
【ACM MM2021】Cross-modality Discrepant Interaction Network for RGB-D Salient Object Detection
【MM2021】Cross-modality Discrepant Interaction Network for RGB-D Salient Object Detection
代码: https:// rmcong.github.io/proj_CDINet.html
1、研究动机
这是来自北京交通大学 丛润民 老师组的工作,解决的问题是 RGB-D 显著性物体检测。当前的RGB-D 分割工作,主要分为两个类别:(1) Unidirectional interaction mode shown in Figure 1(a), which uses the depth cues as auxiliary information to supplement the RGB branch. (2) Undifferentiated bidirectional interaction shown in Figure 1(b), which treats RGB and depth cues equally to achieve cross-modality interaction.
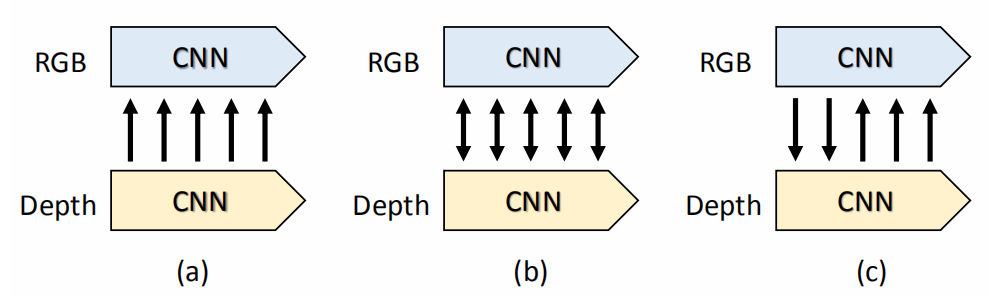
作者提出一个问题: since these two modalities have their own strong points, can we design a discrepant interaction mode for RGB-D SOD based on their roles to make full use of the advantages of both?
作者指出,和之前方法观点不同,we believe that the interaction of the two modalities information should be carried out in a separate and discrepant manner. The low-level RGB features can help the depth features to distinguish different object instances at the same depth level, while the high-level depth features can further enrich the RGB semantics and suppress background interference. Therefore, a perfect RGB-D SOD model should give full play to the advantages of each modality, and simultaneously utilize another modality to make up for itself to avoid causing interference. 框架如上图(c)所示。
