 浙公网安备 33010602011771号
浙公网安备 33010602011771号