tensorflow踩坑合集2. TF Serving & gRPC 踩坑
这一章我们借着之前的NER的模型聊聊tensorflow serving,以及gRPC调用要注意的点。以下代码为了方便理解做了简化,完整代码详见Github-ChineseNER ,里面提供了训练好的包括bert_bilstm_crf, bilstm_crf_softlexcion,和CWS+NER多任务在内的4个模型,可以开箱即用。这里tensorflow模型用的是estimator框架,整个推理环节主要分成:模型export,warmup,serving, client request四步
Model Export
要把estimator保存成线上推理的格式,需要额外定义两个字段,serving的输出和输入格式。
输出定义
serving的输出在tf.estimator.EstimatorSpec中定义,比较容易混淆的是EstimatorSpec中有两个和推理相关的字段predictions和export_outputs,默认predictions是必须传入,export_outputs是可选传入。
差异在于predictions是estimator.predict的返回,并且允许predictions中的字段和features&labels的字段存在重合,例如我经常会把一些用于debug的字段像中文的tokens放在predictions,这些字段既是模型输入也是predict输出。
如果export_outputs=None,estimator会默认用如下方式生成export_output,signature_name='serving_default',字段和predictions完全相同。
export_output = {
tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY:
tf.estimator.export.PredictOutput(predictions)
}
但是对后面raw tensor输入的serving input,是不允许export_output和input显式出现相同字段。所以我习惯单独定义export_output,只保留线上serving需要返回的预测字段
def model_fn(features, labels, mode, params):
... build tf graph
if mode == tf.estimator.ModeKeys.PREDICT:
output = {'serving_default':
tf.estimator.export.PredictOutput({'pred_ids': pred_ids})
}
spec = tf.estimator.EstimatorSpec(mode,
predictions= {'pred_ids': pred_ids,
'label_ids': features['label_ids'],
'tokens': features['tokens']
},
export_outputs=output)
return spec
输入定义
serving的输入在tf.estimator.export.ServingInputReceiver中定义,其中features是传入模型的特征格式,receiver_tensors是推理服务的请求格式,这俩啥差别呢?这个要说到serving input有两种常见的定义方式,一种是传入序列化后的tf.Example(receiver_tensor),然后按照tf_proto的特征定义对example进行解析(feature)再输入模型。这种方式的好处是请求接口一致,不管模型和特征咋变服务请求字段永远是example。哈哈还有一个好处就是tf_proto的定义可以复用dataset里面的定义好的
def serving_input_receiver_fn():
tf_proto = {
'token_ids': tf.io.FixedLenFeature([150], dtype=tf.int64),
'segment_ids': tf.io.FixedLenFeature([150], dtype=tf.int64)
}
serialized_tf_example = tf.placeholder(
dtype=tf.dtypes.string,
shape=[None],
name='input_tensor')
receiver_tensors = {'example': serialized_tf_example}
features = tf.parse_example(serialized_tf_example, tf_proto)
## 可能还会有feature preprocess逻辑在这里
return tf.estimator.export.ServingInputReceiver(features, receiver_tensors)
另一种就是直接用原始特征请求,这时features和receiver_tensors是一样滴。这种方式的好处是用saved_model_cli可以直接检查serving的input格式,以及在请求特征size非常大的时候,这种请求能多少节省一点以上序列化所需的时间。
def serving_input_receiver_fn():
token_ids = tf.placeholder(dtype=tf.int64, shape=[None, 150], name='token_ids')
segment_ids = tf.placeholder(dtype=tf.int64, shape=[None,150], name='segment_ids')
receiver_tensors = {'token_ids': token_ids,