2、 Cross-modality Discrepant Interaction Network (CDINet)
CDINet 框架如下图所示,encoder有五层,前两层用RGB信息增强 depth,后面三层用 depth 增强RGB。包括三个核心部分:RGB-induced detail enhancemnet (RDE),Depth-induced semantic enhancement (DSE),Dense decoding reconstruction(DDR).
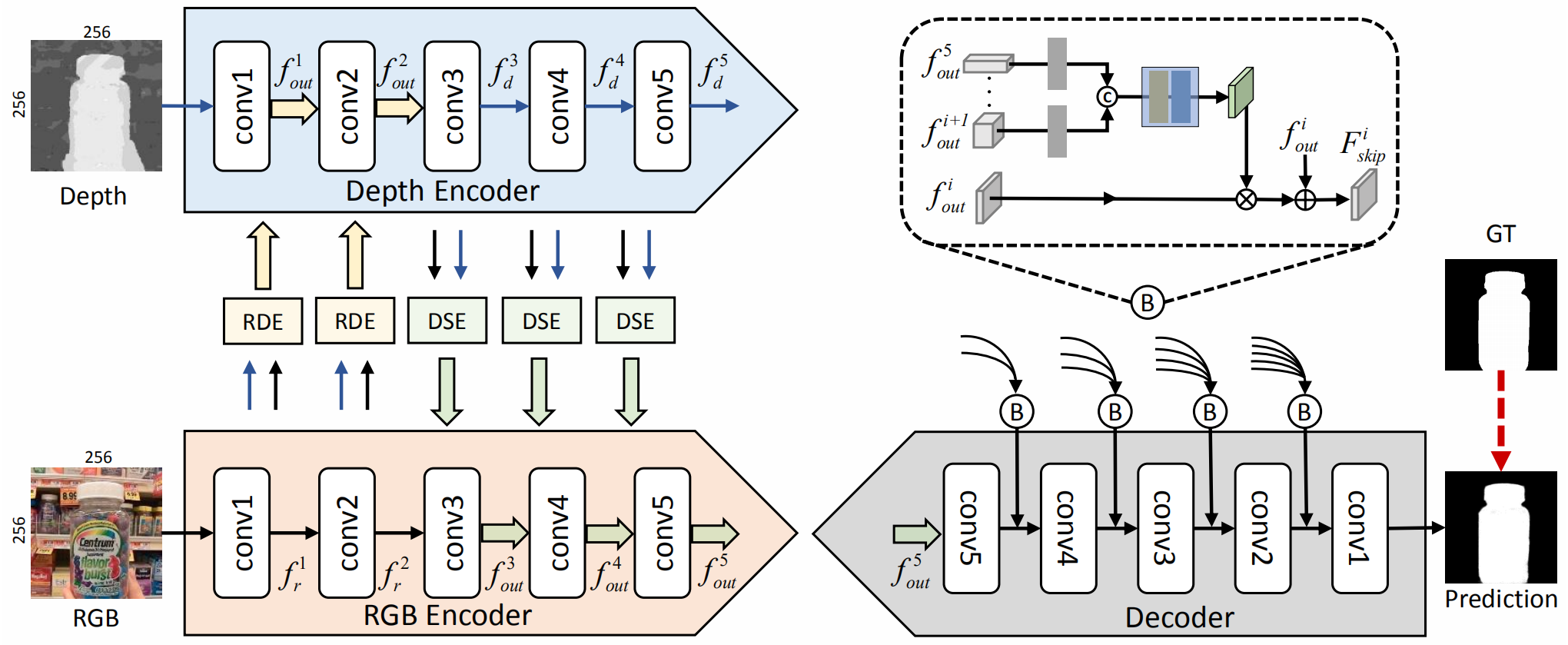
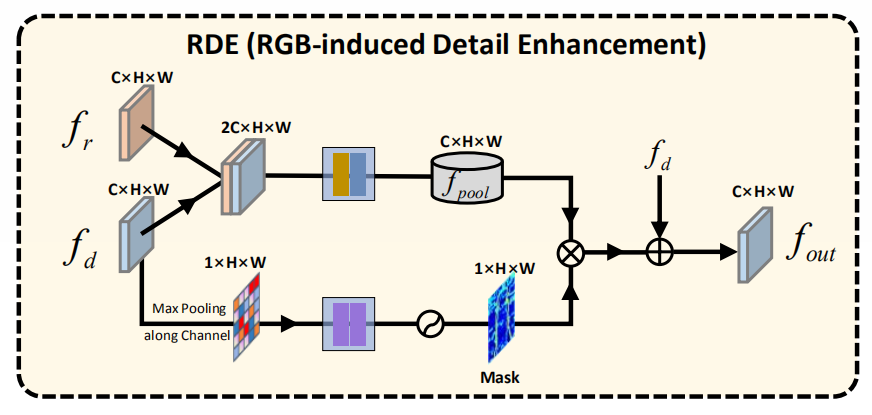
**1)RGB-induced detail enhancemnet. ** 在低级编码器特征中,深度特征包含更详细信息(例如边界和形状),可以提供比 RGB 特征更好的细节表示,这有利于初始特征学习。因此,在网络浅层设计RDE模块,通过低层中的 RGB 特征来增强 depth。该模块如下图所示,本质上是对 depth做注意力,不过在初始输入上将RGB直接与 depth 特征拼接。
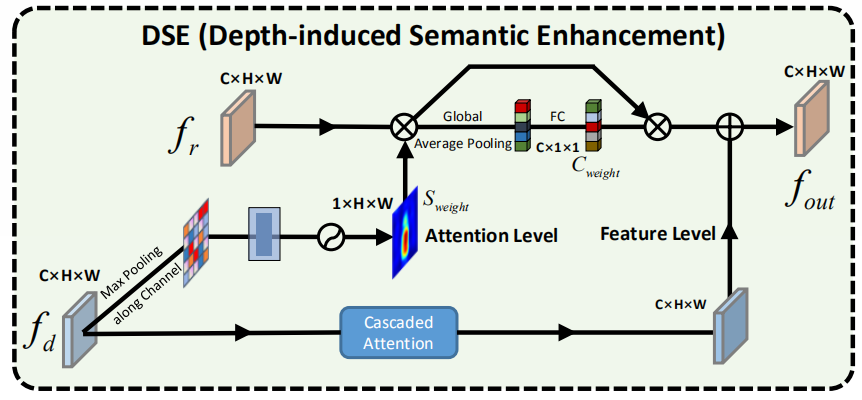
2)Depth-induced semantic enhancement. 在网络的深层,网络要学习更多的语义信息,RGB里的语义信息比depth更加全面。作者设计了两种交互模式实现特征融合:attention level 和 feature level。attention level 比较容易理解,就是得到每一个位置的权重。feature level 使用了一些其它论文里的attention方法,叫做 cascaded attention,最后与其它分支结果相加。
3)Dense decoding reconstruction. 因为这个任务本质上是做逐像素的预测,encoder部分会获得高层语义信息,但容易丢失空间细节。作者设计了一种密集的结构,以更加全面的引入之前的信息。
3、实验分析
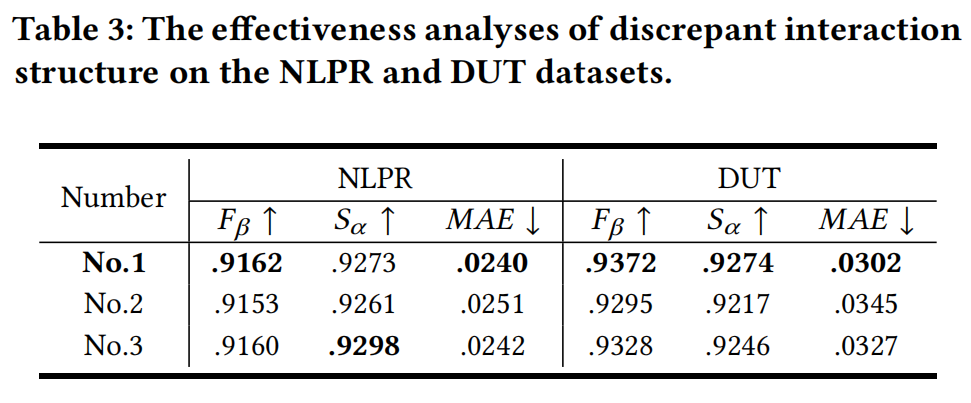
论文有趣的实验是,作者把 encoder 中的5层,都用 depth 增强 RGB,称为 NO.2 。然后,研究把两种模态双向交互,称为 NO.3。除个别指标外,性能不如作者所提出的 CDINet。同时,NO.3 的计算量、网张参数量均有显著增加,也证明了作者所提模型的有效性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号