'segment_ids': segment_ids}
return tf.estimator.export.ServingInputReceiver(receiver_tensors, receiver_tensors)
Export
定义好serving的输入输出后,直接export model即可,这里可以是训练完后export。也可以用已经训练好的checkpoint来build estimator然后直接export,这里会默认使用model_dir里面latest ckpt来export。
estimator._export_to_tpu = False
estimator.export_saved_model('serving_model/bilstm_crf', serving_input_receiver_fn)
输出的模型默认用当前timestamp作为folder_name, 按需要rename成version=1/2即可
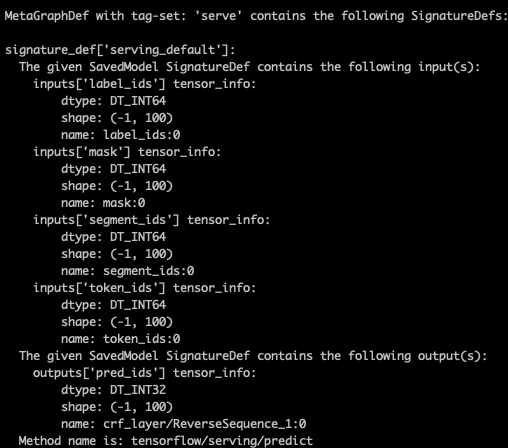
然后我们可以通过saved_model_cli来检查模型输入输出。图一是tf.Example类型的输入,图二是raw tensor输入,raw tensor类型的输入debug更方便一点。
saved_model_cli show --all --dir ./serving_model/bilstm_crf/1

Warm up
在得到上面的servable model后,在serving前还有一步可选操作,就是加入warm up文件。这主要是因为tensorflow模型启动存在懒加载的逻辑,部分组件只在请求后才被触发运行,所以我们会观察到第一次(前几次)请求的latency会显著的高。warm up简单说就是在模型文件里带上几条请求的测试数据,在模型启动后用测试数据先去trigger懒加载的逻辑。具体操作就是在serving model的assets.extra目录里写入请求数据
NUM_RECORDS=5
with tf.io.TFRecordWriter("./serving_model/{}/{}/assets.extra/tf_serving_warmup_requests".format(MODEL, VERSION)) as writer:
# 生成request的逻辑
log = prediction_log_pb2.PredictionLog(
predict_log=prediction_log_pb2.PredictLog(request=req))
for r in range(NUM_RECORDS):
writer.write(log.SerializeToString())
Server
server部分比较简单,比较推荐Docker部署,方便快捷。只需要三步
- 下载Docker https://docs.docker.com/get-docker/
- 下载和环境适配的Image,不指定版本默认是latest
docker pull tensorflow/serving:1.14.0
- 在本地运行运行服务,注意port 8500是给gRPC的,8501是給REST API的不要写错
docker run -t --rm -p 8500:8500 \
-v "$(pwd)/serving_model/${MODEL_NAME}:/models/${MODEL_NAME}" \
-e MODEL_NAME=${MODEL_NAME} tensorflow/serving:1.14.0
gRPC client
Demo
这里我们以上面tf.Example的serving请求格式,看下如何用gRPC请求服务。请求主要分成3步:建立通信,生成request, 请求并解析response
第一步建立通信
channel = grpc.insecure_channel(‘localhost:8500’)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
第二步生成请求
# 得到tf_feature dict
example = tf.train.Example(
features=tf.train.Features(feature=tf_feature)
).SerializeToString() # 得到example并序列化成string
example = [example] # add batch_size dimension
# 生成request
request = predict_pb2.PredictRequest()
request.model_spec.signature_name = 'serving_default' # set in estimator output
request.model_spec.name = 'bilstm_crf'
request.model_spec.version.value = 1
request.inputs['example'].CopyFrom(
tensor_util.make_tensor_proto(example, dtype=tf.string)
)
第三步请求服务,解析response
resp = stub.Predict.future(request, timeout=5)
res = resp.result().outputs
pred_ids = np.squeeze(tf.make_ndarray(res['pred_ids']))
gRPC踩坑
在使用gPRC client的过程中有几个可能会踩坑的点,哈哈但不排除出坑的姿势不完全正确,如果是的话求指正~
Not fork safe,使用多进程要注意!
官方文档:grpc/fork_support
gRPC并不是fork safe的,如果在fork之前创建channel,可能会碰到deadlock或者报错,取决于你用的gRPC版本。。。我使用的1.36版本会检查fork,如果channel在fork之前创建且未close,会raise‘ValueError: Cannot invoke RPC: Channel closed due to fork’,之前用的忘记是啥版本的会deadlock。想要在client侧使用多进程,合理的方案是在fork之后,在每个子进程中创建channel,如果主进程有channel需要先close掉。multiprocessing/client 给了一个多进程client的demo
channel重用大法好
官方文档:Performance Guide
最开始用gRPC我习惯性的在单条请求以后会channel.close,或者用with管理,后来发现channel创建销毁本身是比较耗时的。看了官方文档才发现正确使用方式是在整个client生命周期里复用同一个channel。至于stub,个人感觉创建成本很低,复用和每次从channel重新创建差别不大。
channel保活
官方文档:Keepalive User Guide
上面的channel复用会延伸到channel保活的问题。grpc客户端默认是长链接,避免了链接建立和销毁的开销,但需要keep-alive机制来保证客户端到服务端的链接持续有效。如果客户端发送请求的间隔较长,在一段时间没有请求后,需要知道到底是server掉线了,还是真的没有数据传输,这个链接还需不需要保持。grpc通过发送keep-alive ping来保活。
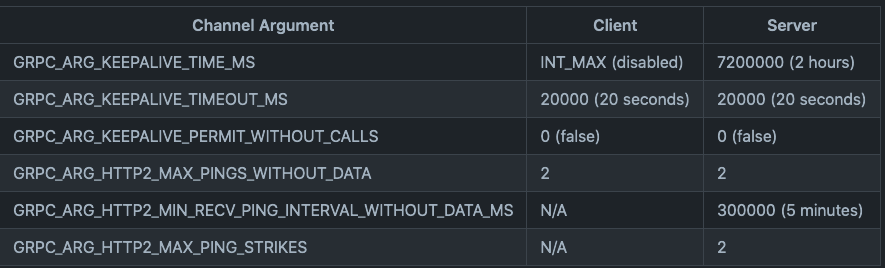
在链接建立后,keep-alive计时器开始,通过以下参数控制是否发送ping,发送的时间,次数,间隔。
- grpc.keepalive_permit_without_calls,set=1则无请求进行,也可以发送keepalive ping
- grpc.http2.max_pings_without_data,没有数据传输的情况下,最多允许send多少ping,set=0是无限发送
- grpc.keepalive_time_ms,client发送ping的时间间隔
- grpc.keepalive_timeout_ms,确认ping应答的超时时间
- grpc.http2.min_ping_interval_without_data_ms,没有数据传输的情况下,server允许收到ping的最小时间间隔,小于这个间隔的ping会被认为是ping strike。这个数值设置要>=以上keepalive_time_ms
- grpc.http2.max_pring_strikes, server最多允许ping strike的次数,超出会发送GOAWAY自动断开链接,set=0允许无限次
以下是参数的默认取值
statusCode.UNAVAILABLE,‘connection reset by peer’
针对偶发UNAVAILABLE的报错,部分情况可能是server部署环境和保活参数的设置有一些冲突,详见Docker Swarm 部署 gRPC 服务的坑,不过多数情况下都能被retry解决。grpc issue里提到一个interceptor 插件现在是experimental API。简单拆出来就是下面exponential backoff的retry逻辑。果然解决bug两大法器restart+retry。。。
RETRY_TIEMS = {
StatusCode.INTERNAL: 1,
StatusCode.ABORTED: 3,
StatusCode.UNAVAILABLE: 3,
StatusCode.DEADLINE_EXCEEDED: 5 # most-likely grpc channel close, need time to reopen
}
def grpc_retry(default_max_retry=3, sleep=0.01):
def helper(func):
@wraps(func)
def handle_args(*args, **kwargs):
counter = 0
while True:
try:
return func(*args, **kwargs)
except RpcError as e:
max_retry = RETRY_TIEMS.get(e.code(), default_max_retry)
if counter >= max_retry:
raise e
counter += 1
backoff = min(sleep * 2 ** counter, 1) # exponential backoff
time.sleep(backoff) # wait for grpc to reopen channel
return handle_args
return helper

 浙公网安备 33010602011771号
浙公网安备 33010602011771号